能够与流感病毒的核内蛋白质结合的抗体、使用其的复合材料、检测装置和方法与流程
通过引用的方式并入2018年5月31日创建和文件大小为20,601比特的名为“对cn的p10009397序列表.txt”的ascii文本文件中所含的材料。
背景
1.技术领域
本发明涉及能够与流感病毒的核内蛋白质结合的抗体、使用其的复合材料、检测装置和方法。
2.相关技术的描述
专利文献1和专利文献2公开了各自能够与流感病毒结合的抗体。至少部分在专利文献1和专利文献2中公开的抗体衍生自羊驼。专利文献1和专利文献2通过引用的方式并入本文作为参考。
引文清单
专利文献
专利文献1:美国专利号9,771,415
专利文献2:美国专利号9,868,778
发明概述
本发明的目的是提供能够与流感病毒的核内蛋白质结合的新抗体、使用其的复合材料、检测装置和方法。
本发明是包含氨基酸序列的抗体,其中氨基酸序列按n至c方向包含以下结构域:n-fr1-cdr1-fr2-cdr2-fr3-cdr3-fr4-c,其中
fr指构架区氨基酸序列并且cdr指互补决定区氨基酸序列;
cdr1包含由seqidno:1代表的氨基酸序列;
cdr2包含由seqidno:2代表的氨基酸序列;
cdr3包含由seqidno:3代表的氨基酸序列;并且
抗体能够与甲型流感病毒的核内蛋白质结合。
本发明提供能够与流感病毒的核内蛋白质结合的新抗体。本发明还提供包含新抗体的复合材料。本发明还提供使用新抗体的检测装置和检测方法。
附图简述
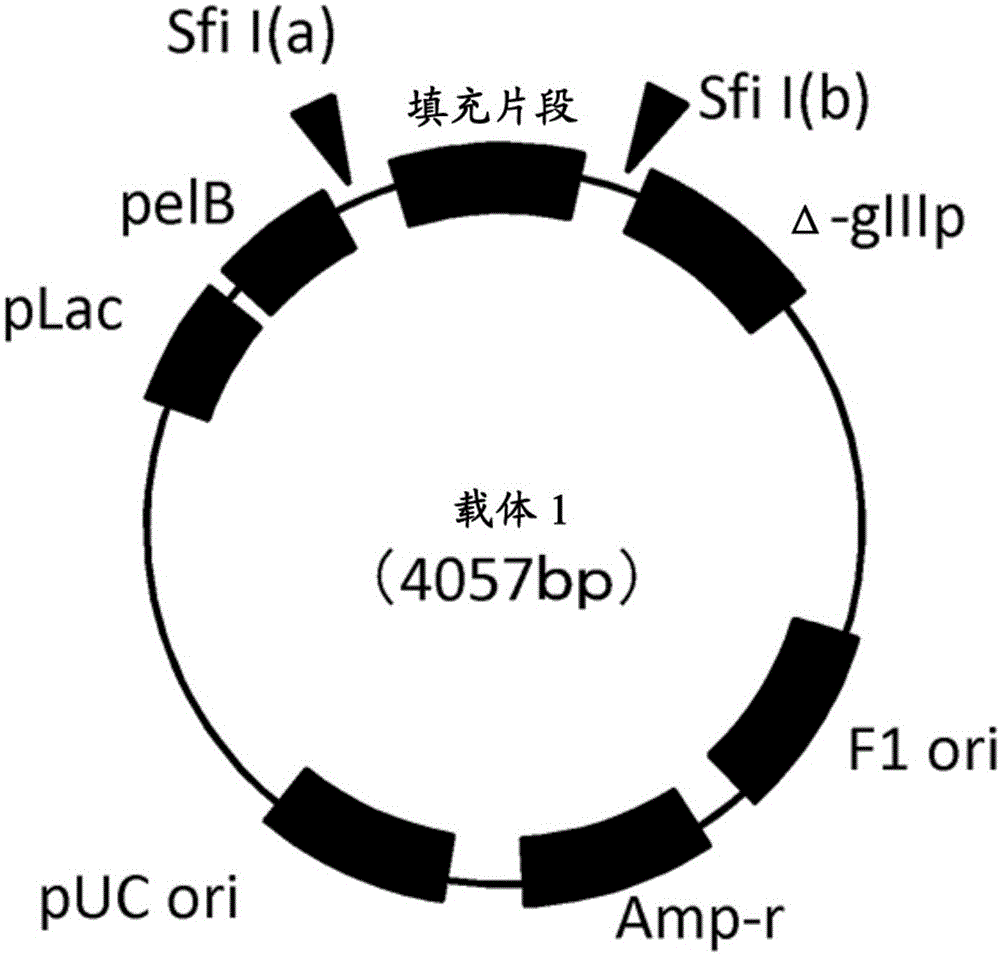
图1a是用来连接vhh抗体的基因文库中所含多种基因的载体图。
图1b显示图1a中所示载体图的细节。
图2显示用来表达vhh抗体的载体图。
图3a是显示vhh抗体(浓度:0.78nm)与重组核内蛋白质的结合能力的spr评估结果图,所述vhh抗体包含seqidno:8代表的氨基酸序列。
图3b是显示vhh抗体(浓度:1.56nm)与重组核内蛋白质的结合能力的spr评估结果图,所述vhh抗体包含seqidno:8代表的氨基酸序列。
图3c是显示vhh抗体(浓度:3.125nm)与重组核内蛋白质的结合能力的spr评估结果图,所述vhh抗体包含seqidno:8代表的氨基酸序列。
图3d是显示vhh抗体(浓度:6.25nm)与重组核内蛋白质的结合能力的spr评估结果图,所述vhh抗体包含seqidno:8代表的氨基酸序列。
图3e是显示vhh抗体(浓度:12.5nm)与重组核内蛋白质的结合能力的spr评估结果图,所述vhh抗体包含seqidno:8代表的氨基酸序列。
图3f是显示vhh抗体(浓度:25nm)与重组核内蛋白质的结合能力的spr评估结果图,所述vhh抗体包含seqidno:8代表的氨基酸序列。
图4a是显示vhh抗体与甲型流感病毒h1n1a/北海道/11/2002的交叉反应性的测量结果图,所述抗体包含seqidno:8代表的氨基酸序列。
图4b是显示vhh抗体与甲型流感病毒h1n1a/兵库/ys/2011的交叉反应性的测量结果图,所述抗体包含seqidno:8代表的氨基酸序列。
图4c是显示vhh抗体与甲型流感病毒h1n1a/北海道/6-5/2014的交叉反应性的测量结果图,所述抗体包含seqidno:8代表的氨基酸序列。
图4d是显示vhh抗体与甲型流感病毒h3n2a/北海道/m1/2014的交叉反应性的测量结果图,所述抗体包含seqidno:8代表的氨基酸序列。
图4e是显示vhh抗体与甲型流感病毒h5n1a/鸭/北海道/vac-3/2007的交叉反应性的测量结果图,所述抗体包含seqidno:8代表的氨基酸序列。
图4f是显示vhh抗体与甲型流感病毒h7n7a/鸭/北海道/vac-2/2004的交叉反应性的测量结果图,所述抗体包含seqidno:8代表的氨基酸序列。
图4g是显示vhh抗体与甲型流感病毒h7n9a/鸭/蒙古/119/2008的交叉反应性的测量结果图,所述抗体包含seqidno:8代表的氨基酸序列。
图4h是显示vhh抗体与乙型流感病毒b/北海道/30-4/2014的交叉反应性的测量结果图,所述抗体包含seqidno:8代表的氨基酸序列。
实施方案详述
本发明的抗体能够与甲型流感病毒结合。特别地,本发明的抗体能够与甲型流感病毒的核内蛋白质结合。如专利文献1中公开,能够与流感病毒结合的抗体包含氨基酸序列,所述氨基酸序列按n至c方向包含以下结构域:
n-fr1-cdr1-fr2-cdr2-fr3-cdr3-fr4-c
其中
fr指构架区氨基酸序列并且cdr指互补决定区氨基酸序列。
在本发明中,cdr1包含drtdsnyamg(seqidno:1)代表的氨基酸序列
在本发明中,cdr2包含aisgtgyvtgyadsarn(seqidno:2)代表的氨基酸序列。
在本发明中,cdr3包含tsdqrypgprssgydy(seqidno:3)代表的氨基酸序列。
合乎需要地,cdr1、cdr2和cdr3分别由seqidno:1、seqidno:2和seqidno:3代表。此种情况下,更合乎需要地,fr1、fr2、fr3和fr4分别地包含qvqlvesggglvqtggplrlscavs(seqidno:4)、wfrqapgkerefva(seqidno:5)、rftlsrdngknavylqmnslepadtavyycaa(seqidno:6)和wgqgtqvtvss(seqidno:7)代表的氨基酸序列。
换句话说,合乎需要的是本发明的抗体包含qvqlvesggglvqtggplrlscavsdrtdsnyamgwfrqapgkerefvaaisgtgyvtgyadsarnrftlsrdngknavylqmnslepadtavyycaatsdqrypgprssgydywgqgtqvtvss(seqidno:8)代表的氨基酸序列。包含seqidno:8代表的氨基酸序列的抗体与甲型流感病毒之外的流感病毒没有抗原交叉反应性。甲型流感病毒之外的流感病毒的例子是乙型流感病毒。
注意在本说明书中,“包含”包括“由……组成”和“基本上由……组成”。
本发明的抗体可以应用于检测装置中或应用于检测甲型流感病毒的核内蛋白质的检测方法中。在这种情况下,本发明的抗体可以按照结合于另一种材料的复合材料状态(例如,以其中本发明抗体已经与选自固相支持物和标记物质中的至少一种结合的复合材料状态)使用。
只要固相支持物是在用于抗原-抗体反应的反应体系的溶剂中不溶的支持物,不限制固相支持物的形状和材料。固相支持物的形状的例子是平板、珠、盘、管、滤器和膜。固相支持物的材料的例子是聚合物如聚对苯二甲酸乙二酯、醋酸纤维素、聚碳酸酯、聚苯乙烯或聚甲基丙烯酸甲酯、金属如金、银或铝或玻璃。使用已知的方法如物理吸附法、共价结合法、离子键合法或交联法作为使抗体结合于固相支持物的方法。
例如,使用标记物质如荧光物质、发光物质、染料、酶或放射性物质。使用已知的方法如物理吸附法、共价结合法、离子键合法或交联法作为使抗体结合于标记物质的方法。
在使用本发明抗体的检测方法中,使包含抗体的复合材料与分析物接触。随后,基于分析物中所含甲型流感病毒的核内蛋白质和复合材料中所含抗体的抗原-抗体反应,检测物理量的变化。物理量的例子是发光强度、色度、透光性、浊度、吸光度或辐射剂量。使用已知的方法如酶免疫测定法、免疫色谱法、胶乳凝集反应法、放射免疫测定法、荧光免疫测定法或表面等离子体共振光谱法作为检测方法的具体例子。
使用本发明抗体的检测装置包括基于抗原-抗体反应检测变化的任一个物理量的检测器。检测器包含已知的装置如光度计、分光镜或剂量计。
抗体不仅可以作为与另一种材料结合的复合材料使用,还可以作为包含本发明抗体的组合物使用或作为包含本发明抗体的试剂盒使用。
实施例
(发明的实施例1)
根据以下方法制备能够与甲型流感病毒h1n1中所包含的核内蛋白质结合的vhh抗体(即,重链抗体的重链可变结构域)。下文中将核内蛋白质称作“np”。
(免疫接种羊驼和获得单核的细胞)
为了形成vhh抗体基因文库,使用衍生自甲型流感病毒h1n1(a/puertorico/8/34/mountsinai)的重组核内蛋白质(seqidno:24)作为抗原,对羊驼免疫接种。由higetashoyu有限公司使用短小芽孢杆菌(brevibacillus)表达系统制备重组核内蛋白质。在施用至羊驼之前用佐剂配制重组核内蛋白质。
下文显示用于发明的实施例1中的重组核内蛋白质(seqidno:24)。
masqgtkrsyeqmetdgerqnateirasvgkmiggigrfyiqmctelklsdyegrliqnsltiermvlsafderrnkyleehpsagkdpkktggpiyrrvngkwmrelilydkeeirriwrqanngddataglthmmiwhsnlndatyqrtralvrtgmdprmcslmqgstlprrsgaagaavkgvgtmvmelvrmikrgindrnfwrgengrktriayermcnilkgkfqtaaqkammdqvresrnpgnaefedltflarsalilrgsvahksclpacvygpavasgydferegyslvgidpfrllqnsqvyslirpnenpahksqlvwmachsaafedlrvlsfikgtkvlprgklstrgvqiasnenmetmesstlelrsrywairtrsggntnqqrasagqisiqptfsvqrnlpfdrttimaafngntegrtsdmrteiirmmesarpedvsfqgrgvfelsdekaaspivpsfdmsnegsyffgdnaeeydn(seqidno:24)
具体而言,将具有100微克/毫升浓度的重组核内蛋白质施用至羊驼。在一周后,具有相同浓度的重组核内蛋白质再次施用至羊驼。以这种方式,用重组核内蛋白质免疫接种羊驼,五周五次。在另一周后,抽取羊驼血液。随后,从血液如下获得单核的细胞。
将血细胞分离液(从cosmobioco.可获得,商品名:lymphoprep)添加至淋巴细胞分离管(从greinerbio-oneco.,ltd.可获得,商品名:leucosep)。随后,将溶液以1000xg在20摄氏度的温度离心一分钟。
用肝素处理从羊驼抽取的血液。随后,将等量的磷酸缓冲盐水(下文中称为“pbs”)添加至如此处理的血液以获得样品溶液。随后,将样品溶液添加至含有血细胞分离液的淋巴细胞分离管。
将淋巴细胞分离管在20摄氏度的温度以800xg离心三十分钟。
