一种基于PCA_CNNS的轴承故障诊断方法与流程
一种基于pca_cnns的轴承故障诊断方法
技术领域
1.本发明属于故障诊断领域,具体涉及一种基于卷积神经网络(pca_cnns)的轴承故障诊断方法。
背景技术:
2.目前,在木门生产领域中,对木门生产加工设备的故障诊断是研究的一个核心点,故障诊断的准确率与时效性是衡量木门加工设备健康评估的标准,反映当前设备的健康状态,准确及时的判断出故障源能让木门厂商快速做出应对从而保证生产经营效益。因此,对木门生产线关键设备的故障诊断是木门生产线柔性化、智能化研究的关键。
3.现阶段主流的故障诊断方法主要分为基于解析模型、基于定性经验知识的方法以及基于数据驱动的方法。基于分析模型的方法适用于能够建模、有足够传感器的“信息充足”的系统,需要过程较精确的定量数学模型,并且如果建立过程的数学模型则必须了解过程的机理结构,这对于复杂的多变量系统建模代价高,且建立的模型在解决同类问题上普适性较差在实际应用中具有局限性;基于经验知识的方法不适用于不能或者不易建立机理模型、传感器数不充分的“信息缺乏”的系统,对于海量数据的系统其使用成本过高;总结来说,常规基于分析模型以及基于经验知识的故障诊断模型算法对于故障诊断的不足之处主要有以下几点:
4.(1)对于动态的生产线过程数据,传统故障诊断方法不能及时挖掘数据深层次的特征信息,因其稳定性与实时性较差而难以满足实际生产环境的需求。
5.(2)对于海量过程数据输入的系统,其构建与使用成本过高。
6.(3)所构建模型泛化能力太低导致其在具体对象的故障诊断中准确率得不到保证。
技术实现要素:
7.本发明的目的在于提供了一种基于pca_cnns的轴承故障诊断方法,以解决在生产加工过程中关键设备的轴承故障诊断问题。
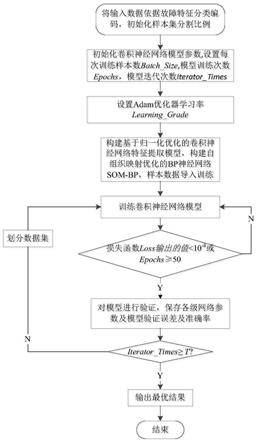
8.实现本发明目的的技术解决方案为:一种基于pca_cnns的轴承故障诊断方法,以完成对于轴承的故障诊断为目标,利用主成分分析法完成数据降维,采用自组织映射算法优化卷积神经网络模型,利用现有的轴承故障数据与分类完成模型训练,结合k折交叉验证选取最优表现模型,从而提升轴承故障诊断的准确率,具体包括如下步骤:
9.步骤1:利用主成分分析法提取输入的轴承数据集v中代表原始n维数据特征信息的m维主成分数据集w,将主成分数据集w按分割比例进行分割,分为训练样本集w
train
和测试样本集w
test
,其中m<n,转入步骤2。
10.步骤2:初始化卷积神经网络模型参数:
11.设置每次训练样本数batch_size、模型训练次数epochs和卷积神经网络模型迭代次数iterator_times,所述卷积神经网络模型包括特征提取器和分类器som
‑
bp,确定特征
提取器的多层次卷积层、激活层及池化层,转入步骤3。
12.步骤3:设置adam优化器学习率learning_grade,对特征提取器进行归一化,再利用自组织映射,优化bp神经网络得到som
‑
bp,设置交叉熵函数为损失函数loss,进而获得卷积神经网络,转入步骤4。
13.步骤4:利用训练样本集w
train
训练卷积神经网络,直至loss的值小于设定的阈值threshold或者epochs大于max_epochs,获得卷积神经网络模型,转入步骤5。
14.步骤5:将测试样本集w
test
输入卷积神经网络模型,计算卷积神经网络模型的误差error与准确率accuracy,保存各级网络参数,转入步骤6。
15.步骤6:判断卷积神经网络模型迭代次数iterator_times是否大于设定的最大迭代次数t:
16.若大于等于设定的最大迭代次数,则获得t组模型验证结果,转入步骤7;
17.若小于设定的最大迭代次数,则更新iterator_times的值,将w按步骤1中的分割比例进行重新分割,分为与步骤1中不同的训练样本集w
train
和测试样本集w
test
,返回步骤4。
18.步骤7:对比求解t组模型验证结果,选取其中准确率最高的模型作为输出模型。
