一种语音合成方法和系统与流程
本发明涉及语音技术领域,尤其涉及一种语音合成方法和系统。
背景技术:
语音合成技术指将输入的文本转换成自然流畅的语音,让机器可以开口说话,扩展了人机交互方式,让人机沟通更加方便。语音合成技术是一种多学科交叉融合技术,主要涉及语言学、数字信号处理、声学、统计学和计算机科学等,目前已在语音客服网络、移动通信,智能家居等领域得到了广泛的应用。
传统语音合成技术一般采用单元挑选和拼接的方法,通过缝合技术把预先录制的语音波形小片段拼接在一起输出对应文本的语音。还有一种方法是统计参数语音合成方法,其采用隐马尔科夫模型(hiddenmarkovmodel,hmm)预测输出语音特征的平滑轨迹,然后由声码器来合成语音。传统的语音合成过程一般需要文本处理前端、语音持续时间模型、声学特征预测模型、声码器合成模型等多个组件的组合,而这些组件的设计需要大量专业领域知识,同时每个组件通常是单独训练的,在最后组装合成语音时会出现误差累计效应,给工程实践人员设计和调试带来极大的困难。
另外,目前提出的语音合成方法都只针对一种语言的合成,对于不同场景下多种语言的语音合成,需要切换多个模型来合成相应的语音,最后通过拼接合成多种语言混合的语音,这往往需要消耗额外的计算资源,同时拼接合成的语音也不够自然。
技术实现要素:
本发明实施例的目的是提供一种语音合成方法和系统,能够合成多种语言的语音,减少合成语音的误差,节省资源。
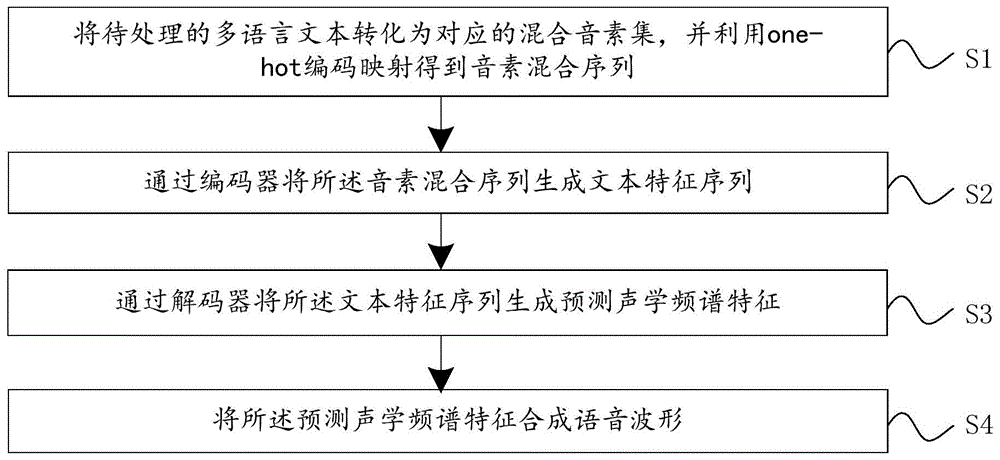
为实现上述目的,本发明实施例提供了一种语音合成方法,包括:
将待处理的多语言文本转化为对应的混合音素集,并利用one-hot编码映射得到音素混合序列;
通过编码器将所述音素混合序列生成文本特征序列;
通过解码器将所述文本特征序列生成预测声学频谱特征;
将所述预测声学频谱特征合成语音波形。
与现有技术相比,本发明公开的语音合成方法,首先,将待处理的多语言文本转化为对应的混合音素集,并利用one-hot编码映射得到音素混合序列;然后,通过编码器将所述音素混合序列生成文本特征序列;最后,通过解码器将所述文本特征序列生成预测声学频谱特征,并将所述预测声学频谱特征合成语音波形。解决了现有技术中传统的语音合成过程需要多个组件的组合,在最后组装合成语音时会出现误差累计效应的问题;同时还解决了现有技术中对于不同场景下多种语言的语音合成,需要切换多个模型来合成相应的语音,从而消耗额外的计算资源的问题。本发明实施例能够合成多种语言的语音,减少合成语音的误差,节省资源。
作为上述方案的改进,所述编码器由神经网络训练得到;其中,所述神经网络包括卷积神经网络和循环神经网络中的至少一种;则,所述通过编码器将所述音素混合序列生成文本特征序列,具体包括:
利用混合音素集与所述神经网络的神经元构建音素向量表;
根据所述音素向量表将所述音素混合序列转换为与所述神经网络输入维度相同的音素向量;
利用所述神经网络对所述音素向量施加非线性变换,得到文本特征序列。
作为上述方案的改进,所述通过解码器将所述文本特征序列生成预测声学频谱特征,具体包括:
在初始阶段,采用特征标记帧输入到预先训练好的循环神经网络中,得到预测声学频谱特征;
在后续每个时间步上,将所述预测声学频谱特征与所述文本特征序列拼接,并输入到所述循环神经网络中,循环迭代得到所述预测声学频谱特征。
作为上述方案的改进,所述将所述预测声学频谱特征合成语音波形,具体包括:
利用griffin-lim算法将所述预测声学频谱特征进行迭代更新,合成语音波形。
作为上述方案的改进,所述将待处理的多语言文本转化为对应的混合音素集,并利用one-hot编码映射得到音素混合序列,具体包括:
预先获取多语言的音频数据及对应的多语言文本;
调用音频处理包利用傅里叶变换将时域状态的所述音频数据转化为对应的真实声学频谱特征;其中,所述音频处理包包括但不限于python中的librosa和pydub;
将所述多语言文本转化为对应的混合音素集,并利用one-hot编码映射得到音素混合序列。
作为上述方案的改进,所述解码器的训练方法包括:
