基于IMF能量矩和遗传算法优化SVM的储能电池过充诊断方法与流程
本发明涉及一种基于imf能量矩和遗传算法优化svm的储能电池过充诊断方法,属于储能电池故障监测领域。
背景技术:
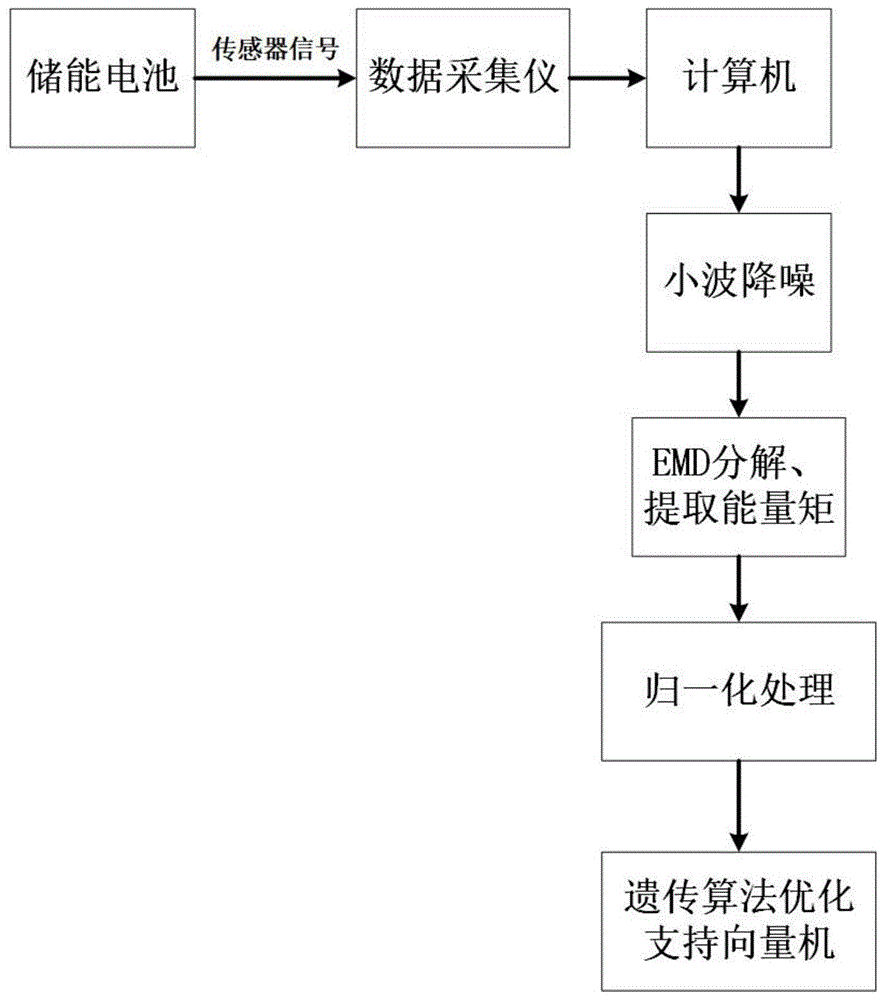
:在智能电网建设背景下,储能电池已经成为保证电网安全、稳定、高效运行的关键性技术,在削峰填谷、平抑波动、提升供电质量方面发挥着重要作用。当前锂电池已经在电网储能系统中得到了广泛应用,但是储能电池在运行过程中存在安全问题,尤其在大规模储能领域,常需要通过串并联将大量单体组成电池组、电池包,极大地增加了系统的复杂程度,增加了运行的安全隐患。鉴于过充电是引起电池单体内部温升进而引发爆炸的重要原因,因此,有必要对电池过充状态进行诊断识别。目前常用的故障诊断手法主要有建立电池模型诊断电池状态,这种方法通过建立电池模型,寻找电池各项参数的数学关系来表现电池内部的化学反应,以各项参数是否超过预先设定阈值作为判断故障的依据,但这种方法对于电池模型的精度、可靠性要求非常高,且需要单独实验测试才能确定。另一种常用方法是采集电池的电压、电流、温度数据,利用神经网络进行建模,但想要使神经网络具有良好的故障诊断能力,需要获取大量的典型数据对其进行训练,对样本数据密度以及质量要求高。同时,电压、电流、温度与电池内部故障并没有严格对应关系,因此需要研究更能直接反映电池故障的特征量。技术实现要素:本发明的目的是克服现有技术中的不足,提供了一种基于imf能量矩和遗传算法优化svm的储能电池过充诊断方法,提取振动信号数据进行分析,能够精准识别储能电池过充故障。为了解决上述技术问题,本发明是通过如下方案实现:步骤一、将加速度传感器粘附于储能电池单体表面正中央处,通过设定不同的充电截止电压实现电池的正常充电和过充电两种不同状态,采集振动信号构成原始信号;步骤二、对原始信号进行小波降噪处理,这种降噪方法既能够有效去噪又能够保留大部分有用信号,具体实现方法为:利用matlab的函数ddencmp()获取信号的默认阈值,再利用函数wdencmp()对原始信号进行降噪,其中参数选取为:db3小波、分解层数2层;步骤三、对降噪后的信号进行经验模态分解,对各本征模函数(imf)分量分别计算其能量矩后再进行归一化处理获得特征向量组成的数据集,具体步骤如下:1、用emd分解信号,得到若干本征模函数(imf)zi(t),i=1,2,……;2、对于离散信号,每一个imf能量矩利用下式计算:式中,δt为采样周期,n为总的采样点数,j为采样点;3、按下式归一化计算得到能量矩特征向量:步骤四、利用步骤三中获得的数据集训练支持向量机模型,其中核函数选择rbf核,并利用遗传算法求解核函数参数和惩罚因子的最优解;步骤五、获取待诊断状态下的信号的特征向量,利用上述建立好的模型进行诊断,判断储能电池是否处于过充状态。