多参数代谢脆弱性指数评估的制作方法
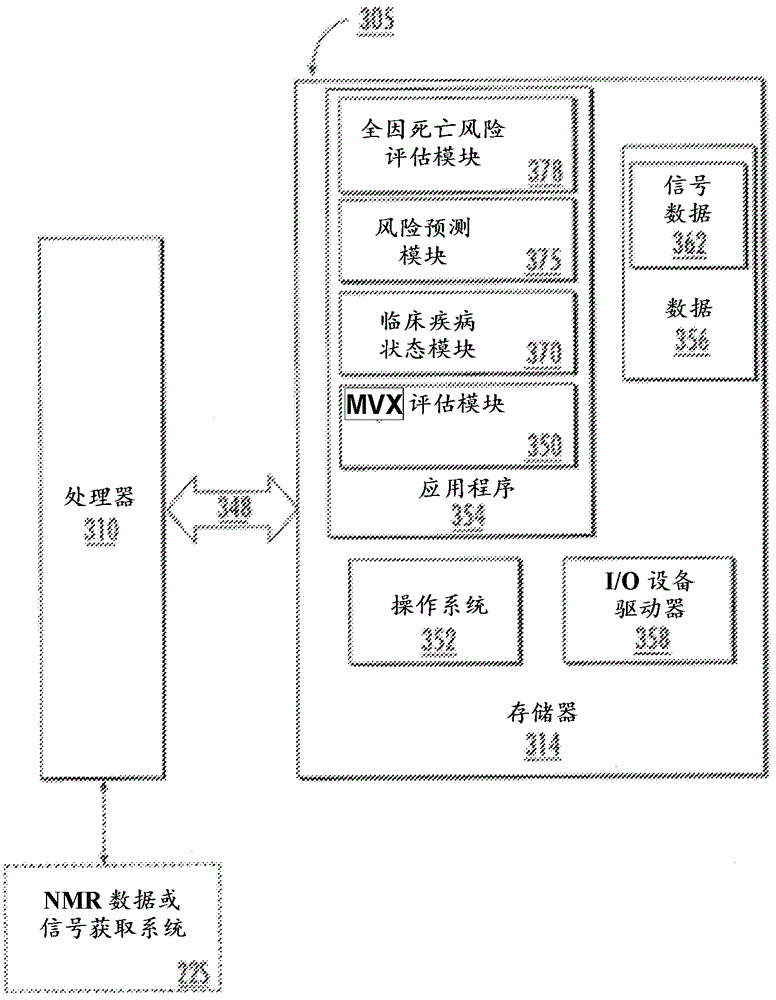
相关专利申请本专利申请要求2017年9月7日提交的标题为用于测量pvx的方法和系统(methodsandsystemsformeasuringpvx)的美国临时专利申请第62/555421号和2018年1月19日提交的标题为多参数代谢脆弱性指数评估(multi-parametermetabolicvulnerabilityindexevaluations)的美国临时专利申请第62/619497号的权益。前述申请的全部内容通过引用结合至本文中,包括所有文本、表格和附图。领域本公开大体上涉及体外生物样品的分析。本公开可特别适合于体外生物样品的nmr分析。背景心血管疾病(cvd)相关的死亡认为是长时间暴露于“传统的”cvd风险因素的最严重后果。这些风险因素已在framingham后代研究中进行了广泛研究和记录,包括年龄、性别、血压、吸烟习惯和胆固醇值。参见wilson等人,impactofnationalguidelinesforcholesterolriskfactorscreening,theframinghamoffspringstudy,jama,1989;262:41-44。这些因素已被长期用于区分正常群体和处于患有cvd相关事件风险下的群体。一般地,起初基于患者ldl和hdl颗粒的胆固醇含量(表示为ldl胆固醇(ldl-c)和hdl胆固醇(hdl-c))而不是这些颗粒数量的测量结果评价患者冠心病(chd)和/或cvd的总体风险。通常以减少“坏的”胆固醇(ldl-c)和/或增加“好的”胆固醇(hdl-c)为目标,其次聚焦于优化可调整的framingham风险因素,做出治疗决定。基于这些framingham因素的风险计算通常能够预测cvd相关事件的发生率。然而,开发了这些风险计算器来预测由非致命性和致命性cvd事件两者组成的复合cvd结果。另外,临床试验一般使用复合cvd结果作为研究终点。最近的临床试验分析表明了异种药物对复合cvd终点的致命性和非致命性组分的影响。尽管例如ldl降低性药物在一些试验中降低了复合cvd终点和该终点的非致命性事件组分的发生率,但是相同药物未能减少合并终点的致命性cvd事件组分或全因死亡。相反,一些糖尿病药物仅通过减少cvd死亡和全因死亡而不是非致命性cvd事件来减少复合cvd终点。这些研究的结果表明,致命性和非致命性cvd事件的决定因素可能有所不同,使得依赖于复合cvd结果可能会出现问题。传统的cvd风险计算器无法考虑各种疾病状态的复杂病理生理学,并且一些传统的cvd风险因素通常与营养不良的慢性病患者的存活自相矛盾地相关。例如,在具有慢性心脏和肾脏疾病的患者中,体重指数较高、血清胆固醇水平较高和血压较高的患者存活率提高。参见kalantar-zadeh等人,reverseepidemiologyofconventionalcardiovascularriskfactorsinpatientswithchronicheartfailure,j.am.collegecardiology,2004;42:1439-44。这对临床依赖于framingham风险因素来确定患者发病和死亡的风险而无论疾病状态如何提出了疑问。鉴于临床医师目前依赖于由基于复合结果的风险计算器的传统cvd风险因素来预测患者预后的事实,仍然需要包含可更好地预测或评价人因任何原因而过早死亡的风险、而不是患有非致命性事件的风险的因素的风险计算器。概述本公开的实施方案包括方法和系统,其通过使用规定的多组分风险评价模型评估体外血浆或血清患者样品的nmr光谱,来评估人的过早全因死亡的相对风险和/或提供死亡风险分级,以确定患者的代谢脆弱性指数(mvx)分数。mvx分数可使用多种nmr导出的测量结果来计算,包括:高密度脂蛋白(hdl)亚类(比如小hdl颗粒(s-hdlp))、炎症标志物glyca、一种或多种支链氨基酸(缬氨酸、亮氨酸和/或异亮氨酸)、一种或多种酮体(β-羟基丁酸酯、乙酰乙酸酯和/或丙酮)以及任选地枸橼酸盐(citrate)和/或血清蛋白(protein)的测量结果。在一个实施方案中,hdlp亚类为小hdl颗粒(s-hdlp)。本公开的实施方案包括确定与人的过早死亡风险相关的标志物水平的方法。方法可包括从人获得样品和测量glyca、至少一种高密度脂蛋白颗粒(hdlp)亚类、至少一种支链氨基酸(bcaa)、至少一种酮体。在一个实施方案中,高密度脂蛋白颗粒为小hdl颗粒(s-hdlp)。在一些实施方案中,这些测量结果用于生成mvx分数。在一些实施方案中,mvx分数通过使用以下模型来确定:mvx=a+β1*lnglyca+β2*lns-hdlp+β4*lnbcaa+β5*lnketonebody。在一些实施方案中,mvx值通过使用以下模型来确定:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody。值得注意的是在整个本公开中,a和β1-βn的经验值可根据所使用的模型而变化。例如,以上第一个mvx公式(即不包括β3*(lnglyca*lns-hdlp)项的公式)中的β1通常分别为与以上第二个公式(即确实包括该乘积项的方程式)中的β1不同的值。在一些实施方案中,方法包括除glyca、至少一种hdlp亚类、至少一种bcaa和至少一种酮体之外测量枸橼酸盐和蛋白中的至少一种。在一些实施方案中,包括枸橼酸盐(citrate)和血清蛋白(protein)中至少一种的测量对认为处于与cvd相关的死亡高风险下的受试者进行。在一些实施方案中,mvx值使用以下模型来确定:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。在一些实施方案中,mvx值规定为包含炎症指数(infx)值和代谢性营养不良指数(mmx)值。在一些实施方案中,至少glyca和至少一种hdlp亚类的测量结果用于生成炎症指数(infx)值。在一些实施方案中,infx值使用以下模型来确定:infx=β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)。在一些实施方案中,至少一种bcaa和至少一种酮体的测量结果用于生成代谢性营养不良指数(mmx)值。在一些实施方案中,mmx值使用以下模型来确定:mmx=β4*lnbcaa+β5*lnketonebody。该模型可表示为mmx1,并且如本文详细讨论的那样,是用于认为低风险(例如没有已知的心血管(cv)事件)的群体/受试者的计算。在其他实施方案中,至少一种bcaa、至少一种酮体、枸橼酸盐和蛋白的测量结果用于生成备选的mmx值。例如,在一些实施方案中,mmx值可使用以下模型来确定:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein。或者,mmx值可使用以下模型来确定:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。在这种实施方案中,mmx可描述如下:mmx=β9*mmx1+β10*mmx2,其中mmx1如上所述,和mmx2=β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。用于生成mmx值的测量(包括枸橼酸盐和蛋白的测量)通常在认为处于与cvd相关的死亡高风险下的受试者和/或群体(例如具有心血管事件或提示潜在cvd的症状的受试者)中进行。因此,在一些实施方案中,代谢脆弱性指数可描述为:mvx=βi*infx+βm*mmx。对于应用于正常(即低)风险患者群体(例如没有已知cv事件的人),代谢脆弱性指数可描述为mvx1=βi*infx+βm*mmx1(其中βi和βm可具有取决于所用模型的独特值)。相反,对于应用于高风险患者群体(例如具有已知cv事件的人),代谢脆弱性指数可描述为mvx=βi*infx+βm*mmx,其中βi和βm可具有取决于所用模型的独特值,和mmx=β9*mmx1+β10*mmx2。在一些情况下,对于低风险和高风险模型两者,βm相同(参见例如图16)。例如,在一些情况下,可在高风险受试者或群体中监测mvx分数,以此来监测受试者的整体健康以及致命性cv事件或其他原因导致死亡的风险。或者,可在临床试验中针对正在高风险群体中进行的新药物监测mvx分数,以此来监测测试药物的功效。对于低风险受试者,临床医师可选择监测mvx1值,以此来评价总体健康(health)和良好程度(wellness)。在某些实施方案中,mvx1值可用作促进心脏健康的生活方式改变的指南。再其他实施方案涉及一种系统。系统包含用于获取体外生物样品的至少一个nmr光谱的nmr光谱仪以及至少一个与nmr光谱仪通信的处理器。至少一个处理器可配置为使用至少一个nmr光谱,基于至少一种规定的过早死亡风险数学模型,对相应的生物样品确定代谢脆弱性指数分数,所述数学模型可考虑从受试者的至少一种体外生物样品获得的至少一种hdl亚类组分测量结果、至少一种支链氨基酸测量结果、至少一种酮体测量结果、glyca测量结果以及任选地枸橼酸盐测量结果和/或蛋白测量结果。在一个实施方案中,hdlp亚类为小hdlp(s-hdlp)。在一些实施方案中,处理器可配置为基于glyca、至少一种酮体、至少一种支链氨基酸和至少一种hdlp亚类的测量结果,使用以下公式来计算mvx分数:mvx=a+β1*lnglyca+β2*lns-hdlp+β4*lnbcaa+β5*lnketonebody。在一些实施方案中,处理器可配置为使用以下模型来计算mvx分数:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody。在一些实施方案中,处理器可配置为使用以下模型来计算mvx分数:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。在一些实施方案中,处理器可配置为计算包含炎症指数(infx)值和代谢性营养不良指数(mmx)值的mvx分数。因此,在一些实施方案中,处理器可配置为基于以下模型来计算mvx分数:mvx=βi*infx+βm*mmx。在这些实施方案中,处理器可配置为使用以下模型来计算infx值:infx=β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)。在一些实施方案中,处理器可配置为使用以下模型来计算mmx值:mmx=β4*lnbcaa+β5*lnketonebody,该模型可表示为mmx1。在一些实施方案中,处理器可配置为使用以下模型来计算mmx:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein。在另一个实施方案中,处理器可配置为使用以下模型来计算mmx:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。在这种实施方案中,mmx可描述如下:mmx=β9*mmx1+β10*mmx2,其中mmx1如上所述,和mmx2=β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。再其他实施方案涉及nmr系统。系统包含nmr光谱仪、与光谱仪通信的流量探头和至少一个与光谱仪通信的处理器。