一种语音处理方法、装置和用于语音处理的装置与流程
1.本发明涉及语音处理技术领域,尤其涉及一种语音处理方法、装置和用于语音处理的装置。
背景技术:
2.随着通信技术的发展,语音通信已经称为目前主要的通信方式,但是语音通信过程中,来自于周围环境中的噪音、干扰一直是影响用户通信体验的重要因素。
3.例如,用户在使用语音通信设备进行语音通信的过程中,周围环境中的噪音、干扰会一同传入用户的语音通信设备,导致通信对方无法听清该用户语音,或者,导致通信对方听到其他语音(如周围说话人的声音)而这些语音是该用户不希望通信对方听到的,这样不仅影响语音通信效果而且可能会暴露该用户的个人隐私。
技术实现要素:
4.本发明实施例提供一种语音处理方法、装置和用于语音处理的装置,可以提高通话语音的质量,以及保护用户隐私。
5.为了解决上述问题,本发明实施例公开了一种语音处理方法,所述方法包括:
6.接收待处理语音,所述待处理语音中包含噪音和目标用户声音,目标用户的个数大于或等于1;
7.获取所述目标用户的注册语音特征;
8.将所述待处理语音和所述目标用户的注册语音特征输入说话人提取模型,所述说话人提取模型根据所述目标用户的注册语音特征,提取所述待处理语音中所述目标用户的目标语音,并输出所述目标语音。
9.可选地,所述方法还包括:
10.收集注册用户的用户语音样本;
11.获取所述注册用户的注册语音特征和纯净语音;
12.将所述用户语音样本、注册语音特征、以及纯净语音输入初始的说话人提取模型,所述说话人提取模型根据所述注册用户的注册语音特征,提取所述用户语音样本中注册用户的目标语音;
13.根据提取的注册用户的目标语音与注册用户的纯净语音之间的特征差异迭代优化所述说话人提取模型的模型参数,达到预设收敛条件得到训练完成的说话人提取模型。
14.可选地,所述说话人提取模型包括第一处理网络和第二处理网络,所述说话人提取模型根据所述注册用户的注册语音特征,提取所述用户语音样本中注册用户的目标语音,包括:
15.将所述用户语音样本进行短时傅里叶变换,得到样本语音幅度谱;
16.将所述纯净语音进行短时傅里叶变换,得到纯净语音幅度谱;
17.通过所述第一处理网络提取所述样本语音幅度谱的含噪语音特征;
18.将所述注册用户的注册语音特征与所述含噪语音特征进行矩阵的元素相乘,得到调制语音特征;
19.通过所述第二处理网络对所述调制语音特征进行特征提取处理,得到幅度谱掩码;
20.将所述样本语音幅度谱与所述幅度谱掩码进行矩阵的元素相乘,得到降噪语音幅度谱;
21.所述根据提取的注册用户的目标语音与注册用户的纯净语音之间的特征差异迭代优化所述说话人提取模型的模型参数,包括:
22.根据预设损失函数,计算所述降噪语音幅度谱与所述纯净语音幅度谱之间的特征差异;
23.根据所述特征差异迭代优化所述说话人提取模型的模型参数。
24.可选地,所述获取所述目标用户的注册语音特征,包括:
25.获取所述目标用户的注册语音;
26.将所述目标用户的注册语音输入特征提取模型,对所述目标用户的注册语音进行特征提取,得到所述目标用户的注册语音特征。
27.可选地,所述方法还包括:
28.收集注册用户的注册语音样本;
29.将所述注册语音样本输入初始的特征提取模型,提取得到所述注册语音样本的特征向量;
30.对所述注册用户的纯净语音进行特征提取,得到纯净语音的特征向量;
31.根据所述注册语音样本的特征向量与所述纯净语音的特征向量之间的特征差异迭代优化所述特征提取模型的模型参数,达到预设收敛条件得到训练完成的特征提取模型。
32.可选地,所述将所述注册语音样本输入初始的特征提取模型,提取得到所述注册语音样本的特征向量,包括:
33.对所述注册语音样本进行话音激活检测,过滤所述注册语音样本中的非语音段,得到过滤后语音;
34.将所述过滤后语音按预设帧长进行切分,得到所述过滤后语音对应的语音帧序列;
35.对所述语音帧序列中的各语音帧进行短时傅里叶变换,得到每个语音帧对应的语音帧幅度谱;
36.将所述语音帧幅度谱输入特征提取模型的特征提取网络,输出每个语音帧幅度谱的特征向量;
37.将所述语音帧序列中各语音帧对应语音帧幅度谱的特征向量进行求平均计算,得到所述注册语音样本的特征向量。
38.可选地,所述注册用户的个数大于1,所述对所述注册语音样本进行话音激活检测,过滤所述注册语音样本中的非语音段,得到过滤后语音,包括:
39.对每个所述注册用户的注册语音样本进行话音激活检测,得到每个注册语音样本的过滤后语音;
40.所述将所述过滤后语音按预设帧长进行切分,得到所述过滤后语音对应的语音帧序列,包括:
41.将每个注册语音样本的过滤后语音按预设帧长进行切分,得到每个注册语音样本对应的语音帧序列;
42.所述对所述语音帧序列中的各语音帧进行短时傅里叶变换,得到每个语音帧对应的语音帧幅度谱,包括:
43.对每个注册语音样本的语音帧序列中的各语音帧进行短时傅里叶变换,得到每个注册语音样本的语音帧序列中各语音帧对应的语音帧幅度谱;
44.所述将所述语音帧幅度谱输入特征提取模型的特征提取网络,输出每个语音帧幅度谱的特征向量,包括:
45.将每个注册语音样本的语音帧序列中各语音帧对应的语音帧幅度谱输入特征提取模型的特征提取网络,输出每个语音帧幅度谱的特征向量;
46.所述将所述语音帧序列中各语音帧对应语音帧幅度谱的特征向量进行求平均计算,得到所述注册语音样本的特征向量,包括:
47.将每个注册语音样本的语音帧序列中各语音帧对应的语音帧幅度谱的特征向量进行求平均计算,得到每个注册语音样本的特征向量。
48.可选地,所述方法还包括:
49.建立所述注册用户的语音特征库,所述语音特征库中保存有注册用户的注册语音特征与注册用户的用户标识之间的映射关系;
50.所述获取所述目标用户的注册语音特征,包括:
51.根据目标用户的用户标识查询所述语音特征库,得到所述目标用户的注册语音特征。
52.可选地,所述目标用户的个数大于1,所述将所述待处理语音和所述目标用户的注册语音特征输入说话人提取模型,包括:
53.将所述待处理语音和每个目标用户的注册语音特征输入说话人提取模型;
54.所述输出所述目标语音,包括:
55.分别输出每个目标用户对应的目标语音,或者,输出包含所有目标用户的目标语音的混合语音。
56.另一方面,本发明实施例公开了一种语音处理装置,所述装置包括:
57.语音获取模块,用于接收待处理语音,所述待处理语音中包含噪音和目标用户声音,目标用户的个数大于或等于1;
58.特征获取模块,用于获取所述目标用户的注册语音特征;
59.语音处理模块,用于将所述待处理语音和所述目标用户的注册语音特征输入说话人提取模型,所述说话人提取模型根据所述目标用户的注册语音特征,提取所述待处理语音中所述目标用户的目标语音,并输出所述目标语音。
