突变的蛋白A结构域C及其应用的制作方法
突变的蛋白a结构域c及其应用
技术领域
1.本发明涉及突变的蛋白a结构域c及其应用。
背景技术:
2.近年来抗体药物以其高特异性成为全球药品市场上炙手可热的药品,而单克隆抗体是生物制药产业增长最快的领域之一。单克隆抗体具有三种独特的作用机制,分别为靶向效应、阻断效应和信号传导效应,单克隆抗体药物主要用来治疗肿瘤、自身免疫性疾病、感染性疾病等,尤其是在癌症治疗方面的疗效突出。
3.当前,抗体药的纯化主要依托亲和介质配基蛋白a(protein a)上的多个区域对抗体fc独特段的特殊的吸附能力实现抗体的捕捉得以实现,目前该方法也是工艺技术最为成熟,运用最广泛的一种亲和层析方式。
4.然而,protein a亲和层析介质在抗体的纯化过程中会出现protein a配基脱落。脱落的配基需要在工艺中除去,避免引起药物免疫反应。而配基的脱落率很大程度上取决于配基的氨基酸分布及稳定性,配基的偶联方式。同时,一般由于经济制约,层析介质会被反复使用,因此需要清洗工序使载体恢复到使用前的状态,通常可使用0.1-0.5m标准naoh溶液(cip)清洗,可以达到高效除去层析介质内的蛋白沉淀物、疏水性蛋白、核酸、内毒素和病毒等。然而,在使用碱性溶液清洗的同时,载体也会暴露在碱性的条件下,对于许多含有蛋白质亲和配体的层析介质的来说,这样的环境是非常严苛的,会导致配基的氨基酸遭到破坏,介质的吸附能力和使用年限也会受到影响。
5.因此如何突破protein a亲和层析介质在碱性环境下的不稳定这一瓶颈,使其在生物亲和层析领域大规模运用,已经成为当前重点需要突破解决的问题。
技术实现要素:
6.本发明提供与天然蛋白a的c结构域相比碱性稳定性提高的该c结构域的突变体多肽。
7.具体而言,本发明提供一种多肽,与seq id no:1所示的蛋白a的天然c结构域相比,该多肽在选自第3位、第6位、第9位和第15位的一个或多个位置上具有取代突变。
8.在一个或多个实施方案中,与seq id no:1所示的蛋白a的天然c结构域相比,该多肽在第3位、第6位、第9位或第15位具有取代突变;在一些实施方案中,与seq id no:1所示的蛋白a的天然c结构域相比,该多肽在第3位和第6位,或在第3位和第9位,或在第3位和第15位,或在第6位和第9位,或在第6位和第15位,或在第9位和第15位具有取代突变;在一些实施方案中,与seq id no:1所示的蛋白a的天然c结构域相比,该多肽在第3位、第6位和第9位,或在第3位、第6位和第15位,或在第6位、第9位和第15位具有取代突变;在一些实施方案中,与seq id no:1所示的蛋白a的天然c结构域相比,该多肽在第3位、第6位和、第9位以及第15位上具有取代突变。
9.在一个或多个实施方案中,与seq id no:1所示的蛋白a的天然c结构域相比,所述
多肽在第15位具有取代突变,并任选地在选自第3位、第6位和第9位的一个或多个位置上具有取代突变。
10.在一个或多个实施方案中,与seq id no:1所示的蛋白a的天然c结构域相比,所述多肽在第9位和第15位具有取代突变,并任选地在选自第3位和第6位的任意一个或全部两个位置上具有取代突变。
11.在一个或多个实施方案中,与seq id no:1所示的蛋白a的天然c结构域相比,所述多肽在第3位、第9位和第15位具有取代突变,并任选地在第6位上具有取代突变。
12.在一个或多个实施方案中,所述第3位上的取代突变为n3l、n3v或n3y。
13.在一个或多个实施方案中,所述第6位上的取代突变为n6s、n6l或n6e。
14.在一个或多个实施方案中,所述第9位上的取代突变为q9i、q9f或q9m。
15.在一个或多个实施方案中,所述第15位上的取代突变为e15t、e15w、e15l、e15v、e15i、e15f、e15s、e15y或e15t。
16.在一个或多个实施方案中,所述多肽的氨基酸序列如seq id no:2-73中任一所示。
17.在一个或多个实施方案中,所述多肽与seq id no:1所示的蛋白a的天然c结构域相比在29位上的氨基酸残基为a。
18.本发明第二方面提供一种多肽,所述多肽由以下(i)、(ii)和(iii)组成:(i)本发明第一方面任一实施方案所述的多肽,(ii)在(i)所述多肽的氨基酸序列的c端或n端的一个或多个偶联元件,和任选的(iii)来自被切下的信号转导序列的残基。
19.在一个或多个实施方案中,所述偶联元件选自:半胱氨酸残基、多个赖氨酸残基和多个组氨酸残基。
20.本发明第三方面提供一种融合蛋白,该融合蛋白由2-8条多肽融合形成,其中,所述多肽的氨基酸序列与seq id no:1所示的蛋白a的天然c结构域相比,在选自第3位、第6位、第9位和第15位的一个或多个位置上具有取代突变。
21.在一个或多个实施方案中,所述多肽为本发明第一方面任一实施方案所述的多肽。
22.在一个或多个实施方案中,所述融合蛋白中,所述2-8条多肽互不相同、部分相同或完全相同。
23.在一个或多个实施方案中,所述融合蛋白所含的每一条所述多肽至少含有e15t、e15w、e15l、e15v、e15i、e15f、e15s、e15y或e15t突变,优选还含有本文所述第3位、第6位和第15位中的一个或多个位置上的取代突变,优选第3位上的取代突变为n3l或n3v,优选第6位上的取代突变为n3l或n3v,优选第9位上的取代突变为q9i或q9f。
24.在一个或多个实施方案中,所述融合蛋白中,所述多肽选自:seq id no:2、3、6、7、8、9、11-19、21-25、58-62和65-69。
25.在一个或多个实施方案中,所述多肽之间存在或不存在接头序列。
26.在一个或多个实施方案中,所述接头序列为含有甘氨酸(g)和丝氨酸(s)的接头序列。
27.在一个或多个实施方案中,所述融合蛋白的c端或n端还包括一个或多个偶联元件。
28.在一个或多个实施方案中,所述偶联元件选自:半胱氨酸残基、多个赖氨酸残基和多个组氨酸残基。
29.在一个或多个实施方案中,所述融合蛋白还包括来自被切下的信号转导序列的残基。
30.在一个或多个实施方案中,所述融合蛋白的氨基酸序列如seq id no:75-108中任一所示。
31.本发明第四方面提供一种重组蛋白a,该重组蛋白a的c结构域为本发明第一方面任一实施方案所述的多肽。
32.本发明第五方面提供一种核酸分子,所述核酸分子的多核苷酸序列选自:
33.(1)编码本发明第一方面任一实施方案所述的多肽、第二方面任一实施方案所述的多肽、第三方面任一实施方案所述的融合蛋白或第四方面任一实施方案所述的重组蛋白a的多核苷酸序列;
34.(2)与(1)所述多核苷酸序列互补的多核苷酸序列。
35.本发明第六方面提供一种核酸构建物,该核酸构建物含有本发明第五方面所述的核酸分子。
36.在一个或多个实施方案中,所述核酸构建物为表达盒。
37.在一个或多个实施方案中,所述核酸构建物为表达载体或克隆载体。
38.本发明第七方面还提供一种表达系统,其含有本发明第六方面任一实施方案所述的核酸构建物或载体。
39.在一个或多个实施方案中,所述表达系统为宿主细胞。
40.本发明第八方面提供一种分离基质,所述分离基包括与固体支持物偶联的本发明第一方面任一实施方案所述的多肽、第二方面任一实施方案所述的多肽、第三方面任一实施方案所述的融合蛋白和/或第四方面任一实施方案所述的重组蛋白a。
41.在一个或多个实施方案中,所述多肽、融合蛋白或重组蛋白a通过硫醚键与所述固体支持物偶联。
42.本发明第九方面提供一种色谱柱,其含有本发明第八方面所述的分离基质。
43.本发明第十方面提供一种分离含fc的蛋白质(如免疫球蛋白)的方法,所述方法包括使含有含fc的蛋白质的样品与本发明第一方面任一实施方案所述的多肽、第二方面任一实施方案所述的多肽、第三方面任一实施方案所述的融合蛋白和/或第四方面任一实施方案所述的重组蛋白a接触的步骤。
44.在一个或多个实施方案中,所述方法包括使含有含fc的蛋白质的样品与本发明第八方面任一实施方案所述的分离基质或第九方面所述的色谱柱接触的步骤。优选地,所述方法还包括,接触后,洗涤分离基质,用洗脱液将所述含fc的蛋白质从所述分离基质上洗脱。
45.本发明第十方面提供本发明第一方面任一实施方案所述的多肽、第二方面任一实施方案所述的多肽、第三方面任一实施方案所述的融合蛋白和/或第四方面任一实施方案所述的重组蛋白a在分离含fc的蛋白质中的应用,或在制备用于分离含fc的蛋白质的分离基质或色谱柱中的应用。
附图说明
46.图1:seq id no:74-90所示的c结构域的耐碱稳定性曲线图。
47.图2:seq id no:74、92-94、96、97、99、100、102和105-107所示的c结构域的耐碱稳定性曲线图。
