生产L-丝氨酸的重组菌及其构建方法与流程
本发明涉及微生物发酵领域,具体涉及一种生产l-丝氨酸的重组菌及其构建方法。
背景技术:
l-丝氨酸是一种蛋白质氨基酸,它可以为哺乳动物中枢神经系统的生长和发育提供营养,能够维持哺乳动物胚胎正常生长和发育。同时,它还是胞内多种重要生物物质合成所需的一碳单位(one-carbon,c1)的直接供体,在生物体整个代谢网络中占据重要位置。l-丝氨酸还可作为多种有用化合物的合成前体,在化工、制药、化妆品及食品等工业领域具有广泛的用途。
目前,l-丝氨酸工业化生产方法主要包括蛋白水解法、固定化酶法、化学合成法和前体发酵法。蛋白质水解提取法存在原料成本高且利用率低、提取工艺复杂和环境污染大等缺点。固定化酶法采用固定化酶或固定化细胞的技术,利用丝氨酸羟甲基转移酶(shmt)逆向反应催化甘氨酸和甲醛生成l-丝氨酸。由于shmt催化专一性强、反应条件温和、副产物较少,而成为世界各国酶法生产l-丝氨酸的主要方法。化学合成法生产的产品为dl-丝氨酸,需要进行化学拆分获得l-丝氨酸,生产成本高、工艺复杂。前体发酵法生产l-丝氨酸主要是添加甘氨酸和甲醇作为l-丝氨酸合成的前体,通过shmt催化的逆向反应合成,或者利用甲基营养型细菌胞内酶系统,催化甘氨酸和c1供体合成l-丝氨酸。前体发酵法存在成本高、底物转化率低的缺点,因此难以满足市场的需求。
l-丝氨酸处于氨基酸代谢的中间位置,代谢转运速度极快,与其他氨基酸相比,非常不容易积累。因此,工业上仍无法实现利用低廉的糖质原料通过微生物直接发酵法生产l-丝氨酸。
现有技术,通常通过直接从环境中筛选、紫外线诱变、底物类似物筛选突变株等传统育种方法分离和筛选能够积累l-丝氨酸的菌株。目前,l-丝氨酸菌株选育的种属(株)主要包括黄色短杆菌(brevibacteruimflavum)、假单胞菌(pseudomonasputida)和谷氨酸棒杆菌(corynebacteriumglutamicum)等。国内主要有新疆农科院微生物研究所和新疆农业大学以黄色短杆菌为出发菌株,通过传统诱变、筛选的方法得到l-丝氨酸产生菌。江南大学通过直接筛选法获得一株能够直接利用糖质原料发酵产l-丝氨酸的菌株谷氨酸棒杆菌syps-062,通过分析培养基中不同碳源、不同氮源、不同维生素等物质的浓度对l-丝氨酸积累的影响,建立了最适的发酵条件,使得l-丝氨酸产量达到6.6g/l。但经过传统诱变育种筛选得到的l-丝氨酸菌株不可避免地积累次级突变,导致菌株生长缓慢,并且菌种的环境耐受力低、产生副产物、性状容易退化等特点都限制了l-丝氨酸的生产效率。
现有技术也可通过系统代谢工程改造构建l-丝氨酸工程菌。peters-wendisch等通过增加丝氨酸合成途径中的seracb基因的表达,所构建的工程菌能够产l-丝氨酸9g/l(peters-wendisch,p.,stolz,m.,etterich,h.,kennerknecht,n.,sahm,h.,eggeling,l.appliedandenvironmentalmicrobiology,2005,71:7139-7144.)。zhang等通过阻断叶酸的代谢途径,抑制丝氨酸羟甲基转移酶的活性,阻断丝氨酸分解为甘氨酸,l-丝氨酸的产酸量仅达到8g/l(zhang,x.,xu,g.,li,h.,dou,w.,xu,z.appliedbiochemistrybiotechnology,2014,173:1607-1617)。但是该方法严重抑制了菌体生长,且发酵时间长。
因此,目前尚缺乏性能优良的采用直接发酵法生产l-丝氨酸的生产菌。
技术实现要素:
本发明的目的在于提供一种性能优良的生产l-丝氨酸的重组菌及其构建方法。
为实现上述目的,本发明的第一方面提供了一种生产l-丝氨酸的重组菌,其中,所述重组菌与出发菌相比具有提高的甘氨酸裂解系统gcv的表达,所述出发菌为能够累积l-丝氨酸的菌株。
根据本发明第一方面提供的重组菌,其中,所述重组菌与出发菌相比具有降低的丝氨酸o-乙酰转移酶cyse的表达。优选地,所述重组菌中编码丝氨酸o-乙酰转移酶cyse基因失活和/或cyse基因的表达以低转录或低表达活性的调控元件介导。更优选地,所述失活为敲除所述重组菌中的cyse基因,所述低转录或低表达活性的调控元件为phom启动子。再优选地,phom启动子的核苷酸序列如seqidno.2自5’末端第928-1057位核苷酸所示。根据本发明第一方面提供的重组菌,其中,所述重组菌具有一个或多个编码甘氨酸裂解系统的gcv基因的拷贝。优选地,gcv基因来源选自大肠杆菌escherichiacoli、恶臭假单胞菌pseudomonasputida、伯克氏菌burkholderiamultivorans、枯草杆菌bacillussubtilis和蜡样芽胞杆菌bacilluscereus中的一种或多种。更优选地,所述gcv基因选自编码氨甲基转移酶的gcvt基因、编码载体蛋白的gcvh基因和编码甘氨酸脱氢酶的gcvp基因中的一种或多种。再优选地,所述gcvt基因和gcvh基因的核苷酸序列如seqidno.3所示,所述gcvp基因的核苷酸序列如seqidno.4所示。
根据本发明第一方面提供的重组菌,所述gcv基因的表达以高转录或高表达活性的调控元件介导。优选地,所述高转录或高表达活性的调控元件为p45启动子。更优选地,所述p45启动子的核苷酸序列如seqidno.5自5’末端第1005-1182位核苷酸。
根据本发明第一方面提供的重组菌,其中,所述重组菌与出发菌相比具有降低的丝氨酸羟甲基转移酶glya、丝氨酸脱水酶sdaa、丙酮酸羧化酶pyc和/或顺乌头酸酶acn的表达。优选地,所述重组菌中glya的转录因子glyr基因、编码丝氨酸脱水酶的sdaa基因、编码丙酮酸羧化酶的pyc基因和/或编码顺乌头酸酶的acn基因失活和/或编码glya的glya基因、sdaa基因、cyse基因、pyc基因和/或acn基因的表达以低转录或低表达活性的调控元件介导。更优选地,所述失活为敲除所述重组菌中的glyr基因、sdaa基因、pyc基因和/或acn基因,所述低转录或低表达活性的调控元件为phom启动子。再优选地,phom启动子的核苷酸序列如seqidno.2自5’末端第928-1057位核苷酸所示。
根据本发明第一方面提供的重组菌,其中,所述重组菌与出发菌相比具有提高的3-磷酸甘油酸脱氢酶serar、磷酸丝氨酸转氨酶serc、磷酸丝氨酸磷酸酶serb和/或苏氨酸外排转运蛋白thre的表达,其中serar为被解除丝氨酸反馈抑制的sera。优选地,所述重组菌中具有一个或多个编码serar的serar基因、编码serc的serc基因、编码serb的serb基因和/或编码thre的thre基因的拷贝,和/或serar基因、serc基因、serb基因和/或thre基因的表达以高转录或高表达活性的调控元件介导。更优选地,所述高转录或高表达活性的调控元件为peftu启动子和/或psod启动子。还优选地,所述serar基因的核苷酸序列如seqidno.13所示,所述serc基因的核苷酸序列如seqidno.11所示,所述serb基因的核苷酸序列如seqidno.12所示,所述thre基因的核苷酸序列如seqidno.16自5’末端第332-1801位核苷酸所示,所述peftu启动子的核苷酸序列如seqidno.23自5’末端第629-828位核苷酸所示,所述psod启动子的核苷酸序列如seqidno.26自5’末端第635-826位核苷酸所示。
根据本发明第一方面提供的重组菌,其中,所述出发菌选自棒杆菌属、小杆菌属、短杆菌属中的一株细菌。优选地,所述棒杆菌属的细菌选自谷氨酸棒杆菌corynebacteriumglutamicum、北京棒杆菌corynebacteriumpekinense、有效棒杆菌corynebacteriumefficiens、钝齿棒杆菌corynebacteriumcrenatum、嗜热产氨棒杆菌corynebacteriumthermoaminogenes、产氨棒杆菌corynebacteriumaminogenes、百合棒杆菌corynebacteriumlilium、美棒杆菌corynebacteriumcallunae和力士棒杆菌corynebacteriumherculis中的一株细菌,所述小杆菌属的细菌选自嗜氨小杆菌microbacteriumammoniaphilum中的一株细菌,所述短杆菌属的细菌选自黄色短杆菌brevibacteriaceaeflvum、乳酸发酵短杆菌brevibacteriaceaelactofermentum和产氨短杆菌brevibacteriaceaeammoniagenes中的一株细菌。更优选地,所述出发菌为野生型谷氨酸棒杆菌atcc13032。
虽然在上述不同的实施方式中给出了高转录或高表达活性的调控元件的示例,但对于高转录或高表达活性的调控元件,在本发明中均没有特别限制,只要能够起到增强所启动基因的表达即可。可以列举的可用于本发明的调控元件有出发菌的p45、peftu、psod、pglya、ppck、ppgk启动子等,但不限于此。
虽然在上述不同的实施方式中给出了低转录或低表达活性的调控元件的示例,但对于低转录或低表达活性的调控元件,在本发明中均没有特别限制,只要能够起到降低所启动基因的表达即可。
本发明的第二方面提供了一种第一方面所述的重组菌的构建方法,其中,所述构建方法包括如下步骤:
提高出发菌中甘氨酸裂解系统gcv的表达,所述出发菌为能够累积l-丝氨酸的菌株。
根据本发明第二方面的构建方法,其中,所述提高出发菌中gcv的表达通过如下方式实现:
向出发菌中导入编码gcv的gcv基因,
增加所述出发菌中gcv基因的拷贝数,和/或
将出发菌中gcv基因的调控元件替换为高转录或高表达活性的调控元件。
优选地,所述gcv基因选自编码氨甲基转移酶的gcvt基因、编码载体蛋白的gcvh基因和编码甘氨酸脱氢酶的gcvp基因中的一种或多种,所述高转录或高表达活性的调控元件为p45启动子。
更优选地,所述gcvt基因和gcvh基因的核苷酸序列如seqidno.3所示,所述gcvp基因的核苷酸序列如seqidno.4所示,所述p45启动子的核苷酸序列如seqidno.5自5’末端第1005-1182位核苷酸。
根据本发明第二方面的构建方法,其中,所述构建方法包括如下步骤:
降低所述出发菌中的丝氨酸羟甲基转移酶glya、丝氨酸脱水酶sdaa、丝氨酸o-乙酰转移酶cyse、丙酮酸羧化酶pyc和/或顺乌头酸酶acn的表达。
优选地,所述降低glya、sdaa、cyse、pyc和/或acn的表达通过以下方式实现:
失活所述出发菌中编码glya转录因子glyr的glyr基因、编码sdaa的sdaa基因、编码cyse的cyse基因、编码pyc的pyc基因和/或编码acn的acn基因,和/或
将glya基因、sdaa基因、cyse基因、pyc基因和/或acn基因的调控元件替换为低转录或低表达活性的调控元件。
更优选地,所述失活为敲除所述出发菌中的glyr基因、sdaa基因、cyse基因、pyc基因和/或acn基因,所述低转录或低表达活性的调控元件为phom启动子。
再优选地,所述敲除glyr基因、sdaa基因、cyse基因、pyc基因和/或acn基因为将所述出发菌glyr基因、sdaa基因、cyse基因、pyc基因和/或acn基因的上下游同源臂片段导入所述出发菌中进行同源重组。
还优选地,所述出发菌glyr基因的上下游同源臂片段的核苷酸序列如seqidno.1所示,所述sdaa基因的上下游同源臂片段的核苷酸序列如seqidno.8所示,所述cyse基因的上下游同源臂片段的核苷酸序列如seqidno.10所示,所述pyc基因的上下游同源臂片段的核苷酸序列如seqidno.15所示,phom启动子的核苷酸序列如seqidno.2自5’末端第928-1057位核苷酸所示。
根据本发明第二方面的构建方法,其中,所述构建方法包括如下步骤:
提高所述出发菌的3-磷酸甘油酸脱氢酶serar、磷酸丝氨酸转氨酶serc、磷酸丝氨酸磷酸酶serb和/或苏氨酸外排转运蛋白thre的表达,其中serar为被解除丝氨酸反馈抑制的sera。
优选地,所述提高通过以下方式实现:
向出发菌中导入编码serar的serar基因、编码serc的serc基因、编码serb的serb基因和/或编码thre的thre基因,
增加所述出发菌中serar基因、serc基因、serb基因和/或thre基因的拷贝数,和/或
将出发菌中serar基因、serc基因、serb基因和/或thre基因的调控元件替换为高转录或高表达活性的调控元件。
更优选地,所述高转录或高表达活性的调控元件为peftu启动子和/或psod启动子。
还优选地,所述serar基因的核苷酸序列如seqidno.13所示,所述serc基因的核苷酸序列如seqidno.11所示,所述serb基因的核苷酸序列如seqidno.12所示,所述thre基因的核苷酸序列如seqidno.16自5’末端第332-1801位核苷酸所示,所述peftu启动子的核苷酸序列如seqidno.23自5’末端第629-828位核苷酸所示,所述psod启动子的核苷酸序列如seqidno.26自5’末端第635-826位核苷酸所示。
在本发明的构建方法中,导入某基因或增加某基因的拷贝数可通过构建包含该基因的重组质粒,再将重组质粒导入出发菌中实现,或也可直接将某基因插入出发菌染色体上的合适位点实现。
在本发明的构建方法中,“失活”指的是相应被改造的对象发生变化,从而达到一定的效果,包括但是不限于,定点突变、插入失活和/或敲除。
本发明的第三方面提供了一种生产l-丝氨酸的方法,包括发酵培养第一方面所述的重组菌的步骤。
本发明所述的生产l-丝氨酸的重组菌,发酵24小时的l-丝氨酸生产强度为0.01~1g/l/h,发酵结束时的l-丝氨酸产量为0.5~50g/l。
本发明首次提出了在降低丝氨酸羟甲基转移酶的表达基础上,同时表达来源于大肠杆菌的甘氨酸裂解系统(gcvthp),提高胞内活性一碳单位的供给的组合改造策略,解决了由于减弱丝氨酸羟甲基转移酶的表达引发一碳单位供应减少对菌体生长的抑制作用,能够最大程度地减弱l-丝氨酸分解为甘氨酸,同时由甘氨酸裂解系统补充细菌生长代谢所必须的一碳单位,显著提高l-丝氨酸的产量,从而在实践上可用于细菌发酵生产l-丝氨酸。
本发明的实验证明,与现有的l-丝氨酸工程菌和l-丝氨酸发酵生产方法相比,本发明构建了遗传背景清楚的生产l-丝氨酸的重组菌;通过采用降低出发菌中丝氨酸羟甲基转移酶的表达,并且同时表达甘氨酸裂解系统,提高胞内活性一碳单位的供给的组合改造策略,本发明提供的的重组菌的生长和葡萄糖消耗能力与野生型菌株相比未见明显减弱,l-丝氨酸产量显著提高。
本发明所提供生产l-丝氨酸的重组菌的发酵周期短,易于过程和成本控制,其开辟并且实践证明了新的提高l-丝氨酸的发酵产量的方法,观察到了可以叠加提高产量的效果,从而在实践上可用于细菌发酵生产l-丝氨酸,便于推广应用。
附图说明
图1为表达serarcb重组质粒pwye1151的示意图;
图2为实施例4丝氨酸羟甲基转移酶glya的酶活图;
图3为实施例5sds-page和westernblotting检测gcv系统的蛋白表达,其中a为sds-page电泳检测胞内蛋白表达,b为westernblotting检测gcv系统的蛋白表达,泳道1为cg220工程菌胞内蛋白,泳道2为cg050工程菌胞内蛋白,泳道3为cg067工程菌胞内蛋白;
图4为表达thre重组质粒pwye1153的示意图;
图5为实施例10l-丝氨酸工程菌cg383的发酵罐发酵过程曲线图;以及
图6为实施例10l-丝氨酸工程菌cg454的发酵罐发酵过程曲线图。
具体实施方式
以下结合附图和实施例,对本发明的具体实施方式进行更加详细的说明,以便能够更好地理解本发明的方案以及其各个方面的优点。然而,以下描述的具体实施方式和实施例仅是说明的目的,而不是对本发明的限制。
本发明所使用或构建的菌株和质粒如下表所示。
表本发明所使用或构建的菌株和质粒
本文提及的“出发菌”(或又称“底盘菌”)是指用于本发明基因改造策略的初始菌株。该菌株可以是天然存在的菌株,也可以是通过诱变或遗传工程改造等方式选育的菌株。
本文提及的方法中各步骤的执行顺序,除特别说明外,并不限于本文的文字所体现出来的顺序,也就说,各个步骤的执行顺序是可以改变的,而且两个步骤之间根据需要可以插入其他步骤。
为了便于理解,以下将通过具体的实施例对本发明进行详细地描述。需要特别指出的是,这些描述仅仅是示例性的描述,并不构成对本发明范围的限制。依据本说明书的论述,本发明的许多变化、改变对所属领域技术人员来说都是显而易见的。
另外,本发明引用了公开文献,这些文献是为了更清楚地描述本发明,它们的全文内容均纳入本文进行参考,就好像它们的全文已经在本文中重复叙述过一样。
以下通过实施例进一步说明本发明的内容。如未特别指明,实施例中所用的技术手段为本领域技术人员所熟知的常规手段和市售的常用仪器、试剂,可参见《分子克隆实验指南(第3版)》(科学出版社)、《微生物学实验(第4版)》(高等教育出版社)以及相应仪器和试剂的厂商说明书等参考。以下实施例中的定量试验,均设置三次重复实验,结果取平均值。
对比例1ser-3和ser-8重组菌的构建
根据文献metabolicengineeringandfluxanalysisofcorynebacteriumglutamicumforl-serineproduction(lai,s.,zhang,y.,liu,s.,liang,y.,shang,x.,chai,x.,wen,t.y.,sciencechinalifesciences,2012,55:283-290.)所述材料和方法构建ser-3和ser-8重组菌。
其中,ser-3重组菌是由将野生型c.glutamicumatcc13032中sdaa基因内部缺失398bp,sera基因编码的蛋白从第197位氨基酸至末端进行缺失,glyr基因进行缺失所获得的的重组菌wt-δsdaaserarδglyr;ser-8重组菌是由重组质粒pxmj19-serar-pgk导入ser-3重组菌获得的重组菌ser-3/pwye1118。
实施例1l-丝氨酸底盘工程菌的获得
根据本发明人的前期研究,本实施例对野生型谷氨酸棒杆菌atcc13032进行了阻断丝氨酸分解代谢和解除丝氨酸对关键酶sera的反馈抑制作用,以获得实施本发明上述多靶点改造的底盘菌。
首先,将编码丝氨酸水合酶的sdaa基因敲除(seqidno.17),阻断丝氨酸分解为丙酮酸的分解代谢。其次,将染色体上的编码3-磷酸甘油酸脱氢酶的sera基因(seqidno.18)进行缺失末端的突变(seqidno.13),解除丝氨酸对sera的反馈抑制作用。
一、谷氨酸棒杆菌野生型atcc13032中l-丝氨酸分解途径的阻断
根据genbank中谷氨酸棒杆菌atcc13032的sdaa基因及其上下游序列分别设计引物。
以谷氨酸棒杆菌atcc13032基因组dna为模板,以p1和p2为引物,pcr扩增439bpsdaa基因上游同源臂;以p3和p4为引物,扩增481bpsdaa基因下游同源臂。再以纯化的上述pcr产物为模板,以p1和p4为引物,采用重叠延伸pcr技术(soe)扩增,得到920bp的pcr产物,为sdaa基因上下游同源臂的片段(seqidno.8)。
其中,seqidno.8自5’末端第1-439位核苷酸为sdaa基因的上游同源臂,seqidno.8自5’末端第440-920位核苷酸为sdaa基因下游同源臂。
将上述920bp的pcr产物经ecori和hindiii双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb(可购自美国典型微生物保藏中心atcc,货号87097)连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p1和p4为引物,采用菌落pcr鉴定转化子,得到920bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行ecori和hindiii双酶切鉴定,得到920bp的为阳性克隆。
将阳性质粒送去测序,结果该质粒为将序列表中seqidno.8所示的核苷酸插入载体pk18mobsacb中得到的重组质粒,命名为pk18mobsacb-δsdaa。
上述所用的引物序列如下:
p1gcggaattcatcggtatcggaccatcatc(ecori)
p2ctgcctctggatgaatggtt
p3aaccattcatccagaggcaggcgggattttttgacaggtt
p4gggtaagcttaacactccgtcatcgacac(hindiii)
p5atggctatcagtgttgttga
p6tcgccaagcaagacaaaatc
将序列测定正确的同源重组质粒pk18mobsacb-δsdaa电转化至谷氨酸棒杆菌atcc13032中,通过卡那霉素抗性正向筛选得到重组质粒整合至染色体上的菌落,通过蔗糖致死反向筛选,得到发生两次同源重组的阳性菌落。将阳性菌落以p5和p6为引物进行pcr扩增鉴定,得到1019bp的为重组菌,命名为谷氨酸棒杆菌cg007(wt-δsdaa)。
经该重组菌提取基因组dna进行测序,结果为证实已成功将谷氨酸棒杆菌野生型atcc13032中的sdaa基因内部缺失398bp,谷氨酸棒杆菌cg007(wt-δsdaa)构建成功。
二、染色体上基因sera的突变
染色体sera基因的突变,通过同源重组的方法将sera基因编码的蛋白从第197位氨基酸至末端进行缺失,通过去除c末端的方式,实现解除代谢终产物丝氨酸对sera基因所编码的3-磷酸甘油酸脱氢酶的反馈抑制调节作用。
具体如下:
以谷氨酸棒杆菌atcc13032基因组dna为模板,以p7和p8为引物pcr扩增sera基因的序列1045bp,以p9和p10为引物扩增sera基因的下游同源臂489bp。再以纯化的上述pcr产物为模板,以p7和p10为引物,采用重叠延伸pcr技术(soe)扩增,得到1534bp含sera基因及其下游同源臂的片段(seqidno.9)。
其中,seqidno.9自5’末端第1-1045位核苷酸为sera基因,seqidno.9自5’末端第1046-1534位核苷酸为sera基因下游同源臂的片段。
纯化回收的pcr产物分别经bamhi和sphi双酶切后,分别与经同样双酶切处理的敲除载体pk18mobsacb连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p7和p10为引物,采用菌落pcr鉴定转化子,得到1534bp为重组质粒的阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行bamhi和sphi双酶切鉴定,得到1534bp的为重组质粒。
将阳性质粒送去测序,结果该质粒为将序列表中seqidno.9所示的核苷酸插入载体pk18mobsacb中得到的重组质粒,命名为pk18mobsacb-serar。
上述所用的引物序列如下:
p7cgggatccgcctgttgtagacggaca(bamhi)
p8ttaagccagatccatccacacag
p9ctgtgtggatggatctggcttaaggcggttttcgctctttt
p10acatgcatgcccgggtaaagtgcatgaaac(sphi)
p11tgtttctagtcgcacgcca
p12aatgttgagcattgcgcc
将序列测定正确的同源重组质粒pk18mobsacb-serar电转化至谷氨酸棒杆菌cg007中,通过卡那霉素抗性正向筛选得到重组质粒整合至染色体上的菌落,通过蔗糖致死反向筛选,得到发生两次同源重组的阳性菌。将阳性菌落以p11和p12为引物进行pcr扩增鉴定,得到1591bp的为重组菌,命名为谷氨酸棒杆菌cg019(wt-δsdaaserar)。
