一种基于集成学习的近红外光谱定量建模方法与流程
本发明涉及一种光谱分析技术,尤其涉及的是一种近红外光谱定量分析技术。
背景技术:
光谱分析技术特别是近红外光谱技术,具有快速、简单、非破坏性的特点,在复合体系诸如环境、化工、药品和食品中可以作为定量分析的手段。由于样品背景、噪声和谱带重叠的影响,通常需要借助化学计量学方法来建立光谱和测试对象的关联模型,因此基于化学计量学方法的多元校正技术在光谱分析中占据重要地位。
传统的经典校正方法如偏最小二乘,将测量得到的光谱数据和实验对象的成分含量进行关联,经常会出现预测精度低和模型鲁棒性差的问题,究其原因,主要是因为基于经典校正方法的偏最小二乘建模对校正样中噪声和异常值敏感,且校正样本的数量和不均匀性等因素会使偏最小二乘建模方法对不同的校正样和预测样的分析效果相差很大,降低了模型的适用性。
集成学习作为一种机器学习方法,它试图通过调用一些简单的学习算法,以获得多个不同的基学习机(通常是预测性能比较弱的学习机),然后采用某种策略将这些基学习机组合成一个集成学习机,由于它能显著提高一个学习系统的泛化能力,因此集成学习的理论和算法研究已经成了机器学习领域中的热点问题。目前集成学习方法结合多元校正产生了两类建模方法:bagging和boosting,两者主要的不同在于构建子模型的样品抽取方法和子模型的集成方法。其中bagging采用有放回抽取的原则构造子模型校正样本集,其中会有部分样品重复出现,最后采用求平均的策略集合多个子模型;boosting方法采用按概率抽取部分校正集样品构成子模型校正集的原则,随着迭代的进行更新各个样本被抽取的概率,按照训练集误差越大抽取概率越大的策略,实现了对误差较大样本的多次重复抽取,在子模型集成策略上,boosting方法构造一个可信度指标,按照可信度指标越大权重越大的策略对迭代中产生的所有子模型预测结果进行加权求和。
综上,现有的经典校正方法对校正样中的噪声信息和异常值敏感,样品数量的变化和不均匀性会导致所建立模型的预测精度下降和鲁棒性变差。传统bagging方法按照有放回抽取的原则构造子模型的校正集样本,会导致子模型的校正集样本的均匀性不足,无法完全覆盖验证集,往往容易出现过拟合的情形。
技术实现要素:
本发明所要解决的技术问题在于提供了一种使整个模型的输出结果更加接近真实值的基于集成学习的近红外光谱定量建模方法。
本发明是通过以下技术方案解决上述技术问题的:一种基于集成学习的近红外光谱定量建模方法,包括以下步骤:
步骤s101,确定初始数据集,包含用于建模的校正集(xc,yc)和验证的预测集(xp,yp),并对数据进行预处理;
步骤s102,将初始数据集中的校正集样本按照聚类的策略分成p类,从每类中随机抽取一个样本构成子模型的验证集,余下的部分构成该子模型的校正集;
步骤s103,采用选取的定量建模方法对子模型的校正集进行训练,通过模型输出对初始数据集中预测集的预测误差信息进行统计,并获得以预测误差的方差为参数的权函数;
步骤s104,重复步骤102和步骤103一定次数,构建出多个子模型,并对各个子模型按照预测误差的方差加权得到稳健性强的定量校正模型;
步骤s105,利用稳健性强的整体定量校正模型结合预测集样本完成定量建模。
作为优化的技术方案,在步骤s101中,对光谱数据进行预处理,包括:求导,归一化,平滑,背景扣除。
作为优化的技术方案,在步骤s102中,对光谱数据进行聚类分析,将样本分成p类,同时对参与建模样本的化学含量数据进行聚类。
作为优化的技术方案,在步骤s103中,建模方法选取以下任一种:偏最小二乘、主成分回归,独立分量分析。