具体实施方式
48.应理解,在本发明范围中,本发明的上述各技术特征和在下文(如实施例)中具体描述的各技术特征之间都可以互相组合,从而构成优选的技术方案。
49.本文中,“抗体”和“免疫球蛋白”可互换使用,其具有本领域周知含义。本文所述的抗体或免疫球蛋白也包括抗体的片段,以及含有抗体片段的融合蛋白或辍合物,只要这类片段、融合蛋白或辍合物含有抗体的fc部分并可通过与蛋白a的结合而实现分离纯化即可。抗体的片段可以是其功能活性片段。
50.在本说明书中,氨基酸残基也以下列简写符号记载:丙氨酸(ala或a),精氨酸(arg或r),天冬酰胺(asn或n),天冬氨酸(asp或d),半胱氨酸(cys或c),谷氨酰胺(gln或q),谷氨酸(glu或e),甘氨酸(gly或g),组氨酸(his或h),异亮氨酸(ile或i),亮氨酸(leu或l),赖氨酸(lys或k),甲硫氨酸(met或m),苯丙氨酸(phe或f),脯氨酸(pro或p),丝氨酸(ser或s),苏氨酸(thr或t),色氨酸(trp或w),酪氨酸(tyr或y),缬氨酸(val或v),以及任意的氨基酸残基(xaa或x)。此外,在本说明书中,肽的氨基酸序列是依常法以氨基末端(以下称为n末端)位于左侧,羧基末端(以下称为c末端)位于右侧的方式加以记载。
51.蛋白a被广泛用作纯化免疫球蛋白的亲和介质配基。天然的蛋白a具有5个接合免疫球蛋白尤其是igg的结构域,从n端到c端依次为e结构域、d结构域、a结构域、b结构域以及c结构域。在免疫球蛋白纯化过程中,免疫球蛋白与蛋白a结合后需要用碱洗脱,此过程会造成蛋白a从亲和层析介质上脱落,对免疫球蛋白产品造成污染。
52.本发明发现,对蛋白a的天然c结构域的第3、6、9和15位中的至少一位进行取代突变,得到的该c结构域的突变体相对于天然c结构域,在碱清洗过程中具有明显提升的碱性稳定性,所用碱液浓度可从0.1-0.5m提高到0.5-2.0m,如0.5-1.0m,由此完成本发明。
53.具体而言,本发明提供一种多肽,该多肽与seq id no:1所示的蛋白a的天然c结构域相比,在选自第3位、第6位、第9位和第15位的一个或多个位置上具有取代突变。所述取代突变对c结构域的原有结构不产生影响,反而明显提升所得突变体的碱性稳定性。
54.优选地,本发明中,第3位上的取代为天然的n被选自甘氨酸、丙氨酸、缬氨酸、亮氨酸、异亮氨酸、酪氨酸或苯丙氨酸的氨基酸残基取代。进一步优选地,第3位上的取代为天然的n被选自亮氨酸、缬氨酸或酪氨酸的氨基酸残基取代。特别优选地,第3位上的取代为天然的n被亮氨酸或缬氨酸取代。在一些优选的实施方案中,本发明的多肽与seq id no:1相比,在第3位存在取代突变;优选地,该多肽的氨基酸序列如seq id no:2、3或4所示。
55.优选地,本发明中,第6位上的取代突变优选为天然的n被甘氨酸、丙氨酸、丝氨酸、苏氨酸、亮氨酸、异亮氨酸、缬氨酸、谷氨酸或天冬氨酸取代。进一步优选地,第6位上的取代为天然的n被选自丝氨酸、亮氨酸或谷氨酸的氨基酸残基取代。特别优选地,第6位上的取代为天然的n被亮氨酸或谷氨酸取代。在一些优选的实施方案中,本发明的多肽与seq id no:1相比,在第6位存在取代突变;优选地,该多肽的氨基酸序列如seq id no:5、6或7所示。
56.优选地,本发明中,第9位上的取代突变优选为天然的q被甘氨酸、丙氨酸、亮氨酸、缬氨酸、酪氨酸、丝氨酸、异亮氨酸、精氨酸、苯丙氨酸或甲硫氨酸取代,优选被异亮氨酸、苯丙氨酸或甲硫氨酸取代。在一些优选的实施方案中,本发明的多肽与seq id no:1相比,在第9位存在取代突变;优选地,该多肽的氨基酸序列如seq id no:8、9或10所示。
57.优选地,本发明中,第15位上的取代突变优选为天然的e被甘氨酸、亮氨酸、丙氨酸、甲硫氨酸、苯丙氨酸、酪氨酸、异亮氨酸、丝氨酸、苏氨酸、色氨酸、缬氨酸、天冬氨酸、谷氨酸或精氨酸取代。进一步优选地,第15位上的取代为天然的e被苏氨酸、色氨酸、亮氨酸、缬氨酸、异亮氨酸、苯丙氨酸、丝氨酸、酪氨酸或天冬氨酸残基取代。在一些优选的实施方案中,本发明的多肽与seq id no:1相比,在第15位存在取代突变;优选地,该多肽的氨基酸序列如seq id no:11-19中任一项所示。
58.在优选的实施方案中,本发明的多肽与seq id no:1所示的蛋白a天然c结构域相比,在选自第3位、第6位、第9位和第15位的任意两个位置上、三个位置上或全部四个位置上具有取代突变。优选地,所述取代突变如前文所述。进一步优选地,所述第9位上的取代突变为q9i、q9f或q9m,第3位上的取代突变为n3l、n3v或n3y,第6位上的取代突变为n6s、n6l或n6e,第15位上的取代突变为e15t、e15w、e15l、e15v、e15i、e15f、e15s、e15y或e15t。
59.进一步优选地,与seq id no:1所示的蛋白a的天然c结构域相比,本发明的多肽在第15位具有取代突变,并任选地在选自第3位、第6位和第9位的一个位置上具有取代突变。优选地,所述取代突变如前文所述。进一步优选地,第15位上的取代突变为e15t、e15w、e15l、e15v、e15i、e15f、e15s、e15y或e15t,所述第9位上的取代突变为q9i、q9f或q9m,第3位上的取代突变为n3l、n3v或n3y,第6位上的取代突变为n6s、n6l或n6e。进一步优选地,与seq id no:1所示的蛋白a的天然c结构域相比,本发明的多肽在第15位具有取代突变,并在选自第3位、第6位和第9位的任意一个位置上具有取代突变;优选地,所述多肽的示例性氨基酸序列如seq id no:20-37所示。进一步优选地,与seq id no:1所示的蛋白a的天然c结构域相比,本发明的多肽在第15位具有取代突变,并在选自第3位、第6位和第9位的任意两个位置上具有取代突变;优选地,所述多肽的示例性氨基酸序列如seq id no:38-57所示。进一步优选地,与seq id no:1所示的蛋白a的天然c结构域相比,本发明的多肽在第15位具有取代突变,同时在第3位、第6位和第9位也具有取代突变;优选地,所述多肽的示例性氨基酸序列如seq id no:58-73所示。
60.在一些优选的实施方案中,与seq id no:1所示的蛋白a的天然c结构域相比,本发明的多肽在第9位和第15位具有取代突变,并任选地在选自第3位和第6位的任意一个或全部两个位置上具有取代突变。在进一步优选的实施方案中,与seq id no:1所示的蛋白a的天然c结构域相比,所示多肽在第3位、第9位和第15位具有取代突变,并任选地在第6位上具有取代突变。优选地,所述取代突变如前文所述。进一步优选地,所述第9位上的取代突变为q9i、q9f或q9m,第3位上的取代突变为n3l、n3v或n3y,第6位上的取代突变为n6s、n6l或n6e,第15位上的取代突变为e15t、e15w、e15l、e15v、e15i、e15f、e15s、e15y或e15t。
61.本领域已知,将蛋白a的天然c结构域第29位的氨基酸残基g突变成a,能提高所得突变体的耐碱性。因此,在本发明的优选实施方案中,除所述第3、6、9和15位中的一个或多个位置上的突变外,本发明的多肽还可在第29位存在g29a突变。
62.本发明所述多肽可直接作为配体,用于结合并分离免疫球蛋白。因此,在一些实施
方案中,所述多肽还在其c端或n端包含一个或多个用于将该多肽偶联到固体支持物上的偶联元件。合适的偶联元件为本领域所周知,包括但不先于半胱氨酸残基、多个赖氨酸残基(如3-15个或5-10个)和多个组氨酸残基(如3-15个或5-10个)。偶联元件可以是1个半胱氨酸残基,且位于多肽的c端,从而可利用半胱氨酸残基中的硫醇基与固体支持物上的亲电子基团反应而将多肽偶联到固体支持物上。偶联元件可直接与多肽连接,或者可通过接头与多肽的n或c端连接。接头可以是本领域常规使用的接头,其存在不影响到多肽的结合活性。示例性的接头为含有g和s或由g和s组成的接头序列,通常长2-20个氨基酸残基。示例性的接头序列如(gs)n、(gss)n、(gsss)n以及(gssss)n,n可为2-10的整数,但接头总长度通常不超过20个氨基酸残基。所述多肽在n端还可包含多个(如15个以内,10个以内或5以内)氨基酸残基,其源自克隆过程或来自信号转导序列的残基。作为具体实例,多肽可在n端包含aq。