经该重组菌提取基因组dna进行测序,结果为证实已成功将谷氨酸棒杆菌野生型atcc13032中sera基因编码的蛋白从第197位氨基酸至末端进行缺失,谷氨酸棒杆菌cg019(wt-δsdaaserar)构建成功。
实施例2染色体上基因cyse的敲除,获得重组菌cg029
丝氨酸在cyse基因编码的丝氨酸乙酰基转移酶的催化下转化为o-乙酰基-丝氨酸,其进一步转化可以直接生成半胱氨酸。将编码丝氨酸乙酰基转移酶的cyse基因进行缺失(seqidno.19),阻断丝氨酸参与半胱氨酸的合成。
根据genbank中谷氨酸棒杆菌atcc13032的cyse基因及其上下游序列分别设计引物。
以谷氨酸棒杆菌atcc13032基因组dna为模板,以p13和p14为引物,pcr扩增262bpcyse基因上游同源臂;以p15和p16为引物,扩增331bpcyse基因下游同源臂。再以纯化的上述pcr产物为模板,以p13和p16为引物,采用重叠延伸pcr技术(soe)扩增,得到593bp的pcr产物,为cyse基因上下游同源臂的片段(seqidno.10)。
其中,seqidno.10自5’末端第1-262位核苷酸为cyse基因的上游同源臂,seqidno.10自5’末端第263-593位核苷酸为cyse基因下游同源臂。
将上述593bp的pcr产物经bamhi和hindiii双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb(可购自美国典型微生物保藏中心atcc,货号87097)连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p13和p16为引物,采用菌落pcr鉴定转化子,得到593bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行bamhi和hindiii双酶切鉴定,得到593bp的为阳性克隆。
将阳性质粒送去测序,结果该质粒为将序列表中seqidno.10所示的核苷酸插入载体pk18mobsacb中得到的重组质粒,命名为pk18mobsacb-δcyse。
上述所用的引物序列如下:
p13cgggatccagcgactgttaaccactcaagctc(bamhi)
p14tttctaaatcgcctcgggctgct
p15agcagcccgaggcgatttagaaaatcttaggtcccatcaccatcgg
p16cccaagcttctaaagaactagctggcacaggg(hindiii)
p17cgctacgtctccaccgttctttac
p18ctctgcagtcgctggcttcattca
将序列测定正确的同源重组质粒pk18mobsacb-δcyse电转化至谷氨酸棒杆菌cg019中,通过卡那霉素抗性正向筛选得到重组质粒整合至染色体上的菌落,通过蔗糖致死反向筛选,得到发生两次同源重组的阳性菌落。将阳性菌落以p17和p18为引物进行pcr扩增鉴定,得到690bp的为重组菌,命名为谷氨酸棒杆菌cg029(wt-δsdaaserarδcyse)。
经该重组菌提取基因组dna进行测序,结果为证实已成功将谷氨酸棒杆菌野生型atcc13032中的cyse基因缺失,谷氨酸棒杆菌cg029(wt-δsdaaserarδcyse)构建成功。
实施例3含有质粒的l-丝氨酸重组菌cg381的构建
在本实施例中,在实施例1中获得的cg029的基础上,进一步过表达serar基因,并同时过表达serc基因和serb基因,增加丝氨酸合成途径的代谢流量,然后将敲除编码转录激活因子的glyr基因,glyr是glya基因的激活因子,通过敲除glyr实现减弱glya基因的转录表达水平,将其和过表达serarcb的改造进行组合,获得重组工程菌cg381。
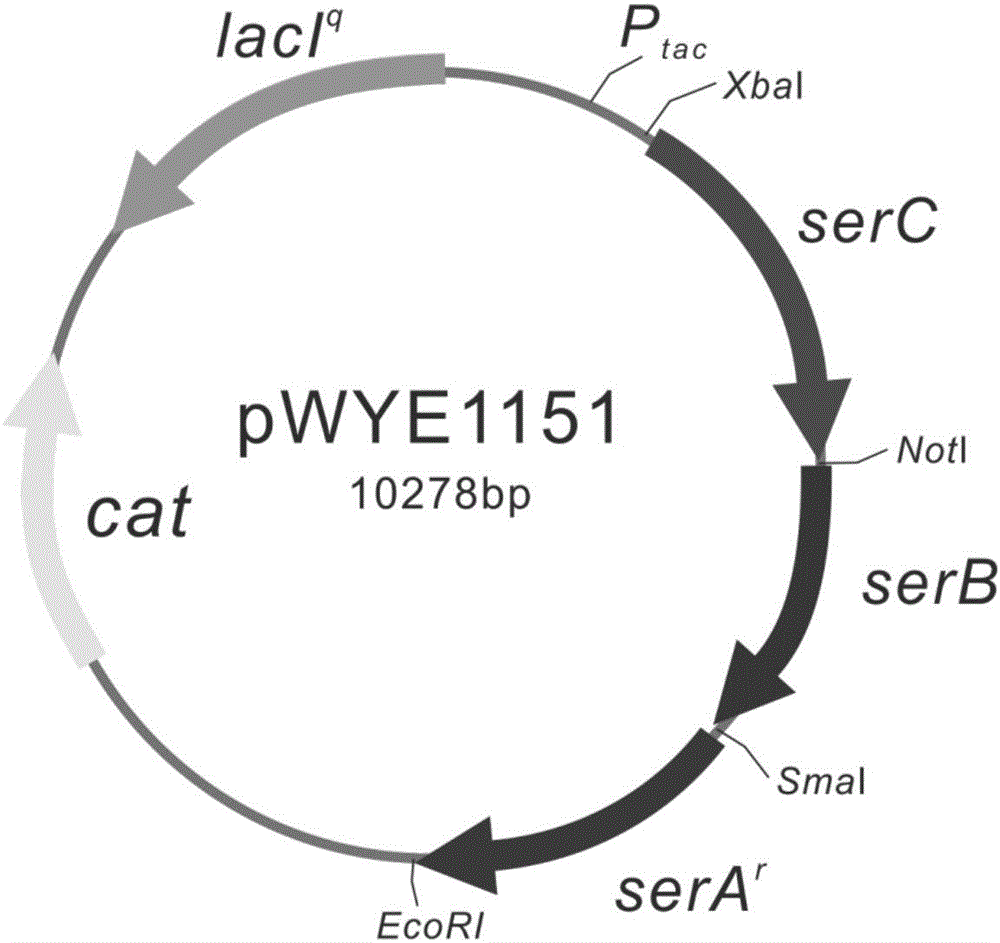
一、含有serarsercserb三个基因的重组质粒pwye1151的构建
以谷氨酸棒杆菌atcc13032的基因组dna为模板,以p19和p20为引物pcr扩增serc基因。将上述pcr产物经xbai和noti双酶切后,与经同样双酶切处理的谷氨酸棒杆菌-大肠杆菌穿梭表达质粒pxmj19连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含氯霉素(20μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p19和p20为引物,采用菌落pcr鉴定转化子,得到1144bp的为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行xbai和noti双酶切鉴定,得到1144bp的为阳性,命名为重组质粒pxmj19-serc。pxmj19-serc经进一步序列测定分析,该质粒为将serc片段插入质粒pxmj19得到的重组质粒。
以谷氨酸棒杆菌atcc13032的基因组dna为模板,以p21和p22为引物pcr扩增serb基因。将上述pcr产物经noti和smai双酶切后,与经同样双酶切处理的pxmj19-serc连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含氯霉素(20μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p21和p22为引物,采用菌落pcr鉴定转化子,得到1332bp的为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行noti和smai双酶切鉴定,得到1332bp的为阳性,命名为重组质粒pxmj19-sercb。pxmj19-sercb经进一步序列测定分析,该质粒为将serb片段插入重组质粒pxmj19-serc得到的重组质粒。
以谷氨酸棒杆菌atcc13032的基因组dna为模板,以p23和p24为引物pcr扩增serar基因。将上述pcr产物经smai和ecori双酶切后,与经同样双酶切处理的pxmj19-sercb连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含氯霉素(20μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p23和p24为引物,采用菌落pcr鉴定转化子,得到1016bp的为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行smai和ecori双酶切鉴定,得到1016bp的为阳性,获得重组质粒pxmj19-sercb-serar,命名为pwye1151(参见图1)。
其中,seqidno.11自5’末端第14-1144位核苷酸为serc,seqidno.12自5’末端第16-1318位核苷酸为serb,seqidno.13自5’末端第15-1017位核苷酸为serar。
pxmj19-serar-sercbr经进一步序列测定分析,该质粒为将serar片段插入质粒pxmj19-sercb的smai和ecori得到的载体。
p19gctctagaaaaggaggaagacatgaccgacttccccacc(xbai)
p20gcggccgctattacttccttgcaaaaccgccatc(noti)
p21gcggccgcaaaggaggagttgccatgactgaactcatccag(noti)
p22tcccccgggtcgagaagcgaatctttaggcattg(smai)
p23tcccccgggaaaggaggaaacttgtgagccagaatggccgtc(smai)
p24gcggaattcttaagccagatccatccacacagc(ecori)
二、l-丝氨酸的重组菌cg039和cg381的构建
根据genbank中谷氨酸棒杆菌atcc13032的glyr转录调控因子的上下游序列分别设计引物。
以谷氨酸棒杆菌atcc13032基因组dna为模板,以p25和p26为引物,pcr扩增532bpglyr转录调控因子基因上游同源臂;以p27和p28为引物,扩增513bpglyr转录调控因子下游同源臂。再以纯化的上述pcr产物为模板,以p25和p28为引物,采用重叠延伸pcr技术(soe)扩增,得到1045bp的pcr产物,为glyr转录调控因子上下游同源臂的片段(seqidno.1)。
其中,seqidno.1自5’末端第1-532位核苷酸为glyr转录调控因子的上游同源臂,seqidno.1自5’末端第533-1045位核苷酸为glyr基因下游同源臂。
将上述1045bp的pcr产物经bamhi和hindiii双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb(可购自美国典型微生物保藏中心atcc,货号87097)连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p25和p28为引物,采用菌落pcr鉴定转化子,得到1045bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行bamhi和hindiii双酶切鉴定,得到1045bp的为阳性克隆。
将阳性质粒送去测序,结果该质粒为将序列表中seqidno.1所示的核苷酸插入载体pk18mobsacb中得到的重组质粒,命名为pk18mobsacb-δglyr。
上述所用的引物序列如下:
p25caggatccacattttgagccagcgct(bamhi)
p26tgtttaagtttagtggatggggatatcggttgctgaaatt
p27cccatccactaaacttaaacatgggataacggaggtcat
p28tcaagcttatattcaaccctactcaa(hindiii)
p29ttccgggcagctttttgtagttcc
p30tcgacgccggtgttgcagtaaaga
将序列测定正确的同源重组质粒pk18mobsacb-δglyr电转化至谷氨酸棒杆菌cg029中,通过卡那霉素抗性正向筛选得到重组质粒整合至染色体上的菌落,通过蔗糖致死反向筛选,得到发生两次同源重组的菌落。将阳性菌落以p29和p30为引物进行pcr扩增鉴定,得到1578bp的为重组菌,命名为谷氨酸棒杆菌cg039(wt-δsdaaδcyseserarδglyr)。
经该重组菌提取基因组dna进行测序,结果为证实已成功将谷氨酸棒杆菌野生型atcc13032中的glyr转录调控因子进行缺失,谷氨酸棒杆菌cg039(wt-δsdaaδcyseserarδglyr)构建成功。
将质粒pwye1151转化至上述构建的底盘工程菌cg039中,对鉴定正确的转化子提取质粒鉴定进一步确定过表达质粒成功转化至工程菌中,l-丝氨酸工程菌cg381(wt-δsdaaδcyseserarδglyr/pwye1151)构建成功。
实施例4减弱丝氨酸羟甲基转移酶活性的l-丝氨酸工程菌cg067和cg188的构建
glya基因编码丝氨酸羟甲基转移酶(seqidno.20),在以上获得的工程菌cg039基础上,通过替换丝氨酸羟甲基转移酶glya基因的自身启动子为弱启动子phom(seqidno.2自5’末端第928-1058位核苷酸),构建了工程菌cg067,和过表达serarcb的改造进行组合,获得重组工程菌cg188。
一、l-丝氨酸的重组菌cg067和cg188的构建
根据genbank中谷氨酸棒杆菌atcc13032的glya基因序列及其上游序列分别设计引物。
以谷氨酸棒杆菌atcc13032基因组dna为模板,以p31和p32为引物,pcr扩增927bpglya上游同源臂;以p33和p34为引物,扩增130bpphom启动子序列(zhang,y.,shang,x.,lai,s.,zhang,g.,liang,y.,wen,t.,2012.developmentandapplicationofanarabinose-inducibleexpressionaystembyfacilitatinginduceruptakeincorynebacteriumglutamicum.applenvironmicrobiol.78,5831-5838.);以纯化的上述pcr产物为模板,以p31和p34为引物,采用重叠延伸pcr技术(soe)扩增,得到1057bp的pcr产物,为glya基因上游同源臂的片段和phom启动子序列片段。以谷氨酸棒杆菌atcc13032基因组dna为模板,以p35和p36为引物,pcr扩增919bpglya基因部分序列,再以纯化的上述pcr产物为模板,以p31和p36为引物,采用重叠延伸pcr技术(soe)扩增,得到1976bp的pcr产物,该pcr产物经测序分析,为glya基因上游同源臂的片段和phom启动子序列片段及glya基因部分序列(seqidno.2)。
其中,seqidno.2自5’末端第1-927位核苷酸为glya转录调控因子的上游同源臂,seqidno.2自5’末端第928-1058位核苷酸为phom启动子序列,seqidno.2自5’末端第1059-1976位核苷酸为glya基因部分序列。
将上述1976bp的pcr产物经hindiii和xbai双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb(可购自美国典型微生物保藏中心atcc,货号87097)连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p31和p36为引物,采用菌落pcr鉴定转化子,得到1976bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行bamhi和hindiii双酶切鉴定,得到1976bp的为阳性克隆。
将阳性质粒送去测序,结果该质粒为将序列表中seqidno.2所示的核苷酸插入载体pk18mobsacb中得到的重组质粒,命名为pk18mobsacb-phom-glya。
上述所用的引物序列如下:
p31cccaagcttcatcctcacccgttccac(hindiii)
p32agttttcaacgggtgaaaccttccccacgc
p33ggaaggtttcacccgttgaaaactaaaaagctgg
p34ttgtcctccttttactttgtttcggccaccc
p35cgaaacaaagtaaaaggaggacaaccatgaccgatgcccaccaag
p36gctctagaatgcgagcaccctccaacg(xbai)
p37agcaaaaatgaacagcttgg
p38aacctcagtgaatgcaggaa
将序列测定正确的同源重组质粒pk18mobsacb-phom-glya电转化至谷氨酸棒杆菌cg039中,通过卡那霉素抗性正向筛选得到重组质粒整合至染色体上的菌落,通过蔗糖致死反向筛选,得到发生两次同源重组的阳性菌落。将阳性菌落以p37和p38为引物进行pcr扩增鉴定,得到1578bp的为重组菌,命名为谷氨酸棒杆菌cg067(wt-δsdaaδcyseserarδglyrphom-glya)。
经该重组菌提取基因组dna进行测序,结果为证实已成功将谷氨酸棒杆菌野生型atcc13032中的glyr转录调控因子进行缺失,谷氨酸棒杆菌cg067(wt-δsdaaδcyseserarδglyrphom-glya)构建成功。
将重组质粒pwye1151电转化至谷氨酸棒杆菌cg067(wt-δsdaaδcyseserarδglyrphom-glya),获得l-丝氨酸的重组菌cg188。
二、测定工程菌中丝氨酸羟甲基转移酶(shmt)的比酶活性
测定反应体系如下(0.5ml):50mmd,l-β-苯基丝氨酸(d,l-β-phenylserine),50μm磷酸吡哆醛,1mmna2edta,25mm硫酸钠,50mmhepes缓冲液(ph7.5),适量的细胞裂解液。30℃,反应5min。通过检测279nm处吸光值的变化反映产物苯甲醛(benzaldehyde)的生成量。酶活单位(u)定义为每分钟生成1nmol苯甲醛所需的酶量。
结果如图2所示,在野生菌atcc13032(即wt)中shmt在对数期的比活力为43.47±3.19nmolmin-1mg-1,而在稳定期shmt的比活力提高至56.34±3.12nmolmin-1mg-1;在glyr激活转录因子敲除的工程菌cg039中,shmt在对数期的比活力为26.48±1.43nmolmin-1mg-1,而在稳定期shmt的比活力为27.11±1.01nmolmin-1mg-1,比活力在对数期和稳定期分别降低了39.0%和51.8%;进一步将glya基因自身的启动子替换为phom启动子的工程菌cg067中,shmt在对数期的比活力为10.07±0.37nmolmin-1mg-1,而在稳定期shmt的比活力为14.87±1.69nmolmin-1mg-1,比活力在对数期和稳定期分别降低了76.9%和73.6%,表明两种改造策略能够显著降低胞内shmt酶的比活力。
实施例5整合甘氨酸裂解系统的l-丝氨酸高产重组菌cg220、cg383和cg050的构建
gcvthp基因编码甘氨酸裂解系统,其中gcvt基因编码氨甲基转移酶,gcvh基因编码载体蛋白(seqidno.3),gcvp基因编码甘氨酸脱氢酶(seqidno.4)。在已构建的工程菌cg067的基础上,通过同源重组分别将p45-gcvth和p45-gcvp分别整合到敲除glyr的位点,构建工程cg220,和过表达serarcb的改造进行组合,获得重组工程菌cg383。在已构建的工程菌cg039的基础上,导入表达gcvthp系统的质粒,获得重组工程菌cg050。
一、甘氨酸裂解系统整合到工程菌cg067的染色体
根据genbank中大肠杆菌w3110的gcvthp操纵子的序列,设计引物分别扩增gcvth基因和gcvp基因的开放阅读框。
将大肠杆菌甘氨酸裂解系统的gcvth基因和gcvp基因分别与谷氨酸棒杆菌自身的强启动子p45相融合(融合方法参见zhang,y.,shang,x.,lai,s.,zhang,g.,liang,y.,wen,t.,2012.developmentandapplicationofanarabinose-inducibleexpressionaystembyfacilitatinginduceruptakeincorynebacteriumglutamicum.applenvironmicrobiol.78,5831-5838.),与无痕敲除载体pk18mobsacb相连,分别构建两个重组载体pk18mobsacb-up-p45-gcvth-down和pk18mobsacb-gcvth-p45-gcvp-down,将过两轮重组实验将p45-gcvth和p45-gcvp先后整合到δglyr位点,构建基因工程菌cg220(wtδsdaaserarδcyseδglyr::p45-gcvth::p45-gcvpphom-glya)。
二、重组质粒pk18mobsacb-up-p45-gcvth-down的构建
以谷氨酸棒杆菌atcc13032基因组dna为模板,以p41和p42为引物,pcr扩增1005bpδglyr上游同源臂;以p43和p44为引物,扩增177bpp45启动子序列;以纯化的上述pcr产物为模板,以p41和p44为引物,采用重叠延伸pcr技术(soe)扩增,得到1182bp的pcr产物,为δglyr基因上游同源臂的片段和p45启动子序列片段(seqidno.5)。
其中,seqidno.5自5’末端第1-1005位核苷酸为δglyr的上游同源臂,seqidno.5自5’末端第1006-1182位核苷酸为p45启动子序列。
将上述1182bp的pcr产物经nhei和hindiii双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb(可购自美国典型微生物保藏中心atcc,货号87097)连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p41和p44为引物,采用菌落pcr鉴定转化子,得到1182bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行nhei和hindiii双酶切鉴定,得到1182bp的为阳性克隆。
将阳性质粒送去测序,结果该质粒为将序列表中seqidno.5所示的核苷酸插入载体pk18mobsacb中得到的重组质粒,命名为pk18mobsacb-up-p45。
以大肠杆菌w3110基因组dna为模板,以p39和p40为引物,pcr扩增1624bpgcvth基因序列(seqidno.3);将上述1624bp的pcr产物经hindiii和bamhi双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb-up-p45连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p39和p40为引物,采用菌落pcr鉴定转化子,得到1624bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行hindiii和bamhi双酶切鉴定,得到1624bp的为阳性克隆。
将阳性质粒送去测序,结果该质粒为将序列表中seqidno.3所示的核苷酸插入载体pk18mobsacb-up-p45中得到的重组质粒,命名为pk18mobsacb-up-p45-gcvth。
以谷氨酸棒杆菌atcc13032基因组dna为模板,以p45和p46为引物,pcr扩增δglyr下游同源臂序列(seqidno.6);将上述的pcr产物经bamhi和ecori双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb-up-p45-gcvth连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p45和p46为引物,采用菌落pcr鉴定转化子,得到649bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行bamhi和ecori双酶切鉴定,得到649bp的为阳性克隆。
将阳性质粒送去测序,结果该质粒为将序列表中seqidno.6所示的核苷酸插入载体pk18mobsacb-up-p45-gcvth中得到的重组质粒,命名为pk18mobsacb-up-p45-gcvth-down。
三、重组质粒pk18mobsacb-gcvth-p45-gcvp-down的构建
以大肠杆菌w3110基因组dna为模板,以p49和p50为引物,pcr扩增544bpgcvth部分序列;以p51和p52为引物,扩增177bpp45启动子序列;以纯化的上述pcr产物为模板,以p49和p52为引物,采用重叠延伸pcr技术(soe)扩增,得到721bp的pcr产物,为gcvth部分序列和p45启动子序列片段(seqidno.7)。
其中,seqidno.7自5’末端第1-544位核苷酸为gcvth部分序列,seqidno.7自5’末端第545-721位核苷酸为p45启动子序列。
将上述721bp的pcr产物经nhei和hindiii双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb(可购自美国典型微生物保藏中心atcc,货号87097)连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p49和p52为引物,采用菌落pcr鉴定转化子,得到721bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行nhei和hindiii双酶切鉴定,得到721bp的为阳性克隆。
