快速筛选高纯合度天麻的方法及其所用引物组合物
1.本发明涉及分子遗传育种领域,具体涉及快速筛选高纯合度天麻的方法及其所用引物组合物。
背景技术:
2.天麻为兰科植物天麻(gastrodia elata bl.)的干燥块茎,性甘、平,归肝经,具有熄风止痉、平抑肝阳、祛风通络的功效,用于小儿惊风,癫痫抽搐,破伤风,头痛眩晕,手足不遂,肢体麻木,风湿痹痛。现代研究表明,天麻不仅可作为药物用于镇静催眠、镇痛、抗炎、抗眩晕、抗惊厥、防止衰老等,也可制成供人们直接食用的保健膳食,如天麻酒、天麻鲜湿面条、天麻豆渣蛋糕、天麻片等。2019年底,天麻被纳为“按照传统既是食品又是中药材的物质”管理的试点品种,成为法定意义上的“药食两用”品种。目前,天麻的人工栽培主要通过无性繁殖的方式进行。其无性繁殖方式是直接用地下块茎或原球茎与蜜环菌及其菌材进行栽培,具有生长周期短、繁殖快的特点。但无性繁殖易引起品种退化的问题。目前,针对无性繁殖引起品种退化问题主要有两种解决方法,一种是进行组织培养,另一种是开展杂交育种。组织培养采用脱病毒处理来避免品种退化问题。但天麻的组织培养技术存在生长慢,成活率低、易受共生蜜环菌污染死亡的问题。杂交育种是通过亲本之间进行杂交获得具有稳定遗传特性的后代来避免品种退化问题,但要获得具有稳定遗传特性后代的前提是有纯合度高的纯系品种作为亲本,而目前天麻缺乏纯系品种。
3.目前作物获得纯系品种的方法主要有单倍体育种(haploid breeding)和纯系育种(pure-line selection)。单倍体育种是利用植物组织培养技术诱导产生单倍体植株,再通过某种手段使染色体组加倍(如用秋水仙素处理),从而使植物恢复正常染色体数。单倍体的获得方法有离体培养和孤雌生殖,离体培养又包括花药离体培养和花粉离体培养;孤雌生殖主要包括辐射花粉、化学诱导、异种属花粉延迟授粉、异种属细胞质-核替换法、远缘杂交等。纯系育种是从现有群体中选择具有优良性状的个体,通过后裔鉴定,保纯繁育,育成新品种。由于天麻尚不具备单倍体育种需要的组织培养技术,但拥有遗传多样性高的群体,所以使用纯系育种方法获得纯合度高的纯系品种更加可行。而纯系育种首先要解决的问题是如何快速从大量个体中筛选纯合度较高的个体做为初代育种材料。目前通过基因组重测序技术可准确获得样品的纯合度,但是经济成本和时间成本较高。如何快速从大量个体中筛选纯合度高的个体,是天麻育种首先要解决的问题。因此,急需寻找一种成本低廉、快速、能够有效评估天麻纯合度的方法。
技术实现要素:
4.本发明所要解决的技术问题是如何鉴定或辅助鉴定高纯合度天麻品种。
5.为解决上述技术问题,本发明首先提供了鉴定或辅助鉴定高纯合度天麻品种的分子标记,并对该标记的实用性进行了验证,为鉴定或辅助培育高纯合度天麻品种提供了可靠的分子标记。
6.本发明首先提供了鉴定天麻的rflp分子标记位点的试剂。
7.本发明提供的鉴定天麻的rflp分子标记位点的试剂,所述rflp分子标记位点为20个snp位点,所述20个snp位点可由e1标记位点、e2标记位点、e3标记位点、e4标记位点、e5标记位点、e6标记位点、e7标记位点、e8标记位点、e9标记位点、e10标记位点、e11标记位点、h1标记位点、h2标记位点、h3标记位点、s1标记位点、x1标记位点、x2标记位点、x3标记位点、x4标记位点和x5标记位点组成。
8.所述e1标记位点是天麻3号染色体上的一个位点,其核苷酸种类为t或g,为天麻基因组中seq id no.1的第435位核苷酸,所述e2标记位点是天麻7号染色体上的一个位点,其核苷酸种类为a或c,为天麻基因组中seq id no.2的第392位核苷酸,所述e3标记位点是天麻1号染色体上的一个位点,其核苷酸种类为g或c,为天麻基因组中seq id no.3的第360位核苷酸,所述e4标记位点是天麻2号染色体上的一个位点,其核苷酸种类为c或t,为天麻基因组中seq id no.4的第409位核苷酸,所述e5标记位点是天麻2号染色体上的一个位点,其核苷酸种类为c或g,为天麻基因组中seq id no.5的第171位核苷酸,所述e6标记位点是天麻8号染色体上的一个位点,其核苷酸种类为t或c,为天麻基因组中seq id no.6的第313位核苷酸,所述e7标记位点是天麻17号染色体上的一个位点,其核苷酸种类为a或g,为天麻基因组中seq id no.7的第280位核苷酸,所述e8标记位点是天麻2号染色体上的一个位点,其核苷酸种类为c或a,为天麻基因组中seq id no.8的第347位核苷酸,所述e9标记位点是天麻3号染色体上的一个位点,其核苷酸种类为a或g,为天麻基因组中seq id no.9的第140位核苷酸,所述e10标记位点是天麻4号染色体上的一个位点,其核苷酸种类为g或a,为天麻基因组中seq id no.10的第333位核苷酸,所述e11标记位点是天麻5号染色体上的一个位点,其核苷酸种类为g或a,为天麻基因组中seq id no.11的第330位核苷酸,所述h1标记位点是天麻5号染色体上的一个位点,其核苷酸种类为c或t,为天麻基因组中seq id no.12的第194位核苷酸,所述h2标记位点是天麻14号染色体上的一个位点,其核苷酸种类为c或t,为天麻基因组中seq id no.13的第460位核苷酸,所述h3标记位点是天麻14号染色体上的一个位点,其核苷酸种类为c或t,为天麻基因组中seq id no.14的第133位核苷酸,所述s1标记位点是天麻10号染色体上的一个位点,其核苷酸种类为g或c,为天麻基因组中seq id no.15的第387位核苷酸,所述x1标记位点是天麻1号染色体上的一个位点,其核苷酸种类为a或c,为天麻基因组中seq id no.16的第350位核苷酸,所述x2标记位点是天麻5号染色体上的一个位点,其核苷酸种类为a或g,为天麻基因组中seq id no.17的第288位核苷酸,所述x3标记位点是天麻8号染色体上的一个位点,其核苷酸种类为g或a,为天麻基因组中seq id no.18的第310位核苷酸,所述x4标记位点是天麻12号染色体上的一个位点,其核苷酸种类为t或c,为天麻基因组中seq id no.19的第311位核苷酸,所述x5标记位点是天麻6号染色体上的一个位点,其核苷酸种类为a或g,为天麻基因组中seq id no.20的第186位核苷酸。
