一种共享单车骑行路线的智能推荐方法
本发明涉及智能交通领域,具体来说是一种共享单车骑行路线的智能推荐方法。
背景技术:
共享单车是以公用自行车为主体的一种分时租赁模式,主要内容为将大量公用自行车及少量电动车放置在校园、地铁站点、公交站点、居民区、商业区、公共服务区等人流涌动的区域提供服务。共享单车作为一种新兴的出行方式,以其方便、迅捷、低价的公共交通特征和绿色、节能、健康的优点,受到越来越多人们的青睐,被形象的称为完成了交通行业最后一块“拼图”,已然成为很多人短距离内的最佳出行选择。同时其可以有效解决公共汽车交通的“最后一公里”难题,也起到了缓解城市交通拥堵的重要作用,提升城市交通的整体服务水平。
但是在为广大市民和游客带来出行方便的同时,也存在着一些局限,例如用户在完全陌生的道路上骑行时很难进行路线规划,更不用提最优路线,而且不合理的路线选择会造成用户时间延误及骑行满意度的下降。在考虑因素方面,现市面上的导航对于用户骑行路线的推荐很大程度上依赖于一个单变量——骑行时间或骑行距离。国内外虽有一些研究进行了相关问题的探讨,增加了部分道路环境因素如红绿灯数量、路面坡度等对骑行者路线选择的考量,却较少联系国内实际交通情况,考虑非机动车道类型、路内停车段和道路等级等影响用户骑行安全性的因素对骑行者选择路线的影响。且在研究时,研究者通常选择的是传统的多项logit模型,但共享单车的实质上是为解决城市较短途出行问题,即用户骑行时的出行范围不会很大,会存在实际路径与可选路径集的路段重复现象,而传统的多项logit模型因为缺乏对路径重叠情况的考量,无法为用户推荐更加精确的路径。
技术实现要素:
本发明是为了解决上述现有技术存在的不足之处,提出一种共享单车骑行路线的智能推荐方法,以期能为共享单车用户推送一条令用户相对满意且安全系数较高的路线,提升用户的骑行体验,以达到共享单车出行畅行的目的。
本发明为达到上述发明目的,采用如下技术方案:
本发明一种共享单车骑行路线的智能推荐方法的特点包括如下步骤:
步骤1,收集多个共享单车用户历史骑行数据,建立原始数据集;所述原始数据集中的数据类型包括非机动车道类型x1、路内停车段x2、红绿灯数量x3、骑行距离x4、道路等级x5和路面坡度x6;
步骤2,根据用户n的历史骑行数据生成带有k条可选路径的可选路径集cn,并利用式(1)计算用户n从所述可选路径集cn中选择的路径i的重复系数psni:
式(1)中,ζi为路径i中所有路段的集合;la为路径i中路段a的长度;li为路径i的长度;若路段a在所述可选路径集cn中用户n未选的路径j上,则令σaj=1,否则,令σaj=0;
步骤3,根据用户n的历史骑行数据,假设用户n以路径效用最大化为原则选择路径,则利用式(2)构造路径i的效用函数uni:
uni=vni+εni(2)
式(2)中,vni为用户n选择骑行路径i后的路径效用值;εni为用户n选择路径i的随机效用误差,且服从相互独立的gumbel分布;并有:
式(3)中,β0为常数项,xm表示原始数据集中第m种数据类型的数据;βm表示第m种数据类型对用户骑行路线选择的影响系数;βps表示路径重复系数对用户骑行路线选择的影响系数;
步骤4,根据式(4)得到用户n选择可选路径集cn中路径i的概率值p(i|cn),从而可确定可选路径集cn中每条路径被选择的概率;
步骤5,根据用户历史评价、安全系数和骑行连续程度构建修正矩阵,用于修正概率值,以确定可选路径集cn中每条路径被选择的最终概率;
步骤5.1,获取其他用户对可选路径集cn中每条路径或路段的评价数据并取均值后归一化,得到可选路径集cn中每条路径或路段的平均评价分数:
