转化辅助用质粒和使用其的转化物的制造方法以及转化方法与流程
本发明涉及对宿主导入目的基因时使用的转化辅助用质粒、使用该转化辅助用质粒的转化物的制造方法、使用该转化辅助用质粒的转化方法。
背景技术:
一般,将从外部将目的基因导入宿主细胞的技术称为转化或者基因重组,将该导入了目的基因的细胞称为转化物或重组物。通过利用转化技术高效地制作转化物,例如可以利用合成生物学方法进行微生物代谢工程加速-高效化。这里,合成生物学方法是使生产宿主的设计-构建-评价-学习的周期迅速运转成立的技术。其中,在以酵母为宿主的合成生物学中,高效的宿主构建、即能够高效地制作重组酵母是一个重要课题。
以酵母为宿主的转化大体分为使用组入有目的基因的环状质粒的方法和使用含有目的基因的线状载体的方法。使用环状质粒将目的基因导入酵母是容易的,能够以10-2左右的高效率制作转化酵母(非专利文献1)。另一方面,使用线状载体将目的基因导入酵母时,有必要通过同源重组使目的基因组入基因组,因此仅能以10-6左右的效率制作转化酵母(非专利文献2)。
使用环状质粒将目的基因导入酵母的方法虽然如上所述效率高,但也存在环状质粒脱落的情况,无法制作稳定的重组酵母。另一方面,使用线状载体将目的基因导入酵母的方法中,虽然由于目的基因组入基因组,是稳定的,但如上所述,说不上是效率高的方法。
已知下述技术:为了提高目的基因对基因组的导入效率,在基因组中的导入预定部位预先导入归巢核酸内切酶等靶特异性核酸内切酶的靶序列,切割该部位的双链(非专利文献2)。此外还已知下述技术:代替靶特异性核酸内切酶,使用crispr-cas9、talen等能够切割任意碱基序列的技术,同样地切割基因组中的导入预定部位的双链(非专利文献3)。以这种方式,通过对导入目的基因的部位的双链进行切割,能够使同源重组效率提高至10-2~10-1左右。
然而,在这些提高目的基因的导入效率的方法中,有必要在基因组中的导入预定部位预先导入核酸内切酶的靶序列,或者,有必要制作针对目标部位的向导rna等。以这种方式,这些提高目的基因的导入效率的方法是除了制作包含目的基因的同源重组用dna片段、用其进行转化以外还需要有各种工序的复杂的方法。
此外,专利文献1中公开了具有将归巢核酸内切酶靶序列用端粒种子序列夹着的构成的内含子的筛选标记的质粒。专利文献1中公开的该质粒通过归巢核酸内切酶的表达从环状质粒转变为线状分子,可以利用末端的端粒种子序列稳定存在。
现有技术文献
专利文献
专利文献1:us2016/0017344
非专利文献
非专利文献1:gietz,r.d.,等“利用liac/ss载体dna/peg法的高效酵母转化(high-efficiencyyeasttransformationusingtheliac/sscarrierdna/pegmethod)”natureprotocols.2(2007):31-34.
非专利文献2:storici,f,等“酵母中的染色体位点特异性双链断裂被寡核苷酸有效地靶向修复(chromosomalsite-specificdouble-strandbreaksareefficientlytargetedforrepairbyoligonucleotidesinyeast)”proc.natl.acad.sci.usa.100(2003):14994-14999.
非专利文献3:dicarlo,j.e.,等“使用crispr-cas系统在酿酒酵母中进行基因组工程(genomeengineeringinsaccharomycescerevisiaeusingcrispr-cassystems)”nucleicacidsres.41(2013):4336-4343.
发明概述
发明所要解决的课题
然而,上述任何方法均存在无法简便且高效地制作使目的基因组入基因组的稳定转化物的问题。因此,鉴于上述实际情况,本发明的目的在于,提供能够简便且高效地制作使目的基因组入基因组的稳定转化物的转化物的制造方法和转化方法、以及能够用于这些方法的转化辅助用质粒。
用于解决课题的方法
本发明实现了上述目的,包括以下方案。
(1)一种转化物的制造方法,具有:
将具有用于导入至基因组上的规定位置的目的基因的1种或多种线状基因组导入核酸片段和具有用于组入该线状基因组导入核酸片段的一对同源重组序列的转化辅助用质粒导入宿主的工序,其中,配置用于在上述线状基因组导入核酸片段组入转化辅助用质粒的状态下在上述目的基因外侧和基因组的规定位置进行同源重组的一对同源重组序列和在该一对同源重组序列外侧的一对核酸内切酶靶序列,以及
筛选上述目的基因组入上述宿主基因组中的上述规定位置、表达上述目的基因的转化物的工序。
(2)根据(1)所述的转化物的制造方法,其特征在于,上述转化辅助用质粒具有与上述线状基因组导入核酸片段中的目的基因外侧同源重组的一对同源重组序列和在介由该同源重组序列而组入上述线状基因组导入核酸片段的位置的相反侧配置的一对核酸内切酶靶序列。
(3)根据(1)所述的转化物的制造方法,其特征在于,上述线状基因组导入核酸片段在夹着上述目的基因的位置具有用于组入上述基因组的规定位置的上述一对同源重组序列、在该一对同源重组序列外侧具有上述一对核酸内切酶靶序列、并且在该一对核酸内切酶靶序列外侧具有用于与上述转化辅助用质粒同源重组的上述一对同源重组序列。
(4)根据(1)所述的转化物的制造方法,其特征在于,上述转化辅助用质粒具有可表达的特异性切割上述核酸内切酶靶序列的双链的靶特异性核酸内切酶基因。
(5)根据(4)所述的转化物的制造方法,其特征在于,上述靶特异性核酸内切酶基因为归巢核酸内切酶基因。
(6)根据(5)所述的转化物的制造方法,其特征在于,上述核酸内切酶靶序列为归巢核酸内切酶特异性识别的序列。
(7)根据(4)所述的转化物的制造方法,其特征在于,上述转化辅助用质粒具有控制上述靶特异性核酸内切酶基因的表达的诱导型启动子。
(8)根据(1)所述的转化物的制造方法,其特征在于,上述多种线状基因组导入核酸片段由第1线状基因组导入核酸片段至第n线状基因组导入核酸片段(n为2以上的整数)组成,第m线状基因组导入核酸片段(m为满足1≤m≤n-1的整数)3’末端侧具有与第m+1线状基因组导入核酸片段5’末端侧同源重组的序列。
(9)一种转化方法,其特征在于,具有:将具有用于导入至基因组上的规定位置的目的基因的1种或多种线状基因组导入核酸片段和具有用于组入该线状基因组导入核酸片段的一对同源重组序列的转化辅助用质粒导入宿主的工序,其中,配置用于在上述线状基因组导入核酸片段组入转化辅助用质粒的状态下在上述目的基因外侧和基因组的规定位置进行同源重组的一对同源重组序列和在该一对同源重组序列外侧的一对核酸内切酶靶序列,
上述目的基因是表达的。
