用于多重PCR文库构建的连接序列及其设计方法与流程
本发明属于高通量测序领域,更具体地涉及用于多重pcr文库构建的连接序列及其设计方法。
背景技术:
:核酸测序已经成为生物学研究、疾病筛查、医学辅助诊断中不可缺少的一项重要技术,从根本上改变了人类研究生命蓝图的方式。高通量测序是目前主流的核酸测序方法,其具有费用低、通量大、速度快的优势。现有的高通量测序平台主要包括illumina公司的solexa测序平台、roche公司的454平台、life公司的iontorrent平台。随着测序平台硬件及软件的提升,阻碍高通量测序技术发展的却是文库构建以及后续的数据分析。其中,所有测序平台都涉及复杂的文库构建过程,一方面需要捕获目标片段,另一方面还需要将平台配套的测序接头和区分样本的标签连接到捕获片段上。以基于多重pcr捕获的文库构建过程为例,基础方法包括如下步骤:(1)多重pcr捕获目的片段;(2)引物和/或修饰清除;(3)测序接头和/或标签连接;(4)磁珠纯化;(5)pcr扩增富集。在此基础流程上做出的改进主要有:(1)测序接头和标签的连接与pcr扩增合并为一步;(2)多重pcr捕获目标片段与测序接头和/或标签连接合并为一步;(3)无引物和/或修饰清除步骤,(4)以上情况的组合等等,其主要目的都是简化流程,节约成本。文库构建过程的简化并非易事,每个步骤的改进或去除都会影响文库构建的质量,如文库浓度,文库片段分布,进而影响扩增子均一性、数据利用率等。此外,更不容忽视的是,pcr测序文库构建过程中,涉及的反应序列复杂多样,如特异性引物序列、测序接头序列、多个标签序列等等,如何在建库步骤中排除或降低序列之间的相互干扰,获得良好的文库质量,并且兼顾序列的通用性,是需要设计者有创造性地去设计和改进才能实现的。技术实现要素:基于
背景技术:
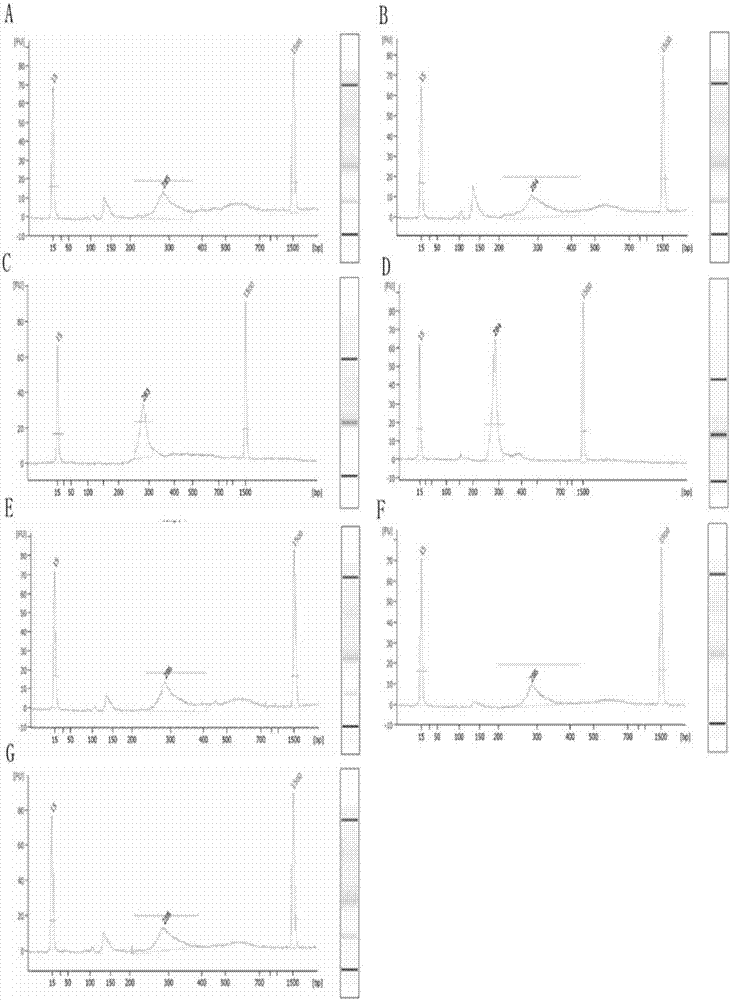
谈及的技术问题,本发明的目的在于提供一种用于多重pcr文库构建的连接序列及其设计方法;还提供以上连接序列和基于连接序列构成的连接引物、连接接头、连接标签在核酸测序文库构建和制备核酸测序试剂盒中的应用。本发明所采取的技术方案是:一种用于多重pcr文库构建的连接序列,所述连接序列设置于目标片段特异性引物的5’端,构成连接引物;所述连接序列还设置于测序接头的3’端,构成连接接头;基于连接序列的设置,通过pcr扩增实现目标片段与测序接头的连接。作为上述连接序列的改进,所述连接序列还可设置于标签的3’端,构成连接标签,通过pcr扩增实现标签、测序接头、目标片段的连接。作为上述连接序列的优选,所述连接序列选自seqidno:1~seqidno:7任意一条核苷酸序列。作为上述连接序列的优选,所述连接序列用于iontorrent测序平台。作为上述连接序列的优选,所述连接序列适用于人核酸测序文库构建。如上所述的连接序列的设计方法,包括如下步骤:获取候选序列集:采用滑窗法构建人类远源物种基因组核苷酸序列集n和人类基因组核苷酸序列集m,将序列集m中出现的序列从序列集n中剔除,获得候选序列集;候选序列初筛:在候选序列集中,筛选满足以下条件的序列:(1)解链温度为55~65℃的序列;(2)不包含未知碱基的序列;(3)与序列自身、测序接头不形成二聚体的序列;e-pcr复筛:将初筛获得的序列对人类参考基因组进行e-pcr分析,筛选不生成模拟扩增产物的序列作为连接序列。作为上述设计方法的优选,获取候选序列集时,滑窗法以15~20bp为窗口大小,1bp为步长,扫描相应的参考基因组。作为上述设计方法的优选,筛选与序列自身、测序接头不形成二聚体的序列的方法为:利用primer软件,将候选序列集中的各条序列分别与序列自身、测序接头进行二聚体分析,剔除能够形成二聚体的序列。