一种语音分离方法、装置、电子设备和存储介质与流程
1.本技术涉及计算机技术领域,尤其涉及语音处理技术领域,提供一种语音分离方法、装置、电子设备和存储介质。
背景技术:
2.相关的端到端语音分离系统,广泛使用编码器-分离器-解码器结构,其中编码器部分用于对输入音频信号(mixture waveform signal)进行变换(transform)以获得更丰富的特征,分离器接收编码器生成的特征以进行分离操作,解码器将分离器的输出重建为波形信号。
3.在相关技术中,编码器与解码器部分,在大多数端到端分离系统中为两个线性变换(linear transform)部分。在对编码器与解码器的网络参数进行优化时,常采用随机初始化+联合优化的方式,即在网络训练开始前随机初始化,在网络训练过程中与分离器一起联合优化。
4.但是,联合优化的编码器与解码参数,具有过多集中在低频信号的特性,且低频部分存在对同一幅度(magnitude)的不同相位(phase)特征进行重复建模的现象,降低了中高频信号的建模能力,以及编码器与解码器的参数利用率。
技术实现要素:
5.本技术实施例提供一种语音分离方法、装置、电子设备和存储介质,用以提高语音分离系统的建模能力与参数利用率,进而提高语音分离的准确性。
6.本技术实施例提供的一种语音分离方法,包括:
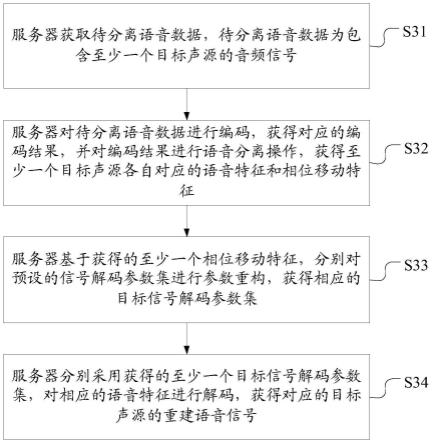
7.获取待分离语音数据,所述待分离语音数据为包含至少一个目标声源的音频信号;
8.对所述待分离语音数据进行编码,获得对应的编码结果,并对所述编码结果进行语音分离操作,获得所述至少一个目标声源各自对应的语音特征和相位移动特征,每个相位移动特征包括:对相应目标声源进行相位调整的相位参考值;
9.基于获得的至少一个相位移动特征,分别对预设的信号解码参数集进行参数重构,获得相应的目标信号解码参数集;
10.分别采用获得的至少一个目标信号解码参数集,对相应的语音特征进行解码,获得对应的目标声源的重建语音信号。
11.本技术实施例提供的一种语音分离装置,包括:
12.获取单元,用于获取待分离语音数据,所述待分离语音数据为包含至少一个目标声源的音频信号;
13.处理单元,用于对所述待分离语音数据进行编码,获得对应的编码结果,并对所述编码结果进行语音分离操作,获得所述至少一个目标声源各自对应的语音特征和相位移动特征,每个相位移动特征包括:对相应目标声源进行相位调整的相位参考值;
14.调整单元,用于基于获得的至少一个相位移动特征,分别对预设的信号解码参数集进行参数重构,获得相应的目标信号解码参数集;
15.解码单元,用于分别采用获得的至少一个目标信号解码参数集,对相应的语音特征进行解码,获得对应的目标声源的重建语音信号。
16.可选的,所述待分离语音数据包括通过分帧处理得到的多个语音帧;每个目标声源的相位移动特征包括:所述目标声源的各个语音帧各自对应的相位移动矩阵;
17.所述调整单元具体用于:
18.对于每个目标声源,分别执行以下操作:
19.分别基于一个目标声源的各个语音帧各自对应的相位移动矩阵,对所述信号解码参数集进行参数重构,获得所述一个目标声源的各个语音帧各自对应的目标信号解码参数集。
20.可选的,所述调整单元具体用于:
21.将所述信号解码参数集,划分为多个信号解码参数子集,每个信号解码参数子集对应相位移动矩阵中的一个相位参考值;
22.对于一个目标声源的各个语音帧,分别执行以下操作:分别基于所述一个目标声源的一个语音帧对应的相位移动矩阵中的各个相位参考值,对相应的信号解码参数子集进行参数重构,获得相应的目标信号解码参数子集;将获得的各个目标信号解码参数子集进行拼接,得到所述一个目标声源的一个语音帧对应的目标信号解码参数集。
23.可选的,所述信号解码参数集为用于对信号解码器的输入特征进行线性变换的参数矩阵;所述信号解码参数集的维度包括:基于信号解码器特征维度确定的第一维度,基于所述待分离语音数据中语音帧的帧长确定的第二维度;
24.所述调整单元具体用于:
25.将所述信号解码参数集,按照所述第一维度,划分为多个信号解码参数子集,每个信号解码参数子集中的参数的数量与所述第二维度相同。
26.本技术实施例提供的一种电子设备,包括处理器和存储器,其中,所述存储器存储有计算机程序,当所述计算机程序被所述处理器执行时,使得所述处理器执行上述任意一种语音分离方法的步骤。
27.本技术实施例提供一种计算机可读存储介质,其包括计算机程序,当所述计算机程序在电子设备上运行时,所述计算机程序用于使所述电子设备执行上述任意一种语音分离方法的步骤。
28.本技术实施例提供一种计算机程序产品,所述计算机程序产品包括计算机程序,所述计算机程序存储在计算机可读存储介质中;当电子设备的处理器从计算机可读存储介质读取所述计算机程序时,所述处理器执行所述计算机程序,使得所述电子设备执行上述任意一种语音分离方法的步骤。
29.本技术有益效果如下:
30.本技术实施例提供了一种语音分离方法、装置、电子设备和存储介质。由于本技术在对待分离语音数据的编码结果进行语音分离操作时,除了可以获得所述待分离语音数据中各个目标声源各自对应的语音特征之外,还可获取各个目标声源各自对应的相位移动特征,基于相位移动特征中的相位参考值,可对预设的信号解码参数集进行参数重构,使得解
码部分可建模更广泛的相位信息;进而,采用获得的目标信号解码参数集,对相应的语音特征进行解码,获得对应的目标声源的重建语音信号。该方式下,通过相位移动可提高中高频信号的建模能力,并且,仅需要结合相位移动特征,对预设的信号解码参数集进行参数重构,几乎没有额外增加参数量或复杂度,可在基本不增加参数与计算量的基础上,有效提升端到端语音分离系统的性能,提高语音分离的准确性。
31.本技术的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本技术而了解。本技术的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所特别指出的结构来实现和获得。
附图说明
32.此处所说明的附图用来提供对本技术的进一步理解,构成本技术的一部分,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
33.图1为相关技术中的一种语音分离系统的示意图;
34.图2为本技术实施例中的一种应用场景的一个可选的示意图;
35.图3为本技术实施例中的一种语音分离方法的流程示意图;
36.图4为本技术实施例中的一种语音分离系统的示意图;
37.图5为本技术实施例中的一种对信号解码参数集进行参数重构的流程示意图;
38.图6为本技术实施例中的一种分帧结果的示意图;
39.图7为本技术实施例中的一种语音分离方法的逻辑示意图;
40.图8a为本技术实施例中的一种信号解码参数集的划分方式示意图;
41.图8b为本技术实施例中的一种目标信号解码参数子集拼接过程示意图;
42.图9为本技术实施例中的一种语音分离方法的具体时序流程示意图;
43.图10为本技术实施例中的一种语音分离装置的组成结构示意图;
44.图11为应用本技术实施例的一种电子设备的一个硬件组成结构示意图;
45.图12为应用本技术实施例的一种电子设备的一个硬件组成结构示意图。
具体实施方式