将阳性质粒送去测序,结果该质粒为将序列表中seqidno.7所示的核苷酸插入载体pk18mobsacb中得到的重组质粒,命名为pk18mobsacb-gcvth-p45。
以大肠杆菌w3110基因组dna为模板,以p47和p48为引物,pcr扩增2896bpgcvp基因序列;将上述2896bp的pcr产物经hindiii和bamhi双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb-gcvth-p45连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p47和p48为引物,采用菌落pcr鉴定转化子,得到2896bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行hindiii和bamhi双酶切鉴定,得到2896bp的为阳性克隆。
将阳性质粒送去测序,结果该质粒为将序列表中seqidno.4所示的核苷酸插入载体pk18mobsacb-gcvth-p45中得到的重组质粒,命名为pk18mobsacb-gcvth-p45-gcvp。
以谷氨酸棒杆菌atcc13032基因组dna为模板,以p45和p46为引物,pcr扩增649bpδglyr下游同源臂序列;将上述649bp的pcr产物经bamhi和ecori双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb-gcvth-p45-gcvp连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p45和p46为引物,采用菌落pcr鉴定转化子,得到649bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行bamhi和ecori双酶切鉴定,得到649bp的为阳性克隆。
将阳性质粒送去测序,结果该质粒为将序列表中seqidno.6所示的核苷酸插入载体pk18mobsacb-gcvth-p45-gcvp中得到的重组质粒,命名为pk18mobsacb-gcvth-p45-gcvp-down。
上述所用的引物序列如下:
p39cccaagcttaaaggaggacaagatggcacaacagac(hindiii)
p40cgggatccaaacgtgcagtgaattgtga(bamhi)
p41ctagctagcatcaacgcagaaacccg(nhei)
p42agaaaaacacgatacggttgctgaaatt
p43caaccgtatcgtgtttttctgtgatcctc
p44gataagcttgcttttaaaaccatgca(hindiii)
p45cgggatccgtcggggcctttcactg(bamhi)
p46acagaattcgcctggcattagcgtttag(ecori)
p47gataagcttaaaggaggaaccatcgctcatgacaca(hindiii)
p48cgggatccgaattactggtattcgctaatcggt(bamhi)
p49ctagctagctgtgcgtaacggcaaagc(nhei)
p50agaaaaacacaaacgtgcagtgaattgtga
p51ctgcacgtttgtgtttttctgtgatcctc
p52gataagcttgcttttaaaaccatgca(hindiii)
p53aaaaagacctctcctggattac
p54ttgccgttacgcacaaa
p55acagcgaaaccgaaatga
p56agcgtacccgccacc
四、重组菌cg216、cg220和cg383的构建
将序列测定正确的同源重组质粒pk18mobsacb-up-p45-gcvth-down电转化至l-丝氨酸重组菌cg067中,通过卡那霉素抗性正向筛选得到重组质粒整合至染色体上的菌落,通过蔗糖致死反向筛选,得到发生两次同源重组的阳性菌落。将阳性菌落以p53和p54为引物进行pcr扩增鉴定,得到728bp的为重组菌wtδsdaaserarδcyseδglyr::p45-gcvth-phom-glya,命名为cg216。
将序列测定正确的同源重组质粒pk18mobsacb-gcvth-p45-gcvp-down电转化至谷氨酸棒杆菌cg216中,通过卡那霉素抗性正向筛选得到重组质粒整合至染色体上的菌落,通过蔗糖致死反向筛选,得到发生两次同源重组的阳性菌落。将阳性菌落以p55和p56为引物进行pcr扩增鉴定,得到1118bp的为重组菌wt-δsdaaserarδcyseδglyr::p45-gcvth::p45-gcvpphom-glya,命名为谷氨酸棒杆菌cg220。
经该重组菌提取基因组dna进行测序,结果为证实已成功将p45启动子调控下的大肠杆菌中的gcv系统p45-gcvth::p45-gcvp整合到谷氨酸棒杆菌cg067中,无质粒l-丝氨酸重组菌cg220(wt-δsdaaserarδcyseδglyr::p45-gcvth::p45-gcvpphom-glya)构建成功。
将重组质粒pwye1151电转化至谷氨酸棒杆菌cg220(wt-δsdaaserarδcyseδglyr::p45-gcvth::p45-gcvpphom-glya),获得l-丝氨酸的重组菌cg383。
五、质粒上表达gcvthp系统的l-丝氨酸高产重组菌cg050的构建
以谷氨酸棒杆菌atcc13032的基因组dna为模板,以p101和p44为引物pcr扩增p45启动子。将上述pcr产物经nari和hindiii双酶切后,与经同样双酶切处理的谷氨酸棒杆菌-大肠杆菌穿梭表达质粒pxmj19连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含氯霉素(20μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p101和p44为引物,采用菌落pcr鉴定转化子,得到177bp的为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行nari和hindiii双酶切鉴定,得到177bp的为阳性,命名为重组质粒pxmj19-p45。pxmj19-p45经进一步序列测定分析,该质粒为将p45启动子片段(seqidno.5自5’末端第1005-1182位核苷酸)插入质粒pxmj19得到的重组质粒。
以大肠杆菌w3110基因组dna为模板,以p39和p40为引物pcr扩增gcvth基因(1624bp)。将上述pcr产物经hindiii和bamhi双酶切后,与经同样双酶切处理的pxmj19-p45连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含氯霉素(20μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p39和p40为引物,采用菌落pcr鉴定转化子,得到1624bp的为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行hindiii和bamhi双酶切鉴定,得到1624bp的为阳性,命名为重组质粒pxmj19-p45-gcvth。pxmj19-p45-gcvth经进一步序列测定分析,该质粒为将gcvth片段(seqidno.3)插入重组质粒pxmj19-p45得到的重组质粒。
以大肠杆菌w3110的基因组dna为模板,以p102和p103为引物pcr扩增gcvp基因(2896bp)。将上述pcr产物经bamhi和ecori双酶切后,与经同样双酶切处理的pxmj19-p45-gcvth连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含氯霉素(20μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p102和p103为引物,采用菌落pcr鉴定转化子,得到2896bp的为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行bamhi和ecori双酶切鉴定,得到2896bp的为阳性,获得重组质粒pxmj19-sercb-p45-gcvthp。pxmj19-p45-gcvthp经进一步序列测定分析,该质粒为将gcvp片段(seqidno.4)插入重组质粒pxmj19-p45-gcvth得到的重组质粒。上述所用的引物序列如下:
p101agtcatggcgcccaaccgtatcgtgtttttctgtgatcctc(nari)
p44gataagcttgcttttaaaaccatgca(hindiii)
p39cccaagcttaaaggaggacaagatggcacaacagac(hindiii)
p40cgggatccaaacgtgcagtgaattgtga(bamhi)
p102cgggatccaaaggaggaaccatcgctcatgacaca(bamhi)
p103gcggaattcgaattactggtattcgctaatcggt(ecori)
将重组质粒pxmj19-p45-gcvthp电转化至谷氨酸棒杆菌cg039(wt-δsdaaserarδcyseδglyr)中,获得重组菌cg050。
六、甘氨酸裂解系统在l-丝氨酸工程菌cg220和cg050中的表达
通过蛋白质印迹westernblotting检测gcvthp蛋白的表达。
为检测整合到谷氨酸棒杆菌基因组中的gcvt、gcvh和gcvp蛋白是否表达,在大肠杆菌中表达并纯化了gcvt、gcvh和gcvp蛋白,制备并获得了三个蛋白的多克隆抗体。
利用超声破碎的方法提取l-丝氨酸的重组菌cg220、cg050和cg067的胞内总蛋白,取20ul样品进行常规的sds-page凝胶电泳。电泳结束后,取出分离胶并在右上角裁一个小角作为标记,在加有转移液的培养皿里放入裁好的胶、浸过甲醇的pvdf膜和滤纸,平衡10min左右,除去滤纸和转移膜中的气泡以及胶上多余的sds。带上手套,平放转移槽的底座,依次叠放3张浸泡过缓冲液的滤纸、pvdf膜、刚刚完成电泳的凝胶和另外3张浸泡过缓冲液的滤纸。用玻璃棒在叠层的滤纸上滚动,除去气泡。在10ma恒定电流下转膜1h,结束后取出转移膜。
将膜移至含有封闭液的平皿中,室温下脱色摇床上摇动封闭1h或4℃孵育过夜。将一抗用封闭液进行1:10000稀释;从封闭液中取出膜,用滤纸吸去残留液后,放入杂交袋中,将膜蛋白面朝下放于抗体液面上,掀动膜四角以赶出残留气泡,用封口器封上,室温下孵育1h。用tbst在室温下脱色摇床上洗四次,每次10min。在培养皿内加入1:10000tbst稀释二抗稀释液,放在摇床上室温下孵育1~2h后,用tbst在室温下脱色摇床上洗四次,每次10min。
先将pvdf膜放在保鲜膜上。将ecl的a和b两种试剂在ep管内等体积混合,然后均匀滴在pvdf膜的蛋白面,反应1~2min后,将pvdf膜上多余的ecl工作液吸干,之后转移到在x片夹中预先铺好的保鲜膜上一侧,把另一侧翻过来盖在其上。用透明胶把保鲜膜固定在片夹上。
在暗室中,将显影液和定影液分别到入塑料盘中;在红灯下取出x-光片,用切纸刀剪裁适当大小;打开x-光片夹,把x-光片放在膜上,曝光1-2min;曝光完成后,取出x-光片,迅速浸入显影液中显影,待出现明显条带后,即刻终止显影。显影结束后,马上把x-光片浸入定影液中,定影时间一般为5~10min,以胶片透明为止;用自来水冲去残留的定影液后,室温下晾干。
通过westernblotting实验,在基因工程菌中检测到gcvt、gcvh和gcvp蛋白的表达(参见图3),证明甘氨酸裂解系统在p45启动子的调控下在工程菌cg220和cg050中能够进行组成型表达。
实施例6减弱acn基因表达的l-丝氨酸高产重组菌cg395和cg399的构建
acn基因编码顺乌头酸酶(seqidno.21),在已构建的工程菌cg220的基础上,通过将acn基因的自身启动子替换为弱启动子phom,减少acn基因的表达,构建了工程菌cg391,和过表达serarcb的改造进行组合,获得高产工程菌cg399。
根据genbank中谷氨酸棒杆菌atcc13032的acn基因序列及其上游序列分别设计引物。
以谷氨酸棒杆菌atcc13032基因组dna为模板,以p57和p58为引物,pcr扩增573bpacn上游同源臂;以p59和p60为引物,扩增130bpphom启动子序列(zhang,y.,shang,x.,lai,s.,zhang,g.,liang,y.,wen,t.,2012.developmentandapplicationofanarabinose-inducibleexpressionsystembyfacilitatinginduceruptakeincorynebacteriumglutamicum.applenvironmicrobiol.78,5831-5838.);以纯化的上述pcr产物为模板,以p57和p60为引物,采用重叠延伸pcr技术(soe)扩增,得到703bp的pcr产物,为acn基因上游同源臂的片段和phom启动子序列片段。以谷氨酸棒杆菌atcc13032基因组dna为模板,以p61和p62为引物,pcr扩增599bpacn基因部分序列,再以纯化的上述pcr产物为模板,以p57和p62为引物,采用重叠延伸pcr技术(soe)扩增,得到1302bp的pcr产物,为acn基因上游同源臂的片段和phom启动子序列片段及acn基因部分序列(seqidno.14)
其中,seqidno.14自5’末端第1-573位核苷酸为acn转录调控因子的上游同源臂,seqidno.14自5’末端第574-703位核苷酸为phom启动子序列,seqidno.14自5’末端第704-1302位核苷酸为acn基因部分序列。
将上述1302bp的pcr产物经bamhi和ecori双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb(可购自美国典型微生物保藏中心atcc,货号87097)连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p57和p62为引物,采用菌落pcr鉴定转化子,得到1302bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行bamhi和ecori双酶切鉴定,得到1302bp的为阳性克隆。
将阳性质粒送去测序,结果该质粒为将序列表中seqidno.14所示的核苷酸插入载体pk18mobsacb中得到的重组质粒,命名为pk18mobsacb-phom-acn。
上述所用的引物序列如下:
p57cgggatccgccaaagcaaccaacccc(bamhi)
p58ctttttagttttcaacggtcggatttgctcgaaat
p59cgagcaaatccgaccgttgaaaactaaaaagctgg
p60gcgtctgcttcggctactttgtttcggccaccc
p61gccgaaacaaagtagccgaagcagacgccgtcg
p62cggaattctgacctggtggacgatac(ecori)
p63gtgaatcgaatttcggggct
p64gagggatcagcatggacact
将序列测定正确的同源重组质粒pk18mobsacb-phom-acn电转化至谷氨酸棒杆菌cg220中,通过卡那霉素抗性正向筛选得到重组质粒整合至染色体上的菌落,通过蔗糖致死反向筛选,得到发生两次同源重组的阳性菌落。将阳性菌落以p63和p64为引物进行pcr扩增鉴定,得到883bp的为重组菌,命名为谷氨酸棒杆菌cg395(wtδsdaaserarδcyseδglyr::p45-gcvth::p45-gcvpphom-glyaphom-acn)。
经该重组菌提取基因组dna进行测序,结果为证实已成功将谷氨酸棒杆菌野生型atcc13032中的acn基因的启动子替换为弱启动子phom,谷氨酸棒杆菌cg395(wtδsdaaserarδcyseδglyr::p45-gcvth::p45-gcvpphom-glyaphom-acn)构建成功。
将重组质粒pwye1151电转化至谷氨酸棒杆菌cg399(wtδsdaaserarδcyseδglyr::p45-gcvth::p45-gcvpphom-glyaδpycphom-acn),获得l-丝氨酸的重组菌cg399。
实施例7阻断草酰乙酸回补途径的l-丝氨酸高产重组菌cg452和cg453的构建
pyc基因编码丙酮酸羧化酶(seqidno.22),在已构建的工程菌cg395的基础上,通过将pyc基因敲除,阻断丙酮酸回补草酰乙酸的途径,构建了工程菌cg452,和过表达serarcb的改造进行组合,获得工程菌cg453。
根据genbank中谷氨酸棒杆菌atcc13032的pyc基因及其上下游序列分别设计引物。
以谷氨酸棒杆菌atcc13032基因组dna为模板,以p65和p66为引物,pcr扩增727bppyc基因上游同源臂;以p67和p68为引物,扩增644bppyc基因下游同源臂。再以纯化的上述pcr产物为模板,以p65和p68为引物,采用重叠延伸pcr技术(soe)扩增,得到1371bp的pcr产物,为pyc基因上下游同源臂的片段(seqidno.15)。
其中,seqidno.15自5’末端第1-727位核苷酸为pyc基因的上游同源臂,seqidno.15自5’末端第728-1371位核苷酸为pyc基因下游同源臂。
将上述1371bp的pcr产物经hindiii和ecori双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb(可购自美国典型微生物保藏中心atcc,货号87097)连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p65和p68为引物,采用菌落pcr鉴定转化子,得到1371bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行hindiii和ecori双酶切鉴定,得到1371bp的为阳性克隆。
将阳性质粒送去测序,结果该质粒为将序列表中seqidno.15所示的核苷酸插入载体pk18mobsacb中得到的重组质粒,命名为pk18mobsacb-δpyc。
上述所用的引物序列如下:
p65cccaagcttatccgtttgaagactgttg(hindiii)
p66ccttggtctcctcactgcgtcctagtatcg
p67ggacgcagtgaggagaccaaggctcaaag
p68ccggaattcgctcatacaacgccaacg(ecori)
p69cgattactgaagcagcacg
p70caatgagcaccaccacct
将序列测定正确的同源重组质粒pk18mobsacb-δpyc电转化至谷氨酸棒杆菌cg395中,通过卡那霉素抗性正向筛选得到重组质粒整合至染色体上的菌落,通过蔗糖致死反向筛选,得到发生两次同源重组的阳性菌落。将阳性菌落以p69和p70为引物进行pcr扩增鉴定,得到683bp的为重组菌,命名为谷氨酸棒杆菌cg452(wt-δsdaaserarδcyseδglyr::p45-gcvth::p45-gcvpphom-glyaphom-acnδpyc)。
经该重组菌提取基因组dna进行测序,结果为证实已成功将谷氨酸棒杆菌野生型atcc13032中的pyc基因缺失,重组菌cg452(wt-δsdaaserarδcyseδglyr::p45-gcvth::p45-gcvpphom-glyaphom-acnδpyc)构建成功。
将重组质粒pwye1151电转化至谷氨酸棒杆菌cg452(wt-δsdaaδcyseserarδglyrphom-glya),获得l-丝氨酸的重组菌cg453。
实施例8过表达外排转运蛋白thre的l-丝氨酸高产重组菌cg454的构建
thre基因编码苏氨酸外排转运蛋白(seqidno.16自5’末端第332-1801位核苷酸),通过将thre基因与serarcb的进行共表达,获得高产工程菌cg454。
一、含有thre基因的重组质粒pwye1153的构建
以谷氨酸棒杆菌atcc13032的基因组dna为模板,以p71和p72为引物pcr扩增thre基因(1991bp)。将上述pcr产物经hindiii和xbai双酶切后,与经同样双酶切处理的谷氨酸棒杆菌-大肠杆菌穿梭表达质粒pwye1151连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含氯霉素(20μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p71和p72为引物,采用菌落pcr鉴定转化子,得到1991bp的为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行hindiii和xbai双酶切鉴定,得到1991bp的为阳性,命名为重组质粒pwye1153(参见图4)。
pwye1153经进一步序列测定分析,该质粒为将thre片段(seqidno.16)插入质粒pwye1151的hindiii和xbai得到的载体。
上述所用的引物序列如下:
p71cccaagcttgggaaaagaaagcccctaag(hindiii)
p72gctctagagaagtccttagaataggtggc(xbai)
二、l-丝氨酸高产重组菌cg454的构建
将重组质粒pwye1153电转化至谷氨酸棒杆菌cg452(wt-δsdaaserarδcyseδglyr::p45-gcvth::p45-gcvpphom-glyaδpycphom-acn),获得l-丝氨酸的重组菌cg454。
实施例9无质粒丝氨酸工程菌cg466和cg468的构建
在本实施例中,在以上实施例7的基础上,用强启动子peftu替换serar、serb和serc基因的启动子,以提高丝氨酸合成途径的代谢流量,从而进一步构建cg466;然后以psod强启动子替换thre基因启动子,以增强外排转运蛋白的表达(thre,seqidno.16),加强丝氨酸向胞外的转运,从而构建cg468。
一、工程菌cg466的构建
根据genbank中谷氨酸棒杆菌atcc13032的sera、serb和serc基因及其上下游序列和peftu启动子序列分别设计引物。
以谷氨酸棒杆菌atcc13032基因组dna为模板,以p73和p74为引物扩增sera启动子上游同源臂;以p75和p76为引物扩增peftu启动子;以p77和p78为引物扩增sera启动子下游同源臂。再以纯化的上述pcr产物为模板,以p73和p78为引物,采用重叠延伸pcr技术(soe)扩增,得到1454bp的pcr产物,为含替换启动子peftu及被替换启动子psera的上下游同源臂的片段(seqidno.23)。
其中,seqidno.23自5’末端第1-617位核苷酸为被替换启动子psera的上游同源臂,seqidno.23自5’末端第618-817位核苷酸为启动子peftu,seqidno.23自5’末端第818-1454位核苷酸为被替换启动子psera的下游同源臂。
