用于测定序列的系统和方法与流程
用于测定序列的系统和方法
1.相关申请的交叉引用
2.本技术是2018年11月29日提交的标题为“sequencing by emergence”的美国专利申请第16/205,155号的部分连续申请,所述美国专利申请要求2017年11月29日提交的标题为“sequencing by emergence”的美国专利申请第62/591,850号的优先权,所述专利申请据此通过引用并入。
技术领域
3.本公开总体上涉及通过探针与一种或多种多核苷酸的瞬时结合对核酸进行测序的系统和方法。
背景技术:
4.dna测序首先通过基于凝胶电泳的方法:双脱氧链终止法(例如,sanger等人,proc.natl.acad.sci.74:5463-5467,1977)以及化学降解方法(例如,maxam等人,proc.natl.acad.sci.74:560-564,1977)成为现实。这些核苷酸测序方法既耗时又昂贵。然而,前者导致了人类基因组的首次测序,尽管花费了十多年和数亿美元。
5.随着个性化医疗保健的梦想越来越接近实现,人们越来越需要廉价的大规模方法来对个体人类基因组进行测序(mir,sequencing genomes:from individuals to populations,briefings in functional genomics and proteomics,8:367-378,2009)。几种避免凝胶电泳(并且随后价格更低)的测序方法已被发展为“下一代测序”。一种使用可逆终止子(如由illumina inc.实施的)的这样的测序方法占主导地位。sanger测序的最先进形式和目前占主导地位的illumina技术中使用的检测方法涉及荧光。检测单核苷酸插入的其它可能手段包括使用质子释放(例如,通过场效应晶体管、通过纳米孔的离子电流和电子显微镜)的检测。illumina化学包括使用可逆终止子循环添加核苷酸(canard等人,metzker nucleic acids research 22:4259-4267,1994),所述核苷酸具有荧光标记物(bentley等人,nature 456:53-59,2008)。illumina测序从克隆扩增单个基因组分子开始,需要大量前期样品处理来将靶基因组转化为文库,然后将所述文库克隆扩增成簇。
6.然而,有两种方法后来进入市场,在测序之前避开了对扩增的需要。这两种新方法都是在单分子dna上进行荧光合成测序(sbs)。第一种方法,来自helicosbio(现为seqll),通过可逆终止进行逐步sbs(harris等人,science,320:106-9,2008)。第二种方法(来自pacific biosciences的smrt测序法)在末端磷酸上使用标记物,一种掺入核苷酸的反应的天然离去基团,这使得可以连续进行测序,而不需要交换试剂。这种方法的缺点之一是通量低,因为检测器需要保持固定在一个视场上(例如,levene等人,science 299:682-686,2003和eid等人,science,323:133-8,2009)。与pacific bioscience测序的有点类似的方法是由genia(现为roche的一部分)开发的方法,通过纳米孔而不是通过光学方法检测sbs。
7.最常用的测序方法在读取长度上受到限制,这增加了测序的成本和组装读取结果的难度。通过sanger测序获得的读取长度在1000个碱基的范围内(例如,kchouk等人,
biol.med.9:395,2017)。roche 454测序和离子洪流(ion torrent)两者均具有在数百个碱基的范围内的读取长度。illumina测序最初以大约25个碱基的读数开始,现在通常为150-300个碱基对的读数。然而,由于需要为读取长度的每个碱基提供新鲜试剂,对250个碱基而不是25个碱基进行测序需要多10倍的时间和多10倍的昂贵试剂。最近,illumina仪器的标准读取长度已经减少到约150个碱基,大概是因为它们的技术受到定相(phasing)的影响(簇内分子不同步),随着读取时间的延长,会引入误差。
8.商业系统中可能的最长读取长度是通过oxford nanopores technology(ont)的纳米孔链测序和pacific bioscience(pacbio)测序(例如,kchouk等人,biol.med.9:395,2017)获得的。后者通常具有长度平均约10,000个碱基的读数,而前者在非常罕见的情况下能够获得长度为数十万个碱基的读数(例如,laver等人,biomol.det.quant.3:1-8,2015)。虽然这些较长的读取长度在比对方面是可取的,但它们是以牺牲准确性为代价的。准确度通常很低,因此对于大多数人类测序应用来说,这些方法只能作为illumina测序的补充,而不能作为独立的测序技术。此外,对于常规的人类基因组规模测序,现有的长读技术的通量太低。
9.除了ont和pacbio测序以外,还有存在许多本身不是测序技术而是样品制备方法的方法,它们补充了illumina短读取测序技术,为构建更长读取提供了一个支架。在这些方法当中,一种方法是由10x genomics开发的基于液滴的技术,所述技术将液滴中的100-200kb片段(例如,提取后片段的平均长度范围)分离出来,并将其加工成较短长度片段的文库,每个片段包含序列标识符标签,该标签对其所源自的100-200kb具有特异性,在对来自多个液滴的基因组进行测序时,所述标签可被去卷积成约50-200kb的桶(goodwin等人,nat.rev.genetics 17:333-351,2016)。另一种方法是由bionano genomics开发的,所述方法通过暴露于切刻核酸内切酶来拉伸并诱发dna中的切刻。该方法荧光检测切刻点,以提供分子的图谱或支架。这种方法目前还没有发展到有足够高的密度来帮助组装基因组,但其仍然提供了基因组的直接可视化,并且能够检测大的结构变异和确定长程单倍型(long-range haplotypes)。
10.尽管开发了不同的测序方法,而且测序成本呈普遍下降趋势,但人类基因组的大小仍然导致患者的测序成本居高不下。单个人的基因组由46条染色体组成,其中最短的为约50兆碱基,最长的为250兆碱基。ngs测序方法仍有许多影响性能的问题,包括对参考基因组的依赖,这可大大增加分析所需的时间(例如,如kulkarni等人,comput struct biotechnol j.15:471
–
477,2017中所论述的)。
11.鉴于上述背景,本领域需要的是用于提供独立测序技术的装置、系统和方法,所述独立测序技术在试剂和时间的使用方面是高效的,并且提供长时间的、单体型解析的读取而不损失准确性。
12.在背景技术部分中公开的信息仅仅是为了增强对一般背景的理解,并且不应该被认为是对该信息形成了本领域技术人员已知的现有技术的认可或任何形式的暗示。
技术实现要素:
13.本公开解决了本领域对用于提供改进的核酸测序技术的装置、系统和方法的需求。在一个宽泛的方面,本公开包括通过将分子探针与分子的一个或多个单元结合来鉴定
多单元分子的至少一个单元的方法。本公开基于一个或多个种类的分子探针与分子的单分子相互作用的检测。在一些实施方案中,探针与分子的至少一个单元瞬时结合。在一些实施方案中,探针与分子的至少一个单元反复结合。在一些实施方案中,分子实体以纳米级精度定位在大分子、表面或基质上。
14.一方面,本文公开了核酸测序的方法。该方法包括(a)将核酸以双链线性化拉伸形式固定在测试基板上,从而形成固定的拉伸双链核酸。该方法还包括(b)使固定的拉伸双链核酸在测试基板上变性为单链形式,从而获得核酸的固定的第一链和固定的第二链,其中固定的第二链的相应碱基与固定的第一链的相应互补碱基相邻。该方法通过(c)将固定的第一链和固定的第二链暴露于寡核苷酸探针组中的相应的寡核苷酸探针的相应库中而继续,其中该寡核苷酸探针组中的每个寡核苷酸探针具有预定的序列和长度。暴露(c)在允许相应的寡核苷酸探针的相应库中的单个探针与固定的第一链或固定的第二链的与所述相应的寡核苷酸探针互补的每个部分结合并形成相应的异源双链体的条件下发生,从而产生相应的光学活性实例。该方法继续进行(d):使用二维成像器测量在暴露(c)期间发生的每个相应的光学活性实例在测试基板上的位置和持续时间。然后,该方法通过(e)对该寡核苷酸探针组中的相应的寡核苷酸探针重复暴露(c)和测量(d)来进行,从而获得测试基板上的多组位置。测试基板上的每组相应位置对应于该寡核苷酸探针组中的一个寡核苷酸探针。该方法还包括(f)通过汇编由多组位置代表的测试基板上的位置,确定来自测试基板上的多组位置的核酸的至少一部分的序列。
15.在一些实施方案中,暴露(c)在允许相应的寡核苷酸探针的相应库中的单个探针与固定的第一链或固定的第二链的与所述单个探针互补的每个部分瞬时地且可逆地结合并形成相应的异源双链体的条件下发生,从而产生相应的光学活性实例。在一些实施方案中,暴露(c)在允许相应的寡核苷酸探针的相应库中的单个探针与固定的第一链或固定的第二链的与所述单个探针互补的每个部分瞬时地且可逆地结合并形成相应的异源双链体的条件下发生,从而重复产生相应的光学活性实例。在一些此类实施方案中,所述寡核苷酸探针组中的每个寡核苷酸探针与标记物(例如,染料、荧光纳米颗粒或光散射颗粒)结合。
16.在一些实施方案中,权利要求1的方法,所述暴露是在呈嵌入染料形式的第一标记物存在的情况下进行的,所述寡核苷酸探针组中的每个寡核苷酸探针与第二标记物结合,第一标记物与第二标记物具有重叠的供体发射光谱和受体激发光谱,当第一标记物和第二标记物彼此紧邻时,导致第一标记物和第二标记物之一发出荧光,并且相应的光学活性实例来自嵌入染料与第二标记物的接近,所述嵌入染料嵌入寡核苷酸与固定的第一链或固定的第二链之间的相应异源双链体。
17.在一些实施方案中,所述暴露是在呈嵌入染料形式的第一标记物存在的情况下进行的,所述寡核苷酸探针组中的每个寡核苷酸探针与第二标记物结合,当第一标记物与第二标记物彼此紧邻时,第一标记物使第二标记物发出荧光,并且相应的光学活性实例来自嵌入染料(其嵌入寡核苷酸与固定的第一链或固定的第二链之间的相应异源双链体)与第二标记物的接近。
18.在一些实施方案中,所述暴露是在呈嵌入染料形式的第一标记物存在的情况下进行的,所述寡核苷酸探针组中的每个寡核苷酸探针与第二标记物结合,当第一标记物与第二标记物彼此紧邻时,第二标记物使第一标记物发出荧光,并且相应的光学活性实例来自
嵌入染料(其嵌入寡核苷酸与固定的第一链或固定的第二链之间的相应异源双链体)与第二标记物的接近。
19.在一些实施方案中,所述暴露是在嵌入染料存在的情况下,并且相应的光学活性实例来自嵌入寡核苷酸与固定的第一链或固定的第二链之间的相应异源双链体的嵌入染料的荧光。在此类实施方案中,相应的光学活性实例大于嵌入染料在其嵌入相应的异源双链体之前的荧光。
20.在一些实施方案中,在暴露(c)的单个实例期间中,将所述寡核苷酸探针组中的多于一个寡核苷酸探针暴露于固定的第一链和固定的第二链,并且在暴露(c)的单个实例期间中暴露于固定的第一链和固定的第二链的所述寡核苷酸探针组中的每个不同的寡核苷酸探针与不同的标记物缔合。在一些此类实施方案中,在暴露(c)的单个实例期间中,将所述寡核苷酸探针组中的第一寡核苷酸探针的第一库(第一寡核苷酸探针与第一标记物缔合)暴露于固定的第一链和固定的第二链,在暴露(c)的单个实例期间中,将所述寡核苷酸探针组中的第二寡核苷酸探针的第二库(第二寡核苷酸探针与第二标记物缔合)暴露于固定的第一链和固定的第二链,并且第一标记物与第二标记物不同。或者,在暴露(c)的单个实例期间中,将所述寡核苷酸探针组中的第一寡核苷酸探针的第一库(第一寡核苷酸探针与第一标记物缔合)暴露于固定的第一链和固定的第二链,在暴露(c)的单个实例期间中,将所述寡核苷酸探针组中的第二寡核苷酸探针的第二库(第二寡核苷酸探针与第二标记物缔合)暴露于固定的第一链和固定的第二链,在暴露(c)的单个实例期间中,将所述寡核苷酸探针组中的第三寡核苷酸探针的第三库(第三寡核苷酸探针与第三标记物缔合)暴露于固定的第一链和固定的第二链,并且第一标记物、第二标记物和第三标记物各不相同。
21.在一些实施方案中,对所述寡核苷酸探针组中的每个单个寡核苷酸探针各自进行重复(e)、暴露(c)和测量(d)。
22.在一些实施方案中,在第一温度下对所述寡核苷酸探针组中的第一寡核苷酸探针进行暴露(c),并且重复(e)、暴露(c)和测量(d)包括在第二温度下对第一寡核苷酸进行暴露(c)和测量(d)。
23.在一些实施方案中,在第一温度下对所述寡核苷酸探针组中的第一寡核苷酸探针进行暴露(c),(e)重复暴露(c)和测量(d)的实例包括在多个不同温度中的每个温度下对第一寡核苷酸进行暴露(c)和测量(d),并且该方法还包括使用由针对第一温度和多个不同温度中的每个温度进行的测量(d)而记录的光学活性的测量的位置和持续时间来构建第一寡核苷酸探针的解链曲线。
24.在一些实施方案中,所述寡核苷酸探针组包含多个所述寡核苷酸探针亚组,并且对多个寡核苷酸探针亚组中的每个相应的寡核苷酸探针亚组进行重复(e)、暴露(c)和测量(d)。在一些此类实施方案中,每个相应的寡核苷酸探针亚组包含来自所述寡核苷酸探针组的两种或更多种不同的探针。或者,每个相应的寡核苷酸探针亚组包含来自所述寡核苷酸探针组的4种或更多种不同的探针。在一些此类实施方案中,所述寡核苷酸探针组由四个寡核苷酸探针亚组组成。在一些实施方案中,该方法还包括基于每个寡核苷酸探针的计算的或实验推导的解链温度将所述寡核苷酸探针组划分成多个寡核苷酸探针亚组,其中通过划分将具有相似解链温度的寡核苷酸探针置于相同的寡核苷酸探针亚组中,并且其中暴露(c)的实例的温度或持续时间由相应的寡核苷酸探针亚组中的寡核苷酸探针的平均解链温
度确定。更进一步地,在一些实施方案中,该方法还包括基于每个寡核苷酸探针的序列将所述寡核苷酸探针组分成多个寡核苷酸探针亚组,其中将具有重叠序列的寡核苷酸探针置于不同的亚组中。
25.在一些实施方案中,测量测试基板上的位置包括用拟合函数鉴定和拟合相应的光学活性实例,以鉴定和拟合通过二维成像器获得的数据帧中的相应的光学活性实例的中心,并且相应的光学活性实例的中心被认为是相应的光学活性实例在测试基板上的位置。在一些此类实施方案中,拟合函数是高斯函数、第一矩函数、基于梯度的方法或傅立叶变换。
26.在一些实施方案中,相应的光学活性实例在多个通过二维成像器测量的帧上持续存在,测量测试基板上的位置包括用拟合函数在多个帧上鉴定和拟合相应的光学活性实例,以在多个帧上鉴定相应的光学活性实例的中心,并且相应的光学活性实例的中心被认为是多个帧上相应的光学活性实例在测试基板上的位置。在一些此类实施方案中,拟合函数是高斯函数、第一矩函数、基于梯度的方法或傅立叶变换。
27.在一些实施方案中,测量测试基板上的位置包括将通过二维成像器测量的数据帧输入到经训练的卷积神经网络中,该数据帧包括多个光学活性实例中的相应的光学活性实例,多个光学活性实例中的每个光学活性实例对应于结合到固定的第一链或固定的第二链的一部分的单个探针,并且响应于该输入,经训练的卷积神经网络鉴定多个光学活性实例中的一个或多个光学活性实例的每一个在测试基板上的位置。
28.在一些实施方案中,测量以至少20nm、至少2nm、至少60nm或至少6nm的定位精度将相应的光学活性实例的中心解析为测试基板上的位置。
29.在一些实施方案中,测量将相应的光学活性实例的中心解析为测试基板上的位置,其中该位置是亚衍射极限位置。
30.在一些实施方案中,测量(d)相应的光学活性实例在测试基板上的位置和持续时间测量该位置处超过5000个光子,测量该位置处超过50,000个光子,或者测量该位置处超过200,000个光子。
31.在一些实施方案中,相应的光学活性实例比对于测试基板观察到的背景高出预定数量的标准偏差(例如,超过3、4、5、6、7、8、9或10个标准偏差)。
32.在一些实施方案中,多个寡核苷酸探针中的每个相应的寡核苷酸探针包含独特的n聚体序列,其中n是集合{1,2,3,4,5,6,7,8和9}中的整数,并且其中所有长度为n的独特n聚体序列由多个寡核苷酸探针表示。在一些此类实施方案中,独特的n聚体序列包含被一个或多个简并核苷酸占据的一个或多个核苷酸位置。在一些此类实施方案中,一个或多个核苷酸位置中的每个简并核苷酸位置被通用碱基(例如,2
′‑
脱氧肌苷)占据。在一些此类实施方案中,独特的n-聚体序列的5’侧是单个简并核苷酸位置,并且3’侧是单个简并核苷酸位置。或者,5’单个简并核苷酸和3’单个简并核苷酸各自为2
’‑
脱氧肌苷。
33.在一些实施方案中,核酸的长度为至少140个碱基,并且确定(f)确定核酸序列的序列覆盖度大于70%。在一些实施方案中,核酸的长度为至少140个碱基,并且确定(f)确定核酸序列的序列覆盖度大于90%。在一些实施方案中,核酸的长度为至少140个碱基,并且确定(f)确定核酸序列的序列覆盖度大于99%。在一些实施方案中,确定(f)确定核酸序列的序列覆盖度大于99%。
34.在一些实施方案中,核酸的长度为至少10,000个碱基或为至少1,000,000个碱基。
35.在一些实施方案中,在重复暴露(c)和测量(d)之前,洗涤测试基板,从而在将测试基板暴露于所述寡核苷酸探针组中的另一个寡核苷酸探针之前,从测试基板移除相应的寡核苷酸探针。
36.在一些实施方案中,固定(a)包括通过分子梳理(后退弯月面)、流动拉伸纳米约束(flow stretching nanoconfinement)或电拉伸(electro-stretching)将所述核酸施加到测试基板。
37.在一些实施方案中,每个相应的光学活性实例具有满足预定阈值的观察度量。在一些此类实施方案中,观察度量包括持续时间、信噪比、光子计数或强度。在一些实施方案中,预定阈值区分(i)第一结合形式和(ii)第二结合形式,在所述第一结合形式中独特的n聚体序列的每个残基与核酸的固定的第一链或固定的第二链中的互补碱基结合,在所述第二结合形式中独特的n聚体序列与核酸的固定的第一链或固定的第二链中的序列之间存在至少一个错配,相应的寡核苷酸探针已与核酸的所述固定的第一链或所述固定的第二链中的序列结合以形成相应的光学活性实例。
38.在一些实施方案中,所述寡核苷酸探针组中的每个相应的寡核苷酸探针都具有其自己相应的预定阈值。在一些此类实施方案中,所述寡核苷酸探针组中的每个相应的寡核苷酸探针的预定阈值源自训练数据集。例如,在一些实施方案中,所述寡核苷酸探针组中的每个相应的寡核苷酸探针的预定阈值源自训练数据集,并且对于所述寡核苷酸探针组中的每个相应的寡核苷酸探针,所述训练集包括对在与参考序列结合时相应的寡核苷酸探针的观察度量的测量值,与参考序列的结合使得所述相应的寡核苷酸探针的独特n聚体序列的每个残基与参考序列中的互补碱基结合。在一些此类实施方案中,将参考序列固定在参考基板上。或者,将参考序列包含所述核酸中并固定在测试基板上。在一些实施方案中,参考序列包含phix174、m13、λ噬菌体、t7噬菌体或大肠杆菌、酿酒酵母或粟酒裂殖酵母的基因组的全部或一部分。在一些实施方案中,参考序列是已知序列的合成构建体。在一些实施方案中,参考序列包含兔珠蛋白rna的全部或一部分。
39.在一些实施方案中,所述寡核苷酸探针组中的相应的寡核苷酸探针通过与固定的第一链的互补部分结合而产生第一光学活性实例,通过与固定的第二链的互补部分结合而产生第二光学活性实例。
40.在一些实施方案中,所述寡核苷酸探针组中的相应的寡核苷酸探针通过与固定的第一链的两个或更多个互补部分结合而产生两个或更多个第一光学活性实例,且通过与固定的第二链的两个或更多个互补部分结合而产生两个或更多个第二光学活性实例。
41.在一些实施方案中,相应的寡核苷酸探针在暴露(c)过程中与固定的第一链或固定的第二链的与所述相应的寡核苷酸探针互补的部分结合3次或更多次,从而产生3个或更多个光学活性实例,每个光学活性实例代表多个结合事件中的一个结合事件。
42.在一些实施方案中,相应的寡核苷酸探针在暴露(c)过程中与固定的第一链或固定的第二链的与所述相应的寡核苷酸探针互补的部分结合5次或更多次,从而产生5个或更多个光学活性实例,每个光学活性实例代表多个结合事件中的一个结合事件。
43.在一些实施方案中,相应的寡核苷酸探针在暴露(c)过程中与固定的第一链或固定的第二链的与所述相应的寡核苷酸探针互补的部分结合10次或更多次,从而产生10个或
更多个光学活性实例,每个光学活性实例代表多个结合事件中的一个结合事件。
44.在一些实施方案中,暴露(c)发生五分钟或更短时间,两分钟或更短时间,或一分钟或更短时间。
45.在一些实施方案中,暴露(c)发生在二维成像器的一个或多个帧、二维成像器的两个或更多个帧、二维成像器的500个或更多个帧或者二维成像器的5,000个或更多个帧上。
46.在一些实施方案中,对所述寡核苷酸探针组中的第一寡核苷酸探针进行暴露(c)持续第一时间段,所述重复(e)、所述暴露(c)和所述测量(d)包括对第二寡核苷酸进行所述暴露(c)持续第二时间段,并且所述第一时间段长于所述第二时间段。
47.在一些实施方案中,对所述寡核苷酸探针组中的第一寡核苷酸探针进行暴露(c)持续二维成像器的第一帧数,重复(e)、暴露(c)和测量(d)包括对第二寡核苷酸进行暴露(c)持续二维成像器的第二帧数,并且所述第一帧数大于所述第二帧数。
48.在一些实施方案中,所述寡核苷酸探针组中的每个寡核苷酸探针都具有相同的长度。
49.在一些实施方案中,所述寡核苷酸探针组中的每个寡核苷酸探针具有相同的长度m,m为2或更大的正整数(例如,m为2、3、4、5、6、7、8、9、10或大于10),并且确定(f)来自测试基板上的多组位置的核酸的至少一部分的序列还使用由多组位置表示的寡核苷酸探针的重叠序列。在一些此类实施方案中,所述寡核苷酸探针组中的每个寡核苷酸探针与该寡核苷酸探针组中的另一个寡核苷酸探针共享m-1序列同源性。在一些此类实施方案中,确定来自测试基板上的多组位置的核酸的至少一部分的序列,包括确定对应于固定的第一链的第一覆瓦式途径(tiling path)和对应于固定的第二链的第二覆瓦式途径。在一些此类实施方案中,使用第二平覆瓦式途径的相应部分来解决第一覆瓦式途径中的中断。或者,使用参考序列解决第一覆瓦式途径或第二覆瓦式途径中的中断。或者,使用从核酸的另一实例获得的第三覆瓦式途径或第四覆瓦式途径的相应部分来解决第一覆瓦式途径或第二覆瓦式途径中的中断。在一些此类实施方案中,使用第一覆瓦式途径和第二覆瓦式途径的相应部分来增加序列的序列分配的可信度。或者,使用从核酸的另一实例获得的第三覆瓦式途径或第四覆瓦式途径的相应部分来增加序列的序列分配的可信度。
50.在一些实施方案中,暴露(c)的实例的时间长度由暴露(c)的实例中使用的寡核苷酸探针组中相应的寡核苷酸探针的估计的解链温度确定。
51.在一些实施方案中,所述方法还包括(f)将固定的双链或固定的第一链和固定的第二链暴露于抗体、亲和体(affimer)、纳米抗体(nanobody)、适体或甲基结合蛋白,从而确定对核酸的修饰或与来自测试基板上的多组位置的核酸的一部分的序列相关联。
52.在一些实施方案中,测试基板是二维表面。在一些此类实施方案中,二维表面涂覆有凝胶或基质。
53.在一些实施方案中,测试基板是细胞、三维基本原理质或凝胶。
54.在一些实施方案中,在固定(a)之前,测试基板与序列特异性寡核苷酸探针结合,并且固定(a)包括使用与测试基板结合的序列特异性寡核苷酸探针捕获测试基板上的核酸。
55.在一些实施方案中,核酸在包含另外的多种细胞组分的溶液中,并且固定(a)或变性(b)还包括在核酸已被固定到测试基板上之后并且在暴露(c)之前洗涤测试基板,从而从
核酸中纯化出另外的多种细胞组分。
56.在一些实施方案中,在暴露(c)之前,用聚乙二醇、牛血清白蛋白-生物素-链霉抗生物素蛋白、酪蛋白、牛血清白蛋白(bsa)、一种或多种不同的trna、一种或多种不同的脱氧核糖核苷酸、一种或多种不同的核糖核苷酸、鲑鱼精dna、pluronic f-127、吐温-20、氢硅倍半氧烷(hydrogen silsesquioxane)(hsq)或其任何组合对测试基板进行钝化。
57.在一些实施方案中,在固定(a)之前,用包含7-辛烯基三氯硅烷的乙烯基硅烷涂层涂覆测试基板。
58.本公开的另一方面提供了核酸测序的方法,其包括(a)将核酸以线性化拉伸形式固定在测试基板上,从而形成固定的拉伸核酸,(b)将固定的拉伸核酸暴露于寡核苷酸探针组中的相应的寡核苷酸探针的相应库中,其中所述寡核苷酸探针组中的每个寡核苷酸探针具有预定的序列和长度,所述暴露(b)在允许相应的寡核苷酸探针的相应库中的单个探针瞬时且可逆地与所述固定的核酸的与所述相应的寡核苷酸探针互补的每个部分瞬时且可逆地结合的条件下发生,从而产生相应的光学活性实例,(c)使用二维成像器测量在暴露(b)期间发生的每个相应的光学活性实例在测试基板上的位置和持续时间,(d)对所述寡核苷酸探针组中的相应的寡核苷酸探针重复暴露(b)和测量(c),从而获得测试基板上的多组位置,测试基板上的每个相应组的位置对应于所述寡核苷酸探针组中的寡核苷酸探针,以及(e)通过汇编由多组位置代表的测试基板上的位置,确定来自测试基板上的多组位置的核酸的至少一部分的序列。在一些此类实施方案中,核酸是双链核酸,并且该方法还包括使固定的双链核酸在测试基板上变性为单链形式,从而获得核酸的固定的第一链和固定的第二链,其中所述固定的第二链与所述固定的第一链互补。在一些实施方案中,核酸是单链rna。
59.本公开的另一方面提供了分析核酸的方法,所述方法包括(a)将核酸以双链形式固定在测试基板上,从而形成固定的双链核酸,(b)使固定的双链核酸在测试基板上变性为单链形式,从而获得核酸的固定的第一链和固定的第二链,其中所述固定的第二链与所述固定的第一链互补,以及(c)将固定的第一链和固定的第二链暴露于一种或多种寡核苷酸探针,并确定所述一种或多种寡核苷酸探针与固定的第一链结合还是与固定的第二链结合。
60.本公开的另一方面提供了确定来自物种的受试者的核酸的至少一部分的序列的方法。该方法包括a)以电子形式获得包括一个或多个图像文件的数据集;b)对于一个或多个图像文件中的每个图像文件,至少部分基于每个相应的多个荧光团定位确定组合的多个定位;c)将多个定位分段成一个或多个靶聚合物链;以及d)使用每个相应的靶聚合物链的每个定位子集组装相应的靶聚合物序列,从而提供一组靶聚合物序列。组合的多个定位中的每个定位包括靶聚合物位置标识和空间定位。每个靶聚合物链对应于来自多个定位的相应的定位子集和靶聚合物位置标识的相应子集。
61.在一些实施方案中,所述确定(b)还包括将一个或多个图像文件应用于图像处理模型。图像处理模型i)根据预定比对标准比对一个或多个图像文件;ii)对于一个或多个图像文件中的每个图像文件,确定相应的多个荧光团;以及iii)对于一个或多个图像文件中的每个相应的图像文件,通过汇编多个荧光团来输出组合的多个定位。每个荧光团的相应空间定位至少部分基于一个或多个点扩展函数。
62.在一些实施方案中,所述分段(c)还包括将组合的多个定位应用于分段模型。分段模型i)至少部分基于组合的多个定位中的每个定位的相应空间定位来确定一个或多个定位子集;以及ii)将相应的曲线与每个定位子集拟合,从而获得一条或多条拟合曲线。每条拟合曲线包括沿着相应的拟合曲线的相应的荧光团子集中的每个荧光团的定位。
63.在一些实施方案中,重复分段(c)至少一次。
64.在一些实施方案中,组装(d)还包括确定每个相应的靶聚合物序列的相应概率。
65.在一些实施方案中,所述方法还包括e)通过将每个相应的靶聚合物序列与靶聚合物序列的组中的每隔一个靶聚合物序列进行比较来确定组合的靶聚合物序列。
66.在一些实施方案中,组装(d)还包括,对于每个靶聚合物链,将相应的定位子集应用于优化模型以获得所述相应的靶聚合物序列。
67.在一些实施方案中,靶聚合物包括核酸。
68.在一些实施方案中,每个靶聚合物位置标识对应于核酸碱基。
69.附图简述
70.图1a和1b共同示出了示例性的系统拓扑结构,其包括具有参与结合事件的多个探针的聚合物、用于收集和存储与结合事件的定位和序列鉴定相关的信息并随后根据本公开的各种实施方案进一步执行分析以确定聚合物序列的计算机存储介质。
71.图2a和图2b共同提供了根据本公开的各种实施方案的用于确定靶聚合物的序列和/或结构特征的方法的过程和特征的流程图。
72.图3提供了根据本公开的各种实施方案的用于确定靶聚合物的序列和/或结构特征的另外方法的过程和特征的流程图。
73.图4提供了根据本公开的各种实施方案的用于确定靶聚合物的序列和/或结构特征的另外方法的过程和特征的流程图。
74.图5a、图5b和图5c共同示出了根据本公开的各种实施方案的探针与多核苷酸的瞬时结合的实例。
75.图6a和图6b共同示出了根据本公开的各种实施方案的具有长度不同的k聚体的探针与靶多核苷酸的结合的实例。
76.图7a、图7b和图7c共同示出了根据本公开的各种实施方案的使用具有寡核苷酸组的连续循环的参考寡核苷酸的实例。
77.图8a、图8b和图8c共同示出了根据本公开的各种实施方案的将不同的探针组应用于单个参考分子的实例。
78.图9a、图9b和图9c共同示出了根据本公开的各种实施方案的在使用多种类型探针的情况下的瞬时结合的实例。
79.图10a和图10b共同示出了根据本公开的各种实施方案的实例,即所收集的瞬时结合事件的数量与可实现的探针的定位程度相关联。
80.图11a和图11b共同示出了根据本公开的各种实施方案的覆瓦式探针(tiling probes)的实例。
81.图12a、图12b和图12c共同示出了根据本公开的各种实施方案的直接标记的探针的瞬时结合的实例。
82.图13a、图13b和图13c共同示出了根据本公开的各种实施方案的在嵌入染料存在
的情况下瞬时探针结合的实例。
83.图14a、图14b、图14c、图14d和图14e共同示出了根据本公开的各种实施方案的不同探针标记技术的实例。
84.图15示出了根据本公开的各种实施方式的探针在变性的、梳理双链dna上的瞬时结合的实例。
85.图16a和图16b共同示出了根据本公开的各种实施方案的细胞裂解以及核酸固着(immobilization)和伸长的实例。
86.图17示出了根据本公开的各种实施方案的示例性微流控体系结构,所述微流控体系结构捕获单个细胞,并任选地提供核酸从细胞中的提取、核酸的伸长和核酸的测序。
87.图18示出了根据本公开的各种实施方案的向单个细胞提供不同的id标签的示例性微流控体系结构。
88.图19示出了根据本公开的各种实施方案的对来自单个细胞的多核苷酸进行测序的实例。
89.图20a和图20b共同示出了根据本公开的各种实施方案的用于对瞬时探针结合成像的示例性器件布局。
90.图21示出了根据本公开的各种实施方案的包含被气隙分隔的试剂的示例性毛细管道。
91.图22a、图22b、图22c、图22d和图22e共同示出了根据本公开的各种实施方案的荧光的实例。
92.图23a、图23b和图23c共同示出了根据本公开的各种实施方案的荧光的实例。
93.图24示出了根据本公开的各种实施方式的合成变性双链dna上的瞬时结合。
94.图25a和图25b共同提供了根据本公开的各种实施方案的用于确定靶聚合物的至少一部分的序列的方法的过程和特征的流程图。
具体实施方式
