声音事件的识别装置和方法与流程
[0001]
本公开涉及声音处理的技术领域,具体地涉及声音事件的识别装置和识别方法。
背景技术:
[0002]
这个部分提供了与本公开有关的背景信息,这不一定是现有技术。
[0003]
声音带有关于日常环境和发生在其中的物理事件的大量信息。人可以感知到其所处的声音场景(繁忙的街道、办公室等),并且可以识别个别声音事件(汽车经过、脚步声等)。这些声音事件的自动检测在现实生活中具有许多应用。例如,其对于环境意识中的智能设备、机器人等非常有用,此外,当雷达或视频系统在某些情况下可能无法工作时,声音事件的自动检测可以帮助构建完整的监控系统。
技术实现要素:
[0004]
这个部分提供了本公开的一般概要,而不是其全部范围或其全部特征的全面披露。
[0005]
本公开的目的在于提供一种声音事件的识别装置和方法,其通过端到端设备来更有效地进行自动声音事件检测。与传统的基于递归神经网络的模型不同,根据本公开的设备完全基于纯一维卷积神经网络模型,其更易于并行化并且在某些环境中性能更佳。同时,根据本公开的设备是一个完整的端到端系统,无需使用人工的参与。其输入是原始声音信号,输出是声音事件的后验概率。
[0006]
根据本公开的一方面,提供了一种声音事件的识别装置,包括:编码器,其配置成将其中含有多个声音事件的声音信号转换为低维空间中的特征;以及检测器,其配置成将所述特征映射为每个声音事件的后验概率,其中,所述检测器对所述特征执行多次空洞卷积运算。
[0007]
根据本公开的另一方面,提供了一种声音事件的识别方法,包括:将其中含有多个声音事件的声音信号转换为低维空间中的特征;以及将所述特征映射为每个声音事件的后验概率,其中,对所述特征执行多次空洞卷积运算。
[0008]
根据本公开的另一方面,提供了一种程序产品,该程序产品包括存储在其中的机器可读指令代码,其中,所述指令代码当由计算机读取和执行时,能够使所述计算机执行根据本公开的声音事件的识别方法。
[0009]
根据本公开的另一方面,提供了一种机器可读存储介质,其上携带有根据本公开的程序产品。
[0010]
从在此提供的描述中,进一步的适用性区域将会变得明显。这个概要中的描述和特定例子只是为了示意的目的,而不旨在限制本公开的范围。
附图说明
[0011]
在此描述的附图只是为了所选实施例的示意的目的而非全部可能的实施,并且不
旨在限制本公开的范围。在附图中:
[0012]
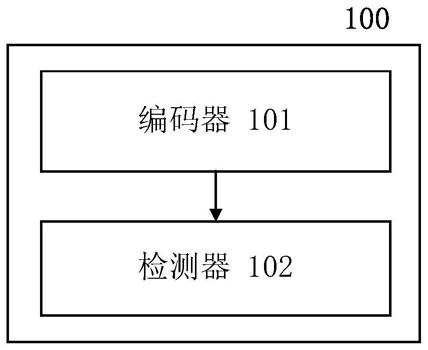
图1示出根据本公开的一个实施例的声音事件的识别装置的框图;
[0013]
图2示出根据本公开的一个实施例的声音事件的识别网络的整体框架;
[0014]
图3示出根据本公开的一个实施例的声音事件的识别方法的流程图;
[0015]
以及
[0016]
图4为其中可以实现根据本公开的实施例的声音事件的识别装置和声音事件的识别方法的通用个人计算机的示例性结构的框图。
[0017]
虽然本公开容易经受各种修改和替换形式,但是其特定实施例已作为例子在附图中示出,并且在此详细描述。然而应当理解的是,在此对特定实施例的描述并不打算将本公开限制到公开的具体形式,而是相反地,本公开目的是要覆盖落在本公开的精神和范围之内的所有修改、等效和替换。要注意的是,贯穿几个附图,相应的标号指示相应的部件。
具体实施方式
[0018]
现在参考附图来更加充分地描述本公开的例子。以下描述实质上只是示例性的,而不旨在限制本公开、应用或用途。
[0019]
提供了示例实施例,以便本公开将会变得详尽,并且将会向本领域技术人员充分地传达其范围。阐述了众多的特定细节如特定部件、装置和方法的例子,以提供对本公开的实施例的详尽理解。对于本领域技术人员而言将会明显的是,不需要使用特定的细节,示例实施例可以用许多不同的形式来实施,它们都不应当被解释为限制本公开的范围。在某些示例实施例中,没有详细地描述众所周知的过程、众所周知的结构和众所周知的技术。
[0020]
根据本公开的一个实施例,提供了一种声音事件的识别装置,包括:编码器,其配置成将其中含有多个声音事件的声音信号转换为低维空间中的特征;以及检测器,其配置成将所述特征映射为每个声音事件的后验概率,其中,所述检测器对所述特征执行多次空洞卷积运算。
[0021]
如图1所述,根据本公开的声音事件的识别装置100可以包括编码器101和检测器102。
