一种基于3D卷积的孪生网络声纹识别方法与流程
【技术领域】
本发明属于声纹识别技术领域,尤其涉及一种基于3d卷积的孪生网络声纹识别方法。
背景技术:
声纹识别(speakerverification)是通过分析录音设备记录的说话人的语音特点来鉴别说话人身份的一种算法。声纹识别可进一步的分为文本相关声纹识别和文本无关声纹识别,文本相关声纹识别需要说话人说出预先指定的内容,而文本无关声纹识别对说话人的语音内容不作要求。
现在声纹识别领域应用最多的框架是无监督高斯混合模型(gmm),gmm模型是一种统计模型,在数据不足的情况下,gmm模型很难建立说话人的空间分布,因此后来有学者提出基于gmm的高斯混合通用背景模型(gmm-ubm),gmm-ubm引入了背景模型,进一步提高了识别精度。一些基于gmm-ubm的方法包括i向量(i-vector)已经在声纹识别领域展现出了自己的高效性。尽管现有的方法可以高效的完成声纹识别的任务,但目前的算法仍有自己的缺点,其中最主要的是现有算法无法有效的利用说话人的独特的语音特点,这主要是因为gmm模型本身是非监督模型。当前,一些算法开始采用监督的模型来改进gmm等非监督算法,例如基于gmm-ubms的svm分类模型,pldai-vectors模型。还有一些学者收到深度学习的启发,讲dnns网络从语义识别领域迁移到声纹识别领域,并取得了不错的效果。但是这些算法都没有考虑不同说话人可能存在相似语音,同一说话人也可能在不同状态下说话差异较大的情况。而在基于深度学习的声纹识别方法中,虽然卷积神经网络cnns已经作为主要的特征提取的网络被广泛的应用,但是目前的cnns特征提取网络知识利用的为一维卷积和二维卷积的方法。但是一维卷积和二维卷积的方法忽略语音信息的空域和时域特征,识别率不高。
技术实现要素:
本发明的目的是提供一种用于声纹识别的基于3d卷积的孪生网络,既可以对语音信息进行充分的监督学习,还可以兼顾语音信息的时域信息,进一步提高了声纹识别的正确率。
本发明采用以下技术方案:一种用于声纹识别的基于3d卷积的孪生网络,包括:
特征提取单元:用于将音频数据转化为三维张量,三维张量即为mflc特征。
sia-net网络:用于处理mflc特征,缩短同一说话人之间数据的特征距离,增大不同说话人之间数据的特征距离。
cnn网络:用于建立每一个说话人的模型库。
预测单元:用于测试音频数据的说话人身份。
进一步地,该sia-net网络:为两个,每一个sia-net网络均包括:依次相连接的三个3d卷积层、一个池化层、四个3d卷积层、一个连接层、一个池化层、一个flatten层和一个全连接层。
进一步地,该cnn网络包括依次相连接的三个全连接层和一个softmax层。
进一步地,该距离为欧氏距离。
本发明还公开了上述的一种用于声纹识别的基于3d卷积的孪生网络的训练方法,包括如下步骤:
步骤1.1、构建训练样本数据集:选取多个不同的音频数据,将每一个音频数据转化为一个与之对应的三维张量,所述三维张量即为mflc特征;多个所述三维张量即组成训练样本数据集;
对所述三维张量进行随机两两配对组合,产生的配对组合共有
步骤1.2、搭建sia-net网络;
步骤1.3、将所述步骤1.1中的配对组合输入sia-net网络,得到与之对应的第一s特征,多个所述第一s特征组成的集合即为样本集合;然后,选择sia-net网络中的一个,并固定参数,得训练后的sia-net网络;
步骤1.4、构建cnn卷积网络;
步骤1.5、将步骤1.3中的所述第一s特征输入到所述cnn卷积网络;
