表面分析装置的制作方法
1.本发明涉及一种用于调查试样上的一维或二维测定区域中存在的成分或元素的分布的表面分析装置。该表面分析装置包括电子射线显微分析仪(electron probe micro analyzer:epma)、扫描电子显微镜(scanning electron microscope:sem)、x射线荧光分析装置等。
背景技术:
2.在使用了epma的元素映射分析中,能够对试样上的二维区域内的大量的微小区域分别调查含有元素的种类及量。经常使用下面的方法、即相解析(或相分析):在对利用这样的元素映射分析得到的结果进行解析时,制作针对2个元素或3个元素的特征x射线强度的散布图、或根据该强度计算出的元素浓度的散布图(分别对2轴或3轴的各轴取元素的相对强度而成的图),并根据该图上的标记点的分布,确认试样中包含的化合物的种类、含有比例(参照专利文献1、2)。例如,专利文献2的图10示出了二元散布图的一例,该文献的图11示出了三元散布图的一例。
3.散布图上的1个点(下面,将散布图上标记的点称为“数据点”)与试样上的1个点(微小区域)对应。因而,散布图上的数据点密集的区域被估计为对应于试样上的以相同的比例包含含有元素的部位。因此,在相解析中,一般来说,分析者将散布图上的数据点密集的区域识别为1个簇、也就是说关联的数据点的集合,使用鼠标等指示设备来进行以多边形等适当的图形包围该区域的操作,还进行对每个该区域指定不同的显示色的操作。当完成了这样的操作时,在epma的显示装置的画面上显示相映射图,在该相映射图中,以指定的颜色对试样上的与1个或多个簇区域中包含的各数据点分别对应的位置进行了着色。
4.近年,伴随着ai(人工智能)技术的急速发展,尝试利用这样的技术来进行自动地将上述那样的散布图上的大量数据点分配至多个集合的处理。在这样的处理中,优选的是作为无监督机器学习的代表性的方法的聚类分析。对于聚类分析,已知各种算法的聚类分析,但是作为用于将散布图上的数据点根据其密度分为多个簇的方法,例如非专利文献1、2等中公开的基于密度的聚类分析(density-based clustering)是有效的。在图12中示出针对通过实测得到的二元散布图使用基于密度的聚类分析来自动地提取簇的例子。在该例中,可知提取出6个簇。
5.现有技术文献
6.专利文献
7.专利文献1:日本特开2006-125952号公报
8.专利文献2:日本特开2011-153858号公报
9.非专利文献
10.非专利文献1:ester m.等其他3人,“a density-based algorithm for discovering clusters in large spatial databases with noise”,proceedings of 2nd international conference on knowledge discovery and data mining(kdd-96),
pp.226-231,1996年
11.非专利文献2:ricardo j.g.b.campello等其他2人,“density-based clustering based on hierarchical density estimates”,springer,pp.160-172,2013年
技术实现要素:
12.发明要解决的问题
13.然而,在基于利用epma得到的数据制作出的散布图中,有时由于各种因素而产生数据点的不均匀、特异性的分布,因此,在应用了上述那样的现有的聚类分析方法的情况下有时会检测到伪簇。
14.例如,图4是示出自动地对基于实测结果制作出的二元散布图上的数据点进行聚类而得到的结果的图。图中,被多边形状的线包围的范围是自动地检测到的1个簇区域。在图中箭头所示的2个位置处,检测到多个沿纵向线状地延伸的小的簇,但是它们本来在各位置处分别被检测为一个大的簇是合适的。即,沿纵向线状地延伸的小的簇是伪簇。
15.另外,图8是示出自动地对基于实测结果制作出的三元散布图上的数据点进行聚类而得到的结果的图。图中,被多边形状的线包围的范围是自动地检测到的1个簇区域。由图8可知,在三元散布图中,有时连接成线状的数据点的集合放射状地出现,但是检测到多个包含该数据点的集合的一部分的、小范围的簇。它们中包含未必适合作为簇的簇,大多是伪簇。