95.现将详细地参考实施方案,其实例在附图中示出。在以下详细描述中,阐述了许多具体细节,以便提供对本公开的透彻理解。然而,对于本领域的普通技术人员来说显而易见的是,可在没有这些具体细节的情况下实施本公开。在其它情况下,没有详细描述公知的方法、程序、组件、电路和网络,以免不必要地模糊实施方案的各个方面。
96.定义
97.本公开中使用的术语学仅用于描述特定实施方案的目的,并不旨在限制本发明。如说明书和所附权利要求书中所使用的,除非上下文另有明确指示,否则单数形式“一个/种(a)”、“一个/种(an)”和“该(the)”旨在包括复数形式。还应当理解,如本文中所用,术语“和/或”是指并且涵盖相关列出项目中的一个或多个项目的任何和所有可能的组合。还应当理解,当在本说明书中使用时,术语“包括”和/或“包含”指定所陈述的特征、整数、步骤、操作、元件和/或组件的存在,但不排除一个或多个其它特征、整数、步骤、操作、元件、组件和/或其组合的存在或添加。
98.如本文中所用,取决于上下文,术语“如果(if)”可被解释为表示“当......时”或“根据”或“响应于确定”或“响应于检测”。类似地,短语“如果确定了”或“如果检测到[规定
的条件或事件]”可被解释为意指“根据确定”或“响应于确定”或“根据检测到[规定的条件或事件]”或“响应于检测到[规定的条件或事件]”,这取决于上下文。
[0099]
术语“或”旨在表示包含性的“或”,而不是排他性的“或”。也就是说,除非另有说明,或者根据上下文很清楚,短语“x使用a或b”旨在表示任何自然的包含性排列。也就是说,下列任何一种情况均满足短语“x使用a或b”:x采用a;x采用b;或x同时采用a和b。另外,除非另有说明或从上下文中清楚得知,否则如本技术和所附权利要求书中所使用的冠词“一个/种(a)”和“一个/种(an)”通常应被解释为表示“一个或多个”。
[0100]
还应当理解,尽管术语第一、第二等可在本文中用来描述各种元件,但是这些元件不应受这些术语限制。这些术语只用于区分一个元件与另一元件。例如,在不脱离本公开的范围的情况下,第一过滤器可以被称为第二过滤器,类似地,第二过滤器可以被称为第一过滤器。第一个过滤器和第二个过滤器都是过滤器,但它们不是同一种过滤器。
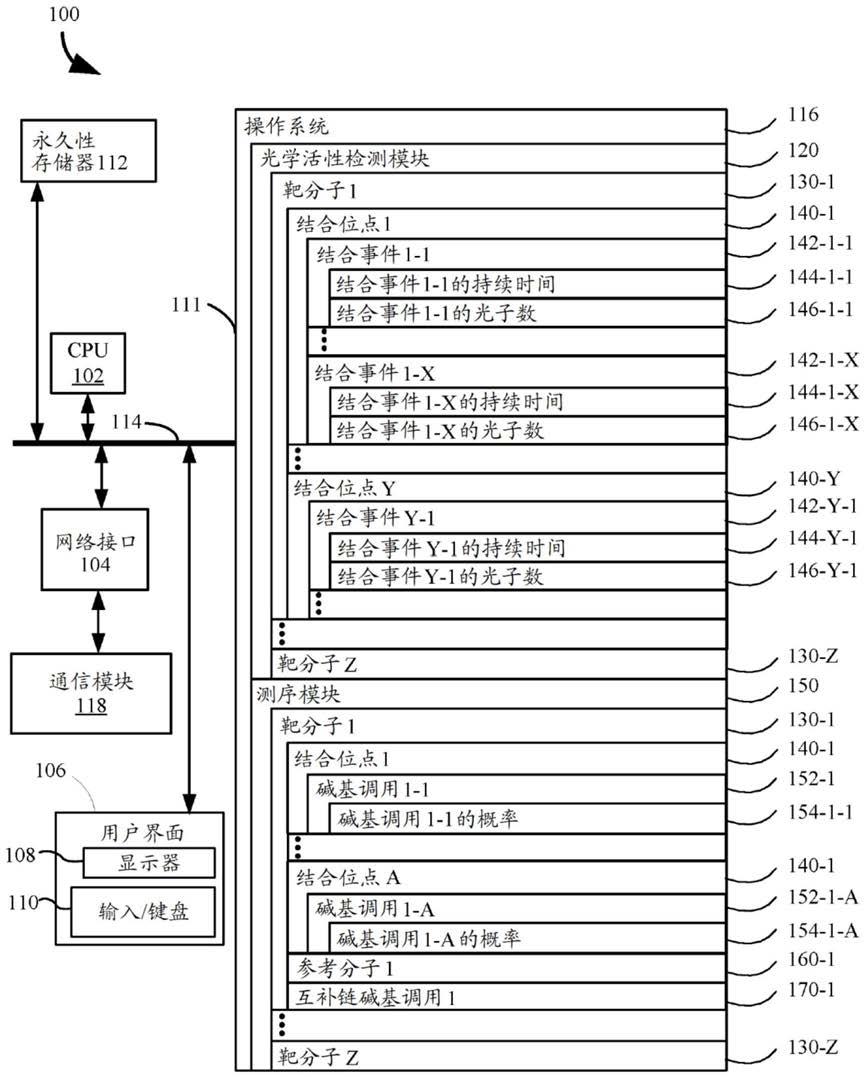
[0101]
术语“约”或“大约”指在由本领域的普通技术人员定义的特殊值的可接受误差范围内,这可部分取决于如何测量或测定该值,例如,测量系统的限制。例如,“约”可指本领域每次实践中,在1个或1个以上的标准偏差内。“约”可以表示给定值的
±
20%、
±
10%、
±
5%或
±
1%的范围。术语“约”或“大约”可表示在数值的数量级内,优选地在5倍内,更优选地在2倍内。当在本技术和权利要求书中描述特定数值时,除非另外指明,否则应假设术语“约”对特定数值表示在可接受的误差范围内。术语“约”可具有与本领域普通技术人员通常理解相同的含义。术语“约”可以指
±
10%。术语“约”可以指
±
5%。
[0102]
如本文中所用,术语“核酸”、“核酸分子”和“多核苷酸”可互换使用。该术语指具有任何组成形式的核酸,诸如脱氧核糖核酸(dna,例如,互补dna(cdna)、基因组dna(gdna)等)、核糖核酸(rna,例如,信使rna(mrna)、短抑制rna(sirna)、核糖体rna(rrna)、转运rna(trna)、微rna、胎儿或胎盘高度表达的rna等)和/或dna或rna类似物(例如,含有碱基类似物、糖类似物和/或非天然骨架等)、rna/dna杂交体和聚酰胺核酸(pna),它们都可以是单链或双链形式。除非另有限制,否则核酸可包含天然核苷酸的已知类似物,其中一些可以以与天然存在的核苷酸相似的方式起作用。核酸可以呈可用于进行本文中的方法的任何形式(例如,线性、环形、超螺旋、单链、双链等)。在一些情况下,核酸是或来自质粒、噬菌体、自主复制序列(ars)、着丝粒、人工染色体、染色体或在某些实施方案中其它能够在体外或在宿主细胞、细胞、细胞的细胞核或细胞质中复制或被复制的核酸。在一些实施方案中,核酸可来自单个染色体或其片段(例如,来自从二倍体生物获得的样品的一条染色体的核酸样品)。核酸分子可包含天然多核苷酸的全长(例如,长的非编码(lnc)rna、mrna、染色体、线粒体dna或多核苷酸片段)。多核苷酸片段的长度应该为至少200个碱基,但优选长度为至少几千个核苷酸。甚至更优选地,在基因组dna的情况下,多核苷酸片段的长度为数百千碱基至数兆碱基。
[0103]
在某些实施方案中,核酸包括核小体、核小体的片段或部分或核小体样结构。核酸有时包含蛋白质(例如,组蛋白、dna结合蛋白等)。通过本文所述方法分析的核酸有时基本上是分离的,并且基本上不与蛋白质或其它分子缔合。核酸还包括从单链(“有义”或“反义”、“正”链或“负”链、“正向”阅读框或“反向”阅读框)和双链多核苷酸合成、复制或扩增的rna或dna的衍生物、变体和类似物。脱氧核糖核苷酸包括脱氧腺苷、脱氧胞苷、脱氧鸟苷和脱氧胸苷。对于rna,碱基胞嘧啶被尿嘧啶取代,糖的2’位包括羟基部分。在一些实施方案
中,使用从受试者获得的核酸作为模板制备核酸。
[0104]
如本文中所用,术语“结束位置”或“末端位置”(或仅“末端”)可指无细胞dna分子(例如血浆dna分子)的最外碱基(例如在终端)的基因组坐标或基因组身份或核苷酸身份。末端位置可以对应于dna分子的任一末端。这样,如果一个指的是dna分子的起点和终点,则两者都可以对应结束位置。在一些实施方案中,一个末端位置是通过分析方法检测或确定的无细胞dna分子的一个终端上的最外碱基的基因组坐标或核苷酸身份,所述分析方法是例如大规模平行测序或下一代测序、单分子测序、双链或单链dna测序文库制备方案、聚合酶链式反应(pcr)或微阵列。在一些实施方案中,此类体外技术可以改变无细胞dna分子的一个或多个真实体内物理末端。因此,每个可检测的末端可代表生物学上的真实末端,或者该末端是例如通过klenow片段对非平端双链dna分子的悬突的5’平端化和3’填充从分子的原始末端向内的一个或多个核苷酸,或者是从分子的原始末端延伸的一个或多个核苷酸。末端位置的基因组身份或基因组坐标可以从序列读数与人类参考基因组(例如,hg19)的比对结果导出。其可从代表人类基因组的原始坐标的索引或代码目录中导出。其可指无细胞dna分子上的位置或核苷酸身份,所述位置或核苷酸身份通过但不限于靶特异性探针、微测序、dna扩增来读取。术语“基因组位置”可指多核苷酸(例如,基因、质粒、核酸片段、病毒dna片段)中的核苷酸位置。术语“基因组位置”不限于基因组(例如,配子或微生物中的单倍体染色体组,或多细胞生物的每个细胞中的单倍体染色体组)中的核苷酸位置。
[0105]
如本文中所用,术语“突变”、“单核苷酸变体”、“单核苷酸多态性”和“变体”是指一个或多个细胞的遗传物质中的可检测的变化。在特定的实例中,一个或多个突变可发现于癌细胞中,并且可鉴定癌细胞(例如,驱动突变和过客突变)。突变可以从亲代细胞传递到子细胞。本领域技术人员将理解,亲代细胞中的遗传突变(例如,驱动突变)可在子代细胞中诱导另外的不同突变(例如,过客突变)。突变或变体通常发生在核酸中。在特定的实例中,突变可以是一个或多个脱氧核糖核酸或其片段中的可检测的变化。突变通常是指在核酸中被添加、删除、取代、倒位或转位到新的位置的核苷酸。突变可以是自发突变或实验诱导的突变。特定组织的序列中的突变是“组织特异性等位基因”的实例。例如,肿瘤可具有在基因座中导致在正常细胞中不存在的等位基因的突变。“组织特异性等位基因”的另一个实例是存在于胎儿组织中但不存在于母体组织中的胎儿特异性等位基因。术语“等位基因”在一些情况下可以与突变互换使用。
[0106]
术语“瞬时结合”意指结合试剂或探针与多核苷酸上的结合位点可逆地结合,并且探针通常不保持附着于其结合位点。这在分析过程中提供了关于结合位点位置的有用信息。通常,一种试剂或探针与固着的聚合物结合,然后在一段停留时间后从聚合物上脱离。然后同一种或另一种试剂或探针将在另一个位点与聚合物结合。在一些实施方案中,沿着聚合物的多个结合位点也同时被多个试剂或探针结合。在一些情况下,不同的探针与重叠的结合位点结合。试剂或探针可逆地与聚合物结合的过程在分析过程中重复多次。此类结合事件的位置、频率、停留时间、光子发射最终产生聚合物的化学结构图谱。事实上,这些结合事件的瞬时性质使得能够检测到数量增加的此类结合事件。因为,如果探针长时间保持结合,那么每个探针都会抑制其它探针的结合。
[0107]
术语“重复结合”意指在分析过程中,聚合物中相同的结合位点被相同的结合试剂或探针或相同种类的结合试剂或探针多次结合。通常,一种试剂与位点结合然后解离,另一
种试剂结合然后解离,等等,直至绘制出聚合物的图谱。重复结合增加了从探针获得的信息的灵敏度和准确性。积累了更多的光子,多个独立的结合事件增加了检测到真实信号的概率。在当仅检测到一次时信号太低而无法从背景噪声中调用的情况下,灵敏度会增加。在此类情况下,当持续看到信号时,该信号变得可调用(例如,当同一信号被多次看到时,信号是真实的可信度增加)。结合位点调用的准确性增加了,因为信息的多次读取可用另一次读取证实一次读取。
[0108]
如本文中所用,术语“探针”可包含连接有任选的荧光标记物的寡核苷酸。在一些实施方案中,探针是任选地用荧光染料或荧光或光散射颗粒标记的肽或多肽。这些探针用于确定针对核酸或蛋白质的结合位点的定位。
[0109]
如本文中所用,术语“寡核苷酸(oligonucleotide)”和“寡聚体(oligo)”是指短的核酸序列。在一些情况下,寡聚体具有确定的大小,例如,每个寡聚体的长度为k个核苷酸碱基(在本文中也称为“k聚体”)。典型的寡聚体大小为3聚体、4聚体、5聚体、6聚体等等。寡聚体在本文中也称为n聚体。
[0110]
如本文中所用,术语“标记物”涵盖单个可检测的实体(例如波长发射实体)或多个可检测的实体。在一些实施方案中,标记物与核酸瞬时结合或与探针结合。不同类型的标记物在荧光发射时会闪烁,在其光子发射时会波动,或者光开关会关闭和打开。不同的标记物用于不同的成像方法。特别是,一些标记物特别适合不同类型的荧光显微镜。在一些实施方案中,荧光标记物发出不同波长的荧光,并且具有不同的寿命。在一些实施方案中,背景荧光存在于成像视野中。在一些此类实施方案中,通过由于散射而拒绝荧光的早期时间窗,从分析中去除此类背景。如果标记物存在于探针的一端(例如,寡探针的3’端)上,则定位的准确性对应于探针的该端(例如,探针序列的3’端和靶序列的5’端)。标记物的明显瞬时、波动或闪烁行为可以区分附着的探针是否与其结合位点结合。
[0111]
如本文中所用,术语“瓣”是指充当结合第二实体的受体的实体。所述两个实体可以包含分子结合对。此类结合对可包括核酸结合对。在一些实施方案中,瓣包含与标记的寡核苷酸结合的一段寡核苷酸或多核苷酸序列。在对结合靶的探针部分的瞬时结合进行成像的过程中,瓣与寡核苷酸之间的这种结合应该是基本稳定的。
[0112]
术语“伸长的”、“延长的”、“拉伸的”、“线性化的”和“拉直的”可以互换使用。特别地,术语“伸长的多核苷酸”(或“延伸的多核苷酸”,等)表示核酸分子已经以某种方式粘附于表面或基质上,然后被拉伸成线性形式。通常,这些术语意味着沿着多核苷酸的结合位点被物理距离分开,所述物理距离或多或少与它们之间的核苷酸数量相关(例如,多核苷酸是直的)。物理距离与碱基数量匹配程度的一定的不精确性是可以容忍的。
[0113]
如本文中所用,术语“成像”包括二维阵列或二维扫描检测器。在大多数情况下,本文使用的成像技术必须包括荧光激活剂(例如,合适波长的激光器)和荧光检测器。
[0114]
如本文中所用,术语“序列位(sequence bit)”表示序列的一个或几个碱基(例如,长度为1至9个碱基)。特别地,在一些实施方案中,序列对应于用于瞬时结合的寡聚体(或肽)的长度。因此,在此类实施方案中,序列是指靶多核苷酸的区域。
[0115]
如本文中所用,术语“单倍型”是指通常一起遗传的一组变异。这是因为变异组紧密相邻地存在于多核苷酸或染色体上。在一些情况下,单倍型包含一个或多个单核苷酸多态性(snp)。在一些情况下,单倍型包含一个或多个等位基因。
[0116]
如本文中所用,术语“甲基结合蛋白”指含有甲基-cpg结合结构域的蛋白,其包含约70个核苷酸残基。此类结构域对dna的未甲基化区域具有低亲和力,因此可用于鉴定核酸中已被甲基化的位置。一些常见的甲基结合蛋白包括mecp2、mbd1和mbd2。然而,存在一系列不同的包含甲基-cpg-结合结构域的蛋白质(例如,如roloff等人,bmc genomics 4:1,2003所描述的)。
[0117]
如本文中所用,术语“纳米抗体”是指仅含有重链的抗体片段的专有蛋白质组。这些是高度稳定的蛋白质,并且可被设计成具有与多种人抗体相似的序列同源性,从而使得能够特异性靶向体内的细胞类型或区域。纳米抗体生物学的综述可见于bannas等人,frontiers in immu.8:1603,2017中。
[0118]
如本文中所用,术语“亲和体”是指非抗体结合蛋白。这些是高度可定制的蛋白质,具有两个肽环和一个n末端序列,在一些实施方案中,其被随机化以提供对所需蛋白质靶的亲和力和特异性。因此,在一些实施方案中,亲和体用于鉴定蛋白质中目标序列或结构区域。在一些此类实施方案中,亲和体用于鉴定许多不同类型的蛋白质表达、定位和相互作用(例如,如tiede等人,elife 6:e24903,2017中所述的)。
[0119]
如本文中所用,术语“适体”是指另一类高度通用、可定制的结合分子。适体包含核苷酸和/或肽区域。通常产生一组随机的可能的适体序列,然后选择与特定的目标靶分子结合的所需序列。适体除了它们的稳定性和柔性之外还具有另外的特性,这使得它们比其它种类的结合蛋白更受欢迎(例如,如song等人,sensors 12:612-631,2012和dunn等人,nat.rev.chem.1:0076,2017中所描述的)。
[0120]
为了举例说明,下面参考示例性应用来描述几个方面。应当理解,阐述了许多具体细节、关系和方法,以提供对本文所述特征的全面理解。然而,相关领域的普通技术人员将会理解,本文所述的特征可在没有一个或多个具体细节的情况下实施或者利用其它方法来实施。本文描述的特征不受所示的动作或事件的顺序限制,因为一些动作可以以不同的顺序发生和/或与其它动作或事件同时发生。此外,并非所有示出的动作或事件都是实现根据本文所述的特征的方法所必需的。
[0121]
示例性系统实施方案。
[0122]
现在结合图1描述示例性系统的细节。图1是示出根据一些实现的系统100的方框图。在一些实现中,设备100包括一个或多个处理单元(一个或多个cpu)102(也称为处理器或处理核心)、一个或多个网络接口104、用户接口106、非永久性存储器111、永久性存储器112以及用于互连这些组件的一个或多个通信总线114。一个或多个通信总线114任选地包括互连和控制系统组件之间的通信的电路(有时称为芯片组)。非永久性存储器111通常包括高速随机存取存储器,诸例如dram、sram、ddr ram、rom、eeprom、闪存,而永久性存储器112通常包括cd-rom、数字多功能盘(dvd)或其它光学存储器、盒式磁带、磁带、磁盘存储器或其它磁存储设备、磁盘存储设备、光盘存储设备、闪存设备或其它非易失性固态存储设备。永久性存储器112任选地包括远离一个或多个cpu 102的一个或多个存储设备。永久性存储器112和非永久性存储器112内的一个或多个非易失性存储器设备包括非易失性计算机可读存储介质。在一些实现中,非永久性存储器111或者可替换地,非易失性计算机可读存储介质存储以下程序、模块和数据结构或者其亚组,有时结合永久性存储器112:
[0123]
·
任选的操作系统116,其包括用于处理各种基本系统服务和用于执行依赖于硬
件的任务的程序;
[0124]
·
用于将系统100与其它设备或通信网络连接的任选的网络通信模块(或指令)118;
[0125]
·
光学活性检测模块120,用于收集每个目标分子130的信息;
[0126]
·
每个靶分子130的多个结合位点中的每个相应的结合位点140的信息;
[0127]
·
每个结合位点140的多个结合事件中的每个相应的结合事件142的信息,至少包括(i)持续时间144和(ii)发射的光子数146;
[0128]
·
用于确定每个靶分子130的序列的测序模块150;
[0129]
·
每个靶分子130的多个结合位点中的每个相应的结合位点140的信息,至少包括(i)碱基调用152和(ii)概率154;
[0130]
·
关于每个靶分子130的参考基因组160的任选信息;以及
[0131]
·
关于每个靶分子130的互补链170的任选信息。
[0132]
在各种实现中,上面鉴定的元素中的一个或多个被存储在前述存储器设备中的一个或多个中,并且对应于用于执行上述功能的一组指令。上述鉴定的模块、数据或程序(例如,指令集)不需要被实现为单独的软件程序、过程、数据集或模块,因此可以在各种实现中组合或以其它方式重新排列这些模块和数据的各种亚组。在一些实现中,非永久性存储器111任选地存储上述鉴定的模块和数据结构的亚组。此外,在一些实施方案中,存储器存储上面没有描述的附加模块和数据结构。在一些实施方案中,上述鉴定的元素中的一个或多个被存储在除可视化系统100的计算机系统外的计算机系统中,所述计算机系统可由可视化系统100寻址,使得可视化系统100可在需要时检索所有或部分这样的数据。
[0133]
网络通信模块118的实例包括但不限于万维网(www)、内联网和/或无线网络,诸如蜂窝电话网络、无线局域网(lan)和/或城域网(man),以及通过无线通信的其它设备。无线通信任选地使用多种通信标准、协议和技术中的任一种,包括但不限于全球移动通信系统(gsm)、增强型数据gsm环境(edge)、高速下行链路分组接入(hsdpa)、高速上行链路分组接入(hsupa)、演进、纯数据(ev-do)、hspa、hspa+、双小区hspa(dc-hspda)、长期演进(lte)、近场通信(nfc)、宽带码分多址(w-cdma)、码分多址(cdma)、时分多址(tdma)、蓝牙、无线保真(wi-fi)(例如,ieee 802.11a、ieee 802.11ac、ieee 802.11ax、ieee 802.11b、ieee 802.11g和/或ieee 802.11n)、基于互联网协议的语音(voip)、wi-max、电子邮件协议(例如,互联网消息访问协议(imap)和/或邮局协议(pop))、即时消息(例如,可扩展消息和存在协议(xmpp)、用于即时消息收发和呈现利用扩展的oma会话初始协议(simple)、即时消息和存在服务(imps))和/或短消息服务(sms)或任何其它合适的通信协议,包括截至本公开的申请日尚未开发的通信协议。
[0134]
尽管图1描绘了“系统100”,但该图更多地是作为计算机系统中可能存在的各种特征的功能描述,而不是作为本文描述的实现的结构示意图。在实践中,并且如本领域普通技术人员所认识到的,可组合单独显示的项目,并且可将一些项目分开。此外,尽管图1描绘了非永久性存储器111中的某些数据和模块,但这些数据和模块中的一些或全部可存在于永久性存储器112中。此外,在一些实施方案中,存储器111和/或112存储上面没有描述的附加模块和数据结构。
[0135]
虽然已经参照图1公开了根据本公开的系统,但是现在参照图2a、图2b、图3和图4
详细描述根据本公开的方法。
[0136]
块202。提供了确定分子的化学结构的方法。本公开的目的是能够实现核酸的单核苷酸解析测序。在一些实施方案中,提供了表征一种或多种探针与分子之间相互作用的方法。该方法包括在使一种或多种探针种类与分子瞬时结合的条件下,向分子中添加一种或多种探针种类。该方法通过在检测器上连续监测分子上的单个结合事件并记录一段时间内的每个结合事件来进行。分析来自每个绑定事件的数据,以确定相互作用的一个或多个特征。
[0137]
在一些实施方案中,提供了确定聚合物的身份的方法。在一些实施方案中,提供了确定细胞或组织的身份的方法。在一些实施方案中,提供了确定生物体的身份的方法。在一些实施方案中,提供了确定个体的身份的方法。在一些实施方案中,将该方法应用于单个细胞测序。
[0138]
靶聚合物。
[0139]
在一些实施方案中,分子是核酸,优选为天然多核苷酸。在各种实施方案中,该方法还包括从细胞、细胞器、染色体、病毒、外来体或体液中提取单一靶多核苷酸分子作为完整的靶多核苷酸。
[0140]
在一些实施方案中,聚合物是短的多核苷酸(例如,《1千碱基或《300个碱基)。在一些实施方案中,短的多核苷酸的长度为100-200个碱基、150-250个碱基、200-350个碱基或100-500个碱基,正如对于体液诸如尿液和血液中的无细胞dna所发现的一样。
[0141]
在一些实施方案中,核酸的长度为至少10,000个碱基。在一些实施方案中,核酸的长度为至少1,000,000个碱基。
[0142]
在各种实施方案中,单个靶多核苷酸是染色体。在各种实施方案中,单个靶多核苷酸的长度为约102、103、104、105、106、107、108或109个碱基。
[0143]
在一些实施方案中,该方法使得能够分析靶蛋白质上的氨基酸序列。在一些实施方案中,提供了分析靶多肽上氨基酸序列的方法。在一些实施方案中,提供了分析靶多核苷酸上的肽修饰以及氨基酸序列的方法。在一些实施方案中,分子实体是包含至少5个单元的聚合物。在此类实施方案中,结合探针是分子探针,包括寡核苷酸、抗体、亲和体、纳米抗体、适体结合蛋白或小分子等。
[0144]
在此类实施方案中,20个氨基酸中的每一个都被相应的特异性探针结合,所述探针包括n识别子(recognin)、纳米抗体、抗体、适体等。每个探针的结合对多肽链中的每个相应的氨基酸都是特异性的。在一些实施方案中,确定多肽中亚单位的顺序。在一些实施方案中,结合是与结合位点的替代物的结合。在一些实施方案中,替代物是附接在某些氨基酸或肽序列上的标签,并且瞬时结合将是与替代物标签的结合。
[0145]
在一些实施方案中,分子是非均相分子。在一些实施方案中,异质分子包括超分子结构。在一些实施方案中,该方法使得能够鉴定非均相聚合物的化学结构单元并对其进行排序。此类实施方案包括伸长聚合物和结合多个探针,以鉴定沿着伸长的聚合物的多个位点上的化学结构。伸长杂聚物允许探针结合位点的亚衍射水平(例如,纳米级)定位。
[0146]
在一些实施方案中,提供了通过识别聚合物的亚单位的探针的结合对聚合物进行测序的方法。通常,一个探针的结合不足以对聚合物进行测序。例如,图1a是实施方案,在该实施方案中聚合物130的测序基于测量与探针182的库的瞬时相互作用(例如,变性多核苷
酸与寡核苷酸的库的相互作用,或变性多肽与一小组纳米抗体或亲和体的相互作用)。
[0147]
靶聚合物的提取和/或制备。
[0148]
在一些实施方案中,在进行核酸提取之前,有必要将目标细胞与其它非目标细胞分开。在一个这样的实例中,从血液中分离循环肿瘤细胞或循环胎儿细胞(例如,通过使用用于亲和捕获的细胞表面标志物)。在一些实施方案中,有必要从人细胞中分离微生物细胞,其中感兴趣的是检测和分析来自微生物细胞的多核苷酸。在一些实施方案中,将调理素用于亲和捕获多种微生物并将它们与哺乳动物细胞分离。另外,在一些实施方案中,进行差异裂解。在相对温和的条件下,首先裂解哺乳动物细胞。微生物细胞通常比哺乳动物细胞坚韧,因此它们在经历哺乳动物细胞裂解后保持完整。洗掉裂解的哺乳动物细胞碎片。然后使用更苛刻的条件来裂解微生物细胞。然后对靶微生物多核苷酸进行选择性测序。
[0149]
在一些实施方案中,在测序之前从细胞中提取靶核酸。在替代实施方案中,测序(例如,染色体dna的测序)在细胞内进行,其中染色体dna在分裂间期遵循盘旋路径。寡聚体在原位的稳定结合已由beliveau等人,nature communications 6:7147(2015)证明。寡聚体的这种原位结合和它们在三维空间中的纳米级定位使得能够确定染色体分子的序列以及其在细胞内的结构排列。
[0150]
靶多核苷酸通常以天然折叠状态存在。在一个这样的实例中,基因组dna在染色体中高度浓缩,而rna形成二级结构。在一些实施方案中,在从生物样品中提取的过程中,获得了长的长度的多核苷酸(例如,通过基本上保留多核苷酸的天然长度)。在一些实施方案中,将多核苷酸线性化,使得沿着其长度的位置被几乎无歧义地追踪或无歧义地追踪。理想地,在线性化之前或之后,将靶多核苷酸拉直、拉伸或伸长。
[0151]
该方法特别适合于对非常长的聚合物长度进行测序,其中天然长度或其相当大的比例得以保留(例如,对于dna全染色体或约1兆碱基的片段)。然而,普通的分子生物学方法会导致意想不到的dna片段化。例如,移液和涡流会产生剪切力,使dna分子断裂。核酸酶污染会导致核酸降解。在一些实施方案中,在固着、拉伸和测序开始之前保存天然长度或天然长度的相当大的高分子量(hmw)片段。
[0152]
在一些实施方案中,在进行测序之前,有意地将多核苷酸片段化为相对均一的长的长度(例如,约1mb的长度)。在一些实施方案中,在固定或伸长之后或期间,将多核苷酸片段化为相对均一的长的长度。在一些实施方案中,片段化是通过酶促实现的。在一些实施方案中,片段化是通过物理方式实现的。在一些实施方案中,片段化是通过超声处理。在一些实施方案中,物理片段化是通过离子轰击或辐照。在一些实施方案中,物理片段化是通过电磁辐射。在一些实施方案中,物理片段化是通过uv照射。在一些实施方案中,控制uv照射的剂量以实现对给定长度的片段化。在一些实施方案中,物理片段化是通过uv照射与染料(例如,yoyo-1)染色的组合。在一些实施方案中,通过物理作用或添加试剂来停止片段化过程。在一些实施方案中,实现片段化过程停止的试剂是还原剂,诸如β-巯基乙醇(bme)。
[0153]
通过辐照剂量片段化以及测序
[0154]
当二维传感器的视野允许在传感器的一个维度上观察到完整的兆碱基长度的dna时,那么其对于产生长度为1mb的基因组dna是高效的。还应该注意的是,减小染色体长度片段的大小也最大限度地减少链的缠结,并以以拉伸的、良好分离的形式获得最大长度的dna。
[0155]
用于对染色体的长亚片段进行测序的方法包括以下步骤:
[0156]
i)用染料对染色体双链dna进行染色,所述染料嵌入双链的碱基对之间
[0157]
ii)将染色的染色体dna暴露于预定剂量的电磁辐射下,以产生所需大小范围内的染色体dna的亚片段(sub-fragment)
[0158]
iii)将已染色的染色体亚片段dna伸长并固定在表面上
[0159]
iv)使已染色的染色体亚片段变性以破坏碱基对,从而释放嵌入染料
[0160]
v)将所得的脱色的、伸长的、固定的单链暴露于具有给定长度和序列的寡核苷酸序列的库中
[0161]
vi)确定沿着所述库中每个寡核苷酸的脱色的伸长的单链的结合位置
[0162]
vii)汇编所述库中所有寡聚体的结合位置,以获得染色体亚片段的完整测序。
[0163]
在上述的一些实施方案中,当染色体存在于细胞中时进行染色。在上述的一些实施方案中,标记的寡核苷酸仅被标记,因为当双链体形成时,更多的染色剂被添加并嵌入到双链体中。在上述的一些实施方案中,任选地,除了变性之外,还施加了一定剂量的能够漂白染色的电磁辐射。在上述的一些实施方案中,所述预定剂量是通过控制暴露的强度和持续时间以及通过化学暴露停止片段化来实现的,其中所述化学暴露是还原剂,诸如β-巯基乙醇。在上述的一些实施方案中,将剂量预定以产生约1mb的片段长度的泊松分布
[0164]
固定(fixation)和固着(immobilization)的方法。
[0165]
块204。将核酸以双链线性化拉伸形式固定在测试基板上,从而形成固定的拉伸双链核酸。任选地,将分子被固着在表面或基质上。在一些实施方案中,固定片段化的聚合物或天然聚合物。在一些实施方案中,固定的双链线性化核酸不是直的,而是沿着曲线或扭曲的路径。
[0166]
在一些实施方案中,固定包括通过分子梳理(后退弯月面)、流动拉伸、纳米约束或电拉伸将所述核酸施加到测试基板。在一些实施方案中,将核酸施加到基板上还包括uv交联步骤,其中将核酸共价键合至基板上。在一些实施方案中,该应用不需要核酸的uv交联,并且通过其它方式(例如,诸如疏水相互作用、氢键合,等)将核酸键合至基板上。
[0167]
仅在一个末端上固着(例如,固着)多核苷酸,允许多核苷酸以不协调的方式拉伸和收缩。因此,无论使用何种伸长方法,对于靶标中的任何特定位置都不能保证沿着聚合物长度的拉伸程度。在一些实施方案中,沿着聚合物的多个位置的相对位置必须不受波动的影响。在此类实施方案中,应该将伸长的分子通过沿其长度的多个接触点固着或固定至表面上(例如,如在michalet等人,science 277:1518-1523,1997的分子梳理技术中所进行的;关于可使用在表面上进行的拉伸(例如acs nano.2015jan 27;9(1):809-16),另请参见molecular combing of dna:methods and applications,journal of self-assembly and molecular electronics(same)1:125-148)。
[0168]
在一些实施方案中,将多核苷酸的阵列固着在表面上,并且在一些实施方案中,阵列中的多核苷酸相距足够远以至可通过衍射极限成像来单独解析。在一些实施方案中,以有序的方式将多核苷酸呈现在表面上,使得分子最大限度地聚集在给定的表面区域内,并且它们不重叠。在一些实施方案中,这是通过制作图案化表面(例如,疏水贴片或条带在多核苷酸的末端将结合的此类位置处的有序排列)来完成的。在一些实施方案中,阵列的多核苷酸相距不够远以至不能通过衍射极限成像来单独解析,而是通过超解析方法来单独解
析。
[0169]
在一些实施方案中,将多核苷酸组织在dna帘中(greene等人,methods enzymol.472:293-315,2010)。这对于长的多核苷酸特别有用。在此类实施方案中,当一端附着的dna链被流动或电泳力伸长时,或者在链的两端均被捕获后,记录瞬时结合。在一些实施方案中,当相同序列的许多拷贝在dna帘中形成多个多核苷酸时,该序列是以呈聚集体的结合模式从来自多个多核苷酸而不是一个多核苷酸组装而成的。在一些实施方案中,多核苷酸的两个末端与垫(例如,比表面的其它部分更能粘附至多核苷酸的表面区域)结合,每个末端结合至不同的垫。在此类实施方案中,单个线性多核苷酸所结合的两个垫将多核苷酸的拉伸构型保持在适当的位置,并允许形成等间距、非重叠或非相互作用的多核苷酸的有序阵列。在一些实施方案中,只有一个多核苷酸占据单独的垫。在一些实施方案中,当使用泊松过程填充垫,一些垫未被多核苷酸占据,一些被一个多核苷酸占据,一些垫被一个以上多核苷酸占据。
[0170]
在一些实施方案中,靶分子被捕获至有序超分子支架(例如,dna折纸结构)上。在一些实施方案中,支架结构开始在溶液中游离,以利用溶液相动力学来捕获靶分子。一旦它们被占据,支架就在表面上沉淀或自组装,并被锁定在表面上。有序阵列实现了分子的高效亚衍射堆积,从而允许每个视野有更高密度的分子(高密度阵列)。单分子定位方法允许在高密度阵列内的多核苷酸被超解析(例如,40nm或更小的点到点的距离)。
[0171]