[0022]
编码器101可以将含有多个声音事件的声音信号转换为低维空间中的特征。这样的特征可以用于更有效地提取用于识别声音事件的任务。这里,本领域技术人员应该清楚,多个声音事件可以是包括两个或更多个不同类型(例如街道上行人脚步和汽车喇叭的声音等)的声音事件。编码器101可以将含有这些声音事件的信号转换为低维空间中的特征向量。
[0023]
接下来,检测器102可以将该低维空间中的特征向量映射为每个声音事件的后验概率,例如,针对每一帧的街道上行人脚步或汽车喇叭的声音的后验概率。根据本公开的一个实施例,这些后验概率可以表示声音事件的类型、开始和结束时间等。这里,本领域技术人员应该清楚,上述事件仅是示例性的,本公开并不限于此。
[0024]
根据本公开的一个实施例,检测器102可以对所述特征向量执行多次空洞卷积运算,以获得每个声音事件的后验概率。空洞卷积也称作膨胀卷积或扩张卷积,其是向卷积层引入了一个称为“扩张率(dilation rate)”的新参数,该参数定义了卷积核处理数据时各值的间距。根据本公开的一个实施例,检测器102可以对所述特征向量执行三次空洞卷积运
算,以提供更大的感受野(receptive field)。在卷积神经网络cnn中,决定某一层输出结果中一个元素所对应的输入层的区域大小(映射)被称作感受野。换言之,更大的感受野即更多的信息量。这里,本领域技术人员应该清楚,本公开执行三次空洞卷积运算仅是示例性的,本公开并不限于此。本领域技术人员当然可以根据实际运算量等需求执行更多或更少的空洞卷积运算。
[0025]
根据本公开的一个实施例,编码器101可以对所述声音信号执行一维卷积运算、带参数的relu运算、归一化运算以及1
×
1卷积运算以得到所述特征向量。归一化运算即对特征向量进行归一化处理,以提高训练速度。1
×
1卷积运算可以用于修改所述特征向量的最后一维的尺寸。亦即,经由1
×
1卷积运算处理后的特征向量可以保持一致的尺寸。这里,本领域技术人员应该清楚,上述运算仅是示例性的,本公开并不限于此。本领域技术人员当然可以根据实际需要添加、删除或替换其中的运算。
[0026]
根据本公开的一个实施例,检测器102可以在对所述特征执行多次空洞卷积运算之后,进一步执行1
×
1卷积运算、全连接运算和softmax运算以得到所述后验概率。这里,本领域技术人员应该清楚,上述运算仅是示例性的,本公开并不限于此。本领域技术人员当然可以根据实际需要添加、删除或替换其中的运算。
[0027]
根据本公开的一个实施例,检测器102可以在执行每次空洞卷积运算的过程中进一步执行1
×
1卷积运算、带参数的relu运算、归一化运算和深度卷积运算。这里,本领域技术人员应该清楚,上述运算仅是示例性的,本公开并不限于此。本领域技术人员当然可以根据实际需要添加、删除或替换其中的运算。
[0028]
例如,如图2所示,输入的含有多个声音事件的声音信号可以在经过一维卷积运算、带参数的relu运算、归一化运算以及1
×
1卷积运算后得到特征向量。接下来,得到的特征向量在经过三次空洞卷积运算之后,又经过1
×
1卷积运算、全连接运算和softmax运算后得到后验概率。
[0029]
再如图2所述,其中,具体图示了一次空洞卷积运算的过程。其中,每一个圆圈从左到右表示时刻点即一个时间序列,而每一卷积层具有一个扩张率。扩张率成指数上升,以确保卷积层能够获得足够时间长度的信息。例如,图2中示意性地示出了四层卷积层,其中,第一层的扩张率d=1,第二层的扩张率d=2,第三层的扩张率d=4,第四层的扩张率d=8。所述扩张率表示特征向量在时间尺度上的信息量。这里,本领域技术人员应该清楚,本公开图2所示的卷积层仅是示例性的,本公开并不限于此。
[0030]
然后,根据本公开的一个实施例,在空洞卷积运算的过程中可以进一步执行1
×
1卷积运算、带参数的relu运算、归一化运算和深度卷积运算。
[0031]
使用根据本公开的用于声音事件的识别装置,由于其端到端的框架可以更有效地进行自动声音事件检测,并且其中采用的多次空洞卷积运算可以在大范围的时间尺度内增加更多的信息量,进而实现更好的检测结果。
[0032]
根据本公开的一个实施例的声音事件的识别装置,在训练阶段,可以使用具有事件标签的声音数据对编码器101和检测器102进行训练。在评估阶段,训练的编码器101和检测器102可以用于检测输入混合声音中的每个事件并评估训练的编码器101和检测器102的性能。