作为上述设计方法的优选,所述人类远源物种包括细菌、真菌、植物、人类远源动物;所述人类远源物种至少选择一个物种。如上所述的连接序列、连接引物、连接接头、连接标签在核酸测序文库构建及制备核酸测序试剂盒中的应用。本发明的有益效果是:基于本发明的连接序列,能通过pcr扩增实现标签、测序接头、目标片段的连接,其设计方法包括:获取候选序列集、候选序列初筛、e-pcr复筛;本发明的连接序列与扩增体系中其他序列的相互干扰小,构建的文库质量好,并且通用性强,不仅适于一步和两步扩增建库,还适于多种核酸测序文库的构建,如检测遗传性耳聋致病位点、苯丙酮尿症致病基因、肺癌靶向用药基因、乳腺癌brca1/2突变基因、安全用药基因的核酸测序文库,基于连接序列的核酸测序文库构建简化了建库流程,大大节约了测序成本,还可应用于核酸测序试剂盒中,具有非常良好的市场应用前景。此外,发明人基于连接序列的作用,创造性的提出了一套连接序列的设计方法,综合考虑了序列长度、解链温度、序列间相互作用、与人类基因组互斥等方面的因素,通过该设计方法,可以筛选出特异性高,通用性强的连接序列,实现连接序列在核酸测序文库构建及核酸测序试剂盒中的应用。附图说明图1是不同连接序列构建的遗传性耳聋致病位点文库的片段分布,其中,图a~g基于连接序列u1~u7;图2是连接序列u4构建的遗传性耳聋致病位点文库的扩增子均一性箱式图,其中横坐标为扩增子,纵坐标为reads数;图3是实施例3构建的苯丙酮尿症突变基因文库的测序峰图;图4是实施例3构建的苯丙酮尿症突变基因文库的扩增子均一性箱式图,其中横坐标为扩增子,纵坐标为reads数;图5是实施例4构建的肺癌靶向用药基因文库的测序峰图;图6是实施例4构建的肺癌靶向用药基因文库的扩增子均一性箱式图,其中横坐标为扩增子,纵坐标为reads数;图7是实施例5构建的乳腺癌brca1/2突变基因文库的测序峰图;图8是实施例5构建的乳腺癌brca1/2突变基因文库的扩增子均一性箱式图,其中横坐标为扩增子,纵坐标为reads数;图9是实施例6构建的安全用药基因文库的测序峰图;图10是实施例6构建的安全用药基因文库的扩增子均一性箱式图,其中横坐标为扩增子,纵坐标为reads数。具体实施方式一种用于多重pcr文库构建的连接序列,所述连接序列设置于目标片段特异性引物的5’端,构成连接引物;所述连接序列还设置于测序接头的3’端,构成连接接头;基于连接序列的设置,通过pcr扩增实现目标片段与测序接头的连接;更进一步的,所述连接序列还可设置于标签的3’端,构成连接标签,通过pcr扩增实现标签、测序接头、目标片段的连接;所述扩增可选一步或两步扩增,但不限于此。作为优选的,所述连接序列选自seqidno:1~seqidno:7任意一条核苷酸序列。进一步优选的,所述连接序列用于iontorrent测序平台。进一步优选的,所述连接序列适用于人核酸测序文库构建。其中,目标片段特异性引物、测序接头和标签属于本领域的公知常识,目标片段特异性引物可根据本领域公知技术设计获得,如oligo引物设计软件;测序接头是依据测序平台的适应性选择,如实施例中利用iontorrent测序平台的a接头和p接头,标签可利用本领域公知的常规标签,如life平台提供的96标签(barcode01~barcode96)。基于本发明的“连接序列”,可将文库构建流程简化,经过一步或两步pcr扩增,即可获得测序文库。具体地,两步法的建库流程无需清除引物和/或修饰,将测序接头和标签的连接与pcr扩增富集合并为一步,多重pcr捕获目的片段另为一步;优选的,一步法可在两步法建库流程的基础上,实现多重pcr捕获目的片段、测序接头和标签的连接、pcr扩增富集三步骤合一,大大节约了时间成本和经济成本。