在初始阶段,采用特征标记帧输入到预设参数的循环神经网络中,得到预测声学频谱特征;
在后续每个时间步上,将所述预测声学频谱特征与所述文本特征序列拼接,并输入到预设参数的循环神经网络中,循环迭代得到所述预测声学频谱特征;
利用损失评价函数对所述真实声学频谱特征与所述预测声学频谱特征之间的误差进行评价,将误差进行反向传播;
更新预设参数,最小化所述预测声学频谱特征与所述真实声学频谱特征的误差。
作为上述方案的改进,所述将所述预测声学频谱特征合成语音波形后,还包括:
对所述语音波形进行处理,得到处理后的语音波形。
为实现上述目的,本发明实施例还提供了一种语音合成系统,包括:
预处理单元,用于将待处理的多语言文本转化为对应的混合音素集,并利用one-hot编码映射得到音素混合序列;
编码器单元,用于通过编码器将所述音素混合序列生成文本特征序列;
解码器单元,用于通过解码器将所述文本特征序列生成预测声学频谱特征;
语音波形合成单元,用于将所述预测声学频谱特征合成语音波形。
与现有技术相比,本发明公开的语音合成系统,首先,预处理单元将待处理的多语言文本转化为对应的混合音素集,并利用one-hot编码映射得到音素混合序列;然后,编码器单元通过编码器将所述音素混合序列生成文本特征序列;最后,解码器单元通过解码器将所述文本特征序列生成预测声学频谱特征,语音波形合成单元将所述预测声学频谱特征合成语音波形。解决了现有技术中传统的语音合成过程需要多个组件的组合,在最后组装合成语音时会出现误差累计效应的问题;同时还解决了现有技术中对于不同场景下多种语言的语音合成,需要切换多个模型来合成相应的语音,从而消耗额外的计算资源的问题。本发明实施例能够合成多种语言的语音,减少合成语音的误差,节省资源。
作为上述方案的改进,所述编码器由神经网络训练得到;其中,所述神经网络包括卷积神经网络和循环神经网络中的至少一种;则,所述编码器单元具体用于:
利用混合音素集与所述神经网络的神经元构建音素向量表;
根据所述音素向量表将所述音素混合序列转换为与所述神经网络输入维度相同的音素向量;
利用所述神经网络对所述音素向量施加非线性变换,得到文本特征序列。
作为上述方案的改进,所述解码器单元具体用于:
在初始阶段,采用特征标记帧输入到预先训练好的循环神经网络中,得到预测声学频谱特征;
在后续每个时间步上,将所述预测声学频谱特征与所述文本特征序列拼接,并输入到所述循环神经网络中,循环迭代得到所述预测声学频谱特征。
附图说明
图1是本发明实施例提供的一种语音合成方法的流程图;
图2是本发明实施例提供的一种语音合成方法中步骤s1的流程图;
图3是本发明实施例提供的一种语音合成方法中步骤s2的流程图;
图4是本发明实施例提供的一种语音合成方法中解码器的训练方法的流程图;
图5是本发明实施例提供的一种语音合成系统的结构框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一
参见图1,图1是本发明实施例提供的一种语音合成方法的流程图;包括:
s1、将待处理的多语言文本转化为对应的混合音素集,并利用one-hot编码映射得到音素混合序列;
s2、通过编码器将所述音素混合序列生成文本特征序列;
s3、通过解码器将所述文本特征序列生成预测声学频谱特征;
s4、将所述预测声学频谱特征合成语音波形。
具体的,在步骤s1中,在将待处理的多语言文本转化为对应的混合音素集之前,还需要对所述待处理的多语言文本进行分词、多音字及标点符号处理。在本发明实施例中,所述混合音素集为所述待处理的多语言文本对应的混合音素的集合,若所述待处理的多语言文本由中文和英文组成,则音素集为中文的23个声母、39个韵母、声调以及中文标点符号与英文的39音素、26个英文字母及英文的标点符号组合构成的混合音素集。
经过步骤s1能够将多语言文本如中文和英文转化为对应的音素,结合以下实施例进行具体说明:
对于中文文本,可选用23个声母、39个韵母、声调以及中文标点符号来构成中文音素集,在将文本转化为音素时,先将汉字转化为拼音,再由拼音转化为对应的音素;如示例文本“我爱你,我亲爱的祖国”先转化为拼音可得到“wo3ai4ni3,wo3qin1ai4de5zu3guo2”,利用数字1-5来表示汉字拼音的音调,其中5表示轻声。再将拼音转化为对应的音素可得到“uuuo3aaai4ni3,uuuo3qin1aaai4de5zu3guo2”;对于中文标点符号需要利用unicode编码将其转化为英文标点符号,方便后续音素集的one-hot编码;
对于英文文本,可选用卡耐基梅隆大学提供的基于39音素的英文-音素词典来对英文文本进行转化,将卡耐基梅隆大学提供的39音素与26个英文字母及英文的标点符号组合构成英文音素集;对于文本中的英文在英文-音素词典中的直接转化为英文音素组合,对于不在词典中的英文用英文的26个字母来表示;如示例文本“intenseanxiety,shyness,feelingsofawkwardnessandinsecurity,endquote.”转化为英文序列可得到“ih2nteh1nsanxiety,shyness,fiy1lihongzah1vao1kwerodnahosahondinsecurity,eh1ndquote”;其中,部分单词如“anxiety,shyness,insecurity”等无法在英文-音素词典中找到对应的,将直接用英文字母来表示;
若输入文本既有中文又有英文,则需要先将中文与英文区分出来,然后利用对应语言的音素集来变换得到文本对应的音素。
在得到多语言文本对应的音素后,还需要对音素进行one-hot编码得到音素混合序列。对于中文和英文这两种语言,可利用中文的23个声母、39个韵母、声调与英文的39个音素及英文的标点符号组成中英文混合音素集,然后对中英文混合音素集进行one-hot编码构成音素id映射表。在本发明实施例中,除中文音素、英文音素、字母及英文标点符号外,还增加两个特殊符号表示序列的开始与结束。
将得到的多语言文本对应的音素通过查阅所述音素id映射表,最终可得到音素的混合序列。对于上文英文示例中无法找到的英文单词如“anxiety”在进行one-hot编码时,需要将其拆开成单个的字母“anxiety”然后再查阅音素id映射表来完成编码。
优选的,参见图2,图2是本发明实施例提供的一种语音合成方法中步骤s1的流程图;包括:
s11、预先获取多语言的音频数据及对应的多语言文本;
s12、调用音频处理包利用傅里叶变换将时域状态的所述音频数据转化为对应的真实声学频谱特征;其中,所述音频处理包包括但不限于python中的librosa和pydub;
s13、将所述多语言文本转化为对应的混合音素集,并利用one-hot编码映射得到音素混合序列。
具体的,在步骤s2中,所述编码器由神经网络训练得到;其中,所述神经网络包括卷积神经网络和循环神经网络中的至少一种。参见图3,图3是本发明实施例提供的一种语音合成方法中步骤s2的流程图,包括:
s21、利用混合音素集与所述神经网络的神经元构建音素向量表;
s22、根据所述音素向量表将所述音素混合序列转换为与所述神经网络输入维度相同的音素向量;
s23、利用所述神经网络对所述音素向量施加非线性变换,得到文本特征序列。
具体的,本发明实施例中的语音合成方法采用卷积神经网络与循环神经网络的组合网络来获得更好的文本特征表达。首先,需要利用混合音素集与第一层神经网络的神经元来构建一个音素向量表;然后,利用音素向量表将音素混合序列转换为神经网络输入维度相同的音素向量;最后,利用所述神经网络对音素向量施加非线性变换,同时使用dropout的脖颈层可在训练中加速收敛及增强泛化能力,采用卷积神经网络的卷积核提取高级文本特征,最后输入到循环神经网络来编码得到最终的文本特征序列。
优选的,在本发明实施例中可以采用双向gru循环神经网络来对音素混合序列进行编码得到文本特征序列,但在其他实施例中可以采用其他循环神经网络如双向lstm、纯卷积网络、纯注意力网络等皆可编码输出得到文本特征序列,本发明对此不做具体限定。
值得说明的是,在所述编码器的训练阶段中利用所述步骤s12中的真实声学频谱特征与预测声学频谱特征的误差的反向传播,利用一定的最优化的方法来优化更新编码器模型中卷积神经网络和循环神经网络的参数。而在模型推理阶段(即实际操作中)则直接利用已训练好的编码器模型直接输出预测文本特征序列即可。