所述至少一个处理器可配置为获得:(i)与流量探头中的血浆或血清样本的glyca相关的nmr光谱的规定glyca拟合区域的至少一个nmr信号;(ii)与流量探头中的样本相关的nmr光谱的规定酮体拟合区域的至少一个nmr信号;(iii)与流量探头中的样本相关的nmr光谱的规定bcaa拟合区域的至少一个nmr信号;和(iv)hdlp亚类参数的至少一个nmr信号。处理器可进一步配置为计算glyca、至少一种酮体、至少一种支链氨基酸和hdlp亚类参数的测量结果。系统可进一步配置为使用规定的全因死亡风险数学模型来计算mvx分数,所述数学模型使用经计算的glyca、至少一种酮体、至少一种支链氨基酸、至少一种hdlp亚类参数以及任选地血清蛋白(protein)和/或枸橼酸盐(citrate)的测量结果。在一个实施方案中,hdlp亚类为小hdlp(s-hdlp)。在一些实施方案中,系统可进一步配置为基于glyca、至少一种酮体、至少一种支链氨基酸和至少一种hdlp亚类的测量结果,使用以下公式来计算mvx分数:mvx=a+β1*lnglyca+β2*lns-hdlp+β4*lnbcaa+β5*lnketonebody。在一些实施方案中,系统可进一步配置为使用以下模型来计算mvx分数:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody。在一些实施方案中,系统可进一步配置为使用以下模型来计算mvx分数:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。在一些实施方案中,系统可进一步配置为计算包含炎症指数(infx)值和代谢性营养不良指数(mmx)值的mvx分数。因此,在一些实施方案中,系统可进一步配置为基于以下模型来计算mvx分数:mvx=βi*infx+βm*mmx。在这些实施方案中,系统可进一步配置为使用以下模型来计算infx值:infx=β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)。在一些实施方案中,系统可进一步配置为使用以下模型来计算mmx值:mmx=β4*lnbcaa+β5*lnketonebody,该模型可表示为mmx1。在一些实施方案中,系统可进一步配置为使用以下模型来计算mmx:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein。在另一个实施方案中,系统可进一步配置为使用以下模型来计算mmx:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。在这种实施方案中,mmx可描述如下:mmx=β9*mmx1+β10*mmx2,其中mmx1如上所述,和mmx2=β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。本公开的另外方面涉及监测患者以评估治疗或确定患者是否处于过早死亡风险下的方法。方法可包括:以编程方式提供如本文所公开的至少一种规定的mvx数学模型,所述数学模型包括多种组分,这些组分包括对至少一种选择的hdlp亚类、至少一种支链氨基酸、至少一种酮体和glyca以及任选地蛋白或枸橼酸盐中至少一种的nmr导出的测量结果。方法可进一步包括以编程方式对包含nmr导出的测量结果的光谱进行去卷积。方法还可包括使用至少一种规定的模型和相应的患者样品测量结果以编程方式计算相应患者的mvx分数;和评估以下至少一项:(i)mvx分数是否高于与全因死亡风险增加相关的群体常值(populationnorm)的规定水平;和/或(ii)代谢脆弱性指数响应于治疗是随着时间的推移增大还是减小。在一些实施方案中,mvx分数可基于glyca、至少一种酮体、至少一种支链氨基酸和至少一种hdlp亚类的测量结果,使用以下公式来计算:mvx=a+β1*lnglyca+β2*lns-hdlp+β4*lnbcaa+β5*lnketonebody。在一些实施方案中,mvx分数可使用以下模型来计算:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody。在一些实施方案中,mvx分数可使用以下模型来计算:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。在一些实施方案中,mvx分数计算可包含炎症指数(infx)值和代谢性营养不良指数(mmx)值。因此,在一些实施方案中,mvx分数的计算可基于以下模型:mvx=βi*infx+βm*mmx。在这些实施方案中,infx值的计算可使用以下模型:infx=β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)。在一些实施方案中,mmx值的计算可使用以下模型:mmx=β4*lnbcaa+β5*lnketonebody;该模型可表示为mmx1。在一些实施方案中,mmx分数的计算可使用以下模型:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein。在另一个实施方案中,mmx分数的计算可使用以下模型:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。在这种实施方案中,mmx可描述如下:mmx=β9*mmx1+β10*mmx2,其中mmx1如上所述,和mmx2=β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。通过阅读随后的附图和优选实施方案的详细描述,本领域的普通技术人员将意识到本公开的其他特征、优点和细节,这种描述仅为本公开的说明。关于一个实施方案所述的特征可与其他实施方案结合,尽管没有对其具体讨论。也就是说,值得注意的是,关于一个实施方案描述的本公开的方面可结合于不同的实施方案中,尽管没有相对于其进行具体描述。也就是说,可以任何方式和/或组合来组合所有实施方案和/或任何实施方案的特征。在以下阐述的说明书中详细解释了本公开的前述和其他方面。如本领域技术人员根据本公开将意识到的,本公开的实施方案可包括方法、系统、装置和/或计算机程序产品或其组合。附图简述图1显示根据本公开的一个实施方案测量mvx的方法的示意图。图2显示根据本公开的一个实施方案使用mvx测量结果的方法的示意图。图3为显示根据本公开的实施方案通过mvx分数分级的cathgen参与者亚组在5年内的累积死亡率的图表。在5年随访期间,总共1263名参与者死亡。图4为一份表格,显示出根据本公开的实施方案,cathgen研究群体中死亡的cox比例风险预测模型中的参数(包括用于计算infx、mmx和mvx的参数)的预测强度(χ2)和统计显著性(p值)。在5年随访期间,6936名cathgen参与者中有1259名死亡。图5显示两份表格,显示出cathgen研究中,在5年随访期间死亡的cox预测模型中的参数的预测强度和统计显著性。各自根据本公开的实施方案,左侧模型包括炎症指数(infx)和代谢性营养不良指数(mmx)参数,和右侧模型包括mvx参数。图6显示两份表格,显示出根据本公开的一个实施方案,在cathgen研究群体中1年随访期间短期发生的(左表)和平均7年随访期间长期发生的(右表)死亡的cox预测模型中的参数(包括mvx)的预测强度和统计显著性。图7为一份表格,显示出根据本公开的实施方案,在cathgen研究群体中3个随访期期间发生的死亡的cox预测模型(仅含有mvx(上排)或含有mvx加上9个另外协变量参数(下排))的由似然比卡方统计量提供的预测强度。图8左图为显示根据本公开的实施方案,按mvx分数的五分位数分级的mesa研究中女性参与者在12年随访中的累积死亡率的图表。在3581名女性mesa参与者中,有412名在12年随访期间死亡。图8右图为显示根据本公开的实施方案,按mvx分数的五分位数分级的mesa研究中男性参与者在12年随访中的累积死亡率的图表。在3198名男性mesa参与者中,有554名在12年随访期间死亡。图9为一份表格,显示出如以多分类逻辑回归模型针对mesa参与者评价的,根据本公开的实施方案确定的mvx以及用于非cvd死亡及复合cvd结果的致命性和非致命性组分的其他参数的预测强度和统计显著性。图10为一份表格,显示出如以多分类逻辑回归模型针对mesa参与者评价的,根据本公开的实施方案确定的mvx以及充血性心力衰竭(chf)和死亡双重结果的其他参数的预测强度和统计显著性。图11为一份表格,显示出如以多分类逻辑回归模型针对mesa参与者评价的,根据本公开的实施方案确定的mvx以及癌症和死亡双重结果的其他参数的预测强度和统计显著性。图12为一份表格,显示出如以多分类逻辑回归模型针对mesa参与者评价的,根据本公开的实施方案确定的mvx以及慢性肾病(ckd)和死亡双重结果的其他参数的预测强度和统计显著性。图13显示本公开实施方案的用于mvx评估模块和/或线路的系统的示意图。图14显示本公开实施方案的nmr光谱设备的示意图。图15显示本公开实施方案的数据处理系统的示意图。图16显示本公开实施方案的用于通常和在不同患者群体中显示infx、mmx1、mmx2、mmx分数的分析的实例。在以下阐述的说明书中详细解释了本公开的前述以及其他目的和方面。详细描述本公开现在下文参考其中显示本公开实施方案的附图进行更充分地描述。然而,本公开可以许多不同的形式来体现,并且不应解释为限于本文阐述的实施方案;而是,提供这些实施方案使得本公开将是完全和完整的,并将向本领域的技术人员充分地传达本公开的范围。自始至终,相同的数字指同样的元件。在附图中,为了清楚起见,某些线、层、组分、元件或特征的厚度可被放大。除非另外说明,否则虚线说明任选的特征或操作。a.规定和术语本文使用的术语仅出于描述特定实施方案的目的,并且不旨在限制本公开。本文使用的单数形式“一(a)”、“一个(an)”和“该(the)”也旨在包括复数形式,除非上下文另外明确指明。将进一步理解的是,术语“包含(comprises)”和/或“包含(comprising)”当在本说明书中使用时,具体说明存在所述特征、整数、步骤、操作、元件和/或组分,但不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组分和/或其组。本文使用的术语“和/或”包括一个或多个相关所列项的任何和所有组合。本文使用的短语比如“在x和y之间”和“在约x和y之间”应解释为包括x和y。本文使用的短语比如“在约x和y之间”意指“在约x和约y之间”。本文使用的短语比如“从约x到y”意指“从约x到约y”。除非另外规定,否则本文使用的所有术语(包括技术和科学术语)具有与本公开所属领域的普通技术人员通常理解的相同含义。将进一步理解的是,术语,比如常用词典中规定的那些术语,应解释为具有与其在说明书的上下文和相关技术中的含义一致的含义,并且不应以理想化或过于正式的意义进行解释,除非本文明确地如此规定。为了简洁和/或清楚起见,可能没有详细描述众所周知的功能或构造。将理解的是,尽管本文可使用术语第一、第二等来描述各种元件、组分、区域、层和/或部分,但是这些元件、组分、区域、层和/或部分不应受到这些术语的限制。这些术语仅用于区分一个元件、组分、区域、层或部分与另一区域、层或部分。因此,以下讨论的第一元件、组分、区域、层或部分可称为第二元件、组分、区域、层或部分而不背离本公开的教导。除非另外具体指明,否则操作(或步骤)的顺序不限于权利要求或附图中呈现的顺序。