步骤5.2,计算安全系数sni:
利用式(5)构造共享单车用户n骑行路径i的骑行时间t的危险率函数h(t|x):
h(t|x)=h0(t)g(x)(5)
式(5)中,h0(t)为骑行时间t的基准危险率,g(x)代表因素x对危险率的影响,并有:
g(x)=exp(β′1x1+β′2x2+β′3x3)(6)
式(6)中,β′1-β′3分别表示用户n的可选路径集cn中各条路径中非机动车道类型x1、路内停车段x2和红绿灯数量x3对骑行危险率的影响系数;
利用式(7)得到用户n选择路径i在骑行时间t后的安全系数sni,从而得到可选路径集cn中所有路径的安全系数:
步骤5.3,计算骑行连续程度con:
利用式(8)得到可选路径集cn中各条路径的骑行连续程度con:
logcon=β″0+β″3x3+β″5x5+β″6x6+ε(8)
式(8)中,β″0为常数项;β″3、β″5和β″6分别表示用户n的可选路径集cn中各条路径中红绿灯数量x3、道路等级x5和路面坡度x6对用户骑行连续程度con的影响系数;ε为骑行连续程度con的随机效用误差;
步骤5.4,构建修正矩阵:
有各路径的平均评价分数、安全系数、骑行连续程度与每条路径被选择的概率构成修正矩阵
步骤5.5,计算出每条路径被选择的最终概率;
利用式(9)确定可选路径集cn中每条路径被选择的最终概率,并将概率最大值作为最优路径推荐给用户;
[p1p2…pk]=[ω1ω2ω3ω4]·r(9)
式(9)中,pk为第k条路径被选择的最终概率;ω1为修正之前确定的每条路径被选择的概率所占权重;ω2为用户评价所占权重;ω3为安全系数所占权重;ω4为骑行连续程度所占权重,且ω1+ω2+ω3+ω4=1。
与现有技术相比,本发明的有益效果在于:
1、本发明通过考虑骑行距离、红绿灯数量、非机动车道类型、道路等级、路内停车段、路面坡度和路径重复系数这七个显著因素对共享单车用户骑行路径选择的影响,兼顾用户的骑行效率、骑行安全性及骑行连续程度,最后为用户推送概率最高的一条路线进行导航,辅助用户骑行,从而提升了用户的骑行体验,提高了出行效率和骑行安全性,有利于共享单车这种出行方式更能为大众所接受、使用、喜爱,以响应全民低碳生活的号召。
2、本发明通过结合国内道路的实际情况,如混行状态下其余车辆对骑行者的影响,增加更多用户对自身安全性的考虑。根据效用最大化理论,利用考虑路径长度的logit模型(path-sizelogit,psl)构造路径效用函数,从而得到考虑了路径重叠因素的路径选择模型。通过此模型可预测出用户选择系统所提供的各路线集的概率,考虑不同用户对于用户历史评价、骑行安全系数和骑行连续程度的关注程度,构建修正矩阵得到用户选择各路径集中路径的最终概率,最后为用户推送概率最高的一条路线进行导航,辅助用户骑行。由于考虑因素的广而全面,利用本发明得到的推荐路径精确度更高,构建的修正矩阵使最后的推荐路径具备个性化的特点,更能使用户满意,从而提升了用户的骑行体验。
附图说明
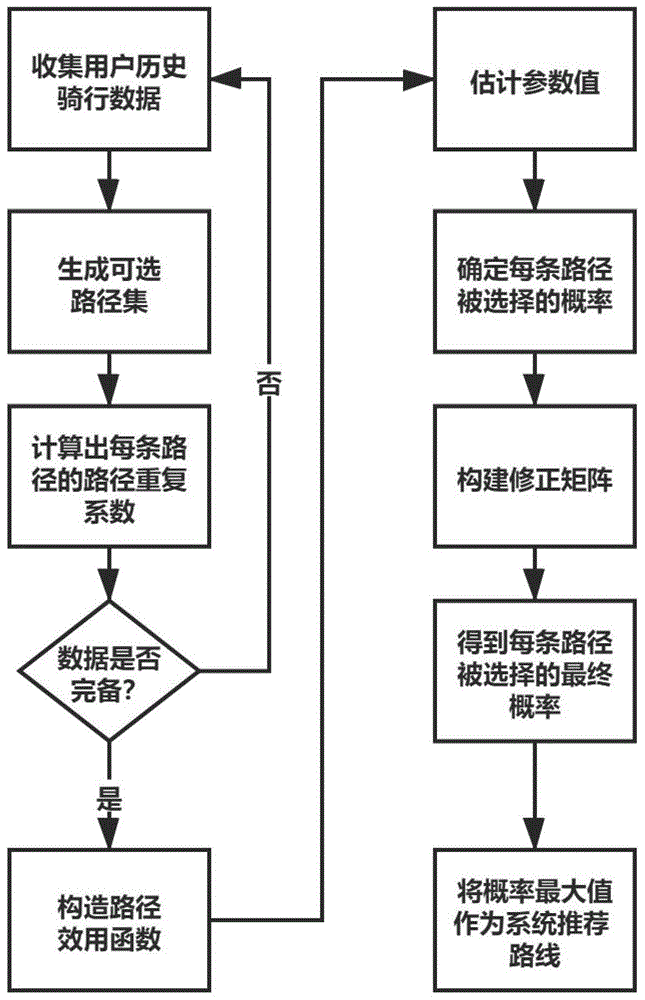
图1为本发明智能推荐方法的流程示意图;
图2为本发明确定每条路径被选择的最终概率的流程示意图。
具体实施方式
本实施例中,如图1所示,一种共享单车骑行路线智能推荐方法包括如下步骤:
步骤1,收集多个共享单车用户历史骑行数据,建立原始数据集;原始数据集中的数据类型包括非机动车道类型x1、路内停车段x2、红绿灯数量x3、骑行距离x4、道路等级x5、和路面坡度x6;因为上述解释变量都属于骑行时会遇到的实际路面情况,与骑行者的个人因素及社会因素相关性不大,故可以避免遗漏变量的偏差问题。
