语音识别的制作方法
本发明涉及语音识别,且具体涉及一种系统,该系统能够检测到密码短语已经被讲出,并且也能够证实该密码短语由指定的说话人讲出,允许该系统被用作激活更高功耗功能(诸如消费者设备中的语音识别)的免提低功耗装置,其中智能电话只是这样的消费者设备的一个实施例。本发明的多个方面还涉及适合用在这样的系统或设备中的模拟-数字转换器。
背景技术:
提供当在待机模式时能够连续监听语音命令的电路系统是已知的。这免除了对用于将该设备从待机模式总体“唤醒”(例如以激活语音识别功能)的按钮或其他机械触发器的需求。
启动免提操作的一种可能方式是使电话的用户说一个关键短语,例如“电话你好(hellophone)”。然后,该设备能够识别该关键短语已被讲出,并唤醒语音识别功能,以及还可能唤醒该设备的其余部分。此外,该免提命令可以被编程为用户专用的,在此情况下,只有先前注册的用户(或多个用户)能够说出该关键短语,且该设备将能够验证就是那个特定用户在讲话(识别讲话人)且进而唤醒语音识别功能。
然而,这样的电路系统实施了相对复杂的算法且因此具有相对高的功耗,意味着将这样的电路系统在具有有限电池容量或其他电力可用性约束的便携设备之内保持连续激活是有点不切实际的。
为了执行对声音的数字处理,通常有必要用传声器检测声音,传声器生成模拟信号,并且以适合这样的处理的形式进行模拟-数字转换,以生成数字信号。
为了在语音信号的数字化中为可靠的语音识别或用户识别提供足够的准确度,需要高性能的模拟-数字转换器(adc)。通常,这将包含嵌入在反馈回路中以将量化噪音频谱塑形的一些单个位(single-bit)或多位(multi-bit)量化器,例如作为δ-σ模拟-数字转换器。
量化器可采取多种形式,包含电压-频率转换器(或电压控制振荡器(vco)),后跟计数器。vco以取决于其输入模拟电压信号的当前值的频率生成脉冲串(pulsetrain)。该计数器可以计数在给定时间区间内由该电压控制振荡器生成的脉冲的数量。在每个区间期间累积的数字计数值因此取决于生成脉冲的频率,且因此是对呈现给该量化器的模拟信号的当前值的度量。
adc反馈回路通常也会包括数字-模拟转换器(dac),以从该量化器的数字输出提供模拟反馈信号;以及模拟运放积分器,以接纳此反馈信号和输入信号。这些模拟组件必须具有低的热噪声和足够的速度,且因此它们将会消耗相对高的功率。同样,将这样的adc电路系统在具有有限电池容量或其他电力可用性约束的便携设备之内保持连续激活是有点不切实际的。
技术实现要素:
根据本发明,提供了一种语音识别系统,包括:
一个输入,用于接收来自至少一个传声器的输入信号;
第一缓存器,用于存储所述输入信号;
降噪模块,用于接收所述输入信号并且生成一个降噪输入信号;
语音识别引擎,用于接收从所述第一缓存器输出的输入信号或接收来自所述降噪模块的降噪输入信号;以及
选择电路,用于将从所述第一缓存器输出的输入信号或来自所述降噪模块的降噪输入信号导引到所述语音识别引擎。
附图说明
为了更好地理解本发明,以及示出如何实施本发明,将以示例方式参照附图,在附图中:
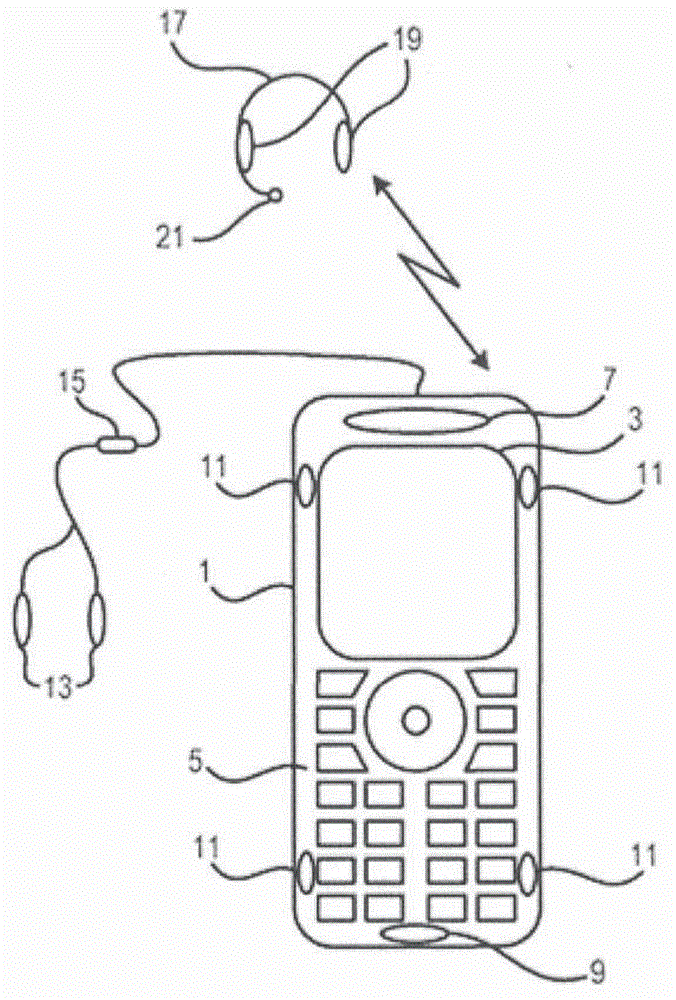
图1示出了移动电话和多种外围设备;
图2示出了图1的移动电话中的音频处理电路系统的组件;
图3示出了图2的涉及该设备的语音识别的组件的简化示意图;
图4是例示了用于使能语音识别系统的过程的总体形式的流程图;
图5a例示了在语音识别系统中的功能模块;
图5b-5e例示了图5a的系统的运行;在图5c中,
图6是例示了图4中示出的过程的修改形式的流程图;
图7a-7k例示了图5的系统中的信号的时间关系曲线图(timehistory);图7a为模拟环境噪声&语音;图7b为数字环境噪声&语音,为
图8是例示了模拟-数字转换器的示意图;
图9是例示了图5的系统的部件的示意图;
图10是在一般意义上例示了模拟-数字转换器的形式的图;
图11是例示了与图10中示出的模拟-数字转换器相同的总体形式的模拟-数字转换器的电路图;
图12是更详细地示出了在图11的电路中的一个组件的形式的电路图;
图13是更详细地示出了在图11的电路中的另一个组件的形式的电路图;
图14是更详细地示出了在图11的电路中的组件的一种替代形式的电路图;
图15是时间关系曲线图,例示了图11的模拟-数字转换器的运行;
图16是例示了与图10中示出的模拟-数字转换器相同的总体形式的模拟-数字转换器的电路图;
图17是例示了与图10中示出的模拟-数字转换器相同的总体形式的模拟-数字转换器的电路图;
图18是例示了与图17中示出的模拟-数字转换器相同的总体形式的模拟-数字转换器的电路图;
图19是例示了与图10中示出的模拟-数字转换器相同的总体形式的模拟-数字转换器的电路图;
图20是传声器封装的示意图;以及
图21是例示了模拟-数字转换器的使用的电路图。
具体实施方式
图1示出了根据本发明的一方面的消费者设备,在此实施例中,该消费者设备是使用语音识别能够至少部分地被控制的移动电话1的形式的通信设备,更具体地是智能电话的形式的通信设备。在此实施例中,移动电话1具有屏幕3和键盘5,然而本发明当然同样可适用于具有触摸屏和/或其他用户界面的设备,以及诸如像平板计算机的用户设备,或具有更有限的通信能力的设备诸如(纯粹)蓝牙tm使能的设备,或不具有通信能力的设备。移动电话1还具有内置扬声器7和内置主传声器9,两者都是模拟换能器。该移动电话1还具有多个(在此具体实施例中是4个)传声器11(其可以是模拟或数字传声器),允许多个声学信号被接收并且被转换成相应的电信号,例如以提供用于在噪声抵消系统中使用的多个环境噪声电信号,或者例如提供多个信号以允许波束成形能力从而增强到语音识别系统的信号输入。
如图1中示出的,移动电话1可具有插孔插座(未例示)或类似的连接装置(诸如usb插座或多针脚连接器插座),允许头戴送受话器(headset)(包括一对立体声耳塞13并且可能地还包括传声器15)通过相应的导线和插孔插头(未例示)或类似的连接装置(诸如usb插头或多针脚连接器插头)连接到该移动电话。替代地,移动电话1可被无线连接(例如使用蓝牙tm通信协议)到无线头戴送受话器17,该无线头戴送受话器17具有耳塞19并且可能地还具有传声器21。虽然未例示,耳塞13、19也可包括一个或多个环境噪声传声器(其可以是模拟或数字传声器),允许接收一个或多个环境噪声信号,例如用于在噪声抵消系统中使用。
图2示出了移动电话1中的音频处理系统的组件。与蜂窝电话网络29的通信是通过一个基带处理器(有时称为通信处理器)31处理的。应用处理器33处理的过程包括但不限于,其中从存储器35复制音频数据或将音频数据存储到存储器35(存储器可以是固态的或在磁盘上的,且存储器例如可以是内置的或是可附接的,例如或是永久地在该移动电话之内或是在可拆卸的存储器设备上)内的过程,以及其中在电话1之内内部地生成音频数据的其他过程。例如,应用处理器33可以处理:语音识别;以数字方式存储在存储器35之内的立体声音乐的复制;将电话会话和其他音频数据向存储器35之内的记录;卫星导航命令的生成;以及用于确认键盘5上任何按钮的按下的音调的生成。无线收发机(或无线编解码器)37用蓝牙tm协议或其他短程通信协议处理通信,例如用无线头戴送受话器17。
基带处理器31、应用处理器33和无线收发器37都向音频集线器39形式的开关电路系统发送音频数据,并且从音频集线器39形式的开关电路系统接收音频数据。音频集线器39在这个所描述的实施方案中采取集成电路形式。
在上述实施方案中,音频集线器39与基带处理器31、应用处理器33和无线收发器37之间的音频信号都是数字的,并且它们中的一些可以是立体声的,包括左音频数据流和右音频数据流。附加地,至少在与应用处理器33通信的情况下,又一些数据流可以被复用到这些音频信号中,例如以使得应用处理器33能够提供立体声音乐,同时也提供其他音频信号,诸如按键确认音调。
音频集线器39经由相应的音频数据链路(即,总线38b、38a、38c)与基带处理器31、应用处理器33和无线收发器37通信,并且音频集线器39具有用于这些数据链路的相应的数字接口40b、40a、40c。
应理解,在例如其中不要求无线收发机37的应用中,音频集线器39仅需要具有两个音频数据链路和两个相应的数字接口。
音频集线器39也向移动电话1的内置模拟音频换能器提供音频信号,并且从移动电话1的内置模拟音频换能器接收音频信号。如图2中所示,音频集线器39向扬声器7提供输出音频信号,并且从传声器9、11接收输入音频信号。
音频集线器39也可以被连接到其他输出换能器43,输出换能器43可以是模拟或数字换能器,并且可以被内置到移动电话1(例如在触觉输出换能器的情况下)或者移动电话1外部的设备(例如图1中示出的有线头戴送受话器的耳塞13)。音频集线器39也可以被连接到其他输入换能器45,输入换能器45也可以是模拟或数字换能器,并且也可以被内置到移动电话1(例如超声传声器)或者移动电话1外部的设备(例如有线头戴送受话器的传声器15)。