46.为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例中的附图,对本技术的技术方案进行清楚、完整地描述,显然,所描述的实施例是本技术技术方案的一部分实施例,而不是全部的实施例。基于本技术文件中记载的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本技术技术方案保护的范围。
47.下面对本技术实施例中涉及的部分概念进行介绍。
48.音频和音频信号:音频是指能被人体感知的声音频率。音频信号是带有语音、音乐和音效的有规律的声波的频率、幅度变化信息载体。根据声波的特征,可把音频信息分类为规则音频和不规则声音。其中规则音频又可以分为语音、音乐和音效。规则音频是一种连续变化的模拟信号,可用一条连续的曲线来表示,称为声波。声音的三个要素是音调、音强和音色。声波或正弦波有三个重要参数:频率、幅度和相位,这也就决定了音频信号的特征。
49.编码和解码:编码是信息从一种形式或格式转换为另一种形式的过程。用预先规
定的方法将文字、数字或其它对象编成数码,或将信息、数据转换成规定的电脉冲信号;解码,是编码的逆过程,即将信息从已经编码的形式恢复到编码前原状的过程。本技术实施例中的编码和解码都是针对语音数据(音频信号)而言,因而,编码具体是指将模拟的音频信号转换为数字信号的过程,而解码是指将数字信号转换输出为模拟信号的过程。
50.语音分离操作:用于从信号中过滤掉噪声等因素的干扰,分离出来自不同发音源的语音信号的关键信息。在本技术实施例中,待分离语音数据为包含至少一个目标声源的音频信号,通过对待分离语音数据进行编码所得到的编码结果,仍旧为包含至少一个目标声源的音频信号(编码前后为不同形式的音频信号),通过语音分离操作,可以从编码结果中提取出来自不同的目标声源的语音特征和相位移动特征这些关键信息。
51.傅立叶变换:能将满足一定条件的某个函数表示成三角函数(正弦和/或余弦函数)或者它们的积分的线性组合。在不同的研究领域,傅里叶变换具有多种不同的变体形式,如连续傅立叶变换和离散傅立叶变换。
52.离散傅里叶变换(discrete fourier transform,dft)傅里叶分析方法是信号分析的最基本方法,傅里叶变换是傅里叶分析的核心,通过它把信号从时间域变换到频率域,进而研究信号的频谱结构和变化规律。
53.编码器(encoder):即信号编码器,是将信号(如比特流)或数据进行编制、转换为可用以通讯、传输和存储的信号形式的设备。在本技术实施例中,编码器是端到端语音分离系统中的一部分,用于对输入音频信号进行变换,以获得更丰富的特征,一般为线性变换。例如,经过该线性变换,将输入的模拟音频信号转换为可用以通讯、传输和存储的数字信号。
54.分离器:用于对混合语音数据进行分离。在本技术实施例中,分离器也是端到端语音分离系统中的一部分,用于接收编码器生成的特征以进行语音分离操作。获取音频信号中每一个目标声源各自的声音特征,也称语音特征。
55.解码器:即信号解码器,也称译码器,是电子技术中的一种多输入多输出的组合逻辑电路,负责将二进制代码翻译为特定的对象(如逻辑电平等),功能与编码器相反。在本技术实施例中,解码器是端到端语音分离系统中的一部分,用于将分离器的输出重建为波形信号,最终获得每个目标声源各自的目标波形,即,将音频信号拆分为每个目标声源各自的目标波形信号。
56.信号解码参数集:是在可用于进行语音分离的系统或模型中设置的,用于进行信号解码的参数所组成的集合,包括至少一个信号解码参数。例如,语音分离系统的信号解码器中可配置有二维的参数矩阵,基于该参数矩阵,可对信号解码器的输入特征进行线性变换。
57.相位移动特征和相位参考值:相位移动特征是本技术实施例中新提出的一个特征信息,用于对信号解码参数集中的参数进行相位的调整,因而,相位移动特征包含有用于进行相位调整的相位参考值,同信号解码参数集类似,该特征也可以是二维矩阵的形式。具体地,相位参考值即在对信号解码参数的相位进行调整时的参考值,一般可限制其取值范围为[-π,π],例如,某一相位参考值为π/2,基于该相位参考值,对某一信号解码参数的相位进行调整时,则可将该信号解码参数的相位增大π/2,或者,还可以是其他调整方式,例如将该信号解码参数的相位减小π/2等等。
[0058]
参数重构:指在不改变信号解码参数集自身的大小、自身作用的前提下,对信号解码集中的信号解码参数的数值进行调整或修改,以改进信号解码参数集所能处理的信号的频率范围。在本技术实施例中,主要是指:基于相位移动特征中的相位参考值,对信号解码参数集中的信号解码参数进行相位调整。
[0059]
重叠加(overlap add,ola):一种信号重建方法,在对原始信号进行分帧时,相邻的两帧是有一部分的重叠区域的,对于语音信号处理,一般情况下,这个重叠区域为50%或75%,那么在信号重建时,每个帧经过逆变换后,也需要进行对应的叠加,该过程即为重叠加操作。
[0060]
本技术实施例涉及人工智能(artificial intelligence,ai)、自然语言处理(nature language processing,nlp)和机器学习技术(machine learning,ml),基于人工智能中的计算机视觉技术和机器学习而设计。
[0061]
人工智能是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。
[0062]
人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。人工智能技术主要包括计算机视觉技术、自然语言处理技术、以及机器学习/深度学习、自动驾驶、智慧交通等几大方向。随着人工智能技术研究和进步,人工智能在多个领域展开研究和应用,例如常见的智能家居、智能客服、虚拟助理、智能音箱、智能营销、无人驾驶、自动驾驶、机器人、智能医疗等,相信随着技术的发展,人工智能将在更多的领域得到应用,并发挥越来越重要的价值。
[0063]
自然语言处理是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。因此,这一领域的研究将涉及自然语言,即人们日常使用的语言,所以它与语言学的研究有着密切的联系。自然语言处理技术通常包括语音分离、文本处理、语义理解、机器翻译、机器人问答、知识图谱等技术。
[0064]
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。对比于数据挖掘从大数据之间找相互特性而言,机器学习更加注重算法的设计,让计算机能够自动地从数据中“学习”规律,并利用规律对未知数据进行预测。
[0065]
机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习等技术。
[0066]
本技术实施例中的语音分离系统就是采用机器学习或深度学习技术训练得到的,其中的信号编码器、分离器、信号解码器都可以是机器学习模型或深度学习模型。基于本技术实施例中的语音分离方法,可以提高语音分离系统的语音分离的准确性。
[0067]
随着高端智能设备如智能耳机、助听器、会议记录器等快速发展,语音交互作为人机互动最便捷的方式得到越来越广泛的研究。在语音信号处理领域,语音分离技术作为连
接前端和后端的纽带,不仅可以过滤掉噪声等因素的干扰,还可以提取语音识别等技术需要的关键信息,因此起到至关重要的作用。
[0068]