[0033]
下面将结合图3来描述根据本公开的实施例的用于声音事件的识别方法。如图3所
示,根据本公开的实施例的用于声音事件的识别方法开始于步骤s310。
[0034]
在步骤s510中,将其中含有多个声音事件的声音信号转换为低维空间中的特征。
[0035]
接下来,在步骤s320中,将所述特征映射为每个声音事件的后验概率。
[0036]
其中,在所述步骤s320中,对所述特征执行多次空洞卷积运算。
[0037]
根据本公开的一个实施例的用于声音事件的识别方法进一步包括对所述声音信号执行一维卷积运算、带参数的relu运算、归一化运算以及1
×
1卷积运算以得到所述特征的步骤。
[0038]
根据本公开的一个实施例的用于声音事件的识别方法进一步包括在对所述特征执行多次空洞卷积运算之后执行1
×
1卷积运算、全连接运算和softmax运算以得到所述后验概率的步骤。
[0039]
根据本公开的一个实施例的用于声音事件的识别方法进一步包括对所述特征执行3次空洞卷积运算的步骤。
[0040]
根据本公开的一个实施例的用于声音事件的识别方法进一步包括在执行每次空洞卷积运算的过程中执行1
×
1卷积运算、带参数的relu运算、归一化运算和深度卷积运算的步骤。
[0041]
根据本公开的一个实施例的用于声音事件的识别方法进一步包括使用具有事件标签的声音数据对所述编码器和所述检测器进行训练的步骤。
[0042]
根据本公开的一个实施例的用于声音事件的识别方法,其中,所述特征为基于声音信号的每一帧的特征。
[0043]
使用根据本公开的用于声音事件的识别方法,由于其端到端的框架可以更有效地进行自动声音事件检测,并且其中采用的多次空洞卷积运算可以在大范围的时间尺度内增加更多的信息量,进而实现更好的检测结果。
[0044]
根据本公开的实施例的用于声音事件的识别方法的上述步骤的各种具体实施方式前面已经作过详细描述,在此不再重复说明。
[0045]
显然,根据本公开的用于声音事件的识别方法的各个操作过程可以以存储在各种机器可读的存储介质中的计算机可执行程序的方式实现。
[0046]
而且,本公开的目的也可以通过下述方式实现:将存储有上述可执行程序代码的存储介质直接或者间接地提供给系统或设备,并且该系统或设备中的计算机或者中央处理单元(cpu)读出并执行上述程序代码。此时,只要该系统或者设备具有执行程序的功能,则本公开的实施方式不局限于程序,并且该程序也可以是任意的形式,例如,目标程序、解释器执行的程序或者提供给操作系统的脚本程序等。
[0047]
上述这些机器可读存储介质包括但不限于:各种存储器和存储单元,半导体设备,磁盘单元例如光、磁和磁光盘,以及其他适于存储信息的介质等。
[0048]
另外,计算机通过连接到因特网上的相应网站,并且将依据本公开的计算机程序代码下载和安装到计算机中然后执行该程序,也可以实现本公开的技术方案。
[0049]
图4为其中可以实现根据本公开的实施例的用于声音事件的识别装置和识别方法的通用个人计算机1300的示例性结构的框图。
[0050]
如图4所示,cpu 1301根据只读存储器(rom)1302中存储的程序或从存储部分1308加载到随机存取存储器(ram)1303的程序执行各种处理。在ram 1303中,也根据需要存储当
cpu 1301执行各种处理等等时所需的数据。cpu 1301、rom 1302和ram 1303经由总线1304彼此连接。输入/输出接口1305也连接到总线1304。
[0051]
下述部件连接到输入/输出接口1305:输入部分1306(包括键盘、鼠标等等)、输出部分1307(包括显示器,比如阴极射线管(crt)、液晶显示器(lcd)等,以及扬声器等)、存储部分1308(包括硬盘等)、通信部分1309(包括网络接口卡比如lan卡、调制解调器等)。通信部分1309经由网络比如因特网执行通信处理。根据需要,驱动器1310也可连接到输入/输出接口1305。可拆卸介质1311比如磁盘、光盘、磁光盘、半导体存储器等等根据需要被安装在驱动器1310上,使得从中读出的计算机程序根据需要被安装到存储部分1308中。
[0052]
在通过软件实现上述系列处理的情况下,从网络比如因特网或存储介质比如可拆卸介质1311安装构成软件的程序。
