一种快速迭代收缩波束形成声源识别方法与流程
本发明属于声场识别技术领域。
背景技术:
基于反卷积的波束形成清晰化算法能够有效提高传统波束形成的空间分辨率、抑制旁瓣鬼影,提高声源识别性能。该类型方法的核心思想是基于传统波束形成的输出可近似于声源分布和阵列点传播函数的卷积的事实,通过反卷积获取声源真实信息。常见的方法有damas、nnls、richardson-lucy等,然而上述方法存在计算耗时长、收敛速度慢等问题,限制了其实际应用。为克服上述问题,在假设阵列点传播函数空间转移不变的基础上,基于空间快速傅立叶变换,将空间卷积转化为波数域乘积,提出了其对应的算法分别为damas2、fft-nnls、fft-richardson-lucy等,根据文献的对比,其中fft-nnls方法综合性较好。2015年lylloff等提出fft-fista算法,并与fft-nnls反卷积方法进行对比,结果表明:fft-fista方法具有更高的计算效率和更快的收敛速度。
为了进一步提高运算效率、收敛性、收敛速度等声源识别综合性能,提出了本发明的快速迭代收缩波束形成声源识别方法。
fft-fista是在2009年由beck等提出用于解决信号图像处理中线性逆问题的fista迭代收缩算法。为提高fista方法图像处理的收敛速度和图形的重构性,2015年,bhotto等在梯度函数最小化中引入正定权矩阵,提出ifista方法。
技术实现要素:
本发明所要解决的技术问题就是提供一种快速迭代收缩波束形成声源识别方法,它能提高运算效率、收敛性和收敛速度。
本发明的思路是:在互谱成像波束形成理论和ifista算法基础上,引入正定权矩阵wn,进行傅里叶变换,从而提高收敛性和收敛速度,同时减少了运算量,提高了运算效率。
本发明所要解决的技术问题是通过这样的技术方案实现的,它包括以下步骤:
步骤1、构建差函数
在阵列点传播函数、声源分布、传统波束形成输出结果之间构建差函数
式中,‖·‖2代表2范数,a=[psf(r|r′)]为n×n维已知阵列点传播函数矩阵,n为聚焦网格点数目,n=nr×nc,nr和nc分别为网格点行数和列数;q=[q(r′)],为n维未知列向量,q表示声源分布,且q(r′)≥0;r′为声源坐标向量,b=[b(r)]为n维已知列向量,b表示波束形成的输出结果;
步骤2、将aq-b进行傅里叶变换后求结果误差最小,由差函数中非负最小二乘问题转变成基于傅里叶变化的最小化式:
式中,‖·‖fro代表frobenius范数;"f"和"f-1"为傅里叶正变换和逆变换;ql为ql的元素组成的nr行nc列的矩阵,ql表示第l次迭代的声压贡献;a为阵列点传播函数矩阵,
给定一个初始矩阵q0=0,令y1=q0,t1=1,迭代过程如下:
第一步、
第二步、
第三步、
以上三步为一个循环,将yl+1代入第一步求得ql+1进入下一次循环,如此反复迭代直到满足程序所设迭代次数的限制条件要求;
上式中,р+表示在非负象限的欧几里得投影,tl第l次迭代步长;
"(·)○(·)"表示hadamard幂运算,"○"表示hadamard积运算;n表示权重系数,j表示变量,
本发明基于近场球面波假设,将互谱成像波束形成理论与ifista反卷积理论结合,本发明的技术效果是:
与现有的fft-nnls,fft-fista等其他反卷积清晰化方法相比,本发明的计算效率更高,收敛性更好,收敛速度更快,声源识别综合性能更佳。
附图说明
本发明的附图说明如下:
图1为声源识别布局示意图;
图2为声源识别结果显示图;
图3为聚焦网格的正面图;
图3(a)为规则平面网格;图3(b)为不规则平面网格;
图4为本发明与fft-nnls、fft-fista反卷积方法的规则聚焦网格2000hz声源识别模拟仿真对比图;
