一种基于语音驱动的测发口令监测系统和方法与流程
本发明涉及一种基于语音驱动的测发口令监测系统和方法,属于语音识别
技术领域:
。
背景技术:
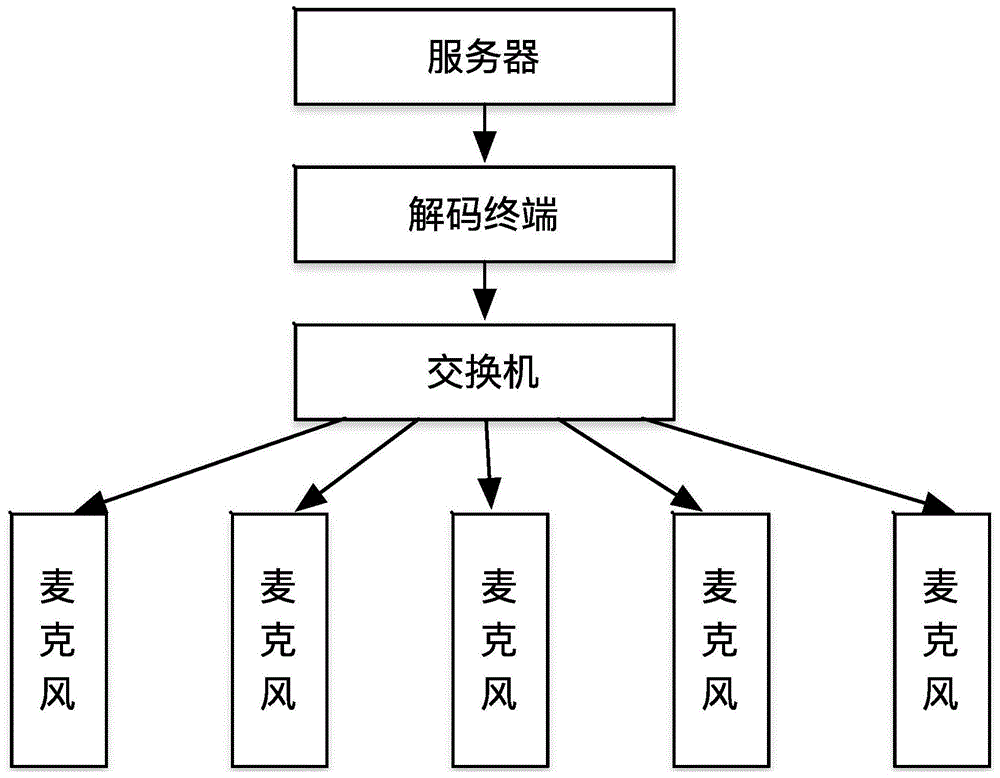
:语音识别的意思是将人说话的内容和意思转换为计算机可读的输入,例如按键、二进制编码或者字符序列等。与说话人的识别不同,后者主要是识别和确认发出语音的人而非其中所包含的内容。语音识别的目的就是让机器听懂人类口述的语言,包括了两方面的含义:第一是逐字逐句听懂而不是转化成书面的语言文字;第二是对口述语言中所包含的命令或请求加以领会,做出正确回应,而不仅仅只是拘泥于所有词汇的正确转换。运载火箭的测发试验流程中,一般采用故障诊断、健康监测系统辅助试验人员监测试验参数、流程状态、设备状态,达到保障预警的目的。现有故障诊断、健康监测系统多采用实时采集设备数据进行判读,系统在测发流程中缺失了对于语音信息的采集和利用,通常是通过人工去听取口令做出判断,在操作过程中难免会由于语音信息传达有误造成问题。因此有必要引入命令词语音识别技术,识别指挥人员口令,并将语音口令转换为文字当人员操作与指挥员口令不一致时可以进行预警提醒,辅助二岗人员对测发流程操作的监督工作;同时将语音信息作为一个输入源提供给全箭健康监测软件,实现基于语音驱动的测发流程监测、设备监测和故障诊断,提升测发流程的鲁棒性和自动性。技术实现要素:本发明的技术解决问题是:克服现有技术的不足,提出一种基于语音驱动的测发口令监测系统和方法,通过对测试发射语音口令的采集、处理,实现对测试发射语音信息的识别、存储、监测,提升测发流程的鲁棒性和自动性。本发明的技术解决方案是:一种基于语音驱动的测发口令监测方法,其特征在于采用多线程并发模型,符合预设语法文件结构的语音口令对应的n路音频信号进行循环侦听,每检测到一路音频输入时,记录当前时刻为该音频输入对应的语音口令接收时刻,开启一个语音处理子线程,每个语音处理子线程执行如下步骤:(1)、对音频信号进行预处理,消除音频信号中的噪音,对音频信号进行音频分割、波形变换,提取每个字所对应的特征向量,利用每个字所对应的特征向量,结合用户自定义的口令词库,将语音口令转换为口令文字信息并存储至数据库;(2)、根据预设的语法文件结构,对口令文字信息进行语义分析,对口令文字信息进行分词并识别出测发口令信息,把测发口令信息转换成状态量,把状态量及其对应的语音口令接收时刻一并存储至数据库,所述状态量,用于指导相应的操作手对相应的操作设备执行相应的操作动作。2、根据权利要求1所述的一种基于语音驱动的测发口令监测方法,其特征在于所述语法文件结构为:操作手编号|条件操作|操作设备|功能操作|运行操作。3、根据权利要求1所述的一种基于语音驱动的测发口令监测方法,其特征在于所述步骤(1)利用每个字所对应的特征向量,结合用户自定义的口令词库,将语音口令转换为口令文字信息的具体过程为:(1.1)、根据用户自定义的口令词库,将所得到的文字进行组合,生成语音识别树;(1.2)、将语音识别树中每个分支按照语法文件结构进行分解,与用户自定义的口令词库进行匹配,得到每个部分词语的识别置信度,再将每个部分的置信度进行加权平均,即可得到每个分支的置信度;(1.3)、选择置信度最高的分支对应的文字信息作为口令文字信息。4、根据权利要求1所述的一种基于语音驱动的测发口令监测方法,其特征在于所述语音口令按照预设的标准测发流程给出,所述步骤(2)中做完语义分析得到状态量之后,根据该状态量对应的语音口令接收时刻,将该状态量与标准测发流程中的状态量进行比对,如果匹配,则存储,否则,作出异常提示并存储。