一种基于生成式对抗神经网络的高质量声码器模型的制作方法
1.本发明涉及一种声码器模型,特别是一种基于生成式对抗神经网络的高质量声码器模型。
背景技术:
2.声码器(vocoder)或声音合成器技术是针对音频波形数据进行编码和解码的数字信号处理技术。声码器技术目前已经得到了相当广泛的应用,包括信号数据压缩、语音及声纹识别、语音及歌声合成、音频编辑与效果器等。
3.在神经网络语音合成系统中,上游模型的输出通常是目标音频数据在该模型的某个隐空间中的编码,或是人为设计的某种更通用的频域音频编码,如:mel谱、mfcc (mel-frequency ceptral coefficients,梅尔频率倒谱系数)特征等。但这些编码无法直接通过声学输出设备产生可由人耳收听的声波,而需要先使用声码器将这些编码数据解码成时域的音频波形才能经扬声器等设备播放出来。声码器因而是此类声音处理系统中不可或缺的组件。
4.目前基于数字信号处理方法的传统声码器音质不佳、可控度小,而基于神经网络的声码器训练开销很大,忽略了对于音频的频域相位和时域自相似等信息的有效利用,导致训练收敛缓慢、合成波形仍有细节瑕疵等结果。
技术实现要素:
5.发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种基于生成式对抗神经网络的高质量声码器模型。
6.为了解决上述技术问题,本发明公开了一种基于生成式对抗神经网络的高质量声码器模型,包括以下步骤:
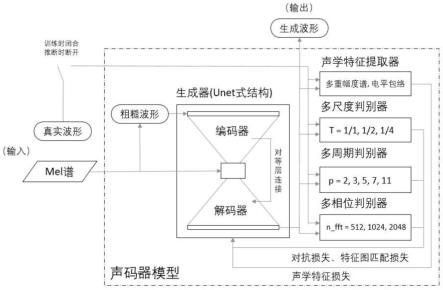
7.步骤1,构建基于生成式对抗神经网络的高质量声码器模型,该模型包括:生成器、声学特征提取器、多尺度判别器、多周期判别器和多相位判别器;
8.步骤2,从数据集获取pcm编码的音频数据,得到真实波形;
9.步骤3,对步骤2中所得真实波形进行预处理,训练集与验证集划分,训练集的切片化,得到mel谱和粗糙波形;
10.步骤4,将步骤3中所得的mel谱和粗糙波形送入生成器得到生成波形;
11.步骤5,将步骤2中的真实波形与其对应的步骤4中的生成波形送入声学特征提取器及三个判别器,即多尺度判别器、多周期判别器和多相位判别器,得到声学特征、三个判别器的评分以及三个判别器的特征图,再代入判别器损失函数计算得到三个判别器损失值,优化判别器参数;
12.步骤6,将步骤5所述的声学特征、判别器的评分和特征图代入生成器损失函数计算得到生成器损失,优化生成器参数;重复步骤5和6的训练过程,直到声码器模型收敛;
13.步骤7,使用步骤3中所得验证集数据对进行模型性能评估,完成基于生成式对抗
神经网络的高质量声码器模型的构建和训练。
14.本发明步骤2中,所述数据集不对音频数据内容是音乐、人声或噪声进行限制,音频数据为pcm编码的一组音频文件。
15.本发明步骤3中所述预处理包括:线性幅度谱、相位谱、mel谱、粗糙波形和电平包络特征的提取,方法如下:
16.先将所有音频数据以统一的采样率进行重采样,然后提取音频特征,包括:通过短时傅里叶变换提取线性幅度谱和相位谱;再通过mel滤波器组提取mel谱,进而通过griffin-lim算法获取粗糙波形;通过maxpooling池化层提取电平包络。
17.本发明步骤3中所述训练集与验证集划分包括:将数据划分为不相交的训练集和测试集。
18.本发明步骤3中所述训练集的切片化包括:对于训练集的数据再进行可重叠的、固定长度的切片,以实现局部化训练策略。
19.本发明步骤4中所述生成器为多视野融合与unet式沙漏形结构的卷积神经网络;该网络以给定mel谱为参照,将粗糙波形通过编码器缩短以及解码器拉伸的多步变换得到生成波形;该网络包括:
20.由conv1d下采样层组成的编码器,将粗糙波形从时域空间转换到谱空间;
21.由convtransposed1d上采样层组成的解码器,将谱空间的隐层编码还原到时域空间;
22.编码器和解码器中包含的多个带残差的多视野融合块resblock,作为特征映射的主干网络;