(10)根据(9)所述的转化方法,其特征在于,上述转化辅助用质粒具有与上述线状基因组导入核酸片段中的目的基因外侧同源重组的一对同源重组序列和在介由该同源重组序列而组入上述线状基因组导入核酸片段的位置的相反侧配置的一对核酸内切酶靶序列。
(11)根据(9)所述的转化方法,其特征在于,上述线状基因组导入核酸片段在夹着上述目的基因的位置具有用于组入上述基因组的规定位置的上述一对同源重组序列、在该一对同源重组序列外侧具有上述一对核酸内切酶靶序列、并且在该一对核酸内切酶靶序列外侧具有用于与上述转化辅助用质粒同源重组的上述一对同源重组序列。
(12)根据(9)所述的转化方法,其特征在于,上述转化辅助用质粒具有可表达的特异性切割上述核酸内切酶靶序列的双链的靶特异性核酸内切酶基因。
(13)根据(12)所述的转化方法,其特征在于,上述靶特异性核酸内切酶基因为归巢核酸内切酶基因。
(14)根据(13)所述的转化方法,其特征在于,上述核酸内切酶靶序列为归巢核酸内切酶特异性识别的序列。
(15)根据(12)所述的转化方法,其特征在于,上述转化辅助用质粒具有控制上述靶特异性核酸内切酶基因的表达的诱导型启动子。
(16)根据(9)所述的转化方法,其特征在于,上述多种线状基因组导入核酸片段由第1线状基因组导入核酸片段至第n线状基因组导入核酸片段(n为2以上的整数)组成,第m线状基因组导入核酸片段(m为满足1≤m≤n-1的整数)3’末端侧具有与第m+1线状基因组导入核酸片段5’末端侧同源重组的序列。
(17)一种转化辅助用质粒,其能够通过同源重组将具有用于导入至基因组上的规定位置的目的基因的线状基因组导入核酸片段组入,具有与上述线状基因组导入核酸片段中的目的基因外侧同源重组的一对同源重组序列和在介由该同源重组序列而组入上述线状基因组导入核酸片段的位置的相反侧配置的一对核酸内切酶靶序列。
(18)根据(17)所述的转化辅助用质粒,其特征在于,具有可表达的特异性切割上述核酸内切酶靶序列的双链的靶特异性核酸内切酶基因。
(19)根据(18)所述的转化辅助用质粒,其特征在于,上述靶特异性核酸内切酶基因为归巢核酸内切酶基因。
(20)根据(19)所述的转化辅助用质粒,其特征在于,上述核酸内切酶靶序列为归巢核酸内切酶特异性识别的序列。
(21)根据(18)所述的转化辅助用质粒,其特征在于,具有控制上述靶特异性核酸内切酶基因的表达的诱导型启动子。
发明效果
此外,本发明涉及的转化物的制造方法是在将具有目的基因的线状基因组导入核酸片段组入转化辅助用质粒的状态下由一对核酸内切酶靶序列夹着目的基因的配置,因此能够高效地制作使目的基因组入宿主基因组而形成的转化物。
进一步,本发明涉及的转化用方法是在将具有目的基因的线状基因组导入核酸片段组入转化辅助用质粒的状态下由一对核酸内切酶靶序列夹着目的基因的配置,因此能够制作使目的基因组入宿主基因组而形成的转化物,实现优异的转化效率。
通过利用本发明涉及的转化辅助用质粒,能够高效地制作目的基因组入宿主基因组而形成的转化物。
附图说明
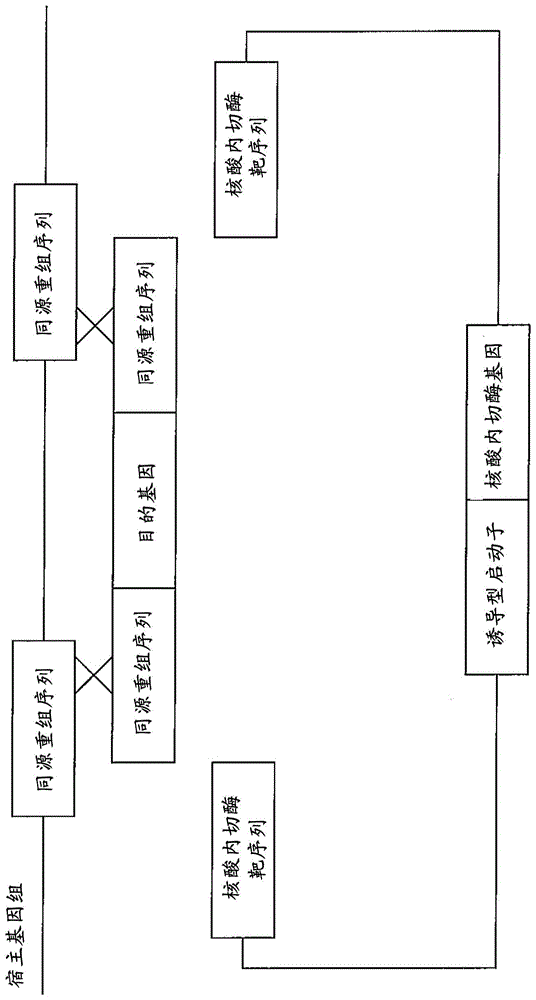
图1为示意性显示通过本发明涉及的转化物的制造方法和转化法将目的基因组入基因组的机制的构成图。
图2为示意性显示本发明涉及的转化辅助用质粒的一个构成例的构成图。
图3为示意性显示本发明涉及的转化辅助用质粒和线状基因组导入核酸片段的构成图。
图4为示意性显示本发明涉及的转化辅助用质粒的另一构成例的构成图。
图5为示意性显示使用本发明涉及的转化辅助用质粒将多个目的基因组入基因组的机制的构成图。
图6为示意性显示作为第2实施方式给出的线状基因组导入核酸片段和转化辅助用质粒的一个构成例的构成图。
图7为示意性显示通过作为第2实施方式给出的转化物的制造方法和转化法将目的基因组入基因组的机制的构成图。
图8为示意性显示通过作为第2实施方式给出的转化物的制造方法和转化法将多个目的基因组入基因组的机制的构成图。
图9为示意性显示扩增实施例中制作的3种线状基因组导入核酸片段的方案的构成图。
图10为示意性显示扩增实施例中制作的转化辅助用质粒的方案的构成图。
具体实施方式
以下,使用附图和实施例更详细地对本发明进行说明。
本发明涉及的转化物的制造方法和转化方法(以下总称为本方法。)中,将具有组入宿主基因组的预定目的基因的线状基因组导入核酸片段和使该线状基因组导入核酸片段通过同源重组组入的转化辅助用质粒导入宿主。本方法中,线状基因组导入核酸片段通过同源重组组入转化辅助用质粒。然后,在宿主内,一对同源重组序列夹着的目的基因被规定的核酸内切酶切出,通过与宿主基因组之间的同源重组,可以使目的基因组入基因组。
此时,通过以一对同源重组序列夹着的目的基因被一对核酸内切酶靶序列夹着的方式配置,能够用特异性识别该核酸内切酶靶序列的核酸内切酶将一对同源重组序列夹着的目的基因切出。即,如图1中示意性显示的那样,用核酸内切酶从质粒切出的片段呈下述构成:两端部具有一对同源重组序列,由该一对同源重组序列夹着目的基因。然后,在一对同源重组序列中与宿主基因组之间发生同源重组,结果,能够使目的基因组入宿主基因组内。
这里,一对核酸内切酶靶序列可以预先配置在导入宿主的线状基因组导入核酸片段中,也可以预先配置在转化辅助用质粒中。或者,还可以将一对核酸内切酶靶序列中的一方预先配置在线状基因组导入核酸片段中,另一方预先配置在转化辅助用质粒中。
[第1实施方式]
以下对使一对核酸内切酶靶序列配置在转化辅助用质粒中的方式进行说明。如图2所示,本发明涉及的转化辅助用质粒具有用于使线状基因组导入核酸片段组入的一对同源重组序列和在介由该同源重组序列而组入上述线状基因组导入核酸片段的位置的相反侧配置的一对核酸内切酶靶序列。换句话说,转化辅助用质粒在对将上述线状基因组导入核酸片段组入的位置进行切割形成线状时,两端部具有一对同源重组序列,与各同源重组序列相连地具有核酸内切酶靶序列。
如图3所示,转化辅助用质粒可以通过同源重组使具有目的基因的线状基因组导入核酸片段介由上述一对同源重组序列组入。这里,线状基因组导入核酸片段具有目的基因和夹着该目的基因的一对同源重组序列。即,通过线状基因组导入核酸片段中的同源重组序列与转化辅助用质粒中的同源重组序列之间发生同源重组,能够使线状基因组导入核酸片段组入转化辅助用质粒。此外,通过与线状基因组导入核酸片段中的同源重组序列在基因组中的规定位置发生同源重组,能够使目的基因组入基因组(参照图1)。
目的基因的意思是导入宿主基因组的预定核酸。因此,目的基因不限于编码特定蛋白的碱基序列,意思包括编码sirna等的碱基序列、控制转录产物的转录时期和产量的启动子、增强子等转录调控区域的碱基序列、编码转运rna(trna)、核糖体rna(rrna)等的碱基序列等所有由碱基序列构成的核酸。
此外,目的基因优选以可表达的状态组入上述部位。可表达的状态的意思是,以在宿主生物中在规定启动子的控制下表达的方式使目的基因和启动子连接。
