基于不重叠分帧和串行FFT的极低功耗语音特征提取电路
基于不重叠分帧和串行fft的极低功耗语音特征提取电路
技术领域
1.本发明公开了基于不重叠分帧和串行fft的极低功耗语音特征提取电路,涉及信号处理和集成电路设计技术,属于计算、推算或计数的技术领域。
背景技术:
2.随着计算机技术的飞速发展,人机交互成为越来越热门的研究方向,而语音是进行信息交流的重要手段,目前语音识别技术已经得到广泛应用,例如iphone 的siri、智能音箱、机器人、车载系统等。语音识别技术是人机交互的入口,而语音唤醒又是复杂系统的接口,如何高效准确地对用户的指令给出反应成为人机交互技术的最重要目标,其中,在面向电池供电的智能设备中,其资源受限的特性决定了超低功耗成为迫切需要解决的问题。语音唤醒的过程包含两个阶段:音频信号的特征提取,关键词的特征识别。对于语音唤醒系统而言,良好的语音特征可以极大提高系统的最终识别精度,因此语音特征提取电路的设计是整个系统设计的一个关键点。
3.目前,常用的语音特征提取算法为梅尔频率倒谱分析(mel
‑
frequency cepstralcoefficients,简称mfcc)。mfcc是通过快速傅里叶变换(fft,fast fouriertransform)将时域信号转化为频域信号,再对频域信号进行梅尔滤波,梅尔滤波的本质是将最终特征尽可能接近人的生理感官(因为人对声音的感知是非线性的),然后再对梅尔滤波结果做自然对数运算,再对对数运算结果进行离散余弦变换(dct,discrete cosine transform)得到声音的一系列特征。传统的mfcc 算法对应硬件的适配性很差,fft运算过程以及梅尔滤波运算所需的大量乘加运算和存储面积,增大了硬件的实现难度和代价。为克服传统mfcc算法的缺陷,一种优化的低功耗mfcc语音特征提取电路通过串行fft和优化梅尔滤波算法架构以及预处理模块的乘加方式,极大减小了语音特征提取电路的运算量和存储量,但该优化的语音特征提取电路分帧加窗处理相邻两帧数据后存在重叠数据,而重叠的数据量通常为一帧数据点数的一半,存储重叠数据的存储器的容量与一帧数据点数以及数据精度相关,仍然存在运算量大以及需要大面积存储的缺陷。本申请旨在优化语音特征提取电路中的分帧加窗操作模块以避免整个特征提取过程中的分帧操作,进而实现进一步降低运算量、存储面积及硬件功耗的发明目的。
技术实现要素:
4.本发明的发明目的是针对上述背景技术的不足,提供了基于不重叠分帧和串行fft的极低功耗语音特征提取电路,利用不重叠分帧加窗操作精简电路包含的大部分存储,并采用串行fft算法处理输入数据,在适应串行输入数据流的特点的情况下极大地减小电路的面积以及功耗,使得语音特征提取电路的功耗极低,从而解决了语音特征提取算法在硬件上的高功耗和大存储量的技术问题。
5.本发明为实现上述发明目的采用如下技术方案:
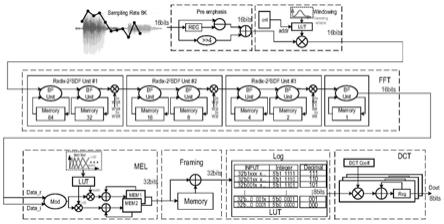
6.基于不重叠分帧和串行fft的极低功耗语音特征提取电路,包括:预处理模块,加
窗模块、fft模块、梅尔滤波模块、相邻帧合并模块以及对数和dct模块。
7.预处理模块,功能等同于一个高通滤波器,该模块保证了信号在频谱上的信噪比。具体操作为将语音序列串行输入进预处理模块,输入的数据与相邻的前一个数据乘以系数后的结果做减法,得到预加重后的语音信号。
8.加窗模块,功能为将t(t为小数,常取10到20)毫秒的数据作为一个汉明窗的数据长度,t毫秒的数据点数(数据点数为帧长乘以采样率)为t(t为整数,为了满足后续fft模块,t常取2的n次方),数据精度为a比特(a为大于1的整数)。输入数据以t为周期依次流入加窗模块与存储在只读存储器中的 t个汉明窗函数值相乘后依次输出,即可得到该模块的输出。
