基于深度信念网络的测井岩性识别方法与流程
本发明涉及一种有关岩性识别的测井解释方法,尤其是一种基于深度信念网络的地层岩性识别方法。
背景技术:
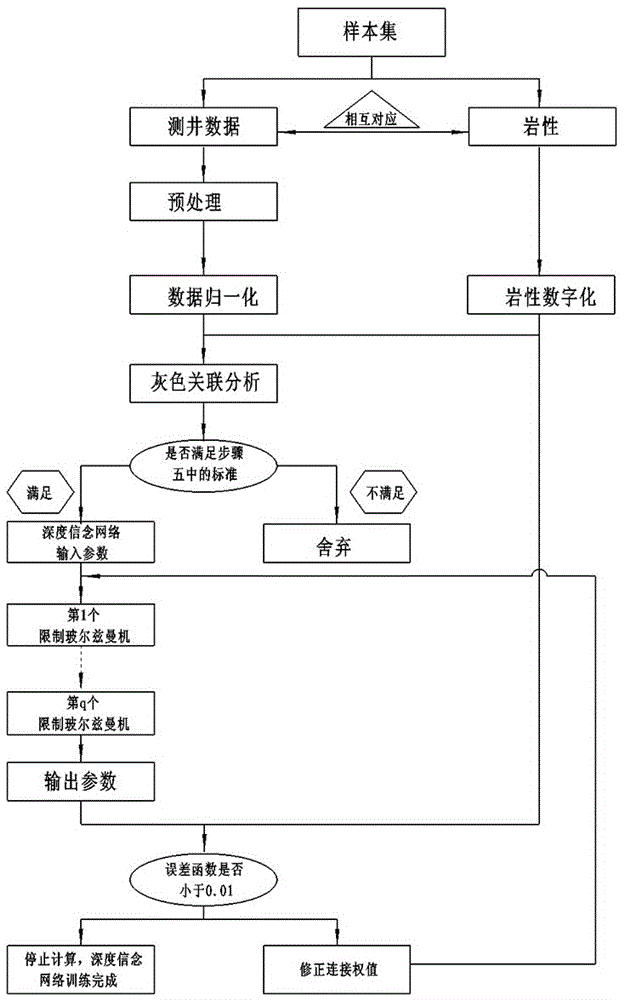
:目前火成岩储层岩性识别最有效的方法是地层元素测井与成像测井。但两者成本较高,无法大规模开展。在只有常规测井曲线的情况下,目前常用的解释方法有交会图法、多元统计分析法及bp神经网络法等。交会图法简单易用,但其对于复杂储层效果较差;多元统计分析法工作量小、速度快,但其需要调整的参数较多,容易产生较大误差;bp神经网络法本身是一种“浅层”神经网络,存在局部极小化问题,经常无法获得全局最优解,同时还存在收敛慢的缺点。技术实现要素:本发明的目的在于针对缺少地层元素测井和成像测井资料的地区,提供一种预测简单、实用可靠的基于深度信念网络的地层岩性识别方法。本发明公开了一种基于深度信念网络的测井岩性识别方法,主要通过计算机完成,其特征在于实现该方法所需设备包括测井仪器、数据通讯接口及计算机;所述测井仪器,用于采集测井数据;所述数据通讯接口,用于将现场测井仪器采集的上述测井数据,传输到计算机中;所述计算机,用于运行深度信念网络的地层岩性识别算法,根据测井数据,对井口周围地层岩性进行识别;该方法包括如下步骤:步骤一、利用测井数据识别井口周围的岩性,测井数据主要包括传统的九条常规测井曲线,分别为深侧向电阻率、浅侧向电阻率、微球聚焦、密度、声波时差、中子、自然电位、自然伽马以及井径,预测输出变量为地层岩性;步骤二、测井数据的预处理:现场测井仪器采集测井数据,首先需要进行预处理,至少包括深度校正、平滑滤波及环境校正;步骤三、归一化处理:每一种测井方法的物理原理不同,其测量的物理参数的量纲和数量级均有很大的差别,需要对测井数据进行归一化处理,使其具有相同的量纲和数值分布范围;经过归一化处理的测井数据均为无量纲量,且分布区间为[0,1];步骤四、岩性分类的数字化:计算机无法认知地层的岩性,因而必须将岩性进行数字化以满足计算机的读取;设所识别的岩性共有n种,将n种岩性记为表格的形式,所述表格在首行和首列均分别列出对应的这n种岩性的名称,在表格中行与列的交叉位置填上1或0,其中1代表是某种岩性,0代表不是某种岩性;如下表所示:岩性分类数字化方法继而,将上述表格中不同深度测井数据对应的岩性记为矩阵y,y由n组向量构成,其取值为0或者1,1代表是某种岩性,0代表不是某种岩性,即,矩阵y即为岩性分类数字化的结果;步骤五、测井曲线与岩性之间关联度的计算:采用灰色关联分析法分析各测井曲线与岩性之间的相关性:在某区块内,针对所要识别的n种岩性,选取具备完整地质资料的n种岩性对应的各m组常规测井数据,作为样本集s;各岩性对应的样本数量m应当大于500;分别计算测井曲线与矩阵y中n组向量的灰色关联度后,可以进行关联度的排序,从而选取合适的测井曲线;其选取标准为:(1)该测井曲线,对于每种岩性,灰色关联度均大于0.7;(2)该测井曲线,对应各种岩性的灰色关联度的几何平均值大于0.8;以此为标准剔除关联度较小的测井曲线,保留关联度较高的测井曲线作为深度信念网络的输入参数;步骤六、预设深度信念网络的结构:不少于5个限制玻尔兹曼机,隐含层神经元个数为样本数量的十分之一;将步骤五中确定的该测井曲线作为样本,输入第1个限制玻尔兹曼机进行无监督训练,训练结果输入第二个限制玻尔兹曼机,直至最后一个限制玻尔兹曼机的输出结果为yout;步骤七、经过无监督学习,深度信念网络的连接权值矩阵基本可以确定,需利用有监督学习对权值矩阵进行微调:样本集s中,测井数据对应的岩性数字化后的结果为ye,则误差函数为误差函数对隐含层各神经元的偏导数为δv(k);连接权值调整规则为w=ηδvfi,k,η为学习率,k=1,2,3,…,n