语音分离技术是自然语言处理领域的一个分支,用于处理多说话人噪声环境下无法识别有效语音信息的问题。语音分离的目标是把目标语音从背景干扰中分离出来。
[0069]
在相关技术中,常见的语音分离系统广泛使用编码器-分离器-解码器结构,编码器与解码器部分在大部分端到端分离系统中为两个线性变换(linear transform),对应的参数可记作e与d。如图1所示,其为相关技术中的一种语音分离系统的示意图。将待分离语音数据(mixture)输入到语音分离系统中的编码器(endocer)后,经过编码器中的矩阵e对该输入进行线性变换,再将输出结果经由分离器(separator)处理后,获得各个目标声源各自对应的语音特征,并输入解码器(decoder),经过解码器中的矩阵d对该输入进行线性变换,最终可获得各个目标声源各自的语音波形信号,即图1中的source 1、
…
、source c。
[0070]
其中,信号编码器与解码器的参数e与d的设计除了背景技术中所列举的方式外,还有以下两种方式:
[0071]
(1)随机初始化+单独优化:e与d在网络训练开始前随机初始化且单独进行优化,优化完成后将参数进行固定再进行分离器的训练。
[0072]
但是,单独进行优化的信号编码器与解码器可能影响分离器的上限性能。
[0073]
(2)人工设计:人工设计e与d的参数。
[0074]
但是,人工设计的编码器与解码器可能无法获得最适合语音分离任务的特征。
[0075]
有鉴于此,本技术实施例提出了一种语音分离方法、装置、电子设备和存储介质。由于本技术在对待分离语音数据的编码结果进行语音分离操作时,除了可以获得所述待分离语音数据中各个目标声源各自对应的语音特征之外,还可获取各个目标声源各自对应的相位移动特征,基于相位移动特征中的相位参考值,可对预设的信号解码参数集进行参数重构,使得解码部分可建模更广泛的相位信息;进而,采用获得的目标信号解码参数集,对相应的语音特征进行解码,获得对应的目标声源的重建语音信号。该方式下,通过相位移动可提高中高频信号的建模能力,并且,仅需要结合相位移动特征,对预设的信号解码参数集进行参数重构,几乎没有额外增加参数量或复杂度,可在基本不增加参数与计算量的基础上,有效提升端到端语音分离系统的性能,提高语音分离的准确性。
[0076]
以下结合说明书附图对本技术的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本技术,并不用于限定本技术,并且在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。
[0077]
如图2所示,其为本技术实施例的应用场景示意图。该应用场景图中包括两个终端设备210和一个服务器220。
[0078]
在本技术实施例中,终端设备210包括但不限于手机、平板电脑、笔记本电脑、台式电脑、电子书阅读器、智能语音交互设备(智能音箱)、智能家电、车载终端、机顶盒等设备;终端设备上可以安装有语音分离相关的客户端,该客户端可以是软件(例如录音软件、会议软件、浏览器等),也可以是网页、小程序等,服务器220则是与软件或是网页、小程序等相对应的后台服务器,或者是专门用于进行语音分离的服务器,本技术不做具体限定。服务器220可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服
务、域名服务、安全服务、cdn(content delivery network,内容分发网络)、以及大数据和人工智能平台等基础云计算服务的云服务器。
[0079]
需要说明的是,本技术各实施例中的语音分离方法可以由电子设备执行,该电子设备可以为终端设备210或者服务器220,即,该方法可以由终端设备210或者服务器220单独执行,也可以由终端设备210和服务器220共同执行。比如由终端设备210和服务器220共同执行时,可通过终端设备210采集待分离语音数据,并发送给服务器220,由服务器220进行编码,分离,参数重构,解码等处理,最终采用获得的目标信号解码参数集,对相应的语音特征进行解码,获得对应的目标声源的重建语音信号,进而将各个目标声源的重建语音信号反馈给终端设备210,由终端设备210进行展示或播放等。
[0080]
在一种可选的实施方式中,终端设备210与服务器220之间可以通过通信网络进行通信。
[0081]
在一种可选的实施方式中,通信网络是有线网络或无线网络。
[0082]
需要说明的是,图2所示只是举例说明,实际上终端设备和服务器的数量不受限制,在本技术实施例中不做具体限定。
[0083]
本技术实施例中,当服务器的数量为多个时,多个服务器可组成为一区块链,而服务器为区块链上的节点;如本技术实施例所公开的语音分离方法,其中所涉及的待分离语音数据、信号解码参数集、相位移动特征、重建语音信号等都可保存于区块链上。
[0084]
此外,本技术实施例可应用于各种场景,包括但不限于云技术、人工智能、智慧交通、辅助驾驶等场景。例如,在智慧交通场景下,可通过车载语音系统进行多人通话、车载智能对话等,基于本技术实施例中的语音分类方法,对通话数据、对话数据进行语音分离。
[0085]
下面结合上述描述的应用场景,参考附图来描述本技术示例性实施方式提供的语音分离方法,需要注意的是,上述应用场景仅是为了便于理解本技术的精神和原理而示出,本技术的实施方式在此方面不受任何限制。
[0086]
参阅图3所示,为本技术实施例提供的一种语音分离方法的实施流程图,以服务器为执行主体为例,该方法的具体实施流程如下:
[0087]
s31:服务器获取待分离语音数据,待分离语音数据为包含至少一个目标声源的音频信号。
[0088]
需要说明的是,本技术实施例中的语音分离方法可以应用到很多和语音相关的产品应用中,例如音视频会议系统、智能语音交互、智能语音助手、在线语音识别系统、车载语音交互系统等,本文不做具体限定。
[0089]
在上述所列举的产品应用中,常见场景可以是从带噪信号(即一种音频信号)中提取说话人语音的语音增强任务,该场景下,待分离语音数据中仅包含一个目标声源;还可以是从混合波形信号(即另一种音频信号)中提取多说话人语音的语音分离任务,例如在多人会议、多人通话等,这些场景下,都可产生包含多个目标声源的混合波形信号,也即待分离语音数据。
[0090]
综上,本技术实施例中的语音分离,可以是指音频提取、音频分离等任何一种涉及至少一个目标声源的语音分离。下文主要是以多说话人语音分离为例进行举例说明的。
[0091]
s32:服务器对待分离语音数据进行编码,获得对应的编码结果,并对编码结果进行语音分离操作,获得至少一个目标声源各自对应的语音特征和相位移动特征。
[0092]
以该方法应用于语音分离系统为例,语音分离系统一般结构为:编码器-分离器-解码器。如图4所示,其为本技术实施例中的一种语音分离系统的示意图,与图1所示的相关技术中的语音分离系统相比,分离器和解码器部分存在区别。
[0093]
在本技术实施例中,可将待分离语音数据表示为y∈r1×
t
,其中t为采样点个数。首先对输入波形y进行分窗/分帧(windowing/framing)操作,其中窗长(window length)或帧长(frame length)为l,跳距(hop length/frame step)为p(p一般为0.5l或0.25l)。定义分帧后信号编码器的输入波形y∈r
l
×b,其中b为语音帧的数量,则信号编码器中的参数可定义为二维矩阵e∈r
