一种跳跃网络的实时语音降噪方法与流程
1.本发明涉及一种语音降噪方法,特别是涉及一种跳跃网络的语音降噪方法。
背景技术:
2.语音增强技术一直是一个热门的研究领域,其在生活中有着具大的实用性,比如视频会议,语音通信等,利用语音增强降噪技术,能够极大提高人们语音视频的通话质量。传统的语音降噪方法主要使用谱减法和基于统计模型的方法,此类算法在应对非平稳的噪声信号往往不能取得很好的效果。传统如维纳滤波等方法很难处理非平稳或多人谈话的噪声信号,后面出现的深度神经网络的去噪方法对此有所改善,但往往处理速度较慢,难以在实际应用中发挥效果。
3.近年来,随着深度学习的不断发展,深度学习也被用来对音频信号进行降噪处理,也取得了很不错的效果。普通的深度神经网络参数量大,模型复杂,因此处理音频时间较长。
技术实现要素:
4.针对上述技术问题,本发明的目的在于提供一种跳跃网络的语音降噪方法,采用了一种更轻量的网络结构,将带噪的音频信息作为网络的输入信息传到输入层,用纯净不带噪声的音频信息作为输出目标数据去做一个有监督的训练。
5.本发明的技术方案如下:一种跳跃网络的实时语音降噪方法,所述方法是基于多层短时傅里叶变换损失函数,其特征在于,包括如下步骤:s1:利用频段屏蔽和信号混响数据增强方法构建网络训练的音频训练集,其中频段屏蔽让音频通过带阻滤波器去掉音频中的部分频率,而信号混响通过把音频进行不断衰减和延时后添加到原有的音频中;s2:构建跳跃的unet轻量网络结构,通过把特征进行卷积和转置卷积,得到不同通道数的特征,连接相加相同通道数的特征,使unet轻量网络能够同时学习高层次和低层次特征之间的关系;s3:利用多层短时傅里叶变换损失函数以及绝对均值误差作为模型的损失函数,通过adam优化算法训练模型,使用训练后的模型进行降噪。
6.本发明优选的技术方案在于,步骤s1中的构建网络训练的音频训练集包括如下步骤:s101:通过valentini数据集和dns2020基准数据集获取纯净语音信号和噪声信号作为模型的训练数据; s102:将多种噪声信号进行叠加,得到混合噪声信号;s103:随机截取混合噪声信号和语音信号进行合成,获得带有混合噪声的语音信号;
s104:对语音信号和原始的噪声信号进行延迟,衰减处理添加到带有混合噪声的语音信号中,获得带有混响的噪声语音信号。
7.本发明优选的技术方案在于,步骤s2具体包括:s201:构建编码模块,音频信号经过一维卷积模块,再通过relu激活函数对小于零的数值作置零处理,之后继续由两倍通道数的卷积核进行卷积处理,最后经过门控线性单元得到编码后的信号;s202:编码后的信号经过lstm信号处理模块进行处理,其中lstm信号处理模块通过单向lstm网络或者双向lstm网络构建的; s203:构建解码模块,编码后的信号经过lstm信号处理模块处理后,通过一维卷积模块降低通道数,再通过门控线性单元处理信号,最后通过一维转置卷积模块得到语音增强后的音频;s204:对编码模块的输出通道数等于解码模块的输入通道数的模块进行连接以构建跳跃的unet轻量网络结构。
8.本发明优选的技术方案在于,步骤s3具体包括:s301:对输入的噪声信号与纯净音频信号构建损失函数;s302:对输入的噪声信号与纯净音频信号分别经过不同参数的短时傅里叶变换构建损失函数;s303:把编码模块、解码模块以及lstm的模型参数输入到adam优化器中优化学习,训练出最终模型;s304:把带有噪声的语音信号直接输入到上面训练好的最终模型中,得到语音增强后的语音信号。
9.本发明优选的技术方案在于,所述门控线性单元的公式如下:其中,x是卷积模块的输出,w、b、v、c都是可学习的参数,
⨂
为元素积,σ(
·
)是sigmoid函数。
10.本发明优选的技术方案在于,所述损失函数的公式如下:其中为纯净的语音信号,为增强后的语音信号,t为音频长度,不同的样本之间t值不一样。
11.本发明优选的技术方案在于,所述损失函数的公式如下:其中,为短时傅里叶变换,为纯净的语音信号,为增强后的语音信号,t为音频长度,不同的样本之间t值不一样,变换参数傅里叶变换点数选择为512、1024和2048,帧移相对应为50、120和240,窗口长度相对应为240、600和1200。
12.与现有技术相比,本发明具有以下有益效果:本发明可以获得较好的语音降噪效果,本发明的方法具有失真小,泛化能力强,降噪效果好的优点。
附图说明
13.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它附图。
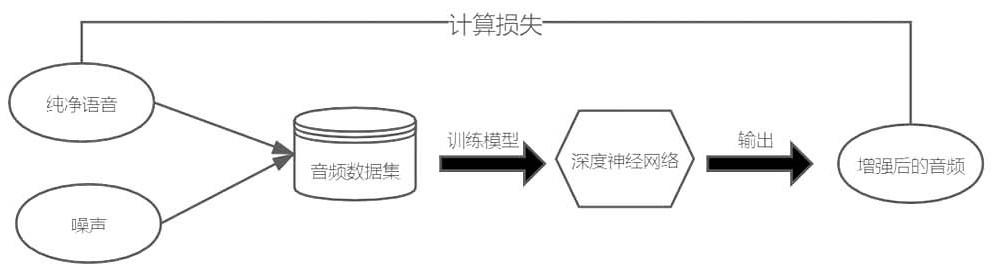
14.图1为本发明实施例一种跳跃网络的语音降噪方法的示意图;图2为本发明实施例1的一种跳跃网络的语音降噪方法的流程图;图3为跳跃去噪网络的示意图;图4为lstm网络的示意图。
具体实施方式