应理解,图2仅仅示出了能够通过语音识别被控制的一种可能的设备,并且应理解总体类似的架构(例如基于如本文所描述的音频集线器集成电路周围的架构)可用在各种各样的电子设备中,包含工业设备、专业设备或消费者设备,诸如摄像机(dsc和/或录像机)、便携媒体播放器、pda、游戏控制台、卫星导航设备、平板电脑、笔记本计算机、电视,或诸如此类。构成本发明的其他实施方案或方面的设备可具有不同的架构,例如只具有单个数据接口,或甚至不具有到其他处理器的音频数据接口。
图3是示出了在语音识别功能中可涉及的音频系统的组件的方框图。该一个传声器或多个传声器11、音频集线器39以及应用处理器33位于移动电话1之内,而外围音频输入设备46通过有线或无线连接被连接到移动电话1。
响应于相应的声学刺激由一个或多个传声器11或外围音频输入设备46连续地生成的电信号被输入到音频集线器39之内。这些生成的一个或多个音频信号然后被路由经过音频集线器39,其中所述音频信号可以通过一个或多个数字信号处理(dsp)元件来处理。在音频集线器39之内,音频信号并非被限制于一个路由,且能够以许多不同方式被处理。如下文更详细描述的,此处理可以包括关键短语检测、降噪、改变频率响应以及改变信号增益。当其他组件诸如该音频系统的应用处理器33是在待机模式(即,在低功率模式)时,可以在音频集线器39中进行音频信号分析和处理。
在这个已描述的实施例中,语音识别功能使用多阶段过程运行。
图4是例示了此多阶段过程的总体形式的流程图。此过程始于步骤80,在此步骤从传声器接收到一个信号。如参照图3所描述的,该传声器可被置于手持机(handset)之内,或可以在分立的外围设备中。
在步骤82处,在阶段1的处理中,确定已接收的电子信号是否含有信号活动。这样的信号活动可表示语音。如果没有检测到信号活动,则该过程继续监视已接收的电子信号以查找这样的活动。当在步骤82中检测到可以表示语音的信号活动时,该过程传到步骤84和阶段2的处理,在该处理中确定所检测到的信号是否含有表示预设触发词或短语——即“神秘词”或“神秘短语”——的语音。在一个实施例中,触发短语是由该手持机或其他设备的制造商预设的,且因此对于所有这样的设备可能都是相同的,或者至少对于在一个特定地区内销售的或是向讲一种特定语言的人销售的所有这样的设备是相同的。因此,该触发短语可能是通用的问候诸如“你好电话(hellophone)”。在其他实施方案中,该触发短语可以是任何(可能是非语言的)发声。
在其他实施例中,该手持机或其他设备可能允许用户设置他们自己的触发短语,但是这将需要满足特定准则。例如,该短语可能具有最大允许长度,且该短语将需要被选择以避免过度的误检测,例如该短语不应是一个常用的会话短语也不应该太短例如是单个音素(phoneme)。
如果在步骤84中确定该信号含有不表示预设触发短语的语音,则该过程返回到开始以继续监视已接收的电子信号以查找活动。
当在步骤84中确定该信号含有表示预设触发短语的语音时,该过程传到步骤86和阶段3的处理,在该处理中确定该触发短语是否由与该触发短语相关联的用户讲出,请注意可能有多个用户使用该设备且每个用户都可能具有他们自己的相关联的触发短语。
具体地,如果在步骤84中确定,在该信号中已经被检测到的触发短语正在由该用户讲出,则该过程将传到步骤88,在该步骤中使能一个语音识别引擎。否则,该过程返回到开始,以继续监视已接收的电子信号以查找活动。
一旦传到步骤88,语音识别引擎则检测该用户的后续的语音,且例如将其转换成用于通过该手持机执行的命令以用于本地执行,或可能转换成用于通过连接到蜂窝电话网络29的另一些设备执行的命令以用于远程执行。
此多阶段方法能够允许语音识别以“始终接通”方式运行。也就是说,用户无需按下按钮或执行任何其他动作来激活语音识别。因此,语音识别是完全无需手动操作的,这是有利的。只要说出触发短语,就足以激活语音识别。此外,优选地,该触发短语的同样的实例可被用在第三阶段中来执行讲话者验证,以确保只有被授权的用户能够以此方式向该设备发送命令或从该设备给出命令。
该多阶段方法具有的优点是,“始终接通”的运行不使用过多量的功率。因此,只有第一阶段即信号活动检测阶段是始终运行的,而第二阶段即触发短语检测,则是仅当第一阶段检测到可能表示语音的信号时才激活。
第一阶段能够使用非常低的功率运行,且因此该第一阶段始终接通这一事实不会导致高的连续功率消耗。
第二阶段使用相对低的功率运行,且在相对小份额的时间内接通,且因此当在包括高份额的无活动的时间区间上取平均时,这也不会导致高的功率消耗。
第三阶段使用相对高的功率,但被预期仅在非常小份额的时间内运行,且因此这还是不会导致高的平均功率消耗。
在图3中示出的一般类型的音频系统中,其中有两个或更多个处理器,可以在一个集成电路诸如音频集线器39中执行第一阶段(且还有第二阶段)处理,而可以在另一个集成电路诸如移动电话1中的应用处理器33中执行第三阶段处理。这具有的优点是,当手持机处于待机模式时,除非第二阶段处理确定已经有触发短语被讲出,否则应用处理器33甚至不需要被唤醒。
另外,与可以用该设备的计算和数据库资源实时地执行的相比,尤其是为了为语音识别(或者甚至其他应用诸如实时语言翻译)提供更复杂的算法,可以有利地根本不在移动电话1中执行实际的语音识别,而是可能通过建立一个来自移动电话的网络连接、使用基于云的处理来执行。因为这将会在极少情况下被触发,且当实际需要时,用该网络连接所涉及的功率消耗也不会大幅提高总的平均功率消耗。
因此,这种处理功率的累进式投入使用意味着,该系统作为一个整体能够以表面上“始终接通”的方式运行,而该系统的平均功率消耗保持相对低。
图5a是更详细地例示了如本文所描述的语音识别系统的功能性的一个方框图。所要求的功能性可以按照要求以硬件或软件提供,且具体地本文描述的任何功能可以作为计算机可读代码来提供,该计算机可读代码可以存储在非易失性介质上以用于在任何适合的计算资源上运行以提供所要求的功能。应理解,根据要求,此功能可以分布在多个分立的集成电路中,或者甚至遍及几个较大的设备。例如,在基于图2中所示的架构的一个实施方案中,可以在音频集线器集成电路之内的一个数字信号处理器中执行第一阶段和第二阶段运行,而可以在应用处理器中执行第三阶段运行,并且可以在通过互联网接入的服务器计算机中执行实际语音识别。存在其他可能,尤其是在具有不同处理器架构的设备中。
在一个替代架构中,第三阶段运行也可在音频集线器中执行。
在另一个替代架构中,在单个主机处理器之内执行所有处理,在此情况下第一阶段(且可能地还有第二阶段)处理可以在该处理器的一个独立供电区(powerisland)内执行,该独立供电区始终通电,而该处理器的其余部分仅当第二阶段确定所述触发短语已被讲出时才被通电或被使能执行第三阶段。
图5a示出了用于声音系统的多个可能的资源。具体地,图5a示出了一个系统,其具有多个内部传声器100。例如,手持机可在其前表面上设有一个传声器以及在其后表面上设有一个传声器,但是当然其他配置也是相当可能的。如下所述,在具有多个传声器的一个系统中,至少对于语音检测的启动阶段使用仅来自一个传声器的信号可能就是足够的。
此外,在图5a中示出的系统有可能具有与其相连接的至少一个外围设备102。例如,该外围设备可以是头戴送受话器,具有有线的或无线的(例如蓝牙tm)连接。当这样的头戴送受话器被佩戴时,在该头戴送受话器上的传声器通常将会比在手持机上的传声器更好地拾取用户的语音,且因此每当该头戴送受话器被连接到该手持机时通常将会优选使用由该头戴送受话器上的传声器检测到的信号以用于语音识别的目的。因此,源选择模块104被连接,以接收来自(一个或多个)内部传声器100和外围设备102上的多个传声器的信号,并且选择这些信号之一以用于进一步处理。在这个实施例中,当检测到头戴送受话器被插入到手持机时,或当检测到手持机具有到头戴送受话器的蓝牙tm连接时,源选择模块104就可以选择来自外围设备102的信号。
如上文提到的,多阶段的语音识别系统的至少启动阶段能够有利地使用来自单个传声器的输入,即使当多个传声器可用时。然而,可能优选的是不依赖于来自预定传声器的输入,因为手持机上的一个或多个传声器可能被遮挡,例如如果手持机被放置在平坦表面上或是装在包或衣袋中。因此该系统在此实施例中包含传声器轮询功能106,其检测所述传声器中是否有一个或多个被遮挡,并从被确定为未被遮挡的传声器选择信号。
例如,在音频集线器39(或主机处理器33)上运行的算法可以周期性地依次使能每个传声器(包含头戴送受话器,如果连接的话),比较在频谱的不同部分上每个传声器的输出的幅度,确定哪个传声器具有最强和“最平坦”的信号(即,与可能的或想要的语音信号最相似的频谱形状),并且将此传声器选作阶段1运行的源,禁用其余传声器。
从模块104所选择的传声器接收到的信号被传到至少一个缓存器110,该缓存器110通常能够存储表示一个时间段(比方说例如2至10秒)的声音的信号:显然,该缓存器可被调整大小,以便存储所要求的时间段的变化(一个或多个)信号。在此实施例中,缓存器110仅存储由所选择的传声器产生的信号dout。然而,应理解,缓存器110可以存储由所选择的多个传声器或所有可用的传声器生成的信号,如果源选择器104具有此能力且被控制以同时地选择和输出多个信号。
