一种限制性骑行路径规划装置及方法与流程
本发明涉及数据分析领域,尤其是一种限制性骑行路径规划装置及方法。
背景技术:
随着共享单车的兴起,骑行运动方式渐渐推广,骑行市场被逐步开发出来。作为全球八大无线产业之一,gps为代表的导航定位服务占领了广大市场,gps因为全天、高精、高效等优势及其导航追踪、精准授时等各方面的实用功能,已经逐步应用到各个领域。
现有的导航设备主要是根据行驶时间和出行方式来推荐路径,当用户确定出发地和目的地后,系统会根据出行方式生成路径和相应的时间。然而,面向骑行的导航设备比较少见,主要原因包括:投入成本巨大而盈利有限,单车上的导航设备使用场景单一,通常只涉及短途通勤场景,根据起点和终点规划最短路径。
技术实现要素:
本发明针对上述问题及技术需求,提出了一种限制性骑行路径规划装置及方法。
本发明的技术方案如下:
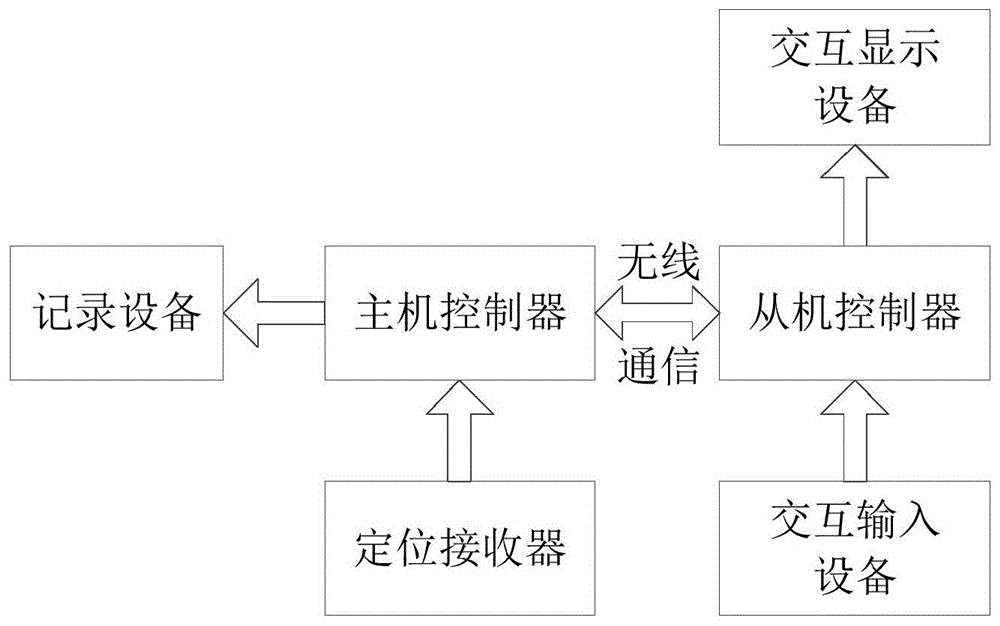
第一方面,一种限制性骑行路径规划装置,包括:主机电路和从机电路,所述主机电路和所述从机电路通过无线通信连接;所述主机电路包括主机控制器、定位接收器、记录设备,所述主机控制器分别与所述定位接收器和所述记录设备连接;所述从机电路包括从机控制器、交互输入设备、交互显示设备,所述从机控制器分别与所述交互输入设备和所述交互显示设备连接;
所述定位接收器用于定位帧数据中的经度数据和纬度数据,并对各个路径点进行标记;
所述记录设备用于记录和存储位置数据;
所述交互输入设备用于输入骑行目的地;
所述交互显示设备用于显示用户的实时位置和骑行路径。
其进一步的技术方案为:所述主机控制器和所述从机控制器采用stm32f103vet6单片机,所述定位接收器是ublox-neo-6m模组和stm32f103vet6上自带的at24c02eeprom模块,其中,ublox-neo-6m模组作为gps信号分析处理模组,at24c02存储gps配置信息;所述记录设备采用microsd卡;所述交互输入设备采用按键模块;所述交互显示设备采用带ili9341控制器的tfl液晶屏。
其进一步的技术方案为:所述主机电路还包括第一无线通信模块,所述第一无线通信模块与所述主机控制器连接,所述从机电路还包括第二无线通信模块,所述第二无线通信模块与所述从机控制器连接;所述第一无线通信模块和所述第二无线通信模块用于实现所述主机电路和所述从机电路之间的无线通信。
其进一步的技术方案为:所述第一无线通信模块和所述第二无线通信模块采用stm32f103vet6单片机上自带的esp8266wifi模块。
第二方面,一种限制性骑行路径规划方法,应用于第一方面所述的限制性骑行路径规划装置中,所述方法包括:
确定预定区域内的各个路径点,所述路径点为至少两条道路的交汇点;
采集各个路径点的经纬度数据,记录各个路径点的海拔高度,对每个路径点预设风景评分,将每个路径点的经纬度数据、海拔高度、风景评分对应存储;
接收用户选择的起点和终点,对于每个行驶路段,获取同时间段内gps数据中其他骑行者的所有骑行路径,确定出起点与终点之间的所有待选路径集合,所述待选路径集合包括有向路段集、每条待选路径的最大海拔差集和每条待选路径的综合风景评分集;
接收用户选择的骑行模式,所述骑行模式包括最短距离模式、风景最优模式、锻炼身体模式;
根据用户选择的骑行模式,通过约束深度强化学习算法确定出对骑行模式对应的目标路径。