23.采用解码器中包含的多个conv1d拼接层,融合来自编码器中的对等层的隐层编码信息,得到生成波形。
24.本发明步骤5中,所述声学特征提取器为一个用于以提取相位谱的短时傅里叶变换过程;
25.所述三个判别器分别为:多尺度判别器、多周期判别器和多相位判别器;
26.其中,多尺度鉴别器使用conv1d网络在三个不同波形尺度上鉴别生成波形的真伪,包括原波形、两倍降采样波形和四倍降采样波形;多周期判别器分别在分组周期为2、3、5、7和11这五种情况下,使用conv2d网络鉴别分组化后的生成波形的真伪;多相位判别器在fft点数分别为512、1024和2048这三套设置下,使用conv2d 网络鉴别生成波形经过声学特征提取器所得相位谱的真伪;
27.所述判别器损失为三项判别器对抗损失之和,所用优化器为adam。
28.本发明步骤5中,计算三个判别器损失值的方法包括:
29.每个判别器都有两个输出:判别器的评分d
x
,判别器的特征图其中下标x取 s、f和p以分别指代多尺度鉴别器、多周期鉴别器和多相位鉴别器;
30.所述判别器损失包含:来自三个判别器的评分所构成的判别器对抗损失,方法为:
31.lossd=ds+df+d
p
32.其中,三个判别器对抗损失ds、df和d
p
分别为:
33.[0034][0035][0036]
其中,多尺度判别器的评分为ds,多周期判别器的评分为df,多相位判别器的评分为d
p
,生成器为g,目标真实波形为y,待解码mel谱为mel,待解码mel谱的粗糙波形为wav;三个判别器评分上的短横线表示均值。
[0037]
本发明步骤6中,所述声学特征提取器包含:一个用于以提取相位谱的短时傅里叶变换过程,一个用以提取波形实际电平包络的maxpooling层;
[0038]
所述判别器与优化器与步骤5中一致;
[0039]
生成器损失lossg包括:三项生成器对抗损失,三项生成器特征图损失,多重谱幅度损失,电平包络损失,波形自相似损失,具体计算方法包括:
[0040]
lossg=(gs+gf+g
p
)+α*(fms+fmf+fm
p
)+β*mstft+γ*dyn+δ*sm
[0041]
三个生成器对抗损失gs、gf和g
p
为:
[0042][0043][0044][0045]
三个特征图匹配损失fms、fmf和fm
p
为:
[0046][0047][0048][0049]
多重谱幅度损失mstft为:
[0050][0051]
电平包络损失dyn为:
[0052]
dyn=|maxpooling(y)-maxpooling(g(mel,wav)))| +|maxpooling(-y)-maxpooling(-g(mel,wav)))|
[0053]
波形自相似损失sm为:
[0054]
sm=|y
even-y
odd
|
[0055]
其中,多尺度判别器的特征图为多周期判别器的特征图为多相位判别器的特征图为第i套短时傅里叶变换所得对数尺度的幅度谱为stfti,y
even
和y
odd
分别为原信号的偶数位和奇数位上的采样点,α、β、γ和δ为平衡因子常量;双竖线表示绝对值。
[0056]
本发明步骤7中所述性能评估基于步骤3中的验证集数据得出,包含客观模型损失、泛化性评估和主观音质听觉评估。
[0057]
有益效果:
[0058]
本发明利用unet式网络结构融合mel谱和粗糙波形进行波形生成,同时采用了多
种判别器和声学特征来对生成波形进行优化,提供了一种基于生成式对抗网络架构的高质量神经网络声码器模型。与现有的声码器模型相比,本发明最大的特点是利用了 unet结构来融合粗糙波形的信息以大幅度降低神经网络学习难度,同时又有效利用了相位信息和时域上的电平包络和自相似特征来对生成波形进行优化,最终实现减少训练资源以及提升语音质量的双重目标。
[0059]
通过本神经网络声码器模型实现了基于mel谱的语音数据高质量解码。由于使用了目标真实波形的粗糙版本作为参照输入,大幅度降低了神经网络的学习难度,从而节省训练时间和计算资源开销。由于利用了相位信息和时域上的自相似特征来对生成波形进行优化,能获得更高音质的波形。由于使用了局部化训练策略,该声码器可以更自然流畅地合成任意长度的长音频序列。本发明将生成式对抗网络架构应用于神经网络声码器的构建,设计了上述模块以实现高质量的音频解码,训练开销低、音质好、可控度高,可作为各类音频处理系统的核心基础组件。