;对于初始连接权值,随机选取正态分布(0.001,1)中的随机数即可;不断调整连接权值,设定e≤0.01,直到误差函数满足要求,深度信念网络训练完成;步骤八、再选取具备完整地质资料的n种岩性对应的各r组常规测井数据,作为测试集t,r应当大于500;将测试集t中的测井数据输入已经训练完成的深度信念网络,输出结果记做矩阵y1,测试集t中测井数据对应的岩性数字化后的结果记为y0,利用均方误差函数衡量网络性能,即设△y1=y1-y0,△y1中所有元素的平方和为均方误差mse△y1;由第5个起调整限制玻尔兹曼机的数量,得到均方误差与限制玻尔兹曼机个数之间的关系,进而确定合适的限制玻尔兹曼机数量p;步骤九、确定限制玻尔兹曼机个数:理想的隐含层神经元个数比样本数少一个数量级,当样本数量为n·m,假设其数量级为w,那么隐含层神经元个数在10w-1~10w之间;设p个限制玻尔兹曼机的隐含层神经元个数分别为n1,n2,n3,…np,记为n,且10w-1≤n≤10w;将输出的n个向量所组成的矩阵记做y2,△y2=y2-y0,△y2中所有元素的平方和为均方误差mse△y2;将n1,n2,n3,…np的可能取值限定为1·10w-1、2·10w-1、3·10w-1、4·10w-1、5·10w-1、6·10w-1、7·10w-1、8·10w-1、9·10w-1;求出mse△y2取最小值时,对应的n,记为n1a,n2a,n3a,…npa,记为na;这样就确定了各限制玻尔兹曼机个数的最高数位;将n可能取值限定为na-5·10w-2、na-4·10w-2、na-3·10w-2、na-2·10w-2、na-1·10w-2、na、na+1·10w-2、na+2·10w-2、na+3·10w-2、na+4·10w-2、na+5·10w-2;求出mse△y2取最小值时,对应的n1,n2,n3,…np,记为nb;设△n2=5,10个隐含层神经元个数的取值范围为nb-△n2≤n≤nb+△n2;将n的可能取值限定为nb-5、nb-4、nb-3、nb-2、nb-1、nb、nb+1、nb+2、nb+3、nb+4、nb+5;这样就确定了各限制玻尔兹曼机个数的第二高数位;以此类推,直到确定各限制玻尔兹曼机个数的个位,即可得到理想的限制玻尔兹曼机个数;步骤十、确定岩性分类界限:计算机的输出结果是一个矩阵y,因此需要将矩阵重新转化为岩性分类;计算机输出的矩阵不是由0和1组成,而是由[0,1]区间内的小数组成;设分类界限为i∈[0.3,0.7],将测试集测井数据输入深度信念网络计算得到的矩阵记为y3,理论岩性分类结果为矩阵y0;将y3中大于等于i的元素近似为1,小于i的元素近似为0;设△y3=y3-y0,△y3中所有元素的平方和取最小值时对应的i为最佳分类界限;步骤十一、确定了限制玻尔兹曼机个数、隐含层神经元个数以及分类界限后,用于识别地层岩性的深度信念网络训练完成;将待解释井测井数据输入该网络,可进行岩性识别工作。本发明在步骤九中,通过逐步确定限制玻尔兹曼机隐含层神经元个数各数位的“值”来得到最佳隐含层神经元个数。本发明将交会图法、bp神经网络以及深度信念网络(dbn)三种方法同时运用于松辽盆地yuxx井储层岩性识别,并对三种方法的效果进行对比。选取松辽盆地东部凹陷的测井数据,根据钻探资料,该区块地区地层主要由火成岩和沉积岩构成。沉积岩主要为砂岩和泥岩,火成岩主要包括玄武岩、粗面岩、辉绿岩、辉长岩等。考虑到实际情况、测井识别的可行性以及储层研究的需要,进一步将玄武岩分成致密玄武岩和非致密玄武岩,将粗面岩分成致密粗面岩和非致密粗面岩。对于交会图法而言,ac-gr及gr-rlld效果最好。实验表明,ac-gr中辉绿岩与辉长岩、粗面岩与非致密粗面岩及非致密粗面岩与非火成岩(砂岩、泥岩)之间存在明显的分类重叠;由gr-rlld交会图可知,gr-rlld中非致密粗面岩与非火成岩(砂岩、泥岩)之间存在明显的分类重叠。