基于深度学习的移动机器人视觉导航方法与流程
本发明涉及目标检测,深度学习,移动机器人室内导航技术领域,尤其涉及基于深度学习的移动机器人视觉导航方法。
背景技术:
近些年来,不管是在学术界还是产业界,智能机器人的研究都引起了广泛的关注。
目前技术比较成熟且应用较为广泛的定位技术为全球定位系统(globalpositioningsystem,gps)定位技术,这种定位技术的定位方法是车辆、手机等移动设备通过搭载gps模块实现对自身的定位,从而实现导航。gps定位技术要求移动设备能够接收gps信号,适用于室外开阔场景,而在建筑物内部,gps信号往往很弱,无法为机器人提供精确的位置信息,导航效果不佳。
目前室内机器人导航技术应用较多的为基于激光雷达的导航技术和基于视觉的导航技术,通过激光雷达或者视觉传感器进行移动机器人室内定位和建图,从而实现室内移动机器人的导航。激光雷达技术相对较成熟并且精度较高,但是激光雷达往往价格较高,存在镜面问题,只能探测物理距离机器人自身的位置和方向,无法识别室内的物体。视觉传感器价格较为低廉,且能够获得更多的环境信息,能够对环境中存在的物体进行识别,实现目标导向的导航。
技术实现要素:
本发明提出一种基于深度学习的移动机器人室内导航方法,该方法以机器人搭载的rgb-d深度相机采集的图像信息作为输入,通过目标检测算法检测目标物体,通过深度图目标位置的距离,实现机器人的导航。
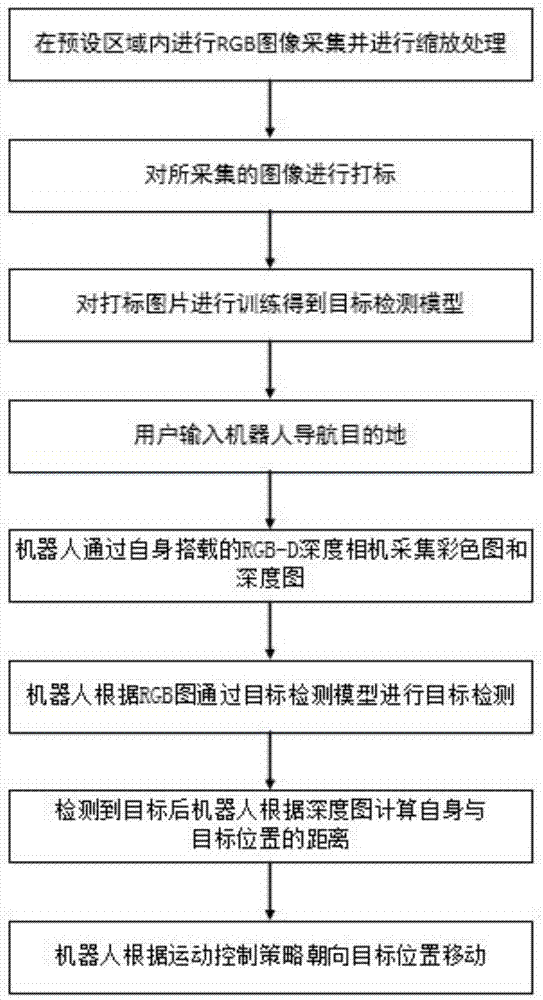
本发明采用的技术方案为基于深度学习的移动机器人视觉导航方法,包括以下步骤:
步骤1:机器人在未知环境中随机探索,并以给定的频率拍摄图像,并将图像按拍摄时间序列进行命名并保存。
步骤2:采用打标工具对采集的rgb图像进行打标。
步骤3:用目标检测模型对打标图像进行训练,得到满足要求的目标检测模型。
步骤4:用户输入机器人要到达的目标。
步骤5:机器人通过自身搭载的rgb-d深度相机采集图片。
步骤6:机器人根据rgb图通过目标检测模型进行目标检测。
步骤7:检测到目标后机器人根据彩色图与深度图计算目标位置的坐标。
步骤8:机器人根据运动控制策略朝向目标位置行进。
本发明实施例的基于深度学习的移动机器人视觉导航方法,以图片为输入,通过目标检测模型对目标进行识别,对目标大致基本方位进行认知,再根据深度图计算机器人距离目标的精确距离。使用轮式移动机器人搭载视觉传感器,成本低且能够识别室内环境中不同的物体,更加符合室内服务机器人的性能要求。
另外,根据本实施例的基于深度学习的视觉导航方法还具有如下附加的技术特征:
在步骤1中需要对图片进行处理,其中对图片的处理为缩放处理,采集到的图片像素值为640*480,经过缩放后像素值为320*240。
在步骤3中目标检测模型为卷积神经网络,网络采用卷积层和池化层的结构。输入层为480*480*3,后面是3个卷积池化层,最后是一个平均池化层和softmax层。第一层是96个3*3步长为2的卷积核,然后是一个2*2的池化层。第二层是72个3*3步长为2的卷积核,然后是一个2*2的池化层。第三层是48个3*3步长为2的卷积核,然后是一个2*2的池化层。最后是一个24个2*2卷积核的平均池化层和全连接层,其中全连接层的神经元个数为3*3*15。
目标检测算法的输入为经过打标的rgb图像,输出为目标类别和在图像中的位置向量[pc,bx,by,bh,bw,c],其中pc为边框中物体为类别c的概率,bx为边框中心的横坐标,by为边框中心的纵坐标,bh为边框的高度,bw为边框的宽度,c为目标类别向量[c1,c2,c3,…,cn],n为目标类别向量元素的个数。
在步骤4中对目标的输入是语音输入或者是文字输入,机器人根据输入的字符找到其对应的编码,其中编码为[0,1,2,…,n-1]。
在步骤5中对所采集图片进行同步骤1相同的缩放处理。
在步骤6中目标物体在图片中的位置信息[bx,by,bh,bw]。
在步骤7中,以相机坐标系作为世界坐标系,相机所在位置为坐标原点,以步骤6中边框的中心[bx,by]作为目标在深度图中的位置,根据像素坐标与相机坐标的转换关系得到目标位置的实际坐标。