附图说明
[0060]
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/ 或其他方面的优点将会变得更加清楚。
[0061]
图1为本发明的架构示意图。
[0062]
图2为本发明训练时的数据流图。
[0063]
图3为本发明推断时的数据流图。
[0064]
图4为采用本发明所生成的波形与原始波形的对比示意图。
[0065]
图5为采用本发明所生成的波形对应频谱与原始波形对应频谱的对比示意图。
具体实施方式
[0066]
如图1所示,一种基于生成式对抗神经网络的高质量声码器模型,包括以下步骤:
[0067]
步骤1,构建基于生成式对抗神经网络的高质量声码器模型,该模型包括:生成器、声学特征提取器、多尺度判别器、多周期判别器和多相位判别器;
[0068]
步骤2,从数据集获取pcm(pulse code modulation)编码的音频数据,得到真实波形;其中,所述数据集不对音频数据内容是音乐、人声或噪声进行限制,音频数据为pcm编码的一组音频文件。
[0069]
步骤3,对步骤2中所得真实波形进行预处理,训练集与验证集划分,训练集的切片化,得到mel谱和粗糙波形;
[0070]
其中,所述预处理包括:线性幅度谱、相位谱、mel谱、粗糙波形和电平包络特征的提取,方法如下:
[0071]
先将所有音频数据以统一的采样率进行重采样,然后提取音频特征,包括:通过短时傅里叶变换提取线性幅度谱和相位谱;再通过mel滤波器组提取mel谱,进而通过griffin-lim算法(参考文献:griffin,daniel,and jae lim.“signal estimation frommodified short-time fourier transform.”ieee transactions on acoustics,speech,andsignal processing 32.2(1984):236-243.)获取粗糙波形;通过maxpooling池化层提取电平包络。
[0072]
所述训练集与验证集划分包括:将数据划分为不相交的训练集和测试集。
[0073]
所述训练集的切片化包括:对于训练集的数据再进行可重叠的、固定长度的切片,以实现局部化训练策略。
[0074]
步骤4,将步骤3中所得的mel谱和粗糙波形送入生成器得到生成波形;其中,所述生成器为多视野融合与unet(参考文献:u-net模型,ronneberger,o.,p.fischer,andt.brox."u-net:convolutionalnetworksforbiomedicalimagesegmentation."springerinternationalpublishing(2015).)式沙漏形结构的卷积神经网络(convolutionalneuralnetwork,cnn);该网络以给定mel谱为参照,将粗糙波形通过编码器缩短以及解码器拉伸的多步变换得到生成波形;该网络包括:
[0075]
由conv1d下采样层组成的编码器(可以是多个,一般为三个或四个。),将粗糙波形从时域空间转换到谱空间;
[0076]
由convtransposed1d上采样层组成的解码器(可以是多个,与上述编码器数量一致即可),将谱空间的隐层编码还原到时域空间;
[0077]
编码器和解码器中包含的多个带残差的多视野融合块resblock,作为特征映射的主干网络;
[0078]
采用解码器中包含的多个conv1d拼接层,融合来自编码器中的对等层的隐层编码信息,得到生成波形。
[0079]
步骤5,将步骤2中的真实波形与其对应的步骤4中的生成波形送入声学特征提取器及三个判别器,即多尺度判别器、多周期判别器和多相位判别器,得到声学特征、三个判别器的评分以及三个判别器的特征图,再代入判别器损失函数计算得到三个判别器损失值,优化判别器参数;