收集含有单核的细胞的级分。添加三倍体积的pbs。将级分在20摄氏度的温度以300xg离心五分钟。用pbs温和地悬浮沉淀物。在悬浮后,分出10微升悬液以计数细胞数目。将剩余悬液在20摄氏度的温度以300xg离心五分钟。
将具有体积2毫升的rna贮液(商品名:rnalater)添加至沉淀物。随后,温和地悬浮溶液。将悬液注入各自具有1.5毫升体积的二根管。每根管包含1毫升悬液。该管贮存在-20摄氏度的温度。分出供计数细胞数的悬液(5微升)与türk溶液(15微升)混合,并用计数板计数单核的细胞的数目。
(形成vhh抗体的cdna基因文库)
随后,从单核的细胞提取总rna,并根据以下方法形成vhh抗体的cdna基因文库。在以下方法中,使用无rna酶级试剂和仪器。
将总rna分离试剂(商品名:trizol试剂,1毫升)添加至单核的细胞级分。将试剂温和地混合并在室温静置五分钟。将氯仿(200微升)添加至试剂,并强烈振摇试剂十五秒。将试剂在室温静置二–三分钟。随后,将试剂以12000xg或更小在4摄氏度的温度离心15分钟。
将上清液移至一根新管。向该管添加无rna酶水和氯仿(各200微升)。此外,向该管添加500毫升异丙醇。将管中所含液体用涡旋混合器搅拌。将液体在室温静置十分钟。随后,将液体以12000xg或更小在4摄氏度的温度离心十五分钟。移除上清液,并用一毫升75%的乙醇漂洗沉淀物。将这种溶液以7500xg或更小在四摄氏度的温度离心五分钟。将溶液干燥以获得总rna。将获得的总rna溶解于无rna酶的水中。
为了从总rna获得cdna,使用包含逆转录酶的试剂盒。从takarabioinc.以商品名primescriptii第一链cdna合成试剂盒可获得试剂盒。使用试剂盒中所含的随机6聚和寡聚dt引物作为引物。根据试剂盒随附的标准方案获得cdna。
通过pcr方法从cdna获得羊驼中所含的vhh抗体的基因。从takarabioinc.以商品名ex-taq可获得pcr用酶。
混合以下试剂以获得混合物溶液。
对混合物溶液实施以下pcr方法。
首先,将混合物溶液在95摄氏度的温度加热两分钟。
随后,根据以下循环变动混合物溶液的温度。
九十六摄氏度三十秒,
五十二摄氏度三十秒,和
六十八摄氏度四十秒
这个循环重复三十次。
最后,将混合物溶液在六十八摄氏度的温度加热四分钟并在四摄氏度的温度储存。
以下引物用于本pcr方法中。
引物1:5’-ggtggtcctggctgc-3’(seqidno:9)
引物2:5’-ctgctcctcgcggcccagccggccatggctsagktgcagctcgtggagtc-3’(seqidno:10)
引物3:5’-tggggtcttcgctgtggtgcg-3’(seqidno:11)
引物4:5’-ttgtggttttggtgtcttggg-3’(seqidno:12)
引物5:5’-tttgctctgcggccgcagaggccgtggggtcttcgctgtggtgcg-3’(seqidno:13)
引物6:5’-tttgctctgcggccgcagaggccgattgtggttttggtgtcttggg-3’(seqidno:14)
(参考文献:biomedenvironsci.,2012;27(2):118-121)
实施了三个pcr测定法。
在第一pcr测定法中,使用包含cdna、引物1和引物3的引物套装a和包含cdna、引物1和引物4的引物套装b。
在第二pcr测定法中,使用包含引物套装a扩增的基因、引物2和引物3的引物套装c;和包含引物套装b扩增的基因、引物2和引物4的引物套装d。
在第三pcr测定法中,使用包含引物套装c扩增的基因、引物2和引物5的引物套装e;和包含引物套装d扩增的基因、引物2和引物6的引物套装f。
以这种方式,形成vhh抗体的基因文库。换句话说,vhh抗体的基因文库包含用引物套装e和f扩增的基因。
(形成噬菌体文库)
接下来,根据以下方法从vhh抗体的基因文库形成噬菌体文库。
用限制性酶sfii处理质粒载体1(4057bp,参见图1a),所述质粒载体1衍生自市售质粒puc119(例如,从takarabioinc.可获得)。图1a中所示的限制性酶位点sfii(a)由ggcccagccggcc(seqidno:15)代表的基因序列组成。限制性酶位点sfii(b)由ggcctctgcggcc(seqidno:16)代表的基因序列组成。图1b显示质粒载体1的详细载体图。
质粒载体1由以下基因序列组成。
gacgaaagggcctcgtgatacgcctatttttataggttaatgtcatgataataatggtttcttagacgtcaggtggcacttttcggggaaatgtgcgcggaacccctatttgtttatttttctaaatacattcaaatatgtatccgctcatgagacaataaccctgataaatgcttcaataatattgaaaaaggaagagtatgagtattcaacatttccgtgtcgcccttattcccttttttgcggcattttgccttcctgtttttgctcacccagaaacgctggtgaaagtaaaagatgctgaagatcagttgggtgcacgagtgggttacatcgaactggatctcaacagcggtaagatccttgagagttttcgccccgaagaacgttttccaatgatgagcacttttaaagttctgctatgtggcgcggtattatcccgtattgacgccgggcaagagcaactcggtcgccgcatacactattctcagaatgacttggttgagtactcaccagtcacagaaaagcatcttacggatggcatgacagtaagagaattatgcagtgctgccataaccatgagtgataacactgcggccaacttacttctgacaacgatcggaggaccgaaggagctaaccgcttttttgcacaacatgggggatcatgtaactcgccttgatcgttgggaaccggagctgaatgaagccataccaaacgacgagcgtgacaccacgatgcctgtagcaatggcaacaacgttgcgcaaactattaactggcgaactacttactctagcttcccggcaacaattaatagactggatggaggcggataaagttgcaggaccacttctgcgctcggcccttccggctggctggtttattgctgataaatctggagccggtgagcgtgggtctcgcggtatcattgcagcactggggccagatggtaagccctcccgtatcgtagttatctacacgacggggagtcaggcaactatggatgaacgaaatagacagatcgctgagataggtgcctcactgattaagcattggtaactgtcagaccaagtttactcatatatactttagattgatttaaaacttcatttttaatttaaaaggatctaggtgaagatcctttttgataatctcatgaccaaaatcccttaacgtgagttttcgttccactgagcgtcagaccccgtagaaaagatcaaaggatcttcttgagatcctttttttctgcgcgtaatctgctgcttgcaaacaaaaaaaccaccgctaccagcggtggtttgtttgccggatcaagagctaccaactctttttccgaaggtaactggcttcagcagagcgcagataccaaatactgtccttctagtgtagccgtagttaggccaccacttcaagaactctgtagcaccgcctacatacctcgctctgctaatcctgttaccagtggctgctgccagtggcgataagtcgtgtcttaccgggttggactcaagacgatagttaccggataaggcgcagcggtcgggctgaacggggggttcgtgcacacagcccagcttggagcgaacgacctacaccgaactgagatacctacagcgtgagctatgagaaagcgccacgcttcccgaagggagaaaggcggacaggtatccggtaagcggcagggtcggaacaggagagcgcacgagggagcttccagggggaaacgcctggtatctttatagtcctgtcgggtttcgccacctctgacttgagcgtcgatttttgtgatgctcgtcaggggggcggagcctatggaaaaacgccagcaacgcggcctttttacggttcctggccttttgctggccttttgctcacatgttctttcctgcgttatcccctgattctgtggataaccgtattaccgcctttgagtgagctgataccgctcgccgcagccgaacgaccgagcgcagcgagtcagtgagcgaggaagcggaagagcgcccaatacgcaaaccgcctctccccgcgcgttggccgattcattaatgcagctggcacgacaggtttcccgactggaaagcgggcagtgagcgcaacgcaattaatgtgagttagctcactcattaggcaccccaggctttacactttatgcttccggctcgtatgttgtgtggaattgtgagcggataacaatttcacacaggaaacagctatgaccatgattacgccaagcttcgaaggagacagtcataatgaaatacctgctgccgaccgctgctgctggtctgctgctcctcgcggcccagccggccatggagctcaagatgacacagactacatcctccctgtcagcctctctgggagacagagtcaccatcagttgcagggcaagtcaggacattagcgattatttaaactggtatcagcagaaaccagatggaactgttaaactcctgatctattacacatcaagtttacactcaggagtcccatcaaggttcagtggcggtgggtctggaacagattattctctcaccattagcaacctggagcaagaagatattgccacttacttttgccaacagggtaatacgcttccgtggacgtttggtggaggcaccaagctggaaatcaaacgggctgatgctgcaccaactgtaggcctctgcggccgcagagcaaaaactcatctcagaagaggatctgaatggggccgcatagggttccggtgattttgattatgaaaagatggcaaacgctaataagggggctatgaccgaaaatgccgatgaaaacgcgctacagtctgacgctaaaggcaaacttgattctgtcgctactgattacggtgctgctatcgatggtttcattggtgacgtttccggccttgctaatggtaatggtgctactggtgattttgctggctctaattcccaaatggctcaagtcggtgacggtgataattcacctttaatgaataatttccgtcaatatttaccttccctccctcaatcggttgaatgtcgcccttttgtctttagcgctggtaaaccatatgaattttctattgattgtgacaaaataaacttattccgtggtgtctttgcgtttcttttatatgttgccacctttatgtatgtattttctacgtttgctaacatactgcgtaataaggagtcttaataagaattcactggccgtcgttttacaacgtcgtgactgggaaaaccctggcgttacccaacttaatcgccttgcagcacatccccctttcgccagctggcgtaatagcgaagaggcccgcaccgatcgcccttcccaacagttgcgcagcctgaatggcgaatggcgcctgatgcggtattttctccttacgcatctgtgcggtatttcacaccgcatatgaaaattgtaagcgttaatattttgttaaaattcgcgttaaatttttgttaaatcagctcattttttaaccaataggccgaaatcggcaaaatcccttataaatcaaaagaatagaccgagatagggttgagtgttgttccagtttggaacaagagtccactattaaagaacgtggactccaacgtcaaagggcgaaaaaccgtctatcagggcgatggcccactacgtgaaccatcaccctaatcaagttttttggggtcgaggtgccgtaaagcactaaatcggaaccctaaagggagcccccgatttagagcttgacggggaaagccggcgaacgtggcgagaaaggaagggaagaaagcgaaaggagcgggcgctagggcgctggcaagtgtagcggtcacgctgcgcgtaaccaccacacccgccgcgcttaatgcgccgctacagggcgcgtcccatatggtgcactctcagtacaatctgctctgatgccgcatagttaagccagccccgacacccgccaacacccgctgacgcgccctgacgggcttgtctgctcccggcatccgcttacagacaagctgtgaccgtctccgggagctgcatgtgtcagaggttttcaccgtcatcaccgaaacgcgcga(seqidno:17)
类似地,用限制性酶sfii处理vhh抗体的基因文库。以这种方式,获得vhh抗体基因片段。
如此处理的质粒载体1与vhh抗体基因片段按1:2的比率混合。将酶(从toyobo有限公司可获得,商品名:ligationhighver.2)注入混合物溶液。将混合物溶液在16摄氏度的温度静置两小时。以这种方式,将vhh抗体基因片段各自连接入质粒载体1。
将大肠杆菌(从takarabioinc.可获得,商品名:hst02)用如此连接的质粒载体1转染。
随后,将大肠杆菌在含有100微克/毫升浓度的氨苄青霉素的2yt平板培养基上温育十五小时。以这种方式,获得噬菌体文库,所述噬菌体各自展示从vhh抗体的基因文库中所含基因片段获得的蛋白质。
在温育后,通过计数2yt平板培养基上形成的单菌落数目,计算文库的浓度。作为结果,噬菌体文库具有5x107/毫升的浓度。
(生物淘洗)
根据以下方法从噬菌体文库获得能够与核内蛋白质特异性结合的vhh抗体。
为了从表达vhh抗体的噬菌体中提取能够与抗原结合的每一克隆,实施生物淘洗两次。
将引入了vhh抗体的基因文库中所含vhh抗体基因片段的大肠杆菌(hst02)在30摄氏度的温度,在含有100微克/毫升氨苄青霉素和1%葡萄糖的2ytag培养基中温育,直至表示吸光度的od600值达到1.0为止。2ytag培养基具有100毫升的体积。以这种方式,增殖大肠杆菌。
将辅助噬菌体(从invitrogen公司可获得,商品名:m13ko7)以这种方式添加至大肠杆菌培养基,从而感染复数(moi)是大约20。
随后,将培养基在37摄氏度的温度温育约三十分钟。随后,将培养基以4000转/分钟的转速离心十分钟以收集大肠杆菌。将大肠杆菌在30摄氏度的温度在2ytak培养基(即,含有100微克/毫升氨苄青霉素和50微克/毫升卡那霉素的2yt培养基)中温育过夜,并以213转/分钟离心。2ytak培养基具有100毫升的体积。
将含有如此温育的大肠杆菌的温育液体(100毫升)注入两根离心管(体积:各50毫升)。将两根离心管以4000转/分钟的转速离心十分钟。随后,收集上清液(各自20毫升)。
将上清液(40毫升)添加至含有nacl(2.5m)的20%聚乙二醇溶液(10毫升)。随后,将混合物溶液颠倒混合。随后,混合物溶液在冰上冷却大约一小时。将混合物溶液以4000转/分钟的转速离心十分钟。随后,移除上清液。将含有10%甘油的pbs注入沉淀物。最后,将沉淀物蓬松并溶解。以这种方式,获得各自展示vhh抗体的噬菌体文库。
(筛选能够与np特异性结合的vhh抗体)
(a)np抗原的固定
将np与pbs混合以制备np溶液。np的浓度是2微克/毫升。将np溶液(2毫升)注入免疫管(从nuncco.,ltd.可获得)。将np溶液静置在免疫管中过夜。以这种方式,将np固定在免疫管中。
随后,用pbs洗涤免疫管的内部三次。
用含有3%脱脂乳(从wakopurechemicalindustries,ltd.可获得)的pbs填充免疫管的内部。以这种方式,将np作为免疫管中的抗原封闭。
将免疫管在室温静置一小时。随后,用pbs洗涤免疫管的内部三次。
(b)淘洗
各自展示vhh抗体的噬菌体的文库(浓度:大约5e+11/毫升)与3毫升含有3%脱脂乳的pbs混合,以制备混合物溶液。将混合物溶液注入其中固定有np抗原的免疫管。
将石蜡膜形成的盖附于免疫管上。随后,将免疫管在旋转器中颠倒转动十分钟。
将免疫管在室温静置一小时。
用含有0.05%吐温20的pbs洗涤免疫管的内部十次。下文中这类pbs称作“pbst”。
用pbst填充免疫管的内部。随后,静置免疫管十分钟。随后,用pbst洗涤免疫管的内部十次。
为了提取各自展示与np抗原结合的vhh抗体的噬菌体,将100mm三甲胺溶液(1毫升)注入免疫管。
将石蜡膜形成的盖附于免疫管上。随后,将免疫管在旋转器中颠倒转动十分钟。
为了中和溶液,将该溶液移至含有1ml0.5mtris/hcl(ph:6.8)的管。再次,使用100mm三甲胺溶液(1毫升)重复噬菌体的提取。以这种方式,获得3ml提取液。
将提取液(1ml)与9ml大肠杆菌hst02混合。将混合物溶液在30摄氏度的温度静置一小时。
为了计数菌落的数目,将10微升含有大肠杆菌hst02的混合物溶液分布到包含2tya培养基(10毫升/平板)的小平板上。
将其余的混合物溶液离心。移除上清液,并将沉淀物分布到包含2tya培养基(40毫升/平板)的大平板上。将这两块平板在30摄氏度的温度静置过夜。以这种方式,实施第一淘洗。
按照与第一淘洗流程相同的方式实施第二淘洗。换句话说,重复淘洗。以这种方式,纯化了其上展示vhh抗体的单克隆噬菌体。
在第二淘洗后,用牙签挑出大肠杆菌菌落。挑出的菌落置于96孔平底平板的一个孔中。重复这个步骤。一个孔含有200微升2ytag培养基。
将孔中所含溶液以213转/分钟的转速在30摄氏度的温度搅拌。
收集含有长成的大肠杆菌的溶液(50微升)。将收集的溶液与平板中所含的50微升2yta培养基混合。2yta培养基含有辅助噬菌体,从而感染复数设定成20。随后,将溶液在37摄氏度的温度静置四十分钟。
将包含2yta培养基的平板以1800转/分钟离心二十分钟。移除上清液。沉淀物含有大肠杆菌。将沉淀物与200微升2ytak培养基混合。将混合物溶液在30摄氏度的温度静置过夜。
混合物溶液以1800转/分钟离心二十分钟。收集含有大肠杆菌的上清液。
(c)通过elisa定性评估噬菌体展示的vhh抗体和抗原
将具有2微克/毫升浓度的核内蛋白质溶液作为抗原注入96孔板(从thermoscientific公司可获得,商品名:maxisorp)的各孔。每个孔中核内蛋白质溶液的体积是50微升。将96孔板在4摄氏度的温度静置过夜。以这种方式,在每个孔中固定np抗原。
用pbs洗涤每个孔三次。随后,将含有3%脱脂乳(从wakopurechemicalindustries,ltd.可获得)的pbs注入每个孔(200微升/孔)。将96孔板在室温静置一小时。以这种方式,在每个孔中封闭核内蛋白质。随后,用pbs洗涤每个孔三次。
将各自展示vhh抗体的单克隆噬菌体注入每个孔(50微升/孔)。随后,将96孔板静置一小时。以这种方式,噬菌体与np抗原反应。
用pbst洗涤每个孔三次。随后,将抗m13抗体(从abcam公司可获得,商品名:ab50370,10,000倍稀释度)注入每个孔(50微升/孔)。随后,用pbst洗涤每个孔三次。
将生色试剂(从thermoscientific可获得,商品名:1-stepultratmb-elisa)注入每个孔(50微升/孔)。将96孔板静置两分钟以使生色试剂与抗体反应。
硫酸水溶液(常规,即,1n)以50微升/孔的浓度注入每个孔,以终止反应。
在450纳米的波长处测量溶液的吸光度。
选择各自具有良好吸光度测量结果的十四个孔。由greiner公司分析选择的十四孔中所含的噬菌体内包含的dna序列。下文将描述dna序列的分析结果。发现了以下一个dna序列。
