一种基于FPGA的声阵列定向拾音方法
一种基于fpga的声阵列定向拾音方法
技术领域
1.本发明涉及声阵列信号采集和信号处理,特别涉及一种基于fpga的声阵列定向拾音方法。
背景技术:
2.声阵列系统被广泛应用于工业监测、军事、商务办公等领域。在更多智能化、小型化、数字化的设计需求和理念下,阵列系统将更多地代替人类在特定的场合进行特定的工作完成特定的任务。
3.声阵列信号处理相对于传统阵列信号处理技术有以下四项难点:
4.1、接收信号的带宽:声阵列信号处理的对象是宽带语音信号,典型频带处于300~3400hz。接收阵列对此类信号源形成非相干阵,各阵元接收信号并非只是相位上的差异,不能直接加权相加。
5.2、接收信号的非平稳性:语音信号需要做预处理,如抗混叠滤波、预加重、加窗、分帧以保证接收信号的短时平稳,从而获得更低失真更高音质的数字信号。
6.3、接收信号的物理特性:接收信号通常为机械纵波,由于波的反射、衍射,麦克风收到的信号除了直达信号以外,还有多径信号的叠加和干涉,产生声学混响;在室内环境中,受房间边界或者障碍物衍射和反射导致声信号传播到每个阵元的幅度和相位发生了未知的变化。
7.4、阵列所处的外部环境:信号处理算法应当适应于室内室外环境、适应于近场远场条件;近场相对于远场,既需考虑声源的入射角度还需考虑声源相对于阵列的距离。
8.针对以上四项技术难点,目前广泛采用的采集卡+dsp处理器的硬件方案和宽带自适应波束形成的算法虽然能得到一些高信噪比的定向拾音效果,但是也会遇到未解决的种种技术问题:如阵元数目少、拾音距离不足、抑制非平稳干扰不足、增加大量阵元导致的运算量大以及硬件成本高。
技术实现要素:
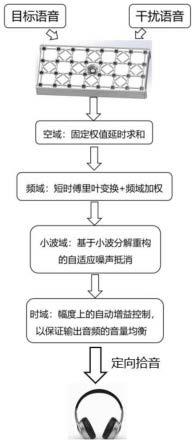
9.针对上述存在问题或不足,为解决基于目前声阵列波束形成技术实现的定向拾音效果存在阵元数目少、拾音距离不足、抑制非平稳干扰不足、增加大量阵元导致的运算量大、硬件成本高等问题,本发明提供了一种基于fpga的声阵列定向拾音方法,以fpga作为主控的基于空时频的宽带波束形成器,输出音频满足实时性地要求,并在增强目标声源的同时能极大程度抑制干扰声源以及环境噪声。
10.一种基于fpga的声阵列定向拾音方法,具体步骤如下:
11.步骤1、上位机uart(通用异步收发)模块发送的映射于范围从-80
°
到80
°
的方位角-俯仰角组的控制字符至fpga。fpga同步采集32阵元的麦克风阵列的输出字并通过i2s解码得到的48khz、24bit、32ch并数字行pcm(脉冲编码调制)流。
12.然后fpga将上述控制字符经由ascii解码得到目标和干扰两个方向的方位角-俯
仰角组,再采用映射于从-80
°
到80
°
的不同长度(量化为-4到4)的抽头延迟线将输入的32ch并行数字pcm流进行固定权值延时求和;延时求和的顺序是先执行4行横向排列的麦克风的延时求和,再在纵向上执行前一步4行求和结果的延时求和。
13.最终通过mux9_1(9选1分支器)使得麦克风阵列分别对齐目标和干扰方向的方位角-俯仰角组,并输出8khz、24bit、2ch数字pcm流。
14.步骤2、对于步骤1输出的8khz、24bit、2ch数字pcm流进行系统信干比提升处理。
15.fpga将步骤1得到的两路对齐目标和干扰方向的信号(方位角-俯仰角组)分别以24k点数的矩形窗进行加窗的短时傅里叶变换,并计算互功率谱。对传统mmse(最小均方误差)准则下的带wiener后置滤波的最优权值进行改进,所述改进即添加一个可变系数α以改善加权效果。将改进后的权值与目标方向的频域加权。最后将加权结果逆变换至时域单通道去非平稳干扰信号。变换时序为natural order(自然排序)、变换实现为radix-2(基-2)。以提升系统的信干比。
16.最终输出48khz、24bit、1ch数字pcm流,为经过频域加权后得到的高信干比的单路目标方向输出信号s(n)。
17.步骤3、对于步骤2输出的48khz、24bit、1ch数字pcm流s(n)。
