一种跨节点并行的三维起伏地表声波正演模拟方法与流程
本发明涉及地球物理勘探技术领域,尤其是一种跨节点并行的三维起伏地表声波正演模拟方法。
背景技术:
地震勘探是首先利用人工的方法引起地壳振动,然后利用地震波从地下地层界面反射回来的旅行时间和波形变化的信息,推断地下的地层构造和岩性的一种方法。经典的地震勘探理论往往假设地表是水平的,基于这种近似假设的地震数据处理和偏移成像技术,在很多符合近似条件的地区得到了非常好的应用。随着地震勘探技术的不断发展,油气地震勘探的重点正转向起伏地表条件和复杂地质条件的区域。这些地区地表起伏大、地下构造复杂,并不符合水平地表的近似假设。因此,研究起伏地表条件下的偏移成像技术具有重要的意义。目前主流的偏移成像技术有Kirchhoff偏移、单程波深度偏移、逆时偏移等。其中逆时偏移由于直接求解双程波方程,利用了全部的波场信息,是最为精确的成像方法,其核心算法就是地震正演模拟算法。
随着野外地震数据采集技术的发展,地震数据的数据量越来越大,使得油气勘探对高性能计算环境的内存需求和数据处理应用软件的性能需求日益增长,尤其是以逆时偏移和全波形反演为代表的基于波动方程的处理技术的应用,更是对地震正、反演算法的跨节点并行方案设计提出了极大的挑战。
技术实现要素:
为了克服上述技术问题,本发明提供一种跨节点并行的三维起伏地表声波正演模拟方法,在节点内部采用基于共享内存的并行结构,以避免启动多个MPI进程造成的额外开销,并且减少节点内不必要的进程间通信开销。在节点间,本发明的方法采用了非阻塞通信实现数据交换,利用计算掩盖通信延迟,达到比较高的并行效率。
本发明解决其技术问题所采用的技术方案是:一种跨节点并行的三维起伏地表声波正演模拟方法,包括以下步骤:
(1)将模型网格沿着内存中最慢的维度划分成不同的区域,不同的MPI进程处理不同区域内的计算。
(2)在每一步的时间推进时,首先由各个节点发起非阻塞点对点通信的请求,以供相邻的MPI进程交换区域边界的波场数据。
(3)每个进程在非阻塞通信请求返回后,立即开始进行PML区域的计算,其中涉及的三维空间循环采用OpenMP实现多线程并行计算,该步骤的具体实现为:
1.首先利用高阶中心差分格式计算:
例如4阶的中心差分格式为:
2.更新θxu
3.更新ηxu
4.更新ψxu
5.计算偏导数
此时,数据通信和吸收边界的计算同时进行,这样每个进程进行密集的计算任务来掩盖通信的延迟,以提高多节点的并行效率。
(4)每个进程等待数据通信完成后,利用高阶中心差分格式计算空间偏导数的近似值
然后更新下一时刻的波场,
若空间位置位于起伏地表以上,则将该处的波场值置为0。
(5)在边界区域采用PML区域计算的结果对波场进行修正。该部分涉及的所有循环也采用OpenMP实现并行。
(6)最后以交换指针的方式,交换新旧时刻的波场,并且将需要输出的数据规约到主进程上。
(7)随后所有进程进入下一个时间步的计算。
(8)完成所有时间步的计算后,输出地震记录。
本发明的有益效果是,相比纯MPI的并行方法,本发明的方法在节点内部采用基于共享内存的并行结构,以避免启动多个MPI进程造成的额外开销,并且减少节点内不必要的进程间通信开销。在节点间,本发明的方法采用了非阻塞通信实现数据交换,利用计算掩盖通信延迟,达到比较高的并行效率。
附图说明
下面结合附图和实施例对本发明进一步说明。
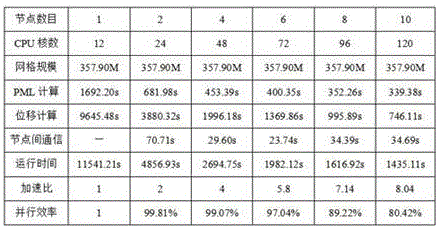
图1是本方法的强可扩展性测试结果。
图2是本方法的弱可扩展性测试结果。
图3是本方法在不同节点下的并行加速曲线。
图4是本方法的弱可扩展性曲线。
具体实施方式
实施例1
(1)首先在配置文件中配置正演模拟的参数:
(2)利用Madagascar软件生成标准雷克子波时间点列作为震源:
(3)利用Madagascar软件生成用于正演模拟的速度场:
(4)配置观测系统的参数:
然后利用Madagascar软件生成观测系统的输入文件:
(5)准备好步骤(1)、(2)、(3)中的正演参数后,编写程序运行脚本
和并行任务提交脚本
其中N为节点数,n为进程数,在本测试中,将不断增加N和n的数目,统计正演模拟所需的时间,观察程序运行时间随着节点数目的变化曲线。运行任务提交脚本后依据本发明提出的方法实现的正演程序就开始进行模拟,即:
(6)模型网格沿着内存中最慢的维度被划分成不同的区域,不同的MPI进程处理不同区域内的计算。
(7)在每一步的时间推进时,首先由各个节点发起非阻塞点对点通信的请求,以供相邻的MPI进程交换区域边界的波场数据。
(8)每个进程在非阻塞通信请求返回后,立即开始进行PML区域的计算,其中涉及的三维空间循环采用OpenMP实现多线程并行计算,该步骤的具体实现为:
1.首先利用高阶中心差分格式计算:
例如4阶的中心差分格式为:
2.更新θxu
3.更新ηxu
4.更新ψxu
5.计算偏导数
此时,数据通信和吸收边界的计算同时进行,这样每个进程进行密集的计算任务来掩盖通信的延迟,以提高多节点的并行效率。
(9)每个进程等待数据通信完成后,利用高阶中心差分格式计算空间偏导数的近似值
然后更新下一时刻的波场
若空间位置位于起伏地表以上,则将该处的波场值置为0。
(10)在边界区域采用PML区域计算的结果对波场进行修正。该部分涉及的所有循环也采用OpenMP实现并行。
(11)最后以交换指针的方式,交换新旧时刻的波场,并且将需要输出的数据规约到主进程上。
(12)所有进程进入下一个时间步的计算。
(13)完成所有时间步的计算后,输出地震记录。
(14)
实施例2
(1)首先在配置文件中配置正演模拟的参数:
T=1.0
dt=0.001
f0=15
order=8
jdata=2
jsnap=2
fm=2.5*f0
dx=0.01
dy=0.01
dz=0.01
nxx=1000
nyy=300
nzz=1000
在本测试中,将不断增加问题的规模(即增加y方向采样点的数目nyy),同时增加进程数目,保证每个进程分配到的计算网格大小一致,然后统计正演模拟所需的时间,观察程序运行时间随着的变化曲线。
(2)利用Madagascar软件生成标准雷克子波时间点列作为震源:
(3)利用Madagascar软件生成用于正演模拟的速度场:
(4)配置观测系统的参数:
然后利用Madagascar软件生成观测系统的输入文件:
(5)准备好步骤(1)、(2)、(3)中的正演参数后,编写程序运行脚本
和并行任务提交脚本
其中N为节点数,n为进程数,本测试中进程数目n将根据速度模型网格规模的大小来决定。运行任务提交脚本后依据本发明提出的方法实现的正演程序就开始进行模拟,即:
(6)模型网格沿着内存中最慢的维度被划分成不同的区域,不同的MPI进程处理不同区域内的计算。
(7)在每一步的时间推进时,首先由各个节点发起非阻塞点对点通信的请求,以供相邻的MPI进程交换区域边界的波场数据。
(8)每个进程在非阻塞通信请求返回后,立即开始进行PML区域的计算,其中涉及的三维空间循环采用OpenMP实现多线程并行计算,该步骤的具体实现为:
1.首先利用高阶中心差分格式计算:
例如4阶的中心差分格式为:
2.更新θxu
3.更新ηxu
4.更新ψxu
5.计算偏导数
此时,数据通信和吸收边界的计算同时进行,这样每个进程进行密集的计算任务来掩盖通信的延迟,以提高多节点的并行效率。
(9)每个进程等待数据通信完成后,利用高阶中心差分格式计算空间偏导数的近似值,
然后更新下一时刻的波场,
若空间位置位于起伏地表以上,则将该处的波场值置为0。
(10)在边界区域采用PML区域计算的结果对波场进行修正。该部分涉及的所有循环也采用OpenMP实现并行。
(11)最后以交换指针的方式,交换新旧时刻的波场,并且将需要输出的数据规约到主进程上。
(12)所有进程进入下一个时间步的计算。
(13)完成所有时间步的计算后,输出地震记录。
- 还没有人留言评论。精彩留言会获得点赞!