针对胃促胰酶的适配体及其应用的制作方法
本发明涉及针对胃促胰酶(chymase,糜酶)的适配体及其利用方法等。
背景技术:
人胃促胰酶(ec.3.4.21.39)是胰凝乳蛋白酶样丝氨酸蛋白酶的一种,储存在肥大细胞的分泌颗粒中。若肥大细胞受到外部刺激则发生脱颗粒,使人胃促胰酶与各种炎症介质一同被释放到细胞外。释放的人胃促胰酶特异性地识别作为底物的蛋白或肽中所含的苯丙氨酸或酪氨酸这样的芳族氨基酸,切割与该氨基酸相邻的肽键。作为人胃促胰酶的代表性底物,可列举血管紧张素i(angi)。人胃促胰酶切割angi,产生作为血管收缩因子的血管紧张素ii(angii)。
哺乳类的胃促胰酶在系统学上被分为α和β两个亚家族。包括人在内的灵长类所表达的胃促胰酶仅有一种且属于α家族。另一方面,啮齿类表达α和β两个家族的胃促胰酶。在小鼠的情况下,已知有多种胃促胰酶,根据底物特异性或在组织中的表达方式,认为属于β家族的小鼠肥大细胞蛋白酶-4(mmcp-4)最接近于人胃促胰酶。另外,即使在仓鼠中,也是属于β家族的仓鼠胃促胰酶-1与其对应。另一方面,与人胃促胰酶属于相同α家族的mmcp-5或仓鼠胃促胰酶-2具有弹性蛋白酶样活性,底物特异性不同。
胃促胰酶与转化生长因子β(tgf-β)的活化密切相关。tgf-β以潜在型(潜在的tgf-β)的形式存在于上皮细胞或内皮细胞周围的细胞外基质中,经由大的潜在的tgf-β结合蛋白(ltbp)保持在细胞外基质中。根据需要,由细胞外基质中释放,活化的tgf-β参与细胞的生长分化、组织障碍后的修复或再生,对生物体而言是极其重要的细胞因子。另外,还已知其信号的破绽与各种疾病的发病和进展有关。在该过程中,认为胃促胰酶参与潜在的tgf-β由细胞外基质的游离、以及由潜在的tgf-β向活性型tgf-β的转换反应。
已知胃促胰酶与纤维化(纤维症)、循环系统疾病、炎症、过敏性疾病、脏器粘连等各种疾病有关。纤维化是指在肺或心脏、肝脏、肾脏、皮肤等中发生细胞外基质的代谢异常,结缔组织蛋白过度沉积的疾病。例如,在肺纤维化中,胶原等结缔组织蛋白过度沉积于肺中,导致肺泡硬且缩小,会陷入呼吸困难。已知肺的纤维化是以暴露于大量的灰尘而引起的尘肺、因使用抗癌药等药物而引起的药物性肺炎、过敏性肺炎、肺结核、胶原病这样的自身免疫疾病等为原因而发生的。另一方面,还有不少原因不明的病例。
纤维化的分子水平的发病机理尚未充分明确。通常在正常状态下成纤维细胞的生长或其功能被充分控制,但在炎症或外伤严重或持续的情况下,组织修复机制过度工作,发生成纤维细胞的异常生长或结缔组织蛋白的过度生产。作为引起这种现象的因子,已知有tgf-β。作为暗示其参与的报道,有人报道了:若对纤维化动物模型给予抗tgf-β中和抗体,则胶原表达减少,纤维化得到明显抑制。另外,在特发性肺纤维化患者中,可见tgf-β或胃促胰酶阳性肥大细胞的增加。
另一方面,通过使用模型动物的实验显示了胃促胰酶与纤维化有关。在仓鼠的博来霉素诱发性肺纤维化模型中,胃促胰酶活性亢进、胶原iiimrna的表达增加、组织纤维化这些现象因胃促胰酶抑制剂而显著减少。在小鼠的博来霉素诱发性肺纤维化模型中也同样,通过给予胃促胰酶抑制剂,可获得胃促胰酶活性抑制、羟基脯氨酸量减少这样的效果。
由以上可知:胃促胰酶抑制剂可用作纤维化等与胃促胰酶有关的疾病的预防药或治疗药。作为胃促胰酶抑制剂,开发了作为低分子化合物的tpc-806或sun-13834、sun-c8257、sun-c8077、jnj-10311795等(专利文献1)。
然而,近年来rna适配体在治疗药、诊断药、试剂中的应用受到关注,几种rna适配体已进入临床阶段或实用阶段。2004年12月作为世界上第一个rna适配体药物的macugen在美国被批准作为老年性黄斑变性的治疗药。rna适配体是指特异性地与蛋白等靶物质结合的rna,可使用selex法(指数富集配体系统进化(systematicevolutionofligandsbyexponentialenrichment))来制作(专利文献2~4)。selex法是指从1014个左右的具有不同的核苷酸序列的rna库(rnapool)中选出特异性地与靶物质结合的rna的方法。所使用的rna形成了通过引物序列夹入40个核苷酸左右的随机序列的结构。使该rna库与靶物质缔合,使用滤器等仅回收与靶物质结合的rna。回收的rna通过rt-pcr扩增,将其用作下一轮的模板。通过重复进行10次左右该操作,有时可获取特异性地与靶物质结合的rna适配体。
适配体药物与抗体药物同样能够以细胞外蛋白为靶,但若参考已公开发表的多篇学术论文等,则其有可能在几个方面超过抗体药物。例如,适配体往往会对靶分子显示出较抗体高的亲和性或特异性。另外,认为不易受到免疫排斥、不易发生抗体特有的抗体依赖性细胞毒作用(adcc)或补体依赖性细胞毒作用(cdc)等副作用。从递送的角度考虑,因适配体为抗体的1/10左右的分子尺寸,故容易发生组织转移,更容易将药物递送至靶位点。适配体是通过化学合成来生产的,因此可进行位点选择性的化学修饰,如果大量生产,则可谋求降低成本。此外,长期保存稳定性或热/溶剂抗性也是适配体的优越特征。另一方面,通常适配体的血中半衰期较抗体短。然而,在考虑毒性的情况下,这一点有时也会成为优点。根据以上情况,即使是以相同分子为靶的药品,适配体药物也有可能胜过抗体药物。
作为与胃促胰酶结合、且抑制胃促胰酶活性的适配体,本发明人制造了包含x1gauagan1n2uaax2(式中,x1和x2相同或不同、且为a或g;n1和n2相同或不同、且为a、g、c、u或t)所表示的核苷酸序列的适配体(专利文献5(该序列在专利文献5中由seqidno:21表示))。
现有技术文献
专利文献
专利文献1:美国专利公报6500835号;
专利文献2:国际公开wo91/19813号小册子;
专利文献3:国际公开wo94/08050号小册子;
专利文献4:国际公开wo95/07364号小册子;
专利文献5:国际公开wo2010/143714号小册子。
技术实现要素:
发明所要解决的课题
本发明的目的在于:提供针对胃促胰酶的适配体及其利用方法等。
用于解决课题的手段
为了解决上述课题,本发明人进行了深入研究,结果成功地制作了针对胃促胰酶的优质的适配体,其具有以下特征:序列完全不同于专利文献5所记载的胃促胰酶适配体,并且活性明显高,因此完成了本发明。
即,本发明提供以下的发明等:
[1]适配体,其是与胃促胰酶结合的适配体,该适配体包含uaacr1n1r2gggg(式中,r1和r2为任意的一个碱基,n1为3~30个碱基)所表示的通用序列(其中,尿嘧啶可以是胸腺嘧啶)。
[2]适配体,其是与胃促胰酶结合的适配体,具有以下的式(1)所表示的潜在的二次结构(其中,尿嘧啶可以是胸腺嘧啶):
[化学式1]
这里,式(1)中的下述式(1’)所表示的部分显示茎/环部分结构,r1和r2显示任意的一个碱基,
[化学式2]
[3][1]或[2]的适配体,其中,该适配体抑制胃促胰酶的活性。
[4][1]~[3]中任一项的适配体,其中,r1与r2的组合为a/u、c/g、a/c或g/u(其中,尿嘧啶可以是胸腺嘧啶)。
[5][1]~[4]中任一项的适配体,其中,嘧啶核苷酸中的至少一个被修饰或改变。
[6][1]~[5]中任一项的适配体,其中,序列uaacr1中的u和/或c被修饰或改变。
[7][2]~[6]中任一项的适配体,其中,(1’)部分的茎/环部分的碱基长度为3~21。
[8][1]~[7]中任一项的适配体,其中,n1或下述式(1’)所表示的茎/环部分结构的序列为uugu、cugg或aauu(其中,尿嘧啶可以是胸腺嘧啶):
[化学式3]
[9][1]或[2]的适配体,其中,该适配体包含以下的(a)、(b)或(c)中的任一条核苷酸序列:
(a)选自seqidno:1~11和14~33的任一条的核苷酸序列(其中,尿嘧啶可以是胸腺嘧啶);
(b)在选自seqidno:1~11和14~33的任一条的核苷酸序列(其中,尿嘧啶可以是胸腺嘧啶)中有1个~多个核苷酸被取代、缺失、插入或添加而得到的核苷酸序列;或者
(c)与选自seqidno:1~11和14~33的任一条的核苷酸序列(其中,尿嘧啶可以是胸腺嘧啶)具有70%以上的同源性的核苷酸序列。
[10][9]的适配体,其中,适配体中所含的至少一个核苷酸被修饰或改变。
[11][1]或[2]的适配体,其中,适配体中所含的各嘧啶核苷酸的核糖2’位的羟基相同或不同、且未取代或被选自氢原子、氟原子和甲氧基的原子或基团取代。
[12][1]或[2]的适配体,其中,适配体中所含的各嘌呤核苷酸的核糖2’位的羟基相同或不同、且未取代或被选自氢原子、氟原子和甲氧基的原子或基团取代。
[13]复合物,该复合物包含[1]~[12]中任一项的适配体和功能性物质。
[14]药物,该药物包含[1]~[12]中任一项的适配体或[13]的复合物。
[15][14]的药物,该药物为涉及脏器或组织的纤维化的疾病、或循环系统疾病的治疗药。
[16][14]的药物,该药物为纤维化的治疗药。
[17]胃促胰酶的检测方法,其特征在于:使用[1]~[12]中任一项的适配体或[13]的复合物。
[18]涉及脏器或组织的纤维化的疾病、或循环系统疾病的治疗方法,该治疗方法包括:向对象给予[1]~[12]中任一项所述的适配体、[13]的复合物或[14]的药物。
[19][1]~[12]中任一项的适配体、[13]的复合物或[14]的药物在涉及脏器或组织的纤维化的疾病、或循环系统疾病的治疗中的应用。
[20][1]~[12]中任一项的适配体或[13]的复合物在涉及脏器或组织的纤维化的疾病、或循环系统疾病的治疗用药物的制备中的应用。
发明效果
本发明的适配体和复合物例如可用作针对纤维化或循环系统疾病等由胃促胰酶引起的各种疾病的药物、或诊断药、试剂。本发明的适配体和复合物还可用于胃促胰酶的纯化和浓缩、以及胃促胰酶的检测和定量。
附图说明
[图1]是显示seqidno:1~6所表示的序列的适配体的二次结构预测的图。
[图2]是显示seqidno:7~8所表示的序列的适配体的二次结构预测的图。
[图3]是显示seqidno:9~10所表示的序列的适配体的二次结构预测的图。
[图4]是显示seqidno:14~18、20所表示的序列的适配体的二次结构预测的图。
[图5]是显示优化selex中的dna模板的随机序列部分的图。
[图6]是显示seqidno:26~31所表示的序列的适配体的二次结构预测的图。
[图7]是显示seqidno:32~33所表示的序列的适配体的二次结构预测的图。
具体实施方式
本发明提供对胃促胰酶具有结合活性的适配体。本发明的适配体可抑制胃促胰酶的活性。
适配体是指对规定的靶分子具有结合活性的核酸分子。适配体通过与规定的靶分子结合,可抑制规定的靶分子的活性。本发明的适配体对胃促胰酶具有结合活性,可抑制胃促胰酶的活性。另外,本发明的适配体可以是rna、dna、修饰核酸或它们的混合物。另外,本发明的适配体可以是直链状或环状的形式。
胃促胰酶是已知的丝氨酸蛋白酶之一,储存在肥大细胞的分泌颗粒内。胃促胰酶例如与生理活性肽的产生/降解、细胞外基质的重建、与细胞因子形成网络、免疫等涉及肥大细胞的各种生物体反应密切相关。本发明的适配体可对源自任意哺乳动物的胃促胰酶具有抑制活性。作为这样的哺乳动物,例如可列举:灵长类(例如,人、猴)、啮齿类(例如,小鼠、大鼠、豚鼠、仓鼠)、以及宠物、家畜和役用动物(役畜)(例如,狗、猫、马、牛、山羊、绵羊、猪),优选为人。人胃促胰酶的氨基酸序列虽然是登录号aab26828所表示的序列,但也可以是导入1个~多个残基的突变而得到的序列、或其结构域部分、肽部分。另外,人胃促胰酶的结构不仅可以是单体,还可以是二聚体或多聚体。
本发明的适配体在生理缓冲液中与胃促胰酶结合。作为缓冲液,没有特别限定,优选使用ph为约5.0~10.0左右的缓冲液,作为这样的缓冲液,例如可列举后述的溶液a或溶液c(参照实施例1和2)。本发明的适配体以可通过以下的任一个试验进行检测的程度的强度与胃促胰酶结合。
在结合强度的测定中使用gehealthcare公司制造的biacoret100。作为一种测定方法,首先将适配体固定在传感器芯片上。固定量设为约1000ru。将分析物用的胃促胰酶溶液调制成0.2μm后注射20μl,来检测胃促胰酶与适配体的结合。以包含由30或40个核苷酸构成的随机核苷酸序列的rna作为阴性对照,在与该对照rna相比胃促胰酶以同等或明显强的强度与适配体结合的情况下,可判定为该适配体对胃促胰酶具有结合能力。
作为另一种测定方法,首先将胃促胰酶固定在传感器芯片上。固定量设为约4000ru。将分析物用的适配体溶液调制成0.01μg/μl后注射20μl,来检测适配体与胃促胰酶的结合。以包含由30或40个核苷酸构成的随机核苷酸序列的rna作为阴性对照,在与该对照rna相比胃促胰酶以同等或明显强的强度与适配体结合的情况下,判断为该适配体对胃促胰酶具有结合能力。
对胃促胰酶的抑制活性是指对胃促胰酶所持有的任意活性的抑制能力。例如,胃促胰酶的功能之一是通过水解来切割肽链的酶活性,是指抑制该酶活性。接受作为针对酶活性的底物的物质并不限于生物体内存在的蛋白或生理活性肽(例如angi、潜在的tgf-β等),还包括在包含这些肽的一部分氨基酸序列的肽中添加显色物质或荧光物质而得到的肽。显色物质或荧光物质为本领域技术人员所已知。另外,作为经由蛋白或生理活性肽的降解反应而发生的现象,可列举胶原i/iii的表达增加、羟基脯氨酸量的增加、ige表达增加等,对胃促胰酶的抑制活性还包括对这些现象的抑制效果。此外,对胃促胰酶的抑制活性还包括:抑制嗜中性粒细胞、单核细胞、嗜酸性粒细胞对胃促胰酶的迁移活性的活性。而且,对胃促胰酶的抑制活性还包括:对由胃促胰酶诱导的组胺游离(释放)促进、肥大细胞数的增加、血管通透性的增大、组织的纤维化、炎症、血管形成、血管内膜肥厚等的抑制效果。
胃促胰酶底物是指通过胃促胰酶发生水解而被切割的肽或蛋白等。作为生物体内存在的胃促胰酶底物,已知有angi、潜在的tgf-β、干细胞因子(stemcellfactor,scf)、原胶原、原胶原酶、纤连蛋白、基质金属蛋白酶原-1(pro-mmp-1)、pro-mmp-9、基质金属蛋白酶-1组织抑制剂(tissueinhibitorofmatrixmetalloproteinase-1,timp-1)、载脂蛋白a-i(apoa-i)、apoe、磷脂转运蛋白、il-1β前体、big-et-1(大-内皮素-1)、big-et-2、结缔组织激活肽iii、il-18前体、p物质、血管活性肠肽(vip)、胰激肽(kallidin)、缓激肽(bradykinin)、c3a等肽或蛋白。作为本说明书中的胃促胰酶的底物,并不限于这些,还包括:包含胃促胰酶特异性地识别的phe或tyr等氨基酸残基作为它们的一部分氨基酸序列的人工设计的模型肽、或在这样的肽中添加显色物质或荧光物质而得到的肽。
适配体是否抑制胃促胰酶的酶活性,可通过以下的试验进行评价。作为例子,以下给出两种方法。