caggtgcagctcgtggagtctggggggggattggtgcagactgggggcccgctgagactctcctgcgcagtctctgatcgcaccgacagtaactatgccatgggctggttccgccaggctccagggaaggagcgtgagtttgtagcagctattagcggcactggttatgtcactggctatgcagactccgcgaggaatcgcttcaccctctccagagacaacggcaagaacgcggtgtatctgcaaatgaacagcctggaacctgcggacacggccgtttattactgtgcagccacatcagatcaacgctatcctggtcctcgctcctcgggatatgactactggggccaggggacccaggtcaccgtctcctca(seqidno:18)
从seqidno:18代表的dna序列合成的蛋白质由以下氨基酸序列组成。
qvqlvesggglvqtggplrlscavsdrtdsnyamgwfrqapgkerefvaaisgtgyvtgyadsarnrftlsrdngknavylqmnslepadtavyycaatsdqrypgprssgydywgqgtqvtvss(seqidno:8)
(抗npvhh抗体的表达)
使用载体pra2(+)作为表达载体(参见图2)。载体pra2(+)购自merckmillipore公司。使用in-fusionhd克隆试剂盒(从takarabioinc.可获得),将vhh序列连接入载体pra2(+)。下文将更详细地描述连接过程。
首先,通过使用以下两种引物(seqidno:19和seqidno:20)的pcr方法从质粒载体1扩增vhh抗体基因片段,在所述质粒载体中连接了vhh抗体的基因文库中所含的vhh抗体基因片段。以这种方式,获得包含基因序列的以下一个dna(seqidno:21),所述基因序列编码seqidno:8代表的氨基酸序列。
引物1:5’-cagccggccatggctcaggtgcagctcgtggagtctgg-3’(seqidno:19)
引物2:5’-atggtgtgcggccgctgaggagacggtgacctgggtcc-3’(seqidno:20)
5'-cagccggccatggctcaggtgcagctcgtggagtctggggggggattggtgcagactgggggcccgctgagactctcctgcgcagtctctgatcgcaccgacagtaactatgccatgggctggttccgccaggctccagggaaggagcgtgagtttgtagcagctattagcggcactggttatgtcactggctatgcagactccgcgaggaatcgcttcaccctctccagagacaacggcaagaacgcggtgtatctgcaaatgaacagcctggaacctgcggacacggccgtttattactgtgcagccacatcagatcaacgctatcctggtcctcgctcctcgggatatgactactggggccaggggacccaggtcaccgtctcctcagcggccgcacaccat-3’(seqidno:21)
在另一方面,通过使用以下二种引物(seqidno:22和seqidno:23)的pcr方法,扩增了载体pra2中所包含的一部分碱基序列。以这种方式,获得了dna(seqidno:25)。
引物1:5’-gcggccgcacaccatcatcaccaccattaatag-3’(seqidno:22)
引物2:5’-agccatggccggctgggccgcgagtaataac-3’(seqidno:23)
gcggccgcacaccatcatcaccaccattaatagcactagtcaagaggatccggctgctaacaaagcccgaaaggaagctgagttggctgctgccaccgctgagcaataactagcataaccccttggggcctctaaacgggtcttgaggggttttttgctgaaaggaggaactatatccggatgaattccgtgtattctatagtgtcacctaaatcgtatgtgtatgatacataaggttatgtattaattgtagccgcgttctaacgacaatatgtacaagcctaattgtgtagcatctggcttactgaagcagaccctatcatctctctcgtaaactgccgtcagagtcggtttggttggacgaaccttctgagtttctggtaacgccgtcccgcacccggaaatggtcagcgaaccaatcagcagggtcatcgctagccagatcctctacgccggacgcatcgtggccggcatcaccggcgccacaggtgcggttgctggcgcctatatcgccgacatcaccgatggggaagatcgggctcgccacttcgggctcatgagcgcttgtttcggcgtgggtatggtggcaggccccgtggccgggggactgttgggcgccatctccttgcatgcaccattccttgcggcggcggtgctcaacggcctcaacctactactgggctgcttcctaatgcaggagtcgcataagggagagcgtcgaatggtgcactctcagtacaatctgctctgatgccgcatagttaagccagccccgacacccgccaacacccgctgacgcgccctgacgggcttgtctgctcccggcatccgcttacagacaagctgtgaccgtctccgggagctgcatgtgtcagaggttttcaccgtcatcaccgaaacgcgcgagacgaaagggcctcgtgatacgcctatttttataggttaatgtcatgataataatggtttcttagacgtcaggtggcacttttcggggaaatgtgcgcggaacccctatttgtttatttttctaaatacattcaaatatgtatccgctcatgagacaataaccctgataaatgcttcaataatattgaaaaaggaagagtatgagtattcaacatttccgtgtcgcccttattcccttttttgcggcattttgccttcctgtttttgctcacccagaaacgctggtgaaagtaaaagatgctgaagatcagttgggtgcacgagtgggttacatcgaactggatctcaacagcggtaagatccttgagagttttcgccccgaagaacgttttccaatgatgagcacttttaaagttctgctatgtggcgcggtattatcccgtattgacgccgggcaagagcaactcggtcgccgcatacactattctcagaatgacttggttgagtactcaccagtcacagaaaagcatcttacggatggcatgacagtaagagaattatgcagtgctgccataaccatgagtgataacactgcggccaacttacttctgacaacgatcggaggaccgaaggagctaaccgcttttttgcacaacatgggggatcatgtaactcgccttgatcgttgggaaccggagctgaatgaagccataccaaacgacgagcgtgacaccacgatgcctgtagcaatggcaacaacgttgcgcaaactattaactggcgaactacttactctagcttcccggcaacaattaatagactggatggaggcggataaagttgcaggaccacttctgcgctcggcccttccggctggctggtttattgctgataaatctggagccggtgagcgtgggtctcgcggtatcattgcagcactggggccagatggtaagccctcccgtatcgtagttatctacacgacggggagtcaggcaactatggatgaacgaaatagacagatcgctgagataggtgcctcactgattaagcattggtaactgtcagaccaagtttactcatatatactttagattgatttaaaacttcatttttaatttaaaaggatctaggtgaagatcctttttgataatctcatgaccaaaatcccttaacgtgagttttcgttccactgagcgtcagaccccgtagaaaagatcaaaggatcttcttgagatcctttttttctgcgcgtaatctgctgcttgcaaacaaaaaaaccaccgctaccagcggtggtttgtttgccggatcaagagctaccaactctttttccgaaggtaactggcttcagcagagcgcagataccaaatactgttcttctagtgtagccgtagttaggccaccacttcaagaactctgtagcaccgcctacatacctcgctctgctaatcctgttaccagtggctgctgccagtggcgataagtcgtgtcttaccgggttggactcaagacgatagttaccggataaggcgcagcggtcgggctgaacggggggttcgtgcacacagcccagcttggagcgaacgacctacaccgaactgagatacctacagcgtgagctatgagaaagcgccacgcttcccgaagggagaaaggcggacaggtatccggtaagcggcagggtcggaacaggagagcgcacgagggagcttccagggggaaacgcctggtatctttatagtcctgtcgggtttcgccacctctgacttgagcgtcgatttttgtgatgctcgtcaggggggcggagcctatggaaaaacgccagcaacgcggcctttttacggttcctggccttttgctggccttttgctcacatgttctttcctgcgttatcccctgattctgtggataaccgtattaccgcctttgagtgagctgataccgctcgccgcagccgaacgaccgagcgcagcgagtcagtgagcgaggaagcggaagagcgcccaatacgcaaaccgcctctccccgcgcgttggccgattcattaatgcagctggcttatcgaaattaatacgactcactatagggagacccaagctttatttcaaggagacagtcataatgaaatacctattgcctacggcagccgctggattgttattactcgcggcccagccggccatggct(seqidno:25)