9.所述试剂可由名称为e1组的组合物、e2组的组合物、e3组的组合物、e4组的组合物、e5组的组合物、e6组的组合物、e7组的组合物、e8组的组合物、e9组的组合物、e10组的组合物、e11组的组合物、h1组的组合物、h2组的组合物、h3组的组合物、s1组的组合物、x1组的组合物、x2组的组合物、x3组的组合物、x4组的组合物、x5组的组合物共20种组合物组成。
10.所述e1组由名称为e1引物对的扩增包括所述e1标记位点在内的天麻基因组dna片
段的引物组合物和限制性核酸内切酶ecorⅰ组成,所述e2组由名称为e2引物对的扩增包括所述e2标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶ecorⅰ组成,所述e3组由名称为e3引物对的扩增包括所述e3标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶ecorⅰ组成,所述e4组由名称为e4引物对的扩增包括所述e4标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶ecorⅰ组成,所述e5组由名称为e5引物对的扩增包括所述e5标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶ecorⅰ组成,所述e6组由名称为e6引物对的扩增包括所述e6标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶ecorⅰ组成,所述e7组由名称为e7引物对的扩增包括所述e7标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶ecorⅰ组成,所述e8组由名称为e8引物对的扩增包括所述e8标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶ecorⅰ组成,所述e9组由名称为e9引物对的扩增包括所述e9标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶ecorⅰ组成,所述e10组由名称为e10引物对的扩增包括所述e10标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶ecorⅰ组成,所述e11组由名称为e11引物对的扩增包括所述e11标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶ecorⅰ组成,所述h1组由名称为h1引物对的扩增包括所述h1标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶hindⅲ组成,所述h2组由名称为h2引物对的扩增包括所述h2标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶hindⅲ组成,所述h3组由名称为h3引物对的扩增包括所述h3标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶hindⅲ组成,所述s1组由名称为s1引物对的扩增包括所述s1标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶salⅰ组成,所述x1组由名称为x1引物对的扩增包括所述x1标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶xbai组成,所述x2组由名称为x2引物对的扩增包括所述x2标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶xbai组成,所述x3组由名称为x3引物对的扩增包括所述x3标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶xbai组成,所述x4组由名称为x4引物对的扩增包括所述x4标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶xbai组成,所述x5组由名称为x5引物对的扩增包括所述x5标记位点在内的天麻基因组dna片段的引物组合物和限制性核酸内切酶xhoi组成。
11.上述试剂中,所述e1引物对可由名称分别为e1-f和e1-r的两种单链dna组成,所述e1-f的核苷酸序列是序列表中序列1的第1-20位,所述e1-r的核苷酸序列与序列表中序列1的第691-710位反向互补,所述e2引物对可由名称分别为e2-f和e2-r的两种单链dna组成,所述e2-f的核苷酸序列是序列表中序列2的第1-20位,所述e2-r的核苷酸序列与序列表中序列2的第565-584位反向互补,所述e3引物对可由名称分别为e3-f和e3-r的两种单链dna组成,所述e3-f的核苷酸序列是序列表中序列3的第1-20位,所述e3-r的核苷酸序列与序列表中序列3的第571-590位反向互补,所述e4引物对可由名称分别为e4-f和e4-r的两种单链dna组成,所述e4-f的核苷酸序列是序列表中序列4的第1-20位,所述e4-r的核苷酸序列与序列表中序列4的第554-573位反向互补,所述e5引物对可由名称分别为e5-f和e5-r的两种单链dna组成,所述e5-f的核苷酸序列是序列表中序列5的第1-20位,所述e5-r的核苷酸序
