一种基于数据驱动的SCR脱硝系统氨量的优化预测方法与流程
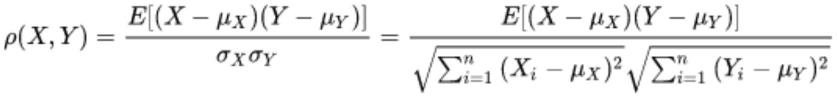
一种基于数据驱动的scr脱硝系统氨量的优化预测方法
技术领域
1.本发明涉及优化scr烟气脱硝系统氨用量技术领域,具体涉及一种基于数据驱动的scr脱硝系统氨量的优化预测方法。
背景技术:
2.scr脱硝技术是目前应用最多的脱硝技术,由于没有副产物不形成二次污染,装置结构简单,脱除效率高,运行可靠且便于维护,在各火电厂得到了广泛的应用。随着国内电力环保排放标准的日趋严格,国家要求燃煤机组总排口no
x
排放浓度不得高于50mg/nm3。由于火电厂在负荷升降前,锅炉给煤量、风量、燃烧条件都会提前发生变化,在燃烧平衡重新建立起来之前,no
x
含量都会大斜率上升,而此时cems出口测量仪表滞后,无法及时响应并加大氨量,等入口no
x
含量降下来后,又无法及时减小氨量,因此在锅炉负荷升降前甚至整个锅炉运行过程中,运行人员会采取过量喷氨的方法来保证脱硝系统的达标排放。过量喷氨的方法不仅会造成氨耗量增加,还会由于漏氨生成硫酸铵盐,导致催化剂积灰严重脱硝效率下降,同时空预器堵塞频繁使引风机出口阻力增大造成机组运行能耗偏高。
技术实现要素:
3.本发明的目的在于通过对出口烟气no
x
的预测调整氨供应量,避免氨过量或已满足排放标准后还继续增加氨降低出口烟气no
x
的浓度而造成的氨浪费,提供一种基于数据驱动的scr脱硝系统氨量的优化预测方法,实现火电厂节约氨量且保护设备的目的。
4.为解决上述的技术问题,本发明采用以下技术方案:一种基于数据驱动的scr脱硝系统氨量的优化预测方法,其特征在于包括如下步骤:
5.s1、获取scr烟气脱硝系统原始数据,对数据进行预处理,预处理包括删除无效数据、剔除异常数据,获得干净数据集;
6.s2、分析原始数据集中各变量的重要性,删除对出口烟气no
x
浓度没有明显影响的变量及其对应的数据,得到以反应器入口cems烟气no
x
折算值、反应器入口cems烟气o2、反应器入口烟气温度一、反应器入口烟气温度二、反应器入口烟气温度三、反应器氨气供应流量、反应器氨气供应压力、反应器氨气供应温度、氨混合器调节门开度反馈、反应器入口烟气流量、反应器出口cems烟气no
x
折算值、反应器出口cems烟气o2、发电机有功功率13个变量及其对应的数据来建立预测模型;
7.s3、将步骤s2中处理后的数据按4:1的比例分成训练数据集和测试数据集,构建随机森林模型,采用默认参数的随机森林模型,使用训练数据集训练随机森林模型,通过随机搜索找到最佳参数后保存模型;
8.s4、将测试数据集传入步骤s3中训练好的随机森林模型得到预测数据,并计算模型的性能;
9.s5、将氨供应量范围设置0到140步伐为0.5,画出每一条样本数据中出口烟气no
x
浓度值与氨供应量的折线图,分析所有样本的折线图中趋势变化,探索得到出口烟气no
x
浓
度值与氨供应量间规律,根据出口烟气no
x
浓度没有随氨供应量增加而减少的规律性判断火电厂氨供应情况是氨过量,可减少氨供应量进行节氨;
10.s6、结合步骤s5中每一条样本数据的出口烟气no
x
浓度值与氨供应量关系图,对干净的原始数据进行数据探索,在氨过量的数据中确定合适的氨供应量的范围,a侧范围57~72kg/h,b侧范围50~65kg/h,在这个范围中取使随机森林模型预测结果最小的氨供应量,作为第一阶段优化得到的最佳氨供应量;
11.s7、将步骤s4中得到的随机森林模型进行部署,结合步骤s6中得到的优化结果滚动优化后,获得新数据;
12.s8、得到步骤s7中数据后重复步骤s1~s5,根据出口烟气no
x
浓度值随氨供应量增加而减小,且氨供应量的增加量与出口烟气no
x
浓度值减小值为1:1关系的规律性判断火电厂氨供应情况为已满足排放标准后还继续增加氨降低出口烟气no