进一步,目的基因上可以连接启动子和终止子,可以根据希望连接增强子等顺式元件、剪切信号、polya添加信号、筛选标记、核糖体结合序列(sd序列)等。其中,作为筛选标记,可列举例如氨苄青霉素抗性基因、卡那霉素抗性基因、潮霉素抗性基因等抗生素抗性基因。
一对同源重组序列的意思是与宿主基因组中的规定区域具有同源性的一对核酸区域。通过线状基因组导入核酸片段中的一对同源重组序列与具有同源性的宿主基因组之间分别交叉,能够使该一对同源重组序列夹着的目的基因组入宿主基因组。因此,作为一对同源重组序列,具体的碱基序列没有任何限定,例如可以设为与存在于宿主基因组中的规定基因的上游区域和下游区域同源性高的碱基序列。这种情况下,线状基因组导入核酸片段与宿主基因组之间发生同源重组时,该基因从宿主基因组缺失,因此可以通过对该基因的缺失导致的表型进行观察来判断同源重组是否成功。
例如,作为一对同源重组序列,可以设为与腺嘌呤生物合成路径相关的ade1基因的编码区域上游的区域和同一ade1基因的编码区域下游的区域。这种情况下,线状基因组导入核酸片段中的一对同源重组序列与宿主基因组之间发生同源重组时,腺嘌呤中间代谢物5-氨基咪唑核苷累积,由于其聚合而成的聚核糖基氨基咪唑,转化物呈红色。因此,通过对该红色着色进行检测,能够判断线状基因组导入核酸片段中的一对同源重组序列与宿主基因组之间发生了同源重组。
这里,线状基因组导入核酸片段中的一对同源重组序列与宿主基因组的重组区域之间具有高至可同源重组(可交叉)程度的序列一致性。各区域间的碱基序列的相同性可以使用以往公知的序列比对软件blastn等来计算。各区域间的碱基序列具有60%以上的一致性即可,优选为80%以上,进一步优选为90%以上,特别优选为95%以上,最优选具有99%以上的一致性。
此外,线状基因组导入核酸片段中的一对同源重组序列相互之间可以是相同的长度,也可以是不同的长度。这些线状基因组导入核酸片段中的一对同源重组序列只要是在基因组之间可同源重组(可交叉)程度的长度即可,例如,分别优选为0.1kb~3kb,进一步优选为0.5kb~3kb,特别优选为0.5kb~2kb。
本发明涉及的转化辅助用质粒具有用于组入上述线状基因组导入核酸片段的一对同源重组序列。只要转化辅助用质粒中的同源重组序列在与线状基因组导入核酸片段中的同源重组序列之间发生同源重组即可,可以与线状基因组导入核酸片段中的同源重组序列为相同长度,也可以为不同长度。转化辅助用质粒中的同源重组序列是与线状基因组导入核酸片段中的同源重组序列具有同源性的碱基序列,例如可以设为30b~300b,优选设为40b~200b,更优选设为50b~100b。
此外,本发明涉及的转化辅助用质粒中,用于组入线状基因组导入核酸片段的一对同源重组序列的意思包括与线状基因组导入核酸片段中的一对同源重组序列之间能够直接同源重组和与线状基因组导入核酸片段中的一对同源重组序列之间能够介由1个以上的线状核酸片段间接同源重组这两者。这里,1个以上的线状核酸片段是,1个核酸片段或多个核酸片段通过同源重组连接而成的核酸片段中,一个端部具有能够与转化辅助用质粒中的同源重组序列之间同源重组的序列、另一端部具有能够与线状基因组导入核酸片段中的同源重组序列之间同源重组的序列的片段。
此外,本发明涉及的转化辅助用质粒具有与上述一对同源重组序列相连的核酸内切酶靶序列。核酸内切酶靶序列的意思是核酸内切酶识别的碱基序列。
作为核酸内切酶没有特别限定,泛指具有识别特定碱基序列来切割双链dna的活性的酶。作为核酸内切酶,可以列举例如限制酶、归巢核酸内切酶、cas9核酸酶、(兆碱基)大范围核酸酶(mn)、锌指核酸酶(zfn)、转录激活样效应核酸酶(talen)等。此外,作为归巢核酸内切酶,意思是包括内含子编码的核酸内切酶(带有i-前缀)和内含肽所含的核酸内切酶(带有pi-前缀)这两者。作为归巢核酸内切酶,更具体地,可以列举i-ceui、i-scei、i-onui、pi-pspi和pi-scei。其中,这些具体的核酸内切酶特异性识别的靶序列、即核酸内切酶靶序列是公知的,本领域技术人员可以适当获得。
此外,如图4所示,本发明涉及的转化辅助用质粒也可以包含诱导型启动子和核酸内切酶基因。其中,核酸内切酶基因的表达不限于诱导型启动子,也可以使用组成性表达型启动子。
该核酸内切酶基因编码具有特异性识别上述一对核酸内切酶靶序列切割双链的活性的酶。即,作为核酸内切酶基因,可以列举限制酶基因、归巢核酸内切酶基因、cas9核酸酶基因、(兆碱基)大范围核酸酶基因、锌指核酸酶基因、转录激活样效应核酸酶基因等。
诱导型启动子意思是具有在特定条件下诱导表达功能的启动子。作为诱导型启动子没有特别限定,可以列举例如在特定物质的存在下诱导表达的启动子、在特定温度条件下诱导表达的启动子、对各种压力做出应答而诱导表达的启动子等,所使用的启动子可以根据要转化的宿主适当选择。
例如,作为诱导型启动子,可以列举gal1和gal10等半乳糖诱导性启动子、通过四环素或其诱导体的添加或除去而诱导的tet-on系统/tet-off系启动子、编码hsp10、hsp60、hsp90等热休克蛋白(hsp)的基因的启动子等。此外,作为诱导型启动子,也可以使用通过铜离子的添加而活化的cup1启动子。进一步,作为诱导型启动子,宿主为大肠杆菌等原核细胞时,可以列举用iptg诱导的lac启动子、通过冷休克诱导的cspa启动子、用阿拉伯糖诱导的arabad启动子等。
此外,核酸内切酶基因的表达控制不限定为利用诱导型启动子、组成性表达型启动子等启动子的方法,例如也可以应用使用dna重组酶的方法。作为使用dna重组酶进行基因表达的开-关方法,可以列举例如flexswitch法(flex开关将channelrhodopsin-2靶向多种细胞类型,以进行成像和远距离电路映射(aflexswitchtargetschannelrhodopsin-2tomultiplecelltypesforimagingandlong-rangecircuitmapping)。atasoy等thejournalofneuroscience,28,7025-7030,2008.)。flexswitch法中,可以通过利用dna重组酶发生使启动子序列方向改变的重组而进行基因的表达的开-关。
另一方面,本发明涉及的转化辅助用质粒可以基于以往公知的能够获得的质粒来制作。作为这样的质粒,可列举例如prs413、prs414、prs415、prs416、ycp50、paur112或paur123等ycp型大肠杆菌-酵母穿梭载体、pyes2或yep13等yep型大肠杆菌-酵母穿梭载体、prs403、prs404、prs405、prs406、paur101或paur135等yip型大肠杆菌-酵母穿梭载体、大肠杆菌来源的质粒(pbr322、pbr325、puc18、puc19、puc118、puc119、ptv118n、ptv119n、pbluescript、phsg298、phsg396或ptrc99a等cole系质粒、pacyc177或pacyc184等p15a系质粒、pmw118、pmw119、pmw218或pmw219等psc101系质粒等)、农杆菌来源的质粒(例如pbi101等)、枯草芽孢杆菌来源的质粒(例如pub110、ptp5等)等。