具体的,在步骤s3中,所述通过解码器根据所述文本特征序列生成预测声学频谱特征,具体包括:在初始阶段,采用特征标记帧(如全0的向量帧)输入到预先训练好的循环神经网络中,得到预测声学频谱特征;在后续每个时间步上,将所述预测声学频谱特征与所述文本特征序列拼接,并输入到所述循环神经网络中,循环迭代所述预测声学频谱特征。
具体的,在本发明实施例中可以采用双向gru循环神经网络作为所述解码器来输出所述预测声学频谱特征,但在其他实施例中也可以采用其他循环神经网络如双向lstm网络、纯卷积网络、纯注意力网络等皆可解码输出声学频谱特征。采用了基于内容的tanh注意力模型来在每个时间步上对步骤s2中得到的所述文本特征序列进行加权变换。实践中也可以采用点积注意力模型、单调注意力模型、位置敏感注意力模型等对文本特征序列进行加权变换。
优选的,本发明实施例中的注意力模型采用单向gru循环神经网络模型来实现,实践中也可采用其他循环神经网络如单向lstm网络或其他卷积神经网络皆可。
进一步的,参见图4,图4是本发明实施例提供的一种语音合成方法中解码器的训练方法的流程图;所述解码器的训练方法包括:
s31、在初始阶段,采用特征标记帧(如全0的向量帧)输入到预设参数的循环神经网络中,得到预测声学频谱特征;
s32、在后续每个时间步上,将所述预测声学频谱特征与所述文本特征序列拼接,并输入到预设参数的循环神经网络中,循环迭代得到所述预测声学频谱特征;
s33、利用损失评价函数对所述真实声学频谱特征与所述预测声学频谱特征之间的误差进行评价,将误差进行反向传播;
s34、更新预设参数,最小化所述预测声学频谱特征与所述真实声学频谱特征的误差。
优选的,采用l1范数作为所述真实声学频谱特征与所述预测声学频谱特征的损失评价函数。实践中也可采用l2范数或其他合适的损失评价函数皆可。采用学习率自适应的adam梯度下降优化函数来更新预设参数,实践中也可采用其他梯度下降优化方法来更新预设参数。其中,所述预设参数包括所述注意力模型、循环神经网络、卷积神经网络和循环神经网络的权重参数。
具体的,在步骤s4中,利用griffin-lim算法将所述预测声学频谱特征进行迭代更新,合成语音波形。优选的,在执行步骤s4之前,还可以将所述预测声学频谱的振幅提高一定倍数,然后再利用griffin-lim算法进行自回归合成波形,这样可相对减少人工合成的痕迹。
在本发明实施例中,采用无需任何训练的相位自回归的griffin-lim算法对步骤s3中得到的预测声学频谱特征进行迭代更新生成语音波形。其中,griffin-lim算法是目前广泛研究和应用的公知技术,在此不再赘述。但在其他发明实施例中,也可采用其他声码器模型如wavenet、waveglow等方法将所述预测声学频谱特征作为输入来迭代合成语音波形。
值得说明的是,wavenet与waveglow这两种声码器模型需要预先训练才能合成波形。在模型训练阶段:首先,需要将步骤s12中的所述真实声学频谱特征作为输入,迭代输出预测音频帧;然后,利用损失评价函数对真实音频帧与预测音频帧之间的误差进行评价,将误差进行反向传播;最后,利用一定的最优化方法来更新注意力模型与循环神经网络及步骤s2中的卷积神经网络和循环神经网络的权重参数,最小化预测音频帧与真实音频帧的差异。而在模型推理阶段(即实际操作中)直接利用已训练好的声码器模型将所述预测声学频谱特征进行转换合成语音波形即可。
优选的,在得到所述语音波形后,还需要对所述语音波形进行处理,即所述语音合成方法还包括步骤s5:对所述语音波形进行处理,得到处理后的语音波形。
具体的,利用一些常用的操作对所述语音波形进行处理,常包括修剪语音的无声片段、调整语音播放速度及调整语音音色等操作。在本发明实施例中,剪掉声贝数小于某个阈值、沉默时间小于某个时间段的音频片段,其中,最小声贝阈值及最小的沉默时间段根据训练音频数据的停顿时长来定,在此不做具体限定。语音播放速度调整可通过直接调用一些音频处理包如librosa或pydub等来完成。音色变换可通过一些音频处理软件来调整变换。