第一种给出使用合成底物的评价方法。作为胃促胰酶底物,例如使用包含作为胰凝乳蛋白酶样蛋白酶的标准底物的4氨基酸肽“ala-ala-pro-phe”(seqidno:41)而形成的suc-ala-ala-pro-phe-mca(4-甲基香豆素-7-酰氨基)(peptide研究所公司制造)。
测定中使用96孔板(f16blackmaxisorpfluoronunc、nunc公司制造),反应液量设为100μl,在缓冲液(溶液c;参照后述的实施例1)中进行反应。首先,将核酸在溶液c中调制,准备50μl所得的调制物。向其中添加10μl在溶液c中调制的1mm的底物后,将板放在酶标仪spectramax190(moleculardevices公司制造)中,在37℃下保温5分钟。另一方面,将0.05μg胃促胰酶(重组、sigma公司制造)在溶液c中稀释,准备40μl所得的稀释物,在37℃下保温5分钟。在由核酸和底物构成的混合液中加入胃促胰酶溶液,引发酶反应。将包含反应液的板放在酶标仪spectramax190(moleculardevices公司制造)中,在37℃下随时间测定荧光强度的变化达5分钟(激发波长380nm、检测波长460nm)。通过胃促胰酶活性,求出由底物释放的amc(7-氨基-4-甲基香豆素)的荧光增加的线性近似,以其斜率值作为初速度。作为对照,在使用包含30或40个核苷酸的随机序列的核酸库的情况下(阴性对照)和使用已知的作为胰凝乳蛋白酶样丝氨酸蛋白酶抑制剂的胰凝乳蛋白酶抑制剂(chymostatin)的情况下(阳性对照),同样地进行处理、测定。以不含核酸、抑制剂的情况下的反应初速度作为100%酶活性,算出各受试物质的抑制率,求出抑制50%酶活性所需的抑制剂的浓度(ic50)。将与作为已知的抑制剂的胰凝乳蛋白酶抑制剂相比ic50显示出低值的适配体判定为具有优异的抑制活性的适配体。
第二种给出使用天然底物的评价方法。作为胃促胰酶的天然底物,例如使用血管紧张素i。这里说明以下方法:对通过血管紧张素i的降解而游离的肽片段即his-leu进行荧光诱导,定量地测定其荧光强度。
测定中的酶反应的溶液量设为50μl,在溶液c中进行反应。首先,将0.3~0.75ng的胃促胰酶(重组、sigma公司制造;或者天然、calbiochem公司制造)在溶液c中稀释,准备5μl所得的稀释物。将核酸在溶液c中调制,准备25μl所得的调制物。将5μl胃促胰酶溶液和25μl核酸溶液混合,在37℃下保温5分钟。另一方面,准备20μl在溶液c中调制的125μm的血管紧张素i(peptide研究所公司制造),在37℃下保温5分钟。在由胃促胰酶和核酸构成的混合液中加入血管紧张素i溶液,引发酶反应。在37℃下反应90分钟后,添加25μl冰冷的30%三氯乙酸溶液,使反应停止。将混合液整体在4℃、14000rpm下离心10分钟,将30μl该上清用于以下的荧光诱导反应。
在96孔板(黑色、costar公司制造)中加入30μl上述的上清,向各孔中混合15μl溶解于甲醇的2%的邻苯二甲醛(sigma公司制造)溶液和170μl0.3m的naoh溶液,在室温下放置10分钟。之后,添加25μl3m的hcl溶液,使反应停止。将板放在酶标仪spectramax190(moleculardevices公司制造)中,在激发波长355nm、荧光波长460nm的条件下测定荧光强度。
需要说明的是,作为对照,在使用seqidno:58的情况下(阴性对照)和使用已知的作为胰凝乳蛋白酶样丝氨酸蛋白酶抑制剂的胰凝乳蛋白酶抑制剂的情况下(阳性对照),同样地进行处理、测定。在各条件下以反应时间0分钟的荧光强度作为空白。在胃促胰酶的酶反应中,以在添加等量的溶液c来代替添加核酸的情况下所检测的荧光强度作为100%,算出各受试物质的抑制率,求出抑制50%酶活性所需的抑制剂的浓度(ic50)。将与作为已知的抑制剂的胰凝乳蛋白酶抑制剂相比ic50显示出低值的适配体判定为具有优异的抑制活性的适配体。
如后述的实施例中详细所示,与已报道的wo2010/143714的针对胃促胰酶的适配体相比,本发明的适配体具有大约10~100倍高的对胃促胰酶的抑制活性。具体而言,wo2010/143714中公开的针对胃促胰酶的适配体因显示出0.1μm以下的ic50值而被视为优异的适配体(参照第[0105]段等),但在本发明的适配体中,如实施例3(表4)所示,还存在多个显示出1nm以下的ic50值的适配体。
因此,发明人没有预料到在完成本发明的时间点可获得这样优质的针对胃促胰酶的适配体。由以上结果,可以说本发明的适配体发挥即使是本领域技术人员也无法容易地由已知文献想到的那样有利的效果。
对本发明的适配体没有特别限定,只要与胃促胰酶的任意部分结合、且可抑制其活性即可。
对本发明的适配体的长度没有特别限定,通常可以是约25~约200个核苷酸,例如为约100个核苷酸以下,优选为约50个核苷酸以下,更优选为约40个核苷酸以下,最优选可以是约35个核苷酸以下。如果总核苷酸数少,则化学合成和大量生产更为容易,并且在成本方面的优点也大。另外,认为化学修饰也容易,生物体内稳定性也高,毒性也低。另一方面,本发明的适配体的长度通常为约25个核苷酸以上,优选可以是约28个核苷酸以上。若总核苷酸数太少,则无法具有以下说明的通用序列,潜在的二次结构变得不稳定,根据情况有时还不具有活性。
本发明的适配体中所含的各核苷酸各自相同或不同,可以是在核糖(例如,嘧啶核苷酸的核糖、嘌呤核苷酸的核糖)的2’位包含羟基的核苷酸(即,未取代的核苷酸),或者可以是在核糖的2’位羟基被任意的原子或基团取代的核苷酸。作为这样的任意的原子或基团,例如可列举:被氢原子、氟原子或-o-烷基(例如,-o-me基)、-o-酰基(例如,-o-come基)、氨基(例如,-nh2基)取代的核苷酸。
本发明的适配体是具有uaacr1n1r2gggg所表示的通用序列(以下,有时称为本发明的通用序列)的适配体。具有该序列的适配体通过与胃促胰酶强力结合而抑制胃促胰酶的活性。即,已知晓抑制胃促胰酶活性的适配体无需确认其与胃促胰酶的结合,也可知其是与胃促胰酶结合的适配体。
上述通用序列中,r1和r2显示任意的一个碱基。对r1与r2的组合没有特别限定,只要本发明的适配体与胃促胰酶结合即可,例如,作为r1与r2的组合,有a/u、c/g、a/c或g/u(其中,尿嘧啶可以是胸腺嘧啶),更优选为由r1和r2形成沃森-克里克碱基对的组合(a/u或c/g)。
对上述r1与r2的组合没有特别限定,只要本发明的适配体与胃促胰酶结合即可,r1和r2可替换。即,r1与r2的组合显示为a/u的情形包括:r1为a而r2为u的情形和r1为u而r2为a的情形。在c/g、a/c或g/u中也同样。
对通用序列uaacr1n1r2gggg中的n1部分的序列没有特别限定,只要本发明的适配体与胃促胰酶结合即可,可采用任意序列。对该部分的碱基长度没有特别限定,只要本发明的适配体与胃促胰酶结合即可,通常为3~30,优选为3~21,更优选为3~19。
另外,本发明的适配体为具有以下的式(1)所表示的潜在的二次结构的适配体。具有该序列的适配体通过与胃促胰酶强力结合而抑制胃促胰酶的活性。
[化学式4]
上述式(1)中,在uaacr1与r2gggg之间形成茎结构(包含两个a/g错配)。即,在通用序列中的uaacr1与r2gggg之间形成茎结构。换言之,通用序列中的n1部分形成环结构。
上述式(1)中,r1和r2显示任意的一个碱基。对r1与r2的组合没有限定,只要在上述式(1)中的uaacr1与r2gggg之间形成茎结构即可。然而,作为r1与r2的组合,优选为a/u、c/g、a/c或g/u(其中,尿嘧啶可以是胸腺嘧啶),更优选为由r1和r2形成沃森-克里克碱基对的组合(a/u或c/g)。
上述r1与r2的组合只要在上述式(1)中的uaacr1与r2gggg之间形成茎结构即可,r1和r2可替换。即,r1与r2的组合显示为a/u的情形包括:r1为a而r2为u的情形和r1为u而r2为a的情形。在c/g、a/c或g/u中也同样。
这里,式(1)中的下述式(1’)所示的部分显示茎/环部分结构:
[化学式5]
对该部分结构的碱基长度没有特别限定,只要本发明的适配体与胃促胰酶结合即可,通常为3~30个,优选为3~21个,更优选为3~19个。若该部分结构的碱基长度小于3,则无法形成环结构,若超过30,则该部分结构中的碱基的影响变得明显,适配体的活性有时会下降。特别是在碱基长度为21以下的情况下,显示出稳定的适配体活性。在该茎/环部分结构中,可存在茎结构,也可不存在茎结构而全部为环结构。即,对于本发明的适配体具有对胃促胰酶的结合活性而言,重要的是以下的式(1)的结构整体上采取茎/环结构:
[化学式6]
由于在uaacr1与r2gggg之间已形成茎结构,所以在式(1)中的下述式(1’)所示的部分结构中是否存在茎结构并不重要。另一方面,在存在茎结构的情况下,该茎结构可具有凸起结构(突起结构)。
[化学式7]
如上所述,在本发明的适配体中式(1)的结构整体上采取茎/环结构在作为针对胃促胰酶的适配体的活性表达方面非常重要:
[化学式8]
即,在本发明中,只要具有上述式(1)的结构、并且具有对胃促胰酶的结合活性(或者胃促胰酶抑制活性)即可,对式(1)中的如下述式(1’)所示的茎/环部分结构中的序列没有特别限定。
[化学式9]
实际上,如后述的实施例中所示,上述茎/环部分结构中的序列并不限于特定的序列,在各种各样的序列中可同样具有茎/环部分结构,并且可具有对胃促胰酶的结合活性。
然而,作为上述式(1’)中的优选序列,有uugu、uugc、cugg或aauu(其中,尿嘧啶可以是胸腺嘧啶),更优选为uugu。
而且,即使在上述式(1)所示的结构的两侧、即5’末端侧和3’末端侧,其序列也不限于特定的序列,在各种各样的序列中可具有同样的对胃促胰酶的结合活性(或胃促胰酶抑制活性)。
本发明的适配体中,至少1种(例如,1、2、3或4种)核苷酸可以是在核糖的2’位包含羟基或上述的任意的原子或基团、例如选自氢原子、氟原子、羟基和甲氧基的至少2种(例如,2、3或4种)基团的核苷酸。特别是通用序列和式(1)所表示的结构中的u和/或c优选在核糖的2’位可用选自氢原子、氟原子和甲氧基的基团修饰。
在本发明的适配体中,所有的嘧啶核苷酸均为在核糖的2’位相同或不同、且被氟原子取代的核苷酸;或者可以是被上述的任意的原子或基团、优选选自氢原子、羟基和甲氧基的原子或基团取代的核苷酸。
在本发明的适配体中,所有的嘌呤核苷酸均为在核糖的2’位相同或不同、且被羟基取代的核苷酸;或者可以是被上述的任意的原子或基团、优选选自氢原子、甲氧基和氟原子的原子或基团取代的核苷酸。
在本发明的适配体中,所有的核苷酸均可以是在核糖的2’位包含羟基或上述的任意的原子或基团、例如选自氢原子、氟原子、羟基和甲氧基的相同基团的核苷酸。
尚需说明的是,在本说明书中,将构成适配体的核苷酸假定为rna(即,将糖基假定为核糖),对核苷酸中的糖基的修饰方案进行说明,但这并不意味着从构成适配体的核苷酸中排除了dna,可适当理解为对dna的修饰。例如,在构成适配体的核苷酸为dna的情况下,核糖的2’位的羟基取代成x可理解为脱氧核糖的2’位的一个氢原子取代成x。
本发明的适配体还可以是以下的适配体:
(a)包含选自seqidno:1~11和14~33的任一条的核苷酸序列(其中,尿嘧啶可以是胸腺嘧啶)的适配体;
(b)包含在选自seqidno:1~11和14~33的任一条的核苷酸序列(其中,尿嘧啶可以是胸腺嘧啶)中有1个或多个核苷酸被取代、缺失、插入或添加而得到的核苷酸序列的适配体;或者
(c)包含与选自seqidno:1~11和14~33的任一条的核苷酸序列(其中,尿嘧啶可以是胸腺嘧啶)具有70%以上(优选80%以上、更优选90%以上、最优选95%以上)的同源性的核苷酸序列的适配体;
或者,作为本发明的适配体,还包括(d):
(d)选自多个上述(a)的连接物、多个上述(b)的连接物、多个上述(c)的连接物、多个上述(a)和(b)和(c)的连接物的连接物。
不仅上述(a)的适配体、就连(b)~(d)的适配体也可与胃促胰酶结合且/或抑制胃促胰酶的活性(胃促胰酶的酶活性等)。
本发明的适配体还可以是以下的适配体:
(a’)包含选自seqidno:17(1)~17(25)和33(1)~33(18)的任一条的核苷酸序列(其中,尿嘧啶可以是胸腺嘧啶)的适配体;
(b’)包含在选自seqidno:17(1)~17(25)和33(1)~33(18)的任一条的核苷酸序列(其中,尿嘧啶可以是胸腺嘧啶)中有1~5个核苷酸被取代、缺失、插入或添加而得到的核苷酸序列的适配体;或者
(c’)包含与选自seqidno:17(1)~17(25)和33(1)~33(18)的任一条的核苷酸序列(其中,尿嘧啶可以是胸腺嘧啶)具有70%以上的同源性的核苷酸序列的适配体;
或者,作为本发明的适配体,还包括下述的(d):
(d’)选自多个上述(a’)的连接物、多个上述(b’)的连接物、多个上述(c’)的连接物、多个上述(a’)和(b’)的(c’)的连接物的连接物。
而且,作为本发明的适配体,还包括下述的(e):
(e)由选自上述(a)、(b)和(c)的适配体的一个以上和选自(a’)、(b’)的(c’)的适配体的一个以上构成的连接物。
上述(a’)~(d’)和(e)的适配体也可与胃促胰酶结合且/或抑制胃促胰酶的活性(胃促胰酶的酶活性等)。
在上述(b)和(b’)中,对被取代、缺失、插入或添加的核苷酸数没有特别限定,只要适配体可与胃促胰酶结合且/或抑制胃促胰酶的活性(胃促胰酶的酶活性等)即可,例如可以是约30个以下,优选约20个以下,更优选约10个以下,更进一步优选5个以下,最优选4个、3个、2个或1个。
在上述(c)和(c’)中,“同源性”是指,在利用该技术领域中已知的数学算法比对两条核苷酸序列的情况下,最适比对(优选该算法可考虑到向其中一条或两条序列中导入空位以进行最适比对)中的同源核苷酸残基与重叠的总核苷酸残基的比例(%)。
在本说明书中,核苷酸序列中的同源性例如可采用同源性计算算法ncbiblast-2(nationalcenterforbiotechnologyinformationbasiclocalalignmentsearchtool),在以下的条件(空位开放(gapopen)=5罚分(penalties);空位扩展(gapextension)=2罚分;x_drpooff=50;期待值(expectedvalue)=10;过滤(filtering)=on)下通过比对2条核苷酸序列来进行计算。
在上述(d)、(d’)和(e)中,连接可通过串联结合来进行。另外,在连接时可利用接头。作为接头,可列举核苷酸链(例如,1个~约20个核苷酸)、非核苷酸链(例如,-(ch2)n-接头、-(ch2ch2o)n-接头、六甘醇接头、teg接头、包含肽的接头、包含-s-s-键的接头、包含-conh-键的接头、包含-opo3-键的接头)。上述多个的连接物中的多个如果是2以上,则没有特别限定,例如可以是2个、3个或4个。上述(a)~(d)、(a’)~(d’)和(e)中的各核苷酸各自相同或不同,可以是在核糖(例如,嘧啶核苷酸的核糖)的2’位包含羟基的核苷酸,或者可以是在核糖的2’位羟基被任意的基团(例如,氢原子、氟原子或-o-me基)取代的核苷酸。