列与序列表中序列5的第395-416位反向互补,所述e6引物对可由名称分别为e6-f和e6-r的两种单链dna组成,所述e6-f的核苷酸序列是序列表中序列6的第1-20位,所述e6-r的核苷酸序列与序列表中序列6的第474-494位反向互补,所述e7引物对可由名称分别为e7-f和e7-r的两种单链dna组成,所述e7-f的核苷酸序列是序列表中序列7的第1-22位,所述e7-r的核苷酸序列与序列表中序列7的第439-458位反向互补,所述e8引物对可由名称分别为e8-f和e8-r的两种单链dna组成,所述e8-f的核苷酸序列是序列表中序列8的第1-20位,所述e8-r的核苷酸序列与序列表中序列8的第446-466位反向互补,所述e9引物对可由名称分别为e9-f和e9-r的两种单链dna组成,所述e9-f的核苷酸序列是序列表中序列9的第1-20位,所述e9-r的核苷酸序列与序列表中序列9的第382-401位反向互补,所述e10引物对可由名称分别为e10-f和e10-r的两种单链dna组成,所述e10-f的核苷酸序列是序列表中序列10的第1-22位,所述e10-r的核苷酸序列与序列表中序列10的第495-514位反向互补,所述e11引物对可由名称分别为e11-f和e11-r的两种单链dna组成,所述e11-f的核苷酸序列是序列表中序列11的第1-21位,所述e11-r的核苷酸序列与序列表中序列11的第501-522位反向互补,所述h1引物对可由名称分别为h1-f和h1-r的两种单链dna组成,所述h1-f的核苷酸序列是序列表中序列12的第1-20位,所述h1-r的核苷酸序列与序列表中序列12的第482-501位反向互补,所述h2引物对可由名称分别为h2-f和h2-r的两种单链dna组成,所述h2-f的核苷酸序列是序列表中序列13的第1-20位,所述h2-r的核苷酸序列与序列表中序列13的第634-653位反向互补,所述h3引物对可由名称分别为h3-f和h3-r的两种单链dna组成,所述h3-f的核苷酸序列是序列表中序列14的第1-20位,所述h3-r的核苷酸序列与序列表中序列14的第517-536位反向互补,所述s1引物对可由名称分别为s1-f和s1-r的两种单链dna组成,所述s1-f的核苷酸序列是序列表中序列15的第1-20位,所述s1-r的核苷酸序列与序列表中序列15的第543-564位反向互补,所述x1引物对可由名称分别为x1-f和x1-r的两种单链dna组成,所述x1-f的核苷酸序列是序列表中序列16的第1-20位,所述x1-r的核苷酸序列与序列表中序列16的第630-649位反向互补,所述x2引物对可由名称分别为x2-f和x2-r的两种单链dna组成,所述x2-f的核苷酸序列是序列表中序列17的第1-22位,所述x2-r的核苷酸序列与序列表中序列17的第564-585位反向互补,所述x3引物对可由名称分别为x3-f和x3-r的两种单链dna组成,所述x3-f的核苷酸序列是序列表中序列18的第1-20位,所述x3-r的核苷酸序列与序列表中序列18的第512-531位反向互补,所述x4引物对可由名称分别为x4-f和x4-r的两种单链dna组成,所述x4-f的核苷酸序列是序列表中序列19的第1-21位,所述x4-r的核苷酸序列与序列表中序列19的第526-547位反向互补,所述x5引物对可由名称分别为x5-f和x5-r的两种单链dna组成,所述x5-f的核苷酸序列是序列表中序列20的第1-20位,所述x5-r的核苷酸序列与序列表中序列20的第511-530位反向互补。
12.上述试剂的应用也属于本发明保护的范围。
13.上述试剂的应用具体可为在如下任一中的应用:(1)鉴定或辅助鉴定天麻纯合度;(2)筛选或选育高纯合度的天麻单株或株系或品系或品种;(4)天麻育种;(5)制备鉴定或辅助鉴定天麻高纯合度的产品;(6)制备筛选或选育高纯合度的天麻单株或株系或品系或品种的产品;(7)制备筛选或选育高纯合度的天麻单株或株系或品系或品种的产品;(8)制备天麻育种的产品。
14.本发明还提供了鉴定或辅助鉴定天麻的rflp分子标记位点的引物组合物。
15.所述rflp分子标记位点为上述的20个snp位点,所述引物组合物由如下20种引物对组成:上述的e1引物对、上述的e2引物对、上述的e3引物对、上述的e4引物对、上述的e5引物对、上述的e6引物对、上述的e7引物对、上述的e8引物对、上述的e9引物对、上述的e10引物对、上述的e11引物对、上述的h1引物对、上述的h2引物对、上述的h3引物对、上述的s1引物对、上述的x1引物对、上述的x2引物对、上述的x3引物对上述的x4引物对、上述的x5引物对。
16.本发明还提供了上文所述的引物组合物的应用,具体可为如下任一中的应用:
17.(1)鉴定或辅助鉴定天麻品种纯合度;(2)筛选或选育高纯合度的天麻单株或株系或品系或品种;(4)天麻育种;(5)制备鉴定或辅助鉴定天麻高纯合度的产品;(6)制备筛选或选育高纯合度的天麻单株或株系或品系或品种的产品;(7)制备筛选或选育高纯合度的天麻单株或株系或品系或品种的产品;(8)制备天麻育种的产品。
18.本发明还提供了鉴定或辅助鉴定天麻纯合度的方法。
19.本发明提供的鉴定或辅助鉴定天麻纯合度的方法,包括如下步骤:
20.1)分别以待测天麻的基因组dna为模板,用所述的20种引物对分别进行pcr扩增,得到所述20种引物对的待测天麻pcr产物,将用所述e1引物对进行pcr扩增得到的待测天麻pcr产物命名为e1-pcr产物,将用所述e2引物对进行pcr扩增得到的待测天麻pcr产物命名为e2-pcr产物,将用所述e3引物对进行pcr扩增得到的待测天麻pcr产物命名为e3-pcr产物,将用所述e4引物对进行pcr扩增得到的待测天麻pcr产物命名为e4-pcr产物,将用所述e5引物对进行pcr扩增得到的待测天麻pcr产物命名为e5-pcr产物,将用所述e6引物对进行pcr扩增得到的待测天麻pcr产物命名为e6-pcr产物,将用所述e7引物对进行pcr扩增得到的待测天麻pcr产物命名为e7-pcr产物,将用所述e8引物对进行pcr扩增得到的待测天麻pcr产物命名为e8-pcr产物,将用所述e9引物对进行pcr扩增得到的待测天麻pcr产物命名为e9-pcr产物,将用所述e10引物对进行pcr扩增得到的待测天麻pcr产物命名为e10-pcr产物,将用所述e11引物对进行pcr扩增得到的待测天麻pcr产物命名为e11-pcr产物,将用所述h1引物对进行pcr扩增得到的待测天麻pcr产物命名为h1-pcr产物,将用所述h2引物对进行pcr扩增得到的待测天麻pcr产物命名为h2-pcr产物,将用所述h3引物对进行pcr扩增得到的待测天麻pcr产物命名为h3-pcr产物,将用所述s1引物对进行pcr扩增得到的待测天麻pcr产物命名为s1-pcr产物,将用所述x1引物对进行pcr扩增得到的待测天麻pcr产物命名为x1-pcr产物,将用所述x2引物对进行pcr扩增得到的待测天麻pcr产物命名为x2-pcr产物,将用所述x3引物对进行pcr扩增得到的待测天麻pcr产物命名为x3-pcr产物,将用所述x4引物对进行pcr扩增得到的待测天麻pcr产物命名为x4-pcr产物,将用所述x5引物对进行pcr扩增得到的待测天麻pcr产物命名为x5-pcr产物;
