识别P53中的R175H或Y220C突变的T细胞受体的制作方法
识别p53中的r175h或y220c突变的t细胞受体
相关申请的交叉引用
1.本专利申请要求2019年6月27日提交的美国临时专利申请号62/867,619的权益,其通过引用以其整体并入。关于政府资助的研究或开发的声明
2.本发明由美国国家癌症研究所美国国立卫生研究院在项目号bc010985的政府支持下完成。政府享有本发明的某些权力。电子提交的材料的通过引用并入
3.通过引用以其整体并入本文的是随此电子提交的并且如下鉴定的计算机可读的核苷酸/氨基酸序列表:日期为2020年6月23日的一个名称为“749338_st25.txt”的357,775个字符的ascii(文本)文件。发明背景
4.一些癌症的治疗选择可以非常有限,尤其是当癌症变为转移性且不可切除时。尽管在诸如手术、化学疗法及放射疗法的治疗中取得进展,但诸如(例如)胰腺癌、结肠直肠癌、肺癌、子宫内膜癌、卵巢癌及前列腺癌的许多癌症的预后可能是不佳的。因此,对癌症的其他治疗存在未满足的需求。
技术实现要素:
5.本发明的一实施方案提供一种经分离或经纯化的t细胞受体(tcr),其对人类p53
r175h
或人类p53
y220c
氨基酸序列具有抗原特异性,其中所述tcr包含以下氨基酸序列:(1)seq id no:3-8全部;(2)seq id no:14-19全部;(3)seq id no:25-30全部;(4)seq id no:36-41全部;(5)seq id no:47-52全部;(6)seq id no:58-63全部;(7)seq id no:69-74全部;(8)seq id no:80-85全部;或(9)seq id no:131-136全部。
6.在本发明的一实施方案中,所述tcr对人类p53
r175h
或人类p53
y220c
氨基酸序列具有抗原特异性,其中所述人类p53
r175h
氨基酸序列为seq id no:2或seq id no:96。
7.在本发明的一实施方案中,所述tcr对人类p53
r175h
或人类p53
y220c
氨基酸序列具有抗原特异性,其中所述人类p53
y220c
氨基酸序列为seq id no:113。
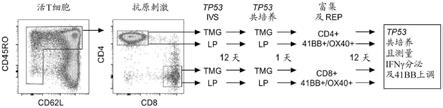
8.在本发明的一实施方案中,所述tcr对野生型人类p53氨基酸序列seq id no:95不具有抗原特异性。
9.在本发明的一实施方案中,所述tcr对野生型人类p53氨基酸序列seq id no:112不具有抗原特异性。
10.本发明的其他实施方案提供相关的多肽及蛋白质,以及相关的核酸、重组表达载体、宿主细胞、细胞群及与本发明的tcr相关的药物组合物。
11.本发明的一实施方案提供一种经分离或经纯化的核酸,其自5
′
至3
′
包含第一核酸序列及第二核苷酸序列,其中所述第一及第二核苷酸序列分别编码氨基酸序列seq id no:9及10;10及9;20及21;21及20;31及32;32及31;42及43;43及42;53及54;54及53;64及65;65及64;75及76;76及75;86及87;87及86;137及138;138及137;142及143;143及142;144及
145;145及144;146及147;147及146;148及149;149及148;150及151;1 51及150;152及153;153及152;154及155;155及154;156及157;157及156;159及158;158及159;178及10;10及178;181及21;21及181;184及32;32及184;187及43;43及187;190及54;54及190;193及65;65及193;196及76;76及196;199及87;87及199;137及202;202及137;9及205;205及9;20及207;207及20;31及209;209及31;42及211;211及42;53及213;213及53;64及215;215及64;75及217;217及75;86及219;219及86;137及221;221及137;223及202;202及223;223及221;221及223;20及226;226及20;181及226;或226及181。
12.本发明的一实施方案提供一种经分离或经纯化的核酸,其自5
′
至3
′
包含第一核酸序列及第二核苷酸序列,其中所述第一及第二核苷酸序列分别编码氨基酸序列seq id no:11及12;12及11;22及23;23及22;33及34;34及33;44及45;45及44;55及56;56及55;66及67;67及66;77及78;78及77;88及89;89及88;139及140;140及139;160及161;161及160;162及163;163及162;164及165;165及164;166及167;167及166;168及169;169及168;170及171;171及170;172及173;173及172;174及175;175及174;176及177;177及176;179及12;12及179;182及23;23及182;185及34;34及185;188及45;45及188;191及56;56及191;194及67;67及194;197及78;78及197;200及89;89及200;139及203;203及139;11及206;206及11;22及208;208及22;33及210;210及33;44及212;212及44;55及214;214及55;66及216;216及66;77及218;218及77;88及220;220及88;139及222;222及139;224及203;203及224;224及222;222及224;22及227;227及22;182及227;或227及182。
13.在本发明的一实施方案中,所述经分离或经纯的化核酸进一步包含插入所述第一与第二核苷酸序列之间的第三核苷酸序列,其中所述第三核苷酸序列编码可裂解接头肽。
14.在本发明的一实施方案中,所述可裂解接头肽包含氨基酸序列seq id no:94。
15.在本发明的一实施方案中,所述经分离或经纯化的核酸编码选自以下的氨基酸序列:seq id no:13、24、35、46、57、68、79、90、141、180、183、186、189、192、195、198、201、204、225、228及229。
16.在本发明的一实施方案中,所述重组表达载体为转座子或慢病毒载体。
17.本发明的另一实施方案提供一种经分离或经纯化的tcr、多肽或蛋白质,其由本文中描述的核酸或载体中的任一者编码。
18.本发明的另一实施方案提供一种经分离或经纯化的tcr、多肽或蛋白质,其由本文中描述的核酸或载体中的任一者在细胞中表达产生。
19.本发明的另一实施方案提供一种产生表达对seq id no:2、96或113的肽具有抗原特异性的tcr的宿主细胞的方法,所述方法包含使细胞与本文中描述的载体中的任一者在允许所述载体引入所述细胞中的条件下接触。
20.本发明的另一实施方案提供一种经分离或经纯化的宿主细胞,其包含本文中描述的核酸或重组表达载体中的任一者。
21.在本发明的一实施方案中,所述宿主细胞为人类淋巴细胞。
22.在本发明的一实施方案中,所述宿主细胞选自:t细胞、天然杀伤t(nkt)细胞、恒定(invariant)天然杀伤t(inkt)细胞及天然杀伤(nk)细胞。
23.本发明的另一实施方案提供一种产生本文中描述的tcr、多肽或蛋白质中的任一者的方法,所述方法包含培养本文中描述的宿主细胞或宿主细胞群中的任一者,使得产生
所述tcr、所述多肽或所述蛋白质。
24.本发明的另一实施方案提供本文中描述的tcr、多肽、蛋白质、核酸、重组表达载体、宿主细胞、细胞群或药物组合物中的任一者,其用于在哺乳动物中诱导针对癌症的免疫反应。在一实施方案中,本发明提供一种诱导针对哺乳动物的癌症的免疫反应的方法,所述方法包括施用本文中描述的tcr、多肽、蛋白质、核酸、重组表达载体、宿主细胞、细胞群或药物组合物中的任一者。
25.本发明的其它实施方案提供检测哺乳动物中癌症的存在的方法,及治疗或预防哺乳动物的癌症的方法。在一实施方案中,本发明提供一种治疗或预防哺乳动物的癌症的方法,所述方法包括施用本文中描述的tcr、多肽、蛋白质、核酸、重组表达载体、宿主细胞、细胞群或药物组合物中的任一者。在一实施方案中,所述癌症为胆管癌、黑素瘤、结肠癌、直肠癌、卵巢癌、子宫内膜癌、非小细胞肺癌(nsclc)、胶质母细胞瘤、子宫颈癌、头颈癌、乳癌、胰腺癌或膀胱癌。
26.在本发明的一实施方案中,已知所述癌症包含人类p53中的r175h或y220c突变。附图的简单说明
27.图1a为展示实验设计的示意图,其中亲本门为淋巴细胞
→
单细胞
→
活体(pi阴性)
→
cd3
+
(t细胞)。
28.图1b至图1c为展示在ivs(tp53-tmg-ivs(b)或p53-lp-ivs(c))及4-1bb/ox40富集之后检测到的4-1bb阳性细胞的百分比的图。视为阳性的培养物为粗体。展示对突变tp53(tmg(实心圆);lp(实心正方形))及野生型(wt)对应物(tmg(空心圆);lp(空心正方形))的反应。
29.图1d展示来自在与经wt或突变(mut)tp53串联小型基因(tmg)电穿孔的自体抗原呈递细胞共培养之后4141-cd8 tp53-tmg-ivs培养物的代表性流式细胞测量图。
30.图1e展示在抗原刺激的cd4 t细胞分选且用突变tp53-tmg电穿孔的未成熟树突状细胞进行活体外刺激之后测量的干扰素γ分泌(左轴)或4-1bb的上调(右轴)。接着将培养物与经突变tp53-tmg电穿孔的未成熟树突状细胞共培养,且第二天将4-1bb+及/或ox40+细胞分选并通过快速扩增方案扩增。在扩增12-14天之后,通过干扰素γelispot(左轴)或通过流式细胞术的4-1bb的上调(右轴)对培养物(4285-cd4 tp53-tmg-ivs)对p53-r175h新抗原的特异性进行测试。
31.图1f为展示如通过elisa所测量的4285-cd4 tp53-tmg-ivs及肽脉冲自体抗原呈递细胞共培养上清液中的干扰素γ分泌的图。将4285-cd4 tp53-tmg-ivs培养物与未成熟树突状细胞共培养,所述未成熟树突状细胞经减小浓度的wt(空心圆)或具有25个氨基酸长度的突变(实心正方形)p53-r175肽脉冲。在孵育过夜之后,通过elisa分析共培养物上清液的干扰素γ分泌。数据为平均值
±
sem(n=3个技术拷贝)。
32.图2a为展示总群体的克隆性的图,该图为样品多样性的归一化估计,其中更接近于1的数值具较小多样性。在通过ivs及4-1bb/ox40富集用lp或tmg扩增之前或之后,对pbl进行tcrb测序。具有经验证p53新抗原反应的培养物用星号突出显示。
33.图2b为展示来自各群体的最大生产独特cdr3b频率的图。在通过ivs及4-1bb/ox40富集用lp或tmg扩增之前或之后,对pbl进行tcrb测序。具有经验证p53新抗原反应的培养物用星号突出显示。
34.图2c为展示其中将未经转导的t细胞(经tcr转导的t细胞的阴性对照)与未成熟树突状细胞共培养的实验结果的图,所述未成熟树突状细胞经减小浓度的wt(空心圆)或具有25个氨基酸长度的突变(实心正方形)p53-r175肽脉冲。在孵育过夜之后,通过elisa分析共培养物上清液的干扰素γ分泌。数据为平均值
±
sem(n=3)。
35.图2d为展示其中将经4285-pbl-tcr1转导的t细胞与未成熟树突状细胞共培养的实验结果的图,所述未成熟树突状细胞经减小浓度的wt(空心圆)或具有25个氨基酸长度的突变(实心正方形)p53-r175肽脉冲。在孵育过夜之后,通过elisa分析共培养物上清液的干扰素γ分泌。数据为平均值
±
sem(n=3)。
36.图2e为展示其中将经4285-pbl-tcr2转导的t细胞与未成熟树突状细胞共培养的实验结果的图,所述未成熟树突状细胞经减小浓度的wt(空心圆)或具有25个氨基酸长度的突变(实心正方形)p53-r175肽脉冲。在孵育过夜之后,通过elisa分析共培养物上清液的干扰素γ分泌。数据为平均值
±
sem(n=3)。
37.图2f为展示其中将经4285-pbl-tcr3转导的t细胞与未成熟树突状细胞共培养的实验结果的图,所述未成熟树突状细胞经减小浓度的wt(空心圆)或具有25个氨基酸长度的突变(实心正方形)p53-r175肽脉冲。在孵育过夜之后,通过elisa分析共培养物上清液的干扰素γ分泌。数据为平均值
±
sem(n=3)。
38.图2g为展示其中将经4285-pbl-tcr5转导的t细胞与未成熟树突状细胞共培养的实验结果的图,所述未成熟树突状细胞经减小浓度的wt(空心圆)或具有25个氨基酸长度的突变(实心正方形)p53-r175肽脉冲。在孵育过夜之后,通过elisa分析共培养物上清液的干扰素γ分泌。数据为平均值
±
sem(n=3)。
39.图2h为展示其中将经4285-pbl-tcr6转导的t细胞与未成熟树突状细胞共培养的实验结果的图,所述未成熟树突状细胞经减小浓度的wt(空心圆)或具有25个氨基酸长度的突变(实心正方形)p53-r175肽脉冲。在孵育过夜之后,通过elisa分析共培养物上清液的干扰素γ分泌。数据为平均值
±
sem(n=3)。
40.图2i为展示其中将经4285-pbl-tcr7转导的t细胞与未成熟树突状细胞共培养的实验结果的图,所述未成熟树突状细胞经减小浓度的wt(空心圆)或具有25个氨基酸长度的突变(实心正方形)p53-r175肽脉冲。在孵育过夜之后,通过elisa分析共培养物上清液的干扰素γ分泌。数据为平均值
±
sem(n=3)。
41.图2j为展示其中将经4285-pbl-tcr9转导的t细胞与未成熟树突状细胞共培养的实验结果的图,所述未成熟树突状细胞经减小浓度的wt(空心圆)或具有25个氨基酸长度的突变(实心正方形)p53-r175肽脉冲。在孵育过夜之后,通过elisa分析共培养物上清液的干扰素γ分泌。数据为平均值
±
sem(n=3)。
42.图2k至图2l为展示在ivs及4-1bb富集方案之前(pbl)及之后(ivs/富集)在追踪对突变tp53具已知特异性的cdr3b之后测量的tcrb克隆型的百分比的图。p53
r175h
特异性克隆型以k展示。p53
r248w
特异性克隆型以l展示。
43.图3a为展示在经所指示hla转染cos7猴细胞系且用所指示最小p53肽(wt(空心条);突变(实心条))脉冲之后测量的4-1bb阳性细胞的百分比的图。展示来自4141-cd8 tp53-tmg-ivs培养物的结果。tmg-wtr175在除r175h以外的所有位置处具有突变tp53。序列hmtevvrrc为seq id no:95。序列hmtevvrhc为seq id no:96。
44.图3b为展示在经所指示hla转染cos7猴细胞系且用所指示最小p53肽(wt(空心条);突变(实心条))脉冲之后测量的ifn-γ的量的图。展示来自4266-cd8 tp53-tmg-ivs培养物的结果。序列sscmggmnrr为seq id no:97。序列sscmggmnwr为seq id no:98。
45.图3c为展示其中用对应于患者4285的单倍型的hla质粒dna及仅r175h位置处的wt tp53 tmg(wt-r175-tmg;空心条)或含有p53-r175h新抗原的突变tp53-tmg(实心条)转染cos7猴肿瘤细胞系的实验结果的图。第二天,添加且共培养4285-cd4tp53-tmg-ivs培养物。在孵育过夜之后,通过elisa分析共培养物上清液的干扰素γ分泌。数据为平均值土sem(n=3)。
46.图3d展示流式细胞测量图,其展示在与tc#4266(来自患者4266的自体异种移植物;a*68:01;p53
r248w
)及过表达全长p53
r175h
基因的saos2细胞(a*02:01)共培养之后来自tp53-tmg-ivs培养物(4266-cd8在左侧且4141-cd8在右侧)的cd8
+
t细胞上的4-1bb的上调。
47.图4为展示其中用dra1*01:01:01及drb1*13:01:01以及无关的(空心条)、仅r175h位置处的wt tp53 tmg(wt-r175-tmg;灰色条)或含有p53-r175h新抗原的突变tp53-tmg(实心条)转染cos7猴肿瘤细胞系的实验结果的图。第二天,添加且共培养经4285-pbl-tcr转导或未经转导的t细胞。在孵育过夜之后,通过elisa分析共培养物上清液的干扰素γ分泌。数据为平均值
±
sem(n=3)。
48.图5为展示其中在自4259-f1肿瘤片段培养物分选cd8
+
t细胞之后通过限制稀释法制备t细胞克隆的实验结果的图。将24种培养物与经dmso(肽载体)、wt p53-y220肽或mut p53-y220c肽脉冲的t2肿瘤细胞(hla-a*02:01)共培养。在孵育过夜之后,针对cd3、cd8及4-1bb对细胞进行染色,接着通过流式细胞术进行分析。自培养物显示cd8
+
4-1bb
+
t细胞的频率。
49.图6为展示其中将4259-f1-tcr转导至供体外周血t细胞中,接着与t2肿瘤细胞(hla-a*02:01)共培养的实验结果的图,所述t2肿瘤细胞经减小浓度的wt p53-y220肽(vvpyeppev)(seq id no:112)或mut p53-y220c肽(vvpceppev)(seq id no:113)脉冲。在孵育过夜之后,通过elisa分析共培养物上清液的干扰素γ分泌。数据为平均值
±
sem(n=3)。
50.图7为展示其中将不表达tcr(未经转导)、p53-r175h特异性tcr或4259-f1-tcr的t细胞与表达或不表达hla-a*02:01、p53-r175h或p53-y220c的肿瘤细胞共培养的实验结果的图。在孵育过夜之后,针对cd3、cd8及4-1bb对细胞进行染色,接着通过流式细胞术进行分析。自培养物显示cd8
