工程改造铰链区以驱动抗体二聚化的制作方法
1.本发明涉及生物制药领域。特别地,本发明涉及能够特异性结合至少两种靶抗原的多特异性抗原结合蛋白。所述多特异性抗原结合蛋白在铰链区包含两个不同的重链,所述两个不同的重链利用电荷对突变来促进异二聚体形成,同时抑制同二聚体形成。
背景技术:
2.抗体已经成为生物制药工业中的选择形式,因为抗体具有一些吸引那些开发治疗性分子的特性。除了能够靶向特定结构或细胞外,抗体还能使其靶标易受fc受体细胞介导的吞噬和杀伤作用的影响(raghavan和bjorkman 1996)。此外,抗体以ph依赖方式与新生儿fc受体(fcrn)相互作用的能力使其具有延长的血清半衰期(ghetie和ward 2000)。抗体的这种独特特性允许通过工程改造fc融合分子来延长血清中治疗性蛋白或肽的半衰期。
3.在某些情况下,希望产生包含抗体的fc部分但包含异二聚体的分子。fc异二聚体分子的一个重要应用是产生多特异性抗体,例如,双特异性抗体。双特异性抗体是指对至少两种不同抗原具有特异性的抗体(nolan和o'kennedy 1990;de leij,molema等人1998;carter2001)。双特异性抗体不是在两个fab中具有相同的序列,而是在两个fab中具有不同的序列,以便y型分子的每个臂都能与不同的抗原结合。fc异二聚体的另一个应用是将半衰期延长部分添加到治疗性分子中。在这种情况下,两个不同的fc部分中的一个或两个可以融合到需要延长半衰期的一个或多个治疗性分子上。
4.产生fc异二聚体的经典方法是由carter及其合作者开发的,当时他们使用“杵-臼(knobs-into-holes)”策略对重链工程改造用于异二聚化(ridgway,presta等人1996;atwell,ridgway等人1997;merchant,zhu等人1998;carter 2001)。杵-臼概念最初由crick提出,作为相邻α-螺旋间氨基酸侧链堆积的模型(crick 1952)。carter及其合作者通过用较大的氨基酸侧链替换较小的氨基酸侧链(例如,t366y),在第一链的ch3结构域界面处产生了杵;并且通过用较小的氨基酸侧链替换较大的氨基酸侧链(例如y407t),在第二链的ch3界面处的并置位置上产生了臼。在并置位置产生杵和臼的基础是杵和臼的相互作用有利于异二聚体的形成,而杵-杵和臼-臼的相互作用分别由于有利相互作用的空间冲突和缺失而阻碍同二聚体形成。杵-臼突变还与被工程改造以增强异二聚体形成的ch3结构域间二硫键相组合(sowdhamini,srinivasan等人1989;atwell,ridgway等人1997)。除了这些突变外,还改变了输入dna比率以使产量最大化(merchant,zhu等人1998)。“杵-臼”技术在美国专利号5,731,168和7,183,076中公开。
5.多特异性抗体(同时靶向多个靶标的分子,例如双特异性和三特异性抗体)以及半衰期延长的治疗性蛋白的临床潜力显示出用于靶向复杂疾病的巨大希望。然而,这些分子的产生提出了巨大的挑战,因为在许多情况下,我们希望特异性地驱动存在于溶液中的多个多肽链的配对。在这里,我们描述了用少量突变对铰链区进行工程改造,这些突变能够单独成功地驱动fc二聚化。
技术实现要素:
6.在一个方面,本发明涉及一种分离的异多聚体,所述异多聚体包含异二聚免疫球蛋白铰链结构域,所述异二聚免疫球蛋白铰链结构域包含第一免疫球蛋白铰链结构域多肽和第二免疫球蛋白铰链结构域多肽,其中:
7.(i)所述第一免疫球蛋白铰链结构域多肽包含下列氨基酸取代:p243k、a244k、p245k、n/e246k和l247k;并且
8.(ii)所述第二免疫球蛋白铰链结构域多肽包含下列氨基酸取代:p243d、a244d、p245d、n/e246d和l247d;
9.其中氨基酸残基的编号是根据kabat中列出的eu索引。
10.在另一方面,本发明涉及一种分离的异多聚体,所述异多聚体包含异二聚免疫球蛋白铰链结构域,所述异二聚免疫球蛋白铰链结构域包含第一免疫球蛋白铰链结构域多肽和第二免疫球蛋白铰链结构域多肽,其中:
11.(i)所述第一免疫球蛋白铰链结构域多肽包含下列氨基酸取代:a244h;并且
12.(ii)所述第二免疫球蛋白铰链结构域多肽包含下列氨基酸取代:n/e246d和l247d;
13.其中氨基酸残基的编号是根据kabat中列出的eu索引。
14.在另一方面,本发明涉及一种分离的异多聚体,所述异多聚体包含异二聚免疫球蛋白铰链结构域,所述异二聚免疫球蛋白铰链结构域包含第一免疫球蛋白铰链结构域多肽和第二免疫球蛋白铰链结构域多肽,其中:
15.(i)所述第一免疫球蛋白铰链结构域多肽包含下列氨基酸取代:h237k、t238k、a244k和n/e246k;并且
16.(ii)所述第二免疫球蛋白铰链结构域多肽包含下列氨基酸取代:h237d、t238d、a244d和n/e246d;
17.其中氨基酸残基的编号是根据kabat中列出的eu索引。
18.在某些实施例中,异多聚体的每个铰链结构域多肽还包含l248c取代。
19.在某些实施例中,每个免疫球蛋白铰链结构域多肽还包含ch3结构域。在一个实施例中,一个ch3结构域包含f405l、f405a、f405d、f405e、f405h、f405i、f405k、f405m、f405n、f405q、f405s、f405t、f405v、f405w、或f405y突变;并且另一个ch3结构域包含k409r突变;其中氨基酸残基的编号是根据kabat中列出的eu索引。在一个实施例中,一个ch3结构域包含t366w突变;并且另一个ch3结构域包含t366s、l368a、y407v突变;其中氨基酸残基的编号是根据kabat中列出的eu索引。在一个实施例中,一个ch3结构域包含k/r409d和k392d突变;并且另一个ch3结构域包含d399k和e356k突变;其中氨基酸残基的编号是根据kabat中列出的eu索引。在一个实施例中,一个ch3结构域包含y349c突变;并且另一个ch3结构域包含e356c或s354c突变;其中氨基酸残基的编号是根据kabat中列出的eu索引。在一实施例中,一个ch3结构域包含y349c和t366w突变;并且另一个ch3结构域包含e356c、t366s、l368a和y407v突变;其中氨基酸残基的编号是根据kabat中列出的eu索引。在一实施例中,一个ch3结构域包含y349c和t366w突变;并且另一个ch3结构域包含s354c、t366s、l368a、y407v突变;其中氨基酸残基的编号是根据kabat中列出的eu索引。
20.在某些实施例中,免疫球蛋白铰链区是igg1铰链区。
21.在某些实施例中,异多聚体是双特异性或多特异性抗体。
附图说明
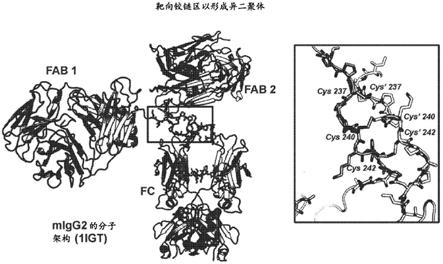
22.图1描述了靶向铰链区以形成异二聚体。
23.图2描述了人igg1晶体结构,其在cppc处没有显示第二个二硫键,尽管这可能是由x射线数据收集期间的辐射损伤引入的伪影。此外,igg1鼠晶体结构(1igy),以及“内部”质谱数据,强烈表明二硫化物c242应该是完整的。因此,利用migg1和huigg2结构作为指导可以更好地理解cppc基序下游残基的旋转异构体位置。
24.图3描述了igg1、igg2和igg4的序列比对。
25.图4描述了铰链设计和质量控制评估(msqc)的汇总表。
26.图5描述了带电拉链铰链-设计czh01。根据晶体结构,c239是在igg1铰链(saphire和wilson,science[科学],2001(抗hiv-1b12抗体)内形成二硫桥的唯一c。然而,其他数据表明,第二个cys(c242)仍然可以形成二硫键,而且p241似乎对所述相同键的发生很重要。那么合理的是在该第二个二硫键下游设计cpm串(见橙色线中的突变),然后在l248c插入新的二硫键(橙色虚线)。
[0027]
图6描述了分析型cex和质谱-czh01。
[0028]
图7描述了带电拉链铰链-设计czh09。
[0029]
图8描述了分析型cex和质谱-czh09。
[0030]
图9描述了igg2中带电拉链铰链的结构指导。
[0031]
图10描述了分析型cex和质谱-czh11。
[0032]
图11描述了靶向铰链区以形成异二聚体+ch3 cpm v11。
[0033]
图12描述了铰链设计+ch3-ch3’cpm v11的汇总表。
[0034]
图13描述了对铰链设计的热稳定性分析。铰链突变对ab的稳定性没有负面影响,并且ch3 cpm v11突变似乎降低了tm+/-2deg。
具体实施方式
[0035]
在一个方面,本发明涉及一种分离的异多聚体,所述异多聚体包含异二聚免疫球蛋白铰链结构域,所述异二聚免疫球蛋白铰链结构域包含第一免疫球蛋白铰链结构域多肽和第二免疫球蛋白铰链结构域多肽,其中:
[0036]
(i)所述第一免疫球蛋白铰链结构域多肽包含下列氨基酸取代:p243k、a244k、p245k、n/e246k和l247k;并且
[0037]
(ii)所述第二免疫球蛋白铰链结构域多肽包含下列氨基酸取代:p243d、a244d、p245d、n/e246d和l247d;
[0038]
其中氨基酸残基的编号是根据kabat中列出的eu索引。
[0039]
在另一方面,本发明涉及一种分离的异多聚体,所述异多聚体包含异二聚免疫球蛋白铰链结构域,所述异二聚免疫球蛋白铰链结构域包含第一免疫球蛋白铰链结构域多肽和第二免疫球蛋白铰链结构域多肽,其中:
[0040]
(i)所述第一免疫球蛋白铰链结构域多肽包含下列氨基酸取代:a244h;并且
[0041]
(ii)所述第二免疫球蛋白铰链结构域多肽包含下列氨基酸取代:n/e246d和
l247d;
[0042]
其中氨基酸残基的编号是根据kabat中列出的eu索引。
[0043]
在另一方面,本发明涉及一种分离的异多聚体,所述异多聚体包含异二聚免疫球蛋白铰链结构域,所述异二聚免疫球蛋白铰链结构域包含第一免疫球蛋白铰链结构域多肽和第二免疫球蛋白铰链结构域多肽,其中:
[0044]
(i)所述第一免疫球蛋白铰链结构域多肽包含下列氨基酸取代:h237k、t238k、a244k和n/e246k;并且
[0045]
(ii)所述第二免疫球蛋白铰链结构域多肽包含下列氨基酸取代:h237d、t238d、a244d和n/e246d;
[0046]
其中氨基酸残基的编号是根据kabat中列出的eu索引。
[0047]
在某些实施例中,异多聚体的每个铰链结构域多肽还包含l248c取代。
[0048]
在某些实施例中,每个免疫球蛋白铰链结构域多肽还包含ch3结构域。在一个实施例中,一个ch3结构域包含f405l、f405a、f405d、f405e、f405h、f405i、f405k、f405m、f405n、f405q、f405s、f405t、f405v、f405w、或f405y突变;并且另一个ch3结构域包含k409r突变;其中氨基酸残基的编号是根据kabat中列出的eu索引。在一个实施例中,一个ch3结构域包含t366w突变;并且另一个ch3结构域包含t366s、l368a、y407v突变;其中氨基酸残基的编号是根据kabat中列出的eu索引。在一个实施例中,一个ch3结构域包含k/r409d和k370e突变;并且另一个ch3结构域包含d399k和e357k突变;其中氨基酸残基的编号是根据kabat中列出的eu索引。
[0049]
在特定实施例中,异二聚抗体包含第一重链和第二重链,所述第一重链包含在位置392和409处的带负电的氨基酸(例如,k392d和k409d取代),所述第二重链包含在位置356和399处的带正电的氨基酸(例如,e356k和d399k取代)。在其它特定实施例中,异二聚抗体包含第一重链和第二重链,所述第一重链包含在位置392、409和370处的带负电的氨基酸(例如,k392d、k409d和k370d取代),所述第二重链包含在位置356、399和357处的带正电的氨基酸(例如,e356k、d399k和e357k取代)。在相关实施例中,第一重链来自抗cgrp受体抗体,并且第二重链来自抗pac1受体抗体。在其他相关实施例中,第一重链来自抗-pac1受体抗体,并且第二重链来自抗-cgrp受体抗体。
[0050]
在一个实施例中,一个ch3结构域包含y349c突变;并且另一个ch3结构域包含e356c或s354c突变;其中氨基酸残基的编号是根据kabat中列出的eu索引。在一实施例中,一个ch3结构域包含y349c和t366w突变;并且另一个ch3结构域包含e356c、t366s、l368a和y407v突变;其中氨基酸残基的编号是根据kabat中列出的eu索引。在一实施例中,一个ch3结构域包含y349c和t366w突变;并且另一个ch3结构域包含s354c、t366s、l368a、y407v突变;其中氨基酸残基的编号是根据kabat中列出的eu索引。