16.本发明是为了解决上述问题而完成的,其主要目的在于提供一种能够抑制在自动地对散布图上的数据点进行聚类时检测到伪簇从而提高该聚类的精度的表面分析装置。
17.用于解决问题的方案
18.为了解决上述问题而完成的本发明所涉及的表面分析装置的第一方式具备:
19.测定部,其在试样上的多个位置处分别获取反映了作为分析对象的多个成分或元素的量的信号;
20.散布图制作部,其基于由所述测定部得到的测定结果来制作二元散布图;
21.聚类分析部,其使用基于密度的聚类分析的方法来对所述二元散布图中的数据点进行聚类;以及
22.参数调整部,其利用所述二元散布图中的某一方的成分或元素的信号值的分布信息,来调整距离阈值,所述距离阈值是在所述基于密度的聚类分析中应设定的参数之一。
23.另外,为了解决上述问题而完成的本发明所涉及的表面分析装置的第二方式具备:
24.测定部,其在试样上的多个位置处分别获取反映了作为分析对象的多个成分或元素的量的信号;
25.散布图制作部,其基于由所述测定部得到的测定结果来制作三元散布图;
26.数据点选择部,其利用与所述三元散布图中的数据点对应的将3个成分或元素的信号值相加而得到的相加信号值的分布信息,来从存在于该三元散布图上的全部数据点中排除该相加信号值相对小的规定的信号值范围的数据点;以及
27.聚类分析部,其使用基于密度的聚类分析的方法,来对所述三元散布图中的未被所述数据点选择部排除的数据点进行聚类。
28.本发明所涉及的第一方式及第二方式的表面分析装置例如是epma、sem、x射线荧光分析装置等分析装置。在这样的分析装置中,能够通过一边变更试样上的照射激发射线(电子射线、x射线等)的位置一边重复进行测定,来获取反映了试样上的二维区域或一维区域内的大量位置的各个位置处的多个元素的存在量的信号。
29.另外,在本发明所涉及的第一方式及第二方式的表面分析装置中,作为聚类分析方法,能够使用改进了一般的基于密度的聚类分析(density-based spatial clustering of applications with noise:dbscan)而得到的基于密度的层次聚类分析(hierarchical density-based spatial clustering of applications with noise)。
30.发明的效果
31.在基于密度的聚类分析中,距离阈值ε是用于聚类的重要参数,尤其在基于密度的层次聚类分析中,自动地根据散布图上的数据点的密度调整该阈值ε。如上述那样,在图4所示的二元散布图中,检测到多个沿纵向线状地延伸的伪簇。另一方面,该二元散布图中的位于下侧区域(fe的强度高的区域)的数据点的集合被适当地识别为1个簇。
32.在根据散布图上的数据点的密度进行推测时,在该二元散布图中的下侧区域,数据点的频数原本就不是很高,因此阈值ε被适当地设定,由此,认为被分类为1个簇的数据点间的距离变大。另一方面,在二元散布图中的上侧区域(fe的强度低的区域),数据点的频数与下侧区域相比非常高。如该例那样,在2个元素中的一方的元素(本例中为mn)的强度极低而该元素的数据的测定范围(作为测定结果的x射线强度的范围)窄的情况下,在一个方向(本例中为纵向)上数据点高密度地聚集,在其它方向(本例中为横向)上数据点离散地存在。因此,推测为:在通常的自动的参数调整的过程中,反映纵向的数据点极密集的状态地决定阈值ε,在横向上离散地出现的数据点的集合分别被误认为独立的簇。
33.与此相对,在本发明所涉及的表面分析装置的第一方式中,参数调整部利用二元散布图中的数据点处的某一方的元素的信号值的分布信息、也就是说表示该信号值的集中或离散程度的信息,来调整距离阈值ε的值。即,由于测定范围窄,因此参数调整部根据在散布图上的数据点的密度高时容易形成离散的线状的数据点集合的轴方向的数据点的信号值分布程度,来调整距离阈值ε。由此,能够以使在散布图上接近的多个离散的线状的数据点集合整体包含于1个簇的方式调整距离阈值ε,从而进行合适的聚类。