+
4-1bb
+
t细胞的频率。数据为平均值
±
sem(n=3)。
51.图8展示九种p53剪接变体的氨基酸序列的比对。sp|p04637|p53_human(seq id no:1);sp|p04637-2|p53_human(seq id no:114);sp|p04637-3|p53_human(seq id no:115);sp|p04637-4|p53_human(seq id no:116);sp|p04637-5|p53_human(seq id no:117);sp|p04637-6|p53_human(seq id no:118);sp|p04637-7|p53_human(seq id no:119);sp|p04637-8|p53_human(seq id no:120);及sp|p04637-9|p53_human(seq id no:121)。
52.图9展示trbv7-9*03的序列的部分的氨基酸序列与trbv7-9*01的序列的部分的氨基酸序列的比对。“l36092|trbv7-9*01|homo”为seq id no:129。“af009663|trbv7-9*03|homo”为seq id no:130。
53.图10为展示在将来自患者4141的til(片段培养物12)与自体apc共培养之后测量的4-1bb阳性细胞(cd8+的百分比)(右侧y轴;黑色条)的百分比及ifn-γ(点/2
×
104个细胞)(左侧y轴;阴影条)的图,所述自体apc经编码无关突变的tmg(tmg-irr)、wt p53序列(tp53-wt-tmg)或包括r175h的突变p53序列(tp53-mut-tmg)转染。单独培养基以及pma及离子霉素分别为阴性及阳性对照。
54.图11为展示在将来自患者4141的til(片段培养物12)与cos7细胞共培养之后测量的ifn-γ-阳性点/2
×
104个效应细胞的数目的图,所述cos7细胞经所指示hla等位基因共转染且无额外基因(仅hla;空心条)、wt tp53 tmg(灰色阴影条)或含有p53-r175h序列的突变(黑色条)tp53 tmg。
55.图12为展示在将表达模拟物(无tcr)或4141-tcr1a2的t细胞与t2肿瘤细胞(表达hla-a*02:01)共培养之后测量的ifn-γ的浓度(pg/ml)的图。t2细胞系经肽载体(dmso;灰色条)或由wt p53-r175肽(阴影灰色条)或突变p53-r175h肽(黑色条)构成的经纯化(>95%,通过hplc)肽脉冲。单独的培养基(空心条)以及pma及离子霉素(晶格条)分别为阴性及阳性对照。数据为平均值
±
sem(n=3)。
56.图13为展示在将表达4141-tcr1a2的t细胞与saos2细胞(p53-null及hla-a*02:01+)共培养之后阳性表达所指示标志物中的一者的细胞的百分比的图,所述saos2细胞未经操控(无阴影条)或过表达全长p53-r175h蛋白质(阴影条)。数据为平均值
±
sem(n=3)。对两个细胞系之间的各细胞因子进行学生双尾t检验以用于统计分析(***p<0.001)。发明的详细描述
57.肿瘤蛋白质p53(亦称为“tp53”或“p53”)通过例如调节细胞分裂而充当肿瘤抑制因子。p53蛋白质位于细胞的细胞核中,p53蛋白质在细胞核中与dna直接结合。当dna受损时,p53蛋白质参与确定是否将修复dna或受损细胞将经历凋亡。若可修复dna,则p53活化其他基因以修复损坏。若不能修复dna,则p53蛋白质阻止细胞分裂,且传信该细胞以经历凋亡。通过阻止具有突变或受损dna的细胞分裂,p53有助于预防肿瘤的出现。wt(正常)全长p53包含氨基酸序列seq id no:1。
58.p53蛋白质中的突变可能减小或消除p53蛋白质的肿瘤抑制因子功能。替代地或另外,p53突变通过以显性阴性方式干扰wt p53可以为功能获得型突变。突变p53蛋白质可在多种人类癌症中的任一者中表达,所述人类癌症诸如胆管癌、黑素瘤、结肠癌、直肠癌、卵巢癌、子宫内膜癌、非小细胞肺癌(nsclc)、胶质母细胞瘤、子宫颈癌、头颈癌、乳癌、胰腺癌或膀胱癌。
59.本发明的一实施方案提供一种对突变人类p53(下文中,“突变p53”)具有抗原特异性的经分离或经纯化的t细胞受体(tcr)。在下文中,除非另外指定,否则参考“tcr”亦指tcr的功能部分及功能变体。本文中通过参考氨基酸序列全长wt p53(seq id no:1)来定义p53的突变。本文中通过参考存在于特定位置处的氨基酸残基,随后位置编号,随后藉以在所论述特定突变中置换残基的氨基酸来描述p53的突变。p53氨基酸序列(例如,p53肽)可包含少于全长wt p53蛋白质的所有氨基酸残基。因此,在理解p53氨基酸序列的一特定实例中的对应残基的实际位置可不同的情况下,本文中通过参考wt全长p53蛋白质(亦即seq id no:1)来定义位置编号。因为位置如seq id no:1所定义,所以术语“r175”是指存在于seq id no:1的位置175处的精氨酸,“r175h”指示存在于seq id no:1的位置175处的精氨酸是经组氨
酸置换,而“y220c”指示存在于seq id no:1的位置220处的酪氨酸已经半胱氨酸置换。举例而言,当p53氨基酸序列的一特定实例为例如ykqsqhmtevvrrcphhercsdsdg(seq id no:110)(对应于seq id no:1的连续氨基酸残基163至187的例示性wt p53肽)时,“r175h”是指seq id no:110中的加底线的精氨酸由组氨酸取代,尽管seq id no:110中的加底线的精氨酸的实际位置为13。下文中将具有r175h突变的人类p53氨基酸序列称为“r175h”或“p53
r175h”。下文中将具有y220c突变的人类p53氨基酸序列称为“y220c”或“p53
y220c”。如本文中所使用,“突变p53”是指人类p53
r175h
或人类p53
y220c
。
60.p53具有九种已知剪接变体。本文中描述的p53突变保留于全部九种p53剪接变体上。九种p53剪接变体的比对示于图8中。因此,本发明tcr可对本文中描述的由九种p53剪接变体中的任一者编码的任何突变p53氨基酸序列具有抗原特异性。因为位置如由seq id no:1所定义,故p53的特定剪接变体的氨基酸序列的实际位置相对于seq id no:1的对应位置来定义,且如由seq id no:1定义的位置可不同于特定剪接变体中的实际位置。因此,举例而言,在理解剪接变体中的实际位置可不同的情况下,突变是指对应于seq id no:1的393-氨基酸序列的所指示位置的p53的特定剪接变体的氨基酸序列中的氨基酸残基的置换。
61.在本发明的一实施方案中,tcr对在位置175处具有突变的人类p53具有抗原特异性,如由seq id no:1所定义。在位置175处的p53突变可为任何错义突变。因此,在位置175处的突变可为存在于位置175处的原生(wt)精氨酸残基由除精氨酸以外的任何氨基酸残基取代。在本发明的一实施方案中,tcr对具有r175h突变的人类p53具有抗原特异性。举例而言,本发明tcr可对一或多个选自以下的突变p53氨基酸序列具有抗原特异性:evvrhcphher(seq id no:2)、hmtevvrhc(seq id no:96)、kqsqhmtevvrhcph(seq id no:100)、qsqhmtevvrhcphh(seq id no:101)、sqhmtevvrhcphhe(seq id no:102)、qhmtevvrhcphher(seq id no:103)、hmtevvrhcphherc(seq id no:104)、mtevvrhcphhercs(seq id no:105)、tevvrhcphhercsd(seq id no:106)、evvrhcphhercsds(seq id no:107)、vvrhcphhercsdsd(seq id no:108)、vrhcphhercsdsdg(seq id no:109)、ykqsqhmtevvrhcphhercsdsdg(seq id no:111)。
62.在本发明的一实施方案中,tcr对在位置220处具有突变的人类p53具有抗原特异性,如由seq id no:1所定义。在位置220处的p53突变可为任何错义突变。因此,在位置220处的突变可为存在于位置220处的原生(wt)酪氨酸残基由除酪氨酸以外的任何氨基酸残基取代。在本发明的一实施方案中,tcr对具有y220c突变的人类p53具有抗原特异性。举例而言,本发明tcr可对(seq id no:113)的突变p53氨基酸序列具有抗原特异性。
63.在本发明的一实施方案中,本发明tcr可能能够以hla(人类白血球抗原)分子依赖性方式识别突变p53。如本文中所使用的“hla分子依赖性方式”意指tcr在hla分子的背景内与突变p53结合后引发免疫反应,该hla分子由分离tcr的患者表达。本发明tcr可能能够识别由可适用hla分子呈递的突变p53,且除突变p53以外还可与hla分子结合。
64.在本发明的一实施方案中,本发明tcr能够识别由ii类hla分子呈递的r175h。在此方面,tcr可在于ii类hla分子的背景内与r175h结合后引发免疫反应。本发明tcr能够识别由ii类hla分子呈递的r175h,且除r175h以外还可与ii类hla分子结合。
65.在本发明的一实施方案中,ii类hla分子为hla-dr异二聚体。hla-dr异二聚体为包括α链及β链的细胞表面受体。hla-drα链由hla-dra基因编码。在一实施方案中,ii类hla分子的α链由hla-dra1*01:01:01等位基因表达。hla-drβ链由hla-drb1基因、hla-drb3基因、hla-drb4基因或hla-drb5基因编码。由hla-drb1基因编码的分子的实例可包括(但不限于)hla-dr1、hla-dr2、hla-dr3、hla-dr4、hla-dr5、hla-dr6、hla-dr7、hla-dr8、hla-dr9、hla-dr10、hla-dr11、hla-dr12、hla-dr13、hla-dr14、hla-dr15、hla-dr16及hla-dr17。hla-drb3基因编码hla-dr52。hla-drb4基因编码hla-dr53。hla-drb5基因编码hla-dr51。在本发明的一实施方案中,ii类hla分子为hla-drb1:hla-dra异二聚体。ii类hla分子的β链可由以下表达:hla-drb1*13:01、hla-drb1*13:02、hla-drb1*13:03、hla-drb1*13:04、hla-drb1*13:05、hla-drb1*13:06、hla-drb1*13:07、hla-drb1*13:08、hla-drb1*13:09或hla-drb1*13:10等位基因。在一特别优选的实施方案中,ii类hla分子的β链由hla-drb1*13:01等位基因表达。
66.在本发明的一实施方案中,本发明tcr中的一者能够识别由i类hla分子呈递的y220c。在此方面,tcr可在于i类hla分子的背景内与y220c结合后引发免疫反应。本发明tcr能够识别由i类hla分子呈递的y220c,且除y220c以外还可与i类hla分子结合。
67.在本发明的一实施方案中,i类hla分子为hla-a分子。hla-a分子为α链及β2微球蛋白的异二聚体。hla-aα链可由hla-a基因编码。β2微球蛋白与α链的α1、α2及α3域非共价结合以构建hla-a复合物。hla-a分子可为任何hla-a分子。在本发明的一实施方案中,i类hla分子为hla-a2分子。hla-a2分子可为任何hla-a2分子。hla-a2分子的实例可包括(但不限于)hla-a*02:01、hla-a*02:02、hla-a*02:03、hla-a*02:05、hla-a*02:06、hla-a*02:07或hla-a*02:11。优选地,i类hla分子为hla-a*02:01分子。
68.本发明的tcr可提供许多优点中的任一者或多者,包括当由用于过继细胞转移的细胞表达时。突变p53由癌细胞表达且不由正常非癌性细胞表达。不受特定理论或机制束缚,认为本发明tcr有利地靶向癌细胞的破坏,同时最小化或消除正常非癌性细胞的破坏,藉此例如通过最小化或消除来降低毒性。此外,本发明tcr可有利地成功治疗或预防对诸如(例如)化学疗法、手术或辐射的其他类型的治疗无反应的突变p53阳性癌症。另外,本发明tcr可提供突变p53的高度亲合识别,这可提供识别未经操控的肿瘤细胞(例如,尚未经干扰素(ifn)-γ治疗、经编码突变p53及可适用hla分子中的一者或两者的载体转染、经具有p53突变的p53肽脉冲或其组合的肿瘤细胞)的能力。所有肿瘤中的大约一半携带p53中的突变,其中约一半将为错义突变。r175h突变由所有癌症的约4.5%表达,且hla-drb1*13:01等位基因由美国人口的约15%表达。y220c突变出现于全部癌症的约1.5%中,且hla-a*02:01等位基因由美国人口的约40%至约50%表达。r175h及y220c突变出现于许多癌症组织结构中,从而表明多种患者可得益于本发明tcr。因此,本发明tcr可增加可适用于用免疫疗法治疗的患者数目。
69.如本文中所使用的词组“抗原特异性”意指tcr可以高亲合力特异性结合于且免疫识别突变p53。举例而言,在与(a)经低浓度的突变p53肽(例如,约0.05ng/ml至约5ng/ml、0.05ng/ml、0.1ng/ml、0.5ng/ml、1ng/ml、5ng/ml,或由前述值中的任两者限定的范围)脉冲的抗原阴性、可适用hla分子阳性目标细胞或(b)已引入编码突变p53的核苷酸序列以使得目标细胞表达突变p53的抗原阴性、可适用hla分子阳性目标细胞共培养后,若约1
×
104至
约1
×
105个表达tcr的t细胞分泌至少约200pg/ml或更多(例如,200pg/ml或更多、300pg/ml或更多、400pg/ml或更多、500pg/ml或更多、600pg/ml或更多、700pg/ml或更多、1000pg/ml或更多、5,000pg/ml或更多、7,000pg/ml或更多、10,000pg/ml或更多、20,000pg/ml或更多,或由前述值中的任两者限定的范围)的ifn-γ,则可将tcr视为对突变p53具有“抗原特异性”。在与经高浓度的突变p53肽脉冲的抗原阴性、可适用hla分子阳性目标细胞共培养后,表达本发明tcr的细胞亦可分泌ifn-γ。
70.替代地或另外,与由阴性对照表达的ifn-γ的量相比,在与(a)经低浓度的突变p53肽脉冲的抗原阴性、可适用hla分子阳性目标细胞或(b)已引入编码突变p53的核苷酸序列以使得目标细胞表达突变p53的抗原阴性、可适用hla分子阳性目标细胞共培养后,若表达tcr的t细胞分泌至少两倍的ifn-γ,则可将tcr视为对突变p53具有“抗原特异性”。举例而言,阴性对照可为(i)表达tcr的t细胞,其与(a)经相同浓度的无关肽(例如,具有与突变p53肽不同序列的一些其他肽)脉冲的抗原阴性、可适用hla分子阳性目标细胞或(b)已引入编码无关肽的核苷酸序列以使得目标细胞表达无关肽的抗原阴性、可适用hla分子阳性目标细胞共培养;或(ii)未经转导的t细胞(例如,衍生自不表达tcr的pbmc),其与(a)经相同浓度的突变p53肽脉冲的抗原阴性、可适用hla分子阳性目标细胞或(b)已引入编码突变p53的核苷酸序列以使得目标细胞表达突变p53的抗原阴性、可适用hla分子阳性目标细胞共培养。可通过本领域中已知的方法,诸如酶联免疫吸附分析(elisa)来测量ifn-γ分泌。
71.替代地或另外,与分泌ifn-γ的阴性对照t细胞的数目相比,在与(a)经低浓度的突变p53肽脉冲的抗原阴性、可适用hla分子阳性目标细胞或(b)已引入编码突变p53的核苷酸序列以使得目标细胞表达突变p53的抗原阴性、可适用hla分子阳性目标细胞共培养后,若至少两倍数目的表达tcr的t细胞分泌ifn-γ,则可将tcr视为对突变p53具有“抗原特异性”。肽的浓度及阴性对照可如本文中关于本发明的其他方面所描述。可通过本领域中已知的方法,诸如酶联免疫斑点(elisot)分析来测量分泌ifn-γ的细胞数目。
72.替代地或另外,与通过elispot针对与相同目标细胞共培养的阴性对照t细胞检测的点数目相比,在与(a)经低浓度的突变p53肽脉冲的抗原阴性、可适用hla分子阳性目标细胞或(b)已引入编码突变p53的核苷酸序列以使得目标细胞表达突变p53的抗原阴性、可适用hla分子阳性目标细胞共培养后,若通过elispot针对表达tcr的t细胞检测到至少两倍的点,则可将tcr视为对突变p53具有“抗原特异性”。肽的浓度及阴性对照可如本文中关于本发明的其他方面所描述。
73.替代地或另外,在与(a)经低浓度的突变p53肽脉冲的抗原阴性、可适用hla分子阳性目标细胞或(b)已引入编码突变p53的核苷酸序列以使得目标细胞表达突变p53的抗原阴性、可适用hla分子阳性目标细胞共培养后,若通过elispot针对表达tcr的t细胞检测到大于约50个点,则可将tcr视为对突变p53具有“抗原特异性”。肽的浓度可如本文中关于本发明的其他方面所描述。
74.替代地或另外,如通过例如流式细胞术所测量,在用表达突变p53的目标细胞刺激之后,若表达tcr的t细胞上调4-1bb及ox40中的一者或两者的表达,则可将tcr视为对突变p53具有“抗原特异性”。
75.本发明的一实施方案提供包含两种多肽(亦即,多肽链)的tcr,诸如tcr的α(α)链、tcr的β(β)链、tcr的γ(γ)链、tcr的δ(δ)链,或其组合。本发明tcr的多肽可包含任何氨基
酸序列,其限制条件为tcr对突变p53具有抗原特异性。
