基于降噪自动编码器及增量学习的旋转机械故障诊断方法与流程
本发明属于旋转机械故障诊断技术领域,更为具体地讲,
涉及一种基于降噪自动编码器及类别增量学习的旋转机械故障诊断方法。
背景技术:
旋转机械作为机械设备中的关键机构,在飞机、列车和风机等现代大型工业设备中起着重要作用。由于系统复杂、工作强度高、工作环境恶劣等因素的影响,旋转机械在运行过程中易发生各种故障。如果这些故障不能及时发现和处理,会使机械设备可靠性和安全性降低,造成经济损失甚至人身安全事故。因此,对旋转机械进行故障诊断具有重大意义。
随着计算机软硬件技术的发展,旋转机械的故障诊断越来越趋向基于机器学习方法的智能诊断。传统的智能诊断方法,基本都是采用批量学习方法。即在训练之前需要将所有类别的训练样本准备好,根据这些样本训练一个诊断模型;而当新类别的样本加进来后需要舍弃之前训练好的模型,基于新类别的样本和之前的样本重新训练诊断模型。然而在实际中,所有故障模式的样本不是一时就能全部得到的,通常是随着时间慢慢获取的。诚然,如果等待所有故障类型的样本全部获得时才进行分类算法的训练及故障分类,这是不可取的。或当旋转机械出现新的故障模式时,获得了新故障模式的样本,舍弃之前训练得到的分类模型,重新训练,势必会浪费大量的时间和计算资源。并且,在传统的旋转机械智能诊断方法中,特征选择及提取是一个必要的步骤,而这个步骤需要依赖专家经验知识,特征选取不当可能会导致诊断模型泛化能力差,诊断效果不好。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种基于降噪自动编码器及增量学习的旋转机械故障诊断方法,通过增量学习的方式来监测旋转机械是否出现新故障,进而来训练降噪自动编码器(denoisingauto-encoder,简称dae),再利用基于dae的类别增量学习模型判断旋转机械故障。
为实现上述发明目的,本发明提供一种基于降噪自动编码器及增量学习的旋转机械故障诊断方法,其特征在于,包括以下步骤:
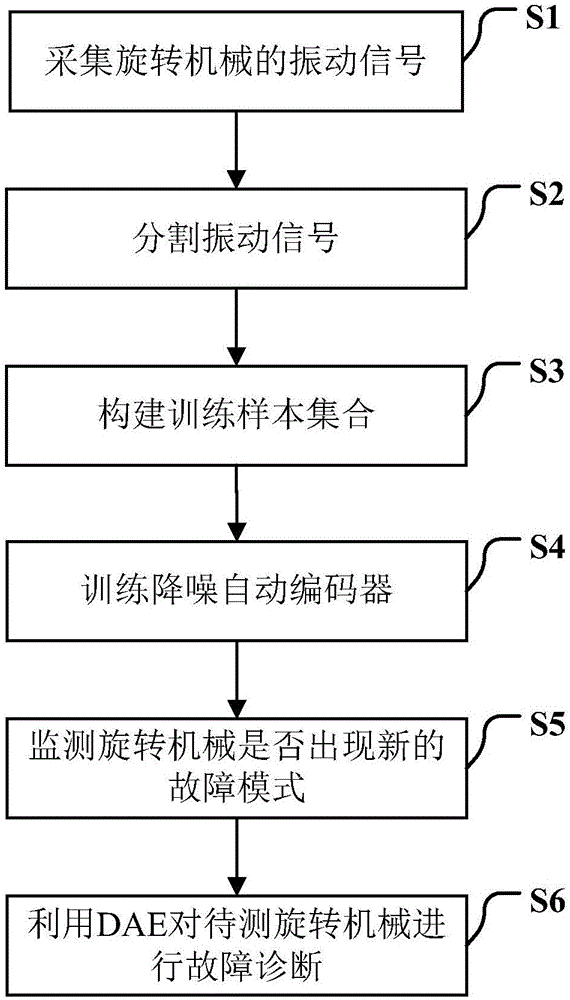
(1)、采集旋转机械的振动信号
使用振动数据采集仪分别采集旋转机械在单一故障模式下的振动信号,得到旋转机械在每一类故障模式下的故障数据dk,其中,k表示故障模式编号;
(2)、分割振动信号
对故障数据dk进行等距分割,得到n段故障数据,设每段故障数据包含n个数据点;
(3)、构建训练样本集合
将每段故障数据作为一个训练样本xk_i,则n段故障数据构成一个训练样本集合sk,其中,i=1,2,…,n;
(4)、训练降噪自动编码器(denoisingauto-encoder,简称dae)
(4.1)、根据训练样本集合sk产生相同维度的噪声noisek={noisek_i|i=1,2,…,n};
(4.2)、利用训练样本集合sk和噪声noisek训练一个隐含层节点数为m的dae,即:
得到dae的网络参数为w1,k,b1,k,w2,k,和b2,k,其中,w1,k是dae输入层到隐含层的权重矩阵,b1,k是隐含层的偏差向量,w2,k是隐含层到输出层的权重矩阵,b2,k是输出层的偏差向量;