[0051]
在某些实施例中,免疫球蛋白铰链区是igg1铰链区。
[0052]
在某些实施例中,异多聚体是双特异性或多特异性抗体。
[0053]
如本文所使用,术语“抗原结合蛋白”是指特异性结合至一个或多个靶抗原的蛋白质。抗原结合蛋白可包括抗体及其功能片段。“功能性抗体片段”是抗体中不含全长重链和/或轻链中存在的氨基酸的至少一部分,但仍能够特异性结合至抗原的部分。功能性抗体片段包括但不限于fab片段、fab'片段、f(ab')2片段、fv片段、fd片段和互补决定区(cdr)片
段,且可以衍生自任何哺乳动物来源,例如人类、小鼠、大鼠、兔或骆驼。功能性抗体片段可以与完整抗体竞争结合靶抗原且这些片段可以通过修饰完整抗体(例如酶或化学裂解)或使用重组dna技术或肽合成从头合成获得。
[0054]
抗原结合蛋白还可包括包含并入单一多肽链中或并入多个多肽链中的一个或多个功能性抗体片段的蛋白质。例如,抗原结合蛋白可以包括但不限于单链fv(scfv)、双抗体(diabody)(参见,例如,ep 404,097;wo 93/11161;和hollinger等人,proc.natl.acad.sci.usa[美国科学院院报],第90卷:6444-6448,1993);内抗体;结构域抗体(单vl或vh结构域或者通过肽接头接合的两个或多个vh结构域;参见ward等人,nature[自然],第341卷:544-546,1989);大分子抗体(2个scfv与fc区的融合物,参见fredericks等人,protein engineering[蛋白质工程改造],design&selection[设计和选择],第17卷:95-106,2004;和powers等人,journal of immunological methods[免疫法杂志],第251卷:123-135,2001);三抗体(triabody);四抗体(tetrabody);微抗体(minibody)(scfv与ch3结构域的融合物;参见olafsen等人,protein eng des sel[蛋白质工程设计与选择].,第17卷:315-23,2004);肽抗体(一个或多个肽附接至fc区,参见wo00/24782);线性抗体(一对串联的fd区段(vh-ch1-vh-ch1),其与互补轻链多肽一起形成一对抗原结合区,参见zapata等人,protein eng.[蛋白质工程化],第8卷:1057-1062,1995);小模块免疫药物(small modular immunopharmaceutical)(参见美国专利公开号20030133939);免疫球蛋白融合蛋白(例如igg-scfv、igg-fab、2scfv-igg、4scfv-igg、vh-igg、igg-vh和fab-scfv-fc)。
[0055]“多特异性”是指抗原结合蛋白能够特异性结合两种或更多种不同的抗原。“双特异性”是指抗原结合蛋白能够特异性结合两种不同的抗原。如本文所用,当抗原结合蛋白在类似结合测定条件下对靶抗原的结合亲和力明显高于其对其他不相关蛋白质的亲和力且因此能够相区分时,所述抗原结合蛋白“特异性结合至”所述抗原。特异性结合抗原的抗原结合蛋白的平衡解离常数(kd)≤1x10-6
m。当kd≤1x10-8
m时,抗原结合蛋白以“高亲和力”特异性结合抗原。
[0056]
使用多种技术,例如亲和elisa测定确定亲和力。在各种实施例中,通过表面等离子共振测定(例如,基于的测定)确定亲和力。使用此技术,可以测量缔合速率常数(以m-1
s-1
表示的ka)和解离速率常数(以s-1
表示的kd)。平衡解离常数(以m表示的kd)则可以由动力学速率常数的比率(kd/ka)计算。在一些实施例中,通过动力学方法,例如rathanaswami等人,analytical biochemistry[分析生物化学],第373卷:52-60,2008中所描述的动力学排除测定(kinexa)确定亲和力。使用kinexa测定,可以测量平衡解离常数(以m表示的kd)和缔合速率常数(以m-1
s-1
表示的ka)。解离速率常数(以s-1
表示的kd)可以由这些值计算(k
d x ka)。在其他实施例中,通过平衡/溶液方法确定亲和力。在某些实施例中,通过facs结合测定确定亲和力。
[0057]
在一些实施例中,本文所述的双特异性抗原结合蛋白表现出期望的特性,例如通过kd(解离速率常数)测量的约10-2
、10-3
、10-4
、10-5
、10-6
、10-7
、10-8
、10-9
、10-10
s-1
或更低的结合亲合力(更低的值表示更高的结合亲合力)、和/或通过kd(平衡解离常数)测量的约10-9
、10-10
、10-11
、10-12
、10-13
、10-14
、10-15
、10-16
m的结合亲和力(更低的值表示更高的结合亲和力)。
[0058]
如本文所用,术语“抗原结合结构域”可与“结合结构域”互换使用,是指抗原结合蛋白的区域,所述区域含有与抗原相互作用并赋予抗原结合蛋白对抗原的特异性和亲和力的氨基酸残基。
[0059]
如本文所用,术语“cdr”是指抗体可变序列内的互补决定区(也称为“最小识别单元”或“高变区”)。有三个重链可变区cdr(cdrh1、cdrh2和cdrh3)和三个轻链可变区cdr(cdrl1、cdrl2和cdrl3)。本文中使用的术语“cdr区”是指出现在单个可变区中的三个cdr的组(即三个轻链cdr或三个重链cdr)。两个链的每个中的cdr典型地通过框架区对齐以形成与靶蛋白上的特定表位或结构域特异性结合的结构。自n末端至c末端,天然存在的轻链和重链可变区典型地遵循这些组件的以下次序:fr1、cdr1、fr2、cdr2、fr3、cdr3及fr4。编号系统是将编号指派给在这些结构域的每一个中占据位置的氨基酸来获得。该编号系统定义于kabat sequences of proteins of immunological interest[具有免疫学意义的蛋白质的kabat序列](1987和1991,nih,贝塞斯达(bethesda),马里兰州)或chothia&lesk,1987,j.mol.biol.[分子生物学杂志]196:901-917;chothia等人,1989,nature[自然]342:878-883。给定抗体的互补决定区(cdr)和框架区(fr)可以使用此系统标识。
[0060]
在本发明的双特异性抗原结合蛋白的一些实施例中,结合结构域包括fab、fab'、f(ab')2、fv、单链可变片段(scfv)或纳米抗体。在一个实施例中,两个结合结构域都是fab片段。在另一个实施例中,一个结合结构域是fab片段,另一个结合结构域是scfv。
[0061]
木瓜蛋白酶消化抗体产生两个相同的抗原结合片段,称为“fab”片段,每个片段有单抗原结合位点和含有免疫球蛋白恒定区的残余“fc”片段。fab片段包含所有可变结构域,以及轻链的恒定结构域和重链的第一恒定结构域(ch1)。因此,“fab片段”由一个免疫球蛋白轻链(轻链可变区(vl)和恒定区(cl))以及一个免疫球蛋白重链的ch1区和可变区(vh)构成。fab分子的重链不能与另一重链分子形成二硫键。fc片段展示碳水化合物,并负责许多抗体效应子功能(如结合补体和细胞受体),所述抗体效应子功能区分一类抗体和另一类抗体。“fd片段”包含来自免疫球蛋白重链的vh和ch1结构域。fd片段代表fab片段的重链组分。
[0062]“fab'片段”是在ch1结构域的c末端具有一个或多个来自抗体铰链区的半胱氨酸残基的fab片段。
[0063]“f(ab')2片段”是包含两个fab'片段的二价片段,所述两个fab'片段通过在铰链区的重链之间的二硫桥连接。
[0064]“fv”片段是包含来自抗体的完整抗原识别和结合位点的最小片段。该片段由一个免疫球蛋白重链可变区(vh)和一个免疫球蛋白轻链可变区(vl)紧密非共价结合的二聚体组成。正是在这种构型中,每个可变区的三个cdr相互作用,以在vh-vl二聚体表面定义抗原结合位点。单个轻链或重链可变区(或仅包含三个对抗原特异的cdr的fv片段的一半)具有识别和结合抗原的能力,尽管其亲和力低于包含vh和vl的整个结合位点。
[0065]“单链可变抗体片段”或“scfv片段”包含抗体的vh和vl区,其中这些区存在于单个多肽链中,并且任选包含vh和vl区域之间的肽接头,所述肽接头使fv能够形成用于抗原结合的所需结构(参见例如,bird等人,science[科学],第242:423-426,1988;和huston等人,proc.natl.acad.sci.usa[美国科学院院报],第85卷:5879-5883,1988)。
[0066]“纳米抗体”是重链抗体的重链可变区。这类可变结构域是这类重链抗体中最小的全功能抗原结合片段,分子量仅为15kda。参见cortez-retamozo等人,cancer research[癌
症研究]64:2853-57,2004。不含轻链的功能性重链抗体天然存在于某些动物物种中,例如护士鲨、沃比贡鲨和骆驼科,例如骆驼、单峰骆驼、羊驼和美洲驼。在这些动物中,抗原结合位点被减少为单一结构域,即vhh结构域。这些抗体仅使用重链可变区形成抗原结合区,即,这些功能性抗体是仅具有结构h2l2的重链同二聚体(称为“重链抗体”或“hcab”)。据报道,骆驼化的vhh与igg2和igg3恒定区重组,这些恒定区含有铰链、ch2和ch3结构域并且缺少ch1结构域。已发现骆驼化vhh结构域以高亲和力与抗原结合(desmyter等人,j.biol.chem.[生物化学杂志],卷276:26285-90,2001)并在溶液中具有高稳定性(ewert等人,biochemistry[生物化学],第41卷:3628-36,2002)。用于产生具有骆驼化重链的抗体的方法在例如美国专利公开号2005/0136049和2005/0037421中描述。可替代的支架可以由更接近于鲨鱼v-nar支架的人可变样结构域制成,并且可能提供用于长穿透环结构的框架。
[0067]
特别是本发明的双特异性抗原结合蛋白的实施例,结合结构域包含特异性结合所需抗原的抗体或抗体片段的免疫球蛋白重链可变区(vh)和免疫球蛋白轻链可变区(vl)。
[0068]
本文中可与“可变结构域”互换使用的“可变区”(轻链(vl)的可变区,重链(vh)的可变区)是指轻和重免疫球蛋白链中的每一个中直接参与抗体与抗原结合的区。如上所述,可变轻链和可变重链的区具有相同的一般结构,并且每个区包含四个框架(fr)区,所述框架区的序列是广泛保守的,由三个cdr连接。框架区呈β-折叠构形且cdr可以形成连接该β-折叠结构的环。各链中的cdr通过框架区保持其三维结构,且与来自另一链的cdr一起形成抗原结合位点。
[0069]
与靶抗原特异性结合的结合结构域可以衍生自a)这些抗原的已知抗体,或者b)通过使用抗原蛋白或其片段的从头免疫方法,通过噬菌体展示或其它常规方法获得的新抗体或抗体片段。衍生出双特异性抗原结合蛋白的结合结构域的抗体可以是单克隆抗体、多克隆抗体、重组抗体、人抗体或人源化抗体。在某些实施例中,衍生结合结构域的抗体是单克隆抗体。在这些和其他实施例中,抗体是人抗体或人源化抗体,并且可以是igg1-、igg2-、igg3-或igg4-型。
[0070]
如本文所使用,术语“单克隆抗体”(或“mab”)是指自基本上同源的抗体群获得的一种抗体,即,构成该群体的个别抗体除以微量存在的可能天然存在的突变外为一致的。相对于典型地包括针对不同表位的不同抗体的多克隆抗体制剂,单克隆抗体针对个别抗原位点或表位具有高度特异性。可使用本领域中已知的任何技术,例如通过在完成免疫程序之后使自转基因动物收集的脾脏细胞永生化来产生单克隆抗体。可以使用本领域中已知的任何技术,例如通过使脾细胞与骨髓瘤细胞融合以产生杂交瘤来使脾细胞永生化。用于产生杂交瘤的融合程序的骨髓瘤细胞优选地是非抗体产生的,具有高融合效率和酶缺陷,并且使得它们不能在某些选择性培养基中生长,所述培养基仅支持所希望的融合细胞(杂交瘤)的生长。适用于小鼠融合的细胞系的实例包括sp-20、p3-x63/ag8、p3-x63-ag8.653、ns1/1.ag 4 1、sp210-ag14、fo、nso/u、mpc-11、mpc11-x45-gtg 1.7及s194/5xxo bul;用于大鼠融合的细胞系的实例包括r210.rcy3、y3-ag 1.2.3、ir983f及4b210。可用于细胞融合的其他细胞系是u-266、gm1500-grg2、licr-lon-hmy2和uc729-6。
[0071]
在一些情况下,通过以下来来产生杂交瘤细胞系:用靶抗原免疫动物(例如,具有人免疫球蛋白序列的转基因动物);自经免疫动物收集脾细胞;使收集的脾细胞与骨髓瘤细胞系融合,由此产生杂交瘤细胞;从所述杂交瘤细胞建立杂交瘤细胞系,并鉴定产生结合靶