76.在本发明的一实施方案中,tcr包含两条多肽链,其中的每一者包含可变区,该可变区包含tcr的互补决定区(cdr)1、cdr2及cdr3。在本发明的一实施方案中,tcr包含第一多肽链,其包含α链cdr1(cdr1α)、α链cdr2(cdr2α)及α链cdr3(cdr3α);及第二多肽链,其包含β链cdr1(cdr1β)、β链cdr2(cdr2β)及β链cdr3(cdr3β)。在本发明的一实施方案中,tcr包含以下的氨基酸序列:(1)seq id no:3-8全部;(2)seq id no:14-19中的全部;(3)seq id no:25-30全部;(4)seq id no:36-41中的全部;(5)seq id no:47-52全部;(6)seq id no:58-63中的全部;(7)seq id no:69-74全部;(8)seq id no:80-85中的全部;或(9)seq id no:131-136全部。此段落中的氨基酸序列的前述九个集合中的每一者阐述对突变人类p53具有抗原特异性的九种不同tcr中的每一者的六个cdr区。各集合中的六个氨基酸序列分别对应于tcr的cdr1α、cdr2α、cdr3α、cdr1β、cdr2β及cdr3β。
77.在本发明的一实施方案中,tcr包含α链可变区氨基酸序列及β链可变区氨基酸序列,一起包含上文所阐述的cdr的集合中的一者。就此而言,tcr可例如包含以下中的任一者的氨基酸序列:seq id no:9、10、20、21、31、32、42、43、53、54、64、65、75、76、86、87、137、138、142-159、178、181、184、187、190、193、196、199、202、205、207、209、211、213、215、217、219、221、223及226。举例而言,tcr可包含:(1)seq id no:9及10两者;(2)seq id no:20及21两者;(3)seq id no:31及32两者;(4)seq id no:42及43两者;(5)seq id no:53及54两者;(6)seq id no:64及65两者;(7)seq id no:75及76两者;(8)seq id no:86及87两者;(9)seq id no:137及138两者;(10)seq id no:142及143两者;(11)seq id no:144及145两者;(12)seq id no:146及147两者;(13)seq id no:148及149两者;(14)seq id no:150及151两者;(15)seq id no:152及153两者;(16)seq id no:154及155两者;(17)seq id no:156及157两者;(18)seq id no:159及158两者;(19)seq id no:178及10两者;(20)seq id no:181及21两者;(21)seq id no:184及32两者;(22)seq id no:187及43两者;(23)seq id no:190及54两者;(24)seq id no:193及65两者;(25)seq id no:196及76两者;(26)seq id no:199及87两者;(27)seq id no:137及202两者;(28)seq id no:9及205两者;(29)seq id no:20及207两者;(30)seq id no:31及209两者;(31)seq id no:42及211两者;(32)seq id no:53及213两者;(33)seq id no:64及215两者;(34)seq id no:75及217两者;(35)seq id no:86及219两者;(36)seq id no:137及221两者;(37)seq id no:223及202两者;(38)seq id no:223及221两者;(39)seq id no:20及226两者;或(40)seq id no:181及226两者。此段落中的氨基酸序列的前述集合中的每一者阐述对突变人类p53具有抗原特异性的不同tcr中的每一者的两个可变区。各集合中的两个氨基酸序列分别对应于tcr的α链的可变区及β链的可变区。
78.本发明tcr可进一步包含恒定区。恒定区可衍生自诸如(例如)人类或小鼠的任何适合物种。在本发明的一实施方案中,tcr进一步包含鼠类恒定区。如本文中所使用,当参考tcr或本文中描述的tcr的任何组分(例如,互补决定区(cdr)、可变区、恒定区、α链及/或β链)时,术语“鼠类”或“人类”分别意指衍生自小鼠或人类的tcr(或其组分),亦即同时分别来源于小鼠t细胞或人类t细胞或由其表达的tcr(或其组分)。在本发明的一实施方案中,tcr可包含鼠类α链恒定区及鼠类β链恒定区。鼠类α链恒定区可经修饰或未经修饰。经修饰鼠类α链恒定区可例如经半胱氨酸取代、经lvl修饰或经半胱氨酸取代及经lvl修饰两者,如
例如在美国专利第10,174,098号中所描述。鼠类β链恒定区可经修饰或未经修饰。经修饰鼠类β链恒定区可例如经半胱氨酸取代,如例如在美国专利第10,174,098号中所描述。在本发明的一实施方案中,tcr包含经半胱氨酸取代、经lvl修饰的鼠类α链恒定区,该恒定区包含氨基酸序列seq id no:91或92。在本发明的一实施方案中,tcr包含经半胱氨酸取代的鼠类β链恒定区,该恒定区包含氨基酸序列seq id no:93。
79.在本发明的一实施方案中,本发明tcr可包含tcr的α链及tcr的β链。tcr的α链可包含α链的可变区及α链的恒定区。此类型的α链可与tcr的任何β链配对。β链可包含β链的可变区及β链的恒定区。
80.在一些实施方案中,本文中所公开的α链及/或β链中的任一者的氨基酸序列在c端末端处进一步包含氨基酸序列rakr(seq id no:230)。
81.在本发明的一实施方案中,tcr包含以下中的任一者的氨基酸序列:seq id no11、12、22、23、33、34、44、45、55、56、66、67、77、78、88、89、139、140、160-177、179、182、185、188、191、194、197、200、203、206、208、210、212、214、216、218、220、222、224及227。举例而言,tcr可包含:(1)seq id no:11及12两者;(2)seq id no:22及23两者;(3)seq id no:33及34两者;(4)seq id no:44及45两者;(5)seq id no:55及56两者;(6)seq id no:66及67两者;(7)seq id no:77及78两者;(8)seq id no:88及89两者;(9)seq id no:139及140两者;(10)seq id no:160及161两者;(11)seq id no:162及163两者;(12)seq id no:164及165两者;(13)seq id no:166及167两者;(14)seq id no:168及169两者;(15)seq id no:170及171两者;(16)seq id no:172及173两者;(17)seq id no:174及175两者;(18)seq id no:176及177两者;(19)seq id no:179及12两者;(20)seq id no:182及23两者;(21)seq id no:185及34两者;(22)seq id no:188及45两者;(23)seq id no:191及56两者;(24)seq id no:194及67两者;(25)seq id no:197及78两者;(26)seq id no:200及89两者;(27)seq id no:139及203两者;(28)seq id no:11及206两者;(29)seq id no:22及208两者;(30)seq id no:33及210两者;(31)seq id no:44及212两者;(32)seq id no:55及214两者;(33)seq id no:66及21 6两者;(34)seq id no:77及218两者;(35)seq id no:88及220两者;(36)seq id no:139及222两者;(37)seq id no:224及203两者;(38)seq id no:224及222两者;(39)seq id no:22及227两者;或(40)seq id no:182及227两者。此段落中的氨基酸序列的前述集合中的每一者阐述对突变人类p53具有抗原特异性的不同tcr中的每一者的α链及β链。各集合中的两个氨基酸序列分别对应于tcr的α链及β链。
82.本文中描述的本发明tcr的功能变体包括在本发明的范畴中。如本文中所使用,术语“功能变体”是指与亲本tcr、多肽或蛋白质具有实质或显著序列一致性或类似性的tcr、多肽或蛋白质,该功能变体保留其变体的tcr、多肽或蛋白质的生物活性。功能变体涵盖例如本文中描述的tcr、多肽或蛋白质(亲本tcr、多肽或蛋白质)的那些变体,其保留以与亲本tcr、多肽或蛋白质类似的程度、相同的程度或更高的程度特异性结合于亲本tcr对其具有抗原特异性或该亲本多肽或蛋白质所特异性结合的突变p53的能力。参考亲本tcr、多肽或蛋白质,功能变体可在氨基酸序列中分别与亲本tcr、多肽或蛋白质例如至少约30%、至少约50%、至少约75%、至少约80%、至少约90%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或更多一致。
83.功能变体可例如包含具有至少一个保守氨基酸取代的亲本tcr、多肽或蛋白质的
氨基酸序列。保守氨基酸取代在本领域中已知且包括氨基酸取代,其中一个具有某些物理及/或化学特性的氨基酸经另一个具有相同化学或物理特性的氨基酸交换。举例而言,保守氨基酸取代可为取代另一酸性氨基酸(例如,asp或glu)的酸性氨基酸、取代另一具有非极性侧链的氨基酸(例如,ala、gly、val、ile、leu、met、phe、pro、trp、val等)的具有非极性侧链的氨基酸、取代另一碱性氨基酸(lys、arg等)的碱性氨基酸、取代另一具有极性侧链的氨基酸(asn、cys、gln、ser、thr、tyr等)的具有极性侧链的氨基酸等。
84.替代地或另外,功能变体可包含具有至少一个非保守氨基酸取代的亲本tcr、多肽或蛋白质的氨基酸序列。在此情况下,优选的是,非保守氨基酸取代未干扰或抑制功能变体的生物活性。优选地,非保守氨基酸取代增强功能变体的生物活性,使得与亲本tcr、多肽或蛋白质相比,功能变体的生物活性增加。
85.tcr、多肽或蛋白质可基本上由指定氨基酸序列或本文中描述的序列组成,使得tcr、多肽或蛋白质的其他组分(例如,其他氨基酸)不实质上改变tcr、多肽或蛋白质的生物活性。
86.本发明还提供一种包含本文中所描述的tcr中的任一者的功能部分的多肽。如本文中所使用,术语“多肽”包括寡肽且是指由一或多个肽键连接的单个氨基酸链。
87.关于本发明多肽,功能部分可为包含作为部分的tcr的连续氨基酸的任何部分,其限制条件为功能部分特异性结合于突变p53。当参考tcr使用时,术语“功能部分”是指本发明tcr的任何部分或片段,该部分或片段保留作为部分的tcr(亲本tcr)的生物活性。举例而言,功能部分涵盖保留以与亲本tcr类似的程度、相同的程度或更高的程度特异性结合于突变p53(例如,以可适用hla分子依赖性方式)或检测、治疗或预防癌症的能力的tcr的那些部分。参考亲本tcr,功能部分可包含例如约10%、约25%、约30%、约50%、约68%、约80%、约90%、约95%或更多的亲本tcr。
88.功能部分可在该部分的氨基或羧基端、或在两个末端处包含额外氨基酸,所述额外氨基酸在亲本tcr的氨基酸序列中未发现。理想地,额外氨基酸不干扰功能部分的生物功能,例如特异性结合于突变p53;及/或具有检测癌症、治疗或预防癌症等的能力。更加期望额外氨基酸使生物活性相较于亲本tcr的生物活性增强。
89.多肽可包含本发明的tcr的α及β链中任一者或两者的功能部分,诸如包含本发明的tcr的α链及/或β链的可变区的cdr1、cdr2及cdr3中的一或多者的功能部分。在本发明的一实施方案中,多肽可包含功能部分,该功能部分包含以下氨基酸序列:(1)seq id no:3-8全部;(2)seq id no:14-19中的全部;(3)seq id no:25-30全部;(4)seq id no:36-41中的全部;(5)seq id no:47-52全部;(6)seq id no:58-63中的全部;(7)seq id no:69-74全部;(8)seq id no:80-85中的全部;或(9)seq id no:131-136全部。
90.在本发明的一实施方案中,本发明多肽可包含例如本发明tcr的可变区,该可变区包含上文阐述的cdr区的组合。就此而言,多肽可包含例如以下氨基酸序列:(1)seq id no:9及10两者;(2)seq id no:20及21两者;(3)seq id no:31及32两者;(4)seq id no:42及43两者;(5)seq id no:53及54两者;(6)seq id no:64及65两者;(7)seq id no:75及76两者;(8)seq id no:86及87两者;(9)seq id no:137及138两者;(10)seq id no:142及143两者;(11)seq id no:144及145两者;(12)seq id no:146及147两者;(13)seq id no:148及149两者;(14)seq id no:150及151两者;(15)seq id no:152及153两者;(16)seq id no:154
及155两者;(17)seq id no:156及157两者;(18)seq id no:159及158两者;(19)seq id no:178及10两者;(20)seq id no:181及21两者;(21)seq id no:184及32两者;(22)seq id no:187及43两者;(23)seq id no:190及54两者;(24)seq id no:193及65两者;(25)seq id no:196及76两者;(26)seq id no:199及87两者;(27)seq id no:137及202两者;(28)seq id no:9及205两者;(29)seq id no:20及207两者;(30)seq id no:31及209两者;(31)seq id no:42及211两者;(32)seq id no:53及213两者;(33)seq id no:64及215两者;(34)seq id no:75及217两者;(35)seq id no:86及219两者;(36)seq id no:137及221两者;(37)seq id no:223及202两者;(38)seq id no:223及221两者;(39)seq id no:20及226两者;或(40)seq id no:181及226两者。
91.在本发明的一实施方案中,本发明多肽可进一步包含上文阐述的本发明tcr的恒定区。就此而言,多肽可包含例如氨基酸序列(i)seq id no 91-93中的一者或(ii)seq id no:93及seq id no:91及92中的一者。
92.在本发明的一实施方案中,本发明多肽可包含本发明tcr的α链及β链。就此而言,多肽可包含例如以下氨基酸序列:(1)seq id no:11及12两者;(2)seq id no:22及23两者;(3)seq id no:33及34两者;(4)seq id no:44及45两者;(5)seq id no:55及56两者;(6)seq id no:66及67两者;(7)seq id no:77及78两者;(8)seq id no:88及89两者;(9)seq id no:139及140两者;(10)seq id no:160及161两者;(11)seq id no:162及163两者;(12)seq id no:164及165两者;(13)seq id no:166及167两者;(14)seq id no:168及169两者;(15)seq id no:170及171两者;(16)seq id no:172及173两者;(17)seq id no:174及175两者;(18)seq id no:176及177两者;(19)seq id no:179及12两者;(20)seq id no:182及23两者;(21)seq id no:185及34两者;(22)seq id no:188及45两者;(23)seq id no:191及56两者;(24)seq id no:194及67两者;(25)seq id no:197及78两者;(26)seq id no:200及89两者;(27)seq id no:139及203两者;(28)seq id no:11及206两者;(29)seq id no:22及208两者;(30)seq id no:33及210两者;(31)seq id no:44及212两者;(32)seq id no:55及214两者;(33)seq id no:66及216两者;(34)seq id no:77及218两者;(35)seq id no:88及220两者;(36)seq id no:139及222两者;(37)seq id no:224及203两者;(38)seq id no:224及222两者;(39)seq id no:22及227两者;或(40)seq id no:182及227两者。
