一种用于声纹识别的低功耗模拟域特征向量提取方法与流程
本发明属于声纹识别技术领域,特别涉及一种用于声纹识别的低功耗模拟域特征向量提取方法。
背景技术:
随着电子信息技术的发展,物联网逐渐成为人们关注的焦点。在物联网时代,信息技术正改变着人们与电子设备的交互方式。因为人的声音是一种最自然和最具信息量的人机交互方式,类似语音自动控制的人机交互在智能家居等应用场景中被广泛采用,而其中智能声纹识别或关键词检测唤醒电路具有重要的应用前景。通过语音来唤醒设备能有效提高能量效率,且无需接触,使用方便。智能声纹识别电路以低功耗的工作模式实时采集环境中的音频信号,并检测其中是否存在特定个体的语音信号,当侦测到特定说话人的有效语音信号时,启动唤醒更高层次的系统。
此外,相比于语音活动检测唤醒,声纹识别唤醒能够针对特定说话人发生响应,关键词检测唤醒能够针对特定语音控制命令发生响应。其中一个应用场景是家庭中电视的语音唤醒,如果希望电视只对家长的语音唤醒而不唤醒小孩的语音,就需要对不同说话人进行声纹识别从而判断出具有唤醒权限的用户。同时,声纹识别与其他生物特征识别技术相比还具有方便直接,语音传感采集设备成本低廉等优点。
由于不同说话人的发音器官在形态、大小和尺寸等物理结构方面有差异,加之受年龄、性别、读音习惯等因素的影响,因此不同说话人的发音频率和共振峰不会完全相同。可以说不同说话人的声纹图谱都略有差异,所以通过声纹来识别不同说话人进而判断说话人身份的方式是可行的。声纹识别的传统做法是将语音信号调理放大之后直接经过模-数转换器(adc)转换成数字信号,在数字域完成特征提取和识别的任务。数字域梅尔频率倒谱系数特征(mfcc)提取的过程包括对输入的语音信号进行预加重、分帧和加窗这些预处理操作,然后做fft变换,取模平方,经过mel三角滤波器组并将输出取对数,最后做dct变换。因为其拥有良好的可分辨性,包含语音信息充分,成为语音识别、声纹识别、关键词检测等语音信号处理任务中的经典特征。但是由于mfcc特征提取需要fft、dct等操作会消耗大量功耗,且计算复杂度较高,不利于低功耗的硬件实现。
此外,经典mfcc特征通常包含13维静态特征,13维一阶差分系数和13维二阶差分系数共39维特征。较高的特征维度使得输入后续识别模型例如神经网络的特征比特率也很高,从而神经网络识别模型的参数量和乘累加运算量较大,导致神经网络的功耗较大。这限制了声纹识别从服务器端向边缘端扩展,难以满足电池容量较小且需要连续工作的智能声纹识别设备唤醒应用的需求。
技术实现要素:
为了克服上述现有技术中经典数字域mfcc特征提取存在的主要缺点,本发明的目的在于提供一种用于声纹识别的低功耗模拟域特征向量提取方法,可降低特征输入后续识别模型的比特率,进一步减小识别模型的功耗和计算量,具有低功耗,低维度,低计算复杂度等特点。并可将特征进一步输入数字域神经网络等模型进行声纹识别,对智能声纹识别唤醒等语音信号处理任务的边缘端实现和性能优化产生重要意义。
为了实现上述目的,本发明采用的技术方案是:
一种用于声纹识别的低功耗模拟域特征向量提取方法,输入为麦克风输出的语音信号,从时域和模拟域提取特征,通过构造一组带通滤波器逼近mfcc特征提取中的mel三角滤波器组,使得构造的带通滤波器组的中心频率与mel三角滤波器组相同,满足非线性对数频率特性,再将模拟滤波输出的时域信号通过adc后取模平方得到对应特征值。
本发明包括对应于全模拟滤波特征提取的高性能模式和对应于混合特征提取的超低功耗模式两种模式,其中:
所述高性能模式使用16个带通滤波器进行全模拟滤波特征提取,首先将麦克风输出的语音信号通过低噪声前置放大器调理放大,然后分别输入16个通道进行带通滤波,每个带通滤波器的中心频率模拟mfcc特征提取中mel三角滤波器的中心频率设计;然后将提取到的模拟滤波特征通过12位逐次逼近型adc转换到数字域,在数字域完成求取模平方的操作得到对应特征向量;
所述超低功耗模式通过压缩相似的冗余特征以进一步降低特征维度,采用5个带通滤波器,1个比较器和数字逻辑电路实现混合特征提取,通过比较器和计数器提取语音信号的过零率,即统计信号幅值为0的次数,过零率反映了语音信号的变化快慢,是一种从时域进行提取而反映频域信息的特征,输入信号经比较器与0电平比较后输出一系列含高低电平的脉冲,其中高电平的上升沿和下降沿对应语音信号的负过零和正过零,对高电平脉冲计数,再乘以2得到语音信号的过零率,该模式提取的混合特征的维度是8维,包括5维模拟滤波特征及其均值和方差,再加上1维过零率特征。
所述每个带通滤波器的中心频率模拟mfcc特征提取中mel三角滤波器的中心频率设计的具体实现方式是将语音信号的常用采样频率按照该公式mel(f)=2595*log10(1+f/700)转换到梅尔频率域,然后在梅尔频率域按照滤波器个数进行等间隔划分,再将划分的结果按上式转换为对应的自然频率作为带通滤波器的中心频率,其中mel(f)是梅尔频率,f是自然频率。
本发明中,所述带通滤波器可为非理想物理可实现的带通滤波器,其阶数为2阶。
本发明中,所述带通滤波器可采用gm-c结构,通过调整跨导器偏置电流的大小从而改变跨导器的gm值,来达到改变滤波器中心频率的目的。
本发明中,可通过调整所述带通滤波器的个数以得到不同维度的特征,从而满足不同应用场景下识别精度和功耗的折中。
本发明中,所述麦克风输出的语音信号可先进行分帧和加窗的预处理。
本发明的方法除用于声纹识别外,还用于关键词检测等相近领域。
本发明提取的特征向量可进一步输入数字域神经网络进行识别,所述神经网络可为cnn、lstm或gru等。
与现有技术相比,本发明的有益效果是:
1.在功耗方面,本发明提出的基于模拟滤波的特征提取方法相比于经典数字域mfcc特征提取硬件开销较小,省去了fft、dct等操作,功耗有所降低,可以达到亚μw级的功耗指标。
2.在特征数据量方面,经典数字域mfcc特征一般包括39维,而本发明提出的全模拟滤波特征的维度是16维,混合特征的维度是8维。这可以使得后续识别模型的参数量和计算量降低,从而进一步减小识别模型的功耗。
3.在计算复杂度方面,本发明提出的模拟域特征提取方法基于时域滤波。因为时域滤波相当于卷积,而对于某帧语音,卷积和求模平方的计算复杂度对帧长均呈线性关系,因此模拟滤波特征提取的计算复杂度是o(n)。而mfcc特征包含fft和dct操作,计算复杂度是o(nlogn),基于模拟滤波的特征提取方法计算复杂度有所降低。
4.本发明的抗噪性能良好,在加入高斯白噪声的语音信号中,当信噪比(snr)大于等于0db时本发明基于模拟滤波提取的特征在维度较低的同时仍有良好的抗噪能力。
附图说明
图1是基于模拟滤波特征提取方法原理图。
图2是本发明提出的基于模拟域的语音特征提取方法的结构示意图。
图3是全模拟滤波特征提取结构框图。
图4是梅尔频率与自然频率对应关系。
图5是混合特征提取结构框图。
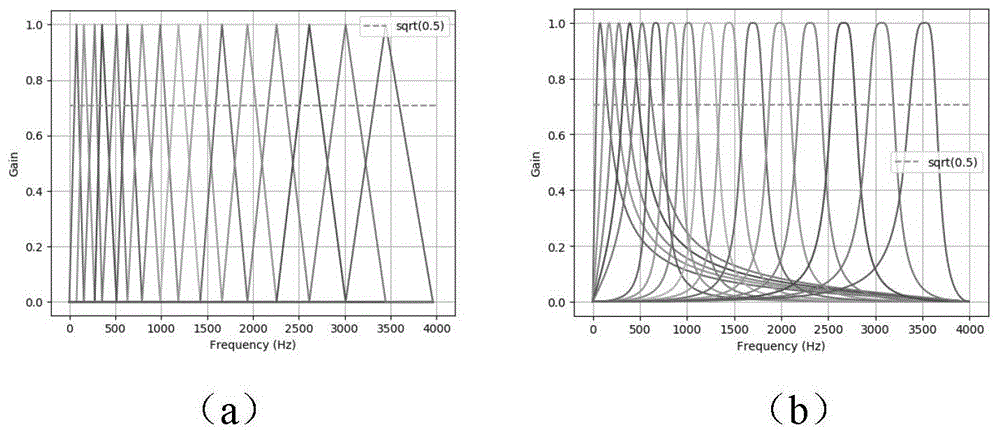