将上述1454bp的pcr产物经xbai和smai双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p97和p98为引物,采用菌落pcr鉴定转化子,得到1666bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行xbai和smai双酶切鉴定,得到1454bp的为阳性。
将阳性质粒送去测序,结果该质粒为将序列表中seqidno.23所示的核苷酸插入载体pk18mobsacb中得到的重组质粒,命名为pk18mobsacb-peftu::psera。
采用相同的方法构建同源重组质粒pk18mobsacb-peftu::pserc,将serc基因的启动子替换为强启动子peftu。具体如下:以p79和p80为引物扩增serc基因启动子上游同源臂;以p81和p82为引物扩增启动子peftu;以p83和p84为引物扩增serc基因启动子下游同源臂。以p79和p84为引物,采用重叠延伸pcr技术(soe)扩增,得到1457bp的pcr产物,为含替换启动子petfu及被替换启动子pserc上下游同源臂的长片段(seqidno.24),其中,seqidno.24自5’末端第1-628位核苷酸为被替换启动子pserc的上游同源臂,seqidno.24自5’末端第629-828位核苷酸为启动子peftu,seqidno.24自5’末端第829-1457位核苷酸为被替换启动子pserc的下游同源臂。
将上述1457bp的pcr产物经xbai和smai双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p97和p98为引物,采用菌落pcr鉴定转化子,得到1669bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行xbai和smai双酶切鉴定,得到1457bp的为阳性。将阳性质粒送去测序,结果该质粒为将序列表中seqidno.24所示的核苷酸插入载体pk18mobsacb中得到的重组质粒,命名为pk18mobsacb-peftu::pserc。
采用相同的方法构建同源重组质粒pk18mobsacb-peftu::pserb,将serb基因的启动子替换为强启动子peftu。具体如下:以p85和p68为引物扩增serb基因启动子上游同源臂;以p87和p88为引物扩增启动子peftu;以p89和p90为引物扩增serb基因启动子下游同源臂。以p85和p90为引物,采用重叠延伸pcr技术(soe)扩增,得到1431bp的pcr产物,为含替换启动子petfu及被替换启动子pserb上下游同源臂的长片段(seqidno.25),其中,seqidno.25自5’末端第1-600位核苷酸为被替换启动子pserb的上游同源臂,seqidno.25自5’末端第601-800位核苷酸为启动子peftu,seqidno.25自5’末端第801-1431位核苷酸为被替换启动子pserb的下游同源臂。
将上述1431bp的pcr产物经xbai和smai双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p97和p98为引物,采用菌落pcr鉴定转化子,得到1643bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行xbai和smai双酶切鉴定,得到1431bp的为阳性。将阳性质粒送去测序,结果该质粒为将序列表中序列25所示的核苷酸插入载体pk18mobsacb中得到的重组质粒,命名为pk18mobsacb-peftu::pserb。
上述所用的引物序列如下:
p73:gctctagatcgcttgttggcaatgtg(xbai)
p74:cagggtaacggccagattcatgctgtgagatt
p75:tcacagcatgaatctggccgttaccctgcgaatg
p76:ccattctggctcactgtatgtcctcctggac
p77:aggaggacatacagtgagccagaatggccgtc
p78:tcccccgggcagtttccttggtcttag(smai)
p79:gctctagacagccttgttgttatcag(xbai)
p80:agggtaacggccaaaaactggcgacaccgaac
p81:gtgtcgccagtttttggccgttaccctgcgaatg
p82:gggaagtcggtcattgtatgtcctcctggac
p83:caggaggacatacaatgaccgacttccccacc
p48:tcccccgggctcatcgctgcaagccac(smai)
p58:gctctagatccacttggctgactcct(xbai)
p68:cagggtaacggccagcttttagcggctggagtc
p78:agccgctaaaagctggccgttaccctgcgaatg
p88:atgagttcagtcactgtatgtcctcctggac
p89:aggaggacatacagtgactgaactcatccag
p90tcccccgggcacaatcgaagcacaccag(smai)
p97:atgtgctgcaaggcgattaa
p98:tatgcttccggctcgtatgt
p99:gcgctagatctgtgtgct
将序列测定正确的同源重组质粒pk18mobsacb-peftu::psera电转化至丝氨酸重组菌cg452中,通过卡那霉素抗性正向筛选得到重组质粒整合至染色体上的菌落,通过蔗糖反向筛选,得到发生两次同源重组的阳性菌落。将阳性菌落以p99和p78为引物进行pcr扩增鉴定,得到744bp的为重组菌wt-δsdaaserarδcyseδglyr::p45-gcvth::p45-gcvp-phom-glyaδpyc-phom-acn-peftu::psera。
将序列测定正确的同源重组质粒pk18mobsacb-peftu::pserc电转化至上述鉴定正确的重组菌wt-δsdaaserarδcyseδglyr::p45-gcvth::p45-gcvp-phom-glyaδpyc-phom-acnpeftu::psera,通过卡那霉素抗性正向筛选得到重组质粒整合至染色体上的菌落,通过蔗糖反向筛选,得到发生两次同源重组的阳性菌落。将阳性菌落以p99和p84为引物进行pcr扩增鉴定,得到736bp的为重组菌wt-δsdaaserarδcyseδglyr::p45-gcvth::p45-gcvp-phom-glyaδpyc-phom-acn-peftu::psera-peftu::pserc。
将序列测定正确的同源重组质粒pk18mobsacb-peftu::pserb电转化至上述鉴定正确的重组菌wt-δsdaaserarδcyseδglyr::p45-gcvth::p45-gcvp-phom-glyaδpyc-phom-acnpeftu::pserapeftu::pserc,通过卡那霉素抗性正向筛选得到重组质粒整合至染色体上的菌落,通过蔗糖反向筛选,得到发生两次同源重组的阳性菌落。将阳性菌落以p99和p90为引物进行pcr扩增鉴定,得到738bp的为重组菌wtδsdaaserarδcyseδglyr::p45-gcvth::p45-gcvp-phom-glyaδpyc-phom-acn-peftu::psera-peftu::pserc-peftu::pserb。
经该重组菌提取基因组dna进行测序,结果为证实已成功将cg452中的sera,serb和serc基因的启动子分别替换为谷氨酸棒杆菌内源强启动子peftu,无质粒丝氨酸重组菌cg466(wt-δsdaaserarδcyseδglyr::p45-gcvth::p45-gcvp-phom-glyaδpyc-phom-acn-peftu::psera-peftu::pserc-peftu::pserb)构建成功。
二、工程菌cg468的构建
根据genbank中谷氨酸棒杆菌atcc13032的thre基因及其上下游序列和psod启动子序列分别设计引物。
采用相同的方法构建同源重组质粒pk18mobsacb-psod::pthre,将thre基因的启动子替换为强启动子psod。具体如下:以p91和p92为引物扩增thre基因启动子上游同源臂;以p93和p94为引物扩增启动子psod;以p95和p96为引物扩增thre基因启动子下游同源臂。以p91和p96为引物,采用重叠延伸pcr技术(soe)扩增,得到1466bp的pcr产物,为含替换启动子psod及被替换启动子pthre上下游同源臂的长片段(seqidno.26),其中,seqidno.26自5’末端第1-634位核苷酸为被替换启动子pthre的上游同源臂,seqidno.26自5’末端第635-834位核苷酸为启动子psod,seqidno.26自5’末端第835-1466位核苷酸为被替换启动子pthre的下游同源臂。
将上述1466bp的pcr产物经xbai和smai双酶切后,与经同样双酶切处理的同源重组载体pk18mobsacb连接。连接产物采用化学转化法转化至大肠杆菌dh5α,在含卡那霉素(50μg/ml)的lb平板上筛选转化子,转化子传代培养三代后,以p97和p98为引物,采用菌落pcr鉴定转化子,得到1678bp为阳性转化子,对鉴定正确的转化子提取质粒,并对质粒进行xbai和smai双酶切鉴定,得到1466bp的为阳性。将阳性质粒送去测序,结果该质粒为将序列表中seqidno.26所示的核苷酸插入载体pk18mobsacb中得到的重组质粒,命名为pk18mobsacb-psod::pthre。
上述所用的引物序列如下:
p91:gctctagaagcgatctagttcgcaac(xbai)
p92:ataattggcagctacagcgcaacgcacttgt
p93:gtgcgttgcgctgtagctgccaattattccg
p94:gcaaaactcaacatgggtaaaaaatcctttcg
p95:ggattttttacccatgttgagttttgcgacc
p96:tcccccggggcgtggcaataaaaccac(smai)
p100:gcaccaagtacttttgcg
将序列测定正确的同源重组质粒pk18mobsacb-psod::pthre电转化至上述鉴定正确的重组菌cg466中,通过卡那霉素抗性正向筛选得到重组质粒整合至染色体上的菌落,通过蔗糖反向筛选,得到发生两次同源重组的阳性菌落。将阳性菌落以p100和p96为引物进行pcr扩增鉴定,得到729bp的为重组
wt-δsdaaserarδcyseδglyr::p45-gcvth::p45-gcvp-phom-glyaδpyc-phom-acn-peftu::psera
-peftu::pserc-peftu::pserb-psod::pthre。
经该重组菌提取基因组dna进行测序,结果为证实已成功将cg466中的thre基因的启动子替换为谷氨酸棒杆菌内源强启动子psod,无质粒丝氨酸重组菌cg468(wt-δsdaaserarδcyseδglyr::p45-gcvth::p45-gcvp-phom-glyaδpyc-phom-acnpeftu::psera-peftu::pserc-peftu::pserb-psod::pthre)构建成功。
实施例10l-丝氨酸工程菌在生成l-丝氨酸中的应用
一、高产l-丝氨酸的重组菌摇瓶发酵
摇瓶发酵采用的发酵培养基具体如下:葡萄糖40g/l,(nh4)2so420g/l,kh2po4500mg/l,k2hpo4·3h2o500mg/l,mgso4·7h2o250mg/l,feso4·7h2o10mg/l,mnso4·h2o10mg/l,znso4·7h2o1mg/l,cuso4200μg/l,nicl2·6h2o20μg/l,cys24mg/l,生物素50μg/l,ph7.0-7.2,2%caco3,121℃高压灭菌20min。葡萄糖分开灭菌,115℃高压灭菌15min。mgso4·7h2o,以及无机盐离子分开灭菌,121℃高压灭菌20min。维生素采用0.22μm无菌滤膜过滤除菌。
种子培养基具体如下:葡萄糖20g/l,硫酸铵5g/l,k2hpo4·3h2o1g/l,mgso4·7h2o400mg/l,生物素50μg/l,维生素b11mg/l,酵母粉10g/l,蛋白胨10g/l。
1)、种子液的获得
将上述实施例中制备的工程菌cg039、cg050、cg381,cg188,cg383,cg399,cg453和cg454以及对比例中制备的ser-3和ser-8分别接种到种子培养基中,种子液培养条件为培养温度32℃,摇床转速为220r/min,培养时间12h,得到种子液,od600可为15。
2)、发酵
将有质粒的重组菌种子液按照体积百分含量为3%接种到含有终浓度为10μg/ml氯霉素的发酵培养基(500ml挡板三角瓶装液量为30ml)中,32℃,220r/min,培养60h,并于发酵培养4h时加入终浓度为0.1mmol/l的异丙基-β-d-硫代吡喃半乳糖苷(iptg)进行目的基因的诱导表达。间歇补加浓氨水控制发酵液的ph在7.0-7.2之间,根据残糖情况,补加浓度为600g/l的葡萄糖母液,控制发酵液残糖在5-10g/l。无质粒的重组菌种子液发酵过程类似,不同的是不需要加入氯霉素和诱导剂iptg。
收集发酵产物12000×g,离心5min,收集上清液。
3)、检测l-丝氨酸含量
采用高效液相法,具体方法(2,4-二硝基氟苯柱前衍生高效液相法)如下:取50μl上述上清液于2ml离心管中,加入100μlnahco3水溶液(500mmol/l,ph9.0)和100μl1%的2,4-二硝基氟苯-乙腈溶液(体积比),于60℃水浴中暗处恒温加热60min,然后冷却至25℃,加入750μlkh2po4水溶液10mmol/l,ph7.2±0.05,用naoh水溶液调整ph,放置15min过滤后可进样,进样量为15μl。
所用色谱柱为c18柱(zorbaxeclipsexdb-c18,4.6*150mm,agilent,usa);柱温:40℃;紫外检测波长:360nm;流动相a为40mmol/lkh2po4水溶液(ph7.2±0.05,用40g/lkoh水溶液调整ph),流动相b为55%乙腈水溶液(体积比),流动相流速为1ml/min,洗脱过程如下表1所示:
表1为洗脱过程
以野生型菌株c.glutamicumatcc13032为对照。
4)、发酵结果及分析
结果如表2所示。
表2为摇瓶发酵实验中l-丝氨酸工程菌ser-3、ser-8、cg039、cg050、cg381,cg188,cg383,cg399,cg453和cg454的最大od600,比生长速率,葡萄糖消耗速率和l-丝氨酸产量。
表2摇瓶发酵结果
摇瓶发酵实验中,发酵60h,野生型菌株c.glutamicumatcc13032未检测到l-丝氨酸的积累。
敲除cyse基因的工程菌cg039与未敲除cyse的工程菌ser-3相比,产量提高了30倍。进一步在质粒上过表达gcv系统,工程菌cg050的丝氨酸产量比不表达gcv系统的cg039提高了5.6倍。在过表达serarcb基因的基础上,仅通过敲除丝氨酸羟甲基转移酶基因的转录激活因子glyr,工程菌cg381l-丝氨酸产量比ser-8提高了15.6倍。在此基础上,通过弱启动子进一步降低glya基因的表达,工程菌cg188的l-丝氨酸产量比ser-8提高了22.2倍。通过引入大肠杆菌gcv系统所构建的工程菌cg383的l-丝氨酸产量比ser-8提高了31.4倍。
减弱glya基因的表达可以降低胞内一碳单位的供给,导致工程菌cg188的比生长速率和葡萄糖消耗速率的降低,与仅敲除glyr的菌株cg381相比,l-丝氨酸产量提高了1.4倍。gcv系统的整合能够为工程菌cg383提供一碳单位,导致比生长速率和葡萄糖消耗速率的恢复,与工程菌cg381相比,l-丝氨酸产量提高了2倍。通过减弱三羧酸循环中acn基因编码的顺乌头酸酶的表达,所构建的工程菌cg399的比生长速率下降,l-丝氨酸产量为1.89g/l。通过敲除pyc基因,阻断丙酮酸回补草酰乙酸的途径,所构建的工程菌cg453的l-丝氨酸产量与cg399相比提高了1倍。通过增加苏氨酸转运蛋白thre的表达,所构建的工程菌cg454的l-丝氨酸产量,与工程菌cg399和cg453相比,分别提高了1.25和1.1倍。
二、l-丝氨酸工程菌cg383和cg454发酵罐发酵生产l-丝氨酸
种子培养基具体如下:葡萄糖20g/l,硫酸铵5g/l,k2hpo4·3h2o1g/l,mgso4·7h2o0.4g/l,生物素50μg/l,维生素b11mg/l,酵母粉10g/l,蛋白胨10g/l。
发酵采用的发酵培养基具体如下:葡萄糖40g/l,硫酸铵20g/l,kh2po4500mg/l,k2hpo4·3h2o500mg/l,mgso4·7h2o600mg/l,feso4·7h2o10mg/l,mnso4·h2o10mg/l,维生素b1500μg/l,cys24mg/l,柠檬酸钠0.4g/l。
1)、种子液的获得
将工程菌cg383、cg454种子培养基中,种子液培养条件为培养温度32℃,摇床转速为220r/min,培养时间12h,得到种子液,od600可为15。
2)、发酵
将种子液按照体积百分含量为10%接种到含有终浓度10μg/ml氯霉素的发酵培养基中。
采用的发酵罐为7.5l发酵罐(bioflo115,nbs):内置定速可编程控泵,可以实现恒速补料。发酵过程中通过蠕动泵补加600g/l的葡萄糖,控制发酵体系中葡糖糖的浓度为5-10g/l。通过加热套和冷却水控制发酵温度维持在32℃;通入空气提供溶氧,转速与溶氧信号级联控制溶氧维持在30%;补加浓氨水调控ph,维持在6.9左右。发酵连续进行60h。当od600=4-5时,加入iptg(终浓度为0.1mmol/l)诱导重组质粒携带的基因表达。
收集发酵产物12000×g,离心5min,收集上清液。
3)、检测l-丝氨酸含量
按照上述一的3)的高效液相法检上清液中的l-丝氨酸含量,结果如图5和图6所示,可以看出,发酵50h,工程菌cg383的l-丝氨酸产量为10g/l,生产强度为0.20g/l/h;工程菌cg454的l-丝氨酸产量为13g/l,生产强度为0.22g/l/h。
最后应说明的是:显然,上述实施例仅仅是为清楚地说明本发明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引申出的显而易见的变化或变动仍处于本发明的保护范围之中。
序列表
<110>中国科学院微生物研究所
<120>生产l-丝氨酸的重组菌及其构建方法
<160>26
<170>siposequencelisting1.0
<210>1
<211>1045
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>1
acattttgagccagcgctaaggagaacccagtgacagaaattgcagaaaaccttcagcgc60
ttgggtattgaattacctgatctaccagcaccgcagtattcctacgtaccgttcaaccgc120
caaggaaacaccctctatgtatcggggcagatttcacgaaccgcagcgggagacatcctc180
gccggacgagttggcgaagacgcaacattagaagaaggaatccacgccgcagaggtagcc240
accatcaatctgctggccagaatccaccaatccatcggtttagacaatgtggcccaaatt300
ctgaaactgaatgtgtgggtcaatagctccgatgactttattcagcagcctcaagtggcc360
gacggtgcatcccagctccttgaggcagtgttgggtgaggccggaaaacatgcacgcaca420
gcactacccacaaatactctcccccagggagcactagtggaattggatgctgtcgttgcg480
gtcaccgaggccgccgaagtttaggacgcgtgggcgaaaatttcagcaaccgtgggataa540
cggaggtcattcactcaatatataggtatggcaagcctaagtgaattgattgagtgaatt600
gaatgcatcacacccgattacaggggtattgaaaatctttttaaagaagcccttttaaga660
atcctcagtgggcttctctggaccttcttctgagctttcaggctttgcgtagcgttccct720
ggcccgtttgagacgttcttcctcttctaattgggcagcctcgtcggcgcgacgctgttt780
gaagcgattcttttcaatattccacaagaattcttcatcatcgtcggggcctttcactgc840
acgaggtgcctggccctgattgatctccgcgttacgcttccatgtagatggcttgaaggc900
cttccacagcaagacgattgcgacgataaccaaaataatcagcaaaagcctacccacttg960
aacctctccttaaatatttgcttcaacctcccacaatacggaactttgaggcattcttgg1020
gtatcggtatgtattgagtagggtt1045
<210>2
<211>1976
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>2
catcctcacccgttccaccaagtgatcgctaccttttttcagtaccaacgacgcgcgaac60
tcgggtgggaagaatattctccaccaagttgggcaggttgatcgattgccacagttctcg120
agcgacggcgatggactctggatcagccatgtcggcgtaatgggagaagtgggcaccggg180
gcgacggaatgcagtgtcgcggagtttgaggaagcggtcgatgtaccatttttcgatatc240
ttcggtgcgggcatctacgtagacgctgaagtcgaaaaggtcactgaccatcaatgttgg300
gccagtttggaggacgtttaagccttcgacgatcaaaatgtcgggttggcggactgtggt360
gaattcgcctggaactcggtcgtacgcggtgtgggagtagacaggtgcgttgacttcgag420
ttttccggattttacgtcggtgacaaagcggaggagtgcacgttggtcgtagctttcggg480
gaatccttttcgggacattaatccgcggcggattagttccgcgccgggatagaggaatcc540
gtcggtggtgacgaggtccacgcgggggtgggaattccagcgctgaagcagaacttggag600
gagtcgggcggtggttgatttaccgacggcgacggatcccgcgacaccaatgacaaacgg660
cacagagatagagggggaagttccgaggaaggtttcggtggctgcagtaagttgctgtcg720
ggccgctacctggaggtgaatcagacgggacagcggaaggtagacttctgccacttcagc780
gaggtcaatgttttctccgatgcctcgaagttcaatgacttctttttgggtcagcacctg840