步骤1.6、提取所述cnn卷积网络的倒数第二层输出的样本的第一d特征,多个所述样本的第一d特征组成的集合即为语音模型匹配数据库;然后,选择去除softmax层的cnn卷积网络,并固定参数,得训练后的cnn卷积网络;
步骤1.7、即得训练后的用于声纹识别的基于3d卷积的孪生网络。
本发明还公开了一种基于3d卷积的孪生网络声纹识别方法,采用上述的sia-net网络和训练方法,包括如下步骤:
步骤2.1、采集音频数据,提取出mflc特征;
步骤2.2、将所述mflc特征输入到训练后的基于3d卷积的孪生网络中,由训练后的sia-net网络提取第二s特征,将第二s特征输入训练后的所述cnn卷积网络中,提取出第二d特征;
步骤2.3、将所述第二d特征与所述语音模型匹配数据库中的样本的第一d特征进行匹配,确定并输出匹配结果。
进一步地,步骤2.1的具体过程为:
对音频数据进行频域变化:对输入的音频数据进行傅里叶变换,得到对应的矩阵数据。
频域滤波:采用mel滤波器组对所述矩阵数据进行频域滤波,得滤波后的数据。
对滤波后的数据进行对数运算,得mflc特征。
进一步地,上述第二d特征和第一d特征均为余弦距离。
本发明的有益效果是:mflc特征通过舍弃dct变换加强了特征之间的相关性,更有利于深度学习网络模型的处理。既可以对语音信息进行充分的监督学习,还可以兼顾语音信息的时域信息,进一步提高了声纹识别的正确率。
【附图说明】
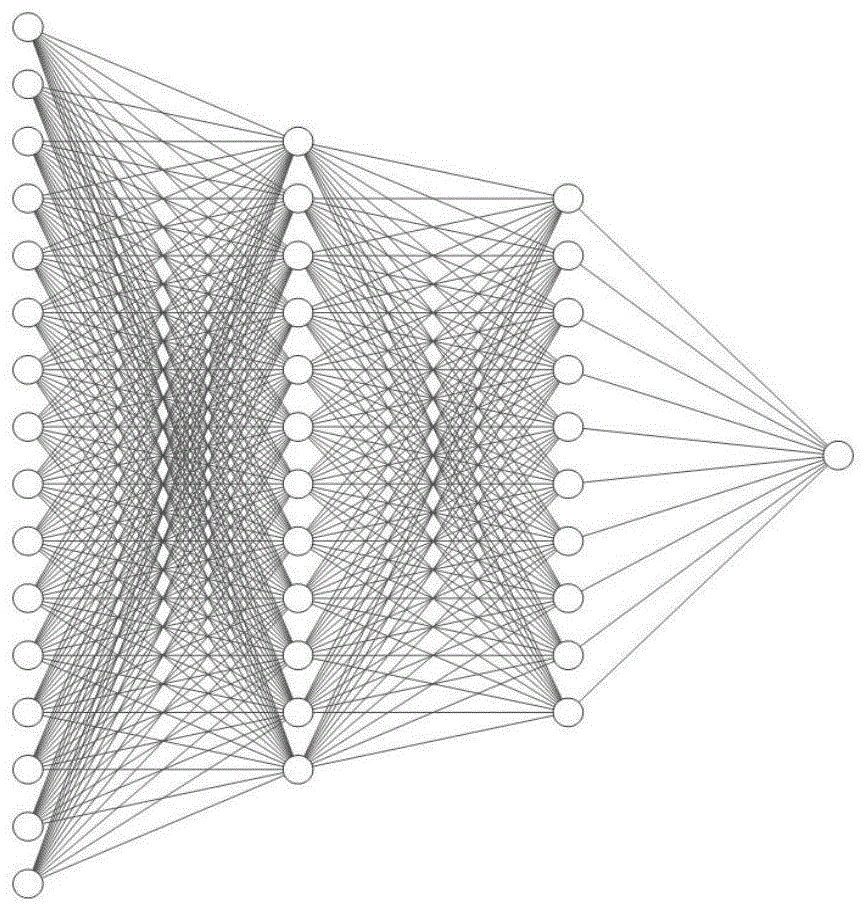
图1为本发明中cnn网络的结构图;
图2为本发明中的声纹识别方法的流程图。
【具体实施方式】
下面结合附图和具体实施方式对本发明进行详细说明。
本发明实施例公开了一种用于声纹识别的基于3d卷积的孪生网络,siamese-net网络简写为sia-net网络,包括:特征提取单元:用于将音频数据转化为三维张量,三维张量即为mflc特征。
sia-net网络:用于处理所述的mflc特征,缩短同一说话人之间数据的特征距离,增大不同说话人之间数据的特征距离。该距离为欧氏距离。cnn网络:用于建立每一个说话人的模型库。预测单元:用于测试确定音频数据的说话人身份。
该sia-net网络:为两个,每一个所述sia-net网络均包括:依次相连接的三个3d卷积层、一个池化层、四个3d卷积层、一个连接层、一个池化层、一个flatten层和一个全连接层。该cnn网络包括依次相连接的三个全连接层和一个softmax层。
本发明还公开了上述的一种用于声纹识别的基于3d卷积的孪生网络的训练方法,包括如下步骤:
步骤1.1、构建训练样本数据集:选取多个不同的音频数据,将每一个音频数据转化为一个与之对应的三维张量,三维张量即为mflc特征;多个所述三维张量即组成训练样本数据集;对三维张量进行随机两两配对组合,产生的配对组合共有个,其中:m为三维张量的个数。
步骤1.2、搭建sia-net网络。
步骤1.3、将步骤1.1中的配对组合输入sia-net网络,得到与之对应的第一s特征,多个第一s特征组成的集合即为样本集合;然后,选择sia-net网络中的一个,并固定参数,得训练后的sia-net网络;
步骤1.4、构建cnn卷积网络;
步骤1.5、将步骤1.3中的第一s特征输入到cnn卷积网络;
步骤1.6、提取所述cnn卷积网络的倒数第二层输出的样本的第一d特征,多个所述样本的第一d特征组成的集合即为语音模型匹配数据库;然后,选择去除softmax层的cnn卷积网络,并固定参数,得训练后的cnn卷积网络;