本发明涉及的转化辅助用质粒可以进一步包含复制起点、自主复制序列(ars)、着丝粒序列(cen)。通过含有这些元件,能够在导入宿主细胞后稳定地复制。此外,本发明涉及的转化辅助用质粒可以包含筛选标记。作为筛选标记没有特别限定,可以列举例如药物抗性标记基因、营养缺陷型标记基因。通过含有这些筛选标记,能够高效地筛选导入有转化辅助用质粒的宿主细胞。
通过使用如上所述构成的转化辅助用质粒,能够简便且高效地制作使目的基因组入基因组的稳定转化物。为了制作转化物,首先,按照常规方法将具有目的基因的线状基因组导入核酸片段和转化辅助用质粒导入宿主细胞。此时,线状基因组导入核酸片段通过同源重组组入转化辅助用质粒,形成环状质粒(参照图3)。然后,如图1中示意性显示的那样,一对核酸内切酶靶序列中双链被核酸内切酶切割,切出包含一对同源重组序列夹着的目的基因的线状基因组导入核酸片段。切出的线状基因组导入核酸片段在该线状基因组导入核酸片段中的一对同源重组序列与宿主基因组中的同源重组序列之间交叉,组入基因组内。由此能够制作使目的基因组入基因组的稳定转化物。
此时,作为将具有目的基因的线状基因组导入核酸片段和转化辅助用质粒导入宿主细胞的方法没有特别限定,可以适当使用以往公知的方法,例如氯化钙法、感受态细胞法、原生质体或原生质球法、电脉冲法等。然后,转化辅助用质粒具有筛选标记的情况下,可以使用筛选标记筛选导入有转化辅助用质粒的宿主细胞。
此外,为了使核酸内切酶在诱导型启动子的控制下表达,根据诱导型启动子设定适合的条件。例如,使用gal1和gal10等半乳糖诱导性启动子作为诱导型启动子的情况下,可以通过在培养导入有转化用质粒的宿主细胞的培养基中添加半乳糖、或者将该宿主细胞移入含有半乳糖的培养基进行培养,能够诱导表达核酸内切酶。此外,使用编码热休克蛋白(hsp)的基因的启动子作为诱导型启动子的情况下,通过在培养导入有转化用质粒的宿主细胞时在期望的时刻实施热休克,可以在该时刻诱导表达核酸内切酶。
其中,也可以在诱导型启动子诱导表达的条件下进行将线状基因组导入核酸片段和转化辅助用质粒导入宿主细胞的处理,在诱导型启动子的控制下表达核酸内切酶。这种情况下,不需要转移至表达诱导条件的处理,能够更简便地获得转化物。
此外,上述转化辅助用质粒中,将一对同源重组序列设为与规定基因的上游区域和下游区域同源性高的碱基序列的情况下,通过同源重组,包含目的基因的线状基因组导入核酸片段被组入基因组,并且该规定基因从基因组缺失。因此,通过对该规定基因的缺失导致的表型进行观察,能够判断包含目的基因的线状基因组导入核酸片段是否被组入基因组。例如,利用ade1基因作为规定基因时,如果包含目的基因的线状基因组导入核酸片段组入基因组,则ade1基因从基因组缺失。其结果是,5-氨基咪唑核苷在宿主中累积,由于其聚合而成的聚核糖基氨基咪唑,转化物呈红色。因此,通过对该红色着色进行检测,能够判断包含目的基因的线状基因组导入核酸片段是否被组入宿主的基因组。
予以说明,上述例子中,设为转化辅助用质粒具有诱导型启动子和核酸内切酶基因的构成,但本发明涉及的转化辅助用质粒也可以是不具有诱导型启动子和核酸内切酶基因的构成。这种情况下,可以与具有诱导型启动子和核酸内切酶基因的表达载体分别准备,具有目的基因的线状基因组导入核酸片段和本发明涉及的转化辅助用质粒一起导入宿主细胞。这种情况下也同样,通过在导入了具有诱导型启动子和核酸内切酶基因的表达载体和线状基因组导入核酸片段以及转化用质粒的宿主细胞中,核酸内切酶基因在诱导型启动子的控制下表达,如图1所示,包含一对同源重组序列夹着的目的基因的线状基因组导入核酸片段被切出,能够制作使目的基因组入基因组的转化物。
另一方面,通过使用本发明涉及的转化辅助用质粒,能够串联配置多个线状基因组导入核酸片段来组入宿主基因组。假设将多种线状基因组导入核酸片段设为第1线状基因组导入核酸片段至第n线状基因组导入核酸片段(n为2以上的整数),通过将第m线状基因组导入核酸片段(m为满足1≤m≤n-1的整数)3’末端侧与第m+1线状基因组导入核酸片段5’末端侧设为同源重组序列,能够通过同源重组使第1~n线状基因组导入核酸片段按上述顺序连接。作为一例,如图5所示,在将第1~3线状基因组导入核酸片段组入宿主基因组的情况下,通过将第1线状基因组导入核酸片段3’末端侧和第2线状基因组导入核酸片段5’末端侧设为同源重组序列2、将第2线状基因组导入核酸片段3’末端侧和第3线状基因组导入核酸片段5’末端侧设为同源重组序列3,能够通过同源重组使第1~第3线状基因组导入核酸片段按上述顺序连接。第1~第3线状基因组导入核酸片段连接而成的片段在转化辅助用质粒和宿主基因组之间通过介由同源重组序列1和同源重组序列4的同源重组,组入转化辅助用质粒和宿主基因组。
为了通过同源重组串联配置多个线状基因组导入核酸片段,在邻接的线状基因组导入核酸片段之间设有同源重组序列。这些同源重组序列只要是与邻接的线状基因组导入核酸片段中的同源重组序列之间发生同源重组即可,可以是与邻接的线状基因组导入核酸片段中的同源重组序列相同的长度,也可以是不同的长度。该同源重组序列是与邻接的线状基因组导入核酸片段中的同源重组序列具有同源性的碱基序列,例如可以设为30b~300b,优选设为40b~200b,更优选设为50b~100b。
如上所述,通过使用本发明涉及的转化辅助用质粒,能够使多个线状基因组导入核酸片段串联配置组入宿主基因组。这里,多个线状基因组导入核酸片段可以分别具有目的基因,也可以仅一部分线状基因组导入核酸片段具有目的基因。
予以说明,利用本发明涉及的转化辅助用质粒的转化方法、转化物的制造方法没有特别限定,对于任何宿主细胞均可适用。作为宿主细胞,可以列举丝状真菌、酵母等真菌、大肠杆菌、枯草芽孢杆菌等细菌、植物细胞、包括哺乳类、昆虫的动物细胞。其中,优选以酵母为宿主细胞。作为酵母没有特别限定,可以列举属于酵母菌属(saccharomyces)的酵母、属于克鲁维酵母属(kluyveromyces)的酵母、属于念珠菌属(candida)的酵母、属于毕赤酵母属(pichia)的酵母、属于裂殖酵母属(schizosaccharomyces)的酵母、属于汉逊酵母属(hansenula)的酵母等。更具体地,可以适用于酿酒酵母(saccharomycescerevisiae)、贝酵母(saccharomycesbayanus)、布拉氏酵母(saccharomycesboulardii)等属于酵母菌属的酵母。
[第2实施方式]
