一种离线式多语种语音识别方法与流程
本发明涉及一种语音识别方法,特别是涉及一种离线式多语种语音识别方法。
背景技术:
随着语音识别技术的飞速发展,语音智能产品开始从实验室走向市场,广泛的应用于工业、家电、通信、汽车电子、医疗、家庭服务、电子产品等各个领域。以时下备受青睐的智能卫浴产品(例如智能马桶)的语音智能终端为例,使用时,用户只需先语音输入唤醒词唤醒该语音智能终端,再输入语音指令,即可使该语音智能终端输出与该语音指令对应的结果,例如控制智能马桶启动冲水、开启盖板等等。
由于人类语言发音的差异,不同语种的语音识别算法模型不同,而目前基于离线识别的语音智能产品为单语言识别,导致无法兼容满足其他语言的用户。
技术实现要素:
本发明提供了一种离线式多语种语音识别方法,其克服了现有技术基于离线识别的语音智能产品无法识别多种语言的不足之处。
本发明解决其技术问题所采用的技术方案是:一种离线式多语种语音识别方法,包括以下步骤:
1)采集语音信息;
2)判断采集到的语音信息是否为特定语音,若是则识别出该特定语音的语种及设定该语种的声学模型为默认的声学识别模型,并根据该特定语音唤醒该默认的声学识别模型,或者,根据下一条为唤醒词的语音信息唤醒该默认的声学识别模型,否则执行步骤3);
3)按照此前默认的声学识别模型进行语音识别。
进一步的,所述特定语音为切换指令,若采集到的语音信息为切换指令,则识别出该切换指令的语种及设定该语种的声学模型为默认的声学识别模型,并根据下一条为唤醒词的语音信息唤醒该默认的声学识别模型。
进一步的,所述步骤3)包括以下步骤:
a1)判断此前默认的声学识别模型是否为唤醒状态,若是则执行步骤a2),否则执行步骤a3);
a2)判断采集到的语音信息是否为执行指令,若是则识别出对应的指令,并输出与指令相应的结果,否则执行步骤a5);
a3)判断采集到的语音信息是否为唤醒词,若是则执行步骤a4),否则执行步骤a5);
a4)开启此前默认的声学模型为唤醒状态,并保持t秒,t>0;
a5)结束。
进一步的,所述切换指令包括“中文模式”、“englishmode”、“方言”中的至少两种。
进一步的,所述特定语音为唤醒词,若采集到的语音信息为唤醒词,则识别出该唤醒词的语种及设定该语种的声学模型为默认的声学识别模型,并唤醒该默认的声学识别模型。
进一步的,所述步骤3)包括以下步骤:
b1)判断此前默认的声学模型是否为唤醒状态,若是则执行步骤b2),否则执行步骤b3);
b2)判断采集到的语音信息是否为执行指令,若是则识别出对应的指令,并输出与指令相应的结果,否则执行步骤b3);
b3)结束。
进一步的,所述步骤2)中,所述默认的声学模型被唤醒后,保持唤醒状态t秒,t>0。
相较于现有技术,本发明具有以下有益效果:
本发明通过判断采集到的语音信息是否为特定语音,若是则识别出该特定语音的语种及设定该语种的声学模型为默认的声学识别模型,并根据该特定语音唤醒该默认的声学识别模型,或者,根据下一条为唤醒词的语音信息唤醒该默认的声学识别模型,因而本发明能够实现多语种语音识别,从而能够兼容满足其他语言的用户。此外,本发明为离线式多语种语音识别,硬件上采用同一个语音识别模块即可实现该方法,从而可以节省语音智能产品的硬件成本。