与现有技术相比,本发明的有益效果是:振动量是有效反映电池状态的量,实际测到的电池表面振动信号为非平稳信号,本发明采用经验模态分解(emd)方法分析信号,该方法对非平稳信号具有较强适应性,能有效分析振动信号;本发明选取imf能量矩作为特征指标,imf能量矩是imf分量基于时间轴积分得到,其体现了imf分量的能量在时间轴上的分布特点,能有效反映出信号的特征;本发明采用的遗传算法优化支持向量机模型在解决小样本分类问题方面具备优势,同时利用遗传算法可以获取模型最优参数,能够有效提高识别率;本发明对储能电池过充故障诊断准确率可以达到100%,是对储能电池故障诊断手段的有力补充,大大提高了储能电池安全运行的可靠性。附图说明图1是本发明的整体流程图;图2是本发明实例的60组训练样本下得到的遗传算法优化支持向量机模型对60组测试样本分类测试图。具体实施方式下面结合附图与实例对本发明的具体实施进一步说明。步骤一、考虑到储能电站大多选用磷酸铁锂电池,选取某电池厂家的容量为50ah,充电截止电压为3.65v,放电截止电压为2v的磷酸铁锂电池进行实验,分别设定充电截止电压为3.65v和5v以满足电池处于正常充电和过充电两种状态下,将加速度传感器放置于电池单体表面正中央,在两种状态下分别采集振动信号,采样频率为20khz,每组采样时间为1s,共得到120组样本数据,其中正常状态样本72组,过充状态样本48组。步骤二、利用小波降噪对原始信号进行降噪,优选地,选取db3小波,分解层数为2层。步骤三、利用emd方法对处理后的信号分解,提取分解出的imf分量的能量矩并进行归一化处理,得到特征向量数据集,同时定义正常状态用“1”表示,过充状态用“2”表示,最终得到一个120*10的矩阵,每一行为一个样本,前9列为特征向量各属性值,第10列为样本标签。限于篇幅,此处只列出正常状态和过充状态下前二组的特征向量的前三个分量,如表1所示:表1组别/分量12310.00400.01350.023620.00480.01370.0176……………………730.00170.02860.1931740.00160.02740.1382步骤四、随机选取60组样本作为训练样本,训练支持向量机模型,该模型核函数选择为rbf核,并利用遗传算法确定其惩罚因子和核函数参数,最终得到本实例中参数的最优组合为(1.00012,39.1086),至此,模型建立。步骤五、为验证模型效果,选取剩下的60组样本作为测试样本,输入上述模型进行检验,模型检验分类测试图如附图2所示,本实例中识别率达到了100%。本发明中涉及的未说明部分与现有技术相同或采用现有技术加以实现。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1