一种基于强化学习的污水处理控制方法与流程
本发明涉及一种基于强化学习的污水处理控制方法。
背景技术:
目前,强化学习在工业控制中的应用逐渐增多,但一般都限于特定的模型,其主要原因在于强化学习的训练需要环境支持,而在很多污水处理控制方面,完全模拟真实场景的环境所需要的计算量远远大于强化学习模型训练本身所需要的计算量,导致得不偿失,而且就目前的企业技术发展而言,原始的数据积累也很成问题。
技术实现要素:
为解决上述技术问题,本发明提供了一种基于强化学习的污水处理控制方法,该基于强化学习的污水处理控制方法通过三阶段在真实场景中训练强化学习模型的方式,能有效避免现有的训练强化学习模型所需要的收集数据、建立虚拟环境的过程。
本发明通过以下技术方案得以实现。
本发明提供的一种基于强化学习的污水处理控制方法,包括如下步骤:
1).模型训练:在现场控制器控制的过程中,获取现场控制器的输入信号及输出指令,并根据获取的输入信号及n个时序前的输出指令对环境模型建模;
2).策略调整:在现场控制器控制的过程中,获取现场控制器的输入信号至环境模型,环境模型输出作为策略模型的输入,将现场控制器的输出指令和策略模型的输出指令合并为最终输出指令输出控制;
3).介入控制:停止现场控制器,采用环境模型获取输入、环境模型输出作为策略模型的输入、策略模型输出指令进行控制。
所述对环境模型建模采用rnn算法。
所述环境模型输出为概率值向量。
所述步骤2)中,策略模型采用如下方式更新:
a.获取当前环境模型输出,计算当前环境模型输出与前一模拟输出的误差值;
b.根据误差值更新值函数;
c.将当前环境模型输出代入至值函数中计算当前输出指令值;
d.将当前输出指令值代入至环境模型中计算当前模拟输出;
e.当前模拟输出更新至前一模拟输出,将当前输出指令发送,然后进入下一时序,等待获取环境模型输出。
所述步骤2)中,将现场控制器的输出指令和策略模型的输出指令合并为最终输出指令采用如下方式:
a.获取现场控制器的输出指令和策略模型的输出指令;
b.将现场控制器的输出指令和策略模型的输出指令中的数值取出为现场控制器输出指令数值和策略模型输出指令数值;
c.将策略模型输出指令数值乘以系数n后更新为新的策略模型输出指令数值;
d.将现场控制器输出指令数值乘以系数(1-n)后更新为新的现场控制器输出指令数值;
e.将新的现场控制器输出指令数值和新的策略模型输出指令数值叠加得到输出指令叠加值;
f.将输出指令叠加值封装为输出指令发送指令。
所述n为0.1~0.2。
所述n初始为0.1,每经过m次将现场控制器的输出指令和策略模型的输出指令合并为最终输出指令的步骤后,n自加0.005直到n为0.2。
所述m取值由用户设定,但限定为10~30。
本发明的有益效果在于:通过三阶段在真实场景中训练强化学习模型的方式,能有效避免现有的训练强化学习模型所需要的收集数据、建立虚拟环境的过程,从而有效降低企业在应用强化学习的方式进行自动控制时所需的成本,方便用户完成从传统控制倒强化学习控制的过程。
附图说明
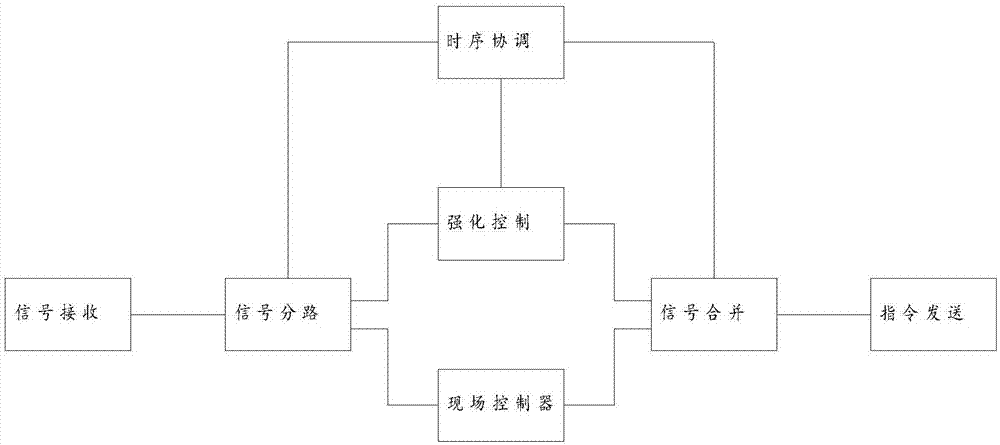
图1是本发明所应用的污水处理控制系统的连接示意图。
具体实施方式
下面进一步描述本发明的技术方案,但要求保护的范围并不局限于所述。