除以下二个dna(i)和(ii)之外的dna用限制性酶dpni(从toyobo可获得)片段化。换句话说,以下二个dna(i)和(ii)保持不变;然而,将其余的dna片段化。
(i)seqidno:21代表的dna,和
(ii)seqidno:25代表的dna。
使用in-fusionhd克隆试剂盒(从takarabioinc.可获得),将seqidno:21代表的dna与seqidno:25代表的dna融合。以这种方式,将vhh抗体基因片段连接入载体pra2(+)。
在冰上混合连接溶液(10微升)和大肠杆菌jm109(从takarabio可获得,100微升)。将混合物溶液在冰上静置三十分钟。随后,将混合物溶液在42摄氏度的温度加热四十五秒。最后,将混合物溶液在冰上静置三分钟。该方法称作通用热休克法。
在37摄氏度的温度振摇下温育一小时后,将混合物溶液的总量分布到含有100微克/毫升浓度氨苄青霉素的lba培养基上。将lba培养基在37摄氏度的温度静置过夜。
从lba培养基上形成的菌落选择三个菌落。将选择的三个菌落在lba培养基(3毫升)中温育过夜。
使用质粒提取试剂盒(从sigma可获得,商品名:geneelute质粒微量试剂盒),从lba培养基提取在温育的大肠杆菌中所含的质粒。为了证实靶向的vhh抗体的基因插在质粒中,由greiner公司分析质粒的序列。为了分析序列,使用通用t7启动子引物套装。
选择通过分析序列而证实已经如计划那样形成的质粒。
通过热休克法,用选择的质粒转染大肠杆菌(感受态细胞bl21(de3)plyss,从lifetechnologiescompany可获得)。
将lba培养基(1毫升)注入含有转染的大肠杆菌的溶液。随后,大肠杆菌在37摄氏度的温度恢复一小时,同时以213转/分钟振摇。
随后,收集大肠杆菌液。将收集的大肠杆菌液(1毫升)分布到lba培养基上。将lba培养基在37摄氏度的温度静置过夜。
从lba培养基上形成的菌落选择一个菌落。用牙签挑出选择的菌落。将挑出的菌落在lba培养基(3毫升)中在37摄氏度的温度温育,同时以213转/分钟振摇。以这种方式,获得培养液。
此外,将培养液(3毫升)与lba培养基(1,000毫升)混合。直至混合物溶液在600纳米波长处的吸光度达到0.6,将混合物溶液以120转/分钟在28摄氏度的温度振摇。
在吸光度达到0.6后,将异丙基硫代半乳糖苷溶液(下文中称为“iptg溶液”)添加至混合物溶液。iptg溶液的终浓度是0.5mm。将混合物溶液中所含的大肠杆菌在20摄氏度的温度温育过夜。为了收集如此温育的大肠杆菌,将混合物溶液以6000转/分钟在4摄氏度的温度离心十分钟。
收集的大肠杆菌与含有50mmtris-hcl、500mmnacl和5mm咪唑的混合物溶剂混合。混合物溶剂具有50毫升体积。用超声波分解混合物溶液中所含的大肠杆菌。
将含有大肠杆菌的分解液以40000g在4摄氏度的温度离心三十分钟以获得洗脱物。收集上清液。通过0.45微米滤器过滤所收集的上清液。
用ni-nta-琼脂糖(从qiagen可获得)根据推荐的方案纯化滤液。对于纯化,将具有3毫升总量的洗脱缓冲液用于1毫升ni-nta-琼脂糖。
另外,用柱色谱(从generalelectriccompany可获得,商品名:akta纯化仪)纯化含有抗np抗体的洗脱物。以这种方式,获得含有抗np抗体的溶液。
用吸收谱仪(从scruminc.可获得,商品名:nanodrop),基于280纳米波长的吸收测量值,定量如此获得的溶液中所含的抗np抗体。作为结果,抗np抗体的浓度是6.60毫克/毫升。
(d-1)使用重组np对抗np抗体的表面等离子体共振评估
用重组np和表面等离子体共振评估装置如下评估抗np抗体。下文将描述表面等离子体共振(下文中称为“spr”)的细节。
spr评估装置:t200(从gehealthcare可获得)
固定缓冲液:含有0.05%吐温20的pbs
运行缓冲液:含有0.05%吐温20的pbs
传感芯片:cm5(从gehealthcare可获得)
固定试剂:n-羟基琥珀酰亚胺(nhs)和n-[3-(二甲基氨基)丙基]-n'-乙基碳二亚胺(edc)
抗flag抗体:单克隆抗flag抗体(从sigma可获得)
np:与flag标签融合并使用杆状病毒制备的衍生自流感病毒h1n1的重组核蛋白(np)
根据spr评估装置t200的控制软件中包含的指导程序,固定抗flag抗体。为了固定抗flag抗体,使用具有ph5.0的乙酸溶液。
使用由seqidno:8代表的氨基酸序列组成的抗np抗体作为分析物。在第一至第六分析中,将运行缓冲液中所含的抗np抗体的浓度分别调节至0.78nm、1.56nm、3.125nm、6.25nm、12.5nm和25nm。首先,用抗flag抗体捕获重组核内蛋白质。随后,供应抗np抗体。以这种方式,评估抗np抗体。附图3a–3f是显示从spr评估装置t200输出的评估结果的图。使用评估软件(从gehealthcare可获得)计算解离常数kd。作为结果,解离常数kd是0.199nm。
(d-2)评估与其他流感病毒亚型的交叉反应性
接下来,为了评估包含seqidno:8代表的氨基酸序列的vhh抗体与衍生自甲型流感病毒亚型h1n1(a/北海道/11/2002)、h1n1(a/兵库/ys/2011)、h1n1(a/北海道/6-5/2014)、h3n2(a/北海道/m1/2014)、h5n1(a/鸭/北海道/vac-3/2007)、h7n7(a/鸭/北海道/vac-2/2004)和h7n9(a/鸭/蒙古/119/2008)的核蛋白(即,np)的结合能力,通过elisa测量法评估与含有核内蛋白质的病毒液的结合能力。
准备病毒液,所述病毒液包含衍生自甲型流感病毒亚型h1n1(a/北海道/11/2002)的核内蛋白质。病毒液从北海道大学兽医学校/学院获得。
类似地,准备六种病毒液,其包含衍生自甲型流感病毒亚型h1n1(a/兵库/ys/2011)、h1n1(a/北海道/6-5/2014)、h3n2(a/北海道/m1/2014)、h5n1(a/鸭/北海道/vac-3/2007)、h7n7(a/鸭/北海道/vac-2/2004)和h7n9(a/鸭/蒙古/119/2008)的核内蛋白质。病毒液从北海道大学兽医学校/学院获得。
另外,准备病毒液,其包含衍生自乙型流感病毒(b/北海道/30-4/2014)的核内蛋白质。病毒液从北海道大学兽医学校/学院获得。
将含有包含seqidno:8代表的氨基酸序列的vhh抗体的溶液a(浓度10微克/毫升)的一部分用含有3%脱脂乳(从wakopurechemicalindustries,ltd.可获得)和0.05%吐温20的pbs稀释4倍。下文中将含有3%脱脂乳和0.05%吐温20的pbs称作“含有脱脂乳的pbst”。以这种方式,提供含有包含seqidno:8代表的氨基酸序列的vhh抗体的溶液的稀释溶液b(浓度:2.5微克/毫升)。重复这个步骤以提供稀释的溶液c(浓度:0.625微克/毫升)、稀释的溶液d(浓度:0.15625微克/毫升)、稀释的溶液e(浓度:0.0390625微克/毫升)、稀释的溶液f(浓度:9.76562x10-4微克/毫升)和稀释的溶液g(浓度:2.44141x10-4微克/毫升)。
将包含衍生自甲型流感病毒亚型h1n1(a/北海道/11/2002)、h1n1(a/兵库/ys/2011)、h1n1(a/北海道/6-5/2014)、h3n2(a/北海道/m1/2014)、h5n1(a/鸭/北海道/vac-3/2007)、h7n7(a/鸭/北海道/vac-2/2004)、h7n9(a/鸭/蒙古/119/2008)和乙型流感病毒(b/北海道/30-4/2014)的核内蛋白质的病毒液注入96孔板(maxisorp,nunc)的孔。每孔含有50微升溶液。将96孔板在室温静置两小时以固定孔中的病毒。
将含有脱脂乳的pbst注入每个孔以封闭病毒。注入每个孔的pbst的体积是200微升。将96孔板在室温静置三小时。
将含有0.05%吐温20的pbst注入每个孔以洗涤诸孔。pbst具有ph7.4。注入每个孔的pbst的体积是200微升。重复该洗涤三次。
将稀释溶液a–g中所包含的包含seqidno:8代表的氨基酸序列的vhh抗体的稀释溶液各自注入每个孔。作为参比,将含有脱脂乳的pbst注入另一个孔。使用仅包含含脱脂乳的pbst的这个孔作为参比,以去除测量中的背景。注入每个孔的溶液的体积是50微升。将96孔板在室温静置。以这种方式,稀释溶液a–g中包含的vhh抗体与孔中含有的核内蛋白质结合。将96孔板在室温静置一小时。
将含有0.05%吐温20的pbst注入每个孔以洗涤诸孔。pbst具有ph7.4。注入每个孔的pbst的体积是200微升。重复该洗涤五次。
将标记的抗体(从medicalandbiologicallaboratoriesco.,ltd可获得,商品名:anti-his-tagmab-hrp-direct)用含有0.05%吐温20的pbst稀释10,000倍。将如此稀释的标记抗体注入每个孔(50微升/孔)。随后,将96孔板静置一小时。
将含有0.05%吐温20的pbst注入每个孔以洗涤诸孔。pbst具有ph7.4。注入每个孔的pbst的体积是200微升。重复该洗涤五次。
将生色试剂(从thermoscientific可获得,商品名:1-stepultratmb-elisa)注入每个孔(50微升/孔)。将96孔板静置三十分钟以使生色试剂与抗体反应。
将含有低浓度硫酸和氢氯酸的生色终止剂(从scytek实验室可获得,商品名:tmb终止缓冲液)以50微升/孔的浓度注入每个孔,以终止反应。
在450纳米的波长处测量溶液的吸光度。图4a–4h是显示包含seqidno:8代表的氨基酸序列的vhh抗体分别与甲型流感病毒亚型h1n1(a/北海道/11/2002)、h1n1(a/兵库/ys/2011)、h1n1(a/北海道/6-5/2014)、h3n2(a/北海道/m1/2014)、h5n1(a/鸭/北海道/vac-3/2007)、h7n7(a/鸭/北海道/vac-2/2004)、h7n9(a/鸭/蒙古/119/2008)和乙型流感病毒交叉反应的测量结果的图。
