高速公路口礼貌用语评分方法与流程
本发明属于语音关键词检索技术领域,特别涉及一种礼貌用语评分方法,可用于高速公路口收费站。
技术背景
把人类中简单重复的工作由机器代替一直是人们研究机器化发展的最初动力,人与机器进行交流是目前人工智能的发展要求之一。作为一种实现人类与机器直接“对话”的技术,语音识别技术可以很便利地将语音信号转换成相应的机器语言,进而实现无障碍交流。
在现如今的人类工作生活中,有些工作需要通过检测工作人员的礼貌用语标准与否来评估工作状况,例如高速公路口的收费站工作人员就需要说完规定的某些礼貌用语方才达标。而这些检测和评估的重复类工作一旦由机器代替,在一定程度上就减轻了管理者的工作负担和提升了管理效果。因而实现一些场景下的关键词语音识别显得尤为有用,且能对非特定人的被评估人员进行评分。
我国具有五千年文明历史,素有“礼仪之邦”之称,中华民族也以彬彬有礼的风貌而著称于世。礼仪文明作为我国传统文化的一个重要组成部分,其内容十分丰富,涉及的范围十分广泛,几乎渗透于社会的各个方面。例如高速公路口收费站的工作人员在与过往司机交流时就需要说一些礼貌用语,收费站的工作人员是否使用特定礼貌用语和使用频数是管理员评估他们工作的重要依据。
现有的监督评估工作在行为交流上已由视频监控承担,例如大华高速公路视频监控系统中的收费站子系统就连续24小时全天监控收费亭内收费员的工作情况,但这种方法只能监测到收费员的礼貌动作,在语音交流上的监督评估仍是由人工完成的,需要管理员全程监督,过程重复枯燥,而且还需要为每个收费亭专门设置管理员的职位,浪费劳动力。
技术实现要素:
本发明的目的在于针对上述现有技术的不足,提出一种高速公路口礼貌用语评分系统,以实现对收费员语音监控的智能化,便利管理者对收费员工作的监督和评估。
为实现上述目的,本发明包括:
(1)选定高速公路口收费员m个礼貌用语作为关键词,选取n人作为发音者,每个人对每个关键词完整并清晰地说x遍,总共得m×n×x条wav文件作为语料库文件;
(2)构建关键词模型和filler模型并行的网络模型:
2a)对每个关键词的语料库文件依次进行预加重、分帧加汉明窗的预处理,得到一帧一帧的语音数据,从该语音数据中提取24维梅尔频率倒谱系数mfcc作为特征参数;采用baum-welch算法对该特征参数进行训练,得到该关键词的隐马尔科夫模型hmm参数模型;
2b)将高速公路可预测的非礼貌语音音节作为非关键词,用与2a)相同的方法建立非关键词hmm模型;用与2a)相同的方法对静音建立单状态hmm模型,用非关键词模型和静音模型组成filler模型;
2c)将关键词模型和filler模型并行设置,组成无语法约束的网络模型;
(3)选取k人作为测试发音者,每个人分别对包含1到m个关键词的m个语音段说一遍,总共得到k×m!条wav文件,作为语音测试文件;
(4)对语音测试文件经过与2a)相同的预处理和mfcc特征提取,得到测试语音特征参数;在(2)所得的关键词模型和filler模型并行的网络模型中调整网络边的权重后,采用viterbi算法,计算该测试语音特征参数对与网络模型中每一个模型的匹配得分,保留匹配得分较高的s个模型,作为关键词初始检索结果;