34.另外,在制作如图8所示的三元散布图时,如专利文献1中也记载的那样,需要针对三元散布图的每个数据点以3个元素的强度的合计值进行标准化。因此,在3个元素的强度比为相同程度的数据点大量存在的情况下,三元散布图上出现放射状地延伸的线状的数据点的分布。本发明人发现到:在检测到如图8所示那样包含线状的点分布的伪簇的情况下,3个元素的强度均小的数据点大量存在,该大量的数据点对放射状地延伸的线状的数据点分布的产生具有显著贡献。
35.与此相对,在本发明所涉及的表面分析装置的第二方式中,例如,作为与三元散布图中的数据点分别对应的将3个成分或元素的信号值相加而得到的相加信号值的分布信息,数据点选择部制作表示相加信号值阶梯与频数的关系的直方图。在如上述那样3个元素的强度均小的数据点大量存在的情况下,在上述直方图中的相加信号值小的位置处出现较大的峰。因此,数据点选择部从全部数据点中排除形成该峰的数据点。聚类分析部仅对剩余的数据点执行聚类。由此,在三元散布图中放射状地延伸的线状的数据点的分布消失,还避
免了检测到与其相伴的伪簇。
36.如上述那样,根据本发明所涉及的第一方式及第二方式的表面分析装置,能够抑制在自动地对散布图上的数据点进行聚类时检测到伪簇,从而提高该数据点的聚类的精度,也就是说,提高基于多个成分或元素的浓度进行的试样上的微小区域的聚类的精度。由此,用户例如能够准确且高效地进行基于散布图上的数据点的聚类结果的相解析。
附图说明
37.图1是作为本发明的第一实施方式的epma的主要部分的结构图。
38.图2是示出第一实施方式的epma中的聚类分析参数调整处理的一例的流程图。
39.图3是示出测定范围窄的元素的强度值的直方图的一例的图。
40.图4是示出自动地对二元散布图上的数据点进行聚类所得到的结果为检测到了伪簇的例子的图。
41.图5是示出针对图4所示的二元散布图上的数据点在调整聚类分析参数后进行聚类所得到的结果的图。
42.图6是作为本发明的第二实施方式的epma的主要部分的结构图。
43.图7是示出第二实施方式的epma中的相加强度值数据选择处理的一例的流程图。
44.图8是示出自动地对三元散布图上的数据点进行聚类所得到的结果为检测到伪簇的例子的图。
45.图9是示出相加强度值的直方图的一例的图。
46.图10是示出针对图9所示的相加强度值排除了强度值大的一侧的离群值之后的相加强度值的直方图的图。
47.图11是示出针对图8所示的三元散布图上的数据点实施相加强度值数据选择处理之后进行聚类所得到的结果的图。
48.图12是示出自动地对二元散布图进行聚类所得到的结果的一例的图。
49.附图标记说明
50.1:电子射线照射部;100:电子枪;2:试样台;3:试样;4:分光晶体;5:x射线检测器;7:试样台驱动部;8:分析控制部;9:数据处理部;90:元素强度计算部;91:数据保存部;92:散布图制作部;93:聚类分析参数调整部;94:聚类分析部;95:簇区域检测部;96:显示处理部;97:三元散布图制作部;98:相加强度值数据选择处理部;10:中央控制部;11:操作部;12:显示部。
具体实施方式
51.[第一实施方式]
[0052]
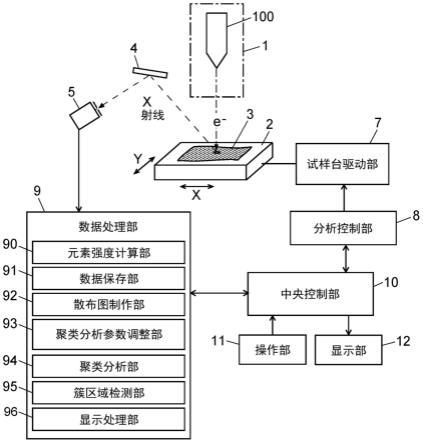
参照附图对作为本发明所涉及的表面分析装置的第一实施方式的epma进行说明。图1是第一实施方式的epma的主要部分的结构图。
[0053]
如图1所示,电子射线照射部1包括电子枪100、未图示的偏转线圈等,用于将微小直径的电子射线照射到试样台2上载置的试样3。试样3接受到该电子射线而从试样3的表面放出具有元素特有的波长的特征x射线。另外,还从试样3的表面放出二次电子等。
[0054]
从试样3放出的特征x射线被分光晶体4进行波长色散,利用x射线检测器5检测特
定波长的衍射x射线。试样3上的电子射线照射位置、分光晶体4以及x射线检测器5始终位于罗兰圆上,通过未图示的驱动机构来使分光晶体4一边直线地移动一边倾斜,x射线检测器5与该移动联动地转动。由此,以满足布拉格衍射条件的方式、也就是说在保持为特征x射线向分光晶体4入射的入射角与衍射x射线从分光晶体4出射的出射角相等的状态的同时,实现作为分析对象的x射线的波长扫描。由x射线检测器5得到的x射线强度的检测信号被输入到数据处理部9。
[0055]
