重组禽流感亚单位疫苗及其制备方法与流程
本发明涉及疫苗制备技术领域,尤其涉及重组禽流感亚单位疫苗及其制备方法。
背景技术:
流感病毒(influenzavirus)属于正粘病毒科,是单股负链分节段的rna病毒。根据核蛋白(np)和基质蛋白(m1)上抗原决定簇的不同,流感病毒可分为a、b、c、d四型,其中a型和b型可给人类的健康带来威胁,尤其是a型,每年因全球季节性流感和散发性流感而导致大约30万~50万人死亡,死亡率高达60%。按照流感病毒感染对象来说可将病毒分为人类流感病毒、猪流感病毒、马流感病毒以及禽流感病毒等类群。禽流感是由禽流感病毒引起的一类人畜共患传染性疾病,属于甲型流感病毒,野生禽类是甲型流感病毒的天然宿主,根据流感病毒对禽类的致病力不同,分为高致病性、低致病性和非致病性三大类。禽流感病毒(aiv)是由perroncito(1878)于1878年在意大利首次报道的,此后又在世界上多个国家和地区被陆续发现。
高致病力禽流感(hpaiv)已被国际兽疫局列为a类烈性传染病。至今发现能直接感染人的禽流感病毒亚型有:h5n1、h7n1、h7n2、h7n3、h7n7、h9n2和h7n9亚型。自1905年禽流感病原被确认后,世界上暴发了多次由h5亚型、h7亚型引起的高致病力禽流感(hpaiv),并有研究发现在自然界广泛流行的低致病力毒株(lpaiv)的ha基因发生突变后形成高致病力毒株,禽流感病毒通常对野禽不具有致病性,但跨物种传播时往往具有高致病性。因此对于任何一种形式的禽流感,包括在水禽和野鸟体内持续存在,偶尔传播给家禽导致低致病力禽流感的发生都是不容忽视的。
目前ha蛋白广泛应用于亚单位苗的研发中,已有研究表明,在细菌、昆虫细胞、哺乳动物细胞等多种表达系统中表达的ha蛋白均有活性,利用ha蛋白研制基因工程疫苗在禽流感防控中发挥着重要的作用。研究人员认为ha蛋白头部球状结构是禽流感主要的保护性抗原。ha抗体滴度的高低从某种程度上能够反映机体对于禽流感病毒的抵抗力。随着基因工程技术的飞速发展,研究人员将ha基因克隆至真核表达载体上,转化至真核生物或细胞中进行表达来获得流感亚单位疫苗,进一步完成对动物免疫的研究。
范文辉等利用毕赤酵母表达系统表达纯化h5ha蛋白,将不同剂量的h5ha与不同佐剂联用后免疫试验动物,进行免疫效力的评价。试验结果表明,h5ha具有较好的免疫原性,可诱导spf鸡产生较高水平的igg,血凝抑制效价达1:64,病毒中和抗体效价为1:218,研究结果为h5亚型流感病毒亚单位疫苗的研制提供了理论支撑。周陈陈等人利用昆虫杆状病毒表达系统纯化的h7-ha蛋白免疫spf鸡后进行攻毒保护试验,评价该蛋白作为免疫对spf鸡的免疫保护效力,结果显示ha蛋白免疫组鸡只得到100%保护。研究表明以sf9细胞表达的h-ha、l-ha重组蛋白配制成油乳剂疫苗免疫14日龄的spf鸡。免疫后第14、21、28天翅下静脉采血,通过血凝抑制试验(hi)和elisa试验检测抗体效价,结果表明免疫后的各组均能够刺激机体产生较高的抗体。在免疫后的第3、5、7、10天,经fcas检测cd3+/cd4+和cd3+/cd8+t淋巴细胞亚群的变化规律和淋巴细胞转化试验。结果表明,2个重组蛋白组鸡的cd3+/cd4+和cd3+/cd8+t淋巴细胞亚群比例稍高于灭活疫苗组,淋巴细胞转化试验亦表明,2个重组蛋白组鸡的淋巴细胞转化效率略高于常规灭活疫苗组。以上结果表明,重组蛋白制备的疫苗能够刺激机体产生体液免疫和细胞免疫,具有较好的免疫原性,综合效果略优于现有h5亚型禽流感灭活疫苗。
但是,现有技术中的疫苗大多仅针对一种亚型,无法具有广谱性。通常具有多价疫苗是将多种病毒灭活或对多个片段分别重组后制备的疫苗。其生产成本较高,生产周期也较长。因此,进一步研发,生产成本低,能同时刺激机体产生针对多种亚型病毒的免疫力的禽流感疫苗具有重要意义。
技术实现要素:
有鉴于此,本发明要解决的技术问题在于提供重组禽流感亚单位疫苗及其制备方法,该疫苗具有广谱的免疫性。
本发明提供了ha亚单位,其具有如seqidno:1所示的氨基酸序列。
本发明提供了编码ha亚单位的核酸,其具有如seqidno:2所示的序列。
本发明提供了ha重组抗原,包括顺序连接的:信号肽片段、本发明所述的ha亚单位、凝血酶片段、三聚体标签和筛选标记。
其中,信号肽片段的氨基酸序列为mkvkllvllctftatya。
ha亚单位的氨基酸序列如seqidno:1所示。
dqicigysannsteqvdtimeknvtvtqaqdilekkhngklcdldgvkplilrdcsvagwllgnpmcdefinvpewsyivekanpvndlcypgdfndyeelkhllsrinhfekiqiipksswssheaslgvssacpyqgkssffrnvvwlikkdstyptikrsynntnqedllvlwgihhpndaaeqtklyqnpttyisvgtstlnqrlvpriatrskvkglsgrmeffwtilkpndainfesngnfiapeyaykivkkgdstimkseleygncntkcqtpmgainssmpfhnihpltigecpkyvksnrlvlaiglrnspqretqglfgaiagfteggwtgmvdglygyhhqneqgsgyaadqkstqnaingitnkvnsviekmntqytavgkefnkserrmenlnkkvddgfidiwtynaellvllenertldfhdsnvknlyekvksqlknnakeigngcfefyhkcndecmesvkngtydypkyseesklnrekidgvkr
凝血酶片段的氨基酸序列为lvprgs。
三聚体标签的氨基酸序列为gyipeaprdgqayvrkdgewvllstflg。
所述筛选标记为6×his标签,即hhhhhh。
本发明中,所述ha重组抗原的氨基酸序列如seqidno:3所示。
atmkvkllvllctftatyadqicigysannsteqvdtimeknvtvtqaqdilekkhngklcdldgvkplilrdcsvagwllgnpmcdefinvpewsyivekanpvndlcypgdfndyeelkhllsrinhfekiqiipksswssheaslgvssacpyqgkssffrnvvwlikkdstyptikrsynntnqedllvlwgihhpndaaeqtklyqnpttyisvgtstlnqrlvpriatrskvkglsgrmeffwtilkpndainfesngnfiapeyaykivkkgdstimkseleygncntkcqtpmgainssmpfhnihpltigecpkyvksnrlvlaiglrnspqretqglfgaiagfteggwtgmvdglygyhhqneqgsgyaadqkstqnaingitnkvnsviekmntqytavgkefnkserrmenlnkkvddgfidiwtynaellvllenertldfhdsnvknlyekvksqlknnakeigngcfefyhkcndecmesvkngtydypkyseesklnrekidgvkrlvprgspgsgyipeaprdgqayvrkdgewvllstflghhhhhh*
编码ha重组抗原的核酸,其具有如seqidno:4所示的序列。
gccaccatgaaggtcaagctgctggtcctcctctgcaccttcaccgccacctacgccgaccagatttgcatcggctactccgccaacaacagcaccgagcaggtggacaccatcatggagaagaacgtgacagtgacccaagcccaggatatcctggagaagaagcacaacggcaagctctgcgacctggacggagtgaaacccctgatcctgagggattgtagcgtggcaggttggctgctgggaaaccccatgtgcgacgagttcatcaacgtccccgagtggagctatatcgtggagaaggccaacccagtgaacgacctctgctacccaggcgacttcaacgactacgaggagctgaagcacctgctgagccggatcaaccacttcgagaagatccagatcatccccaagagctcttggagcagccacgaagcctctctgggagtgtctagcgcctgtccttaccagggcaagagcagcttcttccggaacgtcgtctggctgatcaagaaggatagcacctaccccaccatcaagcggagctacaacaacaccaaccaggaggacctgctcgtgctgtggggcattcaccaccctaacgacgcagccgagcagaccaagctgtaccagaaccctaccacctacatcagcgtgggcacctctaccctgaaccagagactggtgcccaggatcgccaccagaagcaaagtgaagggcctgagcggccggatggagttcttttggaccatcctgaagcccaacgacgccatcaacttcgagagcaacggcaacttcatcgcccccgagtacgcctacaagatcgtgaagaagggcgacagcaccatcatgaagagcgagctggagtacggcaactgcaacaccaagtgccagacccctatgggcgccatcaacagcagcatgcccttccacaacatccaccccctgaccattggcgagtgtcctaagtacgtgaagagcaaccgcctggtgctggctatcggcctgagaaacagcccccagagagagacacaaggcctgttcggagccattgccggattcacagagggcggttggacaggcatggtggacggactgtacggataccaccaccagaacgagcagggatcaggatacgccgccgatcagaagagcacccagaacgccatcaacggcatcaccaacaaggtcaacagcgtgatcgagaagatgaacacccagtacaccgccgtgggcaaggagttcaacaagagcgagcggcggatggagaacctgaacaagaaggtggacgacggcttcatcgacatttggacctacaacgccgagctgctggtgctgctggaaaacgagaggaccctggacttccacgacagcaacgtgaagaacctgtacgagaaggtcaagagccagctgaagaacaacgccaaggagatcggcaacggctgcttcgagttctaccacaagtgcaacgacgagtgcatggagagcgtgaagaacggcacctacgactaccccaagtacagcgaggagagcaagctgaaccgggagaagatcgacggcgtgaagagactggtgccaagaggctctccaggaagcggctacatcccagaagcccctagagacggacaggcttacgtgcgaaaagacggcgagtgggtgctgctgagcacatttctgggacaccatcatcaccaccactag