60.可选地,所述装置还包括:
61.第一收集模块,用于收集注册用户的用户语音样本;
62.第一获取模块,用于获取所述注册用户的注册语音特征和纯净语音;
63.特征提取模块,用于将所述用户语音样本、注册语音特征、以及纯净语音输入初始
的说话人提取模型,所述说话人提取模型根据所述注册用户的注册语音特征,提取所述用户语音样本中注册用户的目标语音;
64.第一迭代模块,用于根据提取的注册用户的目标语音与注册用户的纯净语音之间的特征差异迭代优化所述说话人提取模型的模型参数,达到预设收敛条件得到训练完成的说话人提取模型。
65.可选地,所述说话人提取模型包括第一处理网络和第二处理网络,所述特征提取模块,包括:
66.第一傅里叶变换子模块,用于将所述用户语音样本进行短时傅里叶变换,得到样本语音幅度谱;
67.第二傅里叶变换子模块,用于将所述纯净语音进行短时傅里叶变换,得到纯净语音幅度谱;
68.第一网络处理子模块,用于通过所述第一处理网络提取所述样本语音幅度谱的含噪语音特征;
69.特征调制子模块,用于将所述注册用户的注册语音特征与所述含噪语音特征进行矩阵的元素相乘,得到调制语音特征;
70.第二网络处理子模块,用于通过所述第二处理网络对所述调制语音特征进行特征提取处理,得到幅度谱掩码;
71.相乘子模块,用于将所述样本语音幅度谱与所述幅度谱掩码进行矩阵的元素相乘,得到降噪语音幅度谱;
72.所述第一迭代模块,包括:
73.差异计算子模块,用于根据预设损失函数,计算所述降噪语音幅度谱与所述纯净语音幅度谱之间的特征差异;
74.迭代优化子模块,用于根据所述特征差异迭代优化所述说话人提取模型的模型参数。
75.可选地,所述特征获取模块,包括:
76.注册语音获取子模块,用于获取所述目标用户的注册语音;
77.模型提取子模块,用于将所述目标用户的注册语音输入特征提取模型,对所述目标用户的注册语音进行特征提取,得到所述目标用户的注册语音特征。
78.可选地,所述装置还包括:
79.第二收集模块,用于收集注册用户的注册语音样本;
80.第一提取模块,用于将所述注册语音样本输入初始的特征提取模型,提取得到所述注册语音样本的特征向量;
81.第二提取模块,用于对所述注册用户的纯净语音进行特征提取,得到纯净语音的特征向量;
82.第二迭代模块,用于根据所述注册语音样本的特征向量与所述纯净语音的特征向量之间的特征差异迭代优化所述特征提取模型的模型参数,达到预设收敛条件得到训练完成的特征提取模型。
83.可选地,所述目标用户的个数大于1,所述语音处理模块,具体用于将所述待处理语音和每个目标用户的注册语音特征输入说话人提取模型,分别输出每个目标用户对应的
目标语音,或者,输出包含所有目标用户的目标语音的混合语音。
84.再一方面,本发明实施例公开了一种用于语音处理的装置,所述装置包括有存储器,以及一个或者一个以上的程序,其中一个或者一个以上程序存储于存储器中,且经配置以由一个或者一个以上处理器执行所述一个或者一个以上程序包含用于执行如权利要求1至9中任一所述的语音处理方法的指令。
85.又一方面,本发明实施例公开了一种机器可读介质,其上存储有指令,当由一个或多个处理器执行时,使得装置执行如前述一个或多个所述的语音处理方法。
86.本发明实施例包括以下优点:
87.本发明实施例可以对待处理语音进行去噪处理,提取待处理语音中目标用户的目标语音。当目标用户处于嘈杂的环境中时,本发明实施例可以获取目标用户的注册语音特征,并且将目标用户的待处理语音与目标用户的注册语音特征输入说话人提取模型,通过说话人提取模型将目标用户声音以外的声音作为噪音过滤掉。所述目标用户的个数可以大于或等于1。这样,在目标用户的个数为1时,可以将这一个目标用户声音以外的所有声音(包括其他用户的声音)作为噪音过滤掉,仅保留这一个目标用户的目标语音。在目标用户的个数大于1时,可以保留多个目标用户的目标语音。通过本发明实施例,可以对待处理语音进行去噪处理,仅保留用户指定的目标语音,可以提高通话语音的质量,以及保护用户隐私。
附图说明
88.为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例的描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
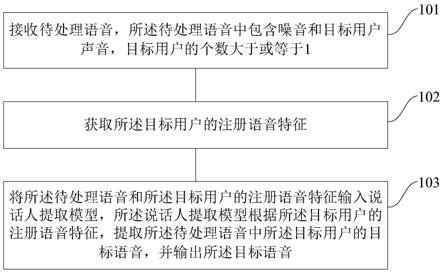
89.图1是本发明的一种语音处理方法实施例的步骤流程图;
90.图2是本发明的一种特征提取模型的处理流程示意图;
91.图3是本发明的一种对3个注册用户的注册语音样本进行特征提取的流程示意图;
92.图4是本发明的一种用户间余弦相似度矩阵的示意图;
93.图5是本发明的一种训练说话人提取模型的流程示意图;
94.图6是本发明的一种在线使用说话人提取模型提取目标用户的目标语音的流程示意图;
95.图7是本发明的一种语音处理装置实施例的结构框图;
96.图8是本发明的一种用于语音处理的装置800的框图;
97.图9是本发明的一些实施例中服务器的结构示意图。
具体实施方式
98.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
99.方法实施例
100.参照图1,示出了本发明的一种语音处理方法实施例的步骤流程图,所述方法具体可以包括如下步骤:
101.步骤101、接收待处理语音,所述待处理语音中包含噪音和目标用户声音,目标用户的个数大于或等于1;
102.步骤102、获取所述目标用户的注册语音特征;
103.步骤103、将所述待处理语音和所述目标用户的注册语音特征输入说话人提取模型,所述说话人提取模型根据所述目标用户的注册语音特征,提取所述待处理语音中所述目标用户的目标语音,并输出所述目标语音。
104.本发明实施例提供的语音处理方法可应用于终端设备,所述终端设备包括但不限于:耳机、录音笔、家居智能终端(包括:空调、冰箱、电饭煲、热水器等),商务智能终端(包括:可视电话、会议桌面智能终端等),可穿戴设备(包括智能手表、智能眼镜等),金融智能终端机,以及智能手机、平板电脑、个人数字助理(personal digital assistant,pda)、车载设备、计算机等。
105.本发明实施例可用于对待处理语音进行去噪处理,以过滤待处理语音中的噪音,提取待处理语音中目标用户的目标语音。过滤的噪音包括但不限于背景噪音、干扰音、以及其他说话人(非目标用户)的声音等。