x
的浓度而造成了氨浪费;
13.s9、使用卡边方法确定氨供应量,作为第二阶段优化得到的最佳氨供应量;具体的,将出口烟气no
x
浓度设置不大于45mg/nm3的安全阈值,将每一条数据样本的氨供应量范围设置0到140步伐为0.5,使预测出口烟气no
x
浓度在45
±
5mg/nm3时的结果对应的氨供应量作为第二阶段最佳氨供应量。
14.更进一步的技术方案是所述步骤s2中分析原始数据集中各变量的重要性,使用过滤法中皮尔森相关系数法做特征选择,保留相关性强的数据,删除相关性弱的数据,得到原始特征的子集;
15.使用皮尔森系数作为特征评分标准,相关系数绝对值越大,相关性越强,即相关系数越接近于1或-1时相关性越强,相关系数越接近于0时相关性越弱。具体公式为:
[0016][0017]
其中,x为scr烟气脱硝系统数据中每一变量,y为反应器出口cems烟气nox折算值,μ
x
为x的平均数,μy为y的平均数,e为(x-μ
x
)(y-μy)期望。
[0018]
相关系数0.8-1.0极强相关;0.6-0.8强相关;0.4-0.6中等程度相关;0.2-0.4弱相关;0.0-0.2极弱相关或无相关。选择与反应器出口cems烟气no
x
折算值相关系数大于等于0.4的特征数据,最终得到反应器入口cems烟气no
x
折算值、反应器入口cems烟气o2、反应器入口烟气温度一、反应器入口烟气温度二、反应器入口烟气温度三、反应器氨气供应流量、反应器氨气供应压力、反应器氨气供应温度、氨混合器调节门开度反馈、反应器入口烟气流量、反应器出口cems烟气no
x
折算值、反应器出口cems烟气o2、发电机有功功率13个特征变量。
[0019]
更进一步的技术方案是所述步骤s2中反应器入口烟气温度一、反应器入口烟气温度二、反应器入口烟气温度三为同一反应器入口设置的3个温度传感器对应的采样温度。
[0020]
更进一步的技术方案是所述步骤s4中检测随机森林模型的性能,利用均方根误差rmse、平均绝对误差mae、平均绝对百分比误差mape和拟合优度r2来衡量模型的准确性,其中yi为真实值,为预测值,具体计算公式如下:
[0021]
均方根误差rmse:
[0022][0023]
其中,rmse的取值范围为[0,+∞),rmse取值越小模型性能越好。
[0024]
平均绝对误差mae:
[0025][0026]
其中,mae的取值范围为[0,+∞),mae的值越小模型性能越好。
[0027]
平均绝对百分比误差mape:
[0028][0029]
其中,mape的取值范围为[0,+∞),mape的值越小模型性能越好。
[0030]
拟合优度r2:
[0031][0032]
其中,分子部分表示真实值与预测值差的平方和,分母部分表示真实值与平均值差的平方和,根据r2的取值范围为[0:1],取值越大模型性能越好。
[0033]
与现有技术相比,本发明的有益效果是:通过对火电厂氨使用情况的数据探索,无论是氨过量还是已满足排放标准后继续增加氨量降低出口烟气no
x
的浓度,均可以以满足排放标准为前提节约大量氨量;提供通过默认参数得到的随机森林模型性能与随机搜索得到参数的随机森林模型性能进行比较的思路,可避免随机搜索得到参数的模型占据超大保存空间而导致火电厂部署调用困难;对火电厂出口烟气no
x
的预测具有较高的准确性,在满足排放标准的同时不仅可节约大量氨,还避免了过量氨生成硫酸铵盐导致的催化剂积灰严重脱硝效率下降,空预器堵塞频繁损耗设备,引风机出口阻力增大机组运行能耗偏高的问题。
附图说明
[0034]
图1为本发明的流程图;
[0035]
图2为本发明3号机a侧预测的出口烟气no
x
浓度与实际出口烟气no
x
浓度对比图;
[0036]
图3为本发明3号机b侧预测的出口烟气no