阶段1处理将会花费有限的时间以确定已接收信号dout是否含有语音。虽然缓存器110有可能相对迅速地被激活(即,被唤醒),但当阶段1的处理确定已接收信号dout可能含有语音以便从该时间点起保存已接收信号dout时,将可理解已接收信号dout中的一些将不会是已经存储在缓存器100之内的且因此将会被永久地丢失,这是不利的。避免已接收信号dout(即数据)的丢失的一个解决方案将是,作为阶段1处理的一部分,运行整个缓存器110,以便连续地存储表示已接收信号的最后2至10秒的信号。因此,无论缓存器110被设计为存储数据(即已接收信号dout)达多久,数据都是基于先进先出而被连续地存储的。
就功率消耗方面而言,在这样的连续基础上运行缓存器110不是高效的。
为了在功率消耗和信号(dout)丢失之间折衷,在一个示例实施方案中,缓存器110被分区成为多个部分,该多个部分响应于所述多阶段的语音识别系统而运行。因此,缓存器110可以响应于多阶段的语音识别系统以多个模式运行。
在一个分区缓存器实施方案中,缓存器110被分区成至少两个区(section)或部分,且因此可以在至少两个独立模式下运行,其中第一区小于第二区。
缓存器110的第一区应该是使得它连续地缓存——即记录——至少足够的已接收信号dout,以便考虑需要阶段1处理以确定已接收信号dout确实含有语音所花费的有限时间。因此,这样的部分缓存,相对于完全缓存,保证没有语音信号被丢失。在现实中,缓存器110的第一区将会缓存的时间比需要阶段1处理以确定已接收信号dout确实含有语音所花费的有限时间更长,例如长200ms。这个额外的缓存,例如相当于200ms,确保语音识别系统的功能所要求的密码短语不会丢失。
缓存器110应当优选地具有低功率性质,其中计时(clocking)是最少化的,并且在存储位置之间的数据移动如果不是不存在的话,至少是最少化的。本领域技术人员将理解,可以从静态随机存取存储器(ram)构造适合的低功率型缓存器1110,例如其中指针被用来相对于时间事件而指示存储位置。
图5b例示了如何相对于已接收信号dout将缓存器110分区的一个原则。
已接收信号dout被例示为包括三个组成部分:环境噪声、触发短语以及一个或多个句子。
应当理解的是,在此图5b中例示的信号dout是关于实际数字信号dout在事实上是什么样的模拟类型的表示,且为清楚和易于解释的原因已经以此方式进行例示。将会注意到,这个有代表性的已接收信号dout的环境噪声部分被例示为具有比密码短语和句子更小的幅度。
在阶段1
如上文所讨论的,为了确保没有语音信号丢失,缓存器110(110a、110b)应该优选地被分区到至少如下程度:使得第一区110a能够存储阶段1处理延迟的等同物,即,相当于t2-t1的已接收信号dout。
在现实中,最佳的设计实践应该允许与在阶段1处理中的延迟相比更多的缓存。因此,图5c例示了缓存器110被分区成(110a、100b)以使得第一区110a能够存储得多于阶段1处理延迟的等同物相当的接收信号dout,这在图5c中被描绘为(t1-t0),其中(t1-t0)>(t2-t1)。
作为一个非限制性的实施例,
一旦阶段1处理确定已接收信号dout含有语音,其输出一个信号
如在下文将讨论的,来自阶段1处理电路系统的此
相对于图5b在时间t1所示的已接收信号dout,图5c示出缓存器110的第一元件110a的内容。如图5c中可见,缓存器110的第一元件110a在时间段t1-t0上已经存储了已接收信号dout,其中t1是密码短语开始的时间,而时间段t1-t0是只有环境噪声的时间。因此,第一元件110a在此时间段t1-t0期间仅存储了环境噪声。应理解,时间段t1-t0表示了为确保语音识别系统的功能所要求的密码短语不丢失所要求的最小缓存时间,即,(t1-t0)>(t2-t1)。因此,在时间段t1-t0期间,缓存器运行在第一模式或阶段1模式(即,最小缓存器模式)。
相对于图5b在时间t2所示的已接收信号dout,图5d示出缓存器110的第一区段110a的内容。如图5d中可见,缓存器110的第一元件110a已经在时间段t2-t0’上存储了已接收信号dout,其中t2是这样的时间,在该时间所述阶段1处理电路系统和/或软件输出一个信号(
相对于图5b在时间t3’所示的已接收信号dout,图5e示出缓存器110的第一区段110a的内容。如图5e中可见,缓存器110的整个第一元件110a和缓存器110的第二元件110b的一部分已经在它们之间存储了至少整个密码短语t3-t1。时间段t3’-t3表示了在疑似表示该触发短语的信号的末尾处的一个短的暂停(例如约100ms)。
从上文的描述中且从图5a-5e中,可以理解,缓存器110将需要足够大以存储例如2到10秒之间的已接收信号dout,该已接收信号dout将包含某些环境噪声、密码短语以及一个(或多个)命令短语,命令短语例如是至少一个句子的形式。
图5的分区缓存器实施方案例示了在存储足够的已接收信号dout用于触发短语检测的背后的原理。本领域技术人员应理解,不依赖于以物理方式将缓存器(110a、110b)分区的其他技术也可被用来缓存已接收信号dout。例如,不是将缓存器110以物理方式划分,而是可以使用一对指针,所述一对指针在足够的已接收信号dout被写入经过——即行波(ripple)传送经过——缓存器110时,指示用于对触发短语检测的足够的已接收信号dout的起始和结束的位置。
因此,当阶段1处理电路系统确定已接收信号dout可能含有语音时,缓存器110被控制以使得它能够被用来在相关的时间段内存储更多的信号dout。
回见图5a,从源选择模块104输出的信号dout是数字形式的。当传声器100和外围设备102生成模拟信号时,可以在源选择模块104中设置模拟-数字转换器,例如使得只有所选择的信号被转换成数字形式。这具有的好处是模拟-数字转换只在实际待要被使用的(一个或多个)信号上执行,而不是浪费功率来提供将不会被使用的信号的已转换形式。
在其他实施方案中,传声器100和外围设备102可能生成数字信号,在此情况下它们通常均会包含至少一个模拟-数字转换器。
从由模块104选择的(一个或多个)传声器接收到的信号dout,也被传到第一阶段处理电路系统112,且具体地是到一个或多个滤波器模块114。第一阶段处理的目的是在已接收到的信号dout中检测可能表示语音的信号。
滤波器模块114可以例如在相应的频带移除或衰减该信号的分量。这些频带可以是相对窄的,例如用于以特定频率移除干扰信号,或者可以是相对宽的,例如为了确保语音中通常不会含有的频带中的信号不被传送通过。因此,在一个实施例中,滤波器模块114包含带通滤波器,其使语音典型的频率范围(诸如300hz—3khz)内的信号通过。
经滤波的信号sf被传送到信号活动检测(sad)模块116。如上文所提到的,此模块116的目的是为了辨识已接收到的可能表示语音的传声器信号dout,以使得接下来能够更详细地检查这样的信号以确定它们是否含有预定的触发短语。已经存在许多信号或语音活动检测(vad)电路116(例如用在降噪系统或语音无线通信协议中的),且任何适当的语音/信号活动检测模块/电路116可以用在这里。然而,应注意的是,某些活动检测模块/电路116旨在以高可靠性检测用户的语音且因此是相对复杂的,从而要求相对高的功率消耗。
在此情况,由信号活动检测模块116做出的一次肯定性确定的结果(
因此,使用相对简单形式的活动检测模块116可能是有利的,其具有相对较低的功率消耗,并且容忍更多数量的误检测事件。例如,活动检测模块116可以简单地确定其已接收的信号是否超过一个阈值水平。应当基于该信号的总体包络而不是阈值水平以上的单个采样做出这样的确定。
当该信号活动检测模块116确定该信号可能含有语音时,阶段2处理(模块118)被使能。具体地,阶段2处理包含触发短语检测模块120。
在此实施例中,从所选择的传声器接收到的信号dout被传送通过滤波器114,然后确定它是否可能表示语音。来自所选择的传声器的信号dout也被存储在缓存器110之内。当信号活动检测模块116确定信号dout的一个特定部分可能表示语音时,由所选择的传声器在同一时间段t3’-t0’内生成的未滤波的信号dout被从缓存器110中取出,并且被传送到触发短语检测模块/电路120。(这里,“未滤波”被用来指未通过滤波器模块114的信号:这样的信号可能已经通过源选择器104中包含的某些滤波器、或从100/102到110和112的路径的公共部分中包含的某些滤波器。)
更具体地,被传送到触发短语检测模块120的信号,不仅含有来自与由该信号活动检测模块辨识的信号相应的时间段的未滤波信号,而且还含有来自在那个时间段之前的一个短时间段(例如200ms)和在那个时间段之后的一个短时间段(例如100ms)的未滤波信号。这允许触发短语检测模块120检测环境噪声,并且在当试图检测触发短语时将环境噪声纳入考虑。这还允许在阶段1之内的信号检测中的任何延迟(t2-t1)。各种不同形式的触发短语检测模块的一般操作是本领域技术人员已知的,且在本文中不做进一步描述。
当触发短语检测模块120确定已接收信号含有表示触发短语的语音时,使能信号(
为了最小化该语音识别系统的总体功率消耗,对如下一个过程进行调整是有用的,即,模块112中的阶段1处理藉以通过该过程导致模块118中的阶段2处理被使能,图6例示了可以如何做到这一点。
图6是流程图,例示了图4的过程,带有合适的修改。除了在此描述的以外,图6的过程与图4的过程完全相同。图5a示出了在此过程中使用的计数电路123,包括计数器124、126和计数分析模块128。当该过程开始时,两个计数器124、126被设置成零。