将ac-gr交会图和gr-rlld交会图应用于yuxx井储层岩性识别,准确率仅为72.3%。按照本发明的处理流程,将具有完善岩性资料的测井数据及其对应的岩性分为样本集和测试集。样本集用于训练深度训练网络,包括该地区典型的砂岩、泥岩、致密玄武岩、非致密玄武岩、致密粗面岩、非致密粗面岩、辉绿岩、辉长岩层各1000组测井数据。另取各类岩性500组测井数据作为测试集,用于测试网络性能。分别对样本集测井数据进行归一化,对岩性资料进行数字化,继而进行灰色关联分析,按照本发明的标准,最终选取深侧向、自然伽马、密度、声波时差、中子、光电截面吸收指数作为深度信念网络的输入参数。利用bp神经网络建立岩性识别模型,再按照本发明介绍的方法,分别确定限制玻尔兹曼机个数(10)、各限制玻尔兹曼机隐含层神经元个数(723、645、620、664、532、581、538、416、363、284)及分类界限(0.563),建立岩性识别模型。将深度信念网络和bp神经网络分别应用于yuxx井岩性识别。表1.3456.00m至3474.50m深度信念网络计算结果表2.3456.00m至3474.50mbp神经网络计算结果表3.4102.00m至4122.00m深度信念网络岩性识别结果表4.4102.00m至4122.00mbp神经网络岩性识别结果表5.2890.50m至2897.00m深度信念网络岩性识别结果表6.2890.50m至2897.00mbp神经网络岩性识别结果表1-表6分别为深度信念网络和bp神经网络的计算结果,其中,表1和表2为3456.00m至3474.50m深度信念网络和bp神经网络岩性识别结果;表3和表4为4102.00m至4122.00m深度信念网络和bp神经网络岩性识别结果;表5和表6为2890.50m至2897.00m深度信念网络和bp神经网络岩性识别结果。对于测井响应差别比较大的岩性来说(火成岩与非火成岩),深度信念网络和bp神经网络的岩性识别的准确率均接近100%。但对于复杂储层岩性识别来说,相对于深度信念网络,bp神经网络更容易出现3方面的问题。(1)bp神经网络对于不同致密性的判断能力弱于深度信念网络。对比表1和表2,在3456.00m至3474.50m之间,bp神经网络将3467.25m至3467.50m之间的非致密玄武岩错误的识别为致密玄武岩(即表格中加粗的部分),而深度信念网络则识别正确。(2)分类重叠是指岩性分类结果出现既属于一种岩性,又属于另一种岩性的现象。对比表3和表4,对于4102.00m至4122.00m之间致密粗面岩,bp神经网络出现分类重叠现象,(即表格中加粗的部分所示),而深度信念网络则识别正确。(3)将样本集中不存在的岩性识别为样本集中的某一岩性。由于某些岩性较少,为了保证深度信念网络的性能,样本集中并未选取这类岩性样本。对比表5和表6,在2890.50m至2897.00m之间,出现了角砾岩。bp神经网络将2896.75m的角砾岩识别为非致密玄武岩(即表格中加粗的部分),而深度信念网络则正确的识别为其它岩性。表7.深度信念网络与bp神经网络识别准确率对比交会图法bp神经网络深度信念网络准确率72.3%80.4%87.5%对比交会图法、bp神经网络和深度信念网络的准确率,深度信念网络的效果最好。与现有技术相比,本发明的优点:针对缺少地层元素测井和成像测井资料的地区,本发明提供的识别方法,预测简单、识别准确率高,效果好且实用可靠。附图说明图1为本发明实施例深度信念网络的算法的运行过程的示意图。图2为本发明实施例深度信念网络的优化过程的的示意图。图3为本发明实施例深度信念网络的应用过程的示意图。