步骤1.7、即得训练后的用于声纹识别的基于3d卷积的孪生网络。
本发明还公开了一种基于3d卷积的孪生网络声纹识别方法,采用上述的sia-net网络和训练方法,如图2所示,包括如下步骤:
步骤2.1、采集音频数据,提取出mflc特征;
步骤2.2、将mflc特征输入到训练后的基于3d卷积的孪生网络中,由训练后的sia-net网络提取第二s特征,s特征为欧氏距离;将第二s特征输入训练后的所述cnn卷积网络中,提取出第二d特征;d特征为余弦距离。
步骤2.3、将所述第二d特征与所述语音模型匹配数据库中的样本的第一d特征进行匹配,确定并输出匹配结果第二d特征和第一d特征均为余弦距离。通过比较余弦距离的大小,进行匹配,余弦距离越小,匹配度越高。
mfcc特征是声纹识别领域最为常用的数据表示方式之一,然而由于mfcc最后的dct变化,使得mfcc并不包含语音信息的局部特征。本发明中的方法,舍弃了mfcc的dct操作,使特征更加适合卷积网络学习。
对音频数据进行频域变化,得到对应的矩阵数据,具体为对输入的音频数据进行傅里叶变换,采用公式(1):
其中:x(n)表示音频数据,n是傅里叶变换的长度。
频域滤波:采用mel滤波器组对矩阵数据进行频域滤波,得滤波后的数据;滤波器的个数可根据需求选择,通常设置为24个左右,本实施例中采用的为25。其中每个三角滤波器的频率响应定义为:
其中f(m)是三角滤波器的中心频率;
mel(f(m+1))-mel(f(m))=mel(f(m))-mel(f(m-1));
mel(f)=2595×lg(1+f/700);f为频率,单位hz。
对滤波后的数据进行对数运算,得到mflc特征:
mflc特征通过舍弃dct变换加强了特征之间的相关性,更有利于深度学习网络模型的处理。
在时域维度上,本实施例采用的是20ms,步长设置为10ms,即每段语音信息会有10ms的交叠。以一个1秒的语音信号为例,该信号会被分为100个20ms的小的时域信号,每一个小的时域信号通过声谱转换提取mflc特征,在本发明中我们采取的mflc的长度为40,一个时域信号会被转化成一个80*40的特征矩阵,最终通过数据的堆叠可以得到一个n*80*40的数据立方体,n为堆叠的维度,在本实施例中设置n的值为20。
本发明中,建立每个说话人独一无二的d-vector特征,从而保证声纹识别的准确率,在该部分的难点主要有两点:一是如何尽可能的减小同一个说话人不同语音内容的影响,不同的语音内容会很大程度的影响语音的数据内容;另一个难点是如何尽可能的区分不同的说话人的语音,当不同的说话人说相同的语音信息时语音的数据特征可能很相似,这对后续的处理、识别产生很大的影响。本发明中,一方面通过建立mflc三维特征张量的形式减小两种情况的影响,另一方面建立了siamese-net的网络的结构,来保证声纹识别的准确率。语音信息数据经过sia-net处理后,同组数据的相似性和不同组数据的差别性会大大提高,可以很大程度上提高后续语音识别的准确率。然后通过损失函数起到评价网络输出相似性的目的,使得属于同一说话人语音的数据组尽可能的相似,不同说话人语音的数据组尽可能的增大差别。在该部分选择的损失函数为:
在公式(2)中x1和x2表示同一对数据中的两组数据,y表示同一组的两个数据是否来同一个说话人,若是其值为1,否则为0。margin表示边界值,当数据来自不同说话人时,为了保证损失函数的适用性,采用相减的形式,在本实施例中margin设置为10。
