基于深度学习的炼厂蒸馏塔顶切水离子浓度预测方法与流程
本发明涉及一种基于深度学习的炼厂蒸馏塔顶切水离子浓度预测方法。
背景技术:
常减压装置是炼油企业的龙头装置,腐蚀是影响装置安全、稳定运行的关键问题,对水质进行检测分析是判断和预测腐蚀发展趋势的重要方法。但是,由于检测技术和条件的限制,炼厂还不能做到对水样进行实时在线监测,当工艺条件或原料发生变化时往往不能及时了解水质的改变情况。因此需要开发一种技术能根据现有的状态监测和检测数据预测水中关键离子浓度。由于工艺过程、腐蚀机理的复杂性,很难简单的根据经验模型或解析方法获得水质参数,如铁离子含量、ph等,进而导致对塔顶最为关心的腐蚀评价预测不准确。近年来有对装置关键离子浓度进行预测的研究,顾敏等[bp神经网络在炼油污水回用于循环水系统中腐蚀率的预测.当代化工,2014,43(11):2358-2361.]运用bp神经网络预测循环冷却水腐蚀速率;李皎等[炼油装置的腐蚀监测管理体系[j].腐蚀与防护,2016,37(10):847]针对加氢裂化装置的腐蚀监测数据,运用bp人工神经网络建立了铁离子浓度预测模型。然而,这些研究主要针对有限的腐蚀监检测数据进行分析,忽视了设备工艺、原料及产品采样数据,分析数据样本有限,研究结果也只能在有限范围内得到验证,导致预测结果准确性欠佳,所用方法仅局限于传统数据分析方法。
深度学习是一种模拟人脑的多层感知结构来认识数据模式的学习算法。近年来作为数据挖掘的一个新兴领域,在处理图像识别、语音识别以及人工智能领域取得了卓越的效果。和传统的机器学习方法相比,深度学习的适应面广、效率高、计算结果更准确。目前暂无利用深度学习方法对炼厂水质数据进行分析预测的技术。
技术实现要素:
本发明所要解决的技术问题是现有技术中由于提供数据不及时而导致的人力和时间成本较高的问题,提供一种新的基于深度学习的炼厂蒸馏塔顶切水离子浓度预测方法。该方法具有提供数据及时、人力和时间成本较低的优点。
为解决上述问题,本发明采用的技术方案如下:一种基于深度学习的炼厂蒸馏塔顶切水离子浓度预测方法,首先根据所有监检测数据的最小时间尺度进行时间同步,即通过插入数据的方法使得在任一时间点所有监检测变量都有数据,数据根据现行插值算法得出;针对非量化数据进行量化处理,并进行数据归一化,组建因素表x和对照表y;建立包含多层限制玻尔兹曼机rbm的深度置信网络,第一层rbm的可视层的节点数与因素表x的总列数一致,最后一层rbm的隐藏层的节点数不小于因素表x的总列数的一半,中间层rbm的可视层和隐藏层的节点数相同,整个深度置信网络包含rbm总层数不小于2层;通过逐层学习,获得深度置信网络的最优参数,最后一层rbm输出结果为
(1)数据的收集和预处理
收集常减压装置的工艺生产实时数据、侧线油品分析化验数据和水质分析数据,对数据进行预处理,包括如下步骤:
1)对数据进行时间同步
针对数据时间尺度不一致的情况,按最小时间尺度对数据集进行补充;
2)对非量化数据的处理
监测和检测数据中,部分数据采用非量化的描述,根据数据集中存在非量化的状态总数m,则将这些非量化描述转换成量化整数i(i=1~m);
3)对数据进行补全
如果某个时段采集数据中有缺失,则通过线性插值方法进行补充;
4)数据归一化
针对分析的数据集,选择每列数据的最大值和最小值,通过线性方法将数据变换到0~1范围内;
5)将所有数据根据时间组装成因数表和对照表,因素表中的每一列代表一个因素的时序集,每一行代表一个时间点上因素集;对照表中每一列代表需要预测的变量的时序集,每一行代表一个时间点上多个预测变量的集和;