抗原的抗体的杂交瘤细胞系。
[0072]
由杂交瘤细胞系分泌的单克隆抗体可以使用本领域中已知的任何技术,例如蛋白质a-琼脂糖凝胶、羟磷灰石层析法、凝胶电泳、透析或亲和层析法纯化。可以进一步筛选杂交瘤或mab以鉴定具有特定性质的mab,所述特定性质是例如结合表达靶抗原的细胞的能力、阻断或干扰靶抗原配体与其各自受体结合的能力、或功能性地阻断任一受体的能力,例如camp测定。
[0073]
在一些实施例中,本发明的双特异性抗原结合蛋白的结合结构域可衍生自人源化抗体。“人源化抗体”是指其中区(例如框架区)已被修饰以包含来自人免疫球蛋白的对应区的抗体。通常,人源化抗体可以从最初在非人动物中产生的单克隆抗体产生。该单克隆抗体中的某些氨基酸残基,典型地来自抗体的非抗原识别部分的氨基酸残基经修饰成与相应同种型的人类抗体中的相应残基同源。人源化可以例如使用各种方法,通过将啮齿动物可变区的至少一部分替换人抗体的相应区来进行(参见例如美国专利号5,585,089和5,693,762;jones等人,nature[自然],第321卷:522-525,1986;riechmann等人,nature[自然],第332卷:323-27,1988;verhoeyen等人,science[科学],第239卷:1534-1536,1988)。在另一物种中产生的抗体的轻链可变区和重链可变区的cdr可以嫁接到共有人类fr上。为了确定共有人类fr,可以比对来自若干人类重链或轻链氨基酸序列的fr以鉴别共有氨基酸序列。
[0074]
针对靶抗原产生的新抗体(从其衍生本发明的双特异性抗原结合蛋白的结合结构域)可以是完全人类抗体。“完全人类抗体”是包含来源于或指示人类生殖系免疫球蛋白序列的可变区和恒定区的抗体。提供的用于产生完全人类抗体的一种特定方式是小鼠体液免疫系统的“人源化”。将人类免疫球蛋白(ig)基因座引入内源性ig基因失活的小鼠中是在小鼠中产生完全人类单克隆抗体(mab)的一种方式,小鼠是可以免疫接种任何所需抗原的动物。使用完全人类抗体可以使免疫原性和过敏性应答减到最少,这些应答有时是由向人类施用小鼠或小鼠源性mab作为治疗剂而引起。
[0075]
可以通过对在不产生内源性免疫球蛋白情况下,能够产生人类抗体谱系的转基因动物(通常为小鼠)免疫接种来产生完全人类抗体。用于此目的的抗原典型地具有六个或更多个连续氨基酸,且任选地与运载体,例如半抗原结合。参见例如,jakobovits等人,1993,proc.natl.acad.sci.usa[美国科学院院报]90:2551-2555;jakobovits等人,1993,nature[自然]362:255-258;和bruggermann等人,1993,year in immunol.[免疫学年评]7:33。在此类方法的一个实例中,通过使编码小鼠重链和轻链免疫球蛋白链的内源小鼠免疫球蛋白基因座失去能力,并将含有编码人类重链和轻链蛋白质的含人类基因组dna的基因座的较大片段插入小鼠基因组中来产生转基因动物。接着对具有少于人类免疫球蛋白基因座完全补体的部分修饰的动物进行杂交繁育,以获得具有全部所需免疫系统修饰的动物。当施用免疫原时,这些转基因动物产生对该免疫原具有免疫特异性,同时具有人类而非鼠类氨基酸序列,包括可变区的抗体。有关此类方法的进一步细节,参见例如wo 96/33735和wo 94/02602。有关用于制备人类抗体的转基因小鼠的其他方法描述于美国专利号5,545,807、6,713,610;6,673,986;6,162,963;5,939,598;5,545,807;6,300,129;6,255,458;5,877,397;5,874,299和5,545,806;以及pct公开wo 91/10741、wo 90/04036、wo 94/02602、wo 96/30498、wo 98/24893;以及ep 546073b1和ep 546073a1中。
[0076]
上述转基因小鼠在本文中称为“humab”小鼠,含有编码未重排人类重链(μ和γ)和
κ轻链免疫球蛋白序列以及使内源μ和κ链基因座失活的靶突变的人类免疫球蛋白基因微型基因座(lonberg等人,1994,nature[自然]368:856-859)。因此,所述小鼠展现了小鼠igm或κ表达以及对免疫的应答降低,且使引入的人类重链和轻链转基因经历类别转换和体细胞突变以产生高亲和力人类iggκ单克隆抗体(lonberg等人,同上;lonberg和huszar,1995,intern.rev.immunol.[国际免疫学综述]13:65-93;harding和lonberg,1995,ann.n.y acad.sci.[纽约科学院年鉴]764:536-546)。humab小鼠的制备详细描述于以下中:taylor等人,1992,nucleic acids research[核酸研究]20:6287-6295;chen等人,1993,international immunology[国际免疫学]5:647-656;tuaillon等人,1994,j.immunol.[免疫学杂志]152:2912-2920;lonberg等人,1994,nature[自然]368:856-859;lonberg,1994,handbook of exp.pharmacology[实验药理学手册]113:49-101;taylor等人,1994,international immunology[国际免疫学]6:579-591;lonberg和huszar,1995,intern.rev.immunol.[国际免疫学综述]13:65-93;harding和lonberg,1995,ann.n.y acad.sci.[纽约科学院年鉴]764:536-546;fishwild等人,1996,nature biotechnology[自然生物技术]14:845-851;上述参考文献出于所有目的而通过全文引用并入在此。另参见美国专利号5,545,806、5,569,825;5,625,126;5,633,425;5,789,650;5,877,397;5,661,016;5,814,318;5,874,299和5,770,429;以及美国专利号5,545,807;国际公开号wo 93/1227、wo 92/22646;及wo 92/03918,所有参考文献的披露内容均出于所有目的而通过全文引用并入在此。用于在这些转基因小鼠中产生人类抗体的技术还披露于wo 98/24893和mendez等人,1997,nature genetics[自然遗传学]15:146-156中,其通过引用并入本文中。
[0077]
人类来源的抗体还可使用噬菌体展示技术产生。噬菌体展示描述于例如dower等人,wo 91/17271;mccafferty等人,wo 92/01047;以及caton和koprowski,proc.natl.acad.sci.usa[美国科学院院报],87:6450-6454(1990)中,其各自通过引用以其全文并入本文中。由噬菌体技术产生的抗体通常在细菌中是以抗原结合片段,例如fv或fab片段形式产生,且因此缺乏效应子功能。效应子功能可以通过以下两种策略之一引入:必要时,可以将这些片段工程改造成完整抗体以在哺乳动物细胞中表达,或工程改造成具有能够触发效应子功能的第二结合位点的双特异性抗体片段。典型地,利用pcr分开克隆抗体的fd片段(vh-ch1)和轻链(vl-cl)并在组合噬菌体展示文库中随机重组,接着可以针对与特定抗原的结合进行选择。在噬菌体表面上表达这些抗体片段,并利用抗原结合,经数轮抗原结合和再扩增来选择fv或fab(且因此选择含有编码该抗体片段的dna的噬菌体),此程序称为淘选(panning)。对于抗原具有特异性的抗体片段富集且最终分离。噬菌体展示技术还可用于使啮齿动物单克隆抗体人源化的方法中,称为“导向选择”(参见jespers,l.s.,等人,bio/technology[生物/技术]12、899-903(1994))。为此,可以将小鼠单克隆抗体的fd片段与人类轻链文库组合展示,且接着可以用抗原选出由此获得的杂交fab文库。小鼠fd片段由此提供导向选择的模板。随后,将所选人类轻链与人类fd片段文库组合。所得文库的选择获得完全人类fab。
[0078]
在某些实施例中,本发明的双特异性抗原结合蛋白是抗体。如本文所使用,术语“抗体”是指包含两个轻链多肽(各自约25kda)和两个重链多肽(各自约50-70kda)的四聚免疫球蛋白。术语“轻链”或“免疫球蛋白轻链”是指自氨基末端至羧基末端包含单一免疫球蛋
白轻链可变区(vl)和单一免疫球蛋白轻链恒定结构域(cl)的多肽。免疫球蛋白轻链恒定结构域(cl)可以是kappa(κ)或lambda(λ)。术语“重链”或“免疫球蛋白重链”是指自氨基末端至羧基末端包含单一免疫球蛋白重链可变区(vh)、免疫球蛋白重链恒定结构域1(ch1)、免疫球蛋白铰链区、免疫球蛋白重链恒定结构域2(ch2)、免疫球蛋白重链恒定结构域3(ch3)和任选地免疫球蛋白重链恒定结构域4(ch4)的多肽。重链分类为mu(μ)、delta(δ)、gamma(γ)、alpha(α)、和epsilon(ε)链,且其分别将抗体同种型定义为igm、igd、igg、iga和ige。igg类别和iga类别的抗体进一步细分为数个亚类,即分别为igg1、igg2、igg3和igg4,以及iga1和iga2。igg、iga和igd抗体中的重链具有三个结构域(ch1、ch2和ch3),而igm和ige抗体中的重链具有四个结构域(ch1、ch2、ch3和ch4)。免疫球蛋白重链恒定结构域可以来自任何免疫球蛋白同种型,包括亚型。抗体链是经由在cl结构域与ch1结构域之间(即,在轻链与重链之间)和在抗体重链的铰链区之间的多肽间二硫键连接在一起。
[0079]
在特定的实施例中,本发明的双特异性抗原结合蛋白是异二聚抗体(在此可与“异免疫球蛋白”或“异ig”互换使用),其指的是包含两个不同轻链和两个不同重链的抗体。
[0080]
异二聚抗体可包含任何免疫球蛋白恒定区。如本文所使用,术语“恒定区”是指抗体中除可变区外的所有结构域。恒定区不直接参与抗原的结合,但展现各种效应子功能。如以上所描述,抗体取决于其重链恒定区的氨基酸序列而分为特定同种型(iga、igd、ige、igg和igm)和亚型(igg1、igg2、igg3、igg4、iga1、iga2)。轻链恒定区可以为例如见于全部五个抗体同种型中的κ型或λ型轻链恒定区,例如人类κ型或λ型轻链恒定区。
[0081]
异二聚抗体的重链恒定区可以为例如α、δ、ε、γ或μ型重链恒定区,例如人类α、δ、ε、γ或μ型重链恒定区。在一些实施例中,异二聚抗体包含来自igg1、igg2、igg3或igg4免疫球蛋白的重链恒定区。在一个实施例中,异二聚抗体包含来自人类igg1免疫球蛋白的重链恒定区。在另一实施例中,异二聚抗体包含来自人类igg2免疫球蛋白的重链恒定区。
[0082]
在一个实施例中,本公开的双特异性抗体是duobody
tm
,其可由如以下中所描述的duobody
tm
技术平台(genmab a/s)制备:例如国际公开号wo 2008/119353、wo 2011/131746、wo 2011/147986、和wo 2013/060867,labrijn a f等人,pnas[美国科学院院报],110(13):5145-5150(2013),gramer等人,mabs[单克隆抗体],5(6):962-973(2013)和labrijn等人,nature protocols[自然实验方案],9(10):2450-2463(2014)。该技术可用于将含有两个重链和两个轻链的第一单特异性抗体的一半与含有两个重链和两个轻链的第二单特异性抗体的一半组合。所得的异二聚体包含来自第一抗体的一个重链和一个轻链与来自第二抗体的一个重链和一个轻链配对。当两个单特异性抗体识别不同抗原上的不同表位时,所生成的异二聚体即为双特异性抗体。
[0083]
对于duobody
tm
平台,单特异性抗体中的每个都包括在ch3结构域中具有单点突变的重链恒定区。这些点突变允许产生的双特异性抗体中的ch3结构域之间的相互作用比没有突变的任一单特异性抗体中的ch3结构域之间的相互作用更强。每个单特异性抗体中的单点突变可以在重链恒定区ch3结构域的残基366、368、370、399、405、407或409(eu编号)处(参见wo 2011/131746)。此外,单点突变位于一个单特异性抗体中相对于另一个单特异性抗体的不同残基处。例如,一个单特异性抗体可包含突变f405l(eu编号;残基405处的苯丙氨酸到亮氨酸突变),或f405a、f405d、f405e、f405h、f405i、f405k、f405m、f405n、f405q、f405s、f405t、f405v、f405w和f405y突变之一,而另一个单特异性抗体可包含突变k409r(eu