106.所述待处理语音可以是目标用户通过即时通讯终端发送的语音或者接收的语音。所述待处理语音还可以是目标用户向智能终端设备发出的语音指令。所述待处理语音还可以是终端设备录制的语音段,或者通过网络下载的任意语音段。可以理解,本发明实施例对所述待处理语音的来源不做限制。
107.在本发明实施例中,目标用户为已注册语音的用户。注册语音指用户通过录音设备(具有录音功能的设备均可以,比如手机等)录入一段语音,该段语音作为该用户的注册语音,注册语音中可以包含噪音,且注册语音的具体内容本发明不做限制,可以为注册用户录入的任意一段语音内容。本发明实施例将已注册语音的用户称为注册用户。
108.对于注册用户的注册语音,本发明实施例可以进行特征提取,得到注册用户的注册语音特征,基于注册语音特征,可以从待处理语音中提取目标用户声音,得到目标语音。具体地,本发明实施例将待处理语音和目标用户的注册语音特征输入说话人提取模型,所述说话人提取模型根据所述目标用户的注册语音特征,提取所述待处理语音中所述目标用户的目标语音,并输出所述目标语音。
109.一个示例中,目标用户使用即时通讯终端进行语音通信,目标用户处于比较嘈杂的环境中,环境中有背景噪音比如汽车、风声等,也有其他说话人发出的声音。本发明实施例可以将该目标用户的通话语音作为待处理语音,与该目标用户的注册语音特征一并输入说话人提取模型,通过说话人提取模型将该目标用户声音以外的声音作为噪音过滤掉,只保留该目标用户的通话语音。由此,可以提高通话语音的质量。
110.本发明实施例的语音处理方法可应用于即时通讯场景,对通话语音进行降噪处理,仅保留通话者的声音,提高通话质量。进一步地,对于即时通讯场景,待处理语音可以为语音通话中的语音,也可以为视频通话中提取的语音。此外,本发明实施例还可用于语音识别场景,对语音指令进行降噪处理,仅保留指令发出者的声音,提高语音指令识别的准确
率。
111.本发明实施例在提取目标用户的目标语音之前,需要获取目标用户的注册语音特征。基于目标用户的注册语音特征,可以将目标用户声音以外的声音作为噪音进行过滤,得到仅保留目标用户声音的目标语音。
112.在本发明的一种可选实施例中,所述目标用户的个数可以大于1,所述将所述待处理语音和所述目标用户的注册语音特征输入说话人提取模型,具体可以包括:将所述待处理语音和每个目标用户的注册语音特征输入说话人提取模型;
113.所述输出所述目标语音,具体可以包括:分别输出每个目标用户对应的目标语音,或者,输出包含所有目标用户的目标语音的混合语音。
114.具体地,将所述待处理语音和n(n大于1)个目标用户中每个目标用户的注册语音特征输入说话人提取模型。一个示例中,目标用户包括用户1、用户2、用户3,根据用户的设置,可以分别输出每个目标用户对应的目标语音,如分别输出用户1的目标语音、用户2的目标语音、用户3的目标语音。或者,还可以输出包含所有目标用户的目标语音的混合语音,如输出同时包含用户1的目标语音、用户2的目标语音、用户3的目标语音的混合语音。
115.本发明实施例对获取目标用户的注册语音特征的具体方式不做限制。
116.进一步地,本发明实施例可以预先训练特征提取模型,通过特征提取模型提取目标用户的注册语音特征。此外,本发明实施例还预先训练说话人提取模型,通过说话人提取模型提取待处理语音中目标用户的目标语音。
117.在本发明的一种可选实施例中,所述获取所述目标用户的注册语音特征,具体可以包括:
118.步骤s11、获取所述目标用户的注册语音;
119.步骤s12、将所述目标用户的注册语音输入特征提取模型,对所述目标用户的注册语音进行特征提取,得到所述目标用户的注册语音特征。
120.本发明实施例预先训练特征提取模型,通过特征提取模型提取目标用户的注册语音特征。特征提取模型可以离线使用或者在线使用。离线使用时,可以预先录入每个注册用户的注册语音,并且利用已训练好的特征提取模型对每个注册用户的注册语音进行特征提取,得到每个注册用户的注册语音特征并保存。通过查询已保存的注册用户的注册语音特征,可以得到目标用户的注册语音特征。在线使用时,可以实时录入目标用户的注册语音,并在线提取目标用户的注册语音特征,进而根据实时提取的目标用户的注册语音特征,对待处理语音进行去噪处理。
121.在本发明的一种可选实施例中,所述方法还可以包括:建立所述注册用户的语音特征库,所述语音特征库中保存有注册用户的注册语音特征与注册用户的用户标识之间的映射关系;
122.所述获取所述目标用户的注册语音特征,具体可以包括:根据目标用户的用户标识查询所述语音特征库,得到所述目标用户的注册语音特征。
123.在特征提取模型训练完成之后,可以对每个注册用户的注册语音进行特征提取,得到每个注册用户的注册语音特征,进而可以保存每个注册用户的注册语音特征与注册用户的用户标识之间的映射关系,以建立语音特征库。
124.这样,在使用说话人提取模型从待处理语音中提取目标用户的目标语音时,可以
利用目标用户的用户标识在语音特征库中直接查询得到目标用户的注册语音特征,可以提高提取目标用户的目标语音的效率。
125.在本发明的一种可选实施例中,所述方法还可以包括:
126.步骤s21、收集注册用户的注册语音样本;
127.步骤s22、将所述注册语音样本输入初始的特征提取模型,提取得到所述注册语音样本的特征向量;
128.步骤s23、对所述注册用户的纯净语音进行特征提取,得到纯净语音的特征向量;
129.步骤s24、根据所述注册语音样本的特征向量与所述纯净语音的特征向量之间的特征差异迭代优化所述特征提取模型的模型参数,达到预设收敛条件得到训练完成的特征提取模型。
130.所述特征提取模型可以为根据大量的训练样本和机器学习方法,对现有的神经网络进行有监督训练而得到的。需要说明的是,本公开实施例对所述特征提取模型的模型结构以及训练方法不加以限制。所述特征提取模型可以融合多种神经网络。所述神经网络包括但不限于以下的至少一种或者至少两种的组合、叠加、嵌套:cnn(convolutional neural network,卷积神经网络)、lstm(long short
‑
term memory,长短时记忆)网络、rnn(simple recurrent neural network,循环神经网络)、注意力神经网络等。
131.注册语音样本为收集的大量的注册用户录入的注册语音,将所述注册语音样本输入初始的特征提取模型,提取得到所述注册语音样本的特征向量,如记为x。
132.此外,对于每一个注册语音样本,本发明实施例获取该注册语音样本对应注册用户录入的纯净语音,也即,每个注册语音样本具有对应的纯净语音,纯净语音指注册用户在没有噪音的环境下录入的语音。对所述纯净语音进行特征提取,得到纯净语音的特征向量,如记为y。
133.需要说明的是,本发明实施例对注册语音样本的内容以及纯净语音的内容不做限制。
134.利用预设的损失函数,计算所述注册语音样本的特征向量x与所述纯净语音的特征向量y之间的特征差异,进而根据该特征差异迭代优化特征提取模型的模型参数,直至达到预设收敛条件,可以得到训练完成的特征提取模型。
135.在本发明的一种可选实施例中,所述将所述注册语音样本输入初始的特征提取模型,提取得到所述注册语音样本的特征向量,具体可以包括:
136.步骤s31、对所述注册语音样本进行话音激活检测,过滤所述注册语音样本中的非语音段,得到过滤后语音;
137.步骤s32、将所述过滤后语音按预设帧长进行切分,得到所述过滤后语音对应的语音帧序列;
138.步骤s33、对所述语音帧序列中的各语音帧进行短时傅里叶变换,得到每个语音帧对应的语音帧幅度谱;
139.步骤s34、将所述语音帧幅度谱输入特征提取模型的特征提取网络,输出每个语音帧幅度谱的特征向量;
140.步骤s35、将所述语音帧序列中各语音帧对应语音帧幅度谱的特征向量进行求平均计算,得到所述注册语音样本的特征向量。
141.话音激活检测(vad,voice activity detection)的目的在于检测当前语音信号中是否包含话音信号存在。为了增强特征提取模型对环境变化的鲁棒性,本发明实施例首先对输入的注册语音样本进行话音激活检测,过滤掉其中的非语音段,以减少噪音对特征提取模型的干扰。
142.在对注册语音样本进行话音激活检测,得到过滤后语音之后,将所述过滤后语音按预设帧长进行切分,得到过滤后语音对应的语音帧序列。本发明实施例对所述预设帧长的具体长度不做限制,例如预设帧长可以为20ms到30ms。通过帧级别的处理,可以实现对语音的流式处理,进而使得特征提取模型可以适用于在线实时提取特征的场景,可以提高在线处理的效率,减少处理延迟。
143.在对过滤后语音进行帧级的切分,得到过滤后语音对应的语音帧序列之后,对所述语音帧序列中的各语音帧进行短时傅里叶变换(short
‑
time fourier transform,stft),可以得到每个语音帧对应的语音帧幅度谱。
144.将所述语音帧幅度谱输入特征提取模型的特征提取网络,输出每个语音帧幅度谱的特征向量。为了使得特征提取模型可以适应用户环境的变化,本发明实施例的特征提取网络采用基于lstm的网络结构。在具体实施中,可以根据实际需要灵活设置lstm的层数,例如可以设置1层到3层。一个示例中,所述特征提取网络可以包括3个lstm层和1个linear层。linear层使用矩阵乘法将输入特征转换为输出特征。
145.语音帧幅度谱经过lstm层和linear层后,得到每个语音帧幅度谱的特征向量,将语音帧序列中各语音帧对应语音帧幅度谱的特征向量进行求平均计算,得到注册语音样本的特征向量。具体地,对每个语音帧幅度谱的特征向量在帧的维度计算算数平均,得到注册语音样本的特征向量。通过对多个语音帧的特征向量进行求平均计算,可以降低注册语音样本中噪音的影响。
146.在本发明的一种可选实施例中,所述得到每个注册语音样本的特征向量之后,所述方法还可以包括:
147.将所述注册语音样本的特征向量进行归一化计算,得到所述注册语音样本最终的特征向量。
148.真实环境中用户说话的音量大小可能不同,为了进一步降低注册用户的音量对特征提取模型性能的影响,本发明实施例对得到的注册语音样本的特征向量x进行归一化计算。具体地,可以对特征向量x计算2范数。计算的范数记为x_norm,即eigen_vector=x/x_norm。其中,eigen_vector为单个注册用户的注册语音样本最终的特征向量。
149.最终输出的特征向量的维度通常可以根据实际的需要选择,例如可以选择输出的维度大于或等于64。
150.参照图2,示出了本发明的一种特征提取模型的处理流程示意图。在特征提取模型的训练阶段,模型的输入为注册语音样本,输出为注册语音样本的特征向量。在特征提取模型的在线使用阶段,模型的输入为目标用户的注册语音,输出为目标用户的注册语音特征。
151.在本发明的一种可选实施例中,所述注册用户的个数可以大于1,所述对所述注册语音样本进行话音激活检测,过滤所述注册语音样本中的非语音段,得到过滤后语音,包括:
152.对每个所述注册用户的注册语音样本进行话音激活检测,得到每个注册语音样本
的过滤后语音;
153.所述将所述过滤后语音按预设帧长进行切分,得到所述过滤后语音对应的语音帧序列,包括:
154.将每个注册语音样本的过滤后语音按预设帧长进行切分,得到每个注册语音样本对应的语音帧序列;
155.所述对所述语音帧序列中的各语音帧进行短时傅里叶变换,得到每个语音帧对应的语音帧幅度谱,包括:
156.对每个注册语音样本的语音帧序列中的各语音帧进行短时傅里叶变换,得到每个注册语音样本的语音帧序列中各语音帧对应的语音帧幅度谱;
157.所述将所述语音帧幅度谱输入特征提取模型的特征提取网络,输出每个语音帧幅度谱的特征向量,包括:
158.将每个注册语音样本的语音帧序列中各语音帧对应的语音帧幅度谱输入特征提取模型的特征提取网络,输出每个语音帧幅度谱的特征向量;
159.所述将所述语音帧序列中各语音帧对应语音帧幅度谱的特征向量进行求平均计算,得到所述注册语音样本的特征向量,包括:
160.将每个注册语音样本的语音帧序列中各语音帧对应的语音帧幅度谱的特征向量进行求平均计算,得到每个注册语音样本的特征向量。
161.在本发明实施例中,可以对n(n大于1)个注册用户的注册语音样本同时进行训练。本发明实施例以n=3为例。参照图3,示出了本发明实施例中对3个注册用户的注册语音样本进行特征提取的流程示意图。
162.如图3所示,假设有3个注册用户,用户1、用户2、以及用户3。对每个注册用户的注册语音样本进行话音激活检测,得到每个注册语音样本的过滤后语音。将每个注册语音样本的过滤后语音按预设帧长进行切分,得到每个注册语音样本对应的语音帧序列。例如,将每个注册用户的注册语音样本分别切分成5个语音帧,每个语音帧的长度为2秒到3秒。也即,用户1的注册语音样本被切分为包含5个语音帧的语音帧序列。用户2的注册语音样本被切分为包含5个语音帧的语音帧序列。用户3的注册语音样本被切分为包含5个语音帧的语音帧序列。这三个注册语音样本总共包含15个语音帧。对每个注册语音样本的语音帧序列中的各语音帧进行短时傅里叶变换,得到每个注册语音样本的语音帧序列中各语音帧对应的语音帧幅度谱。将每个注册语音样本的语音帧序列中各语音帧对应的语音帧幅度谱输入特征提取模型的特征提取网络,输出每个语音帧幅度谱的特征向量。也即,对这15个语音帧分别提取出15个特征向量。最后将每个注册语音样本的语音帧序列中各语音帧对应的语音帧幅度谱的特征向量(以下简称为语音帧的特征向量)进行求平均计算,得到每个注册语音样本的特征向量。例如,对于用户1的语音帧序列中的5个语音帧对应的语音帧幅度谱的特征向量进行求平均计算,可以得到用户1的注册语音样本的特征向量。同理,可以计算得到用户2的注册语音样本的特征向量以及用户3的注册语音样本的特征向量。