本发明连接序列的设计方法,包括如下步骤:获取候选序列集:采用滑窗法构建人类远源物种基因组核苷酸序列集n和人类基因组核苷酸序列集m,将序列集m中出现的序列从序列集n中剔除,获得候选序列集。其中,考虑到序列长度过短则难以满足连接序列在扩增中的引物属性,序列长度过长则影响测序产生的read长度;获取候选序列集时,滑窗法以15~20bp为窗口大小,1bp为步长,扫描相应的参考基因组,获得相应的序列集。其中,人类远源物种包括细菌、真菌、植物,人类远源动物,远源物种至少选择一个物种,但不限于此。候选序列初筛:在候选序列集中,筛选满足以下条件的序列:(1)解链温度为55~65℃的序列;(2)不包含未知碱基的序列;(3)与序列自身、测序接头不形成二聚体的序列。其中,解链温度的选择考虑到连接序列的特异性,且需与其他序列在同一体系内作用;其中,连接序列应避免序列之间的杂交互补,筛选与序列自身、测序接头不形成二聚体的序列的方法时:利用primer软件,将候选序列集中的各条序列分别与序列自身、测序接头进行二聚体分析,剔除能够形成二聚体的序列。e-pcr复筛:将初筛获得的序列对人类参考基因组进行e-pcr分析,筛选不生成模拟扩增产物的序列作为连接序列。如前所述,本发明的连接序列、基于连接序列构成的连接引物、连接接头、连接标签在核酸测序文库构建及制备核酸测序试剂盒中的应用。下面结合具体实施例,进一步阐述本发明,实施例涉及的目标片段特异性引物、测序接头和标签均可根据常规技术获得,不作赘述;实施例中未详细说明的实验方法和条件均按本领域常规或厂商建议操作。实施例1、连接序列利用本发明提供的连接序列设计方法,人类远源物种参考下述物种exophialamesophila、photobacteriumprofundum、borreliamiyamotoi、neomicrococcusaestuarii;人类参考基因组为hg19;测序接头由iontorrent测序平台提供的a接头和p接头;最终筛选出7条连接序列,其核苷酸序列如seqidno:1~seqidno:7所示。u1:5’-gggctggcaagccacgtt-3’(seqidno:1);u2:5’-gtctcgtgggctcggaga-3’(seqidno:2);u3:5’-cgtcgccgtccagctcga-3’(seqidno:3);u4:5’-aaatgggcggtaggcttg-3’(seqidno:4);u5:5’-cgtgacgcggtgcagggc-3’(seqidno:5);u6:5’-cgcaaatgggcggtaggc-3’(seqidno:6);u7:5’-ccgggagctgcatgtgtc-3’(seqidno:7)。实施例2、不同连接序列在遗传性耳聋致病位点测序文库构建中的应用以遗传性耳聋致病位点检测为例,分别基于u1~u7的连接序列和本发明的思路构建核酸测序文库;将41对连接引物混合物0.2μl、连接接头0.5μl、连接标签0.5μl、样品基因组dna20ng、pcr反应液mix12.5μl,无酶水补至25μl,一步扩增获得测序文库,扩增条件为95℃预变性3min;35个循环扩增(95℃变性15s,60℃退火90s,72℃延伸30s);72℃延伸1min,16℃forever;扩增产物经磁珠纯化,采用iontorrent测序平台进行高通量测序。agilent2100对测序文库的片段进行分析,结果如图1所示,所有连接序列都能够扩增出目的片段,其中,基于连接序列u3、u4、u6构建的文库质量较优,非特异性扩增较少,更优选的,基于u4构建的文库质量最佳,目的片段峰面积最大,此外,参照图2,其扩增子均一性好。测序数据中,读长低于30bp的比例和数据利用率结果如表1所示,一致的,基于连接序列u3、u4、u6构建的文库质量较优,数据利用率高,并且读长低于30bp的比例较低,其中,基于u4构建的文库最优。