在一些实施方案中,将发夹连接(任选地在抛光核酸的末端之后)至双链体模板的末端。在一些实施方案中,发夹包含将核酸固着至表面的生物素。在替代实施方案中,发夹用于共价连接双链体的两条链。在一些此类实施方案中,将核酸的另一末端加尾以用于例如通过寡聚d(t)进行的表面捕获。变性后,核酸的两条链均可用于与寡聚体相互作用。
[0172]
在一些实施方案中,有序阵列采取连接在一起形成大的dna网格的单个支架的形式(例如,如woo和rothemund,nature communi cations,5:4889中描述的)。在一些此类实施方案中,单个小支架通过碱基配对彼此锁定。然后,它们呈现高度有序的纳米结构阵列,用于本公开的测序步骤。在一些实施方案中,捕获位点以10nm的间距排列在有序的二维网格中。这种网格在完全占据的情况下,能够捕获每平方厘米约一万亿个分子。
[0173]
在一些实施方案中,网格中的捕获位点以5nm间距、10nm间距、15nm间距、30nm间距或50nm间距排列在有序的二维网格中。在一些实施方案中,网格中的捕获位点以5nm间距至50nm间距排列在有序的二维网格中。
[0174]
在一些实施方案中,使用纳米流体创建有序阵列。在一个这样的实例中,将纳米沟槽或纳米槽(例如,100nm宽和150nm深)的阵列在表面上形成纹理,并用于对长的多核苷酸进行排序。在此类实施方案中,一个多核苷酸在纳米沟槽或纳米槽中的出现排除了另一个多核苷酸的进入。在另一个实施方案中,使用纳米坑阵列(nanopit array),其中长多核苷酸的节段存在于凹坑中,并且间插长节段分布在凹坑之间。
[0175]
在一些实施方案中,高密度的多核苷酸仍然允许超分辨成像和精确测序。例如,在一些实施方案中,只有一个亚组的多核苷酸是令人感兴趣的(例如,靶向测序)。在此类实施方案中,当进行靶向测序时,仅需要分析一个亚组的来自复杂样品(例如,全基因组或转录组)的多核苷酸,并且多核苷酸以比通常更高的密度沉积在表面或基质上。在此类实施方案中,即使当衍射极限空间内存在几个多核苷酸时,当检测到信号时,很有可能该信号仅来自
靶基因座中的一个,并且该基因座不在同时与探针结合的另一个此类基因座的衍射极限距离内。进行靶向测序的每个多核苷酸之间所需的距离与被靶向的多核苷酸的百分比相关。例如,如果《5%的多核苷酸被靶向,那么多核苷酸的密度是期望的整个多核苷酸序列的20倍。在靶向测序的一些实施方案中,成像时间比要分析全基因组的情况短(例如,在上面的实例中,靶向测序成像可能比全基因组测序快10倍)。
[0176]
在一些实施方案中,在固定之前,测试基板与序列特异性寡核苷酸探针结合,并且固定包括使用与测试基板结合的序列特异性寡核苷酸探针捕获测试基板上的核酸。在一些实施方案中,核酸在5
′
末端结合。在一些实施方案中,核酸在3
′
末端结合。在另一个实施方案中,当基质上存在两种独立的探针时,一种探针将与核酸的第一末端结合,另一种探针将与核酸的第二末端结合。在使用两种探针的情况下,还需要有关于核酸长度的先验信息。在一些实施方案中,首先用预定的核酸内切酶切割核酸。
[0177]
在各种实施方案中,在固定之前,将靶多核苷酸提取到凝胶或基质中或包埋在凝胶或基质中(例如,如shag等人,nature protocols 7:467-478,2012中所述)。在一个这样的非限制性实例中,多核苷酸沉积在包含经历液体到凝胶转变的介质的流动通道中。最初将多核苷酸伸长并分布在液相中,然后通过将相变为固相/凝胶相(例如,通过加热,或者在聚丙烯酰胺的情况下通过添加辅因子或随时间变化)来进行固定。在一些实施方案中,在固/凝胶相中伸长多核苷酸。
[0178]
在一些替代实施方案中,将探针本身固着在表面或基质上。在此类实施方案中,将一种或多种靶分子(例如,多核苷酸)悬浮在溶液中,并与固定探针瞬时结合。在一些实施方案中,使用空间可寻址的寡核苷酸阵列来捕获多核苷酸。在一些实施方案中,通过使用合适的捕获分子捕获经修饰的或非修饰的末端,将短的多核苷酸(例如,《300个核苷酸)诸如无细胞的dna或微rna或相对短的多核苷酸(例如,《10,000个核苷酸)诸如mrna随机固着在表面上。在一些实施方案中,短的或相对短的多核苷酸与表面进行多重相互作用,并且在平行于表面的方向上进行测序。这使得剪接同构组织得以解决。例如,在一些亚型中,描绘了重复或混洗的外显子的位置。
[0179]
在一些实施方案中,固着的探针包含与多核苷酸退火的共同序列。当靶多核苷酸优选在一个或两个末端具有共同序列时,这种实施方案特别有用。在一些实施方案中,多核苷酸是单链的,并且具有共同的序列,例如polya尾。在一个这样的实例中,将携带polya尾的天然mrna捕获在表面上的寡聚d(t)探针的坪(lawn)上。在一些实施方案中,特别是其中分析短dna的那些实施方案,多核苷酸的末端适于与表面/基质上的捕获分子相互作用。
[0180]
在一些实施方案中,多核苷酸是双链的,具有限制性酶产生的粘性末端。在一些非限制性实例中,使用具有罕见位点(例如,pmme1或not1)的限制性酶来产生多核苷酸的长片段,每个片段包含共同的末端序列。在一些实施方案中,使用末端转移酶进行适应。在其它实施方案中,将连接或加标签用于引入用于illumina测序的衔接子。这使得用户能够使用完善的illumina方案来制备样品,然后通过本文所述的方法对所述样品进行捕获和测序。在此类实施方案中,优选在扩增前捕获多核苷酸,这有引入误差和偏差的趋势。
[0181]
伸长方法
[0182]
在大多数实施方案中,必须将多核苷酸或其它靶分子附接在表面或基质上才能发生伸长。在一些实施方案中,核酸的伸长使其等于、长于或短于其晶体长度(例如,其中已知
从一个碱基到下一个碱基的间隔为0.34nm)。在一些实施方案中,多核苷酸被拉伸超过晶体长度。
[0183]
在一些实施方案中,通过分子梳理(例如,如在michalet等人,science 277:1518-1523,1997和deen等人,acs nano 9:809-816,2015中所描述的)拉伸多核苷酸。这使得数百万和数十亿分子能够平行拉伸和单向对齐。在一些实施方案中,通过将含有所需核酸的溶液洗涤到基板上,然后收起溶液的弯月面来进行分子梳理。在收起弯月面之前,核酸与基板形成共价或其它相互作用。随着溶液后退,核酸被以与弯月面相同的方向拉动(例如,通过表面滞留(surface retention));然而,如果核酸和基板之间的相互作用强度足以克服表面滞留力,则核酸被以均匀的方式在后退的弯月面方向上拉伸。在一些实施方案中,如kaykov等人,sci reports.6:19636(2016)(其据此通过引用整体并入)中所述进行分子梳理。在其它实施方案中,使用方法或方法的改进形式,在通道(例如,微流体装置的)中进行分子梳理,所述方法或方法的改进形式描述于petit等人nano letters 3:1141-1146(2003)中。
[0184]
空气/水界面的形状决定了通过分子梳理拉伸的伸长的多核苷酸的取向。在一些实施方案中,垂直于空气/水界面伸长多核苷酸。在一些实施方案中,在未对其一个或两个末端进行修饰的情况下将靶多核苷酸附着于表面。在一些实施方案中,当双链核酸的末端被疏水相互作用捕获时,用后退的弯月面进行的拉伸使双链体的一部分变性,并与表面形成进一步的疏水相互作用。
[0185]
在一些实施方案中,通过分子穿线(例如,如由payne等人,plos one 8(7):e69058,2013描述的)拉伸多核苷酸。在一些实施方案中,在靶已经变性成单链(例如,通过化学变性剂、温度或酶)之后进行分子穿线。在一些实施方案中,将多核苷酸在一端拴系,然后在流体流中进行拉伸((例如,如greene等人,methods in enzymology,327:293-315中所示)。
[0186]
在各种实施方案中,靶多核苷酸分子存在于微流体通道中。在一个这样的实例中,使多核苷酸流入微流体通道,或者从一个或多个染色体、外来体、细胞核或细胞提取到流动通道中。在一些实施方案中,不是通过微流体或纳米流体流动池将多核苷酸插入到纳米通道中,而是通过以在其上形成通道壁的表面被电偏置的方式构建通道来将多核苷酸插入到顶部开口的通道中(例如,参见asanov等人,anal chem.1998mar.15;70(6):1156-6)。在一个这样的实例中,向表面施加正偏压,使得带负电的多核苷酸被吸引到纳米通道中。同时,通道壁的脊不包含偏压,使得多核苷酸不太可能沉积在脊本身上。
[0187]
在一些实施方案中,延伸是由于流体动力阻力。在一个这样的实例中,通过纳米缝隙中的错流拉伸多核苷酸(marie等人,proc natl acad sci usa 110:4893-8,2013)。在一些实施方案中,核酸的延伸是由于流动通道中的纳米约束(nanoconfinement)。流动拉伸纳米约束包括通过流动梯度将核酸拉伸成线性构象,通常在微流体装置中进行。这种拉伸方法的纳米约束部分通常指微流体装置的狭窄区域。狭窄区域或通道的使用有助于克服分子个体化(例如,单个核酸或其它聚合物在拉伸过程中采用多种构象的趋势)的问题。关于流动拉伸方法的一个问题是流动并不总是沿着核酸分子均匀地施加。这可导致核酸表现出宽范围的延伸长度。在一些实施方案中,流动拉伸方法包括延伸流动和/或流体动力阻力。在多核苷酸被吸引到纳米通道中的一些实施方案中,一种或多种多核苷酸被纳米约束在通道
中,从而被拉长。在一些实施方案中,纳米约束后,多核苷酸沉积在偏置表面上或表面顶上的涂层或基质上。
[0188]
有多种方法可以对表面施加正或负偏压。在一个这样的实例中,表面由具有无污垢特性的材料制成或涂覆有该材料,或者用脂质(例如,脂质双层)、牛血清白蛋白(bsa)、酪蛋白、各种peg衍生物等钝化。钝化用于防止多核苷酸截留在通道的任何一个部分中,从而使伸长成为可能。在一些实施方案中,表面还包括氧化铟锡(ito)。
[0189]
在一些实施方案中,为了在纳米流体通道的表面上产生脂质双层(lbl),将具有1%lissamine
tm
罗丹明b1,2-二十六烷酰基-sn-甘油基-3-磷酸乙醇胺的两性离子popc(1-棕榈酰基-2-油酰基-sn-甘油基-3-磷酸胆碱)脂质涂覆到表面上。添加三乙基铵盐(罗丹明-dhpe)脂质使得能够用荧光显微镜观察lbl形成。在本公开的一些实施方案中使用的脂质双层钝化方法由persson等人,nano lett.12:2260-2265,2012描述。
[0190]
在一些实施方案中,一种或多种多核苷酸的延伸通过电泳进行。在一些实施方案中,将多核苷酸在一端拴系,然后通过电场拉伸(例如,如由greene等人,nature biotechnology 26:317-325,2008所述的)。核酸的电拉伸是基于核酸是高度带负电荷的分子的事实。例如,如randall等人2006,lab chip.6,516-522描述的电拉伸方法涉及通过电流将核酸抽吸通过微通道(以诱导核酸分子的取向)。在一些实施方案中,电拉伸在凝胶内进行或在凝胶不存在的情况下进行。使用凝胶的一个益处是限制了可用于核酸的三维空间,从而有助于克服分子个体性。电拉伸相对于压力驱动拉伸方法(诸如纳米约束)的一个普遍有利方面是缺乏破坏核酸分子的剪切力。
[0191]
在一些实施方案中,当多个多核苷酸存在于一个表面上时,多核苷酸不以相同的取向对齐或者不是直的(例如,多核苷酸附着于表面或者曲线路径穿过凝胶)。在此类实施方案中,多个多核苷酸中的两个或更多个重叠的可能性增加,导致关于关于探针沿着每个多核苷酸长度的定位的混乱。尽管从弯曲序列获得的测序信息与从直的良好对齐的分子获得的测序信息相同,但处理来自弯曲序列的测序信息的图像处理任务比从直的良好对齐的分子获得的测序信息的图像处理任务需要更多的计算能力。
[0192]
在以与平面平行的方向伸长一种或多种多核苷酸的实施方案中,在二维阵列检测器诸如cmos或ccd照相机中的相邻的系列像素上对它们的长度进行成像。在一些实施方案中,以与表面垂直的方向伸长一种或多种多核苷酸。在一些实施方案中,多核苷酸通过光片显微镜、旋转圆盘共焦显微镜、三维超分辨显微镜、三维单分子定位或激光扫描圆盘共焦显微镜或其变体成像。在一些实施方案中,使多核苷酸相对于表面成斜角伸长。在一些实施方案中,可通过二维检测器对多核苷酸成像,并且通过单分子定位算法软件(例如,如ovesny等人,bioinform.30:2389-2390,2014中所述的fiji/imagej plug-in thunderstorm)对图像进行处理。
[0193]
在固定和伸长之前,从单个细胞中提取和分离dna。
[0194]
在一些实施方案中,将用于单细胞的捕集器被设计在微流体结构内,以在释放单个细胞的核酸内容物时将它们保持在一个位置(例如,通过使用wo/2012/056192或wo/2012/055415的装置设计)。在一些实施方案中,代替在纳米通道中提取和拉伸多核苷酸,用聚乙烯基硅烷涂覆用于密封微流体结构/纳米流体结构的盖玻片或箔以实现分子梳理(例如,通过如由petit等人,nano letters 3:1141-1146.2003所述的流体运动)。流控芯片内
部的温和条件使得提取的多核苷酸能够长时间保存。
[0195]
许多不同的方法可用于从单细胞或细胞核中提取生物聚合物(例如,在kim等人,integr biol 1(10),574-86,2009中综述了一些合适的方法)。在一些非限制性实例中,用kcl处理细胞以去除细胞膜。通过添加低渗溶液溶解细胞。在一些实施方案中,将每个细胞单独分离,单独提取每个细胞的dna,然后在微流体容器或装置中对每组dna进行单独测序。在一些实施方案中,通过用去垢剂和/或蛋白酶处理一个或多个细胞来进行提取。在一些实施方案中,在裂解溶液中提供螯合剂(例如,edta)以捕获核酸酶所需的二价阳离子(并从而降低核酸酶活性)。
[0196]
在一些实施方案中,通过以下方法单独提取单个细胞的核和核外成分。向微流体装置的进料通道中提供一个或多个细胞。然后捕获一个或多个细胞,其中每个细胞由一个捕获结构捕获。向溶液中添加第一裂解缓冲液,其中所述第一种裂解缓冲液裂解细胞膜,但有助于保持细胞核的完整性。添加第一裂解缓冲液后,一个或多个细胞的另外核成分被释放到流动池中,在所述流动池中释放的rna被固着。然后通过提供第二裂解缓冲液来裂解所述一个或多个细胞核。第二裂解缓冲液的添加导致一个或多个细胞核的成分(例如,基因组dna)释放到流动池中,随后将dna固着在所述流动池中。一个或多个细胞的另外和细胞内组分被固着在相同流动池的不同位置或同一装置内的不同流动池中。
[0197]
图16a和图16b中的示意图显示了捕获和分离多个单细胞的微流控体系结构。细胞1602被流动池2004内的细胞陷阱1606捕获。在一些实施方案中,在细胞被捕获后,使裂解试剂流过。裂解后,多核苷酸然后被分布在靠近捕获区域,同时保持与从其它细胞提取的多核苷酸分离。在一些实施方案中,如图16b所示,进行电泳诱导(例如,通过使用电荷1610)来操纵核酸。裂解将从细胞1602和细胞核1604中释放核酸1608。核酸1608保持在细胞1602被捕获时它们所处的位置(例如,相对于细胞陷阱1606)。所述陷阱是单细胞的尺寸(例如,2-10um)。在一些实施方案中,将微滴和细胞聚集在一起的通道大于2um或10um。在一些实施方案中,分叉通道与陷阱之间的距离为1-1000微米。
[0198]
在表面提取和伸长高分子量的dna。
[0199]
将用于拉伸hmw多核苷酸的各种方法用于不同的实施方案(例如,acs nano.9(1):809-16,2015)。在一个这样的实例中,表面上的伸长是在流动池中进行的(例如,通过使用petit和carbeck在lett.3:1141-1146,2003中描述的方法)。除了流体方法之外,在一些实施方案中,还使用电场拉伸长多核苷酸,如giess等人,nature biotechnology 26,317-325(2008)中所公开的。当多核苷酸不附着于表面时,有几种方法可用于伸长多核苷酸(例如,frietag等人,biomicrofluidics,9(4):044114(2015);marie等人,proc natl acad sci usa 110:4893-8,2013)。
[0200]
作为在凝胶塞中使用dna的替代方法,通过如由cram等人,methods cell sci.,2002,24,27
–
35描述的聚胺方法制备适合装载到芯片上的染色体,并将其直接移液至设备中。在一些此类实施方案中,使用蛋白酶消化与染色体中的dna结合的蛋白质以释放基本上裸露的dna,然后如上所述将其固定和伸长。
[0201]
处理样品以位置保存读数。
[0202]
在对非常长的区域或聚合物进行测序的实施方案中,聚合物的任何降解都有可能显著降低整体测序的准确性。有利于整个伸长的聚合物保存的方法如下所示。
[0203]
多核苷酸在提取、储存或制备过程中有可能被破坏。切刻和加合物可以在天然双链基因组dna分子中形成。当样品多核苷酸来自ffpe材料时,情况尤其如此。因此,在一些实施方案中,在固着dna之前或之后引入dna修复溶液。在一些实施方案中,这是在将dna提取到凝胶塞中之后进行的。在一些实施方案中,修复溶液包含dna内切酶、激酶和其它dna修饰酶。在一些实施方案中,修复溶液包含聚合酶和连接酶。在一些实施方案中,修复溶液是来自new england biolabs的pre-pcr试剂盒。在一些实施方案中,此类方法主要如karimi-busheri等人,nucleic acids res.oct 1;26(19):4395-400,1998and kunkel等人,proc.natl acad sci.usa,78,6734-6738,1981中所述进行。
[0204]
在一些实施方案中,在使多核苷酸伸长后,施加凝胶覆盖层。在一些此类实施方案中,在表面伸长和变性后,用凝胶层覆盖多核苷酸(双链的或变性的)。或者,当多核苷酸在已经处于凝胶环境中时使其伸长(例如,如上所述的)。在一些实施方案中,在使多核苷酸伸长后,将其浇铸在凝胶中。例如,在一些实施方案中,当将多核苷酸在一端附着于表面并在流动流中或通过电泳电流拉伸时,周围的介质变成铸入凝胶中。在一些实施方案中,这通过在流动流中包含丙烯酰胺、过硫酸铵和temed来进行。此类化合物凝固时会变成聚丙烯酰胺。在替代实施方案中,应用对热有响应的凝胶。在一些实施方案中,用与丙烯酰胺聚合的acrydite修饰修饰多核苷酸的末端。在一些此类实施方案中,施加电场,鉴于天然多核苷酸的负主链,所述电场使多核苷酸向正电极伸长。
[0205]
在一些实施方案中,在凝胶塞或凝胶层中从细胞中提取核酸以保持dna的完整性,然后施加ac电场以拉伸凝胶中的dna;当这在盖玻片顶上的凝胶层中进行时,本发明的方法可以应用于拉伸的dna以检测瞬时寡聚体结合。
[0206]
在一些实施方案中,将样品与其环境的基质交联。在一个实例中,这是细胞环境。例如,当在细胞中原位进行测序时,使用异双功能交联剂将多核苷酸与细胞基质交联。当将测序直接应用于细胞内部时,这是使用诸如fisseq(lee等人,science 343:1360-1363,2014)的技术来完成的。
[0207]
大部分破坏发生在从细胞和组织中提取生物分子的过程中,以及随后在分析生物分子之前对其进行处理的过程中。在dna的情况下,导致其完整性丧失的其操作方面包括移液、涡旋、冻融和过度加热。在一些实施方案中,诸如以chembiochem,11:340-343(2010)公开的方法使机械应力最小化。另外,高浓度的二价阳离子、edta、egta酸或没食子酸(及其类似物和衍生物)抑制核酸酶产生的降解。在一些实施方案中,2:1的样品与二价阳离子重量之比足以抑制核酸酶,即使在存在极端水平和核酸酶的样品诸如粪便中亦如此。
[0208]
为了保持核酸的完整性(例如,不诱导dna损伤或断裂成更小的片段),在一些实施方案中,希望将生物大分子诸如dna保持在其天然保护环境(诸如染色体、线粒体、细胞、细胞核、外来体等)中。在实施方案中,当核酸已经在其保护环境之外时,希望将其包裹在诸如凝胶或微滴的保护环境中。在一些实施方案中,将核酸从其保护性环境中释放出来,所述环境在物理上非常接近其将被测序的地方(例如,将在其中获得测序数据的流体系统或流动池的部分)。因此,在一些实施方案中,将生物大分子(例如核酸、蛋白质)以保护性实体的形式提供,所述保护性实体将生物大分子保持接近其天然状态(例如天然长度),使包含生物大分子的保护性实体与其将被测序的位置非常接近,然后将生物大分子释放到其将被测序的区域或其将被测序的区域附近。在一些实施方案中,本发明包括提供包含基因组dna的琼
脂糖凝胶,所述琼脂糖凝胶将大部分基因组dna保存至大于200kb的长度,将包含基因组dna的琼脂糖放置在要在其中对dna进行测序的环境(例如表面、凝胶、基质)附近,将基因组dna从琼脂糖释放到环境中(或接近环境,以使其进一步运输和处理最小化),并进行测序。释放到测序环境中可以是通过施加电场或通过用琼脂酶消化凝胶。
[0209]
聚合物变性。
[0210]
块206。随后使固定的拉伸双链核酸在测试基板上变性为单链形式,从而获得核酸的固定的第一链和固定的第二链。固定的第二链的相应碱基与固定的第一链的相应互补碱基相邻。在一些实施方案中,通过首先拉长或拉伸多核苷酸,然后添加变性溶液以分离两条链来进行变性。
[0211]
在一些实施方案中,变性是包括一种或多种试剂(例如,0.5m naoh、dmso、甲酰胺、尿素等)的化学变性。在一些实施方案中,变性是热变性(例如,通过将样品加热至85℃或更高)。在一些实施方案中,变性是通过酶促变性,诸如通过使用解旋酶或其它具有解旋酶活性的酶。在一些实施方案中,通过与表面的相互作用或通过物理过程诸如拉伸超过临界长度来使多核苷酸变性。在一些实施方案中,变性是完全的或部分的。
[0212]
在一些实施方案中,探针与聚合物的重复单元上的修饰(例如,多核苷酸中的核苷酸,或多肽上的磷酸化)的结合在任选的变性步骤之前进行。
[0213]
在一些实施方案中,根本不进行双链多核苷酸的任选的变性。在一些此类实施方案中,探针必须能够退火成双链体结构。例如,在一些实施方案中,探针通过链侵入(例如,使用pna探针),通过诱导双链体的过度呼吸,通过识别(通过经修饰的锌指蛋白)双链体中的序列,或者通过使用cas9或类似的蛋白(其使双链体解链,从而允许引导rna结合)来与双链体的单条链结合。在一些实施方案中,引导rna包含询问探针序列,并且提供了包含库的每个序列的grna。
[0214]
在一些实施方案中,双链靶标包含切刻(例如,天然切刻或通过dna酶1处理产生的切刻)。在此类实施方案中,在反应条件下,一条链与另一条链短暂地裂开或剥离(例如,短暂变性),或者发生天然的碱基对呼吸。这允许探针在被天然链取代之前瞬时结合。
[0215]
在一些实施方案中,使单个双链靶多核苷酸变性,使得双链体的每条链都可用于被寡聚体结合。在一些实施方案中,单个多核苷酸被变性过程或测序方法中的另一步骤破坏,并被修复(例如,通过添加合适的dna聚合酶)。
[0216]
在一些优选实施方案中,双链基因组dna的固着和线性化(为表面上的瞬时结合做准备)包括分子梳理、dna与表面的uv交联、任选的润湿、双链dna通过暴露于化学变性剂(例如,碱溶液、dmso等)的变性、洗涤后对酸性溶液的任选暴露,以及对任选的预处理缓冲液的暴露。
[0217]
探针的退火。
[0218]
块208。在任选的变性步骤后,该方法通过将固定的第一链和固定的第二链暴露于寡核苷酸探针组中的相应的寡核苷酸探针的相应库中而继续,其中所述寡核苷酸探针组中的每个寡核苷酸探针具有预定的序列和长度。所述暴露在允许相应的寡核苷酸探针的相应库中的单个探针与固定的第一链或固定的第二链的与所述相应的寡核苷酸探针互补的每个部分(或多个部分)结合并形成相应的异源双链体的条件下发生,从而产生相应的光学活性实例。
[0219]
图5a、图5b和图5c示出了不同探针与一种聚合物502的瞬时结合的实例。每个探针(例如,504、506和508)包含特定的询问序列(例如,核苷酸或肽序列)。在将探针504应用于多核苷酸502之后,用一个或多个洗涤步骤将探针504从聚合物502上洗掉。类似的清洗步骤用于随后移除探针506和508。
[0220]
探针的设计和靶标。
[0221]
在一些实施方案中,向溶液中的靶多核苷酸提供探针。当溶液的体积足以将多核苷酸浸没在表面或基质上时,探针能够通过扩散和分子碰撞与多核苷酸接触。在一些实施方案中,搅拌溶液以使探针与一种或多种多核苷酸接触。在一些实施方案中,交换含有探针的溶液以将新鲜探针带到表面。在一些实施方案中,使用电场将探针吸引到表面,例如,正偏置的表面吸引带负电荷的寡聚体。
[0222]
在一些实施方案中,靶标包含多核苷酸序列,探针的结合部分包含例如3-聚体、4-聚体、5-聚体或6-聚体寡核苷酸序列询问部分,任选的一个或多个简并或通用位置,以及任选的核苷酸间隔区(例如,一个在多个t核苷酸上)或碱基或非核苷酸部分。如图6a和图6b所示,类似的结合沿着多核苷酸602发生,而与所使用的寡聚探针(例如,604和610)的大小无关。不同k聚体长度的寡聚体所固有的主要差异在于,k聚体长度决定了将被相应的探针结合的结合位点的长度(例如,3-聚体探针604将主要与3-核苷酸长的位点诸如606结合,而5-聚体探针610将主要与5-核苷酸长的位点诸如610结合)。
[0223]
在图6a中,3-聚体寡聚探针异常短。通常这种短序列不能用作探针,因为除非使用非常低的温度和长的孵育时间,否则它们不能稳定结合。然而,如本文所述的检测方法所要求的,此类探针确实与靶多核苷酸形成瞬时键合。另外,寡核苷酸探针序列越短,在库中存在的寡核苷酸就越少。例如,对于完整的3-聚体寡聚体库只需要64个寡核苷酸序列,而对于完整的4-聚体库需要256个寡核苷酸序列。此外,在一些实施方案中,超短探针被修饰以升高解链温度,并且在一些实施方案中,包括简并(例如,n)核苷酸。例如,4个n核苷酸将使3-聚体寡聚体的稳定性增加到7-聚体的稳定性。
[0224]
在图6b中,示意图说明了5-聚体与其完全匹配的位置(612-3)、1个碱基错配的位置(612-2)和2个碱基错配的位置(612-1)的结合。
[0225]
通常,任一个探针的结合不足以对聚合物进行测序。在一些实施方案中,需要完整的探针库来重建多核苷酸的序列。关于寡聚体结合位点的位置、探针与重叠结合位点的暂时分离的结合、寡核苷酸与靶核苷酸之间错配的部分结合、结合频率和结合持续时间的信息都有助于推断序列。在伸长或拉伸的多核苷酸的情况下,沿着多核苷酸的长度的探针结合的位置有助于构建稳健的序列。在双链多核苷酸的情况下,双链体的两条链(例如,两条互补链)的同时测序会产生更大的可信度序列。
[0226]
在一些实施方案中,将共同的参考探针序列与库中的每个寡核苷酸探针一起添加。例如,在图7a、图7b和图7c中,共同的参考探针704与靶多核苷酸702上的相同结合位点708结合,而与探针组中包含的另外探针(例如,706、712和716)无关。参考探针704的存在不抑制另外的探针与其各自结合位点(例如,710、714、718、720和722)的结合。
[0227]
如图7c所描绘的,结合位点718、720和722说明了单个探针(716-1、716-2和716-3)将如何结合所有可能的位点,即使这些位点是重叠的。在图7a、图7b和图7c中,探针序列由3-聚体描绘。然而,类似的方法同样可以用为4-聚体、5-聚体、6-聚体等的探针进行。
[0228]
在一些实施方案中,寡核苷酸探针组是寡聚体的完整库(例如,具有给定长度的每一个寡聚体)。例如,根据本公开的一个实施方案,1024个个体5-聚体的整个集合被编码并包括在特定的库中。在一些实施方案中,提供了多个长度的库。在一些实施方案中,所述寡核苷酸探针组是覆瓦式系列的寡聚探针。在一些实施方案中,所述寡核苷酸探针组是一小组寡聚探针。在合成生物学中的某些应用(例如,dna数据存储)的情况下,测序包括寻找特定序列块的顺序,其中所述块被设计成编码所需的数据。
[0229]
如图8a、图8b和图8c所示,在一些实施方案中,将多个探针组(例如,804、806和808)应用于任何靶聚合物802。每种探针类型将优先与其互补结合位点结合。在许多实施方案中,在每个循环之间用缓冲液洗涤有助于移除前一组中的探针。
[0230]
在一些实施方案中,用于核酸测序的探针是寡核苷酸,用于表位修饰的探针是修饰结合蛋白或肽(例如,甲基结合蛋白诸如mbd1)或抗修饰抗体(例如,抗甲基c抗体)。在一些实施方案中,寡聚探针靶向基因组中的特定位点(例如,具有已知突变的位点)。如图9a、图9b和图9c所示,在一些实施方案中,寡核苷酸(例,804、806和808)和替代探针(例如,902)同时(并通过多个循环)应用于多核苷酸或聚合物802。确定目标靶位点的方法由liu等人,bmc genomics 9:509(2008)(其据此通过引用并入)提供。
[0231]
在一些实施方案中,依次应用库中的每个探针或库中的一个亚组的探针(例如,首先检测一个探针或一个探针亚组的结合,然后将其移除,然后和添加下一个,检测和去除,接着进行下一个,等等)。在一些实施方案中,同时添加库中的全部探针或一个亚组的探针,并且将每个结合探针拴系于完全或部分编码其身份的标记物上,并且通过检测解码每个结合探针的编码。
[0232]
如图11a和图11b所示,在一些实施方案中,将覆瓦式系列的探针用于获得关于多个探针结合位点的信息。在图11a中,将第一覆瓦式组1104应用于靶多核苷酸1102。第一覆苡式组1108中的探针亚组中的每个探针包含一个碱基1108,从而导致靶多核苷酸1102中该一个核苷酸的5倍覆盖。覆盖度将与覆瓦式系列中探针的k聚体长度成比例(例如,一组3聚体寡聚体将导致靶多核苷酸中每个碱基的3倍覆盖度)。
[0233]
在一些实施方案中,当寡核苷酸探针组沿着靶核苷酸平铺时,当覆瓦式路径中存在断裂时,有可能出现问题。例如,对于5聚体的寡核苷酸组,没有寡核苷酸能够结合靶分子中长于5个碱基的一段或多段序列。在这种情况下,在一些实施方案中采用一种或多种方法。首先,如果靶多核苷酸包含双链核酸,则一个或多个碱基分配遵从从双链体的互补链获得的一个或多个序列。第二,当靶分子的多个拷贝可用时,一个或多个碱基分配依赖于靶分子的另外的拷贝上相同序列的其它拷贝。第三,在一些实施方案中,如果参考序列可用,则一个或多个碱基分配遵从参考序列,并且将碱基注释成指示它们是从参考序列人工植入的。
[0234]
在一些实施方案中,出于各种原因,某些探针被从库中省略。例如,一些探针序列表现出与其自身的有问题的相互作用-诸如自互补或回文序列,与库中的其它探针或与多核苷酸的相互作用(例如,已知的随机混杂结合)。在一些实施方案中,为每种类型的多核苷酸确定最少数量的信息探针。在完整的寡聚体库内,一半的寡聚体与另一半的寡聚体完全互补。在一些实施方案中,确保这些互补对(以及由于实质上的互补性而成问题的其它互补对)不同时添加到多核苷酸中,而是被分配到不同的探针亚组。在一些实施方案中,当有义
和反义单链dna都存在时,仅用每个寡聚体互补对的一个成员进行测序。将从有义链和反义链获得的测序信息组合以产生整个序列。然而,该方法不是优选的,因为其放弃了同时对双链多核苷酸的两条链进行测序所带来的有利方面。
[0235]