163.本发明实施例对每个注册语音样本的5个语音帧的特征向量求算术平均,对于上述3个注册用户,可以得到3个最终的特征向量,如图3中最右边的三个特征向量。
164.一个示例中,特征提取模型的损失函数可以采用余弦相似度来计算,具体地,可以计算特征向量x和特征向量y的余弦相似度,余弦相似度计算公式如下:
[0165][0166]
其中,x
u,i
为第u个注册用户的注册语音样本中第i个语音帧的特征向量,y
j
为第j个注册用户的注册语音样本对应的纯净语音的特征向量,其中,u和j的取值范围为1~n,i的取值范围由切分的语音帧的帧数确定。在本发明实施例中,将y
j
称为第j个注册用户的质心特征向量。s
((u,i),j)
表示第u个注册用户的第i个语音帧的特征向量与第j个用户的质心特征向量之间的余弦相似度。
[0167]
对n(n大于1)个注册用户的注册语音样本同时进行训练时,可以定义特征提取模型的损失函数loss1如下:
[0168]
loss1=
‑
1*(sum1
‑
sum2)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0169]
其中,sum1用于表示相同注册用户的余弦相似度之和,sum2用于表示不同注册用户的余弦相似度之和。
[0170]
以上述用户1、用户2、用户3这三个注册用户为例,假设每个注册用户的注册语音样本均被切分为5个语音帧,则:
[0171][0172][0173]
在该示例中,i=1,2,3,4,5。
[0174]
参照图4,示出了在该示例中,利用公式(1)计算得到的用户1、用户2、用户3之间的余弦相似度矩阵。该余弦相似度矩阵为15
×
3的矩阵。基于该余弦相似度矩阵,可以利用公式(2)计算特征提取模型的损失函数loss1的值。如图4所示,随着特征提取模型的迭代训练,损失函数loss1使相同用户的相似度不断提高(sum1),以及使不同用户的相似度越来越小(sum2)。当特征提取模型收敛后,可以得到训练完成的特征提取模型。
[0175]
在获取目标用户的注册语音特征之后,可以将所述待处理语音和所述目标用户的注册语音特征输入说话人提取模型,所述说话人提取模型根据所述目标用户的注册语音特征,提取所述待处理语音中所述目标用户的目标语音,并输出所述目标语音。本发明实施例预先训练用于提取目标用户声音的说话人提取模型。
[0176]
在本发明的一种可选实施例中,所述方法还可以包括:
[0177]
步骤s41、收集注册用户的用户语音样本;
[0178]
步骤s42、获取所述注册用户的注册语音特征和纯净语音;
[0179]
步骤s43、将所述用户语音样本、注册语音特征、以及纯净语音输入初始的说话人提取模型,所述说话人提取模型根据所述注册用户的注册语音特征,提取所述用户语音样本中注册用户的目标语音;
[0180]
步骤s44、根据提取的注册用户的目标语音与注册用户的纯净语音之间的特征差异迭代优化所述说话人提取模型的模型参数,达到预设收敛条件得到训练完成的说话人提
取模型。
[0181]
所述说话人提取模型可以为根据大量的训练样本和机器学习方法,对现有的神经网络进行有监督训练而得到的。需要说明的是,本公开实施例对所述说话人提取模型的模型结构以及训练方法不加以限制。所述特征提取模型可以融合多种神经网络。所述神经网络包括但不限于以下的至少一种或者至少两种的组合、叠加、嵌套:cnn、lstm、rnn、注意力神经网络等。
[0182]
用户语音样本为收集的大量的注册用户语音,可以为历史语音,如历史通话语音、历史语音指令等。可以理解,本发明实施例对用户语音样本的来源不做限制。所述纯净语音指注册用户在没有噪音的环境下录入的语音。需要说明的是,本发明实施例对注册用户语音以及纯净语音的内容均不做限制。
[0183]
对于说话人提取模型,可以采用和特征提取模型联合训练的方式,也可以采用独立训练说话人提取模型的方式。
[0184]
在本发明的一种可选实施例中,所述说话人提取模型包括第一处理网络和第二处理网络,所述说话人提取模型根据所述注册用户的注册语音特征,提取所述用户语音样本中注册用户的目标语音,具体可以包括:
[0185]
步骤s51、将所述用户语音样本进行短时傅里叶变换,得到样本语音幅度谱;
[0186]
步骤s52、将所述纯净语音进行短时傅里叶变换,得到纯净语音幅度谱;
[0187]
步骤s53、通过所述第一处理网络提取所述样本语音幅度谱的含噪语音特征;
[0188]
步骤s54、将所述注册用户的注册语音特征与所述含噪语音特征进行矩阵的元素相乘,得到调制语音特征;
[0189]
步骤s55、通过所述第二处理网络对所述调制语音特征进行特征提取处理,得到幅度谱掩码;
[0190]
步骤s56、将所述样本语音幅度谱与所述幅度谱掩码进行矩阵的元素相乘,得到降噪语音幅度谱;
[0191]
所述根据提取的注册用户的目标语音与注册用户的纯净语音之间的特征差异迭代优化所述说话人提取模型的模型参数,具体可以包括:
[0192]
步骤s61、根据预设损失函数,计算所述降噪语音幅度谱与所述纯净语音幅度谱之间的特征差异;
[0193]
步骤s62、根据所述特征差异迭代优化所述说话人提取模型的模型参数。
[0194]
参照图5,示出了本发明的一种训练说话人提取模型的流程示意图。如图5所示,首先将所述用户语音样本进行短时傅里叶变换,得到样本语音幅度谱,以及将所述纯净语音进行短时傅里叶变换,得到纯净语音幅度谱,记为y。用户语音样本为含噪语音(包含噪音、干扰、或者其他说话人的声音),经过短时傅里叶变换(stft)到时频域。纯净语音进行同样的操作。
[0195]
图5所示的说话人提取模型中包括第一处理网络和第二处理网络。第一处理网络中包括:卷积神经网络层、单向lstm层、linear层。为了保证说话人提取模型的实时性,本发明实施例采用流式处理的方式。所示卷积神经网络层(convolutional neural network,cnn)对输入的时频域数据(样本语音幅度谱)进行一维特征提取,也即对输入数据在频域进行特征提取。卷积神经网络层的输入是样本语音幅度谱,输出是样本语音幅度谱的特征。卷
积神经网络层的输出再依次经过单向lstm层、linear层的进一步处理,输出含噪语音特征。
[0196]