能够通过试样台驱动部7使试样台2分别在相互正交的x轴、y轴这两个轴方向上移动,通过该移动来二维地扫描试样3上的电子射线的照射位置。另外,也能够不移动试样台2而在电子射线照射部1中使电子射线的射出方向偏转,由此扫描试样3上的电子射线的照射位置。
[0056]
数据处理部9包括元素强度计算部90、数据保存部91、散布图制作部92、聚类分析参数调整部93、聚类分析部94、簇区域检测部95以及显示处理部96等来作为功能模块。分析控制部8除了控制试样台驱动部7的动作之外,还控制使分光晶体4、x射线检测器5移动的驱动机构等的动作,以对试样3执行分析。中央控制部10承担装置整体的控制、输入输出处理,中央控制部10连接有显示部12以及包括键盘、鼠标(或其以外的指示设备)的操作部11。
[0057]
此外,例如,中央控制部10、分析控制部8以及数据处理部9的全部或一部分由个人计算机构成,通过该计算机执行安装于该计算机的专用的控制/处理软件,能够实现各个功能。
[0058]
在本实施方式的epma中进行元素映射分析的情况下,分析控制部8以如下方式使试样台驱动部7部等进行动作:与作为目标的元素的特征x射线波长对应地固定分光晶体4的位置,一边在试样3上的规定的(通常由分析者指定的)二维区域内以规定的顺序变更电子射线的照射位置(微小区域),一边重复进行特征x射线和二次电子的检测。而且,若完成了关于一个元素的强度分布的获取,则对其它目标元素执行同样的测定。
[0059]
元素强度计算部90针对试样3上的每个微小区域获取目标元素的强度(浓度)。该强度数据被保存于数据保存部91。此外,在使用了能量色散型x射线分光器的情况下,元素强度计算部90针对二维区域内的每个微小区域分别制作x射线谱,在该x射线谱上检测与目标元素对应的特定波长的峰,通过求出该峰强度,能够计算目标元素的强度(浓度)。
[0060]
当完成了针对试样3上的二维区域内的全部的微小区域的测定且分析者通过操作部11进行规定的操作时,散布图制作部92从数据保存部91中读取规定的数据,制作表示规定的2个元素的强度的关系的二元散布图。二元散布图上的各数据点分别与试样3上的微小区域对应。因而,例如若在试样3上针对1000个微小区域执行测定,则散布图上标记的数据点的数量为1000。
[0061]
聚类分析部94按照规定的算法针对所制作的散布图上的全部数据点执行聚类,对各数据点赋予表示属于一个或多个簇的哪一个簇或者是否不属于任何一个簇的标签。
[0062]
已知聚类分析有各种方法。一般地,在这样的散布图上的数据点的聚类中,利用数据点间的距离来进行聚类。在通过epma等的表面分析得到的散布图中,经常会产生数据点以极高密度存在的部分和数据点以低密度存在的部分。在数据点以高密度存在的部分中,若即使数据点间的距离相对短也不分离成独立的簇,则会形成数据点的数量极大的簇。相反,在数据点以低密度存在的部分中,若即使数据点间的距离相对长也不包含于同一簇,则
会大量形成数据点的数量极少的簇。为了应对这样的情况,在此,聚类采用非专利文献2中公开的基于密度的层次聚类分析的方法。该方法是对非专利文献1中公开的一般的基于密度的聚类分析进行了改进而得到的方法,根据本发明人的研究,能够十分良好地对由epma得到的散布图中的数据点进行聚类。
[0063]
在包含上述的基于密度的层次聚类分析的基于密度的聚类分析中,为了将散布图上的数据点的集合判定为簇,需要预先决定以下2个参数。
[0064]
(1)最小簇尺寸:判定为簇所需要的最小的数据点数量(构成1个簇的最小的数据点数量)。
[0065]
(2)距离阈值ε:用于将相邻的2个簇判定为不同的簇的距离阈值。自动地将距离比该阈值近的多个簇进行整合。
[0066]
为了在散布图上良好地进行簇的检测,需要将上述参数设定为合适的值。但是,由于用户(分析者)分别设定这些参数是很麻烦的,因此设为在厂商处将通过实验决定的数值作为默认值设定给各参数,并且用户能够手动地变更该数值。
[0067]
在二元散布图上反映的2个元素各自的强度范围比较近且测定范围(强度区间)为相同程度的情况下,即使使用默认值作为距离阈值ε,也能够进行大致合适的聚类。可是,如上述那样,在2个元素的存在量(浓度)具有较大的差异且存在量较少的元素的测定范围极窄的情况下,容易检测到由此产生的特征性的伪簇,若不根据数据点的空间性的分布来将距离阈值ε调整为合适的值,则无法将多个伪簇整合为1个。因此,实际上聚类分析参数调整部93在执行聚类分析之前,如下面那样调整距离阈值ε。图2是示出聚类分析参数调整处理的一例的流程图。