(2)采用深度学习对数据进行训练
1)组建深度置信网络,深度置信网络由多层限制玻尔兹曼机rbm叠加而成组成;
2)逐层训练
对深度置信网络的每层rbm进行训练;
3)采用支持向量机回归分析方法对塔顶切水浓度进行预测;
4)重复上述步骤直至对照表中所有的浓度都获得svr的最优解,至此,建立了基于深度学习的塔顶切水浓度预测方法;
5)离子浓度预测数据预测
将新采集的数据进行预处理,并输入深度置信网络的第一层rbm的可视层,经过计算后,将最后一层rbm隐藏层的结果代入计算公式,计算出的结果即为塔顶切水中离子浓度的预测值。
上述技术方案中,优选地,组建深度置信网络,深度置信网络由多层限制玻尔兹曼机rbm叠加而成组成,每个rbm层包括可视层和隐藏层。
上述技术方案中,优选地,对深度置信网络的每层rbm进行训练;首先将训练数据输入第1层rbm,经过训练后,固定其网格参数,将第1层rbm隐含层作为第2层rbm的可视层,数据样本经过第1层rbm抽取初步特征数据,再输入第2层rbm的可见层;第2层rbm采用同样的方法进行训练,训练结束后将第2层rbm隐藏层的输出作为第3层rbm的可见层;这样,逐层进行训练到最后一层,使整个置信网格参数稳定;训练数据经过深度置信网络计算后,输出结果为最后一层rbm的隐藏层数据。
上述技术方案中,优选地,所述计算公式为:
上述技术方案中,优选地,如果j>1,则重复上述步骤直至对照表中所有的浓度都获得svr的最优解。
上述技术方案中,优选地,采用的限制玻尔兹曼机的能量函数为:e(v,h|a,b,w)=-∑i,jwijvihj-∑ibivi-∑jajhj,
其中,v和h代表可视层和隐藏层,a和b为网络的偏置,w为连接权重,i和j为分别代表可视层和隐藏层的节点编号。
上述技术方案中,优选地,线性插值方法为
本发明是通过以下技术方案实现的:
1、数据的收集和预处理
收集常减压装置的工艺生产实时数据、侧线油品分析化验数据和水质分析数据,对数据进行预处理,方法如下:
(1)对数据进行时间同步
针对数据时间尺度不一致的情况,按最小时间尺度对数据集进行补充。
(2)对非量化数据的处理
监测和检测数据中,部分数据采用非量化的描述(如硫化物浓度<1.0mg/l),根据数据集中存在非量化的状态总数(如m种),则将这些非量化描述转换成量化整数i(i=1~m)。
(3)对数据进行补全
如果某个时段采集数据中有缺失(没有采集),则通过线性插值方法进行补充,即:
其中,x为t时刻需要补全的值,x1为t1时刻的测量值,x2为t1时刻的测量值。
(4)数据归一化
针对分析的数据集,选择每列数据的最大值和最小值,通过线性方法将数据变换到0~1范围内,即,
其中,
(5)将所有数据根据时间组装成因数表(二维向量x)和对照表(二维向量y),因素表中的每一列代表一个因素的时序集,每一行代表一个时间点上因素集。对照表中每一列代表需要预测的变量的时序集,每一行代表一个时间点上多个预测变量的集和。
2、采用深度学习对数据进行训练
(1)组建深度置信网络(deepbeliefnets,dbns)。深度置信网络由多层限制玻尔兹曼机(restrictedboltzmannmachine,rbm)叠加而成组成,每个rbm层包括可视层v和隐藏层h。
采用的限制玻尔兹曼机的能量函数为:
e(v,h|a,b,w)=-∑i,jwijvihj-∑ibiυi-∑jajhj(3)
式中,v和h代表可视层和隐藏层,a和b为网络的偏置,w为连接权重,i和j为分别代表可视层和隐藏层的节点编号。基于该能量模型,可以得到v和h的联合分布概率为,