为了提高对胃促胰酶的结合性、稳定性、药物递送性等,本发明的适配体可以是各核苷酸的糖残基(例如,核糖)被修饰而得到的适配体。作为糖残基中被修饰的位点,例如可列举:将糖残基的2’位、3’位和/或4’位的氧原子取代成其他原子而得到的适配体等。作为修饰的种类,例如可列举:氟化、o-烷基化(例如,o-甲基化、o-乙基化)、o-烯丙基化、s-烷基化(例如,s-甲基化、s-乙基化)、s-烯丙基化、氨基化(例如,-nh2)。这样的糖残基的改变可通过自身已知的方法进行(例如参照sproat等人,(1991)nucle.acid.res.19,733-738;cotton等人,(1991)nucl.acid.res.19,2629-2635;hobbs等人,(1973)biochemistry12,5138-5145)。
在本发明的适配体中,即使在本发明的通用序列或式(1):
[化学式10]
所表示的结构中也可进行上述修饰,但uaacr1n1r2gggg中的gggg部分的第2个g希望在糖残基的2’位未进行o-甲基化(o-甲基修饰)。因此,本发明的适配体可以是uaacr1n1r2gggg或式(1):
[化学式11]
的结构中的gggg部分的第2个g没有进行o-甲基化(o-甲基修饰)的适配体。这种情况下,gggg部分的第2个g希望用氟原子修饰(氟化)。
另外,为了提高对胃促胰酶的结合活性等,本发明的适配体可以是核酸碱基(例如,嘌呤、嘧啶)被改变(例如,化学取代)的适配体。作为这样的改变,例如可列举:5位嘧啶改变、6和/或8位嘌呤改变、用环外胺的改变、用4-硫代尿苷的取代、用5-溴-尿嘧啶或5-碘-尿嘧啶的取代、用8-(丙基)苯基-ra(n-bz)-2’-tbdms亚酰胺(amidite)的取代。
另外,本发明的适配体中所含的磷酸基可被改变,使对核酸酶和水解呈抗性。例如,p(o)o基可被p(o)s(硫代酸酯)、p(s)s(二硫代酸酯)、p(o)nr2(酰胺化物)、p(o)ch3、p(o)bh3、p(o)r、r(o)or’、co或ch2(甲缩醛)或3’-胺(-nh-ch2-ch2-)取代[这里,各r或r’独立地为h、或者为取代或未取代的烷基(例如,甲基、乙基)]。
作为连接基,例示-o-、-n-或-s-,通过这些连接基可与相邻的核苷酸结合。
另外,改变可包含加帽这样的3’和5’的改变。
改变还可通过在末端添加聚乙二醇、氨基酸、肽、反向dt、核酸、核苷、肉豆蔻酰基、石胆酸-油烯基(lithocolic-oleyl)、二十二烷基(docosanyl)、月桂酰基、硬脂酰基、棕榈酰基、油酰基、亚油酰基(linoleoyl)、其他脂质、甾族化合物(类固醇)、胆固醇、咖啡因、维生素、色素、荧光物质、抗癌药、毒素、酶、放射性物质、生物素等来进行。关于这样的改变,例如可参照美国专利第5,660,985号、美国专利第5,756,703号来进行。
本发明的适配体可通过本说明书中的公开和该技术领域中的自身已知的方法来合成。合成方法之一为使用rna聚合酶的方法。化学合成具有目标序列和rna聚合酶的启动子序列的dna,以其为模板,通过已知的方法进行转录,从而可获得目标rna。另外,通过使用dna聚合酶也可进行合成。化学合成具有目标序列的dna,以其为模板,通过作为已知方法的聚合酶链反应(pcr)进行扩增。通过作为已知方法的聚丙烯酰胺电泳法或酶处理法将其变成单链。在合成加入了修饰的适配体的情况下,可通过使用在特定位置导入了突变的聚合酶来提高延伸反应的效率。如此操作而得到的适配体可通过已知方法容易地进行纯化。
适配体可通过亚酰胺法或亚磷酰胺法等化学合成法进行大量合成。合成方法为熟知的方法,如nucleicacid(第2卷)[1]synthesisandanalysisofnucleicacid(editor:yukiosugiura,hirokawapublishingcompany)等中所记载。实际上使用gehealthcarebio-sciences公司制造的oligopilot100或oligoprocess等合成仪。纯化通过色谱法等自身已知的方法进行。
在亚磷酰胺法等化学合成时,通过向适配体中导入氨基等活性基团,合成后可添加功能性物质。例如,通过在适配体的末端导入氨基,可使导入了羧基的聚乙二醇链缩合。
适配体通过利用了磷酸基的负电荷的离子键、利用了核糖的疏水键和氢键、利用了核酸碱基的氢键或堆积(stacking)相互作用等多种结合方式与靶物质结合。特别是,利用了仅存在构成核苷酸的数的磷酸基的负电荷的离子键较强,与存在于蛋白表面的赖氨酸或精氨酸的正电荷结合。因此,可取代与靶物质的直接结合无关的核酸碱基。特别是,茎结构的部分已形成碱基对,另外还朝向双螺旋结构的内侧,因此核酸碱基难以与靶物质直接结合。因此,即使将碱基对取代成其他的碱基对,适配体的活性也往往不会降低。即使在不形成环结构等碱基对的结构中,在核酸碱基不参与与靶分子的直接结合的情况下,就可进行碱基的取代。关于核糖的2’位的修饰,虽然核糖的2’位的官能团很少与靶分子直接进行相互作用,但往往是无关系的,可取代成其它的修饰分子。如此,适配体只要不取代或不删除参与与靶分子的直接结合的官能团,则往往会保持其活性。另外,整体的立体结构(三维结构)没有大幅变化也很重要。
适配体可通过利用selex法及其改良法(例如,ellington等人,(1990),nature,346,818-822;tuerk等人,(1990),science,249,505-510)来制作。在selex法中,通过增加轮数、或者使用竞争物质,使筛选条件变得严格,对靶物质的结合力更强的适配体被浓缩、选出。因此,通过调节selex的轮数和/或改变竞争状态,有时可得到结合力不同的适配体、结合方式不同的适配体、结合力或结合方式相同但核苷酸序列不同的适配体。另外,selex法包括通过pcr进行的扩增过程,但在其过程中通过使用锰离子等引入突变,可进行更富多样性的selex。
通过selex得到的适配体是对靶物质显示出高亲和性的核酸,但这并不意味着抑制靶物质的生理活性。胃促胰酶为碱性蛋白,认为其容易与核酸非特异性地结合,但与特定位点强力结合的适配体以外的适配体不会对其靶物质的活性产生影响。实际上,虽然用作阴性对照的包含随机序列的rna与胃促胰酶结合较弱,但没有抑制胃促胰酶的酶活性。
可根据如此操作而选择的具有活性的适配体进行selex,以获得具有更高活性的适配体。具体方法如下:制作以某个序列已确定的适配体的一部分为随机序列的模板或掺杂了10~30%左右的随机序列的模板,再次进行selex。
通过selex得到的适配体具有80个核苷酸左右的长度,难以将其直接制成药物。于是,反复进行摸索试验,需要缩短至可容易地进行化学合成的约50个核苷酸以下的长度。通过selex得到的适配体取决于其引物设计,之后的最小化操作的容易度发生变化。若没有顺利地设计引物,则即使通过selex选出了具有活性的适配体,之后的开发也是不可能的。在本发明中,可获得即使是28个核苷酸也保持着活性的适配体。
因适配体可进行化学合成,故容易改变。适配体通过使用mfold程序来预测二级结构、或者通过x射线分析或nmr分析来预测立体结构,可在一定程度上预测可取代或缺失哪个核苷酸,以及可在哪里插入新的核苷酸等。所预测的新的序列的适配体可容易地进行化学合成,其适配体是否保持活性可通过现有的测定体系进行确认。
在通过反复进行如上所述的摸索试验特定出对于所得的适配体与靶物质的结合较为重要的部分的情况下,即使在其序列的两端添加新的序列,多数情况下活性也会保持不变。对新的序列的长度没有特别限定。
关于修饰,也和序列同样,可由本领域技术人员自由地进行设计或改变。
如上所述,适配体可高度地进行设计或改变。本发明还提供适配体的制造方法,该制造方法可高度地设计或改变包含规定序列(例如,选自茎部分、内环部分、凸起部分、发夹环部分和单链部分的部分所对应的序列:以下,根据需要简称为固定序列)的适配体。
例如,这样的适配体的制造方法包括:使用由下述式表示的核苷酸序列构成的单种核酸分子或多种核酸分子(例如,数a、b等不同的核酸分子的文库)、以及引物用序列(i)、(ii)各自所对应的引物对来制造包含固定序列的适配体,
[化学式12]
[上述式中,(n)a显示由a个n构成的核苷酸链,(n)b显示由b个n构成的核苷酸链,n各自相同或不同且为选自a、g、c、u和t(优选a、g、c和u)的核苷酸。a、b各自相同或不同且可以是任意的数,例如可以是1~约100个,优选为1~约50个,更优选为1~约30个,进一步优选为1~约20个或1~约10个]。
本发明还提供包含本发明的适配体和与其结合的功能性物质的复合物。本发明的复合物中的适配体与功能性物质之间的键可以是共价键或非共价键。本发明的复合物可以是本发明的适配体与1个以上(例如,2个或3个)的同种或异种的功能性物质结合而得到的复合物。作为功能性物质,只要是对本发明的适配体新添加了某些功能的物质、或者可使本发明的适配体所能保持的某些特性发生变化(例如,提高)的物质即可,没有特别限定。作为功能性物质,例如可列举:蛋白、肽、氨基酸、脂质、糖质、单糖、多核苷酸、核苷酸。作为功能性物质,例如还可列举:亲和性物质(例如,生物素、链霉亲和素、对靶互补序列具有亲和性的多核苷酸、抗体、谷胱甘肽琼脂糖、组氨酸)、标记用物质(例如,荧光物质、发光物质、放射性同位素)、酶(例如,辣根过氧化物酶、碱性磷酸酶)、药物递送介质(例如,脂质体、微球体、肽、聚乙二醇类)、药物(例如,刺孢霉素或倍癌霉素等在导弹疗法(missiletherapy)中使用的药物;环磷酰胺、美法仑(苯丙氨酸氮芥)、异环磷酰胺或曲磷胺等氮芥子气类似物;噻替哌等吖丙啶类;卡莫司汀等亚硝基脲;替莫唑胺或达卡巴嗪等烷基化剂;甲氨蝶呤或雷替曲塞等叶酸类似代谢拮抗剂;硫鸟嘌呤、克拉屈滨或氟达拉滨等嘌呤类似物;氟尿嘧啶、替加氟或吉西他滨等嘧啶类似物;长春碱、长春新碱或长春瑞滨等长春花生物碱及其类似物;依托泊苷、紫杉烷、多西他赛或紫杉醇等鬼臼毒素衍生物;多柔比星(阿霉素)、表柔比星、伊达比星和米托蒽醌等蒽环类和类似物;博来霉素和丝裂霉素等其他的细胞毒性抗生素;顺铂、卡铂和奥沙利铂等铂化合物;喷司他丁、米替福新、雌莫司汀、拓扑替康、伊立替康和比卡鲁胺)、毒素(例如,蓖麻毒素、liatoxin(リア毒素)和维罗(vero)毒素)。这些功能性分子有时最终会被除去。而且,还可以是凝血酶或基质金属蛋白酶(mmp)、x因子等酶所能识别并切割的肽、核酸酶或限制酶所能切割的多核苷酸。
本发明的适配体和复合物例如可用作药物或诊断药、检测药、试剂。
本发明的适配体和复合物可具有抑制胃促胰酶功能的活性。如上所述,胃促胰酶与纤维化或循环系统疾病密切相关。因此,本发明的适配体和复合物除了用于纤维化或循环系统疾病以外,还可用作用于治疗或预防伴有纤维化、或循环系统疾病的疾病的药物。
本发明的适配体和复合物可特异性地与胃促胰酶结合。因此,本发明的适配体和复合物可用作胃促胰酶检测用探针。该探针可用于胃促胰酶的体内成像、血中浓度测定、组织染色、elisa等。另外,该探针可用作涉及胃促胰酶的疾病(纤维化或循环系统疾病、伴有纤维化或循环系统疾病的疾病等)的诊断药、检测药、试剂等。
另外,根据其与胃促胰酶的特异性结合,本发明的适配体和复合物可用作胃促胰酶的分离纯化用配体。
另外,本发明的适配体和复合物可用作药物递送剂。
纤维化是指,由于某些原因导致脏器或组织的纤维化进展,因该脏器或组织的功能下降而引起的疾病。因此,作为广义的纤维化,可以是涉及脏器或组织的纤维化的疾病。
作为涉及脏器或组织的纤维化的疾病,可列举:肺纤维化、前列腺肥大(前列腺增生)、心肌纤维化、心肌纤维症、肌肉骨骼纤维化、骨髄纤维化、子宫肌瘤、硬皮病、外科手术后的粘连、手术后的疤痕、灼伤性疤痕、肥厚性疤痕、疤痕疙瘩、特应性皮炎、腹膜硬化症、哮喘、肝硬化、慢性胰腺炎、胃硬癌(scirrhouscarcinomaofstomach)、肝纤维化、肾纤维化、纤维性血管病、由作为糖尿病并发症的纤维性微小血管炎引起的视网膜病变、神经(官能)症、肾病、肾小球肾炎、肾小管间质性肾炎、遗传性肾病、动脉硬化外周动脉炎等。此外,还可列举:大肠炎、骨质疏松症、过敏性结膜炎、重症肝炎、皮肤血管炎、色素性荨麻疹、瘙痒、疱疹样皮炎、大疱性类天疱疮、干癣、食道炎、食道松弛不全症、气道炎(呼吸道炎症)、动脉粥样硬化、静脉瘤等。
作为循环系统疾病,可列举:血管损伤、主动脉瘤、肾功能不全(肾衰)、高血压、动脉硬化、心肌梗塞、心脏肥大、心功能不全(心衰)、由经皮腔内冠状动脉形成术等引起的血管损伤后的再狭窄、糖尿病性和非糖尿病性的肾功能障碍、外周循环障碍等。此外,还可列举:肺动脉高压、主动脉瓣狭窄等。
胃促胰酶持有酶活性,切割作为底物的生理活性物质。作为其底物,例如已知angi、潜在的tgf-β、scf、原胶原、原胶原酶、pro-mmp-9、il-1β前体等,经由这些生理活性肽的产生/降解反应,发挥细胞外基质的重建、与细胞因子形成网络、免疫、血管收缩等生理作用。另一方面,胃促胰酶本身具有活化肥大细胞或者促进组胺游离的作用,与炎症密切相关。因此,本发明的适配体和复合物并不受上述列举的底物的限定,可用作与胃促胰酶所接受的底物介导的生物体功能相关的疾病和胃促胰酶本身参与的疾病的药物或诊断药、检测药、试剂。
本发明的药物可掺混药学上可接受的载体。作为药学上可接受的载体,例如可列举:蔗糖、淀粉、甘露醇、山梨醇、乳糖、葡萄糖、纤维素、滑石、磷酸钙、碳酸钙等赋形剂;纤维素、甲基纤维素、羟丙基纤维素、聚丙基吡咯烷酮、明胶、阿拉伯胶、聚乙二醇、蔗糖、淀粉等粘合剂;淀粉、羧甲基纤维素、羟丙基淀粉、钠-乙二醇-淀粉、碳酸氢钠、磷酸钙、枸橼酸钙等崩解剂;硬脂酸镁、气溶胶、滑石、十二烷基硫酸钠等润滑剂;枸橼酸、薄荷醇、甘草甜素(glycyrrhicin)/铵盐、甘氨酸、橙粉等芳香剂;苯甲酸钠、亚硫酸氢钠、对羟基苯甲酸甲酯、对羟基苯甲酸丙酯等保存剂(防腐剂);枸橼酸、枸橼酸钠、乙酸等稳定剂;甲基纤维素、聚乙烯吡咯烷酮、硬脂酸铝等悬浮剂;表面活性剂等分散剂;水、生理盐水、橙汁等稀释剂;可可脂、聚乙二醇、白煤油等基质蜡等,但并不限于这些。
作为本发明的药物的给药路径,没有特别限定,例如可列举口服给药、胃肠外给药。
作为适合口服给药的制剂,可列举:在水、生理盐水、橙汁这样的稀释液中溶解有效量的配体而得到的溶液制剂;以固体或颗粒的形式包含有效量的配体的胶囊剂、香囊剂(sachet)或片剂;在适当的分散介质中悬浮有效量的有效成分而得到的悬浮液制剂;将溶解有有效量的有效成分的溶液分散在适当的分散介质中使其乳化而得到的乳剂;促进水溶性物质的吸收的c10等。