其中,非机动车道类型x1包括机非混行、标线非机动车道、栅栏隔离非机动车道和绿化隔离非机动车道四种类型,其类型的不同会影响用户的主观安全性。其中机非混行指不单独划分非机动车道,非机动车直接行驶在机动车道内,多出现在道路宽度较窄的路面,而标线、栅栏和绿化分别为我国所采用的三种不同的将非机动车道与机动车道分隔开的隔离设施;路内停车段x2指有机动车停车设施的路段,通常设有机动车停车设施的区域机动车需穿过非机动车道停车,有时还会出现将车停在非机动车道的情况,将会给骑行增添危险因素;红绿灯数量x3与用户骑行时需经过的路口数有很强的正相关,此数值间接反映了用户骑行时的连续性;骑行距离x4为用户从出发点到还车点的实际骑行路径长度;道路等级x5考虑城市中允许非机动车通行的道路,也兼顾了共享单车停车点大多位于居住区或工业区外侧这一特点,将道路等级分为主干路、次干路和支路三类,主干路是连接城市各分区的干路,以交通功能为主,机动车多且密集,行车速度平均为50km/h;次干路与主干路结合组成干路网,兼有集散交通和服务两种功能,机动车行车速度平均为40km/h;而支路指与次干路和居住区、工业区等内部道路相连接,用于解决局部地区的道路,常以服务功能为主,虽机动车较少但行人较多,机动车行车素的平均为30km/h;路面坡度x6反映了路面的骑行难度,使用共享单车的用户大部分都不是专业骑手,会更倾向于选择路面平缓且易骑的路径。上述用户骑行历史数据x1-x6可从共享单车公司、第三方app或大量实践调研获得。
步骤2,根据用户n的历史骑行数据生成带有k条可选路径的可选路径集cn;
可选路径集cn中的路径通常指用户可能选择的、不会发生不合理绕行行为的路径。生成的可选路径集的准确性直接关系到后续路径重复系数计算和用户骑行路径选择概率的预测。构造路径选择集通常可采用dijkstra算法、a*算法及分支限界算法等路径生成算法。需要说明的是,本方法可选路径集的确定需要在这些算法的基础上再做一些改动,以满足生成k条可选路径的要求。如在找到最短路径后,可考虑删去某一条边,得到新图后继续寻找新图中的最短路径,也即原图中的次短路径。重复操作可得到一系列次短路径构成用户n的可选路径集。路径选择范围默认为4km,但若可选路径集中最短路径仍大于4km,可合理扩大路径选择范围,建议可选路径集中总路径条数不超过7条。
步骤3,计算用户n从可选路径集cn中选择的路径i的重复系数psni:
路径重复系数是度量用户实际选择路径与可选路径集之间重复情况的变量,表现为用户面对大量骑行者的从众或规避行为,本方法利用式(1)进行计算:
式(1)中,ζi为路径i中所有路段的集合;la为路径i中路段a的长度;li为路径i的长度;若路段a在可选路径集cn中用户n未选的路径j上,则令σaj=1,否则,令σaj=0;
步骤4,根据用户n的历史骑行数据,假设用户n以路径效用最大化为原则选择路径,则利用式(2)构造路径i的效用函数uni:
uni=vni+εni(2)
式(2)中,vni为用户n选择骑行路径i后的路径效用值;εni为用户n选择路径i的随机效用误差,且服从相互独立的gumbel分布,对比正态分布或均匀分布,加入服从gumbel分布的εni可以使路径效用函数uni的拟合更接近真实情况,有利于提高后期的预测精度,并有:
式(3)中,β0为常数项,xm表示原始数据集中第m种数据类型的数据;βm表示第m种数据类型对用户骑行路线选择的影响系数;βps表示路径重复系数对用户骑行路线选择的影响系数;log(psni)表示路径重叠度,即路径i与可选路径集cn中其他路径的重叠程度;