93.本发明进一步提供一种包含本文中所描述的多肽中的至少一者。“蛋白质”意指包含一或多条多肽链的分子。在一实施方案中,本发明的蛋白质可包含:(1)包含seq id no:3-5全部的氨基酸序列的第一多肽链及包含seq id no:6-8全部的氨基酸序列的第二多肽链;(2)包含seq id no:14-16全部的氨基酸序列的第一多肽链及包含seq id no:17-19全部的氨基酸序列的第二多肽链;(3)包含seq id no:25-27全部的氨基酸序列的第一多肽链及包含seq id no:28-30全部的氨基酸序列的第二多肽链;(4)包含seq id no:36-38全部的氨基酸序列的第一多肽链及包含seq id no:39-41全部的氨基酸序列的第二多肽链;(5)包含seq id no:47-49全部的氨基酸序列的第一多肽链及包含seq id no:50-52全部的氨基酸序列的第二多肽链;(6)包含seq id no:58-60全部的氨基酸序列的第一多肽链及包含seq id no:61-63全部的氨基酸序列的第二多肽链;(7)包含seq id no:69-71全部的氨基酸序列的第一多肽链及包含seq id no:72-74全部的氨基酸序列的第二多肽链;(8)包含seq id no:80-82全部的氨基酸序列的第一多肽链及包含seq id no:83-85全部的氨基酸
序列的第二多肽链;或(9)包含seq id no:131-133全部的氨基酸序列的第一多肽链及包含seq id no:134-136全部的氨基酸序列的第二多肽链。
94.在本发明的一实施方案中,蛋白质包含:(1)包含氨基酸序列seq id no:9的第一多肽链及包含氨基酸序列seq id no:10的第二多肽链;(2)包含氨基酸序列seq id no:20的第一多肽链及包含氨基酸序列seq id no:21的第二多肽链;(3)包含氨基酸序列seq id no:31的第一多肽链及包含氨基酸序列seq id no:32的第二多肽链;(4)包含氨基酸序列seq id no:42的第一多肽链及包含氨基酸序列seq id no:43的第二多肽链;(5)包含氨基酸序列seq id no:53的第一多肽链及包含氨基酸序列seq id no:54的第二多肽链;(6)包含氨基酸序列seq id no:64的第一多肽链及包含氨基酸序列seq id no:65的第二多肽链;(7)包含氨基酸序列seq id no:75的第一多肽链及包含氨基酸序列seq id no:76的第二多肽链;(8)包含氨基酸序列seq id no:86的第一多肽链及包含氨基酸序列seq id no:87的第二多肽链;(9)包含氨基酸序列seq id no:137的第一多肽链及包含氨基酸序列seq id no:138的第二多肽链;(10)包含氨基酸序列seq id no:142的第一多肽链及包含氨基酸序列seq id no:143的第二多肽链;(11)包含氨基酸序列seq id no:144的第一多肽链及包含氨基酸序列seq id no:145的第二多肽链;(12)包含氨基酸序列seq id no:146的第一多肽链及包含氨基酸序列seq id no:147的第二多肽链;(13)包含氨基酸序列seq id no:148的第一多肽链及包含氨基酸序列seq id no:149的第二多肽链;(14)包含氨基酸序列seq id no:150的第一多肽链及包含氨基酸序列seq id no:151的第二多肽链;(15)包含氨基酸序列seq id no:152的第一多肽链及包含氨基酸序列seq id no:153的第二多肽链;(16)包含氨基酸序列seq id no:154的第一多肽链及包含氨基酸序列seq id no:155的第二多肽链;(17)包含氨基酸序列seq id no:156的第一多肽链及包含氨基酸序列seq id no:157的第二多肽链;(18)包含氨基酸序列seq id no:158的第一多肽链及包含氨基酸序列seq id no:159的第二多肽链;(19)包含氨基酸序列seq id no:178的第一多肽链及包含氨基酸序列seq id no:10的第二多肽链;(20)包含氨基酸序列seq id no:181的第一多肽链及包含氨基酸序列seq id no:21的第二多肽链;(21)包含氨基酸序列seq id no:184的第一多肽链及包含氨基酸序列seq id no:32的第二多肽链;(22)包含氨基酸序列seq id no:187的第一多肽链及包含氨基酸序列seq id no:43的第二多肽链;(23)包含氨基酸序列seq id no:190的第一多肽链及包含氨基酸序列seq id no:54的第二多肽链;(24)包含氨基酸序列seq id no:193的第一多肽链及包含氨基酸序列seq id no:65的第二多肽链;(25)包含氨基酸序列seq id no:196的第一多肽链及包含氨基酸序列seq id no:76的第二多肽链;(26)包含氨基酸序列seq id no:199的第一多肽链及包含氨基酸序列seq id no:87的第二多肽链;(27)包含氨基酸序列seq id no:137的第一多肽链及包含氨基酸序列seq id no:202的第二多肽链;(28)包含氨基酸序列seq id no:9的第一多肽链及包含氨基酸序列seq id no:205的第二多肽链;(29)包含氨基酸序列seq id no:20的第一多肽链及包含氨基酸序列seq id no:207的第二多肽链;(30)包含氨基酸序列seq id no:31的第一多肽链及包含氨基酸序列seq id no:209的第二多肽链;(31)包含氨基酸序列seq id no:42的第一多肽链及包含氨基酸序列seq id no:211的第二多肽链;(32)包含氨基酸序列seq id no:53的第一多肽链及包含氨基酸序列seq id no:213的第二多肽链;(33)包含氨基酸序列seq id no:64的第一多肽链及包含氨基酸序列seq id no:215的第二多肽链;(34)包含氨基酸
id no:206的第二多肽链;(29)包含氨基酸序列seq id no:22的第一多肽链及包含氨基酸序列seq id no:208的第二多肽链;(30)包含氨基酸序列seq id no:33的第一多肽链及包含氨基酸序列seq id no:210的第二多肽链;(31)包含氨基酸序列seq id no:44的第一多肽链及包含氨基酸序列seq id no:212的第二多肽链;(32)包含氨基酸序列seq id no:55的第一多肽链及包含氨基酸序列seq id no:214的第二多肽链;(33)包含氨基酸序列seq id no:66的第一多肽链及包含氨基酸序列seq id no:216的第二多肽链;(34)包含氨基酸序列seq id no:77的第一多肽链及包含氨基酸序列seq id no:218的第二多肽链;(35)包含氨基酸序列seq id no:88的第一多肽链及包含氨基酸序列seq id no:220的第二多肽链;(36)包含氨基酸序列seq id no:139的第一多肽链及包含氨基酸序列seq id no:222的第二多肽链;(37)包含氨基酸序列seq id no:224的第一多肽链及包含氨基酸序列seq id no:203的第二多肽链;或(38)包含氨基酸序列seq id no:224的第一多肽链及包含氨基酸序列seq id no:222的第二多肽链;(39)包含氨基酸序列seq id no:22的第一多肽链及包含氨基酸序列seq id no:227的第二多肽链;或(40)包含氨基酸序列seq id no:182的第一多肽链及包含氨基酸序列seq id no:227的第二多肽链。
96.本发明的蛋白质可为tcr。替代地,若蛋白质的第一及/或第二多肽链进一步包含其他氨基酸序列,例如编码免疫球蛋白或其部分的氨基酸序列,则本发明蛋白质可为融合蛋白质。就此而言,本发明还提供一种融合蛋白质,其包含本文中所描述的本发明多肽中的至少一者以及至少一种其他多肽。其他多肽可以融合蛋白质的独立多肽的形式存在,或可以多肽的形式存在,其与本文中所描述的本发明多肽中的一者在框内(以串联方式)表达。其他多肽可编码任何肽或蛋白质分子或其部分,包括(但不限于)免疫球蛋白、cd3、cd4、cd8、mhc分子、cd1分子,例如cd1a、cd1b、cd1c、cd1d等。
97.融合蛋白质可包含本发明多肽的一或多个拷贝及/或其他多肽的一或多个拷贝。举例而言,融合蛋白质可包含本发明多肽及/或其他多肽的1个、2个、3个、4个、5个或更多个拷贝。制造融合蛋白质的适合方法为本领域中已知的,且包括例如重组方法。
98.在本发明的一些实施方案中,本发明的tcr、多肽及蛋白质可表达为包含连接α链及β链的接头肽的单个蛋白质。就此而言,本发明的tcr、多肽及蛋白质可进一步包含接头肽。接头肽可有利地促进重组tcr、多肽及/或蛋白质在宿主细胞中的表达。接头肽可包含任何适合的氨基酸序列。举例而言,接头肽可包含氨基酸序列seq id no:94。当通过宿主细胞表达包括接头肽的构建体后,接头肽可经裂解,从而产生分离的α及β链。在本发明的一实施方案中,tcr、多肽或蛋白质可包含氨基酸序列,该氨基酸序列包含全长α链、全长β链及位于α链与β链之间的接头肽。
99.在一些实施方案中,本文中所公开的tcr、多肽或蛋白质包含如本文中所公开的包含信号肽的α链及/或β链。在一些实施方案中,本文中所公开的α链及/或β链中的任一者的信号肽的序列包含在位置2处取代野生型残基的丙氨酸或组氨酸残基。
100.在一些实施方案中,本文中所公开的tcr、多肽或蛋白质包含如本文中所公开的缺乏信号肽的α链及/或β链的成熟形式。
101.本发明的蛋白质可为包含本文中所描述的本发明多肽中的至少一者的重组抗体或其抗原结合部分。如本文中所使用,“重组抗体”是指包含本发明的多肽中的至少一者及抗体的多肽链或其抗原结合部分的重组(例如,经基因工程改造的)蛋白质。抗体或其抗原
结合部分的多肽可为重链、轻链、重链或轻链的可变区或恒定区、单链可变片段(scfv)或抗体的fc、fab或f(ab)2′
片段等。抗体或其抗原结合部分的多肽链可以重组抗体的独立多肽的形式存在。替代地,抗体或其抗原结合部分的多肽链可以多肽的形式存在,该多肽与本发明的多肽在框内(以串联方式)表达。抗体或其抗原结合部分的多肽可为包括本文中所描述的抗体及抗体片段中的任一者的任何抗体或任何抗体片段的多肽。
102.本发明的tcr、多肽及蛋白质可具有任何长度,亦即可包含任何数目的氨基酸,其限制条件为tcr、多肽或蛋白质保留其生物活性,例如特异性结合于突变p53;检测哺乳动物的癌症;或治疗或预防哺乳动物的癌症的能力等。举例而言,多肽可在约50个至约5000个氨基酸长的范围内,诸如长度为50个、70个、75个、100个、125个、150个、175个、200个、300个、400个、500个、600个、700个、800个、900个、1000个或更多个氨基酸。就此而言,本发明的多肽还包括寡肽。
103.本发明的tcr、多肽及蛋白质可包含合成氨基酸代替一或多种天然存在的氨基酸。此类合成氨基酸为本领域中已知的,且包括例如氨基环己烷甲酸、正亮氨酸、α-氨基正癸酸、高丝氨酸、s-乙酰氨基甲基-半胱氨酸、反式-3-羟脯氨酸及反式-4-羟脯氨酸、4-氨基苯丙氨酸、4-硝基苯丙氨酸、4-氯苯丙氨酸、4-羧基苯丙氨酸、β-苯基丝氨酸β-羟基苯基丙氨酸、苯基甘氨酸、α-萘基丙氨酸、环己基丙氨酸、环己基甘氨酸、吲哚啉-2-甲酸、1,2,3,4-四氢异喹啉-3-甲酸、氨基丙二酸、氨基丙二酸单酰胺、n
′‑
苯甲基-n
′‑
甲基-赖氨酸、n
′
,n
′‑
二苯甲基-赖氨酸、6-羟基赖氨酸、鸟氨酸、α-氨基环戊烷甲酸、α-氨基环己烷甲酸、α-氨基环庚烷甲酸、α-(2-氨基-2-降冰片烷)-甲酸、α,γ-二氨基丁酸、α,β-二氨基丙酸、高苯丙氨酸及α-叔丁基甘氨酸。
104.本发明的tcr、多肽及蛋白质可例如经糖基化、酰胺化、羧化、磷酸化、酯化、n-酰基化、经由例如二硫桥键环化或转化为酸加成盐及/或视情况二聚或聚合,或缀合。
105.本发明的tcr、多肽及/或蛋白质可通过本领域中已知的方法获得,诸如(例如)从新合成。另外,多肽及蛋白质可使用本文中所描述的核酸使用标准重组方法以重组方式产生。参见例如green及sambrook,molecular cloning:a laboratory manual,第4版,cold spring harbor press,cold spring harbor,ny(2012)。替代地,本文中所描述的tcr、多肽及/或蛋白质可通过诸如synpep(dublin,ca)、peptide technologies corp.(gaithersburg,md)及multiple peptide systems(san diego,ca)的公司商业合成。在此方面,本发明tcr、多肽及蛋白质可为合成的、重组的、分离的及/或纯化的。
106.本发明的一实施方案提供一种核酸,其包含编码本文中所描述的tcr、多肽或蛋白质中的任一者的核苷酸序列。如本文中所使用,“核酸”包括“多核苷酸”、“寡核苷酸”及“核酸分子”,且通常意指可为单股或双股的dna或rna的聚合物,其可含有天然、非天然或经更改的核苷酸,且可含有天然、非天然或经更改的核苷酸间键,诸如磷酰胺酯键或硫代磷酸酯键,而非未经修饰的寡核苷酸的核苷酸之间发现的磷酸二酯。在一实施方案中,核酸包含互补dna(cdna)。通常优选地,核酸不包含任何插入、缺失、倒位及/或取代。然而,在一些情况下,如本文中所论述,使核酸包含一或多个插入、缺失、倒位及/或取代可为适合的。
107.优选地,本发明的核酸为重组的。如本文中所使用,术语“重组”是指(i)通过将天然或合成核酸片段接合至可在活细胞中复制的核酸分子而在活细胞外部构建的分子,或(ii)由复制上述(i)中描述的那些产生的分子。出于本文中的目的,复制可为体外复制或体
内复制。
108.可使用本领域中已知的程序基于化学合成及/或酶促连接反应来构建核酸。参见例如前述green及sambrook等人。举例而言,可使用天然存在的核苷酸或各种经修饰的核苷酸以化学方式合成核酸,所述经修饰的核苷酸经设计以增加分子的生物稳定性或增加杂交时形成的双螺旋的物理稳定性(例如,硫代磷酸酯衍生物及吖啶取代的核苷酸)。可用于产生核酸的经修饰的核苷酸的实例包括(但不限于)5-氟尿嘧啶、5-溴尿嘧啶、5-氯尿嘧啶、5-碘尿嘧啶、次黄嘌呤、黄嘌呤、4-乙酰胞嘧啶、5-(羧基羟甲基)尿嘧啶、5-羧甲基胺基甲基-2-硫代尿苷、5-羧甲基胺基甲基尿嘧啶、二氢尿嘧啶、β-d-半乳糖苷基q核苷、肌苷、n
6-异戊烯基腺嘌呤、1-甲基鸟嘌呤、1-甲基肌苷、2,2-二甲基鸟嘌呤、2-甲基腺嘌呤、2-甲基鸟嘌呤、3-甲基胞嘧啶、5-甲基胞嘧啶、n
6-取代的腺嘌呤、7-甲基鸟嘌呤、5-甲胺基甲基尿嘧啶、5-甲氧基胺甲基-2-硫尿嘧啶、β-d-甘露糖苷基q核苷、5
′‑
甲氧基羧基甲基尿嘧啶、5-甲氧基尿嘧啶、2-甲硫基-n
6-异戊烯基腺嘌呤、尿嘧啶-5-氧基乙酸(v)、怀丁氧苷(wybutoxosine)、假尿嘧啶、q核苷、2-硫胞嘧啶、5-甲基-2-硫尿嘧啶、2-硫尿嘧啶、4-硫尿嘧啶、5-甲基尿嘧啶、尿嘧啶-5-氧基乙酸甲酯、3-(3-胺基-3-n-2-羧丙基)尿嘧啶及2,6-二胺基嘌呤。替代地,本发明的核酸中的一或多者可购自诸如macromolecular resources(fort collins,co)及synthegen(houston,tx)的公司。
109.在本发明的一实施方案中,核酸包含编码本文中所描述的tcr、多肽或蛋白质中的任一者的密码子优化核苷酸序列。不受任何特定理论或机制束缚,认为核苷酸序列的密码子优化增加mrna转录物的翻译效率。核苷酸序列的密码子优化可涉及用另一密码子取代初始密码子,该另一密码子编码相同氨基酸但可由更容易地细胞内可用的trna翻译,因此增加翻译效率。核苷酸序列的优化也可减少会干扰翻译的二级mrna结构,因此增加翻译效率。
110.本发明还提供一种核酸,其包含与本文中所描述的核酸中任一者的核苷酸序列互补的核苷酸序列,或在严格条件下与本文中所描述的核酸中任一者的核苷酸序列杂交的核苷酸序列。
111.在严格条件下杂交的核苷酸序列优选地在高严格条件下杂交。“高严格条件”意指核苷酸序列以比非特异性杂交强的可检测量与目标序列(本文中所描述的核酸中任一者的核苷酸序列)特异性杂交。高严格条件包括将区分具有准确互补序列的多核苷酸或仅含有少量分散错配的多核苷酸与碰巧具有少量区域(例如3-10个碱基)匹配该核苷酸序列的随机序列的条件。此列互补的小区域比14-17个或更多个碱基的全长互补序列易于熔解,且高严格性杂交使它们可易于区分。相对高的严格条件将包括例如低盐及/或高温条件,诸如由约0.02m-0.1m nacl或等效物在约50-70℃的温度提供。此高严格条件容许核苷酸序列与模板或目标股之间的极少(若存在)错配,且尤其适用于检测本发明tcr中任一者的表达。通常了解,通过添加增量的甲酰胺可使条件更严格。
112.本发明还提供一种核酸,其包含与本文中所描述的核酸中任一者至少约70%或更多,例如约80%、约90%、约91%、约92%、约93%、约94%、约95%、约96%、约97%、约98%或约99%一致的核苷酸序列。就此而言,核酸可基本上由本文中所描述的核苷酸序列中任一者组成。
113.本发明的核酸可并入重组表达载体中。就此而言,本发明提供一种包含本发明的核酸中任一者的重组表达载体。在本发明的一个实施方案中,重组表达载体包含编码α链、β
链及接头肽的核苷酸序列。
114.出于本文的目的,术语“重组表达载体”意指经基因修饰的寡核苷酸或多核苷酸构建体,当该构建体包含编码mrna、蛋白质、多肽或肽的核苷酸序列,且该载体与细胞在足以使该mrna、蛋白质、多肽或肽在该细胞内表达的条件下接触时,允许由宿主细胞表达该mrna、蛋白质、多肽或肽。本发明的载体整体不为天然存在的。然而,部分载体可为天然存在的。本发明重组表达载体可包含任何类型的核苷酸,包括(但不限于)dna及rna,其可为单股或双股、合成的或部分自天然来源获得,且可含有天然、非天然或更改的核苷酸。重组表达载体可包含天然存在的、非天然存在的核苷酸间键联,或两种类型的键联。优选地,非天然存在或更改的核苷酸或核苷酸间键联不妨碍载体的转录或复制。