63.本发明还提供一种融合蛋白,该融合蛋白是一种由2-8条本发明前述多肽融合而形成。形成融合蛋白的各条多肽可全部不同、部分相同或全部相同。各多肽之间可通过c端和n端的肽键各自直接连接,或者任意两条多肽之间也可通过接头连接。接头可以是本领域常规使用的接头,其存在不影响到多肽的结合活性。示例性的接头为含有g和s或由g和s组成的接头序列,通常长2-20个氨基酸残基。示例性的接头序列如(gs)n、(gss)n、(gsss)n以及(gssss)n,n可为2-10的整数,但接头总长度通常不超过20个氨基酸残基。
64.该融合蛋白可作为配体,用于结合并分离免疫球蛋白。因此,在一些实施方案中,该融合蛋白还在其c端或n端包含一个或多个用于将该融合蛋白偶联到固体支持物上的偶联元件。合适的偶联元件为本领域所周知,包括但不限于半胱氨酸残基、多个赖氨酸残基(如3-15个或5-10个)和多个组氨酸残基(如3-15个或5-10个)。偶联元件可以是1个半胱氨酸残基,且位于融合蛋白的c端,从而可利用半胱氨酸残基中的硫醇基与固体支持物上的前电子基团反应而将融合蛋白偶联到固体支持物上。偶联元件可直接与多肽连接,或者可通过接头与多肽的n或c端连接。接头可以是本领域常规使用的接头,其存在不影响到多肽的结合活性。示例性的接头为含有g和s或由g和s组成的接头序列,通常长2-20个氨基酸残基。示例性的接头序列如(gs)n、(gss)n、(gsss)n以及(gssss)n,n可为2-10的整数,但接头总长度通常不超过20个氨基酸残基。所述融合蛋白在n端还可包含多个(如15个以内,10个以内或5以内)氨基酸残基,其源自克隆过程或来自信号转导序列的残基。作为具体实例,该融合蛋白可在其n端包含aq。示例性的融合蛋白的氨基酸序列如seq id no:75-108中任一所示。
65.本发明还提够一种重组蛋白a,其c结构域为本发明任意实施方案所述的多肽。该重组蛋白a的其余结构域可以是本领域周知的e结构域、d结构域、a结构域和b结构域(或z结构域,其为b结构域的改造型结构域),包括天然的e结构域、d结构域、a结构域和b结构域以及已知的突变但保留了生物活性的e结构域、d结构域、a结构域和/或b结构域(如z结构域)。除c结构域采用本发明的多肽外,本领域已知的对蛋白a其余部分做出的突变或修饰均可用于本发明的重组蛋白a。
66.本文也包括与本文任一实施方案所述的多肽、融合蛋白或重组蛋白a具有至少85%的序列相同性,并在选自对应于seq id no:1第3、6、9和15位的一个或多个氨基酸位置上具有本文任一实施方案所述的取代突变的多肽、融合蛋白和重组蛋白a;优选地,此类多肽以及融合蛋白和重组蛋白a中的此类多肽的对应于蛋白a的天然c结构域第29位的氨基酸残基为a。本文中,涉及氨基酸序列和核苷酸序列的“至少85%相同性”,是指85%以上的相
同性,优选为90%以上的相同性,更优选为95%以上的相同性,进一步优选为97%以上的相同性,进一步优选为98%以上的相同性,更进一步优选为99%以上的相同性。可采用本领域周知的工具计算比对的两条序列之间的相同性,这些工具包括用于氨基酸序列比对的blastp等。在优选的实施方案中,本发明包括与seq id no:2-73和75-108中任一所示的氨基酸序列的变体,seq id no:2-73和75-108各自的变体与对应的亲本序列相比具有至少85%、优选至少90%、更优选至少97%、更优选至少99%的序列相同性且其在对应的亲本第3、6、9和15位上的氨基酸残基仍保持为对应亲本的氨基酸残基。
67.本发明也包括编码前述多肽、融合蛋白以及重组蛋白a的核酸分子及其互补序列。本发明包括本发明核酸分子的所有形式,包括rna和dna。应理解,本文所述的互补序列指长度与该核酸分子基本一致的互补序列。
68.含有所述核酸分子或其互补序列的核酸构建物也包括在本发明的范围内。核酸构建物可以是一表达盒,其含有启动子、所述核酸分子以及转录终止序列。启动子和转录终止序列为本领域所周知,并可由本领域技术人员根据所选择的用于表达所述多肽、融合蛋白或重组蛋白a的宿主细胞而做出适当的选择。
69.在一些实施方案中,核酸构建物为载体,包括表达载体和克隆载体。表达载体是适合在宿主细胞中表达外源基因如编码本发明所述多肽、融合蛋白或重组蛋白a的核酸分子的载体,包括原核表达载体和真核表达载体。真核表达系统有酵母表达系统,哺乳细胞表达系统和昆虫细胞表达系统等。克隆载体用于在宿主细胞中进行目的基因(如编码本发明所述多肽、融合蛋白或蛋白a的核酸分子)的扩增。克隆载体包括质粒载体、噬菌体载体、病毒载体、以及由它们互相组合或者与其他基因组dna组合而成的载体。分子克隆中最常用的宿主细胞是大肠杆菌。
70.本发明还提供一种表达系统,其包含本文公开的核酸分子、核酸构建物或载体。表达系统可为例如革兰氏阳性或革兰氏阴性原核宿主细胞系统,例如经修饰以表达本发明的多肽、融合蛋白或重组蛋白a的大肠杆菌或芽孢杆菌。在一些实施方案中,表达系统是真核宿主细胞系统,例如酵母,例如巴斯德毕赤酵母或酿酒酵母。
71.本发明还提供一种分离基质。本发明的分离基质可用于分离免疫球蛋白或含fc的蛋白质。本发明的分离基质含有与固体支持物偶联的本发明任一实施方案所述的多肽、融合蛋白和/或重组蛋白a。由于本发明的多肽、融合蛋白和重组蛋白a的碱稳定性改进,本发明的分离基质在清洗时可承受高碱性条件(0.5-2.0m的naoh)。
72.本发明分离基质中的固体支持物可以是本领域已知的在免疫球蛋白或含fc的蛋白质的分离中使用到的固体支持物。
73.本文中,固相支持物的形状可以为粒子、膜、板、管、针状、纤维状等任意的形状。本发明的固体支持物可以是多孔状的材料,或者为无孔的材料。在一些实施方案中,固体支持物为多孔或无孔的珠状形式或颗粒形式。呈珠状形式或颗粒形式的基质可作为填充床或以悬浮形式使用。悬浮形式包括膨胀床,其中颗粒或小珠自由移动。
74.在该固相支持物为粒子的情况下,粒径优选为20-200μm。例如,在固相支持物为合成聚合物的情况下,粒径优选为20-100μm,优选为30-80μm。在固相支持物为多糖的情况下,粒径优选为50-200μm,更优选为60-150μm。本说明书中的“粒径”是指以按照iso 13320和jis z 8825-1的激光衍射法进行测定而得的体积平均粒径。
75.固体支持物的例子包括但不限于包含多羟基的多聚体,例如多糖。多糖包括葡聚糖、淀粉、纤维素、普鲁兰多糖、琼脂和琼脂糖等。在优选的实施方案中,固体支持物包含琼脂或琼脂糖。
76.在一些实施方案中,本发明的固体支持物为具有清水性表面的合成聚合物。例如,这类聚合物可以是通过亲水化处理而在外表面(以及在存在的情况下也在内表面)具有羟基、羧基、氨基羰基、氨基或寡乙烯氧基或聚乙烯氧基的聚合物,优选为诸如由多官能(甲基)丙烯酸酯、二乙烯基苯等多官能单体进行交联而得的共聚物的合成聚合物。示例性的合成聚合物包括聚乙烯醇、聚苯乙烯、聚苯乙烯二乙烯苯、多羟基烷基丙烯酸酯、多羟基烷基甲基丙烯酸酯、聚丙烯酰胺和聚甲基丙烯酰胺等。在聚合物表面疏水的情况下,可对其表面进行被亲水化处理,以使亲水基团暴露于周围的水性液体中。
77.在一些实施方案中,本发明的固体支持物包含无机性质的支持物,包括但不限于二氧化硅和氧化锆等。
78.在一些实施方案中,本发明的固体支持物呈表面、芯片、毛细管或滤器的形式,例如膜等。
79.本发明中,本发明所述的多肽、融合蛋白和重组蛋白a可通过其所含有的硫醇基、氨基和/或羧基等通过常规偶联技术与相应的固体支持物连接。常用的偶联试剂包括但不限于双环氧化物、表氯醇、cnbr和n-羟基琥珀酰亚胺。在固体支持物和本发明所述多肽、融合蛋白和重组蛋白a之间可引入间隔基,其可促进它们与固体支持物的化学偶联。
80.在一些实施方案中,本发明所述的多肽、融合蛋白或重组蛋白a可通过硫醚键与固体支持物偶联。在一些实施方案中,本发明所述的多肽、融合蛋白或重组蛋白a通过其c端的半胱氨酸偶联,其中,该半胱氨酸硫醇基与固体支持物上的亲电子基团如环氧基、卤代醇基等有效偶联,形成硫醚桥偶联。
81.本发明的分离基质中,与固体支持物偶联的结合配体(如本发明所述的多肽、融合蛋白和/或重组蛋白a)的浓度通常为5-20mg/ml,例如5-15mg/ml。可通过调整偶联过程中所用的多肽、融合蛋白和/或重组蛋白a的浓度、所用的偶联条件和/或所用固体支持物的孔结构,来控制偶联的所述结合配体的量。
82.本发明还提供一种色谱柱,其含有本发明的分离基质。通常,将本发明的分离基质填充于色谱柱中。
83.本发明还提供一种分离含fc的蛋白质(如免疫球蛋白)的方法,该方法包括使本文任一实施方案所述的多肽、融合蛋白和/或重组蛋白a与含有含fc的蛋白质的样品接触的步骤。在一些实施方案中,所述方法包括使样品与本文任一实施方案所述的分离基质或色谱柱接触的步骤。
84.更具体而言,在一些实施方案中,该方法包括:
85.(1)使含有含fc的蛋白质的样品与本文任一实施方案所述的分离基质接触;
86.(2)洗涤分离基质;