aggcattgagtttctcagctcgcgccattgtgcgcggtcgaaatcaaggtaggggctgaa900
atctggtgtgcgtggggaaggtttcacccgttgaaaactaaaaagctgggaaggtgaatc960
gaatttcggggctttaaagcaaaaatgaacagcttggtctatagtggctaggtacccttt1020
ttgttttggacacatgtagggtggccgaaacaaagtaaaaggaggacaaccatgaccgat1080
gcccaccaagcggacgatgtccgttaccagccactgaacgagcttgatcctgaggtggct1140
gctgccatcgctggggaacttgcccgtcaacgcgatacattagagatgatcgcgtctgag1200
aacttcgttccccgttctgttttgcaggcgcagggttctgttcttaccaataagtatgcc1260
gagggttaccctggccgccgttactacggtggttgcgaacaagttgacatcattgaggat1320
cttgcacgtgatcgtgcgaaggctctcttcggtgcagagttcgccaatgttcagcctcac1380
tctggcgcacaggctaatgctgctgtgctgatgactttggctgagccaggcgacaagatc1440
atgggtctgtctttggctcatggtggtcacttgacccacggaatgaagttgaacttctcc1500
ggaaagctgtacgaggttgttgcgtacggtgttgatcctgagaccatgcgtgttgatatg1560
gatcaggttcgtgagattgctctgaaggagcagccaaaggtaattatcgctggctggtct1620
gcataccctcgccaccttgatttcgaggctttccagtctattgctgcggaagttggcgcg1680
aagctgtgggtcgatatggctcacttcgctggtcttgttgctgctggtttgcacccaagc1740
ccagttccttactctgatgttgtttcttccactgtccacaagactttgggtggacctcgt1800
tccggcatcattctggctaagcaggagtacgcgaagaagctgaactcttccgtattccca1860
ggtcagcagggtggtcctttgatgcacgcagttgctgcgaaggctacttctttgaagatt1920
gctggcactgagcagttccgtgaccgtcaggctcgcacgttggagggtgctcgcat1976
<210>3
<211>1624
<212>dna
<213>大肠杆菌(escherichiacoli)
<400>3
aaaggaggacaagatggcacaacagactcctttgtacgaacaacacacgctttgcggcgc60
tcgcatggtggatttccacggctggatgatgccgctgcattacggttcgcaaatcgacga120
acatcatgcggtacgtaccgatgccggaatgtttgatgtgtcacatatgaccatcgtcga180
tcttcgcggcagccgcacccgggagtttctgcgttatctgctggcgaacgatgtggcgaa240
gctcaccaaaagcggcaaagccctttactcggggatgttgaatgcctctggcggtgtgat300
agatgacctcatcgtctactactttactgaagatttcttccgcctcgttgttaactccgc360
cacccgcgaaaaagacctctcctggattacccaacacgctgaacctttcggcatcgaaat420
taccgttcgtgatgacctttccatgattgccgtgcaagggccgaatgcgcaggcaaaagc480
tgccacactgtttaatgacgcccagcgtcaggcggtggaagggatgaaaccgttctttgg540
cgtgcaggcgggcgatctgtttattgccaccactggttataccggtgaagcgggctatga600
aattgcgctgcccaatgaaaaagcggccgatttctggcgtgcgctggtggaagcgggtgt660
taagccatgtggcttgggcgcgcgtgacacgctgcgtctggaagcgggcatgaatcttta720
tggtcaggagatggacgaaaccatctctcctttagccgccaacatgggctggaccatcgc780
ctgggaaccggcagatcgtgactttatcggtcgtgaagccctggaagtgcagcgtgagca840
tggtacagaaaaactggttggtctggtgatgaccgaaaaaggcgtgctgcgtaatgaact900
gccggtacgctttaccgatgcgcagggcaaccagcatgaaggcattatcaccagcggtac960
tttctccccgacgctgggttacagcattgcgctggcgcgcgtgccggaaggtattggcga1020
aacggcgattgtgcaaattcgcaaccgtgaaatgccggttaaagtgacaaaacctgtttt1080
tgtgcgtaacggcaaagccgtcgcgtgatttacttttttggagattgattgatgagcaac1140
gtaccagcagaactgaaatacagcaaagaacacgaatggctgcgtaaagaagccgacggc1200
acttacaccgttggtattaccgaacatgctcaggagctgttaggcgatatggtgtttgtt1260
gacctgccggaagtgggcgcaacggttagcgcgggcgatgactgcgcggttgccgaatcg1320
gtaaaagcggcgtcagacatttatgcgccagtaagcggtgaaatcgtggcggtaaacgac1380
gcactgagcgattccccggaactggtgaacagcgaaccgtatgcaggcggctggatcttt1440
aaaatcaaagccagcgatgaaagcgaactggaatcactgctggatgcgaccgcatacgaa1500
gcattgttagaagacgagtaacggctttattcctcttctgcgggagaggatcagggtgag1560
gaaaatttatgcctcaccctcactctcttcgtaaggagagaggttcacaattcactgcac1620
gttt1624
<210>4
<211>2896
<212>dna
<213>大肠杆菌(escherichiacoli)
<400>4
aaaggaggaaccatcgctcatgacacagacgttaagccagcttgaaaacagcggcgcttt60
tattgaacgccatatcggaccggacgccgcgcaacagcaagaaatgctgaatgccgttgg120
tgcacaatcgttaaacgcgctgaccggccagattgtgccgaaagatattcaacttgcgac180
accaccgcaggttggcgcaccggcgaccgaatacgccgcactggcagaactcaaggctat240
tgccagtcgcaataaacgcttcacgtcttacatcggcatgggttacaccgccgtgcagct300
accgccggttatcctgcgtaacatgctggaaaatccgggctggtataccgcgtacactcc360
gtatcaacctgaagtctcccagggccgccttgaagcactgctcaacttccagcaggtaac420
gctggatttgactggactggatatggcctctgcttctcttctggacgaggccaccgctgc480
cgccgaagcaatggcgatggcgaaacgcgtcagcaaactgaaaaatgccaaccgcttctt540
cgtggcttccgatgtgcatccgcaaacgctggatgtggtccgtactcgtgccgaaacctt600
tggttttgaagtgattgtcgatgacgcgcaaaaagtgctcgaccatcaggacgtcttcgg660
cgtgctgttacagcaggtaggcactaccggtgaaattcacgactacactgcgcttattag720
cgaactgaaatcacgcaaaattgtggtcagcgttgccgccgatattatggcgctggtgct780
gttaactgcgccgggtaaacagggcgcggatattgtttttggttcggcgcaacgcttcgg840
cgtgccgatgggctacggtggcccacacgcggcattctttgcggcgaaagatgaatacaa900
acgctcaatgccgggccgtattatcggtgtatcgaaagatgcagctggcaataccgcgct960
gcgcatggcgatgcagactcgcgagcaacatatccgccgtgagaaagcgaactccaacat1020
ttgtacttcccaggtactgctggcaaacatcgccagcctgtatgccgtttatcacggccc1080
ggttggcctgaaacgtatcgctaaccgcattcaccgtctgaccgatatcctggcggcggg1140
cctgcaacaaaaaggtctgaaactgcgccatgcgcactatttcgacaccttgtgtgtgga1200
agtggccgacaaagcgggcgtactgacgcgtgccgaagcggctgaaatcaacctgcgtag1260
cgatattctgaacgcggttgggatcacccttgatgaaacaaccacgcgtgaaaacgtaat1320
gcagcttttcaacgtgctgctgggcgataaccacggcctggacatcgacacgctggacaa1380
agacgtggctcacgacagccgctctatccagcctgcgatgctgcgcgacgacgaaatcct1440
cacccatccggtgtttaatcgctaccacagcgaaaccgaaatgatgcgctatatgcactc1500
gctggagcgtaaagatctggcgctgaatcaggcgatgatcccgctgggttcctgcaccat1560
gaaactgaacgccgccgccgagatgatcccaatcacctggccggaatttgccgaactgca1620
cccgttctgcccgccggagcaggccgaaggttatcagcagatgattgcgcagctggctga1680
ctggctggtgaaactgaccggttacgacgccgtttgtatgcagccgaactctggcgcaca1740
gggcgaatacgcgggcctgctggcgattcgtcattatcatgaaagccgcaacgaagggca1800
tcgcgatatctgcctgatcccggcttctgcgcacggaactaaccccgcttctgcacatat1860
ggcaggaatgcaggtggtggttgtggcgtgtgataaaaacggcaacatcgatctgactga1920
tctgcgcgcgaaagcggaacaggcgggcgataacctctcctgtatcatggtgacttatcc1980
ttctacccacggcgtgtatgaagaaacgatccgtgaagtgtgtgaagtcgtgcatcagtt2040
cggcggtcaggtttaccttgatggcgcgaacatgaacgcccaggttggcatcacctcgcc2100
gggctttattggtgcggacgtttcacaccttaacctacataaaactttctgcattccgca2160
cggcggtggtggtccgggtatgggaccgatcggcgtgaaagcgcatttggcaccgtttgt2220
accgggtcatagcgtggtgcaaatcgaaggcatgttaacccgtcagggcgcggtttctgc2280
ggcaccgttcggtagcgcctctatcctgccaatcagctggatgtacatccgcatgatggg2340
cgcagaagggctgaaaaaagcaagccaggtggcaatcctcaacgccaactatattgccag2400
ccgcctgcaggatgccttcccggtgctgtataccggtcgcgacggtcgcgtggcgcacga2460
atgtattctcgatattcgcccgctgaaagaagaaaccggcatcagcgagctggatattgc2520
caagcgcctgatcgactacggtttccacgcgccgacgatgtcgttcccggtggcgggtac2580
gctgatggttgaaccgactgaatctgaaagcaaagtggaactggatcgctttatcgacgc2640
gatgctggctatccgcgcagaaattgaccaggtgaaagccggtgtctggccgctggaaga2700
taacccgctggtgaacgcgccgcacattcagagcgaactggtcgccgagtgggcgcatcc2760
gtacagccgtgaagttgcggtattcccggcaggtgtggcagacaaatactggccgacagt2820
gaaacgtctggatgatgtttacggcgaccgtaacctgttctgctcctgcgtaccgattag2880
cgaataccagtaattc2896
<210>5
<211>1182
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>5
atcaacgcagaaacccgatgcattcagctcgacgccggtgttgcagtaaagaaggacggc60
gtggtgctgggtacctcagatatggcgaggtccctgcctcgaaccgccgctggccaagaa120
gcctatgagtacttcttcaaggtggttcgtgaaggcatcatcgggcagctgcgcccgggc180
gtgatctgcgctgacgtgcacgaagcaacccttgattacctaagcccgcagctacctcgc240
atgattgacatcggaatgctgggtgccgacaccgatttcaacaccatctaccgcaagcgc300
aatgttggccacctcatgggcaagcaggaatcctttgccaatgagcttcgccctggatac360
aagcacattcttcaccacggctcctatggtgccgcggagatcccttggcgctacaacggt420
gtagccattggtaccgaggatctgtggtacatcggcgcagacaagacctacattttgagc480
cagcgctaaggagaacccagtgacagaaattgcagaaaaccttcagcgcttgggtattga540
attacctgatctaccagcaccgcagtattcctacgtaccgttcaaccgccaaggaaacac600
cctctatgtatcggggcagatttcacgaaccgcagcgggagacatcctcgccggacgagt660
tggcgaagacgcaacattagaagaaggaatccacgccgcagaggtagccaccatcaatct720
gctggccagaatccaccaatccatcggtttagacaatgtggcccaaattctgaaactgaa780
tgtgtgggtcaatagctccgatgactttattcagcagcctcaagtggccgacggtgcatc840
ccagctccttgaggcagtgttgggtgaggccggaaaacatgcacgcacagcactacccac900
aaatactctcccccagggagcactagtggaattggatgctgtcgttgcggtcaccgaggc960
cgccgaagtttaggacgcgtgggcgaaaatttcagcaaccgtatcgtgtttttctgtgat1020
cctcattcgccgtggcagcgtgggtcgaatgagaatacgaatggattggtcagggatttt1080
ttcccgaagggcactaattttgctaaagtaagtgacgaagaagttcagcgggcacaggat1140
ctgctgaattaccggccgcggaaaatgcatggttttaaaagc1182
<210>6
<211>649
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>6
gtcggggcctttcactgcacgaggtgcctggccctgattgatctccgcgttacgcttcca60
tgtagatggcttgaaggccttccacagcaagacgattgcgacgataaccaaaataatcag120
caaaagcctacccacttgaacctctccttaaatatttgcttcaacctcccacaatacgga180
actttgaggcattcttgggtatcggtatgtattgagtagggttgaatatgtgagtgagtc240
caatacccccaatctccagacacaccaagcgccggaattaaacccggaactacaaaaagc300
tgcccggaaaaacgtgctgatttacggtctggcacgtttgcttctgttcgtcgtgctgac360
cttgattattcatagcctggctctgctgattagtgcgcctgtgccactcgttatgtctgc420
gatgctggctctgattgtggcgttcccattgtccatgctggtgttcagcaaactgcgcat480
gaatgccacccaggctgtttcccagtgggatgcacagcgcaaggcccacaaggaatgggt540
tcgaagcgagctggcggaccgctaaaaaattcccctcgttctttgcggaagcgagaggaa600
aggggaggggagcgtcgaaaagcgttttagctaaacgctaatgccaggc649
<210>7
<211>721
<212>dna
<213>人工序列(artificialsequence)
<220>
<221>gene
<222>(1)..(544)
<223>大肠杆菌escherichiacoligcvth部分序列
<400>7
tgtgcgtaacggcaaagccgtcgcgtgatttacttttttggagattgattgatgagcaac60
gtaccagcagaactgaaatacagcaaagaacacgaatggctgcgtaaagaagccgacggc120
acttacaccgttggtattaccgaacatgctcaggagctgttaggcgatatggtgtttgtt180
gacctgccggaagtgggcgcaacggttagcgcgggcgatgactgcgcggttgccgaatcg240
gtaaaagcggcgtcagacatttatgcgccagtaagcggtgaaatcgtggcggtaaacgac300
gcactgagcgattccccggaactggtgaacagcgaaccgtatgcaggcggctggatcttt360
aaaatcaaagccagcgatgaaagcgaactggaatcactgctggatgcgaccgcatacgaa420
gcattgttagaagacgagtaacggctttattcctcttctgcgggagaggatcagggtgag480
gaaaatttatgcctcaccctcactctcttcgtaaggagagaggttcacaattcactgcac540
gtttgtgtttttctgtgatcctcattcgccgtggcagcgtgggtcgaatgagaatacgaa600
tggattggtcagggattttttcccgaagggcactaattttgctaaagtaagtgacgaaga660
agttcagcgggcacaggatctgctgaattaccggccgcggaaaatgcatggttttaaaag720
c721
<210>8
<211>920
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>8
atcggtatcggaccatcatcctcacataccgtcggccccatgagagccgccctcacgtat60
atctctgaatttcccagctcgcatgtcgatatcacgttgcacggatcccttgccgccacc120
ggtaaaggccactgcactgaccgggcggtattactgggtctggtgggatgggaaccaacg180
atagttcccattgatgctgcaccctcacccggcgcgccgattcctgcgaaaggttctgtg240
aacgggccaaagggaacggtgtcgtattccctgacgtttgatcctcatcctcttccagaa300
caccccaatgccgttacctttaaaggatcaaccacaaggacttatttgtcggtgggtggt360
gggttcattatgacgttggaggatttccggaagctggacgatatcggatcaggtgtgtca420
accattcatccagaggcagcgggattttttgacaggttttggggcggagcaggcgcggac480
gtttttgtataccgcgggtgcggtgggcatcatcattaaggaaaatgcctcgatctctgg540
cgcggaggtggggtgtcagggtgaggttggttcagcgtccgcgatggcggctgccgggtt600
gtgtgcagtcttaggtggttctccgcaacaggtggaaaacgccgcggagattgcgttgga660
gcacaatttgggattgacgtgcgatccggtgggcgggttagtgcagattccgtgtattga720
acgcaacgctattgctgccatgaagtccatcaatgcggcaaggcttgcccggattggtga780
tggcaacaatcgcgtgagtttggatgatgtggtggtcacgatggctgccaccggccggga840
