用于音频识别的模型建构方法与流程
1.本发明涉及一种机器学习(machine learning)技术,尤其涉及用于音频识别的模型建构方法。
背景技术:
2.机器学习算法可通过分析大量数据以推论这些数据的规律,从而对未知数据进行预测。近年来,机器学习已广泛应用在图像识别、自然语言处理、医疗诊断、或语音识别等领域上。
3.值得注意的是,针对语音或其他音频类型的识别技术,在其模型的训练过程中,操作人员会标记(labeling)声音内容的类型(例如,女声、婴儿声、警铃声等),以生成训练数据中的正确输出结果,其中声音内容作为训练数据中的输入数据。若是标记图像,操作人员可在短时间内认出对象,即可提供对应标签。然而,针对声音标签,操作人员可能需要听一长段声音文件才能开始标记,且声音文件可能受噪声干扰而难以识别内容。由此可知,现今训练作业对于操作人员而言是相当没有效率的。
技术实现要素:
4.本发明实施例是针对一种用于音频识别的模型建构方法,提供简易的询问提示,以方便操作人员标记。
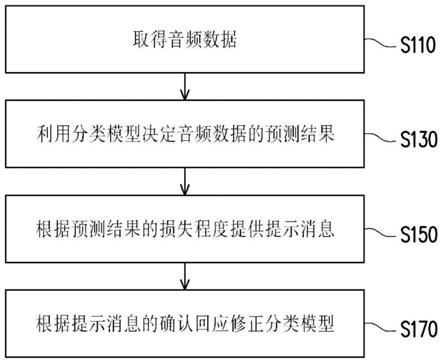
5.根据本发明的实施例,用于音频识别的模型建构方法包括(但不只限于)下列步骤:取得音频数据。利用分类模型决定音频数据的预测结果,这分类模型是基于机器学习算法所训练,且这预测结果包括这分类模型所定义的标签(label)。根据预测结果的损失(loss)程度提供提示消息,这损失程度相关于预测结果与对应的实际结果之间的差异,且提示消息用于询问音频数据与标签的相关性。根据提示消息的确认响应修正分类模型,且这确认响应相关于确认音频数据与标签的相关性。
6.基于上述,本发明实施例的用于音频识别的模型建构方法,可判断已训练的分类模型所得出的预测结果与实际结果的差异,并根据这差异提供简易的提示消息给操作人员。而操作人员只需对这提示消息响应即可完成标记,并据以进一步修正分类模型,从而提升分类模型的识别准确性及操作人员的标记效率。
附图说明
7.包含附图以便进一步理解本发明,且附图并入本说明书中并构成本说明书的一部分。附图说明本发明的实施例,并与描述一起用于解释本发明的原理。
8.图1是根据本发明一实施例的用于音频识别的模型建构方法的流程图;
9.图2是根据本发明一实施例的音频处理的流程图;
10.图3是根据本发明一实施例的噪声抵消的流程图;
11.图4a是一范例说明原始音频数据的波形图;
12.图4b是一范例说明本质模态函数(intrinsic mode function,imf)的波形图;
13.图4c是一范例说明经噪声抵消的音频数据的波形图;
14.图5是根据本发明一实施例的音频分段的流程图;
15.图6是根据本发明一实施例的模型训练的流程图;
16.图7是根据本发明一实施例的神经网络(neural network)的示意图;
17.图8是根据本发明一实施例的更新模型的流程图;
18.图9是根据本发明一实施例的智能门铃应用的流程示意图;
19.图10是根据本发明一实施例的服务器的组件方块图。
20.附图标号说明
21.s110~s170、s210~s230、s310~s350、s510~s530、s610~s630、s810~s870、s910~s980:步骤;
22.710:输入层;
23.730:隐藏层;
24.750:输出层;
25.10:云端服务器;
26.30:训练服务器;
27.31:通信接口;
28.33:存储器;
29.35:处理器;
30.50:智能门铃;
31.51:麦克风;
32.53:存储器。
具体实施方式
33.现将详细地参考本发明的示范性实施例,示范性实施例的实例说明于附图中。只要有可能,相同组件符号在附图和描述中用来表示相同或相似部分。
