基于深度学习的和弦进行生成方法与流程
本发明涉及音乐和声技术领域,特别是涉及一种基于深度学习的和弦进行生成方法。
背景技术:
和弦(chord)源自希腊文,原意是指弦线。在音乐理论里,是指组合在一起的两个或更多不同音高的音。在欧洲古典音乐及受其影响的音乐风格里,更多时候是指三个或以上的音高组合,而两个音高的组合则以音程来描述。和弦的组成音,可分开演奏,亦可同时演奏。
和弦有三度叠置与非三度叠置之分,在西方传统和声中的和弦,均按照三度叠置的原则构成,因此和弦表示为若干组成音的集合。按照现代和声协和理论,当两个不同音高的音同时奏响时,两音之间的音程差决定了这个和声的协和度,并且这个协和度是可以根据音程差进行分类的。
现有的自动伴奏技术需要由用户给出和弦,由琶音生成器(Arpeggiator)生成最终的伴奏。琶音生成器的原理即借由有限状态机(DFA)对给出的和弦里的音进行排列组合,生成一个由和弦音组成的单音序列。
现有技术中已经公开了几种和弦自动生成的技术,如中国专利申请201410582178.1中公开了一种基于遗传算法的和弦伴奏生成方法,其采用遗传算法生成单音序列的和弦,但采用遗传算法生成的和旋准确率仍然较低。
因此,针对上述技术问题,有必要提供一种基于深度学习的和弦进行生成方法。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于深度学习的和弦进行生成方法。
为了实现上述目的,本发明一实施例提供的技术方案如下:
一种基于深度学习的和弦进行生成方法,所述方法包括:
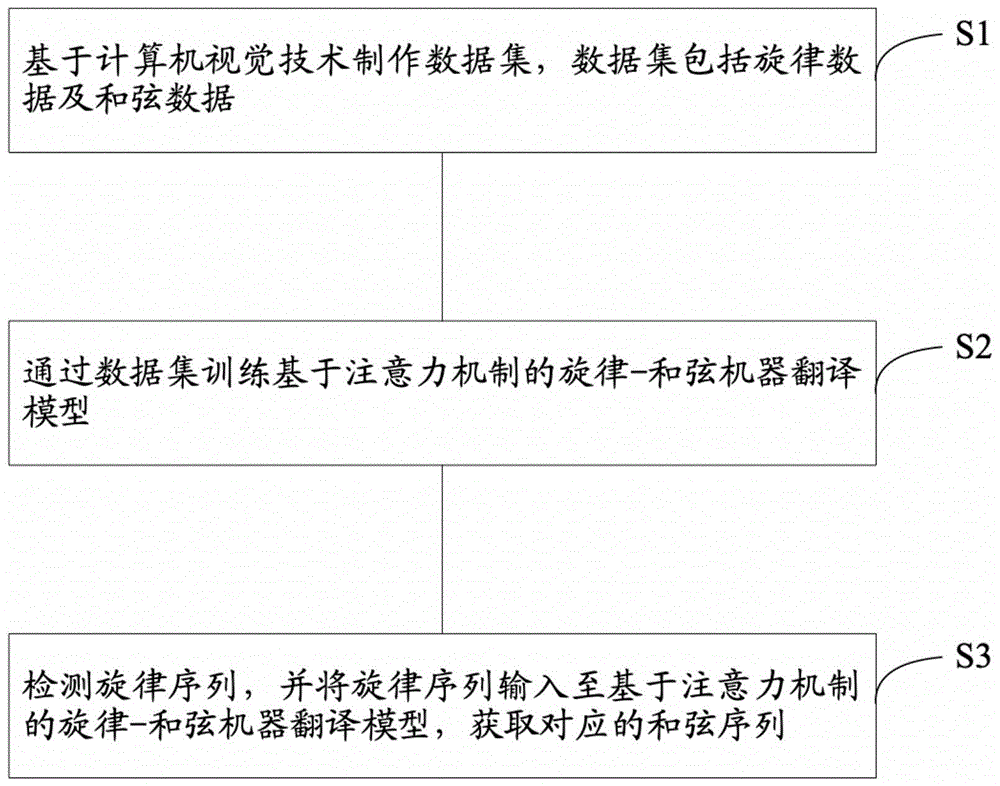
S1、基于计算机视觉技术制作数据集,数据集包括旋律数据及和弦数据;
S2、通过数据集训练基于注意力机制的旋律-和弦机器翻译模型;
S3、检测旋律序列,并将旋律序列输入至基于注意力机制的旋律-和弦机器翻译模型,获取对应的和弦序列。
一实施例中,所述步骤S1具体为:
S11、获取若干乐谱图片;
S12、对乐谱图片进行分割处理,得到旋律区域图片及对应的和弦区域图片;
S13、将旋律区域图片及和弦区域图片对应转化为旋律文本数据及和弦文本数据,旋律文本数据包括高音和时值参数,和弦文本数据包括字母;
S14、对旋律文本数据及和弦文本数据进行处理得到数据集。
一实施例中,所述步骤S12具体为:
对乐谱图片进行一次高斯滤波降噪,再将乐谱图片进行横向投影,得到像素堆积的峰值特征;
追踪峰值特征定位到每行线谱的位置,裁剪出上方的旋律序列和下方的和弦序列;
将线谱、旋律序列、和弦序列标记合在一起的一行乐谱图片做纵向投影,追踪小节线特征将乐谱图片切割为旋律区域图片及和弦区域图片。
一实施例中,所述步骤S14具体为:
对旋律文本数据及和弦文本数据进行降维处理,去除旋律文本数据中的时值参数。
一实施例中,所述旋律-和弦机器翻译模型为旋律序列到和弦序列的机器翻译模型,包括编码器和解码器,所述编码器和解码器均使用LSTM长短期记忆循环神经网络,编码器用于接收旋律序列并加工成中间语义向量C,所述解码器用于将中间语义向量C转换为对应的和弦序列。
一实施例中,所述基于注意力机制的旋律-和弦机器翻译模型中,编码器用于接收旋律序列并加工成中间语义向量Ci,解码器用于将中间语义向量Ci转换为对应的和弦序列,中间语义向量Ci为:
其中,Lx是旋律序列的长度,aij是输出第i个和弦序列时对旋律序列第j段局部旋律的注意力系数,hj是旋律序列第j段局部旋律的语义编码。
一实施例中,所述中间语义向量Ci中,aij的计算方法为:
使用输出和弦序列i-1时刻的隐藏状态Hi-1去逐个与输入旋律序列中每个局部旋律对应的神经网络隐藏状态hj进行比对,通过匹配函数F(hj,Hi-1)来获得当前输入的和弦序列所产生的解码器隐藏状态与之前编码器逐个依次输入局部旋律记录得到的多个编码器隐藏状态进行比较;
