一种基于动作引擎的语音交互方法、系统及存储介质与流程
1.本发明涉及语音交互技术领域,尤其涉及一种基于动作引擎的语音交互方法、系统及存储介质。
背景技术:
2.目前的语音功能交互是基于预先设计好的场景和语法,也就是说某个应用对应的语音指令是相对固定的。同时语音指令和界面存在分离现象,语音指令无法跟随界面变化,缺乏沉浸式体验。不管是离线还是云端语义识别,用户能说的指令都是预先训练好,然后通过语音识别模块进行匹配。这种模式下,用户是有一定学习成本,需要了解哪些指令是支持的,要按什么语法来说。如果用户在界面获取到信息并想当然地发出语音指令,通常得到的回复是“对不起,我没听懂”、“暂不支持改功能”等回复,用户体验差。而扩展不支持的指令,需要通过更新版本来修复,代价较大。
3.同时,由于功能代码是提前预置的,支持该功能的应用也相对固定,需要提前适配好。如果是从市场下载的第三方应用,基本是不支持任何指令的。在这种模式下,语音功能的兼容性和扩展性很差。例如:用户设备上预置了qq音乐,所有音乐控制是通过qq音乐的定制接口实现的。如果用户不喜欢qq音乐的体验,换成网易云音乐,这时之前的音乐控制接口会全部失效,相当于功能缺失。
4.即,现有的语音交互方法存在以下问题:
5.1)语音指令固定,指令和界面分离,用户体验感较差;
6.2)语音功能对应的应用需要提前适配,对非预置的第三方应用基本不支持,兼容性和扩展性差。
技术实现要素:
7.本发明提供一种基于动作引擎的语音交互方法、系统及存储介质,解决了现有的语音交互功能因语音指令固定导致指令和界面分离,以及兼容性和扩展差无法兼容非预置的第三方应用的技术问题。
8.为解决以上技术问题,本发明提供一种基于动作引擎的语音交互方法,包括步骤:
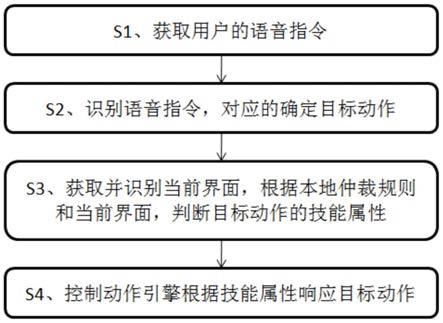
9.s1、获取用户的语音指令;
10.s2、识别所述语音指令,确定对应的目标动作;
11.s3、获取并识别当前界面,根据本地仲裁规则和当前界面,判断所述目标动作的技能属性;
12.s4、动作引擎根据所述技能属性响应所述目标动作。
13.本基础方案从动作引擎的驱动基础上着手,先根据用户的语音指令确定其目标动作,并在设置本地仲裁规则判断目标动作的技能属性,从而通过确定目标动作是否适用当前界面,来进一步的判断用户意图,进而控制根据技能属性响应目标动作。如此,使得用户可以借由语音指令在任何界面完成对应的实用操作,实现全局所见即可说、可说即可实现
的语音交互控制,大幅度地扩大了设备可识别的语音指令集;另外,从动作引擎上响应目标动作,无需额外增加第三方应用适配程序,降低了设备的开发成本,提高了语音交互功能的可移植性与兼容性。
14.在进一步的实施方式中,所述步骤s1包括:
15.s11、获取唤醒指令唤醒语音交互模块;
16.s12、获取用户发出的语音指令并输出至语音交互模块。
17.在进一步的实施方式中,所述步骤s2包括:
18.s21、识别所述语音指令得到语音文本;
19.s22、解析所述语音文本,确认用户意图并确定对应的目标动作。
20.在进一步的实施方式中,所述步骤s3包括:
21.s31、获取语音识别前的应用界面标记为当前界面;
22.s32、识别所述当前界面确定其对应的应用界面,根据本地仲裁规则判断所述目标动作是否属于所述应用界面的可操作动作,若是则进入步骤s4,若否则判断为其它场景动作。
23.本方案对语音识别前的当前界面进行识别,判断出当前用户界面的实际应用界面,随后根据本地仲裁规则判断目标动作是否属于当前用户界面,即确定了用户是否是对当前应用界面的控制,不再局限于有限的指令库,语音指令可跟随界面同步变化,从而提高语音交互的效率,给予用户更好的沉浸式体验。