根据步骤1中搜集的原始数据,利用excel将原始数据集按照可选路径集的条数k划分为不同的数据集。再利用stata统计分析软件,已得出骑行距离、红绿灯数量、非机动车道类型、道路等级、路内停车段、路面坡度和路径重复系数共计7个解释变量,p值均小于显著性水平0.05,即变量与被解释变量用户骑行路线的选择具有相关关系。还可通过最大似然函数估计法估计参数值β0,β1-β6,βps。将第一条路径作为基本选择项,即可构建出k个函数,即路径选择集中k条路径的路径效用函数。
步骤5,根据式(4)得到用户n选择可选路径集cn中路径i的概率值p(i|cn),从而可确定可选路径集cn中每条路径被选择的概率;
步骤6,根据用户历史评价、安全系数和骑行连续程度构建修正矩阵,用于修正概率值,以确定可选路径集cn中每条路径被选择的最终概率,其步骤如图2所示;
步骤6.1,获取其他用户对可选路径集cn中每条路径或路段的评价数据并取均值后归一化。其中,路径集中其余路径的评价分数用与该路径相关的路段评价分数替代,若该条路径缺少相关路段的评价分数则取满分,得到可选路径集cn中每条路径的平均评价分数:
步骤6.2,计算安全系数sni:
令t为连续时间变量,表示用户n选择路径i的骑行时间,选定非机动车道类型x1、路内停车段x2和红绿灯数量x3作为协变量,利用式(5)构造共享单车用户n骑行路径i的骑行时间t的危险率函数h(t|x):
h(t|x)=h0(t)g(x)(5)
式(5)中,h0(t)为骑行时间t的基准危险率,g(x)代表因素x对危险率的影响,即忽略x1-x3的影响,g(x)=1时的危险率;参考cox比例风险模型构造g(x)满足式(6):
g(x)=exp(β′1x1+β′2x2+β′3x3)(6)
式(6)中,β′1-β′3分别表示用户n的可选路径集cn中各条路径中非机动车道类型x1、路内停车段x2和红绿灯数量x3对骑行危险率的影响系数;
随着骑行时间的增长,安全系数会呈下降趋势,利用此关系构造式(7)得到用户n选择路径i在骑行时间t后的安全系数sni,从而得到可选路径集cn中所有路径的安全系数:
步骤6.3,计算骑行连续程度con:
利用式(8)得到可选路径集cn中各条路径的骑行连续程度con:
logcon=β″0+β″3x3+β″5x5+β″6x6+ε(8)
式(8)中,β″0为常数项;β″3、β″5和β″6分别表示用户n的可选路径集cn中各条路径中红绿灯数量x3、道路等级x5和路面坡度x6对用户骑行连续程度con的影响系数;ε为骑行连续程度con的随机效用误差;
步骤6.4,构建修正矩阵:
有各路径的平均评价分数、安全系数、骑行连续程度与每条路径被选择的概率构成修正矩阵
步骤6.5,计算出每条路径被选择的最终概率;
利用式(9)确定可选路径集cn中每条路径被选择的最终概率,并将概率最大值作为最优路径推荐给用户;
[p1p2…pk]=[ω1ω2ω3ω4]·r(9)
式(9)中,pk为第k条路径被选择的最终概率;ω1为修正之前确定的每条路径被选择的概率所占权重;ω2为用户评价所占权重;ω3为安全系数所占权重;ω4为骑行连续程度所占权重,其中ω1+ω2+ω3+ω4=1。
步骤7,方法的优化;
考虑到部分对道路熟悉的用户可能不需要路径推荐和一些特殊情况如用户临时更改目的地、用户中断骑行等。在实施本方法后需收集用户对于本方法推送路径或相关路段的评价,以方便后期修正矩阵的构建。并将用户实际选择路径与系统推荐路径进行对比,估算方法的准确性。同时将用户实际骑行数据进行命名入档,加入训练集,方便未来优化方法时使用分析。
- 还没有人留言评论。精彩留言会获得点赞!