87.(3)从分离基质上洗脱所述含fc的蛋白质;
88.(4)清洗分离基质。
89.本文中,样品可以是各类含有含fc的蛋白质(尤其是免疫球蛋白)的样品。优选地,本文所述的免疫球蛋白指igg。
90.所述方法中使用到的用于洗涤分离基质的洗液、用于洗脱蛋白质的洗脱液以及用于清洗分离基质的清洗液均为本领域(尤其是蛋白a层析领域)常规使用的洗液、洗脱液以及清洗液。例如,洗液可以是pbs缓冲液。洗脱液可以是ph≤5的溶液或缓冲液,优选地,洗脱液的ph为2.5-5或3-5。在一些实施方案中,洗脱液的ph为11或更高,例如洗脱液的ph为11-14或11-13。在一些实施方案中,使用柠檬酸盐溶液,如柠檬酸钠溶液进行洗脱。清洗液通常是碱性的,其ph可为13-14。在一些实施方案中,清洗液为氢氧化钠溶液或氢氧化钾溶液,其浓度为0.1-2.0m,例如0.5-2.0m或0.5-1.0m。
91.在一些实施方案中,本文所述方法还包括回收洗脱物并对其进行进一步分离纯化的步骤。可根据所分离的蛋白,通过阴离子或阳离子交换层析法、复合型离子交换层析法和/或疏水相互作用层析法等进行进一步的分离纯化。
92.本发明还提供本文任一实施方案所述的多肽、融合蛋白以及蛋白a在分离纯化含fc的蛋白质中的应用,或在制备用于分离纯化含fc的蛋白质的分离基质中的应用。
93.本文所述的序列如下:
94.seq id no:1(天然c结构域)
95.adnkfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
96.seq id no:2(n3l)
97.adlkfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
98.seq id no:3(n3v)
99.advkfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
100.seq id no:4(n3y)
101.adykfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
102.seq id no:5(n6s)
103.adnkfskeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
104.seq id no:6(n6l)
105.adnkflkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
106.seq id no:7(n6e)
107.adnkfekeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
108.seq id no:8(q9i)
109.adnkfnkeiqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
110.seq id no:9(q9f)
111.adnkfnkefqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
112.seq id no:10(q9m)
113.adnkfnkemqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
114.seq id no:11(e15t)
115.adnkfnkeqqnafytilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
116.seq id no:12(e15w)
117.adnkfnkeqqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
118.seq id no:13(e15l)
119.adnkfnkeqqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
120.seq id no:14(e15v)
121.adnkfnkeqqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
122.seq id no:15(e15i)
123.adnkfnkeqqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
124.seq id no:16(e15f)
125.adnkfnkeqqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
126.seq id no:17(e15s)
127.adnkfnkeqqnafysilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
128.seq id no:18(e15y)
129.adnkfnkeqqnafyyilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
130.seq id no:19(e15d)
131.adnkfnkeqqnafydilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
132.seq id no:20(q9i,e15t)
133.adnkfnkeiqnafytilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
134.seq id no:21(q9i,e15w)
135.adnkfnkeiqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
136.seq id no:22(q9i,e15l)
137.adnkfnkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
138.seq id no:23(q9i,e15v)
139.adnkfnkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
140.seq id no:24(q9i,e15i)
141.adnkfnkeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
142.seq id no:25(q9i,e15f)
143.adnkfnkeiqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
144.seq id no:26(q9i,e15s)
145.adnkfnkeiqnafysilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
146.seq id no:27(q9i,e15y)
147.adnkfnkeiqnafyyilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
148.seq id no:28(q9i,e15d)
149.adnkfnkeiqnafydilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
150.seq id no:29(q9f,e15t)
151.adnkfnkefqnafytilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
152.seq id no:30(q9f,e15w)
153.adnkfnkefqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
154.seq id no:31(q9f,e15l)
155.adnkfnkefqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
156.seq id no:32(q9f,e15v)
157.adnkfnkefqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
158.seq id no:33(q9f,e15i)
159.adnkfnkefqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
160.seq id no:34(q9f,e15f)