[0068]
首先,为了掌握测定范围较窄的元素(图4的例子中为mn)的强度值的分布状况,聚类分析参数调整部93制作该元素的强度值的直方图(步骤s1)。此时,适当地决定强度值的阶梯数t。图3中示出与图4所示的二元散布图上的数据点对应的直方图。在此,将阶梯数t设为1000。如图3所示,可知:反映了测定范围窄且仅离散地存在的数据点的直方图为特定的阶梯的频数极高且在多个特定的阶梯之间梳状地空开间隙的直方图。由于强度值的频数分布像这样示出特征性的倾向,因此二元散布图如前述那样检测到伪簇。
[0069]
在基于密度的聚类分析中,散布图上数据点的聚集度越高的部分、也就是说频数越高的部分越容易形成簇。因此,聚类分析参数调整部93在上述直方图中检测极大值、也就是说峰,找到与该峰对应的阶梯(步骤s2),并且,在表示该极大值的阶梯中确定频数最大的阶梯(步骤s3)。在图3中,以向下的箭头示出表示极大值的阶梯中的频数最大的阶梯。
[0070]
接着,聚类分析参数调整部93在直方图中,在表示最大的极大值的阶梯与阶梯位于其下侧(强度值比其小的一侧)且表示最近的极大值的阶梯之间,求出频数为0的阶梯的连续数nl(步骤s4)。另外,聚类分析参数调整部93同样在直方图中,在表示最大的极大值的阶梯与阶梯位于其上侧(强度值比其大的一侧)且表示最近的极大值的阶梯之间,求出频数为0的阶梯的连续数nu(步骤s5)。即,在表示最大的极大值的阶梯的两侧,分别求出频数为0的阶梯的连续数。
[0071]
之后,聚类分析参数调整部93将在步骤s4、s5中求出的连续数nu与连续数nl进行比较,将较大的一方决定为连续阶梯数n(步骤s6),判定该连续阶梯数n是否大于该时间点的距离阈值ε(步骤s7)。若连续阶梯数n为距离阈值ε以下,则不需要修正该阈值ε,因此维持
该值(步骤s9),并结束处理。另一方面,在连续阶梯数n大于距离阈值ε的情况下,聚类分析参数调整部93使用下面的式(1)来修正阈值ε的值(步骤s8),并结束处理。
[0072]
ε=(连续阶梯数n/全阶梯数t)+校正常数k
ꢀꢀꢀ…
(1)
[0073]
将校正常数k设为通过实验适当地决定的值即可,在此设为0.002。
[0074]
若使用式(1),则反映在表示最高频数的阶梯的前后存在的频数为0的区间的长度,在二元散布图中表示最高频数的阶梯中包含的数据点所集中的区域中被识别为独立的簇的距离变长。由此,容易将间隔距离小的多个簇整合为1个簇。
[0075]
之后,聚类分析部94将以如上述那样修正后的参数作为条件,对二元散布图上的数据点执行聚类。由此,对二元散布图上的各数据点赋予表示属于一个或多个簇的哪一个簇或者是否不属于任何一个簇的标签。由于在该状态下各数据点仅被单纯地赋予标签,因此难以视为在散布图中簇所占据的区域来处理。因此,簇区域检测部95例如使用凸包法等合适的方法来划定如包含属于各个簇的数据点的全部或大部分那样的多边形状的簇区域。此外,在图4所示的二元散布图中,沿纵向延伸的线状的簇区域以及在图中的下侧区域中绘制的包含大量数据点的矩形形状的区域也是通过上述的簇区域检测处理而得到的。
[0076]
图5是示出针对与图4所示的二元散布图相同的数据点在实施上述的聚类分析参数调整处理之后执行聚类分析和簇区域检测所得到的结果的二元散布图。根据该图5可知,在图4中被划分为多个线状地延伸的簇区域的部分被分别整合为各个大的簇区域。另一方面,在数据点的密度原本就不是很高的位于散布图中的下侧的区域中,簇区域的形状没有变化。这样,在本实施方式的epma中,即使在作为目标的2个元素的存在量具有大幅差异、尤其是由于一方的元素的存在量少且其偏差也小而其测定范围窄的情况下,也能够避免在二元散布图中检测到伪簇从而进行精确的聚类。
[0077]