匹配是指以测发流程开始时刻作为参考,相对于参考时刻相同的时间对应的时刻,状态量相同;5、根据权利要求1所述的一种基于语音驱动的测发口令监测方法,其特征在于所述数据库包括hbase数据库和redis数据库,其中,当前识别的口令文字信息和健康口令信息存储至redis数据库,历史口令文字信息和健康口令信息存储至hbase数据库。6、根据权利要求1所述的一种基于语音驱动的测发口令监测系统,其特征在于包括n个终端采集设备和语音识别服务器;其中:n个终端采集设备,分别通过麦克风采集外部输入的语音口令,并将语音口令发送至语音识别服务器;语音识别服务器,采用多线程并发模型,符合预设语法文件结构的语音口令对应的n路音频信号进行循环侦听,每检测到一路语音口令时,将语音口令解码,得到音频输入,记录当前时刻为该音频输入对应的语音口令接收时刻,开启一个语音处理子线程,每个语音处理子线程调用语音处理模块,进行语音识别和语义识别处理,实现健康口令发射和监测。7、根据权利要求5所述的一种基于语音驱动的测发口令监测系统,其特征在于所述语音处理模块包括语音预处理模块、语音识别模块、语义识别模块和识别结果存储模块;语音预处理模块,对音频信号进行预处理,消除音频信号中的噪音,对音频信号进行音频分割、波形变换,每个字所对应的特征向量;语音识别模块,利用每个字所对应的特征向量,结合用户自定义的口令词库,识别出语音口令,将语音口令转换为口令文字信息并发送至识别结果存储模块;语义识别模块,根据预设的语法文件结构,对口令文字信息进行语义分析,对口令文字信息进行分词并识别出测发口令信息,把测发口令信息转换成状态量并存储至数据库,所述状态量,用于指导相应的操作手对相应的操作设备执行相应的操作动作;识别结果存储模块,将当前识别的口令文字信息和健康口令信息存储至redis数据库,历史口令文字信息和健康口令信息存储至hbase数据库,根据识别的口令文字信息和健康口令信息,记录详细语音口令日志,实现对语音口令的实时监测和历史信息查询,查询结果包括识别时间、识别内容、语音分词结果、原始音频信息,根据该状态量对应的语音口令接收时刻,将该状态量与标准测发流程中的状态量进行比对,如果匹配,则存储,否则,作出异常提示并存储。8、根据权利要求5所述的一种基于语音驱动的测发口令监测系统,其特征在于所述预设的语法文件结构为:操作手编号|条件操作|操作设备|功能操作;其中:所述测发口令信息包括操作手编号、操作动作、操作设备,9、根据权利要求5所述的一种基于语音驱动的测发口令监测系统,其特征在于所述语音识别服务器采用centos7.0操作系统实现。10、根据权利要求6所述的一种基于语音驱动的测发口令监测系统,其特征在于语音识别模块步骤(1)中转换成口令文字信息的具体步骤为:(1.1)、根据用户自定义的口令词库,将所得到的文字进行组合,生成语音识别树;(1.2)、将语音识别树中每个分支按照语法文件结构进行分解,与用户自定义的口令词库进行匹配,得到每个部分词语的识别置信度,再将每个部分的置信度进行加权平均,即可得到每个分支的置信度;(1.3)、选择置信度最高的分支对应的文字信息作为口令文字信息。本发明与现有技术相比的有益效果是:(1)、本发明利用识别出的指令与标准流程做匹配,综合历史参数,对异常报警。(2)、设计了一种表征复杂指令的语法文件结构,能覆盖测发流程的指令,实现语义分词。(3)、本发明的语法文件结构中操作手编号,考虑,用于识别不同的音频来源。