18.fpga采用db3小波基的分解重构fir滤波器组对步骤2得到的单路去非平稳干扰信号进行基底平稳噪声估计。以估计噪声为输入且以误差信号为输出做自适应噪声抵消、基于lms(最小均方)准则做自适应滤波器的权值更新、滤波实现为33-taps(33抽头)fir。以提升系统的信噪比。
19.最终输出48khz、24bit、1ch数字pcm流,为经过自适应噪声抵消后的高信噪比的单路目标方向输出信号s
af
(n)。
20.步骤4、对于步骤3输出的48khz、24bit、1ch数字pcm流s
af
(n)。
21.fpga按照hilbert滤波器提取的信号包络计算步骤3得到的单路信号的短时能量。滤波响应特征为hilbert-transformation(希尔伯特变换)、滤波实现为11-taps fir、通过16阶滑动滤波计算包络直流分量、根据包络直流分量的强度进行4个等级的划分、通过mux4_1输出对应划分下的增益时域信号。目的进行幅度上的自动增益控制,以保证输出音频的音量均衡。
22.最终得到48khz、24bit、1ch数字pcm流s
audio
(n)直接输出至声卡并发声于外接耳机。
23.进一步的,所述步骤1具体如下:
24.步骤1.1、通过上位机反馈的控制字符经由uart协议发送给fpga进行ascii解码,从而获取空域滤波的目标位置和干扰位置其中分别表示方位角和俯仰角、下角标s表示目标、i表示干扰;
25.步骤1.2、根据步骤1.1的方位角和俯仰角信息,将-80
°
到80
°
映射为整数量化的-4到4作为抽头延迟线的长度,采用映射于不同角度信息的长度的抽头延迟线进行固定权值延时求和。在空域上先执行4行横向排列的麦克风的延时求和,得到四路分别对齐目标和干扰方向方位角的合计4*2ch信号,再执行纵向四路的延时求和,得到对齐目标和干扰方向俯仰角的2ch信号。
26.固定权值延时求和表示为其中w=[1,1,...,1]
t
,h=-4,-3...,0,...3,4,即ih衡量了上述的“不同长度”,n表示时域上的采样点,m指当前延时求和使用的麦克风阵元数量,在执行横向麦克风延时求和时为8,在执行纵向麦克风延时求和时为4。
[0027]
步骤1.3、针对步骤1.1到1.2的硬件设计中的时序和溢出问题:横向对齐方位角需要使用4*7*2个加法器,纵向对齐俯仰角需要使用3*2个加法器。加法器采用树状流水线,每个加法器后需将位宽提高1bit,累计求和后将输出右移3bit,再统一cast(转换)至24_0_fixed。uart模块接收控制字符解码为ascii作为多路复用器mux9_1的参考信号,由于h具有9种取值,故每次延时求和都需要做mux9_1的输出选择。
[0028]
步骤1.4、麦克风阵列信号经过步骤1.1-步骤1.3的空域滤波后产生两路对齐信号aligned_s(n)和aligned_i(n),它们从方位角和俯仰角两个方向分别对齐和
[0029]
进一步的,所述步骤2具体如下:
[0030]
步骤2.1、针对步骤1获取的两路对齐信号aligned_s(n)和aligned_i(n),分别按照0.5s(24k长度)的矩形窗进行加窗分帧,并计算相同点数的短时傅里叶变换得到两路频域信号f_s(k)和f_i(k),k表示频域上的采样点。
[0031]
步骤2.2、针对步骤2.1所得的两路频域信号,分别计算其自功率谱密度得到p_s(k)和p_i(k)。自功率谱的计算为p(k)=f(k)
·f*
(k)/n,其中[
·
]
*
表示序列的共轭,n表示帧长。
[0032]
步骤2.3、对mmse准则下的带wiener后置滤波的最优权值进行改进,将权值写为:依据干扰方向的短时功率谱密度的大小调整系数α的取值,p_i越大则α越小以减轻加权过度造成的音乐噪声,p_i越小则α越大以进一步增强对非平稳干扰信号的抑制效果。
[0033]
步骤2.4、在步骤2.3获取加权的权值后,对步骤2.1计算目标方向的频域变换f_s(k)进行如步骤2.3所述的加权再取傅里叶逆变换,计算为:s(n)=f-1
{f_s(k)
·wopt
(k)}。
[0034]
