一种协同软件语音识别系统的制作方法
1.本发明属于电子信息技术领域,具体的,涉及一种协同软件语音识别系统。
背景技术:
2.语音识别技术,也被称为自动语音识别(asr,automatic speech recongnition)是将人类的语音中的词汇内容转换为计算机可读的输入,部分场景下可以理解为语音转换成文字。目前语音识别技术是人工智能领域一项比较通用的技术,一般作为辅助工具使用在应用场景中。例如使用在呼叫中心的语音转文字场景,使用在同声传译中需要实时识别整个说话过程的场景,这些场景上语音识别对于高并发的频繁调用需求要求并不是很高。因此目前大部分的语音识别服务架构都是单体架构方式,一个识别服务完成存储,转码,识别的所有工作。
3.随着语音识别技术的发展,识别准确率,识别速度不断的提高,语音技术开始在各行各业中全面应用,目前迫切需要一些高并发量场景下的语音识别解决方案。在协同软件中用户的日常沟通交流中,语音消息是一种使用频率非常高,数量巨大,且时效性很强的消息。并且在很多交流是在群里面产生的,参与的用户非常多,消息重复量大。另外语音输入法在协同软件中也是一个刚性需求,要求语音能及时的转换成文字提供给消息发送人进行修正。
4.因此需要一种解决协同软件语音识别和构建方法,将协同软件使用场景和语音识别使用场景有机的结合起来,解决该场景下的高并发语音识别需求。
技术实现要素:
5.为了解决上述技术问题至少之一,本发明提供了一种协同软件语音识别系统,技术方案如下:
6.一种协同软件语音识别系统,所述系统包括:客户端、自动语音识别平台和服务器;
7.所述客户端安装有协同软件,所述协同软件接收请求,将所述请求分类:客户端处理录音、转码和提参;
8.所述自动语音识别平台处理语音识别请求并根据动态路由自适应算法为语音识别请求分发服务器并进行服务器调用;
9.所述服务器接收所述语音识别请求并开启识别服务。
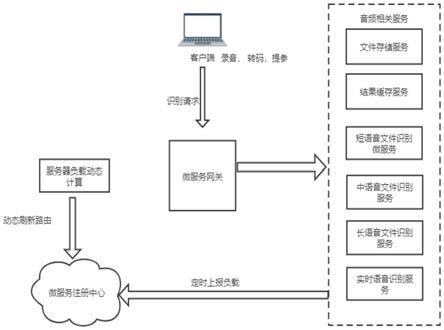
10.所述自动语音识别平台基于微服务架构并包括微服务网关、微服务注册中心和音频相关服务;
11.其中,
12.所述微服务网关接收所述语音识别请求;
13.微服务注册中心分析所述语音识别请求并基于所述动态路由自适应算法为所述语音识别请求分配服务器;
14.所述微服务网关将所述服务器拉取,进行服务器的调用。
15.所述微服务注册中心接收多个服务器的负载参数并计算每台服务器的负载值,根据所述负载值对服务器排序,选择最优服务器处理所述语音识别请求。
16.所述协同软件接收所述语音识别服务,利用声学参数识别所述音频文件,提取出所述音频文件的mfcc参数生成音频参数文件,并将所述音频参数文件发送至所述自动语音识别平台的文件服务进行存储。
17.所述服务器接收所述语音识别请求并开启识别服务,包括,
18.所述语音识别请求中包含有资源id;
19.所述服务器根据所述资源id在结果缓存服务器中查找对应的识别结果,识别成功则返回所述识别结果;
20.识别失败,所述服务器根据所述资源id在文件缓存服务器查找对应的音频参数文件并根据所述音频文件的音频时间将其分配到对应的自动语音识别服务队列中。
21.所述音频相关服务包括文件服务和语音文件识别服务;
22.所述文件服务包括:文件存储服务和结果缓存服务;
23.所述语音文件识别服务包括:
24.短音频文件识别服务、中音频文件识别服务、长音频文件识别服务和实时语音识别服务。
25.所述识别服务队列包括:短音频文件自动语音识别服务、中音频文件自动语音识别服务和实时自动语音识别服务。
26.所述中音频文件识别服务利用语音读点检测技术将所述音频参数文件分片,分片后交由所述短音频文件识别服务处理,处理接口将多个识别结果合并后返回至协同软件并将识别结果和对应的资源id存储到缓存器中。
27.所述服务器将时长超过120秒的音频文件和需要实时识别的音频文件分配至所述实时自动语音识别服务队列;将时长大于10秒并且小于120秒的音频文件分配至中音频文件自动语音识别服务队列;将时长低于10秒的音频文件分配至所述短音频文件自动语音识别服务队列。
28.本发明的有益效果如下:
29.本发明提供了一种协同软件语音识别系统。系统总体采用微服务架构设计,依据请求的消息长短,来设计不同的识别微服务,从而保证高并发量下识别系统的实时性和高可靠性。
附图说明
30.下面结合附图对本发明的具体实施方式作进一步详细的说明。
31.图1为本发明实施例的一种协同软件语音识别系统的整体流程图;