在一些实施方案中,寡聚体包含使用定制微阵列合成制成的文库。在一些实施方案中,微阵列文库包含与基因组的特定靶部分系统性结合的寡聚体。在一些实施方案中,微阵列文库包含与多核苷酸上相隔一定距离的位置系统结合的寡聚体。例如,包含100万个寡聚体的文库可包含设计成约每3000个碱基结合一次的寡聚体。类似地,包含1000万个寡聚体的文库可被设计成约每300个碱基结合一次,包含3000万个寡核苷酸的文库可被设计成每100个碱基结合一次。在一些实施方案中,寡聚体的序列是基于参考基因组序列计算设计的。
[0236]
在一些实施方案中,基因组中被靶向的部分是特定的遗传基因座。在其它实施方案中,基因组的被靶向的部分是一小组基因座(例如,与癌症相关的基因)或由全基因组关联研究鉴定的染色体间隔内的基因。在一些实施方案中,靶向基因座也是基因组的暗物质、基因组中典型重复的异色区以及重复区附近的复杂遗传基因座。此类区域包括端粒、着丝粒、近端着丝粒染色体的短臂以及基因组的其它低复杂度区域。常规测序方法不能解决基因组的重复部分,但是当纳米级精度很高时,这些方法可以全面解决这些区域。
[0237]
在一些实施方案中,多个寡核苷酸探针中的每个相应的寡核苷酸探针包含独特的n聚体序列,其中n是集合{1,2,3,4,5,6,7,8和9}中的整数,并且其中所有长度为n的独特n聚体序列由多个寡核苷酸探针表示。
[0238]
用于制造探针的寡聚体长度越长,回文序列或回折序列(foldback sequence)就越有可能对寡聚体起高效探针的作用。在一些实施方案中,通过去除一个或多个简并碱基来减少此类寡聚体的长度,显著提高了结合效率。出于这个原因,使用较短的询问序列(例如,4-聚体)是有利的。然而,较短的探针序列也表现出不太稳定的结合(例如,较低的结合温度)。在一些实施方案中,使用特定的稳定碱基的修饰或寡聚体缀合物(例如,均二苯代乙烯帽)来增强寡聚体的结合稳定性。在一些实施方案中,使用被完全修饰的3-聚体或4-聚体(例如,锁定的核酸(lna))。
[0239]
在一些实施方案中,独特的n聚体序列包含被一个或多个简并核苷酸占据的一个或多个核苷酸位置。在一些实施方案中,简并位置包括四种核苷酸中的一种,并且在反应混合物中提供了具有四种核苷酸中的每一种的版本。在一些实施方案中,一个或多个核苷酸位置中的每个简并核苷酸位置被通用碱基占据。在一些实施方案中,通用碱基是2
′‑
脱氧肌苷。在一些实施方案中,独特的n-聚体序列的5’侧是单个简并核苷酸位置,并且3’侧是单个简并核苷酸位置。在一些实施方案中,5’单个简并核苷酸和3’单个简并核苷酸各自为2
’‑
脱氧肌苷。
[0240]
在一些实施方案中,所述寡核苷酸探针组中的每个寡核苷酸探针都具有相同的长度m。在一些实施方案中,m为2或更大的正整数。确定(f)来自测试基板上的多组位置的核酸的至少一部分的序列还使用由多组位置表示的寡核苷酸探针的重叠序列。在一些实施方案中,所述寡核苷酸探针组中的每个寡核苷酸探针与该寡核苷酸探针组中的另一个寡核苷酸探针共享m-1序列同源性。
[0241]
探针标记物。
[0242]
在一些实施方案中,所述寡核苷酸探针组中的每个寡核苷酸探针都与标记物结合。图14a-e示出了标记探针的不同方法。在一些实施方案中,标记物是染料、荧光纳米颗粒或光散射颗粒。在一些实施方案中,探针1402直接与标记物1406结合。在一些实施方案中,探针1402通过包含序列1408-b的襟翼序列(flap sequence)1410间接标记,所述该序列1408-b与寡聚体1408-a上的序列互补。
[0243]
许多类型的具有有利特性的有机染料可用于标记,一些具有高光稳定性和/或高量子效率和/或最小暗态和/或高溶解度,和/或低非特异性结合。atto 542是具有许多优良性质的优良染料。cy3b是非常明亮的染料,cy3也是有效的。一些染料可允许避免其中来自细胞或细胞物质的自动荧光普遍存在的波长,诸如红色染料atto 655和atto 647n。许多类型的纳米颗粒可用于标记。除了荧光标记的胶乳颗粒之外,本公开利用金或银颗粒、半导体纳米晶体和纳米金刚石作为纳米颗粒标记物。在一些实施方案中,纳米金刚石作为标签特别有利。纳米金刚石发射具有高量子效率(qe)的光,具有高光稳定性、长荧光寿命(例如,约20ns,其可用于减少从光散射和/或自发荧光观察到的背景),并且很小(例,直径约40nm)。通过将有机染料掺入到它们的结构中或者清除标记物(诸如嵌入染料),dna纳米结构和纳米球可以是异常明亮的标记物。
[0244]
在一些实施方案中,每个间接标记物指定探针的序列询问部分中编码的碱基的身份。在一些实施方案中,标记物包括一种或多种核酸嵌入染料的分子。在一些实施方案中,标记物包括一种或多种类型的染料分子、荧光纳米颗粒或光散射颗粒。在一些实施方案中,优选的是,标记物不会快速光漂白,以允许更长的成像时间。
[0245]
图12a、图12b和图12c示出了具有附着的荧光标记物1202的寡核苷酸1204与靶多核苷酸1206的瞬时开关结合。无论探针1204是否与靶多核苷酸1206上的结合位点结合,标记物1202都会发出荧光。类似地,图13a、图13b和图13c示出了未标记寡核苷酸探针1306的瞬时开关结合。通过将来自溶液1302的染料(例如,yoyo-1)嵌入到瞬时形成的双链体1304中来检测结合事件。与在溶液中自由漂浮相比,嵌入染料在结合到双链核酸中时表现出荧光的显著增加。
[0246]
在一些实施方案中,不直接标记结合靶标的探针。在一些此类实施方案中,探针包含襟翼(flap)。在一些实施方案中,构建寡核苷酸(例如,编码它们)包括将特定的序列单元偶联到寡核苷酸组中每个k聚体的一个末端(例如,襟翼序列)。襟翼编码序列的每一个单元都充当不同荧光标记探针的对接位点。为了编码5个碱基的探针序列,探针上的襟翼包含5个不同的结合位置,例如,每个位置是与下一个位置串联的不同的dna碱基序列。例如,襟翼上的第一个位置与探针序列(将与多核苷酸靶结合的部分)相邻,第二个位置与第一个相邻,依此类推。在测序中使用探针-襟翼之前,将各种探针-襟翼与一组荧光标记的寡聚体偶联,以生成探针序列的独特标识符标签。在一些实施方案中,这是通过使用四种不同标记的寡聚体序列来完成的,所述寡聚体序列与襟翼上的每个位置互补(例如,总共16种同的标记物)。
[0247]
在一些实施方案中,其中定义了a、c、t和g的探针的编码方式如下:标记物仅报告寡核苷酸中特定位置处的一个定义的核苷酸(而其余位置是简并的)。这只需要四色编码,每个核苷酸一种颜色。
[0248]
在一些实施方案中,在整个过程中仅使用一种荧光团颜色。在这样的实施方案中,
每个循环被分成4个子循环,在每个子循环中,在添加下一个碱基之前,在指定位置(例如,位置1)处单独添加4种碱基中的一种。在每个循环中,探针带有相同的标记物。在这种实现中,整个库在20个周期内被用尽,大大节省了时间。
[0249]
在一些实施方案中,序列中的第一个碱基由襟翼中的第一个单元编码,第二个碱基由第二个单元编码,等等。襟翼中单元的顺序对应于寡聚体中碱基序列的顺序。然后将不同的荧光标记物停靠在每个单元上(通过互补碱基配对)。在一个实例中,第一位置在波长500nm
–
530nm处发射,第二位置在波长550nm
–
580nm处发射,第三位置在600nm-630nm处发射,第四位置在650nm-680nm处发射,第五位置在700nm-730nm处发射。然后,每个位置处的碱基身份例如由标记物的荧光寿命编码。在一个这样的实例中,对应于a的标记物具有比c更长的寿命,c具有比g更长的寿命,g具有比t更长的寿命。在上述实例中,位置1处的碱基a以最长的寿命在500nm
–
530nm处发射,位置3处的碱基g以第三长的寿命在600nm
–
630nm处发射,等等。
[0250]
如图14e所示,探针1402将包括对应于序列1408-b的序列1408-a。序列1408-b与襟翼区1410连接。作为可能导致图14e整体构建体的可能序列的实例,1410中的四个位置中的每一个分别由序列aaaa(例如,与1412互补的位置)、cccc(例如,与1414互补的位置)、gggg(例如,与1416互补的位置)和tttt(例如,与1418互补的位置)定义。因此,整个襟翼序列将是5
′‑
aaaaccccggggtttt-3
′
。然后每个位置由特定的发射波长编码,并且可以在该位置处的四个不同的碱基由四个不同的荧光寿命标记的寡聚体编码,其中寿命/亮度比对应于探针1402自身中的特定位置和碱基代码。
[0251]
合适的代码实例如下:
[0252]
·
位置1-a碱基代码-tttt-发射峰值510,寿命/亮度#1
[0253]
·
位置1-c碱基代码-tttt-发射峰值510,寿命/亮度#2
[0254]
·
位置1-g碱基代码-tttt-发射峰值510,寿命/亮度#3
[0255]
·
位置1-t碱基代码-tttt-发射峰值510,寿命/亮度#4
[0256]
·
位置2-a碱基代码-gggg-发射峰值560,寿命/亮度#1
[0257]
·
位置2-c碱基代码-gggg-发射峰值560,寿命/亮度#2
[0258]
·
位置2-g碱基代码-gggg-发射峰值560,寿命/亮度#3
[0259]
·
位置2-t碱基代码-gggg-发射峰值560,寿命/亮度#4
[0260]
·
位置3-a碱基代码-cccc-发射峰值610,寿命/亮度#1
[0261]
·
位置3-c碱基代码-cccc-发射峰值610,寿命/亮度#2
[0262]
·
位置3-g碱基代码-cccc-发射峰值610,寿命/亮度#3
[0263]
·
位置3-t碱基代码-cccc-发射峰值610,寿命/亮度#4
[0264]
·
位置4-a碱基代码-aaaa-发射峰值660,寿命/亮度#1
[0265]
·
位置4-c碱基代码-gggg-发射峰值660,寿命/亮度#2
[0266]
·
位置4-g碱基代码-gggg-发射峰值660,寿命/亮度#3
[0267]
·
位置4-t碱基代码-gggg-发射峰值660,寿命/亮度#4
[0268]
或者,四个位置由荧光寿命编码,碱基由荧光发射波长编码。在一些实施方案中,其它可测量的物理属性可替代地用于编码,或者如果兼容,可以与波长和寿命相结合。例如,还可测量发射的偏振或亮度,以增加可用于包含在襟翼中的代码的库。
[0269]
在一些实施方案中,使用立足点探针(toe-hold-probes)(例如,如levesque等人,nature methods 10:865-867,2013中所述的)。这些探针部分是双链的,当与不匹配的靶标结合时,会竞争性地去稳定化(例如,chen等人,nature chemistry 5,782
–
789,2013中的详细描述)。在一些实施方案中,单独使用立足点探针。在一些实施方案中,使用立足点探针以确保正确杂交。在一些实施方案中,立足点探针用于促进与靶多核苷酸结合的其它探针的关闭反应。
[0270]
由共同激发线激发的标记物的实例是量子点。在根据该实例的一些此类实施方案中,qdot 525、qdot 565、qdot 605和qdot 655被选择为四种相应的核苷酸。或者,使用四条不同的激光线来激发四种不同的有机荧光团,并且检测到的它们的发射被图像分离器分离。在一些其它实施方案中,两种或更多种有机染料的发射波长相同,但是荧光寿命不同。熟练的技术人员将能够设想许多不同的编码和检测方案,而无需过度的努力和实验。
[0271]
在一些实施方案中,不单独添加库中的不同寡聚体,而是将其一起编码和混合。从一次一种颜色和一种寡聚体升级的最简单步骤是一次两种颜色和两种寡聚体。使用5种可区分的单一染料香料的直接检测,可以合理地预期一次混合最多约5种寡聚体,所述5种寡聚体中的每一种都有一种染料香料。
[0272]
在更复杂的情况下,香料或代码的数量增加。例如,要在完整的3-聚体库中为每个碱基单独编码,需要64个不同的代码。同样地,例如,要在完整的5-聚体库中为每个碱基单独编码,需要1024个不同的代码。如此多数量的代码是通过使每个寡核苷酸具有由多种染料香料组成的代码来实现的。在一些实施方案中,使用较小的一组代码来编码库的亚组(亚-库),例如,在一些情况下,使用64个代码来编码5聚体的全部1024个序列的库的16个亚组。
[0273]
在一些实施方案中,以多种方式获得大的寡聚体代码库。例如,在一些实施方案中,珠粒装载有代码特异性染料,或者基于dna纳米结构的代码包含最佳间隔的不同荧光波长发射染料(例如,lin等人,nature chemistry 4:832
–
839,2012)。例如,图14c和图14d示出了珠粒1412在携带荧光标记物1414中的用途。在图14c中,标记物1414被涂覆在珠粒1412上。在图14d中,标记物1414被包封在珠粒1412中。在一些实施方案中,每种标记物1414是不同类型的荧光分子。在一些实施方案中,所有标记物1414都是相同类型的荧光分子(例如,cy3)。
[0274]
在一些实施方案中,使用其中将模块化代码用于描述碱基在寡聚体中的位置及其身份的编码方案。在一些实施方案中,这通过向探针添加编码臂来实现,所述探针包含标识所述探针的标记物的组合。例如,当要编码每种可能的5-聚体寡核苷酸探针的文库时,臂具有5个位点,每个位点对应于5-聚体中的5个核碱基中的每一个,并且这5个位点中的每一个都与5个可区分的种类结合。在一个这样的实例中,具有特定峰值发射波长的荧光团对应于每个位置(例如,对于位置1为500nm,对于位置2为550nm,对于位置3为600nm,对于位置4为650nm,对于位置5为700nm),并且四个荧光团具有相同的波长,但对于每个位置的四个碱基中的每一个荧光寿命代码不同。
[0275]
在一些实施方案中,寡聚体或其它结合试剂上的不同标记物由发射波长编码。在一些实施方案中,不同的标记物由荧光寿命编码。在一些实施方案中,不同的标记物由荧光偏振编码。在一些实施方案中,不同的标记物由波长、荧光寿命的组合编码。
[0276]
在一些实施方案中,不同的标记物由反复开关杂交动力学编码。使用具有不同缔合-解离常数的不同结合探针。在一些实施方案中,探针由荧光强度编码。在一些实施方案中,通过附接不同数量的非自淬灭荧光团来对探针进行荧光强度编码。为了不淬灭,通常需要很好地分离单个荧光团。在一些实施方案中,这是通过使用刚性接头或dna纳米结构将标记物保持在彼此相距适当距离的位置来实现的。
[0277]
用于通过荧光强度进行编码的一个替代实施方案是使用具有相似发射光谱但其量子产率或其它可测量的光学特性不同的染料变体。例如,cy3b(具有558/572的激发/发射)比cy3(具有550/570的激发/发射并且量子产率为0.15,但具有相似的吸收/发射光谱)显著更亮(例如,量子产率为0.67)。在一些此类实施方案中,将532nm的激光用于激发两种染料。其它合适的染料包括cy3.5(具有591/604nm的激发/发射),其具有上移的激发和发射光谱,但仍将用532nm激光进行激发。然而,在该波长下的激发对于cy3.5来说是次优的,并且染料的发射在cy3的带通滤波器中将显得不太亮。atto 532的激发/发射为532/553,量子产率为0.9,当532nm激光命中其最佳位置时,预期其是明亮的。
[0278]
使用单一激发波长获得多个代码的另一种方法是测量染料的发射寿命。在根据这样的实施方案的一个实例中,使用了包括alexa fluor 546、cy3b、alexa fluor 555和alexa fluor 555的组。在一些情况下,其它染料组更有用。在一些实施方案中,通过使用fret对以及通过测量发射光的偏振来扩展代码库。另一种增加标记物数量的方法是用多种颜色编码。
[0279]
图15示出了寡核苷酸探针与多核苷酸瞬时结合的荧光实例。从时间序列中选择的帧(例如,帧号1、20、40、60、80、100)显示信号在特定位点的存在(例如,黑点)和不存在(例如,白色区域)指示开-关结合。每个相应的帧显示了沿着多核苷酸的多个结合的探针的荧光。聚集图像显示所有先前帧的荧光聚集,指示寡核苷酸探针已经结合的所有位点。
[0280]
探针与靶多核苷酸的瞬时结合。
[0281]
探针的结合是动态的过程,不断结合的探针具有一定的回到未结合的可能性(例如,如由包括温度和盐浓度在内的各种因素决定)。因此,总有机会用另一种探针替换一种探针。例如,在一个实施方案中,使用探针互补物,其在与表面上延伸的靶dna退火和与溶液中的互补物退火之间引起连续竞争。在另一个实施方案中,探针具有三个部分,第一部分与靶标互补,第二部分与靶标部分互补,与溶液中的寡聚体部分互补,第三部分与溶液中的寡聚体互补。在一些实施方案中,收集关于化学结构单元的精确空间位置的信息有助于确定大分子的结构和/或序列。在一些实施方案中,探针结合位点的位置以纳米级甚至亚纳米级精度来确定(例如,通过使用单分子定位算法)。在一些实施方案中,物理上更接近的多个观察到的结合位点可通过衍射极限光学成像方法来解析,因为结合事件在时间上是分离的。核酸的序列是基于与每个位置结合的探针的身份来确定的。
[0282]
暴露在允许相应的寡核苷酸探针的相应库中的单个探针与固定的第一链或固定的第二链的与所述单个探针互补的每个部分结合并形成相应的异源双链体的条件下发生,从而产生相应的光学活性实例。在一些实施方案中,停留时间(例如,通过特定探针的结合的持续时间和/或持久性)用于确定结合事件是完全匹配、不匹配还是虚假的。
[0283]
在一些实施方案中,暴露在允许相应的寡核苷酸探针的相应库中的单个探针与固定的第一链或固定的第二链的与所述单个探针互补的每个部分结合并形成相应的异源双
链体的条件下发生,从而重复产生相应的光学活性实例。
[0284]
在一些实施方案中,测序包括使伸长的多核苷酸经受来自逐个提供的探针的全部序列库中的每一个的瞬时相互作用(移除含有一种探针序列的溶液,并且添加含有下一种探针溶液的溶液)。在一些实施方案中,每个探针的结合在允许探针瞬时结合的条件下进行。因此,例如,对一种探针结合将在25℃下进行,对于下一种探针结合将在30℃下进行。还可将探针成组结合,例如,可以以几乎相同的方式将所有可瞬时结合的探针集合成组并一起使用。在一些此类实施方案中,将该组中的每个探针序列差异标记或差异编码。
[0285]
在一些实施方案中,瞬时结合在具有少量二价阳离子但无一价阳离子的缓冲液中进行。在一些实施方案中,缓冲液包含5mm tris-hcl、10mm氯化镁、mm edta、0.05%吐温-20和ph 8。在一些实施方案中,缓冲液包括小于1nm、小于5nm、小于10nm或小于15nm的氯化镁。
[0286]
在一些实施方案中,使用促进瞬时结合的多种条件。在一些实施方案中,一种条件用于一种探针种类,这取决于其tm,另一种条件用于另一种探针种类,这取决于其tm,依此类推,对于探针种类的完整库,例如,来自1024个可能的5-聚体的库的每个5-聚体种类。在一些实施方案中,仅提供了512个非互补5-聚体(例如,因为样品中存在两条靶多核苷酸链)。在一些实施方案中,每次探针添加都包含探针的混合物,所述探针包含5个特定碱基和2个简并碱基,(因此16个七聚体)所有这些碱基都用相同的标记物进行标记,就询问序列的能力而言,所述标记物起到一个五聚体的作用。简并碱基增加了稳定性,但未增加探针组的复杂性。
[0287]
在一些实施方案中,为共享相同或相似的tm的多个探针提供相同的条件。在一些此类实施方案中,库中的每个探针包含不同的编码标记物(或根据其鉴定所述探针的标记物)。在此类情况下,温度通过几次探针交换来保持,然后再升高以用于下一系列共享相同或相似tm的探针。
[0288]
在一些实施方案中,在探针结合期的过程中,改变温度,使得确定探针在多于一个温度下的结合行为。在一些实施方案中,进行解链曲线的模拟,其中与靶聚合物的结合行为或结合模式与通过选定范围(例如,从10℃到65℃或从1℃到35℃)的温度的逐步设定相关联。
[0289]
在一些实施方案中,例如,通过最近邻参数来计算tm。在其它实施方案中,tm是根据经验得出的。例如,最佳解链温度范围是通过进行解链曲线(例如,在一定温度范围内通过吸收测量解链的程度)而得出的。在一些实施方案中,探针组的组成是根据它们的理论匹配tm设计的,所述tm通过经验测试来验证。在一些实施方案中,结合在显著低于tm的温度下完成(例如,比计算的tm低高达33℃)。在一些实施方案中,根据经验确定的每个寡聚体的最佳温度用于测序中每个寡聚体的结合。
[0290]
在一些实施方案中,作为改变用于具有不同tm的寡核苷酸探针的温度的替代或除了改变用于具有不同tm的寡核苷酸探针的温度之外,改变探针和/或盐的浓度和/或改变ph。在一些实施方案中,表面上的电偏压在正与负之间反复切换,以主动促进探针与一个或多个靶分子之间的瞬时结合。
[0291]
在一些实施方案中,所用的寡聚体的浓度根据寡聚体序列的at对比gc的含量来调整。在一些实施方案中,为具有较高gc含量的寡聚体提供较高浓度的寡聚体。在一些实施方案中,使用浓度在2.5m与4m之间的平衡碱基组成的效应的缓冲液(例如,包含ctab、甜菜碱
或诸如四甲基氯化铵(tmacl)的高浓度离液剂(chatoropic reagent)的缓冲液)。
[0292]
在一些实施方案中,由于随机效应或测序室的设计方面的原因(例如,将探针捕获在纳米通道的角落或壁上的流动池中的涡流),探针不均匀地分布在样品(例如,流动室、载玻片、一种或多种多核苷酸的长度和/或多核苷酸的有序阵列)上。通过确保探针溶液的高效混合或搅拌来解决探针的局部耗尽。在一些情况下,这通过声波、通过在溶液中包含产生湍流的颗粒和/或通过构造流动池(例如,一个或多个表面上的人字形图案)以产生湍流来完成。另外,由于流动池中存在层流,通常很少混合,靠近表面的溶液与本体溶液几乎不混合。这在移除靠近表面的试剂/结合探针以及将新的试剂/探针带到表面时产生了问题。可以实施上述湍流产生方法来克服这一点,和/或可以在表面上方进行广泛的流体流动/交换。在一些实施方案中,在已将靶分子排列后,将非荧光珠或球附着到表面,赋予表面景观粗糙的纹理。这就产生了更高效地混合和/或交换靠近表面的流体所需的涡流和涌流(currents)。
[0293]
在一些实施方案中,将整个库或亚组一起添加。在一些此类实施方案中,使用平衡碱基组成效应的缓冲液(例如,tmacl或硫氰酸胍等,如美国专利申请号2004/0058349中所述的)。在一些实施方案中,将具有相同或相似tm的探针种类一起添加。在一些实施方案中,未对一起添加的探针种类进行差异标记。在一些实施方案中,对一起添加的探针种类进行差异标记。在一些实施方案中,差异标记物是具有拥有例如不同亮度、寿命或波长和/或此类物理特性的组合的发射的标记物。
[0294]
在一些实施方案中,将两种或更多种寡聚体一起使用,并且在没有区分不同寡聚体的信号的情况下(例如,寡聚体用相同的颜色标记)确定它们的结合位置。当双链体的两条链都可用时,从两条链获得结合位点数据允许区分两种或更多种寡核苷酸(作为组装算法的一部分)。在一些实施方案中,将一种或多种参考探针与库的每种探针一起添加,然后组装算法可使用此类参考探针的结合位置来支持或锚定序列组装。
[0295]
在一个替代实施方案中,探针稳定地结合,但将环境切换到关闭模式的外部触发器控制它们的瞬态。在非限制性实施方案中,触发器是导致探针解结合的热、ph、电场或试剂交换。然后环境切换回开启模式,允许探针再次结合。在一些实施方案中,当结合没有使第一轮结合中的所有位点饱和时,第二轮结合中的寡聚体与除第一轮外的不同组的位点结合。在一些实施方案中,这些循环以可控的速率进行多次。
[0296]
在一些实施方案中,瞬时结合持续小于或等于1毫秒、小于或等于50毫秒、小于或等于500毫秒、小于或等于1微秒、小于或等于10微秒、小于或等于50微秒、小于或等于500微秒、小于或等于1秒、小于或等于2秒、小于或等于5秒或者小于或等于10秒。
[0297]
由于瞬时结合方法确保了新的探针的连续供应,荧光团的光漂白不会引起重大问题,并且不需要复杂的视场光阑或powell透镜来限制照明。因此,荧光团的选择(或抗衰减(antifade)、氧化还原系统的提供)不是那么重要,并且在一些此类实施方案中,构建相对简单的光学系统(例如,f-光阑(其防止不在照相机视野内的分子的照射)将不是高要求)。
[0298]
在一些实施方案中,瞬时结合的另一个有利方面是可以在沿着多核苷酸的每个结合位点进行多次测量,因此提高了在检测准确性方面的可信度。例如,在一些情况下,由于分子过程的典型随机性质,探针与不正确的位置结合。对于瞬时结合的探针,这种异常的、孤立的结合事件可被丢弃,并且为了序列测定的目的,只有那些被多个检测到的相互作用
证实的结合事件才被接受为有效的检测事件。
[0299]
瞬时结合的检测以及结合位点的定位。
[0300]
瞬时结合是实现亚衍射水平定位的整体组成部分。在任何时候,瞬时结合探针组中的每个探针都有可能与靶分子结合或者存在于溶液中。因此,不是所有的结合位点在任一时刻都被探针结合。这允许在比光的衍射极限更近的位点检测结合事件(例如,靶分子上相距仅10nm的两个位点)。例如,如果序列aagctt在60个碱基后重复,这意味着重复的序列将相距约20nm(当靶标被拉长并拉直至watson-crick碱基长度为约0.34nm时)。光学成像通常无法分辨20纳米。然而,如果探针在成像期间的不同时间与所述两个位点结合,则它们被单独检测到。这允许结合事件的超分辨成像。纳米级精确度对于分辨重复和确定它们的数量特别重要。
[0301]
在一些实施方案中,靶中某一位置的多个结合事件不是来自单个探针序列,而是通过分析来自库的数据并考虑部分重叠序列中发生的事件来确定的。在一个实例中,相同的(实际上是亚纳米量级的接近)位置被探针attaag和ttaagc结合,所述探针是共享共同的5个碱基的序列的6-聚体,并且每个6聚体将验证另一个,以及在5个碱基的任一侧使序列延伸一个碱基。在一些情况下,5个碱基的序列每一侧的碱基是错配的(通常预期末端的错配比内部的错配更能被容忍),并且只有两个结合事件中存在的5个碱基的序列被验证。
[0302]
在一些替代实施方案中,通过非光学方法检测瞬时单分子结合。在一些实施方案中,非光学方法是电法。在一些实施方案中,通过非荧光方法检测瞬时单分子结合,其中没有直接激发方法,而是使用生物发光或化学发光机制。
[0303]
在一些实施方案中,靶核酸中的每个碱基由其序列重叠的多个寡聚体来询问。每个碱基的该重复取样允许检测靶多核苷酸中罕见的单核苷酸变异或突变。
[0304]
本公开的一些实施方案考虑了每个寡核苷酸与被分析的多核苷酸的结合相互作用(高于阈值结合持续时间)的库。在一些实施方案中,测序不仅包括从完全匹配中拼接或重建序列,而且还通过首先分析每个寡聚体的结合倾向来获得序列。在一些实施方案中,瞬时结合被记录为检测手段,但不用于提高定位。
[0305]
检测光学活性和确定结合位点的定位的成像技术。
[0306]
块214。使用二维成像器测量在暴露期间发生的每个相应的光学活性实例在测试基板上的位置和持续时间。
[0307]
测量测试基板上的位置包括将通过二维成像器测量的数据帧输入到经训练的卷积神经网络中。数据帧包括多个光学活性实例中的相应的光学活性实例。多个光学活性实例中的每个光学活性实例对应于与固定的第一链或固定的第二链的一部分结合的单个探针,以及响应于输入,经训练的卷积神经网络鉴定多个光学活性实例中的一个或多个光学活性实例中的每一个在测试基板上的位置。
[0308]
在一些实施方案中,检测器是二维检测器,并且结合事件被定位至纳米级准确性(例如,通过使用单分子定位算法)。在一些实施方案中,相互作用特征包括每个结合事件的持续时间,其对应于一种或多种探针与分子的亲和力。在一些实施方案中,所述特征是表面或基质上的位置,其对应于特定分子(例如,对应于特定基因序列的多核苷酸)的阵列中的位置。
[0309]
在一些实施方案中,每个相应的光学活性实例具有满足预定阈值的观察度量。在
一些实施方案中,观察度量包括持续时间、信噪比、光子计数或强度。在一些实施方案中,当针对一帧观察到相应的光学活性实例时,满足了预定阈值。在一些实施方案中,相应的光学活性实例的强度相对较低,并且当针对十分之一帧观察到相应的光学活性实例时,满足了预定阈值。
[0310]
在一些实施方案中,预定阈值区分(i)第一结合形式和(ii)第二结合形式,在所述第一结合形式中独特的n聚体序列的每个残基与核酸的固定的第一链或固定的第二链中的互补碱基结合,在所述第二结合形式中独特的n聚体序列与核酸的固定的第一链或固定的第二链中的序列之间存在至少一个错配,相应的寡核苷酸探针已与核酸的所述固定的第一链或所述固定的第二链中的序列结合以形成相应的光学活性实例。
[0311]
在一些实施方案中,所述寡核苷酸探针组中的每个相应的寡核苷酸探针都具有其自己相应的预定阈值。
[0312]
在一些实施方案中,基于在沿着多核苷酸的特定位置处观察1个或多个、2个或更多个、3个或更多个、4个或更多个、5个或更多个、或6个或更多个结合事件来确定预定阈值。
[0313]
在一些实施方案中,所述寡核苷酸探针组中每个相应的寡核苷酸探针的预定阈值来自训练数据集(例如,烟灰缸自通过将该方法应用于λ噬菌体测序而获得的信息的数据集)。
[0314]
在一些实施方案中,所述寡核苷酸探针组中的每个相应的寡核苷酸探针的预定阈值源自训练数据集。对于所述寡核苷酸探针组中的每个相应的寡核苷酸探针,所述训练集包括对在与参考序列结合时相应的寡核苷酸探针的观察度量的测量值,与参考序列的结合使得所述相应的寡核苷酸探针的独特n聚体序列的每个残基与参考序列中的互补碱基结合。
[0315]
在一些实施方案中,将参考序列固定在参考基板上。在一些实施方案中,将参考序列包含在所述核酸中并固定在测试基板上。在一些实施方案中,参考序列包含phix174、m13、λ噬菌体、t7噬菌体、大肠杆菌、酿酒酵母或粟酒裂殖酵母的基因组的全部或一部分。在一些实施方案中,参考序列是已知序列的合成构建体。在一些实施方案中,参考序列包含兔珠蛋白rna的全部或一部分(例如,当核酸包含rna时或当只对多核苷酸的一条链进行测序时)。
[0316]
在一些实施方案中,暴露是在呈嵌入染料形式的第一标记物存在的情况下进行的。所述寡核苷酸探针组中的每个寡核苷酸探针都与第二标记物结合。第一标记物和第二标记物具有重叠的供体发射和受体激发光谱,当第一标记物和第二标记物彼此非常接近时,使得第一标记物和第二标记物之一发出荧光。相应的光学活性实例来自嵌入染料与第二标记物的接近,所述嵌入染料嵌入寡核苷酸与固定的第一链或固定的第二链之间的相应的异源双链体中。在一些实施方案中,暴露和荧光包括共振能量转移(fret)方法。在此类实施方案中,嵌入染料包含fret供体,并且第二标记物包含fret受体。
[0317]
在一些实施方案中,通过fret从嵌入染料至探针或靶序列上的标记物来检测信号。在一些实施方案中,在靶标被固着后,所有靶分子的末端被标记,例如,通过末端转移酶掺入作为fret配偶体的荧光标记的核苷酸。在一些此类实施方案中,探针在其一个末端用cy3b或atto 542标记物进行标记。
[0318]
在一些实施方案中,fret被光激活代替。在此类实施方案中,供体(例如,模板上的
标记物)包含光激活剂,而受体(例如,寡核苷酸上的标记物)变成呈失活或暗化状态的荧光团(例如,在荧光成像实验之前,可通过用1mg/ml nabh4(于20mm tris ph 7.5,2mm edta和50mm nacl中)笼住cy5标记物来使其变暗)。在此类实施方案中,当非常接近激活剂时,变暗的荧光团的荧光被打开。