通过匹配函数F(hj,Hi-1)得到多个数值,并统一输出到SoftMax函数中进行归一化后得到符合概率分布区间取值的注意力分配概率分布数值。
一实施例中,所述匹配函数F(hj,Hi-1)为加权求和函数。
一实施例中,所述步骤S3中的“检测旋律序列”包括:
S31、确定拍速BPM;
S32、调整麦克风灵敏度阈值;
S33、使用麦克风检测旋律,得到旋律序列。
一实施例中,所述步骤S33具体为:
按照固定频率BPM/60*4次/秒,调用detect函数来获取当前外界的频率值存入到数组中;
旋律的存储结构采用JAVA内部类,类内包括音高和时值两个成员变量。停止后,数组内音高前后相同的进行合并,转储为旋律序列。
本发明具有以下有益效果:
本发明结合注意力机制模型及相关乐理理论,训练得到旋律-和弦机器翻译模型,实现了旋律至和弦的自动翻译,降低了翻译模型训练损失值,提高了翻译准确率,能够为音乐旋律编配合适、动听的和弦进行。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明中基于深度学习的和弦进行生成方法的流程示意图;
图2为本发明中旋律-和弦机器翻译模型的模块示意图;
图3为本发明中LSTM长短期记忆循环神经网络的原理示意图;
图4为本发明中注意力机制模型的原理示意图;
图5为本发明一具体实施例中吉他乐谱的示意图。
具体实施方式
为了使本技术领域的人员更好地理解本发明中的技术方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
参图1所示,本发明公开了一种基于深度学习的和弦进行生成方法,该方法包括:
S1、基于计算机视觉技术制作数据集,数据集包括旋律数据及和弦数据;
S2、通过数据集训练基于注意力机制的旋律-和弦机器翻译模型;
S3、检测旋律序列,并将旋律序列输入至基于注意力机制的旋律-和弦机器翻译模型,获取对应的和弦序列。
其中,步骤S1具体为:
S11、获取若干乐谱图片;
S12、对乐谱图片进行分割处理,得到旋律区域图片及对应的和弦区域图片;
S13、将旋律区域图片及和弦区域图片对应转化为旋律文本数据及和弦文本数据,旋律文本数据包括高音和时值参数,和弦文本数据包括字母;
S14、对旋律文本数据及和弦文本数据进行处理得到数据集。
进一步地,步骤S12具体为:
对乐谱图片进行一次高斯滤波降噪,再将乐谱图片进行横向投影,得到像素堆积的峰值特征;
追踪峰值特征定位到每行线谱的位置,裁剪出上方的旋律序列和下方的和弦序列;
将线谱、旋律序列、和弦序列标记合在一起的一行乐谱图片做纵向投影,追踪小节线特征将乐谱图片切割为旋律区域图片及和弦区域图片。
进一步地,步骤S14具体为:
对旋律文本数据及和弦文本数据进行降维处理,去除旋律文本数据中的时值参数。
参图2所示,本发明中旋律-和弦机器翻译模型为旋律序列到和弦序列的机器翻译模型,包括编码器和解码器,编码器和解码器均使用LSTM长短期记忆循环神经网络,编码器用于接收旋律序列并加工成中间语义向量C,解码器用于将中间语义向量C转换为对应的和弦序列。
参图3所示,LSTM长短期记忆循环神经网络在RNN神经网络基础上进行改良,在保持输入输出的循环性上增加了遗忘门、输入门和输出门三个神经元控制部件,大幅增强了神经网络对序列信号的筛选能力和记忆程度。
本发明中的旋律-和弦机器翻译模型中加入了注意力机制,结合图4所示,编码器用于接收旋律序列并加工成中间语义向量Ci,解码器用于将中间语义向量Ci转换为对应的和弦序列,中间语义向量Ci为:
其中,Lx是旋律序列的长度,aij是输出第i个和弦序列时对旋律序列第j段局部旋律的注意力系数,hj是旋律序列第j段局部旋律的语义编码。