图6是实施例中2种滤波器幅频特性曲线对比,其中(a)为理想mel三角滤波器;(b)为巴特沃斯带通滤波器。
图7是针对全模拟滤波特征的神经网络识别模型示意图。
具体实施方式
下面结合附图和实施例详细说明本发明的实施方式。
本发明一种低功耗模拟域特征向量提取方法,基于模拟滤波实现特征提取。该方法输入为麦克风输出的语音信号,输出为提取到的特征向量,并可将特征进一步输入数字域神经网络等模型进行声纹识别。下面详细介绍该方法的原理。
如图1所示,本发明基于时域滤波的核心思想,构造一组非理想,对模拟电路友好的带通滤波器(bpf)去逼近mfcc特征提取中的mel三角滤波器组,再将滤波输出的时域信号通过adc后取模平方得到对应特征向量。
该方法的理论基础是帕塞瓦尔定理:
帕塞瓦尔定理描述了时域能量和频域能量的对应关系。其中,x[n]是语音时域信号,x[k]是对应的频域信号,n是语音信号的长度。
经典mfcc特征从频域和数字域角度出发提取语音特征。而本方法从时域和模拟域角度出发提取特征,通过时域滤波得到的特征向量即使与mfcc特征不完全相同,但它们的相对大小具有相关性。而在声纹识别中往往不关心特征向量的绝对大小,而关心其相对大小,因为声纹图谱中由于不同频点频谱的相对大小不同才形成了声纹“纹理”的意义。此外,通过时域滤波方式提取特征省略了快速傅里叶变换(fft),与mel三角滤波器组相乘,离散余弦变换(dct)这些步骤,节省了计算量。
参考图2,本发明基于模拟域滤波的特征提取方法可以针对2个不同的应用场景具体延伸为全模拟滤波特征提取和混合特征提取2种方案,分别对应高性能模式和超低功耗模式。
(1)高性能模式
该模式使用16个带通滤波器实现全模拟滤波特征提取,结构如图3所示。首先将麦克风输出的语音信号通过低噪声前置放大器调理放大,然后分别输入16个通道利用带通滤波器进行带通滤波,每个带通滤波器的中心频率模拟mfcc特征提取中mel三角滤波器的中心频率来设计。然后将提取到的模拟滤波特征通过12位逐次逼近型adc(saradc)转换到数字域,在数字域完成求取模平方的操作得到对应特征向量。在带通滤波器的硬件实现上,带通滤波器的阶数仅为2阶便可提取得到识别性能良好的特征向量。本发明采用gm-c结构的带通滤波器,因为该类型的带通滤波器功耗较低,且中心频率由跨导值(gm)和电容值决定,便于调谐。通过调整跨导器偏置电流的大小从而改变跨导器的gm值,来达到改变带通滤波器中心频率的目的。经过估算,可调整的带通滤波器中心频率范围较大,足够覆盖提取语音信号频域特征的频带范围。
该模式使用16个带通滤波器提取得到关键频点的语音信息,特征向量的维度为16,包含信息充分,能在降低特征数据量的同时提取到关键频点的语音声纹信息。提取的特征在小数据集上与mfcc特征的识别性能基本持平,但是由于并行的带通滤波器数量有16个,硬件实现时占用面积和功耗相对较大。该模式适用于对识别率精度的要求高于超低功耗指标限制的应用场景,例如对于安全性要求较高的唤醒系统。
由于mel三角滤波器从人的听觉模型出发,由于人耳听觉的非线性频率特性,基于听觉感知的mel频率与自然频率呈对数关系:
mel(f)=2595*log10(1+f/700)
因此本发明带通滤波器的中心频率设计的具体实现方式是将语音信号的常用采样频率(8khz)按照上式转换到梅尔频率域,然后在梅尔频率域按照滤波器个数进行等间隔划分,再将划分的结果按上式转换为对应的自然频率作为带通滤波器的中心频率,原理如图4所示。
(2)超低功耗模式
