一种基于人工智能语音的人机交互方法与流程
本发明涉及人机交互技术领域,特别涉及一种基于人工智能语音的人机交互方法。
背景技术:
随着机器学习、人工智能等技术的发展,语音识别技术也得到了极大的发展,语音识别技术的渐渐成熟,渐渐有替代键盘和鼠标之势。在互联网环境下人工智能技术的得到跨越性的发展,将语音识别技术准确率提升到一个历史性的高度,使基于语音人机交互的方式在我们的生活得到了普及。人机交互的发展总共分为几个重要的历史阶段:第一个历史阶段是电脑的诞生,电脑是通过鼠标和键盘操作来完成人机交互。第二个历史阶段是智能手机平板电脑的触屏交互,它是通过手指交互。第三个历史阶段是使用语音交互的。基于语音的人机交互智能设备使用语音识别及语音合成技术对人类的语音进行操作,让各种智能设备能听懂人类的语言并能按照人的语言命令来行动,从而实现人机的语言交流。
传统的人机交互需要集成语音提取以及理解语音模块才能识别用户语音以及反馈给用户或者发出操作指令,从而导致人机交互设备所需的体积较大,而提高了人机交互设备的成本,并且用户与设备之间人机交互的时候,容易受周围环境影响,导致语音识别误差大。
技术实现要素:
本发明的目的就在于为了解决上述人机交互方法需要体积大的设备集成语音交互的功能模块成本变高以及人机交互是易受到噪音干扰的问题提出一种基于人工智能语音的人机交互方法,具有单个云端服务平台可以连接多个用户端,节约成本以及减少噪声干扰的优点。
本发明通过以下技术方案来实现上述目的,一种基于人工智能语音的人机交互方法,该方法包括以下步骤:
用户唤醒用户端设备,并利用用户端设备来接收用户的语音信息,经过语音处理后通过网络接入层输出给云端服务平台;
云端服务平台将多语音源的输入进行归一化处理、差异化输出,准确解析用户语音的意图,并将用户的语音请求关键信息下发了给处理用户意图的后端服务模块;
后端服务模块对用户的意图进行处理,并且对用户的语音请求进行响应;
响应的语音信息通过用户端设备反馈给用户或者以指令的形式控制语音智能控制设备工作。
优选的,所述语音处理包括语音信息提取模块和噪声消除模块,用于准确识别用户语音信息中的特征参数。
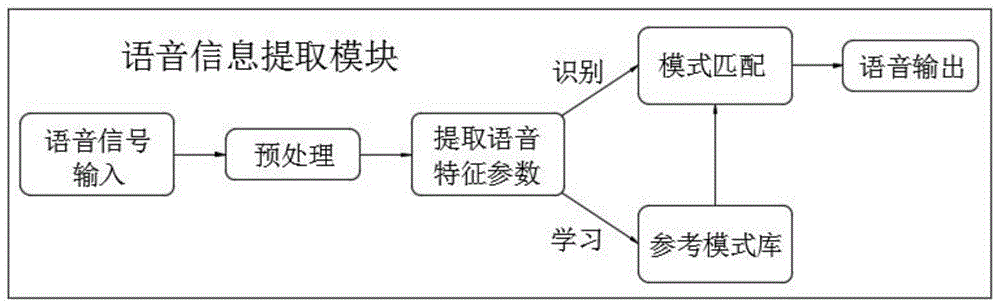
优选的,所述语音信息提取模块的语音特征提取步骤如下:
接收用户语音并对输入语音信号进行采样和自动增益控制预处理,其中预处理还包括数字信号的转换;
提取上述语音数字信号所包含的声音特征参数,其中声音特征参数包括声波的共振峰以及声音的音调;
使用算法进行训练和利用模式库对提取的声音的关键数据进行分类处理;
对所提取的待测语音与模式库语音的进行匹配度测试,最后将语音准确输出给云端服务平台。
优选的,所述噪声消除模块的噪声消除方法包括如下三种:
a、在智能设备播放语音的时候,要使用麦克风来消除掉扬声器自身的噪音以此来获取用户的语音信号;
b、将多组麦克风之间的相位差整合成一路语音信号,将用户输入的声音提高其清晰度,减少其他周围的噪音,且将麦克风组分布呈环形,可实现360度拾音;
c、可利用混响技术使得声音信号在各个方位和不同时间到达音箱设备,形成信号叠加,在用户声音停止时,麦克风内部的声音仍继续存在并反射。
优选的,所述云端服务平台包括:
语音获取和语音合成,用于收到用户的语音请求之后,对用户的语音请求进行处理;
请求接入转发、流量调度、安全和防攻击以及数据分析和请求分发需求,用于接入用户语音请求和转发用户的语音请求以及对全局的请求流量进行调度,分担服务器压力。
优选的,所述后端服务模块包括理解用户语音请求并处理的需求,用于对用户的请求进行归一化处理,听懂用户的真正意图,正确响应用户的需求。