作为优化的技术方案,所述步骤s104的具体步骤为:
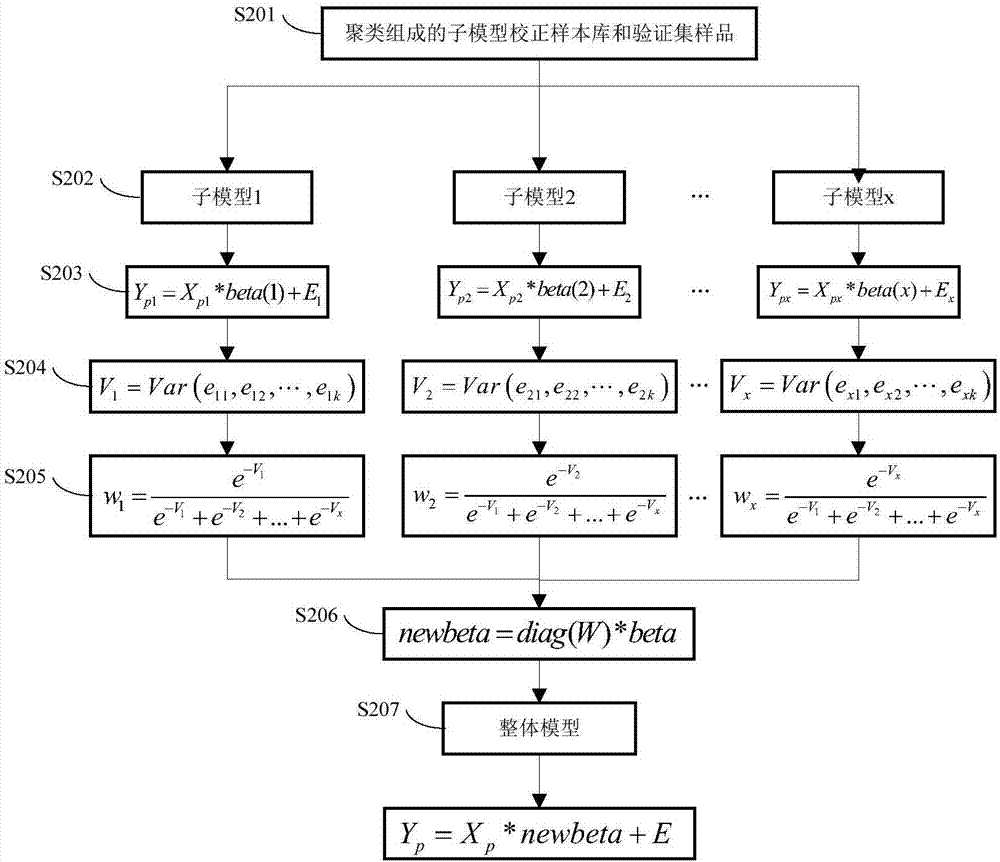
步骤s201:从整体模型中的校正集(xc,yc)选取子模型的校正集样本(xi,yi)和验证集样品(xt,yt);
步骤s202:选取定量校正方法构成弱学习机对子模型进行训练;
步骤s203:利用选取的子模型校正集数据(xi,yi)和定量建模方法建立该子模型yi=xi*betai+ei,并得到该子模型的输出参数betai,根据betai对子模型验证集样品(xt,yt)进行预测ypred=xt*betai+ep,得到预测误差ep=|yt-ypred|;
步骤s204:重复步骤s201,s202和s203x次得到x个子模型对各自验证集样品(xt,yt)的预测误差的方差;
步骤s205:利用各个子模型的方差构造权重函数;
步骤s206:利用权重函数修正各子模型的输出参数betai(i=1...x);
步骤s207:利用修正后的输出参数构成整体模型。
作为优化的技术方案,在步骤s203中,预测误差e的获取方式为:统计第i个子模型中的预测误差
作为优化的技术方案,在步骤s204中,统计出各个子模型的预测误差的方差记为
vi=var(ei1,ei2,…,eik)。
作为优化的技术方案,在步骤s204中,也可以按照下式统计出各个子模型相对预测误差的方差:
vi=var(ei1/yi1,ei2/yi2,…,eik/yik)。
作为优化的技术方案,步骤s205中,按照方差越大则该子模型权重越小的原则构造出高斯型权函数
采用集成学习的思想,构造整体模型的预测系数newbeta,其计算方式如下:
newbeta=diag(w)*betax
其中diag(w)由各个子模型权函数wi构成的对角矩阵。
作为优化的技术方案,在步骤s206中,利用权重函数修正各子模型的输出参数beta为newbeta;
在步骤s207中,通过对x个子模型的加权得到经过集成学习后的模型为:
y=x*newbeta+e
在上述模型中输入s101中的验证集样品的光谱数据即获得该整体模型的预测性能。
本发明相比现有技术具有以下优点:本发明将传统经典的多元校正方法构成集成学习中的弱学习机,按照样品聚类的原则构建多个校正模型的样本空间,有效提高子模型的校正集样本的多样性和代表性,通过高斯加权加权方法将这些弱学习机组合成一个集成学习机,降低预测误差较大的子模型对整体结果的影响,可以有效提高定量校正模型的泛化能力,使其对验证集样品的预测结果更加准确。本发明所述的定量校正方法不仅适用于近红外光谱,同样适用于紫外吸收光谱、荧光光谱、质谱、色谱等多变量校正的光谱分析体系。
附图说明
图1是本发明实施例的基于集成学习的近红外光谱定量建模方法的流程图;
图2是本发明实施例中的对各个子模型按照预测误差的方差加权得到稳健性强的定量校正模型的流程图。
具体实施方式
下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
如图1所示,本发明实施的基于集成学习的近红外光谱定量建模方法包括以下步骤:
步骤s101,确定初始数据集,包含用于建模的校正集和验证的预测集,并对数据进行预处理;
步骤s102,将初始数据集中的校正集样本按照聚类的策略分成p类,从每类中随机抽取一个样本构成子模型的验证集,余下的部分构成该子模型的校正集,最大程度上保证了子模型校正集样品的均匀性,避免因样品代表性不足引起的预测误差偏大的情形出现;
步骤s103,采用选取的定量建模方法对子模型的校正集进行训练,通过模型输出对初始数据集中预测集的预测误差信息进行统计,并获得以预测误差的方差为参数的权函数;
