可检测的目标核酸、探针、确定胎儿F8基因单体型的方法及应用与流程
本发明涉及生物信息领域,具体涉及一种可检测的目标核酸、探针、确定胎儿f8基因单体型的方法及应用。
背景技术:
血友病(hemophilia)为一种先天性血液凝固异常的遗传疾病,依据缺乏的凝血因子种类不同,主要分为a型、b型等,a型血友病约占血友病80%-85%,致病原因是第八凝血因子(factor8,简称f8)基因异常,b型血友病约占15-20%,致病原因是第九凝血因子(factor9,简称f9)基因异常。
血友病a(hemophiliaa,简称ha,omim#306700)患者缺乏第八凝血因子(f8),无法凝血。f8基因位于染色体xq28上,属于x连锁隐形遗传,全长186kb,由26个外显子和25个内含子组成。导致ha的基因突变种类繁多,呈高度异质性。其中重型ha多由大的dna片段缺失、到位或插入等引起,50%-51%是由int22倒位或int1到位引起,由snp/indel引起的在男女患者的比例分别为49%和43%,另外还有6%的患者是因为外显子/整个基因缺失重复引起。而在中度血友病a患者中,主要是由于snp/indel以及外显子/整个基因缺失重复引起的。血友病a患者多为男性,目前仍无法治愈,需终生注射补充凝血因子。依据第八凝血因子活性高低,可以区分成轻度(5-35%)、中度(1-5%)及重度(<1%)。血友病的严重程度因人而异,轻度血友病患者只有在严重创伤或手术时才会有出血的问题。中度血友病患者较不常出血,也许一个月出血一次,出血通常是遭受创伤,也有部分患者可能自发性出血。重度血友病患者时常发生肌肉或关节出血,他们可能每周出血一至两次,出血通常是自发性的,此型患者,没有任何明显的原因,但还是发生出血的情形。
目前我国对于血友病一般采取家族史、临床表现以及基因诊断等才能确诊。这种方法需要有患者的临床表现以及dna样本,而对于新生儿来说往往要在出生以后几个月内或者更晚的时间才能确诊。这种方法不但给新出生的孩子带来了痛苦,更让整个家庭承受着巨大的精神及其物质压力。目前我国对f8的产前诊断建立在羊膜腔穿刺、绒毛吸取等侵入性基础上进行的细胞遗传学诊断,虽然诊断准确,但因其属于侵入性检查,操作有创伤性,易引起宫内感染、流产、甚至对胎儿产生影响。
随着孕妇外周血浆中胎儿游离dna存在的发现,为无创产前检测胎儿基因型提供了可能。然后对于胎儿血友病的筛查方法,还需要进一步改进。
技术实现要素:
本发明旨在至少在一定程度上解决相关技术中的技术问题之一。为此,本发明的一个目的在于提出一种确定胎儿f8基因单体信息的方法和装置。
我们基于高通量测序技术平台和目标区域捕获技术,采用家系致病单体型连锁分析的方法,通过连锁分析从孕妇外周血浆dna测序数据中推断胎儿的单体型信息,该方法通过利用连锁单体型信息极大的降低了假阳性及假阴性的发生。
本发明所提供的方法,利用特异性snp位点进行胎儿含量准确定量,避免传统方法定量不准造成的错误诊断的可能性。而且由于取样方式的无创性,避免珍贵儿流程风险,减少孕妇心里和身体痛苦。较小的探针捕获区域约110.08kb,极大了降低了测序和探针的成本。
具体而言,本发明提供了如下技术方案:
根据本发明的第一方面,本发明提供了一种可检测的目标核酸,包括:f8基因全部外显子区、前导区和尾部区;以及f8基因上下游1m区域中次等位碱基频率为0.3~0.5的snp位点。本文中“可检测的目标核酸”是指可以通过任何手段可以检测目标核酸,例如可以通过对含有目标核酸的基因组dna进行高通量测序,然后特异性性检测目标核酸的核酸序列,例如也可以通过探针捕获目标区域,然后通过高通量测序检测目标区域的核酸序列。
根据本发明的第二方面,本发明提供了一种探针,所述探针游离于溶液中或者固定在芯片上,所述探针用于捕获权利要求1所述的目标区域。本方法利用定制的,小捕获探针,极大降低了测序成本,便于临床推广。
在本发明的一些实施例中,所述探针的gc含量为40~50%。