catgctgaccaaatataaggaaacgtcccttggtggtttggcaaccaccttgggcttccc900
ggtgtcgatgacggagtgtt920
<210>9
<211>1534
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>9
gcctgttgtagacggacattcctagtttttccaggagtaacttgtgagccagaatggccg60
tccggtagtcctcatcgccgataagcttgcgcagtccactgttgacgcgcttggagatgc120
agtagaagtccgttgggttgacggacctaaccgcccagaactgcttgatgcagttaagga180
agcggacgcactgctcgtgcgttctgctaccactgtcgatgctgaagtcatcgccgctgc240
ccctaacttgaagatcgtcggtcgtgccggcgtgggcttggacaacgttgacatccctgc300
tgccactgaagctggcgtcatggttgctaacgcaccgacctctaatattcactccgcttg360
tgagcacgcaatttctttgctgctgtctactgctcgccagatccctgctgctgatgcgac420
gctgcgtgagggcgagtggaagcggtcttctttcaacggtgtggaaattttcggaaaaac480
tgtcggtatcgtcggttttggccacattggtcagttgtttgctcagcgtcttgctgcgtt540
tgagaccaccattgttgcttacgatccttacgctaaccctgctcgtgcggctcagctgaa600
cgttgagttggttgagttggatgagctgatgagccgttctgactttgtcaccattcacct660
tcctaagaccaaggaaactgctggcatgtttgatgcgcagctccttgctaagtccaagaa720
gggccagatcatcatcaacgctgctcgtggtggccttgttgatgagcaggctttggctga780
tgcgattgagtccggtcacattcgtggcgctggtttcgatgtgtactccaccgagccttg840
cactgattctcctttgttcaagttgcctcaggttgttgtgactcctcacttgggtgcttc900
tactgaagaggctcaggatcgtgcgggtactgacgttgctgattctgtgctcaaggcgct960
ggctggcgagttcgtggcggatgctgtgaacgtttccggtggtcgcgtgggcgaagaggt1020
tgctgtgtggatggatctggcttaaggcggttttcgctcttttaatacagttttaaaggt1080
agatttgggagagaagatttcccttaagaaaggttcttaacaaccatgccgcctgcgacg1140
ctgttcaatgttttgacttcagctggacttgaccctcaccagtcaggtgatgccattgtt1200
gtcgagtctgcccatttcacattgacgttcacgtgggatgagtggctgcgagctcaagcg1260
acgtgggtgggggagttgagtgcgtcggattatgtgcgttctattgtggcgattaactct1320
gcccatgatgcacgggcaacgccgaagatgatgttggatgccccgactggtctgacaacg1380
gtgcttaaggcggataagggtcagttgcaggcgtttgccgtggaggcgctgccgattggc1440
gatggcctcagcgaggctcagttggcggggtttgtggctgccgcgtttgatggcgccatc1500
gacctcactcgtgagtttcatgcactttacccgg1534
<210>10
<211>593
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>10
agcgactgttaaccactcaagctctttgcttgggtggttttttcatgtctcaaggtcggg60
tcgggtgcgattcgggtcggttttgagtgtctttgagtccttttaagtccttctttgccc120
gtgaataattctctggatagtttccacgtgcagttaagtcacgctgttagacttgcctgc180
atgctctcgacaataaaaatgatccgtgaagatctcgcaaacgctcgtgaacacgatcca240
gcagcccgaggcgatttagaaaatcttaggtcccatcaccatcggcgaaggctccgcaat300
tggcgccaatgcagttgtcaccaaagacgtgccggcagaacacatcgcagtcggaattcc360
tgcggtagcacgcccacgtggcaagacagagaagatcaagctcgtcgatccggactatta420
catttaagaacagttagcgccctacctgaagttcaggcagggcgcttttttgggaagctc480
cagagtgcgtttgttagccacgcactagggacctttaaccgtctaaaaccgcccctgtgc540
gcttctcagcactacccgtgagaaccacccccctgtgccagctagttctttag593
<210>11
<211>1144
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>11
aaaggaggaagacatgaccgacttccccaccctgccctctgagttcatccctggcgacgg60
ccgtttcggctgcggaccttccaaggttcgaccagaacagattcaggctattgtcgacgg120
atccgcatccgtcatcggtacctcacaccgtcagccggcagtaaaaaacgtcgtgggttc180
aatccgcgagggactctccgacctcttctcccttccagaaggctacgagatcatcctttc240
cctaggtggtgcgaccgcattctgggatgcagcaaccttcggactcattgaaaagaagtc300
cggtcacctttctttcggtgagttctcctccaagttcgcaaaggcttctaagcttgctcc360
ttggctcgacgagccagagatcgtcaccgcagaaaccggtgactctccggccccacaggc420
attcgaaggcgccgatgttattgcatgggcacacaacgaaacctccactggcgccatggt480
tccagttcttcgccccgaaggctctgaaggctccctggttgccattgacgcaacctccgg540
cgctggtggactgccagtagacatcaagaactccgatgtttactacttctccccacagaa600
gtgcttcgcatccgacggtggcctgtggcttgcagcgatgagcccagcagctctcgagcg660
catcgagaagatcaacgcttccgatcgcttcatccctgagttcctcaacctgcagaccgc720
agtggataactccctgaagaaccagacctacaacaccccagctgttgctaccttgctgat780
gctggacaaccaggtcaagtggatgaactccaacggcggcctggatggaatggttgctcg840
caccacagcaagctcctccgccctgtacaactgggctgaggctcgcgaggaggcatcccc900
atacgtggcagatgcagctaagcgctccctcgttgtcggcaccatcgacttcgatgactc960
catcgacgcagcagtgatcgctaagatactgcgcgcaaacggcatcctggacaccgagcc1020
ttaccgcaagctgggacgcaaccagctgcgcatcggtatgttcccagcgatcgattccac1080
cgatgtggaaaagctcaccggagcaatcgacttcatcctcgatggcggttttgcaaggaa1140
gtaa1144
<210>12
<211>1332
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>12
aaaggaggagttgccatgactgaactcatccagaatgaatcccaagaaatcgctgagctg60
gaagccggccagcaggttgcattgcgtgaaggttatcttcctgcggtgatcacagtgagc120
ggtaaagaccgcccaggtgtgactgccgcgttctttagggtcttgtccgctaatcaggtt180
caggtcttggacgttgagcagtcaatgttccgtggctttttgaacttggcggcgtttgtg240
ggtatcgcacctgagcgtgtcgagaccgtcaccacaggcctgactgacaccctcaaggtg300
catggacagtccgtggtggtggagctgcaggaaactgtgcagtcgtcccgtcctcgttct360
tcccatgttgttgtggtgttgggtgatccggttgatgcgttggatatttcccgcattggt420
cagaccctggcggattacgatgccaacattgacaccattcgtggtatttcggattaccct480
gtgaccggcctggagctgaaggtgactgtgccggatgtcagccctggtggtggtgaagcg540
atgcgtaaggcgcttgctgctcttacctctgagctgaatgtggatattgcgattgagcgt600
tctggtttgctgcgtcgttctaagcgtctggtgtgcttcgattgtgattccacgttgatc660
actggtgaggtcattgagatgctggcggctcacgcgggcaaggaagctgaagttgcggca720
gttactgagcgtgcgatgcgcggtgagctcgatttcgaggagtctctgcgtgagcgtgtg780
aaggcgttggctggtttggatgcgtcggtgatcgatgaggtcgctgccgctattgagctg840
acccctggtgcgcgcaccacgatccgtacgctgaaccgcatgggttaccagaccgctgtt900
gtttccggtggtttcatccaggtgttggaaggtttggctgaggagttggagttggattat960
gtccgcgccaacactttggaaatcgttgatggcaagctgaccggcaacgtcaccggaaag1020
atcgttgaccgcgctgcgaaggctgagttcctccgtgagttcgctgcggattctggcctg1080
aagatgtaccagactgtcgctgtcggtgatggcgctaatgacatcgatatgctctccgct1140
gcgggtctgggtgttgctttcaacgcgaagcctgcgctgaaggagattgcggatacttcc1200
gtgaaccacccattcctcgacgaggttttgcacatcatgggcatttcccgcgacgagatc1260
gatctggcggatcaggaagacggcactttccaccgcgttccattgaccaatgcctaaaga1320
ttcgcttctcga1332
<210>13
<211>1016
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>13
aaaggaggaaacttgtgagccagaatggccgtccggtagtcctcatcgccgataagcttg60
cgcagtccactgttgacgcgcttggagatgcagtagaagtccgttgggttgacggaccta120
accgcccagaactgcttgatgcagttaaggaagcggacgcactgctcgtgcgttctgcta180
ccactgtcgatgctgaagtcatcgccgctgcccctaacttgaagatcgtcggtcgtgccg240
gcgtgggcttggacaacgttgacatccctgctgccactgaagctggcgtcatggttgcta300
acgcaccgacctctaatattcactccgcttgtgagcacgcaatttctttgctgctgtcta360
ctgctcgccagatccctgctgctgatgcgacgctgcgtgagggcgagtggaagcggtctt420
ctttcaacggtgtggaaattttcggaaaaactgtcggtatcgtcggttttggccacattg480
gtcagttgtttgctcagcgtcttgctgcgtttgagaccaccattgttgcttacgatcctt540
acgctaaccctgctcgtgcggctcagctgaacgttgagttggttgagttggatgagctga600
tgagccgttctgactttgtcaccattcaccttcctaagaccaaggaaactgctggcatgt660
ttgatgcgcagctccttgctaagtccaagaagggccagatcatcatcaacgctgctcgtg720
gtggccttgttgatgagcaggctttggctgatgcgattgagtccggtcacattcgtggcg780
ctggtttcgatgtgtactccaccgagccttgcactgattctcctttgttcaagttgcctc840
aggttgttgtgactcctcacttgggtgcttctactgaagaggctcaggatcgtgcgggta900
ctgacgttgctgattctgtgctcaaggcgctggctggcgagttcgtggcggatgctgtga960
acgtttccggtggtcgcgtgggcgaagaggttgctgtgtggatggatctggcttaa1016
<210>14
<211>1302
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>14
gccaaagcaaccaacccccaaatcagcaattgaccccaatcaatattccccaccgtcgat60
tccgttacatcctgtaccaaaagctccgttcccagcacgtaatcagtggtcccaagcaaa120
tcatgctgccctgactcaagcgccgccctcgaatgaacatcactcaccaccgcagccgac180
attggagcccgcaccacaacggtgtccagatccgtttgaatcaacagctcctgcgcaata240
tccctcaggttggaagtcatcactggagtttcatcaagaatcacgacccctaaagatcca300
aaatctgattcctttgcatctgtcacaacattaataaggtctttttccaaagtcggaaac360
tggttgcctgtgtgctcccccattgccacggcatcatcaccaagctccgaagcgagctgc420
ttgagatcaatattttctggaatcatctaaaaaccttcattagtgtcgggctcacgaaag480
agcgggaaccgactttactcaataagcaatgggggtgagtaagggggtgatagaaagtca540
catcacgcacgtacccatttcgagcaaatccgaccgttgaaaactaaaaagctgggaagg600
tgaatcgaatttcggggctttaaagcaaaaatgaacagcttggtctatagtggctaggta660
ccctttttgttttggacacatgtagggtggccgaaacaaagtagccgaagcagacgccgt720
cgcgaaatctcaccctaaaaaagttagaattggagctcactgtgactgaaagcaagaact780
ccttcaatgctaagagcacccttgaagttggcgacaagtcctatgactacttcgccctct840
ctgcagtgcctggcatggagaagctgccgtactccctcaaggttctcggagagaaccttc900
ttcgtaccgaagacggcgcaaacatcaccaacgagcacattgaggctatcgccaactggg960
atgcatcttccgatccaagcatcgaaatccagttcaccccagcccgtgttctcatgcagg1020
acttcaccggtgtcccttgtgtagttgacctcgcaaccatgcgtgaggcagttgctgcac1080
tcggtggcgaccctaacgacgtcaacccactgaacccagccgagatggtcattgaccact1140
ccgtcatcgtggaggctttcggccgcccagatgcactggctaagaacgttgagatcgagt1200
acgagcgcaacgaggagcgttaccagttcctgcgttggggttccgagtccttctccaact1260
tccgcgttgttcctccaggaaccggtatcgtccaccaggtca1302
<210>15
<211>1371
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>15
atccgtttgaagactgttgccaccgcagtgtttacccgcccagagatcgcagcagtaggt60
atcacccatgcacaagttgattccggcgaagtgtctgctcgcgtgattgtgcttcctttg120
gctactaacccacgcgccaagatgcgttccctgcgccacggttttgtgaagctgttctgc180
cgccgtaactctggcctgatcatcggtggtgtcgtggtggcaccgaccgcgtctgagctg240
atcctaccgatcgctgtggcagtgaccaaccgtctgacagttgctgatctggctgatacc300
ttcgcggtgtacccatcattgtcaggttcgattactgaagcagcacgtcagctggttcaa360
catgatgatctaggctaatttttctgagtcttagattttgagaaaacccaggattgcttt420
gtgcactcctgggttttcactttgttaagcagttttggggaaaagtgcaaagtttgcaaa480
gtttagaaatattttaagaggtaagatgtctgcaggtggaagcgtttaaatgcgttaaac540
ttggccaaatgtggcaacctttgcaaggtgaaaaactggggcggggttagatcctggggg600
gtttatttcattcactttggcttgaagtcgtgcaggtcaggggagtgttgcccgaaaaca660
ttgagaggaaaacaaaaaccgatgtttgattgggggaatcgggggttacgatactaggac720
gcagtgaggagaccaaggctcaaagggaatccatgccgtcttggtttaatactgcacccg780
tctaatgaaaatcattactattaggtgtcatgatggaccatgcacacgattcctgctcac840
caactctgcgccgtgatttggaggtcactggccagctccaacctgagaaagctgtcgatt900
tagcagcgccgcacgaagggaaggttgccaatataacgaaggtgacctcctcaaatatgg960
agcacaccatcacgcaggcctcaaaagctaaggaggtggtggtgctcattggtcactccc1020
tgctgcccacatttcaggatttggaaaaagacattctgcactttcaggcaggtaataaag1080
ggcgattttctgtagcgattgttgatcctgatcgcagtgcagatgtggttgccagattta1140
ggccaaaacagattccggtggcatacgtggtgaaagatggcgccagcattgcggagttca1200
actcgctcaacaaggagccggttgcacaatggcttgatcattttgtgtcgcgggaaacga1260
tccccaatgaaaaagagggggacgtcgataagcaaatagacccgcgcctgtggcgggcag1320
cggaattggtgaacgccggtgattttcgcgcggcgttggcgttgtatgagc1371
<210>16
<211>1991
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>16
gggaaaagaaagcccctaagccccgtgttattaaatggagactttttggagacctcaagc60
caaaaaggggcattttcattaagaaaatacccctttgacctggtgttattgagctggaga120
agagacttgaactctcaacctacgcattacaagtgcgttgcgctgccaattgcgccactc180
cagcaccgcagatgctgatgatcaacaactacgaatacgtatcttagcgtatgtgtacat240
cacaatggaattcggggctagagtatctggtgaaccgtgcataaacgacctgtgattgga300
ctctttttccttgcaaaatgttttccagcggatgttgagttttgcgacccttcgtggccg360
catttcaacagttgacgctgcaaaagccgcacctccgccatcgccactagccccgattga420
tctcactgaccatagtcaagtggccggtgtgatgaatttggctgcgagaattggcgatat480
tttgctttcttcaggtacgtcaaatagtgacaccaaggtacaagttcgagcagtgacctc540
tgcgtacggtttgtactacacgcacgtggatatcacgttgaatacgatcaccatcttcac600