此外,在上述实施方式的epma中,在图2所示的参数调整处理中,仅着眼于表示最大频数的阶梯的前后,但是也可以对直方图的全部阶梯(也就是说全部的极大值位置的前后)求出频数为0的阶梯的连续数,并将该连续数的最大值设为连续阶梯数n。但是,在多数情况下,即使执行这样的处理,被选择的连续阶梯数n也与图2所示的处理的结果相同,因此从计算处理时间这一方面等来看,实施图2所示的处理是优选的。
[0078]
[第二实施方式]
[0079]
接着,对于作为本发明所涉及的表面分析装置的第二实施方式的epma,参照附图来进行说明。图6是第二实施方式的epma的主要部分的结构图。在图6中,对与图1所示的装置的构成要素相同或相当的构成要素赋予相同的附图标记。
[0080]
第二实施方式的epma的基本结构与第一实施方式的epma相同,不同点在于:在数据处理部9中,代替散布图制作部92而设置三元散布图制作部97,代替聚类分析参数调整部93而设置相加强度值数据选择处理部98。
[0081]
在本实施方式的epma中,与第一实施方式的epma同样地,在分析控制部8的控制下,针对试样3上的二维区域内的大量的微小区域执行分析。元素强度计算部90针对试样3上的二维区域内的每个微小区域获取反映了目标元素的存在量的强度数据。该强度数据被保存于数据保存部91。
[0082]
当分析者通过操作部11进行规定的操作时,三元散布图制作部97从数据保存部91中读取规定的数据,制作表示指定的3个元素的强度的关系的三元散布图。三元散布图上的
各数据点分别与试样3上的微小区域对应。显示处理部96将所制作的三元散布图显示在显示部12的画面上。如图8所示,在三元散布图中观测到放射状地延伸的线状的数据点的集合的情况下,即使进行了自动的聚类分析也无法进行精确的聚类的可能性高。因此,当分析者使用操作部11进行规定的操作时,相加强度值数据选择处理部98执行下面那样的数据选择处理。图7是该数据选择处理的流程图。
[0083]
相加强度值数据选择处理部98针对每个微小区域计算三元散布图中显示的3个元素(图8的例子中为fe、mg、k)的强度的相加值(下面称为“强度相加值”),按相加强度值从大到小的顺序将规定比例的数据作为离群值进行排除(步骤s11)。排除离群值的理由及其具体方法如下。
[0084]
图9是关于图8所示的三元散布图中标记的全部数据点(也就是说试样3上的微小区域)的相加强度值的直方图。这样,在相加强度值=0附近的非常窄的强度范围中,相当比例的数据不均匀而形成峰。假定这样的相加强度值小的大量数据是在三元散布图中放射状地延伸的线状的数据点的集合的主要因素。为了将其消除而需要排除该数据的全部或一部分。但是,在图8所示的直方图中,数据以低的频数扩展到大的相加强度值,因此,表示高的频数的峰成为在横轴方向上被压缩的形状,难以决定用于筛选作为排除对象的数据的阈值。
[0085]
在直方图中假定:相加强度值大的数据的频数低,另外,该数据在横轴上离散地存在。因此,若暂时排除这样的相加强度值大的数据并重新制作直方图,则能够更详细地掌握相加强度值小的区域中的峰的状态、也就是说直方图中的数据的分布状态。因此,在此作为一例,利用在统计中经常使用的基于四分位数的离群值检测方法,来排除相加强度值大的离群值。
[0086]
一般地,在基于四分位数的离群值检测中,利用四分位范围(iqr)来求出离群值,该四分位范围(iqr)是在按升序排列全部数据时从相当于全部数量的75%的第三四分位数(q3)减去相当于全部数量的25%的第一四分位数(q1)而得到的值。具体而言,通常,使用下式求出下侧边界和上侧边界,并将其外侧的数据设为离群值。
[0087]
下侧边界=q1-iqr
×
1.5
[0088]
上侧边界=q3+iqr
×
1.5
[0089]
但是,在此,不需要小值的离群值。因此,为了除去大值的数据,排除具有上侧边界以上的强度的数据。此外,具有大值的离群值的检测方法不限于上述方法,例如也能够使用斯米尔诺夫
·
格鲁布斯(smirnov-grubbs)检验等其它的离群值检测方法。
[0090]
接着,相加强度值数据选择处理部98根据如上所述那样排除了离群值之后的相加强度值数据制作直方图(步骤s12)。然后,在该直方图中使用规定的算法来检测成为极大(峰)及极小的位置(阶梯)(步骤s13)。图10是基于从成为图9所示的直方图的基础的相加强度值数据中排除了离群值之后的数据而制作出的直方图。图10中,以黑圆点表示所检测到的极大值,以白圆点表示极小值。此外,在此,以不会将窄强度范围中的频数的增减识别为极大/极小的方式设定一定的检测宽度。因此,例如距强度=0最近的峰不被检测为极大。