如从图4a–4h理解,包含seqidno:8代表的氨基酸序列的vhh抗体与衍生自甲型流感病毒亚型h1n1(a/北海道/11/2002)、h1n1(a/兵库/ys/2011)、h1n1(a/北海道/6-5/2014)、h3n2(a/北海道/m1/2014)、h5n1(a/鸭/北海道/vac-3/2007)、h7n7(a/鸭/北海道/vac-2/2004)和h7n9(a/鸭/蒙古/119/2008)的核内蛋白质具有高交叉反应性。在另一方面,包含seqidno:8代表的氨基酸序列的vhh抗体与乙型流感病毒具有低交叉反应性。
工业适用性
本发明提供了能够与流感病毒的核内蛋白质结合的新抗体、使用其的复合材料、检测装置和方法。
序列表
<110>松下知识产权经营株式会社
<120>能够与流感病毒的核内蛋白质结合的抗体、使用其的复合材料、检测装置和方法
<130>p1009397cn01
<150>jp2017-174900
<151>2017-09-12
<160>25
<170>patentin版本3.5
<210>1
<211>10
<212>prt
<213>羊驼(vicugnapacos)
<400>1
aspargthraspserasntyralametgly
1510
<210>2
<211>17
<212>prt
<213>羊驼
<400>2
alaileserglythrglytyrvalthrglytyralaaspseralaarg
151015
asn
<210>3
<211>16
<212>prt
<213>羊驼
<400>3
thrseraspglnargtyrproglyproargserserglytyrasptyr
151015
<210>4
<211>25
<212>prt
<213>羊驼
<400>4
glnvalglnleuvalgluserglyglyglyleuvalglnthrglygly
151015
proleuargleusercysalavalser
2025
<210>5
<211>14
<212>prt
<213>羊驼
<400>5
trppheargglnalaproglylysgluarggluphevalala
1510
<210>6
<211>32
<212>prt
<213>羊驼
<400>6
argphethrleuserargaspasnglylysasnalavaltyrleugln
151015
metasnserleugluproalaaspthralavaltyrtyrcysalaala
202530
<210>7
<211>11
<212>prt
<213>羊驼
<400>7
trpglyglnglythrglnvalthrvalserser
1510
<210>8
<211>125
<212>prt
<213>羊驼
<400>8
glnvalglnleuvalgluserglyglyglyleuvalglnthrglygly
151015
proleuargleusercysalavalseraspargthraspserasntyr
202530
alametglytrppheargglnalaproglylysgluargglupheval
354045
alaalaileserglythrglytyrvalthrglytyralaaspserala
505560
argasnargphethrleuserargaspasnglylysasnalavaltyr
65707580
leuglnmetasnserleugluproalaaspthralavaltyrtyrcys
859095
alaalathrseraspglnargtyrproglyproargserserglytyr
100105110
asptyrtrpglyglnglythrglnvalthrvalserser
115120125
<210>9
<211>15
<212>dna
<213>人工序列
<220>
<223>引物
<400>9
ggtggtcctggctgc15
<210>10
<211>50
<212>dna
<213>人工序列
<220>
<223>引物
<400>10
ctgctcctcgcggcccagccggccatggctsagktgcagctcgtggagtc50
<210>11
<211>21
<212>dna
<213>人工序列
<220>
<223>引物
<400>11
tggggtcttcgctgtggtgcg21
<210>12
<211>21
<212>dna
<213>人工序列
<220>
<223>引物
<400>12
ttgtggttttggtgtcttggg21
<210>13
<211>45
<212>dna
<213>人工序列
<220>
<223>引物
<400>13
tttgctctgcggccgcagaggccgtggggtcttcgctgtggtgcg45
<210>14
<211>46
<212>dna
<213>人工序列
<220>
<223>引物
<400>14
tttgctctgcggccgcagaggccgattgtggttttggtgtcttggg46
<210>15
<211>13
<212>dna
<213>人工序列
<220>
<223>sfii(a)位点
<400>15
ggcccagccggcc13
<210>16
<211>13
<212>dna
<213>人工序列
<220>
<223>sfii(b)位点
<400>16
ggcctctgcggcc13
<210>17
<211>4057
<212>dna
<213>人工序列
<220>
<223>质粒载体1
<400>17
gacgaaagggcctcgtgatacgcctatttttataggttaatgtcatgataataatggttt60
cttagacgtcaggtggcacttttcggggaaatgtgcgcggaacccctatttgtttatttt120
tctaaatacattcaaatatgtatccgctcatgagacaataaccctgataaatgcttcaat180
aatattgaaaaaggaagagtatgagtattcaacatttccgtgtcgcccttattccctttt240
ttgcggcattttgccttcctgtttttgctcacccagaaacgctggtgaaagtaaaagatg300
ctgaagatcagttgggtgcacgagtgggttacatcgaactggatctcaacagcggtaaga360
tccttgagagttttcgccccgaagaacgttttccaatgatgagcacttttaaagttctgc420
tatgtggcgcggtattatcccgtattgacgccgggcaagagcaactcggtcgccgcatac480
actattctcagaatgacttggttgagtactcaccagtcacagaaaagcatcttacggatg540
gcatgacagtaagagaattatgcagtgctgccataaccatgagtgataacactgcggcca600
acttacttctgacaacgatcggaggaccgaaggagctaaccgcttttttgcacaacatgg660
gggatcatgtaactcgccttgatcgttgggaaccggagctgaatgaagccataccaaacg720
acgagcgtgacaccacgatgcctgtagcaatggcaacaacgttgcgcaaactattaactg780
gcgaactacttactctagcttcccggcaacaattaatagactggatggaggcggataaag840
ttgcaggaccacttctgcgctcggcccttccggctggctggtttattgctgataaatctg900
gagccggtgagcgtgggtctcgcggtatcattgcagcactggggccagatggtaagccct960
cccgtatcgtagttatctacacgacggggagtcaggcaactatggatgaacgaaatagac1020
agatcgctgagataggtgcctcactgattaagcattggtaactgtcagaccaagtttact1080
catatatactttagattgatttaaaacttcatttttaatttaaaaggatctaggtgaaga1140
tcctttttgataatctcatgaccaaaatcccttaacgtgagttttcgttccactgagcgt1200
cagaccccgtagaaaagatcaaaggatcttcttgagatcctttttttctgcgcgtaatct1260
gctgcttgcaaacaaaaaaaccaccgctaccagcggtggtttgtttgccggatcaagagc1320
taccaactctttttccgaaggtaactggcttcagcagagcgcagataccaaatactgtcc1380
ttctagtgtagccgtagttaggccaccacttcaagaactctgtagcaccgcctacatacc1440
tcgctctgctaatcctgttaccagtggctgctgccagtggcgataagtcgtgtcttaccg1500
ggttggactcaagacgatagttaccggataaggcgcagcggtcgggctgaacggggggtt1560
cgtgcacacagcccagcttggagcgaacgacctacaccgaactgagatacctacagcgtg1620
agctatgagaaagcgccacgcttcccgaagggagaaaggcggacaggtatccggtaagcg1680
gcagggtcggaacaggagagcgcacgagggagcttccagggggaaacgcctggtatcttt1740
atagtcctgtcgggtttcgccacctctgacttgagcgtcgatttttgtgatgctcgtcag1800
gggggcggagcctatggaaaaacgccagcaacgcggcctttttacggttcctggcctttt1860
gctggccttttgctcacatgttctttcctgcgttatcccctgattctgtggataaccgta1920