其进一步的技术方案为:所述骑行模式为最短距离模式,所述通过约束深度强化学习算法确定出对骑行模式对应的目标路径,包括:
待选路径集合w中包括所有路径点组成的路径点集e和有向路径集a,用户的起点位置ei为路径点集e中的第i个路径点,将用户的起点位置ei的状态特征表示为s(ei)=[xi,yi,xd,yd],xi表示起点的经度,yi表示起点的纬度,xd表示终点的经度,yd表示终点的纬度;起点位置ei到终点的骑行时间用q(s(ei))表示,将起点位置ei的状态特征s(ei)输入bp神经网络得到起点到终点的骑行时间q(s(ei));
用户在待选路径集合g中所在路径点ei+n∈e,ei+n表示在起点位置ei后的第n个路径点,与起点位置ei相连接的所有路段ai,j组成起点位置ei的有向路径集a(ei);奖励函数r(ei,ai,i+1)表示用户在起点位置ei选择路段ai,i+1的骑行时间q(s(ei));根据骑行经验执行贪婪策略π和环境交互得到由所在路径点、选择的相邻路段和骑行时间组成的求解:hi:k=ei,ai,i+1,r(ei,ai,i+1),ei+1,ai+1,i+2,...,ek,ek表示终点之前所经过的最后一个路口,即路径点集e中的第k个路径点;
当完成一次求解,q值发生更新,将求解中用户在起点位置ei以及之后经过的每个路径点表示为[s(ei),ai,i+1,r(ei,ai,i+1),s(ei+1)]存储于求解记忆p中;当每次完成成功求解时,计算成功求解中每个起点位置ei到终点位置的累积折减收益g(hi:k);定义节点记忆n={[s(ei),q(ei)|ei∈e,q(ei)=ming(hi:k)]},二元组s(ei),q(ei)存储起点位置ei的状态特征和起点到终点的最短骑行时间;
采用深度q-learning算法,神经网路的训练通过最小化起点位置ei到终点的最短骑行时间q(ei)和起点位置ei到终点的骑行时间估计值q(s(ei))误差平方和,即
采用ε贪婪策略,以ε概率选择当前最佳策略,1-ε概率随机选择策略,基于深度q-learning算法,结合待选路径集合w,选择对应最短距离模式的路径,具体步骤包括:
输入w=(e,a);
初始化节点记忆n,循环执行初始化q值及神经网络权重系数θ,嵌套循环1至k,在起点位置ei用户满足交通规则时,采用ε贪婪策略选择和起点位置相连的路段ai,i+1;
将选择记录[s(ei),ai,i+1,r(ei,ai,i+1)]加入求解,并将记录[s(ei),ai,i+1,r(ei,ai,i+1),s(ei+1)]存储于求解记忆p,直到最后一个路径点ek和终点ed重合结束循环;
计算成功从起点到终点的路径中每个起点位置ei到终点的累积折减收益g(hi:k),并更新节点记忆n;
使用梯度下降更新θ,以最小化[(q(ei)-q(s(ei),θ))]2,输出贪婪策略ai,i+1=π(ei),得到所选择的一个路段,到达终点后,所有选择的路段组成的路径即与最短距离模式对应的路径。
其进一步的技术方案为:所述骑行模式为风景最优模式,所述通过约束深度强化学习算法确定出对骑行模式对应的目标路径,包括:
根据骑行经验设定风景评分初始值g0,待选路径集合w中包括所有路径点组成的路径点集e、有向路径集a、每条待选路径的综合风景评分集g,用户的起点位置ei为路径点集e中的第i个路径点,将用户的起点位置ei的状态特征表示为s(ei)=[xi,yi,xd,yd],xi表示起点的经度,yi表示起点的纬度,xd表示终点的经度,yd表示终点的纬度;起点位置ei到终点的骑行时间用q(s(ei))表示,将起点位置ei的状态特征s(ei)输入bp神经网络得到起点到终点的骑行时间q(s(ei));