根据本发明的实施例,本发明提供了一种构建f8目标区域文库的方法,包括:从待测样本中获得基因组dna,打断得到200~300bp的小片段dna;将所述小片段dna进行末端补平,3’端加碱基a,与3’端带有甲基t的接头连接,获得连接产物;对所述连接产物进行pcr扩增,获得非特异性捕获文库;利用探针对所述非特异性捕获文库中目标区域进行特异性捕获,经pcr扩增获得目标区域捕获文库;其中所述目标区域为本发明第一方面所述的目标区域。
在本发明的一些实施例中,所述探针为本发明第二方面所述的探针。
根据本发明的第四方面,本发明提供了一种确定胎儿目标区域单体型的方法,包括:对孕妇体液中游离核酸的所述目标区域进行序列测定,以便获得第一测序数据;对所述胎儿的家系成员的所述目标区域进行序列测定,以便获得第二测序数据、第三测序数据和第四测序数据,其中,所述第二测序数据为胎儿母亲的测序数据,所述第三测序数据为胎儿父亲的测序数据,所述第四测序数据为先证者的测序数据;基于所述第一测序数据和第二测序数据,确定所述孕妇体液中的胎儿核酸含量;基于所述第二测序数据、第三测序数据和第四测序数据,分别构建所述胎儿母亲的目标区域单体型和所述胎儿父亲的目标区域单体型;以及基于所述胎儿母亲的目标区域单体型、所述胎儿父亲的目标区域单体型以及所述胎儿核酸含量,确定所述胎儿的目标区域单体型;其中所述目标区域为本发明第一方面所述的目标区域。
本技术方案通过利用家系连锁单体型分析策略,对血浆游离dna进行测序分析胎儿f8基因单体型信息。本方法利用特异性snp对血浆胎儿dna含量准确定量,极大的避免由于单个位点测量比例不准,单个位点测序错误等方面带来的假阴性和假阳性结果,使得检测结果更加准确可靠。
根据本发明的实施例,以上所述的方法可以进一步包括如下技术特征:
在本发明的一些实施例中,所述方法用于非诊断目的。以上确定胎儿目标区域单体型的方法可以用作科研或者其他商业用途。
在本发明的一些实施例中,所述孕妇体液中游离核酸包括孕妇血浆游离dna。
在本发明的一些实施例中,对孕妇体液中游离核酸的所述目标区域进行序列测定包括:利用探针对所述游离核酸进行捕获,所述探针特异性识别所述目标区域。
在本发明的一些实施例中,所述探针是以芯片形式提供的。
在本发明的一些实施例中,所述探针为本发明第二方面所述的探针。
在本发明的一些实施例中,所述胎儿核酸含量是通过下列步骤确定的:
确定所述第一测序数据和所述第二测序数据中预定位点的基因型组合,所述预定位点在所述第一测序数据中存在两种基因型,并且所述预定位点在所述第二测序数据中只存在一种基因型,其中,所述基因型组合选自下列组合之一:
(iii)在所述第二测序数据中只存在纯合基因型rr,在所述第一测序数据中存在纯合基因型rr和杂合基因型rr,其中,r和r表示一对等位基因,
(iv)在所述第二测序数据中只存在杂合基因型rr,在所述第一测序数据中有纯合基因型rr和杂合基因型rr;
基于所述第一测序数据中支持所述等位基因r和r的读段数目,确定所述胎儿核酸含量,
其中,
如果所述基因型组合为(i),根据公式f=2d/(c+d)确定所述胎儿核酸含量,
如果所述基因型组合为(ii),根据公式f=(c-d)/(c+d)确定所述胎儿核酸含量,
其中,
c为所述第一测序数据中支持等位基因r的读段数目,
d为所述第一测序数据中支持等位基因r的读段数目,
f为所述胎儿核酸含量。
在本发明的一些实施例中,所述确定胎儿目标区域单体型包括:
利用多个在父亲目标区域单体型上为杂合、在母亲目标区域单体型上为纯合的位点确定胎儿遗传到的父亲目标区域单体型,利用多个在父亲目标区域单体型上为纯合、在母亲目标区域单体型上为杂合的位点以及胎儿核酸含量确定胎儿遗传到的母亲目标区域单体型。