以上结果均说明,基于本发明的连接序列能实现核酸测序文库的建库,更进一步的,可以实现在包含模板、特异性引物、测序接头、标签等多种序列体系下完成一步扩增,其中连接序列u4最优,因此用于后续应用中。表1、不同连接序列的效果比较序列读长低于30bp的比例数据利用率文库评价u117.3%42.2%一般u225.5%32.8%较差u34.6%69.5%优u43.8%74.8%最优u515.5%48.8%一般u67.2%60.5%优u720.1%40.2%较差实施例3、连接序列u4在苯丙酮尿症致病基因测序文库构建中的应用利用连接序列u4,以苯丙酮尿症致病基因检测为例,按本发明思路,采用两步扩增法:将61对连接引物混合物2μl、样品基因组dna200ng、pcr反应液mix10μl、dmso1μl、无酶水补至20μl,进行第一步pcr扩增,实现连接序列与目的片段的连接;第一步pcr扩增反应条件设置如下:95℃预变性5min;15个循环扩增(95℃变性35s,60℃退火90s,72℃延伸30s),72℃延伸1min,16℃forever;然后将磁珠纯化后的第一步pcr扩增反应产物10.5μl、连接接头0.5μl、连接标签0.5μl、dmso1μl,pcr反应液mix12.5μl混合,进行第二步pcr扩增反应,获得测序文库;扩增条件为98℃预变性3min;25个循环扩增(98℃变性20s,60℃退火60s,72℃延伸30s),72℃延伸1min,16℃forever;扩增产物经磁珠纯化,采用iontorrent测序平台进行高通量测序。文库定量检出文库浓度为18.9ng/μl,上机测序峰图如图3所示,非特异性扩增少,文库质量高;测序数据还显示:数据利用率76.5%,比对成功率84.6%、测序覆盖率达100%;大量检测数据显示,参照图4,扩增子均一性高,可见本发明的连接序列也适用于苯丙酮尿症致病基因测序文库构建。实施例4、连接序列u4在肺癌靶向用药基因测序文库构建中的应用利用连接序列u4,以肺癌靶向用药基因检测为例,按本发明思路,采用两步扩增法:将28对连接引物混合物2μl、样品基因组dna20ng、pcr反应液mix12.5μl、无酶水补至25μl,进行第一步pcr扩增,实现连接序列与目的片段的连接;第一步pcr扩增反应条件设置如下:95℃预变性3min;15个循环扩增(95℃变性20s,60℃退火90s,72℃延伸30s),72℃延伸1min,16℃forever;然后将磁珠纯化后的第一步pcr扩增反应产物11.5μl、连接接头0.5μl、连接标签0.5μl、pcr反应液mix12.5μl混合,进行第二步pcr扩增反应,获得测序文库;扩增条件为98℃预变性2min;25个循环扩增(98℃变性10s,60℃退火60s,72℃延伸30s),72℃延伸1min,16℃forever;扩增产物经磁珠纯化,采用iontorrent测序平台进行高通量测序。文库定量检出文库浓度为15.8ng/μl,上机测序峰图如图5所示,非特异性扩增较少,文库质量高;测序数据还显示:数据利用率64.5%,比对成功率99.7%、测序覆盖率达100%;大量检测数据显示,参照图6,扩增子均一性高,可见本发明的连接序列也适用于肺癌靶向用药基因测序文库构建。