161.adnkfnkefqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
162.seq id no:35(q9f,e15s)
163.adnkfnkefqnafysilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
164.seq id no:36(q9f,e15y)
165.adnkfnkefqnafyyilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
166.seq id no:37(q9f,e15d)
167.adnkfnkefqnafydilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
168.seq id no:38(n3l,q9i,e15w)
169.adlkfnkeiqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
170.seq id no:39(n3l,q9i,e15l)
171.adlkfnkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
172.seq id no:40(n3l,q9i,e15v)
173.adlkfnkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
174.seq id no:41(n3l,q9i,e15i)
175.adlkfnkeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
176.seq id no:42(n3l,q9i,e15f)
177.adlkfnkeiqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
178.seq id no:43(n3v,q9i,e15w)
179.advkfnkeiqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
180.seq id no:44(n3v,q9i,e15l)
181.advkfnkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
182.seq id no:45(n3v,q9i,e15v)
183.advkfnkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
184.seq id no:46(n3v,q9i,e15i)
185.advkfnkeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
186.seq id no:47(n3v,q9i,e15f)
187.advkfnkeiqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
188.seq id no:48(n6l,q9f,e15w)
189.adnkflkefqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
190.seq id no:49(n6l,q9f,e15l)
191.adnkflkefqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
192.seq id no:50(n6l,q9f,e15v)
193.adnkflkefqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
194.seq id no:51(n6l,q9f,e15i)
195.adnkflkefqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
196.seq id no:52(n6l,q9f,e15f)
197.adnkflkefqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
198.seq id no:53(n6e,q9f,e15w)
199.adnkfekefqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
200.seq id no:54(n6e,q9f,e15l)
201.adnkfekefqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
202.seq id no:55(n6e,q9f,e15v)
203.adnkfekefqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
204.seq id no:56(n6e,q9f,e15i)
205.adnkfekefqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
206.seq id no:57(n6e,q9f,e15f)
207.adnkfekefqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
208.seq id no:58(n3l,n6l,q9i,e15w)
209.adlkflkeiqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
210.seq id no:59(n3l,n6l,q9i,e15l)
211.adlkflkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
212.seq id no:60(n3y,n6e,q9i,e15l)
213.adykfekeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
214.seq id no:61(n3y,n6e,q9i,e15i)
215.adykfekeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
216.seq id no:62(n3v,n6l,q9i,e15v)
217.advkflkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
218.seq id no:63(n3v,n6e,q9i,e15l)
219.advkfekeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
220.seq id no:64(n3v,n6e,q9i,e15i)
221.advkfekeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
222.seq id no:65(n3v,n6e,q9i,e15f)
223.advkfekeiqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
224.seq id no:66(n3l,n6l,q9f,e15w)
225.adlkflkefqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
226.seq id no:67(n3l,n6l,q9f,e15i)
227.adlkflkefqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
228.seq id no:68(n3l,n6e,q9f,e15l)
229.adlkfekefqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
230.seq id no:69(n3v,n6l,q9f,e15v)
231.advkflkefqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
232.seq id no:70(n3v,n6e,q9f,e15i)
233.advkfekefqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
234.seq id no:71(n3v,n6e,q9f,e15f)
