基于堆叠沙漏网络的音乐源分离方法与流程
[0001]
本发明涉及音乐源分离方法,具体是基于堆叠沙漏网络的音乐源分离方法。
背景技术:
[0002]
音乐源分离是自然语言处理下的一个重要分支,针对不同领域的具体要求,音乐源分离的目的可以是从混合信号中分离出人声或伴奏,也可以是从混合信号中分离出单个乐器的声音。分离后的信号源,在音乐检索领域上可进一步用于乐器识别、音高统计、音乐转录、歌词同步、歌手及歌词识别等应用。在语音识别领域上,可用于人声识别、关键词识别、语音情感识别等应用。随着有关机器学习和深度学习的研究,一系列神经网络在不断丰富和进化。为了有效地将一维的语音信号应用在cnn等神经网络中,可以先通过傅里叶变换将一维语音信号转换成二维幅度谱图,或者通过梅尔尺度滤波器转换成梅尔谱图或对数梅尔谱图。变换得到的二维图像,即可通过cnn或其他适用于信号处理的神经网络来进行训练。但是这些cnn网络深度上往往都比较浅,无法利用深度学习的优势来提取更深层次语音信号的特征,并且结构往往简单,无法处理更复杂的分离任务且分离效果不令人满意。
[0003]
堆叠沙漏网络是是用来解决在人体姿态上的相关问题的一种神经网络,在堆叠沙漏网络中,每个阶段的沙漏模块都是一个简单的轻量级网络,包含自己的下采样和上采样路径,将前一阶段的沙漏网络按照端到端的方式首尾叠加起来就构成了堆叠沙漏网络。堆叠后的沙漏网络通过中间监督来保证网络各层参数的正常更新。堆叠沙漏网络的最初设计的目的是为了解决在人体姿态上的相关问题,它的重复推理的结构可以使得沙漏网络在人体关节的不同尺度上处理特征,并且捕获与身体关节相关的各种空间关系。它不仅有效地解决了人体姿态估计的难题,更重要的是为其他图像处理领域提供了一种新的思路和基体,很多占主导地位的网络结构正是基于堆叠沙漏网络上产生的不同变体。
技术实现要素:
[0004]
本发明的目的在于克服现有技术的神经网络结构语音分离效果较差的不足,提供了一种基于堆叠沙漏网络的音乐源分离方法,基于沙漏模块的上采样和下采样路径,随着四个阶段不同沙漏模块端到端式的堆叠,前一阶段沙漏模块学习到的语音特征信息作为下一个沙漏模块的输入,使得后一阶段的沙漏模块获得了更丰富的特征信息,可以更加充分利用语音信号上下文之间的联系,从而提升了网络的分离效果;同时针对沙漏网络编码部分的不足,在沙漏模块中设计了一种等差式通道递增的结构,来弥补下采样语音谱图时产生的信息丢失,进一步提高了音乐源分离的效果。
[0005]
本发明的目的主要通过以下技术方案实现:
[0006]
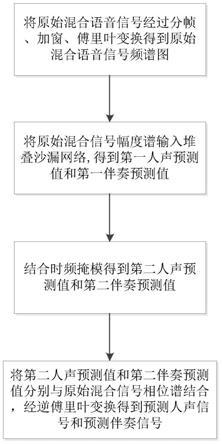
基于堆叠沙漏网络的音乐源分离方法,包括步骤:s1、将原始混合语音信号经过分帧、加窗、傅里叶变换得到原始混合语音信号频谱图,所述原始混合语音信号频谱图包括原始混合信号幅度谱和原始混合信号相位谱;s2、将原始混合信号幅度谱输入堆叠沙漏网络,所述堆叠沙漏网络包括四个以端对端的方式首尾堆叠的沙漏模块,原始混合信号幅度谱经
过堆叠沙漏网络后得到第一人声预测值和第一伴奏预测值;每个沙漏模块下采样第一次卷积后的输出通道等差式递增;s3、将第一人声预测值、第一伴奏预测值结合时频掩模得到经过时频掩模后的第二人声预测值和经过时频掩模后的第二伴奏预测值;将第二人声预测值和第二伴奏预测值分别与原始混合信号相位谱结合,并分别经过逆傅里叶变换得到预测人声信号和预测伴奏信号。
[0007]