以下,对于将一对核酸内切酶靶序列配置于具有目的基因的线状基因组导入核酸片段的方式进行说明。予以说明,以下的说明中,通过使用与关于第1实施方式的说明相同的术语,省略关于该构成等的详细说明。
如图6所示,第2实施方式中线状基因组导入核酸片段在两端部具有能够与转化辅助用质粒之间发生同源重组的一对第1同源重组序列,在第1同源重组序列内侧具有核酸内切酶靶序列,在该核酸内切酶靶序列内侧具有能够与宿主基因组之间发生同源重组的一对第2同源重组序列,并且在该一对第2同源重组序列内侧具有目的基因。本实施方式中,转化辅助用质粒具有用于组入线状基因组导入核酸片段的一对第3同源重组序列。此外,虽然图中未显示,但转化辅助用质粒可以如第1实施方式中图4所示,在诱导型启动子和该诱导型启动子下游具有核酸内切酶基因。
予以说明,第2实施方式中也同样,转化辅助用质粒中的一对第3同源重组序列与线状基因组导入核酸片段中的一对第1同源重组序列可以直接同源重组,也可以介由1个以上的线状核酸片段间接同源重组。这里,1个以上的线状核酸片段是下述片段:1个核酸片段或多个核酸片段通过同源重组连接的核酸片段中,一个端部具有能够与转化辅助用质粒中的第3同源重组序列之间同源重组的序列、另一端部具有能够与线状基因组导入核酸片段中的第1同源重组序列之间同源重组的序列。
通过使用如上所述构成的线状基因组导入核酸片段和转化辅助用质粒,能够简便且高效地制作使目的基因组入基因组的稳定转化物。为了制作转化物,首先,按照常规方法将上述具有目的基因的线状基因组导入核酸片段和转化辅助用质粒导入宿主细胞。此时,在线状基因组导入核酸片段中的第1同源重组序列与转化辅助用质粒中的第3同源重组序列之间发生同源重组,形成线状基因组导入核酸片段组入转化辅助用质粒而成的环状质粒(参照图7)。然后,如图7中示意性显示的那样,一对核酸内切酶靶序列中的双链被核酸内切酶切割,包含一对第2同源重组序列夹着的目的基因的片段被切出。切出的片段在该片段中的一对第2同源重组序列与宿主基因组中的第4同源重组序列之间交叉,组入基因组内。由此能够制作使目的基因组入基因组的稳定转化物。
此外,本实施方式中也可以使多个线状基因组导入核酸片段串联配置组入宿主基因组。作为一例,如图8所示,使第1~3线状基因组导入核酸片段组入宿主基因组的情况下,通过将第1线状基因组导入核酸片段3’末端侧与第2线状基因组导入核酸片段5’末端侧设为同源重组序列2、将第2线状基因组导入核酸片段3’末端侧与第3线状基因组导入核酸片段5’末端侧设为同源重组序列3,能够通过同源重组使第1~第3线状基因组导入核酸片段按上述顺序连接。连接的片段通过其第1同源重组序列与转化辅助用质粒中的第3同源重组序列之间的同源重组组入转化辅助用质粒。此外,利用核酸内切酶在核酸内切酶靶序列切出的片段通过其第2同源重组序列与基因组中的第4同源重组序列的间的同源重组而组入宿主基因组。
实施例
以下使用实施例更详细地对本发明进行说明,但本发明的技术范围不受以下实施例的限制。
〔实施例1〕
本实施例中,使用单倍体的实验酵母s.cerevisiaeby4742株作为测试株。
<载体的制作>
制作的3种载体是由被半乳糖诱导的s.cerevisiae来源的归巢核酸内切酶i-scei(scei基因,ncbi登录号854590)和在一对i-scei靶序列(核酸内切酶靶序列)之间插入有包含基因组导入用的一对同源重组序列的dna片段的序列构成的yep型酵母穿梭载体prs436(sat)-p_gal1-scei-t_cyc1-sce-5u_ade1-p_agtef1-g418-t_agtef1-3u_ade1-sce(参照图9)、以及ycp型酵母穿梭载体prs436cen(sat)-p_gal1-scei-t_cyc1-sce-5u_ade1-p_agtef1-g418-t_agtef1-3u_ade1-sce、由被半乳糖诱导的ophiostomanovo-ulmisubsp.americana来源的归巢核酸内切酶i-onui基因(ncbi登录号ay275136.2)和在一对i-onui靶序列(核酸内切酶靶序列)之间插入有包含基因组导入用的一对同源重组序列的dna片段的序列构成的yep型酵母穿梭载体prs436(sat)-p_gal1-onuii-t_cyc1-onu-5u_ade1-p_agtef1-g418-t_agtef1-3u_ade1-onu。
prs436(sat)-p_gal1-scei-t_cyc1-sce-5u_ade1-p_agtef1-g418-t_agtef1-3u_ade1-sce中,包括带有gal1启动子和cyc1终止子的scei基因(插入有cox5b基因的内含子、全长根据酵母核基因组的密码子使用频率改变了密码子的序列,序列编号1和2)、包含诺尔斯菌素抗性基因的基因序列(nat标记)、作为基因组导入用的同源重组序列的、ade1基因的5’侧末端上游约1000bp区域的基因序列(5u_ade1)和ade1基因3’侧末端下游约950bp区域的dna序列(3u_ade1)、作为同源重组用的标记基因的、带有棉病囊菌来源的tef1启动子和tef1终止子的g418抗性基因的基因序列(g418标记)插入至从作为yep型酵母穿梭载体的prs436gap(ncbi登录号ab304862)去掉ura3基因、tdh3启动子、cyc1终止子而得的载体。予以说明,5u_ade1和3u_ade1以及g418标记序列插入于2处归巢核酸内切酶i-scei靶序列之间,可以通过用碳源为半乳糖的培养基诱导的gal1启动子带有的scei基因切出。
各dna序列可以通过pcr来扩增。为了使各dna片段结合,合成引物以与邻接dna序列重复约15bp的方式添加有dna序列的引物(表1)。使用这些引物,以s.cerevisiaeoc-2株基因组或合成dna为模板,扩增目的dna片段,使用in-fusionhdcloningkit等依次使dna片段结合,克隆入prs436gap载体,制作最终的目的质粒。
prs436cen(sat)-p_gal1-scei-t_cyc1-sce-5u_ade1-p_agtef1-g418-t_agtef1-3u_ade1-sce是下述载体:从prs436(sat)-p_gal1-scei-t_cyc1-sce-5u_ade1-p_agtef1-g418-t_agtef1-3u_ade1-sce去掉2μm质粒来源的复制起点,代之插入有自主复制序列(ars)和着丝粒序列(cen),细胞内的拷贝数保持1拷贝。本载体是以rs436(sat)-p_gal1-scei-t_cyc1-sce-5u_ade1-p_agtef1-g418-t_agtef1-3u_ade1-sce或s.cerevisiaeoc-2株基因组为模板扩增目的dna片段(所用引物如表1所示),使用in-fusionhdcloningkit等使dna片段结合而制作的。