给定可视层v,第j个隐藏层节点被激活的概率为:
给定隐藏层h,第i个可视层节点被激活的概率为:
将给定训练样本输入至可见层节点时,根据上述激活概率,逐层对隐含层进行激活。对深度置信网络的参数进行调整,调整幅度为:
δwij=ε(<υihj>data-<υihj>recon)(7)
δai=ε(<υi>data-<υi>recon)(8)
δbi=ε(<hj>data-<hj>recon)(9)
式中,ε为学习率,<·>data表示训练数据集所定义分布之上的数学期望,<·>recon表示重构后深度置信网络输出的分布上的数学期望。经过多次调整后,深度置信网络参数达到最优。
计算中,第一层rbm的可视层的节点数与训练数据(因素表x)的总列数一致。最后一层rbm的隐藏层的节点数不小于因素表x的总列数一半。中间层rbm的可视层和隐藏层的节点数相同,可以与第一层rbm的可视层的节点数相同。整个深度置信网络包含rbm总层数不小于2层。
(2)逐层训练
运用上述的参数调整方法,对深度置信网络的每层rbm进行训练。首先将训练数据(因素表x)输入第1层rbm,经过训练后,固定其网格参数,将第1层rbm隐含层作为第2层rbm的可视层,数据样本经过第1层rbm抽取初步特征数据,再输入第2层rbm的可见层。第2层rbm采用同样的方法进行训练,训练结束后将第2层rbm隐藏层的输出作为第3层rbm的可见层。这样,逐层进行训练到最后一层,使整个置信网格参数稳定。训练数据(因素表x)经过深度置信网络计算后,输出结果为
3、采用支持向量机回归分析方法(supportvectorregression,svr)对塔顶切水浓度进行预测。
将深度置信网络最后一层rbm的输出
式中,
式中,c为惩罚参数,
4)如果j>1,则按步骤3)重复直至对照表中所有的浓度都获得svr的最优解。至此,基于深度学习的塔顶切水浓度预测方法建立成功。
5)离子浓度预测数据预测
将新采集的数据按照步骤1)进行预处理,并输入深度置信网络的第一层rbm的可视层,经过计算后,将最后一层rbm隐藏层的结果代入式(10),计算出的结果为塔顶切水中离子浓度的预测值。
本发明利用深度学习方法对常减压装置塔顶切水中离子浓度进行预测,首先根据所有监检测数据的最小时间尺度进行时间同步,即通过插入数据的方法使得在任一时间点所有监检测变量都有数据,数据根据现行插值算法得出。针对非量化数据进行量化处理,并进行数据归一化,组建因素表x和对照表y。建立包含多层限制玻尔兹曼机(rbm)的深度置信网络。第一层rbm的可视层的节点数与因素表0的总列数一致,最后一层rbm的隐藏层的节点数不小于因素表0的总列数的一半,中间层rbm的可视层和隐藏层的节点数相同,整个深度置信网络包含rbm总层数不小于2层。通过逐层学习,获得深度置信网络的最优参数,最后一层rbm输出结果为
本发明采用深度学习和支持向量回归方法建立了炼厂常减压装置塔顶切水离子浓度预测方法,该方法对常减压装置的工艺数据和水质数据进行分析和预处理,针对采集数据时间尺度不一致的问题,利用线性插值方法对数据进行补充,并进行量化处理和归一化,组成因素表和对照表。建立包含多层rbm的深度置信网络,将因素表的数据输入第一层rbm,通过逐层学习训练,获得这些数据的最优特征表达。再运用支持向量机回归方法建立这些最优表达与水样离子浓度的非线性关系,从而完成塔顶切水离子浓度的预测方法。本发明从海量的、复杂数据(生产实时数据、油品分析化验、水质分析数据)中预测塔顶切水介质的浓度,计算可靠、速度快,可以及时的向炼油企业的工艺防腐和腐蚀预测提供可靠的数据支持,节省时间和人力物力成本,取得了较好的技术效果。