用户在待选路径集合g中所在路径点ei+n∈e,ei+n表示在起点位置ei后的第n个路径点,与起点位置ei相连接的所有路段ai,j组成起点位置ei的有向路径集a(ei);奖励函数r(ei,ai,i+1)表示用户在起点位置ei选择路段ai,i+1的骑行时间q(s(ei));根据骑行经验执行贪婪策略π和环境交互得到由所在路径点、选择的相邻路段和骑行时间组成的求解:hi:k=ei,ai,i+1,r(ei,ai,i+1),ei+1,ai+1,i+2,...,ek,ek表示终点之前所经过的最后一个路口,即路径点集e中的第k个路径点;
当完成一次求解,q值发生更新,将求解中用户在起点位置ei以及之后经过的每个路径点表示为[s(ei),ai,i+1,r(ei,ai,i+1),s(ei+1)]存储于求解记忆p中;当每次完成成功求解时,计算成功求解中每个起点位置ei到终点位置的累积折减收益g(hi:k);定义节点记忆n={[s(ei),q(ei)|ei∈e,q(ei)=ming(hi:k)]},二元组s(ei),q(ei)存储起点位置ei的状态特征和起点到终点的最短骑行时间;
采用深度q-learning算法,神经网路的训练通过最小化起点位置ei到终点的最短骑行时间q(ei)和起点位置ei到终点的骑行时间估计值q(s(ei))误差平方和,即
采用ε贪婪策略,以ε概率选择当前最佳策略,1-ε概率随机选择策略,基于深度q-learning算法,结合待选路径集合w,选择对应风景最优模式的路径,具体步骤包括:
输入w=(e,a,g);
初始化节点记忆n,循环执行初始化q值及神经网络权重系数θ,嵌套循环1至k,在起点位置ei用户满足交通规则时,采用ε贪婪策略选择和起点位置相连的路段ai,i+1;
将选择记录[s(ei),ai,i+1,r(ei,ai,i+1)]加入求解,并将记录[s(ei),ai,i+1,r(ei,ai,i+1),s(ei+1)]存储于求解记忆p,直到最后一个路径点ek和终点ed重合结束循环;
计算成功从起点到终点的路径中每个起点位置ei到终点的累积折减收益g(hi:k),并更新节点记忆n;
使用梯度下降更新θ,以最小化
其进一步的技术方案为:所述骑行模式为锻炼身体模式,所述通过约束深度强化学习算法确定出对骑行模式对应的目标路径,包括:
设每条待选路径的最低点el海拔为zl,最高点eh海拔为zh,海拔差最大值为z,待选路径集合w中包括所有路径点组成的路径点集e、有向路径集a、每条待选路径的最大海拔差集z,用户的起点位置ei为路径点集e中的第i个路径点,将用户的起点位置ei的状态特征表示为s(ei)=[xi,yi,xd,yd],xi表示起点的经度,yi表示起点的纬度,xd表示终点的经度,yd表示终点的纬度;起点位置ei到终点的骑行时间用q(s(ei))表示,将起点位置ei的状态特征s(ei)输入bp神经网络得到起点到终点的骑行时间q(s(ei));
用户在待选路径集合g中所在路径点ei+n∈e,ei+n表示在起点位置ei后的第n个路径点,与起点位置ei相连接的所有路段ai,j组成起点位置ei的有向路径集a(ei);奖励函数r(ei,ai,i+1)表示用户在起点位置ei选择路段ai,i+1的骑行时间q(s(ei));根据骑行经验执行贪婪策略π和环境交互得到由所在路径点、选择的相邻路段和骑行时间组成的求解:hi:k=ei,ai,i+1,r(ei,ai,i+1),ei+1,ai+1,i+2,...,ek,ek表示终点之前所经过的最后一个路口,即路径点集e中的第k个路径点;