编号;残基409处的赖氨酸到精氨酸突变)。单特异性抗体的重链恒定区可以是igg1、igg2、igg3或igg4同种型(例如,人igg1同种型),并且通过duobody
tm
技术产生的双特异性抗体可以被修饰以改变(例如,减少)fc介导的效应子功能和/或改善半衰期。制作duobody
tm
的一种方法包括以下内容:(i)分开地表达在ch3结构域中含有单个匹配点突变(即k409r和f405l(或f405a、f405d、f405e、f405h、f405i、f405k、f405m、f405n、f405q、f405s、f405t、f405v、f405w和f405y突变之一)(eu编号))的两个亲本igg1;(ii)在体外允许的氧化还原条件下混合亲本igg1以使半分子能够重组;(iii)除去还原剂以允许链间二硫键的再氧化;以及(iv)使用基于色谱或基于质谱(ms)的方法分析交换效率和最终产物(参见labrijn等人,nature protocols[自然实验方案],9(10):2450-2463(2014))。
[0084]
另一种制备双特异性抗体的示例性方法是通过杵-臼技术(ridgway等人,protein eng.[蛋白质工程],9:617-621(1996);wo 2006/028936)。在该技术中,通过对形成igg中ch3结构域界面的选定氨基酸进行突变,减少了ig重链错配问题,所述问题是制备双特异性抗体的主要缺陷。在ch3结构域内两个重链直接相互作用的位置,一个重链的序列中引入具有小侧链的氨基酸(杵臼),另一个重链上的对应相互作用残基位置引入具有大侧链的氨基酸(杵)。在一些情况下,本公开的抗体具有免疫球蛋白链,其中ch3结构域已经通过对在两个多肽之间的界面处相互作用的选定氨基酸进行突变而被修饰,以便优先形成双特异性抗体。双特异性抗体可以由同一亚类或不同亚类的免疫球蛋白链构成。在一个实例中,结合gp120和cd3的双特异性抗体包含“杵链”中的t366w(eu编号)突变和“臼链”中的t366s、l368a、y407v 9eu编号)突变。在某些实施例中,通过例如将y349c突变引入“杵链”并且将e356c突变或s354c突变引入“臼链”,在ch3结构域之间引入另外的链间二硫桥。在某些实施例中,在“杵链”中引入r409d、k370e突变,并且在“臼链”中引入d399k、e357k突变。在其他实施例中,在链之一中引入y349c、t366w突变,并且在对应链中引入e356c、t366s、l368a、y407v突变。在一些实施例中。在一个链中引入y349c、t366w突变,并且在对应链中引入s354c、t366s、l368a、y407v突变。在其他实施例中,在一个链中引入y349c、t366w突变,并且在对应链中引入s354c、t366s、l368a、y407v突变。在又其他实施例中,在一个链中引入y349c、t366w突变,并且在对应链中引入s354c、t366s、l368a、y407v突变(都按照eu编号)。
[0085]
制备双特异性抗体的另一种方法是crossmab技术。crossmab是由两个全长抗体的一半构成的嵌合抗体。为了实现正确的链配对,它组合了两种技术:(i)有利于两个重链之间正确配对的杵-臼;和(ii)两个fab之一的重链和轻链之间的交换,以引入避免轻链错配的不对称性。参见,ridgway等人,protein eng.[蛋白质工程],9:617-621(1996);schaefer等人,pnas[美国科学院院报],108:11187-11192(2011)。crossmab可以组合两个或更多个抗原结合域,用于靶向两个或更多个靶标,或用于向一个靶标引入二价性,例如2:1形式。
[0086]
为了促进特定重链与其同源轻链的缔合,重链和轻链都可以包含互补性氨基酸取代。如本文所用,“互补性氨基酸取代”是指一个链中带正电的氨基酸的取代与另一个链中带负电的氨基酸的取代配对。例如,在一些实施例中,重链包含至少一个氨基酸取代以引入带电氨基酸,并且相应的轻链包含至少一个氨基酸取代以引入带电氨基酸,其中引入重链中的带电氨基酸与引入轻链中的氨基酸具有相反的电荷。在某些实施例中,一个或多个带正电的残基(例如赖氨酸、组氨酸或精氨酸)可被引入第一轻链(lc1)中,并且一个或多个带负电的残基(例如天冬氨酸或谷氨酸)可被引入lc1/hc1结合界面处的相伴重链(hc1)中,而
一个或多个带负电的残基(例如,天冬氨酸或谷氨酸)可被引入第二轻链(lc2)中,并且一个或多个带正电的残基(例如,赖氨酸、组氨酸或精氨酸)可被引入lc2/hc2结合界面处的相伴重链(hc2)中。当界面处相反的带电残基(极性)吸引时,静电相互作用将引导lc1与hc1成对,lc2与hc2成对。在界面处具有相同带电残基(极性)的重/轻链对(例如lc1/hc2和lc2/hc1)将排斥,导致抑制不需要的hc/lc配对。
[0087]
在这些和其他实施例中,重链的ch1结构域或轻链的cl结构域包含与野生型igg氨基酸序列不同的氨基酸序列,使得野生型igg氨基酸序列中的一个或多个带正电的氨基酸被一个或多个带负电的氨基酸替换。可替代地,重链的ch1结构域或轻链的cl结构域包含与野生型igg氨基酸序列不同的氨基酸序列,使得野生型igg氨基酸序列中的一个或多个带负电的氨基酸被一个或多个带正电的氨基酸替换。在一些实施例中,异二聚抗体中的第一和/或第二重链的ch1结构域中在选自f126、p127、l128、a141、l145、k147、d148、h168、f170、p171、v173、q175、s176、s183、v185和k213的eu位置处的一个或多个氨基酸被带电氨基酸替换。在某些实施例中,用带负电或正电的氨基酸取代的优选残基是s183(eu编号系统)。在一些实施例中,s183被带正电的氨基酸取代。在可替代的实施例中,s183被带负电的氨基酸取代。例如,在一个实施例中,s183在第一重链中被带负电的氨基酸(例如s183e)取代,并且s183在第二重链中被带正电的氨基酸(例如s183k)取代。
[0088]
在轻链为κ轻链的实施例中,异二聚抗体中的第一和/或第二轻链的cl结构域中在选自f116、f118、s121、d122、e123、q124、s131、v133、l135、n137、n138、q160、s162、t164、s174和s176的位置(在κ轻链中以eu和kabat编号)处的一个或多个氨基酸被带电氨基酸替换。在轻链为λ轻链的实施例中,异二聚抗体中的第一和/或第二轻链的cl结构域中在选自t116、f118、s121、e123、e124、k129、t131、v133、l135、s137、e160、t162、s165、q167、a174、s176和y178的位置(在λ链中以kabat编号)处的一个或多个氨基酸被带电氨基酸替换。在一些实施例中,用带负电或正电的氨基酸取代的优选残基是κ或λ轻链的cl结构域的s176(eu和kabat编号系统)。在某些实施例中,cl结构域的s176被带正电的氨基酸替换。在可替代的实施例中,cl结构域的s176被带负电的氨基酸替换。在一个实施例中,s176在第一轻链中被带正电的氨基酸(例如s176k)取代,并且s176在第二轻链中被带负电的氨基酸(例如s176e)取代。
[0089]
除了ch1和cl结构域中的互补性氨基酸取代或作为替代,异二聚抗体中轻链和重链的可变区可包含一个或多个互补性氨基酸取代以引入带电氨基酸。例如,在一些实施例中,异二聚抗体的重链的vh区或轻链的vl区包含与野生型igg氨基酸序列不同的氨基酸序列,使得野生型igg氨基酸序列中的一个或多个带正电的氨基酸被一个或多个带负电的氨基酸替换。可替代地,重链的vh区或轻链的vl区包含与野生型igg氨基酸序列不同的氨基酸序列,使得野生型igg氨基酸序列中的一个或多个带负电的氨基酸被一个或多个带正电的氨基酸替换。
[0090]
vh区内的v区界面残基(即,介导vh和vl区组装的氨基酸残基)包括kabat位置1、3、35、37、39、43、44、45、46、47、50、59、89、91和93。vh区中的这些界面残基中的一个或多个可以被带电(带正电或负电)氨基酸取代。在某些实施例中,第一和/或第二重链的vh区中kabat位置39处的氨基酸被带正电的氨基酸(例如赖氨酸)取代。在可替代的实施例中,第一和/或第二重链的vh区中kabat位置39处的氨基酸被带负电的氨基酸(例如谷氨酸)取代。在
一些实施例中,第一重链的vh区中的kabat位置39处的氨基酸被带负电的氨基酸(例如g39e)取代,并且第二重链的vh区中的kabat位置39处的氨基酸被带正电的氨基酸(例如g39k)取代。在一些实施例中,第一和/或第二重链的vh区中kabat位置44处的氨基酸被带正电的氨基酸(例如赖氨酸)取代。在可替代的实施例中,第一和/或第二重链的vh区中kabat位置44处的氨基酸被带负电的氨基酸(例如谷氨酸)取代。在某些实施例中,第一重链的vh区中的kabat位置44处的氨基酸被带负电的氨基酸(例如g44e)取代,并且第二重链的vh区中的kabat位置44处的氨基酸被带正电的氨基酸(例如g44k)取代。
[0091]
vl区内的v区界面残基(即,介导vh和vl区组装的氨基酸残基)包括kabat位置32、34、35、36、38、41、42、43、44、45、46、48、49、50、51、53、54、55、56、57、58、85、87、89、90、91和100。vl区中的一个或多个界面残基可以用带电氨基酸(优选与引入同源重链的vh区中的那些具有相反电荷的氨基酸)取代。在一些实施例中,第一和/或第二轻链的vl区中kabat位置100处的氨基酸被带正电的氨基酸(例如赖氨酸)取代。在可替代的实施例中,第一和/或第二轻链的vl区中kabat位置100处的氨基酸被带负电的氨基酸(例如谷氨酸)取代。在某些实施例中,第一轻链的vl区中的kabat位置100处的氨基酸被带正电的氨基酸(例如g100k)取代,并且第二轻链的vl区中的kabat位置100处的氨基酸被带负电的氨基酸(例如g100e)取代。
[0092]
在某些实施例中,本发明的异二聚抗体包含第一重链和第二重链以及第一轻链和第二轻链,其中所述第一重链在位置44(kabat)、183(eu)、392(eu)和409(eu)处包含氨基酸取代,其中所述第二重链在位置44(kabat)、183(eu)、356(eu)和399(eu)处包含氨基酸取代,其中所述第一和第二轻链在位置100(kabat)和176(eu)处包含氨基酸取代,并且其中所述氨基酸取代在所述位置处引入带电氨基酸。在相关的实施例中,第一重链的位置44(kabat)处的甘氨酸被谷氨酸替代,第二重链的位置44(kabat)处的甘氨酸被赖氨酸替代,第一轻链的位置100(kabat)处的甘氨酸被赖氨酸替代,第二轻链的位置100(kabat)处的甘氨酸被谷氨酸替代,第一轻链的位置176(eu)处的丝氨酸被赖氨酸替代,第二轻链的位置176(eu)处的丝氨酸被谷氨酸替代,第一重链的位置183(eu)处的丝氨酸被谷氨酸替代,第一重链的位置392(eu)处的赖氨酸被天冬氨酸替代,第一重链的位置409(eu)处的赖氨酸被天冬氨酸替代,第二重链的位置183(eu)处的丝氨酸被赖氨酸替代,第二重链的位置356(eu)处的谷氨酸被赖氨酸取替代,和/或第二重链的位置399(eu)处的天冬氨酸被赖氨酸替代。
[0093]
如本文所用,术语“fc区”是指免疫球蛋白重链的c末端区域,其可通过木瓜蛋白酶消化完整抗体产生。免疫球蛋白的fc区一般包含两个恒定结构域,即ch2结构域和ch3结构域,且任选地包含ch4结构域。在某些实施例中,fc区是来自igg1、igg2、igg3或igg4免疫球蛋白的fc区。在一些实施例中,fc区包含来自人类igg1或人类igg2免疫球蛋白的ch2和ch3结构域。fc区可以保持效应子功能,例如c1q结合、补体依赖性细胞毒性(cdc)、fc受体结合、抗体依赖性细胞介导的细胞毒性(adcc)和吞噬作用。在其他实施例中,fc区可以修饰成降低或消除效应子功能,如本文更详细地描述。
[0094]
在本发明的抗原结合蛋白的一些实施例中,位于fc区d羧基末端的结合结构域(即羧基末端结合结构域)是scfv。在某些实施例中,scfv包含通过肽接头连接的重链可变区(vh)和轻链可变区(vl)。可变区可以在scfv内以vh-vl或vl-vh取向定向。例如,在一个实施
例中,scfv从n末端到c末端包含vh区、肽接头和vl区。在另一个实施例中,scfv从n末端到c末端包含vl区、肽接头和vh区。scfv的vh和vl区可以包含一个或多个半胱氨酸取代,以允许在vh和vl区之间形成二硫键。这样的半胱氨酸钳夹稳定了抗原结合构型中的两个可变结构域。在一个实施例中,vh区中的位置44(kabat编号)和vl区中的位置100(kabat编号)各被半胱氨酸残基取代。