在该过程的步骤82中,当模块112中的阶段1处理导致模块118中的阶段2处理被使能时,第一计数器124的计数值在步骤162中被增加1。相似地,在该过程的步骤84中,当模块118中的阶段2处理导致模块122中的阶段3处理被使能时,第二计数器126的计数值在步骤164中被增加1。
在步骤166中,计数分析模块128接收来自计数器124、126的计数值。计数分析模块128然后将在一个预定时间段期间比较已接收的计数值。应理解,此计数分析功能既可以用硬件又可以用软件来执行。如果第二计数器126的计数值与第一计数器124的计数值的比小于一个预定比值(可以根据情况将该预定比值设定到想要的值,例如10%、1%或0.1%),这表明阶段1处理正在生成过多数量的误触发事件。在预定时间段之后,计数值被复位到零,且获取用于后续时间段的计数值。
在另一个实施例中,分析模块128可以检查在第一计数器124的计数值和第二计数器126的计数值之间的差值,而不是它们的比,且如果在一个预定时间段上累计的此差值(代表阶段2处理被错误使能的次数)超过与预定数量对应的阈值,则可采取步骤。在此情况下,两个计数器124、126可以被一个异或门以及单个计数器替代,该异或门被连接以接收阶段2使能信号(
作为另一个实施例,可以只提供第一计数器124,且分析模块128可以简单地检查阶段2处理在预定时间段上被使能的次数,且如果此次数超过一个对应于预定速率的阈值,则可采取步骤。
一般地,可以通过硬件计数器或是在可编程计算电路系统上运行的软件来执行,确定所述阶段1处理是否生成过多数量的误触发事件的计数。
当已经确定所述阶段1处理已生成过多数量的误触发事件时,可采取步骤以减少误触发事件的次数。例如,信号活动检测模块116可以响应于一个定期发生的干扰而使能阶段2处理,该干扰具有与语音相同的性质但却不是语音。因此,有一种可能性是,在当信号活动检测模块116检测到它认为可能是语音的信号的时刻,检验已接收信号的频谱。例如,如果发现已接收信号dout在这样的时刻包括一个特定频率的分量,则计数分析模块128可发送控制信号给滤波器模块114以调整所述滤波,并且更具体地是将在那个特定频率的分量过滤掉。具体地,在具有接近于语音频带或就在语音频带中的恒定高水平噪声的环境中,可以将滤波器模块114中的带通滤波器调整以将该噪声排除。相似地,如果在语音频带之内的一个窄带中有噪声(诸如来自附近设备的一个2khz音调),则在滤波器模块114之内的均衡器中的陷波器(notch)可处理此事。
另一种可能性是让分析模块128发送控制信号给检测模块116,以增大其使能(
如果响应于由计数电路123执行的分析结果而修改阶段1处理,则该处理或是可以随时间的推移返回到基线条件,或是可以当阶段1触发频率落到限定的最小值以下时返回到基线条件。
因此,通过基于错误的肯定性检测的相对数量来调整信号活动检测116的运行,可以减小平均功率消耗,同时维持实际信号活动的检测的足够可靠性。更一般地说,借助于分析模块128调整处理模块112的运行,可以减小平均功率消耗,同时维持实际信号活动的检测的足够可靠性。
如上文所提到的,阶段3处理是由来自触发短语检测模块120的信号(
触发短语证实功能130运行在被触发短语检测模块120使用的初始信号的同一区上,即,在缓存器110中存储的信号区t3’-t0’。(对于有多个传声器可用的情况下,这将会来自由传声器轮询功能106所选择的传声器。)这允许触发短语证实的接连阶段对于用户而言透明地进行,无需该用户重复该短语,在提供安全性的同时而不牺牲相对自然的通信方式,这是有利的。
因此,该触发短语证实功能130需要被用户训练,作为对该系统的初始化的一部分,该用户可能例如需要多次且在多种条件下讲出该触发短语。于是,当阶段3处理被使能时,触发短语证实功能130可以将语音数据和在此初始化期间获得的已存储数据进行比较,以判断该触发短语是否已由该用户讲出。用于执行此功能的技术是对于本领域技术人员已知的,因此在这里不再进一步详细描述这些技术,因为它们对于理解本发明是不相关的。
当触发短语证实功能130确定该触发短语是由已授权的用户讲出的时,则一个使能信号(sren)被发送至语音识别引擎(sre)132,该语音识别引擎可被设置在专用处理器之内,且也可能如前所述,被总体设置在一个分立的设备中。语音识别功能132的目的是在该用户讲出触发短语之后辨识他所讲出的命令。然后可以按照控制目的来行使这些命令,例如用于控制移动电话1或其他设备的运行的一个方面。例如,该命令可以是向该命令中指定的另一人拨打电话的指令。
在一个实施例中,该系统被配置以使得某些功能可以由任何人执行,无须等待短语证实功能130完成其对当前语音采样的分析或做出其决定。如上文所提到的,正常运行是第二阶段处理将会识别指定的触发短语已被讲出,而第三阶段处理将会识别该短语是否由指定的用户讲出。只有当第三阶段处理识别出触发短语是由指定的用户讲出的时,后续的语音才会被发送给语音识别引擎以用于解释和处理。
然而,如果后续的语音含有一个预定短语(其可以例如是“紧急响应”类型短语的一个列表中的一个短语,诸如“呼叫999”、“呼叫救护车”,等等),则这被识别,且采取适当的行动,无需首先确定是否是授权用户讲出该触发短语。为了实现该目的,此识别步骤可以在触发短语检测模块120中进行。替代地,每当在阶段2处理中检测到触发短语时,可以总是将后续的语音发送给语音识别引擎132(与触发短语证实功能130平行),以确定其是否含有指定的紧急呼叫短语之一。
为了能够以高准确度执行语音识别,在执行语音识别之前对语音信号执行降噪会是有利的。
因此,由源选择模块104输出的信号dout可被送到降噪模块134,以使得该降噪模块产生一个降噪输出dnrout。在另一个实施例中,来自多个传声器的信号可被供应给降噪模块134,以使得该降噪模块例如通过自适应波束形成从多个输入生成单个降噪输出dnrout。在降噪模块134中,降噪被专门地优化以用于自动化语音识别。如在下文更详细地描述的,此降噪模块134的输出信号dnrout最终被传到语音识别功能。为了节省功率,仅当触发短语检测模块120已经确定了该触发短语已被讲出时才将降噪模块134接通(即,信号
同时,由源选择模块104输出的信号dout可被传到第二降噪模块136,在第二降噪模块136中降噪被专门地优化以用于人际通信(humancommunication)或是待要使用的网络语音通信信道的特性。在该设备是移动电话的情况下,第二降噪模块136的输出最终通过移动通信链路传输。合适的第二降噪模块136的运行对于本领域技术人员是已知的,且将不会在此进一步描述。
因此应注意,由第一降噪模块134和第二降噪模块136执行的功能是不同的。在一个实施例中,由第二降噪模块136执行的功能是由第一降噪模块134执行的功能的一个子集。更具体地,为人际通信而执行的降噪往往会引起失真和其他假象,这对语音识别有不利影响。因此,在第二降噪模块136中使用低失真形式的处理以用于语音识别。
第一降噪模块134的输出dnrout(其被优化以用于语音识别)和缓存器110的输出dbout(其是缓存的未滤波的数字输入语音信号dout)均能够被传到路径选择模块140,该路径选择模块140由选择驱动器142控制。由路径选择模块140选择的信号(dbout,dnrout)然后可以被传到触发短语证实模块130和语音识别引擎132。
在一个实施例中,如上文所讨论的,阶段2处理118以及相关联的功能(包含缓存器110和路径选择模块140)被设置在一个集成电路诸如音频集线器即音频编解码器之内,而阶段3处理被设置在另一个集成电路诸如移动电话的应用处理器之内。
在阶段3处理被设置在另一个集成电路中的情况下,音频集线器可借助于一个总线而被连接到应用处理器,该总线能够以相对高速的突发(burst)来提供数据。一个能够以相对高速的突发来提供数据的总线是spi总线(串行外设接口总线),所谓的“突发性”类型总线。为了利用spi总线的“突发性”性质,可借助缓存器144将路径选择模块140连接到触发短语证实模块130。在缓存器144之内的对数据的相对高速的转移和后续的存储——即缓存,有利地允许了触发短语证实模块130在被触发短语检测模块120激活(
在一个实施例中,存储在缓存器110之内的信号经由路径选择模块140和缓存器144而被传到触发短语证实模块130。如果触发短语证实模块130确定(sren)该触发短语是由授权用户讲出的,则然后降噪模块134的输出dnrout被传到语音识别引擎132。
然而,为了最优性能,应当协调对信号dbout和dnrout的选择的时序。因此,在另一个实施例中,存储在缓存器110之内的信号被传到触发短语证实模块130。如果触发短语证实模块130确定该触发短语是由授权用户讲出的,则缓存器110的输出dbout被传到语音识别引擎132。语音识别引擎132然后能够确定合适的时间来切换为接收来自降噪模块134的输出信号dnrout,而驱动器142控制路径选择模块140以在那时间开始将从降噪模块134输出的信号dnrout导引到语音识别引擎132。缓存器110提供足够的历史,即存储足够的数据,从而能够管理从缓存器110输出的数据和从降噪模块134输出的数据(在改变数据源时,这些输出的数据具有一定的延迟)的时间校准。