当完成一次求解,q值发生更新,将求解中用户在起点位置ei以及之后经过的每个路径点表示为[s(ei),ai,i+1,r(ei,ai,i+1),s(ei+1)]存储于求解记忆p中;当每次完成成功求解时,计算成功求解中每个起点位置ei到终点位置的累积折减收益g(hi:k);定义节点记忆n={[s(ei),q(ei)|ei∈e,q(ei)=ming(hi:k)]},二元组s(ei),q(ei)存储起点位置ei的状态特征和起点到终点的最短骑行时间;
采用深度q-learning算法,神经网路的训练通过最小化起点位置ei到终点的最短骑行时间q(ei)和起点位置ei到终点的骑行时间估计值q(s(ei))误差平方和,即
采用ε贪婪策略,以ε概率选择当前最佳策略,1-ε概率随机选择策略,基于深度q-learning算法,结合待选路径集合w,选择对应锻炼身体模式的路径,具体步骤包括:
输入w=(e,a,z);
初始化节点记忆n,循环执行初始化q值及神经网络权重系数θ,嵌套循环1至k,在起点位置ei用户满足交通规则时,采用ε贪婪策略选择和起点位置相连的路段ai,i+1;
将选择记录[s(ei),ai,i+1,r(ei,ai,i+1)]加入求解,并将记录[s(ei),ai,i+1,r(ei,ai,i+1),s(ei+1)]存储于求解记忆p,直到最后一个路径点ek和终点ed重合结束循环;
计算成功从起点到终点的路径中每个起点位置ei到终点的累积折减收益g(hi:k),并更新节点记忆n;
使用梯度下降更新θ,以最小化
本发明的有益技术效果是:
通过gps定位骑行的实时情况,针对观景、锻炼等不同用户的需求,根据骑行经验,给出合理的骑行路径,能为骑行者爱好者提供科学的运动指导,根据用户需求以及骑行经验帮助用户选择骑行方案,统筹兼顾,优化路程,增添了骑行运动的乐趣,提高骑行体验,有利于推广绿色出行。
通过约束深度强化学习(cdrl)算法计算与骑行模式对应的最优路径,该算法主要由路径约束和深度q-learning算法两个阶段组成。在第一阶段,生成起点和终点之间可选择的约束路径,通过隐含的骑行者的经验对可选择的路段进行限制,在第二阶段,设计深度q-learning算法学习骑行者经验,根据出发时间在线计算给定最优路径。该方案在线计算用时短,计算效率高。
附图说明
图1是本发明一个实施例提供的限制性骑行路径规划装置的结构示意图。
图2是本发明一个实施例提供的限制性骑行路径规划方法的流程图。
图3是本发明一个实施例提供的路径点采集数据图。
图4是本发明一个实施例提供的路径规划状态转移图。
具体实施方式
下面结合附图对本发明的具体实施方式做进一步说明。
图1是本发明一个实施例提供的限制性骑行路径规划装置的结构示意图,如图1所示,该装置可以包括主机电路和从机电路,主机电路和从机电路通过无线通信连接;主机电路包括主机控制器、定位接收器、记录设备,主机控制器分别与定位接收器和记录设备连接;从机电路包括从机控制器、交互输入设备、交互显示设备,从机控制器分别与交互输入设备和交互显示设备连接;定位接收器用于定位帧数据中的经度数据和纬度数据,并对各个路径点进行标记;记录设备用于记录和存储位置数据;交互输入设备用于输入骑行目的地;交互显示设备用于显示用户的实时位置和骑行路径。