[0091]
相加强度值数据选择处理部98确定比表示最大频数的极大值靠上侧的最近的极小值(步骤s14),并从全部的相加强度值数据(包含在步骤s11中被排除的离群值)中排除从最小强度、也就是说从强度=0到该被确定的极小值为止的强度范围中包含的相加强度值
数据(步骤s15)。在图10所示的例子的情况下,将相加强度值为156以下的的相加强度值数据全部排除。由此,在图10所示的直方图中,形成频数最大的峰的数据全部被排除。
[0092]
此外,在步骤s11中排除了离群值之后的相加强度值数据中,与原始数据相比,最大强度有时大幅变化(变小)。在图9、图10所示的例子中,将制作直方图时的相加强度值的阶梯数设为256,但是假设在排除了离群值之后的数据的最大强度小于256的情况下,需要进行配合该情况来调整强度值的阶梯数的处理。这是由于:若不进行这样的阶梯数的调整,则制作的直方图中梳状地产生频数为0的阶梯,无法精确地得到极小值的位置。
[0093]
在上述那样的过程中,相加强度值数据选择处理部98通过排除相加强度值小且其频数高的数据,来选择作为聚类对象的数据。聚类分析部94对这样被选择后的三元散布图上的数据点执行例如利用基于密度的层次聚类分析的聚类。由此,对三元散布图上的各数据点赋予表示属于一个或多个簇的哪一个簇或者是否不属于任何一个簇的标签。簇区域检测部95例如使用凸包法等合适的方法来划定如包含属于各个簇的数据点的全部或大部分那样的多边形状的簇区域。
[0094]
图11是示出针对图8所示的三元散布图上的数据点在实施上述的相加强度值数据选择处理来减少数据点之后进行聚类所得到的结果的三元散布图。在图11中,图8所示的三元散布图中出现的放射状地延伸的线状的数据点的分布消失,也没有检测到预想为伪簇的簇。根据这种情况,估计为适当地进行了聚类。
[0095]
这样,在第二实施方式的epma中,能够从聚类处理的对象中排除三元散布图中出现的噪音数据点的集合,由此能够抑制检测到错误的簇区域。其结果为,能够提高三元散布图上的簇的检测精度,能够改善利用了该方式的相解析的精确性和效率。
[0096]
此外,在上述说明中,在图10所示的直方图中,排除了从强度=0到表示比最大频数的极大值靠上侧的最近的极小值为止的强度范围中包含的数据,但是能够根据数据的分布状况等来适当地变更要排除的数据的强度范围。例如,也可以设为用户能够选择要排除的数据的强度范围,或者,也可以对多个排除了不同的强度范围的数据之后的数据群分别进行聚类并获取多个聚类结果,将这些结果汇总并呈现给用户。
[0097]
另外,并不需要始终实施上述那样的数据选择处理,因此也可以如上述那样根据用户的操作来实施数据选择处理,还可以设为根据聚类结果等自动地实施数据选择处理。
[0098]
另外,上述第一实施方式及第二实施方式是epma,但是本发明能够全面地应用于sem、x射线荧光分析装置等能够在试样上的一维或二维的区域内的大量微小区域中分别获取反映了元素或成分(化合物等)的量的信号的各种分析装置。即,本发明不特别地限定测定方法和分析方法本身,只要是能够进行映射分析的分析装置即可。
[0099]
另外,上述实施方式均仅是本发明的一例,即使在本发明的主旨的范围内进行适当的变形、修改、追加等,当然也包含于本技术的权利要求书的范围内。
[0100]
[各种方式]
[0101]
本领域技术人员应当明确上述例示的实施方式是以下方式的具体例。
[0102]
(第一项)本发明所涉及的表面分析装置的一个方式具备:
[0103]
测定部,其在试样上的多个位置处分别获取反映了作为分析对象的多个成分或元素的量的信号;
[0104]
散布图制作部,其基于由所述测定部得到的测定结果来制作二元散布图;
[0105]
聚类分析部,其使用基于密度的聚类分析的方法来对所述二元散布图中的点进行聚类;以及
[0106]
参数调整部,其利用所述二元散布图中的某一方的成分或元素的信号值的值分布信息,来调整距离阈值,所述距离阈值是在所述基于密度的聚类分析中应设定的参数之一。
[0107]