115.本发明的重组表达载体可为任何适合的重组表达载体,且可用于转化或转染任何适合的宿主细胞。适合的载体包括经设计用于增殖及扩增,或用于表达,或用于两者的载体,诸如质粒及病毒。载体可选自以下:转座子/转位酶puc系列(fermentas life sciences)、pbluescript系列(stratagene,lajolla,ca)、pet系列(novagen,madison,wi)、pgex系列(pharmacia biotech,uppsala,sweden)及pex系列(clontech,palo alto,ca)。也可使用噬菌体载体,诸如λgt10、λgt11、λzapii(stratagene)、λembl4及λnm1149。植物表达载体的实例包括pbi01、pbi101.2、pbi101.3、pbi121及pbin19(clontech)。动物表达载体的实例包括peuk-cl、pmam及pmamneo(clontech)。优选地,重组表达载体为转座子载体或病毒载体,例如逆转录病毒载体。
116.本发明的重组表达载体可使用描述于例如前述green及sambrook等人中的标准重组dna技术制备。环状或线性表达载体的构建体可经制备含有在原核或真核宿主细胞中起作用的复制系统。复制系统可衍生自例如colel、2μ质粒、λ、sv40、牛乳突状瘤病毒等。
117.理想地,重组表达载体包含诸如转录及翻译起始及终止密码子的调节序列,按需要且考虑载体是否基于dna或基于rna,所述调节序列对将载体引入其中的宿主细胞(例如,细菌、真菌、植物或动物)的类型具有特异性。
118.重组表达载体可包括一或多个标记基因,其允许选择经转化或经转染宿主细胞。标记基因包括杀生物剂耐性(例如,对抗生素、重金属等具有耐性)、营养缺陷型宿主细胞中的互补以提供原营养等。用于本发明表达载体的适合标记基因包括例如新霉素/g418耐性基因、潮霉素耐性基因、组胺醇耐性基因、四环素耐性基因及安比西林(ampicillin)耐性基因。
119.重组表达载体可包含可操作地连接于编码tcr、多肽或蛋白质的核苷酸序列或连接于与编码tcr、多肽或蛋白质的核苷酸序列互补或杂交的核苷酸序列的天然或非天然启动子。启动子的选择(例如,强、弱、诱导性、组织特异性及发育特异性)在技术人员的一般技能内。类似地,核苷酸序列与启动子的组合也在技术人员的技能内。启动子可为非病毒启动子,例如人类延长因子-1α启动子,或病毒启动子,例如巨细胞病毒(cmv)启动子、sv40启动子、rsv启动子,及发现于鼠类干细胞病毒的长端重复序列中的启动子。
120.本发明重组表达载体可经设计以用于瞬时表达、用于稳定表达或用于两者。另外,可使重组表达载体用于组成性表达或用于诱导性表达。
121.此外,可使重组表达载体包括自杀基因。如本文中所使用,术语“自杀基因”是指导致表达自杀基因的细胞死亡的基因。自杀基因可为对表达该基因的细胞赋予对药剂(例如,
药物)的敏感性,且当细胞与药剂接触或暴露于药剂时导致细胞死亡的基因。自杀基因为本领域中已知的,且包括例如单纯疱疹病毒(hsv)胸苷激酶(tk)基因、胞嘧啶脱胺酶、嘌呤核苷磷酸化酶及硝基还原酶。
122.本发明的另一实施方案进一步提供一种宿主细胞,其包含本文中所描述的重组表达载体中的任一者。如本文中所使用,术语“宿主细胞”是指可含有本发明重组表达载体的任何类型的细胞。宿主细胞可为真核细胞(例如,植物、动物、真菌或藻类)或可为原核细胞(例如,细菌或原生动物)。宿主细胞可为经培养细胞或原代细胞,即直接自生物体(例如,人类)分离。宿主细胞可为贴壁细胞或悬浮细胞,即在悬浮液中生长的细胞。适合的宿主细胞为本领域中已知的且包括例如dh5α大肠杆菌(e.coli)细胞、中国仓鼠卵巢细胞、猴vero细胞、cos细胞、hek293细胞等。出于扩增或复制重组表达载体的目的,宿主细胞优选地为原核细胞,例如dh5α细胞。出于制备重组tcr、多肽或蛋白质的目的,宿主细胞优选地为哺乳动物细胞。最佳地,宿主细胞为人类细胞。虽然宿主细胞可为任何细胞类型,可来源于任何类型的组织,且可属于任何发育阶段,但宿主细胞优选地为外周血淋巴细胞(pbl)或外周血单核细胞(pbmc)。更优选地,宿主细胞为t细胞。
123.出于本文中的目的,t细胞可为任何t细胞,诸如经培养t细胞(例如,原代t细胞),或来自经培养t细胞系的t细胞(例如,jurkat,supt1等),或自哺乳动物获得的t细胞。若自哺乳动物获得,则t细胞可自众多来源获得,包括(但不限于)血液、骨髓、淋巴结、胸腺或其他组织或体液。t细胞也可经富集或纯化。优选地,t细胞为人类t细胞。t细胞可为任何类型的t细胞且可属于任何发育阶段,包括(但不限于)cd4
+
/cd8
+
双阳性t细胞、cd4
+
辅助t细胞(例如,th1及th2细胞)、cd4
+
t细胞、cd8
+
t细胞(例如,细胞毒性t细胞)、肿瘤浸润性淋巴细胞(til)、记忆t细胞(例如,中枢记忆t细胞及效应记忆t细胞)、初始t细胞等。
124.本发明还提供一种细胞群,其包含至少一种本文中所描述的宿主细胞。细胞群可为异质群体,其除了不包含重组表达载体中的任一者的至少一种其他细胞,例如宿主细胞(例如,t细胞)或t细胞以外的细胞(例如,b细胞、巨噬细胞、嗜中性白细胞、红细胞、肝细胞、内皮细胞、上皮细胞、肌肉细胞、大脑细胞等)之海,还包含含有所描述的重组表达载体中的任一者的宿主细胞。替代地,细胞群可为实质上均质的群体,其中该群体包含主要包含重组表达载体的宿主细胞(例如,基本上由宿主细胞组成)。该群体也可为克隆细胞群,其中该群体的所有细胞为包含重组表达载体的单个宿主细胞的克隆,使得该群体的所有细胞包含重组表达载体。在本发明的一个实施方案中,细胞群为包含宿主细胞的克隆群体,该宿主细胞包含如本文所描述的重组表达载体。
125.在本发明的一实施方案中,群体中细胞的数目可快速扩增。如例如美国专利8,034,334;美国专利8,383,099;美国专利申请公开案第2012/0244133号;dudley等人,j.immunother.,26:332-42(2003);及riddell等人,j.immunol.methods,128:189-201(1990)中所描述,可通过如本领域中已知的许多方法中的任一者来实现t细胞的数目的扩增。在一实施方案中,通过将t细胞与okt3抗体、il-2及饲养pbmc(例如,经辐照的同种异体pbmc)一起培养来进行t细胞的数目的扩增。
126.本发明tcr、多肽、蛋白质、核酸、重组表达载体及宿主细胞(包括其群体)可经分离及/或经纯化。如本文中所用的术语“分离”意指已自其天然环境移除。如本文中所使用的术语“经纯化”意指纯度已增加,其中“纯度”为相对术语,且未必被解释为绝对纯度。举例而
言,纯度可为至少约50%、至少约60%、至少约70%、至少约80%、至少约90%、至少约95%或可为约100%。
127.可将本发明tcr、多肽、蛋白质、核酸、重组表达载体及宿主细胞(包括其群体)(其皆在下文中统称为“本发明的tcr材料”)调配为组合物,诸如药物组合物。就此而言,本发明提供一种包含本文中所描述的tcr、多肽、蛋白质、核酸、表达载体及宿主细胞(包括其群体)中的任一者的药物组合物及药学上可接受的载剂。含有本发明tcr材料中的任一者的本发明药物组合物可包含超过一种本发明tcr材料,例如多肽及核酸或两种或更多种不同tcr。替代地,药物组合物可包含本发明tcr材料以及另一种药学活性剂或药物,诸如化学治疗剂,例如天冬酰胺酶、硫酸布他卡因(busulfan)、卡铂(carboplatin)、顺铂、道诺比星(daunorubicin)、多柔比星(doxorubicin)、氟尿嘧啶、吉西他滨(gemcitabine)、羟基尿素、甲胺喋呤、太平洋紫杉醇(paclitaxel)、利妥昔单抗(rituximab)、长春碱(vinblastine)、长春新碱(vincristine)等。
128.优选地,载剂为药学上可接受的载剂。关于药物组合物,载剂可为常规用于考虑中的特定本发明tcr材料的载剂中的任一者。制备可施用组合物的方法对本领域技术人员而言为已知或显而易见的且在例如remington:the science and practice of pharmacy,第22版,pharmaceutical press(2012)中更详细地描述。优选的药学上可接受的载剂为在使用条件下不具有有害副作用或毒性的载剂。
129.载剂的选择将部分通过特定本发明tcr材料以及通过用于施用本发明tcr材料的特定方法来确定。因此,存在本发明的药物组合物的多种适合制剂。适合制剂可包括用于非经肠、皮下、静脉内、肌内、动脉内、鞘内、瘤内或腹膜内施用的制剂中的任一者。可使用超过一种途径来施用本发明tcr材料,且在某些情况下,特定途径可提供比另一种途径更实时且更有效的反应。
130.优选地,本发明tcr材料通过注射(例如,静脉内)施用。当本发明tcr材料为表达本发明tcr的宿主细胞时,用于注射的细胞的药学上可接受的载剂可包括任何等张性载剂,诸如(例如)标准生理盐水(约0.90%w/v的nacl于水中、约300mosm/l nacl于水中或每公升水约9.0g nacl)、normosol r电解质溶液(abbott,chicago,il)、plasma-lyte a(baxter,deerfield,il)、约5%右旋糖于水中或林格氏乳酸盐(ringer
′
s lactate)。在一实施方案中,药学上可接受的载剂补充有人类血清蛋白。
131.出于本发明的目的,所施用的本发明tcr材料的量或剂量(例如,当本发明tcr材料为一或多种细胞时,细胞的数目)应足以在合理时间框内在个体或动物中起作用,例如治疗性或预防性反应。举例而言,本发明tcr材料的剂量应足以在自施用时间起约2小时或更长(例如,12至24小时或更多小时)的时段内结合于癌症抗原(例如,突变p53),或检测、治疗或预防癌症。在某些实施方案中,时段可甚至为更长。剂量将通过特定本发明tcr材料的功效及待治疗的动物(例如,人类)的病况以及动物(例如,人类)的体重来确定。
132.用于确定施用剂量的诸多分析为本领域中已知的。出于本发明的目的,当向各自给予不同剂量的t细胞的一组哺乳动物当中的哺乳动物施用给定剂量的此类t细胞时,可使用分析来确定待施用至哺乳动物的起始剂量,该分析包含比较通过表达本发明tcr、多肽或蛋白质的t细胞裂解目标细胞或分泌ifn-γ的程度。在施用某一剂量时,裂解目标细胞或分泌ifn-γ的程度可通过本领域中已知的方法来分析。
133.还将通过可能伴随特定本发明tcr材料的施用的任何不良副作用的存在、性质及程度来确定本发明tcr材料的剂量。通常,主治医师将考虑诸如年龄、体重、一般健康、饮食、性别、待施用的本发明tcr材料、施用途径及所治疗癌症的严重程度的多种因素来确定用于治疗各个体患者的本发明tcr材料的剂量。在本发明tcr材料为细胞群的一实施方案中,每次输注施用的细胞的数目可例如自约1
×
106至约1
×
10
12
个细胞或更多而变化。在某些实施方案中,可施用少于1
×
106个细胞。
134.本领域技术人员将容易了解,可以任何数目的方式修饰本发明的本发明tcr材料,使得经由修饰来增大本发明tcr材料的治疗性或预防功效。举例而言,本发明tcr材料可直接或间接地经由桥键与化学治疗剂缀合。将化合物与化学治疗剂缀合的实践为本领域中已知的。本领域技术人员认识到,对本发明tcr材料的功能不必要的本发明tcr材料上的位点为用于连接桥及/或化学治疗剂的理想位点,其限制条件为一旦连接至本发明tcr材料,桥及/或化学治疗剂不干扰本发明tcr材料的功能,即结合于突变p53或检测、治疗或预防癌症的能力。
135.预期本发明药物组合物、tcr、多肽、蛋白质、核酸、重组表达载体、宿主细胞或细胞群可用于治疗或预防癌症的方法中。不受特定理论或机制束缚,认为本发明tcr特异性结合于突变p53,使得当由细胞表达时,tcr(或相关的本发明多肽或蛋白质)能够介导针对表达突变p53的目标细胞的免疫反应。就此而言,本发明的一实施方案提供一种治疗或预防哺乳动物的癌症的方法,该方法包括以有效治疗或预防哺乳动物的癌症的量向哺乳动物施用本文中描述的药物组合物、tcr、多肽或蛋白质中的任一者、包含编码本文中描述的tcr、多肽、蛋白质中的任一者的核苷酸序列的任何核酸或重组表达载体,或包含编码本文中描述的tcr、多肽或蛋白质中的任一者的重组载体的任何宿主细胞或细胞群。
136.本发明的一实施方案提供本文中描述的任何药物组合物、tcr、多肽或蛋白质、包含编码本文中描述的tcr、多肽、蛋白质中的任一者的核苷酸序列的任何核酸或重组表达载体,或包含编码本文中描述的任何tcr、多肽或蛋白质中的任一者的重组载体的任何宿主细胞或细胞群,其用于治疗或预防哺乳动物的癌症。
137.如本文中所使用,术语“治疗”及“预防”以及自其衍生的词语未必暗示100%或完全治疗或预防。实际上,本领域技术人员识别为具有可能益处或治疗效果的治疗或预防存在变化程度。就此而言,本发明方法可提供任何量的任何水平的哺乳动物中癌症的治疗或预防。此外,通过本发明方法提供的治疗或预防可包括治疗或预防所治疗或预防的癌症的一或多种病况或症状。举例而言,治疗或预防可包括促进肿瘤的消退。另外,出于本文中的目的,“预防”可涵盖推迟癌症或其症状或病况的发作。替代地或另外,“预防”可涵盖预防或推迟癌症或其症状或病况的复发。
138.本发明的一实施方案还提供一种检测哺乳动物中癌症的存在的方法。方法包括(i)使包含来自哺乳动物的一或多种细胞的样品与本文中描述的本发明tcr、多肽、蛋白质、核酸、重组表达载体、宿主细胞、细胞群或药物组合物中的任一者接触,由此形成复合物,以及(ii)检测复合物,其中检测到复合物指示哺乳动物中癌症的存在。
139.关于检测哺乳动物的癌症的本发明方法,细胞的样品可为包含全细胞、其裂解物,或全细胞裂解物的一部分(例如,细胞核或细胞质部分、全蛋白部分或核酸部分)的样品。
140.出于本发明检测方法的目的,可相对于哺乳动物在体外或体内进行接触。优选地,
接触为体外。
141.另外,可经由本领域中已知的任何数目的方式进行复合物的检测。举例而言,可用可检测标记来标记本文中所描述的本发明tcr、多肽、蛋白质、核酸、重组表达载体、宿主细胞或细胞群,该可检测标记诸如放射性同位素、荧光团(例如,异硫氰酸荧光素(fitc)、藻红素(pe))、酶(例如,碱性磷酸酶、辣根过氧化酶)及元素粒子(例如,金粒子)。
142.出于本发明方法的目的,其中施用宿主细胞或细胞群,细胞可为对哺乳动物为同种异体或自体的细胞。优选地,细胞为哺乳动物自体的。
143.关于本发明方法,癌症可为任何癌症,其包括以下中的任一者:急性淋巴细胞性癌症、急性骨髓性白血病、肺泡横纹肌肉瘤、骨癌、脑癌、乳癌、肛门癌、肛管癌或肛肠癌、眼癌、肝内胆管癌、关节癌、颈癌、胆囊癌或胸膜癌、鼻癌、鼻腔癌或中耳癌、口腔癌、阴道癌、外阴癌、慢性淋巴细胞性白血病、慢性骨髓癌、结肠癌、结肠直肠癌、子宫内膜癌、食道癌、子宫颈癌、肠胃类癌瘤、神经胶质瘤、霍奇金淋巴瘤(hodgkin lymphoma)、喉咽癌、肾脏癌、喉癌、肝癌、肺癌、恶性间皮瘤、黑素瘤、多发性骨髓瘤、鼻咽癌、非霍奇金淋巴瘤、口咽癌、卵巢癌、阴茎癌、胰腺癌、腹膜癌、肠网膜癌及肠系膜癌、咽癌、前列腺癌、直肠癌、肾癌、皮肤癌、小肠癌、软组织癌、胃癌、睾丸癌、甲状腺癌、子宫癌、尿管癌及膀胱癌。在优选的实施方案中,癌症为表达突变p53的癌症。癌症可表达在位置175及220中的一者或两者处具有突变的p53,如由seq id no:1所定义。癌症可表达具有以下人类p53突变中的一者或两者的p53:r175h及y220c。优选地,癌症为上皮癌或胆管癌、黑素瘤、结肠癌、直肠癌、卵巢癌、子宫内膜癌、非小细胞肺癌(nsclc)、胶质母细胞瘤、子宫颈癌、头颈癌、乳癌、胰腺癌或膀胱癌。
144.在本发明方法中所提及的哺乳动物可为任何哺乳动物。如本文中所使用,术语“哺乳动物”是指任何哺乳动物,包括(但不限于)啮齿目的哺乳动物(诸如小鼠及仓鼠)及兔形目的哺乳动物(诸如兔)。优选地,所述哺乳动物来自食肉目,包括猫科动物(猫)及犬科动物(狗)。更优选地,所述哺乳动物来自偶蹄目,包括牛科动物(母牛)及猪科动物(猪);或奇蹄目,包括马科动物(马)。最佳地,哺乳动物属于灵长目、四足猴目或猴目(猴)或类人猿目(人类及猿)。尤其优选的哺乳动物为人类。
145.以下实例进一步说明本发明,但当然不应被解释为以任何方式限制本发明的范畴。
实施例
146.以下材料及方法用于实施例1-7中描述的实验中。个体及样品
147.白血球清除术产物及肿瘤样品获自患有转移性上皮癌的个体,所述个体入选经国立癌症研究院(nci)的机构审查委员会(irb)批准的国立卫生研究院方案nct01174121。基于预处理白血球清除术的可用性及til筛选结果来选择患者,且所述患者已接受根据标准护理的先前疗法(手术、化疗、放射疗法)(malekzadeh等人,j.clin.invest.129(3):1109-14(2019);deniger等人,clin.cancer res.,24(22):5562-73(2018))。聚蔗糖-泛影葡胺(ficoll-hypaque)用于将pbl自白血球清除术分离,且将细胞低温贮藏以供进一步使用。所有研究患者已根据如先前描述的临床方案通过全外显子组测序来确认tp53突变(malekzadeh等人,j.clin.invest.129(3):1109-14(2019))。
抗体及facs