具体地,中间语义向量Ci中,aij的计算方法为:
使用输出和弦序列i-1时刻的隐藏状态Hi-1去逐个与输入旋律序列中每个局部旋律对应的神经网络隐藏状态hj进行比对,通过匹配函数F(hj,Hi-1)来获得当前输入的和弦序列所产生的解码器隐藏状态与之前编码器逐个依次输入局部旋律记录得到的多个编码器隐藏状态进行比较;
通过匹配函数F(hj,Hi-1)得到多个数值,并统一输出到SoftMax函数中进行归一化后得到符合概率分布区间取值的注意力分配概率分布数值。
优选地,匹配函数F(hj,Hi-1)为加权求和函数。
普通的机器翻译模型在实现旋律至和弦的翻译时没有侧重点,因为网络解码器在生成所有和弦序列符号时使用的中间语义C都是一样的,也就是说在生成任何一个和弦时,旋律序列中每个局部段落对它的影响力是相同的,没有一个焦点。
本发明中的注意力机制模型在循环生成和弦符号时会通过匹配机制和自学习给旋律序列中每一段局部旋律分配一个概率,概率值大小体现出对于翻译当前和弦时每个旋律段的不同影响程度。经过多次实验表明,添加注意力机制后生成的和弦质量明显提升。
其中,步骤S3中的“检测旋律序列”包括:
S31、确定拍速BPM;
S32、调整麦克风灵敏度阈值;
S33、使用麦克风检测旋律,得到旋律序列。
具体地,步骤S33具体为:
按照固定频率BPM/60*4次/秒,调用detect函数来获取当前外界的频率值存入到数组中;
旋律的存储结构采用JAVA内部类,类内包括音高和时值两个成员变量。停止后,数组内音高前后相同的进行合并,转储为旋律序列。
本发明中的和弦进行生成方法包括数据集制作、基于注意力机制的旋律-和弦机器翻译模型训练、及旋律序列至和弦序列的翻译三大步骤,以下结合具体实施例对本发明作进一步说明。
一、数据集制作
a)在云服务器上使用Python爬虫对国内外网络上现存的大量流行音乐吉他谱进行爬取,爬取数量为一万八千张。
b)对爬取的一万八千余张谱进行三轮筛选。
第一轮去掉没有旋律简谱标识和和弦标识的吉他谱;第二轮去掉不符合4/4拍格式、带有变调夹转调的吉他谱;第三轮去掉制谱水平粗劣,和弦配置水平较差的吉他谱。最终剩余一万余张所需乐谱,乐谱格式参图5所示。
c)使用Matlab做乐谱图像分割处理,分割出旋律与和弦符号两部分图片区域作为有效数据。
吉他谱中旋律序列由六线谱下方的简谱来表示,和声由六线谱上方的和弦标记来表示。
先对乐谱图片进行一次高斯滤波降噪,再将吉他谱进行横向投影,由于每行六线谱的六条线像素最为密集,可以得到6个像素堆积的峰值作为其特征。追踪这一特征便可自动定位到每行六线谱的位置,继而裁剪出其上下的旋律序列和旋律对应的和弦序列。
再将六线谱、简谱、和弦标记合在一起的一行乐谱图片做纵向投影,由于六线谱的每小节都会有纵向小节线标记,追踪这一像素堆积峰值便可将这一行乐谱切割为以小节为单位的图片。
经过上述两次切割,可以得到从第一小节到最后一小节的文件夹,文件夹中为此小节的和弦进行与旋律谱。
d)构建一个基础的深度学习神经网络,通过深度学习识别两部分图片的对应关系,经过模型来处理分割得到的图像数据,输出转化得到的相应文本数据。即问题转化为符号识别,上方的和弦识别为基础的字母并存储,下方简谱识别为音高和时值来表示的旋律序列。
e)音高取值为1-72的整数。中央1的取值pitch=37,每升高一个半音,pitch+1;反之降低一个半音则-1。时值取值为1-16的整数。本实施例只采用和分析4/4的曲谱,所以每小节的时长都界定为16,每拍时长为4,以16分音符为单位。
f)再将得到的数据进行处理为数据集。