在本发明的一些实施例中,对于所述多个在父亲目标区域单体型上为纯合、在母亲目标区域单体型上为杂合的位点,若有多个这样的位点符合r/r=(1+x%)/(1-x%),则判定胎儿遗传了母亲等位基因r所在的目标区域单体型,若有多个这样的位点符合r/r=1,则判定胎儿遗传了母亲等位基因r所在的目标区域单体型,r和r表示一对等位基因,x%表示胎儿核酸含量,r/r=第一测序数据中支持r的读段数目/第一测序数据中支持r的读段数目。
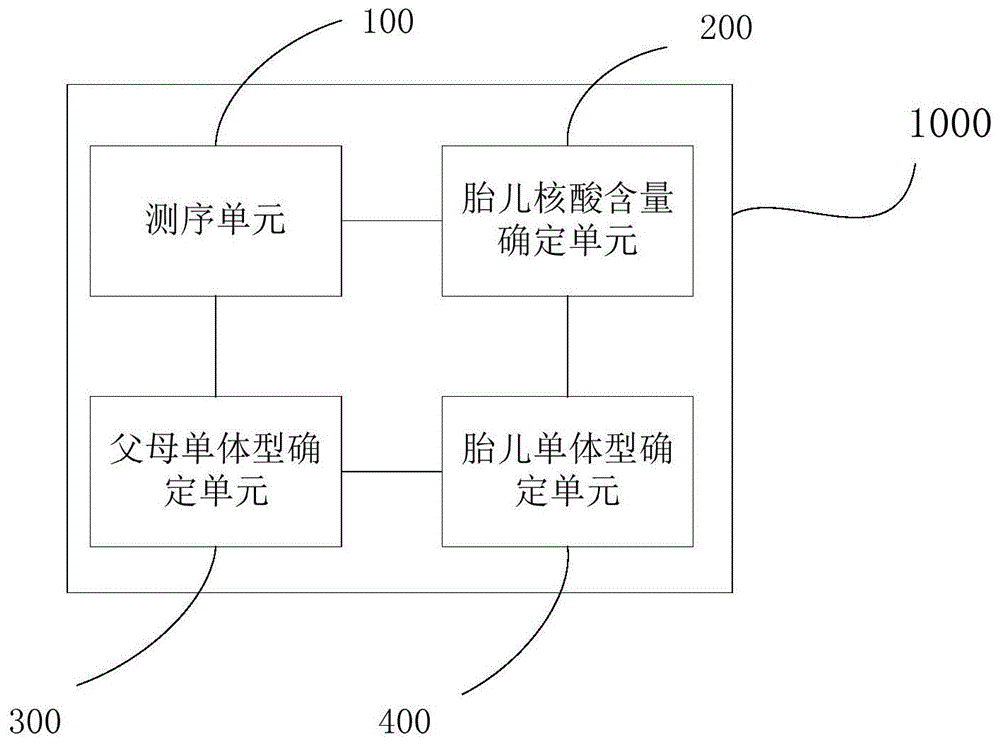
根据本发明的第五方面,本发明提供了一种确定胎儿目标区域单体型的装置,所述目标区域为本发明第一方面所述的目标区域,所述确定胎儿目标区域单体型的装置包括:测序单元,所述测序单元用于对孕妇体液中游离核酸的所述目标区域进行序列测定,以便获得第一测序数据,以及,对所述胎儿的家系成员的所述目标区域进行序列测定,以便获得第二测序数据、第三测序数据和第四测序数据,其中,所述第二测序数据为胎儿母亲的测序数据,所述第三测序数据为胎儿父亲的测序数据,所述第四测序数据为先证者的测序数据;胎儿核酸含量确定单元,所述胎儿核酸含量确定单元与所述测序单元连接,用于基于所述第一测序数据、第二测序数据,确定所述孕妇体液中的胎儿核酸含量;父母单体型确定单元,所述父母单体型确定单元与所述测序单元连接,用于基于所述第二测序数据、第三测序数据和第四测序数据,分别构建所述胎儿母亲的目标区域单体型和所述胎儿父亲的目标区域单体型;以及胎儿单体型确定单元,所述胎儿单体型确定单元与所述胎儿核酸含量确定单元和所述父母单体型确定单元相连,用于基于所述胎儿母亲的目标区域单体型、所述胎儿父亲的目标区域单体型以及所述胎儿核酸含量,确定所述胎儿的目标区域单体型。
附图说明
图1是根据本发明的实施例提供的确定胎儿目标区域单体型的装置的示意图。
图2是根据本发明的实施例提供的确定胎儿目标区域单体型的方法的技术路线图。
图3是根据本发明的实施例提供的确定胎儿目标区域单体型的结果示意图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,旨在用于解释本发明,而不能理解为对本发明的限制。
本专利提出了一种基于定制的f8基因目标区域捕获及家系致病单体型连锁分析的方法,通过连锁分析从孕妇外周血浆dna测序数据中推断胎儿f8基因的单体型信息。该方法通过利用家系连锁单体型信息极大的降低了假阳性及假阴性的发生。同时针对f8基因目标区域所提供的探针,利用较小的探针即可捕获区域,能在实现胎儿单体型分析的前提下,极大降低测序和实验成本,有利于临床推广。由此,所提供的方法对f8基因目标区域进行捕获,测序,测序成本低。
本方法利用家系单体型连锁分析和血浆测序方法对胎儿遗传母亲相同变异同样适用。随着华大自主测序仪开发使用,测序成本大幅度降低,加快该产品在临床推广速度,降低ha疾病新生儿出生缺陷率,减轻家庭和社会心理和精神上的双重负担。
在本发明的至少一些实施方式,提供了一种确定胎儿目标区域单体型的方法,包括以下步骤:
步骤一:获得第一、第二、第三和第四测序数据。
获得孕妇体液中的游离核酸,捕获目标区域,对所述捕获得的目标区域进行序列测定,获得第一测序数据。孕妇体液样本为包含胎儿核酸的样本,比如孕妇外周血血浆包含胎儿核酸,提取的外周血游离核酸是孕妇和胎儿核酸的混合物,混合物是高度片段化的。依据现有测序平台,通过对从孕妇外周血样本提取的游离核酸进行测序文库构建,利用探针或芯片或液相探针捕获获得目标区域测序文库,对目标区域测序文库进行上机测序,获得第一测序数据,第一测序数据是孕妇核酸和胎儿核酸混合物的混合数据。测序平台包括但不限于cg(completegenomics)、illumina/solexa、lifetechnologiesabisolid和roche454,可根据所选用的测序平台进行相应的测序文库制备,可选择单端或双端测序,由此获得的各个测序数据由多个短序列组成,将各个短序列称为读段。捕获所用的芯片是由固相基质和固定在其上的多个探针组成的,探针能够特性识别目标区域,目标区域可以是待测样本基因组dna的一部分也可以是整个基因组,在本发明的一个具体实施方式中,目标区域包括f8基因的全部外显子区,前导区(5’端非编码区,5’utr)和尾部区(3’端非编码区,3’utr),各个区域在参考基因组hg19上的位置如表1所示,还包括f8基因上下游1m区域内高杂合率的snp位点。这些高杂合率的snp位点是次等位基因频率(maf)在0.3-0.5之间的snp位点。snp位点在各个区域的数量分布如表2所示。