148.荧光标记的抗体流式细胞术详述于表1中。在facs canto ii系统(bd biosciences,san jose,ca)上进行分析型流式细胞术,其中通过flowjo软件(treestar,ashland,or)进行分析。通过除去经碘化丙锭(pi)染色的细胞由淋巴细胞及活细胞来门控所有细胞。在facs aria ii细胞分选仪(bd biosciences)上针对ivs及4-1bb/ox40分选细胞。单独地经由cd3
+
cd4
+
cd8-(cd4)及cd3
+
cd4-cd8
+
(cd8)门分选4-1bb
+
及/或ox40
+
细胞。通过单细胞pcr的sh800s细胞分选仪(sony biotechnology)分选共培养物以鉴别tcr基因。表1表1tp53“热点”突变筛选试剂
149.产生wt(tmg-wt-tp53)及突变tp53(tmg-mut-tp53)tmg构建体以用于如先前描述的til筛选(malekzadeh等人,j.clin.invest.129(3):1109-14(2019))。简言之,各tp53“热点”突变(r175h、y220c、g245s、g245d、r248l、r248q、r248w、r249s、r273c、r273h、r273l及r282w)构成在中间具有突变密码子且在上游及下游具有12个正常密码子的小型基因中,且所述小型基因串连至tmg中。还衍生对应于wt序列的类似序列。tmg合成为dna,且框内克隆至lamp信号序列及dc-lamp定位序列,接着根据制造商的说明书(thermo-fisher;waltham,ma)使用mmessage mmachine t7超级试剂盒体外转录成mrna。另外,针对p53
r175h
、p53
r248w
及p53
y220c
合成wt及突变肽,且通过高效液相层析(genscript;piscataway,nj)将wt及突变肽纯化至>95%。所有肽在dmso中复原。抗原呈递细胞
150.通过贴壁方法(tran等人,science,350(6266):1387-90(2015))产生单核细胞衍
生的未成熟树突状细胞(dc)。简言之,将pbl接种于含有dnase(genentech inc.,san francisco,ca)的aim-v培养基(life technologies,waltham,ma)中,且在37℃下孵育1.5-2小时。将非贴壁细胞移除且新鲜使用或低温贮藏。将贴壁细胞在aim-v中洗涤,在37℃下孵育一个小时,且将培养基更换为dc培养基(rpmi-1640,2mm l-谷氨酰胺,具有5%人类血清、100u/ml青霉素、100μg/ml链霉素、两性霉素b、800iu/ml粒细胞-巨噬细胞集落刺激因子(gm-csf)及200u/ml白介素-4(il-4)(peprotech,rocky hill,nj))。每2-3天喂养细胞,且在第5-6天进行收获。ivs、突变体tp53共培养、4-1bb/ox40富集及rep
151.为进行抗原刺激分选,如先前所描述处理预处理pbl(cafri等人,nat.commun.,10(1):449(2019))。将经低温贮藏的血球分离术样品解冻、洗涤、用含有dnase的aim-v培养基设定为5-10
×
106个细胞/毫升,并且每t175烧瓶(corning inc.,corning,ny)接种1.75-2
×
108个活细胞,且在37℃、5%co2下将该培养基孵育90分钟。在90分钟之后,将非贴壁单核细胞耗尽的pbl收集、离心且在37℃及5%co2下在50/50培养基(aim-v培养基、rpmi-1640培养基(lonza,walkersville,md)、5%人类ab血清、100u/ml青霉素及100μg/ml链霉素(life technologies)、2mm l-谷氨酰胺(life technologies)、10μg/ml庆大霉素(quality biological inc.,gaithersburg,md)、12.5mm hepes(life technologies))中孵育过夜。贴壁单核细胞分化为如上文所描述的未成熟dc。在将非贴壁细胞静置过夜之后,收获细胞,且使1-2
×
108个细胞再悬浮于50μl的具有cd3、cd8、cd4、cd62l、cd45ro抗体的染色缓冲液(pbs,0.5%bsa,2mm edta)中。在4℃下将细胞孵育30分钟且在采集之前洗涤两次。为确定分选群体,对活细胞(碘化丙锭阴性)、单细胞、cd3
+
t细胞,接着对抗原刺激细胞(cd62l-cd45ro
+
、cd62l
+
cd45ro
+
、cd62l-cd45ro-)进行门控,将所述抗原刺激细胞进一步细分为cd4
+
或cd8
+
。cd8
+
及cd4
+
抗原刺激记忆t细胞经单独分选、收集、计数且再悬浮于含有浓度为60ng/ml白介素-21(il-21)的50/50培养基中。将自体dc提前用tmg-mut-tp53电穿孔18-24小时或在facs分选当天用患者特异性突变体p53-lp脉冲2-4小时。将目标细胞(dc)在50/50培养基中洗涤两次且再悬浮于无细胞因子的50/50培养基中。在添加dc之后,以1∶3至1∶6比率(dc∶t细胞)共培养以30ng/ml il-21的最终浓度进行活体外刺激(ivs)。如先前所描述在14天的生长及用il-21及白介素-2(il-2;阿地白介素(aldesleukin))(cafri等人,nat.commun.,10(1):449(2019))进行3次喂养之后,将自体dc再次电穿孔或分别用tmg-mut-tp53或突变长肽(lp)脉冲,且在37℃及5%co2下将ivs培养物共培养18-24小时。同时,在4-1bb/ox40富集分选期间,将ivs培养物与针对阴性对照用无关tmg电穿孔或用dmso脉冲的dc共培养。在共培养之后,将细胞收获且再悬浮于50μl的含有cd3、cd4、cd8、4-1bb及ox40抗体的染色缓冲液(pbs,0.5%bsa,2mm edta)中,在4℃下孵育30分钟,且在采集之前洗涤两次。通过rep使用辐照pbl喂养器、30ng/ml okt3抗体(miltenyi biotec,bergisch gladbach,germany)及3,000iu/ml il-2在50/50培养基中扩增分选的4-1bb
+
/ox40
+
富集t细胞。将快速扩增(rep)的培养物喂养3次,且测试反应性或在第14天低温贮藏。共培养
152.ivs及富集t细胞的筛选经由用于筛选til片段的相同策略实现(malekzadeh等人,j.clin.invest.129(3):1109-14(2019))。简言之,将自体dc用tmg(105个细胞/孔)电穿孔且静置过夜或用肽或dmso(8
×
104个细胞/孔)脉冲2-4小时。将目标细胞洗涤两次且再悬浮
于50/50培养基中,且在干扰素γ(ifnγ)酶联免疫斑点(elispot)盘(emd millipore,burlington,ma)中与2
×
104个t细胞共培养。佛波醇12-肉豆蔻酸酯13-乙酸酯(pma)及离子霉素(thermo fisher)用作阳性对照且培养基仅为阴性对照。将共培养细胞移除、染色且通过如上的流式细胞术分析,同时根据制造商的说明书来处理elispot盘。在共培养之前,使肿瘤细胞自低温贮藏储备液生长至少一周,且所述肿瘤细胞系的产生描述于别处(malekzadeh等人,j.clin.invest.129(3):1109-14(2019))。在圆底96孔盘中将肿瘤细胞与t细胞(总共2
×
105个细胞)以1∶1比率共培养过夜。在收获共培养上清液以通过酶联免疫吸附分析(elisa;thermofisher)来评定ifnγ分泌之后,通过流式细胞术分析共培养的细胞。最小肽分析及hla限制映射
153.使用先前所描述的类似方法来鉴别最小肽且确定hla限制(malekzadeh等人,j.clin.invest.129(3):1109-14(2019))。简言之,使用较短netmhc肽结合亲和力算法(v3.4)(lundegaard等人,bioinformatics,24(11):1397-8(2008))来预测hla i类等位基因的新表位。如上文所描述共培养候选9-11个氨基酸。为研究cd4
+
最小新抗原,如上文所描述共培养与14个氨基酸重叠的15氨基酸肽。为确定hla限制,将cos7肿瘤细胞以2.5
×
104个细胞/孔接种于平底96孔盘中的rpmi-1640、2mm l-谷氨酰胺及10%胎牛血清中,且在37℃下孵育过夜。根据制造商的说明书(thermofisher)用lipofectamine 2000转染剂转染dna质粒(pcdna3.1骨架)中的患者特异性个别hla i类等位基因(300ng/孔)或hla ii类α及β链(各自150ng/孔)两者。当tmg与hla共转染时,hla的浓度对于i类减小至150ng/孔,且对于ii类减小至100ng/孔。用于这些实验的wt tmg为仅在所关注位置(例如,r175h)处恢复至wt的tmg-mut-tp53。在24小时孵育之后,移除转染培养基,在50/50培养基中将肽或dmso脉冲2-4小时,用50/50培养基将孔洗涤两次,且将105个t细胞孵育过夜。通过elisa分析共培养上清液的ifnγ分泌,且将细胞染色以用于上调4-1bb并通过流式细胞术进行分析。tcrb测序
154.通过adaptive biotechnologies(seattle,wa)从基因组dna进行tcrb调查测序。发送最少5
×
104个细胞以用于测序。使用immunoseq analyzer 3.0工具(adaptive biotechnologies)进行生产性tcr重排的分析。tcr鉴别及重构建
155.通过将t细胞的共培养物及表达p53新抗原的dc分选至单个孔中,随后类似于先前研究进行tcr基因的单细胞逆转录酶聚合酶链反应(rt-pcr)来鉴别tcr(pasetto等人,cancer immunol.res.,doi 10.1158/2326-6066.cir-16-0001(2016);deniger等人,clin.cancerres.,23(2):351-62(2017))。针对tcrα及tcrβ使pcr产物保持分离且通过桑格测序(sanger sequencing)进行分析。用imgt/v-quest(imgt.org/imgt)及igblast(ncbi.nlm.nih.gov/igblast)网站分析这些部分tcr序列,所述网站鉴别精确cdr3及j或d/j区以及最有可能的trav及trbv家族。使人类全长可变序列融合至鼠类恒定链,如在其他研究中所进行(deniger等人,clin.cancer res.,23(2):351-62(2017);cohen等人,j.clin.invest.,125(10):3981-91(2015)。将鼠化tcrα及tcrβ基因与rakr-sgsg(seq id no:128)及p2a核糖体漏失序列连接以在单个顺反子中产生tcr链的化学计量表达。此序列经合成且克隆至msgv1载体中以用于产生瞬时逆转录病毒上清液。
tcr转导
156.将pbl供体在补充有50ng/ml可溶okt3及300iu/ml il-2的50/50培养基中调整至3
×
106个细胞/毫升,且在逆转录病毒转导之前在低黏附盘上活化两天。使用lipofectamine 2000转染剂(life technologies)将编码突变特异性tcr(1.5μg/孔)的pmsgv1质粒及包膜编码质粒rd114(0.75μg/孔)共转染至106个hek293gp细胞/孔的6孔聚-d-赖氨酸-涂布的盘中。在转染后两天,收集逆转录病毒上清液,用dmem培养基1∶1稀释,且在32℃下在涂布有retronectin试剂(10μg/孔,takara,rockville,md)的未经组织培养物处理的6孔盘上以2000
×
g离心2小时。抽取上清液且将5
×
105个细胞/毫升的2
×
106个经刺激t细胞添加至具有300iu/ml il-2的50/50培养基中的各孔。在retronectin试剂涂布盘上将t细胞以300
×
g离心10min。在3-4天后用300iu/ml il-2更换培养基且在转导后10-14天对经转导细胞进行分析。实施例1
157.此实施例显示抗原刺激具有tp53突变的外周血t细胞的ivs。
158.在患有tp53突变肿瘤的7名结肠癌患者、1名直肠癌患者及1名卵巢癌患者中评估来自pbl的抗原刺激t细胞(表2)。患者4217(p53
r175h
)、4213(p53
r248q
)、4257(p53
r248w
)及4254(p53
r273h
)对p53新抗原无til反应。相比之下,til对患者4141(p53
r175h
)、4285(p53
r175h
)、4149(p53
y220c
)、4266(p53
r248w
)及4273(p53
r248w
)中的自体tp53突变具有反应性(malekzadeh等人,j.clin.invest.129(3):1109-14(2019);deniger等人,clin.cancer res.,24(22):5562-73(2018))。低温贮藏分离术(在任何act之前)用于自pbl分选抗原刺激cd4
+
或cd8
+
t细胞(图1a左侧)。体外用表达突变tp53-tmg mrna(tp53-tmg-ivs)的dc刺激或用患者特异性突变p53-lp(p53-lp-ivs)脉冲经分选cd4
+
或cd8
+
t细胞。在于il-21及il-2的存在下培养12天之后,将体外刺激的cd4
+
及cd8
+
记忆细胞在tp53-tmg-ivs的情况下与经突变tp53-tmg mrna电穿孔的dc共培养,或在p53-lp-ivs的情况下与患者特异性突变p53-lp共培养,且在第二天基于t细胞活化标记物4-1bb及/或ox40的表达进行分选(图1a中间)。tp53-tmg-ivs及p53-lp-ivs之后的细胞产量对于cd4
+
及cd8
+
t细胞两者为相当的,范围介于0.9
×
10
7-18.3
×
107个细胞及0.3
×
10
7-15.6
×
107个起始t细胞(表3)。出于实验的完整性及对称性,自所有群体分选cd4
+
4-1bb
+
/ox40
+
及cd8
+
4-1bb
+
/ox40
+
t细胞的部分,其范围介于2
×
10
2-1.7
×
105个细胞,且0.1%至6.9%来自亲本cd4或cd8门(表3)。经分选t细胞经历rep且在快速扩增14天之后进行分析。最终细胞产量范围介于7
×
10
6-4.2
×
108个t细胞,这有可能受rep中的输入细胞数目影响(表3)。表2
表3
表3.在患者中用p53新抗原反应性培养物进行ivs、4-1bb/ox40富集及快速扩增之后的t细胞产量。开始ivs的细胞数目视pbl中cd4及cd8抗原刺激t细胞的频率而定。所分选的4-1bb/ox40t细胞的百分比基于控制门控以消除尽可能多的非特异性t细胞,且有可能低
估群体中反应性t细胞的百分比。将所有富集细胞置于rep中。实施例2
159.此实施例显示,tp53突变反应性t细胞存在于对p53新抗原具有肿瘤内til反应的患者的pbl中。
160.在ivs、4-1bb/ox40及rep富集之后,对实施例1的培养物进行分析型筛选,其中通过使用elispot分析经由流式细胞术进行的细胞表面标记物4-1bb上调及ifnγ分泌来评估反应性(图1a右侧)。外周血t细胞对患者4213、4217、4254及4257中的p53新抗原不具有反应性,这证实til筛选结果(表2)。这些患者可能尚不具有hla与p53新表位的免疫原性组合。相比之下,在来自对til突变的tp53具有肿瘤内t细胞反应的5名患者(4141及4285:p53
r175h
,4149:p53
y220c
,4266及4273:p53
r248w
)的pbl的抗原刺激t细胞中鉴别出tp53突变特异性t细胞(图1b至图1c及表2)(malekzadeh等人,j.clin.invest.129(3):1109-14(2019))。tp53-tmg-ivs在4141-cd8、4285-cd4、4149-cd4及4266-cd8培养物中产生p53新抗原特异性t细胞(图1b),且p53-lp-ivs在4285-cd4及4273-cd4培养物中产生p53新抗原特异性t细胞(图1c)。通过对wt对应物(图1b至图1c空心形状)的反应的缺乏来例示对突变tp53(图1b至图1c实心形状)的反应特异性。tp53突变反应性细胞的最高频率在4141-cd8 tp53-tmg-ivs培养物中针对p53
r175h
为78%(图1d)。4285-cd4 tp53-tmg-ivs培养物将阳性ifnγ分泌筛选结果例示为:t细胞对突变体tmg-mut-tp53及p53
r175h lp具有反应性,但不针对wt tmg-mut-tp53、无关tmg、dmso(肽载体)或wt p53
r175
lp(图1e)。p53
r175h lp具有氨基酸序列ykqsqhmtevvrhcphhercsdsdg(seq id no:111)。wt p53
r175
lp具有氨基酸序列ykqsqhmtevvrrcphhercsdsdg(seq id no:110)。基于4-1bb上调及/或ifnγ分泌将所选培养物视为反应性的,且进一步研究所述培养物(表4a至表4b)。4285-cd4 tp53-tmg-ivs培养物展示在低至10ng/ml的肽浓度下对同源p53
r175h lp的特异性识别(图1f)。因此,经由ivs及4-1bb/ox40富集,可鉴别靶向公共tp53突变的高度特异性cd8
+
及cd4
+
t细胞。
实施例3
161.此实施例显示,tcrb追踪显示p53新抗原反应性t细胞自pbl富集。