与现有技术相比,本发明的有益效果是:
1、通过用户端设备来采集用户语音信息并发送给云端服务平台,经过平台处理识别后反馈给用户或者控制智能设备,从而实现人机交互,而且利用用户端设备和云端服务平台分开设置可以减少人工智能语音交互机的体积,只需确保用户端设备具备语音特征提取和联网发送语音信号的功能即可,一个云端服务平台可以实现多个用户端设备人机交互,从而节约成本。
2、用户端设备内部的语音处理包括语音信息提取模块和噪声消除模块,其中语音信息提取模块可以提取用户语音中的特征参数,方便云端服务平台理解,而噪声消除模块用来消除用户语音时的噪声,使得用户端设备识别用户语音更加准确。
附图说明
图1为本发明的语音信息提取模块内部提取原理示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种基于人工智能语音的人机交互方法,该方法包括以下步骤:
用户唤醒用户端设备,并利用用户端设备来接收用户的语音信息,经过语音处理后通过网络接入层输出给云端服务平台;
云端服务平台将多语音源的输入进行归一化处理、差异化输出,准确解析用户语音的意图,并将用户的语音请求关键信息下发了给处理用户意图的后端服务模块;
后端服务模块对用户的意图进行处理,并且对用户的语音请求进行响应;
响应的语音信息通过用户端设备反馈给用户或者以指令的形式控制语音智能控制设备工作。
所述语音处理包括语音信息提取模块和噪声消除模块,用于准确识别用户语音信息中的特征参数,如图1所述语音信息提取模块的语音特征提取步骤如下:
接收用户语音并对输入语音信号进行采样和自动增益控制预处理,其中预处理还包括数字信号的转换;
提取上述语音数字信号所包含的声音特征参数,其中声音特征参数包括声波的共振峰以及声音的音调;
使用算法进行训练和利用模式库对提取的声音的关键数据进行分类处理;
对所提取的待测语音与模式库语音的进行匹配度测试,最后将语音准确输出给云端服务平台。
所述噪声消除模块的噪声消除方法包括如下三种:
a、在智能设备播放语音的时候,要使用麦克风来消除掉扬声器自身的噪音以此来获取用户的语音信号;
b、将多组麦克风之间的相位差整合成一路语音信号,将用户输入的声音提高其清晰度,减少其他周围的噪音,且将麦克风组分布呈环形,可实现360度拾音;
c、可利用混响技术使得声音信号在各个方位和不同时间到达音箱设备,形成信号叠加,在用户声音停止时,麦克风内部的声音仍继续存在并反射。
所述云端服务平台包括:
语音获取和语音合成,用于收到用户的语音请求之后,对用户的语音请求进行处理;
请求接入转发、流量调度、安全和防攻击以及数据分析和请求分发需求,用于接入用户语音请求和转发用户的语音请求以及对全局的请求流量进行调度,分担服务器压力。
所述后端服务模块包括理解用户语音请求并处理的需求,用于对用户的请求进行归一化处理,听懂用户的真正意图,正确响应用户的需求。
本发明的工作原理:通过用户端设备来采集用户语音信息并发送给云端服务平台,经过平台处理识别后反馈给用户或者控制智能设备,从而实现人机交互,而且利用用户端设备和云端服务平台分开设置可以减少人工智能语音交互机的体积,只需确保用户端设备具备语音特征提取和联网发送语音信号的功能即可,一个云端服务平台可以实现多个用户端设备人机交互,从而节约成本,用户端设备内部的语音处理包括语音信息提取模块和噪声消除模块,其中语音信息提取模块可以提取用户语音中的特征参数,方便云端服务平台理解,而噪声消除模块用来消除用户语音时的噪声,使得用户端设备识别用户语音更加准确。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!