术语“以编程方式”意指使用计算机程序和/或软件、处理器或asic指导的操作进行。术语“电子的”及其派生词是指使用具有电气线路和/或模块的设备而不是经思维步骤来进行的自动化或半自动化操作,并且一般地是指以编程方式进行的操作。术语“自动化(automated)”和“自动的(automatic)”意指可以最少的或无需手工劳动或输入进行的操作。术语“半自动化”是指使得操作员能够进行一些输入或激活,但是计算和信号获取以及离子化成分浓度的计算以电子方式、一般以编程方式进行,而无需手动输入。术语“约”是指指定值或数的+/-10%(均值(mean)或平均值(average))。术语“患者”被广泛地使用,并且是指提供用于测试或分析的生物样品的个体。术语“glyca”是指源自含有n-乙酰葡萄糖胺和/或n-乙酰半乳糖胺部分的急性期反应物糖蛋白的碳水化合物部分,更特别地是源自2-nacglc和2-nacgal甲基部分的质子的复合nmr信号的测量的生物标志物。在约47℃(+/-0.5℃)下,glyca信号的中心位于血浆nmr光谱的约2.00ppm处。峰位置与光谱仪场无关,但可根据生物样品的分析温度而变化,并且在尿液生物样品中未发现。因此,如果测试样品的温度变化,则glyca峰区域可能变化。glycanmr信号可在规定的峰区域包括nmr信号的子集,以便仅包括临床相关的信号贡献,并且可排除蛋白对该区域中信号的贡献,这将在以下进一步讨论。参见美国专利第9361429、9470771和9792410号,其内容特此通过引用结合,如同本文全文陈述一样。本文使用的化学位移位置(ppm)是指内部或外部参比的nmr光谱。在一个实施方案中,位置可内部参比2.519ppm处的caedta信号。因此,如本领域技术人员众所周知的,本文讨论和/或要求保护的所述峰位置可根据化学位移如何产生或参比而变化。因此,要清楚的是,如本领域技术人员众所周知的,某些所述和/或要求保护的峰位置在其他相应的化学位移中具有等同的不同峰位置。术语“生物样品”是指人或动物的体外血液、血浆、血清、csf、唾液、灌洗液、痰液或组织样品。本公开的实施方案可特别适合于评估人血浆或血清生物样品,特别是适合于glyca(其例如在尿液中未发现)。血浆或血清样品可为禁食或非禁食的。术语“群体常值”和“标准”是指由平均风险患者(比如参加framingham后代研究或动脉粥样硬化多种族研究(multi-ethnicstudyofatherosclerosis,mesa)的患者)或较高风险患者(比如参加导管插入遗传学(catheterizationgenetics,cathgen)心导管生物储备认证计划(cardiaccatheterizationbiorepository)的患者)的一种或多种大型研究或样品量足够大以代表一般群体或目标患者群体的其他研究所规定的值。本文使用的术语低风险(或正常风险)表示没有已知心血管事件的个体。这种群体也称为一级预防群体。例如,mesa为低风险群体。本文使用的术语高风险表示具有已知心血管事件的个体。这种群体也称为二级预防群体。例如,cathgen为高风险群体。然而,本公开不限于mesa或cathgen中的群体值,因为目前规定的正常或低风险和高风险群体值或水平可随着时间的推移变化。因此,可提供与来自风险节段(例如四分位数或五分位数)中规定群体的值相关的参考范围,并将其用于评价升高或降低的水平和/或具有临床疾病状态的风险。术语“临床疾病状态”被广泛地使用并且包括处于风险中的医学病症,其可指示医学干预、治疗、治疗调整或排除某一治疗(例如药物)和/或监测为适当的。对临床疾病可能性的鉴定可使得临床医师能够相应地治疗、延迟或抑制病症的发作。本文使用的术语“nmr光谱分析”意指使用质子(1h)核磁共振光谱技术以获得可测量生物样品(例如血浆或血清)中存在的相应参数的数据。“测量”及其派生词是指确定水平或浓度和/或对于某些脂蛋白亚类测量其平均粒径。术语“nmr导出的”意指使用来自nmr光谱仪中的体外生物样品的一次或多次扫描的nmr信号/光谱计算相关的测量结果。术语“低场”是指nmr光谱上属于某个峰/位置/点左侧的区域/位置(相对于参比而言较高的ppm刻度)。相反,术语“高场”是指nmr光谱上属于某个峰/位置/点右侧的区域/位置。术语“数学模型”和“模型”可互换使用,并且当与“mvx”、“代谢脆弱性指数”或“风险”一起使用时,是指用于评估受试者的未来(一般地在1-12年内)过早死亡风险的风险统计模型。风险模型可为任何合适的模型或包括任何合适的模型,包括但不限于逻辑回归模型、cox比例风险回归模型、混合模型或分级线性模型中的一种或多种。风险模型可基于规定的时间范围内(一般地在1-12年内)过早死亡的概率提供风险的度量。风险模型可特别适合于为具有“中度风险”的患者提供风险分级,中度风险与基于传统风险因素具有轻微至中度发生临床事件的机会相关。mvx风险模型可对如根据标准χ2和/或p值(后者具有足够代表性的研究群体)测量的过早死亡的相对风险进行分级。术语“相互作用参数”是指至少两个不同的规定参数,其被组合为(相乘)乘积和/或比率。相互作用参数的实例包括但不限于(s-hdlp)(glyca)和(蛋白)(枸橼酸盐)。术语“多标志物”是指多组分生物标志物。术语“脂蛋白组分”是指数学风险模型中与脂蛋白颗粒相关的组分,包括脂蛋白的一种或多种亚类(亚型)的大小和/或浓度。脂蛋白组分可包括脂蛋白颗粒亚类、浓度、大小、比率中的任何一种和/或脂蛋白参数的数学乘积(相乘)和/或规定的脂蛋白参数或与其他参数(比如glyca)组合的脂蛋白亚类测量结果。术语“hdlp”是指对规定的hdl亚类的颗粒浓度相加的高密度脂蛋白颗粒数量测量结果(例如hdlp数量)。总hdlp可使用总高密度脂蛋白颗粒测量结果生成,该测量结果将大小范围在约7nm(平均)-约14nm(平均)之间,一般地在7.4-13.5nm之间的所有hdl亚类(其可基于大小分为大小不同的类别,比如大、中和小)的浓度(µmol/l)相加。在一些实施方案中,hdl可识别为许多大小离散的组分,例如不同大小hdlp的7个亚群(h1-h7),范围从与h1相关的最小hdlp大小到与h7相关的最大hdlp大小。在一些实施方案中,hdl颗粒的规定的亚类包括小hdl颗粒(s-hdlp)。在一些实施方案中,s-hdlp可包括直径在约7.3nm(平均)-约9.0nm(平均)之间的hdl颗粒亚类。如本文使用的“未经处理的生物样品”是指与用于质谱分析的样品制备不同,在获得之后不进行导致生物样品物理或化学改变的处理(但可使用缓冲剂和稀释剂)的生物样品。因此,一旦获得生物样品,来自生物样品的组分就不经改变或去除。例如,一旦获得血清生物样品,不对血清进行从血清中去除组分的处理。在一些实施方案中,未经处理的生物样品不进行过滤和/或超滤处理。b.确定受试者的mvx的方法本文公开确定受试者的代谢脆弱性指数(mvx)的方法和系统。方法包括利用规定的生物标志物的多变量模型来预测患者过早死亡的机会。方法包括以下步骤:从受试者获得样品并测量glyca、至少一种高密度脂蛋白颗粒(hdlp)亚类、至少一种支链氨基酸(bcaa)和至少一种酮体,和基于测量结果计算受试者的代谢脆弱性指数值。在一个实施方案中,hdlp为小hdlp(s-hdlp)。在一些实施方案中,mvx分数可基于glyca、至少一种酮体、至少一种支链氨基酸和至少一种hdlp亚类的测量结果,使用以下公式来计算:mvx=a+β1*lnglyca+β2*lns-hdlp+β4*lnbcaa+β5*lnketonebody。在一些实施方案中,mvx分数可使用以下模型来计算:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody。在这些实施方案中,可在认为处于心血管事件低风险下的受试者中确定mvx值。在一些实施方案中,mvx值可包括血清蛋白(protein)和/或枸橼酸盐(citrate)的测量结果。在一些实施方案中,mvx值可使用以下模型来确定:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。在这些实施方案中,可在认为处于心血管事件高风险下的受试者中确定mvx值。在一个备选实施方案中,mvx值可包含如本文更详细公开的炎症指数(infx)和/或代谢性营养不良指数(mmx)。因此,在一些实施方案中,mvx分数的计算可基于以下模型:mvx=βi*infx+βm*mmx。在这些实施方案中,infx值的计算可使用以下模型:infx=β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)。在一些实施方案中,mmx值的计算可使用以下模型:mmx=β4*lnbcaa+β5*lnketonebody,该模型可表示为mmx1,并且用于认为处于与心血管疾病相关的事件低风险下的受试者。在一些实施方案中,mmx分数的计算可使用以下模型:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein。在另一个实施方案中,mmx分数的计算可使用以下模型:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。在这种实施方案中,mmx可描述如下:mmx=β9*mmx1+β10*mmx2,其中mmx1如上所述,和mmx2=β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein),在这些实施方案中,可针对认为处于与心血管疾病相关的事件高风险下的受试者确定mvx分数。在一些实施方案中,bcaa可为亮氨酸、异亮氨酸或缬氨酸中的至少一种。在一些实施方案中,酮体可为丙酮、乙酰乙酸酯或β-羟基丁酸酯中的至少一种。在一些实施方案中,通过nmr进行测量。代谢脆弱性指数可提供短期(1年)至长期(12年)的过早死亡风险评价。这些风险评价可生成与传统风险因素脱钩的mvx值。图1显示确定受试者的mvx值的方法的一个实施方案的示意图。方法可包括获取从受试者获得的血浆或血清样品的核磁共振(nmr)光谱的初始步骤。接下来,可为样品生成经计算的线形,该线形基于样品中可能存在的脂蛋白和代谢物组分的导出浓度(每种组分的导出浓度为该组分的参考光谱和经计算的参考系数的函数)。该方法可基于样品的nmr光谱确定受试者的mvx值而结束。该方法可使得从业者在常规且易于进行的筛查期间识别受试者的过早死亡风险,并开始诊断和治疗与过早死亡相关的病症,或防止受试者接受可能有害的药物。图2为显示如何使用mvx来确定患者对治疗的响应的实例的示意图。多变量模型可用于评价进入临床试验或在临床试验期间、一种或多种治疗期间、用于药物开发和/或鉴定或监测抗炎、抗肥胖或者其他药物或营养治疗候选者的患者。在一些实施方案中,通过获得体外血浆或血清患者样品的nmr信号来确定hdl颗粒亚类、glyca和/或多种代谢性营养不良生物标志物(比如酮体和bcaa)的nmr导出浓度测量结果,来获得测量结果。本公开的实施方案使用规定的预测性生物标志物的多参数(多变量)模型来提供受试者的过早全因死亡风险的风险评价。多变量风险评价模型可包括至少一种规定的hdlp组分,比如(但不限于)s-hdlp、至少一种酮体、至少一种规定的支链氨基酸和glyca。另外,风险评价模型可包括枸橼酸盐和血清蛋白中的一种或多种。多变量模型可包括以下中的至少一种:从同一nmr光谱导出的glyca、支链氨基酸、枸橼酸盐、酮体、总蛋白和hdlp组分(例如亚类)的nmr测量结果。