a、fft-nnls;b、fft-fista;c、本发明n=1;d、n=2;e、n=3;f、n=4;g、n=5;h、n=6;
图5为本发明与fft-nnls、fft-fista反卷积方法的不规则聚焦网格2000hz声源识别模拟仿真对比图;
a、b、c、d、e、f、g、h、同图4;
图6为试验测量现场布置图;
图7为试验测量下本发明与fft-nnls、fft-fista反卷积方法的不规则聚焦网格2000hz声源识别模拟仿真对比图;
a、fft-nnls;b、fft-fista;c、本发明n=1;d、n=3。
具体实施方式
下面结合附图和实施例对本发明作进一步说明:
本发明包括以下步骤:
步骤1、构建差函数
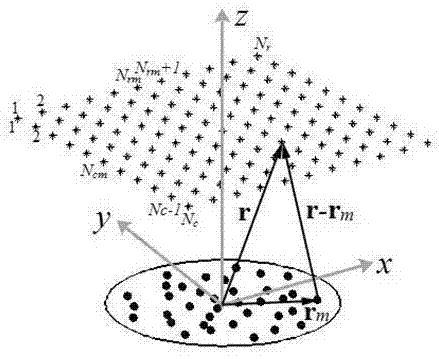
图1为波束形成声源识别布局示意图,其中r为聚焦坐标向量,rm(m=1,2,3,…,m)为第m号传声器的坐标向量,m是传声器个数,nr和nc分别为网格点行数和列数,nrm和ncm分别为中心网格点所在行数和列数。
互谱成像函数是波束形成的常见算法,其在聚焦网格点位置假设单极子声源分布模型,通过最小化模型点声源产生的声信号互谱与实际测量的声信号互谱间的差函数来确定真实声源的位置和强度,声源在计算平面的坐标和声源强度的大小为:
式(1)中,b(r)表示波束形成的输出结果向量的元素,c为互谱矩阵,1为所有元素均是1的m×m矩阵,v(r)=[v1(r),v2(r),…vm(r),…vm(r)]t表示聚焦点位置的转向列向量,
w(r)≡[|v1(r)|2,|v2(r)|2,…|vm(r)|2…|vm(r)|2]t,上标t和*分别表示转置和共轭,v(r)中的元素表达式为:
式(2)中,k=2πf/c为波数,f为信号频率,c为声速,
当聚焦坐标r等于真实声源所在坐标时,b(r)最大,对应形成“主瓣”。当聚焦坐标r不等于真实声源所在坐标时,b(r)相对被衰减,对应形成“旁瓣”,如图2所示的声源识别结果,能有效识别声源。
假设声源互不相干,则阵列传声器接收声信号的互谱等于各声源分别在阵列传声器处产生声信号互谱的和,计算式为:
c=∑r′c(r′)=∑r′q(r′)|r′|[v*(r′)vt(r′)](3)
式(3)中,c为互谱矩阵,r′为声源坐标向量,q(r′)为r′处声源的在阵列中心处声压贡献。
将式(3)代入式(1)得
式(4)中,sf(r|r′)为阵列点传播函数,表示r′位置单位声压贡献点声源在聚焦点r位置的波束形成贡献量。
在阵列点传播函数、声源分布、传统波束形成输出结果之间构建差函数
式(5)中,‖·‖2代表2范数,a=[psf(r|r′)]为n×n维已知阵列点传播函数矩阵,n为聚焦网格点数目,n=nr×nc,nr和nc分别为网格点行数和列数;q=[q(r′)],为n维未知列向量,q表示声源分布,且q(r′)≥0;r′为声源坐标向量,b=[b(r)]为n维已知列向量,b表示波束形成的输出结果。
步骤2、将aq-b进行傅里叶变换后求结果误差最小,由差函数中非负最小二乘问题转变成基于傅里叶变换的最小化式。
ifista算法通过投影梯度下降算法反复迭代来获取声压贡献q,其表达式为:
式(6)中,р+表示在非负象限的欧几里得投影,ql表示第l次的迭代结果,l为lipschitz常数,等于ata的最大特征值,假设点传播函数空间转移不变时,可以根据幂法来求最大特征值;
式(7)中,wn为正定权矩阵,其表达式为:
式(8)中,n表示权重系数,n取1,2,3,4等,j表示变量,
现有fft-nnls、fft-fista等算法均以零边界条件为基础,然而由于ifista算法中引入正定权矩阵wn,使得ifista无法基于零边界条件进行傅立叶转换。因此本发明的傅立叶变换基于周期边界条件,假设阵列点传播函数转移不变,此时阵列点传播函数矩阵a为bccb矩阵(blockcirculantwithcirculantblocks),对任意bccb矩阵有aha=aah,上标h表示转置共轭,对bccb矩阵a进行谱分解:
a=fhλf(9)
式(9)中,f为二维酉离散傅里叶变换(dft)矩阵,fh=f-1,f-1为f的逆矩阵,λ为阵列点传播函数矩阵a的特征值矩阵。
因为a为实矩阵,有:
ata=aha=(fhλf)h(fhλf)=fhλhffhλf(10)
式(10)中,ffh=i,i为单位矩阵,所以式(10)可表达为:
ata=fhλhλf=fhδf(11)
式(11)中,δ=λhλ,为ata的特征值矩阵。
记ql为ql的元素组成的nr行nc列的矩阵。f有下列固有等价关系:
式(12)中,"f"和"f-1"为傅里叶正变换和逆变换,n为聚焦网格点数目,n=nr×nc,由式(9)可得
fa(:,1)=λf(:,1)(13)
式(13)中,":"表示取所有行。
由于
式(15)中,
基于上述分析:
式(16)中,"○"表示hadamard积运算。
将式(11)代入式(8)中,
其中θ为wn的特征值矩阵,
将式(9)、(17)代入式(7)中有
wnat(aql-b)=fhθffhλhf(fhλfql-b)=fh(θλh)f(fhλfql-b)(19)
记b为b中元素组成的nr行nc列的矩阵。在周期边界条件下,对式(19)进行傅里叶变换,有:
其中,
"(·)○(·)"表示hadamard幂运算,上标h表示转置共轭。
基于上述傅里叶变化推导,本方法发明将公式(5)中非负最小二乘问题转变成基于傅里叶变化的最小化式:
式(17)中,‖·‖fro代表frobenius范数;"f"和"f-1"为傅里叶正变换和逆变换;ql为ql的元素组成的nr行nc列的矩阵,ql表示第l次迭代的声压贡献;a为阵列点传播函数矩阵,
步骤3、通过迭代求解q,q为经过傅里叶变化声源分布向量
根据参考文献:m.z.a.bhotto,m.o.ahmad,m.n.s.swamy.animprovedfastiterativeshrinkagethresholdingalgorithmforimagedeblurring.siamj.imagingsci.8(3)(2015)1640-1657(m.z.a.bhotto,m.o.ahmad,m.n.s.swamy.一种用于图像模糊处理改进的快速迭代收缩阈值算法,siamj.imagingsci.8(3)(2015)1640-1657)。本方法发明的求解过程为:通过在差函数
第一步、
第二步、
第三步、
以上三步为一个循环,将yl+1代入第一步求得ql+1进入下一次循环,如此反复迭代直到满足程序所设迭代次数的限制条件要求;
上式中,р+表示在非负象限的欧几里得投影,tl第l次迭代步长,r表达式见公式(21)。
仿真模拟试验
为验证建立本发明的准确性、对比探究其性能上的提升,进行声源识别仿真模拟。传声器阵列采用如图1所示的b&k公司的直径0.65m的36通道圆形阵列。仿真模拟的步骤如下:
1、根据假定的目标声源信息计算阵列上各传声器接收的声压信号,求得阵列各传声器接收声信号的互谱矩阵;
2、基于除自谱的互谱成像函数传统波束形成理论反向聚焦各网格点,得出其输出量;
3、利用反卷积方法对所得到的结果进行清晰化处理;
4、将输出结果转化成声压级并进行声学成像。
需要说明的是,本试验所有的成像云图显示动态范围均为15db。
假设目标声源位于声源平面(-0.2,0.2,1)m和(0.2,0.2,1)m位置,声源声压贡献为100db,采用如图3(a)所示的[-0.5,-0.5,1]m到[+0.5,+0.5,1]m、间距为0.02m规则聚焦网格进行声源成像。