本发明应用于如图1所示的一种污水处理控制系统的控制,具体为基于强化学习的污水处理控制方法,包括如下步骤:
1).模型训练:在现场控制器控制的过程中,获取现场控制器的输入信号及输出指令,并根据获取的输入信号及n个时序前的输出指令对环境模型建模;
2).策略调整:在现场控制器控制的过程中,获取现场控制器的输入信号至环境模型,环境模型输出作为策略模型的输入,将现场控制器的输出指令和策略模型的输出指令合并为最终输出指令输出控制;
3).介入控制:停止现场控制器,采用环境模型获取输入、环境模型输出作为策略模型的输入、策略模型输出指令进行控制。
所述对环境模型建模采用rnn算法。
所述环境模型输出为概率值向量。
所述步骤2)中,策略模型采用如下方式更新:
a.获取当前环境模型输出,计算当前环境模型输出与前一模拟输出的误差值;
b.根据误差值更新值函数;
c.将当前环境模型输出代入至值函数中计算当前输出指令值;
d.将当前输出指令值代入至环境模型中计算当前模拟输出;
e.当前模拟输出更新至前一模拟输出,将当前输出指令发送,然后进入下一时序,等待获取环境模型输出。
所述步骤2)中,将现场控制器的输出指令和策略模型的输出指令合并为最终输出指令采用如下方式:
a.获取现场控制器的输出指令和策略模型的输出指令;
b.将现场控制器的输出指令和策略模型的输出指令中的数值取出为现场控制器输出指令数值和策略模型输出指令数值;
c.将策略模型输出指令数值乘以系数n后更新为新的策略模型输出指令数值;
d.将现场控制器输出指令数值乘以系数(1-n)后更新为新的现场控制器输出指令数值;
e.将新的现场控制器输出指令数值和新的策略模型输出指令数值叠加得到输出指令叠加值;
f.将输出指令叠加值封装为输出指令发送指令。
所述n为0.1~0.2。
所述n初始为0.1,每经过m次将现场控制器的输出指令和策略模型的输出指令合并为最终输出指令的步骤后,n自加0.005直到n为0.2。
所述m取值由用户设定,但限定为10~30。
本发明实质上是通过三个阶段完成强化学习模型对现有的现场控制器的控制权交接,环境模型和策略模型均在强化控制模块中执行,整体而言,是第一步先通过实时采集现有数据进行建模,极大降低收集数据所需的时间和成本,在环境模型完成后就可以对策略模型建模,但策略模型需要实际交互,因此第二步就是通过适当的交互来训练策略模型,显然直接让策略模型进行操控并不现实,会导致系统严重故障,而建立虚拟场景则成本过高,因此采用策略模型在适当比例内直接与真实环境交互是个成本低而又能够被系统容错机制接受的方式,当环境模型和策略模型都训练完成,则强化控制模块的控制已经成熟并可投入使用,此时进入到第三步完成控制交接即可有效利用强化学习根据环境调整控制策略的优势,实现适应性更强、准确度更高的污水处理控制。
技术特征:
技术总结
本发明提供了一种基于强化学习的污水处理控制方法,包括如下步骤:本发明通过三阶段在真实场景中训练强化学习模型的方式,能有效避免现有的训练强化学习模型所需要的收集数据、建立虚拟环境的过程,从而有效降低企业在应用强化学习的方式进行自动控制时所需的成本,方便用户完成从传统控制倒强化学习控制的过程。
技术研发人员:黄孝平;文芳一;黄文哲
受保护的技术使用者:南宁学院
技术研发日:2018.09.04
技术公布日:2019.02.12
- 还没有人留言评论。精彩留言会获得点赞!