9.fft模块,功能为将一帧t长度的时域信号转换为频域信号。fft模块由 n/2(n为上述t中2的指数项)个基22单路径延迟反馈(radix
‑22
single
‑
path delayfeedback,简称radix
‑22
sdf)单元组成,每个radix
‑22
sdf单元内包含两次蝶形运算以及一次与旋转因子的乘积运算,其中,蝶形运算是对两个输入的实数,进行交叉相加减得到一组新的实数,而旋转因子预先存储在只读存储器中。由加窗模块输出的数据以自然顺序串行流入fft模块,经历了n/2个radix
‑22
sdf 单元运算之后,最终数据以比特置换(位翻转为高位和对称的低位进行翻转)的顺序依次输出。
10.梅尔滤波模块,功能为将每一帧的频域信号进行梅尔滤波运算。具体操作为,首先对fft模块输出的实部虚部数据进行平方相加运算,得到频域的能量值,然后将能量值和预存在静态随机存储器的m阶梅尔滤波组(m为整数,通常取 20到40)的函数值进行相乘,并对相乘之后的整帧信号的值进行累加,最终每帧得到m个梅尔值。在电路设计中对梅尔滤波器组的输入数据需要进行奇偶分离处理,数据顺序流入,奇数索引的数据和偶数索引的数据交替在两个累加器中进行运算。由于相邻滤波器的带宽存在重叠,因此完成取模运算后的数据逐个输入时同时会对应两个滤波器,因此需要同时执行两个乘累加运算;另一方面,奇数级滤波器与偶数级滤波器在自身内部不存在重叠,每一个数据仅为对应奇数或者偶数滤波器中的一个值,因此只需要将奇偶滤波器分开运算就可以对逐点输入的数据分别完成乘累加。
11.相邻帧合并模块,功能为将当前帧与下一帧的m阶梅尔滤波结果对应数据相加(即当前帧的第一个梅尔滤波结果和下一帧的第一个梅尔滤波结果相加,以此类推,直至当前帧的第m个梅尔滤波结果和下一帧的第m个梅尔滤波结果相加),得到一组新的m阶梅尔滤波结果。
12.对数和dct模块,功能为对上述相邻帧合并模块输出的梅尔数据进行压缩表示。首先利用查找表(通过寻找输入数据位中最高位
‘1’
出现的位置,查找对应的对数值)的方式对m个梅尔值取以2为底的对数值,然后再进行dct变换。dct变换的具体实现为输入数据与余弦系数相乘后累加计算,余弦系数储存在只读存储器中,最终输出l阶dct变换结果(l为整数,通常小于m),该结果为电路输出的特征值。
13.作为基于改进的串行fft的低功耗mfcc语音特征提取电路的进一步优化方案,整体架构采用了取消重叠步长的分帧操作、相邻合并在梅尔滤波之后的架构。与包含并行fft算法的mfcc架构相比,该算法在牺牲了一定吞吐量和速度下,减小了电路面积以及功耗。而与包含串行fft的算法架构相比,该算法将fft运算数据量减小一半,并且缩减了大量过程
数据的寄存器存储量,更进一步地节省了运算量和存储量。
14.基于改进的串行fft的低功耗mfcc语音特征提取电路的语音特征提取电路的进一步优化方案,在预加重模块中,用下述优化公式替换原公式,其中,data
in
和data
out
分别表示本操作的输入数据和输出数据,k表示数据的位置,从1开始:
[0015][0016]
data
out
[k]=data
in
[k]
‑
data
in
[k
‑
1]+data
in
[k
‑
1]>>4
ꢀꢀꢀ
(优化公式)
[0017]
最终将原本数学公式上的乘加运算,优化为移位加运算,降低了片上系统在实现乘法运算时的额外功耗以及存储量。
[0018]
作为基于改进的串行fft的低功耗mfcc语音特征提取电路的进一步优化方案,采用流水线式的串行fft算法实现傅里叶变换。其具体流程为:
[0019]
步骤一:首先,第一个radix
‑22
sdf运算单元中的第一个蝶形运算(简称 bf1)部分中含有一个大小为t/2*a比特的存储器,输入的一帧t个数据,先将前t/2个数据存入存储器中,然后再将后t/2个数据与前t/2个数据做第一次蝶形运算,运算会得到两组t/2长度的数据,后t/2个数据返回存入存储器中,前 t/2个数据继续第二次蝶形运算(简称bf2),当前t/2个数据完成第二次蝶形运算完再对存储器中存入的后t/2个数据进行第二次蝶形运算。
