一种基于自适应谱底优化的多带谱减法的语音增强方法
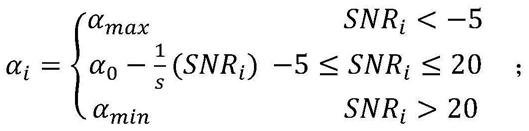
1.本发明属于语音增强领域,尤其涉及一种基于自适应谱底优化的多带谱减法的语音增强方法。
背景技术:
2.语音是人类相互之间进行交流的信息载体。在实际环境中语音信号经常会受到外界噪声环境的干扰从而导致语音信号变差。语音增强是解决噪声干扰的一种方法,可以从带噪语音中提取尽可能纯净的原始语言。语音增强的目的主要有两个:一是改进语音质量,消除背景噪声,使听者乐于接受,不感觉疲劳;二是提高语音可懂度,方便听者理解。
3.由于噪声的种类很多,特性并不完全相同,语音增强方法可以分为三类:第一类是谱减法,第二类是基于统计模型的算法,例如维纳滤波算法和最小均方误差算法,第三类是基于子空间的算法。其中谱减法原理简单易懂,运算量小以及增强效果较好而被广泛应用。谱减法基于一个简单的原理:假设噪声是加性噪声,通过从带噪语音功率谱中减去对噪声谱的估计就可以得到较为纯净的语音频谱,在非语音活动期间可以对噪声谱进行估计和更新,做出这一假设是基于背景噪声环境的平稳性,这样有利于在非语音活动区间估测的平均噪声谱逼近有声段的噪声频谱,增强信号通过计算估计信号谱的逆离散傅里叶变换得到,其相位仍然使用带噪语音信号的相位。
4.虽然谱减法计算复杂度低,但求减过程需要非常谨慎,如果减去的噪声估计过小,则会残留多余的干扰噪声,如果减去的噪声估计过高,可能会导致语音失真,从而影响语音的可懂度。在谱减过程中,对噪声频谱的错误估计而产生一些负值,谱减法中使用半波整流(将负值重设为0)来保证得到非负的幅度谱,但这种对负值的非线性处理,会导致信号帧频谱的随机频率位置上出现小的、独立的峰值,转换到时域,这些峰值听起来就像是帧与帧之间频率随机变化的多频音,被称为“音乐噪声”。
5.为了减弱谱减法所带来的音乐噪声,berouti提出频谱过减算法,通过使用过减因子来减小频谱相减残留的宽带谱峰的幅度,使用频谱下限因子来填充谱谷(频谱相减的负值)从而控制残留噪声的多少以及音乐噪声的大小。过减因子和频谱下限因子为谱减法提供了极大的灵活性,在低信噪比下(语音的低能量段或无语音期间)选取较小的过减因子,在高信噪比下(有语音存在)选取较大的过减因子可以更好地抑制噪声同时又能够达到最小的音乐噪声。如果频谱下限因子太大,则可能听到残留噪声信号但是感觉不到音乐噪声,如果频谱下限因子太小,则可能带来令人讨厌的音乐噪声,但是原噪声信号可以被极大地抑制。实验表明,在低信噪比下,频谱下限因子的取值范围为0.02到0.06,高信噪比下,频谱下限因子的取值范围为0.005到0.02,可以减小谱减过程所带来的音乐噪声。
6.谱减法以及过减谱减法都是在稳态的背景噪声环境下成立的,即噪声对语音的所有频谱分量具有同等程度的影响。但是现实世界中的背景噪声是随时变化的,不同的干扰噪声对语音各个频段的影响不尽相同,某些类型的干扰噪声对低频的影响要大于对高频的影响。因此需要使用一个与频率相关的减法因子来处理不同类型的干扰噪声,从而减小谱
减法所带来的音乐噪声。同时不同信噪比下经过谱减过程后残余噪声量也不尽相同,低信噪比下的残余噪声量相对比高信噪多。过减谱减法使用统一的频谱下限因子没有将残余噪声控制到较低的水平,因此需要一个随信噪比变化的谱底优化函数来控制不同信噪比下的残余噪声。通过设计一个随信噪比变化的谱底优化函数对不同噪声条件下的谱谷进行不同程度填充,可以将残余噪声控制在较低水平。