(5)、监测旋转机械是否出现新的故障模式,如果旋转机械未出现新的故障模式,则进入步骤(6);如果旋转机械出现新的故障模式,则重复步骤(1)~(4),训练出一个新的dae,设此时的故障模式共有k个,则有k个dae及其对应的网络参数w1,k,b1,k,w2,k,和b2,k,k=1,2,…,k;再进入步骤(6);
(6)、利用训练好的dae对待测旋转机械进行故障诊断;
(6.1)、按照步骤(1)-(3)所述方法,获取待测旋转机械的一个测试样本y;
(6.2)、将测试样本y经过每一类故障模式对应的dae重构,计算重构后的重构误差ek_y:
ek_y=||zk_y-y||2,
(6.3)、在所有的重构误差ek_y中找到的最小值,并将对应的故障模式作为待测旋转机械的故障模式。
本发明的发明目的是这样实现的:
本发明基于降噪自动编码器及增量学习的旋转机械故障诊断方法,通过对旋转机械单一故障模式下振动信号的采集、信号分割,然后用分割后的信号构成的样本集合训练一个dae,得到相应网络权重值矩阵和偏差向量w1,k,b1,k,w2,k,和b2,k;对于旋转机械测试样本y,计算其经每类故障模式对应的dae重构后的重构误差ek_y,然后找到重构误差最小值,其对应的故障模式则是待测旋转机械所属的故障模式。本发明在有新的故障出现时,只需要对新故障模式对应的dae进行训练即可,这样可以保留之前学习的结果并且从不断出现的新数据中学习,类似人类渐进获取知识的过程,可以提高效率和节省计算资源;并且,该方法可以直接输入原始振动信号进行训练及测试,不需要提取特征,不依赖经验知识。
附图说明
图1是本发明基于降噪自动编码器及增量学习的旋转机械故障诊断方法流程图;
图2是利用本发明所述方法进行旋转机械故障诊断的准确率;
图3是诊断模型构建时间。
具体实施方式
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
实施例
图1是本发明基于降噪自动编码器及增量学习的旋转机械故障诊断方法流程图。
在本实施例中,如图1所示,本发明一种基于降噪自动编码器及增量学习的旋转机械故障诊断方法,包括以下步骤:
s1、采集旋转机械的振动信号
使用振动数据采集仪分别采集旋转机械在单一故障模式下的振动信号,得到旋转机械在每一类故障模式下的故障数据dk,其中,k表示故障模式编号;
s2、分割振动信号
对故障数据dk进行等距分割,得到n段故障数据,设每段故障数据包含n个数据点;
在本实施例中,取n=400,n=50;选取旋转机械的重要组成部分轴承作为实验对象。振动数据采集仪采用加速度传感器对振动信号进行采集,加速度传感器垂向安装在轴箱上。
s3、构建训练样本集合
将每段故障数据作为一个训练样本xk_i,则n段故障数据构成一个训练样本集合sk,其中,i=1,2,…,n;
s4、训练降噪自动编码器dae(denoisingauto-encoder,简称dae)
s4.1、根据训练样本集合sk产生相同维度的噪声noisek={noisek_i|i=1,2,…,n};
s4.2、利用训练样本集合sk和噪声noisek训练一个隐含层节点数为m的dae,即:
得到dae的网络参数为w1,k,b1,k,w2,k,和b2,k,其中,w1,k是dae输入层到隐含层的权重矩阵,b1,k是隐含层的偏差向量,w2,k是隐含层到输出层的权重矩阵,b2,k是输出层的偏差向量;
在本实施例中,取m=200,noisek_i是高斯白噪声,并且与xk_i的信噪比是10db。