x
浓度与实际出口烟气no
x
浓度对比图;
[0037]
图4为氨供应流量与出口烟气no
x
折算值对应关系图。
[0038]
图5为经本发明3号机a侧优化后氨用量曲线与实际氨用量曲线对比图;
[0039]
图6为经本发明3号机b侧优化后氨用量曲线与实际氨用量曲线对比图;
具体实施方式
[0040]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0041]
如图1所示,scr烟气脱硝系统氨量的优化预测,包括如下步骤:
[0042]
s1、获取火电厂scr烟气脱硝系统的数据,对数据进行无效数据的删除,筛选出异常数据并删除,得到干净的数据集;
[0043]
s2、通过使用过滤法中皮尔森相关系数法做特征选择,保留相关性强的数据,删除相关性弱的数据,得到原始特征的子集。
[0044]
使用皮尔森系数作为特征评分标准,相关系数绝对值越大,相关性越强,即相关系数越接近于1或-1时相关性越强,相关系数越接近于0时相关性越弱。具体公式为:
[0045][0046]
其中,x为scr烟气脱硝系统数据中每一变量,y为反应器出口cems烟气no
x
折算值,μ
x
为x的平均数,μy为y的平均数,e为(x-μ
x
)(y-μy)期望。
[0047]
相关系数0.8-1.0极强相关;0.6-0.8强相关;0.4-0.6中等程度相关;0.2-0.4弱相关;0.0-0.2极弱相关或无相关。选择与反应器出口cems烟气no
x
折算值相关系数大于等于0.4的特征数据,最终得到反应器入口cems烟气no
x
折算值、反应器入口cems烟气o2、反应器入口烟气温度一、反应器入口烟气温度二、反应器入口烟气温度三、反应器氨气供应流量、反应器氨气供应压力、反应器氨气供应温度、氨混合器调节门开度反馈、反应器入口烟气流量、反应器出口cems烟气no
x
折算值、反应器出口cems烟气o2、发电机有功功率13个特征变量。为提高取样准确性,同一反应器入口在不同位置设置有3个温度传感器,每个传感器采样的温度对应反应器入口烟气温度一、反应器入口烟气温度二、反应器入口烟气温度三。
[0048]
s3、将步骤s2中处理后的数据按4:1的比例分成训练数据集和测试数据集。构建随机森林模型,使用训练数据集训练随机森林模型,通过随机搜索找到最佳参数后保存模型,此模型占据7g的超大保存空间。
[0049]
s4、将测试数据集传入步骤s3的随机森林模型中,得到出口烟气no
x
预测值,利用均方根误差rmse、平均绝对误差mae、平均绝对百分比误差mape和拟合优度r2来衡量模型的准确性。由于通过随机搜索得到参数的随机森林模型占据7g的超大保存空间,导致模型加载速度很慢,不利于火电厂的部署调用。经过多次调参的模型性能比较,默认参数得到的随机森林模型性能与通过随机搜索得到参数的随机森林模型性能相差甚微,为便于现场的部署应用采用默认参数的随机森林模型,模型参数如表1所示:
[0050]
表1
[0051][0052][0053]
模型性能计算公式如下:
[0054]
均方根误差rmse:
[0055][0056]
其中,rmse的取值范围为[0,+∞),rmse取值越小模型性能越好。
[0057]
平均绝对误差mae:
[0058][0059]
其中,mae的取值范围为[0,+∞),mae的值越小模型性能越好。
[0060]
平均绝对百分比误差mape:
[0061][0062]
其中,mape的取值范围为[0,+∞),mape的值越小模型性能越好。
[0063]
拟合优度r2:
[0064][0065]
其中,分子部分表示真实值与预测值差的平方和,分母部分表示真实值与平均值差的平方和,根据r2的取值范围为[0:1],取值越大模型越好。
[0066]
随机森林模型得性能结果如表2所示。