示例性的,主机控制器和从机控制器采用stm32f103vet6单片机,定位接收器是ublox-neo-6m模组和stm32f103vet6上自带的at24c02eeprom模块,其中,ublox-neo-6m模组作为gps信号分析处理模组,at24c02存储gps配置信息,保证gps掉电配置不丢失,ublox-neo-6mgps模组上带有usb接口,支持直接连接到上位机,借用上位机软件对模组直接进行配置与数据信息读取,定位接收器与stm32f103vet6的12c/usart接口连接;记录设备采用microsd卡,microsd卡上的位置信息在更改格式为kml之后,可以使用googleearth对运动轨迹进行地图绘制,便于用户对骑行运动查看,记录设备与stm32f103vet6的spi1接口连接;交互输入设备采用按键模块,交互输入设备与stm32f103vet6的gpio接口连接;交互显示设备采用带ili9341控制器的tfl液晶屏。
尽管图中未示出,主机电路还包括第一无线通信模块,第一无线通信模块与主机控制器连接,从机电路还包括第二无线通信模块,第二无线通信模块与所述从机控制器连接;第一无线通信模块和第二无线通信模块用于实现主机电路和从机电路之间的无线通信。
示例性的,第一无线通信模块和第二无线通信模块采用stm32f103vet6单片机上自带的esp8266wifi模块。
本发明实施例还提供一种限制性骑行路径规划方法,应用于如图1所示的限制性骑行路径规划装置中,如图2所示,该方法可以包括以下步骤:
步骤1,确定预定区域内的各个路径点。
路径点为至少两条道路的交汇点。
步骤2,采集各个路径点的经纬度数据,记录各个路径点的海拔高度,对每个路径点预设风景评分,将每个路径点的经纬度数据、海拔高度、风景评分对应存储。
风景评分考虑到时间、天气、季节等因素,因此风景评分可以是动态变化的。
步骤3,接收用户选择的起点和终点,对于每个行驶路段,获取同时间段内gps数据中其他骑行者的所有骑行路径,确定出起点与终点之间的所有待选路径集合。
待选路径集合包括有向路段集、每条待选路径的最大海拔差集和每条待选路径的综合风景评分集。
首先进行模型假设,假设每条路径的骑行时间是随机变量,假设所测数据真实可靠,假设不同路径的客观值和用户需求值相互独立。
由于骑行单车gps数据的稀疏性和低采样率,很多地方之间不能获取足够的信息来推断出行的路径,但是骑行者的经验同样隐藏在行驶路径中,因此可以通过学习该行驶路径来学习骑行者骑行经验。
对于最优路径选择的问题,需要生成骑行路径选择集,在实际中,骑行者往往只选择起点至终点的若干条路径行驶,即可选择的路径存在一定约束,为了避免生成的路径选择集遗漏重要的路径,并且生成路径集满足约束,因此根据同时间段内所有骑行者的骑行路径确定待选路径集合。
步骤4,接收用户选择的骑行模式。
骑行模式包括最短距离模式、风景最优模式、锻炼身体模式。
步骤5,根据用户选择的骑行模式,通过约束深度强化学习算法确定出对骑行模式对应的目标路径。
采用深度q-learning算法来估算q值,q值即骑行者在起点位置选择路段的最大累积折减收益。在深度q-learning算法中,使用深度神经网络作为状态映射到q值的函数近似器。本实施例使用的bp神经网络中,将出行者起点位置的状态特征作为输入,输出起点到终点的骑行时间。