以下结合附图及实施例对本发明作进一步详细说明;但本发明的一种离线式多语种语音识别方法不局限于实施例。
附图说明
图1是实施例一本发明的流程示意图;
图2是实施例二本发明的流程示意图。
具体实施方式
实施例一
本发明的一种离线式多语种语音识别方法,包括以下步骤:
1)采集语音信息;
2)判断采集到的语音信息是否为特定语音,若是则识别出该特定语音的语种及设定该语种的声学模型为默认的声学识别模型,并根据下一条为唤醒词的语音信息唤醒该默认的声学识别模型,否则执行步骤3);
3)按照此前默认的声学识别模型进行语音识别。
本实施例中,所述特定语音为切换指令,该切换指令包括“中文模式”、“englishmode”、“方言”等中的至少两种。其中,“方言”可以为一种或多种,例如智能语音产品所在地区的方言、其它地区的方言等。
本实施例中,所述步骤3)包括以下步骤:
a1)判断此前默认的声学识别模型是否为唤醒状态,若是则执行步骤a2),否则执行步骤a3);
a2)判断采集到的语音信息是否为执行指令,若是则识别出对应的指令,并输出与指令相应的结果,否则执行步骤a5);
a3)判断采集到的语音信息是否为唤醒词,若是则执行步骤a4),否则执行步骤a5);
a4)开启此前默认的声学模型为唤醒状态,并保持t秒,t>0;
a5)结束。
本实施例中,本发明为离线式多语种语音识别,硬件上用同一个语音识别模块即可实现该方法;本发明采用咪头实时采集外界声音。由于切换指令为不同语种,数量较少,因此,采用混合声学模型进行匹配识别,保证切换指令的准确识别。
本实施例中,所述唤醒词相同,即在不同语种的语音识别模式下,唤醒词为同一个,但不局限于此,在其它实施例中,唤醒词与所述切换指令一样采用不同的语种。所述唤醒词例如可以是“你好,xx”,xx指语音智能产品被赋予的名字。各种语种的声学识别模型的建立为现有技术,因此,本实施例对此不进一步展开说明。
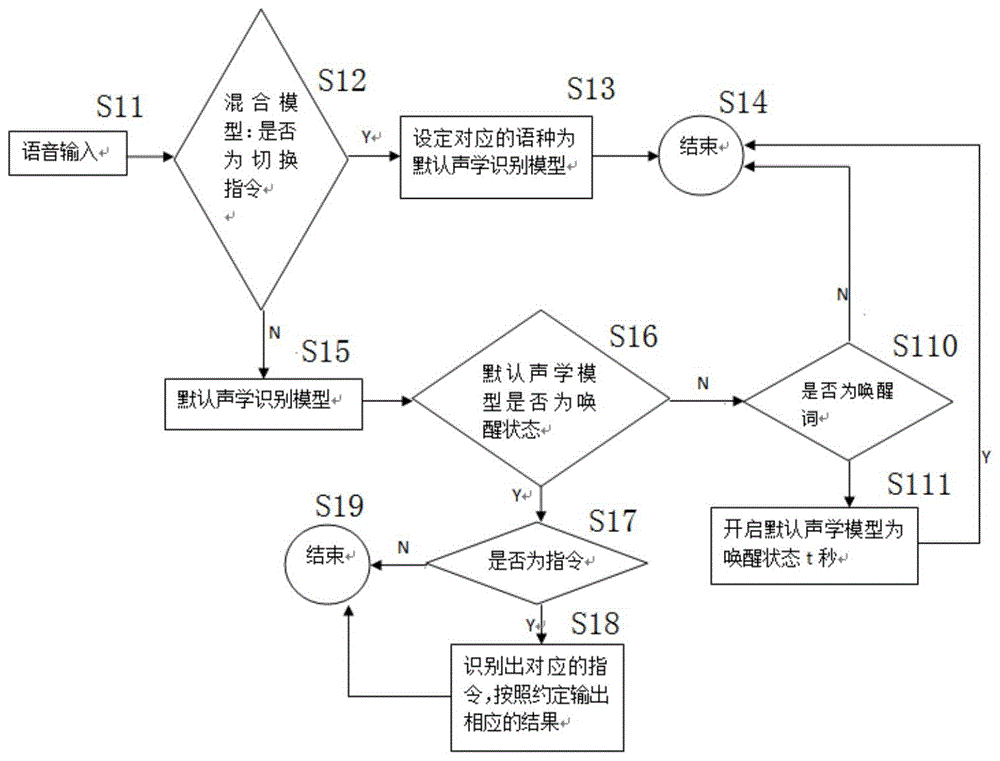
本发明的一种离线式多语种语音识别方法,其具体流程如图1所示,包括以下步骤:
s11语音输入(即所述步骤1);
s12判断采集到的语音信息是否为切换指令,若是则执行步骤s13,否则执行步骤s15;
s13设定切换指令对应的语种为默认的声学识别模型;
s14结束;
s15采用此前默认的声学识别模型;
s16判断此前默认的声学识别模型是否为唤醒状态,若是则执行步骤s17,否则执行步骤s110;
s17判断是否为执行指令,若是则执行步骤s18,否则执行步骤s19;
s18识别出对应的指令,按照约定输出相应的结果;
s19结束;
s110判断采集到的语音信息是否为唤醒词,若是则执行步骤s111,否则回到步骤s14;
s111开启此前默认的声学识别模型为唤醒状态,并保持t秒,t>0,并回到步骤s14。