其中,编码信号肽片段的核酸序列为atgaaggtcaagctgctggtcctcctctgcaccttcaccgccacctacgcc。
编码ha亚单位的核酸序列如seqidno:2所示。
gaccagatttgcatcggctactccgccaacaacagcaccgagcaggtggacaccatcatggagaagaacgtgacagtgacccaagcccaggatatcctggagaagaagcacaacggcaagctctgcgacctggacggagtgaaacccctgatcctgagggattgtagcgtggcaggttggctgctgggaaaccccatgtgcgacgagttcatcaacgtccccgagtggagctatatcgtggagaaggccaacccagtgaacgacctctgctacccaggcgacttcaacgactacgaggagctgaagcacctgctgagccggatcaaccacttcgagaagatccagatcatccccaagagctcttggagcagccacgaagcctctctgggagtgtctagcgcctgtccttaccagggcaagagcagcttcttccggaacgtcgtctggctgatcaagaaggatagcacctaccccaccatcaagcggagctacaacaacaccaaccaggaggacctgctcgtgctgtggggcattcaccaccctaacgacgcagccgagcagaccaagctgtaccagaaccctaccacctacatcagcgtgggcacctctaccctgaaccagagactggtgcccaggatcgccaccagaagcaaagtgaagggcctgagcggccggatggagttcttttggaccatcctgaagcccaacgacgccatcaacttcgagagcaacggcaacttcatcgcccccgagtacgcctacaagatcgtgaagaagggcgacagcaccatcatgaagagcgagctggagtacggcaactgcaacaccaagtgccagacccctatgggcgccatcaacagcagcatgcccttccacaacatccaccccctgaccattggcgagtgtcctaagtacgtgaagagcaaccgcctggtgctggctatcggcctgagaaacagcccccagagagagacacaaggcctgttcggagccattgccggattcacagagggcggttggacaggcatggtggacggactgtacggataccaccaccagaacgagcagggatcaggatacgccgccgatcagaagagcacccagaacgccatcaacggcatcaccaacaaggtcaacagcgtgatcgagaagatgaacacccagtacaccgccgtgggcaaggagttcaacaagagcgagcggcggatggagaacctgaacaagaaggtggacgacggcttcatcgacatttggacctacaacgccgagctgctggtgctgctggaaaacgagaggaccctggacttccacgacagcaacgtgaagaacctgtacgagaaggtcaagagccagctgaagaacaacgccaaggagatcggcaacggctgcttcgagttctaccacaagtgcaacgacgagtgcatggagagcgtgaagaacggcacctacgactaccccaagtacagcgaggagagcaagctgaaccgggagaagatcgacggcgtgaagaga
编码凝血酶片段的核酸序列为ctggtgccaagaggctct。
编码三聚体标签的核酸序列为ggctacatcccagaagcccctagagacggacaggcttacgtgcgaaaagacggcgagtgggtgctgctgagcacatttctggga。
所述筛选标记为6×his标签,其编码核酸序列为caccatcatcaccaccac。
本发明还提供了na亚单位,其具有如seqidno:5所示的氨基酸序列。
psrsvklagnsslcpvsgwaiyskdnsvrigskgdvfvirepfiscsplecrtffltqgallndkhsngtikdrspyrtlmscpigevpspynsrfesvawsasachdginwltigisgpdngavavlkyngiitdtikswrnnilrtqesecacvngscftvmtdgpsngqasykifriekgkivksvemnapnyhyeecscypdsseitcvcrdnwhgsnrpwvsfnqnleyqigyicsgifgdnprpndktgscgpvssngangvkgfsfkygngvwigrtksissrngfemiwdpngwtgtdnnfsikqdivginewsgysgsfvqhpeltgldcirpcfwvelirgrpkentiwtsgssisfcgvnsdtvgwswpdgaelpftidk
编码na亚单位的核酸,具有如seqidno:6所示的序列。
本发明还提供了na重组抗原,包括顺序连接的:信号肽片段、筛选标签、四聚体标签、凝血酶片段和本发明所述的na亚单位。
其中,信号肽片段的氨基酸序列为mgagatgramdgprlllllllgvslgga。
筛选标签为flag标签序列,氨基酸序列为dykddddk。
na亚单位的氨基酸序列如seqidno:5所示。
psrsvklagnsslcpvsgwaiyskdnsvrigskgdvfvirepfiscsplecrtffltqgallndkhsngtikdrspyrtlmscpigevpspynsrfesvawsasachdginwltigisgpdngavavlkyngiitdtikswrnnilrtqesecacvngscftvmtdgpsngqasykifriekgkivksvemnapnyhyeecscypdsseitcvcrdnwhgsnrpwvsfnqnleyqigyicsgifgdnprpndktgscgpvssngangvkgfsfkygngvwigrtksissrngfemiwdpngwtgtdnnfsikqdivginewsgysgsfvqhpeltgldcirpcfwvelirgrpkentiwtsgssisfcgvnsdtvgwswpdgaelpftidk
四聚体标签的核酸序列为
agctccagtgattactcggacctacagagggtgaaacaggagcttctggaagaggtgaagaaggaattgcagaaagtgaaagaggaaatcattgaagccttcgtccaggagctgaggaagcggggttct。
凝血酶片段的核酸序列为ctggtgccaagaggctct。
本发明中,na重组抗原的氨基酸序列如seqidno:7所示。
atmgagatgramdgprlllllllgvslggadykddddksssdysdlqrvkqelleevkkelqkvkeeiieafvqelrkrgslvprgspsrsvklagnsslcpvsgwaiyskdnsvrigskgdvfvirepfiscsplecrtffltqgallndkhsngtikdrspyrtlmscpigevpspynsrfesvawsasachdginwltigisgpdngavavlkyngiitdtikswrnnilrtqesecacvngscftvmtdgpsngqasykifriekgkivksvemnapnyhyeecscypdsseitcvcrdnwhgsnrpwvsfnqnleyqigyicsgifgdnprpndktgscgpvssngangvkgfsfkygngvwigrtksissrngfemiwdpngwtgtdnnfsikqdivginewsgysgsfvqhpeltgldcirpcfwvelirgrpkentiwtsgssisfcgvnsdtvgwswpdgaelpftidk*
本发明还提供了编码na重组抗原的核酸,其具有如seqidno:8所示的序列。
gccaccatgggggcaggtgccaccggccgcgccatggacgggccgcgcctgctgctgttgctgcttctgggggtgtcccttggaggtgccgattataaggatgatgatgataagagctccagtgattactcggacctacagagggtgaaacaggagcttctggaagaggtgaagaaggaattgcagaaagtgaaagaggaaatcattgaagccttcgtccaggagctgaggaagcggggttctctggtaccacgaggtagtccatcacgatcagtgaaattagcgggcaattcctctctctgccctgttagtggatgggctatatacagtaaagacaacagtgtaagaatcggttccaagggggatgtgtttgtcataagggaaccattcatatcatgctcccccttggaatgcagaaccttcttcttgactcaaggggccttgctaaatgacaaacattccaatggaaccattaaagacaggagcccatatcgaaccctaatgagctgtcctattggtgaagttccctctccatacaactcaagatttgagtcagtcgcttggtcagcaagtgcttgtcatgatggcatcaattggctaacaattggaatttctggcccagacaatggggcagtggctgtgttaaagtacaacggcataataacagacactatcaagagttggagaaacaatatattgagaacacaagagtctgaatgtgcatgtgtaaatggttcttgctttactgtaatgaccgatggaccaagtaatggacaggcctcatacaagatcttcagaatagaaaagggaaagatagtcaaatcagtcgaaatgaatgcccctaattatcactatgaggaatgctcctgttatcctgattctagtgaaatcacatgtgtgtgcagggataactggcatggctcgaatcgaccgtgggtgtctttcaaccagaatctggaatatcagataggatacatatgcagtgggattttcggagacaatccacgccctaatgataagacaggcagttgtggtccagtatcgtctaatggagcaaatggagtaaaagggttttcattcaaatacggcaatggtgtttggatagggagaactaaaagcattagttcaagaaacggttttgagatgatttgggatccgaacggatggactgggacagacaataacttctcaataaagcaagatatcgtaggaataaatgagtggtcaggatatagcgggagttttgttcagcatccagaactaacagggctggattgtataagaccttgcttctgggttgaactaatcagagggcgacccaaagagaacacaatctggactagcgggagcagcatatccttttgtggtgtaaacagtgacactgtgggttggtcttggccagacggtgctgagttgccatttaccattgacaagtaa
其中,编码信号肽片段的核酸序列为atgggggcaggtgccaccggccgcgccatggacgggccgcgcctgctgctgttgctgcttctgggggtgtcccttggaggtgcc。
筛选标签为flag标签序列,氨基酸序列为dykddddk,编码该标签的核酸序列为gattataaggatgatgatgataag。
编码na亚单位的核酸序列如seqidno:6所示。
ccatcacgatcagtgaaattagcgggcaattcctctctctgccctgttagtggatgggctatatacagtaaagacaacagtgtaagaatcggttccaagggggatgtgtttgtcataagggaaccattcatatcatgctcccccttggaatgcagaaccttcttcttgactcaaggggccttgctaaatgacaaacattccaatggaaccattaaagacaggagcccatatcgaaccctaatgagctgtcctattggtgaagttccctctccatacaactcaagatttgagtcagtcgcttggtcagcaagtgcttgtcatgatggcatcaattggctaacaattggaatttctggcccagacaatggggcagtggctgtgttaaagtacaacggcataataacagacactatcaagagttggagaaacaatatattgagaacacaagagtctgaatgtgcatgtgtaaatggttcttgctttactgtaatgaccgatggaccaagtaatggacaggcctcatacaagatcttcagaatagaaaagggaaagatagtcaaatcagtcgaaatgaatgcccctaattatcactatgaggaatgctcctgttatcctgattctagtgaaatcacatgtgtgtgcagggataactggcatggctcgaatcgaccgtgggtgtctttcaaccagaatctggaatatcagataggatacatatgcagtgggattttcggagacaatccacgccctaatgataagacaggcagttgtggtccagtatcgtctaatggagcaaatggagtaaaagggttttcattcaaatacggcaatggtgtttggatagggagaactaaaagcattagttcaagaaacggttttgagatgatttgggatccgaacggatggactgggacagacaataacttctcaataaagcaagatatcgtaggaataaatgagtggtcaggatatagcgggagttttgttcagcatccagaactaacagggctggattgtataagaccttgcttctgggttgaactaatcagagggcgacccaaagagaacacaatctggactagcgggagcagcatatccttttgtggtgtaaacagtgacactgtgggttggtcttggccagacggtgctgagttgccatttaccattgacaagtaa
编码四聚体标签的核酸序列为ctggtaccacgaggtagt。
编码凝血酶片段的核酸序列为ctggtaccacgaggtagt。
本发明还提供了包含编码ha重组抗原的核酸的重组载体。
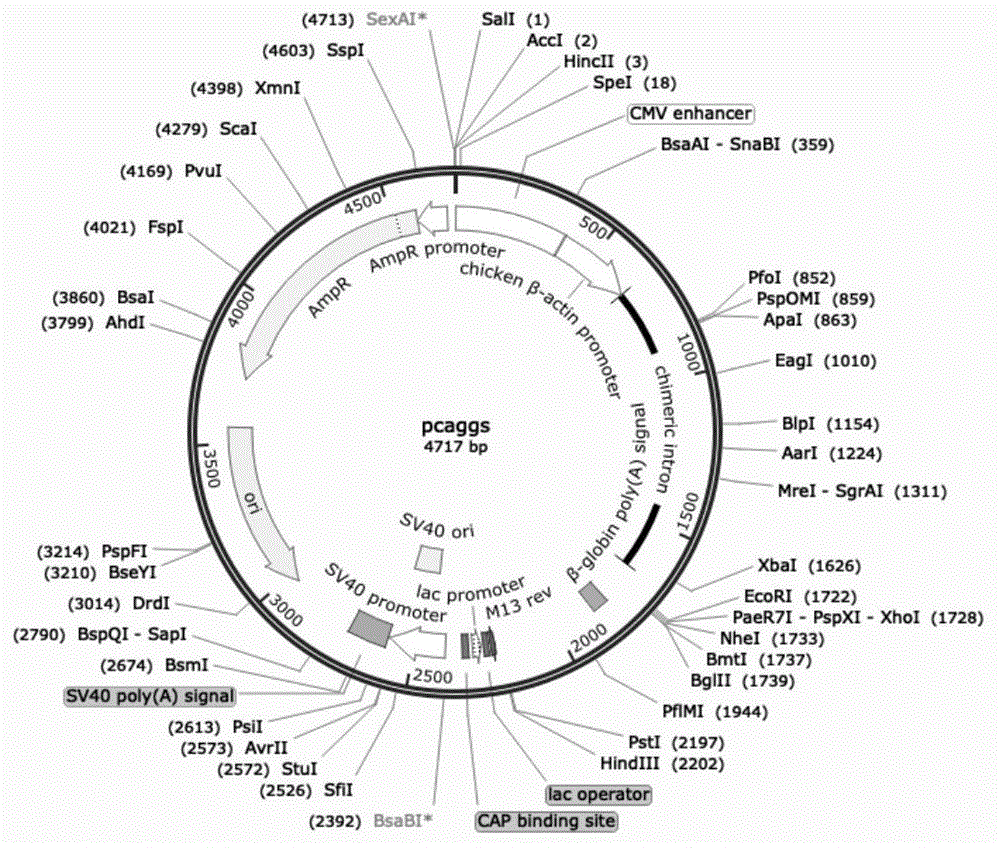
所述重组载体的骨架载体为pcaggs载体,核酸片段的插入位点为ecorⅰ和xhoⅰ。
本发明还提供了包含编码na重组抗原的核酸的重组载体。
所述重组载体的骨架载体为pcaggs载体,核酸片段的插入位点为ecorⅰ和xhoⅰ。
本发明还提供了转化或转染有包含编码ha重组抗原的核酸的重组载体的宿主细胞。
本发明中,所述宿主细胞中还转化或转染有包含编码na重组抗原的核酸的重组载体。
一些实施例中,所述宿主细胞293t细胞
本发明还提供了一种重组ha蛋白,其由本发明所述的宿主细胞表达获得。
本发明所述的重组ha蛋白由宿主细胞表达编码重组ha抗原的核酸获得,该核酸片段上携带有三聚体标签,因此形成的蛋白具有三聚体结构,三聚体标签在thrombin酶切后从ha蛋白上脱落。宿主中同时表达na,用于辅助ha的表达和分泌,从而大幅提高ha的表达量,提高免疫效果。
本发明还提供了一种疫苗,其包括本发明所述的重组ha蛋白。
所述疫苗中,还包括佐剂,所述佐剂为弗氏完全佐剂和弗氏不完全佐剂、mf59佐剂。
所述疫苗中,重组ha蛋白的浓度为10mg/ml。
本发明还提供了所述的疫苗在制备防治禽流感的制剂中的应用。
本发明还提供了一种防治禽流感的方法,其为给予本发明所述的疫苗。
本发明所述禽流感包括h1亚型禽流感、h5亚型禽流感或h9亚型禽流感。
本发明所述的禽流感为禽类的禽流感。一些实施例中,所述禽流感为鸡的禽流感。
本发明通过保留h5亚型禽流感主要保护性抗原ha骨架中的头部结构,同时将疫苗h5的颈部区替换为经过结构生物学设计改造后的具有广谱免疫保护的流感ha颈部区,该颈部区在动物实验中证实可以保护不同亚型的禽流感病毒。
附图说明
图1示pcaggs空载图谱;
图2示典型的h5/h1-lsq蛋白(a)和h5/h1全长蛋白(b)的分子筛图谱和sds-page胶图;
图3中,a、b是抗体fl6v3结合h5/h1-lsq(a)和h5/h1(b)蛋白表面等离子共振动力学曲线;c、d是抗体cr6261结合h5/h1-lsq(c)和h5/h1(d)蛋白表面等离子共振动力学曲线。横坐标是结合解离时间,单位是秒(s);纵坐标是芯片表面的结合响应强度,单位是ru(即responseunit);
图4示免疫组血清对流感病毒h5n8的中和实验结果;
图5示免疫组血清对流感病毒h1n1的中和实验结果;
图6示elisa检测鸡血清中特异性的抗体,包板蛋白为h5/h1全长蛋白(a)、h5/h1-lsq嵌合蛋白(b)、h9蛋白(c);其中,柱子编号1~7分别为1:h5/h1-lsq嵌合苗免疫血清、2:h5/h1全长免疫血清、3:空白组血清、4:h9+新城疫二联苗免疫血清、5:h5+h7二联苗免疫血清、6:pbs免疫血清、7:无关抗体strep阴性对照;
图7示病毒血凝试验的操作方法及h9病毒效价;
图8a示血抑试验结果;
图8b示抗体效价统计结果,其中柱子1~5分别为1:h5/h1-lsq嵌合苗;2:h5/h1疫苗;3:h9+新城疫二联苗;4:h5+h7二联苗;5:pbs免疫组;
图9示h5/h1-lsq嵌合苗、h9+新城疫二联苗、h5/h1疫苗、h5+h7二联苗免疫小鸡2周后h9攻毒4天、10天后,血凝试验检测h9攻毒后的病毒效价。
具体实施方式
本发明提供了重组禽流感亚单位疫苗及其制备方法,本领域技术人员可以借鉴本文内容,适当改进工艺参数实现。特别需要指出的是,所有类似的替换和改动对本领域技术人员来说是显而易见的,它们都被视为包括在本发明。本发明的方法及应用已经通过较佳实施例进行了描述,相关人员明显能在不脱离本发明内容、精神和范围内对本文的方法和应用进行改动或适当变更与组合,来实现和应用本发明技术。
本发明采用的试材皆为普通市售品,皆可于市场购得。
除非另有定义,本文使用的所有科技术语具有本领域普通技术人员所理解的相同含义。关于本领域的定义及术语,专业人员具体可参考currentprotocolsinmolecularbiology(ausubel)。氨基酸残基的缩写是本领域中所用的指代20个常用l-氨基酸之一的标准3字母和/或1字母代码。
h5亚型禽流感病毒(avianinfluenzavirus,aiv)是严重危害着我国养禽业的发展。流感病毒的结构是从外到内依次为囊膜、蛋白质外壳、核衣壳。病毒粒子的表面有三种膜蛋白,分别是血凝素(hemagglutinin,ha)、神经氨酸酶(neuraminidase,na)以及matrix2(m2)蛋白。
ha在病毒囊膜近端呈现出紧密盘绕的结构为ha颈部区,远离囊膜表面的一端结构域呈球形结构的是ha头部区,头部区有受体结合位点。ha前体蛋白分子ha0被宿主蛋白酶裂解为ha1和ha2,ha头部区由大部分的ha1构成,是主要的抗原靶位,一小部分的ha1和ha2组成ha颈部区,ha1比ha2的保守性差,但是自然感染或是接种流感疫苗后,产生的大部分中和抗体是针对ha头部区的。
本发明所述的ha亚单位根据h5亚型禽流感病毒的核酸序列设计,以该片段免疫机体能够产生广谱保护性,不仅对h5亚型的流感病毒有效,对h1亚型和h9亚型同样具有良好的保护作用。
本本发明基于自主研发的流感表面关键抗原ha的三聚体哺乳动物表达形式蛋白,构建了新型重组蛋白疫苗。通过保留h5亚型禽流感主要保护性抗原ha骨架中的头部结构,同时将疫苗h5的颈部区替换为经过结构生物学设计改造后的具有广谱免疫保护的流感ha颈部区,该颈部区在动物实验中证实可以对不同亚型的禽流感病毒可提供广谱保护。新重组蛋白疫苗与天然h5三聚体蛋白在结构、分子量上保持一致。可继续采用哺乳细胞表达系统表达纯化重组三聚体蛋白,不仅降低了生产成本,还打破了灭活疫苗所需要培养病毒的限制,在一定程度上保证了安全性。