堆叠沙漏网络是是用来解决在人体姿态上的相关问题的一种神经网络,在堆叠沙漏网络中,每个阶段的沙漏模块都是一个简单的轻量级网络,包含自己的下采样和上采样路径,将前一阶段的沙漏网络按照端到端的方式首尾叠加起来就构成了堆叠沙漏网络。堆叠后的沙漏网络通过中间监督来保证网络各层参数的正常更新。在堆叠沙漏单个模块中,很多结构采用的都是等宽度的通道进行重复的下采样和上采样。这样的结构设计虽然看起来是拓扑的美观对称结构,但是效果远远不如resnet等主流网络,对此本技术方案将堆叠沙漏网络使用在音乐源分离中,基于沙漏模块的上采样和下采样路径,随着四个阶段不同沙漏模块端到端式的堆叠,前一阶段沙漏模块学习到的语音特征信息作为下一个沙漏模块的输入,使得后一阶段的沙漏模块获得了更丰富的特征信息,可以更加充分利用语音信号上下文之间的联系,从而提升了网络的分离效果。本技术方案用四个以端到端的方式首尾堆叠起来的沙漏模块来进行分离,随着四个阶段不同沙漏模块端到端式的堆叠,前一阶段沙漏模块学习到的语音特征信息作为下一个沙漏模块的输入,使得后一阶段的沙漏模块获得了更丰富的特征信息,可以更加充分利用语音信号上下文之间的联系,从而提升了网络的分离效果。另一方面,堆叠起来的沙漏网络使得网络更加深入,有助于学习更深层次的语义特征。由于时频掩模可以针对混合信号中不同源之间的关系,在输入混合信号和输出预测信号之间产生约束,进而可以产生平滑的预测结果。故我们利用时频掩模来作为分离后的源的输出。将时频掩模与混合信号的输入谱图相乘后,可以得到网络所估计的语音谱图。每一个沙漏模块对应一个损失,所以4个损失之和对应最终的损失函数,这种中间监督可以保证网络各层参数的正常更新,从而提高分离性能;本技术方案所提出的堆叠沙漏网络没有改变原始信号的相位,所以可以通过逆stft,即结合语音谱图的幅度与原始相位来得到预测分离源的信号。此外,针对沙漏网络编码部分的不足,在沙漏模块中设计了等差式通道递增的结构来对混合信号的语音谱图进行下采样,利用每个沙漏模块下采样第一次卷积后的输出通道等差式递增,构建了一种强大的特征编码器,从而减少了信息丢失,来弥补下采样语音谱图时产生的信息丢失,进一步提高了音乐源分离的效果。
[0008]
进一步的,堆叠沙漏网络还包括一个由五个连续卷积层构成的初始卷积模块,所述卷积模块设置在四个沙漏模块之前,所述卷积模块不改变输入图像的大小,只增加图像的输出通道数。
[0009]
本技术方案在分离时首先要将原始混合的语音信号通过傅里叶变换转换成频谱图,再进一步输入到第一阶段的沙漏模块中。具体来说,通过设置傅里叶变换时滑动的窗长为1024,相邻窗之间的距离为256。对于时间帧长度不足64的语音信号进行补0操作。傅里叶变换后得到的语音谱图分辨率大小为512x64-分别对应图像的高度和宽度。在四个不同阶段的沙漏模块中,最小的特征通道数为256。由于傅里叶变换得到的语音谱图是单通道的-通道数为,即灰白图像,故为了避免由于特征维数的差异过大导致的网络性能不稳定,把得到的语音谱图输入到第一阶段的沙漏模块之前,先经过一个初始卷积模块,目的是为了增
加语音谱图的特征通道数。初始卷积模块由五个连续的卷积层构成,它们不改变输入图像的大小,只增加图像的输出通道数。具体来说,维度为512x64x1的语音谱图依次经过7x7x64,3个3x3x128,3x3x256构成的五个卷积层后,得到的混合信号的输入谱图维度为512x64x256-最后一个乘法因子代表着输出通道数。
[0010]
进一步的,四个沙漏模块均为四阶沙漏模块,输入的谱图在每个沙漏模块中都要经过四个连续的下采样,以不断减半输入谱图分辨率大小。
[0011]
本技术方案在单个沙漏模块的编码部分,混合信号的输入谱图-512x64x256要依次经过四个连续的下采样,来不断减半输入谱图的分辨率大小。
[0012]
进一步的,在每个沙漏模块内的卷积层后还设有一个注意力层,在每个沙漏模块的卷积层中还设有批标准化和leaky_relu激活函数来改进反向梯度传播和参数的更新。