例如,语音识别引擎132可被设计以使得能够确定在用户的语音中有停顿时(例如代表着讲出的句子的末尾)的时间。这是语音识别引擎的共同特征,以允许讲出的语音的整个句子被一起发送到远程语音识别系统。
语音识别引擎132然后可以识别语音中的停顿,且可以确定这是合适的时间以切换到对来自降噪模块134的信号dnrout的接收。
为了确保由语音识别引擎132接收稳定的数据流,必须进行合适的缓存。
图7是时间关系曲线图,示出了在不同时间遍及该语音识别系统的多种信号形式。在这个纯粹示意性的表示中,高水平的数字信号表示含有语音的信号,而低水平的数字信号表示不含有语音的信号。
图7a例示了在语音识别系统所处的设备外部的模拟环境噪声和语音信号的表示,这些模拟环境噪声和语音信号待要被该系统的一个或多个传声器捕获且随后被用于语音识别。
图7a更具体地例示了模拟环境噪声和语音的表示,其包括:
模拟环境噪声的第一时间段,到t1为止,接下来是;
语音的时间段t1-t3,其出于此解释目的表示一个触发词或短语,接下来是;
模拟环境噪声的第二时间段t3-t4,接下来是;
语音的时间段t4-t5;其出于此解释目的以第一句子(句子1)的形式表示一个命令短语,接下来是;
模拟环境噪声的第三第二(thirdsecond)时间段t5-t6,接下来是;
语音的时间段t6-t7;其出于此解释目的以第二句子(句子2)的形式表示另一个命令短语;以及
模拟环境噪声的第三时间段t7-t8。
图7b例示了图7a的模拟环境噪声和语音的数字表示。
应当注意的是,为解释清楚起见,假设在模拟环境噪声和语音信号到数字环境噪声和语音信号(dout)的转换中没有延迟。因此,上文关于图7a描述的在t0-t8之间的多个时间段同样也可适用于图7b。
图7c例示了数字信号
指示语音的可能的存在的信号
在此实施例中,从可选择的源接收的信号dout,作为阶段1处理的一部分,被通过滤波器114,然后确定它是否可能表示语音。信号dout也被存储在缓存器110之内。当信号活动检测模块116确定信号dout的一个特定部分可能表示语音时,在时间段t3’-t0’期间由所选择的(一个或多个)传声器生成的未滤波的信号dout(参见图5b)从缓存器110中被取出,并且被传到触发短语检测模块/电路120作为阶段2处理的一部分。在这里,术语“未滤波”被用来指代未通过滤波器模块114的信号:这样的信号可能已经通过源选择器104之内包含的某些滤波器、或从100/102到110和112的路径的公共部分之内包含的某些滤波器。
更具体地,如图7d中所例示的,被传到触发短语检测模块120的信号dbout不仅含有来自与由信号活动检测模块辨识的信号相对应的时间段的未滤波信号,而且还含有来自在那个时间段之前一个短时间段(例如200ms)和在那个时间段之后一个短时间段(例如100ms)的未滤波信号。这允许触发短语检测器120检测环境噪声,并且当试图检测触发短语时将环境噪声纳入考虑。这还允许在阶段1之内的信号检测中的任何延迟(t2-t1)。多种形式的触发短语检测模块的一般运行对于本领域技术人员是已知的,从而在此不做进一步描述。
因此,阶段2处理器118接收来自缓存器110的信号dbout输出,并且试图确定信号dout的起初相对短的突发是否含有触发短语。如果作为阶段2的处理的结果,检测到了可能的触发短语,则阶段2处理模块118输出一个阶段3使能信号
响应于阶段3使能信号(
在现实中,阶段3处理将会要求一段有限的时间来变得有效。因此,来自缓存器110的输出(psdout)经由路径选择140被传到另一个缓存器144以施加另一个延迟,如图7g中所例示的。阶段3处理122当其已经经由缓存器144在时间t4”接收了全部的初始短暂突发的语音之后,确定——即证实——该触发短语是否确实由授权用户讲出,并且输出一个控制语音识别引擎(sre)132的控制信号sren。图7h例示了sren控制信号。
如上文所描述的,如果来自可选择的源的原始信号dout在通过了降噪模块134之后被语音识别引擎132接收到,则语音识别引擎能够非常成功地运行。因此,在信号dout被缓存器110接收的同时,降噪模块134接收来自源选择模块104的信号dout,如图7i中所例示的。降噪模块134包括缓存器146,用于缓存输入到降噪模块134的输入信号dout。缓存器146以与缓存器110相同的方式运行,且允许原始信号dout被存储以供降噪模块134的后续处理。
仅当阶段3处理通过控制信号sren证实触发短语是由授权用户讲出时,才开始降噪处理。对于语音识别引擎132来说,通过路径选择140立即开始处理降噪电路系统的输出信号psdnrout是不实际的,因为在切换期间的任何瞬态效应都将会破坏语音识别。此外,降噪模块134中的降噪算法需要花时间来“热身”或收敛到最终降噪方案,并且使用在此初始时间段期间的该降噪算法的输出会导致失真。另外,降噪算法的延迟不是完全可预测或恒定的,且因此,当进行路径选择切换时,未必有可能将来自缓存器110的数据和来自降噪模块134的数据可靠地时间校准,而不导致重复的或丢失的采样。
因此,缓存器110的输出psdbout经由路径选择140最初被传到语音识别引擎132。对这样的电路系统的常规要求是,它应该能够识别语音中的间隙,诸如在t3-t4和t5-t6等等之间例示的那些间隙。因此,在此实施例中,当语音识别引擎132识别出在该语音中的间隙时,就抓住机会来切换路径选择模块140,以使得降噪模块134的输出被传到语音识别引擎132。在语音中的间隙期间进行此切换,减轻或避免了上文讨论的问题。
因此,在这个例示的实施例中,语音识别引擎132识别出在语音中的间隙,该间隙在触发短语和第一个句子之间。此时,路径选择模块140被切换以使得,降噪模块134的输出被传到语音识别引擎132。因为由降噪模块134中的降噪电路系统施加的延迟通常小于由缓存器110施加的延迟,降噪模块134也缓存降噪信号,这施加了进一步的延迟(如图7j和7k中所例示的),以使得降噪模块134的输出可以是和缓存器110的输出基本时间对准的。任何细微的未对准都是无关紧要的,因为它将会落在该信号不含有语音时的时间内。
因此,降噪模块134的输出可以在时间t5开始供应给语音识别引擎132。
图8包含图8(a)–(d),且含有例示在不同场景中的语音识别系统的运行的时间关系曲线图。在这些时间关系曲线图的每一个中,环境噪声的起初时间段200都跟随着语音202,该语音202说出如下词语“电话你好,请导航到最近的咖啡馆”,其中“电话你好”是触发短语,而“请导航到最近的咖啡馆”是待要被语音识别引擎解释的语音命令且被用作对诸如卫星导航应用等功能的输入。在讲出的词语之后跟随着另一个时间段204的环境噪声。
此外,在图8(a)–(d)中例示的每一种情况下,含有语音的时间段202在时间t11开始,而阶段1处理在时间t12识别语音的存在。当语音的存在被信号活动检测功能识别时,阶段2处理即开始。缓存器的作用是,存储含有语音的信号,并且也存储在时间t13开始的至少大约200ms的在先时间段期间的信号。
如上文所提到的,在时间段202期间的语音以触发短语“电话你好”开始,而阶段2处理模块在时间t14识别该触发短语已被讲出。在这个时间点,阶段2处理模块发送信号以激活阶段3处理模块,但由于初始化所述阶段3处理模块所花费的时间,直到时间t15才能够开始读取来自缓存器110的存储信号。当然,在时间t15,阶段3处理模块开始读取从时间t13起的缓存器数据。
图8(a)例示了一个实施例,其中如箭头210所示出的,响应于由阶段2处理模块在时间t14的肯定性确定,(在诸如图3所示的一个实施方式中,在音频集线器39中)立即做出决定以启动降噪模块134。即,一检测到触发短语,就开始降噪。图8(a)还例示了一种情况,其中在从缓存器110输出的原始数据和从降噪模块134输出的数据之间有一个无缝过渡。
图8(b)例示了一个实施例,其中如箭头212所示出的,在诸如图3中所示出的一个实施方式中,在阶段2处理模块的肯定性确定之后将应用处理器初始化以后,在应用处理器33中做出启动降噪模块134的决定。即,在时间t16启动降噪。图8(b)还例示了一种情况,其中在从缓存器110输出的原始数据和从降噪模块134输出的数据之间有一个无缝过渡。
图8(c)例示了一个实施例,其中如箭头214所示出的,在诸如图3中所示出的一个实施方式中,在阶段2处理模块的肯定性确定之后将应用处理器初始化以后,在应用处理器33中做出启动降噪模块134的决定。图8(c)例示了一种情况,其中在从缓存器110输出的原始数据和从降噪模块134输出的数据之间的过渡并不是无缝的,且可能导致死区时间(deadtime)。即,在降噪模块134启动之后紧接着的时间段内的数据可能被丢失。因此,在图8(c)中例示的实施例中,降噪模块134的启动被延迟直到语音202的末尾,且因此在从t17到t18的时间段内可能被丢失的数据仅含有环境噪声。
图8(d)例示了一个实施例,其中如箭头216所示出的,在诸如图3中所示出的一个实施方式中,在阶段2处理模块的肯定性确定之后将应用处理器初始化以后,在应用处理器33中做出启动降噪模块134的决定。图8(d)也例示了一种情况,其中在从缓存器110输出的原始数据和从降噪模块134输出的数据之间的过渡并不是无缝的,且可能导致死区时间。即,在降噪模块134启动之后紧接着的时间段内的数据可能被丢失。在图8(d)中所示出的实施例中,降噪模块134在应用处理器33已被初始化之后的任意时间被启动,且因此数据在从t19到t20的潜在死区时间内可能被丢失。