[0020]
步骤二:第一radix
‑22
sdf运算单元中的bf2部分中含有一个大小为t/4*a 比特的存储器,第一次部分输出的t/2个数据,首先存t/4个数据进入到存储器中,和bf1部分类似,接下来的t/4个数据与存储器中的t/4个数据做bf2蝶形运算,再返回存储得到的后t/4个数据,输出前t/4个数据。输出的数据再乘以其相应的旋转因子,旋转因子的值存在一个大小为t/4*a比特的存储器中,所有radix
‑22
sdf单元中的旋转因子乘积单元皆可以调用相同的存储器中的数值。
[0021]
步骤三:接下来串行数据流入到下一个radix
‑22
sdf单元仍然重复上述操作,不过radix
‑22
sdf单元中蝶形运算模块对应的存储器大小会逐次减半。最后直至第n/2个radix
‑22
sdf单元中的bf1的存储器单元大小为2*a比特,bf2将直接输出fft模块的复数结果,最终数据是按照比特置换的顺序流出的,由于在梅尔滤波之后,整帧数据乘加求和,因此顺序不影响结果,该模块将不会调整顺序,因此可以节省控制逻辑部分的硬件消耗。
[0022]
作为基于改进的串行fft的低功耗mfcc语音特征提取电路的进一步优化方案,在取对数模块中,通过查找表的方式实现对数运算,此对数运算可以不采用传统的坐标旋转数字计算方法(coordinate rotation digital computer,简称 cordic)进行运算,而是采用寻找输入数据的最高位
‘1’
出现的位置,以此查找出对应的对数值。
[0023]
本发明采用上述技术方案,具有以下有益效果:本发明的基于不重叠分帧和串行fft的极低功耗语音特征提取电路,能够电路上实现mfcc算法,有效地提取出音频的特征值。
[0024]
(1)对比传统基于通用的串行fft的mfcc电路,由于本发明优化了传统的分帧加窗的算法架构,舍弃了含重叠部分的分帧操作,节省了所需的大存储量,并且使得fft运算的数据长度相较传统的串行fft减半。因此,本发明的面积、存储量和计算量均大幅度降低,具有极低的功耗。
[0025]
(2)利用串行方式实现的fft,存储量下降到并行方式实现的fft的1/n (n为t的指
数项,t为一帧的点数,即一帧fft的输入数据量,常取2的n 次方),计算量也随之大幅度下降。
[0026]
(3)利用查找表的优化取对数方式,减轻对数运算的复杂性,降低了功耗。
[0027]
(4)预处理模块中乘法运算的近似运算,利用。移位运算代替了乘法运算,降低了运算的功耗。
附图说明
[0028]
图1为本发明公开的语音特征提取电路的系统架构图。
[0029]
图2为本发明公开的语音特征提取电路的加窗模块的架构图。
[0030]
图3为本发明公开的语音特征提取电路的串行fft模块的架构图。
[0031]
图4为本发明公开的语音特征提取电路的梅尔滤波模块的架构图。
[0032]
图5为本发明公开的语音特征提取电路的梅尔滤波读写时序图。
[0033]
图6为本发明公开的语音特征提取电路的分帧取对数模块的架构图。
具体实施方式
[0034]
下面结合附图对发明的技术方案进行详细说明,以帧长128个点、20阶梅尔值、10阶dct值(t=128,m=20,l=10)为例说明本发明的具体实现,但本发明的范围不限于此实施例。
[0035]
如图1所示,本发明设计的基于改进的串行fft的低功耗mfcc语音特征提取电路主要分为七个模块:预加重模块、加窗模块、fft模块、梅尔滤波模块、相邻帧合并模块、对数模块和dct模块。电路输入时钟信号、语音模数转换(adc) 采样数据信号,输出语音特征值,该电路的工作可分为以下7个步骤。
[0036]