(4)、本发明将测发口令信息转换成状态量,节约了存储空间,提升了查询效率;(5)、根据本发明所提供的系统和方法当人员操作与指挥员口令不一致时可以进行预警提醒,辅助二岗人员对测发流程操作的监督工作;同时将语音信息作为一个输入源提供给全箭健康监测软件,实现基于语音驱动的测发流程监测、设备监测和故障诊断,提升测发流程的鲁棒性和自动性。附图说明图1为本发明实施例的语音识别系统结构示意图;图2为本发明实施例的语音识别系统网络拓扑示意图。具体实施方式以下结合附图和具体实施例对本发明进行详细说明。(1)、系统概述语音识别系统功能包括语音预处理,语音识别,用户自定义词库,语音分析及语音结果存储与查询功能。如图1所示,本发明提供的一种基于语音驱动的测发口令监测系统包括n个终端采集设备和语音识别服务器,n大于等于1,在实际使用中会存在多个人同时下达语音口令的情况,此时n大于1。1、终端采集设备n个终端采集设备,分别通过麦克风采集外部输入的语音口令,并将语音口令发送至语音识别服务器。终端采集设备麦克风可以选用带网络接口的麦克风,通过网线连接交换机,同时,在服务器端配置一个与麦克风对应的解码终端,解码终端的音频输出连接服务器端的音频输入。为麦克风和解码终端都分配固定ip,并设置同一网段,使二者可以相互通信。2、语音识别服务器语音识别服务器采用多线程并发模型,符合预设语法文件结构的语音口令对应的n路音频信号进行循环侦听,每检测到一路语音口令时,将语音口令解码,得到音频输入,记录当前时刻为该音频输入对应的语音口令接收时刻,开启一个语音处理子线程,每个语音处理子线程调用语音处理模块,进行语音识别和语义识别处理,实现健康口令发射和监测。语音识别服务器运行核心的语音识别服务,在本发明的某一具体实施例中,语音识别服务器采用centos7.0操作系统。centos是一个开源的操作系统,是redhat公司发布的redhat系统开源版本,目前全球服务器上安装的系统中,大多数是centos及其衍生版本。centos操作系统的底层基于linux,是linux的发行版之一。centos支持大量开源软件的运行和使用,并原生支持c、java、python等程序语言的编写。此外,centos具有独有的yum命令支持软件包在线和离线升级,可以即时更新系统。另外,centos的兼容性较强,绝大多数的开源软件和源码(如hadoop生态环境)都能够完美支持centos。上述具体实施例中,语音识别服务的硬件指标如下表所示:配置项配置指标要求cpu型号intelxeone5-2620v3cpu数量≥2颗,建议配置2颗内存≥8gb,建议配置32gb(4*8gb)ddr31333mhzecc硬盘≥4tb,建议配置4.8tb(8*600gtb)sata7.2krpm,raid5网卡四段口千兆网卡2.1语音处理模块如图2所示,所述语音处理模块采用由上到下的四层结构,包括语音预处理模块、语音识别模块、语义识别模块和识别结果存储模块。2.1.1语音预处理模块语音预处理模块对音频信号进行预处理,消除音频信号中的噪音,对音频信号进行音频分割、波形变换,每个字所对应的特征向量。2.1.2语音识别模块语音识别模块利用每个字所对应的特征向量,结合用户自定义的口令词库,识别出语音口令,将语音口令转换为口令文字信息并发送至识别结果存储模块,具体步骤为:(1.1)、根据用户自定义的口令词库,将所得到的文字进行组合,生成语音识别树;(1.2)、将语音识别树中每个分支按照语法文件结构进行分解,与用户自定义的口令词库进行匹配,得到每个部分词语的识别置信度,再将每个部分的置信度进行加权平均,即可得到每个分支的置信度,置信度可以设置为从0到100,数值越高代表对识别结果越有把握;所述用户自定义的口令词库通过手动输入关键词或定义词库文件上传并存储至数据库中。