另外,本发明的药物根据需要为了掩盖味道、肠溶性或持续性等目的,可通过自身已知的方法进行包衣。作为包衣中使用的包衣剂,例如可使用:羟丙基甲基纤维素、乙基纤维素、羟甲基纤维素、羟丙基纤维素、聚氧化亚乙基二醇、吐温80、pluronicf68、乙酸纤维素邻苯二甲酸酯、羟丙基甲基纤维素邻苯二甲酸酯、羟甲基纤维素乙酸琥珀酸酯、eudragit(rohm公司制造、德国、甲基丙烯酸/丙烯酸共聚物)和色素(例如,铁丹、二氧化钛等)等。该药物可以是速释制剂、缓释制剂的任一种。
作为适合胃肠外给药(例如,静脉内给药、皮下给药、肌肉内给药、局部给药、腹腔内给药、经鼻给药等)的制剂,有水性和非水性的等渗无菌注射液制剂,其中可包含抗氧化剂、缓冲剂、抑菌剂、等渗剂等。另外,可列举水性和非水性的无菌悬浮液制剂,其中可包含悬浮剂、增溶剂、增稠剂、稳定化剂、防腐剂等。该制剂可像安瓿或小瓶那样以每单位给药量或每多次给药量封在容器内。另外,还可将有效成分和药学上可接受的载体冷冻干燥,并以可在临使用前溶解或悬浮于适当的无菌溶剂的状态保存。
另外,作为合适的制剂,还可列举缓释制剂。作为缓释制剂的剂型,可列举由人工骨或生物降解性基材或非生物降解性海绵、袋子等埋入体内的载体或容器缓慢释放的形式。或者,缓释制剂还包括药物泵、渗透压泵等由体外持续或断续地向体内或局部递送的装置等。作为生物降解性基材,可列举:脂质体、阳离子脂质体、聚乳酸-乙醇酸(poly(lactic-co-glycolic)acid,plga)、缺端胶原(atelocollagen)、明胶、羟基磷灰石、裂褶多糖(schizophyllan)等。
除注射液制剂、悬浮液制剂或缓释制剂以外,还可列举:适合于经肺给药的吸入剤、适合于经皮给药的软膏剂等。
在吸入剂的情况下,将冷冻干燥状态的有效成分微细化,并使用适当的吸入装置进行吸入给药。在吸入剂中可进一步适当掺混根据需要所使用的表面活性剂、油、调味剂、环糊精或其衍生物等。吸入剂可按照常规方法来制造。即,通过将本发明的适配体或复合物制成粉末或液态,掺混在吸入喷射剂和/或载体中,填充在适当的吸入容器中来制造。另外,在上述本发明的适配体或复合物为粉末状的情况下可使用普通的机械粉末吸入器,在其为液态的情况下可使用雾化器等吸入器。这里,作为吸入喷射剂,可广泛使用以往已知的喷射剂,可例示:氯氟烃-11、氯氟烃-12、氯氟烃-21、氯氟烃-22、氯氟烃-113、氯氟烃-114、氯氟烃-123、氯氟烃-142c、氯氟烃-134a、氯氟烃-227、氯氟烃-c318、1,1,1,2-四氟乙烷等氯氟烃系化合物;丙烷、异丁烷、正丁烷等烃类;二乙醚等醚类;氮气、二氧化碳气体等压缩气体等。
作为表面活性剂,例如可列举:油酸、卵磷脂、二甘醇二油酸酯、油酸四氢糠酯、油酸乙酯、肉豆蔻酸异丙酯、三油酸甘油酯、单月桂酸甘油酯、单油酸甘油酯、单硬脂酸甘油酯、单蓖麻油酸甘油酯、十六烷醇、硬脂醇、聚乙二醇400、氯化十六烷基吡啶鎓、脱水山梨糖醇三油酸酯(商品名span85)、脱水山梨糖醇单油酸酯(商品名span80)、脱水山梨糖醇单月桂酸酯(span20)、聚氧乙烯氢化蓖麻油(商品名hco-60)、聚氧乙烯(20)脱水山梨糖醇单月桂酸酯(商品名tween20)、聚氧乙烯(20)脱水山梨糖醇单油酸酯(商品名tween80)、源自天然资源的卵磷脂(商品名epiclon)、油烯基聚氧乙烯(2)醚(商品名brij92)、硬脂基聚氧乙烯(2)醚(商品名brij72)、月桂基聚氧乙烯(4)醚(商品名brij30)、油烯基聚氧乙烯(2)醚(商品名genapol0-020)、氧化乙烯与氧化丙烯的嵌段共聚物(商品名synperonic)等。作为油,例如可列举:玉米油、橄榄油、棉籽油、葵花油等。另外,在软膏剂的情况下,使用适当的药学上可接受的基质(基剂)(黄色凡士林、白色凡士林、石蜡、plastibase(液体石蜡和聚乙烯的复合软膏基质)、有机硅、白色软膏、蜂蜡、猪油、植物油、亲水软膏、亲水凡士林、纯化羊毛脂、加水羊毛脂、吸水软膏、亲水plastibase、聚乙二醇软膏等),与作为有效成分的本发明的适配体混合并制成制剂,进行使用。
本发明的药物的给药量根据有效成分的种类/活性、疾病的严重度、作为给药对象的动物种、给药对象的药物耐受性、体重、年龄等而不同,作为成人每天的有效成分量,通常可以是约0.0001~约100mg/kg,例如为约0.0001~约10mg/kg,优选为约0.005~约1mg/kg。
本发明还提供固定有本发明的适配体和复合物的固相载体。作为固相载体,例如可列举:基板、树脂、板(例如,多孔板)、过滤器、药筒、柱、多孔材料。基板可以是dna芯片或蛋白芯片等中使用的基板等,例如可列举:镍-ptfe(聚四氟乙烯)基板或玻璃基板、磷灰石基板、硅基板、氧化铝基板等、以及对这些基板实施聚合物等的包覆而得到的基板。作为树脂,例如可列举:琼脂糖颗粒、二氧化硅颗粒、丙烯酰胺与n,n’-亚甲基双丙烯酰胺的共聚物、聚苯乙烯交联二乙烯基苯颗粒、将葡聚糖用环氧氯丙烷交联而得到的颗粒、纤维素纤维、烯丙基葡聚糖与n,n’-亚甲基双丙烯酰胺的交联聚合物、单分散系合成聚合物、单分散系亲水性聚合物、琼脂糖、toyopearl等,另外,还包括在这些树脂上结合有各种官能团而得到的树脂。本发明的固相载体例如可用于胃促胰酶的纯化和胃促胰酶的检测、定量。
本发明的适配体和复合物可通过自身已知的方法固定在固相载体上。例如可列举下述方法:将亲和性物质(例如,上述的物质)或规定的官能团导入本发明的适配体和复合物中,然后利用该亲和性物质或规定的官能团固定在固相载体上。本发明还提供这样的方法。规定的官能团可以是可供于偶联反应的官能团,例如可列举:氨基、巯基、羟基、羧基。本发明还提供导入了这样的官能团的适配体。
本发明还提供胃促胰酶的纯化和浓缩方法。特别是,本发明可由其他的家族蛋白分离胃促胰酶。本发明的纯化和浓缩方法可包括:使胃促胰酶吸附于本发明的固相载体,利用洗脱液洗脱所吸附的胃促胰酶。在本发明的固相载体上吸附胃促胰酶可利用自身已知的方法进行。例如,将含有胃促胰酶的样品(例如,细菌或细胞的培养物或培养上清、血液)导入本发明的固相载体或其含有物中。胃促胰酶的洗脱可使用中性溶液等洗脱液来进行。对中性洗脱液没有特别限定,例如ph可以是约6~约9,优选为约6.5~约8.5,更优选为约7~约8。另外,中性溶液例如可包含尿素、螯合剂(例如,edta)、钠盐(例如,nacl)、钾盐(例如,kcl)、镁盐(例如,mgcl2)、表面活性剂(例如,tween20、triton、np40)、甘油。本发明的纯化和浓缩方法可进一步包括:在吸附胃促胰酶之后,使用洗涤液洗涤固相载体。作为洗涤液,例如可列举:包含尿素、螯合剂(例如,edta)、tris、酸、碱、转运rna、dna、tween20等表面活性剂、nacl等盐的洗涤液等。本发明的纯化和浓缩方法可进一步包括:对固相载体进行加热处理。通过所涉及的步骤,可进行固相载体的再生、灭菌。
本发明还提供胃促胰酶的检测和定量方法。特别是,本发明可将胃促胰酶与其他的家族蛋白区别开来进行检测和定量。本发明的检测和定量方法可包括:利用本发明的适配体(例如,通过使用本发明的复合物和固相载体)测定胃促胰酶。胃促胰酶的检测和定量方法除了使用本发明的适配体代替抗体以外,可利用与免疫学方法同样的方法来进行。因此,通过使用本发明的适配体作为探针来代替抗体,可通过与酶免疫测定法(eia)(例如,直接竞争elisa、间接竞争elisa、夹层elisa)、放射免疫测定法(ria)、荧光免疫测定法(fia)、蛋白质印迹法、免疫组织化学染色法、细胞分选法等方法同样的方法进行检测和定量。另外,还可用作pet等的分子探针。这样的方法例如可用于生物体或生物学样品中的胃促胰酶量的测定、胃促胰酶相关疾病的诊断。
本说明书中列举的包括专利和专利申请说明书在内的所有出版物所记载的内容均通过在本说明书中的引用,而与其全部明示同等程度地纳入本说明书中。
以下列举实施例,以进一步详细说明本发明,但本发明并不受下述实施例等的任何限制。
实施例
实施例1:特异性地与胃促胰酶结合的rna适配体的制作(1)
特异性地与胃促胰酶结合的rna适配体采用selex法进行制作。selex参考ellington等人的方法(ellington和szostak,nature346,818-822,1990)和tuerk等人的方法(tuerk和gold,science249,505-510,1990)来进行。作为靶物质,使用在nhs-activatedsepharose4fastflow(gehealthcare公司制造)的载体上固相化的胃促胰酶(人类皮肤、calbiochem公司制造)。胃促胰酶在载体上固相化的方法按照gehealthcare公司的工艺说明书(仕様書)进行。固相化量通过利用sds-page研究固相化前的胃促胰酶溶液与刚刚固相化后的上清来确认。sds-page的结果,从上清中没有检测到胃促胰酶的谱带,确认到所使用的胃促胰酶几乎全部偶联。约167pmol的胃促胰酶在约3μl的树脂上固相化。
最初一轮中使用的rna(30n)是使用durascribetmt7转录试剂盒(epicentre公司制造)转录通过化学合成得到的dna而得到的。通过该方法得到的rna其嘧啶核苷酸的核糖的2’位被氟化。作为dna模板,使用以下所示的在30个核苷酸的随机序列的两端具有引物序列的长度为72个核苷酸的dna。dna模板和引物通过化学合成来制作。
dna模板:5’-tcacactagcacgcataggnnnnnnnnnnnnnnnnnnnnnnnnnnnnnncatctgacctctctcctgctccc-3’(seqidno:34)
正向引物:5’-taatacgactcactatagggagcaggagagaggtcagatg-3’(seqidno:35)
反向引物:5’-tcacactagcacgcatagg-3’(seqidno:36)
dna模板(seqidno:34)中的n的连续是任意组合的30个核苷酸(30n:各n为a、g、c或t),生成所得适配体独特的序列区。正向引物包含t7rna聚合酶的启动子序列。最初一轮中使用的rna库的变异在理论上为1014。
在固相化有胃促胰酶的载体中加入rna库,在室温下保持30分钟后,用溶液a洗涤树脂,以去除未与胃促胰酶结合的rna。这里,溶液a是145mm氯化钠、5.4mm氯化钾、1.8mm氯化钙、0.8mm氯化镁、20mmtris(ph7.6)的混合溶液。加入溶液b作为洗脱液,在95℃下进行10分钟的热处理,由其上清回收与胃促胰酶结合的rna。这里,溶液b是7m脲、3mmedta、100mmtris-hcl(ph6.6)的混合液。回收的rna通过rt-pcr扩增,通过durascribetmt7转录试剂盒转录,用作下一轮的库。将以上作为1轮,重复多次进行同样的操作。selex结束后,将pcr产物克隆到pgem-teasy载体(promega公司制造)中,转化大肠杆菌株dh5α(toyobo公司制造)。由单一集落(菌落)提取质粒后,使用dna测序仪(3130xl基因分析仪、abi公司制造)研究克隆的核苷酸序列。
在进行9轮selex后,研究56个克隆的序列时,在序列中可见收敛(趋同性)。这些克隆的一部分序列见seqidno:1~6。在这些序列中包含以下所示的通用序列。
uaacr1n1r2gggg
56个克隆中有7个克隆包含上述通用序列。利用mfold程序(m.zuker,nucleicacidsres.31(13),3406-3415,2003)预测这些序列的二次结构时,由上述通用序列的uaacr1和r2gggg形成的部分形成了极其相似的茎结构,且由其夹持的n1形成的部分形成了极其相似的环结构。seqidno:1~6所表示的序列的适配体的二次结构预测见图1。可知上述通用序列采取以下的式(1)所表示的茎/环结构。该茎/环结构部分用矩形(□)围起来。
[化学式13]
以下显示各核苷酸序列。如果没有特别提及,则以下列举的各序列以5’到3’的方向表示,嘌呤碱基(a和g)为2’-oh体,嘧啶碱基(u和c)为2’-氟修饰体。
seqidno:1
gggagcaggagagaggucagaugagcaugcuuuuugguaaccgauaaugggggccuaugcgugcuaguguga
seqidno:2
gggagcaggagagaggucagaugaucggacauaacauuguuggggugucaaggccuaugcgugcuaguguga
seqidno:3
gggagcaggagagaggucagaugauaaccaguuggggggucaauuacaugggaccuaugcgugcuaguguga
seqidno:4
gggagcaggagagaggucagauguaacucuauugaggggcaucagcacaguagccuaugcgugcuaguguga
seqidno:5
gggagcaggagagaggucagaugaugaccgauuauagguaaccacuuagggggccuaugcgugcuaguguga
seqidno:6
gggagcaggagagaggucagaugucaugacuuauagguaaccgauaaugggggccuaugcgugcuaguguga
[通用序列]uaacr1n1r2gggg
在同样条件下继续进行已进行至9轮的上述selex,第10轮研究8个克隆,第11轮研究47个克隆,研究了总计55个克隆的序列。这些克隆的一部分序列见seqidno:7~8。与第9轮同样,这些序列中包含通用序列。55个克隆中有3个克隆包含通用序列。seqidno:7~8所表示的序列的适配体的二次结构预测见图2。茎/环结构用矩形(□)围起来。与图1同样,它们均形成了特征性的茎/环结构。
以下显示各核苷酸序列。如果没有特别提及,则以下列举的各序列以5’到3’的方向表示,嘌呤碱基(a和g)为2’-oh体,嘧啶碱基(u和c)为2’-氟修饰体。
seqidno:7
gggagcaggagagaggucagauguuugguaguaacuggaauaggggcuacaggccuaugcgugcuaguguga
seqidno:8
gggagcaggagagaggucagaugauugacgacuauagguaaccuuuacgggggccuaugcgugcuaguguga