首先进行降维,将时值这一参数去掉。旋律每拍取样4次,和弦每拍取样一次(注意4/4乐谱中一小节为4拍)实现和弦序列与旋律序列的分开存储但又互相关联对应;另外把每拍的旋律的四个值前后拼接作为一个单词,每拍的和弦作为一个单词,使其适应语言模型。为最大程度保留每小节和弦间的相互影响,把每两小节作为一句,即ABCD四小节转化为AB、BC和CD。
如本实施例中数据集样例(A、B、C三小节)具体为:
旋律数据:
A:41 39 39 39 39 39 42 42 41 41 41 41 44 44 49 49
B:49 49 49 49 41 41 46 46 46 46 44 44 44 44 51 51
C:51 51 49 51 51 51 41 42 42 42 44 44 44 44 53 53。
和弦数据:
A:G G C C
B:Am Am F F
C:G G C C。
最终经过处理和整合得到的数据集为:
G G C C Am Am F F@41393939 39394242 41414141 44444949 4949494941414646 46464444 44445151
Am Am F F G G C C@49494949 41414646 46464444 44445151 5151495151514142 42424444 44445353。
二、基于注意力机制的旋律-和弦机器翻译模型训练
本发明的核心在于使用人工智能机器机器翻译模型(Sequence to Sequence Network)实现旋律序列到和弦序列的转换。
旋律-和弦机器翻译模型为旋律序列到和弦序列的机器翻译模型,由两个基本的循环神经网络分别处理两个时序序列,包括编码器和解码器,编码器用于接收旋律序列并加工成中间语义向量C,所述解码器用于将中间语义向量C转换为对应的和弦序列。
这两个过程即为音乐序列的编码解码加工过程,因为输入和输出都处理的是类似于自然语言序列的时序模型,故两个编码器和解码器均使用LSTM长短期记忆循环神经网络。
首先编码器将依次输入的旋律序列(数值表示)进行编码处理,将一个定长的输入序列转化成循环神经网络输出的最后一个隐藏状态,这个隐藏状态相当于学习后将输入的这一个旋律序列浓缩在一起(即为得到的中间语义C),将其传递给解码器使用。
解码器循环神经网络的初始隐藏状态就是编码器生成的中间语义C,解码器将根据此来生成相应的和弦符号,自定义的起始标志作为第一个输入,依据C来生成和弦符号作为输出,然后此输出作为解码器的下一个输入继续在解码器中生成后续的和弦符号,每个后续和弦符号都是建立在解码器中间语义向量C和上一个和弦符号的共同作用下而在和弦符号词池中选择的,直至输出生成了结束标志方停止循环,完成由旋律序列到和弦序列的翻译过程。
在此基础上,本发明在循环神经网络模型上添加了注意力机制。注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标是从众多信息中选择出对当前任务目标更关键的信息。因为音乐和自然语言一样具有规则性和乐理组织性:比如一段旋律的局部声调就主要对应于相应部分的一个和弦符号,其余和弦序列中的和弦会因为音乐的前后关联性而受到该局部旋律的一定影响,但是远远比不上该局部旋律对应位置和弦所受到的影响大。因此我们的机器翻译模型在工作时,当翻译一个生成的和弦符号时,要更加关注中间语义C中其相对应的一部分,这一部分对翻译和弦起到的影响权重应高于其它部分才是符合常理和规则的(相当于在逐个依次生成和弦符号时模拟了一个关注焦点在旋律序列上移动)。
加入注意力机制在旋律-和弦机器翻译模型上,是本发明中较好完成功能提高准确率的关键之处。其具体实现原理为:注意力模型在生成和弦符号时会给旋律序列中的每个局部旋律分配一个概率值,概率值的大小表征对于翻译某个和弦符号时这个局部旋律的影响程度大小。由此训练集中的和弦序列都应该学会其对应旋律序列中局部旋律段的注意力分配概率信息,那么原先的固定中间语义C会更改为根据当前生成和弦符号而不断变化的Ci。即每次的中间向量C需要根据解码器的当前输入重新计算,计算公式为:
其中,Lx是旋律序列的长度,aij是输出第i个和弦符号时对旋律序列第j段局部旋律的注意力系数,hj则是旋律序列第j段局部旋律的语义编码。
其中,每个局部旋律段的注意力系数aij计算方法为:
使用输出和弦序列i-1时刻的隐藏状态Hi-1去逐个与输入旋律序列中每个局部旋律对应的神经网络隐藏状态hj进行比对,通过一个匹配函数F(hj,Hi-1)来获得当前输入的和弦符号所产生的一个解码器隐藏状态与之前编码器逐个依次输入局部旋律段记录得到的多个编码器隐藏状态进行比较,此处使用的比较函数F的形式是加权求和。
通过该比较函数得到多个数值,将此多个数值统一输出到SoftMax函数中进行归一化得到符合概率分布区间取值的注意力分配概率分布数值。这些注意力系数作为aij作用于各个hj局部旋律的语义编码,所有局部旋律的语义编码共同生成基于注意力机制的中间语义向量Ci。
以上是基于注意力机制的旋律-和弦机器翻译模型的基本核心内容,构建完成该模型后,使用模型通过网络爬虫获取的数据集进行批量训练。由于常用的和弦符号相对于常用的语言文字数量少得多,因此和弦符号应采取高维度的词向量表示(词向量是一种高维向量,每一维是一个实数,反应这个和弦符号的某一属性,那么维度的大小表示了和弦的特征,特征越多越能更好的将和弦符号之间的不同区分开,但是相应的和弦符号之间的关系也会被略微淡化,在该模型中经过测验每个和弦使用200维的特征词向量来表示)。经过网络批量训练测试后,在训练集上损失值降低至0.7121,反映出该网络模型在训练上的预测翻译程度上已经相当准确,将此时模型中编码器与解码器的参数保存到文件中,基于此可以完成输入经过处理后的音频文件得到的数据值,输出得到为其基于深度学习大量数据后的编配出的和弦序列。
三、旋律序列至和弦序列的翻译
a)先选择适合的拍速BPM(每分钟多少拍),这个值将决定下一步检测频率函数的调用频率,频率公式为:BPM/60*4(次/秒)。
b)再调整麦克风灵敏度的阈值,在检测时忽略低于该值响度的所有声音信号,以此来控制外界噪音干扰程度。
c)使用手机内置麦克风检测并保存旋律,同步生成旋律曲线。
这一步的基本原理是,在一个进程中按照固定频率调用C语言层的detect函数来获取当前外界的频率值存入到数组中。
旋律的存储结构采用一个JAVA内部类,类内包括音高(Pitch)和时值(Duration)两个成员变量。停止后,数组内音高前后相同的进行合并,转储为旋律序列。
进程每调用4次detect函数(即完成一拍),便依次调用事先存储在soundpool里的crash(大镲)和kick(底鼓)音效来提醒用户,使旋律录入更精确。
检测到旋律序列后,将旋律序列输入至上述基于注意力机制的旋律-和弦机器翻译模型中,即可翻译得到对应的和弦序列。
例如,输入的旋律序列为:
0 0 0 0 44 44 44 44 44 44 44 42 42 42 42 44;
41 41 41 41 41 41 41 41 0 0 39 41 39 36 36 37;
37 37 37 37 37 37 37 37 0 0 39 39 37 39 39 39。
翻译得到的和弦序列为:
C C G G;
Am Am Em Em;
F F G G。
由以上技术方案可以看出,本发明具有以下优点:
本发明结合注意力机制模型及相关乐理理论,训练得到旋律-和弦机器翻译模型,实现了旋律至和弦的自动翻译,降低了翻译模型训练损失值,提高了翻译准确率,能够为音乐旋律编配合适、动听的和弦进行。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!