prs436(sat)-p_gal1-onuii-t_cyc1-onu-5u_ade1-p_agtef1-g418-t_agtef1-3u_ade1-onu是下述质粒:从prs436(sat)-p_gal1-scei-t_cyc1-sce-5u_ade1-p_agtef1-g418-t_agtef1-3u_ade1-sce将scei基因替换为i-onui基因,进一步将i-scei靶序列替换为i-onui靶序列。本载体是以rs436(sat)-p_gal1-scei-t_cyc1-sce-5u_ade1-p_agtef1-g418-t_agtef1-3u_ade1-sce或i-onui基因的合成基因为模板扩增目的dna片段(所用引物如表1所示),使用in-fusionhdcloningkit等使dna片段结合而制作的。
[表1]
<ade1破坏用的线状基因组导入核酸片段的制作>
本实施例中,以上述制作的载体中的yep型酵母穿梭载体prs436(sat)-p_met25-scei-t_cyc1-sce-5u_ade1-p_agtef1-g418-t_agtef1-3u_ade1-sce为模板,使用表2所示引物,通过pcr扩增包含ade1基因的5’同源重组序列的片段、包含ade1基因的3’同源重组序列的片段、以及包含g418标记的片段。详细地,如图9中示意性显示的那样,使用引物p1和p2扩增包含ade1基因的5’同源重组序列的片段,使用引物p3和p4扩增包含g418标记的片段,使用引物p5和p6扩增包含ade1基因的3’同源重组序列的a片段。予以说明,以各个片段重复约60bp的方式设计引物。其中,将各引物的碱基序列示于表2。
[表2]
<转化辅助用质粒的制作>
本实施例中,以作为上述制作的载体的yep型酵母穿梭载体prs436(sat)-p_gal1-scei-t_cyc1-sce-5u_ade1-p_agtef1-g418-t_agtef1-3u_ade1-sce、ycp型酵母穿梭载体prs436cen(sat)-p_gal1-scei-t_cyc1-sce-5u_ade1-p_agtef1-g418-t_agtef1-3u_ade1-sce或yep型酵母穿梭载体prs436(sat)-p_gal1-onuii-t_cyc1-onu-5u_ade1-p_agtef1-g418-t_agtef1-3u_ade1-onu为模板,使用与包含ade1的5’或者3’同源重组序列的线状基因组导入核酸片段重复约60bp的表3所示的引物,扩增转化辅助用质粒。详细地,如图10中示意性显示的那样,使用引物p7和p8,通过pcr扩增转化辅助用质粒。予以说明,将各引物的碱基序列示于表3。
[表3]
<使用线状基因组导入核酸片段和转化辅助用质粒的转化>
用如上所述制作的3种线状基因组导入核酸片段和转化辅助用质粒分别以2fmol/μl的浓度进行s.cerevisiaeby4742株的转化(106细胞/μl),用ypga(碳源半乳糖2%)液体培养基培养7小时后,用分光光度计测定细胞浓度,涂布在含有g418的ypga琼脂培养基(106和107细胞/板)上,对长出的菌落进行计数。转化按照akada[akada,r.等,“高温大大改善酵母中新鲜和冷冻感受态细胞的转化(elevatedtemperaturegreatlyimprovestransformationoffreshandfrozencompetentcellsinyeast)”biotechniques28(2000):854-856]等人的方法进行。
认为在含有半乳糖的培养基中,归巢核酸内切酶i-scei被诱导,以连接有3种线状基因组导入核酸片段的状态切出,在ade1基因座发生同源重组,ade1基因被破坏。ade1基因是腺嘌呤生物合成路径的基因,其破坏株中,腺嘌呤的中间代谢物5-氨基咪唑核苷累积,其聚合而成的聚核糖基氨基咪唑呈红色,因此能够容易地判断ade1基因破坏株。予以说明,对ade1基因座的同源重组效率通过下述算式算出。
ade1基因破坏效率(%)=琼脂培养基上长出的红色菌落数/散布在琼脂培养基上的细胞数
予以说明,为了进行比较,不使用转化辅助用质粒,仅使用如上所述制作的3种线状基因组导入核酸片段进行转化,同样地算出ade1基因破坏效率。
<结果-考察>
将计算使用3种线状基因组导入核酸片段和3种转化辅助用质粒时的ade1基因破坏效率和仅使用3种线状基因组导入核酸片段时的ade1基因破坏效率的结果示于表4。
[表4]
由表4可以判断,使用转化辅助用质粒的情况下,与仅使用线状基因组导入核酸片段的情况相比,以约50~240倍的效率获得了ade1破坏株。由此可见,通过使用具有用于在宿主基因组中导入目的基因的一对同源重组序列和夹着该一对同源重组序列的一对核酸内切酶靶序列的转化辅助用质粒,能够提高线状基因组导入核酸片段向基因组的导入效率。
序列表
<110>丰田自动车株式会社
<120>转化辅助用质粒和使用其的转化物的制造方法以及转化方法
<130>ph-8039-cn
<150>jp2019-116358
<151>2019-06-24
<160>52
<170>patentinversion3.5
<210>1
<211>796
<212>dna
<213>酿酒酵母
<400>1
agcatgtataacaaacactgatttttgttttgagttttaaaagatatccatttactaaca60
ttcgaggtgtacaagcacaagttttgcagtgaaaaacattaagaaaaaccaagttatgaa120
tttgggtccaaacagtaagttattgaaagaatacaagtcacaattgatagaattaaatat180
agaacaatttgaagccggtatcggtttgattttaggtgacgcttatattagatccagaga240
cgaaggtaaaacttactgtatgcaattcgaatggaaaaacaaggcatatatggatcatgt300
atgcttgttatacgaccaatgggtcttgtcaccacctcataaaaaggaaagagtcaatca360
cttgggtaacttagttattacctggggtgcccaaacttttaagcaccaagcttttaataa420
gttggcaaatttgtttattgttaacaacaaaaagacaatcccaaacaacttggtagaaaa480
ctatttgacccctatgtctttggcttactggttcatggatgacggtggtaaatgggatta540
caataagaactccacaaataagagtatcgttttgaacactcaatcttttactttcgaaga600