l
×n,编码后的输出波形为f∈rn×b,f=e
t
y,即编码结果。
[0094]
进而,经由分离器对f∈rn×b进行语音分离操作,得到各个目标声源各自对应的语音特征和相位移动特征(即图4中的kernel phase shift p)。其中,每个相位移动特征包括:对相应目标声源进行相位调整的相位参考值。基于相位移动特征,可对解码器中的参数(即信号解码参数集)进行相位调整,基于调整后的参数,对目标声源的语音特征进行解码,最终即可获得各个目标声源的重建语音信号。
[0095]
与图1所示的语音分离系统不同的是,相关技术中的分离器以f作为输入,针对混合信号中的每一个目标声源输出一个与f维度一致的语音特征wc∈rn×b,c=1,
…
,c,其中c为目标声源个数。信号解码器中的参数可定义为二维矩阵d∈rn×
l
,解码后的特征为xc∈r
l
×b,xc=d
t
wc。而在本技术实施例中,分离器除了输出各个目标声源各自的语音特征wc之外,还额外输出相位移动特征pc,一般可限制其取值范围为-π≤pc≤π。其中,n表示编码器和解码器的特征维度,一般自定义,例如n=64。
[0096]
具体地,分离器输出的wc∈rn×b,pc∈rn×b,表示语音特征和相位移动特征的维度相同,都是n
×
b。在本技术实施例中,基于相位移动特征pc,可对解码器中的信号解码参数集d∈rn×
l
进行参数重构,进而,再对信号进行解码。
[0097]
需要说明的是,本技术实施例中可用于输出相位移动特征的分离器可以是通过机器学习训练得到的,通过机器学习训练模型学习信号的频率特征,设置输出相位移动特征。基于此,使得模型可使用更少的信号解码参数进行低频信号建模,提高模型对中高频信号的建模能力,而并非集中在低频信号上。
[0098]
s33:服务器基于获得的至少一个相位移动特征,分别对预设的信号解码参数集进行参数重构,获得相应的目标信号解码参数集。
[0099]
s34:服务器分别采用获得的至少一个目标信号解码参数集,对相应的语音特征进行解码,获得对应的目标声源的重建语音信号。
[0100]
在本技术实施例中,信号解码参数集是在可用于进行语音分离的系统或模型中设置的,用于进行信号解码的参数所组成的集合。例如,语音分离系统的信号解码器中可配置有二维的参数矩阵,基于该参数矩阵,可对信号解码器的输入特征进行线性变换。
[0101]
具体地,可用d∈rn×
l
表示,即信号解码参数集d是一个n
×
l的二维矩阵。由于每个目标声源都对应的有一个相位移动特征pc,因而,在对信号解码参数集进行参数重构时,对于每个目标声源,都有其各自对应的目标信号解码参数集。进而,在进行信号解码时,则是基于每个目标声源各自的目标信号解码参数集,对相应的语音特征进行解码。
[0102]
例如,待分离语音数据中共包含3个目标声源,即c=3,c=1,2,3。
[0103]
这样,对于目标声源1,对应的语音特征可表示为w1,相位移动特征可表示为p1,基
于p1对信号解码集d进行参数重构后,得到的目标信号解码参数集可表示为d1,d1与d的维度相同,仍为n
×
l。在对w1进行解码时,具体是基于d1对w1进行解码。
[0104]
同理,对于目标声源2,对应的语音特征可表示为w2,相位移动特征可表示为p2,基于p2对信号解码集d进行参数重构后,得到的目标信号解码参数集可表示为d2,d2与d的维度相同,仍为n
×
l。在对w2进行解码时,具体是基于d2对w2进行解码。
[0105]
对于目标声源3,对应的语音特征可表示为w3,相位移动特征可表示为p3,基于p3对信号解码集d进行参数重构后,得到的目标信号解码参数集可表示为d3,d3与d的维度相同,仍为n
×
l。在对w3进行解码时,具体是基于d3对w3进行解码。
[0106]
对待分离语音数据的编码结果进行语音分离操作时,除了可以获得待分离语音数据中各个目标声源各自对应的语音特征之外,还可获取各个目标声源各自对应的相位移动特征,基于相位移动特征中的相位参考值,可对预设的信号解码参数集进行参数重构,使得解码部分可建模更广泛的相位信息;进而,采用获得的目标信号解码参数集,对相应的语音特征进行解码,获得对应的目标声源的重建语音信号。该方式下,通过相位移动可提高中高频信号的建模能力,并且,仅需要结合相位移动特征,对预设的信号解码参数集进行参数重构,几乎没有额外增加参数量或复杂度,可在不增加参数与计算量的基础上,有效提升端到端语音分离系统的性能,提高语音分离的准确性。
[0107]
下面对基于相位移动特征,对信号解码参数集进行参数重构的过程进行详细说明:
[0108]
一种可选的实施方式为,可以按照如图5所示的流程图实施s33,包括以下步骤:
[0109]
s51:服务器对信号解码参数集进行傅里叶变换,获得信号解码参数集中的各个参数各自的初始相位。
[0110]
本技术对分离器的输出与解码器参数d∈rn×
l
进行修改。对于d中的每一行di∈r1×
l
,i=1,
…
,n,计算其离散傅里叶变换(dft):si=dft(di)。取si的幅度xi=|si|,与相位yi=angle(si),),-π≤yi≤π,yi即初始相位。
[0111]
s52:服务器对于每个目标声源,分别执行以下操作:基于一个目标声源的相位移动特征,对信号解码参数集中的各个参数的初始相位进行调整,获得针对该目标声源的中间信号解码参数集。
[0112]
其中,步骤s52又可划分为以下子步骤:
[0113]
s521:服务器根据一个目标声源的相位移动特征,确定与信号解码参数集中的各个参数对应的相位参考值;
[0114]
在本技术实施例中,可基于一个目标声源的相位移动特征pc∈rn×b中的各个参数,对信号解码参数集d∈rn×
l
进行参数重构。
[0115]
其中,相位移动特征pc中有n
×
b个元素,信号解码参数集d中有n
×
l个元素,即这两个矩阵中的元素并非是一一对应的,因而,需要根据一个目标声源的相位移动特征,确定与信号解码参数集中的各个参数对应的相位参考值。
[0116]
例如,一般信号解码参数集中的多个参数对应一个相位参考值时,可根据信号解码参数集中的参数在d中的位置(例如所在的行、列),来确定相应的相位参考值,也可根据
相位移动特征中的参数在pc中的位置(例如所在的行、列),来确定相应的信号解码参数等。
[0117]
需要说明的是,上述所列举的根据一个目标声源的相位移动特征,确定与信号解码参数集中的各个参数对应的相位参考值的方式,只是简单的举例说明,本文不做具体限定。
[0118]
s522:服务器分别将各个参数对应的相位参考值,与对应的初始相位之和,作为对应的调整后的相位。
[0119]
具体地,通过相位平移的方式,来进行相位调整。比如一个信号解码参数的初始相位为:a,对应的相位参考值为:b,则该信号解码参数对应的调整后的相位为a+b,这些经过相位调整后的信号解码参数所组成的集合,即为相应的中间信号解码参数集。
[0120]
在本技术实施例中,初始的信号解码参数集到中间信号解码参数集,经过了傅里叶变换,因而,还需要将中间信号解码参数集进行逆傅里叶变换,获得对应的目标信号解码参数集,具体地:
[0121]
s53:服务器对于每个目标声源,分别执行以下操作:对一个目标声源的中间信号解码参数集进行逆傅里叶变换,获得该目标声源对应的目标信号解码参数集。
[0122]