图4为本发明的岩性分类的数字化中,将n种岩性记为表格形式的示意图,所述表格在首行和首列均分别列出对应的n种岩性的名称,在表格中行与列的交叉位置填上1或0,其中1代表是某种岩性,0代表不是某种岩性。具体实施方式实施例1:参照图1、图2、图3,为本发明实施例的结构示意图,将该方法应用于松辽盆地火成岩储层。主要通过计算机完成,其中实现该方法所需设备包括测井仪器、数据通讯接口及计算机;所述测井仪器,用于采集测井数据;所述数据通讯接口,用于将现场测井仪器采集的上述测井数据,传输到计算机中;所述计算机,用于运行深度信念网络的地层岩性识别算法,根据测井数据,对井口周围地层岩性进行识别;该方法包括如下步骤:步骤一、利用测井数据识别井孔周围岩性,主要的测井数据为深侧向电阻率、浅侧向电阻率、微球聚焦、密度、声波时差、中子、自然电位、自然伽马、井径九种常规测井数据,此外,具备条件的情况下,也可以添加其它类型测井数据,本实施例中,添加了光电吸收截面指数,预测输出变量为地层岩性。步骤二、测井数据的预处理:现场测井仪器采集测井数据,首先需要进行预处理,主要包括深度校正、平滑滤波及环境校正。步骤三、归一化处理:每一种测井方法的物理原理不同,其测量的物理参数的量纲和数量级均有很大的差别,需要对测井数据进行归一化处理,使其具有相同的量纲和数值分布范围;本实例主要采用传统的9条常规测井曲线,fi(h)为某一条常规测井曲线,i=1,2,…,9,则:式中,fig(h)为归一化后的数据,fi(h)为某测井方法的原始数据,fimax,fimin为该测井数据的最大值和最小值;经过归一化处理的测井数据均为无量纲量,且分布区间为[0,1];步骤四、岩性分类的数字化:该地区主要涉及的岩性有8种,包括砂岩、泥岩、致密玄武岩、非致密玄武岩、致密粗面岩、非致密粗面岩、辉绿岩、辉长岩,计算机无法认知每一种岩性。因而必须将8种岩性数字化以满足计算机的读取。可将8种岩性记为表1,表1.岩性分类数字化方法那么岩性分类数字化矩阵y可以记为:步骤五、测井曲线与岩性之间关联度的计算:采用灰色关联分析法分析各测井曲线与岩性之间的相关性:在某区块内,典型的砂岩、泥岩、致密玄武岩、非致密玄武岩、致密粗面岩、非致密粗面岩、辉绿岩、辉长岩层各m组测井数据作为样本集,选取标准是:岩层较厚,厚度大于1m,样本的数量m应当大于500,本实施例中m=1000;归一化后的样本测井数据,记为fi,其中,i=1,2,…,9,而fi=(fi1(h),fi2(h),…,fin(h)),对应的岩性数字化结果记为y=(g1(h),g2(h),…,g8(h));各测井数据与各岩性之间的灰色关联度表示为:式中,γ(gk(h),fik(h))称为关联系数,表达式为:式中,ξ为常数,称为分辨系数,取0.5;分别计算测井曲线与矩阵y中8组向量的灰色关联度后,可以进行关联度的排序,从而选取合适的测井曲线。选取标准为:(1)该测井曲线,对于每种岩性,灰色关联度均大于0.7;(2)该测井曲线,对应各种岩性的灰色关联度的几何平均值大于0.8。以此为标准剔除关联度较小的该测井曲线,保留关联度较高的6条测井曲线作为深度信念网络的输入参数,即深侧向、自然伽马、密度、声波、中子及光电截面吸收指数。步骤六、预设深度信念网络的结构:不少于5个限制玻尔兹曼机,隐含层神经元个数为样本数量的十分之一。将步骤五中确定的该测井曲线作为样本,输入第1个限制玻尔兹曼机进行无监督训练。第一个限制玻尔兹曼机的训练过程:将步骤五中确定的测井数据fip作为输入参数,将其赋于可视层,首先,计算隐含层神经元的激励值:h=wfip;式中,f为测井数据。然后,利用s形函数计算隐含层神经元处于开启状态(用1来表示)的概率值:式中,hm∈h;那么,隐含层神经元处于关闭状态的概率值为:p(hm=0)=1-p(hm=1);式中,hm∈h;最后,需要将隐含层神经元开启的概率与一个从均匀分布中抽取的随机值u(u∈[0,1])进行如下对比:以此,决定隐含层神经元的开启与否,这样一来,可以求取每一个隐含层神经元的开启状态。