步骤s104,重复步骤102和步骤103一定次数,构建出多个子模型,并对各个子模型按照预测误差的方差加权得到稳健性强的定量校正模型;
步骤s105,利用稳健性强的整体定量校正模型结合预测集样本完成定量建模。
进一步具体的:
在步骤s101中,对光谱数据进行预处理,包括:求导,归一化,平滑,背景扣除。
在步骤s102中,对光谱数据进行聚类分析,将样本分成p类,同时也可以对参与建模样本的化学含量数据进行聚类。
在步骤s103中,建模方法可以选取偏最小二乘、主成分回归,独立分量分析等。
如图2所示,本发明的步骤s104的具体步骤为:
步骤s201:选取子模型的校正集和验证集样本;
步骤s202:选取定量校正方法构成弱学习机对子模型进行训练;
步骤s203:利用选取的子模型校正集数据(xi,yi)和定量建模方法建立该子模型yi=xi*betai+ei,并得到该子模型的输出参数betai,根据betai对子模型验证集样品(xt,yt)进行预测ypred=xt*betai+ep,得到预测误差ep=|yt-ypred|;
步骤s204:统计各个子模型的预测误差的方差;
步骤s205:利用各个子模型的方差构造权重函数;
步骤s206:利用权重函数修正各子模型的输出参数beta;
步骤s207:利用修正后的输出参数构成整体模型。
在步骤s203中,预测误差e的获取方式为:统计第i个子模型中的预测误差
在步骤s204中,统计出各个子模型的预测误差的方差记为
vi=var(ei1,ei2,…,eik)
在步骤s204中,按照下式统计出各个子模型的预测误差的方差:
vi=var(ei1/yi1,ei2/yi2,…,eik/yik)
步骤s205中,按照方差越大则该子模型权重越小的原则构造出高斯型权函数
在步骤s205中,重复步骤s201/s202/s203和s204计x次,可以得到x个子模型对应的高斯型权函数
采用集成学习的思想,构造整体模型的预测系数newbeta,其计算方式如下:
newbeta=diag(w)*betax
其中diag(w)由各个子模型权函数wi构成的对角矩阵。
在步骤s206中,利用权重函数修正各子模型的输出参数beta为newbeta。
在步骤s207中,通过对x个子模型的加权得到经过集成学习后的模型为:
y=x*newbeta+e
在上述模型中输入s101中的验证集样品的光谱数据即可获得该整体模型的预测性能。
调整聚类数目p和子模型数量k的大小,可以获得不同的预测模型,利用各个预测模型的输出结果可以对整体模型的预测性能进行优化。改变p的大小,获得一系列整体模型对验证集样本(xp,yp)的预测误差信息,统计得到使误差最小的p值即为最优。不断增加k值,以整体模型对验证集样本(xp,yp)的预测误差稳定为子模型数量的选取原则。
本发明首先将校正集样品进行分类,从每一类中选取一个样品作为子模型的验证集,剩余的样品作为该子模型的校正集,最大程度上保证了子模型校正集样品的均匀性,避免因样品代表性不足引起的预测误差偏大的情形出现。在子模型集成策略上,传统bagging方法采用求平均的策略来实现各子模型预测结果集成,对预测结果和真实值之间的偏移量没有任何改变,本方法采用基于各子模型预测结果的方差,构造高斯型加权函数对各子模型的输出结果进行集成,降低预测误差较大的子模型对最终输出结果权重的同时,提高了预测误差较小的子模型的权重,使整个模型的输出结果更加接近真实值。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!