agttgaatacttggtaaagggtttgagaaataagttccaattgaactgttacgttaaaat660
taataagaacaagccaattatatacattgattctatgtcatatttgatattctacaattt720
gatcaaaccttatttgattccacaaatgatgtataagttaccaaacactatctcctccga780
aaccttcttgaaatga796
<210>2
<211>235
<212>prt
<213>酿酒酵母
<400>2
metlysasnilelyslysasnglnvalmetasnleuglyproasnser
151015
lysleuleulysglutyrlysserglnleuilegluleuasnileglu
202530
glnpheglualaglyileglyleuileleuglyaspalatyrilearg
354045
serargaspgluglylysthrtyrcysmetglnpheglutrplysasn
505560
lysalatyrmetasphisvalcysleuleutyraspglntrpvalleu
65707580
serproprohislyslysgluargvalasnhisleuglyasnleuval
859095
ilethrtrpglyalaglnthrphelyshisglnalapheasnlysleu
100105110
alaasnleupheilevalasnasnlyslysthrileproasnasnleu
115120125
valgluasntyrleuthrprometserleualatyrtrpphemetasp
130135140
aspglyglylystrpasptyrasnlysasnserthrasnlysserile
145150155160
valleuasnthrglnserphethrpheglugluvalglutyrleuval
165170175
lysglyleuargasnlyspheglnleuasncystyrvallysileasn
180185190
lysasnlysproileiletyrileaspsermetsertyrleuilephe
195200205
tyrasnleuilelysprotyrleuileproglnmetmettyrlysleu
210215220
proasnthrilesersergluthrpheleulys
225230235
<210>3
<211>20
<212>dna
<213>人工
<220>
<223>合成dna
<400>3
acggattagaagccgccgag20
<210>4
<211>29
<212>dna
<213>人工
<220>
<223>合成dna
<400>4
ggttttttctccttgacgttaaagtatag29
<210>5
<211>48
<212>dna
<213>人工
<220>
<223>合成dna
<400>5
tcaaggagaaaaaaccagcatgtataacaaacactgatttttgttttg48
<210>6
<211>38
<212>dna
<213>人工
<220>
<223>合成dna
<400>6
tcttaatgtttttcactgcaaaacttgtgcttgtacac38
<210>7
<211>29
<212>dna
<213>人工
<220>
<223>合成dna
<400>7
tgaaaaacattaagaaaaaccaagttatg29
<210>8
<211>37
<212>dna
<213>人工
<220>
<223>合成dna
<400>8
gcgtgacataactaatcatttcaagaaggtttcggag37
<210>9
<211>26
<212>dna
<213>人工
<220>
<223>合成dna
<400>9
ttagttatgtcacgcttacattcacg26
<210>10
<211>59
<212>dna
<213>人工
<220>
<223>合成dna
<400>10
aattgcccgactcatattaccctgttatccctaagcttgcaaattaaagccttcgagcg59
<210>11
<211>18
<212>dna
<213>人工
<220>
<223>合成dna
<400>11
atgagtcgggcaattccg18
<210>12
<211>46
<212>dna
<213>人工
<220>
<223>合成dna
<400>12
ctgggcctccatgtctatcgttaatatttcgtatgtgtattctttg46
<210>13
<211>20
<212>dna
<213>人工
<220>
<223>合成dna
<400>13
gacatggaggcccagaatac20
<210>14
<211>24
<212>dna
<213>人工
<220>
<223>合成dna
<400>14
ggttgtttatgttcggatgtgatg24
<210>15
<211>41
<212>dna
<213>人工
<220>
<223>合成dna
<400>15
cgaacataaacaaccatgggtaaggaaaagactcacgtttc41
<210>16
<211>46
<212>dna
<213>人工
<220>
<223>合成dna
<400>16
tattgtcagtactgattagaaaaactcatcgagcatcaaatgaaac46
<210>17
<211>35
<212>dna
<213>人工
<220>
<223>合成dna
<400>17
tcagtactgacaataaaaagattcttgttttcaag35
<210>18
<211>27
<212>dna
<213>人工
<220>
<223>合成dna
<400>18
cagtatagcgaccagcattcacatacg27
<210>19
<211>48
<212>dna
<213>人工
<220>
<223>合成dna
<400>19
atagcatacattatacgaagttatcccacacaccatagcttcaaaatg48
<210>20
<211>37
<212>dna
<213>人工
<220>
<223>合成dna
<400>20
caccgaaatcttcatcccttagattagattgctatgc37
<210>21
<211>41
<212>dna
<213>人工
<220>
<223>合成dna
<400>21
gctggtcgctatactgcgtgatttacatatactacaagtcg41