利用下述方法评价seqidno:1~8所表示的核酸是否抑制胃促胰酶的酶活性。选择胰凝乳蛋白酶样蛋白酶的标准底物即包含4个氨基酸肽ala-ala-pro-phe的suc-ala-ala-pro-phe-mca(peptide研究所公司制造)作为胃促胰酶的底物。这里,suc是作为保护基的琥珀酰基,mca为4-甲基香豆素-7-酰氨基,若苯丙氨酸的c末端侧被切割,则amc(7-氨基-4-甲基香豆素)游离。通过检测该amc的荧光,可测定胃促胰酶的酶活性。测定中使用96孔板(f16blackmaxisorpfluoronunc、nunc公司制造),反应液量设为100μl,在溶液c的缓冲液中实施。这里,溶液c是145mm氯化钠、5.4mm氯化钾、1.8mm氯化钙、0.8mm氯化镁、20mmtris(ph7.6)、0.05%tween20的混合溶液。首先,将核酸在溶液c中梯度稀释,准备各50μl的所得稀释物。向其中添加10μl在溶液c中调制的1mm的底物后,将板放在酶标仪spectramax190(moleculardevices公司制造)中,在37℃下保温5分钟。另一方面,将0.05μg胃促胰酶(重组、sigma公司制造)在溶液c中稀释,准备40μl所得的稀释物,在37℃下保温5分钟。在由核酸和底物构成的混合液中加入胃促胰酶溶液,引发酶反应。反应溶液中的最终胃促胰酶浓度为16.7nm,最终底物浓度为100μm。将包含反应液的板放在酶标仪spectramax190(moleculardevices公司制造)中,在37℃下花5分钟(或30分钟)随时间测定荧光强度的变化(激发波长380nm、检测波长460nm)。通过胃促胰酶活性,求出由底物释放的amc的荧光增加的线性近似,以其斜率值作为初速度(vmax)。作为对照,在使用30n(30个连续的核苷酸;n为a、g、c或t)的核酸库的情况下(阴性对照)和使用已知的作为胰凝乳蛋白酶样丝氨酸蛋白酶抑制剂的胰凝乳蛋白酶抑制剂的情况下(阳性对照),同样地进行处理、测定。以不含核酸、抑制剂的情况下的反应初速度(v0)作为100%酶活性,利用下式算出各受试物质的抑制率。
抑制率(%)=(1﹣vmax/v0)×100
求出抑制50%酶活性所需的抑制剂的浓度(ic50)。其结果见表1。“>0.5”显示直到0.5μm的浓度范围未见抑制活性。ic50值显示2~3次测定的平均值。
[表1]
作为阴性对照的30n没有显示出抑制活性(ic50>0.5μm)。另外,作为阳性对照的胰凝乳蛋白酶抑制剂的ic50值显示出0.1μm~0.2μm的值。
由以上结果可知:包含表1所记载的通用序列的适配体显示出对胃促胰酶的抑制活性。特别是显示出0.1μm以下的ic50值的适配体可以说显示出了优异的抑制效果。另外,由该结果显示:作为这些通用序列中所含的r1与r2的组合,可以是a/u、c/g、a/c或g/u中的任一个组合。
使用随机序列为30个核苷酸、且引物序列不同于上述selex中使用的引物序列的模板,进行与上述同样的selex。作为selex的靶物质,使用在nhs-activatedsepharose4fastflow(gehealthcare公司制造)的载体上固相化的胃促胰酶(重组、sigma公司制造)。使用的模板和引物的序列如下所示。dna模板和引物通过化学合成来制作。
dna模板:5’-tctgtcctcagtacttgannnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnngtctgtcgcttcgttccc-3’(seqidno:37)
正向引物:5’-taatacgactcactatagggaacgaagcgacagac-3’(seqidno:38)
反向引物:5’-tctgtcctcagtacttga-3’(seqidno:39)
dna模板(seqidno:37)中的n的连续是任意组合的40个核苷酸(40n:各n为a、g、c或t),生成所得适配体独特的序列区。正向引物包含t7rna聚合酶的启动子序列。最初一轮中使用的rna库的变异在理论上为1014。
在固相化有胃促胰酶的载体中加入rna库,在室温下保持30分钟后,用溶液a洗涤树脂,以去除未与胃促胰酶结合的rna。这里,溶液a是145mm氯化钠、5.4mm氯化钾、1.8mm氯化钙、0.8mm氯化镁、20mmtris(ph7.6)的混合溶液。加入溶液b作为洗脱液,在95℃下进行10分钟的热处理,由其上清回收与胃促胰酶结合的rna。这里,溶液b是7m脲、3mmedta、100mmtris-hcl(ph6.6)的混合液。回收的rna通过rt-pcr扩增,通过durascribetmt7转录试剂盒转录,用作下一轮的库。将以上作为1轮,重复多次进行同样的操作。selex结束后,将pcr产物克隆到pgem-teasy载体(promega公司制造)中,转化大肠杆菌株dh5α(toyobo公司制造)。由单一集落提取质粒后,使用dna测序仪(3130xl基因分析仪、abi公司制造)研究克隆的核苷酸序列。
在进行了8轮selex后,研究38个克隆的序列时,在序列中可见收敛。这些克隆的一部分序列见seqidno:9~10。其中,seqidno:10所表示的序列存在2个序列。38个克隆中有3个克隆包含通用序列。利用mfold程序(m.zuker,nucleicacidsres.31(13),3406-3415,2003)预测这些序列的二次结构时,通用序列的部分形成了极其相似的环结构。seqidno:9~10所表示的序列的适配体的二次结构预测见图3。茎/环结构用矩形(□)围起来。
以下显示各核苷酸序列。如果没有特别提及,则以下列举的各序列以5’到3’的方向表示,嘌呤碱基(a和g)为2’-oh体,嘧啶碱基(u和c)为2’-氟修饰体。
seqidno:9
gggaacgaagcgacagacguuccagcgucuaauacgugaauaaccugaucguaggggguucaaguacugaggacaga
seqidno:10
gggaacgaagcgacagaccgaaucagaaguucaacauggacauaacaucgauggggugucaaguacugacgacaga
利用下述方法评价seqidno:9和10所表示的核酸是否抑制胃促胰酶的酶活性。血管紧张素i通过胃促胰酶转换成血管紧张素ii,此时作为肽片段的his-leu游离。由于该肽his-leu通过邻苯二甲醛会形成荧光诱导体,因此可定量测定其荧光强度。
测定中的酶反应的溶液量设为50μl,在溶液c的缓冲液中实施。首先,将天然胃促胰酶(calbiochem公司制造)在溶液c中稀释,准备5μl所得的稀释物。这里天然胃促胰酶是由人皮肤肥大细胞纯化的胃促胰酶。将核酸在溶液c中以0.0027~2μm的浓度进行梯度稀释,准备各25μl所得的稀释物。将5μl胃促胰酶溶液和25μl核酸溶液混合,在37℃下保温5分钟。另一方面,准备20μl在溶液c中调制的125mm的血管紧张素i(peptide研究所公司制造),在37℃下保温5分钟。在由胃促胰酶和核酸构成的混合液中加入血管紧张素i溶液,引发酶反应。反应溶液中的最终胃促胰酶浓度为0.5nm,最终底物浓度为50μm。在37℃下反应90分钟后,添加25μl冰冷的30%三氯乙酸溶液,使反应停止。将混合液整体在4℃、14000rpm下离心10分钟,将其30μl上清用于以下的荧光诱导化反应。
将上述的30μl上清添加至96孔板(空白、costar公司制造)中,向各孔中混合15μl溶解于甲醇的2%的邻苯二甲醛(sigma公司制造)溶液和170μl0.3m的naoh溶液,在室温下放置10分钟。之后,添加25μl3m的hcl溶液,使反应停止。将板放在酶标仪spectramax190(moleculardevices公司制造)中,在激发波长355nm、荧光波长460nm的条件下测定荧光强度。
在各条件下,以反应时间0分钟的荧光强度为空白。在胃促胰酶的酶反应中,以在添加等量的溶液c代替添加核酸的情况下所检测的荧光强度为100%,利用下式算出各受试物质的抑制率。
抑制率(%)=[1-{(受试物质的荧光强度﹣受试物质的空白的荧光强度)/(不含受试物质的情况下的荧光强度﹣不含受试物质的情况下的空白的荧光强度)}]×100
求出抑制50%酶活性所需的抑制剂的浓度(ic50)。其结果见表2。表中,ic50值显示2~3次测定的平均值。
[表2]
用于阳性对照的胰凝乳蛋白酶抑制剂的ic50值为0.35~0.5μm,表2中所含的所有的核酸即使在使用作为天然底物的血管紧张素i的情况下也具有对胃促胰酶的强抑制活性,因此被期待作为涉及血管紧张素的各种疾病的预防和/或治疗药。
实施例2:适配体的短链化
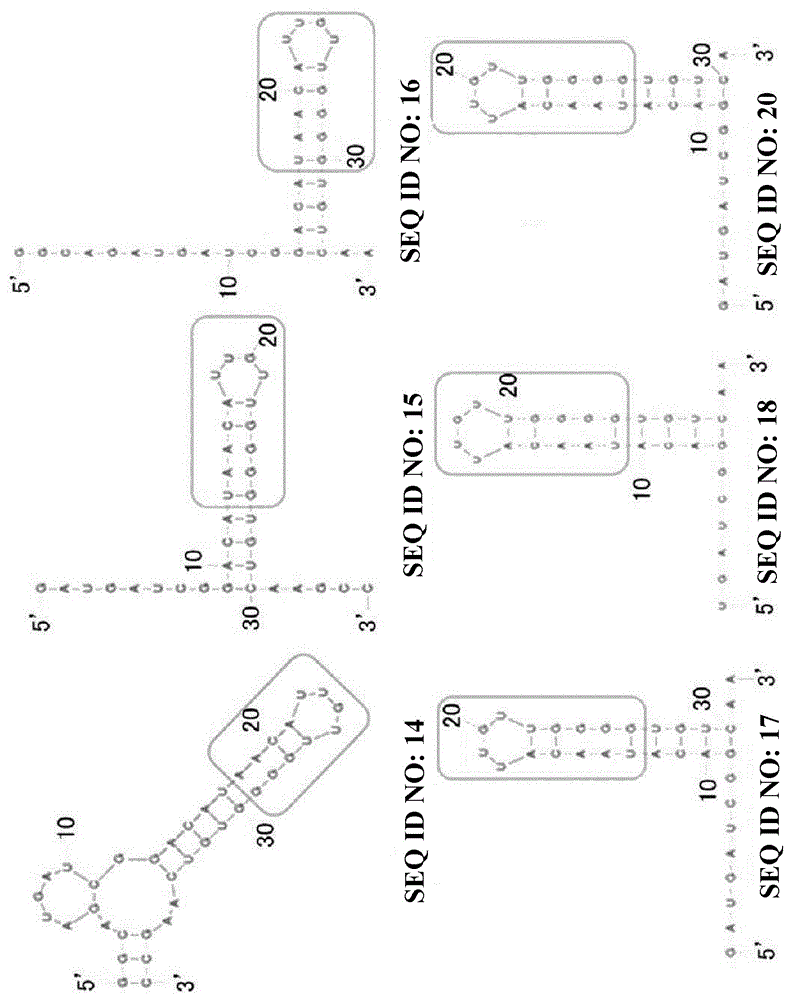
进行了seqidno:2所表示的适配体的短链化。seqidno:2所表示的适配体包含通用序列。已短链化的序列见seqidno:11~20。关于seqidno:11~20所表示的适配体的一部分的二次结构预测见图4。图4中,通用序列用矩形(□)围起来。
以下显示seqidno:11~20所表示的各核苷酸序列。如果没有特别提及,则以下列举的各序列以5’到3’的方向表示,嘌呤碱基(a和g)为2’-oh体,嘧啶碱基(u和c)为2’-氟修饰体。
seqidno:11
(将seqidno:2所表示的序列短链化至包含通用序列的43个核苷酸的长度而得到的序列)
gggucagaugaucggacauaacauuguuggggugucaaggccc
seqidno:12
(将seqidno:2所表示的序列短链化至包含通用序列的22个核苷酸的长度而得到的序列)
gacauaacauuguugggguguc
seqidno:13
(将seqidno:2所表示的序列短链化至包含通用序列的27个核苷酸的长度而得到的序列)
ggacauaacauuguuggggugucaagg
seqidno:14
(将seqidno:2所表示的序列短链化至包含通用序列的39个核苷酸的长度而得到的序列)
ggcagaugaucggacauaacauuguuggggugucaagcc
seqidno:15
(将seqidno:2所表示的序列短链化至包含通用序列的35个核苷酸的长度而得到的序列)
gaugaucggacauaacauuguuggggugucaagcc
seqidno:16
(将seqidno:2所表示的序列短链化至包含通用序列的36个核苷酸的长度而得到的序列)
ggcagaugaucggacauaacauuguuggggugucaa
seqidno:17
(将seqidno:2所表示的序列短链化至包含通用序列的32个核苷酸的长度而得到的序列)
gaugaucggacauaacauuguuggggugucaa
seqidno:18
(将seqidno:2所表示的序列短链化至包含通用序列的30个核苷酸的长度而得到的序列)
ugaucggacauaacauuguuggggugucaa
seqidno:19
(将seqidno:2所表示的序列短链化至包含通用序列的28个核苷酸的长度而得到的序列)
aucggacauaacauuguuggggugucaa
seqidno:20
(将seqidno:2所表示的序列短链化至包含通用序列的31个核苷酸的长度而得到的序列)
gaugaucggacauaacauuguugggguguca
seqidno:11~20的核酸均通过化学合成来制作。在seqidno:11~20的评价中,采用与实施例1中所示的使用血管紧张素i作为底物的情况下的对胃促胰酶的抑制活性评价方法同样的方法进行测定。测定的结果见表3。表中,“>1”显示在直至1μm的浓度范围未见抑制活性。ic50值显示2~3次测定的平均值。
[表3]
表3所记载的seqidno:2的短链化体中的多数显示出了对胃促胰酶的抑制活性。特别是显示出0.01μm以下的ic50值的适配体可以说显示出了优异的抑制效果。由seqidno:18的结果可知:即使是短链化至包含通用序列的30个核苷酸的长度也维持着活性。这显示了:通用序列在对胃促胰酶的结合和抑制活性中较为重要。
实施例3:已短链化的适配体的改变
为了提高seqidno:17所表示的适配体的核酸酶抗性,制作了末端修饰的改变体、在序列中的嘌呤碱基的核糖的2’位导入了o-甲基或f修饰的改变体、此外还有导入了硫代磷酸酯的改变体。序列见seqidno:17(1)~17(25)。
以下显示各核苷酸序列。如果没有特别提及,则以下列举的各序列以5’到3’的方向表示,核苷酸中的括弧显示其核糖的2’位的修饰,f显示氟原子,m显示o-甲基,phe显示8-(丙基)苯基-ra(n-bz)-2’-tbdms亚酰胺。另外,各序列末端的idt显示利用反向-dt进行的修饰,s显示巯基的修饰。x显示由苯丙氨酸的c末端与半胱氨酸的n末端形成肽键而得到的肽序列,y显示由苯丙氨酸的n末端与半胱氨酸的c末端形成肽键而得到的肽序列。序列中的s显示将核苷酸彼此结合的磷酸基已被硫代磷酸酯化。z显示tc6f亚酰胺。
seqidno:17(1)
在seqidno:17所表示的序列的通用序列gggg中的最初的g和第2个g中导入2’-o-甲基修饰而得到的序列
gau(f)gau(f)c(f)ggac(f)au(f)aac(f)au(f)u(f)gu(f)u(f)g(m)g(m)ggu(f)gu(f)c(f)aa
seqidno:17(2)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的12处导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(f)au(f)u(f)g(m)u(f)u(f)g(m)gg(m)g(m)u(f)g(m)u(f)c(f)a(m)a(m)-idt
seqidno:17(3)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的12处导入2’-o-甲基修饰、并在通用序列gggg中的除第1个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(f)au(f)u(f)g(m)u(f)u(f)gg(m)g(m)g(m)u(f)g(m)u(f)c(f)a(m)a(m)-idt
seqidno:17(4)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的12处导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(f)attg(m)u(f)u(f)g(m)gg(m)g(m)u(f)g(m)u(f)c(f)a(m)a(m)-idt
seqidno:17(5)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的12处导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(f)attg(m)u(f)u(f)g(m)gg(m)g(m)tg(m)tca(m)a(m)-idt
seqidno:17(6)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的13处导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(f)a(m)ttg(m)u(f)u(f)g(m)gg(m)g(m)tg(m)tca(m)a(m)-idt