34.图1是根据本发明一实施例的用于音频识别的模型建构方法的流程图。请参照图1,服务器取得音频数据(步骤s110)。具体而言,音频数据是指对对声波(例如,人声、环境声、机器运作声等音源所生成)收音而转换为模拟或数字形式的声音频号,或是通过处理器(例如,中央处理器(central processing unit,cpu)、特殊应用集成电路(application specific integrated circuit,asic)、或数字信号处理器(digital signal processor,dsp)等)设定声音的振福、频率、音色、节奏和/或旋律所生成的声音频号。换句而言,音频数据可以是通过麦克风录制或计算机编辑所生成。例如,通过智能手机录制婴儿哭声,或者用户在计算机上以音乐软件编辑音轨。在一实施例中,音频数据可以是经网络下载、无线或有线传输(例如,低功耗蓝牙(bluetooth low energy,ble)、wi-fi、光纤网络等)以实时性或非实时性的分组或串流模式传递、或者存取外部或内建存储媒介(例如,u盘、光盘、外接硬盘、存储器等)从而取得音频数据并供后续模型建构使用。例如,音频数据存储在云端服务器,而训练服务器经由fts下载音频数据。
35.在一实施例中,音频数据是对原始音频数据(其实施方式及类型可参酌音频数据)
经音频处理后所得。图2是根据本发明一实施例的音频处理的流程图。请参照图2,服务器可对原始音频数据抵消其噪声分量(步骤s210),并对音频数据分段(步骤s230)。换句而言,原始音频数据经噪声抵消和/或音频分段即可取得音频数据。在一些实施例中,噪声抵消及音频分段的顺序可能根据实据需求而变更。
36.针对音频的噪声抵消方法有很多种。在一实施例中,服务器可分析原始音频数据的特性以决定原始音频数据的噪声分量(即,对信号的干扰)。音频相关特性例如是振幅、频率、能量或其他物理特性上的变化,且噪声分量通常具有特定特性。
37.举例而言,图3是根据本发明一实施例的噪声抵消的流程图。请参照图3,特性包括数个本质模态函数(imf)。而满足以下条件的数据可被称为本质模态函数:第一,局部极大值(local maxima)及局部极小值(local minima)的数量总和与过零(zero crossing)的数量相等或是至多相差一;第二,在任何时间点,局部最大值的上包络线(upper envelope)与局部极小值的下包络线的平均接近零。服务器可分解原始音频数据(即,模态分解)(步骤s310),以生成原始音频数据的数个模态分量(作为基本(fundamental)信号)。而各模态分量即对应到一个本质模态函数。
38.在一实施例中,原始音频数据可通过经验模态分解(empirical mode decomposition,emd)或其他根据时间尺度特征的信号分解,即可取得对应的本质模态函数分量(即,模态分量)。而模态分量包括原始音频数据在时域的波形上不同时间尺度的局部特征信号。
39.举例而言,图4a是一范例说明原始音频数据的波形图,且图4b是一范例说明本质模态函数(imf)的波形图。请参照图4a及图4b,图4a的波形通过经验模态分解可得出图4b所示的七个不同本质模态函数及一个剩余分量。
40.须说明的是,在一些实施例中,各本质模态函数可再经希尔伯特-黄转换(hilbert-huang transform,hht)以取得对应瞬时频率和/或振幅。
41.服务器可进一步决定各模态分量的自相关性(步骤s330)。例如,去趋势波动分析(detrended fluctuation analysis,dfa)可用于判断信号的统计自相似性质(即,自相关性),并通过最小平方法(least square method)线性拟合得到各模态分量的斜率。又例如,对各模态分量进行自相关(autocorrelation)运算。
42.服务器可根据那些模态分量的自相关性选择一个或更多个模态分量作为原始音频数据的噪声分量。以去趋势波动分析所得出的斜率为例,若第一模态分量的斜率小于斜率阈值(例如,0.5或其他数值),则第一模态分量为反相关(anti-correlated)并被作为噪声分量;若第二模态分量的斜率未小于斜率阈值,则第二模态分量为相关(correlated)且不会被作为噪声分量。
43.在其他实施例中,针对其他类型的自相关性分析,若第三模态分量的自相关最小、次小或较小,则第三模态分量也可能作为噪声分量。
44.决定噪声分量之后,服务器可对原始音频数据抵消噪声分量以生成音频数据。以模态分解为例,请参照图3,服务器可根据模态分量的自相关性抵消作为噪声分量的模态分量,并根据非噪声分量的模态分量生成去噪声音频数据(步骤s350)。换句而言,服务器根据原始音频数据中噪声分量以外的非噪声分量重建信号,并据以生成去噪声的音频数据。其中,噪声分量可被移除或删除。