规定的风险数学模型的至少一种hdlp组分可包括glyca测量结果的第一相互作用参数乘以规定的hdlp亚群的浓度。规定的hdl颗粒亚群可包括小hdl颗粒(s-hdlp)。在一些实施方案中,s-hdlp可包括直径在约7.3nm(平均)至约9.0nm(平均)之间的hdl颗粒亚类。本公开的实施方案提供新的生物标志物,其可对处于低风险和高风险类别两者的患者的过早死亡风险进行分级。本公开的实施方案可特别适合于对具有类似传统风险因素的患者的风险进行分级。一般说来,预期mvx分数可用于对过早死亡的相对风险进行分级。mvx分数可将年龄、性别、血压和bmi相同的患者的过早死亡风险进行分级,而与这些临床因素无关。本公开的实施方案可使用多种风险模型参数来评估患者在1-12年时间范围内的过早死亡风险。如上所述,本公开的实施方案可包括与炎症(例如infx)和代谢性营养不良(例如mmx)相关联的生物标志物,如表1所示。在一些实施方案中,mvx分数可规定为包含炎症指数(infx)值和代谢性营养不良指数(mmx)值。在本公开的一些实施方案中,一种确定与受试者的过早死亡的相对风险相关的标志物水平的方法可包括:从受试者获得样品;测量glyca、至少一种高密度脂蛋白颗粒(hdlp)亚类、至少一种支链氨基酸(bcaa)和至少一种酮体(ketonebody)以及任选地枸橼酸盐(citrate)和血清蛋白(protein)中的至少一种;使用glyca和至少一种hdlp亚类的测量结果来生成炎症指数(infx)值;使用至少一种bcaa和至少一种酮体以及任选地蛋白(protein)和枸橼酸盐(citrate)的测量结果来生成至少一种代谢性营养不良指数(mmx)值;和基于infx和mmx值确定代谢脆弱性指数(mvx)值。表1:病理生理学/生物标志物病理生理学生物标志物炎症glyca、hdl代谢性营养不良血清蛋白、酮体、枸橼酸盐、bcaa炎症可与许多不同的疾病状态(包括但不限于cvd)相关。还认为炎症可调节hdl功能。参见例如fogelman,whengoodcholesterolgoesbad,naturemedicine,2004。糖蛋白的碳水化合物组分可在蛋白分选、免疫和受体识别、炎症和其他细胞过程中执行生物学功能。如本文公开的,mvx模型可包括至少两种炎性标志物,比如glyca和s-hdlp以及至少两种代谢性营养不良生物标志物,比如至少一种酮体和至少一种bcaa。在一些实施方案中,mvx模型包括至少一个相互作用参数。mvx数学模型可考虑其他临床参数,比如性别、年龄、bmi、是否涉及高血压药物等,或者mvx数学模型可独立于任何临床参数来生成mvx值。如上所述,本公开的实施方案可用于使用一种或多种规定的风险数学模型来生成至少一个mvx分数。模型可利用来自处于过早死亡风险下的可受益于药物、医学、营养、运动或其他干预的患者的体外生物样品的不同的规定生物标志物或参数的测量结果。mvx评估可与传统的framingham或其他风险评估脱钩,并可相对易于用作筛查工具,并且能够比用常规测试时间更早地识别处于风险下的个体。例如,图3为显示根据本公开的实施方案通过mvx分数分级的参加catxgen的9个高风险心导管插入术患者亚组在5年内的累积死亡率的图表。在5年随访期间,6971名参与者中总共有1263名死亡。如图3所示,mvx分数越高,过早死亡的风险越高。例如,mvx分数高(>70(红线))的个体的过早死亡率为mvx分数低(<35(深绿线))的个体的超出10倍。如图3中9个亚组的每一个的平均年龄和性别组成所示,与mvx分数相关联的死亡率差异大很大程度上与年龄和性别无关。在一些实施方案中,预期mvx可用于对高风险群体(比如cathgen研究中的群体)中的死亡风险进行分级,如图3所示。如本文所公开,mvx值使用多种参数(至少包括glyca、s-hdlp、至少一种支链氨基酸和至少一种酮体的测量结果)来计算。参数还可包括枸橼酸盐和蛋白以及各种相互作用参数的测量结果。图4为一份表格,显示出cathgen研究群体中死亡的cox比例风险预测模型中的传统风险因素和mvx相关参数的预测强度(χ2)和统计显著性(p值)。在该表格中,“bcaa”为3种支链氨基酸(缬氨酸、亮氨酸、异亮氨酸)浓度之和,和“酮体”为3种酮体(β-羟基丁酸酯、乙酰乙酸盐、丙酮)浓度之和。图4所示的6种mvx参数(包括lnglyca*lns-hdlp和lncitrate*lnprotein的相互作用参数)用于使用通式mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)计算用于图3中死亡风险分级的mvx分数。mvx值也可分解为两个组成部分:由炎症指数(infx)参数给出的假定炎性部分和由代谢性营养不良指数(mmx)参数给出的假定营养不良部分。图5显示两份表格,显示出cathgen研究中5年随访期间死亡的cox预测模型中这些参数以及mvx的预测强度和统计显著性。左侧模型包括infx和mmx参数,和右侧模型包括mvx参数。在一些实施方案中,mvx可用于预测短期和长期过早全因死亡风险。图6显示两份表格,显示出在cathgen研究群体中1年随访期间短期发生的(左表)和平均7年随访期间长期发生的(右表)死亡的cox预测模型中的参数(包括mvx)的预测强度和统计显著性。在一些实施方案中,mvx独立于传统风险评估参数来计算。图7为一份表格,显示出在cathgen研究群体中3个随访期期间发生的死亡的cox预测模型(含有mvx单独(上排)或含有mvx加上9个另外的协变量参数(年龄、种族、性别、吸烟、高血压、糖尿病、bmi、富含甘油三酯的脂蛋白颗粒和低密度脂蛋白颗粒))的由似然比卡方统计量提供的预测强度。在一些实施方案中,预期mvx可用于对低风险群体中的死亡风险进行分级,如图8所示。图8左图为显示根据本公开的实施方案,按低风险mvx分数(例如mvx1)的五分位数分级的mesa研究中女性参与者在12年随访中的累积死亡率的图表。在3581名女性mesa参与者中,有412名在12年随访期间死亡。图8右图为显示根据本公开的实施方案,按mvx1分数的五分位数分级的mesa研究中男性参与者在12年随访中的累积死亡率的图表。在3198名男性mesa参与者中,有554名在12年随访期间死亡。在一些实施方案中,预期mvx可用于预测过早死亡的相对风险,而与认为是死亡“原因”的疾病状态无关。图9为一份表格,显示出如以多分类逻辑回归模型针对mesa参与者(低风险)评价的mvx(例如mvx1)以及4种不同cvd和死亡结果的其他参数的预测强度和统计显著性。4种结果中的3种包含通常称为“cvd”的复合结果:左列:非致命性cvd事件,随访期间没有发生死亡(n=432);左起第二列:非致命性cvd事件,随访期间随后发生死亡(n=128);左起第三列:致命性cvd事件(n=225)。右列中评价的结果为没有更早或同时cvd而发生的死亡(n=610)。结果表明,mvx对包括死亡在内的3个结果具有高度预测性(p<0.0001),但在未伴有死亡或随后的死亡时不能预测cvd(p=0.50)。因此,通过mvx对复合cvd结果的致命性和非致命性组成部分的预测显著不同,表明非致命性和致命性cvd的病因学可能比人们认为的更为不同,并且质疑将致命性和非致命性cvd合并为单一结果的基本原理。通过mvx还可预测认为是由除cvd之外的其他疾病引起或促成的死亡,如图10-12中的结果所示。图10为一份表格,显示出如以多分类逻辑回归模型针对mesa参与者(低风险)评价的mvx(例如mvx1)以及充血性心力衰竭(chf)和死亡合并结果的其他参数的预测强度和统计显著性。图11为一份表格,显示出如以多分类逻辑回归模型针对mesa参与者评价的mvx以及癌症和死亡合并结果的其他参数的预测强度和统计显著性。图12为一份表格,显示出如以多分类逻辑回归模型针对mesa参与者评价的mvx以及慢性肾病(ckd)和死亡合并结果的其他参数的预测强度和统计显著性。在一些实施方案中,性别可作为因素包括在mvx模型中。在一些实施方案中,年龄可作为因素包括在mvx模型中。在其他实施方案中,例如,mvx模型可排除性别或年龄考虑因素,以便避免基于不与生物样品直接相关的这种辅助数据的数据损坏而产生假阴性或假阳性。在一些实施方案中,基于与样品电子相关的数据或者基于临床医师或摄取实验室的输入(例如患者的禁食“f”或非禁食“nf”和他汀类药物“s”或非他汀类药物的“ns”特征),将mvx分数提供给临床医师,所述数据可提供在与生物样品关联的标签上,以在nmr分析仪上与样品电子关联。或者,患者特征数据可保存在计算机数据库中(远程或经服务器或其他规定的途径),并可包括由临床医师或摄取实验室输入到电子相关文件中的患者标识符、样品类型、测试类型等,这可由与nmr分析仪通信的摄取实验室访问或托管。患者特征数据可使得适当的mvx模型能够用于特定患者。预期代谢脆弱性指数可用于监测临床试验和/或药物治疗中的受试者、识别药物矛盾和/或监测可能与特定药物、可能是患者特有的患者生活方式等相关的风险状态(阳性或阴性)变化。脂蛋白脂蛋白包括在血浆、血清、全血和淋巴中发现的广泛种类的颗粒,包括各种类型和量的甘油三酯、胆固醇、磷脂、鞘脂和蛋白。这些各种颗粒使得溶解血液中原本疏水的脂质分子,并提供与脂肪分解、脂肪生成和脂质在肠、肝脏、肌肉组织和脂肪组织之间的转运相关的多种功能。在血液和/或血浆中,脂蛋白已以许多方式进行分类,通常基于物理特性(比如密度或电泳迁移率)或载脂蛋白含量(比如apob或apoa-1,分别为ldl和hdl中的主要蛋白)的测量结果。基于核磁共振确定的粒度的分类可基于大小或大小范围区分不同的脂蛋白颗粒。例如,nmr测量结果可识别至少15种不同的脂蛋白颗粒亚型,包括至少7种高密度脂蛋白(hdl)亚型、至少3种低密度脂蛋白(ldl)亚型和至少5种极低密度脂蛋白(vldl)亚型,其也可称为trl(富含甘油三酯的脂蛋白)。当前的分析方法使得能够进行可提供vldl、ldl和hdl亚群的浓度的nmr测量,以产生对各组的小亚群和大亚群的组的测量结果。例如,为了优化与过早全因死亡相关的风险,可使用hdl亚群的不同大小分组,这将在以下进一步讨论。本文所述的nmr导出的估计脂蛋白大小一般是指平均测量结果,但其他大小划分可使用。在优选的实施方案中,mvx风险评价模型参数可包括使用规定的表征蛋白和脂蛋白(包括hdl、ldl、vldl/trl)的去卷积组分的去卷积模型由nmr导出的与脂蛋白(并且特别是hdl)的常见nmr光谱相关的去卷积信号的测量结果。这种类型的分析可提供2分钟以内的快速获取时间,一般地在约20s-90s之间,并提供相应的快速编程计算以生成模型组分的测量结果,然后是使用一种或多种规定的风险模型对一个或多个mvx风险分数的编程计算。进一步地,还应注意,尽管预期脂蛋白颗粒的nmr测量结果特别适合于本文所述的分析,但是预期现在或将来可使用其他技术来测量这些参数,并且本公开的实施方案不限于这种测量方法。还预期可采用使用nmr的不同方案(例如包括不同的去卷积方案)来代替本文所述的去卷积方案。参见例如kaess等人,thelipoproteinsubfractionprofile:heritabilityandidentificationofquantitativetraitloci,jlipidres.vol.49pp.715-723(2008);和suna等人,1hnmrmetabolomicsofplasmalipoproteinsubclasses:elucidationofmetabolicclusteringbyself-organisingmaps,nmrbiomed.2007;20:658-672。