图4为fft-nnls、fft-fista与本发明(公式8中的权重系数n取值分别为1~6)在声源频率2000hz,迭代次数为1000次时声源成像结果。从图4可以看出:各反卷积方法均能够有效地消除旁瓣的干扰,减小主瓣宽度,识别声源最大位置与声源真实位置吻合。但由于在上述模拟仿真皆基于图3(a)的规则聚焦网格,实际阵列点传播函数转移变化特性较大,上述反卷积方法的声源识别性能受到一定影响,在2000hz频率位置,由于主瓣较宽,识别出的声源区域较大,三种反卷积方法识别的声源且都呈无规则长条形,声源识别性能较差,但经对比看出,本发明声源识别性能优于fft-nnls、fft-fist这两种方法。
为降低阵列点传播函数空间转移变化特性对反卷积清晰化方法声源识别结果的影响,采用如图3(b)所示的不规则聚焦网格进行聚焦计算。但由于变换后的部分网格点超出目标声源区域,为了对比方便,按照坐标变化前规则网格的成像区域大小进行声学成像。
图5为不规则聚焦网格的声源识别结果,声源频率为2000hz,迭代次数为1000次。相比于规则聚焦网格点声源识别结果,各反卷积方法可以有效减小主瓣宽度,提高空间分辨率,清除旁瓣,且声源呈现规则的圆形。
从图5看出:本方法发明在权重系数n=1的识别结果中的主瓣宽度与fft-fista相当,随着权重系数n的增加,本方法发明主瓣宽度逐渐减小,即增加权重系数n可以提高本方法发明的收敛性,本方法发明声源识别效果逐步优于其他两种方法。但当n取值超过4时,本方法发明声源主瓣宽度减小速度减缓,收敛性提高不明显。大量仿真结果表明:选取较大的权重系数n可以获取较好收敛性,对于本仿真的阵列形式,当n取值超过4时,声源识别效果提升不明显。
为了进一步比较fft-nnls、fft-fista和本方法发明计算效率,通过对比三种方法在5000次迭代内所需时间,对于本方法发明,权重系数n的取值不影响其计算效率下,取n=3。试验结果如下:迭代5000次,本发明仅耗时3.11秒、fft-fista耗时8.35秒、fft-nnls耗时12.71秒,本发明计算效率最高。
验证试验
为了验证运用不规则聚焦网格的本方法发明在实际声源识别中的有效性,进行了算例试验,试验通过扬声器声源向外辐射声音信号,利用36通道的直径为0.65m的圆形阵列在距离声源1m的位置采集声音信号。
算例试验布置如图6所示,采用36通道pluse3660c型数据采集系统同时采集阵列所有传声器接收的声压信号后并将数据传输到pulselabshop软件进行fft分析,进而得到所有传声器信号的互功率谱矩阵,进一步,基于除自谱的互谱成像函数传统波束形理论,反向计算声源平面上各聚焦网格点位置的输出量,接着,利用反卷积方法对所得到的结果进行清晰化处理,最后将输出结果转化成声压级并进行声学成像。
声源位于声源平面(-0.2,0.2,1)m和(0.2,0.2,1)m位置,图7为2000hz频率,fft-nnls、fft-fista和本方法发明采用不规则聚焦网格时的声源识别结果,迭代次数为1000次。根据上述关于权重系数n的取值建议,以下试验结果中本方法翻权重系数仅取1和3。
图7与图5中fft-nnls、fft-fista、本发明权重系数n取1和3分别进行对比,可以看出:仿真结果是可靠性的,跟实际测试完全一致,同时验证了本发明在实际声源识别是有效的。
通过上述测试可得:
1、与现有fft-nnls,fft-fista等其他反卷积清晰化方法相比,本发明的计算效率更高,收敛性更好,收敛速度更快,声源识别综合性能更佳。
2、本发明适当增加权重系数,获得的主瓣宽度更窄,收敛性更好,但鬼影亦增多;综合各方面性能,应用本发明,最优权重系数取3。
3、本发明、fft-nnls和fft-fista运用不规则聚焦网格比规则聚焦网格都能得到更好的声源识别效果。
- 还没有人留言评论。精彩留言会获得点赞!