19.本发明与现有技术相比,其显著优点在于:
20.(1)本发明提出了一种基于pca
‑
cnns的故障诊断方法,通过线性变换寻找m维主成分数据替换输入n维轴承数据,实现减少数据集的维数,同时保持数据集的对方差贡献最大的特征,实现数据的去冗余,降低了算法的运算量,利于实际工程运用。
21.(2)本发明提出一种利用t折交叉验证的方式对于pca_cnns算法流程进行优化,通过对于数据集的拆分以及对应模型的训练的方式,达到对比求取泛化能力最强及准确率最高的模型。
22.(3)本发明提出利用som
‑
bp神经网络作为pca_cnns算法的分类器,可以有效克服传统分类器参数冗余,空间结构的表达性不足的缺点,具有更高的训练收敛效率、更好的网络稳定性以及更高的故障诊断的准确率。
附图说明
23.图1为基于pca
‑
cnns的故障诊断方法流程图。
24.图2为t折交叉验证图(t=10)。
25.图3为cnns特征提取器网络层次图。
26.图4为som
‑
bp神经网络结构图。
27.图5为模型测试集误差收敛图。
具体实施方式
28.下面结合附图对本发明作进一步详细描述。
29.结合图1,本发明的一种基于pca
‑
cnns的故障诊断方法,包括以下步骤:
30.步骤1:利用主成分分析法pca提取输入的轴承数据集v中代表原始n维数据特征信息的m维主成分数据集w,其中m<n,将w按分割比例7:3进行分割,分为训练样本集w
train
和测试样本集w
test
,转入步骤2。
31.为了减少后期网络模型内部变量转移,提高网络的训练效率,增强网络的泛化能
力,本发明利用pca在轴承数据集输入对其进行降维,首先是通过奇异值分解计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值特征向量,将特征值按照从大到小的顺序排序,选择特征值最大的m个特征所对应的特征向量组成的矩阵。这样就可以将数据矩阵转换到新的空间当中,实现数据特征的降维。
32.步骤2:初始化卷积神经网络模型参数:
33.设置每次训练样本数batch_size、模型训练次数epochs和卷积神经网络模型迭代次数iterator_times,所述卷积神经网络模型包括特征提取器和分类器som
‑
bp,确定特征提取器的多层次卷积层、激活层及池化层,转入步骤3。
34.卷积层使用卷积核对输入信号(或特征)的局部区域进行卷积运算,并产生相应的特征。卷积层最重要的特点是权值共享,即同一个卷积核将以固定的步长(stride)遍历一次输入。权值共享减少了卷积层的网络参数,避免了由于参数过多造成的过拟合,并且降低了系统所需内存。具体的卷积层运算如下式所示:
[0035][0036]
y
l(i,j)
——第l层的第i个卷积核对第j个被卷积的局部区域进行卷积运算的结果。
[0037]
——第l层的第i个卷积核的第j'个权值。
[0038]
——第l层的第j个被卷积的局部区域。
[0039]
w——卷积核的宽度。
[0040]
经过卷积操作之后,激活函数将对每一个卷积输出的logits值进行非线性变换。激活函数的目的,是将原本线性不可分的多维特征映射到另一空间,在此空间内,特征的线性可分性将增强。鉴于利用误差反向传播来更新权值时,会出现梯度弥散现象,故采用relu函数作为激活函数以克服梯度弥散现象,relu激活函数表达式如下式所示:
[0041]
a
l(i,j)
=f(x
l(j+j')
)
[0042]
式中a
l(i,j)
——卷积层输出y
l(i,j)
的激活值。
[0043]
池化层进行的是降采样操作,主要目的是减少神经网络的参数,这里采用的降采样操作为最大值池化,这样可以获取位置无关的特征,其数学描述如下:
[0044][0045]
式中a
l(i,t)
——第l层第i帧第t个神经元的激活值。
[0046]
w——池化区域的宽度。
[0047]
p
l(i,j
——池化区域的输出值。
[0048]