162.需要进一步表征各患者的tp53突变反应性t细胞群的tcr多样性,且确定ivs及4-1bb/ox40富集是否更改t细胞基因谱。为实现此,进行tcrb深度测序(pasetto等人,cancer immunol.res.,4(9):734-43(2016)),且基于独特cdr3b序列及总样品克隆性来测量生产性t细胞克隆型频率,该总样品克隆性为群体多样性的归一化测量值,其中更多寡克隆样品接近1(boyd等人,sci.transl.med.,1(12):12ra23)(2009);howie等人,sci.transl.med.,7(301):301ra131(2015))。相对于ivs pbl前,tcrb克隆性在由所有患者pbl样品产生的tp53-tmg-ivs及p53-lp-ivs培养物中显著增加(图2a)。类似地,各tp53-tmg-ivs及p53-lp-ivs样品中最频繁的独特tcrb克隆型具有比在ivs pbl前中更高的频率(图2b)。p53新抗原反应性tcrb序列的排名在最终p53-lp-ivs或tp53-tmg-ivs培养物中范围介于1-167,但在原始pbl中未检测到或排名5,020(表5)。增加的克隆性或最大tcrb克隆型频率不限于对p53新抗原具有t细胞反应的培养物(图2a至图2b;星号表示阳性培养物)。这表明,存在斜穿ivs及4-1bb/ox40富集的t细胞基因谱,但对最高频率及克隆性的评定不足以预测培养物对突变tp53的反应。表5
表5.在ivs、共培养、4-1bb/ox40分选及rep之前及之后对p53新抗原反应性细胞进行tcrb追踪。用至少50,000个细胞进行adadptive biotechnologies tcrb调查测序。实施例4
163.此实施例显示p53新抗原反应性tcr的分离及通过tcrb测序进行追踪。
164.随后自p53新抗原反应性ivs群鉴别tcr以供潜在治疗性及研究用途且在培养期间追踪tcrb克隆型以评估tp53突变反应性t细胞富集的程度。在将反应性ivs培养物与同源p53新抗原(tmg或lp)共培养之后鉴别出tcr,从而类似于先前研究来分选tcrα及β基因的4-1bb
+
t细胞及单细胞rt-pcr(pasetto等人,cancer immunol.res.,4(9):734-43(2016))。将tcr对重构建、克隆至逆转录病毒载体中且转导至供体pbl中。将第二氨基酸残基变为丙氨酸(a)以具有用于高效翻译的较强kozak序列。用经半胱氨酸取代的经lvl修饰的鼠类α链恒定区置换tcrα链恒定区。用经半胱氨酸取代的鼠类β链恒定区置换tcrβ链恒定区。
165.鉴别出靶向p53
r175h
(患者4141及4285)及p53
r248w
(患者4266及4273)新抗原的总共11个tcr(表5)。归因于t细胞的受限可用性,无法确定患者4149的tcr。在分别靶向p53
r175h
/hla-a*02:01、p53
r248w
/hla-a*68:01及p53
r248w
/hla-dpb1*02:01的患者4141、4266及4273中进行ivs及4-1bb/ox40富集之后,在pbl中鉴别出来自til的相同p53新抗原反应性tcr(malekzadeh等人,j.clin.invest.129(3):1109-14(2019))。在这些患者中未鉴别出额外tp53突变反应性t细胞。相比之下,自pbl鉴别出来自患者4285的7种独特p53
r175h
新抗原特异性tcr,其不存在于til研究中,且在pbl群中未发现衍生自til的tcr。pbl衍生的tcr(4285-pbl-tcr)的功能亲合力与til衍生的tcr(4285-til-tcr)相当,其中识别到p53
r175h lp为10ng/ml且对wt p53
r175
lp无反应(图2c至图2j)。相较于起始pbl,对来自患者4141及4285的p53
r175h
新抗原特异性tcrb克隆型的追踪显示在ivs及4-1bb/ox40富集之后的指数扩增(图2k)。此外,来自患者4285的cdr3b序列低于批量pbl中的检测极限(自2
×
105次读取,<0.001%),但在ivs及4-1bb/ox40富集之后具有充足频率,包括前10个总cdr3b克隆型中的四个tcr(表5)。来自患者4266的p53
r248w
新抗原特异性tcr也低于pbl中的检测极限,但在4266-cd8 tp53-tmg-ivs培养物中为2.6%(4266-pbl-tcr3)及7.5%(4266-pbl-tcr2)(图2l)。对p53
r248w
新抗原具有特异性的tcr在4273-cd4 p53-lp-ivs培养物中自0.002%富集至0.017%(图2l)。共同地,数据显示,pbl可为与肿瘤内tcr一致或相当的公共tp53突变反应性tcr的来源。实施例5
166.此实施例显示,共同hla限制组件及p53新表位为免疫原性的。
167.接着评估所识别的最小p53新表位及对应hla限制。类似于先前报导,通过将对应于患者的个别hla等位基因中的每一者的dna质粒转染至cos7猴细胞系(缺乏hla)及脉冲肽中或与tmg共转染来实现hla映射(malekzadeh等人,j.clin.invest.129(3):1109-14(2019);deniger等人,clin.cancer res.,24(22):5562-73(2018))。如通过4-1bb表达所测量,4141-cd8 tp53-tmg-ivs培养物在hla-a*02:01(在美国人群中常见的hla)的背景下对p53
r175h hmtevvrhc(seq id no:96)新表位具有特异性(gonzales等人,hisp.health careint.,15(4):180-8(2017))(图3a)。如通过ifnγ分泌所测量,hla-a*68:01限制由cd8 tp53-tmg-ivs培养物识别的p53
r248w
新表位sscmggmnwr(seq id no:98)(图3b)。此经预期为来自患者4141及4266中的til的tcr发现于这些ivs培养物中,且已建立最小新表位及hla限制组件(malekzadeh等人,j.clin.invest.129(3):1109-14(2019))。类似地,4273-pbl-tcr发现于4273-cd4 p53-lp-ivs培养物中且具有来自til研究的已知p53
r248w
与hla-dpb1*02:01组合。尽管tcr对于患者4285在pbl与til之间不同,但4285-cd4 tp53-tmg-ivs培养物对发现于til中的相同p53
r175h
与hla-dbr1*13:01组合具有特异性(图3c)。此外,所有4285-pbl-tcr对p53
r175h
及hla-dbr1*13:01具有特异性,且所有通过tcrb测序存在于4285-cd4 tp53-tmg-ivs培养物中(表5;图4)。在来自患者4285的dc上脉冲与14个氨基酸重叠的十五个氨基酸p53
r175h
肽且将其与经tcr转导的t细胞共培养,且在hla-drb1*13:01的背景下,将核心肽evvrhcphher(seq id no:2)确定为由4285-pbl-tcr识别的共同序列(表6)。总之,在三种情况下发现识别相同hla及最小p53新表位的来自pbl中的til的相同tcr,且在一种情况下,发现具有与肿瘤内t细胞相同p53新抗原特异性的额外tcr。表6
实施例6
168.此实施例显示,在ivs之后,肿瘤细胞在hla上处理且呈递由pbl衍生的t细胞识别的p53新表位。
169.针对识别表达于肿瘤细胞表面上的经天然处理及呈递的抗原的能力来评估tp53突变反应性t细胞。将saos2-r175h骨肉瘤肿瘤细胞系(hla-a*02:01且过表达全长p53
r175h
)及tc#4266人类异种移植肿瘤细胞系(p53
r248w
及hla-a*68:01:02结肠癌)用作模型。在过夜共培养之后,来自4141-cd8 tp53-tmg-ivs及4266-cd8 tp53-tmg-ivs培养物的cd8
+
t细胞分别响应于saos2-r175h及tc#4266细胞系而上调4-1bb,其中交叉匹配细胞系的活化最少(图3d)。因此,来自pbl的tp53突变特异性t细胞可识别具有经天然处理及呈递的p53新表位的肿瘤细胞。实施例7
170.此实施例显示在实施例4中构建且在表6的表头中命名的tcr的氨基酸序列。这些tcr的tcrα及β链可变区的氨基酸序列示于表7中。cdr加底线。表7
171.tcr名称:4285-pbl-tcr1
172.上文阐述自患者4285分离的tcr 4285-pbl-tcr1的序列。自氨基端开始,第一加底线区为cdr1β(seq id no:6),第二加底线区为cdr2β(seq id no:7),第三加底线区为cdr3β
(seq id no:8),第四加底线区为cdr1α(seq id no:3),第五加底线区为cdr2α(seq id no:4),及第六加底线区为cdr3α(seq id no:5)。粗体区为接头(seq id no:94)。自氨基端开始,第一斜体区为β链恒定区(seq id no:93),及第二斜体区为α链恒定区(seq id no:91)。β链可变区(seq id no:10)包括自氨基端开始且在β链恒定区开始之前即终止的序列。α链可变区(seq id no:9)包括在接头之后即开始且在α链恒定区开始之前即终止的序列。全长β链(seq id no:12)包括自氨基端开始且在接头开始之前即终止的序列。全长α链(seq id no:11)包括在接头之后即开始且以羧基端结束的序列。
173.包含野生型α链信号肽的4285-pbl-tcr1的变体示于seq id no:180中。变体包含如seq id no:178中所述的α链可变区(具有野生型信号肽)。变体的全长α链示于seq id no:179中。
174.4285-pbl-tcr1的另一变体包含如seq id no:205中所述的β链可变区(具有野生型信号肽)。变体的全长β链示于seq id no:206中。
175.不具有n端信号肽的预测4285-pbl-tcr1α及β链可变区成熟序列示于表7中。不具有n端信号肽的该成熟序列的预测α链可变区示于seq id no:142中。不具有n端信号肽的预测全长α链(包括α链可变区及恒定区)示于seq id no:160中。不具有n端信号肽的预测β链可变区示于seq id no:143中。不具有n端信号肽的预测全长β链(包括β链可变区及恒定区)示于seq id no:161中。
176.tcr名称:4285-pbl-tcr2
177.紧接在上文阐述自患者4285分离的tcr 4285-pbl-tcr2的序列。自氨基端开始,第一加底线区为cdr1β(seq id no:17),第二加底线区为cdr2β(seq id no:18),第三加底线区为cdr3β(seq id no:19),第四加底线区为cdr1α(seq id no:14),第五加底线区为cdr2α(seq id no:15),且第六加底线区为cdr3α(seq id no:16)。粗体区为接头(seq id no:94)。自氨基端开始,第一斜体区为β链恒定区(seq id no:93),且第二斜体区为α链恒定区(seq id no:91)。β链可变区(seq id no:21)包括自氨基端开始且在β链恒定区开始之前立即终止的序列。α链可变区(seq id no:20)包括在接头之后立即开始且在α链恒定区开始之前立即终止的序列。全长β链(seq id no:23)包括自氨基端开始且在接头开始之前立即终止的序列。全长α链(seq id no:22)包括在接头之后立即开始且以羧基端结束的序列。
178.包含野生型α链信号肽的4285-pbl-tcr2的变体示于seq id no:183中。变体包含如seq id no:181中所示的α链可变区(具有野生型信号肽)。变体的全长α链示于seq id no:182中。
179.4285-pbl-tcr2的另一变体包含如seq id no:207中所示的β链可变区(具有野生型信号肽)。变体的全长β链示于seq id no:208中。
180.不具有n端信号肽的预测4285-pbl-tcr2α及β链可变区成熟序列示于表7中。不具有n端信号肽的成熟序列的预测α链可变区示于seq id no:144中。不具有n端信号肽的预测全长α链(包括α链可变区及恒定区)示于seq id no:162中。不具有n端信号肽的预测β链可变区示于seq id no:145中。不具有n端信号肽的预测全长β链(包括β链可变区及恒定区)示于seq id no:163中。
181.tcr名称:4285-pbl-tcr3
182.紧接在上文阐述自患者4285分离的tcr 4285-pbl-tcr3的序列。自氨基端开始,第一加底线区为cdr1β(seq id no:28),第二加底线区为cdr2β(seq id no:29),第三加底线区为cdr3β(seq id no:30),第四加底线区为cdr1α(seq id no:25),第五加底线区为cdr2α(seq id no:26),且第六加底线区为cdr3α(seq id no:27)。粗体区为接头(seq id no:94)。自氨基端开始,第一斜体区为β链恒定区(seq id no:93),且第二斜体区为α链恒定区(seq id no:91)。β链可变区(seq id no:32)包括自氨基端开始且在β链恒定区开始之前立即终止的序列。α链可变区(seq id no:31)包括在接头之后立即开始且在α链恒定区开始之前立即终止的序列。全长β链(seq id no:34)包括自氨基端开始且在接头开始之前立即终止的序列。全长α链(seq id no:33)包括在接头之后立即开始且以羧基端结束的序列。
183.包含野生型α链信号肽的4285-pbl-tcr3的变体示于seq id no:186中。变体包含如seq id no:184中所示的α链可变区(具有野生型信号肽)。变体的全长α链示于seq id no:185中。
184.4285-pbl-tcr3的另一变体包含如seq id no:209中所示的β链可变区(具有野生型信号肽)。变体的全长β链示于seq id no:210中。
185.不具有n端信号肽的预测4285-pbl-tcr3α及β链可变区成熟序列示于表7中。不具有n端信号肽的成熟序列的预测α链可变区示于seq id no:146中。不具有n端信号肽的预测
全长α链(包括α链可变区及恒定区)示于seq id no:164中。不具有n端信号肽的预测β链可变区示于seq id no:147中。不具有n端信号肽的预测全长β链(包括β链可变区及恒定区)示于seq id no:165中。
186.tcr名称:4285-pbl-tcr5
187.紧接在上文阐述自患者4285分离的tcr 4285-pbl-tcr5的序列。自氨基端开始,第一加底线区为cdr1β(seq id no:39),第二加底线区为cdr2β(seq id no:40),第三加底线区为cdr3β(seq id no:41),第四加底线区为cdr1α(seq id no:36),第五加底线区为cdr2α(seq id no:37),且第六加底线区为cdr3α(seq id no:38)。粗体区为接头(seq id no:94)。自氨基端开始,第一斜体区为β链恒定区(seq id no:93),且第二斜体区为α链恒定区(seq id no:91)。β链可变区(seq id no:43)包括自氨基端开始且在β链恒定区开始之前立即终止的序列。α链可变区(seq id no:42)包括在接头之后立即开始且在α链恒定区开始之前立即终止的序列。全长β链(seq id no:45)包括自氨基端开始且在接头开始之前立即终止的序列。全长α链(seq id no:44)包括在接头之后立即开始且以羧基端结束的序列。
188.包含野生型α链信号肽的4285-pbl-tcr5的变体示于seq id no:189中。变体包含如seq id no:187中所示的α链可变区(具有野生型信号肽)。变体的全长α链示于seq id no:188中。
189.4285-pbl-tcr5的另一变体包含如seq id no:211中所示的β链可变区(具有野生型信号肽)。变体的全长β链示于seq id no:212中。
190.不具有n端信号肽的预测4285-pbl-tcr5α及β链可变区成熟序列示于表7中。不具有n端信号肽的成熟序列的预测α链可变区示于seq id no:148中。不具有n端信号肽的预测全长α链(包括α链可变区及恒定区)示于seq id no:166中。不具有n端信号肽的预测β链可变区示于seq id no:149中。不具有n端信号肽的预测全长β链(包括β链可变区及恒定区)示于seq id no:167中。
191.tcr名称:4285-pbl-tcr6
192.紧接在上文阐述自患者4285分离的tcr 4285-pbl-tcr6的序列。自氨基端开始,第一加底线区为cdr1β(seq id no:50),第二加底线区为cdr2β(seq id no:51),第三加底线区为cdr3β(seq id no:52),第四加底线区为cdr1α(seq id no:47),第五加底线区为cdr2α(seq id no:48),且第六加底线区为cdr3α(seq id no:49)。粗体区为接头(seq id no:94)。自氨基端开始,第一斜体区为β链恒定区(seq id no:93),且第二斜体区为α链恒定区(seq id no:91)。β链可变区(seq id no:54)包括自氨基端开始且在β链恒定区开始之前立即终止的序列。α链可变区(seq id no:53)包括在接头之后立即开始且在α链恒定区开始之前立即终止的序列。全长β链(seq id no:56)包括自氨基端开始且在接头开始之前立即终止的序列。全长α链(seq id no:55)包括在接头之后立即开始且以羧基端结束的序列。
193.包含野生型α链信号肽的4285-pbl-tcr6的变体示于seq id no:192中。变体包含如seq id no:190中所示的α链可变区(具有野生型信号肽)。变体的全长α链示于seq id no:191中。