[0067]
表2
[0068][0069]
随机森林模型预测结果与历史数据实际值对比如图2和图3所示。
[0070]
s5、将氨气供应量范围设置0到140步伐为0.5,画出每一条样本数据出口烟气no
x
浓度值与氨供应量的折线图,分析所有样本的折线图中趋势变化,探索出口烟气no
x
浓度值与氨供应量间规律如图4所示,没有得到其出口烟气no
x
浓度值随氨供应量增加而减小,其中间歇性存在出口烟气no
x
浓度值减小的趋势但氨供应量的增加量与出口烟气no
x
浓度值减小值没有近似1:1的关系,由此判断火电厂氨供应情况是氨过量;
[0071]
s6、结合步骤s5中每一条样本数据的出口烟气no
x
浓度值与氨供应量关系图,对干净的原始数据进行数据探索,在氨过量的数据中确定合适的氨供应量的范围,a侧范围57-72kg/h,b侧范围50-65kg/h,在这个范围中取使随机森林模型预测结果最小值的氨供应量,作为第一阶段优化得到的最佳氨供应量;
[0072]
s7、将步骤s4中得到的随机森林模型进行部署,结合步骤s6中得到的优化结果滚动优化后,获得新数据;
[0073]
s8、得到步骤s7中数据后重复步骤s1-s3,通过随机搜索找到最佳参数的随机森林模型保存空间小于1g,高效应用于模型部署。第二阶段随机森林模型参数如表3所示。
[0074]
表3
[0075]
参数名称参数含义参数设置n_estimators决策树个数160max_depth树的最大的深度15min_samples_split拆分内部节点的最小样本2min_samples_leaf叶节点所需的最小样本数1max_features最佳分割的特征数量3max_leaf_nodes最大叶节点6
[0076]
第二阶段随机森林模型性能如表4所示。
[0077]
表4
[0078][0079]
重复步骤s5,根据出口烟气no
x
浓度值随氨供应量增加而减小,且氨供应量的增加量与出口烟气no
x
浓度值减小值存在近似为1:1的关系,同时出口烟气no
x
浓度值在24-31mg/nm3远小于排放标准50mg/nm3,进而判断火电厂氨供应情况为已满足排放标准后继续增加氨降低出口烟气no
x
的浓度而造成了氨浪费;
[0080]
s9、使用卡边方法确定氨供应量,作为第二阶段优化得到的最佳氨供应量。出口烟气no
x
浓度需满足不大于50mg/nm3,为了避免模型误差造成出口烟气no
x
浓度超标,将出口烟气no
x
浓度设置不大于45mg/nm3的安全阈值。即将每一条数据样本的氨供应范围设置0到140步伐为0.5,使模型预测出口烟气no
x
浓度刚好为45mg/nm3或最接近45mg/nm3(45
±
5mg/nm3范围内)时的结果对应的氨供应量作为第二阶段最佳氨供应量。
[0081]
将节省的氨量作为直接性收益,精准喷氨减少的空预器堵塞而节约的清洗费用,以及减少引风机阻力而节约的电耗费用作为间接性收益,经综合性计算3号机可为火电厂收益约380万/年。
[0082]
以上选取了某发电厂3号机a侧和b侧两个月的scr烟气脱硝系统的数据,通过随机森林模型输出的氨供应量与技术员以经验操作得到的氨供应量数据进行对比,如图5和图6所示。通过模型预测优化得到精准的氨供应量,在满足排放标准的同时不仅可节约大量氨,还避免了过量氨生成硫酸铵盐,导致催化剂积灰严重脱硝效率下降,空预器堵塞频繁损耗设备以及引风机出口阻力增大机组运行能耗偏高的问题,为发电厂的经济性运行提供了很大的价值。
[0083]
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,相关领域技术人员可使用不同方式或方法进行更改,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1