下面结合实施例,进一步阐述本发明:
实施例1
一、h5亚型ha基因、na基因质粒构建:
我们将编码ha或na的dna片段进行双酶切(ecorⅰ和xhoⅰ酶切位点)连入pcaggs载体(图谱如图1)中,并在蛋白的编码片段前加入信号肽序列有助于蛋白分泌表达,在蛋白的编码片段后插入6个组氨酸标签(hexa-his-tag)的编码序列及翻译终止密码子,这样会得到一个c-端带有组氨酸标签的重组蛋白,便于后续的蛋白纯化。重组质粒通过pcr、酶切鉴定和测序证实插入的外源片段完全正确。因ha在哺乳动物细胞中表达时,其上会粘附有唾液酸导致与受体没有结合能力,因此也进行了na的表达,选取了09na的基因,并加上flag标签以便于检测。
ha基因序列(全长如seqidno:4所示):ecori酶切位点--信号肽序列--ha基因序列--凝血酶位点--三聚体标签--histag-xhoi
na基因序列(全长如seqidno:8所示):ecori酶切位点--信号肽序列--flag标签dykdddd--四聚体标签--凝血酶酶切位点--09na序列--xhoi酶切位点
ha基因序列为:
gaccagatttgcatcggctactccgccaacaacagcaccgagcaggtggacaccatcatggagaagaacgtgacagtgacccaagcccaggatatcctggagaagaagcacaacggcaagctctgcgacctggacggagtgaaacccctgatcctgagggattgtagcgtggcaggttggctgctgggaaaccccatgtgcgacgagttcatcaacgtccccgagtggagctatatcgtggagaaggccaacccagtgaacgacctctgctacccaggcgacttcaacgactacgaggagctgaagcacctgctgagccggatcaaccacttcgagaagatccagatcatccccaagagctcttggagcagccacgaagcctctctgggagtgtctagcgcctgtccttaccagggcaagagcagcttcttccggaacgtcgtctggctgatcaagaaggatagcacctaccccaccatcaagcggagctacaacaacaccaaccaggaggacctgctcgtgctgtggggcattcaccaccctaacgacgcagccgagcagaccaagctgtaccagaaccctaccacctacatcagcgtgggcacctctaccctgaaccagagactggtgcccaggatcgccaccagaagcaaagtgaagggcctgagcggccggatggagttcttttggaccatcctgaagcccaacgacgccatcaacttcgagagcaacggcaacttcatcgcccccgagtacgcctacaagatcgtgaagaagggcgacagcaccatcatgaagagcgagctggagtacggcaactgcaacaccaagtgccagacccctatgggcgccatcaacagcagcatgcccttccacaacatccaccccctgaccattggcgagtgtcctaagtacgtgaagagcaaccgcctggtgctggctatcggcctgagaaacagcccccagagagagacacaaggcctgttcggagccattgccggattcacagagggcggttggacaggcatggtggacggactgtacggataccaccaccagaacgagcagggatcaggatacgccgccgatcagaagagcacccagaacgccatcaacggcatcaccaacaaggtcaacagcgtgatcgagaagatgaacacccagtacaccgccgtgggcaaggagttcaacaagagcgagcggcggatggagaacctgaacaagaaggtggacgacggcttcatcgacatttggacctacaacgccgagctgctggtgctgctggaaaacgagaggaccctggacttccacgacagcaacgtgaagaacctgtacgagaaggtcaagagccagctgaagaacaacgccaaggagatcggcaacggctgcttcgagttctaccacaagtgcaacgacgagtgcatggagagcgtgaagaacggcacctacgactaccccaagtacagcgaggagagcaagctgaaccgggagaagatcgacggcgtgaagaga
09na序列为:ccatcacgatcagtgaaattagcgggcaattcctctctctgccctgttagtggatgggctatatacagtaaagacaacagtgtaagaatcggttccaagggggatgtgtttgtcataagggaaccattcatatcatgctcccccttggaatgcagaaccttcttcttgactcaaggggccttgctaaatgacaaacattccaatggaaccattaaagacaggagcccatatcgaaccctaatgagctgtcctattggtgaagttccctctccatacaactcaagatttgagtcagtcgcttggtcagcaagtgcttgtcatgatggcatcaattggctaacaattggaatttctggcccagacaatggggcagtggctgtgttaaagtacaacggcataataacagacactatcaagagttggagaaacaatatattgagaacacaagagtctgaatgtgcatgtgtaaatggttcttgctttactgtaatgaccgatggaccaagtaatggacaggcctcatacaagatcttcagaatagaaaagggaaagatagtcaaatcagtcgaaatgaatgcccctaattatcactatgaggaatgctcctgttatcctgattctagtgaaatcacatgtgtgtgcagggataactggcatggctcgaatcgaccgtgggtgtctttcaaccagaatctggaatatcagataggatacatatgcagtgggattttcggagacaatccacgccctaatgataagacaggcagttgtggtccagtatcgtctaatggagcaaatggagtaaaagggttttcattcaaatacggcaatggtgtttggatagggagaactaaaagcattagttcaagaaacggttttgagatgatttgggatccgaacggatggactgggacagacaataacttctcaataaagcaagatatcgtaggaataaatgagtggtcaggatatagcgggagttttgttcagcatccagaactaacagggctggattgtataagaccttgcttctgggttgaactaatcagagggcgacccaaagagaacacaatctggactagcgggagcagcatatccttttgtggtgtaaacagtgacactgtgggttggtcttggccagacggtgctgagttgccatttaccattgacaagtaa
二、h5亚型ha蛋白的表达纯化:
将重组质粒转化top10感受态细胞,吸取适量菌液用划线法涂在带有氨苄(氨苄母液浓度:100mg/ml)抗性的固体lb平板(lb平板配方:1%nacl,1%tryptone,0.5%yeastextract,1.5%agarpowder;氨苄使用为1:1000)上,37℃过夜培养。挑取单克隆,5ml小摇菌液(氨苄抗性),之后再300ml过夜中摇,用无内毒素质粒大提试剂盒(tiangen,dp117)获得流感病毒抗原质粒。
用含10%fbs的dmem在37℃、5%co2培养箱中培养293t细胞。当293t细胞汇合度达到约70%时,用pei转染试剂将流感病毒抗原质粒(ha:na=20μg:20μg/盘)转染至293t细胞中,当转染4-6小时后,用无血清的dmem换液继续培养3天,收集细胞培养上清液,补加无血清的dmem继续培养4天,收集细胞培养上清液。
将细胞培养上清液与histraptmexcel(ge)于4℃结合过夜,准备蛋白洗脱缓冲液a液(20mmtris,150mmnacl,ph8.0)和缓冲液b液(20mmtris,150mmnacl,ph8.0,1mimidazole)。之后用缓冲液a液洗涤his柱,以去除非特异结合的蛋白,再用缓冲液2%的b液(20mmtris,150mmnacl,ph8.0,20mmimidazole)除去杂蛋白,最后将目的蛋白用30%的b液(20mmtris,150mmnacl,ph8.0,300mmimidazole)从his柱上洗脱下来,并以30kd截留(30kdcutoff)的蛋白浓缩管用缓冲液a液(20mmtris,150mmnacl,ph8.0)进行换液,以去除蛋白溶液里的咪唑浓度,最后将蛋白溶液浓缩至0.5ml,加入thrombin酶(1mg蛋白加5μlthrombin酶)4℃酶切过夜。将酶切后的蛋白溶液用分子筛进一步纯化,使用akta-purifier(ge)和columnhiload16/60superdex200pg分子筛(ge),分子筛用缓冲液a液(20mmtris,150mmnacl,ph8.0)进行柱平衡,1mlloop环上样,同时监测280nm的紫外吸收值,收取目的蛋白,并通过sds-page鉴定蛋白纯度。典型的目的蛋白的分子筛图谱和sds-page分析如图2所示:该蛋白在columnhiload16/60superdex200pg分子筛出峰位置为62.5ml,由于构建中在thrombin酶切位点(lvpr↓gs)后加入了三聚体标签,蛋白主峰三聚体形式,三聚体标签在thrombin酶切后从ha脱落,单体大小约为70kd。sds-page胶图泳道分别对应分子筛图中h5/h1-lsq蛋白的三聚体和单体。
三、表面等离子共振技术检测h5/h1-lsq和h5/h1蛋白与抗体cr6261及fl6v3的亲和力
表面等离子共振分析是用biacore8000(biacoreinc.)进行的。具体步骤如下:
首先,将抗原h5/h1-lsq和h5/h1蛋白固定在sa芯片(ge)上,然后将浓度梯度为6.25nm-100nm的抗体cr6261及fl6v3分别注入芯片,分析在恒温25℃进行,使用的缓冲液是hepes-tween缓冲液(10mmhepes[ph7.4],150mmnacl,0.005%tween-20),流速为30μl/min。芯片表面的再生使用的是10mmnaoh,结合曲线如图3所示,不同浓度的曲线组成图示的动力学曲线。结合动力学常数的计算是利用biaevaluationsoftwareversion3.2(biacore,inc.)软件进行的。结果表明,抗体fl6v3和h5/h1-lsq蛋白的亲和力常数为165nm(a);抗体fl6v3和h5/h1蛋白的亲和力常数为2.5nm(b);抗体cr6261和h5/h1-lsq蛋白的亲和力常数为1.46μm(c);抗体cr6261和h5/h1-lsq蛋白的亲和力常数为8.12nm(d)。
实施例2h5/h1-lsq疫苗制备
h5/h1-lsq蛋白浓度为10mg/ml,用pbs稀释蛋白,将蛋白与等体积的弗氏完全佐剂或弗氏不完全佐剂进行混合完全乳化至浴水不化开用于动物接种。
对比例1h5/h1疫苗的制备
h5/h1蛋白浓度为10mg/ml,用pbs稀释蛋白,将蛋白与等体积的弗氏完全佐剂或弗氏不完全佐剂进行混合完全乳化至浴水不化开用于动物接种。
实施例3
1,实验动物:4-6周龄balb/c雌鼠,每组6只,免疫方式为肌肉注射。
2,组别设置:①阴性对照(佐剂mf59);②阳性对照(流感病毒裂解疫苗tiv);③实验组h5/h1-lsq(实施例2制得的疫苗);④实验组h5/h1(对比例1制得的疫苗)。
3、实验步骤:
3.1动物免疫:
一免:阴性组及实验组免疫剂量为每只100μl;阳性组免疫剂量为每只100μl。
实验组每只动物免疫剂量为20μg/100μl/只,用pbs稀释蛋白,每组6只,将不同实验组蛋白与等体积的mf59佐剂进行混合,振荡至完全乳化至浴水不化开用于动物免疫。
二免:(一免14天后进行二免):阴性组及实验组免疫剂量每只100μl;阳性组免疫剂量为每只100μl。
实验组每只动物免疫剂量为20μg/100μl/只,用pbs稀释蛋白,每组6只,将不同实验组蛋白与等体积的mf59佐剂进行混合振荡至完全乳化至浴水不化开用于动物免疫。
三免:(二免14天后进行三免):阴性组及实验组免疫剂量每只100μl;
实验组每只动物免疫剂量为20μg/100μl/只,用pbs稀释蛋白,每组6只,将不同实验组蛋白与等体积的mf59佐剂进行混合振荡至完全乳化至浴水不化开用于动物免疫。
3.2血清分离:
将以上免疫组别的小鼠进行眼球取血,制备血清,小鼠血清利用red进行处理,按照1体积的血清,加入4体积的rde,37℃水浴18h,56℃灭活30min,用于后续实验。
3.3,h5n8毒株以及h1n1毒株进行tcid50测定
a,采用10倍连续稀释的方式,即10-1、10-2....10-10,可采用1.5ep管,900μl病毒稀释液+100μl的病毒原液。
b,提前18-24h铺好96孔板,每孔加入100μl(2×105个/ml)mdck细胞。37℃,5%的co2培养箱内进行培养。
c,病毒接种,用pbs洗涤细胞1次,每孔150μl,之后按照第一步稀释好的病毒液加入96孔板中,每一稀释度接种一纵排,每孔100μl,在11列和12列设定稀释液对照,37℃培养箱培养。
d,逐日观察并记录结果,72h后结果计算按照reed-muench法。
3.4,中和实验:
a,病毒稀释
利用病毒培养液稀释到200tcid50/100μl。
b,血清阴性对照(只添加细胞维持液)
血清稀释:小鼠血清起始稀释倍数为1:20,按照2倍比稀释进行中和试验。
c,病毒孵育
将稀释好的病毒(100tcid50)50μl加入到50μl的血清中,混合均匀,放置37℃,孵育1h。
d,mdck细胞吸附
mdck细胞,利用pbs洗涤150μl洗涤一次,之后弃净,每孔添加100μl的病毒-血清混合液,平行三孔,放入细胞培养箱中培养72h。
e,利用血抑实验进行结果观察计算,结果如图4~5所示。
图4显示:“i”表示鸡红细胞垂直流动,细胞结构完整,说明血清能抑制流感病毒的入侵;“·”表示鸡红细胞开始发生凝集现象并未垂直流动,说明血清能中和部分流感病毒;
图5显示:“i”表示鸡红细胞垂直流动,细胞结构完整,说明血清能抑制流感病毒的入侵;“·”表示鸡红细胞开始发生凝集现象并未垂直流动,说明血清能中和部分流感病毒;
实施例4
1、实验动物:
7日龄小鸡,每组5只,免疫方式为颈部皮下注射。
2、实验组别设置:
①空白对照;②阴性对照(pbs);③阳性对照(h9+新城疫二联苗);④阳性对照组(h5+h7二联苗);⑤实验组h5/h1-lsq(实施例2制得的疫苗);⑥实验组h5/h1(对比例1制得的疫苗)。
3、实验步骤:
3.1动物免疫:
一免:对照组免疫剂量每只200μl;
实验组每只动物免疫剂量为50μg/100μl/只,用pbs稀释蛋白,每组5只,将不同实验组蛋白与等体积的弗氏完全佐剂进行混合(每只小鸡免疫体积为200μl)完全乳化至浴水不化开用于动物接种。
二免:(一免14天后进行二免):对照组免疫剂量每只200μl;
实验组每只动物免疫剂量为50μg/100μl/只,用pbs稀释蛋白,每组5只,将不同实验组蛋白与等体积的弗氏不完全佐剂进行混合(每只小鸡免疫体积为200μl)完全乳化至浴水不化开用于动物接种。
攻毒:(二免2周后):滴鼻攻毒h9,每只小鸡攻毒剂量300μl(四单位病毒液1:25)。用棉签对每只小鸡的口和肛进行攻毒后4天、10天采样,保存在1ml病毒保存液中。用血凝实验检测h9病毒的增值情况。
3.2血清分离:
二免2周后心脏采血,低温下离心,收集血清,分装冻存-80℃。
3.3elisa检测鸡血清中特异性的抗体:
a,按照每孔蛋白量200ng包板4℃过夜;
b,洗涤:次日用含0.05%tween-20的pbst洗涤包被板,洗4次,每次5min;
c,封闭:加封闭液(5%脱脂奶粉,用pbst配置)200μl,室温封闭2h;
d,洗涤:用pbst洗涤待检测板子,洗4次,每次5min;
e,一抗孵育:用pbst稀释待检测血清,每孔加100μl待检测血清稀释液,37℃孵育1h;无关抗体(strep的一抗1:5000稀释(鼠源))做阴性对照;
f,洗涤:pbst冲洗包被板,洗涤5次,每次5min;
g,二抗孵育:以pbst(1:5000稀释)稀释hrp标记的羊抗鸡二抗,每孔加100μl,37℃孵育1h;无关抗体(strep的一抗1:5000稀释(鼠源))的二抗(羊抗鼠二抗(1:5000稀释))做阴性对照;
h,洗涤:pbst冲洗包被板,洗涤5次,每次5min;
i,显色:加入tmb底物缓冲液色,50μl/孔,避光显色3min,elisa终止液终止反应,50μl/孔,在od450nm下读数。
结果如图3,结果显示:h5/h1-lsq嵌合苗免疫后比空白组以及pbs免疫组激发产生的更多的抗体,与h9+新城疫二联苗免疫后相比也能产生较高的抗体;与pbs组相比,h5/h1-lsq嵌合苗和h5/h1疫苗免疫后也能激发较多与h9毒株ha结合的抗体。
3.4血凝试验
a,在血凝板中每孔加入25μlpbs。第一孔加入灭活h9亚型禽流感病毒25μl,依次作2倍系列稀释,同时设立阴性对照孔。
b,每孔加入25μl1%鸡红细胞悬浮液,水平振荡器上振荡1~2min混匀,37℃静置30min后判定结果。
注:1%鸡红细胞悬浮液制备:
准备:新鲜鸡抗凝血,pbs,离心管,低速离心机
步骤:抗凝血第一次离心:1500rpm/min离心5min,去除上层白细胞血浆等,加pbs颠倒混匀;第二次离心:1500rpm/min离心5min,去除上层白细胞血浆等;第三次离心:1500rpm/min离心5min,去除上层白细胞血浆等;99mlpbs+1ml红细胞制得1%鸡红细胞悬浮液。
具体操作方法参见图7,结果表明:以100%凝集(++++)的病毒最大稀释度为该病毒血凝价,即为一个凝集单位,从图6中可以看出,h9亚型禽流感病毒血凝效价为1:128(27)。
3.5,血凝抑制试验
根据3.4中结果制备四单位病毒液:将灭活h9亚型禽流感病毒的血凝价除以4作为四单位病毒液的稀释度(即128/4=32(25));
a,在血凝板中每孔加入25μlpbs,第一孔加入25μl待检血清(原血清1:4稀释后),依次作2倍梯度稀释,同时设立阴性对照孔(pbs);
b,除阴性对照孔之外,每孔加入25μl四单位病毒液:置水平振荡器上振荡12min后,37℃静置15min;
c,每孔加入25μl1%鸡红细胞悬浮液,水平振荡器上振荡1~2min混匀,37℃静置30min后判定结果。
结果如图8a和图8b所示,结果显示:“i”表示鸡红细胞垂直流动,细胞结构完整,说明血清能抑制流感病毒的入侵;“·”表示鸡红细胞开始发生凝集现象并未垂直流动,说明血清能中和部分流感病毒;
3.6,血凝试验检测h9病毒:
a,在血凝板中每孔加入25μlpbs。第一孔加入灭活h9亚型禽流感病毒25μl,依次作2倍系列稀释,同时设立阴性对照孔。
b,每孔加入25μl1%鸡红细胞悬浮液,水平振荡器上振荡1~2min混匀,37℃静置30min后判定结果。
结果如图9所示,结果显示:攻h9毒后,h5/h1-lsq嵌合苗的免疫效果与h9+新城疫二联苗和h5/h1疫苗相比能较好抑制h9病毒增殖。
以上仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
序列表
<110>山西高等创新研究院
<120>重组禽流感亚单位疫苗及其制备方法
<130>mp2031561
<160>8
<170>siposequencelisting1.0
<210>1
<211>504
<212>prt
<213>人工序列(artificialsequence)
<400>1
aspglnilecysileglytyrseralaasnasnserthrgluglnval
151015
aspthrilemetglulysasnvalthrvalthrglnalaglnaspile
202530
leuglulyslyshisasnglylysleucysaspleuaspglyvallys
354045
proleuileleuargaspcysservalalaglytrpleuleuglyasn
505560
prometcysaspglupheileasnvalproglutrpsertyrileval
65707580