[0080]
其中,所述声学特征提取器为一个用于以提取相位谱的短时傅里叶变换过程;
[0081]
所述三个判别器分别为:多尺度判别器、多周期判别器和多相位判别器;
[0082]
其中,多尺度鉴别器使用conv1d网络在三个不同波形尺度上鉴别生成波形的真伪,包括原波形、两倍降采样波形和四倍降采样波形;多周期判别器分别在分组周期为2、3、5、7和11这五种情况下,使用conv2d网络鉴别分组化后的生成波形的真伪;多相位判别器在fft点数分别为512、1024和2048这三套设置下,使用conv2d网络鉴别生成波形经过声学特征提取器所得相位谱的真伪;
[0083]
所述判别器损失为三项判别器对抗损失之和,所用优化器为adam(参考文献:kingma,d.andj.ba"adam:amethodforstochasticoptimization."computerscience(2014).)。
[0084]
计算三个判别器损失值的方法包括:
[0085]
每个判别器都有两个输出:判别器的评分d
x
,判别器的特征图其中下标x取s、f和p以分别指代多尺度鉴别器、多周期鉴别器和多相位鉴别器;
[0086]
所述判别器损失包含:来自三个判别器的评分所构成的判别器对抗损失,方法为:
[0087]
lossd=ds+df+d
p
[0088]
其中,三个判别器对抗损失ds、df和d
p
分别为:
[0089]
[0090][0091][0092]
其中,多尺度判别器的评分为ds,多周期判别器的评分为df,多相位判别器的评分为d
p
,生成器为g,目标真实波形为y,待解码mel谱为mel,待解码mel谱的粗糙波形为wav;三个判别器评分上的短横线表示均值。
[0093]
步骤6,将步骤5所述的声学特征、判别器的评分和特征图代入生成器损失函数计算得到生成器损失,优化生成器参数;重复步骤5和6的训练过程,直到声码器模型收敛;
[0094]
其中,所述声学特征提取器包含:一个用于以提取相位谱的短时傅里叶变换过程,一个用以提取波形实际电平包络的maxpooling层;
[0095]
所述判别器与优化器与步骤5中一致;
[0096]
生成器损失lossg包括:三项生成器对抗损失,三项生成器特征图损失,多重谱幅度损失,电平包络损失,波形自相似损失,具体计算方法包括:
[0097]
lossg=(gs+gf+g
p
)+α*(fms+fmf+fm
p
)+β*mstft+γ*dyn+δ*sm
[0098]
三个生成器对抗损失gs、gf和g
p
为:
[0099][0100][0101][0102]
三个特征图匹配损失fms、fmf和fm
p
为:
[0103][0104][0105][0106]
多重谱幅度损失mstft为:
[0107][0108]
电平包络损失dyn为:
[0109]
dyn=|maxpooling(y)-maxpooling(g(mel,wav)))| +|maxpooling(-y)-maxpooling(-g(mel,wav)))|
[0110]
波形自相似损失sm为:
[0111]
sm=|y
even-y
odd
|
[0112]
其中,多尺度判别器的特征图为多周期判别器的特征图为多相位判别器的特征图为第i套短时傅里叶变换所得对数尺度的幅度谱为stfti,y
even
和y
odd
分别为原信号的偶数位和奇数位上的采样点,α、β、γ和δ为平衡因子常量;双竖线表示绝对值。
[0113]
步骤7,使用步骤3中所得验证集数据对进行模型性能评估,完成基于生成式对抗神经网络的高质量声码器模型的构建和训练;其中,所述性能评估基于步骤3中的验证集数
据得出,包含客观模型损失、泛化性评估和主观音质听觉评估。
[0114]
下面结合附图及实施例对本发明做进一步说明。
[0115]
实施例
[0116]
本实施例提供了一种基于生成式对抗神经网络的神经网络声码器模型构建和训练方法,其模型结构如图1所示,训练过程如图2所示,详细过程如下:
[0117]
1、构建基于生成式对抗神经网络的高质量声码器模型
[0118]
本实施例中使用python语言和pytorch框架实现所述声码器模型。其由以下部分组成:1.一个由多视野融合块、unet式沙漏形结构cnn(convolutional neural network,卷积神经网络)搭建的生成器模块;2.一个由多种传统信号处理方法组成的声学特征提取器;3.三个由cnn分别搭建的鉴别器模块,即多尺度鉴别器、多周期鉴别器、多相位鉴别器;4.相对性对抗和特征图匹配损失,三项声学特征损失。各模块细节将在下述步骤中相关的地方予以给出。
[0119]
2、从数据集获取音频数据
[0120]
本实施例中使用的数据集为标贝(databaker)科技有限公司开源公布的中文女声语音数据集“chinese mandarin female db-1”,但也可以使用任何其他的音频数据集,例如:任意收集得到的一组pcm编码wav格式文件。
[0121]
3、数据预处理
[0122]
先将所有音频重采样到统一的采样率,如16khz。而后对每个音频文件,依次经过短时傅里叶变换、mel滤波器组、数值下截断、取对数等过程,得到125~7600hz频段上的80段对数标度下的mel谱。再基于所得mel谱,依次通过逆mel滤波器组、较少迭代次数的griffin-lim算法等过程,得到含有底噪的粗糙波形。然后将mel谱与其对应粗糙波形两两配对为二元组data=(mel,wav)。
[0123]
以恰当的比例将整个数据集切分为不相交的两个子集,即训练集和验证集。对于训练集,以固定的分段大小segment_size将每个二元组可重叠地切片、作长度对齐使得 segment_size=length(wavi)=length(meli)
×
hop_length,其中hop_length为前述短时傅里叶变换所用的跳帧长度,如256;从而得到一组固定长度的数据对datai= (meli,wavi),用于模型训练时的输入。此局部化训练策略的训练技巧有助于提高长序列合成的质量。
[0124]
4、经生成器得到生成波形
[0125]
使用预处理所得的数据训练一个由多视野融合、unet式沙漏形结构的cnn生成器模块。所述模块包含:1.由多个conv1d下采样层组成的编码器,用以将时域空间转换到谱空间;2.包含由多个convtransposed1d上采样层组成的解码器,用以将谱空间还原到时域空间;3.编码器和解码器中包含额多个带残差的多视野融合块,用作特征映射的主干网络;4.解码器中包含多个conv1d拼接层,用于融合来自编码器中的对等层的隐层编码信息。整体搭建形成unet式沙漏形的对称结构,从而可以在对等层实现参数复用、节省接近一半的参数量。
[0126]
具体数据流如下述。先将粗糙波形wav经过编码器转换为谱空间中的编码e
wav
,在谱空间中使用一个拼接层以融合该编码与mel谱形成的二元组(e
wav
,mel)的信息。然后将信息融合后的编码经解码器还原到时域空间,得到生成波形,尤其注意在解码器的每一层都
使用一个拼接层去融合来自于编码器对等层的中间输出信息。
[0127]
5、计算得到判别器损失,优化判别器参数
[0128]
将生成波形与目标真实波形送入所述声学特征提取器和三个判别器,得到判别器损失,进而使用adam优化器优化判别器的参数。
[0129]
所述声学特征提取器包含:一个短时傅里叶变换过程以提取相位谱。
[0130]
所述三个判别器分别为:多尺度鉴别器、多周期鉴别器、多相位鉴别器。其中,多尺度鉴别器分别在生成波形的原波形、两倍降采样版本、四倍降采样版本这三个尺度上,使用conv1d网络鉴别生成波形的真伪;多周期鉴别器分别在分组周期为2、3、5、7、11这五种情况下,使用conv2d网络鉴别分组化后的生成波形的真伪;多相位鉴别器在fft点数分别为512、1024、2048这三套设置下,使用conv2d网络鉴别生成波形经过声学特征提取器所得相位谱的真伪。注意,每个判别器都有两个输出:判别器的评分d
x