实施例5、连接序列u4在乳腺癌brca1/2突变基因测序文库构建中的应用利用连接序列u4,以乳腺癌brca1/2突变检测为例,按本发明思路,采用两步扩增法:首先将316对连接引物混合物2μl、样品基因组dna20ng、pcr反应液mix12.5μl、无酶水补至25μl,进行第一步pcr扩增,实现连接序列与目的片段的连接;第一步pcr扩增反应条件设置如下:95℃预变性3min;15个循环扩增(95℃变性20s,60℃退火90s,72℃延伸30s),72℃延伸1min,16℃forever;然后将磁珠纯化后的第一步pcr扩增反应产物11.5μl、连接接头0.5μl、连接标签0.5μl、pcr反应液mix12.5μl混合,进行第二步pcr扩增反应,获得测序文库;扩增条件为98℃预变性2min;25个循环扩增(98℃变性10s,60℃退火60s,72℃延伸30s),72℃延伸1min,16℃forever;扩增产物经磁珠纯化,采用iontorrent测序平台进行高通量测序。文库定量检出文库浓度为16.9ng/μl,上机测序峰图如图7所示,非特异性扩增少,文库质量高;测序数据还显示:数据利用率56.6%,比对成功率96.7%、测序覆盖率达100%;大量检测数据显示,参照图8,扩增子均一性高,可见本发明的连接序列也适用于乳腺癌brca1/2突变基因测序文库构建。实施例7、连接序列u4在安全用药基因测序文库构建中的应用利用连接序列u4,以安全用药基因检测为例,按本发明思路,将90对连接引物混合物0.6μl、连接接头0.25μl、连接标签2.5μl、样品基因组dna200ng、pcr反应液mix12.5μl,无酶水补至25μl,一步扩增获得测序文库,扩增条件为95℃预变性3min;35个循环扩增(95℃变性10s,60℃退火90s,72℃延伸30s);72℃延伸1min,16℃forever;扩增产物经磁珠纯化,采用iontorrent测序平台进行高通量测序。文库定量检出文库浓度为12.3ng/μl,上机测序峰图如图9所示,非特异性扩增较少,文库质量较高;测序数据还显示:数据利用率62.5%,比对成功率87.6%、测序覆盖率达100%;大量检测数据显示,参照图10,扩增子均一性高,可见本发明的连接序列也适用于安全用药基因测序文库构建。以上实施例基于连接序列的一步或两步pcr扩增,有效的构建了检测遗传性耳聋致病位点、苯丙酮尿症致病基因、肺癌靶向用药基因、乳腺癌brca1/2突变基因、安全用药基因的核酸测序文库,说明本发明的连接序列具备一定的通用性,更证实了本发明的连接序列可应用于多种核酸测序文库构建,也可预想将其应用于制备适于相应检测的核酸测序试剂盒中。此外,以上实施例仅为阐述本发明的示例,其保护范围不局限于此,在不脱离本发明连接序列及其设计方法的基础上,本领域技术人员未进行创作性劳动获得的技术方案均属于本发明的保护范围。序列表<110>东莞博奥木华基因科技有限公司<120>用于多重pcr文库构建的连接序列及其设计方法<160>7<170>siposequencelisting1.0<210>1<211>18<212>dna<213>人工序列()<400>1gggctggcaagccacgtt18<210>2<211>18<212>dna<213>人工序列()<400>2gtctcgtgggctcggaga18<210>3<211>18<212>dna<213>人工序列()<400>3cgtcgccgtccagctcga18<210>4<211>18<212>dna<213>人工序列()<400>4aaatgggcggtaggcttg18<210>5<211>18<212>dna<213>人工序列()<400>5cgtgacgcggtgcagggc18<210>6<211>18<212>dna<213>人工序列()<400>6cgcaaatgggcggtaggc18<210>7<211>18<212>dna<213>人工序列()<400>7ccgggagctgcatgtgtc18当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1