本文中,次等位碱基频率是由等位基因频率衍生而来的。举例来说,假设在100个人里面,某条染色体上某个位点有一个snp,这个snp位点有三个等位碱基:a,c和g。通过全基因组测序的方法发现这100个人里面这个位点的碱基a出现100次,c出现80次,g出现20次。所以这三个等位碱基的频率分别为a=100/200,c=80/200,g=20/200。其中出现第二多的就是次等位碱基频率,即碱基c的maf为0.4。
在设计能够特异性识别上述区域的探针时,为了保证捕获的特异性、检测的准确性,使包含至少一个上述snp位点的探针在参考基因组上唯一比对,设计探针时,使得每条探针的gc含量在40%-50%,这样有利于在同一个体系中整组探针一起特异性结合目标区域、在同一个反应体系中能够一起洗脱下来。
表1f8基因外显子、前导区和尾部区捕获范围
表2f8基因上下游1m区域snp分布
获取胎儿家系成员的样本,包括胎儿生物学母亲(孕妇)、胎儿生物学父亲以及先证者的核酸样本,提取各个家系成员样本中的核酸,参考上述获取第一测序数据的方式,捕获胎儿家系成员核酸中的同样目标区域,对各个家系成员的同样目标区域进行序列测定,获得家系成员测序数据,所述家系成员测序数据包括第二、第三和第四测序数据,分别对应胎儿生物学母亲、胎儿生物学父亲和先证者的同样目标区域的测序数据。其中第二测序数据,即母亲测序数据的获得,可以通过分离上述获得第一测序数据的孕妇外周血样本,分离孕妇外周血样本获得孕妇外周血血浆样本和孕妇血细胞,从孕妇血细胞,比如白细胞,可以获得母亲基因组核酸,进而获得第二测序数据。
本文中“先证者”是该家系中是确定带有目标区域相关变异的的成员,在这里,先证者具体可以是指与待测胎儿同样生物学父母的胎儿的兄弟姐妹,包括出生的和未出生,包括体外培养的胚胎或受精卵,包括在世和不在世的。另外,在其他具体实施方式中,先证者也可以是待测胎儿的父母的兄弟姐妹,比如胎儿的舅舅、叔叔、姑姑等,这时,胎儿的家系成员的测序数据还应包括胎儿的祖父母和/或外祖父母,这样能够利用父母的兄弟姐妹的测序数据以及父母的测序数据构建祖父母或外祖父母的目标区域单体型,进而判断父母的遗传到的目标区域单体型。第一、第二、第三和第四测序数据的获得没有必需遵循的先后关系,可同时获得,比如利用标签标记多个样本,对多个样本核酸混合建库混合上机测序同时获得多个样本的测序数据,也可一个个获得或几个几个获得核酸样本的测序数据。
步骤二:确定胎儿核酸含量。
基于第一和第二测序数据,确定所述孕妇体液样本中的胎儿核酸含量。
其中,基于第一和第二测序数据确定孕妇体液样本中的胎儿核酸含量,是这样进行的:首先是筛选出在第一测序数据中有两种基因型以及在第二测序数据中只有一种基因型的位点。位点的筛选可以通过比对来进行,比对可以利用soap(shortoligonucleotideanalysispackage),bwa,samtools等软件进行,本实施方式对此不作限制,比对的进行也可以识别出多态性位点。比对所使用的参考序列是已知序列,可以是预先获得的目标个体所属生物类别中的任意的参考模板。例如,若目标个体是人类,参考序列可选择ncbi数据库提供的hg19。进一步地,也可以预先配置包含更多参考序列的资源库,在进行序列比对前,先依据目标个体的性别、人种、地域等因素选择或是测定组装出更接近的序列来作为参考序列,有助于获得更准确的检测分析结果。