(第二项)在第一项记载的表面分析装置中,能够设为:所述参数调整部利用所述二元散布图中的信号值范围较窄的成分或元素的信号值分布,来调整所述距离阈值。
[0108]
例如,在试样中包含的2个元素的存在量具有大幅差异的情况下,由于存在量较少的元素的测定范围很窄,而有时在二元散布图上极其接近地出现多个线状的数据点的集合。根据第一项及第二项记载的表面分析装置,不会将这样的多个线状的数据点的集合误识别为独立的簇,而能够将其识别为1个簇。即,根据第一项及第二项记载的表面分析装置,能够抑制在自动地对二元散布图中标记的数据点进行聚类时检测到伪簇,从而提高该数据点的聚类的精度,也就是说,提高基于多个成分或元素的存在量或浓度进行的试样上的微小区域的聚类的精度。由此,用户例如能够准确地进行基于聚类结果的相解析。
[0109]
(第三项)在第二项记载的表面分析装置中,能够设为:所述参数调整部制作所述成分或元素的信号值的直方图,基于该直方图中的至少1个表示极大值的信号值阶梯的前后的频数分布,来调整所述距离阈值。
[0110]
(第四项)另外,在第三项记载的表面分析装置中,能够设为:所述参数调整部基于所述直方图中的表示频数最大的极大值的信号值阶梯的前后的频数分布,来调整所述距离阈值。
[0111]
根据第三项及第四项记载的表面分析装置,能够提取在二元散布图中容易被误检测为伪簇的、数据点特征性地分布的区域,以避免在该区域中检测到伪簇的方式适当地决定聚类的参数(距离阈值)。另外,这样的用于调整参数的处理也简单,因此处理不耗费时间,例如能够迅速地显示聚类结果。
[0112]
(第五项)在第一项至第四项中的任一项中记载的表面分析装置中,能够设为:所述聚类分析部进行基于密度的层次聚类分析。
[0113]
根据第五项记载的表面分析装置,能够良好地对基于例如利用epma等收集到的数据制作出的二元散布图上的数据点进行聚类。由此,用户例如能够准确地进行基于聚类结果的相解析。
[0114]
(第六项)另外,本发明所涉及的表面分析装置的其它方式具备:
[0115]
测定部,其在试样上的多个位置处分别获取反映了作为分析对象的多个成分或元素的量的信号;
[0116]
散布图制作部,其基于由所述测定部得到的测定结果来制作三元散布图;
[0117]
数据点选择部,其利用与所述三元散布图中的数据点对应的将3个成分或元素的信号值相加而得到的相加信号值的分布信息,来从存在于该三元散布图上的全部数据点中排除该相加信号值相对小的规定的信号值范围的数据点;以及
[0118]
聚类分析部,其使用基于密度的聚类分析的方法,来对所述三元散布图中的未被所述数据点选择部排除的数据点进行聚类。
[0119]
例如,在试样中包含的3个元素的信号值的比率为大致相同程度的数据点大量存在的情况下,在三元散布图上出现放射状地延伸的线状的数据点的分布,这有时会成为检
测到伪簇的原因。根据第六项记载的表面分析装置,能够消除这样的成为伪簇的原因的数据点的特征性的分布。由此,能够抑制在自动地对三元散布图中标记的数据点进行聚类时检测到伪簇,从而提高该数据点的聚类的精度,也就是说,提高基于多个成分或元素的存在量或浓度进行的试样上的微小区域的聚类的精度。由此,用户例如能够准确地进行基于聚类结果的相解析。
[0120]
(第七项)在第六项记载的表面分析装置中,能够设为:所述数据点选择部制作所述相加信号值的直方图,并利用该直方图中的表示检测到的极大值和/或极小值的阶梯,来决定要排除的数据的信号值范围。
[0121]
根据第六项记载的表面分析装置,能够准确地排除容易成为伪簇的原因的、相加信号值相对小且频数高的数据点。由此,不仅能够排除容易成为伪簇的原因的数据点,还能够避免意外地排除不是这样的数据点,从而在三元散布图上划定准确的簇区域。
[0122]
(第八项)在第六项或第七项记载的表面分析装置中,能够设为:所述聚类分析部进行基于密度的层次聚类分析。
[0123]
根据第八项记载的表面分析装置,能够良好地对基于例如利用epma等收集到的数据制作出的三元散布图上的数据点进行聚类。由此,用户能够准确地进行基于聚类结果的相解析。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1