s5、监测旋转机械是否出现新的故障模式,如果旋转机械未出现新的故障模式,则进入步骤s6;如果旋转机械出现新的故障模式,在本实施例中,当轴承出现新的故障模式时,则重复步骤s1~s4,训练出一个新的dae,设此时的故障模式共有k个,则有k个dae及其对应的网络参数w1,k,b1,k,w2,k,和b2,k,k=1,2,…,k;,再进入步骤s6;
s6、利用训练好的dae对待测旋转机械进行故障诊断;
s6.1、按照步骤s1-s3所述方法,获取待测旋转机械的一个测试样本y;
s6.2、将测试样本y经过每一类故障模式对应的dae重构,计算重构后的重构误差ek_y:
ek_y=||zk_y-y||2,
ek_y=||zk_y-y||2,
s6.3、在所有的重构误差ek_y中找到的最小值,并将对应的故障模式作为待测旋转机械的故障模式。
实例
在本实施例中,以某高速列车轮轴轴承实验台采集的数据为例,具体过程如下:
该轴承试验台由驱动电机、传送带系统、水平加载台、垂直加载台、轮轴和轮对轴箱等组成。测试轴承安装在轴箱里,实验中所用的轴承型号是skf197726,轴承的故障模式如表1所示。对于每一种故障模式,均采集了9种工况下振动信号,如表2所示,采样率是5120hz。
表1是用于诊断分析的测试轴承故障模式列表;
表2是实验中模拟的9种工况列表。
表1
表2
针对表1中每一类故障模式,样本数为1350,总共11类,一共的样本数为14850个。
本实施例中,将其中每类的1080个样本,一共11880个样本作为训练样本,来训练dae。剩余的2970个样本作为测试样本用于诊断过程,以验证本发明的有效性。同时,实验过程中,为了模拟类别增量过程,从2类样本开始,往后依次增加1类样本,测试时则将这些类的测试集全部测试。比如,刚开始的2类样本得到两个dae,测试则将这两类的测试集测试诊断模型的性能,当第3类样本加进来时,训练则可以得到三个dae,测试则将第3类样本的测试集加上前2类的测试集测试分诊断模型的性能,以此类推。
此外,还将本发明与支持向量机(supportvectormachine,简称svm)进行比较,svm的惩罚参数c=1,核函数选用高斯径向基函数,参数γ=0.2,选取和提取的特征为绝对均值、峭度、均方根、偏度和方差,实验结果见图2和图3。
诊断准确度的结果如图2所示。结果表明,在轴承故障诊断中,本发明比svm表现更好。具体而言,平均比svm高9%。更重要的是,svm作为一种经典的智能轴承诊断方法,很容易受到特征选择的影响,这在很大程度上依赖于先验知识。而对于本发明,不需要提取和选择特征。因此,本发明可以直接输入原始信号进行诊断,并且分类准确率较对比方法更好。
模型构建所消耗的时间的结果如图3所示。可以看出,本发明比svm消耗更多的时间。然而,当使用本发明时,时间随着故障模式的数量线性增加,但是svm的模型构建时间是非线性增加。这是因为当新的故障模式出现时,批量学习的svm需要重新训练模型并丢弃先前训练好的诊断模型。而本发明作为一种增量方法,可以保留之前的模型,只需要为新的故障模式训练一个dae。因此,从长远来看,本发明效率更高。
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
- 还没有人留言评论。精彩留言会获得点赞!