[0319]
在一些实施方案中,暴露是在呈嵌入染料(例如,光激活剂)形式的第一标记物存在的情况下进行的。所述寡核苷酸探针组中的每个寡核苷酸探针都与第二标记物(例如,暗化的荧光团)结合。当第一标记物和第二标记物彼此非常接近时,第一标记物使第二标记物发出荧光。相应的光学活性实例来自嵌入染料与第二标记物的接近,所述嵌入染料嵌入寡核苷酸与固定的第一链或固定的第二链之间的相应的异源双链体中。
[0320]
在一些实施方案中,暴露是在呈嵌入染料(例如,暗化的荧光团)形式的第一标记物存在的情况下进行的。所述寡核苷酸探针组中的每个寡核苷酸探针都与第二标记物(例如,光激活剂)结合。当第一标记物和第二标记物彼此非常接近时,第二标记物使第一标记物发出荧光。相应的光学活性实例来自嵌入染料与第二标记物的接近,所述嵌入染料嵌入寡核苷酸与固定的第一链或固定的第二链之间的相应的异源双链体中。
[0321]
在一些实施方案中,暴露是在嵌入染料存在的情况下进行的。相应的光学活性实例来自嵌入寡核苷酸与固定的第一链或固定的第二链之间的相应的异源双链体的嵌入染料的荧光,其中相应的光学活性实例大于嵌入染料在其嵌入相应的异源双链体之前的荧光。嵌入双链体的一种或多种染料的荧光增加(100倍或更多),为单分子定位算法提供点源样信号,并允许精确确定结合位点的位置。嵌入染料嵌入到双链体中,为每个结合位点产生大量的异双链体结合事件,所述结合事件被强有力地检测和精确定位。
[0322]
在一些实施方案中,所述寡核苷酸探针组中的相应的寡核苷酸探针通过与固定的第一链的互补部分结合而产生第一光学活性实例,通过与固定的第二链的互补部分结合而产生第二光学活性实例。在一些实施方案中,固定的第一链的一部分通过其互补寡核苷酸探针的结合产生光学活性实例,而与固定的第一链的一部分互补的固定的第二链的一部分通过其互补寡核苷酸探针的结合产生另一个光学活性实例。
[0323]
在一些实施方案中,所述寡核苷酸探针组中的相应的寡核苷酸探针通过与固定的第一链的两个或更多个互补部分结合而产生两个或更多个第一光学活性实例,通过结合固定的第二链的两个或更多个互补部分结合而产生两个或更多个第二光学活性实例。
[0324]
在一些实施方案中,相应的寡核苷酸探针在暴露过程中与固定的第一链或固定的第二链的与所述相应的寡核苷酸探针互补的部分结合3次或更多次,从而产生3个或更多个光学活性实例,每个光学活性实例代表多个结合事件中的一个结合事件。
[0325]
在一些实施方案中,相应的寡核苷酸探针在暴露过程中与固定的第一链或固定的第二链的与所述相应的寡核苷酸探针互补的部分结合5次或更多次,从而产生5个或更多个光学活性实例。每个光学活性实例代表多个结合事件中的一个结合事件。
[0326]
在一些实施方案中,相应的寡核苷酸探针在暴露过程中与固定的第一链或固定的第二链的与所述相应的寡核苷酸探针互补的部分结合10次或更多次,从而产生10个或更多个光学活性实例,每个光学活性实例代表多个结合事件中的一个结合事件。
[0327]
在一些实施方案中,暴露发生5分钟或更短时间,4分钟或更短时间,3分钟或更短时间,两分钟或更短时间,或一分钟或更短时间。
[0328]
在一些实施方案中,暴露发生在二维成像器的1个或多个帧上。在一些实施方案中,暴露发生在二维成像器的2个或更多个帧上。在一些实施方案中,暴露发生在二维成像器的500个或更多个帧上。在一些实施方案中,暴露发生在二维成像器的5,000个或更多个帧上。在一些实施方案中,当光学活性稀疏时(例如,探针结合的情况很少),一帧瞬时结合足以定位信号。
[0329]
在一些实施方案中,暴露的实例的时间长度由暴露的实例中使用的寡核苷酸探针组中相应的寡核苷酸探针的估计的解链温度确定。
[0330]
在一些实施方案中,光学活性包括来自标记物的荧光发射。激发相应的标记物,并使用滤光轮中不同的滤光器分别检测相应的发射波长。在一些实施方案中,使用荧光寿命成像(flim)系统来测量发射寿命。或者,波长被分割并投射到单个传感器的不同象限或四个单独的传感器上。lundquit等人,opt lett.,33:1026-8,2008已描述了使用棱镜在ccd的像素上分割光谱的方法。在一些实施方案中,也使用摄谱仪。或者,在一些实施方案中,将发射波长与亮度水平相结合,以提供关于探针在结合位点的停留时间的信息。
[0331]
当在检测平面中拉长多核苷酸分子时,几种检测方法,诸如扫描探针显微镜(包括高速原子力显微镜)和电子显微镜,能够分辨纳米级距离。然而,这些方法没有提供关于荧光团的光学活性的信息。有多种光学成像技术可以以超分辨精度检测荧光分子。这些包括受激发射损耗(sted)、随机光学重建显微术(storm)、超分辨光学波动成像(sofi)、单分子定位显微术(smlm)和全内反射荧光(tirf)显微术。在一些实施方案中,最类似于纳米级形貌(paint)中的点累积的smlm方法是优选的。这些方法通常需要一个或多个激发荧光团的激光器、焦点检测/保持机构、ccd摄像机、合适的物镜、中继透镜和反射镜。在一些实施方案中,检测步骤包括获取多个图像帧(例如,电影或视频)来记录探针的结合和脱离。
[0332]
smlm方法依赖高光子计数。高光子计数提高了高斯图案的生成的荧光团的质心的确定精度,但对高光子计数的需求也与长图像采集和对明亮且光稳定的荧光团的依赖相关。通过使用淬灭的探针分子信标,或具有两个或更多个相同类型的标记物,例如在寡聚体的每一侧各有一个,可以实现探针的高溶液浓度,而不会造成有害的背景。在此类实施方案中,通过染料-染料相互作用在溶液中淬灭这些标记物。然而,当与它们的靶标结合时,标记物开始分离,并且能够发出明亮的荧光(例如,亮度为单一染料的两倍),使得它们更容易被检测。
[0333]
在一些实施方案中,通过增加探针浓度、升高加温度或增加分子拥挤度(例如,通过在溶液中包含peg 400、peg 800等)来操纵(例如,增加)探针的结合速率。通过工程化其探针的化学成分,添加去稳定附件,或者在寡核苷酸的情况下,缩短其长度来降低探针的热稳定性,可以增加解离速率。在一些实施方案中,还通过升高温度、降低盐浓度(例如,提高严格性)或改变ph来加速解离速率。
[0334]
在一些实施方案中,通过使探针在它们结合之前基本上无荧光来增加所用探针的浓度。做到这一点的一个方法是,结合引发光激活事件。另一个是在结合发生之前淬灭标记物(例如,分子信标)。另一个是将信号检测为能量转移事件(例,fret、cret、bret)的结果。在一个实施方案中,表面上的生物聚合物具有供体,并且探针具有受体),反之亦然。在另一个实施方案中,在溶液中提供嵌入染料,并且在标记的探针结合时,在嵌入染料与探针之间存在fret相互作用。嵌入染料的实例是yoyo-1,探针上标记物的实例是atto 655。在另一个
实施方案中,嵌入是在没有fret机制的情况下使用的染料-表面上的单链靶序列和探针序列都是未标记的,并且只有当结合产生嵌入染料所嵌入的双链时才检测到信号。嵌入染料,取决于其身份,当其未嵌入dna中并且在溶液中处于游离状态时,亮度要低至1/100或1/1000。在一些实施方案中,tirf或大入射角光学薄层照明成像(highly inclined and laminated optical)(hilo)(例如,如mertz等人,j.of biomedical optics,15(1):016027,2010中所描述的)显微镜用于消除溶液中嵌入染料的任何背景信号。
[0335]
然而,在一些实施方案中,高浓度的标记探针导致高背景荧光,这使得表面上的信号检测变得模糊。在一些实施方案中,这通过用dna染色剂或嵌入染料来标记在表面上形成的双链体来解决。当靶标为单链或单链探针时,染料都不会嵌入,但当探针与靶之间形成双链体时,染料会嵌入。在一些实施方案中,探针是未标记的,并且检测到的信号仅仅是由嵌入染料导致的。在一些实施方案中,探针用作为嵌入染料或dna染色剂的fret伴侣的标记物标记。在一些实施方案中,嵌入染料是供体并与不同波长的受体偶联,因此允许探针被多个荧光团编码。
[0336]
在一些实施方案中,检测步骤涉及检测针对每个互补位点的多个结合事件。在一些实施方案中,多个事件来自相同探针分子的结合或不结合,或者被具有相同特异性的另一种分子(例如,其对相同的序列或分子结构具有特异性)替代,并且这发生多次。在一些实施方案中,结合的结合速率或解离速率不受改变条件的影响。例如,结合和解离均在相同的条件(例如,盐浓度、温度等)下发生,并且是由于探针-靶标相互作用弱导致的。
[0337]
在一些实施方案中,测序是通过对单个靶多核苷酸上的多个位置处的多个开关结合事件成像来进行的,所述单个靶多核苷酸比探针的长度短、与探针的长度相同或在探针长度的数量级内。在此类实施方案中,将较长的靶多核苷酸片段化,或者已预先选择一小组片段并将其排列在表面上,使得每个多核苷酸分子是可单独分辨的。在这些情况下,探针与特定位置结合的频率或持续时间用于确定探针是否对应于靶序列。探针结合的频率或持续时间决定了探针是对应于靶序列的全部还对应于其部分(其余碱基是错配的)。
[0338]
在一些实施方案中,通过增加来自dna染色的荧光来检测靶多核苷酸之间并排重叠的发生。在不使用染色剂的一些实施方案中,通过沿着节段的表观结合位点频率的增加来检测重叠。例如,在衍射极限分子在光学上似乎重叠但实际上并不物理重叠的一些情况下,如本公开中其它地方所述,使用单分子定位来对它们进行超解析。在端对端重叠确实发生的情况下,在一些实施方案中,标记多核苷酸末端的标记物被用于区分并列的多核苷酸与真实的连续长度。在一些实施方案中,如果预期基因组有许多拷贝,并且只发现一个表观嵌合体存在,则此类光学嵌合体被认为是假象。同样,在分子末端(衍射极限的)光学上看起来重叠但物理上不重叠的一些实施方案中,它们通过本公开的方法解决。在一些实施方案中,位置确定如此精确,以至于可分辨出从非常接近的标记物发出的信号。
[0339]
在一些实施方案中,测序是通过对单个靶多核苷酸上的多个位置处的多个开关结合事件成像来进行的,所述单个靶多核苷酸比探针长。在一些实施方案中,确定探针结合事件在单个多核苷酸上的位置。在一些实施方案中,探针结合事件在单个多核苷酸上的位置是通过拉长靶多核苷酸来确定的,使得可检测和分辨沿其长度的不同位置。
[0340]
在一些实施方案中,区分未结合的探针的光学活性与已经与靶分子结合的探针的光学活性需要拒绝或去除来自未结合的探针的信号。在一些此类实施方案中,这是使用例
如用于照明的渐逝场或波导或者通过利用fret对标记物或者通过利用光激活来检测特定位置中的探针来完成的(例如,如hylkje等人,biophys j.2015;108(4):949
–
956中所描述的)。
[0341]
在一些实施方案中,探针未被标记,但与靶标的相互作用通过诸如嵌入染料1302的dna染色来检测,所述嵌入染料1302嵌入双链体中,并且随着结合的发生或已经发生而开始发荧光1304(例如,如图13a-13c所示)。在一些实施方案中,一种或多种嵌入染料在任一时间嵌入双链体中。在一些实施方案中,嵌入染料一旦被嵌入,其发射的荧光比由于嵌入染料在溶液中自由漂浮而产生的荧光强几个数量级。例如,来自嵌入的yoyo-1染料的信号比来自溶液中游离的yoyo-1染料的信号强约100倍。在一些实施方案中,当对轻度染色的(或部分光漂白的)双链多核苷酸成像时,沿着多核苷酸观察到的单个信号可能对应于单个嵌入染料分子。在一些实施方案中,为了促进yoyo-1染料在双链体中的交换并获得明亮的信号,在结合缓冲液中提供了包含甲基紫精和抗坏血酸的氧化还原-氧化系统(rox)。
[0342]
在一些实施方案中,通过检测用单个染料分子标记的核苷酸的掺入对单个分子进行测序(例如,如在helicos和pacbio测序中所进行的那样),当未检测到染料时,会引入错误。在一些情况下,这是因为染料已被光漂白,由于染料闪烁,检测到的累积信号很弱,染料发射太弱,或者染料进入长时间黑暗的光物理状态。在一些实施方案中,这可通过多种替代方式来克服。第一种方法是用具有良好光物理性质的强劲的单独染料(例如,cy3b)来标记染料。另一种是提供缓冲条件和添加剂,以减少光漂白和暗光物理状态(例如,β-巯基乙醇、trolox、维生素c及其衍生物、氧化还原系统)。另一种方法是最大程度地减少暴露(例如,使用要求较短暴露时间的更灵敏的探测器或提供频闪照明)。第二种是用纳米颗粒诸如量子点(例,qdot 655)、荧光球、纳米金刚石、等离子共振颗粒、光散射颗粒等而非单一染料来进行标记。另一种是使每个核苷酸具有许多染料,而不是一种染料(例如,如图14c和图14d所示)。在这种情况下,将多种染料1414以最小化其自淬灭的方式组织(例如,使用刚性纳米结构1412,诸如将它们间隔足够远的dna折纸),或者通过刚性接头线性间隔。
[0343]
在一些实施方案中,在溶液中存在一种或多种选自尿素、抗坏血酸或其盐以及异抗坏血酸或其盐、β-巯基乙醇(bme)、dtt、氧化还原系统或trolox的化合物的情况下,检测错误率进一步降低(并且信号寿命增加)。
[0344]
在一些实施方案中,探针仅与靶分子的瞬时结合就足以减少由于染料光物理引起的误差。成像步骤中获得的信息是携带不同标记物的探针的许多开/关相互作用的集合。因此,即使一个标记物被光漂白或处于黑暗状态,落在分子上的其它结合探针上的标记物也不会被光漂白或处于黑暗状态,因此在一些实施方案中,将提供关于它们的结合位点位置的信息。
[0345]
在一些实施方案中,来自每个瞬时结合事件中的标记物的信号通过光路(通常,提供放大系数)投射,以覆盖2d检测器的一个以上的像素。绘制了信号的点扩展函数(psf),并将psf的质心作为信号的精确位置。在一些实施方案中,这种定位可进行至亚衍射(例如,超分辨率),甚至亚纳米精度。定位精度与收集的光子数成反比。因此,荧光标记物每秒发射的光子越多,或者收集光子的时间越长,精度就越高。
[0346]
在一个实例中,如图10a和图10b所示,每个结合位点处的结合事件数和收集的光子数都与实现的定位程度相关。对于靶聚合物1002,针对结合位点记录的最少数量的结合
事件1004-1和最少数量的光子1008-1分别与最不精确的定位1006-1和1010-1相关。随着对于结合位点的结合事件1004-2、1004-3的数量或记录的光子1008-2、1008-3的数量增加,对于1006-2、1006-3以及1010-2、1010-3的定位程度也分别增加。在图10a中,不同数量的标记探针在多核苷酸1002上的检测到的随机结合事件(例如,1004-1、1004-2、1004-4)导致探针(1006-1、1006-2、1006-3)的不同程度的定位,其中较大数量的结合事件(例如,1004-2)与更高程度的定位(例如,1006-2)相关,并且较小数量的结合事件(例如,1004-1)与较低程度的定位(例如,1006-1)相关。在图10b中,不同数量的检测到的光子(例如,1008-1、1008-2和1008-3)类似地导致不同程度的定位(分别为1010-1、1010-2和1010-3)。
[0347]
在替代实施方案中,来自每个瞬时结合事件中的标记物的信号不通过光学放大路径投射。相反,将基板(通常是靶分子所在的光学透明表面)直接偶联至二维检测器阵列。当检测器阵列的像素很小(例如,1平方微米或更小)时,信号在表面上的一对一投影允许结合信号以至少1微米的精度被定位。在核酸已经被充分拉伸(例如,多核苷酸的2000个碱基已经被拉伸至1微米长)的一些实施方案中,仅相距2000个碱基的信号被解析。例如,在预期信号每4096个碱基或每2微米出现一次的6聚体探针的情况下,该分辨率将足以明确地定位单个结合位点。部分落在两个像素之间的信号提供了中间位置(例如,如果信号落在两个像素之间,则对于1平方微米的像素,分辨率可以是500nm)。在一些实施方案中,可将基板相对于二维阵列检测器物理平移(例如,以100nm的增量)以提供更高的分辨率。在此类实施方案中,设备更小(或更薄),因为其不需要透镜或透镜之间的空间。在一些实施方案中,基板的平移还提供了分子存储读出至与现有计算机和数据库更兼容的电子读出的直接转换。
[0348]
在一些实施方案中,为了捕获高速瞬时结合,增加捕获帧的速率,并且数据传输速率相对于标准显微技术增加。在一些实施方案中,通过将高帧检测与增加的探针浓度相结合来提高过程的速度。然而,个体暴露保持在最小阈值暴露,以降低与每次暴露相关的电子噪声。200毫秒暴露的累积电子噪声将小于两次100毫秒的暴露。
[0349]
更快的cmos照相机正在变得可用,这将实现更快的成像。例如,andor zyla plus在512x 1024平方像素的范围内仅通过一个usb3.0连接每秒可支持398帧,在受限目标区域(roi)内或通过cameralink连接甚至更快。
[0350]
获得快速成像的替代方法是使用检流计反射镜或数字微镜向不同的传感器发送时间增量图像。然后,根据它们的采集时间,通过交错来自不同传感器的帧来重构影片帧的正确顺序。
[0351]
通过调谐各种生化参数,诸如盐浓度,可以加速瞬时结合过程。有许多具有高帧频的相机可用来匹配结合的速度,通常视场被限制从像素亚组获得更快的读出。一种替代方法是使用检流计反射镜将连续信号临时分布到单个传感器的不同区域或分离传感器。后者允许利用传感器的全部视场,但在汇编分布式信号时增加了总的时间分辨率
[0352]
构建多个结合事件的数据集。
[0353]
块218。对所述寡核苷酸探针组中的相应的寡核苷酸探针重复暴露和测量,从而获得测试基板上的多组位置,测试基板上的每个相应组的位置对应于所述寡核苷酸探针组中的寡核苷酸探针。
[0354]
在一些实施方案中,所述寡核苷酸探针组包含多个所述寡核苷酸探针亚组,并且对多个寡核苷酸探针亚组中的每个相应的寡核苷酸探针亚组进行重复、暴露和测量。
[0355]
在一些实施方案中,每个相应的寡核苷酸探针亚组包含来自所述寡核苷酸探针组的两种或更多种不同的探针。在一些实施方案中,每个相应的寡核苷酸探针亚组包含来自所述寡核苷酸探针组的四种或更多种不同的探针。在一些实施方案中,寡核苷酸探针组由四个寡核苷酸探针亚组组成。
[0356]
在一些实施方案中,该方法还包括基于每个寡核苷酸探针的计算的或通过实验获得的解链温度,将所述寡核苷酸探针组划分成多个寡核苷酸探针亚组。通过划分,将具有相似解链温度的寡核苷酸探针置于相同的寡核苷酸探针亚组中。另外,暴露实例的温度或持续时间由相应的寡核苷酸探针亚组中的寡核苷酸探针的平均解链温度确定。
[0357]
在一些实施方案中,该方法还包括基于每个寡核苷酸探针的序列将所述寡核苷酸探针组划分成多个寡核苷酸探针亚组,其中将具有重叠序列的寡核苷酸探针置于不同的亚组中。
[0358]
在一些实施方案中,对所述寡核苷酸探针组中的每个单个寡核苷酸探针进行重复暴露和测量。
[0359]
在一些实施方案中,在第一温度下对所述寡核苷酸探针组中的第一寡核苷酸探针进行暴露,并且重复暴露和测量包括在第二温度下对第一寡核苷酸进行暴露和测量。
[0360]
在一些实施方案中,在第一温度下对所述寡核苷酸探针组中的第一寡核苷酸探针进行暴露。重复暴露和测量的实例包括在多个不同温度的每个温度下对第一寡核苷酸进行暴露和测量。该方法还包括使用光学活性的测量的位置和持续时间(通过针对第一温度和多个不同温度中的每个温度的测量而记录的)来构建第一寡核苷酸探针的解链曲线。
[0361]
在一些实施方案中,在重复暴露和测量之前,洗涤测试基板,从而在将测试基板暴露于另一个寡核苷酸探针组之前,从测试基板移除一种或多种相应的寡核苷酸探针。任选地,首先用一种或多种清洗溶液替换探针,然后添加下一组探针。
[0362]
在一些实施方案中,测量测试基板上的位置包括用拟合函数鉴定和拟合相应的光学活性实例,以鉴定和拟合通过二维成像器获得的数据帧中的相应的光学活性实例的中心。相应的光学活性实例的中心被认为是相应的光学活性实例在测试基板上的位置。
[0363]
在一些实施方案中,拟合函数是高斯函数、第一矩函数、基于梯度的方法或傅立叶变换。高斯拟合将仅仅是显微镜的psf的近似,但在一些实施方案中,样条(例如,三次样条)或傅立叶变换方法的添加用于提高确定psf的质心的精确度(例如,如babcock等人,sci rep.7:552,2017和zhang等人,46:1819-1829,2007中描述的)。
[0364]
在数据处理之后,单分子定位鉴定(例如,由于检测到的颜色)组1-5中的哪些探针在多核苷酸上具有相同的定位足迹(例如,其与相同的纳米位级置结合)。在一个实例中,纳米级位置以1nm中心(+/-0.5nm)的精度来定义,并且其psf的质心落在相同的1nm内的所有探针将因此被装箱在一起。每个单个定义的寡聚体种类必须结合多次(例如,取决于发射和收集的光子的数量),以使得能够精确定位至纳米(或亚纳米)质心。
[0365]
在一些实施方案中,纳米级或亚纳米级定位确定,例如,对于5
′‑
agtcg-3
′
的寡聚体序列,第一碱基是a,第二碱基是g,第三碱基是t,第四碱基是c,第五碱基是t。这种模式暗示了5
′‑
cgact-3
′
的靶序列。因此,仅在5个循环中应用或测试所有单碱基定义的1024个5-聚体寡聚探针,其中每个循环包括寡聚体添加和洗涤步骤。在此类实现中,组中每种特定的寡聚体的浓度低于单独使用时的浓度。在这种情况下,为了达到结合事件的阈值数量,数据
的获取需要更长的时间。此外,在一些实施方案中,使用比特定寡聚体更高浓度的简并寡聚体。在一些实施方案中,这种编码方案通过探针的直接标记来实现,例如,通过在寡聚体的3’或5’处合成或结合标记物。然而,在一些替代实施方案中,这是通过间接标记来完成的(例如,通过将襟翼序列连接至每个标记的寡聚体)。
[0366]
在一些实施方案中,每个寡聚体的位置通过确定该位置的多个事件的psf来精确定义,然后通过来自偏移事件的部分序列重叠(以及在可用的情况下,来自双链体互补链的数据)来证实。该实施方案高度依赖于达到1或数纳米的探针结合的单分子定位。
[0367]
在一些实施方案中,相应的光学活性实例在通过二维成像器测量的多个帧上持续。测量测试基板上的位置包括在多个帧上用拟合函数鉴定和拟合相应的光学活性实例,以鉴定多个帧上的相应的光学活性实例的中心。相应的光学活动实例的中心被认为是多个帧上的相应的光学活动实例在测试基板上的位置。在一些实施方案中,拟合函数单独找到多个帧中每个帧的中心。在其它实施方案中,拟合函数可选择地在多个帧上共同找到每个帧上的中心。
[0368]
在一些实施方案中,拟合涉及跟踪步骤,其中如果定位在下一帧中紧邻(例如,在半个像素内),则将它们一起平均,按它们的亮度加权;假设这是同一结合定事件。然而,如果存在由多个帧分隔的事件(例如,结合事件之间有至少5帧间隙、至少10帧间隙、至少25帧间隙、至少50帧间隙或至少100帧间隙),则拟合函数假设它们是不同的结合事件。跟踪不同的结合事件有助于提高序列分配的可信度。
[0369]
在一些实施方案中,测量以至少20nm的定位精度将相应的光学活性实例的中心解析为测试基板上的位置。在一些实施方案中,测量以至少2nm、至少60nm或至少6nm的定位精度将相应的光学活性实例的中心解析为测试基板上的位置。在一些实施方案中,测量以2nm与100nm之间的定位精度将相应的光学活性实例的中心解析为测试基板上的位置。在一些实施方案中,测量将相应的光学活性实例的中心解析为测试基板上的位置,其中该位置是亚衍射极限位置。在一些实施方案中,分辨率比精度更具限制性。
[0370]
在一些实施方案中,测量相应的光学活性实例在测试基板上的位置和持续时间测量该位置处超过5000个光子。在一些实施方案中,测量相应的光学活性实例在测试基板上的位置和持续时间测量该位置处超过50,000个光子,或在该位置处测量了超过200,000个光子。
[0371]
每种染料都有其产生光子的最大速率(例如,1khz-1mhz)。例如,对于一些染料,1秒钟内只可能测量200,000个光子。染料的典型寿命是10纳秒。在一些实施方案中,测量相应的光学活性实例在测试基板上的位置和持续时间测量该位置处超过1,000,000个光子。
[0372]
在一些情况下,某些异常序列以非watson crick方式结合,或者短基序导致异常高的结合速率或异常低的解离速率。例如,rna与dna之间的一些嘌呤-聚嘧啶相互作用非常强(例如,rna基序诸如agg)。由于成核顺序更加稳定,这些序列不仅具有较低的解离速率,而且还具有较高的结合速率。在一些情况下,结合发生在不一定符合某些已知规则的异常值中。在一些实施方案中,算法用于鉴定此类异常值或考虑了此类异常值的预期。
[0373]
在一些实施方案中,相应的光学活性实例比对于测试基板观察到的背景高出预定数量的标准偏差(例如,超过3、4、5、6、7、8、9或10个标准偏差)。
[0374]
在一些实施方案中,对所述寡核苷酸探针组中的第一寡核苷酸探针进行暴露持续
第一时间段。在一些此类实施方案中,重复暴露和测量包括在对第二寡核苷酸进行暴露持续第二时间段。第一时间段长于第二时间段。
[0375]
在一些实施方案中,对寡核苷酸探针组中的第一寡核苷酸探针进行暴露持续二维成像器的第一帧数。在一些此类实施方案中,重复暴露和测量包括对第二寡核苷酸进行暴露持续二维成像器的第二帧数。所述第一帧数大于所述第二帧数。
[0376]
在一些实施方案中,一个或多个覆瓦组中的互补探针用于与变性双链体的每条链结合。如图11b所示,可能确定来自测试基板上的多组位置的核酸的至少一部分的序列,包括确定对应于固定的第一链1110的第一覆瓦式途径1114和对应于固定的第二链1112的第二覆瓦式途径1116。
[0377]
在一些实施方案中,使用第二平覆瓦式途径的相应部分来解决第一覆瓦式途径中的中断。在一些实施方案中,使用参考序列解决第一覆瓦式途径或第二覆瓦式途径中的中断。在一些实施方案中,使用从核酸的另一实例获得的第三覆瓦式途径或第四覆瓦式途径的相应部分来解决第一覆瓦式途径或第二覆瓦式途径中的中断。
[0378]
在一些实施方案中,使用第一覆瓦式途径和第二覆瓦式途径的相应部分来增加序列对于每个结合位点的序列分配的可信度。在一些实施方案中,使用从核酸的另一实例获得的第三覆瓦式途径或第四覆瓦式途径的相应部分来增加序列的序列分配的可信度。
[0379]
序列的比对或组装。
[0380]
块222。通过汇编由多组位置代表的测试基板上的位置,确定来自测试基板上的多组位置的核酸的至少一部分的序列。
[0381]
优选地,通过从头组装获得连续序列。然而,在一些实施方案中,参考序列也用于促进组装。这允许从头构建组件。当全基因组测序需要合成来自跨越基因组的相同节段的多个分子(理想情况下是来源于相同亲本染色体的分子)的信息时,需要算法来处理从多个分子获得的信息。一种算法是这种类型的算法:其基于多个分子之间共有的序列对分子进行对齐,并通过从覆盖该区域的共对齐分子中进行输入来填充每个分子中的缺口(例如,一个分子中的缺口被另一个共对齐分子中的读数覆盖)。
[0382]
在一些实施方案中,鸟枪组装法(例如,如schuler等人.,science 274:540-546,1996中所述)适于使用如本文所述获得的序列分配来进行组装。当前方法优于鸟枪测序的有利方面是:可对大量读数进行预组装,因为它们是从全长、完整的靶分子中收集的(例如,已经知道读数相对于彼此的位置,并且读数之间的缺口长度是已知的)。在各种实施方案中,参考基因组用于促进组装,其或具有长程基因组结构或具有短程多核苷酸序列或者两者兼备。在一些实施方案中,将读数部分从头组装,然后与参考序列对齐,然后将参考辅助的组件进一步从头组装。在一些实施方案中,各种参考组件用于为基因组组装提供一些指导。然而,在典型的实施方案中,从实际分子获得的信息(尤其是如果其被两个或更多个分子证实的话)的权重大于来自参考序列的任何信息。
[0383]
在一些实施方案中,基于靶标之间的序列重叠的节段,将从其获得序列位的靶标对齐,并产生较长的电子重叠群,最终产生整个染色体的序列。
[0384]
在一些实施方案中,多核苷酸的身份由沿其长度的探针结合模式决定。在一些实施方案中,身份是rna种类或rna同种型的身份。在一些实施方案中,身份是多核苷酸所对应的参考中的位置。
[0385]
在一些实施方案中,定位准确度或精确度不足以将序列位缝合在一起。在一些实施方案中,发现探针亚组结合在特定的局部内,但严格地从定位数据来看,在一些实施方案中,很难有把握地确定它们的顺序。在一些实施方案中,分辨率受衍射限制。在一些实施方案中,局部或衍射极限点内的短程序列通过位于局部或点内的探针的序列重叠来组装。因此,例如通过使用关于寡聚体亚组的单个序列如何重叠的信息,来组装短程序列。在一些实施方案中,然后基于以这种方式构建的短程序列在多核苷酸上的顺序将它们缝合在一起,成为长程序列。因此,通过结合从相邻或重叠点获得的短距离序列,获得了长程序列。
[0386]
在一些实施方案中(例如,对于为天然双链的靶多核苷酸),将参考序列和获得的互补链的序列信息用于促进序列分配。
[0387]
在一些实施方案中,核酸的长度为至少140个碱基,并且所述确定确定核酸序列的序列覆盖度大于70%。在一些实施方案中,核酸的长度为至少140个碱基,并且所述确定确定核酸序列的序列覆盖度大于90%。在一些实施方案中,核酸的长度为至少140个碱基,并且所述确定确定核酸序列的序列覆盖度大于99%。在一些实施方案中,所述确定确定核酸序列的序列覆盖度大于99%。
[0388]
非特异性或错配结合事件。
[0389]
通常,测序假设靶多核苷酸含有与结合的核苷酸互补的核苷酸。然而,情况并非总是如此。结合错配错误就是这种假设不成立的情况的一个实例。然而,当根据已知的规则或行为发生错配时,错配对于确定靶标的序列是有用的。使用短的寡核苷酸(例如,5-聚体)意味着单个错配对稳定性有很大影响,因为1个碱基是5-聚体长度的20%。因此,在适当的条件下,通过短寡探针可以获得高度特异性。即使如此,错配也可能发生,并且由于分子相互作用的随机性质,在一些情况下,它们的结合持续时间可能与所有5个碱基都是特异性的结合不可区分。然而,用于进行碱基(或序列)调用和组装的算法通常会考虑错配的发生。许多类型的错配是可预测的,并且符合某些规则。这些规则中的一些是通过理论考虑推导出来的,而其它规则是通过实验推导出来的(例如,如maskos和southern,nucleic acids res 21(20):4663
–
4669,2013;williams等人,nucleic acids res 22:1365-1367,1994所描述的)。
[0390]
由于探针与非特异性位点的结合的非持久性不是持久性的,因此与表面的非特异性结合的影响减轻,并且一旦一个成像器占据了非特异性(例如,不在互补靶序列上)结合位点,其就可被漂白,但在一些情况下保持在原位,阻止与该位置的进一步结合(例如,由于g-quartet形成而导致的相互作用)。通常,大多数非特异性结合位点(其阻碍了成像器与靶多核苷酸的结合的解析)在成像的早期阶段被占据和漂白,使得成像器与多核苷酸位点的开/关结合在此后易于观察。因此,在一个实施方案中,高激光功率用于漂白最初占据非特异性结合位点的探针,任选地,在该阶段不拍摄图像,然后任选地降低激光功率,并开始成像以捕获与多核苷酸的开-关结合。在最初的非特异性结合之后,进一步的非特异性结合不太频繁(因为已经漂白的探针经常保持粘附在非特异性结合位点上),并且在一些实施方案中,通过应用例如被认为是对对接位点的特异性结合的阈值来计算过滤掉,对同一位置的结合必须是持续的,例如应该在同一位点发生至少5次或更优选至少10次。通常,检测到约20个针对停靠位点的特异性结合事件。