,判别器的特征图其中下标x取s、f、p以分别指代多尺度鉴别器、多周期鉴别器、多相位鉴别器。
[0131]
所述判别器损失包含:来自三个判别器的评分所构成的判别器对抗损失,公式为:
[0132]
lossd=ds+df+d
p
[0133]
判别器对抗损失:
[0134][0135][0136][0137]
其中各符号分别为:多尺度判别器的评分ds、多周期判别器的评分df、多相位判别器的评分d
p
,生成器g,目标真实波形y、待解码mel谱mel、待解码mel谱的粗糙波形wav;短横线表示均值。
[0138]
6、计算得到生成器损失,优化生成器参数
[0139]
将生成波形与目标真实波形送入所述声学特征提取器和三个判别器,得到生成器损失,进而使用adam优化器优化生成器的参数。
[0140]
所述声学特征提取器包含:一个短时傅里叶变换过程以提取相位谱,一个 maxpooling层以提取波形的实际电平包络。
[0141]
所述三个判别器与步骤4中的描述一致。
[0142]
所述生成器损失包含:来自三个判别器的评分所构成的生成器对抗损失,来自三个判别器的特征图所构成的特征图匹配损失,来自声学特征提取器的多重谱幅度损失、电平包络损失、波形自相似损失,公式为:
[0143]
lossg=(gs+gf+g
p
)+α*(fms+fmf+fm
p
)+β*mstft+γ*dyn+δ*sm
[0144]
生成器对抗损失:
[0145][0146][0147][0148]
特征图匹配损失:
[0149][0150][0151][0152]
多重谱幅度损失:
[0153][0154]
电平包络损失:
[0155]
dyn=|maxpooling(y)-maxpooling(g(mel,wav)))| +|maxpooling(-y)-maxpooling(-g(mel,wav)))|
[0156]
波形自相似损失:
[0157]
sm=|y
even-y
odd
|
[0158]
其中各符号分别为:多尺度判别器的特征图多周期判别器的特征图多相位判别器的特征图第i套短时傅里叶变换所得对数尺度的幅度谱stfti,y
even
和 y
odd
分别为原信号的偶数位和奇数位上的采样点,α、β、γ、δ为平衡因子常量;双竖线表示绝对值。其余符号与步骤4中描述一致。
[0159]
尤其注意到,在声学特征损失中,多重谱幅度损失侧重于在频域方面粗粒度地约束生成波形的声学特征,而电平包络损失和波形自相似损失则侧重在时域方面对波形进行更为细粒度的约束;多方面的损失反馈能促使生成器产生更好的波形。
[0160]
7、模型性能评估
[0161]
使用验证集数据进行生成器损失的客观评估,以评价模型的泛化能力、检测过拟合风险。如图4、图5所示,波形相似、频谱损失小,展示了音频质量的保真性。同时,进行波形生成、人耳听觉实验的主观评估,以评价模型输出的音质。
[0162]
本实施例提供了一种基于生成式对抗神经网络的神经网络声码器模型推断(使用) 方法,推断流程如图3所示,详细过程如下:
[0163]
1、获取已训练好的所述声码器模型
[0164]
本实施例中使用上文所述实施例中所训练好的声码器模型。
[0165]
2、获取待解码的mel谱
[0166]
本实施例中使用的mel谱为125~7600hz频段上的80段对数标度下的mel谱,由音频处理系统的上游模型预测得到,或由原始音频波形依次经过短时傅里叶变换、mel 滤波器组、数值下截断、取对数等过程得到。
[0167]
3、计算粗糙波形
[0168]
对给定的mel谱,先通过逆mel滤波器组将其转化为线性谱,再使用较少迭代次数的griffin-lim算法得到含有底噪的粗糙波形。
[0169]
4、经生成器得到生成波形
[0170]
将给定的mel谱及其对应的粗糙波形送入步骤1所述模型的生成器模块,计算即得到高音质的生成波形。
[0171]
本发明提供了一种基于生成式对抗神经网络的高质量声码器模型的思路及方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1