(1.3)、选择置信度最高的分支对应的文字信息作为口令文字信息。所述文字信息包括中英文文字信息。本发明利用置信度进行两方面的工作。第一,置信度反应识别结果的可信程度,设置置信度阈值,通过阈值可以排除置信度较低的识别结果,从而避免往数据库中存储大量冗余信息。第二,通过置信度的反馈,可将识别过程看做一个监督学习的过程,利用机器学习算法,可以对识别引擎进行训练,使得识别结果更加准确可信。上述语音预处理模块和语音识别模块可以在科大讯飞离线命令词识别软件开发包的语音识别引擎基础上进行二次开发实现。2.1.3语义识别模块语义识别模块根据预设的语法文件结构,对口令文字信息进行语义分析,对口令文字信息进行分词并识别出测发口令信息,把测发口令信息转换成状态量并存储至数据库,所述状态量,用于指导相应的操作手对相应的操作设备执行相应的操作动作。所述预设的语法文件结构为:操作手编号|条件操作|操作设备|功能操作|运行操作;其中:所述测发口令信息包括操作手编号、操作动作、操作设备。定义了语音识别所支持的命令词的集合,本系统利用巴科斯范式(bnf)描述语音识别的语法。本发明语法文件结构采用组合的方式,将一句口令拆分成不同部分的关键词,例如操作打开某个设备的口令,是由以下部分组成。(操作手编号)|(条件操作)|(操作设备)|(功能操作)|(运行操作)举例如下:(101)|(打开)|(阀门1)|(管路放气)|(调压至3mpa)按照以上的方式,将口令拆分并编写成对应的语法文件,经过语音识别,可将一句话自动拆分成对应以上标签的几段文字。做语义分析之后,就可以与这句指令对应的状态量做匹配,进而驱动状态量变化。网络麦克风的通信机制是麦克风直接与语音终端设备通信,再经由终端设备解码,将音频信号输入到服务器的音频输入端口,所以进入到语音识别程序的音频信号已经不具有音频来源的ip信息,需要用其他方法确定音频信号来源。上述语法文件结构考虑到语音口令特点,可以确定由不同人员发出的语音口令具有差异性和唯一性,利用语音口令的这一特点,对不同系统人员口令进行分别编号,对识别出的口令与预置的口令库做精确匹配,由此确定音频信号的来源。2.1.4识别结果存储模块识别结果存储模块将当前识别的口令文字信息和健康口令信息存储至redis数据库,历史口令文字信息和健康口令信息存储至hbase数据库,根据识别的口令文字信息和健康口令信息,记录详细语音口令日志,实现对语音口令的实时监测和历史信息查询,查询结果包括识别时间、识别内容、语音分词结果、原始音频信息,根据该状态量对应的语音口令接收时刻,将该状态量与标准测发流程中的状态量进行比对,如果匹配,则存储,否则,作出异常提示并存储。由于语音信息量大且具有较大的价值,本发明在服务器上搭建hadoop集群,并建立hbase数据库用于存储语音信息,即历史口令文字信息和健康口令信息均存储至hbase数据库。hadoop实现了一个分布式文件系统(hadoopdistributedfilesystem),简称hdfs。hdfs有高容错性的特点,并且设计用来部署在低廉的硬件上,即便硬件出现故障,也可以通过容错策略来保证数据的高可用。此外,分布式系统可以将文件进行块拆分,提升系统的运行效率。另外,它提供对访问数据的极高的吞吐,和极大容量存储,适合那些需要存储着超大数据集和超大文件的应用场景。