一种基于深度学习的视觉里程计及里程方法与流程
本发明涉及轨道交通技术领域,具体涉及一种基于深度学习的视觉里程计及里程方法。
背景技术:
轨道交通领域的里程计量通常依赖于对车轮旋转的计数,由于车轮半径存在机械误差,且在运行时尤其是启动、刹车和转弯时出现车轮打滑及空转现象,车轮计量里程的方式通常会带来难以消除的累计误差。视觉里程基于对现场环境的实际记录,可以像人眼一样观察车辆行进的速度和方向,以确定实际里程位置,几乎不产生累计误差。
视觉里程技术广泛应用于自动驾驶、环境感知及地图测绘等领域。常用的视觉里程方法通常包括对特征点的识别、筛选、及分析比对。其缺点是对场景的要求较高,需要场景具有较多可被识别的特征点信息。然而对于一些光线较为昏暗,环境特征信息量较小,场景重复性强的环境,如轨道交通隧道中,前后帧中的特征极为相似,难以进行特征点的匹配。
技术实现要素:
本发明的目的在于针对现有技术的缺陷和不足,提供一种设计合理的基于深度学习的视觉里程计及里程方法,其能够轨道交通隧道环境下稳定运行并实现较高精度的测量,将累计误差缩小到规定值。
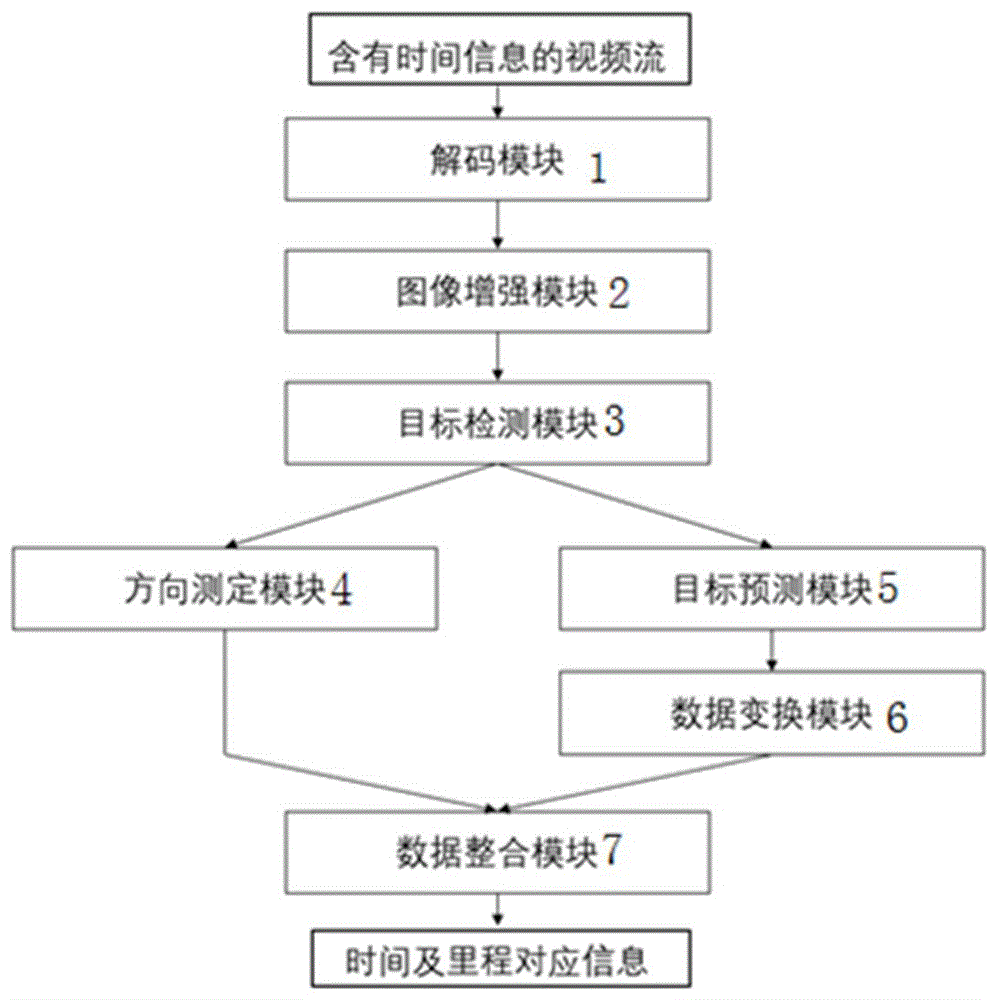
为达到上述目的,本发明所述的一种基于深度学习的视觉里程计:它包含解码模块、图像增强模块、目标检测模块、方向测定模块、目标预测模块、数据变换模块和数据整合模块;解码模块与图像增强模块连接,图像增强模块与目标检测模块连接,目标检测模块分别与方向测定模块和目标预测模块连接,目标预测模块与数据变换模块连接,方向测定模块以及数据变换模块均与数据整合模块连接。
本发明所述的一种基于深度学习的视觉里程方法,它的步骤如下:
步骤一、将含有时间信息的视频流利用解码模块解码为带有时间戳的图片流;
步骤二、利用图像增强模块对解码后的带有时间戳的图片流进行图像增强;
步骤三、利用目标检测模块对增强后的带有时间戳的图片流进行目标检测;
步骤四、利用方向测定模块对目标检测后的结果进行分析,并测定方向;
步骤五、利用目标预测模块对目标检测的结果进行分析,并对未检测出的目标进行预测;
步骤六、利用数据变换模块对检测与预测目标进行分析,经过数据变换,得到里程信息;
步骤七、利用数据整合模块将步骤四和步骤六中的方向和里程信息进行整合。
进一步地,所述的图像增强模块基于深度学习针对轨道交通系统隧道环境进行训练,并根据实际隧道环境对图片进行亮度及对比度调整,以提高轨枕和道钉等标志物与周围环境之间的对比度,同时对里程标和标志牌荧光产生的过曝进行优化,以便于对其上喷涂内容的识别。
进一步地,所述的目标检测模块基于深度学习进行对轨枕、道钉、里程标、标志牌以及配电箱等标志物进行目标检测。
进一步地,所述的方向测定模块定位方向的方向标志物包括里程标、标志牌以及配电箱,在多帧间动态查找相关联的方向标志物,并对其进行位置信息比对以确保方向定位的实时准确性。
进一步地,所述的目标预测模块在单帧图像中,对左右道钉进行对照,对未检出的单侧道钉和轨枕进行预测。
进一步地,所述的目标预测模块在单帧图像中,对前后轨枕进行对照,根据几何关系变换,对未检出的轨枕进行预测。
进一步地,所述的目标预测模块在多帧图像间,基于帧间隔时间内列车速度不变的原则,对连续大于等于三帧图像进行比对,对未检出的轨枕进行预测。
进一步地,所述的数据变换模块对步骤五中的预测结果和步骤三中的检测结果进行比对和合并,在连续两帧间比对像素位置信息,根据现实中轨枕间的尺度信息,得出里程数据。
进一步地,所述的数据整合模块对步骤四中的方向信息和步骤六中的里程数据进行积分计算,同时根据里程标分析结果进行修正。