24.在进一步的实施方式中,在所述步骤s32中,所述本地仲裁规则具体为:根据所述目标动作对应的用户意图,在界面操控类中进行控件定位,若定位到适配的目标界面控件,则判断所述目标动作属于所述应用界面的可操作动作,否则判断为其它场景动作。
25.本方案设置本地仲裁规则作为所见即可说语音交互方案的核心,在获取到用户语音指令后,根据解析得到的用户意图,直接在界面操控类中进行控件定位,根据定位的成功与否即可判断出当前语音指令是否为对当前界面的控制。直接从界面操控类出着手进行控件定位,可有效提高语音指令的识别准确率与识别效率。
26.在进一步的实施方式中,所述步骤s4包括:
27.s41、根据所述目标动作在界面操控类中匹配对应的目标界面控件、解析得到对应的操控意图;
28.s42、根据所述操控意图生成对应的动作脚本并控制动作引擎执行。
29.本方案设计通过动作引擎响应目标动作,当确定语音指令为当前界面的控制操作时,直接在界面操控类中匹配对应的目标界面控件、解析得到对应的操控意图,根据所述操控意图控制动作引擎生成对应的动作脚本并执行,基本上可兼容市面上所有的第三方应用,而无需提前适配和额外的定制接口,语音功能的兼容性和扩展性得到大幅度提升。
30.在进一步的实施方式中,所述应用界面包括音乐场景界面、导航场景界面、车控设置场景界面;所述目标动作包括在界面上的滑动翻页意图、点击文本意图、文本输入意图。
31.本发明还提供一种基于动作引擎的语音交互系统,包括依次连接的收音模块、语音识别模块、语音交互模块;
32.所述收音模块用于获取用户的唤醒指令、语音指令;
33.所述语音识别模块用于识别所述唤醒指令、所述语音指令,得到对应的语音文本;
34.所述语音交互模块用于响应所述唤醒指令,启动语音交互功能;
35.所述语音交互模块还用于响应所述语音指令,确定目标动作;获取并识别当前界面,判断所述目标动作的技能属性;并根据所述技能属性响应所述目标动作。
36.在进一步的实施方式中,所述语音交互模块包括依次连接的语义理解模块、本地仲裁模块、脚本生成模块和动作引擎;
37.所述语义理解模块用于解析所述语音文本,确认用户意图及对应的目标动作;
38.所述本地仲裁模块用于识别所述当前界面确定其对应的应用界面,根据本地仲裁规则判断所述目标动作是否属于所述应用界面的可操作动作;
39.所述脚本生成模块用于根据所述用户意图生成对应的动作脚本;
40.所述动作引擎用于执行所述动作脚本。
41.本基础方案利用设备现有的语义理解模块、脚本生成模块和动作引擎,和新增的本地仲裁模块,建立全局可见即可说机制;通过语音指令与当前界面的场景识别,抛开传统指令集合的桎梏,使得用户的语音指令可随应用界面同时变化,从而使得语音交互功能更为智能化;而在识别到语音指令后直接从脚本生成模块生成对应的动作脚本由动作引擎执行实现,则使得本语音交互系统基本上可兼容市面上的所有的第三方应用,而无需提前适配或定制接口,产品的兼容性和扩展性得到大幅度的提升。
42.本发明还提供一种存储介质,其上存储有计算机程序,所述计算机程序用于被上述基于动作引擎的语音交互系统加载,以实现上述基于动作引擎的语音交互方法。其中,存储介质可以是磁碟、光盘、只读存储器(read only memory,rom)或者随机存取器(random access memory,ram)等。
附图说明
43.图1是本发明实施例1提供的一种基于动作引擎的语音交互方法的工作流程图;
44.图2是本发明实施例2提供的一种基于动作引擎的语音交互系统的系统框架图。
具体实施方式
45.下面结合附图具体阐明本发明的实施方式,实施例的给出仅仅是为了说明目的,并不能理解为对本发明的限定,包括附图仅供参考和说明使用,不构成对本发明专利保护范围的限制,因为在不脱离本发明精神和范围基础上,可以对本发明进行许多改变。
46.实施例1