上文提到,虽然传声器100和外围设备102生成模拟信号,但在源选择模块104之内可以设置模拟-数字转换器,以使得只有所选择的信号被转换成数字形式。这具有的好处是模拟-数字转换只在实际待要被使用的(一个或多个)信号上执行,而不是浪费功率来提供将不会被使用的信号的转换版本。
如上文所提到的,为了在语音信号的数字化中提供足够的准确度以用于可靠的语音识别或用户识别,需要高性能的adc。通常adc也将包括消耗大量功率的低噪声模拟电路系统。在此处所描述的一个实施例中,例如当较低的性能是可接受时,高性能模拟-数字转换器被配置成也能够在第二模式下运行,该第二模式是相对低功率监视模式。
图9是例示了图5的系统的相关部分的示意图。具体地,图9示出了一个模拟-数字转换器(adc)250,如上所述,其可以被设置在源选择模块104之内,或者可被连接以接收被源选择模块104选择和输出的信号。由该模拟-数字转换器250生成的数字信号被供应到语音活动检测(vad)模块,更具体地被描述为信号活动检测(sad)模块252。当vad/sad模块252检测到由模拟-数字转换器250在其监视模式下生成的信号中存在感兴趣信号时,vad/sad模块252发送控制信号给模拟-数字转换器250以将其运行从正常的第一模式切换到所述第二模式。因此,该adc具有第一模式或高性能模式或相对高功率模式或处理模式,以及第二模式或低性能模式或相对低功率模式或监视模式。
图9还示出了一个数字信号处理器(dsp)254,其可以例如含有信号处理功能的相关部分,诸如在图5中示出的实施例中的触发短语检测模块120和后续的处理模块。具体地,由模拟-数字转换器250输出的信号被供应给dsp254(例如在图9的实施例中在通过缓存器110之后)。dsp中的一些或全部可以由所示的控制信号“使能”启用或禁用。
在一些实施方案中,到adc和dsp的这些控制信号可以是等效的(即,除了也许极性或相对延迟以外都是相同的,以补偿在将adc耦合到dsp的路径中的任何信号延迟)。因此,当模拟-数字转换器250是在其低功率监视模式下时,dsp254可以被禁用。且因此,在vad/sad模块252发送控制信号给模拟-数字转换器250以将其转换到其高性能模式的同时,该vad/sad模块252还发送使能信号给dsp254。然后,dsp254能够接收和处理由在第二模式下运行的模拟-数字转换器250所产生的信号。
在其他实施方案中,例如在dsp既可以实施触发短语检测功能又可以实施语音识别功能,且使用较低分辨率的adc输出就可以使得触发短语检测足够准确,然而语音识别功能要求较高质量的adc运行模式的情况下,则vad/sad可以在不同时间改变使能adc的控制信号以及使能dsp的控制信号。
图10是在一般意义上例示了模拟-数字转换器250的一种可能形式的模块示意图。更具体地,图10示出了模拟-数字转换器250,其接收输入模拟信号sin,并且生成输出数字信号dout。模拟-数字转换器250还从检测模块诸如图9中的vad/sad252接收“模式(mode)”信号。
输入信号sin被施加到减法器270的第一输入,并且被施加到多路复用器272的第一输入。输出信号dout通过数字-模拟转换器(dac)274被反馈,而作为结果的模拟信号sfb被传到减法器270的第二输入。减法器270的输出sdiff被传到具有滤波器传递函数g(f)的滤波器模块276,而经滤波的信号sfilt被施加到多路复用器272的第二输入。所选择的从多路复用器272输出的输入信号sin/sfilt表示被传到量化器(q)278的输入信号qin,从该量化器生成输出数字信号dout。
输入“模式”信号被用来生成用于数字-模拟转换器274的使能(en)信号和用于滤波器模块276的使能(en)信号,且被用来选择多路复用器272的哪个输入信号sin/sfilt被选作量化器(q)278的输入信号qin。
因此,在正常运行(即,上文提到的“第一模式”)中,数字-模拟转换器274和滤波器模块276被使能,且多路复用器272的第二输入信号sfilt被传到其输出,即被用作到量化器(q)278的输入信号qin。dac274、减法器270和滤波器模块276然后为输出信号dout在量化器(q)278周围提供一个负反馈路径,且因此有助于抑制由量化器(q)278的有限分辨率(以及其他误差分量,诸如任何非线性)引入的音频频带量化噪声。
然而,在监视模式下(即,上文提到的“第二模式”),“模式”信号运行,以使得多路复用器272的第一输入信号sin被传到其输出,且因此输入信号sin被直接施加到量化器q(即,qin=sin),且量化器输出dout被用作数字输出。(尽管认识到在sin信号路径中可能有其他滤波器和/或放大器,或其他处理模块诸如在量化器之后的抽取滤波器。而且,如虚线路径279所示出的,输入信号sin可通过该滤波器模块276被传到多路复用器272。)因此,模拟-数字转换器250现在在开环模式(即第二模式)下而不是在闭环模式(即第一模式)下运行。
监视模式是低性能模式,因为不再有反馈回路来抑制量化噪声或任何量化器的非线性。为了降低在此模式下的功耗,至少滤波器模块276或数字-模拟转换器274(但优选两者)也响应于“模式”信号被禁用。
如在下文所讨论的,“禁用”滤波器模块276或数字-模拟转换器274可能涉及在信号路径中断开一个串联开关(seriesswitch),或者将相应的输出节点置于高阻抗状态,或者提供一个恒定输出(零)或以其他方式。优选地,禁用包括从有源电路系统诸如放大器的级(stage)移除偏置电流,具有降低功耗的好处。禁用此滤波器模块276可能涉及施加门控的时钟、移除功率供应源或者减少所施加的功率供应来减少泄漏电流。通常,数字-模拟转换器和在模拟滤波器276中的放大器将会消耗模拟-数字转换器的功率的大约80%,且因此在监视模式(即,第二模式)下,功耗可被显著降低。
减法器270的组件可以和滤波器276共享或是物理地定位在滤波器276之内。多路复用器272可以至少部分地通过以下方式来实施,即,将滤波器276的输出、或者替代路径(即,到多路复用器272的第一输入的路径)中的某些缓存级置于高阻抗模式下。该替代路径可以再利用滤波器模块276的元件以提供内部旁路路径。图10示出了在减法器270之前启动的替代路径,但其可以替代地在减法器之后启动,因为如果没有反馈信号则节点是等效的。
滤波器模块276自身可以是可改变的,以改变其系数等,从而提供所述替代路径的等效物。有效地,将可通过在物理上位于滤波器内部而不是在外部的信号路由来提供类似于图10中所示出路径的替代前馈路径。
图10示出了一个dac274,在其输出节点上产生显性信号(explicitsignal),其电压、电流或电荷对应于数字反馈信号sfb。然而,在具有同样接收输入信号sin的电容器的某些开关电容网络的开关时序中,dac功能可以替代地是隐性的,以使得dac功能的输出电荷立即与输入信号电荷相混合,从而没有分立地可测量的电压、电流或甚至电荷直接对应于该数字反馈信号,但信号处理效果和使用离散dac是等效的。
在一些实施例中,量化器(q)278也可以是可被“模式”信号控制的,以使得,当模拟-数字转换器250在其第二模式(即,其监视模式)下运行时,量化器(q)278在低功率模式下运行,例如在对于监视输入信号sin而言足够的低采样率模式或低分辨率模式下运转。当模拟-数字转换器250切换到正常的闭环模式(即,第一模式)下时,量化器(q)278在高功率模式下运行,该模式提供了如准确的语音识别或用户声音识别所要求的更高准确度的数字输出。
如参照图9描述的,“模式”信号可以由本地语音检测器252来提供,其中当模拟-数字转换器250在监视模式下时,下游电路系统(诸如,硬件或软件dsp)不被激活,以最小化总体功率消耗。然而,对于至少一些下游硬件或软件也可能是始终激活的,且将从dout或某个下游信号生成该“模式”信号。
图11是更详细地例示了与图10中所示出的模拟-数字转换器250具有相同的总体形式的模拟-数字转换器290的示意电路图。与图10中示出的电路的元件相同的图11中所示出的元件被用相同的参考数字表示,从而在此不进一步描述。
输入信号sin被施加到电阻器292,该电阻器具有电阻值rin且其另一端附接到运算放大器虚拟地节点以生成对应的电流sin/rin,且数字-模拟转换器274采取电流数字-模拟转换器(idac)的形式,以使得通过它抽取的电流sfb与从电路的输出反馈的数字信号dout成比例。
从对应于输入信号的电流中减去该电流sfb,且最后获得的净电流作为输入被供应到滤波器模块,该滤波器模块在此实施例中采取反相积分器的形式,其中放大器294使其反相输入连接到电阻器292和idac274的连结点,而电容器(cint)296连接在其输出和所述反相输入端子之间。
多路复用器采取由“模式”信号控制的开关298的形式,可能是cmos传输门的形式。
量化器采取电压控制振荡器300的形式,其接收量化器输入信号qin并且被连接到计数器302。
