一种麦克风阵列装置及基于该装置的移动声源可听化方法与流程
本发明涉及音讯处理技术领域,特别涉及一种麦克风阵列装置及基于麦克风阵列的移动声源可听化方法。
背景技术:
可听化是将采集到的或者合成的声音真实的回放给人听的过程。现有的可听化中,移动声源的合成技术主要分为两大类:正向模型和逆向模型。
正向模型需要知道声源的物理原理或者频域时域信息。现有的正向模型里面,主要有物理建模和经验公式两种方式。然而对于复杂声源,比如移动声源或者多零件的大型设备,物理模型很难准确建立。经验公式难以准确还原声源,而且并不是所有声源都有经验公式。除此之外,由于人耳的灵敏度非常高,直接通过正向模型合成的声音往往缺乏真实性。
逆向模型主要通过麦克风采集声音,进行对声音的还原,因而可以克服正向模型真实性不足的劣势。然而麦克风直接采集到的声音包含了空间中所有声源发出的声音,并且含有多普勒效应,不能直接用于波束成形或者可听化回放。波束成形又叫波束成型、空域滤波,是一种使用传感器阵列定向发送和接收信号的信号处理技术。
技术实现要素:
针对现有技术存在的不足,本发明的主要目的在于提供一种为移动声源可听化提供更真实的声源信号的麦克风阵列装置及基于麦克风阵列的移动声源可听化方法。
为实现上述目的,本发明提供了如下技术方案:一种麦克风阵列装置,包括支撑框架以及设置在支撑框架上的多个麦克风组,每个麦克风组均包括若干个麦克风,所述多个麦克风组在支撑框架上呈阿基米德螺线二维阵列设置。
优选的,多个麦克风在支撑框架上所占的区域大小为0.5x0.5m,相邻麦克风之间的距离为0.04~0.06m。
优选的,所述支撑框架为铝制框架。
一种基于麦克风阵列的移动声源可听化方法,包括如下步骤:
a、麦克风阵列采集经过噪声信号;
b、消除步骤a中所采集信号的多普勒效应;
c、将步骤b中消除掉多普勒效应的信号进行波束成形处理;
d、将步骤c中经过波束成形处理的信号进行频谱建模合成形成虚拟声源,实现移动声源可听化。
优选的,所述步骤c中,可利用波束成形聚焦于多个移动声源,定位各个声源的位置并还原声源信号。
优选的,所述步骤c中,将不同速度下还原信号提取出来的各个参数进行插值,实现声重建可预测没有测到的速度下的移动声源信号。
优选的,所述步骤d中,将波束成形的输出信号进行参数化,分别提取出纯音部分的振幅,频率和相位,噪声部分的包络,则可以合成任意长度的信号。
本发明相对于现有技术具有如下优点,本技术先通过消除多普勒效应技术去除麦克风阵列接收移动声源信号的多普勒效应,进而可以利用波束成形技术。波束成形可以滤除空间中非关注点的干扰声源,只聚焦于目标声源,从而优化逆向模型,为可听化提供更真实的声源信号。同时通过频谱建模合成方法,将还原的声源进行再合成,适用于不同的虚拟现实场景。
附图说明
图1为本发明的麦克风阵列装置的结构示意图;
图2为本发明的麦克风装置采集移动声源时的简化示意图;
图3为本发明的基于麦克风阵列的移动声源可听化方法的流程图。
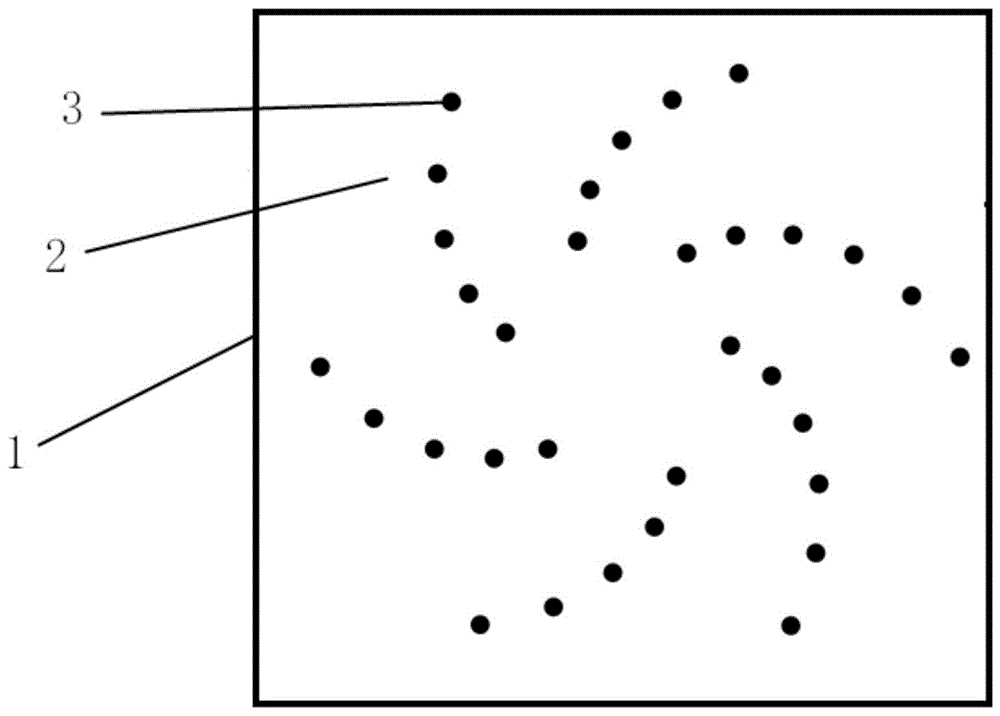
图中:1、支撑框架;2、麦克风组;3、麦克风;4.移动声源。
具体实施方式
下面结合附图对本发明作进一步说明。
如图1所示,一种麦克风阵列装置,包括支撑框架以及设置在支撑框架1上的多个麦克风组2,每个麦克风组2均包括若干个麦克风3,所述多个麦克风组2在支撑框架1上呈阿基米德螺线二维阵列设置。
优选的,多个麦克风3在支撑框架1上所占的区域大小为0.5x0.5m,相邻麦克风3之间的距离为0.04~0.06m。
优选的,所述支撑框架1为铝制框架。