caacatcggtgtggagaggaagatgccggtcaacgtgtttcatgttgtaggcaagttgga660
caccaacttctccaaactgtctgaggttgaccgtttgatccgttccattcaggctggtgc720
gaccccgcctgaggttgccgagaaaatcctggacgagttggagcaatcccctgcgtctta780
tggtttccctgttgcgttgcttggctgggcaatgatgggtggtgctgttgctgtgctgtt840
gggtggtggatggcaggtttccctaattgcttttattaccgcgttcacgatcattgccac900
gacgtcatttttgggaaagaagggtttgcctactttcttccaaaatgttgttggtggttt960
tattgccacgctgcctgcatcgattgcttattctttggcgttgcaatttggtcttgagat1020
caaaccgagccagatcatcgcatctggaattgttgtgctgttggcaggtttgacactcgt1080
gcaatctctgcaggacggcatcacgggcgctccggtgacagcaagtgcacgatttttcga1140
aacactcctgtttaccggcggcattgttgctggcgtgggtttgggcattcagctttctga1200
aatcttgcatgtcatgttgcctgccatggagtccgctgcagcacctaattattcgtctac1260
attcgcccgcattatcgctggtggcgtcaccgcagcggccttcgcagtgggttgttacgc1320
ggagtggtcctcggtgattattgcggggcttactgcgctgatgggttctgcgttttatta1380
cctcttcgttgtttatttaggccccgtctctgccgctgcgattgctgcaacagcagttgg1440
tttcactggtggtttgcttgcccgtcgattcttgattccaccgttgattgtggcgattgc1500
cggcatcacaccaatgcttccaggtctagcaatttaccgcggaatgtacgccaccctgaa1560
tgatcaaacactcatgggtttcaccaacattgcggttgctttagccactgcttcatcact1620
tgccgctggcgtggttttgggtgagtggattgcccgcaggctacgtcgtccaccacgctt1680
caacccataccgtgcatttaccaaggcgaatgagttctccttccaggaggaagctgagca1740
gaatcagcgccggcagagaaaacgtccaaagactaatcagagattcggtaataaaaggta1800
aaaatcaacctgcttaggcgtctttcgcttaaatagcgtagaatatcgggtcgatcgctt1860
ttaaacactcaggaggatccttgccggccaaaatcacggacactcgtcccaccccagaat1920
cccttcacgctgttgaagaggaaaccgcagccggtgcccgcaggattgttgccacctatt1980
ctaaggacttc1991
<210>17
<211>1350
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>17
atggctatcagtgttgttgatctatttagcatcggtatcggaccatcatcctcacatacc60
gtcggccccatgagagccgccctcacgtatatctctgaatttcccagctcgcatgtcgat120
atcacgttgcacggatcccttgccgccaccggtaaaggccactgcactgaccgggcggta180
ttactgggtctggtgggatgggaaccaacgatagttcccattgatgctgcaccctcaccc240
ggcgcgccgattcctgcgaaaggttctgtgaacgggccaaagggaacggtgtcgtattcc300
ctgacgtttgatcctcatcctcttccagaacaccccaatgccgttacctttaaaggatca360
accacaaggacttatttgtcggtgggtggtgggttcattatgacgttggaggatttccgg420
aagctggacgatatcggatcaggtgtgtcaaccattcatccagaggcagaggtgccttgt480
ccttttcagaagagttcccaattactcgcatatggtcgcgattttgcggaggtcatgaag540
gataatgagcgcttaatccacggggatcttggcacagtggatgcccatttggatcgagtg600
tggcagattatgcaggagtgcgtggcacaaggcatcgcaacgccggggattttaccgggt660
gggttgaatgtgcaacgtcgggcgccgcaggtacacgcgctgattagcaacggggatacg720
tgtgagctgggtgctgatcttgatgctgtggagtgggtgaatctgtacgccttggcggtg780
aatgaagaaaacgccgctggtggtcgtgtggttactgctccgactaatggtgctgcgggg840
attattccggcggtgatgcactatgcgcgggattttttgacaggttttggggcggagcag900
gcgcggacgtttttgtataccgcgggtgcggtgggcatcatcattaaggaaaatgcctcg960
atctctggcgcggaggtggggtgtcagggtgaggttggttcagcgtccgcgatggcggct1020
gccgggttgtgtgcagtcttaggtggttctccgcaacaggtggaaaacgccgcggagatt1080
gcgttggagcacaatttgggattgacgtgcgatccggtgggcgggttagtgcagattccg1140
tgtattgaacgcaacgctattgctgccatgaagtccatcaatgcggcaaggcttgcccgg1200
attggtgatggcaacaatcgcgtgagtttggatgatgtggtggtcacgatggctgccacc1260
ggccgggacatgctgaccaaatataaggaaacgtcccttggtggtttggcaaccaccttg1320
ggcttcccggtgtcgatgacggagtgttag1350
<210>18
<211>1593
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>18
gtgagccagaatggccgtccggtagtcctcatcgccgataagcttgcgcagtccactgtt60
gacgcgcttggagatgcagtagaagtccgttgggttgacggacctaaccgcccagaactg120
cttgatgcagttaaggaagcggacgcactgctcgtgcgttctgctaccactgtcgatgct180
gaagtcatcgccgctgcccctaacttgaagatcgtcggtcgtgccggcgtgggcttggac240
aacgttgacatccctgctgccactgaagctggcgtcatggttgctaacgcaccgacctct300
aatattcactccgcttgtgagcacgcaatttctttgctgctgtctactgctcgccagatc360
cctgctgctgatgcgacgctgcgtgagggcgagtggaagcggtcttctttcaacggtgtg420
gaaattttcggaaaaactgtcggtatcgtcggttttggccacattggtcagttgtttgct480
cagcgtcttgctgcgtttgagaccaccattgttgcttacgatccttacgctaaccctgct540
cgtgcggctcagctgaacgttgagttggttgagttggatgagctgatgagccgttctgac600
tttgtcaccattcaccttcctaagaccaaggaaactgctggcatgtttgatgcgcagctc660
cttgctaagtccaagaagggccagatcatcatcaacgctgctcgtggtggccttgttgat720
gagcaggctttggctgatgcgattgagtccggtcacattcgtggcgctggtttcgatgtg780
tactccaccgagccttgcactgattctcctttgttcaagttgcctcaggttgttgtgact840
cctcacttgggtgcttctactgaagaggctcaggatcgtgcgggtactgacgttgctgat900
tctgtgctcaaggcgctggctggcgagttcgtggcggatgctgtgaacgtttccggtggt960
cgcgtgggcgaagaggttgctgtgtggatggatctggctcgcaagcttggtcttcttgct1020
ggcaagcttgtcgacgccgccccagtctccattgaggttgaggctcgaggcgagctttct1080
tccgagcaggtcgatgcacttggtttgtccgctgttcgtggtttgttctccggaattatc1140
gaagagtccgttactttcgtcaacgctcctcgcattgctgaagagcgtggcctggacatc1200
tccgtgaagaccaactctgagtctgttactcaccgttccgtcctgcaggtcaaggtcatt1260
actggcagcggcgcgagcgcaactgttgttggtgccctgactggtcttgagcgcgttgag1320
aagatcacccgcatcaatggccgtggcctggatctgcgcgcagagggtctgaacctcttc1380
ctgcagtacactgacgctcctggtgcactgggtaccgttggtaccaagctgggtgctgct1440
ggcatcaacatcgaggctgctgcgttgactcaggctgagaagggtgacggcgctgtcctg1500
atcctgcgtgttgagtccgctgtctctgaagagctggaagctgaaatcaacgctgagttg1560
ggtgctacttccttccaggttgatcttgactaa1593
<210>19
<211>549
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>19
atgatccgtgaagatctcgcaaacgctcgtgaacacgatccagcagcccgaggcgattta60
gaaaacgcagtggtttactccggactccacgccatctgggcacatcgagttgccaacagc120
tggtggaaatccggtttccgcggccccgcccgcgtattagcccaattcacccgattcctc180
accggcattgaaattcaccccggtgccaccattggtcgtcgcttttttattgaccacgga240
atgggaatcgtcatcggcgaaaccgctgaaatcggcgaaggcgtcatgctctaccacggc300
gtcaccctcggcggacaggttctcacccaaaccaagcgccaccccacgctctgcgacaac360
gtgacagtcggcgcgggcgcaaaaatcttaggtcccatcaccatcggcgaaggctccgca420
attggcgccaatgcagttgtcaccaaagacgtgccggcagaacacatcgcagtcggaatt480
cctgcggtagcacgcccacgtggcaagacagagaagatcaagctcgtcgatccggactat540
tacatttaa549
<210>20
<211>1305
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>20
atgaccgatgcccaccaagcggacgatgtccgttaccagccactgaacgagcttgatcct60
gaggtggctgctgccatcgctggggaacttgcccgtcaacgcgatacattagagatgatc120
gcgtctgagaacttcgttccccgttctgttttgcaggcgcagggttctgttcttaccaat180
aagtatgccgagggttaccctggccgccgttactacggtggttgcgaacaagttgacatc240
attgaggatcttgcacgtgatcgtgcgaaggctctcttcggtgcagagttcgccaatgtt300
cagcctcactctggcgcacaggctaatgctgctgtgctgatgactttggctgagccaggc360
gacaagatcatgggtctgtctttggctcatggtggtcacttgacccacggaatgaagttg420
aacttctccggaaagctgtacgaggttgttgcgtacggtgttgatcctgagaccatgcgt480
gttgatatggatcaggttcgtgagattgctctgaaggagcagccaaaggtaattatcgct540
ggctggtctgcataccctcgccaccttgatttcgaggctttccagtctattgctgcggaa600
gttggcgcgaagctgtgggtcgatatggctcacttcgctggtcttgttgctgctggtttg660
cacccaagcccagttccttactctgatgttgtttcttccactgtccacaagactttgggt720
ggacctcgttccggcatcattctggctaagcaggagtacgcgaagaagctgaactcttcc780
gtattcccaggtcagcagggtggtcctttgatgcacgcagttgctgcgaaggctacttct840
ttgaagattgctggcactgagcagttccgtgaccgtcaggctcgcacgttggagggtgct900
cgcattcttgctgagcgtctgactgcttctgatgcgaaggccgctggcgtggatgtcttg960
accggtggcactgatgtgcacttggttttggctgatctgcgtaactcccagatggatggc1020
cagcaggcggaagatctgctgcacgaggttggtatcactgtgaaccgtaacgcggttcct1080
ttcgatcctcgtccaccaatggttacttctggtctgcgtattggtactcctgcgctggct1140
acccgtggtttcgatattcctgcattcactgaggttgcagacatcattggtactgctttg1200
gctaatggtaagtccgcagacattgagtctctgcgtggccgtgtagcaaagcttgctgca1260
gattacccactgtatgagggcttggaagactggaccatcgtctaa1305
<210>21
<211>2832
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>21
ttggagctcactgtgactgaaagcaagaactccttcaatgctaagagcacccttgaagtt60
ggcgacaagtcctatgactacttcgccctctctgcagtgcctggcatggagaagctgccg120
tactccctcaaggttctcggagagaaccttcttcgtaccgaagacggcgcaaacatcacc180
aacgagcacattgaggctatcgccaactgggatgcatcttccgatccaagcatcgaaatc240
cagttcaccccagcccgtgttctcatgcaggacttcaccggtgtcccttgtgtagttgac300
ctcgcaaccatgcgtgaggcagttgctgcactcggtggcgaccctaacgacgtcaaccca360
ctgaacccagccgagatggtcattgaccactccgtcatcgtggaggctttcggccgccca420
gatgcactggctaagaacgttgagatcgagtacgagcgcaacgaggagcgttaccagttc480
ctgcgttggggttccgagtccttctccaacttccgcgttgttcctccaggaaccggtatc540
gtccaccaggtcaacattgagtacttggctcgcgtcgtcttcgacaacgagggccttgca600
tacccagatacctgcatcggtaccgactcccacaccaccatggaaaacggcctgggcatc660
ctgggctggggcgttggtggcattgaggctgaagcagcaatgctcggccagccagtgtcc720
atgctgatccctcgcgttgttggcttcaagttgaccggcgagatcccagtaggcgttacc780
gcaactgacgttgtgctgaccatcaccgaaatgctgcgcgaccacggcgtcgtccagaag840
ttcgttgagttctacggctccggtgttaaggctgttccactggctaaccgtgcaaccatc900
ggcaacatgtccccagagttcggctccacctgtgcgatgttcccaatcgacgaggagacc960
accaagtacctgcgcctcaccggccgcccagaagagcaggttgcactggtcgaggcttac1020
gccaaggcgcagggcatgtggctcgacgaggacaccgttgaagctgagtactccgagtac1080
ctcgagctggacctgtccaccgttgttccttccatcgctggccctaagcgcccacaggac1140
cgcatccttctctccgaggcaaaggagcagttccgtaaggatctgccaacctacaccgac1200
gacgctgtttccgtagacacctccatccctgcaacccgcatggttaacgaaggtggcgga1260
cagcctgaaggcggcgtcgaagctgacaactacaacgcttcctgggctggctccggcgag1320
tccttggctactggcgcagaaggacgtccttccaagccagtcaccgttgcatccccacag1380
ggtggcgagtacaccatcgaccacggcatggttgcaattgcatccatcacctcttgcacc1440
aacacctctaacccatccgtgatgatcggcgctggcctgatcgcacgtaaggcagcagaa1500
aagggcctcaagtccaagccttgggttaagaccatctgtgcaccaggttcccaggttgtc1560
gacggctactaccagcgcgcagacctctggaaggaccttgaggccatgggcttctacctc1620
tccggcttcggctgcaccacctgtattggtaactccggcccactgccagaggaaatctcc1680
gctgcgatcaacgagcacgacctgaccgcaaccgcagttttgtccggtaaccgtaacttc1740
gagggacgtatctcccctgacgttaagatgaactacctggcatccccaatcatggtcatt1800
gcttacgcaatcgctggcaccatggacttcgacttcgagaacgaagctcttggacaggac1860
caggacggcaacgacgtcttcctgaaggacatctggccttccaccgaggaaatcgaagac1920
accatccagcaggcaatctcccgtgagctttacgaagctgactacgcagatgtcttcaag1980
ggtgacaagcagtggcaggaactcgatgttcctaccggtgacaccttcgagtgggacgag2040
aactccacctacatccgcaaggcaccttacttcgacggcatgcctgtcgagccagtggca2100
gtcaccgacatccagggcgcacgcgttctggctaagctcggcgactctgtcaccaccgac2160
cacatctcccctgcttcctccattaagccaggtacccctgcagctcagtacttggatgag2220
cacggtgtggaacgccacgactacaactccctgggttccaggcgtggtaaccacgaggtc2280
atgatgcgcggcaccttcgccaacatccgcctccagaaccagctggttgacatcgcaggt2340
ggctacacccgcgacttcacccaggagggtgctccacaggcgttcatctacgacgcttcc2400
gtcaactacaaggctgctggcattccgctggtcgtcttgggcggcaaggagtacggcacc2460
ggttcttcccgtgactgggcagctaagggcactaacctgctcggaattcgcgcagttatc2520
accgagtccttcgagcgtattcaccgctccaacctcatcggtatgggcgttgtcccactg2580
cagttccctgcaggcgaatcccacgagtccctgggccttgacggcaccgagaccttcgac2640
atcaccggactgaccgcactcaacgagggcgagactcctaagactgtcaaggtcaccgca2700
accaaggagaacggcgacgtcgtcgagttcgacgcagttgtccgcatcgacaccccaggt2760
gaggctgactactaccgccacggcggcatcctgcagtacgtgctgcgtcagatggctgct2820
tcttctaagtaa2832
<210>22
<211>3423
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>22
gtgtcgactcacacatcttcaacgcttccagcattcaaaaagatcttggtagcaaaccgc60