图12是一个示意电路图,其更详细地示出了在图11的电路中的电流数字-模拟转换器(idac)274的一种可能的形式。
具体地,图12示出了一个参考电流iref,其被供应到idac272,且被镜像通过三个电流镜像晶体管310、312和314,所述电流镜像晶体管用作电流源,以根据晶体管的尺寸比生成相应不同的电流。更具体地,电流镜像电路310生成一个电流,该电流是由电流镜像电路312生成的电流的两倍,而电流镜像电路312继而生成一个电流,该电流是由电流镜像电路314生成的电流的两倍。idac272在偏置电压vb1上运行,偏置电压vb1可以是在idac内部或外部生成。
idac272也接收模拟-数字转换器290的数字输出信号dout,其在此情况下是3比特数字信号,具有比特值α[0]、α[1]、α[2],其中α[0]是最高位。这三个比特值被用来分别接通或关断在电流镜像电路310、312、314中的电流源,因此输出电流sfb与数字输出信号dout成比例。
在其他实施方案中,至少一些电流镜像从属电流源(currentmirrorslavecurrentsource)可以是相等的值,且反馈数字信号可在路由期间受到修改以实施已知技术诸如动态元件匹配(dem)从而改善反馈信号的平均线性,尽管在电流源之间有随机制造不匹配。
图13是示意电路图,其更详细地示出了在图11的电路中的电压控制振荡器(vco)300的形式。
具体地,在图13中示出的实施例中的电压控制振荡器采取三级环形振荡器的形式,具有三个反相器320、322和324,每个都包括一对pmos和nmos晶体管。每个反相器延迟输入信号,且来自输出的反馈导致输出信号vcoout振荡。众所周知,由每个反相器引入的延迟依赖于电压vc,且因此输出信号vcoout的频率依赖于电压vc。在此情况下,电流源326生成电流ib以偏置一个pmos源跟随器,其栅极连接到qin,因此输入信号qin连同由ib限定的几乎恒定的pmos栅源偏置电压一起确定了电压vc,且因此确定了vcoout的频率。
当模拟-数字转换器290处在监视模式时,模式信号被用来减少在电流源326之内的电流,而这继而减小了栅极-源极偏置电压的幅度,因此减小了电压vc,并且因此减少了vco的静态频率。此频率减少也会减少计数器326的动态功率消耗。
对于在此描述的全部模拟电路系统,可使用微分实施方案,例如以帮助提高对来自他处(例如在同一集成电路上)的串扰的敏感性。在此情况下,可将一对互补的微分输入信号施加到一对相应的vco和计数器的各自的输入端,而量化器输出就是在这两个计数器的计数之间的差。
图14是一个示意电路图,其更详细地示出图11的电路中的一个替代的电压控制振荡器(vco)330的形式,其在此情况下是基于电流控制振荡器。
再次,在图14中所示的实施例中的电压控制振荡器采取三级环形振荡器的形式,具有三个反相器332、334、336,每个包括一对pmos和nmos晶体管。电流icp被施加到这三个反相器,而从所述输出到第一反相器332的反馈导致输出信号icoout振荡。
电流icp由一个输入电路生成,该输入电路接收输入电压qin并且将其施加到放大器338的非反相输入。放大器338的反相输入通过数字可编程可变电阻器342而被连接到地,该电阻器342具有电阻值rs,而该放大器338的输出被连接到晶体管340的栅极,晶体管340的源极经过可变电阻器342连接到地且也被连接以给放大器338的反相输入提供反馈路径。此反馈导致运算放大器驱动晶体管340的栅极,从而在电阻器342上施加等于qin的电压。这生成电流isp,其等于qin/rs,通过电阻器342且通过晶体管340到达电流镜像电路344、346,该电流镜像电路344、346生成相对应的电流icp,其可以等于isp也可以是isp的适当地缩放的形式。
于是电流icp随着在qin中的增加而增加,而如果电流icp增加则ico的振荡频率也将增加,因此在icoout处观察到的振荡频率依赖于输入电压qin。
再次,当模拟-数字转换器290处在监视模式时,模式信号被用来通过更改电阻器342的值减小电流,且因此减小vco330的静态频率。
如参照图13所描述的,微分实施方案也是可能的。
图15是时间关系曲线图,例示了图11的模拟-数字转换器290中的量化器以及相似电路的运行。
具体地,图15示出了响应于输入信号qin而生成的、电压控制振荡器300(或者在图13中示出的实施方式中的330)的输出信号vcoout。时钟信号fref由计数器302使用。时钟信号fref的频率可以是恒定的,或者当模拟-数字转换器290处于监视模式时,时钟信号fref的频率可以响应于模式信号而减小,以降低功率消耗。计数器302在时钟信号fref的每个周期的开始被复位到零,然后在fref的那个周期期间对信号vcoout中的脉冲数量计数,并且生成输出信号dout,以表示这样的脉冲的数量。
使用vco作为量化器具有这样的优点,即对于给定的分辨率,低频率量化噪声被减小,以与更常规的一阶δ-σadc相似的方式,但却具有更小的尺寸以及简单性,并且放松了对设备匹配的要求。
在时钟信号fref的每个循环期间,输出信号dout只有有限的准确度(例如,在图15中例示的极其粗糙的分辨率实施例中,该输出信号dout在4和5之间变动)。然而,在长时期内,由于vco未被复位,计数平均数(即,在该长时期上连续振荡的vco的循环总数除以相关的fref时钟循环的数量)对应于在任意长时间上的一个计数的分辨率之内的平均输入信号,也即任意大的总计数,且因此在原则上没有直流量化引入的误差;所有误差都在较高的频率。
也可以从一个不同的视角理解该行为,如果vco在fref周期的开始已经经过了一个循环的一部分,这影响它在下一个fref边沿经过另一个循环何种程度。因此,每个fref循环对其输出波形的“阶段”进行测量,并且添加在循环结束之前构建起的任何更多阶段。因此,它对量化误差做一阶积分,类似于更常规的一阶δ-σadc中的模拟积分器的误差积分功能,所以量化噪声频谱相似于一阶δ–σadc。
因此,量化器不仅是小而简单,它还给出了比单单从计数器302的分辨率可能预期的要少得多的音频频带量化噪声。
图16是更详细地例示了与图10中示出的模拟-数字转换器250相同的总体形式的模拟-数字转换器360的示意电路图。与图10中示出的电路的元件相同的图16中示出的电路的元件被用相同的参考数字表示,且在此不再进一步描述。
在图10的转换器中,在正常运行中,来自dac的反馈信号在输入处被反馈到单个减法器。在更复杂的架构中,例如,为了实施更高阶转换器来获得更多的噪声整形,已知通过在滤波器g(f)之内的中间点处的减法器节点、或甚至在滤波器g(f)输出处的减法器节点提供在正常运行中的信号反馈,如图16中例示的。同样在某些情况下,输入信号可被滤波并且前馈到在滤波器之内或之后的减法节点,绕过输入减法器。本发明的实施方案可以在前向路径中包括这样的滤波器架构,在低功率操作模式下被适当地禁用。
图16还示出滤波器362,其具有在反馈路径中的滤波器传递函数h(f),即,在将输出信号dout滤波之后将其传到数字-模拟转换器274。这再次给出了更多灵活性,以优化信号和噪声传递函数。
图17是更详细地例示了与图11中示出的模拟-数字转换器290相同的总体形式、但却使用开关电容器技术实施的模拟-数字转换器390的示意电路图。与图11中示出的电路的元件相同的在图17中示出的电路的元件被用相同的参考数字表示,且在此不再描述。
输入信号sin经由输入电容器cin402被联接到积分器输入,该输入电容器在其每一端都与开关串联,所述开关受双相位(two-phase)时钟控制,该双相位时钟处于时钟生成模块ckgen400生成的频率fref。
在时钟的第一相位中,cin通过这些开关被连接在sin和地之间,并且存储电荷sin·cin;在第二相位中,cin被连接在地和运算放大器虚接地之间,且运算放大器将此电荷添加到已经存储在积分电容器cint296上的任何电荷。
相似地,电容器cfb阵列被联接到虚接地,以提供反馈信号分量。在第一时钟相位中,该阵列中的每个电容器都在两端被连接到地,以将每个电容器放电。在第二相位中,该阵列的每个电容器在一端连接到虚接地,而另一端可根据从量化器输出信号得出的控制字的相应位的极性被连接到在每个时钟循环中的两个参考电压vrp或vrn中的一个或另一个。该连接可以是通过另外的串联开关、或通过门控被施加至将该每个电容器联接到vrp或vrn的开关元件的时钟。
因此,响应于表示值α的控制字,在每个第二时钟相位中,比方说cfb的一个部份α被充电到vrp,而cfb的剩余部份1-α被充电到vrn,从而在该阵列上的总电荷是(α·vrp+(1-α)·vrn)·cfb。此电荷表示数字量化器输出。(为简便起见,在图17中该阵列仅由两个电容器396、398表示,这两个电容器具有可变尺寸且可连接到相应的参考电压)。
由于电容器在第一相位放电,对应于控制信号α的此电荷须需通过从积分电容器传递来供应。
控制信号其自身是通过解码器模块392从qout得出的(可能包含如上提到的动态元件匹配(dem)功能)。因此每个时钟周期,从在积分电容器上蓄积的电荷中减去一个对应于量化器输出qout的电荷。