在本技术实施例中,修改后的分离器与解码器仍然遵循常见端到端语音分离框架中“随机初始化+联合优化”的训练模式,即新增加的分离器输出pc与系统的其他部分同时进行优化。由于傅里叶变换与逆傅里叶变换过程直接可导,该部分不影响系统其他部分的操作与优化。基于此,利用傅里叶变换使得同一组参数可以建模任意相位移动后的参数,在几乎不增加参数与计算量的基础上提高分离性能。
[0123]
可选的,待分离语音数据包括通过分帧处理得到的多个语音帧,每个语音帧对应一个时间戳;每个目标声源的相位移动特征包括:目标声源的各个语音帧各自对应的相位移动矩阵。
[0124]
如图6所示,其为本技术实施例中所列举的一种分帧结果的示意图,假设将一个待分离语音数据分为三个语音帧,分别为:第一语音帧,第二语音帧和第三语音帧,结果如图6所示,每一个语音帧可以看作是待分离语音数据中的一部分。
[0125]
例如,信号编码器的输入波形y∈r
l
×b,信号编码器中的参数可定义为二维矩阵e∈r
l
×n,编码后的输出波形为f∈rn×b,f=e
t
y,即待分离语音数据的编码结果。进而,通过分离器对信号编码器的输出波形f∈rn×b,进行语音分离操作,获得每个目标声源中的各个语音帧各自对应的语音特征w
c,b
∈r1×n,和相位移动特征p
c,b
∈r1×n。其中,b=1,
…
,b,表示一个语音帧,也称一个时间戳。
[0126]
也就是说,对于每一个时间戳b=1,
…
,b上的分离器额外输出p
c,b
∈r1×n,p
c,b
即一个包含n个相位参考值的相位移动矩阵。
[0127]
可选的,可以按照如下方式执行步骤s33,具体地,对于每个目标声源,分别执行以下操作:
[0128]
分别基于一个目标声源的各个语音帧各自对应的相位移动矩阵,对信号解码参数集进行参数重构,获得一个目标声源的各个语音帧各自对应的目标信号解码参数集。
[0129]
仍以上述所列举的c=3(即待分离语音数据包含三个目标声源),c=1,2,3为例,假设b=3(即待分离语音数据划分为三个语音帧),b=1,2,3,则对于各个目标声源,如图7所示:
[0130]
对于目标声源1,分离器会按照时间戳依次输出三个语音帧各自的语音特征及相位移动矩阵:
[0131]
第一语音帧:w
1,1
∈r1×n,p
1,1
∈r1×n;
[0132]
第二语音帧:w
1,2
∈r1×n,p
1,2
∈r1×n;
[0133]
第三语音帧:w
1,3
∈r1×n,p
1,3
∈r1×n。
[0134]
其中,p
1,1
、p
1,2
、p
1,3
拼接得到的即为目标声源1对应的相位移动特征p1,w
1,1
、w
1,2
、w
1,3
拼接得到的即为目标声源1对应的语音特征w1。
[0135]
同理,对于目标声源2,分离器会按照时间戳依次输出三个语音帧各自的语音特征及相位移动矩阵:
[0136]
第一语音帧:w
2,1
∈r1×n,p
2,1
∈r1×n;
[0137]
第二语音帧:w
2,2
∈r1×n,p
2,2
∈r1×n;
[0138]
第三语音帧:w
2,3
∈r1×n,p
2,3
∈r1×n。
[0139]
其中,p
2,1
、p
2,2
、p
2,3
拼接得到的即为目标声源2对应的相位移动特征p2,w
2,1
、w
2,2
、w
2,3
拼接得到的即为目标声源2对应的语音特征w2。
[0140]
对于目标声源3,分离器会按照时间戳依次输出三个语音帧各自的语音特征及相位移动矩阵:
[0141]
第一语音帧:w
3,1
∈r1×n,p
3,1
∈r1×n;
[0142]
第二语音帧:w
3,2
∈r1×n,p
3,2
∈r1×n;
[0143]
第三语音帧:w
3,3
∈r1×n,p
3,3
∈r1×n。
[0144]
其中,p
3,1
、p
3,2
、p
3,3
拼接得到的即为目标声源3对应的相位移动特征p3,w
3,1
、w
3,2
、w
3,3
拼接得到的即为目标声源3对应的语音特征w3。
[0145]
参阅图7所示,其为本技术实施例中的一种语音分离方法的逻辑示意图。在分离器每输出一个时间戳下的语音特征及相位移动矩阵时,即可基于该相位移动矩阵,对解码器中的信号解码参数集进行参数重构,进而再对相应的语音特征进行解码并输出。
[0146]
在对信号解码参数集进行参数重构时,也是按照各个语音帧各自的相位移动矩阵来执行,其中,相位移动矩阵p
c,b
∈r1×n,信号解码参数集d∈rn×
l
,因而,基于一个相位移动矩阵对信号解码参数集进行参数重构时,一种可选的实施方式为:
[0147]
将信号解码参数集,划分为多个信号解码参数子集,每个信号解码参数子集对应相位移动矩阵中的一个相位参考值;进而,对于一个目标声源的各个语音帧,分别执行以下操作:
[0148]
首先,分别基于一个目标声源的一个语音帧对应的相位移动矩阵中的各个相位参考值,对相应的信号解码参数子集进行参数重构,获得相应的目标信号解码参数子集。
[0149]
可选的,信号解码参数集为用于对信号解码器的输入特征进行线性变换的参数矩阵;信号解码参数集的维度包括:基于信号解码器特征维度确定的第一维度:n,基于待分离语音数据中语音帧的帧长确定的第二维度:l;即,d∈rn×
l
。
[0150]
基于此,在将信号解码参数集,划分为多个信号解码参数子集时,可按照第一维度划分,即按照n进行划分(即上述所列举的按照行划分),参阅图8a所示,其为本技术实施例中的一种信号解码参数集的划分方式示意图,这样划分得到的每个信号解码参数子集中的参数的数量与第二维度相同,即每个信号解码参数子集中有l个元素,即di∈r1×
l
,i=1,
…
,
n。
[0151]
进而,再将获得的各个目标信号解码参数子集进行拼接,得到一个目标声源的一个语音帧对应的目标信号解码参数集。
[0152]
如图8b所示,其为本技术实施例中的一种目标信号解码参数子集拼接过程示意图,将各个信号解码参数子集进行参数重构后,可获得相应的目标信号解码参数子集,进而,将目标信号解码参数子集进行拼接,可获得对应的目标信号解码参数集。其中,图8a和图8b中未按照目标声源和时间戳来进行区分,如图8b所示的di为第一个目标声源的第一语音帧对应的信号解码参数时,可表示为d
i,c,b
=d
i,1,1
,以此类推即可。
[0153]
具体地,参数重构的详细过程同图5相同,首先,需要对信号解码参数子集进行傅里叶变换,例如,可将信号解码参数集d按照行进行划分,每一行可作为一个信号解码参数子集。对于d中的每一行di∈r1×
l
,i=1,
…
,n,计算其离散傅里叶变换:si=dft(di)。取si的幅度xi=|si|,与相位yi=angle(si),-π≤yi≤π。
[0154]
进而,基于相位移动矩阵中的相位参考值,来对信号解码参数子集进行相位平移和逆离散傅里叶变换(inverse discrete fourier transform,idft)。
[0155]
例如,对于每一个时间戳b=1,
…
,b上的分离器额外输出p
c,b
∈r1×n,计算当前时间戳的第i个解码器参数为其中p
i,c,b
∈r为p
c,b
的第i个元素。
[0156]
最后,完整的解码器参数(即目标信号解码参数集)由对所有进行拼接得到。
[0157]
需要说明的是,对于不同的目标声源而言,由于各个目标声源的相位移动特征(相位移动矩阵)不同,因而,对应生成的目标信号解码参数集也不相同。此外,上述只是简单举例,实际上,待分离语音数据可拆分为更多的语音帧,需要根据实际情况而定,在此不做具体限定。