[0095]
在某些实施例中,scfv在其氨基末端通过肽接头融合或以其它方式连接到fc区的羧基末端(例如ch3结构域的羧基末端)。因此,在一个实施例中,scfv与fc区融合,使得所得融合蛋白从n末端到c末端包含ch2结构域、ch3结构域、第一肽接头、vh区、第二肽接头和vl区。在另一个实施例中,scfv与fc区融合,使得所得融合蛋白从n末端到c末端包含ch2结构域、ch3结构域、第一肽接头、vl区、第二肽接头和vh区。“融合蛋白”是包括衍生自一种以上亲本蛋白或多肽的多肽组分的蛋白。典型地,融合蛋白从融合基因表达,其中编码来自一种蛋白的多肽序列的核苷酸序列与编码多肽序列的核苷酸序列附在可读框内,并且任选地通过接头与编码来自不同蛋白的多肽序列的核苷酸序列分开。然后可以通过重组宿主细胞表达融合基因以产生单融合蛋白。
[0096]“肽接头”是指将一个多肽共价连接到另一个多肽的约2-约50个氨基酸的寡肽。肽接头可用于连接scfv内的vh和vl结构域。肽接头还可用于将scfv、fab片段或其他功能性抗体片段连接到fc区的氨基末端或羧基末端,以产生本文所述的双特异性抗原结合蛋白。优选地,肽接头的长度为至少5个氨基酸。在某些实施例中,肽接头的长度为约5个氨基酸至长度为约40个氨基酸。在其他实施例中,肽接头的长度为约8个氨基酸至长度为约30个氨基酸。在其他实施例中,肽接头的长度为约10个氨基酸至长度为约20个氨基酸。
[0097]
优选地,但不是必须地,肽接头包含来自二十个标准氨基酸中的氨基酸,特别是半胱氨酸、甘氨酸、丙氨酸、脯氨酸、天冬酰胺、谷氨酰胺和/或丝氨酸。在某些实施例中,肽接头由空间上无阻碍的大多数氨基酸(例如甘氨酸、丝氨酸和丙氨酸)构成。因此,在一些实施例中优选的接头包括聚甘氨酸、聚丝氨酸和聚丙氨酸,或这些中任何的组合。一些示例性肽接头包括但不限于聚(gly)
2-8
,特别是(gly)3(seq id no:22)、(gly)4(seq id no:23)、(gly)5(seq id no:24)、(gly)6(seq id no:25)和(gly)7(seq id no:26),以及聚(gly)4ser、聚(gly-ala)
2-4
和聚(ala)
2-8
。在某些实施例中,肽接头是(gly
x
ser)n,其中x=3或4且n=2、3、4、5或6。这样的肽连接物包括“l5”(ggggs;或“g4s”;seq id no:27)、“l9”(gggsggggs;或“g3sg4s”;seq id no:28)、“l10”(ggggsggggs;或“(g4s)
2”;seq id no:29)、“l15”(ggggsggggsggggs;或“(g4s)
3”;seq id no:31)、和“l25”(ggggsggggsggggsggggsggggs;或“(g4s)
5”;seq id no:32)。在一些实施例中,连接scfv内的vh和vl区的肽接头是l15或(g4s)3接头(seq id no:31)。在这些和其他实施例中,将羧基末端结合结构域(例如scfv或fab)连接到fc区的c末端的肽接头是l9或g3sg4s接头(seq id no:28)或l10(g4s)2接头(seq id no:29)。
[0098]
可用于本发明的双特异性抗原结合蛋白的肽接头的其他具体实例包括(gly)5lys(seq id no:1);(gly)5lysarg(seq id no:2);(gly)3lys(gly)4(seq id no:3);(gly)3asnglyser(gly)2(seq id no:4);(gly)3cys(gly)4(seq id no:5);glyproasnglygly(seq id no:6);ggeggg(seq id no:7);ggeeeggg(seq id no:8);geeeg(seq id no:9);geee(seq id no:10);ggdggg(seq id no:11);ggdddgg(seq id no:12);gdddg(seq id no:
13);gddd(seq id no:14);ggggsddsdegsdgedggggs(seq id no:15);wewew(seq id no:16);fefef(seq id no:17);eeewww(seq id no:18);eeefff(seq id no:19);wweeeww(seq id no:20);和ffeeeff(seq id no:21)。
[0099]
本文所述的双特异性抗原结合蛋白的重链恒定区或fc区可包含影响抗原结合蛋白的糖基化和/或效应子功能的一个或多个氨基酸取代。免疫球蛋白fc区的功能之一是当免疫球蛋白结合其靶时与免疫系统通信。此通常称为“效应子功能”。通信导致抗体依赖性细胞毒性(adcc)、抗体依赖性细胞吞噬(adcp)和/或补体依赖性细胞毒性(cdc)。adcc和adcp是经由fc区结合至免疫系统细胞表面上的fc受体介导。cdc是经由fc与补体系统,例如c1q的蛋白质结合所介导。在一些实施例中,本发明的双特异性抗原结合蛋白在恒定区中包含一个或多个增强所述抗原结合蛋白的效应子功能(包括adcc活性、cdc活性、adcp活性和/或清除率或半衰期)的氨基酸取代。可以增强效应子功能的示例性氨基酸取代(eu编号)包括但不限于,e233l、l234i、l234y、l235s、g236a、s239d、f243l、f243v、p247i、d280h、k290s、k290e、k290n、k290y、r292p、e294l、y296w、s298a、s298d、s298v、s298g、s298t、t299a、y300l、v305i、q311m、k326a、k326e、k326w、a330s、a330l、a330m、a330f、i332e、d333a、e333s、e333a、k334a、k334v、a339d、a339q、p396l或前述中任何的组合。
[0100]
在其他实施例中,本发明的双特异性抗原结合蛋白在恒定区中包含一个或多个降低效应子功能的氨基酸取代。可以降低效应子功能的示例性氨基酸取代(eu编号)包括但不限于,c220s、c226s、c229s、e233p、l234a、l234v、v234a、l234f、l235a、l235e、g237a、p238s、s267e、h268q、n297a、n297g、v309l、e318a、l328f、a330s、a331s、p331s或前述中任何的组合。
[0101]
糖基化可以促进抗体,特别是igg1抗体的效应子功能。因此,在一些实施例中,本发明的双特异性抗原结合蛋白包含一个或多个影响结合蛋白糖基化的水平或类型的氨基酸取代。多肽的糖基化典型地是n-连接或o-连接的。n-连接是指碳水化合物部分连接至天冬酰胺残基的侧链。三肽序列天冬酰胺-x-丝氨酸和天冬酰胺-x-苏氨酸(其中x为除脯氨酸以外的任何氨基酸)是将碳水化合物部分酶促连接至天冬酰胺侧链的识别序列。因此,在多肽中这些三肽序列中的任一者的存在产生潜在的糖基化位点。o-连接糖基化是指将糖n-乙酰半乳糖胺、半乳糖或木糖中的一种连接至羟基氨基酸,最常见的是丝氨酸或苏氨酸,但是也可使用5-羟基脯氨酸或5-羟基赖氨酸。
[0102]
在某些实施例中,通过向例如本文所述的双特异性抗原结合蛋白的fc区中添加一个或多个糖基化位点来增加所述结合蛋白的糖基化。在抗原结合蛋白中添加糖基化位点通常可以通过改变氨基酸序列,以使其含有上述三肽序列(对于n-连接的糖基化位点)中的一个或多个来实现。还可以通过向起始序列添加一个或多个丝氨酸或苏氨酸残基或由一个或多个丝氨酸或苏氨酸残基取代来作出改变(用于o-连接的糖基化位点)。为便利起见,可以通过在dna层面上的变化,特别是通过使编码靶多肽的dna在预先选择的碱基处突变,由此产生会翻译成所需氨基酸的密码子,来改变抗原结合蛋白的氨基酸序列。
[0103]
本发明还涵盖产生具有改变的碳水化合物结构而引起效应子活性改变的双特异性抗原结合蛋白分子,包括岩藻糖基化不存在或减少的展现改善的adcc活性的抗原结合蛋白。本领域中已知各种减少或消除岩藻糖基化的方法。例如,通过使抗体分子与fcγriii受体结合来介导adcc效应子活性,经显示此取决于在ch2结构域n297残基处n-连接的糖基化
的碳水化合物结构。相较于天然、岩藻糖基化抗体,非岩藻糖基化抗体以增加的亲和力结合此受体且更有效地触发fcγriii介导的效应子功能。例如,在α-1,6-岩藻糖基转移酶已敲除的cho细胞中重组产生非岩藻糖基化抗体使抗体具有100倍增加的adcc活性(参见yamane-ohnuki等人,biotechnol bioeng.[生物技术及生物工程]87(5):614-22,2004)。通过降低α-1,6-岩藻糖基转移酶或岩藻糖基化路径中的其他酶的活性,例如通过sirna或反义rna处理,将细胞系工程改造以敲除一种或多种酶,或与选择性糖基化抑制剂一起培养可以实现类似作用(参见rothman等人,mol immunol.[分子免疫学]26(12):1113-23,1989)。一些宿主细胞系,例如lec13或大鼠杂交瘤yb2/0细胞系天然地产生岩藻糖基化程度较低的抗体(参见shields等人,j biol chem.[生物化学杂志]277(30):26733-40,2002;以及shinkawa等人,j biol chem.[生物化学杂志]278(5):3466-73,2003)。还已确定例如经由在过度表达gntiii酶的细胞中重组产生抗体以增加等分碳水化合物的含量,可增加adcc活性(参见umana等人,nat biotechnol.[自然生物技术]17(2):176-80,1999)。
[0104]
在其他实施例中,通过例如自本文所描述的双特异性抗原结合蛋白的fc区移除一个或多个糖基化位点来减少或消除所述结合蛋白的糖基化。消除或改变n-连接的糖基化位点的氨基酸取代可以减少或消除抗原结合蛋白的n-连接的糖基化。在某些实施例中,本文所描述的双特异性抗原结合蛋白包含在位置n297(eu编号)处的突变,例如n297q、n297a或n297g。在一个特定实施例中,本发明的双特异性抗原结合蛋白包含来自人类igg1抗体的具有n297g突变的fc区。为了改善含n297突变的分子的稳定性,可以对所述分子的fc区进行进一步工程改造。例如,在一些实施例中,fc区中的一个或多个氨基酸经半胱氨酸取代以促进二聚体状态下二硫键的形成。对应于igg1 fc区的v259、a287、r292、v302、l306、v323或i332(eu编号)的残基因此可以经半胱氨酸取代。优选地,特定残基对经半胱氨酸取代以使其优先彼此形成二硫键,由此限制或防止二硫键混乱。优选对包括但不限于,a287c与l306c、v259c与l306c、r292c与v302c,以及v323c与i332c。在特定实施例中,本文所描述的双特异性抗原结合蛋白包含来自人类igg1抗体的具有r292c和v302c突变的fc区。在此类实施例中,fc区还可包含n297g突变。
[0105]
还可能希望对本发明的双特异性抗原结合蛋白进行修饰以增加血清半衰期,例如通过并入或添加补救受体结合表位(例如通过使适当区域突变或通过将该表位并入肽标签中,接着使其与抗原结合蛋白在任一端或在中间融合,例如通过dna或肽合成;参见例如wo96/32478)或添加例如peg或其他水溶性聚合物的分子,包括多糖聚合物。所述补救受体结合表位优选构成这样一种区域,其中来自fc区中一个或两个环的任一个或多个氨基酸残基转移至抗原结合蛋白中的类似位置。甚至更优选地,来自fc区中一个或两个环的三个或更多个氨基酸残基经转移。又更优选地,自fc区(例如igg fc区)的ch2结构域取得表位并将其转移至抗原结合蛋白的ch1、ch3或vh区,或超过一个此类区域。可替代地,自fc区的ch2结构域取得表位并将其转移至抗原结合蛋白的cl区或vl区,或这两个区域。有关fc变体及其与补救受体相互作用的说明,参见国际公开wo97/34631和wo 96/32478。
[0106]
本发明包括编码本文所述的双特异性抗原结合蛋白及其组分的一种或多种分离的核酸。本发明的核酸分子包括呈单链和双链形式的dna和rna,以及相应互补序列。dna包括例如cdna、基因组dna、化学合成的dna、通过pcr扩增的dna及其组合。本发明的核酸分子包括全长基因或cdna分子,以及其片段组合。本发明的核酸优选衍生自人源,但本发明也包
括衍生自非人物种的核酸。
[0107]
来自免疫球蛋白或其区域(例如可变区、fc区等)的相关氨基酸序列或感兴趣的多肽可以通过直接蛋白质测序确定,且适合编码核苷酸序列可以根据通用密码子表设计。可替代地,可以使用常规方法(例如,通过使用能够与编码单克隆抗体的重链和轻链的基因特异性结合的寡核苷酸探针)从产生单克隆抗体抗体的细胞中分离编码所述单克隆抗体(可从中衍生本发明的双特异性抗原结合蛋白的结合结构域)的基因组或cdna并对其进行测序。