在比对过程中,根据比对参数的设置,各测序数据中的每条或每对读段(reads或一对末端读段pair-endreads)最多允许有n个碱基错配(mismatch),n优选为1或2,若reads中有超过n个碱基发生错配,则视为该条/对reads无法比对到参考序列。一个位点,假设在参考序列上该位点是a,第二测序数据的比对结果表明第二测序数据即母亲测序数据中比对上到参考序列该位点的碱基都是a,但是第一测序数据即母亲与胎儿的测序数据的比对结果表明第一测序数据中比对到参考序列该位点的碱基是a和另外一种非a的碱基,非a碱基比如t、c或g,由于第一测序数据中是母亲和胎儿核酸的混合测序数据,而从第二测序数据的比对结果可知母亲的该位点为aa,那么就可判断出第一测序数据中该位点非a碱基来源于胎儿,这样筛选出所有这样的位点,基于这些位点在混合测序数据中占的比例,就能反映出混合核酸中胎儿核酸的含量。类似的,若第二测序数据的比对结果表明母亲某位点的基因型为杂合的,比如ag,而第一测序数据比对结果显示支持该位点ag和aa两种基因型,这样基于第一测序数据中a碱基的数量、含量或比例,也能估算获得孕妇外周血样本中的胎儿核酸含量。当像上面前者情况,在第二测序数据中只有纯合基因型、而在第一测序数据中除有一样的纯合基因型还有杂合基因型时,胎儿核酸含量f=2d/(c+d),而当像上面后者情况,在第二测序数据中只有杂合基因型、而在第一测序数据中除有那杂合基因型还有纯合基因型,胎儿核酸含量f=(c-d)/(c+d),公式中的c为第一测序数据中支持等位基因a的读段数目,d为第一测序数据中支持非a等位基因的读段数目。
考虑到f8基因是x染色体伴性遗传,首先可以判断胎儿的性别。主要参考y染色体特异性序列的深度。若胎儿为男性,比对到y染色体特异性目标区域序列存在较高深度;胎儿为女性,比对到y染色体特异性目标区域序列深度趋近于0。
步骤三:构建父母的目标区域单体型。
基于第二、第三和第四测序数据构建母亲和父亲的目标区域单体型,即基于父母各自的测序数据和已知的该对父母的目标区域带变异的子女(先证者)的测序数据,来构建父母各自的单体型。将父母各自的测序数据以及先证者的测序数据分别与参考序列比对,利用软件比如soapsnp、gatk、bowtite等识别出父母以及先证者目标区域中的snp和获得各个snp的基因型,由于先证者的两条单体型(两组snp集合)是由父亲和母亲的各一条单体型组成的,所以依据孟德尔遗传规律,依据父母及先证者的各个snp所在位点的基因型,比如利用多个区分型snp,区分型snp指该位点父母为不同基因型能够提供给下一代能区分单体型来源的snp,构建父亲和母亲的单体型。单体型倾向作为一个遗传单元遗传给子代,在这里,单体型是一组snp的集合。
需要说明的是,本发明的实施方式对步骤二和步骤三的进行没有先后顺序限制,可以先进行步骤二再进行步骤三,或者先进行步骤三获得父母目标区域单体型再进行步骤二确定胎儿核酸含量。
步骤四:确定胎儿目标区域单体型。
基于母亲和父亲的目标区域单体型以及胎儿核酸含量,确定所述胎儿目标区域单体型。具体地,利用多个在父亲目标区域单体型上为杂合、在母亲目标区域单体型上为纯合的位点确定胎儿遗传到的父亲目标区域单体型,这是由于若胎儿某snp位点为杂合的,由于源自母亲的只可能为一种类型的碱基,所以就可确定该位点的另一碱基来自父亲,利用多个这样的位点,比如可以确定超过10个这样的位点的等位基因源自父亲的一条单体型,就能确定胎儿两条单体型中的源自父亲的那条单体型。而对于胎儿另一条单体型的确定,可类似的利用多个在父亲目标区域单体型上为纯合、在母亲目标区域单体型上为杂合的位点来确定,但由于胎儿核酸样本,即母体外周血样本混有大量的母体dna,单从以上类型snp没法判断胎儿遗传了r还是r所在的母亲单体型,因为该位点任何的等位碱基也都可能就只是母体的,在这里我们结合胎儿核酸含量来确定胎儿遗传到的母亲的单体型。对于多个在父亲单体型上为纯合、母亲单体型上为杂合的多态性位点,这样的位点在母体外周血样本中每个都可表示为rr,若多个这样的位点都符合r/r=(1+x%)/(1-x%),则判定胎儿遗传了母亲等位基因r所在的单体型,若多个这样的位点都符合r/r=1,则判定胎儿遗传了母亲等位基因r所在的单体型,r和r表示一对等位基因,x%表示胎儿核酸含量,r/r=比对后第一测序数据中支持r的读段数目/比对后第一测序数据中支持r的读段数目。由此,确定胎儿的单体型。