[0158]
可选的,待分离语音数据包括通过分帧处理得到的多个语音帧;每个目标声源的语音特征包括:目标声源的各个语音帧各自对应的语音信号矩阵;进而,在执行步骤s34时,具体地,对于每个目标声源,分别执行以下操作:
[0159]
首先,分别基于一个目标声源的各个语音帧各自对应的目标信号解码参数集,对相应的语音信号矩阵进行解码,获得对应的解码结果;例如,对于目标声源c(c=1,
…
,c)当前时间戳的解码器输出的解码结果即为x
c,b
∈r
l
×1,,进而,将获得的各个解码结果进行拼接后,通过重叠加操作得到一个目标声源的重建语音信号。例如,将所有时间戳b=1,
…
,b的输出进行拼接得到xc∈r
l
×b,对其使用重叠加(overlap-add)操作得到目标声源的波形(即重建语音信号)xc∈r1×
t
。
[0160]
需要说明的是,本技术实施例中的r表示实数,c表示复数,例如pc∈rn×b即表示pc是由n
×
b个实数组成的二维矩阵,又如即表示si是由个复数组成的向
量,等等,以此类推即可。
[0161]
在上述实施方式中,通过利用傅里叶变换使得同一组参数可以建模任意相位移动后的参数,在几乎不增加参数与计算量的基础上提高分离性能。并且,该方式下,信号编码器和解码器仍可采用“随机初始化+联合优化”的训练方式,因而,可在“随机初始化+联合优化”框架下,有效提升解码器建模能力与参数利用率的方法。
[0162]
参阅图9所示,其为本技术实施例中的一种语音分离方法的具体时序流程示意图,以多说话人语音分离为例,该方法的具体实施流程如下:
[0163]
步骤s901:服务器获取待分离语音数据,待分离语音数据为包含至少两个目标声源的混合波形信号;
[0164]
步骤s902:服务器对待分离语音数据进行编码,获得对应的编码结果;
[0165]
步骤s903:服务器对编码结果进行语音分离操作,获得待分离语音数据中的各个目标声源各自对应的语音特征和相位移动特征;
[0166]
步骤s904:服务器对信号解码参数集进行傅里叶变换,获得信号解码参数集中的各个参数各自的初始相位;
[0167]
步骤s905:服务器分别基于各个目标声源的相位移动特征,对信号解码参数集中的各个参数的初始相位进行调整,获得针对各个目标声源各自的中间信号解码参数集;
[0168]
步骤s906:服务器分别对各个中间信号解码参数集进行逆傅里叶变换,获得各个目标声源各自对应的目标信号解码参数集;
[0169]
步骤s907:服务器分别采用获得的各个目标信号解码参数集,对相应的语音特征进行解码,获得对应的目标声源的重建语音信号。
[0170]
下面对基于本技术实施例中的语音分离方法的实验效果进行简单说明:
[0171]
下面在单通道语音分离任务中对比传统实值时频遮蔽、时域模型与本技术提出的实值区间滤波对分离性能的影响。例如,使用wsj0-2mix与whamr!的基准数据集,其中包含30小时、10小时与5小时的训练、验证、测试数据。每一条混合语音均包含两个说话人,声源均从wsj0数据中随机选取,说话人之间的相对能量从[-5,5]db范围中随机选取。wsj0-2mix数据不包含背景噪声或混响,whamr!数据包含真实录制的背景噪声与人工生成的混响。
[0172]
在选取模型时,使用基于双递归神经网络-时域音频网络(dual-path recurrent neural network-time-domain audio network,dprnn-tasnet)的神经网络模型进行性能测试。在本技术实施例中,将编码器与解码器中的窗长设为2ms,跳距(hop size)设为1ms;编码器与解码器中的特征维度n=64。基线系统为使用原始“随机初始化+联合优化”的编码器与解码器。在本技术实施例中,使用能量无关信干比提升(si-sdri)作为衡量模型性能的客观评价指标(数字越高越好),实验结果如下表所示:
[0173]
表1
[0174][0175]
由表1可知,使用本技术提出的修改分离器输出与解码器的方法后模型在两个数
据集上的性能都有了明显提升,且几乎没有额外增加参数量或复杂度。
[0176]
另外,需要说明的是,针对分离器与解码器参数的修改可应用于广义的线性变换(如神经网络中的前馈层(fully-connected layer/feedforward layer)):
[0177]
具体地,定义关于矩阵p的线性变换y=w
t
p=w
t
f(x),其中w∈rn×
l
为可优化的参数矩阵(相当于语音分离场景下的信号解码参数集),f(
·
)为任意函数(如神经网络),x为输入矩阵,p=f(x),p∈rn×b为当前线性变换的输入矩阵。
[0178]
针对上述所列举的现象变换,可修改f(
·
)为使其输出p,q两个矩阵,其中p=f(x),q∈r1×n,-π≤q≤π为额外输出。类比语音分离场景中提出的对解码器参数进行修改的方法,可对w进行dft后,将q与dft(w)的相位进行求和,之后与dft(w)的幅度进行整合,然后计算idft,以获得修改后的参数矩阵基于此,线性变换可变为
[0179]
基于相同的发明构思,本技术实施例还提供一种语音分离装置。如图10所示,其为语音分离装置1000的结构示意图,可以包括:
[0180]
获取单元1001,用于获取待分离语音数据,待分离语音数据为包含至少一个目标声源的音频信号;
[0181]
处理单元1002,用于对待分离语音数据进行编码,获得对应的编码结果,并对编码结果进行语音分离操作,获得至少一个目标声源各自对应的语音特征和相位移动特征,每个相位移动特征包括:对相应目标声源进行相位调整的相位参考值;
[0182]
调整单元1003,用于基于获得的至少一个相位移动特征,分别对预设的信号解码参数集进行参数重构,获得相应的目标信号解码参数集;
[0183]
解码单元1004,用于分别采用获得的至少一个目标信号解码参数集,对相应的语音特征进行解码,获得对应的目标声源的重建语音信号。
[0184]
可选的,调整单元1003具体用于:
[0185]
对信号解码参数集进行傅里叶变换,获得信号解码参数集中的各个参数各自的初始相位;
[0186]
对于每个目标声源,分别执行以下操作:基于一个目标声源的相位移动特征,对信号解码参数集中的各个参数的初始相位进行调整,获得针对一个目标声源的中间信号解码参数集;对中间信号解码参数集进行逆傅里叶变换,获得目标声源对应的目标信号解码参数集。
[0187]
可选的,调整单元1003具体用于:
[0188]
根据一个目标声源的相位移动特征,确定与信号解码参数集中的各个参数对应的相位参考值;
[0189]
分别将各个参数对应的相位参考值,与对应的初始相位之和,作为对应的调整后的相位。
[0190]
可选的,待分离语音数据包括通过分帧处理得到的多个语音帧;每个目标声源的相位移动特征包括:目标声源的各个语音帧各自对应的相位移动矩阵;
[0191]
调整单元1003具体用于:
[0192]
对于每个目标声源,分别执行以下操作:
[0193]
分别基于一个目标声源的各个语音帧各自对应的相位移动矩阵,对信号解码参数
集进行参数重构,获得一个目标声源的各个语音帧各自对应的目标信号解码参数集。
[0194]
可选的,待分离语音数据包括通过分帧处理得到的多个语音帧;每个目标声源的语音特征包括:目标声源的各个语音帧各自对应的语音信号矩阵;
[0195]
解码单元1004具体用于:
[0196]
对于每个目标声源,分别执行以下操作:
[0197]
分别基于一个目标声源的各个语音帧各自对应的目标信号解码参数集,对相应的语音信号矩阵进行解码,获得对应的解码结果;
[0198]
将获得的各个解码结果进行拼接后,通过重叠加操作得到一个目标声源的重建语音信号。
[0199]
可选的,调整单元1003具体用于:
[0200]
将信号解码参数集,划分为多个信号解码参数子集,每个信号解码参数子集对应相位移动矩阵中的一个相位参考值;
[0201]
对于一个目标声源的各个语音帧,分别执行以下操作:分别基于一个目标声源的一个语音帧对应的相位移动矩阵中的各个相位参考值,对相应的信号解码参数子集进行参数重构,获得相应的目标信号解码参数子集;将获得的各个目标信号解码参数子集进行拼接,得到一个目标声源的一个语音帧对应的目标信号解码参数集。
[0202]
可选的,信号解码参数集为用于对信号解码器的输入特征进行线性变换的参数矩阵;信号解码参数集的维度包括:基于信号解码器特征维度确定的第一维度,基于待分离语音数据中语音帧的帧长确定的第二维度;
[0203]
调整单元1003具体用于:
[0204]
将信号解码参数集,按照第一维度,划分为多个信号解码参数子集,每个信号解码参数子集中的参数的数量与第二维度相同。
[0205]
由于本技术在对待分离语音数据的编码结果进行语音分离操作时,除了可以获得待分离语音数据中各个目标声源各自对应的语音特征之外,还可获取各个目标声源各自对应的相位移动特征,基于相位移动特征中的相位参考值,可对预设的信号解码参数集进行参数重构,使得解码部分可建模更广泛的相位信息;进而,采用获得的目标信号解码参数集,对相应的语音特征进行解码,获得对应的目标声源的重建语音信号。该方式下,通过相位移动可提高中高频信号的建模能力,并且,仅需要结合相位移动特征,对预设的信号解码参数集进行参数重构,几乎没有额外增加参数量或复杂度,可在不增加参数与计算量的基础上,有效提升端到端语音分离系统的性能,提高语音分离的准确性。
[0206]
为了描述的方便,以上各部分按照功能划分为各模块(或单元)分别描述。当然,在实施本技术时可以把各模块(或单元)的功能在同一个或多个软件或硬件中实现。
[0207]
在介绍了本技术示例性实施方式的语音分离方法和装置之后,接下来,介绍根据本技术的另一示例性实施方式的电子设备。
[0208]
所属技术领域的技术人员能够理解,本技术的各个方面可以实现为系统、方法或程序产品。因此,本技术的各个方面可以具体实现为以下形式,即:完全的硬件实施方式、完全的软件实施方式(包括固件、微代码等),或硬件和软件方面结合的实施方式,这里可以统称为“电路”、“模块”或“系统”。
[0209]
与上述方法实施例基于同一发明构思,本技术实施例中还提供了一种电子设备。
在一种实施例中,该电子设备可以是服务器,如图2所示的服务器220。在该实施例中,电子设备的结构可以如图11所示,包括存储器1101,通讯模块1103以及一个或多个处理器1102。
[0210]
存储器1101,用于存储处理器1102执行的计算机程序。存储器1101可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统,以及运行即时通讯功能所需的程序等;存储数据区可存储各种即时通讯信息和操作指令集等。
[0211]
存储器1101可以是易失性存储器(volatile memory),例如随机存取存储器(random-access memory,ram);存储器1101也可以是非易失性存储器(non-volatile memory),例如只读存储器,快闪存储器(flash memory),硬盘(hard disk drive,hdd)或固态硬盘(solid-state drive,ssd);或者存储器1101是能够用于携带或存储具有指令或数据结构形式的期望的计算机程序并能够由计算机存取的任何其他介质,但不限于此。存储器1101可以是上述存储器的组合。
[0212]
处理器1102,可以包括一个或多个中央处理单元(central processing unit,cpu)或者为数字处理单元等等。处理器1102,用于调用存储器1101中存储的计算机程序时实现上述语音分离方法。
[0213]
通讯模块1103用于与终端设备和其他服务器进行通信。
[0214]
本技术实施例中不限定上述存储器1101、通讯模块1103和处理器1102之间的具体连接介质。本技术实施例在图11中以存储器1101和处理器1102之间通过总线1104连接,总线1104在图11中以粗线描述,其它部件之间的连接方式,仅是进行示意性说明,并不引以为限。总线1104可以分为地址总线、数据总线、控制总线等。为便于描述,图11中仅用一条粗线描述,但并不描述仅有一根总线或一种类型的总线。
[0215]
存储器1101中存储有计算机存储介质,计算机存储介质中存储有计算机可执行指令,计算机可执行指令用于实现本技术实施例的语音分离方法。处理器1102用于执行上述的语音分离方法,如图3所示。
[0216]
在另一种实施例中,电子设备也可以是其他电子设备,如图2所示的终端设备210。在该实施例中,电子设备的结构可以如图12所示,包括:通信组件1210、存储器1220、显示单元1230、摄像头1240、传感器1250、音频电路1260、蓝牙模块1270、处理器1280等部件。
[0217]
通信组件1210用于与服务器进行通信。在一些实施例中,可以包括电路无线保真(wireless fidelity,wifi)模块,wifi模块属于短距离无线传输技术,电子设备通过wifi模块可以帮助用户收发信息。
[0218]
存储器1220可用于存储软件程序及数据。处理器1280通过运行存储在存储器1220的软件程序或数据,从而执行终端设备210的各种功能以及数据处理。存储器1220可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。存储器1220存储有使得终端设备210能运行的操作系统。本技术中存储器1220可以存储操作系统及各种应用程序,还可以存储执行本技术实施例语音分离方法的计算机程序。
[0219]
显示单元1230还可用于显示由用户输入的信息或提供给用户的信息以及终端设备210的各种菜单的图形用户界面(graphical user interface,gui)。具体地,显示单元1230可以包括设置在终端设备210正面的显示屏1232。其中,显示屏1232可以采用液晶显示器、发光二极管等形式来配置。显示单元1230可以用于显示本技术实施例中的应用操作界
面等。
[0220]
显示单元1230还可用于接收输入的数字或字符信息,产生与终端设备210的用户设置以及功能控制有关的信号输入,具体地,显示单元1230可以包括设置在终端设备210正面的触控屏1231,可收集用户在其上或附近的触摸操作,例如点击按钮,拖动滚动框等。
[0221]
其中,触控屏1231可以覆盖在显示屏1232之上,也可以将触控屏1231与显示屏1232集成而实现终端设备210的输入和输出功能,集成后可以简称触摸显示屏。本技术中显示单元1230可以显示应用程序以及对应的操作步骤。
[0222]