采用基于密度的分离技术以评估脂蛋白颗粒和离子迁移率分析的浮选和超速离心为测量脂蛋白亚类颗粒浓度的备选技术。根据本公开的一些特定实施方案,脂蛋白亚类分组可例如加和以确定hdl或ldl颗粒数量。值得注意的是,所述“小、大和中”大小范围可以变化或重新规定以加宽或变窄其上限值或下限值,或者甚至排除所述范围内的某些范围。上述粒度一般是指平均测量结果,但可使用其他划分。本公开的实施方案基于功能/代谢相关性将脂蛋白颗粒分类为按大小范围分组的亚类,如通过其与脂质和代谢变量的相关性所评价的。因此,如上所述,评估可测量超过15种离散的脂蛋白颗粒亚群(大小)。这些离散的亚群可分组为对vldl/trl和hdl和ldl规定的亚类。中密度脂蛋白(idl)可与vldl/trl或ldl组合,或者作为在大ldl和小vldl之间的大小范围内的单独类别。例如,hdl亚类颗粒一般地(平均)在约7nm-约15nm,更一般地在约7.3nm-约14nm(例如7.4nm-13.5nm)之间的范围内。总hdl浓度为其hdl亚类各亚群的颗粒浓度之和。hdlp的不同亚群可通过数字1-7来标识,“h1”代表大小最小的hdl亚群,和“h7”为大小最大的hdl亚群。在一些实施方案中,hdl颗粒的规定的亚类包含小hdl颗粒(s-hdlp)。在一些实施方案中,s-hdlp可包括直径在约7.3nm(平均)-约9.0nm(平均)之间的hdl颗粒亚类。bcaa在一些实施方案中,mvx模型包括至少一种bcaa的测量结果,如美国专利第9361429号和美国专利申请20150149095所述,这些文献通过引用结合至本文中。mvx模型可包括一种或多种bcaa,包括异亮氨酸、亮氨酸和缬氨酸中的一种或多种(如本文所述)。在一些实施方案中,可通过nmr量化3种bcaa(缬氨酸、亮氨酸和异亮氨酸)的组中的一种或多种。酮体在一些实施方案中,mvx模型包括至少一种酮体(β-羟基丁酸酯、乙酰乙酸酯、丙酮)的测量结果,其可经生物样品nmr光谱的nmr分析获得。3种酮体中每一种的nmr量化基于其nmr信号幅度,后者从其中出现酮体nmr信号的3个光谱区域特有的单独去卷积模型导出。由于与来自许多脂蛋白亚种以及已鉴定和未鉴定的小分子代谢物的信号广泛重叠,因此需要去卷积分析而不是简单地积分酮体信号。可使用通过将血清用已知浓度的酮体储备溶液加标而确定的转换因子,将β-羟基丁酸酯、乙酰乙酸酯和丙酮信号的导出幅度转换为μmol/l浓度单位。在一个实施方案中,使用线形去卷积模型对出现在约1.16和1.15ppm处的β-羟基丁酸酯甲基信号双重峰进行量化,该模型涵盖1.07-1.33ppm的光谱区域。该区域包括来自许多trl、ldl和hdl脂蛋白亚种的脂质脂肪酸亚甲基质子的重叠干扰nmr信号、血清蛋白信号、来自乙醇的三重峰信号(在1.13、1.15和1.17ppm处)、来自乳酸盐的双重峰信号(在1.29和1.31ppm处)和来自在人血清样本中很少出现的未鉴定代谢物的双重峰信号(在1.10和1.11ppm处)。在一个实施方案中,去卷积模型包括83种光谱组分的库,以准确地说明来自β-羟基丁酸酯和血清中各种干扰物质的nmr信号的幅度。在一个实施方案中,使用线形去卷积模型对出现在约2.24ppm处的乙酰乙酸酯甲基信号单峰进行量化,该模型涵盖2.22-2.39ppm的光谱区域。该区域包括来自许多trl、ldl和hdl脂蛋白亚种的脂质脂肪酸亚甲基质子的重叠干扰nmr信号、血清蛋白信号、来自β-羟基丁酸酯的八重峰信号(2.25-2.39ppm)以及来自在2.22、2.30和2.35-2.41ppm出现的3种未鉴定代谢物的信号。在一个实施方案中,去卷积模型包括82种光谱组分的库,以准确地说明来自乙酰乙酸酯和血清中各种干扰物质的nmr信号的幅度。在一个实施方案中,使用线形去卷积模型对出现在2.19ppm处的丙酮甲基信号单峰进行量化,该模型涵盖2.14-2.22ppm的光谱区域。该区域包括来自许多trl、ldl和hdl脂蛋白亚种的脂质脂肪酸亚甲基质子的重叠干扰nmr信号、血清蛋白信号以及来自2.22ppm处的未鉴定代谢物的单峰信号。在一个实施方案中,去卷积模型包括70种光谱组分的库,以准确地说明来自丙酮和血清中各种干扰物质的nmr信号的幅度。glyca规定的线形glyca数学去卷积模型可用于测量glyca,如美国专利第9470771号所述,其通过引用以其全部结合至本文中。glyca测量结果可为通过计算nmr光谱中规定的峰位置处的峰区域下面积如经nmr评价的无单位参数。无论如何,可使用针对已知群体(比如mesa)的glyca的测量来规定某些亚组的水平或风险,例如值在规定范围的上半部以内(包括值在第三和第四四分位数或上3-5个五分位数等中)的亚组。枸橼酸盐在一些实施方案中,mvx模型包括枸橼酸盐的测量结果,其可经生物样品nmr光谱的nmr分析获得。枸橼酸盐的nmr量化基于如从采取线性基线和可变偏移的去卷积模型导出的亚甲基质子四重峰的4个成员中3个成员(出现在约2.64、2.60和2.48ppm处)的nmr信号幅度。枸橼酸盐信号四重峰的第4个成员出现在约2.52ppm处,并与来自用作内部化学位移参比的caedta的单峰信号重叠。可使用通过将血清用已知浓度的枸橼酸盐储备溶液加标而确定的转换因子,将枸橼酸盐信号的导出幅度转换为μmol/l浓度单位。血清蛋白在一些实施方案中,mvx模型包括血清蛋白的测量结果,后者可经生物样品nmr光谱的nmr分析获得。或者,如果使用的话,可以常规方式获得血清蛋白或血清白蛋白的测量结果。血清蛋白的nmr量化基于从线形去卷积模型导出的非脂蛋白蛋白的宽nmr信号的幅度,该模型涵盖0.71-1.03ppm的光谱区域。该区域包括来自许多trl、ldl和hdl脂蛋白亚种的脂质脂肪酸甲基质子以及来自支链氨基酸缬氨酸、亮氨酸和异亮氨酸的重叠干扰nmr信号。在一个实施方案中,去卷积模型包括66种光谱组分的库,以准确地说明来自血清蛋白和血清中各种干扰物质的nmr信号的幅度。可以信号幅度的任意单位报告血清蛋白信号的导出幅度,或者使用通过将血清用已知浓度的血清白蛋白储备溶液加标而确定的转换因子转换为浓度的摩尔单位。c.测量mvx的系统指涉本公开的一些实施方案包含能够进行本文所述的每种方法的系统。在一些实施方案中,系统可包含:配置为获取包含glyca的至少一个信号、至少一种高密度脂蛋白颗粒(hdlp)亚类的至少一个信号、至少一种支链氨基酸(bcaa)的至少一个信号和至少一种酮体(ketonebody)的至少一个信号的一个和/或多个nmr光谱的nmr光谱仪;以及基于所测量的glyca、至少一种高密度脂蛋白颗粒(hdlp)亚类、至少一种支链氨基酸(bcaa)和至少一种酮体(ketonebody)的至少一个信号确定代谢脆弱性指数(mvx)值的处理器,其中处理器包含存储器或与存储器通信。系统可进一步包含:配置为获取包含血清蛋白(protein)和/或枸橼酸盐(citrate)的至少一个信号的一个和/或多个nmr光谱的nmr光谱仪;以及基于所测量的血清蛋白(protein)和枸橼酸盐(citrate)的至少一个信号确定代谢脆弱性指数(mvx)值的处理器。指涉本公开的一些实施方案包含能够进行本文所述的每种方法的nmr系统。在一些实施方案中,nmr系统可包含:nmr光谱仪、与光谱仪通信的流量探头以及配置为获得以下信号的与光谱仪通信的处理器:(i)与流量探头中的血浆或血清样本的glyca相关的nmr光谱的规定glyca拟合区域的至少一个nmr信号;(ii)与流量探头中的样本相关的nmr光谱的规定酮体拟合区域的至少一个nmr信号;(iii)与流量探头中的样本相关的nmr光谱的规定bcaa拟合区域的至少一个nmr信号;和(iv)至少一种hdlp亚类的至少一个nmr信号;以及任选地血清蛋白(protein)和/或枸橼酸盐(citrate)的至少一个nmr信号。在一些实施方案中,处理器进一步配置为根据本文公开的任何本发明实施方案基于由光谱仪获得的测量结果来计算mvx分数。本文中某些附图的流程图和方框图说明本发明的分析模型和评估系统和/或程序的可能实施的架构、功能和操作。在这方面,流程图或方框图中的每个方框代表模块、节段、操作或代码部分,其包含用于实施指定逻辑功能的一个或多个可执行指令。还应注意,在一些备选实施中,方框中所述的功能可不按附图中所述的顺序发生。例如,取决于所涉及的功能,接连示出的两个方框实际上可基本上同时执行,或者方框有时可以相反顺序执行。现参考图13,预期大多数(如果不是全部)测量结果可如例如关于美国专利第8013602号所述,基于与nmr临床分析仪22通信或至少部分地机载的系统10或使用系统10进行,该文献的内容由此通过引用结合,如同本文全文引用一样。分析仪22包括光谱仪和样品处理系统。系统10可包括处理器(例如代谢脆弱性指数模块)350,以收集适合于确定mvx值的数据,所述数据可包括例如glyca、bcaa、酮体、hdlp亚群(比如(但不限于)s-hdlp)和/或枸橼酸盐和/或蛋白。在一些实施方案中,处理器可配置为基于glyca、至少一种酮体、至少一种支链氨基酸和至少一种hdlp亚类的测量结果,使用以下公式来计算mvx分数:mvx=a+β1*lnglyca+β2*lns-hdlp+β4*lnbcaa+β5*lnketonebody。在一些实施方案中,处理器可配置为使用以下模型来计算mvx分数:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody。在一些实施方案中,处理器可配置为使用以下模型来计算mvx分数:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。在一些实施方案中,处理器可配置为计算包含炎症指数(infx)值和代谢性营养不良指数(mmx)值的mvx分数。因此,在一些实施方案中,处理器可配置为基于以下模型来计算mvx分数:mvx=βi*infx+βm*mmx。在这些实施方案中,处理器可配置为使用以下模型来计算infx值:infx=β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)。在一些实施方案中,处理器可配置为使用以下模型来计算mmx值:mmx=β4*lnbcaa+β5*lnketonebody,该模型可表示为mmx1。在一些实施方案中,处理器可配置为使用以下模型来计算mmx:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein。在另一个实施方案中,处理器可配置为使用以下模型来计算mmx:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。在这种实施方案中,mmx可描述如下:mmx=β9*mmx1+β10*mmx2,其中mmx1如上所述,和mmx2=β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。系统可包括分析线路20,分析线路20包括至少一个处理器,处理器可被分析仪22机载或至少部分地远离分析仪22。如果是后者,则处理器/分析线路20可全部或部分地存在于服务器上。服务器可使用云计算来提供,云计算包括经计算机网络按需提供计算资源。