7.例如《a multi-band spectral subtraction method for enhancing speech corrupted by colored noise》(s.kamath,and p.c.loizou,《声学、语音和信号处理国际会议论文集》,第4160-4164页,2002年5月)提出了多带谱减算法(multi-band spectral subtraction,mbss)如图1所示,mbss将语音频谱划分为n个互不重叠的子带,分别在每个子带上进行频谱过减,且针对每个子带上噪声的不同设置相应的微调因子来减小噪声估计与真实噪声分量的偏差,从而减小了谱减过程所带来的音乐噪声。mbss在谱减法的基础上使用微调因子来处理不同类型的干扰噪声,在一定程度上减小了音乐噪声。
8.再例如《enhancement of speech corrupted by acoustic noise》(m.berouti等,ieee国际声学会议,语音,信号处理,第208-211页,1979年4月)提出过减谱减法,通过使用过减因子来减小频谱相减残留的宽带谱峰的幅度,达到降低频谱噪声峰值的目的。使用频谱下限因子来填充谱谷(频谱相减的负值),从而达到减小残留的小谱峰的差异,控制残留噪声的多少以及音乐噪声大小的目的,但真实环境下噪声是不断变化的,不同的干扰噪声对语音各个频段的影响不尽相同。
9.现有技术中还有使用随听觉掩蔽阈值变化的频谱下限函数以及过减因子的函数来使语言特征能够得到最大程度的保留,但没有给出最小最大频谱下限因子的参数值,没有模拟出具体的随听觉掩蔽阈值变化的频谱下限因子的变化,从而没有将残余噪声降低到较低的水平。
技术实现要素:
10.为了克服现有过减谱减法通过在平稳的噪声环境下使用过减因子与频谱下限因子来减小音乐噪声,但真实环境下噪声是不断变化的,不同的干扰噪声对语音各个频段的影响不尽相同,效果不理想;现有带谱减法使用一个固定的频谱下限因子没有将残余噪声控制到较低的水平,同样效果不理想的问题,本发明在多带谱减法的基础上设计了一个随信噪比变化的谱底优化函数对不同噪声条件下的谱谷进行不同程度填充,旨在将不同信噪比下的残余噪声量控制到较低水平,以达到减小谱减过程所带来的音乐噪声,从而提高语音质量,提出一种基于自适应谱底优化的多带谱减法的语音增强方法。
11.为达到上述目的,本发明采用的技术方案为:
12.一种基于自适应谱底优化的多带谱减法的语音增强方法,其特殊之处在于,包括以下步骤:
13.步骤1、对带噪语音进行分帧、加窗,分为n个互不重叠的连续子带,n≥1,n为整数,通过fft估计每个子带的幅度谱以及相位信息,同时,根据每个子带的带噪语音频谱获得频谱估计将每个子带的带噪语音频谱经过预处理得到带噪语音频
谱的平滑估计
14.其中i为第i个子带,λ为第i个子带中的第λ帧,ω为第λ帧的频率;
15.步骤2、分别在每个子带上进行频谱过减,并计算每个子带的微调因子δi;
16.步骤3、结合每个子带的幅度谱和平滑估计,计算每个子带的过减因子αi以及频谱下限因子βi;
17.第i个子带的频谱过减因子αi由分段信噪比得到;
18.第i个子带的分段信噪比为snri:
[0019][0020]
其中,ci与c
i+1
为第i个子带的频率起点和频率终点;ω在ci与c
i+1
之间;
[0021]
为带噪语音第i个子带的频谱估计;
[0022]
使用分段信噪比snri,获得频谱过减因子αi为:
[0023][0024]
获得频谱下限因子βi为:
[0025][0026]
步骤4、利用自适应谱底优化函数对不同信噪比下的谱谷进行填充,得到增强语音功率谱|xi(λ,ω)|2;所述谱谷为每个子带的带噪语音频谱减去对应子带的平滑估计差值为负的频谱;
[0027]
所述自适应谱底优化函数为:
[0028][0029]
其中,|xi(λ,ω)|2是第λ帧第ω频率上的增强语音功率谱;
[0030]