hbase是运行在hdfs的非结构化数据库,具有分布式和可扩展的特点。和以mysql、oracle为首的结构化数据库相比,非结构化数据库(如hbase)允许用户动态扩展列,这种存储方式能够节约磁盘空间,提升硬盘的实际利用率。hbase可以自动切分数据,将数据进行分区,以应对未来数据存储设备扩展的场景。另外,hbase可以提供高并发读写操作的支持,当用户查询的hbase节点繁忙时,hbase会自动进行负载均衡,使得繁忙节点只需要进行数据传输的工作,提升系统的可用性和响应速度。同时,为了查询的实时性,将当前识别的单条语音信息存入redis数据库。当前识别的口令文字信息和健康口令信息存储至redis数据库。redis是一个基于内存的key-value(键值地址映射,将数据映射到指定地址中,在最短的时间内能够将存储的数据提取出来)存储系统,采用c语言编写。相比于将数据存储在硬盘上的mysql等数据库,redis运行在内存中。由于内存的访问速度远远高于硬盘(访问速度相差两个数量级),因此redis的读取效率极高,可以作为内存数据库、缓存或消息代理的中间件,适合实时数据的存储。本发明采用b/s架构的软件模式,开发语音识别web端应用。后台采用java开发,前端采用html+css+js。基于上述基于语音驱动的测发口令监测方法,本发明还提供了一种基于语音驱动的测发口令监测方法,该方法采用多线程并发模型,符合预设语法文件结构的语音口令对应的n路音频信号进行循环侦听,每检测到一路音频输入时,记录当前时刻为该音频输入对应的语音口令接收时刻,开启一个语音处理子线程,每个语音处理子线程执行如下步骤:(1)、对音频信号进行预处理,消除音频信号中的噪音,对音频信号进行音频分割、波形变换,提取每个字所对应的特征向量,利用每个字所对应的特征向量,结合用户自定义的口令词库,将语音口令转换为口令文字信息并存储至数据库;具体为:(1.1)、根据用户自定义的口令词库,将所得到的文字进行组合,生成语音识别树;(1.2)、将语音识别树中每个分支按照语法文件结构进行分解,与用户自定义的口令词库进行匹配,得到每个部分词语的识别置信度,再将每个部分的置信度进行加权平均,即可得到每个分支的置信度;(1.3)、选择置信度最高的分支对应的文字信息作为口令文字信息。(2)、根据预设的语法文件结构,对口令文字信息进行语义分析,对口令文字信息进行分词并识别出测发口令信息,把测发口令信息转换成状态量,把状态量及其对应的语音口令接收时刻一并存储至数据库,所述数据库包括hbase数据库和redis数据库,其中,当前识别的口令文字信息和健康口令信息存储至redis数据库,历史口令文字信息和健康口令信息存储至hbase数据库。所述状态量,用于指导相应的操作手对相应的操作设备执行相应的操作动作。所述语法文件结构为:操作手编号|条件操作|操作设备|功能操作|运行操作;其中,操作手编号、操作动作、操作设备为测发口令信息.所述语音口令按照预设的标准测发流程给出,所述步骤(2)中做完语义分析得到状态量之后,根据该状态量对应的语音口令接收时刻,将该状态量与标准测发流程中的状态量进行比对,如果匹配,则存储,否则,作出异常提示并存储,匹配是指以测发流程开始时刻作为参考,相对于参考时刻相同的时间对应的时刻,状态量相同。本说明书中未进行详细描述部分属于本领域技术人员公知常识。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1