[0391]
过滤掉非特异性结合的另一种方法是荧光团信号必须与在表面上拉伸的靶分子
的线性链的位置相关。在一些实施方案中,可通过直接染色线性链或通过在持久结合位点插入一条线来确定线性链的位置。通常,在一些实施方案中,不沿着线下降的信号,无论它们是否是持久的,都会被丢弃。类似地,当使用超分子网格时,在一些实施方案中,与网格的已知结构不相关的结合事件被丢弃。
[0392]
多重结合事件也增加了特异性。例如,从多个调用中获得共同有序列,而不是确定在单个“调用”中检测到的部分或序列的身份。此外,针对靶部分或序列的多个结合事件允许与实际位置的结合与非特异性结合事件相区别,其中(阈值持续时间的)结合不太可能在同一位置发生多次。还观察到,随着时间的推移,多个结合事件的测量允许非特异性结合事件积累到待漂白的表面上,之后几乎没有非特异性结合被再次检测到。这可能是因为尽管来自非特异性结合的信号被漂白了,但非特异性结合位点仍然被占据或阻断。
[0393]
在一些实施方案中,测序因多核苷酸上的错配和非特异性结合而变得复杂。为了规避非特异性结合或异常事件的影响,在一些实施方案中,该方法基于信号的位置和持久性来区分信号的优先级。由于位置而定的优先级基于探针是否共定位于例如拉伸的聚合物或超分子晶格(例如,dna折纸网格),包括晶格结构内的位置。由于结合的持久性而定的优先级关注结合的持续时间和结合的频率,并使用优先级列表来确定完全匹配、部分匹配或非特定结合的可能性。将针对小组或库中的每个结合探针建立的优先级用于确定信号的正确性。
[0394]
在一些实施方案中,通过确定信号持续时间是否大于预定阈值,信号重复或频率是否大于预定阈值,信号是否与靶分子的位置相关,和/或收集的光子数量是否大于预定阈值,将优先级用于促进信号验证和碱基调用。在一些实施方案中,当这些确定中的任一个的答案为真时,信号被接受为真实的(例如,如不是错配或非特异性结合事件)。
[0395]
在一些实施方案中,错配通过它们的时间结合模式来区分,因此被认为是序列信息的第二层。在此类实施方案中,当结合信号由于其时间结合特征而被判断为错配时,根据生物信息学修整序列位以去除假定的错配碱基,并且将剩余的序列位添加到序列重建中。由于错配最有可能发生在杂交寡聚体的末端,因此在一些实施方案中,根据时间结合特征,从末端修剪一个或多个碱基。在一些实施方案中,关于哪个碱基被修剪的决定是由来自相同序列空间上的其它寡核苷酸覆瓦的信息通知的。
[0396]
在一些实施方案中,对似乎是不可逆的信号进行权衡,因为其具有对应于非特定信号(例如,由于荧光污染物至表面的附着)的可能性或一定程度的可能性。
[0397]
块302-304。提供了另一种核酸测序的方法,其包括将核酸以线性化拉伸形式固定在测试基板上,从而形成固定的拉伸的核酸。根据上述方法中的任一种方法将核酸固定至基板上。
[0398]
在表面上分离单个细胞,提取dna和rna。
[0399]
可从单个细胞分离出rna或dna或者这两者,并对其进行测序。在一些实施方案中,当目标是对dna测序时,在测序开始之前向样品中施加rna酶。在一些实施方案中,当目标是对rna测序时,在测序开始之前向样品中施加dna酶。在一些实施方案中,当要对细胞质核酸和细胞核核酸都进行分析时,差异地或顺次地提取它们。在一些实施方案中,首先破坏细胞膜(而不是核膜)以释放和收集细胞质核酸。然后破坏核膜以释放出细胞核核酸。在一些实施方案中,将蛋白质和多肽收集作为细胞质级分的一部分。在一些实施方案中,将rna收集
作为细胞质级分的一部分。在一些实施方案中,将dna收集作为细胞核级分的一部分。在一些实施方案中,将细胞质和细胞核部分一起提取。在一些实施方案中,在提取后,差异地捕获了mrna和基因组dna。例如,通过附着至表面的寡聚dt探针捕获mrna。这可在流动池的第一部分发生,并且在具有疏水性乙烯基硅烷涂层的流动池的第二部分捕获dna,在该涂层上可以捕获dna的末端(例如,可能由于疏水相互作用)。
[0400]
已知带正电荷诸如多聚(l)赖氨酸(pll)的表面(例如,可从microsurfaces inc.获得的或在内部涂覆的)能够与细胞膜结合。在一些实施方案中,使用低高度的流动通道(例如,《30微米),使得细胞与表面碰撞的机会增加。在一些实施方案中,通过在流动池天花板中使用人字形图案来引入湍流,增加了碰撞的次数。在一些实施方案中,细胞附着不需要是高效的,因为在此类实施方案中,希望细胞以低密度分散在表面上(例如,确保细胞之间有足够的空间,使得从每个个体细胞提取的rna和dna将保持空间分离)。在一些实施方案中,使用蛋白酶处理使细胞破裂,使得细胞膜和核膜都被破坏(例如,使得细胞内含物被释放到培养基中并被捕获在分离的细胞附近的表面上)。在一些实施方案中,一旦被固定,dna和rna就被拉伸。在一些实施方案中,使拉伸缓冲液单向流过盖玻片表面(例如,导致dna和rna多核苷酸在流体流动的方向上拉伸和对齐)。在一些实施方案中,条件(例如,诸温度、拉伸缓冲液的组成和流动的物理力)的调节导致大部分的rna二级/三级结构变性,使得rna可用于结合抗体。一旦rna被拉伸,呈现变性的形式,就有可能从变性缓冲液转换成结合缓冲液。
[0401]
或者,首先通过破坏细胞膜并诱导单向流动来提取和固着rna。接着通过使用蛋白酶破坏核膜,并诱导其反向流动。在一些实施方案中,例如,通过使用稀有切割限制性内切酶(例如,not1、pmme1),在释放之前或之后将dna片段化。这种片段化有助于解开dna,并允许分离和梳理单条链。确保系统被设置成使得固着的细胞相隔足够远,使得从每个细胞提取的rna和dna不会相互混合。在一些实施方案中,这通过在细胞破裂之前、之后或期间诱导液体向凝胶转变来辅助。
[0402]
在一些实施方案中,核酸是双链核酸。在此类实施方案中,该方法还包括使固定的双链核酸在测试基板上变性为单链形式。为了进行测序,核酸必须呈单链形式。一旦固定的双链核酸变性,就获得了核酸的固定的第一链和固定的第二链两者。固定的第二链与固定的第一链互补。
[0403]
在一些实施方案中,核酸是单链rna的(例如,mrna、lncrna、微rna)。在核酸是单链rna的一些实施方案中,在测序方法进行之前不需要变性。
[0404]
在一些实施方案中,样品包含单链多核苷酸而无非常接近的天然互补链。在汇编了沿着多核苷酸的库中的每一个寡聚体的结合位置的一些实施方案中,通过根据它们的位置聚集所有序列位并将它们缝合在一起来重建序列。
[0405]
拉伸rna。
[0406]
带电荷的表面上的核酸的拉伸受溶液阳离子浓度的影响。在低盐浓度下,单链且沿其主链带有负电荷的rna将沿其长度与表面随机结合。
[0407]
有多种可能的方法使rna变性并拉伸成线性形式。在一些实施方案中,最初促使rna进入球状形式(例如,通过使用高盐浓度)。在一些此类实施方案中,每个rna分子的末端(例如,特别是poly a尾)变得更易于相互作用。在一些实施方案中,一旦rna以球状形式结
合,将不同的缓冲液(例如,变性缓冲液)施加到流动池中。
[0408]
在替代实施方案中,用寡聚d(t)预涂覆表面以捕获mrna的poly a尾(例如,如由ozsolak等人,cell 143:1018-1029,2010所描述的)。poly a尾通常是应该相对没有二级结构的区域(例如,因为它们是均聚物)。由于在高等真核生物poly a尾相对较长(250-3000个核苷酸),在一些实施方案中,长寡聚d(t)捕获探针被设计成使得杂交在相对高的严格性(例如,高温和/或盐条件)下进行,足以熔解rna中的大部分分子内碱基配对。在结合后,在一些实施方案中,通过使用不足以消除捕获但破坏rna中分子内碱基配对的变性条件,并通过流体流动或电泳力,完成rna结构的其余部分从球状转变成线性状态。
[0409]
块310。在一些实施方案中,将固定的拉伸的核酸暴露于寡核苷酸探针组中相应的寡核苷酸探针的相应库中。所述组寡核苷酸探针组中的每个寡核苷酸探针具有预定的序列和长度,暴露在允许相应的寡核苷酸探针的相应库中的单个探针与固定的核酸的与所述相应的寡核苷酸探针互补的每个部分瞬时且可逆地结合的条件下发生,从而产生相应的光学活性实例。
[0410]
块312。在一些实施方案中,使用二维成像器测量在暴露期间发生的每个相应的光学活性实例在测试基板上的位置和持续时间。
[0411]
块314。在一些实施方案中,对所述寡核苷酸探针组中的相应的寡核苷酸探针重复暴露和测量,从而获得测试基板上的多组位置,测试基板上的每个相应组的位置对应于所述寡核苷酸探针组中的寡核苷酸探针。
[0412]
块316。在一些实施方案中,通过汇编由多组位置代表的测试基板上的位置,确定来自测试基板上的多组位置的核酸的至少一部分的序列。
[0413]
rna测序。
[0414]
rna的长度通常比基因组dna短,但使用现有技术从一端到另一端对rna进行测序是一项挑战。然而,由于选择性剪接,确定mrna的全序列组织是至关重要的。在一些实施方案中,通过固着的寡聚d(t)结合其poly a尾部来捕获mrna,并通过施加的拉伸力(例如》400pn)和变性条件(例如,包含甲酰胺和或7m或8m脲)来去除其二级结构,从而使其在表面上伸长。这就允许结合试剂(例如,外显子特异性的)被瞬时结合。由于rna的长度较短,因此采用本公开中描述的单分子定位方法来解析和区分外显子是有益的。在一些实施方案中,仅分散在整个rna中的几个结合事件就足以为特定mrna同种型确定外显子在mrna中的顺序和身份。
[0415]
双链共有序列
[0416]
用于从样品分子获得序列信息的方法如下:
[0417]
i)提供具有第一颜色标记物的第一寡聚体。提供具有第二颜色标记物的第二寡聚体,其中所述第二寡聚体在序列上与第一寡聚体互补ii)在基板上使双链核酸分子伸长、固定和变性
[0418]
iii)将第一寡聚体和第二寡聚体暴露于ii的变性核酸。
[0419]
iv)确定第一寡聚体和第二寡聚体的结合位置
[0420]
v)当结合位置共定位时,所述位置被认为是正确的
[0421]
vi)沿着伸长的核酸的多个位置被结合。
[0422]
在一些实施方案中,寡聚体瞬时地且可逆地结合。在一些实施方案中,第一寡聚体
和第二寡聚体是给定长度的第一寡聚体和第二寡聚体的竞争库的一部分,对所述库的每个第一寡聚体和第二寡聚体对重复步骤ii-iii,以对整个核酸进行测序。
[0423]
在一些实施方案中,需要进行许多校正,以确保两种颜色在它们应该的时候在光学上共同定位。这包括校正色差。在一些此类实施方案中,该对中的两个寡聚体被一起添加,但为了防止它们彼此退火并因此而中和它们的作用,将经修饰的寡核苷酸化学与非自配对类似物碱基一起使用,其中经修饰的g不能与互补寡核苷酸中的经修饰的c配对,但可以与靶核酸上的未修饰的c配对,并且经修饰的a不能与互补寡核苷酸中的经修饰的t配对,但可以与未修饰的t配对,等等。因此,在此类实施方案中,修饰第一寡聚体和第二寡聚体,使得第一寡聚体不能与第二寡聚体形成碱基对。
[0424]
在一些实施方案中,不将第一寡聚体和第二寡聚体一起添加,而是依次添加。
[0425]
在此类实施方案中,一种寡聚体在另一种之后添加,在两者之间进行洗涤步骤;在这种情况下,用相同的颜色标记互补对的两个寡聚体,并且不需要校正色差。此外,这两种寡聚体也不可能相互结合。
[0426]
在一些实施方案中,将核酸暴露于另外的第一寡聚体和第二寡聚体,直至寡聚体的整个库被耗尽。
[0427]
在一些实施方案中,在第一寡聚体之后,添加第二寡聚体作为下一个寡聚体,然后添加库中的其它寡聚体对。在一些实施方案中,在添加库中的其它寡聚体对之前,不添加第二寡聚体作为下一个寡聚体。
[0428]
这种实施方案的实例包括如下用于从样品分子获得序列信息的方法:
[0429]
i)在基板上使双链核酸分子伸长、固定和变性
[0430]
ii)将第一标记的寡聚体暴露于i)的变性核酸,并检测和记录其结合位置
[0431]
iii)通过洗涤除去第一个标记的寡聚体
[0432]
iv)将第二标记的寡聚体暴露于i)的变性核酸,并检测和记录其结合位置
[0433]
v)任选地校正ii)与iv)的记录之间的偏移
[0434]
vi)当在ii-iv中获得的记录的结合位置共定位时,由此获得的关于该位置序列的序列信息被认为是正确的
[0435]
在一些实施方案中,第一寡聚体和第二寡聚体是给定长度的第一寡聚体和第二寡聚体的竞争库的一部分,对所述库的每个第一寡聚体和第二寡聚体对重复步骤ii-iii,以对整个核酸进行测序。
[0436]
共定位告知序列基因座是否相同。另外,靶向有义链的探针可期待使用4个差异标记的寡聚体来区分中心碱基,而靶向反义链的探针可期待使用4个具有与有义链的探针互补的序列的差异标记的寡聚体来区分中心碱基。为了获得中心位置的有效碱基调用,有义链的数据应证实第二链的数据。因此,如果具有中央a碱基的寡聚体与有义链结合,那么具有中央t碱基的寡聚体应该与反义链结合。
[0437]
获得这种有义链和反义链的确证或共有序列也有助于克服由于g:t或g:u摆动碱基配对引起的结合的模糊性。当这发生在有义链上时,其不太可能在反义链上产生信号,因为c:a不太可能形成碱基对。
[0438]
在一些实施方案中,可在探针中使用经修饰的g碱基或t/u来防止摆动碱基对的形成。在一些其它实施方案中,重建算法考虑了形成摆动碱基对的可能性,特别是当互补链上
没有对c:g碱基对的确证,并且该位置与形成a:t碱基对的寡聚体与互补链的结合相关时。在一些实施方案中,具有仅形成两个氢键而不是3个氢键的能力的7-脱氮杂鸟苷(7-deazaguanisine)被用作g修饰,以降低其形成的碱基对的稳定性和减少其g四链体(g-quadraplex)(以及因此其混杂结合)的出现。
[0439]
并行双链体共有序列组装。
[0440]
在一些实施方案中,双螺旋的两条链都存在,并且在非常接近时暴露于如上所述的寡核苷酸。在一些实施方案中,不可能从检测到的瞬时光信号中区分相应的寡核苷酸组中每个寡聚体已结合两条互补链中的哪一条。例如,当汇编沿着多核苷酸的相应的寡核苷酸组中的每个寡核苷酸的沿着每个多核苷酸的结合位置时,似乎具有不同序列的两个探针已经与同一位置结合。这些寡聚体在序列上应该是互补的,然后困难就变成了确定两个寡聚体中的每一个结合哪条链,这是精确地汇编多核苷酸的序列的先决条件。
[0441]
为了确定单个结合事件是针对一条链还是针对另一条链,必须考虑成套的获得的光学活性数据。例如,如果寡聚体的两个覆瓦系列覆盖了所述位置,那么将基于产生信号的寡聚体序列与哪个系列重叠来分配所述信号所属于两个覆瓦系列中的哪一个。在一些实施方案中,然后通过首先使用结合位置和序列重叠构建两个覆瓦系列中的每一个来重建序列。然后将所述两个覆瓦系列作为反向互补序列进行对齐,并且只有当两条链在这些位置中的每个位置处都是完全反向互补序列时,才接受每个位置的碱基分配(例如,从而提供双链体共有序列)。
[0442]
在一些实施方案中,测序错配被标记为不明确的碱基调用,其中两种可能性之一需要由另外的信息层(诸如来自独立错配结合事件的信息层)证实。在一些实施方案中,一旦获得了双链体共有序列,就通过比较来自覆盖基因组的相同区域的其它多核苷酸的数据来确定常规(多分子)共有序列(例如,当来自多个细胞的结合位点信息可用时)。这种方法的一个问题是多核苷酸含有单倍型序列的可能性。
[0443]
或者,在一些实施方案中,在获得单链共有序列的双链体共有序列之前获得单链的共有序列。在此类实施方案中,双链体的每条链的序列是同时获得的。在一些实施方案中,这在无需另外的样品制备步骤的情况下即可完成,与当前的ngs方法(例如,如由salk等人,proc.natl.acad.sci.109(36),2012所描述的)不同,这种方法用分子条形码差异地给双链体的两条链加标签。
[0444]
有义链和反义链的同时序列获得优于可用于纳米孔的2d或1d2共有序列测序。这些替代方法需要在获得第二链的序列之前获得双链体的一条链的序列。在一些实施方案中,双链体共有序列测序提供106范围内的准确性例如100万个碱基中1个错误(与其它ngs方法的10
2-103原始准确性相比)。这使得该方法与解决指示癌症状况(例如,诸如存在于无细胞dna中的那些)或在肿瘤细胞群体中以低频率存在的罕见变体的需要高度兼容。
[0445]
单细胞解析测序。
[0446]
在各种实施方案中,该方法还包括对单细胞的基因组进行测序。在一些实施方案中,单个细胞没有其它细胞的附着。在一些实施方案中,单个细胞以簇或组织的形式附着于其它细胞在一些实施方案中,此类细胞被解聚成单独的非附着的细胞。
[0447]
在一些实施方案中,使细胞解聚,然后将它们流体转移(例如,通过使用移液器)到多核苷酸在其中被拉长的结构(例如,流动池或微孔)的入口。在一些实施方案中,通过吸取
细胞、施加蛋白酶、超声处理或物理搅拌来完成解聚。在一些实施方案中,使细胞解聚,然后将它们流体转移到它们在其中伸长的结构中。
[0448]
在一些实施方案中,分离单细胞,将多核苷酸从单细胞中释放出来,使得源自同一细胞的所有多核苷酸保持彼此靠近地放置,并且位于不同于放置其它细胞的内容物的位置的位置。在一些实施方案中,使用如由di carlo等人,lab chip 6:1445
–
1449,2006描述的立足点探针。
[0449]
在一些实施方案中,可以使用捕获和分离多个单细胞(例如,在捕集器分离的情况下,诸如图16a和图16b所示的情况)的微流体体系结构,或者使用捕获多个非分离的细胞(例如,在捕集器连续的情况下)的体系结构。在一些实施方案中,捕集器是单细胞的尺寸(例如,2μm-10μm)。在一些实施方案中,流动池的长度为数百微米至毫米,深度为约30微米。
[0450]
在一些实施方案中,例如如图17所示,单细胞流入递送通道1702,被捕获1704,核苷酸被释放,然后被拉长。在一些实施方案中,细胞1602被裂解1706,然后细胞核通过第二裂解步骤1708被裂解,从而顺序释放细胞外和细胞内多核苷酸1608。任选地,使用单个裂解步骤释放核外和核内多核苷酸。释放后,使多核苷酸1608沿着流动池2004的长度固着并伸长。在一些实施方案中,捕集器是单细胞的尺寸(例如2μm
–
10μm宽)。在一个实施方案中,捕集器的尺寸为底部的宽度4.3μm,中间的深度为6μm,顶部为8μm,深度为33μm,并且该装置通过使用注射成型由环烯烃(coc)制成。
[0451]
在一些实施方案中,在将多核苷酸在同一混合物中组合和测序之前,将单细胞裂解到单独的通道中,并且使每个单独的细胞通过转座酶介导的整合与独特的标签序列反应。在一些实施方案中,将转座酶复合物转染到细胞中,或者以液滴形式融合到含有细胞的液滴中。
[0452]
在一些实施方案中,聚集体是细胞的小簇,并且在一些实施方案中,整个簇用相同的测序标签标记。在一些实施方案中,细胞未聚集,而是自由漂浮的细胞,诸如循环肿瘤细胞(ctc)或循环胎儿细胞。
[0453]
在单细胞测序中,存在胞嘧啶至胸腺嘧啶的单核苷酸变异的问题,该问题由细胞裂解后自发的胞嘧啶脱氨作用引起。这可通过在测序之前用尿嘧啶n-糖基化酶(ung)预处理样品来克服(例如,如由chen等人,mol diagn ther.18(5):587
–
593,2014所述的)
[0454]
鉴定单倍型。
[0455]
在各种实施方案中,上述方法用于单倍型测序。单倍型测序包括使用本文描述的方法对跨越二倍体基因组的单倍型的第一靶多核苷酸进行测序。还必须对跨越二倍体基因组的第二单倍型区域的第二靶多核苷酸进行测序。第一靶多核苷酸和第二靶多核苷酸将来自同源染色体的不同拷贝。比较第一靶多核苷酸与第二靶多核苷酸的序列,从而确定第一靶多核苷酸和第二靶多核苷酸的单倍型。
[0456]
因此,从实施方案中获得的单分子读数和组装被归类为单倍型特异性的。单倍型特异性信息不一定容易在长时间内获得的唯一情况是当组装间歇进行时。在此类实施方案中,尽管如此,仍提供了读取的位置。即使在这种情况下,如果分析多个覆盖基因组的相同节段的多核苷酸,单倍型也是通过计算确定的。
[0457]
在一些实施方案中,根据单倍型或亲本染色体特异性分离同源分子。通过本公开的方法获得的信息的视觉性质,实际上在物理上或视觉上,能够显示特定的单倍型。在一些
实施方案中,单倍型的解析使得能够进行改进的遗传或祖先研究。在其它实施方案中,单倍型的解析使得能够进行更好的组织分型。在一些实施方案中,单倍型的解析或特定单倍型的检测使得能够进行诊断。
[0458]
同时对来自多个细胞的多核苷酸进行测序。
[0459]
在各种实施方案中,上述方法用于对来自多个细胞(或细胞核)的多核苷酸进行测序,其中每个多核苷酸保留其来源细胞的信息。
[0460]
在某些实施方案中,转座子介导的序列插入是在细胞内介导的,并且每次插入都包含独特的id序列标签作为来源细胞的标记物。在其它实施方案中,转座子介导的插入发生在已经分离出单细胞的容器内,此类容器包含琼脂糖珠粒、油-水滴等。独特的标签表明所有带有标签的多核苷酸必须源自同一细胞。然后提取所有的基因组dna和或rna,混合,并拉长。然后,当对多核苷酸进行根据本发明的实施方案的测序(或任何其它测序方法)时,id序列标签的读取指示多核苷酸源自哪个细胞。优选保持短的细胞识别标签。对于10,000个细胞(例如,来自肿瘤微生物学),约65,000个独特的序列由长度为8个核苷酸的标识符序列提供,约100万个独特的序列由长度为10个核苷酸的标识符序列提供。
[0461]
在一些实施方案中,用身份(id)标签标记单个细胞。如图19所示,在一些实施方案中,通过加标签将身份标签整合到多核苷酸中,为此将试剂直接提供给单细胞或以与细胞1802融合或吞噬细胞1802的微滴形式提供所述试剂。每个细胞接收不同的id标签(来自大的库,例如,大于100万个可能的标签)。在微滴和细胞融合1804之后,将id标签整合到单个细胞内的多核苷酸中。将单个细胞的内容物在流动池2004内混合。然后测序(例如,通过本文公开的方法)揭示特定多核苷酸源自哪个细胞。在替代实施例中,微滴吞没细胞并将加标签试剂递送至细胞(例如,通过扩散至细胞中或将细胞内容物爆裂至微滴中)。
[0462]
当目标是混合样本,将它们一起进行测序,但是恢复属于每个单独样品的序列信息时,将这个相同的索引原则应用于除细胞外的样品(例如,来自不同个体)。
[0463]
另外,当对多个细胞测序时,可以确定细胞群中的单倍型多样性和频率。在一些实施方案中,分析群体中基因组的异质性,而不需要将单个细胞的内容物保持在一起,因为如果分子足够长,则细胞群体中存在的不同染色体、长染色体节段或单倍型被确定。尽管这并不表明细胞中同时存在哪两种单倍型,但其确实报道了基因组结构类型(或单倍型)的多样性及其频率,以及存在哪种异常结构变体。
[0464]
在一些实施方案中,当多核苷酸是rna并且对cdna拷贝测序时,标签的添加包括利用含有标签序列的引物进行的cdna合成。在对rna直接测序的情况下,通过使用t4 rna连接酶将标签连接到3’rna末端来添加标签。产生标签的替代方法是用末端转移酶,利用四种a、c、g和t碱基中的超过一种核苷酸延伸rna或dna,使得每个单独的多核苷酸随机地获得加在其尾上的核苷酸的独特序列。
[0465]
在一些实施方案中,为了保持一定量的序列保持较短,使得更多的序列读数专用于对多核苷酸序列本身进行测序,将标签序列分布在许多位点上。此处,将多个短标识符序列,比如三个,引入每个细胞或容器。然后,从沿着多核苷酸分布的标签位确定多核苷酸的来源。因此,在这种情况下,从一个位置读取的标签位不足以确定来源细胞,但多个标签位足以做出确定。
[0466]
结构变体的检测。
[0467]
在一些实施方案中,检测到的序列与参考基因组之间的差异包括取代、插入缺失和结构变异。特别地,当未通过本公开的方法组装参考序列时,压缩重复序列,并将重建解压缩。
[0468]
在一些实施方案中,沿着多核苷酸的一系列序列读数的取向将报告是否发生了倒位事件。与参考读数相比,一个或多个读数的方向与其它读数相反,表示倒位。
[0469]
在一些实施方案中,在其附近的其它读取的上下文中未预期到的一个或多个读数的存在指示与参考相比的重排或易位。参考文献中读数的位置表明基因组的哪一部分已经转移到另一部分。在一些情况下,在其新位置的读数是复制的而不是移位的。
[0470]
在一些实施方案中,还可以检测重复区域或拷贝数变化。具有旁系变异的读数或相关读数的重复出现被观察到为在基因组中多个位置处出现的多个或非常相似的读数。在一些情况下,这些多个位置在一些情况下紧密聚集在一起(例如,如在卫星dna中),或者在其它情况下,它们分散在整个基因组中(例如,如在假基因中)。本公开的方法适用于短串联重复序列(strs)、可变数串联重复序列(vntr)、三核苷酸重复序列等。特定读数的缺失或重复表明分别发生了缺失或扩增。在一些实施方案中,该方法特别适用于多核苷酸中存在多个和/或复杂重排的情况。因为所述方法基于分析单个多核苷酸,所以在一些实施方案中,上述结构变体被分解为在少量细胞(例如,仅1%的来自群体的细胞)中罕见现象。
[0471]
类似地,在一些实施方案中,节段复制物或复制子被正确地定位在基因组中。节段复制子通常是具有几乎相同序列的dna序列中的长区域(例如,长度大于1千碱基)。这些节段复制物导致了个体基因组的许多结构变异,包括体细胞突变。节段复制子可能存在于基因组的远端部分。在当前的下一代测序中,很难确定读数产生自哪个节段复制子(从而使组装复杂化)。在本公开的一些实施方案中,在长分子(例如,0.1-10兆碱基的长度范围)上获得序列读数,并且通常可以通过使用读数确定基因组的哪些节段在对应于复制子的基因组的特定节段的侧翼来确定复制子的基因组背景。
[0472]
在本公开的一些实施方案中,结构变体的断点被精确定位。在一些实施方案中,可以检测到基因组的两个部分已经融合,并且确定断点在其处发生的精确的单个读数。如本文所述收集的序列读数包含两个融合区域的嵌合体,断点一侧的所有序列将对应于融合节段之一,而另一侧为所述融合节段的另一个节段。这在确定断点方面给予了高可信度,即使在断点周围的结构很复杂的情况下亦如此。在一些实施方案中,精确的染色体断点信息用于理解疾病机制、检测特定易位的发生或诊断疾病。
[0473]
表观基因组修饰的定位。
[0474]
在一些实施方案中,所述方法还包括将固定的双链或固定的第一链和固定的第二链暴露于抗体、亲和体、纳米抗体、适体或甲基结合蛋白,从而确定对核酸的修饰或与来自测试基板上的多组位置的核酸的一部分的序列相关联。一些抗体与双链或单链结合。预计甲基结合蛋白将结合双链多核苷酸。
[0475]
在一些实施方案中,天然多核苷酸在它们被展示用于测序之前不需要处理。这使得该方法能够将表观基因组信息与序列信息结合起来,因为dna的化学修饰将保持不变。优选地,多核苷酸定向排列良好,因此相对容易成像、成像处理、碱基调用和组装;序列差错率低,并且覆盖度高。描述了用于实施本公开的多个实施方案,但每个实施方案都是为了完全或几乎完全消除样品制备的负担。
mapping method)与通过寡聚体结合获得的序列位发生关系,以便为静观遗传图谱(epi-map)提供上下文。在一些实施方案中,除了序列读数以外,还偶联其它种类的甲基化信息。作为非限制性实例,这包括基于切刻内切核酸酶的图谱、基于寡聚体结合的图谱以及变性和变性-复性图谱。在一些实施方案中,将一种或多种寡聚体的瞬时结合用于绘制多核苷酸的图谱。除了对基因组的功能修饰以外,在一些实施方案中,还将相同的方法应用于映射到基因组上的其它特征,诸如dna损伤以及蛋白质或配体结合的位点。
[0484]
在本公开中,首先进行碱基测序或表观基因组测序。在一些实施方案中,两者同时完成。例如,在一些实施方案中,针对特定表观遗传修饰的抗体是从寡聚体中差异编码的。在此类实施方案中,使用促进两种类型的探针的瞬时结合的条件(例如,低盐浓度)。
[0485]
在一些实施方案中,当多核苷酸包含染色体或染色质时,对染色体或染色质使用抗体来检测对dna上的修饰以及组蛋白上的修饰(例如,组蛋白乙酰化和甲基化)。这些修饰的位置由抗体与染色体或染色质上的位置的瞬时结合确定。在一些实施方案中,抗体用寡聚体标签标记,并且不会瞬时结合,而是永久性或半永久性固定到它们的结合位点。在此类实施方案中,抗体将包括寡聚体标签,并且这些抗体结合位点的位置通过使用互补寡聚体与抗体标签上的寡聚体的瞬时结合来检测。
[0486]
无细胞核酸的分离和分析。
[0487]
用于诊断的一些最容易获得的dna或rna存在于体液或粪便中的细胞外部。此类核酸经常被体内的细胞释放出来。将血液中循环的无细胞dna用于21三体和其它染色体和基因组病症的产前检测。其也是检测肿瘤来源的dna和其它dna或rna的方法,所述dna或rna是某些病理状况的标志物。然而,分子通常存在于小节段(例如,在血液中在约200个碱基对的长度范围内,在尿液中甚至更短)中。基因组区域的拷贝数是通过与跟参考的特定区域对齐的读数相较于基因组的其它部分的数量的比较来确定的。
[0488]
在一些实施方案中,通过两种途径将本公开的方法应用于无细胞dna序列的计数或分析。第一途径涉及在变性之前或之后固着短核酸。将瞬时结合试剂用于询问核酸,以确定核酸的身份、其拷贝数、是否存在突变或某些snp等位基因,以及检测到的序列是否被甲基化或具有其它修饰(生物标志物)。
[0489]
第二途径涉及连接小的核酸片段(例如,在从生物样品中分离出无细胞核酸之后)。串联使得能够拉伸组合的核酸。通过抛光dna末端并进行平端连接来完成连接。或者,将血液或无细胞的dna分成两份等分试样,一个等分试样用poly a(使用末端转移酶)加尾,另一等分试样用poly t加尾。
[0490]
然后对所得的串联体进行测序。然后将所得的“超级”序列读数与参考值进行比较,以提取单个读数。对单个读数进行计算提取,然后以与其它短读数相同的方式进行处理。
[0491]
在一些实施方案中,生物样品包含粪便,其为是含有大量降解核酸的外切核酸酶的介质。在此类实施方案中,使用外切核酸酶发挥功能所需的高浓度二价阳离子螯合剂(例如,edta)来保持dna足够完整并实现测序。在一些实施方案中,无细胞核酸通过包裹在外来体中从细胞中脱落。通过超速离心或使用旋转柱(qiagen)分离外来体,收集其中包含的dna或rna并进行测序。
[0492]
在一些实施方案中,根据上述方法,从无细胞核酸获得甲基化信息。
[0493]
组合测序技术。
[0494]
在一些实施方案中,将本文所述的方法与其它测序技术组合。在一些实施方案中,在通过瞬时结合进行测序之后,通过第二方法在相同分子上开始测序。例如,将更长更稳定的寡核苷酸结合以起始合成测序。在一些实施方案中,所述方法并不是完整的基因组测序,而是用于提供用于短读数测序(short read sequencing)的支架,诸如来自illumina的支架。在这种情况下,通过排除pcr扩增步骤以获得更均匀的基因组覆盖度来进行illumina文库制备是有利的。这些实施方案中的一些的一个有利方面是,例如,所需测序的倍数覆盖度从约40倍减半至20倍。在一些实施方案中,这是由于添加了由方法完成的测序和方法提供的位置信息。在一些实施方案中,可在部分或整个测序过程中在利用短测序寡聚体之前或与之同时(优选地差异标记的),将任选地光学标记的更长更稳定的寡聚体与靶标结合以标记出基因组中的特定目标区域(例如brca1基因座)。