像素坐标为[u,v,d],假设相机坐标pc为[x,y,z],相机坐标到像素坐标的关系为:
其中u=bx,v=by,[u,v]为像素点在像素平面坐标系中的坐标,d为像素点的深度值,[x,y,z]为像素点在相机坐标系中的三维坐标,x轴方向为水平方向,y轴方向为竖直方向,z轴方向为垂直相机平面向外,k为相机的内参数矩阵,k由相机本身决定。
计算目标在相机坐标系下的坐标pc[x,y,z]。
z=d/s
在步骤8中的预设距离为20cm。cx,cy,fx,fy为构成k的相机内参,cx,cy为相机光圈中心,fx,fy为相机在x,y两个轴上的焦距,s为深度图的缩放因子。
附图说明
图1是基于深度学习的移动机器人视觉导航方法的流程图。
图2是目标检测模型的结构图。
具体实施方式
下面详细说明本发明的实施例,本实施例在本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
步骤1:机器人在未知环境中随机探索,并以给定的频率拍摄图像,并将图像按拍摄时间序列进行命名并保存。
本实施例为建筑物室内环境,由于机器人处在未知环境,机器人需在环境空间中进行随机探索对环境进行认知,通过随机探索的方式记录下环境的空间信息。
rgb-d深度相机以的频率从各个角度在环境空间进行图像采集,本步骤中的图像采集只保存彩色图,总共采集1000张图片,其中800张作为训练,200张作为测试。
对采集到的图像进行处理得到预设尺寸的图像,该步骤中对图片的处理为缩放处理,采集到的图片为640*480,经过缩放后尺寸为320*240。
步骤2:采用打标工具对采集的图像进行打标。
采用labelimg对图像进行打标,用边框框出图片中的目标,并给目标打上相应的标签(label=1,2,3,…,n,n=10),生成相应的文件。
步骤3:用目标检测模型对打标图像进行训练,得到满足要求的目标检测模型。
目标检测模型为卷积神经网络,网络采用卷积层和池化层的结构。输入层为480*480*3,后面是3个卷积池化层,最后是一个平均池化层和softmax层。第一层是96个3*3步长为2的卷积核,然后是一个2*2的池化层。第二层是72个3*3步长为2的卷积核,然后是一个2*2的池化层。第三层是48个3*3步长为2的卷积核,然后是一个2*2的池化层。最后是一个24个2*2卷积核的平均池化层和3*3*15个单元的全连接层。
目标检测算法的输入为经过打标的rgb图像,输出为目标类别和在图像中的位置向量[pc,bx,by,bh,bw,c],其中pc为边框中物体为类别c的概率,bx为边框中心的横坐标,by为边框中心的纵坐标,bh为边框的高度,bw为边框的宽度,c为目标类别向量[c1,c2,c3,…,cn]。
步骤4:将机器人放置在环境中的任意位置,输入要到达的目标。
输入可以是语音输入目标对象也可以是文字输入目标对象,机器人根据输入的字符找到其对应的编码。
步骤5:机器人通过自身搭载的rgb-d深度相机采集图片。
本步骤中同时采集彩色图和深度图,并采用与步骤1相同的方法进行缩放,彩色图用于实时的目标检测,深度图用于实时判断机器人与目标位置的距离。
步骤6:根据rgb图进行目标检测。
根据步骤3得到的目标检测模型和步骤5中采集到的图片,检测rgb图像中是否存在目标物体,及目标物体在图片中的位置信息[bx,by,bh,bw]。
步骤7:检测到目标后根据彩色图与深度图计算目标位置的坐标。
以相机坐标系作为世界坐标系,相机所在位置为坐标原点,以步骤6中边框的中心[bx,by]作为目标在深度图中的位置,根据像素坐标与相机坐标的转换关系得到目标位置的实际坐标。
像素坐标为[u,v,d],假设相机坐标pc为[x,y,z],相机坐标到像素坐标的关系为:
其中u=bx,v=by。
计算目标在相机坐标系下的坐标pc[x,y,z]。
z=d/s
步骤8:机器人朝向目标位置移动。
机器人以的速度朝向目标行进并实时检测机器人与目标位置的距离,如果距离大于预设距离则继续前进,否则停止前进。本实施例中的预设距离为20cm。
- 还没有人留言评论。精彩留言会获得点赞!