步骤5、将调整后的每个子带的增强语音功率谱重新组合起来,结合带噪语音的相位信息经过ifft以后得到增强后的语音。
[0031]
进一步地,步骤1中:
[0032]
所述带噪语音频谱经过预处理得到频谱的平滑估计具体通过下式计算:
[0033][0034]
其中γ是平滑因子。
[0035]
进一步地,所述步骤2中:所述δi通过下式计算:
[0036]
在第i个子带设置不同的微调因子δi,对非平稳环境下的背景噪声进行调整,以便减小噪声估计的偏差;
[0037][0038]
其中,fi是第i个子带的频率,fs是采样频率。
[0039]
进一步地,步骤3中,α
max
=4.75,α0=4,α
min
=1。
[0040]
进一步地,步骤1中,所述平滑因子γ=0.9。
[0041]
与现有技术相比,本发明具有的有益技术效果如下:
[0042]
现有过减谱减法通过在平稳的噪声环境下使用过减因子与频谱下限因子来减小音乐噪声,但真实环境下噪声是不断变化的,不同的干扰噪声对语音各个频段的影响不尽相同。由于残余噪声随信噪比的变换而变化,多带谱减法使用一个固定的频谱下限因子没有将残余噪声控制到较低的水平,本发明通过在多个子带中分别使用谱减法来减小不同干扰噪声对语音频谱的影响,通过随信噪比变化的谱底优化函数将残余噪声控制到了较低水平,从而有效减小了音乐噪声。
附图说明
[0043]
图1是现有多带谱减法mbss的结构框图;
[0044]
图2是本发明实施例基于自适应谱底优化的多带谱减法的as-mbss的结构框图;
[0045]
图3是本发明实施例在-5db到20db下as-mbss算法与经典的多带谱减法的分段信噪比比较图;
[0046]
图4是本发明实施例经过as-mbss算法处理后的增强语音信号语谱图与干净语音、带噪语音以及现有mbss算法处理后语谱图比较。
具体实施方式
[0047]
为了使本发明的目的、技术方案及优点更加清楚明白,下面结合附图和具体实施方式对本发明提出的一种基于自适应谱底优化的多带谱减法的语音增强方法作进一步详细说明。本领域技术人员应当理解的是,这些实施方式仅仅用来解释本发明的技术原理,目的并不是用来限制本发明的保护范围。
[0048]
本发明在多带谱减法的基础上设计了一个随信噪比变化而可对谱谷做不同程度填充的自适应谱底优化函数,将不同信噪比下的残余噪声量控制到较低水平,从而提高语音质量。基于多带谱减法mbss,我们提出基于自适应谱底优化的多带谱减法as-mbss。
[0049]
as-mbss:虽然多带谱减法通过设置微调因子减小了噪声估计的偏差,但控制残余噪声量的频谱下限因子却是一个固定的值,没有将不同信噪比下的残余噪声量控制到较低水平。基于此,我们提出了基于自适应谱底优化的多带谱减法as-mbss:对不同信噪比下的
谱谷(频谱过减后的负值)通过自适应谱底优化函数做不同程度的填充,从而将残余噪声量控制到较低水平,达到减小音乐噪声的目的。
[0050]
如图2所示,基于自适应谱底优化的多带谱减法as-mbss的结构框图。首先对带噪语音信号加窗并通过fft估计幅度谱以及相位信息,带噪语音谱经过预处理得到频谱的平滑估计。其次,带噪语音频谱被分为4个连续的子带,并计算每个子带的微调因子,结合幅度信息以及估计出的噪声信息计算每个子带的过减因子以及频谱下限因子。每个子带的带噪语音频谱减去对应子带的噪声谱估计。利用自适应谱底优化函数对不同信噪比下的谱谷进行填充。最后,调整后的各个频带重新组合起来,对增强后的频谱利用带噪语音的相位,经过ifft以后得到增强后的信号。
[0051]
第i个子带增强语音的估计如下:
[0052][0053]
其中,
[0054]
|xi(λ,ω)|2是第λ帧第ω频率上的增强语音功率谱;
[0055]ci