将隐含层神经元总的开启状态表示为矩阵h,将h作为第二个限制玻尔兹曼机的输入参数,重复上述的训练过程,完成第二限制玻尔兹曼机的训练;如此反复,将最后一个限制玻尔兹曼机的隐含层神经元整体的开启状态作为分类器的输入,得到最终的输出结果yout;步骤七、经过无监督学习,深度信念网络的连接权值矩阵基本可以确定,需利用有监督学习对权值矩阵进行微调:样本集s中,测井数据对应的岩性数字化后的结果为ye,则误差函数为误差函数对隐含层各神经元的偏导数为δv(k);连接权值调整规则为w=ηδvfi,k,η为学习率,k=1,2,3,…,n;对于初始连接权值,随机选取正态分布(0.001,1)中的随机数即可;不断调整连接权值,设定e≤0.01,直到误差函数满足要求,深度信念网络训练完成。步骤八、再选取具备完整地质资料的n种岩性对应的各r组常规测井数据,作为测试集t,r应当大于500,本实施例r=1000。将t中的测井数据输入已经训练完成的深度信念网络,输出结果记做矩阵y1,t中测井数据对应的岩性数字化后的结果记为y0,利用均方误差函数衡量网络性能,即设△y1=y1-y0,△y1中所有元素的平方和为均方误差mse△y1。由第5个起调整限制玻尔兹曼机的数量,得到均方误差与限制玻尔兹曼机个数之间的关系,进而确定合适的限制玻尔兹曼机数量p。经过计算,本实施例中p=10。步骤九、本发明通过逐步确定限制玻尔兹曼机隐含层神经元个数各数位的“值”来得到最佳隐含层神经元个数;根据经验,理想的隐含层神经元个数一般比样本数少一个数量级。本实例样本数共有8000个,那么隐含层神经元个数在100~999之间。设10个限制玻尔兹曼机的隐含层神经元个数分别为n1,n2,n3,…n10,记为n,且100≤n≤999。将输出的8个向量看做矩阵y2,△y2=y2-y0,△y2中所有元素的平方和为均方误差mse△y2。将n可能取值限定为100、200、300、400、500、600、700、800、900。求出mse△y2取最小值时,对应的n,即n1a,n2a,n3a,…n10a,记为na。这样一来,确定了隐含层神经元个数的百位。将n的可能取值限定为na-50、na-40、na-30、na-20、na-10、na、na+10、na+20、na+30、na+40、na+50。求出mse△y2取最小值时,对应的n,即n1b,n2b,n3b,…n10b,记为nb。这样一来,确定了隐含层神经元个数的十位。将n的可能取值限定为nb-5、nb-4、nb-3、nb-2、nb-1、nb、nb+1、nb+2、nb+3、nb+4、nb+5。求出mse△y2取最小值时,对应的n,即为理想的隐含层神经元选取结果。经计算,本实例10个限制玻尔兹曼机隐含层神经元个数的取值为723、645、620、664、532、581、538、416、363、284。步骤十、确定岩性分类界限:计算机的输出结果是一个矩阵y,因此需要将矩阵重新转化为岩性分类。一般来说,计算机输出的矩阵并非由0和1组成,而是由[0,1]区间内的小数组成。设分类界限为i∈[0.3,0.7],将测试集测井数据输入深度信念网络计算得到的矩阵记为y3,理论岩性分类结果为矩阵y0。将y3中大于等于i的元素近似为1,小于i的元素近似为0。设△y3=y3-y0,△y3中所有元素的平方和取最小值时对应的i为最佳分类界限。本实施例中,经过计算,i=0.563;步骤十一、确定了限制玻尔兹曼机个数、隐含层神经元个数以及分类界限后,用于识别地层岩性的深度信念网络训练完成。将待解释井测井数据输入该网络,可进行岩性识别工作。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1