21.2)将所述20种引物对的待测天麻pcr产物进行rflp分析,所述rflp分析包括将所述20种引物对的待测天麻pcr产物用限制性核酸内切酶进行酶切,得到20种酶切产物,将所述20种酶切产物进行电泳,根据电泳结果确定所述20种酶切产物的条带的数量;所述rflp分析中,所述e1-pcr产物、所述e2-pcr产物、所述e3-pcr产物、所述e4-pcr产物、所述e5-pcr产物、所述e6-pcr产物、所述e7-pcr产物、所述e8-pcr产物、所述e9-pcr产物、所述e10-pcr产物、所述e11-pcr产物均分别用限制性核酸内切酶ecorⅰ进行酶切,所述h1-pcr产物、所述h2-pcr产物、所述h3-pcr产物均分别用限制性核酸内切酶hindⅲ进行酶切,所述s1-pcr产
物用限制性核酸内切酶sali进行酶切,所述x1-pcr产物、所述x2-pcr产物、所述x3-pcr产物、所述x4-pcr产物均分别用限制性核酸内切酶xbai进行酶切,所述x5-pcr产物用限制性核酸内切酶xhoi进行酶切;
22.3)根据待测天麻所述pcr产物酶切条带的数量,计算纯合度。
23.本发明还提供了天麻育种的方法。
24.在一种实施方式中,所述天麻育种方法可包括利用上述鉴定或辅助鉴定天麻纯合度的方法,选择纯合度大于等于95%的天麻作为亲本(候选亲本)进行育种,所述纯合度的计算公式为:h=(1-n/20)
×
100%,h代表纯合度,n代表所述20种pcr产物经酶切后电泳结果中出现3条带的酶切产物的种数。
25.本研究基于前期获得天麻snp标记开发了20个用于评估天麻纯合度的rflp标记,综合评估精度和筛选效率,建立了一种快速筛选高纯合度天麻个体的方法,该标记方法的精确度好、准确率高,为天麻纯系育种和杂交育种的较高纯合度的纯系品种筛选提供了技术支撑,对从遗传背景不明确的群体中获得遗传稳定的天麻种质资源具有重要意义。而目前其他药用植物也存在品种混杂、退化、低产等严峻问题,因此本方法对其他中药种质资源的开发也具有重要的借鉴意义。
附图说明
26.图1为不同引物对pcr扩增产物酶切结果凝胶电泳图。
具体实施方式
27.下面结合具体实施方式对本发明进行进一步的详细描述,给出的实施例仅为了阐明本发明,而不是为了限制本发明的范围。以下提供的实施例可作为本技术领域普通技术人员进行进一步改进的指南,并不以任何方式构成对本发明的限制。
28.下述实施例中的实验方法,如无特殊说明,均为常规方法,按照本领域内的文献所描述的技术或条件或者按照产品说明书进行。下述实施例中所用的材料、试剂等,如无特殊说明,均可从商业途径得到。
29.下述实施例中的hi-dnasecure plant kit高效植物基因组dna提取试剂盒(天根生化科技(北京)有限公司,批号:w9907);2
×
m5super fasttaq pcr mastermix(北京聚合美生物科技有限公司,批号21kb0808);6
×
loading buffer(大连takara公司,批号p30925);2000bp dna marker(大连takara公司,批号p51018);xhoⅰ酶(new england biolabs,批号10020678);ecorⅰ酶(new england biolabs,批号10107912);hindⅲ酶(new england biolabs,批号10079084);xbaⅰ酶(new england biolabs,批号10116146);rcutsmart buffer(new england biolabs,批号10118973);核酸染料(thermo fisher scientific,批号:2399638a);琼脂粉(bioweste,生产批号:111860)
30.天麻样品分别采自贵州大方、云南昭通、湖北英山和湖北宜昌4个天麻主产区,由金艳副研究员鉴定,材料保存于中国中医科学院中药资源中心(见表2)。
31.实施例1rflp标记筛选高纯合度天麻
32.1.rflp标记的位点选取
33.将前期已获得天麻参考基因组和151个天麻个体的重测序数据,使用gatk进行snp
检测并剔除具有以下任一情况的snp位点:(1)snp位于插入/缺失变异上下游5bp以内;(2)缺失率大于30%;(3)最小等位基因频率小于5%。共获得14,267,316个snp标记。基于上述snp标记计算151个天麻个体纯合度和各snp标记的纯合度,以1%为步长,5%为区间长度,将不同杂合度的snp标记进行分组(例:1%~6%,2%~7%,3%~8%),使用自编脚本从每组中每次随机抽取20个snp标记评估每个个体的纯合度并与使用每个个体全部snp标记计算的纯合度比较,计算在每5%区间鉴定结果一致的样本比例。上述过程使用bootstrap法自助抽样1000次。使用自编脚本,利用biopython包中的restriction模块检测snp标记和其侧翼序列(上下游各800bp)是否存在限制性内切酶识别位点。若snp位点处于限制性内切酶识别位点且其侧翼序列不包含相应的限制性内切酶识别位点,则该snp标记可用作rflp标记。
34.本实施例选取ecorⅰ,hindⅲ,salⅰ,xbaⅰ,xhoⅰ等限制性内切酶的识别位点。使用20个杂合度在7%~12%的位点可以在5%的区间正确鉴定天麻个体纯合度,其中位于酶切位点,可以开发为rflp标记的snp标记有37个,从中选取20个进行rflp标记的开发,其中ecorⅰ酶标记11个,hindⅲ标记3个,salⅰ酶标记1个,xbaⅰ酶标记4个,xhoⅰ标记1个。这20个rflp标记是如下20个snp:
35.1)名称为e1标记位点的snp,e1标记位点是天麻3号染色体上的一个位点(位于天麻基因组第chr3:7756023位,(genbank accession numbergwhbhou00000003的第7756023位)),其核苷酸种类为t或g,为天麻基因组中seq id no.1的第435位核苷酸,
36.2)名称为e2标记位点的snp,所述e2标记位点是天麻7号染色体上的一个位点(位于天麻基因组第chr7:2724136位,(genbank accession number gwhbhou00000007的第2724136位)),其核苷酸种类为a或c,为天麻基因组中seq id no.2的第392位核苷酸,