步骤3:设置adam优化器学习率learning_grade,对特征提取器进行归一化,再利用自组织映射,优化bp神经网络得到som
‑
bp,设置交叉熵函数为损失函数loss,进而获得卷积神经网络,转入步骤4。
[0049]
3.1adam优化算法
[0050]
利用误差反向传播算法计算了目标函数每一个权值的导数之后,接着就是用优化算法来更新权值,求解出最优的权值,使得目标函数的值达到最小,这个过程用公式描述如下式所示
[0051]
θ
*
=argmin
θ
l(f(x
i
,θ))
[0052]
其中l(
·
)、f(
·
)——目标函数值与输出值。
[0053]
θ——卷积神经网络的所有参数。
[0054]
θ
*
——卷积神经网络的最优参数。
[0055]
x
i
——卷积神经网络的输入。
[0056]
对于本发明中提出的深度卷积神经网络,由于参数及超参数多,如果超参数选择不好,使用sgd训练时往往陷入局部最优点。因此,本文中采了adam是一种学习率自适应的优化算法,它利用梯度的一阶矩估计和二阶矩估计,动态调整每个参数的学习率。adam的优点主要在于经过偏置校正后,修正从原点初始化的一阶矩和二阶矩的估计,使得每一次迭代学习率都有个确定范围。
[0057]
3.2som
‑
bp
[0058]
利用som
‑
bp将特征提取器提取出的特征进行分类。先将最后一个池化层的输出,铺展成一维的特征向量,作为som
‑
bp的输入;样本数据进入som
‑
bp网络后,会根据样本向量与各竞争层神经元权值向量的欧式距离确定获胜神经元的位置,并根据获胜神经元的位置确定权值调整范围来更新网络连接权值,随着初级网络的不断迭代,训练样本会被分配到不同的竞争层神经元当中,即实现了对样本的初步分类在对训练样本完成初步分类的基础上进行次级网络的训练,其本质是为训练样本向量增加一个维度,并作为次级网络的输入。新增加的维度用于标记初级网络对样本的分类结果,对于次级网络的训练有很好的促进作用。理论上,可以有效降低次级网络,即bp神经网络的训练时间,使整个串联网络以更快的速度收敛。som
‑
bp神经网络结构如图4所示。
[0059]
3.3交叉熵函数
[0060]
由于平方误差函数是比较每一个类别的不同,而交叉熵函数是衡量两个概率分布的一致性,其在机器学习中常被看作是softmax分布的负对数似然,故本发明采用交叉熵函数作为目标函数。
[0061]
步骤4:利用训练样本集w
train
训练卷积神经网络,直至loss的值小于设定的阈值threshold或者epochs大于max_epochs,获得卷积神经网络模型,转入步骤5。
[0062]
步骤5:将测试样本集w
test
输入卷积神经网络模型,计算卷积神经网络模型的误差error与准确率accuracy,保存各级网络参数,转入步骤6。
[0063]
步骤6:判断训练后的卷积神经网络模型迭代次数iterator_times是否大于设定的最大迭代次数t:
[0064]
若大于等于设定的最大迭代次数,则获得t组模型验证结果,转入步骤7;
[0065]
若小于设定的最大迭代次数,则更新iterator_times的值,将w按步骤1中的分割比例进行重新分割,分为与步骤1中不同的训练样本集w
train
和测试样本集w
test
(此处包含的样本与步骤1中不一样),返回步骤4。
[0066]
t折交叉验证具体过程如下:首先将w分成t个不相交的子集,组成集合m,假设w中的训练样例个数为z,那么每一个子集有z/t个训练样例,相应的子集称作s
i
;每次从集合m取出一个s
j
,在训练子集中选择t
‑
1个子集(s1,
…
,s
j
‑1,s
j+1
,
…
,s
t
),迭代训练后得到模型,使用最后剩下的一份做测试得到模型准确率;重复进行t次得到t个结果,对比选取其中准确率最高的作为最终输出模型。t折交叉验证具体流程如图2所示。
[0067]
步骤7:对比求解t组模型验证结果,选取其中准确率最高的模型作为输出模型。
[0068]
实施例
[0069]
利用本发明所述基于pca
‑