[0108]“分离的核酸”在本文中与“分离的多核苷酸”可互换使用,在自天然存在的来源分离核酸的情况下,是指已与分离出核酸的生物体基因组中存在的相邻基因序列分离的核酸。在由模板酶法合成或化学合成核酸,例如pcr产物、cdna分子或寡核苷酸的情况下,应理解,由此类方法获得的核酸是分离的核酸。分离的核酸分子是指呈独立片段形式或作为较大核酸构建体的一种组分的核酸分子。在一个优选实施例中,核酸基本上不含污染性内源物质。所述核酸分子优选来源于基本上纯的形式和能够利用标准生物化学方法(例如sambrook等人,molecular cloning:a laboratory manual[分子克隆:实验室手册],第2版,cold spring harbor laboratory[冷泉港实验室],cold spring harbor[冷泉港],ny[纽约州](1989)中概述的方法)鉴别、操作和回收其组分核苷酸序列的量或浓度分离至少一次的dna或rna。此类序列优选是以不含典型地存在于真核基因中的内部非翻译序列或内含子的可读框形式提供和/或构建。非翻译dna序列可以存在于可读框的5'或3'处,其中这些序列不干扰编码区的操作或表达。除非另外说明,否则本文所论述的任何单链多核苷酸序列的左手端是5’端;双链多核苷酸序列的左手方向称为5’。新生rna转录物的5'至3'添加方向称为转录方向;dna链上与rna转录物具有相同序列且相对于rna转录物的5'端是5'的序列区称为“上游序列”;dna链上与rna转录物具有相同序列且相对于rna转录物的3'端是3'的序列区称为“下游序列”。
[0109]
本发明还包括在中等严格度条件下,且更优选在高严格度条件下与编码如本文所描述的多肽的核酸杂交的核酸。影响杂交条件选择的基本参数以及有关设计适合条件的指导例如陈述于以下中:sambrook,fritsch和maniatis(1989,molecular cloning:a laboratory manual[分子克隆:实验室手册],cold spring harbor laboratory press[冷泉港实验室出版社],cold spring harbor[冷泉港],n.y.[纽约州],第9和11章;和current protocols in molecular biology[当前分子生物学技术],1995,ausubel等人编辑,john wiley&sons,inc.[约翰威立父子有限公司],第2.10和6.3-6.4部分),且可以由本领域普通技术人员基于例如dna的长度和/或碱基组成容易地确定。实现中等严格度杂交条件的一种方式涉及使用一种含5
×
ssc、0.5%sds、1.0mm edta(ph 8.0)的预洗涤溶液、含约50%甲酰胺、6
×
ssc的杂交缓冲液和约55℃杂交温度(或其他类似的杂交溶液,例如含有约50%甲酰胺的杂交溶液,和约42℃杂交温度),以及约60℃和0.5
×
ssc、0.1%sds的洗涤条件。一般而言,高严格度条件定义为如上所述的杂交条件,但利用在约68℃下0.2
×
ssc、0.1%sds的洗涤条件。sspe(l
×
sspe是0.15m nacl、10mm nah2po4和1.25mm edta,ph 7.4)可以取代杂交和洗涤缓冲液中的ssc(l
×
ssc是0.15m nacl和15mm柠檬酸钠);洗涤是在杂交完成之后进行,持续15分钟。应理解,必要时,可以通过应用本领域普通技术人员所知和以下进一步描述的管理杂交反应和双链体稳定性的基本原理调整洗涤温度和洗涤液盐浓度以达到所需
的严格度(参见例如sambrook等人,1989)。当核酸与未知序列的靶核酸杂交时,假定杂交体长度是杂交核酸的长度。当序列已知的核酸杂交时,杂交体长度可以通过比对核酸序列并鉴别序列互补性最佳的一个或多个区域来确定。预期长度小于50个碱基对的杂交体的杂交温度应比杂交体的熔融温度(tm)低5℃至10℃,其中tm是根据以下等式确定。对于长度小于18个碱基对的杂交体,tm(℃)=2(a+t碱基的数量)+4(g+c碱基的数量)。对于长度超过18个碱基对的杂交体,tm(℃)=81.5+16.6(log10[na+])+0.41(%g+c)-(600/n),其中n是杂交体中碱基的数量,且[na+]是杂交缓冲液中钠离子的浓度(对于l
×
ssc,[na+]=0.165m)。优选地,每个此类杂交核酸的长度为至少15个核苷酸(或更优选地,至少18个核苷酸,或至少20个核苷酸,或至少25个核苷酸,或至少30个核苷酸,或至少40个核苷酸,或最优选地至少50个核苷酸),或为其所杂交的本发明的核酸长度的至少25%(更优选至少50%,或至少60%,或至少70%且最优选地至少80%),且与其所杂交的本发明的核酸具有至少60%(更优选至少70%、至少75%、至少80%、至少81%、至少82%、至少83%、至少84%、至少85%、至少86%、至少87%、至少88%、至少89%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%且最优选地至少99.5%)序列一致性,其中序列一致性是当如以下更详细地描述,比对达到最大重叠和一致性,同时序列空位最少时通过比较杂交核酸的序列来确定。
[0110]
如本文所概述,可以通过使用盒式或pcr诱变,或本领域中熟知的其他技术对编码多肽的dna中的核苷酸进行位点特异性诱变,以产生编码变体的dna,且随后在细胞培养中表达重组dna来制备本文所描述的抗原结合蛋白的变体。不过,还可使用确定的技术,通过体外合成制备包含具有多达约100-150个残基的变体cdr的抗原结合蛋白。这些变体典型地展现与天然存在的类似物相同的定性生物活性,例如结合至抗原。此类变体包括例如在抗原结合蛋白的氨基酸序列内残基的缺失和/或插入和/或取代。进行缺失、插入和取代的组合以达到最终构建体,条件是最终的构建体具有所希望的特征。氨基酸变化还可能改变抗原结合蛋白的翻译后加工,例如改变糖基化位点的数目或位置。在某些实施例中,抗原结合蛋白变体的制备意图修饰直接参与表位结合的氨基酸残基。在其他实施例中,出于本文所论述的目的,需要对不直接参与表位结合的残基或不以任何方式参与表位结合的残基进行修饰。预期在任何cdr区和/或框架区内的诱变。本领域普通技术人员可以采用协方差分析设计抗原结合蛋白的氨基酸序列中的有用修饰。参见例如,choulier等人,proteins[蛋白质]41:475-484,2000;demarest等人,j.mol.biol.[分子生物学杂志]335:41-48,2004;hugo等人,protein engineering[蛋白质工程改造]16(5):381-86,2003;aurora等人,美国专利公开号2008/0318207 a1;glaser等人,美国专利公开号2009/0048122 a1;urech等人,wo 2008/110348 a1;borras等人,wo 2009/000099 a2。由协方差分析确定的此类修饰可以改善抗原结合蛋白的效力、药物代谢动力学、药效学和/或可制造特征。
[0111]
本发明还包括载体,其包含编码本发明的双特异性抗原结合蛋白的一种或多种组分(例如可变区、轻链、重链、修饰的重链、和fd片段)的一个或多个核酸。术语“载体”是指用于将蛋白质编码信息转移至宿主细胞中的任何分子或实体(例如核酸、质粒、噬菌体或病毒)。载体的实例包括但不限于,质粒、病毒载体、非游离型哺乳动物载体和表达载体,例如重组表达载体。如本文所使用,术语“表达载体”或“表达构建体”是指含有所需编码序列和在特定宿主细胞中表达可操作地连接的编码序列所需的适当核酸控制序列的重组dna分
子。表达载体可包括但不限于,影响或控制转录、翻译且在存在内含子时,影响与其可操作地连接的编码区的rna剪接的序列。在原核生物中表达所需的核酸序列包括启动子、任选地操作子序列、核糖体结合位点和可能地存在的其他序列。已知真核细胞可利用启动子、增强子以及终止和聚腺苷酸化信号。可操作地连接至感兴趣的编码序列的分泌信号肽序列还可任选地由表达载体编码,由此使表达的多肽可以由重组宿主细胞分泌,使得在需要时,更容易自细胞中分离出感兴趣的多肽。例如,在一些实施例中,信号肽序列可以被附接/融合到表6a、6b、7a、7b、9和10中列出的任何多肽序列的氨基末端。在某些实施例中,具有mdmrvpaqllgllllwlrgarc(seq id no:32)氨基酸序列的信号肽与表6a、6b、7a、7b,9和10中的任何多肽序列的氨基末端融合。在其他实施例中,具有mawalllltlltqgtgswa(seq id no:33)氨基酸序列的信号肽与表6a、6b、7a、7b,9和10中的任何多肽序列的氨基末端融合。在又其他实施例中,具有mtcspllltllihctgswa(seq id no:34)氨基酸序列的信号肽与表6a、6b、7a、7b,9和10中的任何多肽序列的氨基末端融合。可以与本文所描述的多肽序列的氨基末端融合的其他适合信号肽序列包括:meapaqllfllllwlpdttg(seq id no:35)、mewtwrvlflvaaatgahs(seq id no:36)、metpaqllfllllwlpdttg(seq id no:37)、metpaqllfllllwlpdttg(seq id no:38)、mkhlwfflllvaaprwvls(seq id no:39)、和mewswvflfflsvttgvhs(seq id no:40)。其他信号肽是本领域技术人员已知的,并且可以与表6a、6b、7a、7b、9和10中列出的任何多肽链融合,例如以促进或优化在特定宿主细胞中的表达。
[0112]
典型地,用于宿主细胞中以产生本发明的双特异性抗原蛋白的表达载体将含有用于质粒维持以及用于克隆和表达编码双特异性抗原结合蛋白各组分的外源核苷酸序列的序列。在某些实施例中,统称为“侧接序列”,典型地将包括以下核苷酸序列中的一个或多个:启动子、一个或多个增强子序列、复制起点、转录终止序列、含有供体和受体剪接位点的完整内含子序列、编码用于多肽分泌的前导序列的序列、核糖体结合位点、聚腺苷酸化序列、用于插入编码待表达的多肽的核酸的多接头区和可选择标记物组件。这些序列分别于下文论述。
[0113]
任选地,载体可以含有“标签”编码序列,即,位于多肽编码序列的5'或3'端的寡核苷酸分子;所述寡核苷酸标签序列编码聚组氨酸(例如六组氨酸)、flag、ha(血凝素流感病毒)、myc或现有可商购抗体所针对的另一“标签”分子。该标签典型地在多肽表达时与该抗体融合,且可以用作一种自宿主细胞亲和纯化或检测多肽的方式。亲和纯化可以通过例如柱层析法,使用针对标签的抗体作为亲和基质来实现。任选地,随后可以通过各种方式,例如使用某些肽酶裂解,自纯化的多肽移除标签。
[0114]
侧接序列可以为同源的(即,来自与宿主细胞相同的物种和/或品系)、异源的(即,来自与宿主细胞物种或品系不同的物种)、混合的(即,来自超过一种来源的侧接序列的组合)、合成的或天然的。因此,侧接序列的来源可以为任何原核或真核生物体、任何脊椎动物或非脊椎动物生物体,或任何植物,只要该侧接序列在宿主细胞机器中起作用且可以经宿主细胞机器活化。
[0115]
可用于本发明载体中的侧接序列可以通过本领域中熟知的若干方法中的任一种获得。典型地,可用于本文中的侧接序列将预先通过定位和/或通过限制性核酸内切酶消化鉴别且因此可以使用适当限制性核酸内切酶自适当组织来源分离。在一些情况下,侧接序
列的完全核苷酸序列可能为已知的。此处,侧接序列可以使用常规核酸合成或克隆方法合成。
[0116]
无论已知侧接序列的全部抑或仅一部分,其均可使用聚合酶链反应(pcr)和/或通过用适合探针,例如来自相同或另一物种的寡核苷酸和/或侧接序列片段筛选基因组文库来获得。若侧接序列未知,则可以自可能含有例如编码序列或甚至另外一个或多个基因的较大dna片段分离含有侧接序列的dna片段。可以通过限制性核酸内切酶消化产生适当dna片段,随后使用琼脂糖凝胶纯化、柱层析法(加利福尼亚州查茨沃斯(chatsworth,ca))或熟练技术人员已知的其他方法分离来实现分离。本领域普通技术人员将易于了解实现此目的的适合酶的选择。
[0117]
复制起点典型地是可商购的原核表达载体的一部分,且该起点有助于在宿主细胞中扩增载体。若所选载体不含复制起点,则可以基于已知序列以化学方式合成,并将其连接至载体中。例如,来自质粒pbr322(马萨诸塞州贝弗利的新英格兰生物实验室(new england biolabs,beverly,ma))的复制起点适合大多数革兰氏阴性细菌,且各种病毒起点(例如sv40、多瘤病毒、腺病毒、水疱性口炎病毒(vsv),或乳头瘤病毒,例如hpv或bpv)可用于在哺乳动物细胞中克隆载体。一般而言,哺乳动物表达载体不需要复制起点组分(例如,通常仅使用sv40起点,因为其还含有病毒早期启动子)。