235.advkfekefqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
236.seq id no:72(n3l,n6e,q9f,e15i)
237.adlkfekefqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
238.seq id no:73(n3v,n6l,q9f,e15l)
239.advkflkefqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
240.seq id no:74(天然c结构域)4
241.adnkfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
242.seq id no:75(n3l)4
243.adlkfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
244.seq id no:76(n3v)4
245.advkfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkfnkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
246.seq id no:77(n6l)4
247.adnkflkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkflkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkflkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkflkeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
248.seq id no:78(n6e)4
249.adnkfekeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfekeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfekeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfekeqqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
250.seq id no:79(q9i)4
251.adnkfnkeiqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
252.seq id no:80(q9f)4
253.adnkfnkefqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkefqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkefqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkefqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
254.seq id no:81(q9m)4
255.adnkfnkemqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkemqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkemqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkemqnafyeilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
256.seq id no:82(e15t)4
257.adnkfnkeqqnafytilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafytilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafytilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafytilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
258.seq id no:83(e15w)4
259.adnkfnkeqqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
260.seq id no:84(e15l)4
261.adnkfnkeqqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
262.seq id no:85(e15v)4
263.adnkfnkeqqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
264.seq id no:86(e15i)4
265.adnkfnkeqqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
266.seq id no:87(e15f)4
267.adnkfnkeqqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
268.seq id no:88(e15s)4
269.adnkfnkeqqnafysilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafysilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafysilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafysilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
270.seq id no:89(e15y)4
271.adnkfnkeqqnafyyilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafyyilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafyyilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafyyilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
272.seq id no:90(e15d)4
273.adnkfnkeqqnafydilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafydilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafydilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeqqnafydilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
274.seq id no:91(q9i,e15w)4
275.adnkfnkeiqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
276.seq id no:92(q9i,e15l)4
277.adnkfnkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
278.seq id no:93(q9i,e15v)4
279.adnkfnkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
280.seq id no:94(q9i,e15i)4
281.adnkfnkeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
282.seq id no:95(q9i,e15f)4