glulysalaasnprovalasnaspleucystyrproglyasppheasn
859095
asptyrglugluleulyshisleuleuserargileasnhispheglu
100105110
lysileglnileileprolyssersertrpserserhisglualaser
115120125
leuglyvalserseralacysprotyrglnglylysserserphephe
130135140
argasnvalvaltrpleuilelyslysaspserthrtyrprothrile
145150155160
lysargsertyrasnasnthrasnglngluaspleuleuvalleutrp
165170175
glyilehishisproasnaspalaalagluglnthrlysleutyrgln
180185190
asnprothrthrtyrileservalglythrserthrleuasnglnarg
195200205
leuvalproargilealathrargserlysvallysglyleusergly
210215220
argmetgluphephetrpthrileleulysproasnaspalaileasn
225230235240
phegluserasnglyasnpheilealaproglutyralatyrlysile
245250255
vallyslysglyaspserthrilemetlyssergluleuglutyrgly
260265270
asncysasnthrlyscysglnthrprometglyalaileasnserser
275280285
metprophehisasnilehisproleuthrileglyglucysprolys
290295300
tyrvallysserasnargleuvalleualaileglyleuargasnser
305310315320
proglnarggluthrglnglyleupheglyalailealaglyphethr
325330335
gluglyglytrpthrglymetvalaspglyleutyrglytyrhishis
340345350
glnasngluglnglyserglytyralaalaaspglnlysserthrgln
355360365
asnalaileasnglyilethrasnlysvalasnservalileglulys
370375380
metasnthrglntyrthralavalglylysglupheasnlysserglu
385390395400
argargmetgluasnleuasnlyslysvalaspaspglypheileasp
405410415
iletrpthrtyrasnalagluleuleuvalleuleugluasngluarg
420425430
thrleuaspphehisaspserasnvallysasnleutyrglulysval
435440445
lysserglnleulysasnasnalalysgluileglyasnglycysphe
450455460
gluphetyrhislyscysasnaspglucysmetgluservallysasn
465470475480
glythrtyrasptyrprolystyrserglugluserlysleuasnarg
485490495
glulysileaspglyvallysarg
500
<210>2
<211>1512
<212>dna
<213>人工序列(artificialsequence)
<400>2
gaccagatttgcatcggctactccgccaacaacagcaccgagcaggtggacaccatcatg60
gagaagaacgtgacagtgacccaagcccaggatatcctggagaagaagcacaacggcaag120
ctctgcgacctggacggagtgaaacccctgatcctgagggattgtagcgtggcaggttgg180
ctgctgggaaaccccatgtgcgacgagttcatcaacgtccccgagtggagctatatcgtg240
gagaaggccaacccagtgaacgacctctgctacccaggcgacttcaacgactacgaggag300
ctgaagcacctgctgagccggatcaaccacttcgagaagatccagatcatccccaagagc360
tcttggagcagccacgaagcctctctgggagtgtctagcgcctgtccttaccagggcaag420
agcagcttcttccggaacgtcgtctggctgatcaagaaggatagcacctaccccaccatc480
aagcggagctacaacaacaccaaccaggaggacctgctcgtgctgtggggcattcaccac540
cctaacgacgcagccgagcagaccaagctgtaccagaaccctaccacctacatcagcgtg600
ggcacctctaccctgaaccagagactggtgcccaggatcgccaccagaagcaaagtgaag660
ggcctgagcggccggatggagttcttttggaccatcctgaagcccaacgacgccatcaac720
ttcgagagcaacggcaacttcatcgcccccgagtacgcctacaagatcgtgaagaagggc780
gacagcaccatcatgaagagcgagctggagtacggcaactgcaacaccaagtgccagacc840
cctatgggcgccatcaacagcagcatgcccttccacaacatccaccccctgaccattggc900
gagtgtcctaagtacgtgaagagcaaccgcctggtgctggctatcggcctgagaaacagc960
ccccagagagagacacaaggcctgttcggagccattgccggattcacagagggcggttgg1020
acaggcatggtggacggactgtacggataccaccaccagaacgagcagggatcaggatac1080
gccgccgatcagaagagcacccagaacgccatcaacggcatcaccaacaaggtcaacagc1140
gtgatcgagaagatgaacacccagtacaccgccgtgggcaaggagttcaacaagagcgag1200
cggcggatggagaacctgaacaagaaggtggacgacggcttcatcgacatttggacctac1260
aacgccgagctgctggtgctgctggaaaacgagaggaccctggacttccacgacagcaac1320
gtgaagaacctgtacgagaaggtcaagagccagctgaagaacaacgccaaggagatcggc1380
aacggctgcttcgagttctaccacaagtgcaacgacgagtgcatggagagcgtgaagaac1440
ggcacctacgactaccccaagtacagcgaggagagcaagctgaaccgggagaagatcgac1500
ggcgtgaagaga1512
<210>3
<211>566
<212>prt
<213>人工序列(artificialsequence)
<400>3
alathrmetlysvallysleuleuvalleuleucysthrphethrala
151015
thrtyralaaspglnilecysileglytyrseralaasnasnserthr
202530
gluglnvalaspthrilemetglulysasnvalthrvalthrglnala
354045
glnaspileleuglulyslyshisasnglylysleucysaspleuasp
505560
glyvallysproleuileleuargaspcysservalalaglytrpleu
65707580
leuglyasnprometcysaspglupheileasnvalproglutrpser
859095
tyrilevalglulysalaasnprovalasnaspleucystyrprogly
100105110
asppheasnasptyrglugluleulyshisleuleuserargileasn
115120125
hispheglulysileglnileileprolyssersertrpserserhis
130135140
glualaserleuglyvalserseralacysprotyrglnglylysser
145150155160
serphepheargasnvalvaltrpleuilelyslysaspserthrtyr
165170175
prothrilelysargsertyrasnasnthrasnglngluaspleuleu
180185190
valleutrpglyilehishisproasnaspalaalagluglnthrlys
195200205
leutyrglnasnprothrthrtyrileservalglythrserthrleu
210215220
asnglnargleuvalproargilealathrargserlysvallysgly
225230235240
leuserglyargmetgluphephetrpthrileleulysproasnasp
245250255
alaileasnphegluserasnglyasnpheilealaproglutyrala
260265270
tyrlysilevallyslysglyaspserthrilemetlyssergluleu
275280285
glutyrglyasncysasnthrlyscysglnthrprometglyalaile
290295300
asnsersermetprophehisasnilehisproleuthrileglyglu
305310315320
cysprolystyrvallysserasnargleuvalleualaileglyleu