本领域普通技术人员可以理解,上述实施方式中各种方法的全部或部分步骤可以通过程序来指令相关硬件完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器、随机存储器、磁盘或光盘等。
依据本发明的另一个实施方式,提供一种确定胎儿目标区域单体型的装置,该装置能够用以完成本发明一个实施方式中的方法的部分或全部步骤,如图1所示,该装置1000包括:测序单元100,所述测序单元用以获得孕妇体液中的游离核酸,捕获目标区域,对所述捕获得的目标区域进行序列测定,获得第一测序数据,用以捕获胎儿家系成员核酸中的同样目标区域,对所述家系成员的同样目标区域进行序列测定,获得家系成员测序数据,所述家系成员测序数据包括第二、第三和第四测序数据,分别对应胎儿母亲、胎儿父亲和先证者的同样目标区域的测序数据;胎儿核酸含量确定单元200,所述胎儿核酸含量确定单元与所述测序单元100相连,用于基于第一和第二测序数据,以确定所述孕妇体液样本中的胎儿核酸含量;父母单体型确定单元300,所述父母单体型确定单元与所述测序单元100相连,用于基于第二、第三和第四测序数据构建母亲和父亲的目标区域单体型;胎儿单体型确定单元400,所述胎儿单体型确定单元与所述胎儿核酸含量确定单元200和所述父母单体型确定单元300相连,用于基于母亲和父亲的目标区域单体型以及胎儿核酸含量,确定所述胎儿目标区域单体型。对本发明的一个实施方式中的方法的技术特征和优点的描述,同样适用本发明这一实施方式的装置,在此不再赘述。
以下结合对具体样本依据本发明的方法进行目标区域单体型的确定、基因型的确定、单体型或基因型确定后的用途进行详细的描述及结果展示。下面示例,仅用于解释本发明,而不能理解为对本发明的限制。在本发明中所使用的“第一”、“第二”、“第三”等仅用于方便描述目的,而不能理解为指示或暗示相对重要性,也不能理解为之间有先后顺序关系。本发明的描述中,除非另有说明,“多个”的含义是两个或两个以上。
除另有交待,以下实施例中涉及的未特别交待的试剂、序列(接头、标签和引物)、软件及仪器,都是常规市售产品或者公开的,比如购自illumina公司的hiseq2000测序平台建库相关试剂盒来进行测序文库构建等。
本发明所提供的方案对应的整体技术路线如图2所示。包括:
1、目标捕获区域的选择及探针的设计
目标捕获区域包括f8外显子区,及基因上下游1m区域内高杂合率snp位点的捕获测序。snp的选择参考dbsnp数据库,选择其中参考染色体数大于100条,maf在0.3-0.5之间的snp位点。同时,为了保证检测的准确性,保证snp位点所在序列63mer碱基序列在基因组上为唯一比对,且gc含量在40%-50%。f8区域捕获区域如表1及表2所示。
2、家系单体型的获得
对孕妇、孕妇丈夫及先证者在目标基因及其上下游区域的snp位点基因型进行判断。通过对三者的snp基因型进行连锁分析,以确定与致病突变紧密连锁的snp位点的基因信息,并进一步获得与致病突变连锁的单体型信息。
(1)从孕妇、孕妇丈夫及先证者的外周血中抽提基因组dna,并使用电泳及od对获得的dna进行质量检测。
(2)使用质量检测合格的基因组dna进行目标区域捕获文库的制备。文库制备是将1μg基因组dna打断成主带为200-300bp小片段dna,然后将打断后dna片段进行末端补平,在3'端加碱基“a”,使得dna片段能与3'端带有“t”碱基的特殊接头连接,经non-capturedpcr构建完成的文库,通过f8基因目标区域捕获探针选取的特定基因的exon及侧翼±30bp区域进行富集,再通过pcr扩增富集后产物,最后通过杂交前后pcr产物qpcr检测获得序列捕获杂交效率。