附图说明
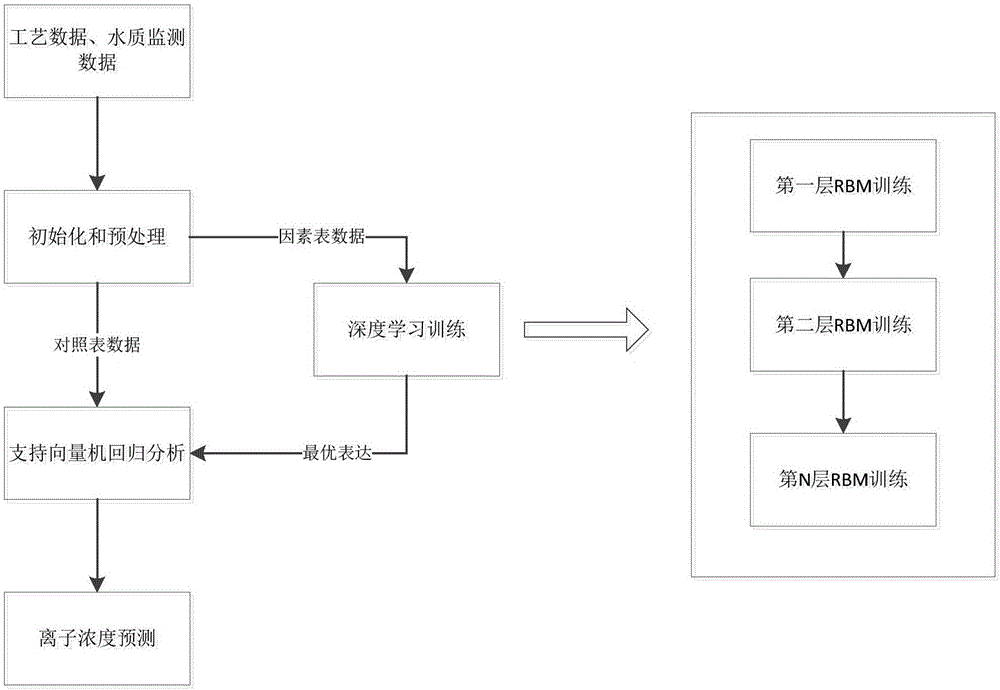
图1为本发明流程图;
图2为深度置信网络图;
图3常压塔顶切水ph的预测值和测量值对比图;
图4常压塔顶切水fe2+的预测值和测量值对比图;
下面通过实施例对本发明作进一步的阐述,但不仅限于本实施例。
具体实施方式
【实施例1】
一种基于深度学习的炼厂蒸馏塔顶切水离子浓度预测方法,如图1-3所示,首先根据所有监检测数据的最小时间尺度进行时间同步,即通过插入数据的方法使得在任一时间点所有监检测变量都有数据,数据根据现行插值算法得出;针对非量化数据进行量化处理,并进行数据归一化,组建因素表x和对照表y;建立包含多层限制玻尔兹曼机rbm的深度置信网络,第一层rbm的可视层的节点数与因素表x的总列数一致,最后一层rbm的隐藏层的节点数不小于因素表x的总列数的一半,中间层rbm的可视层和隐藏层的节点数相同,整个深度置信网络包含rbm总层数不小于2层;通过逐层学习,获得深度置信网络的最优参数,最后一层rbm输出结果为
具体包括如下步骤:
1、数据的收集和预处理
选取某炼油厂常减压装置的2016年1月1日至2016年10月26日的工艺数据和水质分析数据,其中工艺数据包括常减压塔自身的工艺数据和塔侧线分析数据,水质分析数据包括常顶切水、减顶切水、常压电脱盐切水、常压含油污水等数据,水质分析数据中的铁离子和ph值是工艺防腐的重要参数,需要根据其他数据进行预测。所采集的数据共有107个变量。
(1)对数据进行时间同步
常减压塔的工艺数据(从企业lims系统读取)是1小时采集1次,侧线数据是1天采集2次,水质分析是1天1次,则最小时间尺度为1小时,在水质分析、侧线监测的数据集中添加数据统一补充到1天24行数据,并按步骤(2)对数据进行补全。
(2)对非量化数据的处理
上述数据中,部分数据(如硫化物浓度<1.0mg/l)采用非量化的描述,根据数据集中存在非量化的状态总数(如硫化物浓度共有5种),则将这些非量化描述转换成量化整数i(i=1~5)。
(3)对数据进行补全
对于采集数据中有缺失的时段,则通过线性插值方法进行补充,即:
其中,x为t时刻需要补全的值,x1为t1时刻的测量值,x2为t1时刻的测量值。如常压塔塔顶切水ph于9月1日9:00采集的值为8.2,9月7日9:00采集的值为8.6,则x1=8.2,t1=2016.9.19:00,x2=8.6,t2=2016.9.79:00,按1小时间隔在(t1,t2)内插入多个时间点,每个时间点的ph值用式(1)计算得出。
(4)数据归一化
针对分析的数据集,选择每列数据的最大值和最小值,通过线性方法将数据变换到0~1范围内,即,
其中,
(5)将所有数据根据时间组装成因数表(二维向量x,共101列,7199行)和对照表(二维向量y,共6列,7199行,为常减压塔顶切水和电脱盐切水的fe2+、ph),因素表中的每一列代表一个因素的时序集,每一行代表一个时间点上因素集。对照表中每一列代表需要预测的变量的时序集,每一行代表一个时间点上多个预测变量的集和。
2、采用深度学习对数据进行训练
(1)组建深度置信网络。深度置信网络由多层限制玻尔兹曼机叠加而成组成,每个rbm层包括可视层v和隐藏层h。
采用的限制玻尔兹曼机的能量函数为:
e(υ,h|a,b,w)=-∑i,jwijυihj-∑ibivi-∑jajhj(3)