(5)采用viterbi算法,计算出(4)所得的网络模型中s个得分较高的模型与2a)所得关键词模型的匹配分数,按时间长度对s个匹配分数归一化,并以结果分别作为对应于s个模型的s个置信度;设置一个阈值,循环比较每个模型的置信度和该阈值的大小,共s次,若置信度低于该阈值则弃掉该模型,置信度高于该阈值就保留该模型,该模型就作为最终关键词检索结果;
(6)将(3)所得文件中某个人的随机一条语音测试文件经过(4)和(5)后,若包含所有需要检索的m个关键词,则判为100分,若缺少y个关键词,则判为100-y*100/m分,最终得到被评人员的工作评分。
本发明的优点在于:
1)本发明的应用场景是高速公路口的收费站,搭建一套礼貌用语评分系统,实现对收费员语音监控的智能化,便利管理者对收费员的监督评估工作;
2)本发明采用基于hmm的语音关键词检索方法,具有良好的鲁棒性;
3)本发明基于关键词初始检索后的结果,加上采用置信度实现关键词确认,具有较高的检索正确率;
4)本发明严格遵守评分规则为被评人员评分,不漏掉一个礼貌用语,漏识率较低。
附图说明
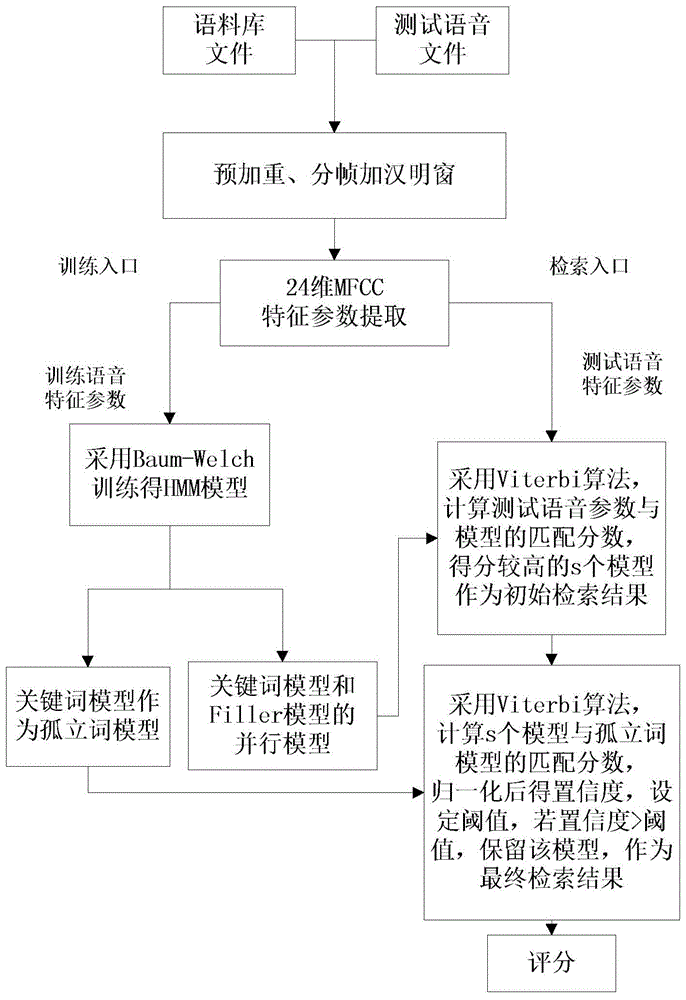
图1是本发明的实现流程图;
图2是本发明中关键词模型和filler模型的并行网络模型图。
具体实施方式
下面结合附图和具体实施方式,进一步阐明本发明。
参照图1,本实施例的具体步骤如下:
步骤1.采集语料库文件。
选定高速公路口收费员m个礼貌用语作为关键词,选取n(n≥20)个人作为发音者,每个人对每个关键词完整并清晰地说x遍,总共得m×n×x条wav文件作为语料库文件。
步骤2.构建关键词和filler并行的网络模型。
2a)对每个关键词的语料库文件依次进行预加重、分帧加汉明窗的预处理:
2a1)用一阶高通数字滤波器对原始信号x(n)进行预加重,得到预加重处理后的信号为:
y(n)=x(n)-0.98x(n-1);
2a2)对预加重处理后的信号y(n)进行分帧加汉明窗,得到分帧加汉明窗处理后的信号为:
2b)经2a)的预处理后得到一帧一帧的语音数据,从该语音数据中提取24维梅尔频率倒谱系数mfcc作为特征参数;
2c)采用baum-welch算法对2b)所得的特征参数进行训练:
2c1)假设观测序列o={ot,t=1,2,…,t},初始模型λ=(π,a,b),设该初始模型的状态集合为{si,i=1,2,…,n},在t时刻所处状态为qt,观测符号为:
v={vk,k=1,2,…,n},
初始模型λ中:π={πi,i=1,2,…,n},
a={aij,i=1,2,…,n,j=1,2,…,n},
b={bjk,j=1,2,…,n,k=1,2,…,m},
πi表示初始状态概率,aij表示在时刻t的状态为si且在t+1时刻转移为状态sj的概率,bjk表示在状态sj观测到符号vk的概率;
2c2)在2c1)的假设下,引入两组概率变量εt(i,j)表示t时刻处于状态si且t+1时刻处于状态sj的概率,γt(i)表示t时刻处于状态si的概率,即:
εt(i,j)=p(qt=si,qt+1=sj|o,λ),
γt(i)=p(o,qt=si|λ);
2c3)由2c2)所引入的两组概率变量计算一组新参数:
π′i=γ1(i),
2c4)由2c3)所得的一组新参数π′i,a′ij,b′j(k),重估得一个新模型:
λ′=(π′,a′,b′),
该模型λ′产生观测序列的概率p(o|λ′)比初始模型λ产生观测序列的概率p(o|λ)要大;