在图17的电路中,在转移到积分电容器上之前,表示sin的电荷被保持在cin上,而表示dout的电荷被保持在cfb上。在一些情况下,反馈电容器阵列中的一些或全部可以和输入电容器阵列相融合,且因此从输入信号中减去反馈信号可能是不明显的,并且从而不能够从输入信号中分离地辨识出反馈模拟信号。然而,电路的运行仍然是等效的。
图18是这样的布置的一个示意电路图,其中模拟-数字转换器420是与图17中示出的模拟-数字转换器390相同的总体形式。与图17中示出的电路的元件相同的在图18中示出的电路的元件被用相同的参考数字表示,且在此不再描述。
在模拟-数字转换器420中,在第一时钟相位中,输入信号sin通过相应的开关422、424被施加到反馈电容器阵列的电容器396、398,生成电荷sin·cfb。在第二相位中,参考电压vrp或vrn被连接到相应的cfb部份以将在cfb上的电荷改变一个代表dout的量,但从没有这样一个相位其中该阵列保持一个完全代表dout而不代表sin的电荷。
为了增加转换增益(以比特每伏特为单位),即在sin和dout之间的输入处改变相对加权,可能需要一个附加的电容器426(cinx)。相反,附加的电容器426也可能不在那里,而是可以提供反馈帽的次级阵列来减少转换增益。
图19是更详细地例示了与图10中示出的模拟-数字转换器250相同的总体形式的模拟-数字转换器440的示意电路图。与图10中示出的电路的元件相同的在图19中示出的电路的元件被用相同的参考数字表示,且在此不再描述。
在图19的模拟-数字转换器440中,输出数字信号dout被传送通过积分器442和第二数字-模拟转换器444,以生成反馈信号sdcfb,该反馈信号被传到在起自sin的路径中的另一个减法器xxx。当激活时,此第二反馈路径以低的(亚音频)频率提供高增益反馈,从而将该电路系统的或在信号sin中明显的任何直流偏移清零。但该路径不经过可觉察的音频信号,从而不影响adc对音频输入信号的响应。
这个第二“直流伺服”反馈回路会消耗相对少的功率,因此在adc的两个模式下均可以是激活的。然而,其可能仅在初始化阶段期间是运行的,且然后被禁用。此禁用的目的主要是避免由输出信号分量对减去的信号做任何调制,而不是为了节省功率。此外,在第二反馈路径中的信号反馈是用于与在第一反馈路径中的反馈(为了通过信号频带负反馈而将该系统线性化)不同的目的(为了移除直流)。
图20是例示了如上文所描述的在半导体芯片469上的模拟-数字转换器的使用的示意图,该半导体芯片469与传声器传感器462共同封装在单个封装器件460中。
更具体地,图20示出传声器462,其接收偏置电压vb并且生成一个信号,该信号被传到预放大器464然后被传到模拟-数字转换器466。除了实际的传声器电容性传感器462之外,所有电路系统都可被一起集成在如示出的单个半导体芯片469上,但在一些实施方案中该电容性传感器也可被集成在与示出的电路系统的全部或至少一部分相同的芯片上。
时钟信号ck被用来给模拟-数字转换器466以及输出数字接口模块(fmt)468计时。
检测模块470检测模拟-数字转换器466的输出,并基于检测结果控制模拟-数字转换器466的运行模式。相同的控制信号也可被用来控制预放大器464和输出接口模块468。例如,检测结果可被用来减少预放大器464在低功率模式下的偏置,以失真或热噪声性能为代价。
输出接口模块468可以仅仅重新定时输出的adc数据,或者可以包含噪声整形比特宽度减小电路系统,以将多比特adc输出转换成方便的单比特格式,或者可以将δ-σ输出信号dout重新格式化成另一种格式,例如脉冲长度调制(plm)格式,或(通过抽取)重新格式成标准多比特格式,例如i2s,处于24比特且fs=48khz。
重新格式化可允许一些控制型比特连同数据一起被传输,例如将检测模块470的输出标记到下游电路系统。例如,检测模块470可充当信号检测模块并且控制下游的触发短语检测模块。下游电路系统诸如计数分析电路系统也可以通信回向设备460,以更改检测参数,或是通过分立的针脚,或是通过调制时钟ck的脉冲的长度或相位、或者时钟ck的边沿的相位。
图21是与图10中示出的模拟-数字转换器250相同的总体形式的另一种模拟-数字转换器480的示意电路图。与图10中示出的电路的元件相同的在图21中示出的电路的元件被用相同的参考数字表示,且在此不再描述。
在图21中示出的电路适合用于多个输入信号可用的情况,在此情况下是两个输入信号可用,且有必要选择哪一个(如果任一均可)应被转换成高质量数字输出。例如,在具有多个传声器的通信设备中,当一个或多个传声器可能有时被遮挡时,周期性地轮询传声器来决定应该使用哪个传声器是非常有用的。
因此,图21的电路接收多个输入模拟信号sina、sinb,并且生成对应的多个相应的输出数字信号douta、doutb。可使用反馈路径选择这些输入信号中的一个以用于高质量的转换,另一些输入信号仍可被转换,但使用的是相应的量化器、开环,仅仅提供低质量的输出但却具有小的额外功率消耗且不需要用于每个信道的数字滤波器或反馈dac。
输入模拟信号sina、sinb被施加到多路复用器482,该多路复用器的输出可被联接(可能经由如所示出的可编程增益放大器)到减法器270的第一输入,且输入模拟信号sina、sinb也被施加到多路复用器486、488的相应的第一输入。输出数字信号douta、doutb被传到多路复用器484,多路复用器484的输出信号被反馈经过数字-模拟转换器(dac)274,并且最后获得的模拟信号sfb被传到减法器270的第二输入。减法器270的输出sdiff被传到具有滤波器传递函数g(f)的滤波器模块276,而经滤波的信号sfilt被施加到多路复用器486、488的相应的第二输入。多路复用器486的输出被传到第一量化器(q)490以形成第一输出数字信号douta,而多路复用器488的输出被传到第二量化器(q)492以形成第二输出数字信号doutb。
控制信号m1、m2和sel控制所述多路复用器且因此控制电路系统的运行模式。另一个控制信号“模式”被用于生成使能(en)信号以用于数字-模拟转换器274,以及以用于滤波器模块276。图21例示了如下三种运行模式所要求的“模式(mode)”的逻辑水平:m1、m2和sel:(a)sina和sinb两者的低功率转换,(b)sina的高质量转换和sinb的低功率转换,以及(c)sina的低功率转换和sinb的高质量转换。由于只有一个反馈dac和一个滤波器g(f),不可能以高质量同时转换两个输入信号(但是可以通过以相似方式添加另外的dac、滤波器和多路复用器来方便地扩展电路,以允许选择更多信道用于并发的高质量转换)。
在此实施例中,存在检测模块252。此模块接收输出数字信号douta、doutb,并且使用这些信号以通过生成如上所述的适当的控制信号水平来选择哪些输入模拟信号应该被用来生成输出。然而在其他实施方案中,这些控制信号可以是从别处供应的,例如从不同种类的下游检测器。
输入选择信号(sel)被用来确定输入模拟信号sina、sinb中的哪个应当由多路复用器482传到减法器270,还被用来确定输出数字信号douta、doutb中的哪个由多路复用器484传到数字-模拟转换器(dac)274。同时,控制信号m1被用来确定多路复用器486的哪个输入被传到第一量化器490,且控制信号m2被用来确定多路复用器488的哪个输入被传到第二量化器492。
因此,在上述的模式(b)和(c)中,数字-模拟转换器274和滤波器模块276被使能,且多路复用器486、488之一的第二输入被传到其相应的输出。dac274、减法器270和滤波器模块276然后为相应的输出信号在相应的量化器周围提供一个负反馈路径。
然而,在上述的模式(a)中,m1和m2信号被设定,以使得多路复用器486、488中每个的第一输入被传到每个相应的输出,且因此每个相应的输入信号被直接施加到相应的量化器q。模拟-数字转换器480因此现在对于两个输入信道都是运行在开环模式下而不是闭环模式下。
由于两个信道都是开环地运行的,不需要dac或滤波器,或不需要可选的可编程增益放大器,因此可以通过将“模式”设定成0来禁用这些模块。虽然未示出,这也可以禁用减法器270和多路复用器482和484。
在一些应用中,可能需要在转换成高质量模式之前将施加到输入信号的增益进行编程,但不需要在低功率模式下调整此增益,例如固定增益可能对于初始信号检测是足够的,但可编程增益对于优化用于更复杂的下游处理的动态范围是有用的。因此,将放大器放置在输入和减法器270之间而不是放置在从输入到量化器多路复用器的路径中是有利的。此外,由于只可能以高质量转换一个信道,故而只需要一个可编程增益放大器。因此,将这样的增益级定位在多路复用器482之后是有利的。
因此公开了一种模拟-数字转换器,其能够提供高质量输出,且也能够在低功率模式下运行。
应注意,上文提到的实施方案例示而非限制了本发明,且本领域技术人员将能够在不背离所附权利要求的范围的前提下设计许多替代实施方案。词语“包括”并不排除在权利要求中所列出的元件和步骤之外存在其他元件或步骤,“一”、“一个”不排除复数,并且权利要求中记载的多个单元的功能可能通过单个特征或其他单元来达成。术语“触发短语”和“触发词”在本说明书中是可互换的。权利要求书中的任何参考标记不应被解释为限制权利要求的范围。
- 还没有人留言评论。精彩留言会获得点赞!