cnns的故障诊断方法进行试验和模型仿真验证。
[0070]
本实验的实验对象为驱动端轴承,被诊断的型号为深沟球轴承skf6205,系统的采样频率为12khz。被诊断的轴承共有3种缺陷位置,分别为滚动体损伤,外圈损伤和内圈损伤,损伤直径的大小分别包括0.007inch,0.014inch和0.021inch,共九种损伤状态。
[0071]
步骤1:利用主成分分析法提取输入的轴承数据集v中代表原始n维数据特征信息的m维主成分数据集w,其中m<n,将w按分割比例7:3进行分割,分为训练样本集w
train
和测试样本集w
test
,转入步骤2。
[0072]
实验准备了12khz工况下的数据集,运用pca在原数据源中提取出10000条轴承在此工况下的运行数据;对于该一万条数据,使用one
‑
hot编码将其分为具有相对独立特征的类别,以此完成故障分类。
[0073]
实验通过选取t=10作为交叉验证的迭代次数,每次迭代以7:3的比例将数据集划分为训练样本集w
train
与测试样本集w
test
,将每次迭代生成的最终评价指标e
i
(测试集验证准确率)保存,迭代完成后选取准确率最高的模型作为输出模型。
[0074]
步骤2:初始化卷积神经网络模型参数:
[0075]
设置每次训练样本数batch_size、模型训练次数epochs和卷积神经网络模型迭代次数iterator_times,所述卷积神经网络模型包括特征提取器和分类器som
‑
bp,确定特征提取器的多层次卷积层、激活层及池化层,转入步骤3。
[0076]
其中设置每次训练样本数batch_size大小为128,模型训练次数epochs大小为50,并初始化卷积神经网络模型迭代次数iterator_times大小为1,体网络层次图如图3所示,表1为卷积神经网络模型的特征提取器具体参数。
[0077]
表1 pca
‑
cnns特征提取器结构参数表
[0078][0079]
步骤3:设置adam优化器学习率learning_grade,对特征提取器进行归一化,再利用自组织映射,优化bp神经网络得到som
‑
bp,设置交叉熵函数为损失函数loss,进而获得初始的卷积神经网络模型,转入步骤4。
[0080]
设置adam优化器学习率learning_grade大小为0.02,梯度的一阶矩衰减系数beta_1大小为0.9,二阶矩衰减系数beta_2大小为0.999,som
‑
bp的神经网络结构如图4所
示。
[0081]
步骤4:利用w
train
训练初始的卷积神经网络模型,直至loss的值小于设定的阈值threshold或者epochs大于max_epochs,获得训练后的卷积神经网络模型,转入步骤5;
[0082]
步骤5:将w
test
输入训练后的卷积神经网络模型,计算模型的误差error与准确率accuracy,保存各级网络参数;转入步骤6。
[0083]
步骤6:判断训练后的卷积神经网络模型迭代次数iterator_times是否大于设定的最大迭代次数t:
[0084]
若大于等于设定的最大迭代次数t,则获得t组模型验证结果,转入步骤7。
[0085]
若小于设定的最大迭代次数t,则更新iterator_times=iterator_times+1,将w重新按分割比例7:3进行分割,分为训练样本集w
train
和测试样本集w
test
,返回步骤4。
[0086]
步骤7:对比求解10组模型验证结果,选取其中准确率最高的模型作为输出模型。
[0087]
对于训练好的模型导入测试集进行测试,获取全连接层输出的结果作为故障诊断的诊断依据。最终模型训练结果如图5所示。其中loss曲线表示测试集在模型迭代训练过程中,其模型估计值与观测值的差异在不断减小;accuracy分别为诊断结果与实际结果相符合的准确率。分析可知,随着大量数据输入,模型的诊断准确率最终可高达98.3%。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1