[0013]
本技术方案保留了下采样时的池化和卷积结构不变,首先在卷积层后添加了一个注意力层,并且针对每个卷积层,添加了批标准化和leaky_relu激活函数来改进反向梯度传播和参数的更新。可以看到添加了通道注意力机制后,各个通道之间的重要程度不同。在堆叠沙漏网络中加入了通道注意力机制,将其作为沙漏网络的基本组件,从而使得整个网络可以根据不同通道之间的重要性来建模,相应地降低具有冗余特征信息的对应通道的权重,提高了整个沙漏网络的表达能力。此外,本技术方案还关注网络结构上的细节,加入了批标准化和leaky-relu激活函数,对堆叠沙漏网络这个具有深层次的网络结构进行了优化,进一步提高了音乐源分离的性能。
[0014]
进一步的,在每个沙漏模块下采样的第一次卷积时保持输出通道数不变,按照输出通道数1:1的比例来学习原始混合信号幅度谱的特征信息,在第一次卷积之后将输出通道依次加128,使每个沙漏模块中编码部分的输出通道大小依次为384、512、640、768。
[0015]
本技术方案使用等差式递增结构来使下采样时卷积层的输出通道数目增加,具体来说,在混合信号的输入谱图下采样时的第一次卷积之后保持通道数不变,仍然为c,c=256,目的是避免因为卷积前后的通道数的差异而造成不必要的信息损失,按照通道数1比1的比例来学习输入谱图的特征信息。在第一次卷积之后,使输出通道依次加n,n=128,故在单个四阶沙漏模块中,编码部分输出通道大小依次为384、512、640、768。在整个下采样的操作完成后,最终得到与混合信号的输入谱图相比为,分辨率大小为其1/16的特征图,且此时的特征通道数目为最大-c+4n。在后续解码部分对应的上采样操作中,由于不存在类似于下采样时的信息丢失,故解码部分的特征通道又恢复成为256,且为最大特征通道数的1/3。
[0016]
进一步的,在每个沙漏模块的下采样和解码部分上采样中,所有卷积层的卷积核大小均为3
×
3。
[0017]
进一步的,沙漏模块采用真实谱图和预测谱图之间的l1范数作为损失函数,具体为:给定一个输入谱图x、第i个真实音乐源y
i
,和第i个音乐源在第j个沙漏模块中生成的掩模m
ij
,那么第i个源的损失定义为:其中
⊙
表示元素相乘,l1范数为矩阵元素的绝对值之和。
[0018]
进一步的,堆叠沙漏网络总的损失函数为:其中c为网络要分
离源的数目。
[0019]
本技术方案中对于mir-1k和dsd100数据集下共同的人声伴奏分离的任务来说,c设置为2,分别对应人声和伴奏。对于dsd100数据集下的多音乐源分离任务,c设置为4,分别用于输出鼓、低音、人声和其他的时频掩模。
[0020]
进一步的,第二人声预测值和第二伴奏预测值的计算方法为:进一步的,第二人声预测值和第二伴奏预测值的计算方法为:其中
⊙
表示元素相乘,和分别是第二人声预测值和第二伴奏预测值,x
t
为原始混合信号幅度谱,为时频掩模,且其中和分别为第一人声预测值和第一伴奏预测值。
[0021]
本技术方案利用时频掩蔽技术进一步平滑源分离结果,使预测结果之和等于原始混合的约束。
[0022]
综上所述,本发明与现有技术相比具有以下有益效果:
[0023]
1、本发明提供的基于堆叠沙漏网络的音乐源分离方法,基于沙漏模块的上采样和下采样路径,随着四个阶段不同沙漏模块端到端式的堆叠,前一阶段沙漏模块学习到的语音特征信息作为下一个沙漏模块的输入,使得后一阶段的沙漏模块获得了更丰富的特征信息,可以更加充分利用语音信号上下文之间的联系,从而提升了网络的分离效果;同时针对沙漏网络编码部分的不足,在沙漏模块中设计了一种等差式通道递增的结构,来弥补下采样语音谱图时产生的信息丢失,进一步提高了音乐源分离的效果。