[0118]
转录终止序列典型地位于多肽编码区3'端且用于终止转录。通常,原核细胞中的转录终止序列是富含g-c的片段,后接聚t序列。尽管该序列易于自文库克隆或甚至作为载体的一部分商购获得,但其还可使用核酸合成方法容易地合成。
[0119]
可选择标记物基因编码使选择性培养基中生长的宿主细胞存活和生长所需的蛋白质。典型的选择标记基因编码如下蛋白质:(a)赋予针对抗生素或其他毒素(例如,对于原核宿主细胞,胺苄青霉素、四环素或卡那霉素)的抗性;(b)补充细胞的营养缺陷;或(c)提供不可得自复杂培养基或限定培养基的重要营养物。特定的可选择标记物为卡那霉素抗性基因、胺苄青霉素抗性基因及四环素抗性基因。有利地,新霉素抗性基因还可用于在原核及真核宿主细胞中进行选择。
[0120]
可以使用其他可选择基因扩增有待表达的基因。扩增是使生长或细胞存活必要的蛋白质产生所需的基因在连续数代重组细胞的染色体内串联性复制的过程。适用于哺乳动物细胞的可选择标记物的实例包括二氢叶酸还原酶(dhfr)和无启动子胸苷激酶基因。使哺乳动物细胞转化株处于选择压力下,其中由于载体中存在可选择基因,所以仅转化株唯一适于存活。选择压力是通过在连续地增加培养基中选择剂的浓度的条件下培养经转化细胞,由此使可选择基因和编码另一基因,例如本文所描述的双特异性抗原结合蛋白的一种或多种组分的dna扩增来施加。因此,由扩增的dna合成较多量的多肽。
[0121]
核糖体结合位点通常是mrna翻译起始所必需的,且以shine-dalgarno序列(原核生物)或kozak序列(真核生物)表征。该组件典型地位于启动子的3'端且在待表达的多肽编码序列的5'端。在某些实施例中,一个或多个编码区可以可操作地连接至内部核糖体结合位点(ires),由此允许自单一rna转录物翻译两个可读框。
[0122]
在一些情况下,例如在真核宿主细胞表达系统中需要糖基化的情况下,可以操作各种前序列或原序列以改善糖基化或产率。例如,可以改变特定信号肽的肽酶裂解位点,或添加原序列,这些序列还可影响糖基化。最终蛋白质产物可以在位置-1(相对于成熟蛋白质
的第一个氨基酸)具有一个或多个易于表达的另外的氨基酸,这些氨基酸可能未完全移除。例如,最终蛋白质产物可能具有一个或两个在肽酶裂解位点中发现的氨基酸残基附接至氨基末端。可替代地,当酶在成熟多肽内的此类区域切割时,使用一些酶裂解位点可能产生所需多肽的略微截短的形式。
[0123]
本发明的表达和克隆载体典型地将含有由宿主生物体识别且可操作地连接至编码多肽的分子的启动子。如本文所使用,术语“可操作地连接”是指两个或多个核酸序列以使得产生能够引导给定基因的转录和/或所需蛋白质分子的合成的核酸分子的方式连接。例如,载体中“可操作地连接”至蛋白质编码序列的控制序列是与该编码序列连接以使得在与控制序列的转录活性相适应的条件下实现该蛋白质编码序列的表达。更具体地,若启动子和/或增强子序列(包括顺式作用转录控制组件的任何组合)在适合宿主细胞或其他表达系统中刺激或调节编码序列的转录,则其可操作地连接至该编码序列。
[0124]
启动子为位于控制结构基因转录的结构基因起始密码子(一般在约100至1000bp内)上游(即,5')的非转录序列。启动子通常分组为两种类别:诱导型启动子及组成型启动子。诱导型启动子起始处于其控制下的dna响应于培养条件的某种变化(诸如营养素的存在或不存在,或者温度变化)以提高的水平转录。另一方面,组成型启动子一致地转录其可操作地连接的基因,即,对基因表达具有极小控制或无控制。许多由多种潜在宿主细胞识别的启动子是众所周知的。通过限制性酶消化移除源dna启动子,并将所需启动子序列插入载体中,将适合启动子可操作地连接至编码例如本发明双特异性抗原结合蛋白的重链、轻链、修饰的重链或其他组分的dna。
[0125]
适用于酵母宿主的适合启动子还是本领域中熟知的。酵母增强子宜与酵母启动子一起使用。用于哺乳动物宿主细胞的适合启动子是众所周知的,且包括但不限于获自病毒基因组的那些启动子,这些病毒为诸如多形瘤病毒、传染性上皮瘤病毒、腺病毒(诸如腺病毒2)、牛乳头状瘤病毒、禽肉瘤病毒、巨细胞病毒、逆转录病毒、b型肝炎病毒以及最优选的猿猴病毒40(sv40)。其他适合哺乳动物启动子包括异源哺乳动物启动子,例如热休克启动子及肌动蛋白启动子。
[0126]
其他感兴趣的启动子包括但不限于:sv40早期启动子(benoist和chambon,1981,nature[自然]290:304-310);cmv启动子(thornsen等人,1984,proc.natl.acad.u.s.a.[美国科学院院报]81:659-663);劳斯肉瘤病毒(rous sarcoma virus)的3'长末端重复序列中所含的启动子(yamamoto等人,1980,cell[细胞]22:787-797);疱疹胸苷激酶启动子(wagner等人,1981,proc.natl.acad.sci.u.s.a.[美国科学院院报]78:1444-1445);来自金属硫蛋白基因的启动子和调控序列(prinster等人,1982,nature[自然]296:39-42);和原核启动子,例如β-内酰胺酶启动子(villa-kamaroff等人,1978,proc.natl.acad.sci.u.s.a.[美国科学院院报]75:3727-3731);或tac启动子(deboer等人,1983,proc.natl.acad.sci.u.s.a.[美国科学院院报]80:21-25)。有意义的还有以下动物转录控制区,它们表现出组织特异性并已用于转基因动物中:在胰脏腺泡细胞中具有活性的弹性蛋白酶i基因控制区(swift等人,1984,cell[细胞]38:639-646;ornitz等人,1986,cold spring harbor symp.quant.biol.[冷泉港数量生物学研讨会]50:399-409;macdonald,1987,hepatology[肝脏病学]7:425-515);在胰脏β细胞中具有活性的胰岛素基因控制区(hanahan,1985,nature[自然]315:115-122);在淋巴样细胞中有活性的免疫球蛋
白基因控制区(grosschedl等人,1984,cell[细胞]38:647-658;adames等人,1985,nature[自然]318:533-538;alexander等人,1987,mol.cell.biol.[分子细胞生物学]7:1436-1444);在睪丸、乳房、淋巴和肥大细胞中具有活性的小鼠乳房肿瘤病毒控制区(leder等人,1986,cell[细胞]45:485-495);在肝中具有活性的白蛋白基因控制区(pinkert等人,1987,genes and devel.[基因与发育]1:268-276);在肝中具有活性的α-胎蛋白基因控制区(krumlauf等人,1985,mol.cell.biol.[分子细胞生物学]5:1639-1648;hammer等人,1987,science[科学]253:53-58);在肝中具有活性的α1-抗胰蛋白酶基因控制区(kelsey等人,1987,genes and devel.[基因与发育]1:161-171);在骨髓细胞中具有活性的β-球蛋白基因控制区(mogram等人,1985,nature[自然]315:338-340;kollias等人,1986,cell[细胞]46:89-94);在脑中的寡树突细胞中具有活性的髓磷脂碱性蛋白基因控制区(readhead等人,1987,cell[细胞]48:703-712);在骨骼肌中具有活性的肌球蛋白轻链-2基因控制区(sani,1985,nature[自然]314:283-286);和在下丘脑中具有活性的促性腺激素释放激素基因控制区(mason等人,1986,science[科学]234:1372-1378)。
[0127]
可以将增强子序列插入载体中以增加高等真核细胞中编码双特异性抗原结合蛋白的组分(例如,轻链、重链、修饰的重链、fd片段)的dna的转录。增强子为dna的顺式作用元件,长度通常为约10-300bp,作用于启动子以增加转录。增强子在方向及位置方面为相对独立的,已见于转录单元的5'及3'位置。已知可得自哺乳动物基因(例如球蛋白、弹性蛋白酶、白蛋白、α-胎蛋白和胰岛素)的若干增强子序列。然而,典型地使用来自病毒的增强子。本领域中已知的sv40增强子、巨细胞病毒早期启动子增强子、多瘤增强子和腺病毒增强子是用于活化真核启动子的示例性强化组件。尽管增强子可以定位于载体中编码序列的5'或3',但其典型地位于启动子5'的位点处。可将编码适当天然或异源信号序列(前导序列或信号肽)的序列并入表达载体中,以促进抗体的细胞外分泌。信号肽或前导序列的选择取决于待产生抗体的宿主细胞的类型,且异源信号序列可替换天然信号序列。信号肽的实例在上文有描述。在哺乳动物宿主细胞中起作用的其他信号肽包括美国专利号4,965,195中所述的白介素-7(il-7)的信号序列;cosman等人,1984,nature[自然]312:768中所描述的白介素-2受体的信号序列;欧洲专利号0367 566中所描述的白介素-4受体信号肽;美国专利号4,968,607中所述的i型白介素-1受体信号肽;ep专利号0 460 846中所述的ii型白介素-1受体信号肽。
[0128]
可由起始载体(例如市售载体)构建所提供的表达载体。这些载体可含有或可不含所有所需侧接序列。在载体中不存在一个或多个本文所描述的侧接序列的情况下,其可以独立地获得且连接至载体中。用于获得各侧接序列的方法是本领域普通技术人员熟知的。可以将表达载体引入宿主细胞中,由此产生由如本文所描述的核酸所编码的蛋白质,包括融合蛋白。
[0129]
在某些实施例中,可以将编码本发明的双特异性抗原结合蛋白的不同组分的核酸插入相同表达载体中。在此类实施例中,该两个核酸可以由内部核糖体进入位点(ires)隔开且处于单一启动子控制下,由此使轻链和重链由相同mrna转录物表达。可替代地,该两个核酸可以处于两个独立启动子控制下,由此使轻链和重链由两个独立的mrna转录物表达。
[0130]
类似地,对于igg-scfv双特异性抗原结合蛋白,可以将编码轻链的核酸克隆到与编码修饰的重链的核酸相同的表达载体中(包含重链和scfv的融合蛋白),其中所述两个核
酸受单个启动子控制并被ires分开,或者其中所述两个核酸受两个单独的启动子控制。对于igg-fab双特异性抗原结合蛋白,编码三个组分中每一个的核酸可被克隆到相同的表达载体中。在一些实施例中,将编码igg-fab分子的轻链的核酸和编码第二多肽(其包含c末端fab结构域的另一半)的核酸克隆到一个表达载体中,而编码修饰的重链(包含重链和半个fab结构域的融合蛋白)的核酸被克隆到第二表达载体中。在某些实施例中,本文所述的双特异性抗原结合蛋白的所有组分都从相同的宿主细胞群表达。例如,即使将一种或多种组分克隆到单独的表达载体中,宿主细胞也用两种表达载体共转染,使得一个细胞产生双特异性抗原结合蛋白的所有组分。
[0131]
在构建出载体并将编码本文所描述的双特异性抗原结合蛋白各组分的一个或多个核酸分子插入一个或多个载体的一个或多个适当位点中之后,可以将一个或多个完整载体插入适当宿主细胞中以进行扩增和/或多肽表达。因此,本发明包括分离的宿主细胞,其包含一个或多个编码双特异性抗原结合蛋白组分的表达载体。如本文所使用,术语“宿主细胞”是指经核酸转化或能够经核酸转化且由此表达感兴趣的基因的细胞。该术语包括亲本细胞的子代,无论该子代是否在形态或遗传组成上与原始亲本细胞一致,只要存在该感兴趣的基因即可。包含本发明的分离核酸优选可操作地连接到至少一个表达控制序列(例如启动子或增强子)的宿主细胞是“重组宿主细胞”。
[0132]
可以通过熟知方法,包括转染、感染、磷酸钙共沉淀、电穿孔、显微注射、脂质体转染、deae-葡聚糖介导的转染或其他已知技术将抗原结合蛋白的表达载体转化至所选宿主细胞中。所选方法将部分随所用宿主细胞的类型而变化。这些方法及其他适合的方法对于技术人员是众所周知的,并且阐述于例如sambrook等人,2001,同上中。
[0133]
宿主细胞当在适当条件下培养时合成抗原结合蛋白,该抗原结合蛋白随后可以自培养基收集(若宿主细胞将其分泌至培养基中)或直接由产生该抗原结合蛋白的宿主细胞收集(若其并非分泌的)。适当宿主细胞的选择将取决于各种因素,例如所需表达水平、活性所需或必需的多肽修饰(例如糖基化或磷酸化)和折叠成生物活性分子的容易性。
[0134]