步骤2.5、针对步骤2.1到2.4的硬件设计中的时序和溢出问题:傅里叶变换使用的fft和傅里叶逆变换使用的ifft模块均采用natural order、基2运算。共轭相乘计算实质是模平方计算,可利用1个加法器+2个乘法器替代复数乘法器,输出皆采用full-scale(满刻度)。“依据干扰方向的短时功率谱密度的大小调整α的取值”采用mux4_1实现。由于ifft只支持上限33bit的fixed-point(定点)输入,所以涉及乘法器的运算结果均做16bit右移防止冗余量化。ifft模块输出的结果带小数,需统一cast至24_0_fixed。
[0035]
步骤2.6、经过步骤2.1到步骤2.5的计算,两路空域对齐信号经过频域加权得到高信干比的单路目标方向输出信号s(n)。
[0036]
进一步的,所述步骤3具体如下:
[0037]
步骤3.1、小波分解和重构各需要一对fir滤波器组,给定所用db3小波基的滤波器系数分别为:
[0038]
用于尺度空间分解的低通滤波器lo_d=[0.035226
ꢀ‑
0.085441
ꢀ‑
0.135011 0.459878 0.806892 0.332671];
[0039]
用于小波空间分解的高度滤波器hi_d=[-0.332671 0.806892
ꢀ‑
0.459878
ꢀ‑
0.135011 0.085441 0.035226];
[0040]
用于尺度空间重构的低通滤波器lo_r=[0.332671 0.806892 0.459878-0.135011
ꢀ‑
0.085441 0.035226];
[0041]
用于小波空间重构的高通滤波器hi_r=[0.332671 0.806892
ꢀ‑
0.459878
ꢀ‑
0.135011 0.085441
ꢀ‑
0.035226]。以上系数均使用32_31_fixed量化。
[0042]
步骤3.2、一层分解:将步骤2所得单路目标方向信号s(n)依次通过步骤3.1给定的lo_d和hi_d,并做2倍抽取,得到小波域系数a1和d1。
[0043]
步骤3.3、二层分解:将步骤3.2计算得到的d1依次通过步骤3.1给定的lo_d和hi_d,并做2倍抽取得到小波域系数a2和d2。
[0044]
步骤3.4、阈值滤噪。让一层的d1的每次采样量化值与阈值λ做以下硬判决和取值,以提取估计噪声:
[0045][0046]
其中阈值λ利用sqtwolog准则计算:
[0047][0048]
其中σ2为当前样本帧的估计方差,n为帧长。
[0049]
如上述,让二层的a2和d2也进行同样的判决和取值,提取对应的估计噪声。
[0050]
步骤3.5、一层重构。让步骤3.2计算的小波空间的估计噪声d1先进行2倍内插后再通过hi_r,还原得到时域序列n_d1(n)。
[0051]
步骤3.6、二层重构。让步骤3.3计算的小波空间的估计噪声d2和尺度空间的估计噪声a2先进行2倍内插后依次通过hi_r和lo_r;完成后再各自进行2倍内插后分别通过lo_r,还原得到时域序列n_d2(n)和n_a2(n)。
[0052]
步骤3.7、时域叠加。将步骤3.5到步骤3.7计算得到对于某一帧的估计噪声进行叠加:
[0053]
n(n)=n_d1(n)+n_d2(n)+n_a2(n)
[0054]
步骤3.8、以步骤3.7计算得到的n(n)作为输入信号,以s(n)作为参考信号,滤波器的输出为以s(n)-yn(n)作为误差信号,基于lms准则做自适应fir滤波。滤波器阶数为32,初始权值w
af
=0,并以梯度下降法给出权值的更新计算公式:w
af
(n+1)=w
af
(n)+2μ(s(n)-yn(n))n(n),其中学习步长μ=0.005。
[0055]
步骤3.9、经过以上步骤3.1到步骤3.8的硬件设计中的时序和溢出问题:用于小波分解重构的fir滤波器均为6-taps、5个延迟单元、6个乘法器和5个加法器,其系数均使用32_31_fixed量化,每个fir滤波器的输出均cast至24_0_fixed。阈值的计算要使用到样本帧的方差,方差采用统计学公式估算,涉及到的加法器和乘法器全部采用full-scale输出,方差估计涉及到的均值计算采用16阶滑动平均滤波实现。阈值滤噪的硬判决通过mux2_1实现。fir自适应滤波器为33-taps、32个延迟单元、33个乘法器和32个加法器,系数(即权值)、