ggcgaaatcgcggtccgtgctttccgtgcagcactcgaaaccggtgcagccacggtagct120
atttacccccgtgaagatcggggatcattccaccgctcttttgcttctgaagctgtccgc180
attggtaccgaaggctcaccagtcaaggcgtacctggacatcgatgaaattatcggtgca240
gctaaaaaagttaaagcagatgccatttacccgggatacggcttcctgtctgaaaatgcc300
cagcttgcccgcgagtgtgcggaaaacggcattacttttattggcccaaccccagaggtt360
cttgatctcaccggtgataagtctcgcgcggtaaccgccgcgaagaaggctggtctgcca420
gttttggcggaatccaccccgagcaaaaacatcgatgagatcgttaaaagcgctgaaggc480
cagacttaccccatctttgtgaaggcagttgccggtggtggcggacgcggtatgcgtttt540
gttgcttcacctgatgagcttcgcaaattagcaacagaagcatctcgtgaagctgaagcg600
gctttcggcgatggcgcggtatatgtcgaacgtgctgtgattaaccctcagcatattgaa660
gtgcagatccttggcgatcacactggagaagttgtacacctttatgaacgtgactgctca720
ctgcagcgtcgtcaccaaaaagttgtcgaaattgcgccagcacagcatttggatccagaa780
ctgcgtgatcgcatttgtgcggatgcagtaaagttctgccgctccattggttaccagggc840
gcgggaaccgtggaattcttggtcgatgaaaagggcaaccacgtcttcatcgaaatgaac900
ccacgtatccaggttgagcacaccgtgactgaagaagtcaccgaggtggacctggtgaag960
gcgcagatgcgcttggctgctggtgcaaccttgaaggaattgggtctgacccaagataag1020
atcaagacccacggtgcagcactgcagtgccgcatcaccacggaagatccaaacaacggc1080
ttccgcccagataccggaactatcaccgcgtaccgctcaccaggcggagctggcgttcgt1140
cttgacggtgcagctcagctcggtggcgaaatcaccgcacactttgactccatgctggtg1200
aaaatgacctgccgtggttccgactttgaaactgctgttgctcgtgcacagcgcgcgttg1260
gctgagttcaccgtgtctggtgttgcaaccaacattggtttcttgcgtgcgttgctgcgg1320
gaagaggacttcacttccaagcgcatcgccaccggattcattgccgatcacccgcacctc1380
cttcaggctccacctgctgatgatgagcagggacgcatcctggattacttggcagatgtc1440
accgtgaacaagcctcatggtgtgcgtccaaaggatgttgcagctcctatcgataagctg1500
cctaacatcaaggatctgccactgccacgcggttcccgtgaccgcctgaagcagcttggc1560
ccagccgcgtttgctcgtgatctccgtgagcaggacgcactggcagttactgataccacc1620
ttccgcgatgcacaccagtctttgcttgcgacccgagtccgctcattcgcactgaagcct1680
gcggcagaggccgtcgcaaagctgactcctgagcttttgtccgtggaggcctggggcggc1740
gcgacctacgatgtggcgatgcgtttcctctttgaggatccgtgggacaggctcgacgag1800
ctgcgcgaggcgatgccgaatgtaaacattcagatgctgcttcgcggccgcaacaccgtg1860
ggatacaccccgtacccagactccgtctgccgcgcgtttgttaaggaagctgccagctcc1920
ggcgtggacatcttccgcatcttcgacgcgcttaacgacgtctcccagatgcgtccagca1980
atcgacgcagtcctggagaccaacaccgcggtagccgaggtggctatggcttattctggt2040
gatctctctgatccaaatgaaaagctctacaccctggattactacctaaagatggcagag2100
gagatcgtcaagtctggcgctcacatcttggccattaaggatatggctggtctgcttcgc2160
ccagctgcggtaaccaagctggtcaccgcactgcgccgtgaattcgatctgccagtgcac2220
gtgcacacccacgacactgcgggtggccagctggcaacctactttgctgcagctcaagct2280
ggtgcagatgctgttgacggtgcttccgcaccactgtctggcaccacctcccagccatcc2340
ctgtctgccattgttgctgcattcgcgcacacccgtcgcgataccggtttgagcctcgag2400
gctgtttctgacctcgagccgtactgggaagcagtgcgcggactgtacctgccatttgag2460
tctggaaccccaggcccaaccggtcgcgtctaccgccacgaaatcccaggcggacagttg2520
tccaacctgcgtgcacaggccaccgcactgggccttgcggatcgtttcgaactcatcgaa2580
gacaactacgcagccgttaatgagatgctgggacgcccaaccaaggtcaccccatcctcc2640
aaggttgttggcgacctcgcactccacctcgttggtgcgggtgtggatccagcagacttt2700
gctgccgatccacaaaagtacgacatcccagactctgtcatcgcgttcctgcgcggcgag2760
cttggtaaccctccaggtggctggccagagccactgcgcacccgcgcactggaaggccgc2820
tccgaaggcaaggcacctctgacggaagttcctgaggaagagcaggcgcacctcgacgct2880
gatgattccaaggaacgtcgcaatagcctcaaccgcctgctgttcccgaagccaaccgaa2940
gagttcctcgagcaccgtcgccgcttcggcaacacctctgcgctggatgatcgtgaattc3000
ttctacggcctggtcgaaggccgcgagactttgatccgcctgccagatgtgcgcacccca3060
ctgcttgttcgcctggatgcgatctctgagccagacgataagggtatgcgcaatgttgtg3120
gccaacgtcaacggccagatccgcccaatgcgtgtgcgtgaccgctccgttgagtctgtc3180
accgcaaccgcagaaaaggcagattcctccaacaagggccatgttgctgcaccattcgct3240
ggtgttgtcaccgtgactgttgctgaaggtgatgaggtcaaggctggagatgcagtcgca3300
atcatcgaggctatgaagatggaagcaacaatcactgcttctgttgacggcaaaatcgat3360
cgcgttgtggttcctgctgcaacgaaggtggaaggtggcgacttgatcgtcgtcgtttcc3420
taa3423
<210>23
<211>1454
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>23
tcgcttgttggcaatgtgagcggtgagttagctttcgaccaaaccacactgcccacgaat60
cctagaaatgggatccgtgggcattcgtgtctggtttaacggccttgaaaccggacagga120
ttgcccaaagtagtcgaatttccagttcgtgggcatgtgtgtttggtcaggtttagtcgg180
gtcgaaaaatgaactcggaatcggtaaaaagtgacctcacagaatcgcttctaagggccg240
ttcaaagtgttgcctatacaaacacatgttctgactgcccgacctcttaaaatggcgtta300
aatggcgcgaaatggaaaacgcctcgtggcctggatggagcgttagtacgagaccagtac360
gagaccagacacacgtgacaaaaaatcctgaaaagtggaatcattgtcacgcctgtctgg420
tttagctctggttcgggacgggcgtggaatggaggcagtgcaccgagaccttgacccgcg480
gcccgacaagccaaaagtccccaaaacaaacccaccccgccggagacgtgaataaaattc540
gcagctcattccatcagcgtaaacgcagctttttgcatggtgagacacctttgggggtaa600
atctcacagcatgaatctggccgttaccctgcgaatgtccacagggtagctggtagtttg660
aaaatcaacgccgttgcccttaggattcagtaactggcacattttgtaatgcgctagatc720
tgtgtgctcagtcttccaggctgcttatcacagtgaaagcaaaaccaattcgtggctgcg780
aaagtcgtagccaccacgaagtccaggaggacatacagtgagccagaatggccgtccggt840
agtcctcatcgccgataagcttgcgcagtccactgttgacgcgcttggagatgcagtaga900
agtccgttgggttgacggacctaaccgcccagaactgcttgatgcagttaaggaagcgga960
cgcactgctcgtgcgttctgctaccactgtcgatgctgaagtcatcgccgctgcccctaa1020
cttgaagatcgtcggtcgtgccggcgtgggcttggacaacgttgacatccctgctgccac1080
tgaagctggcgtcatggttgctaacgcaccgacctctaatattcactccgcttgtgagca1140
cgcaatttctttgctgctgtctactgctcgccagatccctgctgctgatgcgacgctgcg1200
tgagggcgagtggaagcggtcttctttcaacggtgtggaaattttcggaaaaactgtcgg1260
tatcgtcggttttggccacattggtcagttgtttgctcagcgtcttgctgcgtttgagac1320
caccattgttgcttacgatccttacgctaaccctgctcgtgcggctcagctgaacgttga1380
gttggttgagttggatgagctgatgagccgttctgactttgtcaccattcaccttcctaa1440
gaccaaggaaactg1454
<210>24
<211>1457
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>24
cagccttgttgttatcagtagccacgatatccctttcaaacatatttgttcggaaaaaaa60
ctcttccggattacggaagtagtcccgtttattcttaccaactgggatgcgccaagcgca120
tgtcagtttttgttactcgacacatttctttcccaatctggtccggttaacacgctatac180
cgataaatgcggtttagccatatccgaagtgagagccaattcccccacaatcacgttggt240
tacatcattcccgaccacccacagccaccgtaatcagtagccacggtcacgccaatagaa300
ctcagatcaattgtgccgatgtgctgctatttagttctgcaccctcaaggccagcattca360
accccgctagagggtgaaaatgctggcctttaaggcattaaaaatcccacaataagtgga420
ctggtgcacagtttagcaaagtttgtgatgcacgcgacaaggatgggtgccgagtagctt480
tccccatgcaattcgccaccctataacgcaacctcaggggatattaacaacctagaaatt540
gaaaactttgcaaaactttgagctacccccaaattggtggctggtcaactaatccccgcg600
ttttcaatagttcggtgtcgccagtttttggccgttaccctgcgaatgtccacagggtag660
ctggtagtttgaaaatcaacgccgttgcccttaggattcagtaactggcacattttgtaa720
tgcgctagatctgtgtgctcagtcttccaggctgcttatcacagtgaaagcaaaaccaat780
tcgtggctgcgaaagtcgtagccaccacgaagtccaggaggacatacaatgaccgacttc840
cccaccctgccctctgagttcatccctggcgacggccgtttcggctgcggaccttccaag900
gttcgaccagaacagattcaggctattgtcgacggatccgcatccgtcatcggtacctca960
caccgtcagccggcagtaaaaaacgtcgtgggttcaatccgcgagggactctccgacctc1020
ttctcccttccagaaggctacgagatcatcctttccctaggtggtgcgaccgcattctgg1080
gatgcagcaaccttcggactcattgaaaagaagtccggtcacctttctttcggtgagttc1140
tcctccaagttcgcaaaggcttctaagcttgctccttggctcgacgagccagagatcgtc1200
accgcagaaaccggtgactctccggccccacaggcattcgaaggcgccgatgttattgca1260
tgggcacacaacgaaacctccactggcgccatggttccagttcttcgccccgaaggctct1320
gaaggctccctggttgccattgacgcaacctccggcgctggtggactgccagtagacatc1380
aagaactccgatgtttactacttctccccacagaagtgcttcgcatccgacggtggcctg1440
tggcttgcagcgatgag1457
<210>25
<211>1431
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>25
tccacttggctgactcctacttcctgatcgcgcacttccactacaccctcttcggtaccg60
tggtgttcgcatcgtgtgcaggcgtttacttctggttcccgaagatgactggccgcatga120
tggacgagcgtcttggcaagatccacttctggttgaccttcgtcggtttccacggaacct180
tcctcatccagcactgggtgggcaacatgggtatgccacgtcgttacgctgactacctgg240
attctgatggtttcaccatctacaaccagatctccaccgtgttctccttcctgcttggcc300
tgtctgtcattccattcatctggaacgtcttcaagtcctggcgctacggtgagctcgtta360
ccgttgatgatccttggggttacggcaactccctggagtgggcaacctcctgccctcctc420
ctcgccacaacttcgcatccttgcctcgtatccgctccgagcgccctgcgttcgagctgc480
actacccgcacatgattgaacgcatgcgcgcagaggcacacactggacatcacgatgata540
ttaatgctccagaattgggtaccgccccagcccttgcatctgactccagccgctaaaagc600
tggccgttaccctgcgaatgtccacagggtagctggtagtttgaaaatcaacgccgttgc660
ccttaggattcagtaactggcacattttgtaatgcgctagatctgtgtgctcagtcttcc720
aggctgcttatcacagtgaaagcaaaaccaattcgtggctgcgaaagtcgtagccaccac780
gaagtccaggaggacatacagtgactgaactcatccagaatgaatcccaagaaatcgctg840
agctggaagccggccagcaggttgcattgcgtgaaggttatcttcctgcggtgatcacag900
tgagcggtaaagaccgcccaggtgtgactgccgcgttctttagggtcttgtccgctaatc960
aggttcaggtcttggacgttgagcagtcaatgttccgtggctttttgaacttggcggcgt1020
ttgtgggtatcgcacctgagcgtgtcgagaccgtcaccacaggcctgactgacaccctca1080
aggtgcatggacagtccgtggtggtggagctgcaggaaactgtgcagtcgtcccgtcctc1140
gttcttcccatgttgttgtggtgttgggtgatccggttgatgcgttggatatttcccgca1200
ttggtcagaccctggcggattacgatgccaacattgacaccattcgtggtatttcggatt1260
accctgtgaccggcctggagctgaaggtgactgtgccggatgtcagccctggtggtggtg1320
aagcgatgcgtaaggcgcttgctgctcttacctctgagctgaatgtggatattgcgattg1380
agcgttctggtttgctgcgtcgttctaagcgtctggtgtgcttcgattgtg1431
<210>26
<211>1466
<212>dna
<213>谷氨酸棒杆菌(corynebacteriumglutamicum)
<400>26
agcgatctagttcgcaaccagcgccgaaccctcgacatgaatcaagagcatctagctaaa60
gccatagacaaaacccgattctgggtaatcgacctcgaaaaaggaatatcccggagaacc120
ggtgaaccattcaccgtcgatccaatgatgtgtatgaagcttgcagaggctctcgacctt180
gatccagtagaggttttaagtgcagcgaaagttcccgaatctgaatggccaaatttttcg240
aagatcatctcccaaagtgactatgtgaagcatgtagacataacaagactgaccgtccgc300
cagcaagatctagtcatcaatctggtcaacgaatttaaggagcttaatttgaacacgcca360
tatgaaaagtgactaatttcaacccaaacgggagcctaagtgaaatgaaataatcccctc420
accaactggcgacattcaaacaccgtttcatttccaaacatcgagccaagggaaaagaaa480
gcccctaagccccgtgttattaaatggagactttttggagacctcaagccaaaaaggggc540
attttcattaagaaaatacccctttgacctggtgttattgagctggagaagagacttgaa600
ctctcaacctacgcattacaagtgcgttgcgctgtagctgccaattattccgggcttgtg660
acccgctacccgataaataggtcggctgaaaaatttcgttgcaatatcaacaaaaaggcc720
tatcattgggaggtgtcgcaccaagtacttttgcgaagcgccatctgacggattttcaaa780
agatgtatatgctcggtgcggaaacctacgaaaggattttttacccatgttgagttttgc840
gacccttcgtggccgcatttcaacagttgacgctgcaaaagccgcacctccgccatcgcc900
actagccccgattgatctcactgaccatagtcaagtggccggtgtgatgaatttggctgc960
gagaattggcgatattttgctttcttcaggtacgtcaaatagtgacaccaaggtacaagt1020
tcgagcagtgacctctgcgtacggtttgtactacacgcacgtggatatcacgttgaatac1080
gatcaccatcttcaccaacatcggtgtggagaggaagatgccggtcaacgtgtttcatgt1140
tgtaggcaagttggacaccaacttctccaaactgtctgaggttgaccgtttgatccgttc1200
cattcaggctggtgcgaccccgcctgaggttgccgagaaaatcctggacgagttggagca1260
atcccctgcgtcttatggtttccctgttgcgttgcttggctgggcaatgatgggtggtgc1320
tgttgctgtgctgttgggtggtggatggcaggtttccctaattgcttttattaccgcgtt1380
cacgatcattgccacgacgtcatttttgggaaagaagggtttgcctactttcttccaaaa1440
tgttgttggtggttttattgccacgc1466
- 还没有人留言评论。精彩留言会获得点赞!