该模式从压缩相似的冗余特征以进一步降低特征维度出发,采用5个带通滤波器,1个比较器和数字逻辑电路实现混合特征提取,结构如图5所示。其中通过比较器和计数器提取语音信号的过零率,即统计信号幅值为0的次数。过零率反映了语音信号的变化快慢,是一种从时域进行提取而反映频域信息的特征,硬件开销很小,仅采用5个gm-c二阶带通滤波器,1个比较器和简单数字逻辑电路实现特征提取,有效降低了功耗和计算复杂度。过零率特征提取的具体原理如图5中以正弦信号为输入的示意,输入信号经比较器与0电平比较后输出一系列含高低电平的脉冲,其中高电平的上升沿和下降沿对应语音信号的负过零和正过零,因此对高电平脉冲计数,再乘以2便可得到语音信号的过零率。
该模式提取的混合特征的维度是8维,包括5维模拟滤波特征及其均值和方差,再加上1维过零率特征。混合特征的维度比模式(1)全模拟滤波特征减少了2倍,但将该特征向量输入数字域神经网络的识别准确率比经典mfcc特征和全模拟滤波特征下降很少,远小于特征维度的减少。该模式减少了并行滤波器的数量和特征维度,也减少了后端识别模型的参数量和计算量,从而减少了硬件实现的功耗和面积,是一种以识别率的损失换取功耗减少的做法。适用于对低功耗指标限制严格的应用场景,例如对于安全性要求不太高而需要连续工作的初级唤醒系统。
下面介绍本发明提出的全模拟滤波特征和混合特征的实现方式以及与mfcc特征的对比,以验证本发明提出的特征提取方法的有效性。首先是预处理,将语音信号进行分帧和加窗。本发明的特征提取方法在具体实现时,分帧的帧长和帧移可以选择32ms和16ms使得提取的特征向量能够平滑过渡。本方法采用矩形窗,对模拟电路友好,硬件实现代价几乎为0。
使用的巴特沃斯带通滤波器组和mel三角滤波器组的幅频特性曲线如图6所示,其中(a)为理想mel三角滤波器;(b)为巴特沃斯带通滤波器,每个巴特沃斯带通滤波器的中心频点和截止频率尽量逼近理想的mel三角滤波器,带通滤波器的个数为16,阶数为2阶,阻带最小衰减为40db。
此外,本发明提取的特征向量可以进一步使用数字域神经网络完成声纹识别任务。将提取到的特征向量转换成语谱图,分别输入数字域二值化卷积神经网络中进行识别。一种针对前述16维全模拟滤波特征的典型神经网络识别模型如图7所示,8维混合特征对应的神经网络识别模型只需相应调整减小神经网络参数例如卷积核的大小即可。
其中,第2个卷积层采用深度可分离结构设计。该结构包括2个步骤,首先在深度上逐个通道分别卷积,然后做卷积核大小为1×1的逐点卷积,将特征图在深度方面进行加权组合。此外,除第1个卷积层外均进行参数二值化。最后2层分别是卷积核大小为1×1的逐点卷积层和全局平均池化层。全局平均池化层将每个通道的特征图求平均作为相应类别的置信度,再使用softmax函数进行分类。图7所示来自不同说话人的3段语音经过本发明基于模拟滤波的特征提取后输入神经网络,神经网络的输出正确判决了待识别语音所属的说话人。
在本发明更多的实施例中,带通滤波器也可采用其它类型、规格,不限于gm-c二阶,带通滤波器个数可以调整以得到不同维度的特征,以满足不同应用场景下识别精度和功耗的折中。
本发明的特征提取方法除了可用于声纹识别任务外,也可以应用在诸如关键词检测等其他语音信号处理任务中。
本发明后续用于识别的模型可基于上述的二值化cnn设计,也可以采用其他算法设计识别模型。例如基于机器学习的矢量量化模型(vq),基于深度学习的长短时记忆网络(lstm)和门控循环神经网络(gru)等。
- 还没有人留言评论。精彩留言会获得点赞!