15.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。
16.如图1
‑
2所示,本发明具体实施例的语音降噪方法是基于多层短时傅里叶变换损失函数,包括:s1:利用频段屏蔽和信号混响数据增强方法构建网络训练的音频训练集,其中频段屏蔽是让音频通过带阻滤波器,去掉音频中部分的频率,而信号混响是通过把音频进行不断的衰减和延时然后添加到原有音频中;s2:构建跳跃的unet轻量网络结构,如图3所示,通过把特征进行卷积和转置卷积,得到不同通道数的特征,连接相加相同通道数的特征,使模型能够同时学习高层次和低层次特征之间的关系,得到更好的效果;s3:利用多层短时傅里叶变换损失函数以及绝对均值误差作为模型的损失函数,通过adam优化算法训练模型,使用训练后的模型进行降噪。
17.步骤s1中的构建网络训练的音频训练集包括如下步骤:s101:通过valentini数据集和dns2020基准数据集获取纯净语音信号和噪声信号作为模型的训练数据;其中,valentini是由爱丁堡大学语音技术研究中心提供的用来作为语音增强和语音合成算法的训练数据集,dns2020是微软举行的深度语音去噪挑战赛,里面提供了大量的纯净语音信号以及噪声信号。
18.s102:将多种的噪声信号进行叠加,得到混合噪声信号;s103:随机截取混合噪声信号和语音信号进行合成,获得带有混合噪声的语音信号;s104:对语音信号和原始的噪声信号进行延迟,衰减处理添加到带有混合噪声的语音信号中,获得带有混响的噪声语音信号。
19.其中步骤s1中的音频训练集包括如下音频数据以及噪声数据,合成各种类型的带有噪声的音频以及与之对应的用于监督的纯净音频数据。
20.步骤s2具体包括:s201:构建编码模块,模块如下所述,音频信号经过一维卷积模块,再通过relu激活函数处理,之后继续由两倍通道数的卷积核进行卷积处理,最后经过门控线性单元得到编码后的信号;relu激活函数公式如下所示:门控线性单元的公式如下:其中,x是卷积模块的输出,w、b、v、c都是可学习的参数,
⨂
为元素积,σ(
·
)是sigmoid函数。
[0021] s202:采用单向lstm网络或者双向lstm网络构建编码信号处理模块,编码后的信号进过lstm信号处理模块进行处理。长短期记忆(long short term memory,lstm)网络是一种特殊的rnn模型,其特殊的结构设计使得它可以避免长期依赖问题。图4中σ符号代表sigmoid函数,tanh代表tanh函数,+代表向量对应位加法,*代表向量对应位乘法,左边通过输入x和上一单元隐藏状态h作为sigmoid函数的输入,来控制上一个单元状态的遗忘,中间部分输入x和上一单元隐藏状态h经过sigmoid和tanh函数,决定这一单元哪些新输入信息将被保留以及用来对单元状态的更新。最右部分通过结合输入x和上一单元隐藏状态h和单元状态输出,最终输出该单元输出h。
[0022]
s203:构建解码模块,解码模块如下所述,编码后信号经过lstm信号处理模块处理后,首先通过一维卷积模块降低通道数,然后通过门控线性单元处理信号,最后通过一维转置卷积模块得到语音增强后的音频;s204:对编码模块的输出通道数等于解码模块的输入通道数的模块进行连接以此建构建跳跃网络结构。
[0023]
步骤s3具体包括:s301:对增强后的语音信号与纯净语音信号构建损失函数;损失函数的公式如下:其中为纯净的语音信号,为增强后的语音信号,t为音频长度,不同的样本之间t值不一样。
[0024]
s302:对增强后的语音信号与纯净语音信号分别经过不同参数的短时傅里叶变换构建损失函数;损失函数的公式如下
其中,为短时傅里叶变换,为纯净的语音信号,为增强后的语音信号,t为音频长度,不同的样本之间t值不一样,变换参数傅里叶变换点数选择为512、1024和2048,帧移相对应为50、120和240,窗口长度相对应为240、600和1200。
[0025] s303:把编码模块、解码模块以及lstm的模型参数输入到adam优化器中优化学习,训练出最终模型;s304:把带有噪声的语音信号直接输入到网络中,得到语音增强后的语音信号。
[0026]
本发明中构建的数据集的音频数据的目标采样率为16k。对于不同采样率的音频信号,需要先重采样至目标采样率,然后把音频信号直接输入到网络中,即可得到语音增强后的音频信号。经过上述具体的实施方式,本发明可以获得较好的语音降噪效果。该方法具有失真小,泛化能力强,降噪效果好的优点。
[0027]
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本技术的实施例和实施例中的特征可以任意相互组合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1