45.图4c是一范例说明经噪声抵消的音频数据的波形图。请参照图4a及图4c,与图4a相比,图4c的波形已抵消噪声分量。
46.须说明的是,对音频的噪声抵消不限于前述模态及自相关性分析,在其他实施例中也可能应用其他噪声抵消技术。例如,经组态特定或可变阈值的滤波器、或频谱消去(spectral subtraction)等。
47.另一方面,针对音频的音频分段方法有很多种。图5是根据本发明一实施例的音频分段的流程图。请参照图5,在一实施例中,服务器可对音频数据(例如,原始音频数据或去噪声的音频数据)提取声音特征(步骤s510)。具体而言,声音特征可以是振幅、频率、音色、能量或前述至少一者的变化。例如,声音特征是短时能量(short time energy)和/或过零率(zero crossing rate)。短时能量是假设声音频号在短时(或称窗口(window))内的变化较为缓慢甚至不变,并将短时内的能量作为声音频号的特征代表,其中不同能量区间对应到不同类型的声音,甚至可用于区分有声与无声的片段。而过零率相关于声音频号的振幅由正数变成负数和/或由负数变成正数的统计数量,其中数量的多寡对应到声音频号的频率。在一些实施例中,谱通量(spectral flux)、线性预测系数(linear predictive coefficient,lpc)、或带周期性(band periodicity)分析等方式也能取得声音特征。
48.取得声音特征之后,服务器可根据声音特征决定音频数据中的目标片段及非目标片段(步骤s530)。具体而言,目标片段代表受指定一种或更多种声音类型的声音片段,而非目标片段代表前述指定声音类型以外的类型的声音片段。声音类型例如是音乐、环境声、语音、或无声等。而声音特征对应数值可对应到特定声音类型。以过零率为例,语音的过零率大概为0.15,音乐的过零率大概为0.05,且环境声的过零率变化剧烈。此外,以短时能量为例,语音的能量大概为0.15至0.3,音乐的能量大概为0至0.15,且无声的能量为0。须说明的是,不同类型的声音特征所用评断声音类型的数值及区段可能不同,且前述数值也只是用于作为范例说明。
49.在一实施例中,假设目标片段为语音内容(即,声音类型为语音),且非目标片段不为语音内容(例如,环境声、或音乐声等)。服务器可根据音频数据的短时能量及过零率决定目标片段在音频数据中的两端点。例如,音频数据的声音频号的过零率低于过零阈值者被视为语音,且声音频号的能量超过能量阈值者被视为语音。而过零率低于过零阈值或能量超过能量阈值的声音片段即是目标片段。此外,一笔目标片段在时域上的头尾两端点即是其边界,且边界以外的声音片段可能是非目标片段。例如,先利用短时能量检测大致判断出有声语音结尾处,再利用过零率检测出语音片段的真正的开头跟结尾处。
50.在一实施例中,服务器可对原始音频数据或经去噪声的音频数据保留目标片段,并移除非目标片段,以作为最终声音数据。换句而言,一笔声音数据包括一笔或更多笔目标片段,且不存在非目标片段。以语音内容的目标片段为例,若播放经音频分段的音频数据,则只能听到人类讲话声。
51.需说明的是,在其他实施例中,图2中步骤s210和s230中的任一者或两者也可能省略。
52.请参照图1,服务器可利用分类模型决定音频数据的预测结果(步骤s130)。具体而言,分类模型是基于机器学习(machine learning)算法所训练。机器学习算法例如是基本神经网络(neural network,nn)、递归神经网络(recurrent neural network,rnn)、长短期
存储模型(long short-term memory,lstm)或其他音频识别相关算法。服务器可事先训练分类模型或直接取得已初步训练的分类模型。
53.图6是根据本发明一实施例的模型训练的流程图。请参照图6,针对事先训练,服务器可根据目标片段提供初始提示消息(步骤s610)。这初始提示消息用于要求对目标片段赋予标签。在一实施例中,服务器可通过扬声器播放目标片段,并通过显示器或扬声器提供视觉或听觉的消息内容。例如,是否为哭声。操作人员可对初始提示消息提供初始确认响应(即,标记)。例如,操作人员通过键盘、鼠标或触控面板选择“是”或“否”中的一者。又例如,服务器提供哭声、笑声、及尖叫声等选项(即,标签),而操作人员选择其中一个选项。