seqidno:17(7)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的13处导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)tg(m)a(m)u(f)c(f)g(m)g(m)a(m)ca(m)u(f)aac(f)a(m)ttg(m)u(f)u(f)g(m)gg(m)g(m)tg(m)tca(m)a(m)-idt
seqidno:17(8)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的13处导入2’-o-甲基修饰、在通用序列uaac中的u中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(m)aac(f)a(m)ttg(m)u(f)u(f)g(m)gg(m)g(m)tg(m)tca(m)a(m)-idt
seqidno:17(9)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的13处导入2’-o-甲基修饰、在通用序列uaac中的c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(m)a(m)ttg(m)u(f)u(f)g(m)gg(m)g(m)tg(m)tca(m)a(m)-idt
seqidno:17(10)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的14处导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(f)a(m)ttg(m)u(m)u(f)g(m)gg(m)g(m)tg(m)tca(m)a(m)-idt
seqidno:17(11)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的14处导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(f)a(m)ttg(m)u(f)u(m)g(m)gg(m)g(m)tg(m)tca(m)a(m)-idt
seqidno:17(12)
利用巯基在seqidno:17所表示的序列的5’末端导入由苯丙氨酸的c末端与半胱氨酸的n末端形成肽键而得到的肽序列的修饰、在3’末端导入idt修饰、在除通用序列以外的序列中的13处导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
x-s-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(f)a(m)ttg(m)u(f)u(f)g(m)gg(m)g(m)tg(m)tca(m)a(m)-idt
seqidno:17(13)
利用巯基在seqidno:17所表示的序列的5’末端导入由苯丙氨酸的n末端与半胱氨酸的c末端形成肽键而得到的肽序列的修饰、在3’末端导入idt修饰、在除通用序列以外的序列中的13处导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
y-s-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(f)a(m)ttg(m)u(f)u(f)g(m)gg(m)g(m)tg(m)tca(m)a(m)-idt
seqidno:17(14)
在seqidno:17所表示的序列的5’末端导入idt修饰、且利用巯基在3’末端导入由苯丙氨酸的n末端与半胱氨酸的c末端形成肽键而得到的肽序列的修饰、在除通用序列以外的序列中的13处导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(f)a(m)ttg(m)u(f)u(f)g(m)gg(m)g(m)tg(m)tca(m)a(m)-s-y
seqidno:17(15)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的12处导入2’-o-甲基修饰、在1处导入8-(丙基)苯基-ra(n-bz)-2’-tbdms亚酰胺修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(phe)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(f)a(m)ttg(m)u(f)u(f)g(m)gg(m)g(m)tg(m)tca(m)a(m)-idt
seqidno:17(16)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的12处导入2’-o-甲基修饰、在1处导入8-(丙基)苯基-ra(n-bz)-2’-tbdms亚酰胺修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(f)a(m)ttg(m)u(f)u(f)g(m)gg(m)g(m)tg(m)tca(phe)a(m)-idt
seqidno:17(17)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的12处导入2’-o-甲基修饰、在1处导入8-(丙基)苯基-ra(n-bz)-2’-tbdms亚酰胺修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(f)a(m)ttg(m)u(f)u(f)g(m)gg(m)g(m)tg(m)tca(m)a(phe)-idt
seqidno:17(18)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的13处导入2’-o-甲基修饰、将通用序列uaac中的u的核苷酸彼此结合的磷酸基进行硫代磷酸酯化、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)saac(f)a(m)ttg(m)u(f)u(f)g(m)gg(m)g(m)tg(m)tca(m)a(m)-idt
seqidno:17(19)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的13处导入2’-o-甲基修饰、将通用序列uaac中的第1个a核苷酸彼此结合的磷酸基进行硫代磷酸酯化、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)asac(f)a(m)ttg(m)u(f)u(f)g(m)gg(m)g(m)tg(m)tca(m)a(m)-idt
seqidno:17(20)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的13处导入2’-o-甲基修饰、将通用序列uaac中的第2个a核苷酸彼此结合的磷酸基进行硫代磷酸酯化、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aasc(f)a(m)ttg(m)u(f)u(f)g(m)gg(m)g(m)tg(m)tca(m)a(m)-idt
seqidno:17(21)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的13处导入2’-o-甲基修饰、将通用序列uaac中的第2个a的核苷酸彼此结合的磷酸基进行硫代磷酸酯化、在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰、并将第2个g的核苷酸彼此结合的磷酸基进行硫代磷酸酯化而得到的序列
idt-g(m)a(m)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(f)a(m)ttg(m)u(f)u(f)g(m)gsg(m)g(m)tg(m)tca(m)a(m)-idt
seqidno:17(22)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的19处导入2’-o-甲基修饰、在1处导入8-(丙基)苯基-ra(n-bz)-2’-tbdms亚酰胺修饰、在通用序列uaac的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(phe)a(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aac(m)a(m)u(m)u(m)g(m)u(m)u(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:17(23)
在seqidno:17所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的11处导入2’-o-甲基修饰、在1处导入8-(丙基)苯基-ra(n-bz)-2’-tbdms亚酰胺修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-g(m)a(phe)u(f)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(f)aac(f)au(f)u(f)g(m)u(f)u(f)g(m)gg(m)g(m)u(f)g(m)u(f)c(f)a(m)a(m)-idt
seqidno:17(24)
在seqidno:17所表示的序列的5’末端导入tc6f亚酰胺修饰、在3’末端导入idt修饰、在除通用序列以外的序列中的20处导入2’-o-甲基修饰、在通用序列uaac的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-za(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aac(m)a(m)u(m)u(m)g(m)u(m)u(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:17(25)
在seqidno:17所表示的序列的5’末端导入tc6f亚酰胺修饰、在3’末端导入idt修饰、在除通用序列以外的序列中的20处导入2’-o-甲基修饰、在通用序列uaac的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-za(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aac(m)a(m)u(m)u(m)g(m)u(m)u(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:17(1)~17(25)的核酸均通过化学合成来制作。在seqidno:17(1)~17(25)的评价中,采用与实施例1中所示的使用血管紧张素i作为底物的情况下的对胃促胰酶的抑制活性评价方法同样的方法进行测定。测定的结果见表4。表中,ic50值显示2~3次测定的平均值。
[表4]
表4所记载的seqidno:17的改变体中的多数显示出了对胃促胰酶的抑制活性。特别是显示出0.001μm以下的ic50值的适配体可以说显示出了优异的抑制效果。由seqidno:17(11)~seqidno:17(14)的结果显示出:末端修饰对活性没有产生影响。
关于通用序列中所含的核苷酸,若像seqidno:17(1)或seqidno:17(3)那样对通用序列中的gggg的第2个g进行2’-o-甲基修饰,则作为适配体虽然具有充分的活性但活性降低,结果显示出:确认到该部分的修饰方案的变化对活性有影响。另一方面,显示出:即使像seqidno:17(2)那样对通用序列中的gggg的除第2个g以外的g进行2’-o-甲基修饰,对活性也没有影响。
由seqidno:17(1)~seqidno:17(25)所表示的适配体的结果可知:上述通用序列中的gggg的除第2个g以外的修饰会使稳定性提高,因此在本发明的适配体中,只要具有活性,则可以是在至少一个核苷酸中导入了修饰的适配体。作为核苷酸的修饰,除2’-o-甲基修饰以外,例如还可列举2’-氨基修饰等。
由以上结果显示出:通过利用化学修饰改变seqidno:17,对胃促胰酶具有更强的抑制活性,可用作胃促胰酶抑制剂。
实施例4:适配体的环结构中的碱基插入的效果
在seqidno:2所表示的适配体的环结构中插入碱基,研究对结合活性和抑制活性的影响。序列见seqidno:21~seqidno:25。
seqidno:21~25的核酸均通过化学合成来制作。以下显示seqidno:21~25所示的各适配体的核苷酸序列。如果没有特别提及,则以下列举的各序列以5’到3’的方向表示,核苷酸中的括弧显示其核糖的2’位的修饰(例如,在标记为u(f)的情况下,显示尿嘧啶的核糖的2’位用f修饰),f显示氟原子。
seqidno:21
在seqidno:2所表示的序列的环结构中插入17个核酸碱基而得到的序列
ggcagaugaucggacauaacagguuagauagaguuaaaaaccuggggugucaa
seqidno:22
在seqidno:2所表示的序列的环结构中插入15个核酸碱基而得到的序列
ggcagaugaucggacauaacaguuagauagaguuaaaaacuggggugucaa
seqidno:23
在seqidno:2所表示的序列的环结构中插入13个核酸碱基而得到的序列
ggcagaugaucggacauaacaguagauagaguuaaaacuggggugucaa
seqidno:24
在seqidno:2所表示的序列的环结构中插入11个核酸碱基而得到的序列
ggcagaugaucggacauaacauagauagaguuaaaauggggugucaa
seqidno:25
在seqidno:2所表示的序列的环结构中插入9个核酸碱基而得到的序列
ggcagaugaucggacauaacaagauagaguuaaauggggugucaa
seqidno:21~25的核酸均通过化学合成来制作。
在seqidno:21~25的评价中,除了将胃促胰酶的量由0.05μg变更为0.005μg以外,利用与实施例1中所示的使用mca作为底物的情况下的对胃促胰酶的抑制活性评价方法同样的方法进行测定。测定的结果见表5。表中,ic50值显示1次的测定值。
[表5]
表5所记载的序列显示出了对胃促胰酶的抑制活性。均显示出0.01μm以下的ic50值,可以说维持了抑制效果。可知:如果向seqidno:2的环结构中插入多达17个碱基,则可维持活性。
实施例5:通过优化selex进行的rna适配体的制作
为了获得特异性地与胃促胰酶结合、且具有更高活性的适配体,实施了优化selex。优化selex除了使用以下记载的dna模板和引物以外,与实施例1中记载的selex同样。