(3)使用高通量测序仪对获得的样品文库进行测序。使得目标区域平均测序深度达到200×以上。
(4)利用bwa软件进行比对人hg19参考序列,进行测序深度和覆盖度统计,利用gatk软件获得得到f8基因的单核苷酸变异(snv)、少数碱基的插入和缺失(indel)等遗传变异信息。并明确与目标待检致病突变相连锁遗传的snp信息,即致病单体型。
假设先证者分别从父母双方得到一个致病突变,若
a假设先证者致病基因外某一位点的基因型为aa,父亲为ac,母亲为aa。则可知:先证者从父亲处获得了a,从母亲处获得了一个a,且这两个snp位点均与致病突变相连锁遗传。而在父亲中c与非致病allele连锁
b假设先证者致病基因外某一位点的基因型为ac,父亲为ac,母亲为aa。则可知:先证者从父亲处获得了c,从母亲处获得了一个a,且这两个snp位点均与致病突变相连锁遗传。而在父亲中c与非致病allele连锁
c假设先证者致病基因外某一位点的基因型为ac,父亲为aa,母亲为ac。则可知:先证者从父亲处获得了a,从母亲处获得了一个c,且这两个snp位点均与致病突变相连锁遗传。而在母亲中c与非致病allele连锁。
将上述推测方法应用到f8基因及两侧1m区域的snp位点,则可获得父母范围内的单体型信息,获知在这一区域内与致病突变连锁的单体型信息。从而并可进一步推断出与非致病allele紧密连锁的snp信息。
3、孕妇血浆dna目标区域捕获测序
对孕妇血浆dna进行目标区域捕获测序,并进行生物信息学snp/indel分析。以亲缘关系是否正确及胎儿dna含量为质控环节,仅对质控合格的样品进行后续分析。对孕妇的血浆游离dna测序数据进行genotyping,并结合该家系单体型进行连锁分析,判断胎儿是否遗传了夫妇的致病单体型。
(1)从1.2ml孕妇血浆中抽提细胞游离dna,并使用qubit定量dna进行质量检测。
(2)使用质量检测合格的基因组dna进行目标区域捕获文库的制备。首先对dna片段进行末端补平,在3'端加碱基“a”,使得dna片段能与3'端带有“t”碱基的特殊接头连接,经non-capturedpcr构建完成的文库,通过f8目标区域捕获探针选取的特定基因的exon及侧翼±100bp区域进行富集,再通过pcr扩增富集后产物,最后通过杂交前后pcr产物qpcr检测获得序列捕获杂交效率。
(3)使用高通量测序仪对获得的样品文库进行测序。使得目标区域平均测序深度达到500×以上。
4、胎儿性别判断和孕妇血浆游离dna浓度
伴性遗传疾病首先要判断胎儿性别,胎儿性别的判断主要参考y染色体特异性序列的深度,胎儿为男性,比对到y染色体特异性目标区域序列存在较高深度;胎儿为女性,比对到y染色体特异性目标区域序列深度趋近于0。对于家系输出的每个snp位点计算其对应的胎儿dna浓度,输出的胎儿dna浓度分布,取峰值对应胎儿dna浓度为准,并输出每个合适位点父母单体型的判断结果和对应的血浆reads支持数。
5、胎儿单体型推测
(1)对血浆游离dna中胎儿dna的含量进行计算,计算方式如下:
a)假设母亲白细胞dna基因型为aa,胎儿基因组dna为at,则此时血浆中可观察到的基因型为a和t,若支持a的reads数为c,支持c的reads数为d,则此时f=2d/(c+d)
b)假设母亲白细胞dna基因型为at,胎儿基因组dna为aa,则此时血浆中可观察到的基因型为a和t,若支持a的reads数为c,支持t的reads数为d,则此时f=(c-d)/(c+d)
若胎儿dna含量>3%则认为质控合格,进入后续实验
(2)判断胎儿从父亲处遗传的单体型,计算方式如下:
a)选择母亲为纯合,而父亲为杂合的位点进行父亲遗传单体型的判断。假设某一snp位点母亲基因型为aa,父亲基因型为ac,若血浆测序数据callsnp结果为a,c,且c的含量符合估计的胎儿浓度。则表明胎儿从处获得snpc所在的allele.