在第一种可能的实现中,骑行模式为最短距离模式,通过约束深度强化学习算法确定出对骑行模式对应的目标路径,包括:待选路径集合w中包括所有路径点组成的路径点集e和有向路径集a,用户的起点位置ei为路径点集e中的第i个路径点,将用户的起点位置ei的状态特征表示为s(ei)=[xi,yi,xd,yd],xi表示起点的经度,yi表示起点的纬度,xd表示终点的经度,yd表示终点的纬度;起点位置ei到终点的骑行时间用q(s(ei))表示,将起点位置ei的状态特征s(ei)输入bp神经网络得到起点到终点的骑行时间q(s(ei));用户在待选路径集合g中所在路径点ei+n∈e,ei+n表示在起点位置ei后的第n个路径点,与起点位置ei相连接的所有路段ai,j组成起点位置ei的有向路径集a(ei);奖励函数r(ei,ai,i+1)表示用户在起点位置ei选择路段ai,i+1的骑行时间q(s(ei));根据骑行经验执行贪婪策略π和环境交互得到由所在路径点、选择的相邻路段和骑行时间组成的求解:hi:k=ei,ai,i+1,r(ei,ai,i+1),ei+1,ai+1,i+2,...,ek,ek表示终点之前所经过的最后一个路口,即路径点集e中的第k个路径点;当完成一次求解,q值发生更新,将求解中用户在起点位置ei以及之后经过的每个路径点表示为[s(ei),ai,i+1,r(ei,ai,i+1),s(ei+1)]存储于求解记忆p中;当每次完成成功求解时,计算成功求解中每个起点位置ei到终点位置的累积折减收益g(hi:k);定义节点记忆n={[s(ei),q(ei)|ei∈e,q(ei)=ming(hi:k)]},二元组s(ei),q(ei)存储起点位置ei的状态特征和起点到终点的最短骑行时间;采用深度q-learning算法,神经网路的训练通过最小化起点位置ei到终点的最短骑行时间q(ei)和起点位置ei到终点的骑行时间估计值q(s(ei))误差平方和,即
在第二种可能的实现中,骑行模式为风景最优模式,通过约束深度强化学习算法确定出对骑行模式对应的目标路径,包括:根据骑行经验设定风景评分初始值g0,待选路径集合w中包括所有路径点组成的路径点集e、有向路径集a、每条待选路径的综合风景评分集g,用户的起点位置ei为路径点集e中的第i个路径点,将用户的起点位置ei的状态特征表示为s(ei)=[xi,yi,xd,yd],xi表示起点的经度,yi表示起点的纬度,xd表示终点的经度,yd表示终点的纬度;起点位置ei到终点的骑行时间用q(s(ei))表示,将起点位置ei的状态特征s(ei)输入bp神经网络得到起点到终点的骑行时间q(s(ei));用户在待选路径集合g中所在路径点ei+n∈e,ei+n表示在起点位置ei后的第n个路径点,与起点位置ei相连接的所有路段ai,j组成起点位置ei的有向路径集a(ei);奖励函数r(ei,ai,i+1)表示用户在起点位置ei选择路段ai,i+1的骑行时间q(s(ei));根据骑行经验执行贪婪策略π和环境交互得到由所在路径点、选择的相邻路段和骑行时间组成的求解:hi:k=ei,ai,i+1,r(ei,ai,i+1),ei+1,ai+1,i+2,...,ek,ek表示终点之前所经过的最后一个路口,即路径点集e中的第k个路径点;当完成一次求解,q值发生更新,将求解中用户在起点位置ei以及之后经过的每个路径点表示为[s(ei),ai,i+1,r(ei,ai,i+1),s