步骤1:从电路启动开始,语音adc采样端以8k采样率开始对音频进行采样,系统首先需要使用一个寄存器(reg)对相邻的上一个采样数据进行缓存,寄存器的数据输出将作为预加重模块的输入,当前采样数据data
in
[k]在进入预加重模块后通过和寄存器缓存的上一采样数据data
in
[k
‑
1]以及其移位后的数据进行加运算实现了预加重操作。预加重操作的公式如下:
[0037]
data
out
[k]=data
in
[k]
‑
data
in
[k
‑
1]+data
in
[k
‑
1]>>4,
[0038]
其中,k从1开始,表示数据的位置。
[0039]
步骤2:加窗模块使用一个存储器存有128个汉明窗系数,预加重模块流出的数据以每128个数据为循环依次与存储的汉明窗数据相乘后,输出给fft模块。加窗模块的架构如图2所示,通过读取计数器的地址查表获得汉明窗系数,预加重后的采样数据与读取的汉明窗系数形成后送入fft模块。
[0040]
步骤3:经过加窗后的数据流水线进入fft模块。fft模块架构图如图3所示。首先,因为傅里叶变换的点数为128个,所以需要4级radix
‑22
sdf单元,每个radix
‑22
sdf单元包含一个bf1运算单元、一个bf2运算单元和一个旋转因子乘法单元,最后一个radix
‑22
sdf单元只包含一个bf1单元,串行fft模块运算公式如下:
[0041][0042]
在上述公式中,(k1+2k2+4k3)表示输出信号的顺序,k1取0、1,k2取0、1, k3取0到63的整数。等号右式中求和符号内部的公式的实际意义为蝶形运算的数学解释。其中,x(n3)+(
‑
1)
k1
x(n/2+n3)作为bf1蝶形运算,)作为bf1蝶形运算,作为bf2蝶形运算,而为旋转因子。数据一共经历4轮radix
‑22
sdf单元运算,最终依次输出比特置换顺序的fft结果。
[0043]
步骤4:fft输出的复数首先对实部虚部取平方求和,输出的模值只选择奇数索引的数据(设定第一个数据的索引为1)和存储在存储器中的梅尔滤波器的函数值相乘并累加,最终输出一帧20阶梅尔值。滤波过程中需要先从存储阵列中读出部分和,当前奇数索引对应的模值与梅尔系数相乘后累加读取的部分和,累加后得到的部分和更新值再写入存储阵列,这个过程需要两个时钟周期,因为只需要考虑奇数个输入数据的滤波,所以对偶数个输入数据无需运算,因此实际的运算时间也为两个时钟周期,保证了电路吞吐率的前后一致。梅尔滤波模块的架构如图4所示,具体时序图如图5所示。
[0044]
步骤5:由梅尔滤波模块输出的20阶梅尔值保存至相邻帧合并模块的存储器内,并与下一帧的梅尔值相加,相加的结果作为下一帧新的梅尔值。
[0045]
步骤6:梅尔值输出后需要对其取对数,通过寻找梅尔值最高位
‘1’
出现的位置,以查找表的方式来实现取对数功能,以一个八位二进制数10001111为例,它的最高位
‘1’
出现的位置是第7位,因此对应的对数值为7。相邻帧合并模块和实现取对数功能的查找表的架构如图6所示。
[0046]
步骤7:取完对数之后的梅尔值需要进行dct变换,dct变换的公式如下:
[0047][0048]
s(m)为梅尔值,l为dct阶数,m为梅尔阶数,l通常小于m,其在硬件上可以通过数据和相对应的余弦值相乘累加计算,最终输出10阶dct值,作为当前帧音频采集信号的特征值。
[0049]
最后本发明在tsmc28nmtt25℃的环境下仿真,和传统的重叠分帧的mfcc 算法相比,功耗降低了43%,具体功耗对比表格如表1所示。
[0050]
电路类型功耗传统mfcc算法硬件电路275nw不重叠分帧和串行fft的mfcc硬件电路157nw
[0051]
表1。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1