[0495]
机器学习方法。
[0496]
通过数学建模可以最好地解决从定位的预计集合中组装靶聚合物(例如,核酸或多核苷酸)序列的问题。此处,这个问题被视为统计逆问题:目标是从噪声测量(在这种情况下是定位集)中恢复靶聚合物序列,其中(噪声)测量过程是公知的。下面描述了两种可用来解决这个问题的元算法(meta-algorithm)。请注意,下面(以及图25a和25b中)描述的两种算法都可以以滑动窗口方法(sliding-window approach)应用于定位数据的小区段,并且也可以与参考基因组一起用于重新测序或变体调用(例如,除了从头测序之外)。
[0497]
描述了捕捉测量和排序过程的概率模型。该模型定义了给定的已知靶聚合物序列在点集上的分布。对于单一实验,即单一寡聚物或其中靶聚合物是核酸的寡聚物的混合物的单次洗涤,这种分布是模拟实验参数的点过程。在大多数实施方案中,在模型中使用泊松点过程(例如,如实施例7中所述)。例如,参见streit 2010poisson point processes:imaging,tracking,and sensing.springer science&business media。在一些实施方案中,使用更复杂的模型来处理例如非结合位点。参见,例如,cox等人1980chapman&hall/crc monographs on statistics&applied probability.taylor&francis.isbn:9780412219108和daley等人2007springer science&business media。
[0498]
该模型允许产生合成数据,并且也可以适合于实验和/或合成数据(例如,以估计例如上述参数的值)。
[0499]
现在参照图25a和图25b详细描述根据本公开的方法。
[0500]
块2502。提供了确定来自物种的受试者的靶聚合物的至少一部分的序列的方法。在一些实施方案中,将概率模型用于确定靶聚合物的至少一部分的序列。在一些实施方案中,靶聚合物是核酸。在一些实施方案中,物种是人。
[0501]
块2506。以电子形式获得包括一个或多个图像文件的数据集。在一些实施方案中,一个或多个图像文件包括至少1个图像文件、至少2个图像文件、至少3个图像文件、至少4个图像文件、至少5个图像文件、至少6个图像文件、至少7个图像文件、至少8个图像文件、至少9个图像文件、至少10个图像文件、至少25个图像文件、至少50个图像文件、至少75个图像文件、至少100个图像文件、至少250个图像文件、至少500个图像文件、至少750个图像文件、至少1000个图像文件、至少2500个图像文件或至少5000个图像文件。
[0502]
每个测序实验由一系列单独的测量组成(例如,其中每个测量包括至少一个图像
biochem 78,993-1016描述了超分辨率显微技术。
[0509]
块2516。多个定位被分段成一个或多个靶聚合物链。每个靶聚合物链对应于来自多个定位的相应的定位子集和靶聚合物位置标识的相应子集。
[0510]
在一些实施方案中,组合的多个定位被应用于分段模型。分段模型i)至少部分基于组合的多个定位中的每个定位的相应的空间定位来确定一个或多个定位子集;以及ii)将相应的曲线与每个定位子集拟合(例如,将每个定位子集投影到曲线上),从而获得一条或多条拟合曲线。在一些实施方案中,每个定位子集对应于单个靶聚合物链。在一些实施方案中,存在已知的链的定位(例如,对于靶聚合物在流动池中的情况)。每条拟合曲线包括沿着相应的拟合曲线的相应的荧光团子集中的每个荧光团的定位。在一些实施方案中,每条拟合曲线是参数曲线。在一些实施方案中,每条拟合曲线是非参数曲线。在一些实施方案中,至少一条拟合曲线是参数曲线。在一些实施方案中,使用k-均值或ransac拟合每条拟合曲线(例如,如macqueen等人1967proceedings of the fifth berkeley symposium on mathematical statistics and probability 1(14),281-297或fischler等人1981commu nications of the acm 24(6),381-395中所述)。在一些实施方案中,使用对异常值(例如,由于一个或多个原因而被丢弃的定位,诸如远离其它定位或由于相应荧光团的空间定位的不确定性值)稳健的方法来拟合曲线。在一些实施方案中,不是将每个定位子集投影到相应的曲线上,而是基于相应曲线的定位从一个或多个图像文件中重新定位每个定位子集。对于每条链和每个实验,输出id定位(和相关元数据)的集合。
[0511]
在一些实施方案中,重复分段至少一次。在一些实施方案中,重复曲线拟合一次或多次,每次细化荧光团的分段(例如,用于比较每个拟合的优度以确定每个定位子集的最佳拟合)。在一些实施方案中,在曲线拟合之前预先确定定位子集的数量。在一些实施方案中,分段和曲线拟合同时进行。
[0512]
块2522。每个相应的靶聚合物链的每个定位子集用于组装相应的靶聚合物序列和相应的靶聚合物序列的相应概率,从而提供一组靶聚合物序列。
[0513]
在一些实施方案中,组装还包括确定每个相应的靶聚合物序列的对应概率(例如,基于荧光团的每个分段的拟合优度)。
[0514]
在一些实施方案中,对于每个靶聚合物链,将相应的定位子集应用于优化模型以获得相应的靶聚合物序列。
[0515]
在一些实施方案中,优化模型被定义为:
[0516]
最大化(s∈s)(logp(d|s)+logp(s)。
[0517]
在此类实施方案中,s是一组长度为n的可能的靶聚合物序列,其中n对应于靶聚合物位置标识数量方面的长度;s是选自s的可能的靶聚合物序列,其中s的长度为n;d是每个靶聚合物链的定位集,其中定位集包括m个单独的定位;
[0518]
p(d\s)是给定可能的靶聚合物序列s时d定位集发生的可能性;并且p(s)是可能的靶聚合物序列s的先验概率。在一些实施方案中,靶聚合物是核酸并且组s的容量为4n(例如,由于四个核酸碱基)。
[0519]
在一些实施方案中,p(d|-):{a;t;c;g}n→r+
是个概率模型。这种方法在频率论(frequentist)文献中被称为最大似然估计,或在贝叶斯设置中称为最大后验估计(这种方法的一个变型是从后验概率p(s\d)中对样本进行估计,以生成多个可能的序列或估计我们
在潜在序列中的不确定性)(例如,如2003probability theory:the logic of science cambridge university press中所述的)。
[0520]
在一些实施方案中,假设序列的一致先验概率。例如,在一些实施方案中,序列s的先验概率基于s的长度n定义为:
[0521][0522]
在一些实施方案中,假设序列s的更复杂的先验概率来对附加结构建模(例如,其中一些位置标识比其它位置标识更可能出现)。在一些实施方案中,基于序列s的长度n和每个靶聚合物位置标识的非均匀概率分布,序列s的这种更复杂的先验概率被定义为:
[0523][0524]
在此类实施方案中,pb(si)是序列s中位置i处每个靶聚合物位置标识b的非均匀概率分布,其中b选自靶聚合物位置标识的预定集;并且i是用于迭代通过可能的靶聚合物序列的组s中可能的靶聚合物序列s的长度n的索引值。在重新测序(例如,对照参考基因组测序)的情况下,使用为参考基因组附近的序列分配更高概率的先验。
[0525]
在一些实施方案中,例如对于重新测序,每个靶聚合物位置标识pb(si)的非均匀概率分布至少部分基于物种的参考基因组(例如,参考基因组中的a、t、c和g的分布确定了分配给每个相应碱基的概率,目的是计算任何特定可能序列s的先验)。在此类实施方案中,靶聚合物标识定位的数量包括核酸碱基的数量(例如,靶聚合物位置标识的预定集包含a、t、c或g。在此类实施方案中,pb:{a,t,c,g}
→
[0,1]是所有四个核苷酸碱基上的(可能不均匀的)概率分布。
[0526]
在一些实施方案中,优化模型包括一个或多个附加的实验参数,所述参数选自定位误差(例如,随机偏移、假阳性或假阴性)、结合率、解结合率、寡聚物密度、非规范碱基配对、结合错配、背景定位或非结合位点的组。在一些实施方案中,这些参数的值可通过利用生成的数据的实验(例如,如实施例7中描述的实验)来确定。
[0527]
由于s是具有4n个元素的离散集合,通过简单的枚举求解任一个先验方程都是不可能的。一种方法是直接对相应的方程式应用组合算法(例如,贪婪随机游走(greedy random walk)、遗传算法、分支定界等)。另一种方法是首先求解任一先验方程的凸松弛,为在原始离散空间中运行的组合算法产生良好的起点。一种在实践中行之有效的可能的松弛方法是作为一个图上的网络优化问题(例如,如bertsekas1998athena scientific belmont中所述),所述图对关于(k-l)-聚体的de bruijn图的多个副本进行编码(例如,如compeau等人2011nature biotechnology 29(11),987中所述)。利用这个公式,(负)似然是凸函数,其允许应用凸优化的强大机制来解决这个问题。对于这种特定的松弛,有许多高效的算法可用,例如frank-wolfe算法(其中条件梯度步骤是最短路径问题)或投影梯度下降(projected gradient descent)算法(其中投影可通过交替投影(例如,使用共轭梯度法)或frank-wolfe算法来计算)。
[0528]
在一些实施方案中,另一种方法是使用机器学习来学习将观察到的数据d(例如,每个靶聚合物链的定位组)映射到序列的估计的反函数f。这种方法需要两步法。首先,在模拟实验中训练神经网络f以直接最小化预期损失:
[0529]
最小化
f∈f
e[l(f(d),s]。
[0530]
此处期望值是s和d中(在一些实施方案中是f中)的随机性,其每一个都是从模拟实验中采样的。f描述了一类神经网络。l是损失函数,其惩罚(已知的)地面实况序列(ground truth sequence)s(例如,参考基因组或模拟实验中的已知序列)与估计f(d)之间的错配。用统计学的语言来说,其中的目标函数是贝叶斯风险,模拟实验试图通过f直接逼近贝叶斯估计量。
[0531]
这个最小化问题可以直接使用随机优化方法(例如随机梯度下降sgd)来(近似)解决。在对模拟数据训练f之后,在一些实施方案中,f通过将sgd应用于序列/观察对的组,对包含已知序列的真实数据进一步微调。
[0532]
块2528。在一些实施方案中,通过将每个相应的靶聚合物序列与靶聚合物序列的组中的每隔一个靶聚合物序列进行比较,来确定组合的靶聚合物序列(例如,对于其中被测序的靶分子在一组图像文件中以多个拷贝存在的从头测序)。
[0533]
在一些实施方案中,当对照已知序列的聚合物(例如,多核苷酸)进行测试时和/或当多核苷酸的序列与来自另一种方法的数据交叉验证时,将人工智能或机器学习用于学习库的成员的行为。在一些实施方案中,学习算法考虑了特定探针在一种或多种条件或背景下针对一个或多个包含探针的结合位点的多核苷酸靶的全部行为。随着对相同或不同样品进行更多测序,来自机器学习的知识变得越来越强大。除了基于瞬时结合的紧急测序以外,从机器学习中获得的知识还可应用于各种其它测定,尤其是涉及寡聚体与寡聚体/多聚核苷酸的相互作用的那些测定(例如,杂交进行测序)。
[0534]
在一些实施方案中,通过向一个或多个序列已知的多核苷酸提供针对短寡聚体(例如,3-聚体、4-聚体、5-聚体或6-聚体)的完整库的结合实验获得的结合模式的数据,来训练人工智能或机器学习。每个寡聚体的训练数据包括结合位置、结合持续时间和给定时期内结合事件的次数。在这种训练之后,将机器学习算法应用于待确定序列的多核苷酸,并且基于其学习可以组装多核苷酸的序列。在一些实施方案中,还向机器学习算法提供参考序列。
[0535]
在一些实施方案中,序列组装算法包括机器学习元素和非机器学习元素。
[0536]
在一些实施方案中,不是计算机算法从实验获得的结合模式中学习,而是通过模拟获得结合模式。例如,在一些实施方案中,模拟了库中的寡聚体与序列已知的多核苷酸的瞬时结合。模拟基于从实验或公开数据中获得的每个寡聚体的行为模型。例如,结合稳定性的预测可根据最近邻法(例如,如santalucia等人,biochemistry 35,355 5-3562(1996)和breslauer等人,proc.natl.acad.sci.83:3746-3750,1986中所描述的)获得。在一些实施方案中,错配行为是已知的(例如,g与a的错配结合可以是和t与a一样强或比其强的相互作用)或通过实验得到的。另外,在一些实施方案中,寡聚体的一些短亚序列(例如,gga或acc)的异常高的结合强度是已知的。在一些实施方案中,在模拟数据上训练机器学习算法,然后当通过短寡聚体的完整库询问未知序列时,将所述机器学习算法用于确定序列未知的序列。
[0537]
在一些实施方案中,将库或小组的寡聚体的数据(位置、绑定持续时间、信号强度等)插入机器学习算法,所述算法已经优选地在一个或多个(数十个、数百个或数千个)已知序列上训练过。然后将机器学习算法应用于从所述序列生成数据集,并且机器学习算法生成所述未知序列的序列。用于具有相对较小或不太复杂的基因组的生物体(例如,对于细
菌、噬菌体等)测序的算法的训练应该在这种类型的生物体上进行。对于具有较大或更复杂的基因组的生物体(例如,粟酒裂殖酵或人),尤其是具有重复dna区域的那些生物,所述训练应在该类型的生物上进行。对于兆碱基片段至整个染色体长度的长距组装,在一些实施方案中,训练在类似的生物体上进行,使得在训练期间表现基因组的特定方面。例如,人类基因组是二倍体,并显示出具有节段复制物的大序列区域。其它目标基因组,特别是许多农业上重要的植物物种具有高度复杂的基因组。例如,小麦和其它谷物具有高度多倍体的基因组。
[0538]
在一些实施方案中,基于机器学习的序列重建方法包括:(a)提供从一个或多个训练数据集收集的关于库中的每个寡聚体的结合行为的信息,以及(b)提供库中的每个寡聚体与其序列待确定的多核苷酸的物理结合,以及(c)提供关于每个寡聚体的结合位置、和/或结合持续时间和/或在每个位置发生结合的次数(例如,结合重复的持久性)的信息。
[0539]
在一些实施方案中,特定实验的序列首先由非机器学习算法处理。然后,将第一算法的输出序列用于训练机器学习算法,使得训练发生在完全相同的分子的实际实验导出的序列上。在一些实施方案中,序列组装算法包括贝叶斯方法。在一些实施方案中,将从本公开的方法获得的数据提供给wo2010075570中描述的类型的算法,并且任选地将其与其它类型的基因组或测序数据组合。
[0540]
在一些实施方案中,以多种方式从数据中提取序列。在序列重建方法的光谱的一端,单体或一串单体的定位是如此精确(纳米级或亚纳米级),以至于仅通过对单体或串进行排序就可以获得序列。在光谱的另一端,将数据用来排除关于序列的各种假设。例如,一个假设是该序列对应于已知的个体基因组序列。该算法确定了数据在何处与个体基因组偏离。在另一种情况下,假设是该序列对应于“正常”体细胞的已知基因组序列。该算法确定了来自假定的肿瘤细胞的数据在何处与“正常”体细胞的序列偏离。
[0541]
在本公开的一个实施方案中,将包含一种或多种已知靶多核苷酸(例如,λ噬菌体dna或包含超序列的合成构建体,所述超序列包含针对库中的每个寡聚体的互补序列)的训练集用于测试来自库中的每个寡核苷酸的重复结合。在一些实施方案中,使用机器学习算法来确定寡聚探针的结合和错配特征。因此,与直觉相反,错配结合被视为提供进一步数据的方式,所述数据被用于组装序列和/或增加序列的可信度。
[0542]
测序仪器和设备。
[0543]
测序方法具有共同的仪器要求。基本上,仪器必须能够成像和交换试剂。成像要求包括以下一项或多项:物镜、中继透镜、分束器、反射镜、滤光器和照相机或点探测器。所述相机包括ccd或阵列cmos检测器。点探测器包括光电倍增管(pmt)或雪崩光电二极管(apd)。在一些情况下,使用高速照相机。其它任选方面根据方法的格式进行调整。例如,照明源(例如,灯、led或激光器)、照明与基板的耦合(例如,棱镜、光栅、溶胶-凝胶、透镜、可平移台或可平移物镜)、用于相对于成像器移动样品的机构、样品混合/搅拌、温度控制和电控制可针对本文公开的不同实施方案各自独立地进行调整。
[0544]
对于单分子实现,照明优选通过倏逝波的产生,通过例如,基于棱镜的全内反射、基于物镜的全内反射、基于光栅的波导、基于水凝胶的波导或通过以合适的角度将激光引入基板边缘而产生的倏逝波导。在一些实施方案中,波导包括芯层和第一包覆层。照明可选地包括hilo照明或光片。在一些单分子仪器中,通过使用脉冲照明和时间门控检测的同步
来减轻光散射的影响;此处的光散射被屏蔽了。在一些实施方案中,使用暗场照明。一些仪器被设置用于荧光寿命测量。
[0545]
在一些实施方案中,仪器还包含用于从细胞、细胞核、细胞器、染色体等提取多核苷酸的装置。
[0546]
适用于大多数实施方案的仪器是illumina的基因组分析仪iix。该仪器包括基于棱镜的tir、20倍干物镜、光扰频器、532nm和660nm激光器、基于红外激光的聚焦系统、发射滤光轮、photometrix coolsnap ccd照相机、温度控制和用于试剂交换的基于注射泵的系统。在一些实施方案中,用可选的相机组合对该仪器进行改进能够实现更好的单分子测序。例如,传感器优选地具有低电子噪声(《2e)。此外,传感器具有大量像素。在一些实施方案中,基于注射泵的试剂交换系统被基于压力驱动流的试剂交换系统代替。在一些实施方案中,将该系统与兼容的illumina流动池或定制的流动池一起使用,所述定制流动池适合于配合仪器的实际或改进的管件。
[0547]
或者,使用与激光床(激光器取决于标签的选择)或来自基因组分析仪的激光系统和光扰频器、em ccd照相机(例如,hamamatsu imageem)或科学cmos(例如,hamamatsu orca flash)和任选的温度控制耦合的电动nikon ti-e显微镜。在一些实施方案中,使用用户传感器而不是科学传感器。这有可能大幅降低测序成本。这与压力驱动或注射泵系统和专门设计的流动池相结合。在一些实施方案中,流动池由玻璃或塑料(每种都有有利方面和不利方面)制成。在一些实施方案中,流动池使用环烯烃共聚物(coc),例如,topas、其它塑料或pdms制造,或者使用微制造方法在硅或玻璃中制造。在一些实施方案中,热塑性塑料的注射成型为工业规模制造提供了低成本的途径。在一些光学配置中,热塑性塑料需要具有良好的光学性能,且固有荧光最小。理想地应排除不包括包含芳香族或共轭体系的聚合物,因为它们预期具有显著的内在荧光。zeonor 1060r、topas 5013和pmma-vsuvt(例如,如美国专利第8,057,852号中所描述的)已经被报道在绿色和红色波长范围内(例如,对于cy3和cy5)具有合理的光学性质,其中zeonar 1060r具有最有利的性质。在一些实施方案中,有可能在微流体设备中大面积粘合热塑性塑料(例如,如由sun等人,microfluidics and nanofluidics,19(4),913-922,2015报道的)。在一些实施方案中,将其上附着有生物聚合物的玻璃盖玻璃粘贴到热塑性流体体系结构上。
[0548]
或者,在显微镜顶部使用手动操作的流动池。在一些实施方案中,这是通过使用双面粘性片制成流动池、利用激光切割以具有适当尺寸的通道并将其夹在盖玻片与载玻片之间来构造的。从一个试剂交换循环到另一个试剂交换循环,流动池可以保留在仪器/显微镜上,以便逐帧进行配准。在一些实施方案中,将具有线性编码器的电动平台用于确保在大面积成像期间何时平行移载物台。相同的位置被正确地重访。将基准标志用于确保正确配准。在这种情况下,优选在流动池中具有基准标志(诸如蚀刻)或在流动池内具有表面固定的珠粒,所述标志可被光学检测。如果多核苷酸主链被染色(例如,被yoyo-1染色),将这些固定的、已知的位置用于将图像从一帧到下一帧对齐。
[0549]
在一个实施方案中,将使用激光或led照明的照明机构(例如,诸如美国专利第7,175,811号中和ramachandran等人,scientific reports 3:2133,2013描述的照明机构)中与任选的加热机构和试剂交换系统耦合,以执行本文所述的方法。在一些实施方案中,将基于智能手机的成像装置(acs nano 7:9147)与可选的温度控制模块和试剂交换系统耦合。
在此类实施方案中,主要使用电话上的照相机,但也可使用其它方面,诸如iphone或其它智能手机设备的照明和振动能力。
[0550]
图20a和20b示出了使用流动池2004和集成光学布局执行如本文所述的瞬时探针结合的成像的可能设备。将试剂作为由气隙2022分开的试剂/缓冲剂2008的包来输送。图20a示出了示例性布局,其中通过耦合激光2014产生倏逝波2010,所述激光2014透射通过棱镜2016(例如,tirf设置)。在一些实施方案中,反应的温度由集成热控制器2012控制(例如,在一个实例中,透明基板2024包括电耦合的铟锡氧化物,从而改变整个基板2024的温度)。将试剂作为试剂/缓冲液2008的连续流递送。光栅、波导2020或光子结构用于耦合激光2014,以产生倏逝场2010。在一些实施方案中,热控制来自覆盖该空间的块2026。
[0551]
图20a中描述的布局的方面可以与图20b中描述的布局的方面互换。例如,可替换性使用物镜风格的tirf、光导tirf、聚光器tirf。在一些实施方案中,连续或带有空气间隙的试剂递送由注射泵或压力驱动流控制。气隙法允许所有试剂2008预装在毛细管/管道2102(例如,如图21所示)或通道中,并通过注射泵或压力控制系统的推动或拉动来递送。气隙法允许将所有试剂预装在毛细管/管道或通道中,并通过注射泵或压力控制系统的推动或拉动来递送。气隙2022包含空气或气体(诸如氮气)或与水溶液不混溶的液体。气隙2022还可用于进行分子梳理以及试剂递送。流体装置(例如,流体容器、盒或芯片)包括进行多核苷酸固着和任选地伸长的流动池区域、试剂储存、入口、出口和多核苷酸提取以及用于塑造倏逝场形状的任选结构。在一些实施方案中,该装置由玻璃、塑料或玻璃和塑料的混合物制成。在一些实施方案中,导热和导电元件(例如,金属的)被集成到玻璃和/或塑料部件中。在一些实施方案中,流体容器是小孔。在一些实施方案中,流体容器是流动池。在一些实施方案中,表面涂覆有一层或多层化学层、生物化学层(例如,bsa-生物素、链霉抗生物素蛋白)、脂质层、水凝胶或凝胶层。然后于乙烯基硅烷(biotechniques 45:649-658,2008或可从genomic vision获得)中涂覆22x22mm盖玻片或用1.5%的氯苯溶液中的zeonex旋涂盖玻片。基板也可用2%3-氨基丙基三乙氧基硅烷(aptes)或多聚赖氨酸涂覆,在hepes缓冲液中,在ph7.5-8下通过静电相互作用进行拉伸。或者,将硅烷化的盖玻片在含双丙烯酰胺和四甲基乙二胺(temed)1-8%聚丙烯酰胺溶液中进行旋涂或浸涂。为此,除了使用涂覆有乙烯基硅烷的盖玻片之外,可用10%的丙酮中的3-甲基丙烯酰氧丙基三甲氧基硅烷(粘合硅烷;pharmacia biotech)(v/v)涂覆盖玻片1小时。聚丙烯酰胺涂层也可以如所述(liu q等人biomacromolecules,2012,13(4),第1086
–
1092页)获得。在mateescu等人membranes 2012,2,40-69中有描述和引用了许多可使用的水凝胶涂层。
[0552]
通过施加交流电(ac)电场,也可在琼脂糖凝胶中拉长核酸。可将dna分子电泳到凝胶中,或者可将dna与熔融的琼脂糖混合,然后与琼脂糖一起凝固。然后施加频率为约10hz的ac场,并使用200至400v/cm的场强。拉伸可以在0.5-3%的琼脂糖凝胶浓度范围内进行。在一些情况下,在流动通道或小孔中用bsa-生物素涂覆表面,然后添加链霉抗生物素蛋白或中性亲和素。通过首先在ph 7.5的缓冲液中结合dna,然后在ph 8.5的缓冲液中拉伸该dna,可将该涂覆的盖玻片用于拉伸双链基因组dna。在一些情况下,将涂覆有链霉抗生物素蛋白的盖玻片用于捕获和固着核酸链,但不进行拉伸。因此,核酸一端附着,而另一端在溶液中悬空。
[0553]
在一些实施方案中,不是使用光学测序系统的各种显微镜样组件,诸如gaiix,而
是构建更集成的单片装置用于测序。在此类实施方案中,将多核苷酸附着在传感器阵列上或与传感器阵列相邻的基板上,并任选地在其上直接拉长。在传感器阵列上的直接检测已经被证明用于与阵列的dna杂交(例如,如由lamture等人,nucleic acid research 22:2121-2125,1994所描述的)。在一些实施方案中,对传感器进行时间门控,以减少由于rayleigh散射引起的背景荧光,与荧光染料的发射相比,rayleigh散射的寿命较短。
[0554]
在一个实施方案中,传感器是cmos探测器。在一些实施方案中,检测多种颜色(例如,如美国专利申请第2009/0194799号中所述的)。在一些实施方案中,检测器是foveon检测器(例如,如美国专利第6,727,521号中所述的)。在一些实施方案中,传感器阵列是三结二极管阵列(例如,如美国专利第9,105,537号中所述的)。
[0555]
在一些实施方案中,将试剂/缓冲液以单剂量(例如,通过泡罩包装)递送至流动池。包装中的每个泡罩含有来自寡核苷酸库的不同于寡聚体。寡聚体之间没有任何混合或污染,将第一个泡罩刺穿,使核酸暴露于其内含物。在一些实施方案中,在移动到系列中的下一个泡罩之前应用洗涤步骤。这用于物理上分离不同组的寡核苷酸,从而降低背景噪声,其中来自先前组的寡聚体保留在成像视野中。
[0556]
在一些实施方案中,测序在其中放置了细胞和/或提取多核苷酸的同一装置或整体结构中进行。在一些实施方案中,在分析开始之前,将进行该方法所需的所有试剂都预先装载在流体装置上。在一些实施方案中,试剂(例如,探针)以干燥状态处于和存在于装置中,并且在反应进行之前将其润湿和溶解。
[0557]
实施例
[0558]
实施例1:制备用于测序的样品。
[0559]
步骤1:提取长长度的基因组dna。
[0560]
在培养物中使na12878或na18507细胞(coriell biorepository)生长并收获所述细胞。将细胞与加热至60℃的低熔点琼脂糖混合。将混合物倾倒入凝胶模具(例如,购自bio-rad)中,并使其凝固成凝胶塞,产生约4x107个细胞(取决于多核苷酸的所需密度,该数目较高或较低)。通过在含有蛋白酶k的溶液中浸泡凝胶塞来裂解凝胶塞中的细胞。在te缓冲液中温和洗涤凝胶塞(例如,在填充有洗涤缓冲液但留下小气泡以帮助混合的15ml falcon管中,并放置在试管旋转器上)。将塞子放入约1.6ml体积的槽中,通过使用琼脂糖酶消化dna来提取dna。将0.5m mes ph 5.5溶液施加至消化的dna。使用fiberprep试剂盒(genomic vision,france)和相关方案进行该步骤,得到平均长度为300kb的最终dna分子。或者,从这些细胞系中提取的基因组dna本身可从corriel获得,并使用大口径移液器(1.2ml中约10ul,给出《1μm的平均间距)将其直接移至0.5m mes ph 5.5溶液中。
[0561]
步骤2:拉伸表面上的分子。
[0562]
步骤1的最后部分将提取的多核苷酸在0.5m mes ph 5.5溶液中置于槽中。将涂覆有乙烯基硅烷(例如,来自genomic vision的combislips)的基板盖玻片浸入槽中,并允许孵育1-10分钟(取决于所需多核苷酸的密度)。然后,使用机械拉出器诸如附带有夹子(以抓住盖玻片)的注射泵(或者,使用genomic vision的fibercomb系统)慢慢拉出盖玻片。使用交联剂(stratagene,usa),使用10,000微焦耳的能量将盖玻片上的dna交联到表面上。如果小心地进行该过程,其会导致平均长度为200-300kb的高分子量(hmw)多核苷酸在表面上伸长,其中在多核苷酸群体中存在长度大于1mb或甚至约10mb的分子。通过更加小心和优化,
平均长度被转变成兆碱基范围(参见上面的兆碱基范围的梳理段(combing section))。
[0563]
作为替代方案,如上所述,使用预先提取的dna(例如,来自novagen目录号70572-3或promega的人类男性基因组dna),并且包含大部分大于50kb的基因组分子。此处,浓度为约0.2-0.5ng/μl,浸渍约5分钟,足以提供分子密度,其中使用衍射极限成像来单独解析高分数。
[0564]
步骤3:制作流动池。
[0565]
将盖玻片压在流动池垫圈上,该垫圈由已经附着在载玻片上的双面粘性3m薄片制成。垫圈(双面粘性薄片上的保护层的两面都在上面)是使用激光切割机制成的,以产生一个或多个流动通道。流动通道的长度比盖板玻璃的长度长,因此当将盖板玻璃放置在流动通道的中心时,通道的每一端未被盖板玻璃覆盖的部分分别被用作将流体分配到流动通道中和从流动通道分配出的入口和出口。流体从粘附在乙烯基硅烷表面的伸长的多核苷酸上方通过。通过在一端使用安全拭子棒(johnsons,usa)使流体流过通道,从而在另一端吸液时产生抽吸。通道用磷酸盐缓冲盐水-吐温和磷酸盐缓冲盐水(pbs-washes)预润湿。
[0566]
步骤4:双链dna的变性。
[0567]
在可添加下一个寡聚体之前,需要高效地洗掉先前的寡聚体;这可通过用缓冲液交换最多4次并任选地使用变性剂(诸如dmso或碱溶液)去除持久结合来完成。通过将碱(0.5m naoh)冲洗通过流动池并在室温下孵育约20-60分钟来使双链dna变性。接下来进行pbs/pbst洗涤。或者,也可用1m hcl孵育1小时,然后用pbs/pbst洗涤。
[0568]
步骤5:钝化。
[0569]
任选地,将阻断缓冲液诸如blockaid(invitrogen,usa)流入并孵育约5-15分钟。接下来进行pbs/pbst洗涤。
[0570]
实施例2:通过寡核苷酸与变性的多核苷酸的瞬时结合进行测序
[0571]
步骤1:在瞬时结合条件下添加寡聚体。
[0572]
流动池用pbst和任选的缓冲液a(10mm tris-hcl,100mm nacl,0.05%吐温-20,ph 7.5)进行预处理。将约1-10nm的每种寡聚体施加于缓冲液b(5mm tris-hcl,10mm mgcl2,1mm edta,0.05%吐温-20,ph 8)或缓冲液b+5mm tris-hcl,10mm mgcl2,1mm edta,0.05%吐温-20,ph 8,1mm pca,1mm pcd,1mm trolox)中的伸长的变性多核苷酸。寡聚体的长度通常在5至7个核苷酸的范围内,反应温度取决于寡聚体的tm。已使用的一种探针类型具有通式5
′‑
cy3-nxxxxxn-3
′
(x为指定的碱基,n是简并位置),lna核苷酸位于位置1、2、4、6和7;dna核苷酸位于位置3和5,并且购自sigma proligo,且如由pihlak等人先前所使用。温度的结合与每个寡核苷酸序列的tm相关。
[0573]