37.3)名称为e3标记位点的snp,所述e3标记位点是天麻1号染色体上的一个位点(位于天麻基因组第chr1:90614251位,(genbank accession number gwhbhou00000001的第90614251位)),其核苷酸种类为g或c为天麻基因组中seq id no.3的第360位核苷酸;
38.4)名称为e4标记位点的snp,所述e4标记位点是天麻2号染色体上的一个位点(位于天麻基因组第chr2:106091319位,(genbank accession number gwhbhou00000002的第106091319位)),其核苷酸种类为c或t为天麻基因组中seq id no.4的第409位核苷酸;
39.5)名称为e5标记位点的snp,所述e5标记位点是天麻2号染色体上的一个位点(位于天麻基因组第chr2:39372534位,(genbank accession number gwhbhou00000002的第39372534位)),其核苷酸种类为c或g为天麻基因组中seq id no.5的第171位核苷酸;
40.6)名称为e6标记位点的snp,所述e6标记位点是天麻8号染色体上的一个位点(位于天麻基因组第chr8:33125591位(genbank accession gwhbhou00000007的第33125591位)),其核苷酸种类为t或c,为天麻基因组中seq id no.6的第313位核苷酸;
41.7)名称为e7标记位点的snp,所述e7标记位点是天麻16号染色体上的一个位点(位于天麻基因组第chr16:9163271位,(genbank accession number gwhbhou000000016的第9163271位)),其核苷酸种类为a或g,为天麻基因组中seq id no.7的第280位核苷酸;
42.8)名称为e8标记位点的snp,所述e8标记位点是天麻2号染色体上的一个位点(位于天麻基因组第chr2:526568位,(genbank accession number gwhbhou00000002的第526568位)),其核苷酸种类为c或a,为天麻基因组中seq id no.8的第347位核苷酸;
43.9)名称为e9标记位点的snp,所述e9标记位点是天麻3号染色体上的一个位点(位于天麻基因组第chr3:65507245位,(genbank accession number gwhbhou00000003的第65507245位)),其核苷酸种类为a或g,为天麻基因组中seq id no.9的第140位核苷酸;
44.10)名称为e10标记位点的snp,所述e10标记位点是天麻4号染色体上的一个位点(位于天麻基因组第chr4:57186102位,(genbank accession number gwhbhou00000004的第57186102位)),其核苷酸种类为g或a,为天麻基因组中seq id no.10的第333位核苷酸;
45.11)名称为e11标记位点的snp,所述e11标记位点是天麻5号染色体上的一个位点(位于天麻基因组第chr5:23007754位,(genbank accession number gwhbhou00000005的第23007754位)),其核苷酸种类为g或a,为天麻基因组中seq id no.11的第330位核苷酸;
46.12)名称为h1标记位点的snp,所述h1标记位点是天麻5号染色体上的一个位点(位于天麻基因组第chr5:20038961位,(genbank accession number gwhbhou00000005的第20038961位)),其核苷酸种类为c或t,为天麻基因组中seq id no.12的第194位核苷酸;
47.13)名称为h2标记位点的snp,所述h3标记位点是天麻13号染色体上的一个位点(位于天麻基因组第chr13:21721655位,(genbank accession numbergwhbhou00000013的第21721655位)),其核苷酸种类为c或t,为天麻基因组中seq id no.13的第460位核苷酸;
48.14)名称为h3标记位点的snp,所述h2标记位点是天麻1号染色体上的一个位点(位于天麻基因组第chr1:16461737位,(genbank accession numbergwhbhou00000001的第16461737位)),其核苷酸种类为c或t,为天麻基因组中seq id no.14的第133位核苷酸;
49.15)名称为s1标记位点的snp,所述s1标记位点是天麻11号染色体上的一个位点(位于天麻基因组第chr11:47646083位,(genbank accession number gwhbhou00000011的第47646083位)),其核苷酸种类为g或c为天麻基因组中seq id no.15的第387位核苷酸;
50.16)名称为x1标记位点的snp,所述x1标记位点是天麻1号染色体上的一个位点(位于天麻基因组第chr1:82379251位,(genbank accession number gwhbhou00000001的第82379251位)),其核苷酸种类为a或c,为天麻基因组中seq id no.16的第350位核苷酸;
51.17)名称为x2标记位点的snp,所述x2标记位点是天麻5号染色体上的一个位点(位于天麻基因组第chr5:52061619位,(genbank accession number gwhbhou00000005的第52061619位)),其核苷酸种类为a或g,为天麻基因组中seq id no.17的第288位核苷酸;
52.18)名称为x3标记位点的snp,所述x3标记位点是天麻8号染色体上的一个位点(位于天麻基因组第chr8:4676518位,(genbank accession number gwhbhou00000008的第4676518位)),其核苷酸种类为a或g,为天麻基因组中seq id no.18的第310位核苷酸;
53.19)名称为x4标记位点的snp,所述x4标记位点是天麻14号染色体上的一个位点(位于天麻基因组第chr12:4216762位,(genbank accession number gwhbhou00000012的第4216762位)),其核苷酸种类为c或t,为天麻基因组中seq id no.19的第311位核苷酸;