194.4285-pbl-tcr6的另一变体包含如seq id no:213中所示的β链可变区(具有野生型信号肽)。变体的全长β链示于seq id no:214中。
195.不具有n端信号肽的预测4285-pbl-tcr6α及β链可变区成熟序列示于表7中。不具有n端信号肽的成熟序列的预测α链可变区示于seq id no:150中。不具有n端信号肽的预测全长α链(包括α链可变区及恒定区)示于seq id no:168中。不具有n端信号肽的预测β链可变区示于seq id no:151中。不具有n端信号肽的预测全长β链(包括β链可变区及恒定区)示于seq id no:169中。
196.tcr名称:4285-pbl-tcr7
197.紧接在上文阐述自患者4285分离的tcr 4285-pbl-tcr7的序列。自氨基端开始,第一加底线区为cdr1β(seq id no:61),第二加底线区为cdr2β(seq id no:62),第三加底线区为cdr3β(seq id no:63),第四加底线区为cdr1α(seq id no:58),第五加底线区为cdr2α(seq id no:59),且第六加底线区为cdr3α(seq id no:60)。粗体区为接头(seq id no:94)。自氨基端开始,第一斜体区为β链恒定区(seq id no:93),且第二斜体区为α链恒定区(seq id no:91)。β链可变区(seq id no:65)包括自氨基端开始且在β链恒定区开始之前立即终止的序列。α链可变区(seq id no:64)包括在接头之后立即开始且在α链恒定区开始之前立即终止的序列。全长β链(seq id no:67)包括自氨基端开始且在接头开始之前立即终止的序列。全长α链(seq id no:66)包括在接头之后立即开始且以羧基端结束的序列。
198.包含野生型α链信号肽的4285-pbl-tcr7的变体示于seq id no:195中。变体包含如seq id no:193中所示的α链可变区(具有野生型信号肽)。变体的全长α链示于seq id no:194中。
199.4285-pbl-tcr7的另一变体包含如seq id no:215中所示的β链可变区(具有野生型信号肽)。变体的全长β链示于seq id no:216中。
200.不具有n端信号肽的预测4285-pbl-tcr7α及β链可变区成熟序列示于表7中。不具有n端信号肽的成熟序列的预测α链可变区示于seq id no:152中。不具有n端信号肽的预测全长α链(包括α链可变区及恒定区)示于seq id no:170中。不具有n端信号肽的预测β链可变区示于seq id no:153中。不具有n端信号肽的预测全长β链(包括β链可变区及恒定区)示于seq id no:171中。
201.tcr名称:4285-pbl-tcr9
202.紧接在上文阐述自患者4285分离的tcr 4285-pbl-tcr9的序列。自氨基端开始,第一加底线区为cdr1β(seq id no:72),第二加底线区为cdr2β(seq id no:73),第三加底线区为cdr3β(seq id no:74),第四加底线区为cdr1α(seq id no:69),第五加底线区为cdr2α(seq id no:70),且第六加底线区为cdr3α(seq id no:71)。粗体区为接头(seq id no:94)。自氨基端开始,第一斜体区为β链恒定区(seq id no:93),且第二斜体区为α链恒定区(seq id no:91)。β链可变区(seq id no:76)包括自氨基端开始且在β链恒定区开始之前立即终止的序列。α链可变区(seq id no:75)包括在接头之后立即开始且在α链恒定区开始之前立即终止的序列。全长β链(seq id no:78)包括自氨基端开始且在接头开始之前立即终止的序列。全长α链(seq id no:77)包括在接头之后立即开始且以羧基端结束的序列。
203.包含野生型α链信号肽的4285-pbl-tcr9的变体示于seq id no:198中。变体包含如seq id no:196中所示的α链可变区(具有野生型信号肽)。变体的全长α链示于seq id no:197中。
204.4285-pbl-tcr9的另一变体包含如seq id no:217中所示的β链可变区(具有野生型信号肽)。变体的全长β链示于seq id no:218中。
205.不具有n端信号肽的预测4285-pbl-tcr9α及β链可变区成熟序列示于表7中。不具有n端信号肽的成熟序列的预测α链可变区示于seq id no:154中。不具有n端信号肽的预测全长α链(包括α链可变区及恒定区)示于seq id no:172中。不具有n端信号肽的预测β链可变区示于seq id no:155中。不具有n端信号肽的预测全长β链(包括β链可变区及恒定区)示于seq id no:173中。实施例8
206.此实施例显示在将来自患者4259的肿瘤样品的t细胞与突变p53-y220c肽共培养之后检测到的cd8
+
4-1bb
+
t细胞的频率。
207.通过在自4259-f1肿瘤片段培养物分选cd8
+
t细胞之后限制稀释来制备t细胞克隆。将24种培养物与经dmso(肽载体)、wt p53-y220肽(seq id no:112)或mut p53-y220c肽(seq id no:113)脉冲的t2肿瘤细胞(hla-a*02:01)共培养。在孵育过夜之后,针对cd3、cd8及4-1bb对细胞进行染色,接着通过流式细胞术进行分析。来自培养物的cd8
+
4-1bb
+
t细胞的频率示于图5中。如图5中所展示,获得反应性t
细胞克隆。实施例9
208.此实施例显示p53-y220c新抗原反应性t细胞受体4259-f1-tcr的分离。
209.难以确定对p53-y220c及hla-a*02:01(来自实施例8的患者4259的片段培养物f1)具有特异性的tcr的序列。无法使用经典单细胞pcr技术来确定序列。单细胞pcr技术的两个限制为:(1)其仅对围绕高变cdr3区的tcr基因的较短部分进行测序,从而引导研究者使用较少的tcr多态性区(例如可变家族)来推断tcr的剩余部分;及(2)仅一个序列可通过桑格测序法显示以具有功能测序读数。通过利用限制稀释产生t细胞克隆且接着将作为表达的mrna转录物的全长tcrα及tcrβ基因通过5
′
race测序来规避这些问题。接着确定t细胞克隆型对p53-y220c及表达两个tcrα链及两个tcrβ链的hla-a*02:01具有特异性。将此与仅表达一个tcrα及一个tcrβ的大多数t细胞进行对比。tcrβ链中的仅一者起作用,这是因为另一者具有产生过早终止密码子的框移。此外,此tcrβ链属于trbv7-9*03家族而非由单细胞pcr及trbv7-9家族(低分辨率)adaptive biotechnologies tcrb调查测序报导的trbv7-9*01家族。在两个可变链之间存在非保守氨基酸取代(位置26处的n或d),从而指示选择trbv7-9*03为适用的(参见图9)。存在两个鉴别的功能tcrα链,且其中的仅一者与功能tcrβ正确配对以赋予对p53-y220c及hla-a*02:01的特异性。
210.将tcr对重构建且克隆至逆转录病毒载体中。将第二氨基酸残基变为丙氨酸(a)以具有用于高效翻译的较强kozak序列。用经半胱氨酸取代的经lvl修饰的鼠类α链恒定区置换tcrα链恒定区。用经半胱氨酸取代的鼠类β链恒定区置换tcrβ链恒定区。
211.tcr名称:4259-f1-tcr
212.紧接在上文阐述自患者4259分离的p53-y220c新抗原反应性tcr 4259-f1-tcr的序列。自氨基端开始,第一加底线区为cdr1β(seq id no:83),第二加底线区为cdr2β(seq id no:84),第三加底线区为cdr3β(seq id no:85),第四加底线区为cdr1α(seq id no:80),第五加底线区为cdr2α(seq id no:81),且第六加底线区为cdr3α(seq id no:82)。粗体区为接头(seq id no:94)。自氨基端开始,第一斜体区为β链恒定区(seq id no:93),且第二斜体区为α链恒定区(seq id no:91)。β链可变区(seq id no:87)包括自氨基端开始且在β链恒定区开始之前立即终止的序列。α链可变区(seq id no:86)包括在接头之后立即开
始且在α链恒定区开始之前立即终止的序列。全长β链(seq id no:89)包括自氨基端开始且在接头开始之前立即终止的序列。全长α链(seq id no:88)包括在接头之后立即开始且以羧基端结束的序列。
213.包含具有野生型信号肽的α链的4259-f1-tcr的变体示于seq id no:201中。变体包含如seq id no:199中所示的α链可变区(具有野生型信号肽)。变体的全长α链示于seq id no:200中。
214.4259-f1-tcr的另一变体包含如seq id no:219中所示的β链可变区(具有野生型信号肽)。变体的全长β链示于seq id no:220中。
215.4259-f1-tcrα及β链可变区的氨基酸序列示于表8中。cdr加底线。不具有n端信号肽的预测全长α链(包括α链可变区及恒定区)示于seq id no:174中。不具有n端信号肽的预测全长β链(包括β链可变区及恒定区)示于seq id no:175中。表8
实施例10
216.此实施例显示,实施例9的4259-f1-tcr特异性识别突变p53-y220c肽且不识别对应wt肽。
217.将实施例9的4259-f1-tcr转导至供体外周血t细胞中,接着与经减小浓度的wt p53-y220肽(seq id no:112)或mut p53-y220c肽(seq id no:113)脉冲的t2肿瘤细胞(hla-a*02:01)共培养。在孵育过夜之后,通过elisa分析共培养物上清液的干扰素γ分泌。结果示于图6中。实施例11
218.此实施例显示,4259-f1-tcr特异性识别由hla-a*02:01呈递的表达p53-y220c的肿瘤细胞。
219.将不表达实施例9的tcr(未经转导)、p53-r175h特异性tcr或4259-f1-tcr的t细胞
与表达或不表达hla-a*02:01、p53-r175h或p53-y220c的肿瘤细胞共培养。在孵育过夜之后,针对cd3、cd8及4-1bb对细胞进行染色,接着通过流式细胞术进行分析。来自培养物的cd8
+
4-1bb
+
t细胞的频率示于图7中。实施例12
220.此实施例显示来自患者4141的tcr的分离及特异反应性。
221.用p53突变反应性til治疗患者的概述提供于表9中。表9
222.用编码无关突变、wt p53序列或包括r175h的突变p53序列的tmg转染自体apc。单独培养基以及pma及离子霉素分别为阴性及阳性对照。第二天,在37℃下将来自患者4141(片段培养物12)的til与经tmg转染的apc共培养过夜。通过elispot评估ifn-γ的分泌。在门控淋巴细胞
→
活细胞(pi阴性)
→
cd3+(t细胞)
→
cd4-cd8+之后,通过流式细胞术评估4-1bb的表达。结果示于图10中。
223.将cos7细胞(2.5
×
104个/孔)接种于平底96孔盘的孔上。第二天,将细胞与来自患者4141的个别hla等位基因共转染,且无额外基因、wt tp53tmg或含有p53-r175h序列的突变tp53tmg。第二天将对来自患者4141(片段培养物12)的p53-r175h具有特异性的til与经转染cos7细胞共培养,且在37℃下将其孵育过夜。通过elispot评估ifn-γ的分泌。结果示于图11中。
224.将表达模拟物(无tcr)或4141-tcr1a2的t细胞与t2肿瘤细胞(表达hla-a*02:01)共培养。在37℃下用肽载体(dmso)或经纯化(>95%,通过hplc)肽将t2细胞脉冲2小时,该经纯化的肽由wt p53-r175肽hmtevvrrc(seq id no:95)或突变p53-r175h肽hmtevvrhc(seq id no:96)构成。单独培养基以及pma及离子霉素分别为阴性及阳性对照。在37℃下使共培养过夜。通过elisa评估ifn-γ的分泌。结果示于图12中。
225.在37℃下将表达4141-tcr1a2的t细胞与saos2细胞(p53-null及hla-a*02:01+)共培养过夜,所述saos2细胞未经操控或过表达全长p53-r175h蛋白质。将分泌抑制剂(莫能菌素及布雷菲尔德菌素a)添加至共培养物以将细胞因子截留于t细胞内。在共培养6小时之后,细胞经固定且渗透,接着针对il-2、cd107a、ifn-γ及肿瘤坏死因子-α(tnfα)进行染色。流式细胞术用于基于淋巴细胞门分析共培养物。结果示于图13中。
226.下文阐述自患者4141分离的tcr 4141-tcr1a2的序列。自氨基端开始,第一加底线区为cdr1β(seq id no:131),第二加底线区为cdr2β(seq id no:132),第三加底线区为cdr3β(seq id no:133),第四加底线区为cdr1α(seq id no:134),第五加底线区为cdr2α(seq id no:135),且第六加底线区为cdr3α(seq id no:136)。粗体区为接头(seq id no:94)。自氨基端开始,第一斜体区为α链恒定区(seq id no:91),且第二斜体区为β链恒定区(seq id no:93)。α链可变区(seq id no:137)包括自氨基端开始且在α链恒定区开始之前
立即终止的序列。β链可变区(seq id no:138)包括在接头之后立即开始且在β链恒定区开始之前立即终止的序列。全长α链(seq id no:139)包括自氨基端开始且在接头开始之前立即终止的序列。全长β链(seq id no:140)包括在接头之后立即开始且以羧基端结束的序列。
227.如下文所描述鉴别癌症反应性t细胞。如下文所描述分离tcr。tcr名称:4141-tcr1a2p53突变的识别:r175h筛选方法:p53“热点”突变通用筛选鉴别tcr的共培养:将4141输注袋til与p53muttmg及经分选cd8+41bb+t细胞共培养鉴别tcr的方法:单细胞rt-pcr,接着用于α链的ta topo克隆试剂盒(thermo fisher scientific,waltham,ma)tcr定向:α-β表达载体:sb转座子
228.包含具有野生型信号肽的β链的4141-tcr1a2的变体示于seq id no:204中。变体包含如seq id no:202中所示的β链可变区(具有野生型信号肽)。变体的全长β链示于seq id no:203中。
229.包含具有野生型信号肽的α链的4141-tcr1a2的另一变体示于seq id no:225中。变体包含如seq id no:221中所示的β链可变区。变体的全长β链示于seq id no:222中。变体包含如seq id no:223中所示的α链可变区(具有野生型信号肽)。变体的全长α链示于seq id no:224中。
230.4141-tcr1a2α及β链可变区的氨基酸序列示于表10中。cdr加底线。不具有n端信号肽的预测全长α链(包括α链可变区及恒定区)示于seq id no:176中。不具有n端信号肽的预测全长β链(包括β链可变区及恒定区)示于seq id no:177中。表10
231.来自患者4141的4141-tcr1a2的统计示于下表11中。表11参数数目频率总的孔96100%cdr3α未知(ta topo克隆)不适用cdr3β5860.4%
232.分离tcr 4141-tcr1a2,在t细胞中表达且针对相关抗原进行测试。结果的概述示于表12中。表12
233.本文中所引用的所有参考文献(包括公开案、专利申请案及专利)均在此以引用的方式并入,该引用程度如同各参考文献个别地且特定地指示以引用的方式并入且全文阐述于本文中那般。
234.除非本文中另外指示或与上下文明显矛盾,否则在描述本发明的上下文中(尤其在以下申请专利范围的上下文中)使用术语“一(a/an)”及“该”及“至少一个”以及类似参考物应解释为涵盖单数及复数两者。除非本文中另外指示或与上下文明显矛盾,否则应将后接一或多个项目的列表(例如,“a及b中的至少一者”)的术语“至少一个”的使用解释为意指选自所列项目的一个项目(a或b)或所列项目中的两者或更多者的任何组合(a及b)。除非另外指出,否则术语“包含”、“具有”、“包括”及“含有”应解释为开端式术语(即,意指“包括(但不限于)”)。除非本文中另外指示,否则本文中值范围的叙述仅意欲充当单独提及属于该范围内的各独立值的简写方法,且各独立值并入至本说明书中,如同其在本文中单独叙述那般。除非本文中另外指示或另外与上下文明显矛盾,否则本文中所描述的所有方法均可以
任何适合次序进行。除非另外主张,否则使用本文中所提供的任何及所有实例或例示性语言(例如,“诸如”)仅意欲优选地说明本发明,且不对本发明的范畴构成限制。本说明书中的语言不应解释为指示实践本发明所必需的任何未主张要素。
235.本发明的优选实施方案描述于本文中,包括本发明人已知用于实施本发明的最佳模式。在阅读前述描述之后,那些优选实施方案的变化对于本领域技术人员可变得显而易见。本发明人期望本领域技术人员适当时采用此类变化,且本发明人意欲以不同于本文中特定描述的其他方式来实践本发明。因此,当可适用法律允许时,本发明包括在随附于本文的申请专利范围中所叙述的目标物的所有修改及等效物。此外,除非本文中另外指示或另外与上下文明显矛盾,否则本发明涵盖上述要素在其所有可能变化中的任何组合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1