需要说明的是,本发明实施例对lstm的层数不做限制。在说话人提取模型中,考虑到网络的实时因果特性,本发明实施例优选地采用两个单层单向的lstm网络。
[0197]
在样本语音幅度谱经过卷积神经网络层、单向lstm层、linear层的依次处理之后,将输出的含噪语音特征与注册语音特征进行矩阵的元素相乘,得到调制语音特征。具体地,对含噪语音特征的向量与注册语音特征的向量包含的各元素逐个进行元素级乘。该步骤的作用是利用注册语音特征的向量对含噪语音特征进行幅度调制,得到调制语音特征。但是调制后的结果可能并不是很理想,因此,为了提高去噪效果,本发明实施例将调制语音特征输入第二处理网络进行进一步的特征提取处理。
[0198]
所述第二网络中包括:单向lstm层、linear层。调制语音特征经过第二个单向lstm层和linear层的特征提取处理,可以输出最终的掩码(幅度谱掩码)。
[0199]
接下来,将所述样本语音幅度谱与所述幅度谱掩码进行矩阵的元素相乘,可以得到最终降噪后的语音幅度谱,称为降噪语音幅度谱,记为y’。
[0200]
根据预设损失函数,计算所述降噪语音幅度谱与所述纯净语音幅度谱之间的特征差异,并根据所述特征差异迭代优化所述说话人提取模型的模型参数,直至达到预设收敛条件,得到训练完成的说话人提取模型。需要说明的是,本发明实施例对说话人提取模型的预设损失函数的具体形式不做限制。一个示例中,定义说话人提取模型的损失函数loss2如下:
[0201]
loss2=f(y
‑
y')
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0202]
在实际应用中,由于说话人提取模型可能会产生对噪音或者干扰的过多抑制问题。比如当输入的语音为纯净语音时,说话人提取模型会对输入的语音造成损伤,降低语音识别性能。为了避免产生此问题,在训练说话人提取模型的阶段,本发明实施例引入保护措施。具体地,当y
–
y’=0的时候,表示说话人提取模型对噪音的抑制恰到好处;当y
–
y’<0的时候,表示说话人提取模型对噪音的抑制不够;当y
–
y’>0的时候,表示说话人提取模型出现噪音过度抑制的情况,此时可以增加对说话人提取模型的惩罚,如对(y
‑
y’)乘一个因子beta,beta通常选为:1<beta<20。使用计算好的loss2值训练说话人提取模型,直到模型收敛,得到训练完成的说话人提取模型。
[0203]
说话人提取模型训练完成之后,可以在线使用说话人提取模型提取待处理语音中目标用户的目标语音。参照图6,示出了本发明的一种在线使用说话人提取模型提取目标用户的目标语音的流程示意图。
[0204]
如图6所示,待处理语音经过短时傅里叶、卷积神经网络层、单向lstm、linear层的逐层处理之后,输出的结果与目标用户的注册语音特征进行元素级乘。也即,将两个向量的各元素逐个进行元素级乘。相乘的结果再经过单向lstm层、linear层的特征提取处理,得到幅度谱掩码。该幅度谱掩码与待处理语音的短时傅里叶变换结果进行矩阵的元素相乘,最后进行短时逆傅里叶变换输出目标用户的目标语音。
[0205]
综上,本发明实施例可以对待处理语音进行去噪处理,提取待处理语音中目标用户的目标语音。当目标用户处于嘈杂的环境中时,本发明实施例可以获取目标用户的注册语音特征,并且将目标用户的待处理语音与目标用户的注册语音特征输入说话人提取模型,通过说话人提取模型将目标用户声音以外的声音作为噪音过滤掉。所述目标用户的个
数可以大于或等于1。这样,在目标用户的个数为1时,可以将这一个目标用户声音以外的所有声音(包括其他用户的声音)作为噪音过滤掉,仅保留这一个目标用户的目标语音。在目标用户的个数大于1时,可以保留多个目标用户的目标语音。通过本发明实施例,可以对待处理语音进行去噪处理,仅保留用户指定的目标语音,可以提高通话语音的质量,保护用户隐私。
[0206]
需要说明的是,对于方法实施例,为了简单描述,故将其都表述为一系列的动作组合,但是本领域技术人员应该知悉,本发明实施例并不受所描述的动作顺序的限制,因为依据本发明实施例,某些步骤可以采用其他顺序或者同时进行。其次,本领域技术人员也应该知悉,说明书中所描述的实施例均属于优选实施例,所涉及的动作并不一定是本发明实施例所必须的。
[0207]
装置实施例
[0208]
参照图7,示出了本发明的一种语音处理装置实施例的结构框图,所述装置可以包括:
[0209]
语音获取模块701,用于接收待处理语音,所述待处理语音中包含噪音和目标用户声音,目标用户的个数大于或等于1;
[0210]
特征获取模块702,用于获取所述目标用户的注册语音特征;
[0211]
语音处理模块703,用于将所述待处理语音和所述目标用户的注册语音特征输入说话人提取模型,所述说话人提取模型根据所述目标用户的注册语音特征,提取所述待处理语音中所述目标用户的目标语音,并输出所述目标语音。
[0212]
可选地,所述装置还包括:
[0213]
第一收集模块,用于收集注册用户的用户语音样本;
[0214]
第一获取模块,用于获取所述注册用户的注册语音特征和纯净语音;
[0215]
特征提取模块,用于将所述用户语音样本、注册语音特征、以及纯净语音输入初始的说话人提取模型,所述说话人提取模型根据所述注册用户的注册语音特征,提取所述用户语音样本中注册用户的目标语音;
[0216]
第一迭代模块,用于根据提取的注册用户的目标语音与注册用户的纯净语音之间的特征差异迭代优化所述说话人提取模型的模型参数,达到预设收敛条件得到训练完成的说话人提取模型。
[0217]
可选地,所述说话人提取模型包括第一处理网络和第二处理网络,所述特征提取模块,包括:
[0218]
第一傅里叶变换子模块,用于将所述用户语音样本进行短时傅里叶变换,得到样本语音幅度谱;
[0219]
第二傅里叶变换子模块,用于将所述纯净语音进行短时傅里叶变换,得到纯净语音幅度谱;
[0220]
第一网络处理子模块,用于通过所述第一处理网络提取所述样本语音幅度谱的含噪语音特征;
[0221]
特征调制子模块,用于将所述注册用户的注册语音特征与所述含噪语音特征进行矩阵的元素相乘,得到调制语音特征;
[0222]
第二网络处理子模块,用于通过所述第二处理网络对所述调制语音特征进行特征
提取处理,得到幅度谱掩码;
[0223]
相乘子模块,用于将所述样本语音幅度谱与所述幅度谱掩码进行矩阵的元素相乘,得到降噪语音幅度谱;
[0224]
所述第一迭代模块,包括:
[0225]
差异计算子模块,用于根据预设损失函数,计算所述降噪语音幅度谱与所述纯净语音幅度谱之间的特征差异;
[0226]