在用a+和b+溶液洗涤后,对于lna dna嵌合寡聚体3004n tggcgn(其中大写字母是lna,小写字母是dna核苷酸),在室温下用0.5至100nm的b+溶液中的寡聚体(通常为3nm至10nm)进行寡核苷酸的瞬时结合。对于不同的寡聚体序列,根据它们的tm和结合行为,使用不同的温度和/或盐条件(以及浓度)。如果使用fret机制进行检测,可使用高得多的浓度的寡聚体,最高可达1um。在一些实施方案中,fret在嵌入到瞬时形成的双链体中的嵌入染料分子(1/1000至1/10,000的稀释型纯物质,取决于使用哪种嵌合染料(来自yoyo-1、sytox green、sytox orange、sybr gold等;life tech nologies)与寡聚体上的标记物之间。在一些实施方案中,嵌入染料直接用作标记物,而不使用fret。在这种情况下,寡聚体未被标记。
除了便宜之外,未标记的寡聚体可以以比标记的寡聚体更高的浓度使用,因为在异源双链体形成时嵌入染料的背景比未嵌入的染料亮100-1000倍(例如,取决于使用哪种嵌入剂)。
[0574]
步骤2:成像-拍摄多帧图像。
[0575]
将流动通道放置在倒置显微镜(例如,nikon ti-e)上,所述显微镜配备有perfect focus、tirf附件以及tirf物镜激光器和hamama tsu 512x512 back-thinned emccd相机。将探针添加到缓冲液b+中,并任选地补充成像。
[0576]
利用由75-400mw激光(例如,532nm处的绿光)的全内反射产生的倏逝波照射与设置在表面上的多核苷酸结合的探针,所述激光经由光纤扰频器(point source)以约1500
°
的tirf角调节,通过带有tirf附件的nikon ti-e上的1.49na 100x nikon油浸物镜。将图像通过同一透镜以1.5倍的进一步放大率收集,并通过二向色镜和发射滤光器投影到hamamatsu imageem相机。使用perfect focus,以100-140的em增益拍摄5000-30,000帧的50-200毫秒。优选地,在最初的几秒钟内使用高激光功率(例如,400mw)来漂白初始的非特异性结合,这将来自表面的几乎一层信号降低到较低的密度,在该密度下个体结合事件得以解决。此后,可选地降低激光功率。
[0577]
图22a-22e示出了对探针与靶多核苷酸的瞬时结合的照射的实例。在这些图中,靶多核苷酸来自人类dna。黑点表示探针荧光的区域,其中更暗的点表示更多区域更经常被探针结合(例如,收集了更多光子)。图22a-22e是在一个靶多核苷酸的测序过程中捕获的来自时间序列的图像(例如,视频)。点2202、2204、2206、2208在整个时间序列中被指示为多核苷酸中随时间的推移以或多或少的强度结合(例如,当将不同组的寡核苷酸暴露于靶多核苷酸时)的区域的实例。
[0578]
添加了成像缓冲液。在一些实施方案中,成像缓冲液由包含β-巯基乙醇、酶促氧化还原系统和/或抗坏血酸盐和没食子酸的缓冲液补充或替代。沿线检测到荧光团,表明已经发生结合。任选地,如果流动池由多于一个通道构成,则其中一个通道用yoyo-1嵌入染料染色,以用于检查多核苷酸的密度和多核苷酸伸长的质量(例如,使用强光或488nm激光照射)。
[0579]
步骤3:成像-移动至其它位置(任选步骤)。
[0580]
相对于物镜(因此也相对于ccd)平移已安装在nikon ti-e的载玻片架上(通过附着至作为流动池的一部分的载玻片)的盖玻片,以便对不同的位置成像。在多个其它位置进行成像,以便对与在不同位置(在其第一位置的ccd的视野之外)呈现的多核苷酸或多核苷酸的部分结合的探针进行成像。来自每个位置的图像数据均存储在计算机内存中。
[0581]
步骤4:添加下一组寡聚体。
[0582]
添加下一组寡聚体,重复步骤1-3,直至全部多核苷酸已被测序。
[0583]
步骤5:确定结合的位置和身份。
[0584]
检测每个荧光点信号的位置,记录来自结合的标记物的荧光投射在其上的像素位置。结合的寡核苷酸的身份通过确定哪些标记的寡核苷酸已被结合来确定,例如,使用通过滤光器进行的波长选择,荧光团在穿过多个滤光器后被检测,在这种情况下,穿过滤光器组的每个荧光团的发射特征(emission signature)被用于确定荧光团的身份,从而确定寡核苷酸的身份。任选地,如果流动池由多于一个通道构成,其中一个通道用yoyo-1嵌入染料染色,以用于检查多核苷酸的密度和多核苷酸延伸的质量(例如,通过使用强光或488nm激光
照射)。拍摄一幅或多幅图像或影片,对于用于标记寡核苷酸的荧光波长中的每个荧光波长一幅图像或影片。
[0585]
步骤6:数据处理。
[0586]
当双链体的两条链都保持附着于表面时,寡聚体同时结合到它们在双链的两条链上的互补位置。然后分析总数据集,以发现在核酸上的特定位置发出紧密定位的信号的寡核苷酸组,它们的位置通过与对应于多核苷酸中的选定点的寡聚体序列重叠来确认;因此这揭示了每个寡聚体的两个重叠覆瓦系列。该位置中的下一个信号适合的覆瓦系列指示了其与哪条链结合。
[0587]
由于链保持固定在表面上,因此可使用运行算法的软件脚本覆盖针对每个寡核苷酸所记录的结合位置。这导致信号显示寡聚体结合位置落在两条寡核苷酸序列覆瓦式途径的框架内,对于变性双链体的每条链,这是条单独的(但其应该是互补的)途径。每条覆瓦式途径(如果完成的话)都跨越整个链长度。然后比较每条链的覆瓦式序列(tiled sequence),以提供双链(也称为2d)共有序列。如果其中一条覆瓦式途径中存在缺口,则采用互补覆瓦式途径的序列。在一些实施方案中,将该序列与同一序列的多个拷贝或参考序列进行比较,以帮助碱基分配和封闭缺口。
[0588]
实施例3:检测多核苷酸上表观遗传标志物的位置。
[0589]
任选地,在寡聚体结合过程之前(或有时在寡聚体结合过程之后或期间),进行表观基因组结合试剂的瞬时结合。根据所用的结合试剂,结合在变性之前或之后进行。对于抗甲基c抗体,结合是在变性dna上完成的,而对于甲基结合蛋白,结合是在任何变性步骤之前在双链dna上完成的。
[0590]
步骤1-甲基结合试剂的瞬时结合。
[0591]
变性后,用pbs-washes冲洗流动池,在pbs中添加cy3b标记的抗甲基抗体3d3克隆(diagenode)。
[0592]
或者,在变性之前,用pbs冲洗流动池,并添加cy3b标记的mbd1。
[0593]
如上文针对瞬时寡聚体结合所述,进行成像。
[0594]
步骤2:剥离甲基结合试剂。
[0595]
通常,在测序之前完成表观遗传分析。因此,任选地,在测序开始之前,在多核苷酸之前将甲基结合试剂冲洗掉。这是通过流动通过多个循环的pbs/pbst和/或高盐缓冲液和sds,然后通过成像检查是否发生了去除来实现的。如果显而易见有超过可忽略的量的结合试剂残留,则使更苛刻的处理,诸如离液剂,gucl流过以去除残留的试剂。
[0596]
步骤3:数据相关性。
[0597]
在获得测序表观基因组学数据后,在测序结合位置的位置之间产生相关性,并使表观结合(epi-binding)与提供甲基化的序列背景发生关系。
[0598]
实施例4:从λ噬菌体dna中的瞬时结合中收集的荧光。
[0599]
图23a、图23b和图23c示出了瞬时结合事件的实例。它们共同示出了在室温下在缓冲液b+中浓度为1.5nm的oligo i.d.lin2621、cy3标记的5
′
nagcggn 3
′
的瞬时结合。靶多核苷酸是λ噬菌体基因组,已将其在mes ph 5.5缓冲液+0.1m nacl中人工梳理到乙烯基硅烷表面(genomic vision)。400mw的激光532nm,通过点光源光纤扰频器。荧光已用tirf附着和多色收集,包括532nm激发带、tirf物镜100x、1.49na和另外的1.5倍放大率。没有实现隔振。
图像是通过完全聚集在采用100em增益设置的hamamatsu imageem 512x512上捕获的。在100ms内收集了10000帧。寡核苷酸探针组中cy3的浓度为约250nm-300nm。图23a显示了在thunderstorm中在交叉相关漂移校正之前收集的荧光。图23b显示了用比例尺进行互相关漂移校正后收集的荧光。图23c显示了图23b的放大区域中的荧光。图23c显示了通过lin2621与多个位置的持续结合而发现的长多核苷酸链。从图像中可以清楚地看出,靶多核苷酸链在成像表面上以比cy3发射的衍射极限更近的距离固着和伸长。
[0600]
实施例5:从合成dna的瞬时结合中收集的荧光
[0601]
图24示出了从三种不同的多核苷酸链收集的荧光数据的实例。在合成的3千碱基变性双链dna上显示了多个探测和洗涤步骤。在乙烯基硅烷表面上于mes ph 5.5中对合成dna进行了梳理和变性。进行了一系列结合和清洗步骤,并使用thunderstorm在imagej中记录和处理了视频。从超分辨图像中切下三条示例性链(1、2、3)用于在环境温度下,用10nm的缓冲液b+中的寡聚体进行的以下实验系列:寡聚体3004结合、洗涤、寡聚体2879结合、洗涤、寡聚体3006结合、洗涤以及寡聚体3004结合(再次)。这表明结合图谱可从瞬时结合中获得,结合模式可通过洗涤消除,然后在相同的合成dna的第一链和第二链上用不同的寡聚体获得不同的结合模式。在该系列的最后一个实验返回到寡聚体3004,并且其与该系列中第一个实验使用的模式相似,这表明该过程的稳健性,即使没有任何优化尝试。
[0602]
实验确定的结合位置与预期一致,其中双链体的链1和3显示了4个可能的完全匹配结合位点中的3个,双链体的链2显示了所有4个结合位置和一个明显的错配位置。观察到使用寡聚体3004的第二次探测似乎显示出更清晰的信号,这可能是由于更少的错配。这与由于长时间暴露在激光下加热而导致温度略微升高的可能性是一致的。
[0603]
本实验中使用的寡聚体序列如下(大写的碱基为锁核酸(lna)):
[0604]
寡聚体3004:5’cy3 ntggcgn
[0605]
寡聚体2879:5’cy3 nggcgan
[0606]
寡聚体3006:5’cy3 ntgggcn:
[0607]
3kbp合成模板序列的序列列表(文件底部)如下:
[0608]
aaaaaaaaaccggcccagctttcttcattaggttatacatctaccgctcgccagggcggcgacctcgcgggttttcgctatttatgaaaattttccggtttaaggcgtttccgttcttcttcgtcataacttaatgtttttatttaaaataccctctgaaaagataggatagcacacgtgctgaaagcgaggctttttggcctctgtcgtttcctttctctgtttttgtccgtggaatgaacaatggaagtcaacaaaaagcagctggctgacattttcggtgcgagtatccgtaccattcagaactggcaggaacagggaatgcccgttctgcgaggcggtggcaagggtaatgaggtgctttatgactctgccgccgtcataaaatggtatgccgaaagggatgctgaaattgagaacgaaaagctgcgccgggaggttgaagaactgcggttcttatacatctaatagtgattatctacatacattatgaatctacattttaggtaaagattaattgagtaccaggtttcagatttgcttcaataaattctgactgtagctgctgaaacgttgcggttgaactatatttccttataacttttacgaaagagtttctttgagtaatcacttcactcaagtgcttccctgcctccaaacgatacctgttagcaatatttaatagcttgaaatgatgaagagctctgtgtttgtcttcctgcctccagttcgccgggcattcaacataaaaactgatagcacccggagttccggaaacgaaatttgcatatacccattgctcacgaaaaaaaatgtccttgtcgatatagggatgaatcgcttggtgtacctcatctactgcgaaaacttgacctttctctcccatattgcagtcgcggcacgatggaactaaattaataggcatcaccgaaaattcaggataatgtgcaataggaagaaaatgatctatattttttgtctgtcctatatcaccacaaaacctgaaactggcgcgtgagatggggcgaccgtcatcgtaatatgttctagcgggtttgtttttatctcgg
agattattttcataaagcttttctaatttaacctttgtcaggttaccaactactaaggttgtaggctcaagagggtgtgtcctgtcgtaggtaaataactgacctgtcgagcttaatattctatattgttgttctttctgcaaaaaagtggggaagtgagtaatgaaattatttctaacatttatctgcatcataccttccgagcatttattaagcatttcgctataagttctcgctggaagaggtagttttttcattgtactttaccttcatctctgttcattatcatcgcttttaaaacggttcgaccttctaatcctatctgaccattataattttttagaatgcggcgttttccggaactggaaaaccgacatgttgatttcctgaaacgggatatcatcaaagccatgaacaaagcagccgcgctggatgaactgataccggggttgctgagtgaatatatcgaacagtcaggttaacaggctgcggcattttgtccgcgccgggcttcgctcactgttcaggccggagccacagaccgccgttgaatgggcggatgctaattactatctcccgaaagaatccgcataccaggaagggcgctgggaaacactgccctttcagcgggccatcatgaatgcgatgggcagcgactacatccgtgaggtgaatgtggtgaagtctgcccgtgtcggttattccaaaatgctgctgggtgtttatgcctactttatagagcataagcagcgcaacacccttatctggttgccgacggatggtgatgccgagaactttatgaaaacccacgttgagccgactattcgtgatattccgtcgctgctgttaattgagtttatagtgattttatgaatctattttgatgatattatctacatacgactggcgtgccatgcttgccgggatgtcaaatttaataaggtgatagtaaataaaacaattgcatgtccagagctcattcgaagcagatatttctggatattgtcataaaacaatttagtgaatttatcatcgtccacttgaatctgtggttcattacgtcttaactcttcatatttagaaatgaggctgatgagttccatatttgaaaagttttcatcactacttagttttttgatagcttcaagccagagttgtctttttctatctactctcatacaaccaataaatgctgaaatgaattctaagcggagatcgcctagtgattttaaactattgctggcagcattcttgagtccaatataaaagtattgtgtaccttttgctgggtcaggttgttctttaggaggagtaaaaggatcaaatgcactaaacgaaactgaaacaagcgatcgaaaatatccctttgggattcttgactcgataagtctattattttcagagaaaaaatattcattgttttctgggttggtgattgcaccaatcattccattcaaaattgttgttttaccacacccattccgcccgataaaagcatgaatgttcgtgctgggcatagaattaaccgtcacctcaaaaggtatagttaaatcactgaatccgggagcactttttctattaaatgaaaagtggaaatctgacaattctggcaaaccatttaacacacgtgcgaactgtccatgaatttctgaaagagttacccctctaagtaatgaggtgttaaggacgctttcattttcaatgtcggctaatcgatttggccatactactaaatcctgaatagctttaagaaggttatgtttaaaaccatcgcttaatttgctgagattaacatagtagtcaatgctttcacctaaggaaaaaaacatttcagggagttgactgaattttttatctattaatgaataagtgcttgacctatttcttcattacgccattatacatctagcccaccgctgccaaaaaaaaa
[0609]
实施例6:单细胞的综合分离,提取核酸和测序。
[0610]
步骤1:设计和制造微流体体系结构
[0611]
微通道被设计成容纳来自典型直径为15um的人癌细胞系的细胞,因此微流体网络的最小深度和宽度为33um。该装置包括细胞入口和缓冲液入口,这两个入口合并成一个通道,为单细胞捕集器提供进料(如图17所示)。在细胞与缓冲液入口之间的交叉点,细胞沿着一个或多个捕集器所在的进料通道的侧壁排列。每个捕集器都是一个简单的缢缩结构,其大小可以从人癌细胞系中捕获细胞。用于细胞捕获的缢缩部分具有梯形横截面:底部的宽度4.3um,中间的深度6um,顶部的宽度8um,深度33um。每个细胞捕集器将进料通道连接到分叉处,该分叉的一侧是废料通道(图17中未示出),另一侧是包含流动-拉伸部分(用于核酸伸长和测序)的通道,每个细胞一个。流动-拉伸部分由20um(或最多达2mm)宽度、450um-长度、100nm(或最高达2um深度)的通道组成。在一些实施方案中,流动-拉伸通道开始较窄,然后加宽至所述尺寸。
[0612]
步骤2:装置制造
[0613]
所述装置通过使用topas 5013(topas)的注射成型复制镍垫片来制造。简言之,通过uv光刻技术和反应离子刻蚀生产硅母版。沉积100-nm niv晶种层,并将镍电镀至330um的最终厚度。硅母版在koh中被化学腐蚀掉。使用250℃的熔体温度、120℃的模具温度、1500巴的最大保持压力持续2s,以及20cm3/s至45cm3/s之间变化的注射速率进行注射成型。最后,将盖玻片(1.5)粘合至装置上,或者使用150um topas箔,在0.51兆帕的最大压力下通过uv和热处理的组合来密封装置。在密封装置之前,通过在140℃和5.1兆帕下,在两个从硅晶片电镀的平镍板之间压制箔20分钟来降低箔的表面粗糙度。这确保了装置的盖子是光学平坦的,允许进行高na光学显微镜检查。该装置安装在倒置荧光显微镜(nikon ti-e)上,该显微镜配备有油tirf物镜(100x/na 1.49),以及emccd照相机hamamatsu imageem 512)。使用压力控制器(mfcs,fluigent)在0到10毫巴范围内的压力下驱动流体通过该装置。用乙醇灌注该装置,然后脱气,除连接流动-拉伸装置的微通道外,所有微通道中都装有facsflow鞘液(bd biosciences)。选择性装载是通过在废料通道的出口处施加负压或抽吸力,同时在流动拉伸通道的出口施加正压,同时在引入溶液的进料通道的入口处保持正压来实现的。将适用于单分子成像和电泳的缓冲液(0.5x tbe+0.5%v/v triton-x100+1%v/vβ-巯基乙醇,bme)装载在流动-拉伸装置的通道中。该缓冲液防止了dna粘附在流动-拉伸部分中,并在流动-拉伸部分的高度较低时抑制了能够抵消提取的dna的引入的电渗流。
[0614]
步骤3:细胞制备
[0615]
将ls174t结直肠癌细胞在含有10%胎牛血清fbs;autogen-bioclear uk ltd.)和1%青霉素/链霉素(lonza)的达尔伯克改良伊格尔培养基(dmem;gibco)中培养,然后以1.7 106个细胞/ml的浓度(于10%的fbs中的dmso中)冷冻。解冻后,将细胞悬液与facsflow缓冲液1:1混合,以28.8x g(a-4-44,eppendorf)离心5分钟,并重悬于facsflow缓冲液中。最后,细胞用1um钙黄绿素am(invitrogen)染色,并以0.35 106个细胞/ml加载到芯片中。加载约5-10,000个细胞,并分析每个捕集器中捕获的第一个细胞。
[0616]
步骤4:操作
[0617]
将细胞和缓冲液同时引入,沿着捕集器所在的微通道的侧壁排列细胞。单个细胞被捕获并保持在捕集器中,以待缓冲液以30nl/分钟流过捕集器。将由0.5x tbe+0.5%v/v triton-x100+0.1um yoyo-1(invitrogen)组成的裂解缓冲液加载到入口之一,并以10nl/分钟注射通过捕集器,进行10分钟。然后,在所有孔中将溶液交换到不含yoyo-1的缓冲液中,以停止染色。接下来,将细胞核暴露于剂量为1nw/(um)2的蓝色激发光下长达300s,引起dna的部分光切刻(参见www.pnas.org/cgi/doi/10.1073/pnas.1804194115的si附录)。然后,将缓冲液换成含有bme的溶液(0.5x tbe+0.5%v/v triton-x100+1%v/v bme),并将荧光灯的强度降低到仍然允许荧光成像的最小强度。接下来,将温度升至60℃,并引入蛋白水解溶液(蛋白酶k》200μg ml-1
(qiagen),0.5x tbe+0.5%v/v triton-x100+1%v/v bme+200g/ml),将裂解物推过捕集器。dna穿过相邻的流动-拉伸部分,将油浸物镜移动到单分子成像(100x,na 1.49,再加上1.5倍放大倍数,可得到120nm像素大小)的位置。通过在流动-拉伸部分施加5至10v的电压,使用电泳将dna片段从微通道引入流动-拉伸装置。当dna片段的两端都在相对的微通道中时,关闭电压。以100-150%拉伸的分子的450um部分对应于》1兆碱基长度的从单细胞提取的基因组dna。在一些实施方案中,在蛋白水解后,通过用0.5xtbe替代捕获缓冲液,将dna内容物推过装置;在此类实施方案中,流动-拉伸部分的尺
寸任选地更大,使得数千个兆碱基片段可以同时被捕获(通过疏水或静电相互作用)并在通道内被拉伸。这可通过使用ph缓冲液8(例如hepes)来完成,此处被粘合的盖玻片带有正电荷,诸如aptes或多聚赖氨酸或乙烯基硅烷盖玻片被粘合,并且ph 5.5-5.7的0.5m mes缓冲液用于流入dna,然后通过用空气跟随mes缓冲液来梳理所述dna。如果箔包含zeonex,那么分子梳理可用0.6m mes缓冲液在ph 5.7下完成。
[0618]
一旦双链核酸被固着,就流过变性溶液、0.5m naoh和或6%dmso。然后,将单细胞样品准备用于本发明的测序方法,其中将寡聚体的库流过,并对寡聚体结合成像。
[0619]
在一些实施方案中,细胞裂解是两个步骤,使得rna不会在流动-延伸部分内污染和引起荧光。此处,施加第一裂解缓冲液(例如,含有0.5%(v/v)triton x-100的0.5x tbe,其中添加了dna嵌合yoyo-1染料)。这种缓冲液裂解细胞膜,将胞质溶胶内容物释放到装有10
–
20μl无核酸酶h2o的捕集器出口中,将细胞核和dna留在捕集器中(例如,如由van strijp等人sci rep.7:11030(2017)所描述的)。每个细胞的胞质溶胶内容物被裂解并分流到废料出口,或者该装置被设计成具有用于rna的流动-拉伸部分,该部分与用于dna的流动-拉伸部分分开。在一些实施方案中,将rna送至单独的流动拉伸部分,所述流动拉伸部分已涂覆有寡聚dt,其捕获poly a rna。在一些实施方案中,用于rna的流动拉伸部分包括纳米孔或纳米坑(nanopit)(marie等人,nanoscale doi:10.1039/c7nr06016e)2017),其中使用例如polya聚合酶,捕获rna并使用酶试剂来添加捕获序列。用第二种缓冲液(含0.5%(v/v)triton x-100和蛋白酶k的0.5x tbe)进行细胞核裂解,并将dna分流至用于dna的流动-拉伸部分。
[0620]
为了将核酸的损失降至最低,距离捕集器和流动-拉伸部分的距离较短,并且装置壁被很好地钝化,包括通过用脂质涂覆(例如,如persson等人nanoletters 12:2260-5(2012)所述))。
[0621]
实施例7:概率模型和测序算法
[0622]
此处描述了使用泊松点过程确定聚合物(例如,核酸)序列的简单模型。对于这个简化模型,数据d由m个id定位的集合组成,d=(d1,
…
,d m
),每次测量一个。每个集合都包含投影到估计链的第i个测量值的定位。给定核酸序列,每次测量都是独立的,使得总对数似然为每次测量的总和:
[0623][0624]
此处pi是第i次实验的观测模型。
[0625]
测量i的定位通过利用强度函数λi:r
→r+
的泊松点过程来建模,而似然的定义是如由streit 2010在“poisson point processes:imaging,tracking,and sensing.”所述的。
[0626]
强度λi是序列s和几个特定测量特异性参数的函数:
[0627][0628]
指示器功能1(l《t≤u)处理在特定窗口外未观察到定位的事实。这在执行滑动窗口测序时特别有用。此处其中k是测量中使用的探针的长度(例如,对于5聚体寡聚物,k=5),是实验对序列中每个可能的k-聚体的反应。换句话说,r
j(i)
是来自序列上与k-聚
体j匹配的单个结合位点的预期定位数。通常r(i)将是混淆矩阵和第i次实验的探针浓度向量的乘积。c捕获序列中每个探针与每个可能的k-聚体之间的结合速率;在测量i的实验条件(例如,动态图像长度(movie length)、帧速率、激光水平、温度、盐度等)下。
[0629]
集成为一的函数psf对定位不确定性进行建模。psf的一个简单选择是标准高斯pdf,其中σ等于(估计的)定位不确定性,单位为纳米:
[0630][0631]
在上图中,l
p
是序列中第p个位置的定位,单位为纳米。中的第二个和处理反向互补序列(即,与互补链结合的寡核苷酸)中的结合。π是置换矩阵,其用对应的反向互补k-聚体的位置交换每个位置。σ是偏移量,其模拟了这样一个事实,即与互补链结合的探针将使其荧光团偏移已知的量(例如,将探针寡聚物缀合于序列的3’端处的荧光团)。最后,bi是背景强度:每纳米虚假定位的预期数量。
[0632]
运行第一遍模拟实验来测试上述方法。首先,模拟随机分布在2d空间的λ噬菌体基因组的多个拷贝的结合模式。使用两态连续时间马尔可夫链(two-state,continuous-time markov chain)对每个位点进行建模,其中假设探针在某个指数分布的时间长度内与一个位点结合,然后该位点在另一个指数分布的时间长度内保持未结合(例如,其中结合时间和未结合时间各自具有不同的指数参数)。还考虑了虚假的(例如,脱链的)荧光团。使用标准高斯显微镜psf、用于噪声统计的emccd模型和512个5-聚体探针模拟视频。假设不存在结合错配。将交替下降条件梯度(adcg)方法(所述方法描述于boyd等人2017siam journal on optimization 27(2),616-639中)用于定位每个视频中的荧光团。直线被拟合,定位被投射到每条线上。通过首先在λ噬菌体基因组内定位单个短(例如,256个碱基对)区段(例如,通过使用具有粗参数的似然函数),然后最大化参数的似然性,来确定模型参数。使用滑动窗口进行从头组装,步长为1个碱基对,宽度为64个碱基对。为了组装每个区段,直接使用遗传算法来最大化64个碱基对的序列的序列似然性。最后,将每个估计的序列从每个窗口与其邻居配对比对,并执行投票以生成共有序列。这个简单的算法从视野中对所有12000个碱基对进行了测序,错误率仅为0.5%。
[0633]
引用的参考文献和替代实施方案
[0634]
本文引用的所有参考文献出于所有目的通过引用整体并入本文,其程度如同每个单独出版物或专利和专利申请被具体地和单独地指出出于所有目的通过引用整体并入。
[0635]
所有标题和副标题仅仅是为了方便而在本文中使用,不应该被解释为以任何方式限制本发明。
[0636]
除非另外声明,否则本文提供的任何和所有实例或示例性语言(例如,“诸如”)的使用仅仅是为了更好地说明本发明,而不是对范围构成限制。说明书中的任何语言都不应该被解释为指示任何未要求保护的元素对本发明的实践是必要的。
[0637]
还应当理解,尽管术语第一、第二等可在本文中用来描述各种元件,但这些元件不应受这些术语限制。这些术语只用于区分一个元件与另一元件。例如,在不脱离本公开的范围的情况下,第一主题可被称为第二主题,类似地,第二主题可以被称为第一主题。第一主题和第二个主题都是主题,但它们不是同一主题。
[0638]
本公开中使用的术语学仅用于描述特定实施方案的目的,并不旨在限制本发明。如说明书和所附权利要求书中所使用的,除非上下文另有明确指示,否则单数形式“一个/种(a)”、“一个/种(an)”和“该(the)”旨在也包括复数形式。还应当理解,如本文中所用,术语“和/或”是指并且涵盖相关列出项目中的一个或多个项目的任何和所有可能的组合。还应当理解,当在本说明书中使用时,术语“包括”和/或“包含”指定所陈述的特征、整数、步骤、操作、元件和/或组件的存在,但不排除一个或多个其它特征、整数、步骤、操作、元件、组件和/或其组合的存在或添加。
[0639]
如本文中所用,取决于上下文,术语“如果(if)”可被解释为表示“当......时”或“根据”或“响应于确定”或“响应于检测”。类似地,短语“如果确定了”或“如果检测到[规定的条件或事件]”可被解释为意指“根据确定”或“响应于确定”或“根据检测到[规定的条件或事件]”或“响应于检测到[规定的条件或事件]”,这取决于上下文。
[0640]
本文中专利文件的引用和并入只是为了方便而进行的,并不反映对这些专利文件的有效性、可专利性和/或可执行性的任何观点。
[0641]
本发明可以实现为计算机程序产品,其包括嵌入在非易失性计算机可读存储介质中的计算机程序机制。例如,计算机程序产品可包含图1的以任何组合显示的程序模块。这些程序模块可以存储在cd-rom、dvd、磁盘存储产品、usb密钥或任何其他非易失性计算机可读数据或程序存储产品上。
[0642]
根据说明书的教导和其中引用的参考文献,可以最彻底地理解本发明。对于本领域技术人员来说显而易见的是,在不脱离其精神和范围的情况下,可以进行许多修改和变化。本文所述的具体实施方案仅作为示例提供。选择和描述实施方案是为了最好地解释原理及其实际应用,从而使本领域的其他技术人员能够最好地利用本发明和具有各种修改的各种实施例,以适合预期的特定用途。本发明仅由所附权利要求书的条款以及此类权利要求所授权的等同物的全部范围来限制。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1