[0024]
2、本发明提供的基于堆叠沙漏网络的音乐源分离方法在堆叠沙漏网络中加入了通道注意力机制,将其作为沙漏网络的基本组件,从而使得整个网络可以根据不同通道之间的重要性来建模,相应地降低具有冗余特征信息的对应通道的权重,提高了整个沙漏网络的表达能力。此外,还关注网络结构上的细节,加入了批标准化和leaky-relu激活函数,对堆叠沙漏网络这个具有深层次的网络结构进行了优化,进一步提高了音乐源分离的性能。
附图说明
[0025]
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定。在附图中:
[0026]
图1为基于堆叠沙漏网络的音乐源分离方法的流程图。
具体实施方式
[0027]
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
[0028]
实施例1:
[0029]
如图1所示,本实施例包括步骤:
[0030]
s1、将原始混合语音信号经过分帧、加窗、傅里叶变换得到原始混合语音信号频谱图,所述原始混合语音信号频谱图包括原始混合信号幅度谱和原始混合信号相位谱;
[0031]
s2、将原始混合信号幅度谱输入堆叠沙漏网络,所述堆叠沙漏网络包括四个以端对端的方式首尾堆叠的沙漏模块,原始混合信号幅度谱经过堆叠沙漏网络后得到第一人声预测值和第一伴奏预测值;每个沙漏模块下采样第一次卷积后的输出通道等差式递增;
[0032]
s3、将第一人声预测值、第一伴奏预测值结合时频掩模得到经过时频掩模后的第二人声预测值和经过时频掩模后的第二伴奏预测值;将第二人声预测值和第二伴奏预测值分别与原始混合信号相位谱结合,并分别经过逆傅里叶变换得到预测人声信号和预测伴奏信号。
[0033]
本实施例提供的基于堆叠沙漏网络的音乐源分离方法,基于沙漏模块的上采样和下采样路径,随着四个阶段不同沙漏模块端到端式的堆叠,前一阶段沙漏模块学习到的语音特征信息作为下一个沙漏模块的输入,使得后一阶段的沙漏模块获得了更丰富的特征信息,可以更加充分利用语音信号上下文之间的联系,从而提升了网络的分离效果;同时针对沙漏网络编码部分的不足,在沙漏模块中设计了一种等差式通道递增的结构,来弥补下采样语音谱图时产生的信息丢失,进一步提高了音乐源分离的效果。
[0034]
实施例2:
[0035]
本实施例在实施例1的基础上还包括:堆叠沙漏网络还包括一个由五个连续卷积层构成的初始卷积模块,所述卷积模块设置在四个沙漏模块之前,所述卷积模块不改变输入图像的大小,只增加图像的输出通道数。
[0036]
优选的,四个沙漏模块均为四阶沙漏模块,输入的谱图在每个沙漏模块中都要经过四个连续的下采样,以不断减半输入谱图分辨率大小。
[0037]
优选的,在每个沙漏模块内的卷积层后还设有一个注意力层,在每个沙漏模块的卷积层中还设有批标准化和leaky_relu激活函数来改进反向梯度传播和参数的更新。
[0038]
优选的,在每个沙漏模块下采样的第一次卷积时保持输出通道数不变,按照输出通道数1:1的比例来学习原始混合信号幅度谱的特征信息,在第一次卷积之后将输出通道依次加128,使每个沙漏模块中编码部分的输出通道大小依次为384、512、640、768。
[0039]
优选的,在每个沙漏模块的下采样和解码部分上采样中,所有卷积层的卷积核大小均为3
×
3。
[0040]
优选的,沙漏模块采用真实谱图和预测谱图之间的l1范数作为损失函数,具体为:给定一个输入谱图x、第i个真实音乐源y
i
,和第i个音乐源在第j个沙漏模块中生成的掩模m
ij
,那么第i个源的损失定义为:其中
⊙