<210>22
<211>48
<212>dna
<213>人工
<220>
<223>合成dna
<400>22
aaaaacataagacaaattaccctgttatccctatgaccggatgaaacc48
<210>23
<211>37
<212>dna
<213>人工
<220>
<223>合成dna
<400>23
gggataacagggtaatggtacccaattcgccctatag37
<210>24
<211>20
<212>dna
<213>人工
<220>
<223>合成dna
<400>24
taccgcacagatgcgtaagg20
<210>25
<211>44
<212>dna
<213>人工
<220>
<223>合成dna
<400>25
ttacgcatctgtgcggtaaggaatcatagtttcatgattttctg44
<210>26
<211>45
<212>dna
<213>人工
<220>
<223>合成dna
<400>26
caggatgacgcctaaaaagattctctttttttatgatatttgtac45
<210>27
<211>20
<212>dna
<213>人工
<220>
<223>合成dna
<400>27
ttaggcgtcatcctgtgctc20
<210>28
<211>35
<212>dna
<213>人工
<220>
<223>合成dna
<400>28
cacactaaattaataatgaagatttcggtgatccc35
<210>29
<211>33
<212>dna
<213>人工
<220>
<223>合成dna
<400>29
tattaatttagtgtgtgtatttgtgtttgtgtg33
<210>30
<211>40
<212>dna
<213>人工
<220>
<223>合成dna
<400>30
gcagattgtactgagagtacgacatcgtcgaatatgattc40
<210>31
<211>26
<212>dna
<213>人工
<220>
<223>合成dna
<400>31
actctcagtacaatctgctctgatgc26
<210>32
<211>38
<212>dna
<213>人工
<220>
<223>合成dna
<400>32
cggcttctaatccgtgctccagcttttgttccctttag38
<210>33
<211>48
<212>dna
<213>人工
<220>
<223>合成dna
<400>33
tcaaggagaaaaaaccagcatgtataacaaacactgatttttgttttg48
<210>34
<211>38
<212>dna
<213>人工
<220>
<223>合成dna
<400>34
cggcttctaatccgtgctccagcttttgttccctttag38
<210>35
<211>20
<212>dna
<213>人工
<220>
<223>合成dna
<400>35
acggattagaagccgccgag20
<210>36
<211>29
<212>dna
<213>人工
<220>
<223>合成dna
<400>36
ggttttttctccttgacgttaaagtatag29
<210>37
<211>26
<212>dna
<213>人工
<220>
<223>合成dna
<400>37
ttatcgatgataagctgtcaaagatg26
<210>38
<211>30
<212>dna
<213>人工
<220>
<223>合成dna
<400>38
tggttttttctccttgacgttaaagtatag30
<210>39
<211>26
<212>dna
<213>人工
<220>
<223>合成dna
<400>39
ttatcgatgataagctgtcaaagatg26
<210>40
<211>45
<212>dna
<213>人工
<220>
<223>合成dna
<400>40
tcggttagagcggatgtggggggagggcgtgaatgtaagcgtgac45
<210>41
<211>20
<212>dna
<213>人工
<220>
<223>合成dna
<400>41
atccgctctaaccgaaaagg20
<210>42
<211>22
<212>dna
<213>人工
<220>
<223>合成dna
<400>42
agcttgcaaattaaagccttcg22
<210>43
<211>58
<212>dna
<213>人工
<220>
<223>合成dna
<400>43
tttaatttgcaagcttttccacttattcaaccttttaatgagtcgggcaattccgaag58
<210>44
<211>57
<212>dna
<213>人工
<220>
<223>合成dna
<400>44
gcttatcatcgataataaaaggttgaataagtggaaatgaccggatgaaaccaccgg57
<210>45
<211>20
<212>dna
<213>人工
<220>
<223>合成dna
<400>45
acggattagaagccgccgag20
<210>46
<211>18
<212>dna
<213>人工
<220>
<223>合成dna
<400>46
tcatgcccctgagctgcg18
<210>47
<211>20
<212>dna
<213>人工
<220>
<223>合成dna
<400>47
gacatggaggcccagaatac20
<210>48
<211>27
<212>dna
<213>人工
<220>
<223>合成dna
<400>48
cagtatagcgaccagcattcacatacg27
<210>49
<211>26
<212>dna
<213>人工
<220>
<223>合成dna
<400>49
ttaagtgcgcagaaagtaatatcatg26
<210>50
<211>18
<212>dna
<213>人工
<220>
<223>合成dna
<400>50
tgaccggatgaaaccacc18
<210>51
<211>23
<212>dna
<213>人工
<220>
<223>合成dna
<400>51
ggtttcagatcacgatggataac23
<210>52
<211>21
<212>dna
<213>人工
<220>
<223>合成dna
<400>52
gcaacagtaaaagggatcagc21
- 还没有人留言评论。精彩留言会获得点赞!