2c5)重复2c3)和2c4),不断改进模型参数,直到p(o|λ′)不再明显增大,此时模型λ′=(π′,a′,b′)即为训练该关键词的隐马尔科夫模型hmm参数模板;
2d)将高速公路可预测的非礼貌语音音节作为非关键词,用与2a)相同的方法建立非关键词hmm模型;用与2a)相同的方法对静音建立单状态hmm模型,用非关键词模型和静音模型组成filler模型;
2e)将关键词模型和filler模型并行设置,组成无语法约束的网络模型,如图2所示。
步骤3.采集语音测试文件。
选取k个人作为测试发音者,每个人分别对包含1到m个关键词的m个语音段说一遍,总共得到k×m!条wav文件,作为语音测试文件,其中,k>5。
步骤4.关键词初始检索。
4a)对语音测试文件依次经过与2a)相同的预处理和与2b)相同的mfcc特征提取,得到测试语音特征参数;
4b)在步骤2所得的并行的网络模型中调整网络边的权重后,采用viterbi算法,计算4a)所得的测试语音特征参数对网络模型中每一个模型的匹配得分:
4b1)在与2c1)相同的假设下,设时刻t沿一条路径序列q={q1,q2,…,qt}且qt=si产生观测序列的最大概率为δt(si),引入一组中间变量
4b2)初始化4b1)所设的概率变量δt(si)和中间变量
4b3)设时刻t沿一条路径序列q={q1,q2,…,qt}且qt=sj产生观测序列的最大概率为δt(sj),引入一组中间变量
4b4)根据4b3)所得的一组中间变量
4b5)由4b3)所得的δt(si),计算t时刻的观测序列与模型匹配的概率p′(q,o|λ)和状态q′t:
p′(q,o|λ)=max1≤i≤n[δt(si)],
q′t=argmax1≤i≤n[δt(si)],
此时p′(q,o|λ)即为观测序列与模型的匹配得分;
4b6)合并4b4)所得的一组q′1,q′2,…,q′t-1和4b4)所得的q′t,得到最优状态路径序列:
q′={q′1,q′2,…,q′t};
4c)保留4b)中匹配得分较高的s个模型,作为关键词初始检索结果。
步骤5.用置信度实现关键词确认,得到关键词的最终检索结果。
5a)采用与4b)相同的viterbi算法,计算出4c)所得的s个得分较高关键词模型对孤立词模型的匹配分数,按时间长度对s个匹配分数归一化,并把归一化的结果分别作为对应于s个模型的s个置信度;
5b)设置一个阈值,循环比较5a)所得的每个模型置信度和该阈值的大小,共s次,若置信度低于该阈值则弃掉该模型,置信度高于该阈值就保留该模型,保留的模型就作为最终关键词的检索结果。
步骤6.完成评分。
将步骤3所得文件中某个人的随机一条语音测试文件经过步骤4和步骤5后,若包含所有需要检索的m个关键词,则判为100分,若缺少y个关键词,则判为100-y*100/m分,最终得到被评人员的工作评分,其中,0≤y≤m。
以上所述仅是本发明的一个具体实例,并未构成对本发明的任何限制,显然对于本领域的专业人员来说,在了解了本发明内容和原理后,都可能在不背离本发明原理、结构的情况下,进行形式和细节上的各种修改和改变,但是这些基于本发明思想的修正和改变仍在本发明的权利要求保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!