283.adnkfnkeiqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadnkfnkeiqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
284.seq id no:96(n3l,n6l,q9i,e15w)4
285.adlkflkeiqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkflkeiqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkflkeiqnafywilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkflkeiqnafywilhlpnlteeqrngfiqslkddpsvskeilaeak
klndaqapk
286.seq id no:97(n3l,n6l,q9i,e15l)4
287.adlkflkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkflkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkflkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkflkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
288.seq id no:98(n3y,n6e,q9i,e15i)4
289.adykfekeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadykfekeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadykfekeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadykfekeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
290.seq id no:99(n3v,n6l,q9i,e15v)4
291.advkflkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkflkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkflkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkflkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
292.seq id no:100(n3v,n6e,q9i,e15f)4
293.advkfekeiqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkfekeiqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkfekeiqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkfekeiqnafyfilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
294.seq id no:101(n3y,n6e,q9i,e15l)4
295.adykfekeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadykfekeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadykfekeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadykfekeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
296.seq id no:102(n3l,n6l,q9f,e15i)4
297.adlkflkefqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkflkefqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkflkefqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkflkefqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
298.seq id no:103(n3v,n6e,q9i,e15l)4
299.advkfekeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkfekeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkfekeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkfekeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
300.seq id no:104(n3v,n6e,q9i,e15i)4
301.advkfekeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkfekeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkfekeiqnafyiilhlpnlteeqrngf
iqslkddpsvskeilaeakklndaqapkadvkfekeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
302.seq id no:105(n3l,n6l,q9i,e15l)6
303.adlkflkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkflkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkflkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkflkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkflkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkflkeiqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
304.seq id no:106(n3l,n6e,q9i,e15i)6
305.adlkfekeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkfekeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkfekeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkfekeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkfekeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkfekeiqnafyiilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
306.seq id no:107(n3v,n6l,q9i,e15v)6
307.advkflkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkflkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkflkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkflkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkflkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadvkflkeiqnafyvilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