式中,v和h代表可视层和隐藏层,a和b为网络的偏置,w为连接权重,i和j为分别代表可视层和隐藏层的节点编号。基于该能量模型,可以得到v和h的联合分布概率为,
给定可视层v,第j个隐藏层节点被激活的概率为:
给定隐藏层h,第i个可视层节点被激活的概率为:
将给定训练样本输入至可见层节点时,根据上述激活概率,逐层对隐含层进行激活。对深度置信网络的参数进行调整,调整幅度为:
δwij=ε(<υihj>data-<vihj>recon)(7)
δai=ε(<υi>data-<υi>recon)(8)
δbi=ε(<hj>data-<hj>recon)(9)
式中,ε为学习率,<·>data表示训练数据集所定义分布之上的数学期望,<·>recon表示重构后深度置信网络输出的分布上的数学期望。经过多次调整后,深度置信网络参数达到最优。
计算中,第一层rbm的可视层的节点数与训练数据(因素表x)的总列数一致,为101个,最后一层rbm的隐藏层的节点数为51个。中间层rbm的可视层和隐藏层的节点数相同,可以与第一层rbm的可视层的节点数相同。整个深度置信网络包含rbm总层数为5层。
(2)逐层训练
运用上述的参数调整方法,对深度置信网络的每层rbm进行训练。首先将训练数据(因素表x)输入第1层rbm,经过训练后,固定其网格参数,将第1层rbm隐含层作为第2层rbm的可视层,数据样本经过第1层rbm抽取初步特征数据,再输入第2层rbm的可见层。第2层rbm采用同样的方法进行训练,训练结束后将第2层rbm隐藏层的输出作为第3层rbm的可见层。这样,逐层进行训练到最后一层,使整个置信网格参数稳定。训练数据(因素表x)经过深度置信网络计算后,输出结果为
3、采用支持向量机回归分析方法对塔顶切水浓度进行预测。
将深度置信网络最后一层rbm的输出
式中,
式中,c为惩罚参数,
4、则按步骤3再重复7次,直至对照表中所有的浓度都获得svr的最优解。至此,基于深度学习的塔顶切水ph和铁离子浓度预测方法建立成功。
5)离子浓度预测数据预测
将新采集的数据按照步骤1进行预处理,并输入深度置信网络的第一层rbm的可视层,经过计算后,将最后一层rbm隐藏层的结果代入式(10),计算出的结果为切水中介质浓度的预测值。其中,常压塔顶切水ph值预测值和测量值对比图如图3所示,常压塔顶切水铁离子值预测值和测量值对比图如图4所示,结果表明,本发明的方法可以非常准确的预测离子浓度。
本发明采用深度学习和支持向量回归方法建立了炼厂常减压装置塔顶切水离子浓度预测方法,该方法对常减压装置的工艺数据和水质数据进行分析和预处理,针对采集数据时间尺度不一致的问题,利用线性插值方法对数据进行补充,并进行量化处理和归一化,组成因素表和对照表。建立包含多层rbm的深度置信网络,将因素表的数据输入第一层rbm,通过逐层学习训练,获得这些数据的最优特征表达。再运用支持向量机回归方法建立这些最优表达与水样离子浓度的非线性关系,从而完成塔顶切水离子浓度的预测方法。本发明从海量的、复杂数据(生产实时数据、油品分析化验、水质分析数据)中预测塔顶切水介质的浓度,计算可靠、速度快,可以及时的向炼油企业的工艺防腐和腐蚀预测提供可靠的数据支持,节省时间和人力物力成本,取得了较好的技术效果。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无法对所有的实施方式予以穷举。凡是属于本发明的技术方案所引申出的显而易见的变化或变动仍处于本发明的保护范围之列。
- 还没有人留言评论。精彩留言会获得点赞!