b)将f8捕获区域内所有满足a)条件的snp用于判断胎儿从父亲处所获得的snp信息,构成胎儿从父亲处获得的单体型信息。并根据3)中的信息,明确该单体型是否与致病突变相连锁,从而获知胎儿是否从父亲处获得致病allele
(3)判断胎儿从母亲处遗传的单体型,计算方式如下:
选择母亲为杂合,而父亲为纯合的位点进行母亲遗传单体型的判断。假设某一snp位点母亲基因型为ac,父亲基因型为aa,若血浆测序数据callsnp结果为a和c,若胎儿从母亲处遗传了a等位基因,胎儿的基因型为aa,则可观察到a/c近似与(1+f)/(1-f);若胎儿遗传了c等位基因,胎儿的基因型为ac,则可观察到a/c近似为0.5,并使用p值判断每一个位点胎儿遗传了c等位基因或a等位基因的概率。对每一个snp位点均分分别计算胎儿从母亲处遗传到某一条单体型的概率,并将所有snp各点概率一同用于判断胎儿从母亲处获得的单体型信息,并根据单体型是否与致病突变相连锁,得知胎儿是否从母亲处获得致病allele
(4)综合结果,获得胎儿的单体型信息。
下面将结合实施例对本发明的方案进行解释。本领域技术人员将会理解,下面的实施例仅用于说明本发明,而不应视为限定本发明的范围。实施例中未注明具体技术或条件的,按照本领域内的文献所描述的技术或条件或者按照产品说明书进行。所用试剂或仪器未注明生产厂商者,均为可以通过市购获得的常规产品。
实施例
招募1例甲型血友病f8家系进行无创产前检测。孕妇为f8基因第22号内含子倒位的杂合携带者,孕妇弟弟为患者,f8基因第22号内含子倒位半合子,孕妇丈夫为正常。
现孕妇第二次怀孕,抽取孕妇外周血并及时分离血浆,而后通过血浆dna及孕妇、孕妇丈夫、先证者的基因组dna进行捕获测序,对本次妊娠胎儿的基因单体型情况进行分析。
用盐析法提取标本dna,并进行超声打断,目前使用样品打断方法为covaris打断法,将样品dna打碎至100-700bp范围的片段。(注:打断效果一般以所要求制备文库insert片段主带位置在200-250bp位置较为理想,若打断效果不理想则需要进行重新打断。)
用qiaampcirculatingnucleicacidkit(货号:55114)提取血浆游离dna,使用qubit定量后直接进行文库构建。
1.文库制备
1.1末端修复和纯化
将配置好的mix震荡混匀后,每个反应加入25μl酶反应混合液。
反应条件:20℃,30min
使用180μlampurebeads进行产物纯化,回收的dna溶于30μl(其中1.9μl为损耗)的水中。
1.2末端加“a”(a-tailing)
将配置好的mix震荡混匀后,每管加入6.9μl酶反应混合液。
反应条件:20℃,30min
注:末端加“a”后不纯化
1.3adapter的连接和纯化
将配置好的mix震荡混匀,每个反应加入15μl酶反应混合液。
反应条件:16℃,12-16h(过夜)
使用75μlampurebeads进行产物纯化,回收的dna溶于27μl(其中2μl为损耗)的水中。
1.4non-captured样品pre-lm-pcr和纯化
将配置好的反应液震荡混匀。
pcr程序:
94℃2min;
94℃15s,62℃30s,72℃30s,4-8cycles;
72℃5min;
4℃forever
使用60μlampurebeads进行产物纯化,回收的dna溶于32μl(其中2μl为损耗)的水中。2100分析仪和qpcr测量文库浓度。
2.芯片杂交,目标区域捕获富集
本实验中参照nimblegen使用说明书进行杂交洗脱,获取目的基因并pcr富集。
3.上机测序
本实验采用hiseq2500pe101+8+101程序进行上机测序。
4.信息分析
测序仪获取原始短序列;
bwa将序列定位到人类基因组数据相应的位置上;
picard标记测序数据中的接头和低质量数据;
统计测序结果信息,短序列数量、目标区域覆盖大小、平均测序深度等;
gatk注释,确定突变位点发生的基因、坐标、氨基酸改变等;
确定f8捕获区域内各snp的基因型。
5.结果分析
1)数据产出情况
如表3所示,所测样品在目标区域平均测序深度均在80x以上,血浆测序深度达到271x。
表3数据产出情况表
2)胎儿dna含量分析和胎儿性别的确定
血浆测序数据显示胎儿是男胎,选择父亲为杂合而母亲为纯合的点,对血浆中胎儿dna含量进行估计:假设母亲基因型为aa,胎儿基因型为at,若测得为a的reads数为a,为c的reads数为b,则血浆中胎儿dna含量c=2b/(a+b)。结果显示ha血浆样品中胎儿dna含量分别为15.25%。
3)胎儿单体型推断
我们使用父亲、母亲及先证者在f8基因上下游1m以内的snp位点进行先证者单体型构建。表4统计了该区域成功判断用于父亲遗传单体型判断的snp数目(snpusedforpat-hap)及用于母亲遗传单体型判断的snp数目(snpusedformat-hap)。对家系中孕妇外周血浆数据进行分析,利用hmm算法推测本次怀孕胎儿f8基因情况。为了避免重复序列区域对分析结果的影响,仅使用unique序列区域进行分析。
f0和m0代表分别表示父母双方遗传给先证者的带有致病突变的单体型,f1/m1分别表示父母未遗传给先证者的不携带致病突变的单体型。0代表胎儿遗传父母与先证者相同的单体型;1表示胎儿遗传父母与先证者不同的单体型。推测结果如图3所示:本胎儿遗传母亲单体型m1。
表4f8基因相关区域phasesnp情况统计
在本发明的描述中,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括至少一个该特征。在本发明的描述中,“多个”的含义是至少两个,例如两个,三个等,除非另有明确具体的限定。
在本发明中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是机械连接,也可以是电连接或彼此可通讯;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系,除非另有明确的限定。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!