47.本发明实施例提供的一种基于动作引擎的语音交互方法,如图1所示,在本实施例中,包括步骤s1~s4:
48.s1、获取用户的语音指令,包括步骤s11~s12:
49.s11、获取唤醒指令唤醒语音交互模块;
50.s12、获取用户发出的语音指令并输出至语音交互模块。
51.s2、识别语音指令,确定对应的目标动作,包括步骤s21~s22:
52.s21、识别语音指令得到语音文本;
53.s22、解析语音文本,确认用户意图并确定对应的目标动作。
54.s3、获取并识别当前界面,根据本地仲裁规则和当前界面,判断目标动作的技能属
性,包括步骤s31~s32:
55.s31、获取语音识别前的应用界面标记为当前界面;
56.s32、识别当前界面确定其对应的应用界面,根据本地仲裁规则判断目标动作是否属于应用界面的可操作动作,若是则进入步骤s4,若否则判断为其它场景动作,由其它应用响应处理(响应其它场景动作进入其它应用界面并执行对应操作)。
57.本地仲裁规则具体为:根据目标动作对应的用户意图,在界面操控类中进行控件定位,若定位到适配的目标界面控件,则判断目标动作属于应用界面的可操作动作,否则判断为其它场景动作。
58.本实施例:
59.对语音识别前的当前界面进行识别,判断出当前用户界面的实际应用界面,随后根据本地仲裁规则判断目标动作是否属于当前用户界面,即确定了用户是否是对当前应用界面的控制,不再局限于有限的指令库,语音指令可跟随界面同步变化,从而提高语音交互的效率,给予用户更好的沉浸式体验。
60.设置本地仲裁规则作为所见即可说语音交互方案的核心,在获取到用户语音指令后,根据解析得到的用户意图,直接在界面操控类中进行控件定位,根据定位的成功与否即可判断出当前语音指令是否为对当前界面的控制。直接从界面操控类出着手进行控件定位,可有效提高语音指令的识别准确率与识别效率。
61.s4、控制动作引擎根据技能属性响应目标动作,包括s41~s42:
62.s41、根据目标动作在界面操控类中匹配对应的目标界面控件、解析得到对应的操控意图;
63.s42、根据操控意图生成对应的动作脚本并控制动作引擎执行。
64.本实施例设计通过动作引擎响应目标动作,当确定语音指令为当前界面的控制操作时,直接在界面操控类中匹配对应的目标界面控件、解析得到对应的操控意图,根据操控意图控制动作引擎生成对应的动作脚本并执行,基本上可兼容市面上所有的第三方应用,而无需提前适配和额外的定制接口,语音功能的兼容性和扩展性得到大幅度提升。
65.在本实施例中,应用界面包括但不限于音乐场景界面、导航场景界面、车控设置场景界面;目标动作包括但不选育在界面上的滑动翻页意图、点击文本意图、文本输入意图。
66.本发明实施例从动作引擎的驱动基础上着手,先根据用户的语音指令确定其目标动作,并在设置本地仲裁规则判断目标动作的技能属性,从而通过确定目标动作是否适用当前界面,来进一步的判断用户意图,进而控制根据技能属性响应目标动作。如此,使得用户可以借由语音指令在任何界面完成对应的实用操作,实现全局所见即可说、可说即可实现的语音交互控制,大幅度地扩大了设备可识别的语音指令集;另外,从动作引擎上响应目标动作,无需额外增加第三方应用适配程序,降低了设备的开发成本,提高了语音交互功能的可移植性与兼容性。
67.实施例2
68.在本发明实施例附图中出现的附图标记包括:收音模块1;语音识别模块2;语音交互模块3,语义理解模块31、本地仲裁模块32、脚本生成模块33、动作引擎34。
69.本发明实施例还提供一种基于动作引擎34的语音交互系统,包括依次连接的收音模块1、语音识别模块2、语音交互模块3;
access memory,ram)等。
88.上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1