325330335
argasnserproglnarggluthrglnglyleupheglyalaileala
340345350
glyphethrgluglyglytrpthrglymetvalaspglyleutyrgly
355360365
tyrhishisglnasngluglnglyserglytyralaalaaspglnlys
370375380
serthrglnasnalaileasnglyilethrasnlysvalasnserval
385390395400
ileglulysmetasnthrglntyrthralavalglylysglupheasn
405410415
lyssergluargargmetgluasnleuasnlyslysvalaspaspgly
420425430
pheileaspiletrpthrtyrasnalagluleuleuvalleuleuglu
435440445
asngluargthrleuaspphehisaspserasnvallysasnleutyr
450455460
glulysvallysserglnleulysasnasnalalysgluileglyasn
465470475480
glycysphegluphetyrhislyscysasnaspglucysmetgluser
485490495
vallysasnglythrtyrasptyrprolystyrserglugluserlys
500505510
leuasnargglulysileaspglyvallysargleuvalproarggly
515520525
serproglyserglytyrileproglualaproargaspglyglnala
530535540
tyrvalarglysaspglyglutrpvalleuleuserthrpheleugly
545550555560
hishishishishishis
565
<210>4
<211>1701
<212>dna
<213>人工序列(artificialsequence)
<400>4
gccaccatgaaggtcaagctgctggtcctcctctgcaccttcaccgccacctacgccgac60
cagatttgcatcggctactccgccaacaacagcaccgagcaggtggacaccatcatggag120
aagaacgtgacagtgacccaagcccaggatatcctggagaagaagcacaacggcaagctc180
tgcgacctggacggagtgaaacccctgatcctgagggattgtagcgtggcaggttggctg240
ctgggaaaccccatgtgcgacgagttcatcaacgtccccgagtggagctatatcgtggag300
aaggccaacccagtgaacgacctctgctacccaggcgacttcaacgactacgaggagctg360
aagcacctgctgagccggatcaaccacttcgagaagatccagatcatccccaagagctct420
tggagcagccacgaagcctctctgggagtgtctagcgcctgtccttaccagggcaagagc480
agcttcttccggaacgtcgtctggctgatcaagaaggatagcacctaccccaccatcaag540
cggagctacaacaacaccaaccaggaggacctgctcgtgctgtggggcattcaccaccct600
aacgacgcagccgagcagaccaagctgtaccagaaccctaccacctacatcagcgtgggc660
acctctaccctgaaccagagactggtgcccaggatcgccaccagaagcaaagtgaagggc720
ctgagcggccggatggagttcttttggaccatcctgaagcccaacgacgccatcaacttc780
gagagcaacggcaacttcatcgcccccgagtacgcctacaagatcgtgaagaagggcgac840
agcaccatcatgaagagcgagctggagtacggcaactgcaacaccaagtgccagacccct900
atgggcgccatcaacagcagcatgcccttccacaacatccaccccctgaccattggcgag960
tgtcctaagtacgtgaagagcaaccgcctggtgctggctatcggcctgagaaacagcccc1020
cagagagagacacaaggcctgttcggagccattgccggattcacagagggcggttggaca1080
ggcatggtggacggactgtacggataccaccaccagaacgagcagggatcaggatacgcc1140
gccgatcagaagagcacccagaacgccatcaacggcatcaccaacaaggtcaacagcgtg1200
atcgagaagatgaacacccagtacaccgccgtgggcaaggagttcaacaagagcgagcgg1260
cggatggagaacctgaacaagaaggtggacgacggcttcatcgacatttggacctacaac1320
gccgagctgctggtgctgctggaaaacgagaggaccctggacttccacgacagcaacgtg1380
aagaacctgtacgagaaggtcaagagccagctgaagaacaacgccaaggagatcggcaac1440
ggctgcttcgagttctaccacaagtgcaacgacgagtgcatggagagcgtgaagaacggc1500
acctacgactaccccaagtacagcgaggagagcaagctgaaccgggagaagatcgacggc1560
gtgaagagactggtgccaagaggctctccaggaagcggctacatcccagaagcccctaga1620
gacggacaggcttacgtgcgaaaagacggcgagtgggtgctgctgagcacatttctggga1680
caccatcatcaccaccactag1701
<210>5
<211>391
<212>prt
<213>人工序列(artificialsequence)
<400>5
proserargservallysleualaglyasnserserleucysproval
151015
serglytrpalailetyrserlysaspasnservalargileglyser
202530
lysglyaspvalphevalileargglupropheilesercysserpro
354045
leuglucysargthrphepheleuthrglnglyalaleuleuasnasp
505560
lyshisserasnglythrilelysaspargserprotyrargthrleu
65707580
metsercysproileglygluvalproserprotyrasnserargphe
859095
gluservalalatrpseralaseralacyshisaspglyileasntrp
100105110
leuthrileglyileserglyproaspasnglyalavalalavalleu
115120125
lystyrasnglyileilethraspthrilelyssertrpargasnasn
130135140
ileleuargthrglngluserglucysalacysvalasnglysercys
145150155160
phethrvalmetthraspglyproserasnglyglnalasertyrlys
165170175
ilepheargileglulysglylysilevallysservalglumetasn
180185190
alaproasntyrhistyrgluglucyssercystyrproaspserser
195200205
gluilethrcysvalcysargaspasntrphisglyserasnargpro
210215220
trpvalserpheasnglnasnleuglutyrglnileglytyrilecys
225230235240
serglyilepheglyaspasnproargproasnasplysthrglyser
245250255
cysglyprovalserserasnglyalaasnglyvallysglypheser
260265270
phelystyrglyasnglyvaltrpileglyargthrlysserileser
275280285
serargasnglypheglumetiletrpaspproasnglytrpthrgly
290295300
thraspasnasnpheserilelysglnaspilevalglyileasnglu
305310315320
trpserglytyrserglyserphevalglnhisprogluleuthrgly
325330335
leuaspcysileargprocysphetrpvalgluleuileargglyarg
340345350
prolysgluasnthriletrpthrserglyserserileserphecys
355360365
glyvalasnseraspthrvalglytrpsertrpproaspglyalaglu
370375380
leuprophethrileasplys
385390
<210>6
<211>1176
<212>dna
<213>人工序列(artificialsequence)
<400>6
ccatcacgatcagtgaaattagcgggcaattcctctctctgccctgttagtggatgggct60
atatacagtaaagacaacagtgtaagaatcggttccaagggggatgtgtttgtcataagg120
gaaccattcatatcatgctcccccttggaatgcagaaccttcttcttgactcaaggggcc180