54.待所有目标片段都标记后,服务器可根据初始提示消息的初始确认响应训练分类模型(步骤s630)。而这初始确认响应包括目标片段对应的标签。即,将目标片段作为训练数据中的输入数据,且将对应标签作为训练数据中的输出/预测结果。
55.服务器可使用预设或经用户挑选的机器学习算法。例如,图7是根据本发明一实施例的神经网络的示意图。请参照图7,神经网络的结构主要包括三个部分:输入层(input layer)710、隐藏层(hidden layer)730及输出层(output layer)750。在输入层710中,众多神经元(neuron)接收大量非线性输入消息。在隐藏层730中,众多神经元和连结可能组成一或更多层面,且各层面包括线性组合及非线性的激励(activation)函数。在一些实施例中,例如是递归神经网络会将隐藏层730中某一层面的输出作为另一层面的输入。消息在神经元链接中传输、分析、和/或权衡后即可在输出层750形成预测结果。而分类模型的训练即是找出隐藏层750中的参数(例如,权重、偏值(bias)等)及连结。
56.分类模型经训练后,若将音频数据输入至分类模型即可推论出预测结果。预测结果包括分类模型所定义的一个或更多个标签(label)。标签例如是女声、男声、婴儿声、哭声、笑声、特定人物声、警铃声等,且标签可视应用者的需求而变更。在一些实施例中,预测结果可还包括预测各标签的机率。
57.请参照图1,服务器可根据预测结果的损失(loss)程度提供提示消息(步骤s150)。具体而言,损失程度相关于预测结果与对应的实际结果之间的差异。例如,可通过均方误差(mean-square error,mse)、平均绝对值误差(mean absolute error,mae)或交叉熵(cross entropy)决定损失程度。若损失程度未超过损失阈值,则分类模型可维持不变或不用重新训练。而若损失程度超过损失阈值,则可能需要对分类模型重新训练或修正。
58.在本发明实施例中,服务器将可进一步对操作人员提供提示消息。提示消息用于询问音频数据与标签的相关性。在一实施例中,提示消息包括音频数据及问题内容,且问题内容是询问音频数据是否属于标签(或是否相关于标签)。服务器可通过扬声器播放音频数据,并通过扬声器播放或显示器显示以提供问题内容。例如,显示器呈现是否为婴儿哭声的选项。而操作人员只需从“是”及“否”选项中选择一者即可。此外,若音频数据已受如图2所介绍的音频处理,则操作人员只需聆听目标片段或去噪声的声音,且势必能提升标记效率。
59.需说明的是,在一些实施例中,提示消息还可能是讯问复数种标签的选项。例如,“婴儿哭声或成人哭声?”的消息内容。
60.服务器可根据提示消息的确认响应修正分类模型(步骤s170)。具体而言,确认响应相关于确认音频数据与标签的相关性。相关性例如是属于、不属于或相关程度值。在一实施例中,服务器可通过输入设备(例如,鼠标、键盘、触控面板或按键等)接收操作人员的输
入操作(例如,按压、或点击等)。这输入操作对应于问题内容的选项,且这选项是音频数据属于标签、或音频数据不属于标签。例如,提示消息呈现在显示器上并提供“是”及“否”两选项,而操作人员听完目标片段之后,可通过对应于“是”的按键选择“是”的选项。
61.在其他实施例中,服务器也可通过诸如默认关键词识别、默认声学特征比对等其他语音识别手段来生成确认响应。
62.若相关性是音频数据属于所询问的标签或其相关程度值大于程度阈值,则可确认预测结果为正确(即,预测结果等同于实际结果)。另一方面,若相关性是信息数据不属于所询问的标签或其相关程度值小于程度阈值,则可确认预测结果为不正确(即,预测结果不同于实际结果)。
63.图8是根据本发明一实施例的更新模型的流程图。请参照图8,服务器判断预测结果是否正确(步骤s810)。若预测结果为正确,则表示当前分类模型的预测能力符合期待,且不用更新或修正分类模型(步骤s820)。另一方面,若预测结果为不正确(即,确认响应认为预测结果对应的标签有误),则服务器可修正不正确数据(步骤s830)。例如,将“是”的选项修正为“否”的选项。接着,服务器可使用修正后的数据作为训练数据,并重新训练分类模型(步骤s850)。在一些实施例中,若确认响应已指定特定标签,则服务器可将确认响应对应的标签与音频数据作为分类模型的训练数据,并据以重新训练分类模型。重新训练之后,服务器即可更新分类模型(步骤s870)。例如,将重新训练的分类模型取代现有存储的分类模型。