输出均使用24_0_fixed,学习步长使用16_16_ufixed。
[0056]
步骤3.10、经过以上步骤3.1到步骤3.9的计算,最终通过自适应噪声抵消后输出的单路数字音频pcm流表示为s
af
(n)=s(n)-yn(n)。
[0057]
进一步的,所述步骤4具体如下:
[0058]
步骤4.1、hilbert滤波器的响应特性本质是幅频特性为1的全通滤波器,偶数阶的hilbert滤波器要求0和fs/2处严格截止(-20db以上)。hilbert滤波器输出在相位上的特征是延后输入90
°
。利用filter-designer工具箱实现以上性质的滤波器设计,设置响应特性为hilbert-transformation,实现方法为等波纹fir,阶数为10阶,得到[-0.5338 0-0.2263 0-0.64120 0.6412 0 0.2263 0 0.5338]。上述系数采用16_15_fixed量化置于硬件设计的ip核内,ip核为11-taps的fir滤波器。
[0059]
步骤4.2、hilbert滤波器的输入为步骤3所得单路数字音频pcm流s
af
(n),输出为时域上的一对正交iq序列si(n)和sq(n),其中si(n)是5个抽头延迟后的s
af
(n),sq(n)则是经过hilbert滤波器的10个抽头延迟后并加权的输出结果。
[0060]
步骤4.3、计算步骤4.2得到的si(n)和sq(n)的平方和并开方计算,得到输入信号s
af
(n)的包络:
[0061]
步骤4.4、利用16阶滑动平均滤波,计算步骤4.3得到的e
af
(n)的直流分量e
dc
(n),用以给自动增益控制提供mux的参考信号。设计mux4_1,将计算的e
dc
(n)按幅值划分为4个范围,这四个范围分别是e
dc
(n)》2
20
、2
16
《e
dc
(n)≤2
20
、2
14
《e
dc
(n)≤2
16
和e
dc
(n)≤2
12
。根据计算的e
dc
(n)处于的范围区间,将s
af
(n)的幅度分别右移4bit、右移2bit、右移1bit和左移1bit,进行伸缩增益。
[0062]
步骤4.5、针对步骤4.1到步骤4.4的硬件设计中的时序和溢出问题:用于hilbert变换的fir滤波器为11-taps、10个延迟单元、11个乘法器和10个加法器,其系数均使用16_15_fixed量化,每个fir滤波器的输出均cast至24_0_fixed。平方和运算涉及乘加器,和后续的滑动平均滤波都采用full-scale输出。e
dc
(n)输入到mux4_1前通过右移16bit的方法cast至24_0_fixed。
[0063]
步骤4.6、经过以上步骤4.1到步骤4.5的计算,最终输出的信号是对s
af
(n)的幅度进行自动增益控制后的数字音频pcm流s
audio
(n)。该信号通过axi(高级可扩展接口)总线分配到arm的ddr3内存中,再通过tcp/ip协议发送至上位机,再驱动声卡进行播放。
[0064]
本发明具有以下有益效果:
[0065]
(1)阵元数目多。相较于目前已存在的“定向拾音”声阵列产品普遍只有10个以下的麦克风,本发明音频输出的信噪比可达14db以上的提升,使得室外室内场景的拾音范围远,可达20m以上。
[0066]
(2)处理实时、延迟低、硬件成本低。阵元数目增多会导致目前已有的声阵列产品所普遍使用的采集卡+dsp运算平台的硬件方案难以进行“高吞吐量、低延时值”的实时处理。依托于fpga并行运算的加速,本发明的系统整体测试延时在1~2s;并且fpga本身作为数据采集、传输、处理的一体化实现硬件平台,不需要单独为系统配置价格昂贵的采集卡和复杂的数据接口,硬件成本大大降低。以上符合工业监测、军事、商务办公等要求实时精确的应用场景。
[0067]