表示元素相乘,l1范数为矩阵元素的绝对值之和。
[0041]
优选的,堆叠沙漏网络总的损失函数为:其中c为网络要分离源的数目。
[0042]
优选的,第二人声预测值和第二伴奏预测值的计算方法为:
其中
⊙
表示元素相乘,和分别是第二人声预测值和第二伴奏预测值,x
t
为原始混合信号幅度谱,为时频掩模,且其中和分别为第一人声预测值和第一伴奏预测值。
[0043]
本实施例提供的基于堆叠沙漏网络的音乐源分离方法在堆叠沙漏网络中加入了通道注意力机制,将其作为沙漏网络的基本组件,从而使得整个网络可以根据不同通道之间的重要性来建模,相应地降低具有冗余特征信息的对应通道的权重,提高了整个沙漏网络的表达能力。此外,还关注网络结构上的细节,加入了批标准化和leaky-relu激活函数,对堆叠沙漏网络这个具有深层次的网络结构进行了优化,进一步提高了音乐源分离的性能。本实施例的音乐源分离方法基于堆叠沙漏网络,针对沙漏模块设计等差式通道递增的结构,并加入注意力机制,使其具有更强大的特征提取能力和多尺度整合能力,并且具有通道之间的注意力,具有更好的音乐源分离性能
[0044]
验证及对比试验:为了验证实施例2方法的分离效果,发明人对基于现有rpca(鲁棒主成分分析)的神经网络进行语音分离方法的对照组、实施例1的分离方法和实施例2的分离方法,在mir-1k数据集下伴奏部分的分离效果进行了对比。试验条件为:单块型号为tesla p100的gpu,深度环境为tensorflow,使用adam优化器来对网络进行训练,采用相同的初始学习率以及批量大小,迭代次数等的参数设置。
[0045]
(1)性能评估指标:
[0046]
评价分离效果的指标选用基于bss-eval的信噪比(sdr)、源干扰比(sir)和源伪影比(sar)作为评价指标,具体如下:
[0047]
信噪比(sdr):
[0048]
源干扰比((sir):
[0049]
源伪影比(sar):
[0050]
e
target
(t)是预测信号,e
interf
(t)是干扰信号,e
noise
(t)是噪声信号,e
artif
(t)是算法引入的伪像;sdr从比较全面的角度评估分离算法的分离效果,sir从干扰的角度分析分离效果,snr从噪声的角度分析分离效果,sar从伪像的角度分析分离效果;sdr、sir、sar的数值越大,说明人声和背景音乐的分离效果越好。全局nsdr(gnsdr)、全局sir(gsir)和全局sar(gsar)分别计算为nsdr、sir和sar的加权平均值,其权重为音源长度。其中,标准化的sdr(nsdr):nsdr(t
e
,t
o
,t
m
)=sdr(t
e
,t
o
)-sdr(t
m
,t
o
),其中t
e
定义为沙漏网络预测的人声/背景音乐,t
o
为原始信号中纯净的人声/背景音乐,t
m
为原始混合信号。
[0051]
(2)试验结果如下:
[0052][0053]
从上表中可以看出,采用发明实施例1和实施例2分离方法获得的伴奏分离效果,在信噪比、干扰比和伪影比等方面均明显优于采用现有音乐源分离方法的对照组,尤其是实施例2的堆叠沙漏网络在加入了注意力机制,并进一步深化等差式通道递增结构后,具有更强大的特征提取能力和多尺度整合能力,并且具有通道之间的注意力,其在信噪比、干扰比和伪影比的分离效果更好。可见本发明的音乐源分离方法基于堆叠沙漏网络,针对沙漏模块设计等差式通道递增的结构,并加入注意力机制,使其具有更强大的特征提取能力和多尺度整合能力,并且具有通道之间的注意力,具有更好的音乐源分离性能。
[0054]
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1