与c
i+1
是第i个子带的频率起点和频率终点;ω为在ci与c
i+1
之间。
[0056]
αi是第i个子带的过减因子,用来消除频谱过减后残留下来的宽带噪声。
[0057]
δi是第i个子带的微调因子,其取值由每个子带所对应的噪声大小来决定,可以根据噪声的不同而取相应的值,通过对不同噪声的准确估计来减小噪声估计与真实噪声分量的偏差。
[0058]
βi是自适应频谱下限因子,可以通过控制不同信噪比下的残余噪声量来减小音乐噪声。
[0059]
是经过预处理后的带噪语音功率谱,用来减小带噪语音功率谱的波动并减小音乐噪声。
[0060]
对经过语音活动检测器估计出来的噪声进行平滑处理,其公式如下:
[0061][0062]
其中,γ是平滑因子,根据经验取值为0.9;为带噪语音第i个子带的频谱估计。
[0063]
1、频谱过减因子
[0064]
频带过减因子是影响噪声估计的一个非常重要的参数,它的取值可以从外部影响噪声估计的准确程度。若频带过减因子太大,则噪声估计有可能比真实噪声要大,通过谱减法减去噪声估计就会造成语音信号的失真;相反若是过减因子太小(小于真实噪声),则会导致会剩余一些残余噪声,这些噪声最终会产生人们十分讨厌的音乐噪声。因此过减因子的选取就变得至关重要,在berouti提出的过减谱减法中,过减因子由分段信噪比(snr)得到,而第i个子带的分段信噪比的得出如下所示:
[0065][0066]
使用分段信噪比snr,频谱过减因子如下所示:
[0067][0068]
其中α
max
=4.75,α0=4,α
min
=1。
[0069]
在大的分段信噪比下设置较小的过减因子有利于保留低频段的语音信息,减小语音失真;在小的分段信噪比下通过减去较大的过减因子可以减小噪声估计的偏差。
[0070]
2、微调因子
[0071]
由于背景噪声是不断变化的,只使用过减因子与语音活动检测器来估计噪声变得不再准确。在每个子带设置不同的微调因子δi来对非平稳环境下的背景噪声做不同程度的调整,以便减小噪声估计的偏差,根据实验公式如下:
[0072][0073]
其中fi是第i个子带的频率,fs是采样频率。
[0074]
语音能量大部分都集中在低频阶段,使用较小的微调因子可以很大程度上防止语音失真;在中频部分使用较大的微调因子可以很大程度上减少噪声干扰从而减小残余噪声;通过实验发现在高频阶段使用很小的微调因子提高了语音质量。
[0075]
3、自适应频谱下限因子
[0076]
为了能够在不同信噪比下将残余噪声降低到较低水平,我们设计了一个自适应谱底优化函数,其公式如下:
[0077][0078]
其中snri是第i个子带所对应的信噪比。
[0079]
因为大部分残余噪声存在于低信噪比环境中,所以使用较大的频谱下限去填充谱谷以最小化残余噪声量。随着信噪比的不断增大,残余噪声的窄带峰值也不断减小,因此可以使用较小的频谱下限填充谱谷,将残余噪声量尽可能减小,从而减少感知到的音乐噪声。
[0080]
综上,改进算法首先对语音活动检测器估计出的噪声进行平滑处理来减小噪声估计的波动,其次根据实验对子带微调因子做相关调整来提高噪声估计的准确度,最后设计
一个自适应的谱底优化函数对增强语音的谱谷进行填充,以减小频谱过减生成的窄带噪声峰值以及音乐噪声。
[0081]
本发明在多带谱减法mbss的基础上,提出了基于自适应谱底优化的多带谱减法as-mbss。
[0082]
为了评估我们提出的as-mbss算法的性能,在matlab下进行仿真。实验所用到的三句纯净语音,其中两句男性语音来自ieee语句库,女性纯净语音来自noizeus语音库,其采样频率均为25khz。在三个纯净语音样本中加入来自aurora数据库的babble背景噪声形成实验用到的带噪语音。