308.seq id no:108(n3l,n6e,q9f,e15l)6
309.adlkfekefqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkfekefqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkfekefqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkfekefqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkfekefqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapkadlkfekefqnafylilhlpnlteeqrngfiqslkddpsvskeilaeakklndaqapk
310.下文将以具体实施例的方式阐述本发明。应理解,这些实施例仅仅是阐述性的,并非意图限制本发明的范围。实施例中所用到的方法和材料,除非另有说明,否则为本领域常规使用的方法和材料,一些试剂可从市售途径获得。
311.制备例
312.①
c结构域突变体的优化
313.设计好突变位点并委托基因合成公司进行全基因合成。
314.②
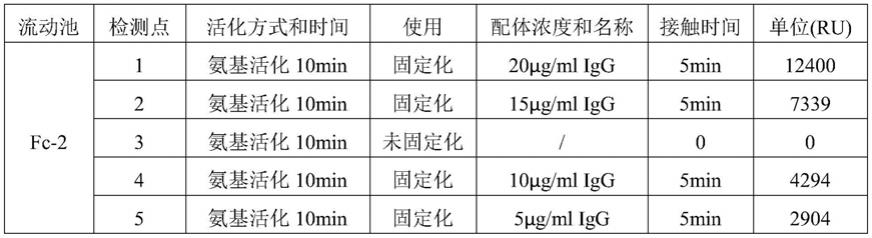
c结构域突变体的表达和纯化
315.利用单个重组质粒转化到大肠杆菌,并通过lb液体培养基进行发酵培养并进行诱导表达。发酵后,收集菌体并采用热裂解的方式破坏细胞壁将表达产物释放出来并离心分离。将分离液体经过igg亲和介质进行纯化,分离液上样经过亲和介质,用10mm的磷酸盐缓冲液清洗介质,并用ph 3.8的缓冲溶液收集目的蛋白,调节到中性环境,保存待用。
316.③
c结构域突变体制备亲和层析介质
317.利用得到的c结构域突变体采用常规的方法制备亲和层析介质。示例性的制备过
程具体包括以下步骤:
318.a.活化
319.取10g高刚性琼脂糖,经纯化水清洗并抽干。称取10g上述琼脂糖,加入20ml纯化水,0.2g氢氧化钠以及10ml环氧氯丙烷加入100ml烧瓶中,在27℃下恒温反应2小时,将活化的凝胶用1l水洗涤,得到活化的琼脂糖微球。
320.b.交联
321.将活化后的琼脂糖微球加入到100ml烧瓶中,再加入150mg nahco3,10mg na2co3,150mg nacl和10mg edta,搅拌均匀后加入50ml重组protein a溶液,在34℃下恒温反应8小时,完成交联;
322.c.封闭
323.在交联产物中加入100ml封闭液(乙醇胺溶液),用氢氧化钠调整ph为8.6,26℃下恒温反应2小时,完成对残留的环氧基团的封闭,减小影响。
324.实施例1
325.使用下面描述的方法对表1的c结构域突变体进行动力学分析。
326.实验步骤如下:
327.1)用igg交联series s cm5芯片。
328.a.用10mm乙酸-naoh(ph5.0)稀释igg至5μg/ml、10μg/ml、15μg/ml、20μg/ml。
329.b.配置运行缓冲液(10mm乙酸-naoh,ph5.0)、解吸液1(0.5%sds)、解吸液2(50mm甘氨酸-naoh,ph9.5)、封闭液(1m乙醇胺ph8.5)、活化剂(0.4m edc、0.1m nhs)。
330.c.在biacore-4000中运行固定化。
331.d.交联结果如下表所示:
[0332][0333]
2)动力学分析
[0334]
a.用1xpbs(ph7.6)稀释蛋白样品(protein a)至0μg/ml、1.615μg/ml、2.4375μg/ml、3.25μg/ml、4.875μg/ml、6.5μg/ml、9.75μg/ml、13μg/ml、19.5μg/ml、26μg/ml。
[0335]
b.配置跑胶缓冲液1xpbs(ph7.6)、再生溶液(50mm柠檬酸-naoh ph3.0)。
[0336]
c.在biacore-4000中运行动力学和亲和学。
[0337]
接触时间流速解离时间再生时间150s30μl/min250s120s
[0338]
实验结果如下:
[0339]
表1:利用biacore对c结构域突变体进行动力学分析结果
[0340][0341][0342]
结果表明,所有突变位点与天然c结构域相比,其kd值基本都处于一个数量级,解离常数并没有明显变化,说明本发明对c结构域进行突变得到的突变体对于igg的结合能力没有影响。
[0343]
实施例2
[0344]
使用下面描述的方法对表2的c结构域突变体亲和层析介质的igg结合能力和耐碱稳定性进行评价。
[0345]
实验步骤如下:
[0346]
1)取4.4ml c结构域突变体亲和层析介质,用20%乙醇,5ml/min的流速装入层析柱中。
[0347]
缓冲液:缓冲液a(pbs,ph 7.6);缓冲液b(0.1m柠檬酸钠,ph 3.0);缓冲液c(1m naoh)。
[0348]
样品:用纯品配制1mg/ml的igg样品(稀释纯品的溶液为缓冲液a)。
[0349]
2)10%动态载量测定:
[0350]
设备:akta pure。
[0351]
测定过程:
[0352]
a.缓冲液a平衡层析柱,流速:1.8ml/min;
[0353]
b.igg样品不流经柱子时,检测其紫外吸收峰值,计为λ
max
,并据此计算10%λ
max
;
[0354]
c.上样:流速:1.8ml/min,记录基础流穿的紫外吸收峰值;
[0355]
d.二者相加得出10%动态载量对应的紫外吸收峰值;
[0356]
e.继续上样至紫外吸收峰值达到步骤d中紫外吸收峰值时所对应的体积为10%动态载量。
[0357]
3)耐碱循环:
[0358]
控制室温:23
±
0.5℃;根据载量的下降更新程序中的上样量,其他程序保持一致。
[0359]
测定过程:
[0360]
a.pbs平衡:流速:1.8ml/min;体积:1cv;
[0361]
b.上样:流速:1.8ml/min;200ml(后续程序根据载量的下降更新上样量);
[0362]
c.pbs清洗:流速:1.8ml/min;体积:5cv;
[0363]
d.0.1m柠檬酸钠洗脱:流速:1.8ml/min;体积:3cv;
[0364]
e.1m naoh处理2h:先用1.8ml/min的流速过1cv使层析柱内充满1m naoh,后改为流速:0.5ml/min;体积:60ml;时间:2h;
[0365]
f.pbs平衡:流速:1.8ml/min;体积:10cv;
[0366]
4)上述碱处理程序进行13次,记录对应载量,绘制图表,结果见表2和图1。表2显示了各样品在10%穿透下(qb10%)的igg能力(以动态结合载量计,mg/ml)。
[0367]
表2:在柱(1m naoh)中评价的具有c结构域突变体的亲和层析介质
[0368][0369]
结果表明,除突变体(e15t)4在碱处理4小时和(n3l)4在碱处理12小时后显示出比天然c结构域稍低的耐碱稳定性(图1)外,所有突变体均具有提高的耐碱稳定性。其中,(q9f)4在碱处理24小时后,仍具有35.18%的igg结合能力,(e15i)4在碱处理24小时后,仍具有41.86%的igg结合能力。其余突变体也都表现出较天然c结构域更好的igg结合能力,这些数据表明本发明选择的突变位点可以改善天然c结构域的碱性稳定性。
[0370]
实施例3
[0371]
用表3中的c结构域突变体制备得到的亲和层析介质重复实施例2,结果见表3和图2。表3显示了各样品在10%穿透下(qb10%)的igg能力(以动态结合载量计,mg/ml)。
[0372]
表3:在柱(1m naoh)中评价的具有c结构域突变体的亲和层析介质
[0373][0374]
结果表明,突变体的耐碱性较天然c结构域均有很大程度提高。另外,c(q9l,e15i)4、c(n3l,n6l,q9i,e15w)4、c(n3v,n6l,q9i,e15v)4、c(n3l,n6l,q9f,e15i)4和c(n3v,n6l,q9i,e15v)6的初始igg结合能力较天然c结构域也有所提升。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1