sia-net网络中,采用了prelu激活函数来代替relu激活函数,prelu激活函数比relu在训练过程中有更高的稳定性。可以进一步提高网络的性能。如下:
sia-net网络:为两个,每一个sia-net网络均包括:依次相连接的三个3d卷积层、一个池化层、四个3d卷积层、一个连接层,一个池化层、一个flatten层和一个全连接层。
cnn网络的结构如图1所示,由三个全连接层和一个softmax层,softmax层的前一特征作为数据库模型。三个全连接层的参数设置为,110,80,64。
预测阶段:该部分的主要功能就是对输入的语音信息进行评测,通过将输入的语音信息和建立的各个说话人的语音模型对比,得出该语音信息与各个说话人的相似分数,从而来确定说话人身份。
衡量特征相似性的最常用的方式之一就是计算输入数据与模型数据的余弦距离,本发明中通过计算第二d特征和第一d特征之间的余弦距离,得到与第二d特征距离最小的第一d特征,从而得到说话人的身份。
本实施例中,各sia-net网络的组成顺序均为依次相连接的三个3d卷积层,卷积核大小全部设置为【3x3x3】,卷积核个数分别设置为【128,64,64】,步长设置为{【1x1x1】,【1x2x1】,【1x2x1】一个连接层、一个3d卷积层,卷积核大小设置为【3x3x5】,卷积核个数设置为128,步长设置为【2x2x2】,1个池化层,4个3d卷积层,卷积核大小全部设置为【3x3x3】,卷积核个数设置为64,前两个步长设置为【1x1x1】,后两个步长设置为【1x2x2】,一个连接层,一个池化层,卷积核大小设置为【1x1x3】,步长设置为【1x1x2】,一个flatten层,最后为一个全连接层,卷积核个数设置为128。如表1所示:
表1sia-net网络结构
为验证本发明中的方法,进行如下实验,本实施例中,根据军事指挥战斗指令进行了音频信息的录制,录制人员一共有8名,每人建立100条纯净语音数据,纯净语音数据指的是在实验室环境录制,无外界噪音,然后根据采用常用的噪声数据对纯净语音数据进行加噪,信噪比依次设置为5db,10db,20db。处理完毕后,每个人对应的语音数据共有400条,含纯净语音。将所有的语音数据转化为mflc三维张量。
在每个人的数据库中随机抽取20%的张量作为训练数据集,共640个张量数据,80%的数据集进行测试。将所有的20%的训练数据集还需要进行两两匹配,在本发明中一共会有204480对训练数据集。
利用204480对数据训练sia-net网络,硬件平台为4张1080ti显卡,内存100g。训练8h。训练完毕后,固定sia-net参数,舍弃其中一个sia-net网络。
利用sia-net网络,将mflc三维张量变换为s特征,利用640个s特征训练cnn网络。本发明中硬件平台为4张1080ti显卡,内存100g。训练2h。训练完毕后,舍弃softmax层。
8个人中,每个人都有80个s特征,将每个人的80个特征输入到cnn网络中,得到每个人对应的80个d特征,将每个人的80个特征,取均值,得到8个模板,作为数据库。
将余下的所有mflc三维张量一次通过训练后的sia-net网络,cnn网络得到d特征。将这些d特征一一与8个模板进行匹配,即计算余弦距离,输出距离最近的模板所代表的身份,得到结果。
同时,还采用现有技术中的gmm算法对验证试验中的数据进行计算。gmm阶数设置50,训练数据集和测试数据集与验证试验一致,即640个mflc三维张量作为训练,其余作为测试。最终得出,采用本发明中的方法进行声纹识别比gmm算法的正确率高出3%。
- 还没有人留言评论。精彩留言会获得点赞!