[0083]
为了更好的比较as-mbss算法与多带谱减法的性能,我们使用5种不同的客观测量标准来评估三个带噪语音在-5db到20db的性能。这5种客观测量标准分别是基于信噪比的语音质量评价标准:分段信噪比(snrseg)[13-14],基于lpc系数的语音质量评价标准:对数似然比距离(llr)[15-16]、itakura
–
saito距离(is)[17]、倒谱距离(cep)[18]以及基于感知的语音质量评价:标准加权谱倾斜测度(wss)[19]。高语音质量由高的snrseg和低的llr、is、cep和wss来表示。其中s01与s02分别代表ieee语句库的s_01_01和s_01_02纯净语音,sp14来自noizeus语音库。
[0084]
图3展示了在-5db到20db下as-mbss算法与经典的多带谱减法的分段信噪比比较图。可以看出,在信噪比较低时,mbss与as-mbss的信噪比量相差不大。随着信噪比的提高,as-mbss算法的信噪比量高于原始的mbss,s01,s02与sp14语音在20db下信噪比量分别提高了1.3db,1.1db,1.6db。这里初步证实了as-mbss算法比多带谱减法有更好的语音质量。
[0085]
表1:s01带噪语音实验结果
[0086]
[0087][0088]
如表1所示,我们发现s01增强语音信号的llr、wss、is和cep的值在各个信噪比以及整体情况下都有明显的减小。在低信噪比下各个客观指标的值都有明显降低,随着信噪比逐渐增大,各个客观指标的值略有降低。虽然在较高信噪比下llr与cep的值减小程度不大,但从整体上看各个指标的值都明显减小。因此,可以得出结论所提出的as-mbss算法优于典型的多带谱减法,也进一步说明了自适应谱底优化的有效性。同样,虽然表2与表3的客观测量结果在各信噪比下减小程度不同,但总体结果和表1一致。
[0089]
由表1、表2和表3的结果可知,我们提出的as-mbss算法在ieee语句库和noizeus语音库上均取得良好的效果,在各个信噪比以及整体情况下都优于经典的多带谱减法,尤其是在低信噪比残余噪声量较大的情况下。从来自ieee语句库所测得的两个男性语音的客观结果来看,在信噪比较高残余噪声量较小时,as-mbss算法的性能比多带谱减法稍好。但从表3来自noizeus语音库所测得女性语音结果来看,as-mbss算法在各个信噪比下的性能都明显优于传统多带谱减法。可见纯净语音的选取会对实验结果产生一定的影响,但总体结论一致,总体的测量结果更进一步的证明了所提出的算法有更好的语音质量。
[0090]
表2:s02带噪语音实验结果
[0091][0092]
表3:sp14带噪语音实验结果
[0093]
[0094][0095]
为了再一次证明所提出的as-mbss算法的优越性,图3给出了三种带噪语音经过mbss与as-mbss算法增强后的语谱图。
[0096]
图4中,a1、b1、c1和d1为s01带噪语音,a2、b2、c2和d2为s02带噪语音,a3、b3、c3和d3为sp14带噪语音;
[0097]
a1、a2和a3均是干净语音,b1、b2和b3均是带噪语音,c1、c2和c3均是经过mbss,d1、d2和d3均是as-mbss的增强语音,可以清楚的看见经过as-mbss算法处理后的增强语音信号有更少的残余噪声。
[0098]
从5种客观指标的测量结果以及实验语谱图可以得出,我们所提出的as-mbss算法性能优于传统的多带谱减法。
[0099]
需要说明的是,上述实施例不以任何形式限制本发明,凡采用等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1