本发明用到的麦克风3阵列为阿基米德螺线二维阵列,同等距规律排布的二维阵列相比,螺旋阵列具有能够限制最大旁瓣值、避免栅瓣的特点,能更精准定位移动声源4位置,从而真实还原声源信号。
阵列长宽均为0.5m,共32个麦克风3,麦克风3间距为0.04~0.06m,呈阿基米德螺线排布。支撑框架1为铝制框架,麦克风3位置被尼龙线圈住并固定,尼龙线两端固定在框架上,当然,也可以采用其它固定方式。32个麦克风3连接到同一数据采集设备,数据采集设备连接电脑,收集麦克风3采集到的数据。
使用时,将麦克风3阵列的中心点高度放置于和被测移动平面(物体)的水平面平齐(x轴),离被测平面移动轨迹1.5m。在移动平面经过阵列时,32个麦克风3采集声源发出的声音。之后进行消除多普勒、波束成形和频谱建模合成,定位声源位置并且合成声源信号。
一种基于麦克风3阵列的移动声源4可听化方法,包括如下步骤:
a、麦克风3阵列采集经过噪声信号;
b、消除步骤a中所采集信号的多普勒效应;
c、将步骤b中消除掉多普勒效应的信号进行波束成形处理;
d、将步骤c中经过波束成形处理的信号进行频谱建模合成形成虚拟声源,实现移动声源4可听化。
优选的,所述步骤c中,可利用波束成形聚焦于多个移动声源4,定位各个声源的位置并还原声源信号。
优选的,所述步骤c中,将不同速度下还原信号提取出来的各个参数进行插值,实现声重建可预测没有测到的速度下的移动声源4信号。
优选的,所述步骤d中,将波束成形的输出信号进行参数化,分别提取出纯音部分的振幅,频率和相位,噪声部分的包络,则可以合成任意长度的信号。
本发明将波束成形技术应用于移动声源4的定位和声音信号重建。首先对麦克风3接收到的信号进行消除多普勒效应处理,之后进行波束成形计算。将波束成形的输出参数化,结合频谱建模合成方法,在虚拟现实环境中生成移动声源4,用于可听化。
具体的,本技术先通过消除多普勒效应技术去除麦克风3阵列接收移动声源4信号的多普勒效应,进而可以利用波束成形技术。波束成形可以滤除空间中非关注点的干扰声源,只聚焦于目标声源,从而优化逆向模型,为可听化提供更真实的声源信号。同时通过频谱建模合成方法,将还原的声源进行再合成,适用于不同的虚拟现实场景。
消除多普勒效应:麦克风3采集移动声源4的经过噪声,信号中含有多普勒效应。由于波束成形的算法只适用于静止声源,为了利用波束成形,更准确定位移动声源4和还原声源信号,需要消除信号中的多普勒效应。本技术在时域消除多普勒效应,同频域的方法比,不需要近似声源的位置,消除多普勒效应之后的信号还原度更高。
波束成形技术:可以分别聚焦于多个移动声源4,从而定位各个声源的位置并还原声源信号,排除其他声源的干扰。还原出来的信号同直接录制的声音信号相比,不仅消除了多普勒效应,而且抑制了其他声源,更准确代表声源原始信号。
频谱建模合成:波束成形需要将各个麦克风3信号进行加窗处理,因此输出信号都很短。而且麦克风3阵列采集一次移动声源4的经过噪声,最终还原的只是该经过速度下的声音。在实际的可听化应用当中,需要模拟声源在不同运动速度下的声音,而且声音长度也要能灵活控制,尤其是在有实时交互的虚拟现实场景里。频谱建模合成方法可以解决以上的问题。将波束成形的输出信号进行参数化,分别提取出纯音部分的振幅,频率和相位,噪声部分的包络,则可以合成任意长度的信号。同时,将不同速度下还原信号提取出来的各个参数进行插值,可预测没有测到的速度下的移动声源4信号。
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!