采用上述结构后,本发明的有益效果是:本发明提供了一种基于深度学习的视觉里程计及里程方法,其能够轨道交通隧道环境下稳定运行并实现较高精度的测量,将累计误差缩小到规定值。
附图说明:
图1是本发明中视觉里程计的模块图。
图2是本发明中目标检测模块工作流程图。
图3是本发明中目标预测模块工作流程图。
附图标记说明:
解码模块1、图像增强模块2、目标检测模块3、方向测定模块4、目标预测模块5、数据变换模块6、数据整合模块7。
具体实施方式:
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本具体实施方式采用如下技术方案:它包含解码模块1、图像增强模块2、目标检测模块3、方向测定模块4、目标预测模块5、数据变换模块6和数据整合模块7;解码模块1与图像增强模块2连接,图像增强模块2与目标检测模块3连接,目标检测模块3分别与方向测定模块4和目标预测模块5连接,目标预测模块5与数据变换模块6连接,方向测定模块4以及数据变换模块6均与数据整合模块7连接;上述目标预测模块5针对轨道交通隧道中部分存在渗水、油污和低反射率等位置中目标检测无法识别的轨枕进行预测,基于同帧内轨枕分布规律,和多帧间存在的轨枕位置关系匹配,将大于一定置信度的位置筛选出,作为真实的轨枕进行计数和运算;上述数据变换模块6对目标检测的原始结果和预测结果进行合并,并以轨枕间距为基础,计算帧间经过的距离;上述数据整合模块7根据数据变换模块6和方向测定模块4输出的结果累计经过的里程,并根据目标检测模块5识别出的里程牌信息对里程位置进行校正,以消除部分累计误差。
本具体实施方式所述的一种基于深度学习的视觉里程方法,它的步骤如下:
步骤一、将含有时间信息的视频流利用解码模块1解码为带有时间戳的图片流;
步骤二、利用图像增强模块2对解码后的带有时间戳的图片进行亮度及对比度调整,以提高轨枕和道钉等标志物与周围环境之间的对比度,同时对里程标和标志牌荧光产生的过曝进行优化,以便于对其上喷涂内容的识别;
步骤三、利用目标检测模块3基于yolov3模型对轨道交通隧道内可能出现的样本训练模型,识别出的模型分为规律性目标:如道钉、轨枕,里程标和其他目标:如其他标志牌、配电箱等;经过置信度筛选后,记录识别框的类型、大小和位置,同时识别读取里程标内容和标志牌内容;将视野中不常出现的其他目标输入方向测定模块4,其通过比对该标志物在前后帧中的位置变化以确定轨道车运行的方向,将规律性目标输入目标预测模块5(参看图2);
步骤四、利用方向测定模块4基于对轨道车可双向行驶的特点,实时通过目标检测定位的标志物移动方向进行判断,以实时确定轨道车的运行方向;
步骤五、利用目标预测模块5对单帧和连续多帧进行比较和对照,对漏检样本进行预测以确保输出结果的准确性,其具体步骤如下:首先做帧内检查,将同一张图像中多个道钉和轨枕的位置封装为状态矩阵
步骤六、利用数据变换模块6对目标预测模块5输出的整合矩阵输入数据变换模块,将图像位置信息,基于轨道交通标准轨枕间距值,换算成实际里程距离;
步骤七、利用数据整合模块7将里程距离与方向测定模块4测定的方向整合,同时基于目标检测模块5检测出的里程标进行修正,以降低累积误差。
采用上述结构后,本发明的有益效果是:本发明提供了一种基于深度学习的视觉里程计及里程方法,其能够轨道交通隧道环境下稳定运行并实现较高精度的测量,将累计误差缩小到规定值。
尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!