54.20)名称为x5标记位点的snp,所述x5标记位点是天麻6号染色体上的一个位点(位于天麻基因组第chr6:53849642位,(genbank accession number gwhbhou00000006的第53849642位)),其核苷酸种类为a或g,为天麻基因组中seq id no.20的第186位核苷酸;
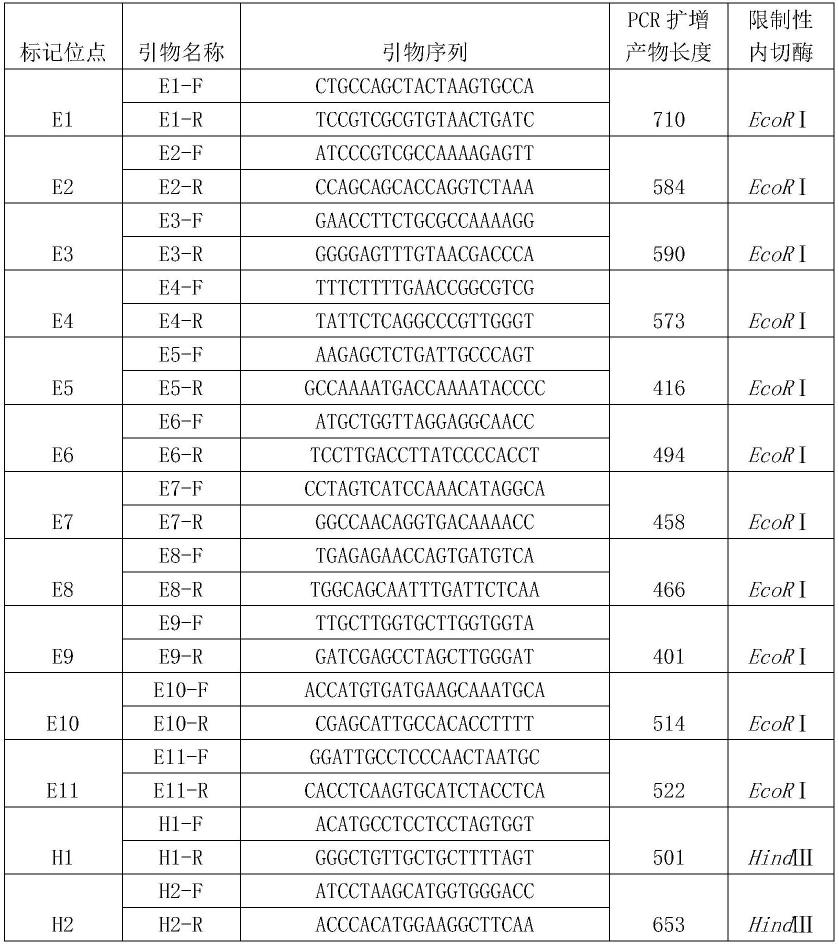
55.人工合成20个rflp标记的pcr正反向引物对,20个pcr正反向引物对组合物(以下又称鉴定天麻高纯合度的pcr引物对组合物或特异性pcr引物对组合物)及其产物长度如表1所示,上述鉴定天麻高纯合度的pcr引物对组合物均独立包装,每种引物对中的两条单链
dna的摩尔比均为1:1。
56.该鉴定天麻高纯合度的pcr引物对组合物为鉴定天麻的rflp分子标记位点的引物组合物,所述引物组合物由如下20种引物对组成:名称为e1引物的用于扩增包括所述e1标记位点在内的天麻基因组dna片段的引物组合物、名称为e2引物的用于扩增包括所述e2标记位点在内的天麻基因组dna片段的引物组合物、名称为e3引物的用于扩增包括所述e3标记位点在内的天麻基因组dna片段的引物组合物、名称为e4引物的用于扩增包括所述e4标记位点在内的天麻基因组dna片段的引物组合物、名称为e5引物的用于扩增包括所述e5标记位点在内的天麻基因组dna片段的引物组合物、名称为e6引物的用于扩增包括所述e6标记位点在内的天麻基因组dna片段的引物组合物、名称为e7引物的用于扩增包括所述e7标记位点在内的天麻基因组dna片段的引物组合物、名称为e8引物的用于扩增包括所述e8标记位点在内的天麻基因组dna片段的引物组合物、名称为e9引物的用于扩增包括所述e9标记位点在内的天麻基因组dna片段的引物组合物、名称为e10引物的用于扩增包括所述e10标记位点在内的天麻基因组dna片段的引物组合物、名称为e11引物的用于扩增包括所述e11标记位点在内的天麻基因组dna片段的引物组合物、名称为h1引物的用于扩增包括所述h1标记位点在内的天麻基因组dna片段的引物组合物、名称为h2引物的用于扩增包括所述h2标记位点在内的天麻基因组dna片段的引物组合物、名称为h3引物的用于扩增包括所述h3标记位点在内的天麻基因组dna片段的引物组合物、名称为s1引物的用于扩增包括所述s1标记位点在内的天麻基因组dna片段的引物组合物、名称为x1引物的用于扩增包括所述x1标记位点在内的天麻基因组dna片段的引物组合物、名称为x2引物的用于扩增包括所述x2标记位点在内的天麻基因组dna片段的引物组合物、名称为x3引物的用于扩增包括所述x3标记位点在内的天麻基因组dna片段的引物组合物、名称为x4引物的用于扩增包括所述x4标记位点在内的天麻基因组dna片段的引物组合物、名称为x5引物的用于扩增包括所述x5标记位点在内的天麻基因组dna片段的引物组合物。
57.e1引物由核苷酸序列是序列表中序列1的第1-20位的单链dna和核苷酸序列与序列表中序列1的第691-710位反向互补的单链dna组成的pcr引物对;
58.e2引物由核苷酸序列是序列表中序列2的第1-20位的单链dna和核苷酸序列与序列表中序列2的第565-584位反向互补的单链dna组成的pcr引物对
59.e3引物由核苷酸序列是序列表中序列3的第1-20位的单链dna和核苷酸序列与序列表中序列3的第571-590位反向互补的单链dna组成的pcr引物对;
60.e4引物由核苷酸序列是序列表中序列4的第1-20位的单链dna和核苷酸序列与序列表中序列4的第554-573位反向互补的单链dna组成的pcr引物对;
61.e5引物由核苷酸序列是序列表中序列5的第1-20位的单链dna和核苷酸序列与序列表中序列5的第395-416位反向互补的单链dna组成的pcr引物对;
62.e6引物由核苷酸序列是序列表中序列6的第1-20位的单链dna和核苷酸序列与序列表中序列6的第474-494位反向互补的单链dna组成的pcr引物对;
63.e7引物由核苷酸序列是序列表中序列7的第1-22位的单链dna和核苷酸序列与序列表中序列7的第439-458位反向互补的单链dna组成的pcr引物对;
64.e8引物由核苷酸序列是序列表中序列8的第1-20位的单链dna和核苷酸序列与序列表中序列8的第446-466位反向互补的单链dna组成的pcr引物对;
65.e9引物由核苷酸序列是序列表中序列9的第1-20位的单链dna和核苷酸序列与序列表中序列9的第382-401位反向互补的单链dna组成的pcr引物对;
66.e10引物由核苷酸序列是序列表中序列10的第1-22位的单链dna和核苷酸序列与序列表中序列10的第495-514位反向互补的单链dna组成的pcr引物对;
67.e11引物由核苷酸序列是序列表中序列11的第1-21位的单链dna和核苷酸序列与序列表中序列11的第501-522位反向互补的单链dna组成的pcr引物对;
68.h1引物由核苷酸序列是序列表中序列12的第1-20位的单链dna和核苷酸序列与序列表中序列12的第482-501位反向互补的单链dna组成的pcr引物对;
69.h2引物由核苷酸序列是序列表中序列13的第1-20位的单链dna和核苷酸序列与序列表中序列13的第634-653位反向互补的单链dna组成的pcr引物对;
70.h3引物由核苷酸序列是序列表中序列14的第1-20位的单链dna和核苷酸序列与序列表中序列14的第517-536位反向互补的单链dna组成的pcr引物对;
71.s1引物由核苷酸序列是序列表中序列15的第1-20位的单链dna和核苷酸序列与序列表中序列15的第543-564位反向互补的单链dna组成的pcr引物对;
72.x1引物由核苷酸序列是序列表中序列16的第1-20位的单链dna和核苷酸序列与序列表中序列16的第630-649位反向互补的单链dna组成的pcr引物对;
73.x2引物由核苷酸序列是序列表中序列17的第1-20位的单链dna和核苷酸序列与序列表中序列16的第564-585位反向互补的单链dna组成的pcr引物对;
74.x3引物由核苷酸序列是序列表中序列18的第1-20位的单链dna和核苷酸序列与序列表中序列18的第512-531位反向互补的单链dna组成的pcr引物对;