迭代优化子模块,用于根据所述特征差异迭代优化所述说话人提取模型的模型参数。
[0227]
可选地,所述特征获取模块,包括:
[0228]
注册语音获取子模块,用于获取所述目标用户的注册语音;
[0229]
模型提取子模块,用于将所述目标用户的注册语音输入特征提取模型,对所述目标用户的注册语音进行特征提取,得到所述目标用户的注册语音特征。
[0230]
可选地,所述装置还包括:
[0231]
第二收集模块,用于收集注册用户的注册语音样本;
[0232]
第一提取模块,用于将所述注册语音样本输入初始的特征提取模型,提取得到所述注册语音样本的特征向量;
[0233]
第二提取模块,用于对所述注册用户的纯净语音进行特征提取,得到纯净语音的特征向量;
[0234]
第二迭代模块,用于根据所述注册语音样本的特征向量与所述纯净语音的特征向量之间的特征差异迭代优化所述特征提取模型的模型参数,达到预设收敛条件得到训练完成的特征提取模型。
[0235]
可选地,所述第一提取模块,包括:
[0236]
话音检测子模块,用于对所述注册语音样本进行话音激活检测,过滤所述注册语音样本中的非语音段,得到过滤后语音;
[0237]
语音切分子模块,用于将所述过滤后语音按预设帧长进行切分,得到所述过滤后语音对应的语音帧序列;
[0238]
第三傅里叶变换子模块,用于对所述语音帧序列中的各语音帧进行短时傅里叶变换,得到每个语音帧对应的语音帧幅度谱;
[0239]
模型处理子模块,用于将所述语音帧幅度谱输入特征提取模型的特征提取网络,输出每个语音帧幅度谱的特征向量;
[0240]
平均计算子模块,用于将所述语音帧序列中各语音帧对应语音帧幅度谱的特征向量进行求平均计算,得到所述注册语音样本的特征向量。
[0241]
可选地,所述注册用户的个数大于1,所述话音检测子模块,具体用于对每个所述注册用户的注册语音样本进行话音激活检测,得到每个注册语音样本的过滤后语音;
[0242]
所述语音切分子模块,具体用于将每个注册语音样本的过滤后语音按预设帧长进行切分,得到每个注册语音样本对应的语音帧序列;
[0243]
所述第三傅里叶变换子模块,具体用于对每个注册语音样本的语音帧序列中的各语音帧进行短时傅里叶变换,得到每个注册语音样本的语音帧序列中各语音帧对应的语音帧幅度谱;
[0244]
所述模型处理子模块,具体用于将每个注册语音样本的语音帧序列中各语音帧对应的语音帧幅度谱输入特征提取模型的特征提取网络,输出每个语音帧幅度谱的特征向量;
[0245]
所述平均计算子模块,具体用于将每个注册语音样本的语音帧序列中各语音帧对应的语音帧幅度谱的特征向量进行求平均计算,得到每个注册语音样本的特征向量。
[0246]
可选地,所述装置还包括:
[0247]
特征库建立模块,用于建立所述注册用户的语音特征库,所述语音特征库中保存有注册用户的注册语音特征与注册用户的用户标识之间的映射关系;
[0248]
所述特征获取模块,具体用于根据目标用户的用户标识查询所述语音特征库,得到所述目标用户的注册语音特征。
[0249]
可选地,所述目标用户的个数大于1,所述语音处理模块,具体用于将所述待处理语音和每个目标用户的注册语音特征输入说话人提取模型,分别输出每个目标用户对应的目标语音,或者,输出包含所有目标用户的目标语音的混合语音。
[0250]
本发明实施例可以对待处理语音进行去噪处理,提取待处理语音中目标用户的目标语音。当目标用户处于嘈杂的环境中时,本发明实施例可以获取目标用户的注册语音特征,并且将目标用户的待处理语音与目标用户的注册语音特征输入说话人提取模型,通过说话人提取模型将目标用户声音以外的声音作为噪音过滤掉。所述目标用户的个数可以大于或等于1。这样,在目标用户的个数为1时,可以将这一个目标用户声音以外的所有声音(包括其他用户的声音)作为噪音过滤掉,仅保留这一个目标用户的目标语音。在目标用户的个数大于1时,可以保留多个目标用户的目标语音。通过本发明实施例,可以对待处理语音进行去噪处理,仅保留用户指定的目标语音,可以提高通话语音的质量,保护用户隐私。
[0251]
对于装置实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
[0252]
本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
[0253]
本发明实施例提供了一种用于语音处理的装置,所述装置包括有存储器,以及一个或者一个以上的程序,其中一个或者一个以上程序存储于存储器中,且经配置以由一个或者一个以上处理器执行所述一个或者一个以上程序包含用于进行以下操作的指令:接收待处理语音,所述待处理语音中包含噪音和目标用户声音,目标用户的个数大于或等于1;获取所述目标用户的注册语音特征;将所述待处理语音和所述目标用户的注册语音特征输入说话人提取模型,所述说话人提取模型根据所述目标用户的注册语音特征,提取所述待处理语音中所述目标用户的目标语音,并输出所述目标语音。
[0254]
图8是根据一示例性实施例示出的一种用于语音处理的装置800的框图。例如,装置800可以是移动电话,计算机,数字广播终端,消息收发设备,游戏控制台,平板设备,医疗设备,健身设备,个人数字助理等。
[0255]
参照图8,装置800可以包括以下一个或多个组件:处理组件802,存储器804,电源组件806,多媒体组件808,音频组件810,输入/输出(i/o)的接口812,传感器组件814,以及
通信组件816。
[0256]
处理组件802通常控制装置800的整体操作,诸如与显示,电话呼叫,数据通信,相机操作和记录操作相关联的操作。处理元件802可以包括一个或多个处理器820来执行指令,以完成上述的方法的全部或部分步骤。此外,处理组件802可以包括一个或多个模块,便于处理组件802和其他组件之间的交互。例如,处理组件802可以包括多媒体模块,以方便多媒体组件808和处理组件802之间的交互。
[0257]
存储器804被配置为存储各种类型的数据以支持在设备800的操作。这些数据的示例包括用于在装置800上操作的任何应用程序或方法的指令,联系人数据,电话簿数据,消息,图片,视频等。存储器804可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,如静态随机存取存储器(sram),电可擦除可编程只读存储器(eeprom),可擦除可编程只读存储器(eprom),可编程只读存储器(prom),只读存储器(rom),磁存储器,快闪存储器,磁盘或光盘。
[0258]
电源组件806为装置800的各种组件提供电力。电源组件806可以包括电源管理系统,一个或多个电源,及其他与为装置800生成、管理和分配电力相关联的组件。