示例性宿主细胞包括原核细胞、酵母或高等真核细胞。原核宿主细胞包括真细菌,例如革兰氏阴性或革兰氏阳性生物体,例如,肠杆菌科(enterobacteriaceae),例如埃希氏菌属(escherichia)(例如大肠杆菌(e.coli))、肠杆菌属(enterobacter)、欧文氏菌属(erwinia)、克氏杆菌属(klebsiella)、变形杆菌属(proteus)、沙门氏菌属(salmonella)(例如鼠伤寒沙门氏菌(salmonella typhimurium))、沙雷氏菌属(serratia)(例如黏质沙雷氏菌(serratia marcescans))和志贺氏菌属(shigella),以及芽孢杆菌属(bacillus),例如枯草芽孢杆菌(b.subtilis)和地衣芽孢杆菌(b.licheniformis),假单胞菌属(pseudomonas)和链霉菌属(streptomyces)。真核微生物,例如丝状真菌或酵母是适用于重组多肽的克隆或表达宿主。酿酒酵母(saccharomyces cerevisiae)或常称为烘焙酵母,是低等真核宿主微生物中最常用的。不过,多种其他属、种和菌株是常用的且可用于本文中,例如毕赤酵母属(pichia),例如巴斯德毕赤酵母(p.pastoris)、裂殖酵母(schizosaccharomyces pombe);克鲁维酵母属(kluyveromyces),耶氏酵母属(yarrowia);假丝酵母属(candida);瑞氏木霉(trichoderma reesia);粗糙脉孢菌;许旺酵母属(schwanniomyces),例如西方许旺酵母(schwanniomyces occidentalis);和丝状真菌,例如脉孢菌属(neurospora)、青霉菌属(penicillium)、木霉菌属(tolypocladium)和曲霉属
(aspergillus)宿主,例如构巢曲霉(a.nidulans)和黑曲霉(a.niger)。
[0135]
用于表达糖基化抗原结合蛋白的宿主细胞可以来源于多细胞生物体。无脊椎动物细胞的实例包括植物细胞和昆虫细胞。已鉴别出来自宿主的多种杆状病毒株和变种以及相应容许的昆虫宿主细胞,例如草地贪夜蛾(spodoptera frugiperda)(毛虫)、埃及伊蚊(aedes aegypti)(蚊子)、白纹伊蚊(aedes albopictus)(蚊子)、黑腹果蝇(drosophila melanogaster)(苍蝇)和家蚕(bombyx mori)。用于转染此类细胞的多种病毒株是公开可得的,例如苜蓿银纹夜蛾(autographa californica)npv的l-1病毒株和家蚕npv的bm-5病毒株。
[0136]
脊椎动物宿主细胞还为适合宿主,且由此类细胞重组产生抗原结合蛋白已成为常规程序。可用作表达宿主的哺乳动物细胞系是本领域中熟知的且包括但不限于,可得自美国典型培养物保藏中心(american type culture collection,atcc)的永生化细胞系,包括但不限于中国仓鼠卵巢(chinese hamster ovary;cho)细胞,包括chok1细胞(atcc ccl61)、dxb-11、dg-44和中国仓鼠卵巢细胞/-dhfr(cho,urlaub等人,proc.natl.acad.sci.usa[美国科学院院报]77:4216,1980);经sv40转化的猴肾cv1细胞细(cos-7,atcc crl 1651);人胚胎肾系(293细胞或亚克隆用于在悬浮培养中生长的293细胞(graham等人,j.gen virol.[普通病毒学杂志]36:59,1977);幼仓鼠肾细胞(bhk,atcc ccl 10);小鼠赛托利细胞(sertoli cell)(tm4,mather,biol.reprod.[生殖生物学]23:243-251,1980);猴肾细胞(cv1 atcc ccl 70);非洲绿猴肾细胞(vero-76,atcc crl-1587);人宫颈癌细胞(hela,atcc ccl 2);犬肾细胞(mdck,atcc ccl 34);布法罗(buffalo)大鼠肝细胞(brl 3a,atcc crl 1442);人肺细胞(w138,atcc ccl 75);人肝癌细胞(hep g2,hb 8065);小鼠乳腺肿瘤(mmt 060562,atcc ccl51);tri细胞(mather等人,annals n.y acad.sci.[纽约科学院年鉴]383:44-68,1982);mrc 5细胞或fs4细胞;哺乳动物骨髓瘤细胞和多种其他细胞系。在另一实施例中,可以自b细胞谱系是选择不产生自身抗体但能够制备并分泌异源抗体的细胞系。在一些实施例中,cho细胞是用于表达本发明的双特异性抗原结合蛋白的优选宿主细胞。
[0137]
宿主细胞用上述核酸或载体转化或转染以产生双特异性抗原结合蛋白且在经适当改善的常规营养培养基中培养以诱导启动子、选择转化株或扩增编码所需序列的基因。此外,具有由选择性标记物隔开的多个转录单元拷贝的新颖载体和经转染细胞系特别是用于表达抗原结合蛋白。因此,本发明还提供了制备本文所述的双特异性抗原结合蛋白的方法,所述方法包括在允许由本文所述的一种或多种表达载体编码的双特异性抗原结合蛋白表达的条件下,在培养基中培养包含所述一种或多种表达载体的宿主细胞;并且从所述培养基中回收所述双特异性抗原结合蛋白。
[0138]
用于产生本发明的抗原结合蛋白的宿主细胞可以在多种培养基中培养。诸如ham's f10(西格玛公司(sigma))、最小必需培养基((mem),(西格玛公司))、rpmi-1640(西格玛公司)和杜尔贝科改良型伊戈尔培养基(dulbecco's modified eagle's medium)((dmem),西格玛公司))等市售培养基适用于培养宿主细胞。此外,ham等人,meth.enz.[酶学方法]58:44,1979;barnes等人,anal.biochem.[分析生物化学]102:255,1980;美国专利号4,767,704;4,657,866;4,927,762;4,560,655;或5,122,469;wo 90103430;wo 87/00195;或美国专利注册号30,985中描述的任何培养基可用作宿主细胞的培养基。必要时,这些培养
基中的任一种可以补充有激素和/或其他生长因子(例如胰岛素、运铁蛋白或表皮生长因子)、盐(例如氯化钠、钙、镁和磷酸盐)、缓冲剂(例如hepes)、核苷酸(例如腺苷和胸苷)、抗生素(例如健他霉素(gentamycin
tm
)药物)、微量元素(定义为通常以在微摩尔浓度范围内的最终浓度存在的无机化合物)和葡萄糖或等效能量来源。还可包括适当浓度的本领域普通技术人员已知的任何其他必要补充物。培养条件,例如温度、ph等,是先前与选择用于表达的宿主细胞一起使用的条件,并且对于普通技术人员来说是显而易见的。
[0139]
在培养宿主细胞后,双特异性抗原结合蛋白可以在细胞内、在周质空间中产生,也可以直接分泌到培养基中。若在细胞内产生抗原结合蛋白,则作为第一个步骤,例如通过离心或超滤来移除宿主细胞或溶解片段的颗粒状碎片。双特异性抗原结合蛋白可以使用例如羟基磷灰石色谱、阳离子或阴离子交换色谱、或优选亲和色谱、使用一种或多种目的抗原或蛋白a或蛋白g作为亲和配体来纯化。蛋白a可用于纯化包括基于人γ1、γ2或γ4重链的多肽的蛋白质(lindmark等人,j.immunol.meth.[免疫学方法杂志]62:1-13,1983)。对于所有小鼠同种型和对于人γ3推荐蛋白g(guss等人,embo j.[欧洲分子生物学学会杂志]5:15671575,1986)。亲和配体所连接的基质最常为琼脂糖,但其他基质也是可用的。相较于用琼脂糖,机械稳定的基质,例如可控孔度玻璃或聚(苯乙烯二乙烯基)苯可以提高流动速率和缩短加工时间。在蛋白质包含ch3结构域的情况下,bakerbond abx
tm
树脂(j.t.baker,phillipsburg,n.j.[新泽西州菲利普斯堡])可用于纯化。根据要回收的特定双特异性抗原结合蛋白,其他用于蛋白质纯化的技术例如乙醇沉淀、反相hplc、色谱聚焦、sds-page和硫酸铵沉淀也是可能的。
[0140]
实例
[0141]
chz01
[0142]
产生多特异性抗原结合蛋白和半衰期延长的治疗性蛋白的能力是将许多治疗性候选物推向临床的首要条件。通常,这意味着成功程度不同的广泛蛋白质设计。在任何一种情况下,两个不同的fc部分聚集在一起并形成异二聚体。为了做到这一点,必须改变蛋白质天然序列。传统上,这些变化集中在fc部分的ch3-ch3’界面中,其中插入了电荷配对突变和杵臼设计。
[0143]
可以看出单克隆抗体中的两个重链有两个主要的接触点:fc-ch3和铰链(图1)。铰链区域将fc连接到两个fab结构域,并且随后它必须显示出允许fab自由旋转的柔性结构,这对于这些弹头部采用正确的接近角度来接合它们的靶标是必要的,同时fc区可以与其多个结合配偶物(如fcγr、fcrn和c1q)相互作用。尽管铰链区周围具有灵活性,但这种界面是由强而结构刚性的基序(即“cppc”基序)所介导的(图1-3)。在这里,脯氨酸残基引入了非常特异和稳定的二级结构,其允许半胱氨酸残基的-sh侧链与它们的对应物相遇并形成二硫键。此外,同样的刚性框架很可能延伸到cpp”基序的上游和下游,提示在这一基序附近的那些残基的侧链也可能呈现稳定的构象。
[0144]
蛋白质数据库(“pdb”)中可获得的人全长igg1抗体的唯一晶体结构(pdb 1hzh)仅显示了部分完整的cppc基序,其中第二半胱氨酸(c242)没有形成二硫键,两个多肽链中位置242的每个侧链指向相反方向(图2)。虽然有小鼠igg1抗体的结构信息显示cppc基序的完整结构,但这两个物种之间的序列变异(图3)不允许准确预测人igg1中cys242下游那些残基的侧链的空间位置。因此,在保持cppc基序的天然序列的情况下,在同一区的下游插入了
一串名为
‘
带电拉链铰链01’(czh01)的带相反电荷的残基(图4)。据信,这种“带电拉链”既能吸引带相反电荷的重链,又能排斥带相同电荷的链。
[0145]
为了检验这一假设,将这些突变插入抗体x中并在hek293细胞中瞬时表达,随后进行单步蛋白纯化(蛋白a,随后cex)。为了验证新产生的抗体是否由两个不同的重链(分别带负电和正电)构成,进行了广泛的还原性和非还原性质谱测定。的确,结果表明这种策略在fc-ch3区没有任何另外突变的情况下成功地驱动了重链配对(图4-6)。最有可能的是赖氨酸串(243至247)正面对着天冬氨酸串(243至247)并与之相互作用。
[0146]
chz11
[0147]
此外,小鼠igg2分子的结构分析表明,一个链中的残基246和247以及对应链中的残基244的侧链彼此指向(图9)。这些残基位于cys242的下游并紧邻cppc基序,这表明构象稳定。此外,电荷残基具有侧链,所述侧链可以配合在结构空间排列中,并且因此不会破坏cppc界面。asn246和leu247均被带负电的天冬氨酸残基替代。为了与这两个残基配对,单个组氨酸以一种方式替代相对链中的ala244,所述方式是使得它可以与相对的带电残基(asp246和asp247)产生生产性接触或显示排斥效应(图9和10)(czh11)。为了检验设计的合理性,表达并纯化了该变异体。出乎意料的是,质谱证实,这三个残基确实形成了三联体,并且足以驱动铰链二聚化(图10)。
[0148]
chz09
[0149]
接下来对cppc区上游区域进行测试,以验证该序列的工程改造是否也能驱动重链二聚化。在cys242残基下游保留两个带电对突变ala244lys/asp和glu246lys/asp的同时,在cys239残基上游插入两个额外的带电对突变his237lys/asp和thr246lys/asp(czh09)(图7)。数据表明,插入在cppc基序上游的cpm同样能够驱动重链二聚化。
[0150]
ch3 cpm
[0151]
此外,插入在铰链区中的cpm(电荷对突变)与先前插入在fc-ch3区中的cpm兼容。在含有czh01、czh09和czh11突变的分子中加入所谓的
‘
v11’ch3 cpm(一个ch3区中的d399k和另一个ch3区中的k409d/k392d)(图11和12)。结果表明,所有三个插入铰链区的cpm(czh01、czh09和czh11)也能在fc-ch3 cpm存在下成功地驱动重链配对。
[0152]
为了获得在铰链区中工程改造的这些新突变的影响,运行稳定性测定,查看这些新变异与野生型分子相比较的热稳定性值。数据显示,czh01、czh09和czh11的tm数据在不存在ch3-cpm v11时与对照chz00(73.3℃)和在存在ch3-cpm v11时与chz00(70.7℃)相比较来说很好(表1)。
[0153]
表1.
[0154]
[0155]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1