以下以智能马桶的语音智能终端为例说明本发明的工作原理:假设用户输入语音之前该语音智能终端的声学识别模型为中文的声学识别模型(此即为此前默认的声学识别模型),此时,若用户想要切换为英文的声学识别模型,则只需输入语音“englishmode”(此即切换指令)即可切换到英文的声学识别模型,且该英文的声学识别模型被设定为默认的声学识别模型。在英文的声学识别模型下,若用户输入下一条为唤醒词的语音,则可唤醒该英文的声学识别模型。若用户输入的不是切换指令,则按此前默认的声学识别模型(即中文的声学识别模型)进行语音识别。所述执行指令即用户要求语音智能产品去执行某一个动作的指令,以智能马桶的语音智能终端为例,在中文的声学识别模型下,所述执行指令例如可以是“请启动冲水”或“请打开马桶盖板”等。
实施例二
本发明的一种离线式多语种语音识别方法,其与上述实施例一的区别在于:所述特定语音为唤醒词,若采集到的语音信息为唤醒词,则识别出该唤醒词的语种及设定该语种的声学模型为默认的声学识别模型,并唤醒该默认的声学识别模型。
本实施例中,所述步骤3)包括以下步骤:
b1)判断此前默认的声学模型是否为唤醒状态,若是则执行步骤b2),否则执行步骤b3);
b2)判断采集到的语音信息是否为执行指令,若是则识别出对应的指令,并输出与指令相应的结果,否则执行步骤b3);
b3)结束。
本实施例中,所述默认的声学模型被唤醒词唤醒后,保持唤醒状态t秒,t>0。
本发明的一种离线式多语种语音识别方法,其具体流程如图2所示,包括以下步骤:
s21语音输入;
s22判断采集到的语音信息是否为唤醒词,若是则执行步骤s23,否则执行步骤s26;
s23识别出唤醒词对应的语种;
s24设定唤醒词的语种对应的声学模型为默认的声学识别模型,开启该默认的声学识别模型为唤醒状态,并保持t秒,t>0;
s25结束;
s26判断此前默认的声学识别模型是否为唤醒状态,若是则执行步骤s27,否则执行步骤s29;
s27判断是否为执行指令,若是则执行步骤s28,否则执行步骤s29;
s28识别出对应的指令,按照约定输出相应的结果,并回到步骤s25;
s29结束。
以下再次以智能马桶的语音智能终端为例说明本发明的工作原理:假设用户输入语音之前该语音智能终端的声学识别模型为中文的声学识别模型(此即为此前默认的声学识别模型),此时,若用户想要切换为英文的声学识别模型,则只需输入以英文语种发音的唤醒词即可切换到英文的声学识别模型,同时该英文的声学识别模型被唤醒;若用户输入的不是唤醒词,则按此前默认的声学识别模型(即中文的声学识别模型)进行语音识别。
上述实施例仅用来进一步说明本发明的一种离线式多语种语音识别方法,但本发明并不局限于实施例,凡是依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与修饰,均落入本发明技术方案的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!