dna模板使用了以下4种模板:根据实施例2中获取的seqidno:17,以其一部分作为随机序列,通过化学合成制作的4种dna模板。引物使用实施例1中使用的seqidno:35、seqidno:36。dna模板的随机序列部分(用矩形围起来的部分)见图5。
dna模板:5’-tcacactagcacgcataggccttgacaccccaacaatgttatgtccgatcatctgacctctctcctgctccc-3’(seqidno:40)
dna模板1:在seqidno:17的用矩形围起来的部分掺杂了9%的随机序列(任意组合的核苷酸为a、g、c或t)而得到的模板
dna模板2:在seqidno:17的用矩形围起来的部分掺杂了9%的随机序列(任意组合的核苷酸为a、g、c或t)而得到的模板
dna模板3:在seqidno:17的用矩形围起来的部分掺杂了15%的随机序列(任意组合的核苷酸为a、g、c或t)而得到的模板
dna模板4:以seqidno:17的用矩形围起来的部分作为随机序列(任意组合的核苷酸为a、g、c或t)的模板
在使用dna模板1、dna模板2进行了6轮selex后分别研究48个克隆的序列时,在序列中可见收敛。同样在使用dna模板3、dna模板4进行了3轮selex后分别研究32个克隆的序列时,在序列中可见收敛。这些克隆中的一部分的序列见seqidno:26~31。seqidno:26~31所表示的序列的二次结构预测见图6。式(1)所表示的茎/环结构用矩形(□)围起来。
以下显示各核苷酸序列。如果没有特别提及,则以下列举的各序列以5’到3’的方向表示,嘌呤碱基(a和g)为2’-oh体,嘧啶碱基(u和c)为2’-氟修饰体。
seqidno:26
gggagcaggagagaggucagauuuucgggcauaacauuguugggguguaacgaccuaugcgugcuaguguga
seqidno:27
gggagcaggagagaggucagaugaacggacauaacauuguuggggugucaaggccuaugcgugcuaguguga
seqidno:28
gggagcaggagagaggucagaugaucggacauaacucuggaggggugucaaggccuaugcgugcuaguguga
seqidno:29
gggagcaggagagaggucagaugaucgggcauaacauuguuggggugucaaggccuaugcgugcuaguguga
seqidno:30
gggagcaggagagaggucagaugaucggacauaacuaauuaggggugucaaggccuaugcgugcuaguguga
seqidno:31
gggagcaggagagaggucagaugaucggacauaacauugcuggggugucaaggccuaugcgugcuaguguga
seqidno:26~31的核酸均通过化学合成来制作。而且,在这些序列所表示的适配体中,确认到了与实施例2中所示的适配体同样的活性。
实施例6:通过优化selex获取的适配体的短链化
进行了seqidno:30所表示的适配体的短链化。seqidno:30所表示的适配体包含通用序列。已短链化的序列见seqidno:32~33。seqidno:32~33所表示的适配体的二次结构预测见图7。图7中,将式(1)所表示的茎/环结构用矩形(□)围起来。
以下显示seqidno:32~33所表示的各核苷酸序列。如果没有特别提及,则以下列举的各序列以5’到3’的方向表示,嘌呤碱基(a和g)为2’-oh体,嘧啶碱基(u和c)为2’-氟修饰体。
seqidno:32
将seqidno:30所表示的序列短链化至包含通用序列的32个核苷酸的长度而得到的序列
gaugaucggacauaacuaauuaggggugucaa
seqidno:33
将seqidno:30所表示的序列短链化至包含通用序列的31个核苷酸的长度而得到的序列
augaucggacauaacuaauuaggggugucaa
seqidno:32~33的核酸均通过化学合成来制作。而且,在这些序列所表示的适配体中,确认到了与实施例2中所示的适配体同样的活性。
实施例7:通过优化selex和短链化获取的适配体的改变
为了提高seqidno:33所表示的适配体的核酸酶抗性,制作了末端修饰的改变体、在序列中的嘌呤碱基的核糖的2’位导入o-甲基或f修饰而得到的改变体、此外还有导入了硫代磷酸酯的改变体。序列见seqidno:33(1)~33(18)。
以下显示各核苷酸序列。如果没有特别提及,则以下列举的各序列以5’到3’的方向表示,核苷酸中的括弧显示其核糖的2’位的修饰,f显示氟原子,m显示o-甲基,phe显示8-(丙基)苯基-ra(n-bz)-2’-tbdms亚酰胺。另外,各序列末端的idt显示利用反向-dt进行的修饰,peg显示利用40kda的支链型聚乙二醇进行的修饰,s显示巯基的修饰。
seqidno:33(1)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的15处导入2’-o-甲基修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aac(m)u(f)aau(f)u(m)ag(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(2)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的13处导入2’-o-甲基修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(m)aac(m)u(f)aau(f)u(m)ag(m)gg(m)g(m)tg(m)tc(m)a(m)a(m)-idt
seqidno:33(3)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的17处导入2’-o-甲基修饰、在1处导入8-(丙基)苯基-ra(n-bz)-2’-tbdms亚酰胺修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(phe)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aac(m)u(f)a(m)a(m)u(f)u(m)a(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(4)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的15处导入2’-o-甲基修饰、在1处导入8-(丙基)苯基-ra(n-bz)-2’-tbdms亚酰胺修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(phe)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(m)aac(m)u(f)a(m)a(m)u(f)u(m)a(m)g(m)gg(m)g(m)tg(m)tc(m)a(m)a(m)-idt
seqidno:33(5)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的16处导入2’-o-甲基修饰、在1处导入8-(丙基)苯基-ra(n-bz)-2’-tbdms亚酰胺修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(phe)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(m)aac(m)u(f)a(m)a(m)u(f)u(m)a(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(6)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的18处导入2’-o-甲基修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(f)a(m)u(m)aac(m)u(f)a(m)a(m)u(m)u(m)a(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(7)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的19处导入2’-o-甲基修饰、在通用序列uaac中的除第2个a以外导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)a(m)ac(m)u(f)a(m)a(m)u(m)u(m)a(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(8)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的19处导入2’-o-甲基修饰、在通用序列uaac中的除第1个a以外导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aa(m)c(m)u(f)a(m)a(m)u(m)u(m)a(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(9)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的19处导入2’-o-甲基修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中导入2’-o-甲基修饰而得到的序列
idt-a(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aac(m)u(f)a(m)a(m)u(m)u(m)a(m)g(m)g(m)g(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(10)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的19处导入2’-o-甲基修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aac(m)ta(m)a(m)u(m)u(m)a(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(11)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的18处导入2’-o-甲基修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aac(m)u(f)a(m)a(m)tu(m)a(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(12)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的18处导入2’-o-甲基修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aac(m)u(f)a(m)a(m)u(m)ta(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(13)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的20处导入2’-o-甲基修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aac(m)t(m)a(m)a(m)u(m)u(m)a(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(14)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的19处导入2’-o-甲基修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aac(m)u(f)a(m)a(m)t(m)u(m)a(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(15)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的19处导入2’-o-甲基修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aac(m)u(f)a(m)a(m)u(m)t(m)a(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(16)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的20处导入2’-o-甲基修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aac(m)u(f)a(m)a(m)u(m)u(m)a(m)g(m)gg(m)g(m)t(m)g(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(17)
在seqidno:33所表示的序列的5’末端和3’末端导入idt修饰、在除通用序列以外的序列中的18处导入2’-o-甲基修饰、在1处导入8-(丙基)苯基-ra(n-bz)-2’-tbdms亚酰胺修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
idt-a(phe)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aac(m)u(f)a(m)a(m)u(m)u(m)a(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(18)
在seqidno:33所表示的序列的5’末端导入40kda的支链型聚乙二醇修饰、在3’末端导入idt修饰、在除通用序列以外的序列中的18处导入2’-o-甲基修饰、在通用序列uaac中的u和c中导入2’-o-甲基修饰、并在通用序列gggg中的除第2个g以外的g中导入2’-o-甲基修饰而得到的序列
peg-a(m)u(m)g(m)a(m)u(f)c(f)g(m)g(m)a(m)c(m)a(m)u(m)aac(m)u(f)a(m)a(m)u(m)ta(m)g(m)gg(m)g(m)tg(m)u(m)c(m)a(m)a(m)-idt