这些资源可体现为各种基础设施服务(例如计算机、存储等)以及应用程序、数据库、文件服务、电子邮件等。在传统计算模型中,数据和软件两者一般完全包含在用户计算机中;在云计算中,用户计算机可能只包含少量软件或数据(也许是操作系统和/或网络浏览器),并且可能只不过充当在外部计算机网络上进行处理的显示终端。云计算服务(或多个云资源的集合)通常可称为“云”。云存储可包括网络化计算机数据存储的模型,其中数据存储于多个虚拟服务器上,而不是托管于一个或多个专用服务器上。数据传输可进行加密,并可使用任何适当的防火墙经互联网进行,以符合行业或监管标准(比如hipaa)。术语“hipaa”是指健康保险携带和责任法案(healthinsuranceportabilityandaccountabilityact)规定的美国法律。患者数据可包括登录号或标识符、性别、年龄和测试数据。mvx确定的结果可经计算机网络(比如互联网227)、经电子邮件等传送给患者、临床医师站点50、健康保险机构或药房51。结果可从分析站点直接发送,或可间接发送。结果可打印出来并经常规邮件发送。该信息还可传送到药房和/或医疗保险公司、或者甚至监测可能会导致不良事件风险增加的处方或药物使用的患者,或者发出医疗警报以防止出现矛盾的药剂处方。可经电子邮件将结果发送到患者的“家用”计算机或普及的计算设备(比如智能手机或笔记本等)。例如,结果可作为整个报告的电子邮件附件,或者作为短信警报。与不同用户例如临床医师站点、患者和/或测试或实验室站点相关联的一个或多个电子设备,可配置为访问与相应电子设备的显示器通信的电子分析线路。分析线路可托管于服务器上,并且可为各种设备提供互联网门户或可下载的app或其他计算机程序。线路可配置为使得用户(例如临床医师)能够输入以下一项或多项:(i)患者的传统风险因素值,(ii)患者的传统风险因素值和个人脆弱性指数分数,或(iii)个人脆弱性指数分数。线路可在登录时基于患者标识符或其他密码自动填充不同的数据字段,或者使得用户能够为相应患者输入mvx分数和传统因素测量结果。可将分析线路配置为跟踪mvx分数随着时间推移的变化,并生成可发送给临床医师、患者或其他用户的电子报告。分析线路还可发送有关对重新测试、后续测试等的建议的通知,例如,如果mvx风险分数升高或高于低风险值(例如在中度风险类别中),则线路可通知临床医师进一步测试可为适当的,或者向患者发送通知以与医生协商看哪种测试为适当的,或者是否可期望对于后续mvx测试增加监测间隔。分析线路可生成风险评价路径或分析,以提供图形信息,从而对具有相同传统风险因素值的患者将来的过早全因死亡风险进行分级。电子分析线路可机载于云中的服务器上或者可经互联网访问,或者可与不同的客户端架构相关联,如本领域技术人员意识到的那样。因此,临床医师、患者或其他用户可生成关于风险评价的定制报告,或者获得风险分级信息。图14显示使用nmr测量mvx的一个实例。本公开的一些实施方案包含能够实施本文所述的每种方法的nmr系统。在一些实施方案中,nmr系统可包含nmr光谱仪、与光谱仪通信的流量探头以及配置为获得以下信息的与光谱仪通信的处理器:(i)与流量探头中的血浆或血清样本的glyca相关的nmr光谱的规定glyca拟合区域的至少一个nmr信号;(ii)与流量探头中的样本相关的nmr光谱的规定酮体拟合区域的至少一个nmr信号;(iii)与流量探头中的样本相关的nmr光谱的规定bcaa拟合区域的至少一个nmr信号;和(iv)至少一种hdlp亚类的至少一个nmr信号;以及任选地血清蛋白(protein)和/或枸橼酸盐(citrate)的至少一个nmr信号。在一些实施方案中,处理器进一步配置为根据本文公开的任何本发明实施方案,基于由光谱仪获得的测量结果来计算mvx分数。现参考图14,说明用于获取和计算所选样品的线形的系统207。系统207包括用于获取样品的nmr测量结果的nmr光谱仪22。在一个实施方案中,光谱仪22配置为使得对于质子信号在400mhz下进行nmr测量;在其他实施方案中,可在200mhz-约900mhz之间或其他合适的频率下进行测量。也可采用与期望的工作磁场强度相对应的其他频率。一般地,安装质子流量探头以及温度控制器,以将样品温度保持在47+/-0.5℃。光谱仪22由数字计算机211或其他信号处理单元控制。计算机211应该能够进行快速傅立叶变换。其还可包括到另一处理器或计算机213的数据链接212,以及可连接到硬盘存储单元215的直接存储器访问通道214。数字计算机211还可包括一组模数转换器、数模转换器和慢速设备i/o端口,其通过脉冲控制和接口线路216连接到光谱仪22的操作元件。这些元件包括rf发射器217(其产生由至少一个可机载于数字计算机211上或与其通信的数字信号处理器引导的持续时间、频率和幅度的rf激励脉冲)和rf功率放大器218(其放大脉冲并将其耦合到环绕样品池220和/或流量探头220的re发射线圈219)。在超导磁体221产生的9.4特斯拉极化磁场的存在下激励样品产生的nmr信号由线圈222接收,并施加于rf接收器223。在224处对放大和滤过的nmr信号进行解调,并将所得正交信号施加于接口线路216,在此将其数字化并通过数字计算机211输入。处理器和/或分析仪线路20(图13和14)和/或多参数mvx风险模块350(图13和15)可位于与数字计算机211相关联的一个或多个处理器和/或辅助计算机213中或其他可在现场或远程(可经全球网络比如互联网227访问)的计算机中。在从测量池220中的样品获取nmr数据之后,由计算机211处理产生另一文件,后者可根据需要存储于存储器215中。该第二文件为化学位移谱的数字表示,并且随后将其读出到计算机213以存储于其存储器225或者与一个或多个服务器相关联的数据库中。在存储于其存储器中或可通过计算机213访问的程序引导下(计算机213可为膝上型计算机、台式计算机、工作站计算机、电子笔记本、电子平板电脑、智能手机或具有至少一个处理器的其他设备或其他计算机),根据本发明的教导处理化学位移谱以生成报告,报告可输出到打印机226或以电子方式存储并中继到期望的电子邮件地址或uri。本领域技术人员将认识到其他输出设备,比如计算机显示屏、电子笔记本、智能手机等,也可用于显示结果。对于本领域技术人员应该显而易见的是,由计算机213及其单独存储器225实施的功能也可合并到由光谱仪的数字计算机211实施的功能中。在这种情况下,打印机226可直接连接到数字计算机211。如本领域技术人员众所周知的,也可采用其他接口和输出设备。本发明的某些实施方案旨在提供使用mvx评估的方法、系统和/或计算机程序产品,其在临床疾病状态的自动筛查测试和/或用于体外生物样品筛查的风险评价评估中可特别有用。本公开的实施方案可采取完全软件实施方案或组合软件和硬件方面的实施方案的形式,所有这些本文通常称为“线路”或“模块”。如本领域技术人员将意识到的,本公开可体现为装置、方法、数据或信号处理系统或计算机程序产品。因此,本公开可采取完全软件实施方案或组合软件和硬件方面的实施方案的形式。此外,本公开的某些实施方案可采取基于计算机可用存储介质的计算机程序产品的形式,具有体现在介质中的计算机可用程序代码工具。可利用任何合适的计算机可读介质,包括硬盘、cd-rom、光学存储设备或磁性存储设备。计算机可用或计算机可读介质可为(但不限于)电、磁、光、电磁、红外或半导体系统、装置、设备或传播介质。计算机可读介质的更具体实例(非穷举列表)将包括以下:具有一根或多根电线的电连接、便携式计算机软盘、随机访问存储器(ram)、只读存储器(rom)、可擦除可编程只读存储器(eprom或闪存)、光纤和便携式光盘只读存储器(cd-rom)。请注意,计算机可用或计算机可读介质甚至可为纸或在其上打印程序的另一合适介质,因为可经例如光学扫描纸或其他介质来以电子方式捕获程序,然后进行编译、解释或者如果必要则以合适的方式另外处理,并然后将其存储于计算机存储器中。可以面向对象的编程语言比如java7、smalltalk、python、labview、c++或visualbasic来编写用于执行本公开操作的计算机程序代码。然而,用于执行本公开操作的计算机程序代码也可以常规程序化编程语言来编写,比如“c”编程语言或者甚至是汇编语言。程序代码可完全在用户计算机上、部分在用户计算机上、作为独立软件包、部分在用户计算机上且部分在远程计算机上或完全在远程计算机上执行。在后者情况下,远程计算机可通过局域网(lan)或广域网(wan)或安全区域网络(san)连接到用户计算机,或者可与外部计算机建立连接(例如通过使用互联网服务提供商的互联网)。图15为数据处理系统305的示例性实施方案的方框图,其说明本发明实施方案的系统、方法和计算机程序产品。处理器310可包含存储器314或经地址/数据总线348与存储器314通信。处理器310可为任何市售或定制微处理器。存储器314代表包含用于实施数据处理系统305的功能的软件和数据的存储器设备的总体层次结构。存储器314可包括但不限于以下类型的设备:高速缓冲存储器、rom、prom、eprom、eeprom、闪存、sram和dram。如图15所示,存储器314可包括在数据处理系统305中使用的几种类别的软件和数据:操作系统352、应用程序354、输入/输出(i/o)设备驱动器358、mvx评估模块350和数据356。mvx评估模块350可使用本文公开的各种方法使nmr信号去卷积以揭示相应生物样品的质子nmr光谱中规定的nmr信号峰区域来计算mvx值。数据356可包括可从数据或信号获取系统225(例如nmr光谱仪22和/或分析仪22)获得的信号(组成和/或复合光谱线形)数据362。如本领域技术人员将意识到的那样,操作系统352可为适合与数据处理系统一起使用的任何操作系统,数据处理系统比如来自internationalbusinessmachinescorporation,armonk,n.y.的os/2、aix或os/390;来自microsoftcorporation,redmond,wash.的windowsce、windowsnt、windows95、windows98、windows2000、windowsxp、windows10;来自palm,inc.的palmos;来自applecomputer的macos;unix、freebsd或linux;专有操作系统或专用操作系统,例如用于嵌入式数据处理系统。i/o设备驱动器358一般包括由应用程序354通过操作系统352访问的软件例程,以与设备比如i/o数据端口、数据存储器356和某些存储器314组件和/或图像获取系统225通信。应用程序354阐释实施数据处理系统305的各种特征的程序,并可包括至少一个支持本发明实施方案的操作的应用。最后,数据356代表由应用程序354、操作系统352、i/o设备驱动器358和可存在于存储器314中的其他软件程序使用的静态和动态数据。尽管例如参照图15中的为应用程序的模块350来说明本发明,但是如本领域技术人员将意识到的,也可利用其他配置,同时仍然受益于本发明教导。因此,本发明不应解释为限于图15的配置,其旨在涵盖能够执行本文所述操作的任何配置。在某些实施方案中,模块350包括用于提供mvx测量结果的计算机程序代码,mvx测量结果可用作评价临床疾病状态或风险和/或指示是否期望治疗干预和/或跟踪治疗功效或者甚至治疗的意外结果的标志物。现将通过以下非限制性实施例描述本公开的其他实施方案。