[0259]
多媒体组件808包括在所述装置800和用户之间的提供一个输出接口的屏幕。在一些实施例中,屏幕可以包括液晶显示器(lcd)和触摸面板(tp)。如果屏幕包括触摸面板,屏幕可以被实现为触摸屏,以接收来自用户的输入信号。触摸面板包括一个或多个触摸传感器以感测触摸、滑动和触摸面板上的手势。所述触摸传感器可以不仅感测触摸或滑动动作的边界,而且还检测与所述触摸或滑动操作相关的持续时间和压力。在一些实施例中,多媒体组件808包括一个前置摄像头和/或后置摄像头。当设备800处于操作模式,如拍摄模式或视频模式时,前置摄像头和/或后置摄像头可以接收外部的多媒体数据。每个前置摄像头和后置摄像头可以是一个固定的光学透镜系统或具有焦距和光学变焦能力。
[0260]
音频组件810被配置为输出和/或输入音频信号。例如,音频组件810包括一个麦克风(mic),当装置800处于操作模式,如呼叫模式、记录模式和语音信息处理模式时,麦克风被配置为接收外部音频信号。所接收的音频信号可以被进一步存储在存储器804或经由通信组件816发送。在一些实施例中,音频组件810还包括一个扬声器,用于输出音频信号。
[0261]
i/o接口812为处理组件802和外围接口模块之间提供接口,上述外围接口模块可以是键盘,点击轮,按钮等。这些按钮可包括但不限于:主页按钮、音量按钮、启动按钮和锁定按钮。
[0262]
传感器组件814包括一个或多个传感器,用于为装置800提供各个方面的状态评估。例如,传感器组件814可以检测到设备800的打开/关闭状态,组件的相对定位,例如所述组件为装置800的显示器和小键盘,传感器组件814还可以语音处理装置800或装置800一个组件的位置改变,用户与装置800接触的存在或不存在,装置800方位或加速/减速和装置800的温度变化。传感器组件814可以包括接近传感器,被配置用来在没有任何的物理接触时检测附近物体的存在。传感器组件814还可以包括光传感器,如cmos或ccd图像传感器,用于在成像应用中使用。在一些实施例中,该传感器组件814还可以包括加速度传感器,陀螺仪传感器,磁传感器,压力传感器或温度传感器。
[0263]
通信组件816被配置为便于装置800和其他设备之间有线或无线方式的通信。装置800可以接入基于通信标准的无线网络,如wifi,2g或3g,或它们的组合。在一个示例性实施
例中,通信组件816经由广播信道接收来自外部广播管理系统的广播信号或广播相关信息。在一个示例性实施例中,所述通信组件816还包括近场通信(nfc)模块,以促进短程通信。例如,在nfc模块可基于射频信息处理(rfid)技术,红外数据协会(irda)技术,超宽带(uwb)技术,蓝牙(bt)技术和其他技术来实现。
[0264]
在示例性实施例中,装置800可以被一个或多个应用专用集成电路(asic)、数字信号处理器(dsp)、数字信号处理设备(dspd)、可编程逻辑器件(pld)、现场可编程门阵列(fpga)、控制器、微控制器、微处理器或其他电子元件实现,用于执行上述方法。
[0265]
在示例性实施例中,还提供了一种包括指令的非临时性计算机可读存储介质,例如包括指令的存储器804,上述指令可由装置800的处理器820执行以完成上述方法。例如,所述非临时性计算机可读存储介质可以是rom、随机存取存储器(ram)、cd
‑
rom、磁带、软盘和光数据存储设备等。
[0266]
图9是本发明的一些实施例中服务器的结构示意图。该服务器1900可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上中央处理器(central processing units,cpu)1922(例如,一个或一个以上处理器)和存储器1932,一个或一个以上存储应用程序1942或数据1944的存储介质1930(例如一个或一个以上海量存储设备)。其中,存储器1932和存储介质1930可以是短暂存储或持久存储。存储在存储介质1930的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对服务器中的一系列指令操作。更进一步地,中央处理器1922可以设置为与存储介质1930通信,在服务器1900上执行存储介质1930中的一系列指令操作。
[0267]
服务器1900还可以包括一个或一个以上电源1926,一个或一个以上有线或无线网络接口1950,一个或一个以上输入输出接口1958,一个或一个以上键盘1956,和/或,一个或一个以上操作系统1941,例如windows servertm,mac os xtm,unixtm,linuxtm,freebsdtm等等。
[0268]
一种非临时性计算机可读存储介质,当所述存储介质中的指令由装置(服务器或者终端)的处理器执行时,使得装置能够执行图1所示的语音处理方法。
[0269]
一种非临时性计算机可读存储介质,当所述存储介质中的指令由装置(服务器或者终端)的处理器执行时,使得装置能够执行一种语音处理方法,所述方法包括:接收待处理语音,所述待处理语音中包含噪音和目标用户声音,目标用户的个数大于或等于1;获取所述目标用户的注册语音特征;将所述待处理语音和所述目标用户的注册语音特征输入说话人提取模型,所述说话人提取模型根据所述目标用户的注册语音特征,提取所述待处理语音中所述目标用户的目标语音,并输出所述目标语音。
[0270]
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本发明的其它实施方案。本发明旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本发明的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本发明的真正范围和精神由下面的权利要求指出。
[0271]
应当理解的是,本发明并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本发明的范围仅由所附的权利要求来限制。以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,
所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
[0272]
以上对本发明所提供的一种语音处理方法、一种语音处理装置和一种用于语音处理的装置,进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1