ttaccgcctttgagtgagctgataccgctcgccgcagccgaacgaccgagcgcagcgagt1980
cagtgagcgaggaagcggaagagcgcccaatacgcaaaccgcctctccccgcgcgttggc2040
cgattcattaatgcagctggcacgacaggtttcccgactggaaagcgggcagtgagcgca2100
acgcaattaatgtgagttagctcactcattaggcaccccaggctttacactttatgcttc2160
cggctcgtatgttgtgtggaattgtgagcggataacaatttcacacaggaaacagctatg2220
accatgattacgccaagcttcgaaggagacagtcataatgaaatacctgctgccgaccgc2280
tgctgctggtctgctgctcctcgcggcccagccggccatggagctcaagatgacacagac2340
tacatcctccctgtcagcctctctgggagacagagtcaccatcagttgcagggcaagtca2400
ggacattagcgattatttaaactggtatcagcagaaaccagatggaactgttaaactcct2460
gatctattacacatcaagtttacactcaggagtcccatcaaggttcagtggcggtgggtc2520
tggaacagattattctctcaccattagcaacctggagcaagaagatattgccacttactt2580
ttgccaacagggtaatacgcttccgtggacgtttggtggaggcaccaagctggaaatcaa2640
acgggctgatgctgcaccaactgtaggcctctgcggccgcagagcaaaaactcatctcag2700
aagaggatctgaatggggccgcatagggttccggtgattttgattatgaaaagatggcaa2760
acgctaataagggggctatgaccgaaaatgccgatgaaaacgcgctacagtctgacgcta2820
aaggcaaacttgattctgtcgctactgattacggtgctgctatcgatggtttcattggtg2880
acgtttccggccttgctaatggtaatggtgctactggtgattttgctggctctaattccc2940
aaatggctcaagtcggtgacggtgataattcacctttaatgaataatttccgtcaatatt3000
taccttccctccctcaatcggttgaatgtcgcccttttgtctttagcgctggtaaaccat3060
atgaattttctattgattgtgacaaaataaacttattccgtggtgtctttgcgtttcttt3120
tatatgttgccacctttatgtatgtattttctacgtttgctaacatactgcgtaataagg3180
agtcttaataagaattcactggccgtcgttttacaacgtcgtgactgggaaaaccctggc3240
gttacccaacttaatcgccttgcagcacatccccctttcgccagctggcgtaatagcgaa3300
gaggcccgcaccgatcgcccttcccaacagttgcgcagcctgaatggcgaatggcgcctg3360
atgcggtattttctccttacgcatctgtgcggtatttcacaccgcatatgaaaattgtaa3420
gcgttaatattttgttaaaattcgcgttaaatttttgttaaatcagctcattttttaacc3480
aataggccgaaatcggcaaaatcccttataaatcaaaagaatagaccgagatagggttga3540
gtgttgttccagtttggaacaagagtccactattaaagaacgtggactccaacgtcaaag3600
ggcgaaaaaccgtctatcagggcgatggcccactacgtgaaccatcaccctaatcaagtt3660
ttttggggtcgaggtgccgtaaagcactaaatcggaaccctaaagggagcccccgattta3720
gagcttgacggggaaagccggcgaacgtggcgagaaaggaagggaagaaagcgaaaggag3780
cgggcgctagggcgctggcaagtgtagcggtcacgctgcgcgtaaccaccacacccgccg3840
cgcttaatgcgccgctacagggcgcgtcccatatggtgcactctcagtacaatctgctct3900
gatgccgcatagttaagccagccccgacacccgccaacacccgctgacgcgccctgacgg3960
gcttgtctgctcccggcatccgcttacagacaagctgtgaccgtctccgggagctgcatg4020
tgtcagaggttttcaccgtcatcaccgaaacgcgcga4057
<210>18
<211>375
<212>dna
<213>人工序列
<220>
<223>编码抗npvhh抗体的dna
<400>18
caggtgcagctcgtggagtctggggggggattggtgcagactgggggcccgctgagactc60
tcctgcgcagtctctgatcgcaccgacagtaactatgccatgggctggttccgccaggct120
ccagggaaggagcgtgagtttgtagcagctattagcggcactggttatgtcactggctat180
gcagactccgcgaggaatcgcttcaccctctccagagacaacggcaagaacgcggtgtat240
ctgcaaatgaacagcctggaacctgcggacacggccgtttattactgtgcagccacatca300
gatcaacgctatcctggtcctcgctcctcgggatatgactactggggccaggggacccag360
gtcaccgtctcctca375
<210>19
<211>38
<212>dna
<213>人工序列
<220>
<223>引物
<400>19
cagccggccatggctcaggtgcagctcgtggagtctgg38
<210>20
<211>38
<212>dna
<213>人工序列
<220>
<223>引物
<400>20
atggtgtgcggccgctgaggagacggtgacctgggtcc38
<210>21
<211>405
<212>dna
<213>人工序列
<220>
<223>包含编码由seqidno:8代表的氨基酸序列的基因序列的dna
<400>21
cagccggccatggctcaggtgcagctcgtggagtctggggggggattggtgcagactggg60
ggcccgctgagactctcctgcgcagtctctgatcgcaccgacagtaactatgccatgggc120
tggttccgccaggctccagggaaggagcgtgagtttgtagcagctattagcggcactggt180
tatgtcactggctatgcagactccgcgaggaatcgcttcaccctctccagagacaacggc240
aagaacgcggtgtatctgcaaatgaacagcctggaacctgcggacacggccgtttattac300
tgtgcagccacatcagatcaacgctatcctggtcctcgctcctcgggatatgactactgg360
ggccaggggacccaggtcaccgtctcctcagcggccgcacaccat405
<210>22
<211>33
<212>dna
<213>人工序列
<220>
<223>引物
<400>22
gcggccgcacaccatcatcaccaccattaatag33
<210>23
<211>31
<212>dna
<213>人工序列
<220>
<223>引物
<400>23
agccatggccggctgggccgcgagtaataac31
<210>24
<211>498
<212>prt
<213>人工序列
<220>
<223>重组核蛋白
<400>24
metalaserglnglythrlysargsertyrgluglnmetgluthrasp
151015
glygluargglnasnalathrgluileargalaservalglylysmet
202530
ileglyglyileglyargphetyrileglnmetcysthrgluleulys
354045
leuserasptyrgluglyargleuileglnasnserleuthrileglu
505560
argmetvalleuseralapheaspgluargargasnlystyrleuglu
65707580
gluhisproseralaglylysaspprolyslysthrglyglyproile
859095
tyrargargvalasnglylystrpmetarggluleuileleutyrasp
100105110
lysglugluileargargiletrpargglnalaasnasnglyaspasp
115120125
alathralaglyleuthrhismetmetiletrphisserasnleuasn
130135140
aspalathrtyrglnargthrargalaleuvalargthrglymetasp
145150155160
proargmetcysserleumetglnglyserthrleuproargargser
165170175
glyalaalaglyalaalavallysglyvalglythrmetvalmetglu
180185190
leuvalargmetilelysargglyileasnaspargasnphetrparg
195200205