(3)抑制非平稳干扰、抑制平稳底噪效果明显。本发明采用的基于空时频的宽带波束形成算法用以实现定向拾音,相较于市面已有产品并不能很好实现非平稳干扰抑制的定向拾音功能,本发明对空间中的非平稳干扰信号和基底噪声抑制效果更为明显。
附图说明
[0068]
图1为本发明的工作示意图;
[0069]
图2为本发明的流程总框架图;
[0070]
图3为本发明的第一部分(空域)框架图;
[0071]
图4为本发明的第二部分(频域)框架图;
[0072]
图5为本发明的第三部分(小波域)框架图;
[0073]
图6为本发明的第四部分(时域)框架图;
[0074]
图7为实施例的性能测试结果。
[0075]
图8为实施例在各个步骤下的时域波形。
具体实施方式
[0076]
下面结合附图和实施例对本发明做进一步的详细说明。
[0077]
本实施例基于fpga的32阵元声阵列定向拾音方法,将其在zynq-xc7z020异构芯片上实现,整个系统的工作示意图参照图1,其中
①
指代本发明的32阵元声阵列定向拾音系统、
②
指代mems数字麦克风、
③
指代130
°
广角摄像头、
④
指代降噪蓝牙耳机,负责实现以下功能:
[0078]
(1)选用数字mems麦克风芯片ics-43432。fpga同步采集周围工作频率位于300~3400hz、空间分布位于全方位360
°
的声压模拟信号,通过ics-43432的内部adc、抗混叠滤波、i2s接口,将各通道采集数据转换为数字系统可处理的pcm格式,采样频率为48khz、量化精度为signed-24bit、同步通道数为32ch。
[0079]
(2)32ch原始采集数字音频信号在fpga中通过“基于空时频的宽带波束形成算法”输出1ch的数字信号,该数据流满足“实时、抑制非平稳干扰、抑制平稳底噪、远拾音距离”的设计要求。
[0080]
(3)上一步输出的1ch数字信号经由fpga内部的axi总线分配到arm部分的ddr3内存中,再通过tcp/ip协议发送至上位机。上位机接收数据、连接蓝牙耳机、驱动声卡通过耳机进行播放。
[0081]
系统的测试环境位于室外或室内。
[0082]
(1)室外环境下,信噪比0~5db,单声源拾音:方位角0
°
、俯仰角3
°
、拾音距离20m。
[0083]
多声源拾音:声源甲的方位角-30
°
、俯仰角5
°
、拾音距离5m;声源乙的方位角30
°
、俯仰角5
°
、拾音距离5m。
[0084]
(2)室内环境下,空间大小为10*8*5m,信噪比20db以上,混响时间rt60=250ms,多声源拾音:声源甲的方位角-30
°
、俯仰角12
°
、拾音距离5m;声源乙的方位角30
°
、俯仰角11
°
、拾音距离5m。
[0085]
以室内测试为例,绘出图7表征本实施例的性能测试结果(以从上至下为顺序,层1表示干扰信号、层2曲线表示目标信号、层3曲线表示2号单麦克风接收信号、层4曲线表示定
向拾音输出)。
[0086]
图8表征了本实施例在本发明的各个步骤下的时域波形(以从上至下为顺序,层1表示2号单麦克风接收信号、层2曲线表示层1信号经过空域处理后、层3曲线表示层2信号经过频域加权后、层4曲线表示层3信号经过自适应噪声抵消(ans)和自动增益控制(agc)后的输出)。
[0087]
从时域信号可见,定向拾音的输出信号复现了目标信号,并大幅度抑制了非平稳干扰信号和平稳基底噪声,证实了本发明的系统可行性。
[0088]
综上可见,本发明以fpga作为主控的基于空时频的宽带波束形成器,实施载体为32阵元的矩形mems数字麦克风阵列,实现功能为室内和室外环境下实时、可靠、稳定的定向拾音和干扰抑制。在fpga芯片主控的硬件电路上,32个麦克风阵元通过i2s接口解码并以48ksps和24bit的业内标准音频采样率和量化精度同步采集和传输,后续依次通过:空域处理、频域处理、小波域处理和为时域处理。最终本发明输出音频在增强目标声源的同时能极大程度抑制干扰声源以及环境噪声,致力于提供智能办公、智能家居、高质量会议、设备健康监测等丰富的需求场景。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1