具体实施时,首先,将待处理的多语言文本转化为对应的混合音素集,并利用one-hot编码映射得到音素混合序列;然后,通过编码器将所述音素混合序列生成文本特征序列;最后,通过解码器根据所述文本特征序列生成预测声学频谱特征,并将所述预测声学频谱特征合成语音波形。
与现有技术相比,本发明公开的语音合成方法,解决了现有技术中传统的语音合成过程需要多个组件的组合,在最后组装合成语音时会出现误差累计效应的问题;同时还解决了现有技术中对于不同场景下多种语言的语音合成,需要切换多个模型来合成相应的语音,从而消耗额外的计算资源的问题。本发明实施例能够合成多种语言的语音,减少合成语音的误差,节省资源。
实施例二
参见图5,图5是本发明实施例提供的一种语音合成系统的结构框图;包括:
预处理单元1,用于将待处理的多语言文本转化为对应的混合音素集,并利用one-hot编码映射得到音素混合序列;
编码器单元2,用于通过编码器将所述音素混合序列生成文本特征序列;
解码器单元3,用于通过解码器将所述文本特征序列生成预测声学频谱特征;
语音波形合成单元4,用于将所述预测声学频谱特征合成语音波形。
优选的,所述编码器由神经网络训练得到;其中,所述神经网络包括卷积神经网络和循环神经网络中的至少一种;则,所述编码器单元2具体用于:
利用混合音素集与所述神经网络的神经元构建音素向量表;
根据所述音素向量表将所述音素混合序列转换为与所述神经网络输入维度相同的音素向量;
利用所述神经网络对所述音素向量施加非线性变换,得到文本特征序列。
优选的,所述解码器单元3具体用于:
在初始阶段,采用特征标记帧输入到预先训练好的循环神经网络中,得到预测声学频谱特征;
在后续每个时间步上,将所述预测声学频谱特征与所述文本特征序列拼接,并输入到所述循环神经网络中,循环迭代得到所述预测声学频谱特征。
优选的,所述语音合成系统还包括后处理单元5,所述后处理单元5用于对所述语音波形进行处理,得到处理后的语音波形。
优选的,所述语音波形合成单元4具体用于利用griffin-lim算法将所述预测声学频谱特征进行迭代更新,合成语音波形。
优选的,所述语音合成预处理方法包括:
预先获取多语言的音频数据及对应的多语言文本;
调用音频处理包利用傅里叶变换将时域状态的所述音频数据转化为对应的真实声学频谱特征;其中,所述音频处理包包括但不限于python中的librosa和pydub;
将所述多语言文本转化为对应的混合音素集,并利用one-hot编码映射得到音素混合序列。
优选的,所述解码器的训练方法包括:
在初始阶段,采用特征标记帧输入到预设参数的循环神经网络中,得到预测声学频谱特征;
在后续每个时间步上,将所述预测声学频谱特征与所述文本特征序列拼接,并输入到预设参数的循环神经网络中,循环迭代得到所述预测声学频谱特征;
利用损失评价函数对所述真实声学频谱特征与所述预测声学频谱特征之间的误差进行评价,将误差进行反向传播;
更新预设参数,最小化所述预测声学频谱特征与所述真实声学频谱特征的误差。
所述语音合成系统中各个单元的具体工作过程和训练过程请参考上述实施例一所述的语音合成方法的具体步骤,在此不再赘述。
具体实施时,首先,预处理单元1将待处理的多语言文本转化为对应的混合音素集,并利用one-hot编码映射得到音素混合序列;然后,编码器单元2通过编码器将所述音素混合序列生成文本特征序列;最后,解码器单元3通过解码器根据所述文本特征序列生成预测声学频谱特征,语音波形合成单元4将所述预测声学频谱特征合成语音波形。
与现有技术相比,本发明公开的语音合成系统,解决了现有技术中传统的语音合成过程需要多个组件的组合,在最后组装合成语音时会出现误差累计效应的问题;同时还解决了现有技术中对于不同场景下多种语言的语音合成,需要切换多个模型来合成相应的语音,从而消耗额外的计算资源的问题。本发明实施例能够合成多种语言的语音,减少合成语音的误差,节省资源。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!