glygluasnglyarglysthrargilealatyrgluargmetcysasn
210215220
ileleulysglylyspheglnthralaalaglnlysalametmetasp
225230235240
glnvalarggluserargasnproglyasnalagluphegluaspleu
245250255
thrpheleualaargseralaleuileleuargglyservalalahis
260265270
lyssercysleuproalacysvaltyrglyproalavalalasergly
275280285
tyraspphegluarggluglytyrserleuvalglyileaspprophe
290295300
argleuleuglnasnserglnvaltyrserleuileargproasnglu
305310315320
asnproalahislysserglnleuvaltrpmetalacyshisserala
325330335
alaphegluaspleuargvalleuserpheilelysglythrlysval
340345350
leuproargglylysleuserthrargglyvalglnilealaserasn
355360365
gluasnmetgluthrmetgluserserthrleugluleuargserarg
370375380
tyrtrpalaileargthrargserglyglyasnthrasnglnglnarg
385390395400
alaseralaglyglnileserileglnprothrpheservalglnarg
405410415
asnleupropheaspargthrthrilemetalaalapheasnglyasn
420425430
thrgluglyargthrseraspmetargthrgluileileargmetmet
435440445
gluseralaargprogluaspvalserpheglnglyargglyvalphe
450455460
gluleuseraspglulysalaalaserproilevalproserpheasp
465470475480
metserasngluglysertyrphepheglyaspasnalagluglutyr
485490495
aspasn
<210>25
<211>3096
<212>dna
<213>人工序列
<220>
<223>从载体pra2扩增的dna
<400>25
gcggccgcacaccatcatcaccaccattaatagcactagtcaagaggatccggctgctaa60
caaagcccgaaaggaagctgagttggctgctgccaccgctgagcaataactagcataacc120
ccttggggcctctaaacgggtcttgaggggttttttgctgaaaggaggaactatatccgg180
atgaattccgtgtattctatagtgtcacctaaatcgtatgtgtatgatacataaggttat240
gtattaattgtagccgcgttctaacgacaatatgtacaagcctaattgtgtagcatctgg300
cttactgaagcagaccctatcatctctctcgtaaactgccgtcagagtcggtttggttgg360
acgaaccttctgagtttctggtaacgccgtcccgcacccggaaatggtcagcgaaccaat420
cagcagggtcatcgctagccagatcctctacgccggacgcatcgtggccggcatcaccgg480
cgccacaggtgcggttgctggcgcctatatcgccgacatcaccgatggggaagatcgggc540
tcgccacttcgggctcatgagcgcttgtttcggcgtgggtatggtggcaggccccgtggc600
cgggggactgttgggcgccatctccttgcatgcaccattccttgcggcggcggtgctcaa660
cggcctcaacctactactgggctgcttcctaatgcaggagtcgcataagggagagcgtcg720
aatggtgcactctcagtacaatctgctctgatgccgcatagttaagccagccccgacacc780
cgccaacacccgctgacgcgccctgacgggcttgtctgctcccggcatccgcttacagac840
aagctgtgaccgtctccgggagctgcatgtgtcagaggttttcaccgtcatcaccgaaac900
gcgcgagacgaaagggcctcgtgatacgcctatttttataggttaatgtcatgataataa960
tggtttcttagacgtcaggtggcacttttcggggaaatgtgcgcggaacccctatttgtt1020
tatttttctaaatacattcaaatatgtatccgctcatgagacaataaccctgataaatgc1080
ttcaataatattgaaaaaggaagagtatgagtattcaacatttccgtgtcgcccttattc1140
ccttttttgcggcattttgccttcctgtttttgctcacccagaaacgctggtgaaagtaa1200
aagatgctgaagatcagttgggtgcacgagtgggttacatcgaactggatctcaacagcg1260
gtaagatccttgagagttttcgccccgaagaacgttttccaatgatgagcacttttaaag1320
ttctgctatgtggcgcggtattatcccgtattgacgccgggcaagagcaactcggtcgcc1380
gcatacactattctcagaatgacttggttgagtactcaccagtcacagaaaagcatctta1440
cggatggcatgacagtaagagaattatgcagtgctgccataaccatgagtgataacactg1500
cggccaacttacttctgacaacgatcggaggaccgaaggagctaaccgcttttttgcaca1560
acatgggggatcatgtaactcgccttgatcgttgggaaccggagctgaatgaagccatac1620
caaacgacgagcgtgacaccacgatgcctgtagcaatggcaacaacgttgcgcaaactat1680
taactggcgaactacttactctagcttcccggcaacaattaatagactggatggaggcgg1740
ataaagttgcaggaccacttctgcgctcggcccttccggctggctggtttattgctgata1800
aatctggagccggtgagcgtgggtctcgcggtatcattgcagcactggggccagatggta1860
agccctcccgtatcgtagttatctacacgacggggagtcaggcaactatggatgaacgaa1920
atagacagatcgctgagataggtgcctcactgattaagcattggtaactgtcagaccaag1980
tttactcatatatactttagattgatttaaaacttcatttttaatttaaaaggatctagg2040
tgaagatcctttttgataatctcatgaccaaaatcccttaacgtgagttttcgttccact2100
gagcgtcagaccccgtagaaaagatcaaaggatcttcttgagatcctttttttctgcgcg2160
taatctgctgcttgcaaacaaaaaaaccaccgctaccagcggtggtttgtttgccggatc2220
aagagctaccaactctttttccgaaggtaactggcttcagcagagcgcagataccaaata2280
ctgttcttctagtgtagccgtagttaggccaccacttcaagaactctgtagcaccgccta2340
catacctcgctctgctaatcctgttaccagtggctgctgccagtggcgataagtcgtgtc2400
ttaccgggttggactcaagacgatagttaccggataaggcgcagcggtcgggctgaacgg2460
ggggttcgtgcacacagcccagcttggagcgaacgacctacaccgaactgagatacctac2520
agcgtgagctatgagaaagcgccacgcttcccgaagggagaaaggcggacaggtatccgg2580
taagcggcagggtcggaacaggagagcgcacgagggagcttccagggggaaacgcctggt2640
atctttatagtcctgtcgggtttcgccacctctgacttgagcgtcgatttttgtgatgct2700
cgtcaggggggcggagcctatggaaaaacgccagcaacgcggcctttttacggttcctgg2760
ccttttgctggccttttgctcacatgttctttcctgcgttatcccctgattctgtggata2820
accgtattaccgcctttgagtgagctgataccgctcgccgcagccgaacgaccgagcgca2880
gcgagtcagtgagcgaggaagcggaagagcgcccaatacgcaaaccgcctctccccgcgc2940
gttggccgattcattaatgcagctggcttatcgaaattaatacgactcactatagggaga3000
cccaagctttatttcaaggagacagtcataatgaaatacctattgcctacggcagccgct3060
ggattgttattactcgcggcccagccggccatggct3096
- 还没有人留言评论。精彩留言会获得点赞!