实施例实施例1使用从6936名参与者的cathgen研究群体收集的数据,开发代谢脆弱性指数(mvx)数学模型。记录每名患者的传统临床参数,包括年龄、种族、性别、吸烟状况、高血压状况、糖尿病状况、bmi、富含甘油三酯的脂蛋白颗粒(trlp)和ldl颗粒(ldlp)。另外,glyca、s-hdlp、bcaa、酮体、枸橼酸盐和蛋白的测量结果均从每名研究参与者的血浆样品的单一核磁共振(nmr)光谱导出。使用死亡的cox比例风险预测模型来生成每种参数的预测强度(χ2)和统计显著性(p值),如图4和5所示。尽管在这种情况下,所有列出的参数均用于预测模型中以生成每种参数的预测强度,但模型中的mvx单独是非常强大、高度统计显著性的死亡风险预测因子,如图7所示。使用从死亡的cox比例风险预测模型生成的mvx数学模型,为cathgen研究中的每名参与者生成mvx分数(1-100)值。然后将这些mvx分数用于将群体细分为9个亚组,在5年随访期内,每个亚组的累积死亡率显示与mvx分数的增大成正比地增大,如图3所示。图16提供可如何使用infx、mmx1、mmx2和mmx的各种模型来开发数字分数(比如图3所示的那些)的实例。对于应用于正常(即非高风险)群体,mvx1=(infx*0.84310)+(mmx1*1.0),其中mmx1=10+(lnbcaa*-1.10056)+(lnketonebody*0.2373)。相比之下,对于高风险群体,mmx的贡献包括mmx1和mmx2(图16)。所使用的实际系数(例如对于mmx1,β4=-1.10056和β5=0.2373)可根据所使用的群体和/或所进行的分析而不同。实施方案a1.一种确定与受试者的过早死亡的相对风险相关的标志物水平的方法,包括:从受试者获得样品;和测量glyca、至少一种高密度脂蛋白颗粒(hdlp)亚类、至少一种支链氨基酸(bcaa)和至少一种酮体(ketonebody)。a2.a1的方法,其中使用glyca、至少一种hdlp亚类、至少一种bcaa和至少一种酮体的测量结果来生成代谢脆弱性指数(mvx)值。a3.a1-a2的方法,其中hdlp亚类为小hdlp(s-hdlp)。a4.a2-a3的方法,其中mvx值使用以下模型来确定:mvx=a+β1*lnglyca+β2*lns-hdlp+β4*lnbcaa+β5*lnketonebody。a5.a2-a3的方法,其中mvx值使用以下模型来确定:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody。a6.a5的方法,其中在认为处于心血管事件低风险下的受试者中确定mvx值。a7.a1-a2的方法,还包括测量枸橼酸盐(citrate)和血清蛋白(protein)中的至少一种。a8.a7的方法,其中在认为处于与cvd相关的死亡高风险下的受试者中进行枸橼酸盐和血清蛋白中至少一种的测量。a9.a7-a8的方法,其中mvx值使用以下模型来确定:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。a10.前述实施方案中任何一项的方法,其中mvx值规定为包含炎症指数(infx)值和代谢性营养不良指数(mmx)值。a11.a10的方法,其中glyca和至少一种hdlp亚类的测量结果用于生成炎症指数(infx)值。a12.a10-a11的方法,其中infx值使用以下模型来确定:infx=β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)。a13.a10的方法,其中至少一种bcaa和至少一种酮体以及任选地蛋白和枸橼酸盐的测量结果用于生成代谢性营养不良指数(mmx)值。a14.a10和a13的方法,其中代谢性营养不良指数(mmx)值规定为:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。a15.a10、a13和a14中任何一项的方法,其中代谢性营养不良指数(mmx)包含第一代谢性营养不良指数mmx1值和第二代谢性营养不良指数mmx2值。a16.a15的方法,其中mmx=β9*mmx1+β10*mmx2。a17.a15-a16的方法,其中mmx1=β4*lnbcaa+β5*lnketonebody。a18.a15-a16的方法,其中mmx2=β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。a19.a15-a17中任何一项的方法,其中mvx值使用以下模型来确定:mvx1=βi*infx+βm*mmx1。a20.a19的方法,其中对认为处于与cvd相关的事件低风险下的受试者确定mvx1。a21.a15的方法,其中mvx值使用以下模型来确定:mvx=βi*infx+βm*mmx,其中mmx=β9*mmx1+β10*mmx2。a22.a21的方法,其中对认为处于与cvd相关的事件高风险下的受试者确定mvx。a23.前述实施方案中任何一项的方法,其中bcaa为亮氨酸、异亮氨酸或缬氨酸中的至少一种。a24.前述实施方案中任何一项的方法,其中酮体为丙酮、乙酰乙酸酯或β-羟基丁酸酯中的至少一种。a25.前述实施方案中任何一项的方法,其中测量通过nmr进行。b1.一种确定与受试者的过早死亡的相对风险相关的标志物水平的方法,包括:从受试者获得样品;测量glyca、至少一种高密度脂蛋白颗粒(hdlp)亚类、至少一种支链氨基酸(bcaa)和至少一种酮体(ketonebody)以及任选地枸橼酸盐(citrate)和血清蛋白(protein)中的至少一种;使用glyca和至少一种hdlp亚类的测量结果来生成炎症指数(infx)值;使用至少一种bcaa和至少一种酮体以及任选地蛋白(protein)和枸橼酸盐(citrate)的测量结果来生成至少一种代谢性营养不良指数(mmx)值;和基于infx和mmx值确定代谢脆弱性指数(mvx)值。b2.b1的方法,其中hdlp亚类为小hdlp(s-hdlp)。b3.b1-b2的方法,其中infx值使用以下模型来确定:infx=β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)。b4.b1-b2的方法,其中代谢性营养不良指数(mmx)值规定为:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。b5.实施方案b1-b4中任何一项的方法,其中代谢性营养不良指数(mmx)包含第一代谢性营养不良指数mmx1值和第二代谢性营养不良指数mmx2值。b6.b5的方法,其中mmx=β9*mmx1+β10*mmx2。b7.b5-b6的方法,其中mmx1=β4*lnbcaa+β5*lnketonebody。b8.b5-b6的方法,其中mmx2=β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。b9.b5-b7的方法,其中mvx值使用以下模型来确定:mvx1=βi*infx+βm*mmx1。b10.b9的方法,其中对认为处于与cvd相关的事件低风险下的受试者确定mvx1。b11.b5-b8中任何一项的方法,其中mvx值使用以下模型来确定:mvx=βi*infx+βm*mmx,其中mmx=β9*mmx1+β10*mmx2。b12.b11的方法,其中对认为处于与cvd相关的事件高风险下的受试者确定mvx。b13.b1-b12中任何一项的方法,其中bcaa为亮氨酸、异亮氨酸或缬氨酸中的至少一种。b14.b1-b13中任何一项的方法,其中酮体为丙酮、乙酰乙酸酯或β-羟基丁酸酯中的至少一种。b15.b1-b14中任何一项的方法,其中测量通过nmr进行。c1.一种实施前述实施方案中任何一项的系统。d1.一种系统,其包含:配置为获取包含glyca的至少一个信号、至少一种高密度脂蛋白颗粒(hdlp)亚类的至少一个信号、至少一种支链氨基酸(bcaa)的至少一个信号和至少一种酮体(ketonebody)的至少一个信号的一个和/或多个nmr光谱的nmr光谱仪;和基于所测量的glyca、至少一种高密度脂蛋白颗粒(hdlp)亚类、至少一种支链氨基酸(bcaa)和至少一种酮体(ketonebody)的至少一个信号来确定代谢脆弱性指数(mvx)值的处理器,其中处理器包含存储器或与存储器通信。d2.d1的系统,其还包含:配置为获取包含血清蛋白(protein)和/或枸橼酸盐(citrate)的至少一个信号的一个和/或多个nmr光谱的nmr光谱仪;和基于所测量的血清蛋白(protein)和/或枸橼酸盐(citrate)的至少一个信号来确定代谢脆弱性指数(mvx)值的处理器。d3.d1-d2的系统,其中hdlp亚类为小hdlp(s-hdlp)。d4.d1或d3中任何一项的系统,其中处理器进一步配置为基于glyca、至少一种酮体、至少一种支链氨基酸和至少一种hdlp亚类的测量结果,使用以下公式来计算mvx分数:mvx=a+β1*lnglyca+β2*lns-hdlp+β4*lnbcaa+β5*lnketonebody。d5.d1或d3中任何一项的系统,其中处理器进一步配置为使用以下模型来计算mvx分数:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody。d6.d1-d3中任何一项的系统,其中处理器进一步配置为使用以下模型来计算mvx值:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。d7.d1-d6中任何一项的系统,其中处理器进一步配置为计算包含炎症指数(infx)值和代谢性营养不良指数(mmx值)的mvx值。d8.d7的系统,其中处理器进一步配置为使用以下模型来计算infx值:infx=β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)。d9.d7的系统,其中处理器进一步配置为使用以下模型来计算mmx值:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。d10.d7-d9中任何一项的系统,其中处理器进一步配置为计算包含第一代谢性营养不良指数mmx1值和第二代谢性营养不良指数mmx2值的代谢性营养不良指数(mmx)。d11.d10的系统,其中处理器进一步配置为使用以下模型来计算mmx值:mmx=β9*mmx1+β10*mmx2。d12.d10-d11的系统,其中处理器进一步配置为使用以下模型来计算mmx1值:mmx1=β4*lnbcaa+β5*lnketonebody。d13.d10-d11的系统,其中处理器进一步配置为使用以下模型来计算mmx2值:mmx2=β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。d14.d10-d12中任何一项的系统,其中处理器进一步配置为使用以下模型来计算mvx值:mvx1=βi*infx+βm*mmx1。d15.d10或d11-d13中任何一项的系统,其中处理器进一步配置为使用以下模型来计算mvx值:mvx=βi*infx+βm*mmx,其中mmx=β9*mmx1+β10*mmx2。d16.d1-d15中任何一项的系统,其中bcaa为亮氨酸、异亮氨酸或缬氨酸中的至少一种。d17.d1-d16中任何一项的系统,其中酮体为丙酮、乙酰乙酸酯或β-羟基丁酸酯中的至少一种。e1.