32.图2为本发明实施例的一种协同软件语音识别系统的动态路由自适应流程图;
33.图3为本发明实施例的一种协同软件语音识别系统服务划分逻辑图。
具体实施方式
34.以下结合附图和实施例对本发明所述的一种协同软件语音识别系统,进行详细说
明,所举实例只用于解释本发明,并非用于限定本发明的范围。
35.一种协同软件语音识别系统,如图1所示,包括客户端、语音识别服务平台
36.其中,所述语音识别微服务平台包括微服务网关、微服务注册中心和音频相关服务,所述音频相关服务包括文件存储服务、结果缓存服务、短语音文件识别服务、中语音文件识别服务、长语音文件识别服务和实时语音识别服务,所述结果缓存服务和文件存储服务分别对应不同的缓存器。
37.在一个优选的实施例中,所述语音识别微服务平台基于springcloud微服务架构,所述微服务网关基于zuul实现,所述微服务注册中心基于eurake实现。
38.在该系统中,客户端对语音服务进行划分,其中,录音、转码和提参由客户端实现,语音识别服务利用自助语音服务平台实现,客户端对用户的音频文件进行mfcc参数提取,提取声学参数的过程放在客户端进行可以有效的利用客户端的计算能力,降低服务端的开发和项目成本,减小需缓存文件的体积,降低保存原始语音的成本。
39.客户端接收到语音识别请求,将其传送至基于微服务架构的自动语音识别平台,微服务网关将其分配至微服务注册中心,所述微服务注册中心识别所述语音识别请求,根据动态路由自适应算法为其分配最优处理器,如图2所示,服务器每隔2秒上报一次本节点的任务状态,在一个实施例中,服务器a的最大的服务连接数c1,目前正在处理的服务连接数c2,以及本计算节点的cpu利用率c3、内存利用率c4、磁盘使用率c5作为评估服务器负载的参数。微服务网关根据所述负载参数,和各参数的权重,计算每台服务器的负载值,服务器a预先设定总连接数权重为w1,当前连接数权重为w2,cpu权重为w3,内存权重为w4,磁盘权重为w5,则该服务器的负载值load=w1*c1-w2*c2-w3*c3-w4*c4-w5*c5,所述微服务网关将多台服务器的负载值按照大小排序,依据排序结果将服务器进行区间划分,每次在最优区间中选择一个服务器作为下一次的计算节点。微服务注册中心选定服务器后,微服务网关向微服务注册中心拉取服务器进行调用。
40.在一个优选的实施例中,客户端根据交互行为区分出实时识别服务和音频文件识别服务,并根据音频文件的时长将所述音频文件识别服务标记对应的语音识别服务类别,包括短音频文件、中音频文件和长音频文件。
41.在一个可选的实施例中,微服务注册中心根据交互行为区分出实时识别服务和音频文件识别服务,并根据音频文件的时长将所述音频文件识别服务标记对应的语音识别服务类别,包括短音频文件、中音频文件和长音频文件。
42.在一个可选的实施例中,服务器根据交互行为区分出实时识别服务和音频文件识别服务,并根据音频文件的时长将所述音频文件识别服务标记对应的语音识别服务类别,包括短音频文件、中音频文件和长音频文件。
43.以上三种文件分别对应三个时长区间:0-10s、10-120s和大于120s,这三种音频文件分别对应短音频文件识别服务、中音频文件识别服务和长音频文件识别服务,服务器在接收到语音识别服务请求后,如图3所示,首先调用结果存储服务,根据客户端传递的资源id在所述结果存储服务器中查找识别结果,命中识别结果后直接将其返回给客户端,若没有识别结果,则针对不同的音频文件类型进行音频处理,处理时先根据资源id从文件缓存服务中调取音频文件的音频参数文件。对于小于10s的短音频文件,所述客户端或服务器调用http的短音频文件识别服务接口,所述短音频文件识别服务接口对对应的音频参数文件
进行解析。对于中音频文件识别服务,调用http的中音频识别服务接口,所述中音频识别服务利用音频断点检测技术(vad)对音频参数文件进行分片,并且将分片后的文件编号,每个分片之间相互独立,结果互相不影响。将编好号的分片放入中音频服务内部队列,利用线程池对队列中的分片语音识别。按照编号将分片识别结果排序,所有分片结果按照顺序合并后返回给客户端或服务器。对于超过120s的长音频文件,所述服务器调用实时识别服务的websocket服务进行处理。所述服务器将处理完毕的识别结果和对应的资源id存入结果存储服务器中,方便下次识别的结果对比。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1