[0053]
本领域的技术人员应当理解,这种存储介质不局限于图4所示的其中存储有程序、与设备相分离地分发以向用户提供程序的可拆卸介质1311。可拆卸介质1311的例子包含磁盘(包含软盘(注册商标))、光盘(包含光盘只读存储器(cd-rom)和数字通用盘(dvd))、磁光盘(包含迷你盘(md)(注册商标))和半导体存储器。或者,存储介质可以是rom 1302、存储部分1308中包含的硬盘等等,其中存有程序,并且与包含它们的设备一起被分发给用户。
[0054]
在本公开的系统和方法中,显然,各部件或各步骤是可以分解和/或重新组合的。这些分解和/或重新组合应视为本公开的等效方案。并且,执行上述系列处理的步骤可以自然地按照说明的顺序按时间顺序执行,但是并不需要一定按照时间顺序执行。某些步骤可以并行或彼此独立地执行。
[0055]
以上虽然结合附图详细描述了本公开的实施例,但是应当明白,上面所描述的实施方式只是用于说明本公开,而并不构成对本公开的限制。对于本领域的技术人员来说,可以对上述实施方式作出各种修改和变更而没有背离本公开的实质和范围。因此,本公开的范围仅由所附的权利要求及其等效含义来限定。
[0056]
关于包括以上实施例的实施方式,还公开下述的附记:
[0057]
附记1.一种声音事件的识别装置,包括:
[0058]
编码器,其配置成将其中含有多个声音事件的声音信号转换为低维空间中的特征;以及
[0059]
检测器,其配置成将所述特征映射为每个声音事件的后验概率,
[0060]
其中,所述检测器对所述特征执行多次空洞卷积运算。
[0061]
附记2.根据附记1所述的装置,其中,所述编码器对所述声音信号执行一维卷积运算、带参数的relu运算、归一化运算以及1
×
1卷积运算以得到所述特征。
[0062]
附记3.根据附记2所述的装置,其中,所述检测器在对所述特征执行多次空洞卷积运算之后,进一步执行1
×
1卷积运算、全连接运算和softmax运算以得到所述后验概率。
[0063]
附记4.根据附记1至3中任一项所述的装置,其中,所述检测器对所述特征执行3次空洞卷积运算。
[0064]
附记5.根据附记4所述的装置,其中,所述检测器在执行每次空洞卷积运算的过程中进一步执行1
×
1卷积运算、带参数的relu运算、归一化运算和深度卷积运算。
[0065]
附记6.根据附记1所述的装置,其中,使用具有事件标签的声音数据对所述编码器和所述检测器进行训练。
[0066]
附记7.根据附记1所述的装置,其中,所述特征为基于声音信号的每一帧的特征。
[0067]
附记8.一种声音事件的识别方法,包括:
[0068]
将其中含有多个声音事件的声音信号转换为低维空间中的特征;以及
[0069]
将所述特征映射为每个声音事件的后验概率,
[0070]
其中,对所述特征执行多次空洞卷积运算。
[0071]
附记9.根据附记8所述的方法,进一步包括对所述声音信号执行一维卷积运算、带参数的relu运算、归一化运算以及1
×
1卷积运算以得到所述特征。
[0072]
附记10.根据附记9所述的方法,进一步包括在对所述特征执行多次空洞卷积运算之后,进一步执行1
×
1卷积运算、全连接运算和softmax运算以得到所述后验概率。
[0073]
附记11.根据附记8至10中任一项所述的方法,其中,对所述特征执行3次空洞卷积运算。
[0074]
附记12.根据附记11所述的方法,进一步包括在执行每次空洞卷积运算的过程中执行1
×
1卷积运算、带参数的relu运算、归一化运算和深度卷积运算。
[0075]
附记13.根据附记8所述的方法,其中,由编码器将其中含有多个声音事件的声音信号转换为低维空间中的特征,由检测器将所述特征映射为每个声音事件的后验概率,
[0076]
所述方法进一步包括使用具有事件标签的声音数据对所述编码器和所述检测器进行训练。
[0077]
附记14.根据附记8所述的方法,其中,所述特征为基于声音信号的每一帧的特征。
[0078]
附记15.一种程序产品,包括存储在其中的机器可读指令代码,其中,所述指令代码当由计算机读取和执行时,能够使所述计算机执行根据附记8-14中任何一项所述的方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1