摄像头1240可用于捕获静态图像,用户可以将摄像头1240拍摄的图像通过应用发布评论。摄像头1240可以是一个,也可以是多个。物体通过镜头生成光学图像投射到感光元件。感光元件可以是电荷耦合器件(charge coupled device,ccd)或互补金属氧化物半导体(complementary metal-oxide-semiconductor,cmos)光电晶体管。感光元件把光信号转换成电信号,之后将电信号传递给处理器1280转换成数字图像信号。
[0223]
终端设备还可以包括至少一种传感器1250,比如加速度传感器1251、距离传感器1252、指纹传感器1253、温度传感器1254。终端设备还可配置有陀螺仪、气压计、湿度计、温度计、红外线传感器、光传感器、运动传感器等其他传感器。
[0224]
音频电路1260、扬声器1261、传声器1262可提供用户与终端设备210之间的音频接口。音频电路1260可将接收到的音频数据转换后的电信号,传输到扬声器1261,由扬声器1261转换为声音信号输出。终端设备210还可配置音量按钮,用于调节声音信号的音量。另一方面,传声器1262将收集的声音信号转换为电信号,由音频电路1260接收后转换为音频数据,再将音频数据输出至通信组件1210以发送给比如另一终端设备210,或者将音频数据输出至存储器1220以便进一步处理。
[0225]
蓝牙模块1270用于通过蓝牙协议来与其他具有蓝牙模块的蓝牙设备进行信息交互。例如,终端设备可以通过蓝牙模块1270与同样具备蓝牙模块的可穿戴电子设备(例如智能手表)建立蓝牙连接,从而进行数据交互。
[0226]
处理器1280是终端设备的控制中心,利用各种接口和线路连接整个终端的各个部分,通过运行或执行存储在存储器1220内的软件程序,以及调用存储在存储器1220内的数据,执行终端设备的各种功能和处理数据。在一些实施例中,处理器1280可包括一个或多个处理单元;处理器1280还可以集成应用处理器和基带处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,基带处理器主要处理无线通信。可以理解的是,上述基带处理器也可以不集成到处理器1280中。本技术中处理器1280可以运行操作系统、应用程序、用户界面显示及触控响应,以及本技术实施例的语音分离方法。另外,处理器1280与显示单元1230耦接。
[0227]
在一些可能的实施方式中,本技术提供的语音分离方法的各个方面还可以实现为一种程序产品的形式,其包括计算机程序,当程序产品在电子设备上运行时,计算机程序用于使电子设备执行本说明书上述描述的根据本技术各种示例性实施方式的语音分离方法中的步骤,例如,电子设备可以执行如图3中所示的步骤。
[0228]
程序产品可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以是但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子(非穷举的列
表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。
[0229]
本技术的实施方式的程序产品可以采用便携式紧凑盘只读存储器(cd-rom)并包括计算机程序,并可以在电子设备上运行。然而,本技术的程序产品不限于此,在本文件中,可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被命令执行系统、装置或者器件使用或者与其结合使用。
[0230]
可读信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了可读计算机程序。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。可读信号介质还可以是可读存储介质以外的任何可读介质,该可读介质可以发送、传播或者传输用于由命令执行系统、装置或者器件使用或者与其结合使用的程序。
[0231]
可读介质上包含的计算机程序可以用任何适当的介质传输,包括但不限于无线、有线、光缆、rf等等,或者上述的任意合适的组合。
[0232]
可以以一种或多种程序设计语言的任意组合来编写用于执行本技术操作的计算机程序,程序设计语言包括面向对象的程序设计语言—诸如java、c++等,还包括常规的过程式程序设计语言—诸如“c”语言或类似的程序设计语言。计算机程序可以完全地在用户计算装置上执行、部分地在用户计算装置上执行、作为一个独立的软件包执行、部分在用户计算装置上部分在远程计算装置上执行、或者完全在远程计算装置或服务器上执行。在涉及远程计算装置的情形中,远程计算装置可以通过任意种类的网络包括局域网(lan)或广域网(wan)连接到用户计算装置,或者,可以连接到外部计算装置(例如利用因特网服务提供商来通过因特网连接)。
[0233]
应当注意,尽管在上文详细描述中提及了装置的若干单元或子单元,但是这种划分仅仅是示例性的并非强制性的。实际上,根据本技术的实施方式,上文描述的两个或更多单元的特征和功能可以在一个单元中具体化。反之,上文描述的一个单元的特征和功能可以进一步划分为由多个单元来具体化。
[0234]
此外,尽管在附图中以特定顺序描述了本技术方法的操作,但是,这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,和/或将一个步骤分解为多个步骤执行。
[0235]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用计算机程序的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0236]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序命令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序命令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产
生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的命令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0237]
这些计算机程序命令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的命令产生包括命令装置的制造品,该命令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0238]
这些计算机程序命令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的命令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0239]
尽管已描述了本技术的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本技术范围的所有变更和修改。
[0240]
显然,本领域的技术人员可以对本技术进行各种改动和变型而不脱离本技术的精神和范围。这样,倘若本技术的这些修改和变型属于本技术权利要求及其等同技术的范围之内,则本技术也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1