64.由此可知,本发明实施例通过损失程度及确认响应的两阶段评估分类模型的预测能力是否符合预期或是否需要修正,从而提升训练效率及预测正确性。
65.除此之外,服务器还能提供分类模型给其他装置使用。举例而言,图9是根据本发明一实施例的智能门铃50应用的流程示意图。请参照图9,训练服务器30自云端服务器10下载音频数据(步骤s910)。训练服务器30可训练分类模型(步骤s920),并存储训练好的分类模型(步骤s930)。训练服务器30可架设数据提供平台(例如,作为文件传输协议(file transfer protocol,fts)服务器或网站服务器),并可提供分类模型经由网络传输给其他装置。以智能门铃50为例,智能门铃50可通过fts下载分类模型(步骤s940),并存储于自身存储器53中以供后续使用(步骤s950)。另一方面,智能门铃50可通过麦克风51对外界收音并接收语音输入(步骤s960)。语音输入例如是人类讲话、人类叫声、或人类哭声等。或者,智能门铃50可通过物联网(iot)无线技术(例如,le、zigbee、或z-wave等)收集来自其他远程装置的声音信息,这声音信息可实时串流并以无线传输方式送至智能门铃50。智能门铃50接收后可解析声音信息并作为语音输入。智能门铃50可自其存储器53加载通过网络所取得的分类模型以对接收的语音输入识别,并据以决定预测/识别结果(步骤s970)。智能门铃50可进一步根据语音输入的识别结果提供事件通知(步骤s980)。例如,识别结果是男主人的呼叫,则智能门铃50发出音乐声的听觉事件通知。又例如,识别结果是外送人员或其他非家庭成员的呼叫,则智能门铃50呈现门前图像的视觉事件通知。
66.图10是根据本发明一实施例的训练服务器30的组件方块图。请参照图10,训练服务器30可以是执行图1、图2、图3、图5、图6及图8所述实施例的服务器,并可以是工作站、个人计算机、智能手机、平板计算机等运算装置。训练服务器30包括(但不只限于)通信接口31、存储器33及处理器35。
67.通信接口31可以支持光纤网络、以太网络、或缆线等有线网络,也可能支持wi-fi、
行动网络、蓝牙(例如,ble、第五代、或更后世代)、zigbee、z-wave等无线网络。在一实施例中,通信接口31用以传送或接收数据。例如,接收音频数据,或传送分类模型。
68.存储器33可以是任何型态的固定或可移动随机存取存储器(radom access memory,ram)、只读存储器(read only memory,rom)、闪存(flash memory)或类似组件,并用以记录程序代码、软件模块、音频数据、分类模型及其相关参数及其他数据或档案。
69.处理器35耦接通信接口31及存储器33,处理器35并可以是中央处理单元(central processing unit,cpu),或是其他可程序化的一般用途或特殊用途的微处理器(microprocessor)、数字信号处理器(digital signal processing,dsp)、可程序化控制器、特殊应用集成电路(application-specific integrated circuit,asic)或其他类似组件或上述组件的组合。在本发明实施例中,处理器35用以执行服务器30的所有或部分作业。例如,训练分类模型、音频处理、或修正数据等。
70.综上所述,在本发明实施例的用于音频识别的模型建构方法中,根据分类模型所得出的预测结果与实际结果之间相差的损失程度提供提示消息,并根据对应的确认响应修正分类模型。对于操作人员而言,只需对提示消息响应即可轻松完成标记。此外,原始音频数据可经噪声抵消及音频分段等处理,以方便操作人员聆听。藉此,可提升分类模型的识别正确性及操作人员的标记效率。
71.最后应说明的是:以上各实施例只用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1