75.x4引物由核苷酸序列是序列表中序列19的第1-21位的单链dna和核苷酸序列与序列表中序列19的第526-547位反向互补的单链dna组成的pcr引物对。
76.x5引物由核苷酸序列是序列表中序列20的第1-20位的单链dna和核苷酸序列与序列表中序列20的第511-530位反向互补的单链dna组成的pcr引物对。
77.表1 20个rflp标记的正反向引物及其产物长度
[0078][0079]
[0080]
2.基因组dna提取
[0081]
取鲜天麻(gastrodia elata bl.)的块茎,粉碎后,取10mg粉末,利用hi-dna secure plant kit高效植物基因组dna提取试剂盒进行dna提取。用nanodrop 2000微量核酸定量分析仪测定其dna浓度,并根据吸光度a260nm/280nm,a260nm/230nm判断dna质量。得到15份天麻的基因组dna。
[0082]
3.pcr扩增
[0083]
使用特异性pcr引物对组合物分别对上述15份天麻的基因组dna进行pcr扩增。pcr反应体系均为25μl,其中包含2
×
m5supper fasttaq pcr mastermix 13μl,正向引物(具体序列见表1)1μl,反向引物(具体序列见表1)1μl,dna模板1μl,加无菌水补足至25μl,反应条件如下:94℃2min,35个循环(94℃30s,58℃15s,72℃1min),72℃5min。分别得到15份天麻的e1-pcr产物(所用的引物对是e1引物,e1引物由核苷酸序列是序列表中序列1的第1至20位的单链dna和核苷酸序列是序列表中序列1的第691-710位反向互补的单链dna组成的pcr引物对),e2-pcr产物(所用的引物对是e2引物,e2引物由核苷酸序列是序列表中序列2的第1-20位的单链dna和核苷酸序列是序列表中序列2的第565-584位反向互补的单链dna组成的pcr引物对),e3-pcr产物(所用的引物对是e3引物,e3引物由核苷酸序列是序列表中序列3的第1-20位的单链dna和核苷酸序列是序列表中序列3的第571-590位反向互补的单链dna组成的pcr引物对),e4-pcr产物(所用的引物对是e4引物,e4引物由核苷酸序列是序列表中序列4的第1-20位的单链dna和核苷酸序列是序列表中序列4的第554-573位反向互补的单链dna组成的pcr引物对),e5-pcr产物(所用的引物对是e5引物,e5引物由核苷酸序列是序列表中序列5的第1-20位的单链dna和核苷酸序列是序列表中序列5的第395-416位的单链dna组成的pcr引物对),e6-pcr产物(所用的引物对是e6引物,e6引物由核苷酸序列是序列表中序列6的第1-20位的单链dna和核苷酸序列是序列表中序列6的第474-494位反向互补的单链dna组成的pcr引物对),e7-pcr产物(所用的引物对是e7引物,e7引物由核苷酸序列是序列表中序列7的第1-22位的单链dna和核苷酸序列是序列表中序列7的第439-458位反向互补的单链dna组成的pcr引物对),e8-pcr产物(所用的引物对是e8引物,e8引物由核苷酸序列是序列表中序列8的第1-20位的单链dna和核苷酸序列是序列表中序列8的第446-466位反向互补的单链dna组成的pcr引物对),e9-pcr产物(所用的引物对是e9引物,e9引物由核苷酸序列是序列表中序列9的第1-20位的单链dna和核苷酸序列是序列表中序列9的第382-401位反向互补的单链dna组成的pcr引物对),e10-pcr产物(所用的引物对是e10引物,e10引物由核苷酸序列是序列表中序列10的第1-22位的单链dna和核苷酸序列是序列表中序列10的第495-514位反向互补的单链dna组成的pcr引物对),e11-pcr产物(所用的引物对是e11引物,e11引物由核苷酸序列是序列表中序列11的第1-21位的单链dna和核苷酸序列是序列表中序列11的第501-522位反向互补的单链dna组成的pcr引物对),h1-pcr产物(所用的引物对是h1引物,h1引物由核苷酸序列是序列表中序列12的第1-20位的单链dna和核苷酸序列是序列表中序列12的第482-501位反向互补的单链dna组成的pcr引物对),h2-pcr产物(所用的引物对是h2引物,h2引物由核苷酸序列是序列表中序列13的第1-20位的单链dna和核苷酸序列是序列表中序列13的第634-653位反向互补的单链dna组成的pcr引物对),h3-pcr产物(所用的引物对是h3引物,h3引物由核苷酸序列是序列表中序列14的第1-20位的单链dna和核苷酸序列是序列表中序列14的第517-536位反向互补的单链dna组成的
pcr引物对),s1-pcr产物(所用的引物对是s1引物,s1引物由核苷酸序列是序列表中序列15的第1-20位的单链dna和核苷酸序列是序列表中序列15的第543-564位反向互补的单链dna组成的pcr引物对),x1-pcr产物(所用的引物对是x1引物,x1引物由核苷酸序列是序列表中序列16的第1-20位的单链dna和核苷酸序列是序列表中序列16的第630-649位反向互补的单链dna组成的pcr引物对),x2-pcr产物(所用的引物对是x2引物,x2引物由核苷酸序列是序列表中序列187的第1-22位的单链dna和核苷酸序列是序列表中序列17的第564-585位反向互补的单链dna组成的pcr引物对),x3-pcr产物(所用的引物对是x3引物,x3引物由核苷酸序列是序列表中序列18的第1-20位的单链dna和核苷酸序列是序列表中序列18的第512-531位反向互补的单链dna组成的pcr引物对),x4-pcr产物(所用的引物对是x4引物,x4引物由核苷酸序列是序列表中序列19的第1-21位的单链dna和核苷酸序列是序列表中序列19的第526-547位的单链dna组成的pcr引物对),x5-pcr产物(所用的引物对是x5引物,x5引物由核苷酸序列是序列表中序列20的第1-20位的单链dna和核苷酸序列是序列表中序列20的第511-530位反向互补的单链dna组成的pcr引物对),共20种pcr产物。
[0084]
pcr反应结束后,取反应产物5μl,加入6
×
loading buffer 1μl,混匀后于核酸染料染色的2.0%琼脂糖凝胶电泳检测,凝胶成像系统观察、成像。
[0085]
4.pcr产物rflp分析