(ei+1)]存储于求解记忆p中;当每次完成成功求解时,计算成功求解中每个起点位置ei到终点位置的累积折减收益g(hi:k);定义节点记忆n={[s(ei),q(ei)|ei∈e,q(ei)=ming(hi:k)]},二元组s(ei),q(ei)存储起点位置ei的状态特征和起点到终点的最短骑行时间;采用深度q-learning算法,神经网路的训练通过最小化起点位置ei到终点的最短骑行时间q(ei)和起点位置ei到终点的骑行时间估计值q(s(ei))误差平方和,即
示例性的,风景评分满分10分,根据骑行经验设定风景评分初始值为5。
在第三种可能的实现中,骑行模式为锻炼身体模式,通过约束深度强化学习算法确定出对骑行模式对应的目标路径,包括:设每条待选路径的最低点el海拔为zl,最高点eh海拔为zh,海拔差最大值为z,待选路径集合w中包括所有路径点组成的路径点集e、有向路径集a、每条待选路径的最大海拔差集z,用户的起点位置ei为路径点集e中的第i个路径点,将用户的起点位置ei的状态特征表示为s(ei)=[xi,yi,xd,yd],xi表示起点的经度,yi表示起点的纬度,xd表示终点的经度,yd表示终点的纬度;起点位置ei到终点的骑行时间用q(s(ei))表示,将起点位置ei的状态特征s(ei)输入bp神经网络得到起点到终点的骑行时间q(s(ei));用户在待选路径集合g中所在路径点ei+n∈e,ei+n表示在起点位置ei后的第n个路径点,与起点位置ei相连接的所有路段ai,j组成起点位置ei的有向路径集a(ei);奖励函数r(ei,ai,i+1)表示用户在起点位置ei选择路段ai,i+1的骑行时间q(s(ei));根据骑行经验执行贪婪策略π和环境交互得到由所在路径点、选择的相邻路段和骑行时间组成的求解:hi:k=ei,ai,i+1,r(ei,ai,i+1),ei+1,ai+1,i+2,...,ek,ek表示终点之前所经过的最后一个路口,即路径点集e中的第k个路径点;当完成一次求解,q值发生更新,将求解中用户在起点位置ei以及之后经过的每个路径点表示为[s(ei),ai,i+1,r(ei,ai,i+1),s(ei+1)]存储于求解记忆p中;当每次完成成功求解时,计算成功求解中每个起点位置ei到终点位置的累积折减收益g(hi:k);定义节点记忆n={[s(ei),q(ei)|ei∈e,q(ei)=ming(hi:k)]},二元组s(ei),q(ei)存储起点位置ei的状态特征和起点到终点的最短骑行时间;采用深度q-learning算法,神经网路的训练通过最小化起点位置ei到终点的最短骑行时间q(ei)和起点位置ei到终点的骑行时间估计值q(s(ei))误差平方和,即
示例性的,如图3所示,其示出了采集预定区域内的路径点,假设用户确定起点和终点分别为医学院和三食堂,根据图3中的路径点和骑行经验依次生成图4所示的状态转换图,用户可以自行选择不同模式的最优路径。当起点选择为医学院,终点为三食堂时,cdrl算法根据骑行经验,在医学院选择下一个骑行地点,由此类推,直至到达三食堂,生成多条路径,用户根据自身需求选择适合的路径。
以上所述的仅是本发明的优先实施方式,本发明不限于以上实施例。可以理解,本领域技术人员在不脱离本发明的精神和构思的前提下直接导出或联想到的其他改进和变化,均应认为包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!