一种nmr系统,其包含:nmr光谱仪;与光谱仪通信的流量探头;和与光谱仪通信的处理器,配置为获得以下信号:(i)与流量探头中的血浆或血清样本的glyca相关的nmr光谱的规定glyca拟合区域的至少一个nmr信号;(ii)与流量探头中的样本相关的nmr光谱的规定酮体拟合区域的至少一个nmr信号;(iii)与流量探头中的样本相关的nmr光谱的规定bcaa拟合区域的至少一个nmr信号;和(iv)与流量探头中的样本相关的nmr光谱的至少一种hdlp亚类拟合区域的至少一个nmr信号;以及任选地与流量探头中的样本相关的nmr光谱的血清蛋白(protein)和/或枸橼酸盐(citrate)拟合区域的至少一个nmr信号。e2.e1的系统,其中hdlp亚类为小hdlp(s-hdlp)。e3.e1-e2的系统,其中处理器进一步配置为基于glyca、至少一种酮体、至少一种支链氨基酸和至少一种hdlp亚类的测量结果,使用以下公式来计算mvx分数:mvx=a+β1*lnglyca+β2*lns-hdlp+β4*lnbcaa+β5*lnketonebody。e4.e1-e2的系统,其中处理器进一步配置为使用以下模型来计算mvx分数:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody。e5.e1-e4中任何一项的系统,其中处理器进一步配置为使用以下模型来计算mvx值:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。e6.e1-e5中任何一项的系统,其中处理器进一步配置为计算包含炎症指数(infx)值和代谢性营养不良指数(mmx值)的mvx值。e7.e6的系统,其中处理器进一步配置为使用以下模型来计算infx值:infx=β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)。e8.e6的系统,其中处理器进一步配置为使用以下模型来计算mmx值:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。e9.e6-e7中任何一项的系统,其中处理器进一步配置为计算包含第一代谢性营养不良指数mmx1值和第二代谢性营养不良指数mmx2值的代谢性营养不良指数(mmx)。e10.e9的系统,其中处理器进一步配置为使用以下模型来计算mmx值:mmx=β9*mmx1+β10*mmx2。e11.e9-e10的系统,其中处理器进一步配置为使用以下模型来计算mmx1值:mmx1=β4*lnbcaa+β5*lnketonebody。e12.e9-e10的系统,其中处理器进一步配置为使用以下模型来计算mmx2值:mmx2=β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。e13.e9-e11中任何一项的系统,其中处理器进一步配置为使用以下模型来计算mvx值:mvx1=βi*infx+βm*mmx1。e14.e10-e13中任何一项的系统,其中处理器进一步配置为使用以下模型来计算mvx值:mvx=βi*infx+βm*mmx,其中mmx=β9*mmx1+β10*mmx2。e15.e1-e14中任何一项的系统,其中bcaa为亮氨酸、异亮氨酸或缬氨酸中的至少一种。e16.e1-e15中任何一项的系统,其中酮体为丙酮、乙酰乙酸酯或β-羟基丁酸酯中的至少一种。f1.一种监测患者的方法,包括:从受试者获得样品;测量样品中的glyca、至少一种高密度脂蛋白颗粒(hdlp)亚类、至少一种支链氨基酸(bcaa)和至少一种酮体(ketonebody)以及任选地枸橼酸盐(citrate)和/或血清蛋白(protein)中的至少一种;基于测量结果确定代谢脆弱性指数(mvx)值;和至少评估mvx值是否高于与全因死亡风险增加相关的群体常值的规定水平。f2.f1的方法,其中hdlp亚类为小hdlp(s-hdlp)。f3.f1-f2的方法,其中mvx值使用以下模型来确定:mvx=a+β1*lnglyca+β2*lns-hdlp+β4*lnbcaa+β5*lnketonebod。f4.f1-f2的方法,其中mvx值使用以下模型来确定:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody。f5.f1-f4的方法,其中在认为处于心血管事件低风险下的受试者中确定mvx值。f6.f1的方法,其中在认为处于与cvd相关的死亡高风险下的受试者中进行枸橼酸盐和血清蛋白中至少一种的测量。f7.f1-f2的方法,其中mvx值使用以下模型来确定:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。f8.f1-f7的方法,其中mvx值规定为包含炎症指数(infx)值和代谢性营养不良指数(mmx)值。f9.f8的方法,其中glyca和至少一种hdlp亚类的测量结果用于生成炎症指数(infx)值。f10.f8-f9的方法,其中infx值使用以下模型来确定:infx=β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)。f11.f8的方法,其中至少一种bcaa和至少一种酮体以及任选地蛋白和枸橼酸盐的测量结果用于生成代谢性营养不良指数(mmx)值。f12.f8或f11中任何一项的方法,其中代谢性营养不良指数(mmx)值规定为:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。f13.f8或f11中任何一项的方法,其中代谢性营养不良指数(mmx)包含第一代谢性营养不良指数mmx1值和第二代谢性营养不良指数mmx2值。f14.f13的方法,其中mmx=β9*mmx1+β10*mmx2。f15.f13或f14中任何一项的方法,其中mmx1=β4*lnbcaa+β5*lnketonebody。f16.f13或f14中任何一项的方法,其中mmx2=β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。f17.f13-f15中任何一项的方法,其中mvx值使用以下模型来确定:mvx1=βi*infx+βm*mmx1。f18.f17的方法,其中对认为处于与cvd相关的事件低风险下的受试者确定mvx1。f19.f13的方法,其中mvx值使用以下模型来确定:mvx=βi*infx+βm*mmx,其中mmx=β9*mmx1+β10*mmx2。f20.f19的方法,其中对认为处于与cvd相关的事件高风险下的受试者确定mvx。f21.f1-f20中任何一项的方法,其中bcaa为亮氨酸、异亮氨酸或缬氨酸中的至少一种。f22.f1-f21中任何一项的方法,其中酮体为丙酮、乙酰乙酸酯或β-羟基丁酸酯中的至少一种。f23.f1-f21中任何一项的方法,其中测量通过nmr进行。g1.一种监测患者的方法,包括:(a)从受试者获得样品;(b)测量样品中的glyca、至少一种高密度脂蛋白颗粒(hdlp)亚类、至少一种支链氨基酸(bcaa)和至少一种酮体(ketonebody)以及任选地枸橼酸盐(citrate)和血清蛋白(protein)中的至少一种;(c)基于测量结果确定代谢脆弱性指数(mvx)值;(d)在随后的时间点重复步骤(a)-(c);和(e)至少评估mvx值是随着时间的推移增大还是减小。g2.g1的方法,其中hdlp亚类为小hdlp(s-hdlp)。g3.g1-g2的方法,其中mvx值使用以下模型来确定:mvx=a+β1*lnglyca+β2*lns-hdlp+β4*lnbcaa+β5*lnketonebody。g4.g1-g2的方法,其中mvx值使用以下模型来确定:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody。g5.g1-g4中任何一项的方法,其中在认为处于心血管事件低风险下的受试者中确定mvx值。g6.g1-g2的方法,其中在认为处于与cvd相关的死亡高风险下的受试者中进行枸橼酸盐和血清蛋白中至少一种的测量。g7.g1、g2或g6中任何一项的方法,其中mvx值使用以下模型来确定:mvx=a+β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)+β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。g8.g1-g7中任何一项的方法,其中mvx值规定为包含炎症指数(infx)值和代谢性营养不良指数(mmx)值。g9.g8的方法,其中glyca和至少一种hdlp亚类的测量结果用于生成炎症指数(infx)值。g10.g8-g9的方法,其中infx值使用以下模型来确定:infx=β1*lnglyca+β2*lns-hdlp+β3*(lnglyca*lns-hdlp)。g11.g8的方法,其中至少一种bcaa和至少一种酮体以及任选地蛋白和枸橼酸盐的测量结果用于生成代谢性营养不良指数(mmx)值。g12.g8或g11中任何一项的方法,其中代谢性营养不良指数(mmx)值规定为:mmx=β4*lnbcaa+β5*lnketonebody+β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。g13.g8、g11或g12中任何一项的方法,其中代谢性营养不良指数(mmx)包含第一代谢性营养不良指数mmx1值和第二代谢性营养不良指数mmx2值。g14.g13的方法,其中mmx=β9*mmx1+β10*mmx2。g15.g13的方法,其中mmx1=β4*lnbcaa+β5*lnketonebody。g16.g13的方法,其中mmx2=β6*lncitrate+β7*lnprotein+β8*(lncitrate*lnprotein)。g17.g15的方法,其中mvx值使用以下模型来确定:mvx1=βi*infx+βm*mmx1。g18.g17的方法,其中对认为处于与cvd相关的事件低风险下的受试者确定mvx1。g19.g13的方法,其中mvx值使用以下模型来确定:mvx=βi*infx+βm*mmx,其中mmx=β9*mmx1+β10*mmx2。g20.g19的方法,其中对认为处于与cvd相关的事件高风险下的受试者确定mvx。g21.g1-g20中任何一项的方法,其中bcaa为亮氨酸、异亮氨酸或缬氨酸中的至少一种。g22.g1-g21中任何一项的方法,其中酮体为丙酮、乙酰乙酸酯或β-羟基丁酸酯中的至少一种。g23.g1的方法,其中测量通过nmr进行。前述内容为对本公开的说明,并且不应解释为对其的限制。尽管已经描述本公开的一些示例性实施方案,但是本领域技术人员将易于意识到,可对示例性实施方案进行许多修改而不实质上背离本公开新的教导和优点。因此,所有这种修改旨在包括在如权利要求限定的本公开范围内。在权利要求中,装置加功能条款在使用时旨在覆盖本文所述的执行所述功能的结构,并且不仅覆盖结构等同物,而且还覆盖等同结构。因此,应当理解,前述内容为本公开的说明,并且不应解释为限于所公开的特定实施方案,并且对所公开的实施方案以及其他实施方案的修改旨在包括在所附权利要求的范围内。本公开由以下权利要求限定,其中包括权利要求的等同物。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1