[0086]
取上述步骤3得到的pcr产物进行rflp分析。酶切反应体系为25μl,包含10
×
buffer 2.5μl、pcr产物15μl、限制性内切酶(10u
·
μl
-1
)0.5μl、dd h2o7μl。37℃水浴反应120min。其中,e1-pcr产物至e12-pcr产物这12种pcr产物均分别用限制性核酸内切酶ecorⅰ进行酶切,h1-pcr产物至h3-pcr产物这3种pcr产物均分别用限制性核酸内切酶hindⅲ进行酶切,s1-pcr产物用限制性核酸内切酶salⅰ进行酶切,x1-pcr产物至x4-pcr产物这4种pcr产物均分别用限制性核酸内切酶xbai进行酶切,x5-pcr产物用限制性核酸内切酶xhoi进行酶切。
[0087]
取酶切产物5μl,加入1μl 6
×
loading buffer,混匀后于核酸染料染色的2.0%琼脂糖凝胶电泳检测,凝胶成像系统观测、成像。不同样品的限制性酶切位点的结果有可能出现1条带、2条带、3条带的情况,其中1条带和2条带代表样品在该标记位点是纯合的;3条带则代表样品在该标记位点是杂合的。
[0088]
使用上述筛选出20个rflp标记位点对15份天麻样品进行dna提取、特异性引物扩增及限制性内切酶实验,结果如图1所示,a:标记位点e1;b:标记位点e2;c:标记位点e3;d:标记位点e4;e:标记位点e5;f:标记位点e6;g:标记位点e7;h:标记位点e8;i:标记位点e9;j:标记位点e10;k:标记位点e11;l:标记位点h1;m:标记位点h2;n:标记位点h3;o:标记位点s1;p:标记位点x1;q:标记位点x2;r:标记位点x3;s:标记位点x4;t:标记位点x5;1-15为15份不同天麻样品;16为空白对照,以ddh2o为模板;m.dl 2000marker。每行代表一种标记位点,1-15列的每列代表不同的天麻样品,
[0089]
由图1可知,样品1、样品3、样品4、样品5、样品7、样品8、样品12在20个标记位点条带都只出现1条带和2条带的情况。样品2在标记位点h1出现3条带;样品6在标记位点e2、标记位点e6、标记位点e10、标记位点x5等4个标记位点出现3条带;样品9在标记位点x5出现3条带;样品10在标记位点e2、标记位点h1、标记位点x5等3个标记位点出现3条带;样品11在标记位点h1出现3条带;样品13、样品14在标记位点e3、标记位点e6、标记位点e7等3个位点
出现3条带;样品15在标记位点e2、标记位点e3、标记位点x5等3个位点出现3条带;样品在除上述位点外,其他位点都只出现1条带或2条带的情况。
[0090]
基于rflp标记评估的纯合度通过如下公式计算:根据图1中每一样品不同位点出现3条带的位点个数,计算纯合度。纯合度的计算公式为:h=(1-n/m)
×
100%,h代表纯合度(homozygosity),n代表出现3条带的位点数(即n代表20种pcr产物经酶切后电泳结果中出现3条带的酶切产物的种数),m代表总位点数,其取值为20,计算结果如表2所示。
[0091]
5基因组重测序验证上述rflp标记鉴定结果的准确性
[0092]
按照步骤2得到15份天麻的基因组dna,使用covaris随机打断成350~500bp的dna小片段,回收500bp左右的dna片段进行文库构建,文库构建合格后采用dnbseq-t7测序平台对插入片段进行双末端测序。获得的原始测序数据经fastp软件质控和过滤后,以天麻基因组(登录号gwhbhou00000000,保存于国家基因组科学数据中心https://ngdc.cncb.ac.cn/gwh)为参考基因组,利用bwa软件进行比对。进一步利用samtools软件对比对结果进行重复序列标记、排序,然后利用gatk软件中的haplotypecaller和genotypegvcfs程序分别检测snp和基因型,最后使用bcftools对获得的snp位点进行质控(qd《4.0||fs》60.0||mq《40.0||maf[0]《0.05||f_missing》0.3)。利用获得的snp和基因型信息,利用plink软件的
”‑‑
het”功能计算每个个体总位点数(结果文件中的n(nm))和纯合位点数(结果文件中的o(hom)),以纯合位点数/总位点数
×
100%作为样品的纯合度。
[0093]
对天麻基于基因组重测序评估的纯合度见表2。
[0094]
表2 15个天麻样品纯合度
[0095]
[0096][0097]
rflp标记评估15份天麻样品纯合度在80~100%区间内,其中10份天麻样品纯合度大于等于95%,分别是样品1、样品2、样品3、样品4、样品5、样品7、样品8、样品9、样品11、样品12;4份天麻样品纯合度为85%,分别是样品10、样品13、样品14、样品15;样品6纯合度为80%。
[0098]
基因组重测序技术评估15份天麻样品纯合度在68%~99%内,其中9份天麻样品纯合度大于等于95%,分别是样品1、样品2、样品3、样品4、样品6、样品7、样品8、样品9、样品12;5份天麻样品的纯合度在70%~80%之间,分别是样品10、样品11、样品13、样品14、样品15;样品5的纯合度为68%。
[0099]
两种方法评估结果一致的有8份样品。8份天麻样品的rflp标记和基因组重测序技术评估的纯合度大于95%,分别是样品1、样品2、样品3、样品4、样品7、样品8、样品9、样品12。该结果表明rflp标记法的精确度为80%,准确率为88.9%,可靠性高。实际应用中可将rflp标记与基因组重测序结合使用。首先使用低成本的rflp标记从大量样品中初步筛选纯合度高于95%的个体,再对初步筛选获得的个体进一步开展重测序,进行精确评估,最终获得可以用于纯系育种的遗传纯合的优良亲本。
[0100]
以上对本发明进行了详述。对于本领域技术人员来说,在不脱离本发明的宗旨和范围,以及无需进行不必要的实验情况下,可在等同参数、浓度和条件下,在较宽范围内实施本发明。虽然本发明给出了特殊的实施例,应该理解为,可以对本发明作进一步的改进。总之,按本发明的原理,本技术欲包括任何变更、用途或对本发明的改进,包括脱离了本技术中已公开范围,而用本领域已知的常规技术进行的改变。按以下附带的权利要求的范围,可以进行一些基本特征的应用。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1