ttgctaaatgacaaacattccaatggaaccattaaagacaggagcccatatcgaacccta240
atgagctgtcctattggtgaagttccctctccatacaactcaagatttgagtcagtcgct300
tggtcagcaagtgcttgtcatgatggcatcaattggctaacaattggaatttctggccca360
gacaatggggcagtggctgtgttaaagtacaacggcataataacagacactatcaagagt420
tggagaaacaatatattgagaacacaagagtctgaatgtgcatgtgtaaatggttcttgc480
tttactgtaatgaccgatggaccaagtaatggacaggcctcatacaagatcttcagaata540
gaaaagggaaagatagtcaaatcagtcgaaatgaatgcccctaattatcactatgaggaa600
tgctcctgttatcctgattctagtgaaatcacatgtgtgtgcagggataactggcatggc660
tcgaatcgaccgtgggtgtctttcaaccagaatctggaatatcagataggatacatatgc720
agtgggattttcggagacaatccacgccctaatgataagacaggcagttgtggtccagta780
tcgtctaatggagcaaatggagtaaaagggttttcattcaaatacggcaatggtgtttgg840
atagggagaactaaaagcattagttcaagaaacggttttgagatgatttgggatccgaac900
ggatggactgggacagacaataacttctcaataaagcaagatatcgtaggaataaatgag960
tggtcaggatatagcgggagttttgttcagcatccagaactaacagggctggattgtata1020
agaccttgcttctgggttgaactaatcagagggcgacccaaagagaacacaatctggact1080
agcgggagcagcatatccttttgtggtgtaaacagtgacactgtgggttggtcttggcca1140
gacggtgctgagttgccatttaccattgacaagtaa1176
<210>7
<211>478
<212>prt
<213>人工序列(artificialsequence)
<400>7
alathrmetglyalaglyalathrglyargalametaspglyproarg
151015
leuleuleuleuleuleuleuglyvalserleuglyglyalaasptyr
202530
lysaspaspaspasplysserserserasptyrseraspleuglnarg
354045
vallysglngluleuleuglugluvallyslysgluleuglnlysval
505560
lysglugluileileglualaphevalglngluleuarglysarggly
65707580
serleuvalproargglyserproserargservallysleualagly
859095
asnserserleucysprovalserglytrpalailetyrserlysasp
100105110
asnservalargileglyserlysglyaspvalphevalileargglu
115120125
propheilesercysserproleuglucysargthrphepheleuthr
130135140
glnglyalaleuleuasnasplyshisserasnglythrilelysasp
145150155160
argserprotyrargthrleumetsercysproileglygluvalpro
165170175
serprotyrasnserargphegluservalalatrpseralaserala
180185190
cyshisaspglyileasntrpleuthrileglyileserglyproasp
195200205
asnglyalavalalavalleulystyrasnglyileilethraspthr
210215220
ilelyssertrpargasnasnileleuargthrglngluserglucys
225230235240
alacysvalasnglysercysphethrvalmetthraspglyproser
245250255
asnglyglnalasertyrlysilepheargileglulysglylysile
260265270
vallysservalglumetasnalaproasntyrhistyrgluglucys
275280285
sercystyrproaspsersergluilethrcysvalcysargaspasn
290295300
trphisglyserasnargprotrpvalserpheasnglnasnleuglu
305310315320
tyrglnileglytyrilecysserglyilepheglyaspasnproarg
325330335
proasnasplysthrglysercysglyprovalserserasnglyala
340345350
asnglyvallysglypheserphelystyrglyasnglyvaltrpile
355360365
glyargthrlysserileserserargasnglypheglumetiletrp
370375380
aspproasnglytrpthrglythraspasnasnpheserilelysgln
385390395400
aspilevalglyileasnglutrpserglytyrserglyserpheval
405410415
glnhisprogluleuthrglyleuaspcysileargprocysphetrp
420425430
valgluleuileargglyargprolysgluasnthriletrpthrser
435440445
glyserserileserphecysglyvalasnseraspthrvalglytrp
450455460
sertrpproaspglyalagluleuprophethrileasplys
465470475
<210>8
<211>1437
<212>dna
<213>人工序列(artificialsequence)
<400>8
gccaccatgggggcaggtgccaccggccgcgccatggacgggccgcgcctgctgctgttg60
ctgcttctgggggtgtcccttggaggtgccgattataaggatgatgatgataagagctcc120
agtgattactcggacctacagagggtgaaacaggagcttctggaagaggtgaagaaggaa180
ttgcagaaagtgaaagaggaaatcattgaagccttcgtccaggagctgaggaagcggggt240
tctctggtaccacgaggtagtccatcacgatcagtgaaattagcgggcaattcctctctc300
tgccctgttagtggatgggctatatacagtaaagacaacagtgtaagaatcggttccaag360
ggggatgtgtttgtcataagggaaccattcatatcatgctcccccttggaatgcagaacc420
ttcttcttgactcaaggggccttgctaaatgacaaacattccaatggaaccattaaagac480
aggagcccatatcgaaccctaatgagctgtcctattggtgaagttccctctccatacaac540
tcaagatttgagtcagtcgcttggtcagcaagtgcttgtcatgatggcatcaattggcta600
acaattggaatttctggcccagacaatggggcagtggctgtgttaaagtacaacggcata660
ataacagacactatcaagagttggagaaacaatatattgagaacacaagagtctgaatgt720
gcatgtgtaaatggttcttgctttactgtaatgaccgatggaccaagtaatggacaggcc780
tcatacaagatcttcagaatagaaaagggaaagatagtcaaatcagtcgaaatgaatgcc840
cctaattatcactatgaggaatgctcctgttatcctgattctagtgaaatcacatgtgtg900
tgcagggataactggcatggctcgaatcgaccgtgggtgtctttcaaccagaatctggaa960
tatcagataggatacatatgcagtgggattttcggagacaatccacgccctaatgataag1020
acaggcagttgtggtccagtatcgtctaatggagcaaatggagtaaaagggttttcattc1080
aaatacggcaatggtgtttggatagggagaactaaaagcattagttcaagaaacggtttt1140
gagatgatttgggatccgaacggatggactgggacagacaataacttctcaataaagcaa1200
gatatcgtaggaataaatgagtggtcaggatatagcgggagttttgttcagcatccagaa1260
ctaacagggctggattgtataagaccttgcttctgggttgaactaatcagagggcgaccc1320
aaagagaacacaatctggactagcgggagcagcatatccttttgtggtgtaaacagtgac1380
actgtgggttggtcttggccagacggtgctgagttgccatttaccattgacaagtaa1437
- 还没有人留言评论。精彩留言会获得点赞!