seqidno:33(1)~33(18)的核酸均通过化学合成来制作。而且,对于这些序列所表示的适配体,采用与实施例1中所示的使用血管紧张素i作为底物的情况下的对胃促胰酶的抑制活性评价方法同样的方法进行测定。结果见表6。表中,ic50值显示2~3次测定的平均值。
[表6]
如表6所示,改变体中的多数显示出了对胃促胰酶的抑制活性。特别是显示出0.0001μm以下的ic50值的适配体可以说显示出了非常优异的抑制效果。由以上可知:对seqidno:33所表示的序列施行各种修饰而得到的适配体会使稳定性提高,因此本发明的适配体只要具有活性即可,可以是在至少一个核苷酸中导入了修饰的适配体。作为核苷酸的修饰,除2’-o-甲基修饰以外,例如还可列举2’-氨基修饰等。
可知:关于通用序列中所含的核苷酸,若像seqidno:33(9)那样对通用序列中的gggg的第2个g进行2’-o-甲基修饰,则作为适配体虽然具有充分的活性,但与具有seqidno:33所表示的序列的其他适配体改变体相比活性降低。另一方面,例如即使像seqidno:33(12)那样进行修饰,对活性也没有影响。
由seqidno:33(18)的结果可知:即使与未结合peg的适配体(seqidno:33(12))相比,peg结合适配体的活性也维持着一定的活性。通过结合peg,体内的药物体内动力学得到大幅改善,因此由该结果可期待在体内显示出效果。
由以上的结果可知:表6中所含的、除对通用序列中的gggg的第2个g进行2’-o-甲基修饰而得到的核酸以外的所有核酸,即使在使用作为天然底物的血管紧张素i的情况下也对胃促胰酶具有极其强的抑制活性,因此被期待作为涉及血管紧张素的各种疾病的预防和/或治疗药。
产业实用性
本发明的适配体可用作涉及纤维化等tgf-β的活化的各种疾病的预防和/或治疗用药物、诊断药或标记物。
本申请以在日本申请的特愿2017-230503(申请日:2017年11月30日)为基础,其内容全部包含在本说明书中。
<110>力博美科股份有限公司
<120>针对胃促胰酶的适配体及其应用
<130>092836
<150>jp2017-230503
<151>2017-11-30
<160>41
<170>patentinversion3.5
<210>1
<211>72
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>1
gggagcaggagagaggucagaugagcaugcuuuuugguaaccgauaaugggggccuaugc60
gugcuaguguga72
<210>2
<211>72
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>2
gggagcaggagagaggucagaugaucggacauaacauuguuggggugucaaggccuaugc60
gugcuaguguga72
<210>3
<211>72
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>3
gggagcaggagagaggucagaugauaaccaguuggggggucaauuacaugggaccuaugc60
gugcuaguguga72
<210>4
<211>72
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>4
gggagcaggagagaggucagauguaacucuauugaggggcaucagcacaguagccuaugc60
gugcuaguguga72
<210>5
<211>72
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>5
gggagcaggagagaggucagaugaugaccgauuauagguaaccacuuagggggccuaugc60
gugcuaguguga72
<210>6
<211>72
<212>rna
<213>人工序列
<220>
<223>gggagcaggagagaggucagaugucaugacuuauagguaaccgauaaugggggccuaugcgugcu
aguguga
<400>6
gggagcaggagagaggucagaugucaugacuuauagguaaccgauaaugggggccuaugc60
gugcuaguguga72
<210>7
<211>72
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>7
gggagcaggagagaggucagauguuugguaguaacuggaauaggggcuacaggccuaugc60
gugcuaguguga72
<210>8
<211>72
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>8
gggagcaggagagaggucagaugauugacgacuauagguaaccuuuacgggggccuaugc60
gugcuaguguga72
<210>9
<211>77
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>9
gggaacgaagcgacagacguuccagcgucuaauacgugaauaaccugaucguaggggguu60
caaguacugaggacaga77
<210>10
<211>76
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>10
gggaacgaagcgacagaccgaaucagaaguucaacauggacauaacaucgaugggguguc60
aaguacugacgacaga76
<210>11
<211>43
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>11
gggucagaugaucggacauaacauuguuggggugucaaggccc43
<210>12
<211>22
<212>rna
<213>人工序列
<220>
<223>未与胃促胰酶结合的核苷酸序列
<400>12
gacauaacauuguugggguguc22
<210>13
<211>27
<212>rna
<213>人工序列
<220>
<223>未与胃促胰酶结合的核苷酸序列
<400>13
ggacauaacauuguuggggugucaagg27
<210>14
<211>39
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>14
ggcagaugaucggacauaacauuguuggggugucaagcc39
<210>15
<211>35
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>15
gaugaucggacauaacauuguuggggugucaagcc35
<210>16
<211>36
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>16
ggcagaugaucggacauaacauuguuggggugucaa36
<210>17
<211>32
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>17
gaugaucggacauaacauuguuggggugucaa32
<210>18
<211>30
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>18
ugaucggacauaacauuguuggggugucaa30
<210>19
<211>28
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>19
aucggacauaacauuguuggggugucaa28
<210>20
<211>31
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>20
gaugaucggacauaacauuguugggguguca31
<210>21
<211>53
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>21
ggcagaugaucggacauaacagguuagauagaguuaaaaaccuggggugucaa53
<210>22
<211>51
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>22
ggcagaugaucggacauaacaguuagauagaguuaaaaacuggggugucaa51
<210>23
<211>49
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>23
ggcagaugaucggacauaacaguagauagaguuaaaacuggggugucaa49
<210>24
<211>47
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>24
ggcagaugaucggacauaacauagauagaguuaaaauggggugucaa47
<210>25
<211>45
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>25
ggcagaugaucggacauaacaagauagaguuaaauggggugucaa45
<210>26
<211>72
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>26
gggagcaggagagaggucagauuuucgggcauaacauuguugggguguaacgaccuaugc60
gugcuaguguga72
<210>27
<211>72
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>27
gggagcaggagagaggucagaugaacggacauaacauuguuggggugucaaggccuaugc60
gugcuaguguga72
<210>28
<211>72
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>28
gggagcaggagagaggucagaugaucggacauaacucuggaggggugucaaggccuaugc60
gugcuaguguga72
<210>29
<211>72
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>29
gggagcaggagagaggucagaugaucgggcauaacauuguuggggugucaaggccuaugc60
gugcuaguguga72
<210>30
<211>72
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>30
gggagcaggagagaggucagaugaucggacauaacuaauuaggggugucaaggccuaugc60
gugcuaguguga72
<210>31
<211>72
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>31
gggagcaggagagaggucagaugaucggacauaacauugcuggggugucaaggccuaugc60
gugcuaguguga72
<210>32
<211>32
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>32
gaugaucggacauaacuaauuaggggugucaa32
<210>33
<211>31
<212>rna
<213>人工序列
<220>
<223>针对胃促胰酶的适配体
<400>33
augaucggacauaacuaauuaggggugucaa31
<210>34
<211>72
<212>dna
<213>人工序列
<220>
<223>dna模板
<220>
<221>misc_feature
<222>(20)..(49)
<223>nisa,c,g,ort
<400>34
tcacactagcacgcataggnnnnnnnnnnnnnnnnnnnnnnnnnnnnnncatctgacctc60
tctcctgctccc72
<210>35
<211>40
<212>dna
<213>人工序列
<220>
<223>正向引物
<400>35
taatacgactcactatagggagcaggagagaggtcagatg40
<210>36
<211>19
<212>dna
<213>人工序列
<220>
<223>反向引物
<400>36
tcacactagcacgcatagg19
<210>37
<211>76
<212>dna
<213>人工序列
<220>
<223>dna模板
<220>
<221>misc_feature
<222>(19)..(58)
<223>nisa,c,g,ort
<400>37
tctgtcctcagtacttgannnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnngt60
ctgtcgcttcgttccc76
<210>38
<211>35
<212>dna
<213>人工序列
<220>
<223>正向引物
<400>38
taatacgactcactatagggaacgaagcgacagac35
<210>39
<211>18
<212>dna
<213>人工序列
<220>
<223>反向引物
<400>39
tctgtcctcagtacttga18
<210>40
<211>72
<212>dna
<213>人工序列
<220>
<223>dna模板
<400>40
tcacactagcacgcataggccttgacaccccaacaatgttatgtccgatcatctgacctc60
tctcctgctccc72
<210>41
<211>4
<212>prt
<213>人工序列
<220>
<223>胰凝乳蛋白酶用底物
<400>41
alaalaprophe
1
- 还没有人留言评论。精彩留言会获得点赞!